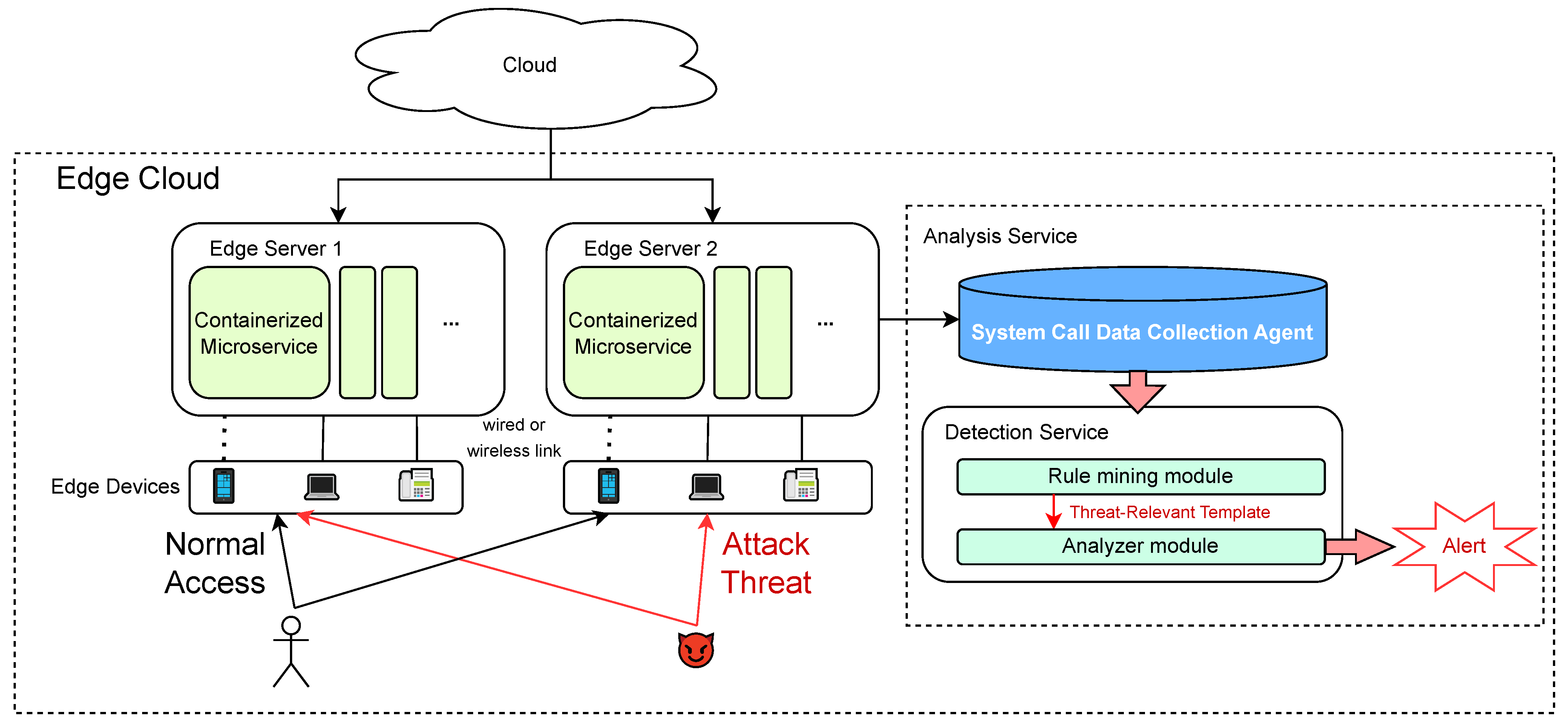
3.3.2. Workflow of Rule Mining
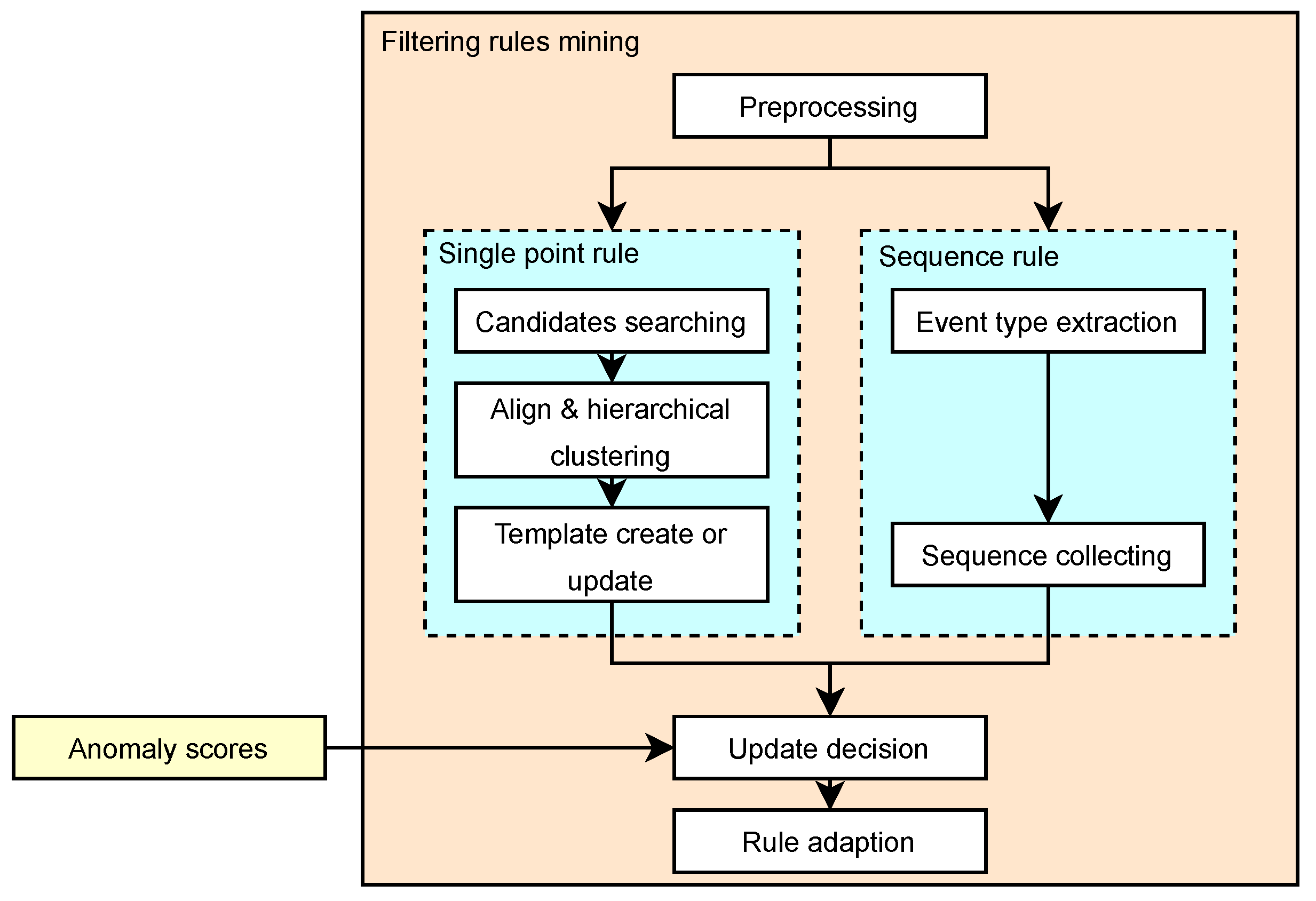
The workflow of the rule mining module is depicted in
Figure 3. For the raw system call events, the following steps are carried out sequentially: preprocessing, single-point rule mining (candidate template search, hierarchical clustering, and active template set updating) [
23], sequence rule mining (event type extraction and sequence collecting), update decision based on the anomaly scores generated by the classification model, and final rule adaption.
Templates, which refer to the type of log that can be obtained by replacing variables in a word sequence with wildcards, within this set are continuously updated based on multiple event records. These templates can be considered intermediate objects between the final generated rules and contain various field information required to create specific rules. They establish a many-to-one or one-to-one relationship with the rules. If a decision is made to generate new rules, further adaptation and updates of the rules are performed. In our method, we employ the comparison and mining algorithms based on templates in [
23]. In
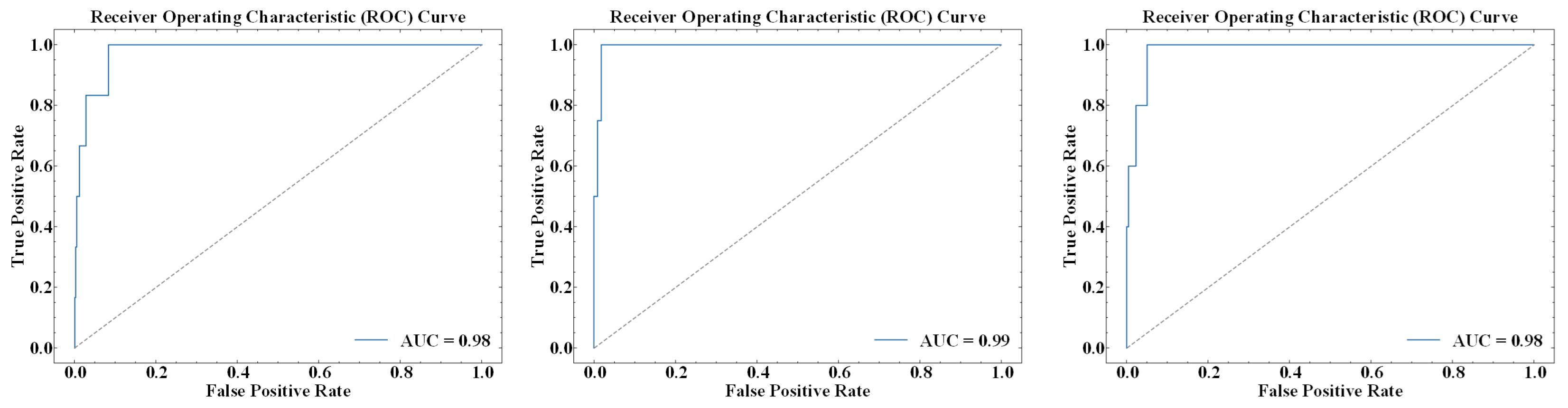
Section 4, we will compare our mining algorithm with the most effective algorithms, such as Drain [
24] and SwissLog [
25], summarized in the literature [
26].
Data preprocessing. Data preprocessing involves field identification, entity recognition, and tokenization of system call events to generate processed system call log objects [
23]. Initially, in field identification, system call parameter information and container/Kubernetes-related metadata are extracted from the raw events to serve as the basis for entity recognition. Subsequently, entity recognition is identified based on container ID, image ID, and process-related information, and assigns identifiers to the log objects. This field can also be replaced by other labels, such as Pod, Deployment labels, etc. Finally, in tokenization, for fields requiring template mining, the following steps are taken: (1) special content in the logs is recognized using regular expressions and masked with identifiers, while recording the specific content in sequence for further analysis during template mining. This approach allows for a more fine-grained matching. (2) For main information within processed logs and system call parameter fields, content is tokenized finely based on separators to create token sequences, which serve as data for the corresponding fields in the system call log objects.
Candidate Search. This step’s input is the token sequences mentioned above. Here, we use the selecting method in [
23], which separately treats short and long token sequences. For short inputs (usually up to 3 tokens), candidate templates are directly selected from the existing active template set based on their length differences from the input within a certain range. For long parameters, the Best Matching 25 (BM25) algorithm, an improved version of term frequency–inverse document frequency (TF-IDF), is used to calculate the coarse-grained similarity between the input and templates. The calculation method is as (
1) and (
2) [
23].
Candidate templates are selected based on this score reaching a certain threshold, forming the candidate template set. Additionally, it is generally considered reasonable to include templates with similar lengths in the candidate search, so during the candidate search, only templates with a certain length difference are included. When the goal is data parsing, if the candidate template set is empty, the template with the highest BM25 score is added to the candidate template set. As a result, the collection of templates for clustering candidate items is obtained.
Hierarchical Clustering. When the candidate template set is empty, a new active template is formed directly as the pattern based on the input token sequence. The form of active templates is a tree, where non-leaf nodes represent patterns matching all input token sequences belonging to that template, and leaf nodes represent individual original input token sequence records. For performance considerations, the degree and maximum height of the tree are set to specific values. If the candidate template set is not empty, for each non-leaf node in the candidate templates, alignment is performed with the input token sequence based on word-level Longest Common Subsequence (LCS). [
23] For templates with the wildcard <*>, they can match any number of tokens until the token after the wildcard matches the input token. However, this matching is not counted in the length of the LCS. After word alignment is complete, similarity is calculated between the corresponding differences, using the original content that was not masked. According to the analysis and comparison in [
27,
28,
29,
30], the algorithm selects the Jaro similarity (
3) as the method for calculating word-level similarity. The overall process involves finding similarities between the input token sequences and the non-leaf nodes in the candidate templates, which leads to hierarchical clustering.
In the equations,
represents the length of string
,
m is the number of matching characters, and
t is the number of transpositions. If two strings do not match at all, the Jaro similarity is 0, and if they are identical, the Jaro similarity is 1. Then, the similarity between the input and the sub-template is calculated as (
4).
D represents the sub-template, Q represents the input, is the length of the Longest Common Subsequence between the two, is the number of differences, and is the similarity between the aforementioned differences. The sub-template with the highest similarity is selected as the best-matching template.
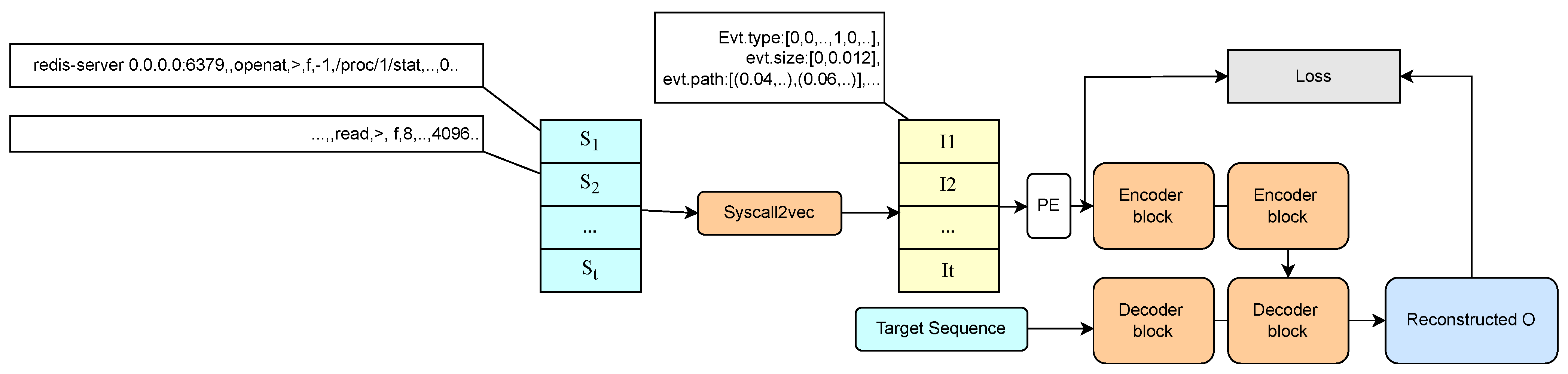
The specific operation of hierarchical clustering is illustrated in
Figure 4. It involves further merging the input with the records under this sub-template (extracting the differing parts as variable identifiers). For different numbers and types of differences, variable identifiers are assigned as enumeration values (<E>), range values (<R>), or free variable values (<*>). If the merged pattern matches the template pattern, no update is made to the template tree. Otherwise, the update is made based on the node’s depth and the number of child nodes [
23].
Sequence rule mining. To achieve system call rules mining at the sequence level, our work additionally implements rule mining based on system call type sequences. The system call type sequence filtering uses a similar concept to the rolling hash algorithm for fast matching. Rolling Hash is a hash function used to quickly calculate the hash value of consecutive substrings in a string. In this method, each system call type is mapped to an integer between 0 and 255, and then the Rabin–Karp algorithm is used to calculate the hash value corresponding to each event and its historical window sequence, to quickly determine whether this sequence is in the sequence filtering rules.
Since a large length can cause the sequence vector space explosion, and a small length can result in a lack of sequence information for events, each rule in this method adopts a fixed-length type sequence of 16, based on the conclusion of the research [
13] and our analysis of the length of real anomaly sequences.
The sequence collecting process initially involves the simple collection of 16-g of system call types present in the training set. Then, these sequences are sorted based on their frequency, and those within the 90th percentile are considered to be candidate sequence filter rules. Finally, the process waits to obtain anomaly scores for each corresponding sequence of n-grams for further filtering.
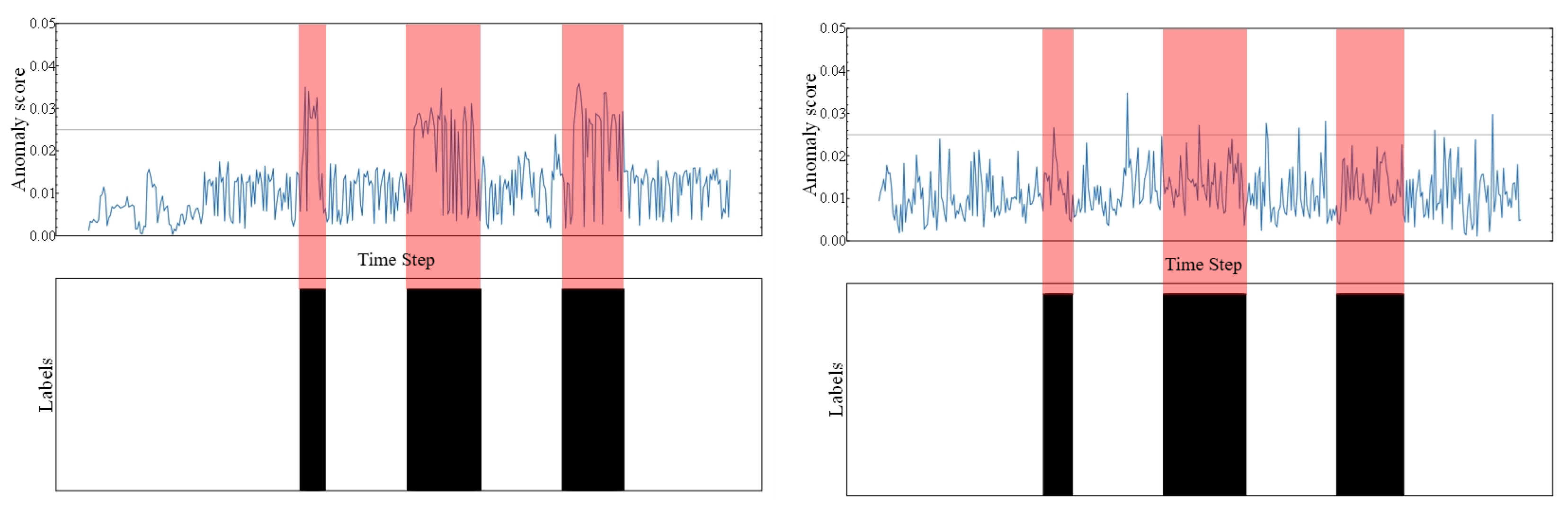
Decision and Update. When templates are generated or updated through clustering, the method makes a decision on whether to accept the update based on certain conditions instead of immediately incorporating them into the rule set to avoid potential pollution of the rule set by templates generated from anomalous noise [
23]. The conditions considered in the decision-making process include: (1) similar system calls produced by the same type of entity in the entire cluster, with a certain level of overall frequency and container count. (2) Minimal time intervals between the occurrences to avoid considering them as multiple anomalous events. (3) Similar contextual information for the events. (4) Sequence anomaly scores generated by the classification model are below the 60% percentile.
Rule Set Adaptation and Update. To prevent frequent updates, the rule adaptation module detects changes in the template set after each cycle. It then converts the changed parts, based on entity information templates, type templates, and parameter templates, into corresponding new rule sets. These new rule sets are stored in the cluster’s internal database. Additionally, messages are sent to the rule detection and filtering modules on various nodes to notify them of the rule set updates. When the rule detection and filtering modules receive this message, they retrieve the new rule sets from the database and perform a hot update of their internal rules.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}