1. Introduction
Knowledge sharing in a security-sensitive community presents unique challenges. This community includes organizations involved in intelligence gathering and research, such as government bodies, military intelligence, and civil defense departments. The intelligence community encourages joint learning, thinking, and originality [
1]. However, its work involves a paradox: while intelligence forces handle data specification, collection, evaluation, and distribution, sharing is restricted by secrecy regulations and compartmentalization [
2]. To evaluate this paradox’s impact on knowledge sharing, we compare communication patterns between homogeneous security-sensitive communities (with uniform information sensitivity) and non-sensitive communities, where sensitivity varies. All communities discuss the same subject matter.
Past studies have examined the relationship between heterogeneous groups, trust, and knowledge sharing [
3], comparing influencing factors in homogeneous versus heterogeneous groups. Cultural diversity also impacts knowledge-sharing [
4]. Pinjani and Palvia [
5] found that reducing diversity dimensions by increasing trust aids knowledge sharing. Ku [
6] used Social Network Analysis (SNA) to show that homophily (similarity between people) improves knowledge sharing, with social capital mediating homophily’s effect in building network ties and spreading knowledge across diverse backgrounds.
This empirical study examines differences in knowledge-sharing in security-sensitive versus non-sensitive communities. Communication among members is represented by network graphs, with metrics reflecting trust’s influence on knowledge-sharing: clustering coefficient, transitivity, diameter, radius, and density. These metrics are divided into measures of communication levels and knowledge-sharing efficiency, calculated for both types of communities.
The paper starts by explaining the unique case of security-sensitive organizations that are the focus of the current research. We proceed to explain metrics from Social Network Analysis, which are useful for understanding the spread of knowledge and the level of communication.
Section 4 describes our unique comparative data. After a report of the findings and their implications, the paper concludes with recommendations for internal and external knowledge-sharing procedures, collective intelligence system design, online sharing regulations to improve knowledge-sharing, and educational outlines for senior management in these organizations.
2. Literature Review
This study examines the effect of a security-sensitive culture on knowledge sharing. The following sections explain the unique characteristics of intelligence communities and elaborate on knowledge-sharing measurements via social and collaborative computing.
2.1. Intelligence Communities
Community refers to a group or network of people with a common denominator, such as geographic location, culture, opinion, or identity [
7]. Communities are dynamic, complex, and diverse [
8], with a structure created by the connections and relationships between members. Social and collaborative computing technologies enable the development of platforms for knowledge sharing and strengthening relationships with the external environment. In these virtual platforms, each member can equally contribute to knowledge production and reception [
9]. Culture affects knowledge sharing, with language differences creating knowledge barriers and intercultural differences influencing knowledge flow [
10]. Other factors include participants’ personal characteristics and their social connections [
11].
Intelligence communities are cautious about information sharing, but social and collaborative computing technologies can improve communication with government, academia, and private companies. Traditionally, a military intelligence community collects and analyzes information to support commanders’ decisions. The intelligence cycle outlines stages of information collection and analysis [
12]. This cycle has long described the transformation of raw information into intelligence knowledge through five stages: specifying essential information, collection, analysis, evaluation, and distribution [
13,
14]. Updating this cycle with technological advancements and knowledge-sharing platforms, including social media [
15,
16,
17] and web-based sources [
18], would be beneficial.
However, intelligence organizations often delay adopting new technologies, creating a gap between industry innovations and traditional intelligence tools [
19]. Implementing advanced social and collaborative computing for knowledge sharing in intelligence faces several challenges. First, the long-standing tradition of secrecy and compartmentalization may hinder progress. Second, each intelligence unit maintains its distinct identity, causing internal competition. Finally, a “need to know” or “knowledge is power” culture leads to sharing knowledge only when deemed necessary [
2]. Effective intelligence analysis relies on quality information reaching the right expert at the right time, requiring knowledge sharing in an “atmosphere of trust” [
20].
Knowledge sharing in intelligence must balance strict security protocols. Trust is the foundation, ensuring only authorized personnel access critical information. Compartmentalization and need-to-know principles rely on trust that individuals will not abuse access rights. This is crucial, as leaked information can have severe national or global repercussions [
21,
22].
A lesser discussed albeit another important element in the information-sharing puzzle in security-sensitive organizations is the balance between security and usability. Complex and cumbersome security measures are likely to hinder sharing and collaboration. Usability considerations may aid in bridging between sharing and security [
23].
The next section discusses the relationship between trust, social behavior, and community structure.
2.2. Trust, Social Behavior, and Network Structure
Mayer et al. [
24] define trust as a behavioral intention and link it to social behavior, including interactions and risk-taking in relationships. Cultural values affect trust and information privacy [
25] and affect how people use social platforms [
26,
27]. Trust and privacy concerns in computer-mediated communication (CMC) also vary by culture, especially in how people obtain and interpret information: direct and formal sources are preferred in cultures like the USA, UK, and Australia, while personal networks and contextual cues are more common in Japan, China, and Korea [
28].
Trust is vital for knowledge sharing in organizations, serving as an antecedent and influencing other variables [
29]. Trust among employees fosters knowledge exchange and the creation of new knowledge, enabling organizations to adapt to change [
30]. Various types of trust, including trust in leadership, colleagues, and technologies, enhance knowledge sharing [
31].
A graph-type data structure represents the relationship between a member, the information source, and factors affecting understanding. We refer to this as a network. There is a reciprocal relationship between network structure and behavior. Structure influences behavior [
32], with network analysis revealing human behavior, such as patterns in email correspondence [
33]. The network structure also depends on member behavior; for example, structured versus open forums lead to different network configurations [
34,
35]. Participants often design their networks to share news with only the “necessary, but sufficient” recipients [
36]. The social behavior of intelligence personnel influences the network’s structure.
Social Network Analysis (SNA) measures and analyzes community structure and interactions [
37,
38]. Social networks represent relationships between social units, such as student friendships [
39,
40,
41], interactions between users during disasters via social media [
42], football movement among players [
43,
44], or corporate email communication [
45,
46]. Modeling knowledge sharing as networks, with actors as nodes and messages as arcs, allows analysis of behavior and interactions. Networks can be directional, like citation networks, or undirected, like co-authorship [
35].
2.3. Homogeneous and Heterogeneous Communities
In addition to trust, knowledge sharing, and network structure, this paper considers community homogeneity. Homogeneity refers to similarity among community members, while heterogeneity denotes diversity. Homophily, a relevant network feature, refers to the similarity between members, fostering interactions and connections [
47]. In homogeneous contexts, homophilic relations form, creating strong connections [
47]. Homogeneity is also linked to the echo chamber effect, where similar opinions strengthen connections [
48].
We argue that an organization’s homogeneity, reflected in its shared culture regarding trust and security sensitivity, influences diversity. A community of security-sensitive organizations is homogeneous in terms of information security sensitivity. The group becomes heterogeneous if it includes both security-sensitive and non-sensitive organizations. The next section connects network properties to knowledge sharing in communities for comparison.
2.4. Measuring and Comparing Knowledge Sharing
Comparing networks is challenging because no clear method exists for evaluating them as complete entities. Researchers use various approaches, such as software tools to visualize network differences [
49], machine learning to classify memes [
50], or mathematical calculations to compare Twitter users’ behavior [
51]. Network comparison looks at interactions across the entire network, not individual member characteristics. One important measure is the speed of information flow, which helps quantify network similarity.
In terms of measurements, Wilkin, Biggs, and Tatem [
52] describe how network-based measures, mathematical evaluations of network structure, can be linked with norms, trust, and reciprocity to quantify social capital. Since network structure reflects community characteristics, this study focuses on security-sensitive organizations, linking network measures to trust. We categorize network metrics based on their relationship to knowledge sharing and communication levels.
2.5. The Spread of Knowledge
The first category includes global metrics representing the entire network, enabling analysis of end-to-end knowledge-sharing. For instance, a network’s average path length allows comparison between networks, with a lower path length indicating faster knowledge spread. This study’s knowledge-sharing metrics include network diameter, radius, and density.
Diameter and radius—In Social Network Analysis (SNA), diameter and radius differ from their geometric meanings. The diameter is the shortest path between the two furthest nodes, while the radius is the minimum eccentricity across all vertices [
53]. Both are non-directional. In communication networks, a small diameter indicates faster information spread [
54,
55]. A community structure that maximizes knowledge transfer results in a smaller diameter. Trust among members influences cooperative behavior, which can affect a network’s radius [
56]. Communication efficiency is measured by the shortest possible path between all nodes, with knowledge flow linked to trust and commitment [
57,
58]. For instance, al-Qaeda’s network had a long average path length, suggesting secrecy over efficiency [
59]. In security-sensitive organizations, when operational tasks are prioritized, the radius and diameter are expected to be smaller than in non-sensitive organizations.
Density—Network density is the ratio of actual to possible ties, indicating the level of knowledge sharing and node interactivity [
60]. In communication networks, density measures a node’s embeddedness in discussions. Dense structures foster commitment and trust among members [
61]. Given the importance of trust in security-sensitive organizations, we expect their density to be higher than that of non-sensitive organizations.
2.6. Level of Communication
We examine metrics reflecting communication, specifically reciprocity and transitivity. Reciprocity refers to mutual communication between two members in a directed graph [
62]. Transitivity measures clustering, indicating the tendency for triads of connections to form (e.g., “a friend of my friend is also my friend”) [
63].
The communication category includes metrics that analyze network segments: reciprocity focuses on pairs, while transitivity, average clustering, and clustering coefficient relate to triads and their neighborhoods. Analyzing neighborhoods helps understand peer communication.
Reciprocity—measures the likelihood of mutual links between nodes in a directed network [
64]. Prell and Skvoretz [
65] discuss how trust and reciprocity reflect in network structure, with “network closure” indicating strong ties through mutual reciprocation. In online platforms, where disinformation spreads [
66], trust is crucial for sharing reliable information. Thus, security-sensitive communities should exhibit stronger ties and higher trust than non-sensitive ones.
Transitivity—The global clustering coefficient measures overall clustering in a network, with transitivity representing the ratio of open to closed triads [
67]. The clustering coefficient reflects how connected a node’s neighborhood is [
68]. Networks with high trust have high clustering [
69]. According to Huang and Fox [
70], rational decisions made in the real world are based on a combination of rational calculation and trust, where trust is transitive. Trust in social networks fosters collaboration and interaction, increasing transitivity [
71]. As trust grows, so does interaction, boosting clustering and transitivity. Transitive linking, where individuals are introduced by mutual acquaintance, drives new interactions [
67]. Small-world networks, which feature high clustering and short path lengths, are common in covert networks [
67,
72]. These networks, often hidden, have high clustering and low average paths [
73]. Studies that examine such networks often refer to networks that aim to remain hidden [
74]. In intelligence communities, where content is classified, secrecy can hinder knowledge sharing. We expect higher transitivity in security-sensitive organizations, similar to covert networks.
Average Clustering—This alternative to the global clustering coefficient averages all nodes’ clustering coefficients, giving more weight to low-degree nodes. Since this study focuses on structure, both metrics are used for validation. We expect higher average clustering in security-sensitive organizations compared to non-sensitive ones.
2.7. Analyzing Text-Based Interactions
A standard method for analyzing text-based interactions between people converts the exchange of messages into communication graphs [
75,
76,
77,
78]. This method contributes to understanding the knowledge-sharing patterns among the participants, for example, during cooperative learning in a group [
75]. Another study proposes an integrated approach to evaluating textual complexity, learning strategies, and learners’ collaborative contributions. It analyzed texts exchanged between learners and teachers to inform an automatic feedback model aimed at enhancing understanding [
76]. Other studies analyze turn-taking sequences in discussions on online social platforms [
77,
78]; identifying conflicts helps in mitigating arguments and preventing negative social processes [
79].
The current study uses the common method of analyzing text-based interactions between community members by converting the interactions into communication graphs and analyzing the structure of these graphs without analyzing the content. The next section elaborates on the research rationale.
3. Research Rationale
We associate each network metric with trust among community participants, represented as network nodes. Trust influences interactions related to knowledge sharing, forming the network’s arcs. We also consider characteristics of security-sensitive organizations that are not accustomed to a culture of knowledge-sharing. While previous studies examined various types of civil organizations and underground organizations, this study focuses on the effect of community trust level on knowledge sharing in security-sensitive organizations. This refers to communities that connect intelligence personnel, where the specific activities of the individuals may not be visible but the community’s existence is acknowledged.
Table 1 summarizes network metrics used in the current study, grouped into the effectiveness of knowledge spread and communication level measures, their relation to trust and behavior, and their expected values in the case of security-sensitive organizations. Due to the relationship between radius and diameter, they are displayed together in
Table 1. In addition, average clustering and transitivity are two measurements of the same network metrics; hence, they appear jointly in the table.
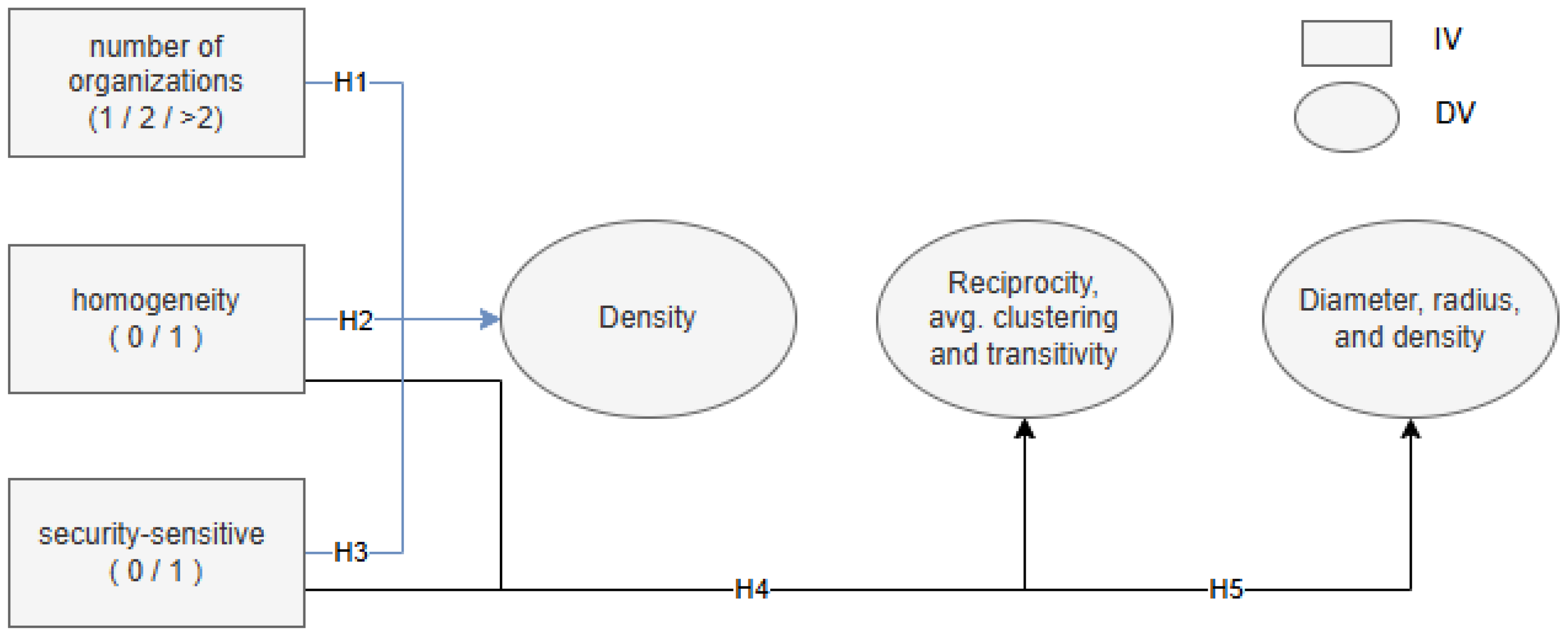
The first three hypotheses sequentially build the research model. The initial hypothesis posits that density increases as the number of organizations decreases. We suggest that the heterogeneity and diversity in more than two organizations hinder knowledge sharing and therefore decrease the density of interactions. We examine how the number of organizations (one, two, or more) affects community discussion.
Figure 1 shows that the effect of multiple organizations on the density of interactions is the foundational layer in the research model.
H1: Network density increases as the number of organizations participating in the discourse decreases.
The second hypothesis continues the first hypothesis and refers specifically to the effect of homogenous organizations, where all group members are from organizations with similar sensitivity to security. To clarify, the first hypothesis examines the effect of the number of participating organizations on conversation density. In contrast, the second hypothesis examines the impact of diversity among organizations on conversation density. The conversation may include people from several organizations. Still, all have the same attitude to information security, in contrast to a conversation among people from several organizations with different attitudes to information security.
H2: Network density increases when homogeneity characterizes the participants of the discourse
The third hypothesis compares organizations that are sensitive to information security with those that are not. It distinguishes between homogeneous security-sensitive organizations and non-sensitive organizations.
H3: Density increases when security sensitivity characterizes all the organizations participating in the discourse compared to the density in heterogeneous groups containing security-sensitive and non-sensitive organizations.
Reciprocity and transitivity are two measures that refer to the structure of a network. The relationship between them is not always positive or negative. Hence, these two metrics should be studied separately [
81]. We examine the metrics that reflect communication between participants: reciprocity, which refers to dual communication between two members in a directed graph [
62], and transitivity, which is the degree of clustering, the tendency for triads of connections to appear in the network and therefore also refers to communication [
63]. Reciprocity and trust are reflected in strong ties [
65], and transitivity is expected to be high within networks with high trust [
70]. Treating the communication level, which is expressed by reciprocity, average clustering, and transitivity, as the extent of message exchange, the fourth hypothesis is as follows:
H4: Reciprocity, average clustering, and transitivity are higher for homogeneous security-sensitive organizations as compared to non-sensitive organizations.
Radius and diameter are the minimum and maximum eccentricity observed among all nodes, respectively. Low radius and diameter imply higher connectivity [
63] and effective information dissemination in the network [
62]. Density, which refers to the proportion of links that exist in the graph and the maximum number of possible links in the graph, implies the level of connectivity in the network [
62,
63] closer relationship between the members and high knowledge sharing among community members [
80]. Hence, the next hypothesis concerns the effectiveness of knowledge sharing and examines the network structure as reflected by diameter, radius, and density.
H5: Diameter and radius are smaller and density is higher in security-sensitive organizations as compared to non-sensitive organizations.
Hypotheses 1–5 refer to the effect of the number of organizations, homogeneity, and sensitivity to information security on the network metrics, especially on density. Network metrics indicate the spread of knowledge and the level of communication [
32,
33,
34,
35,
36,
82]. Since human behavior has a reciprocal effect on the network structure and vice versa, hypothesis 6 refers to the difference in network metrics between organizations that are sensitive to information and those that are not.
H6: There is a difference in reciprocity, diameter, radius, and density, which reflect network structure, representing organizations that are sensitive to information, compared to network structures that represent organizations that are not sensitive to information.
To summarize,
Figure 1 incorporates all hypotheses and shows the relation between them in the research model, which reflects the overall knowledge sharing:
Variables:
Independent variables: (1) Number of organizations participating in the conversation; (2) Homogeneous in terms of sensitivity to information; (3) Type of organization: security-sensitive or not security-sensitive.
Dependent variables: (1) Diameter; (2) Radius; (3) Density; (4) Reciprocity; (5) Avg. clustering; (6) Transitivity.
Diameter, radius, and density reflect the effectiveness of knowledge spread. Reciprocity, average clustering, and transitivity reflect the level of communication.
4. Method
The primary method for examining the influence of secrecy culture on knowledge sharing is a comparative analysis of communication graphs using the metrics described earlier: clustering coefficient, transitivity, diameter, radius, and density. The comparison is conducted between security-sensitive and non-sensitive organizations taking part in communities discussing a common topic, COVID-19.
The dataset—The struggle with COVID-19 supplied a unique opportunity to study the formation of task forces that emerged quickly and began fighting the pandemic. Task forces were formed in parallel by the military intelligence and by the civilian Ministry of Health. Both communities used WhatsApp instant messaging for real-time communication and updates regarding the pandemic. This situation was anomalous for the military community, which usually deals with classified materials. Since a large part of the information was not security-related, knowledge sharing was expected to follow the practices of unclassified communities. The discourse revealed within both intelligence and civil communities provides us with a unique opportunity to use network metrics to analyze knowledge sharing.
To gain access to the classified information, we sent an explanation to intelligence community members including a link to a tool that removes all the content. The tool is our own development in the Node.js programming language. Members who agreed to cooperate and received permission cleaned the content and sent us text files without the content. Most of the groups we gained access to were completely clean. This means we received a .txt file with a list of classified names of message senders and dates according to the sending order. For some groups, we received a textual description of the purpose of establishing the WhatsApp group. Regarding the type of participants in each group, intelligence personnel, industry, or academia, we received reliable information that was checked and verified by three intelligence members.
The research involved only unidentifiable/de-identified private information. In such cases, a IRB review is not required.
Groups—
Table 2 describes each of the 18 analyzed Whatsapp groups engaged in COVID-19 knowledge sharing. The groups are organized as follows: security-sensitive groups are first, followed by non-security-sensitive groups. The inner order is defined by the number of organizations members relate to. Acronyms in
Table 2: military intelligence is “|Int.Army”, the civilian intelligence body “Home Front Command” (HFC) is “Int.Civil”, industry is “Ind“, and academia is “Acd”. The “Homogeneous” column refers to the nature of the analyzed group. If the group includes several security-sensitive organizations, the group is
homogeneous regarding its sensitivity to information security (denoted as 1 in
Table 2). If the group included mixed groups of security-sensitive organizations and civilians, we define the group as
heterogeneous and indicate 0 in the cell. All groups were exported simultaneously and reflected conversations from the same period-about one year.
The nodes in
Table 2 represent participants (N = 593). Arcs represent knowledge sharing between participants. If there is one interaction between a pair of participants, the weight of the arc is 1. Repeated communication increases the weight of the arc proportionately to the number of interactions.
Table 2 suggests that when group participants are from one or two organizations, the group is likely to be homogeneous. When participants are from more than two organizations, the group becomes heterogeneous.
Procedure:
1. Data preparation: we received 18 WhatsApp conversations as clean txt files, after activating a custom script we developed in Node.js to remove the content, resulting in 18 txt files containing only information about the sender and timestamp, while excluding the message content. These files served as the raw data for the study.
2. Network construction: A Python (version 3.7) script was used to gather data about network structure.
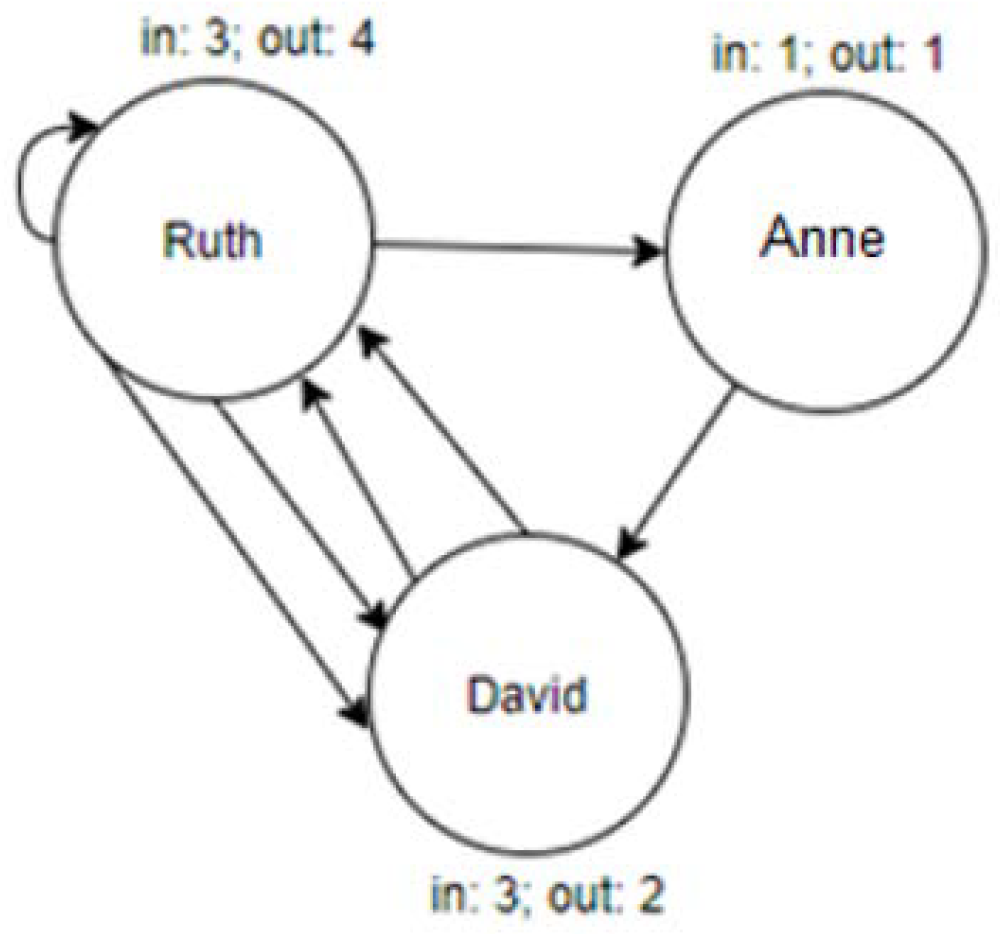
First, we defined the network as Multidigraph, where each participant is a node, and each response to a message is an arc, with directions assigned and multiple arcs enabled between nodes. As an illustration of the construction phase, the following is a conversation sample. In this example, names are displayed. In the original dataset there were aliases instead of names, as follows:
[10:00:01] Ruth: Hello
[10:00:03] David: Hello to you too
[10:00:05] Ruth: How are you?
[10:00:06] Anne: I am fine, thank you
[10:00:07] David: I am also fine
[10:00:11] Ruth: What do you think about the weather?
[10:00:11] Ruth: Is it suitable for a picnic?
[10:00:14] David: I believe it is
Below is the conversation after the data preparation phase:
[10:00:01] Ruth:
[10:00:03] David:
[10:00:05] Ruth:
[10:00:06] Anne:
[10:00:07] David:
[10:00:11] Ruth:
[10:00:11] Ruth:
[10:00:14] David:
Although a conversation involves many people, we define each message as a reply to the previous one. As described before, it is a common method for analyzing text-based interactions between people. We convert the exchange of messages into communication graphs [
75,
76,
77,
78].
Table 3 shows the connections in terms of target and source.
Figure 2 illustrates the multidigraph corresponding to
Table 3. The arrow starts at the message originator and points to the responder. The arc represents the sharing of knowledge.
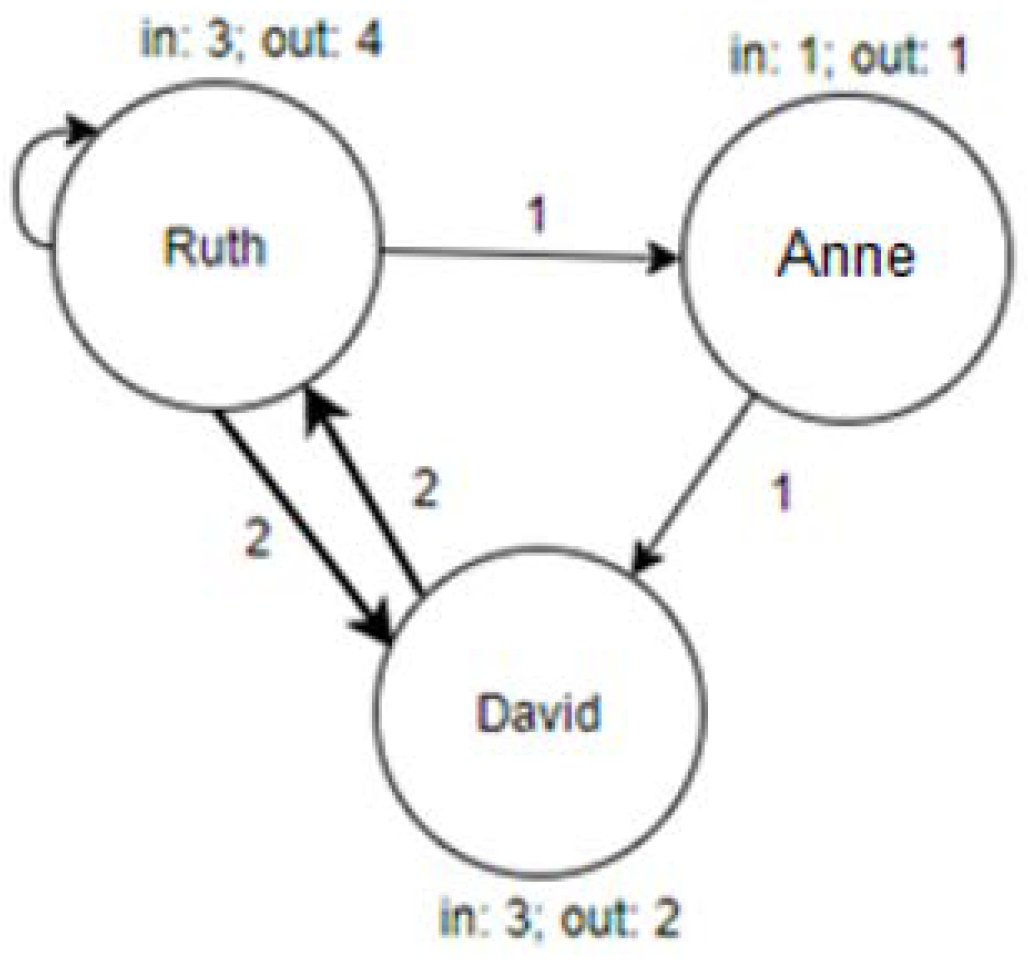
Next, we added the direction of each message. If David sends a message after Anne, David is assumed to be sharing knowledge. The weight of each arc is the sum of responses sent between the respective nodes. According to the previous example,
Figure 3 illustrates the corresponding Digraph (directional graph).
3. Analyzing network structure and behavior: We calculated reciprocity, diameter, transitivity, average clustering, density, and radius for each of the 18 groups. Similarities and differences between security-sensitive and non-sensitive organizations are detailed in
Section 5 together with the particular statistical tests used.
5. Results
Table 4 and
Table 5 display descriptive statistics of the variables for security-sensitive and non-security-sensitive groups, respectively. Both tables are ordered by the number of organizations. In these tables, the low values of the first two columns, diameter and radius, indicate an efficient connection between participants, improving the chance that knowledge will pass. Hence, we bolded
low values. In the next four columns,
high values indicate efficiency and better communication in the network. Hence, we bolded the three highest values.
It is important to note that the above metrics do not directly depend on the network size. The explanation for the density being greater than 1 is that self-loops are considered. This means that posting a sequence of messages by a member is represented on the network as self-loops, which increases density to above 1.
The following sub-sections refer to each of the hypotheses.
5.1. The Influence of the Number of Organizations on Density
A one-way between-subjects ANOVA was conducted to compare the effect of the number of organizations participating in the discourse on density. There was a statistically significant effect of the number of organizations on density F(2,16) = 5.648, p = 0.015.
Post hoc comparisons using the LSD test are reported in
Table 6. The results indicate that the density of interactions between members when one organization participates in the discourse is significantly higher than the density when two, or more than two, organizations are involved.
Table 7 displays descriptive statistics regarding density by the number of participating organizations in each group.
Hypothesis H1 was accepted. Density decreases as the number of organizations participating in the discourse increases.
5.2. The Influence of Homogeneity on Density
To test whether homogeneity in terms of the affiliation of the participants to similar organizations has an impact on density, a t-test for independent samples was conducted. A statistically significant effect was found t(16) = −2.211,
p = 0.020. The density in groups in which homogeneity characterizes the participants of the discourse was higher than in heterogeneous groups.
Table 8 displays density according to homogenous groups.
H2 was accepted. Density increases when homogeneity characterizes the participants of the discourse.
5.3. The Influence of a Security-Sensitive Culture of Organizations on Density
To test whether a security-sensitive culture has an impact on density, a t-test for independent samples was conducted. A statistically significant effect was found t(16) = −2.810,
p = 0.034. The density in security-sensitive groups was higher than in non-security-sensitive organizations.
Table 9 displays density according to homogenous groups.
H3 was accepted. Density increases when sensitivity to security characterizes the culture of the organizations participating in the discourse.
5.4. Communication in the Network
For communication in the network, we performed qualitative assessments based on reciprocity and transitivity (
Table 4 and
Table 5). The visualizations in
Figure 4 and
Figure 5 in this section and
Figure 6,
Figure 7 and
Figure 8 in
Section 5.5 distinguish between the type of group (security-sensitive organization—top of figures, non-sensitive organizations—bottom of figures) and the number of organizations participating in the group (1 organization—blue, two organizations—orange, more than two—red).
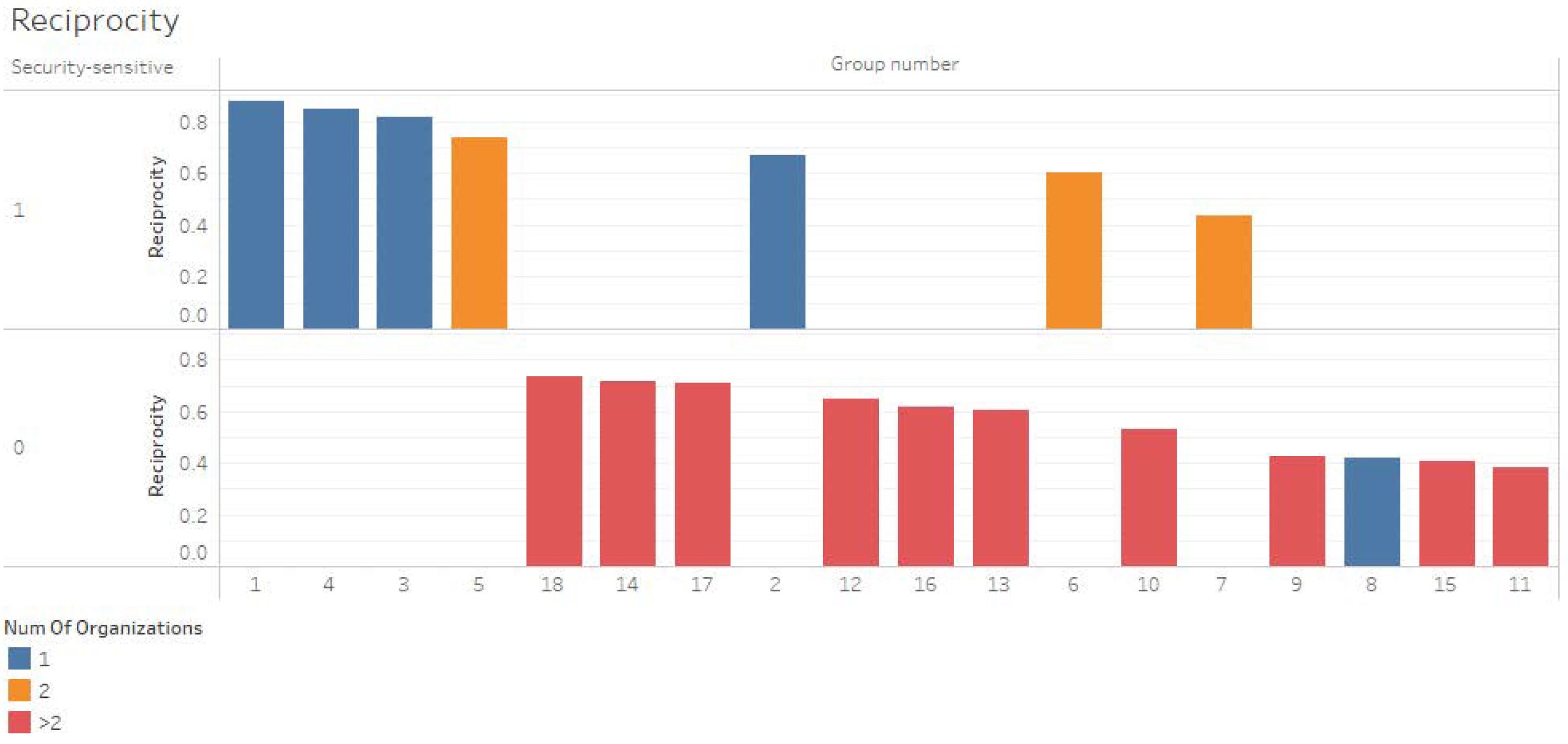
Reciprocity—
Figure 4 displays reciprocity in a bar chart. The four groups with the highest reciprocity are homogenous groups, with all members associated with security-sensitive organizations. Members in the first three groups come from one organization. For comparison, group 8, which is also homogenous with one organization but is a non-security organization, has a lower reciprocity. When two security-sensitive organizations participate in a community, their reciprocity reduces (groups 5, 6, and 7). All groups that include organizations, whether from one or more than two, that are not sensitive to information are, without exception, are placed in the lower places regarding the reciprocity value.
Figure 4.
Reciprocity by number of organizations and security-sensitivity.
Figure 4.
Reciprocity by number of organizations and security-sensitivity.
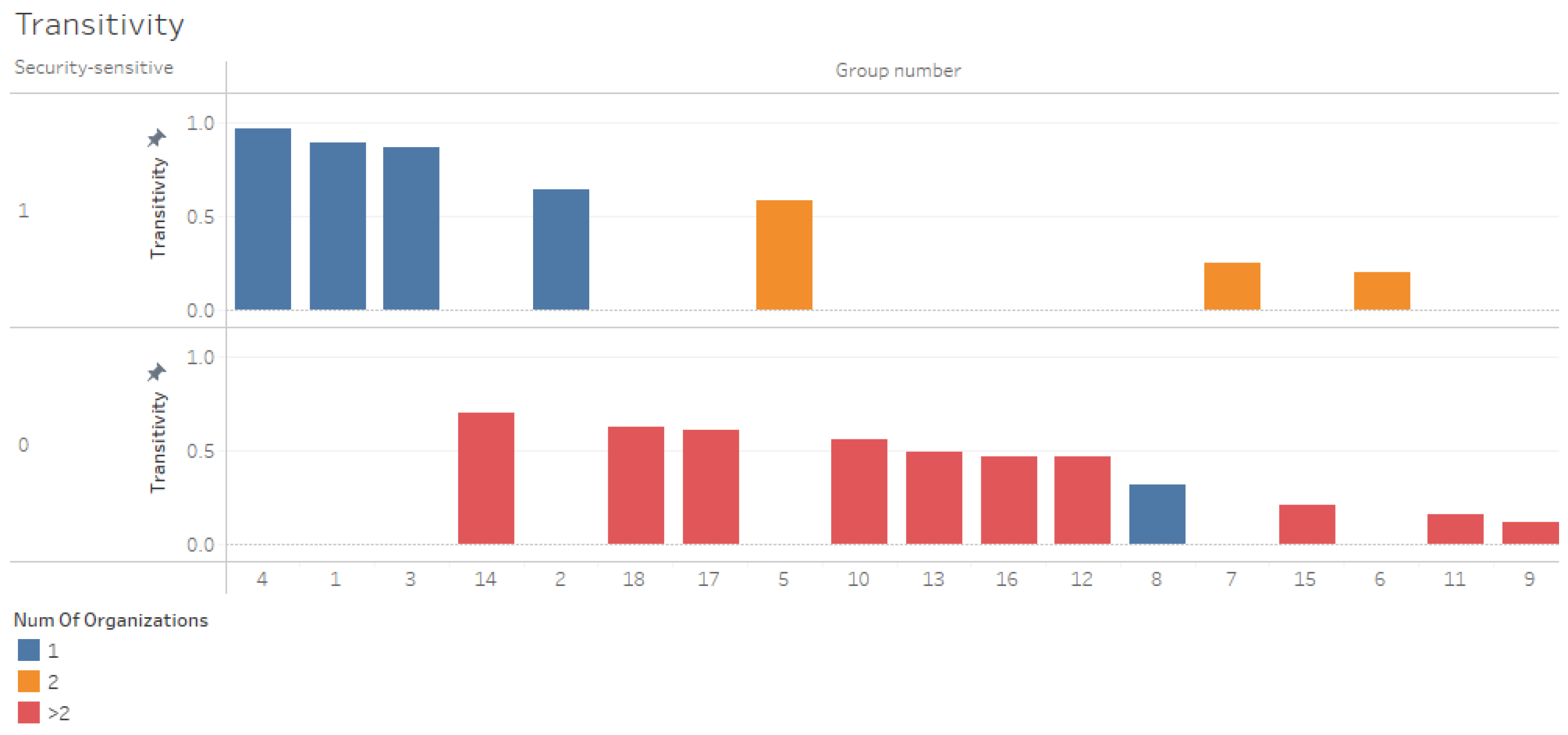
Transitivity—
Figure 5 displays transitivity in a bar chart. The three groups with the highest transitivity are homogeneous groups characterized by a security-sensitive culture. Transitivity decreases when two organizations form a community (groups 5, 6, 7). In contrast, group number 8 is homogenous and non-security-sensitive. It has low transitivity, although its members are from one organization.
Figure 5.
Transitivity by the number of organizations and security-sensitivity.
Figure 5.
Transitivity by the number of organizations and security-sensitivity.
According to the findings regarding reciprocity and transitivity, homogeneous security-sensitive organizations communicate better than non-sensitive organizations. H4 was accepted. Homogeneous security-sensitive organizations communicate better than non-sensitive organizations.
5.5. Spread of Knowledge in the Network
Radius, diameter, and density indicate the spread of knowledge in the groups.
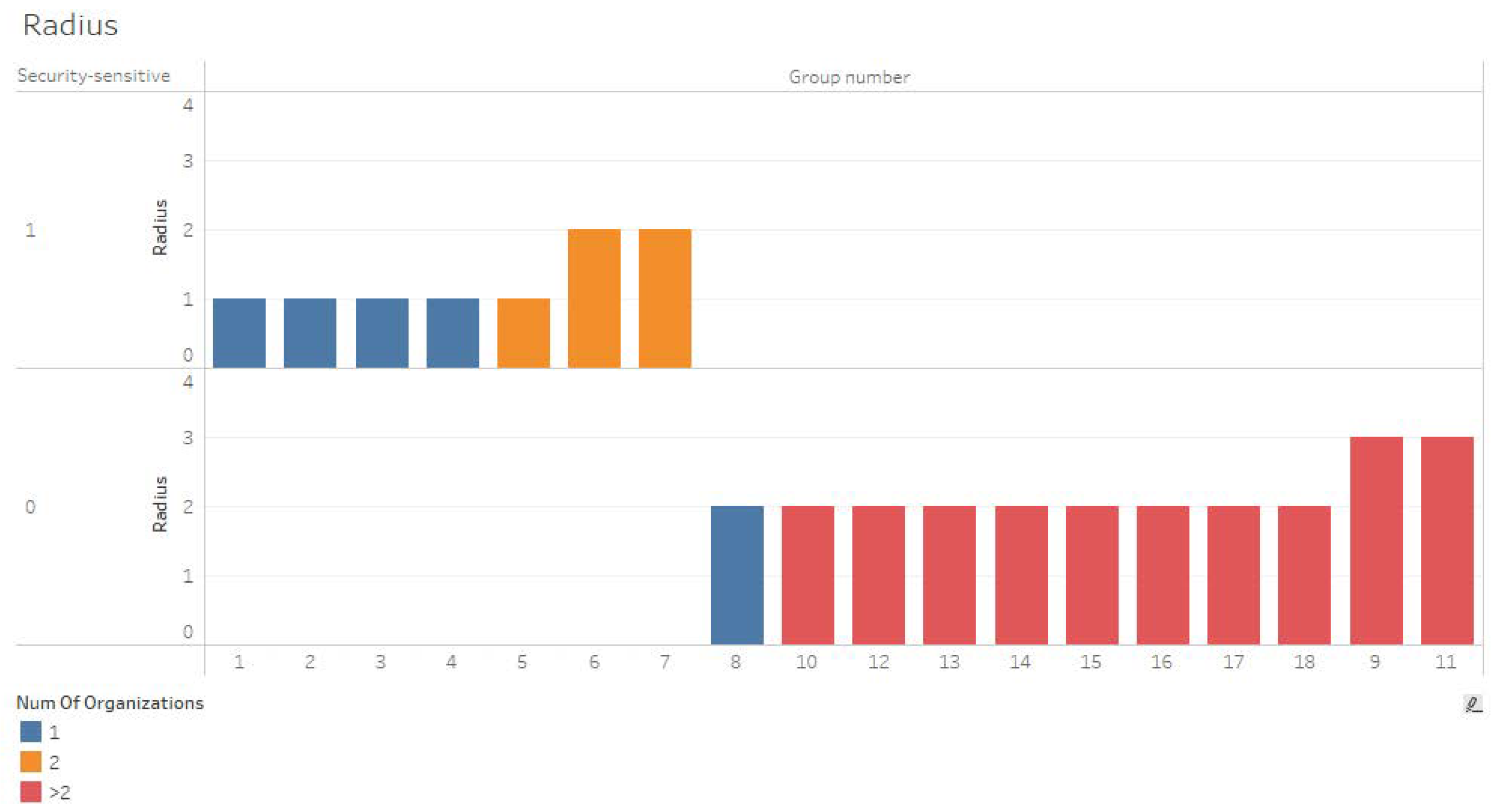
Radius—
Figure 6 displays groups sorted by their radius. Groups whose radius is small indicate effective connectivity in the network. The first groups are from one security-sensitive organization.
Figure 6.
Radius by number of organizations and security sensitivity.
Figure 6.
Radius by number of organizations and security sensitivity.
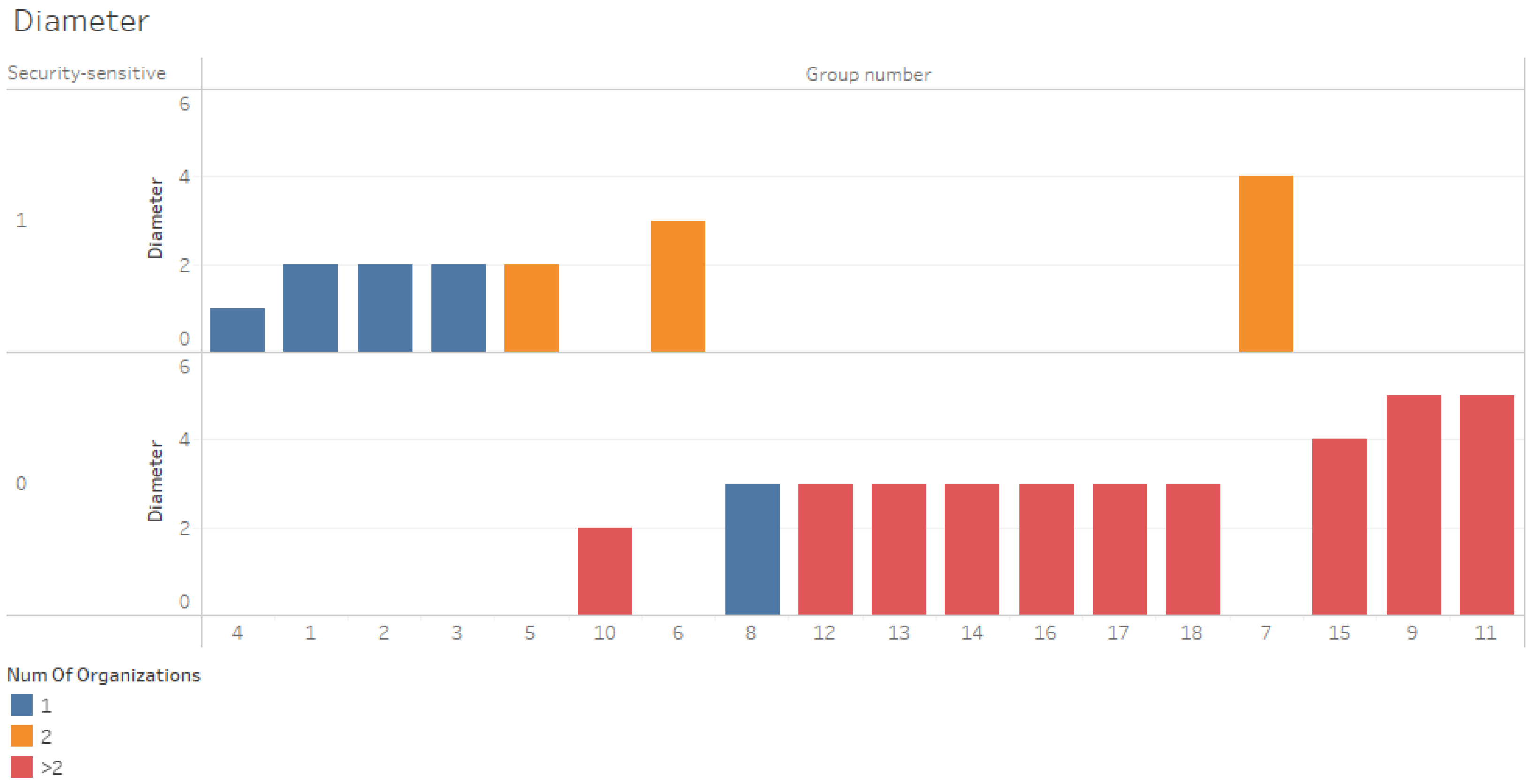
Diameter—
Figure 7 displays groups sorted by their diameter. Groups with low diameters are assumed to have effective connectivity. Groups containing participants from one security-sensitive organization have the lowest diameter. The diameter reflects how “big” the network is regarding the number of steps necessary to get from one side to the other. Therefore, the diameter does not equal the radius (
Figure 6).
Figure 7.
Diameter by number of organizations and security-sensitivity.
Figure 7.
Diameter by number of organizations and security-sensitivity.
Density—
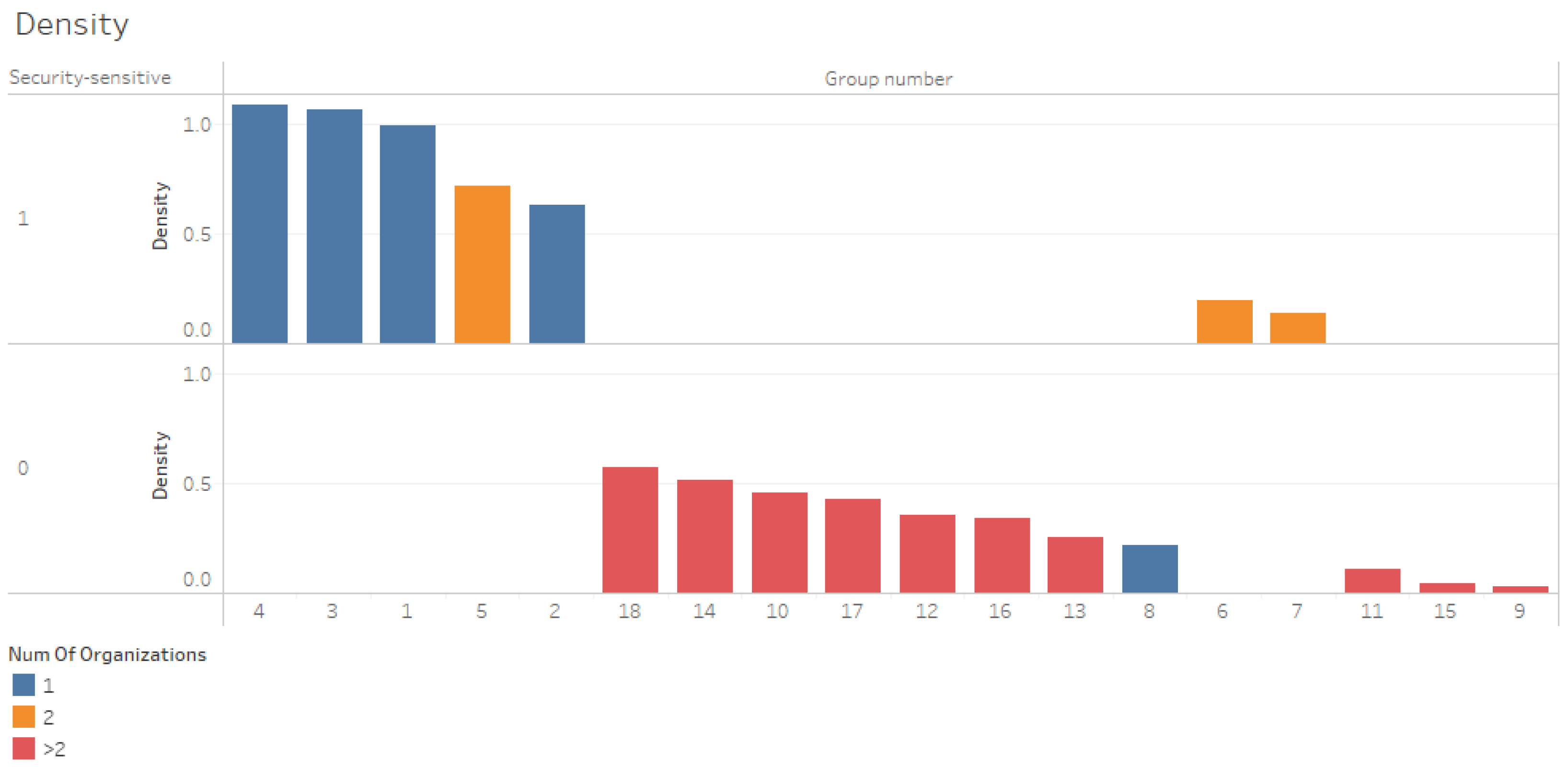
Figure 8 displays the groups sorted by their density. The five groups with the highest density are security-sensitive groups. Four of them include members from one organization.
Figure 8.
Density by number of organizations and security sensitivity.
Figure 8.
Density by number of organizations and security sensitivity.
The findings indicate that knowledge sharing in security-sensitive organizations, as measured by radius, diameter, and density, is more effective than in non-sensitive organizations. H5 was accepted.
5.6. Differences in Community Structure
To test whether there are differences in network structure between security-sensitive and non-sensitive organizations, a Mann–Whitney U test was conducted due to their asymmetrical distributions.
Table 10 details the mean ranks and Mann–Whitney U tests. For diameter and radius, low values represent efficient knowledge sharing.
Statistically significant differences were found between security-sensitive and non-sensitive organizations in the metrics: reciprocity, diameter, radius, and density. H6 was accepted. There is a difference in network structure representing security-sensitive organizations compared to network structure representing non security-sensitive organizations.
6. Discussion
Intelligence organizations are responsible for defining critical information, collecting it, and evaluating and distributing it to the relevant parties. However, information and knowledge sharing occur alongside confidentiality and compartmentalization regulations [
2]. Sharing takes place when network members trust each other and so in a network structure, trust may be quantified and assessed using Social Network Analysis measures. This paper investigates differences in social network measures between group discussions involving military and civilian intelligence personnel (security-sensitive) and group discussions that include members from diverse organizations, such as industry and academia (non-security-sensitive). Trust is fundamental to all aspects of intelligence work [
83]. In international intelligence organizations, social ties and trustworthiness perceptions are more influential than often assumed, with shared professional standards and traits enabling collaboration [
84]. However, trust remains a complex multifaceted phenomenon influenced by various factors, including human interactions with AI systems and end-user involvement in development [
85]. The current study compared the cultural diversity of sharing and trust, based on previous research that presented the impact of cultural diversity on knowledge sharing [
4]—the results of our study confirmed the cultural impact of sharing and trust on information sharing. In addition, previous studies addressed the effect of the trust dimension on human behavior and information sharing, which were reflected in our results [
5].
The method we used, discourse analysis by representing it in a communication graph and using SNA methods, is taken from the literature [
6]. The social network measures of this study indicate that knowledge sharing depends on trust, as evidenced by the current outcomes of Social Network Analysis in 18 instant messaging groups discussing COVID-19. Moreover, the results show that trust and the resulting knowledge sharing depend on the number of organizations represented in a group and their inclination toward information security. All our hypotheses were accepted, showing that knowledge flow is the result of a low number of organizations and having an organizational tradition of information security. In other words, trust and knowledge sharing develop over time in dense communities aided by low heterogeneity. This effect is interesting considering that the intelligence communities in the present study engaged in non-intelligence material as the topic was COVID-19. Possibly, knowledge sharing is enhanced as a result of an organizational requirement that creates a “habit of sharing” that carries over to non-security related topics such as the current example of a health-related topic. The same “habit of sharing” does not support sharing when additional non-intelligence organizations join the conversation. In this case, the “habit of secrecy” becomes dominant.
Knowledge sharing in homogeneous communities faces challenges despite the potential benefits. While homogeneous communities with shared concerns facilitate intra-community knowledge exchange, sharing between them is more complex due to a lack of shared identity and trust [
86]. Online communities, though seemingly boundary-free, still exhibit preferences for sharing with similar others. However, as participants gain experience, they rely more on expertise similarity and less on categorical attributes like location or status [
87]. Factors influencing knowledge sharing in professional virtual communities include reciprocity norms, interpersonal trust, self-efficacy, and perceived advantages [
88].
We examined the relationship between network metrics, trust, homogeneity between members, the number of organizations participating in the observed discussion, and knowledge sharing. We divided network metrics into the spread of knowledge and communication levels.
The spread of knowledge allows knowledge-sharing analysis across the entire network. Measures of the spread of knowledge include network radius, diameter, and density. Results indicate that when the goal is operational tasks, the radius and diameter are smaller than in non-sensitive organizations. In addition, density in a security-sensitive organization is higher than in a non-sensitive organization.
The level of communication allows the analysis of network parts, such as pairs of vertices, triads, neighbors, and clusters. Network metrics that reflect communication include reciprocity and transitivity.
Intelligence organizations operate under constraints, rules, procedures, and norms that impact the behavior of the network and the sharing of knowledge in the community. Communication patterns affect the conversation. For example, participants who are soldiers may only participate in the conversation when their commander is present. However, if the goal of the groups created were to transfer knowledge through a trust-based dialogue, we would expect to see a development of collective intelligence even when civil intelligence joins the group, whose goal is the same—the protection of citizens. Our results show that the intelligence communities are denser than other networks tested. On the one hand, when trust develops within networks, it fosters interactions and collaborations, which enable knowledge sharing and the development of collaborative intelligence. On the other hand, inhibiting factors such as lack of control over the flow of data and organizational culture hinder the sharing of knowledge due to security considerations. In traditional SNA theories, these factors are not considered. In conventional research that analyzes social networks, it is common to analyze different communities in terms of age, size, gender, and different natures or goals of the organizations being examined. However, the present study is unique in analyzing and comparing the unique intelligence community with civilian communities. This study also examined the effect of connecting two security-sensitive organizations, one military and one civilian, on knowledge sharing. The results indicate that when these two organizations participate together in the same group, there is a decrease in knowledge sharing—in the reciprocity of reactions, transitivity, and the density of the network.
When comparing the network structures created by the security-sensitive organizations and non-sensitive organizations, statistically significant differences were found. Moreover, it can be understood that structure affects behavior, and vice versa, the behavior of the participants, their organizational culture, unique education in the intelligence division, etc., produce a defined structure.
7. Limitations and Future Research
The global spread of the pandemic has created a unique situation. Intelligence groups, which typically develop information on secure platforms, have started working from home and used WhatsApp as their primary method for sharing information. This exceptional access has enabled us to conduct our research using real-world data. However, this study is limited by the lack of knowledge regarding the identity of each participant and the inability to read the actual messages. In addition, our analysis was limited to 18 groups. A more comprehensive study might examine a greater number of groups. Since most of the content was not visible to us, we could do a limited content analysis. For this reason, we expanded the analysis on the networks and tried to understand the little content that was visible to us.
Besides lifting the veil from the participants and the content of discussions, future research should also expand on the dimension of usability and its delicate balance with the need for security [
23]. Choosing WhatsApp as the means of communication may possibly be a sign of having to circumvent rigid systems with restrictive security measures [
23]. Future research could address a triangle of challenges: security, information sharing, and usability.
8. Conclusions
The initial impetus for this study stemmed from a problem that arose in interviews with intelligence personnel, who reported suboptimal knowledge-sharing in intelligence communities.
The methodology was a set of SNA tools and analyses carried out in WhatsApp conversations to examine knowledge sharing in security-sensitive organizations, including data preparation, network construction, and network structure analysis. The dataset included .txt files exported from 18 WhatsApp group conversations without the content of the messages. All conversations were exported at the same time during a global crisis. The COVID-19 pandemic gave us a unique opportunity to obtain such sources to examine. The communities used WhatsApp for real-time communication to share unclassified knowledge and, therefore, agreed to share the knowledge with us.
The results show that (1) there is a difference in the network structure of intelligence groups compared to other groups. (2) Intelligence communities have a higher density than heterogeneous groups and from a homogeneous group from the industry. (3) The sharing of knowledge decreases when connecting two intelligence groups. (4) Characteristics relevant to the complex organizational culture of security-sensitive organizations affect the network’s structure, and the network’s structure affects the sharing of knowledge.
As part of the integration processes of intelligence bodies with industry and academia, in order to share knowledge, intelligence personnel should distinguish between public and classified information and support cooperation when this is permitted in terms of national security.
In conclusion, this study contributes to the knowledge of groups, organizations, and communication patterns by analyzing how knowledge is shared in classified environments and showing that intra-organizational sharing in low diversity groups is more efficient than in large and diverse groups.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}