

AI-Driven Framework for Evaluating Climate Misinformation and Data Quality on Social Media



Abstract
1. Introduction
- Proposal of a novel multi-stage classification pipeline: integrating sentiment-aware and domain-specific language models to identify and score the quality of climate-related content across platforms.
- Development of a content credibility scoring metric: combining linguistic features, source reliability, and user feedback signals into a unified quality index.
- Building a cross-platform dataset: composed of labeled social media posts (Twitter, YouTube, Reddit) with expert-reviewed quality tags, spanning diverse climate-related topics and misinformation themes.
- Evaluation of system performance: using metrics such as precision, recall, F1-score, AUC, and Brier score, and benchmarked against state-of-the-art misinformation classifiers.
- Conduct of ablation studies and bias tests: to assess robustness across domains, user demographics, and misinformation types, validating generalizability under real-world conditions.
Operational Definition and Evaluation of Data Quality
- Accuracy: The extent to which social media content reflects scientifically validated facts. Accuracy is verified through natural language inference techniques and content alignment with trusted climate science repositories, such as IPCC and NASA reports.
- Credibility: Credibility is assessed by examining metadata such as user profile verification, posting history, domain expertise, and network behavior. A trust scoring algorithm, enhanced by graph-based modeling, evaluates the source’s historical reliability.
- Completeness: Posts are analyzed for the inclusion of contextually necessary elements, such as data references, source links, and full narrative framing. Incomplete posts are flagged using text structure analysis and missing component detection.
- Relevance: Topic modeling and semantic similarity measures are applied to determine how closely a post aligns with current climate-related topics, discussions, or campaigns.
2. Literature Review
2.1. The Spread of Climate Misinformation on Social Media
2.2. AI and Machine Learning in Misinformation Detection
2.3. Social Media Platform Policies on Climate Misinformation
2.4. Stance Detection in Climate Misinformation Research
3. Materials and Method
3.1. Overview of Methodological Framework and Key Hyperparameters
3.2. Data Collection Module
3.3. Data Preprocessing Module
3.4. Data Labeling Protocol
3.5. Misinformation Detection Module
| Algorithm 1: Fine-tuning RoBERTa for climate misinformation classification. |
 |
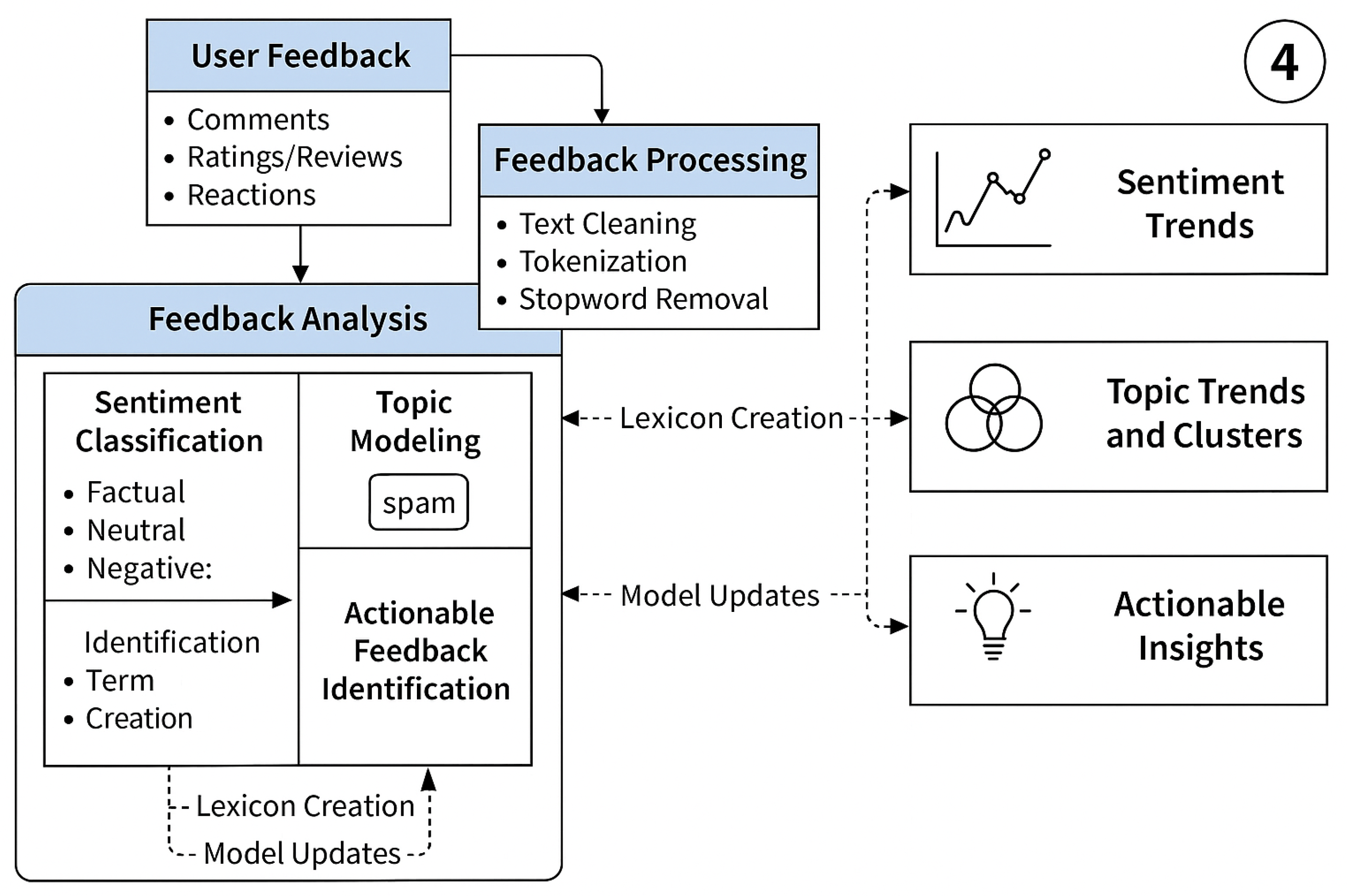
3.6. User Feedback Analysis
4. Results
4.1. Data Acquisition and Source Integrity Evaluation
4.2. Preprocessing Accuracy and Data Hygiene
4.3. Misinformation Detection Performance Evaluation
4.4. Sentiment, Feedback, and Trend Analysis
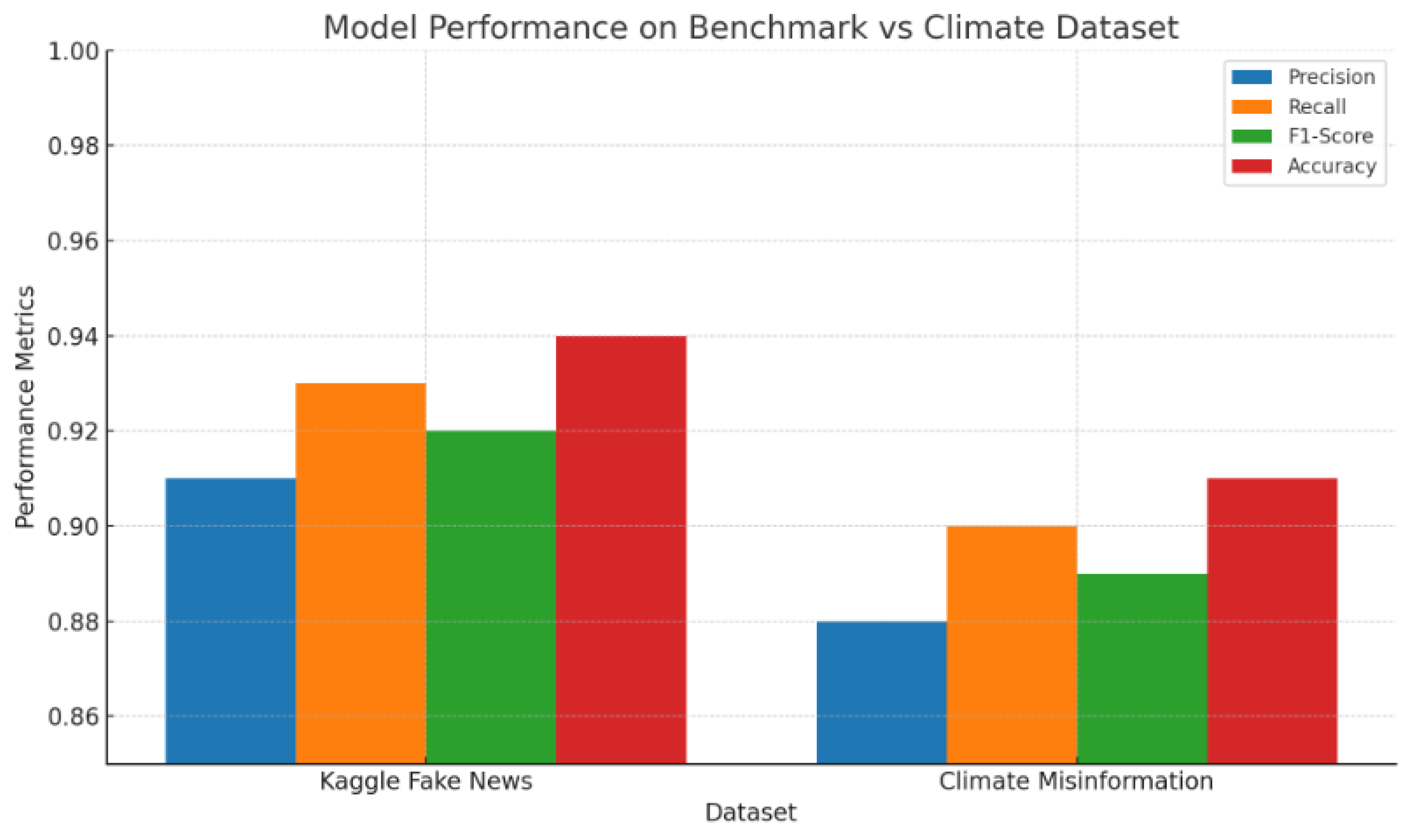
4.5. Benchmark Validation with Public Datasets
4.6. Comparison with Existing Baselines
5. Conclusions
6. Discussion
7. Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Anno, S.; Kimura, Y.; Sugita, S. Using transformer-based models and social media posts for heat stroke detection. Sci. Rep. 2025, 15, 742. [Google Scholar] [CrossRef] [PubMed]
- Chmiel, M.; Fatima, S.; Ingold, C.; Reisten, J.; Tejada, C. Climate change as fake news. Positive attribute framing as a tactic against corporate reputation damage from the evaluations of sceptical, right-wing audiences. Corp. Commun. Int. J. 2025, 30, 388–407. [Google Scholar] [CrossRef]
- Vasileiadou, K. Misinformation, disinformation, fake news: How do they spread and why do people fall for fake news? Envisioning Future Commun. 2025, 2, 239–254. [Google Scholar]
- Hashim, A.S.; Moorthy, N.; Muazu, A.A.; Wijaya, R.; Purboyo, T.; Latuconsina, R.; Setianingsih, C.; Ruriawan, M.F. Leveraging Social Media Sentiment Analysis for Enhanced Disaster Management: A Systematic Review and Future Research Agenda. J. Syst. Manag. Sci. 2025, 15, 171–191. [Google Scholar]
- Podobnikar, T. Bridging Perceived and Actual Data Quality: Automating the Framework for Governance Reliability. Geosciences 2025, 15, 117. [Google Scholar] [CrossRef]
- Cornale, P.; Tizzani, M.; Ciulla, F.; Kalimeri, K.; Omodei, E.; Paolotti, D.; Mejova, Y. The Role of Science in the Climate Change Discussions on Reddit. arXiv 2025, arXiv:2502.05026. [Google Scholar] [CrossRef]
- D’Orazio, P. Addressing climate risks through fiscal policy in emerging and developing economies: What do we know and what lies ahead? Energy Res. Soc. Sci. 2025, 119, 103852. [Google Scholar] [CrossRef]
- ISO/IEC 25012; Software Engineering—Software Product Quality Requirements and Evaluation (SQuaRE)—Data Quality Model. ISO/IEC: Geneva, Switzerland, 2008.
- Bassolas, A.; Massachs, J.; Cozzo, E.; Vicens, J. A cross-platform analysis of polarization and echo chambers in climate change discussions. arXiv 2024, arXiv:2410.21187. [Google Scholar]
- Mahmoudi, A.; Jemielniak, D.; Ciechanowski, L. Echo chambers in online social networks: A systematic literature review. IEEE Access 2024, 12, 9594–9620. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Byun, Y.C. NLP-Based Digital Forensic Analysis for Online Social Network Based on System Security. Int. J. Environ. Res. Public Health 2022, 19, 7027. [Google Scholar] [CrossRef]
- Herasimenka, A.; Wang, X.; Schroeder, R. A Systematic Review of Effective Measures to Resist Manipulative Information About Climate Change on Social Media. Climate 2025, 13, 32. [Google Scholar] [CrossRef]
- Chen, L. Combatting Climate Change Misinformation: Current Strategies and Future Directions. Environ. Commun. 2024, 18, 184–190. [Google Scholar] [CrossRef]
- Freiling, I.; Matthes, J. Correcting climate change misinformation on social media: Reciprocal relationships between correcting others, anger, and environmental activism. Comput. Hum. Behav. 2023, 145, 107769. [Google Scholar] [CrossRef]
- Rojas, C.; Algra-Maschio, F.; Andrejevic, M.; Coan, T.; Cook, J.; Li, Y.F. Hierarchical machine learning models can identify stimuli of climate change misinformation on social media. Commun. Earth Environ. 2024, 5, 436. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, J.; Zhang, L.; Cheng, X.; Hu, Z. MRAN: Multimodal relationship-aware attention network for fake news detection. Comput. Stand. Interfaces 2024, 89, 103822. [Google Scholar] [CrossRef]
- Abimbola, B.; de La Cal Marin, E.; Tan, Q. Enhancing Legal Sentiment Analysis: A Convolutional Neural Network–Long Short-Term Memory Document-Level Model. Mach. Learn. Knowl. Extr. 2024, 6, 877–897. [Google Scholar] [CrossRef]
- Galaz, V.; Metzler, H.; Daume, S.; Olsson, A.; Lindström, B.; Marklund, A. AI could create a perfect storm of climate misinformation. arXiv 2023, arXiv:2306.12807. [Google Scholar]
- Da San Martino, G.; Gao, W.; Sebastiani, F. QCRI at SemEval-2016 Task 4: Probabilistic Methods for Binary and Ordinal Quantification. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; Bethard, S., Carpuat, M., Cer, D., Jurgens, D., Nakov, P., Zesch, T., Eds.; Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 58–63. [Google Scholar] [CrossRef]
- Kim, J.; Malon, C.; Kadav, A. Teaching Syntax by Adversarial Distraction. In Proceedings of the First Workshop on Fact Extraction and VERification (FEVER), Brussels, Belgium, 1 November 2018; Thorne, J., Vlachos, A., Cocarascu, O., Christodoulopoulos, C., Mittal, A., Eds.; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 79–84. [Google Scholar] [CrossRef]
- Hardalov, M.; Arora, A.; Nakov, P.; Augenstein, I. A Survey on Stance Detection for Mis- and Disinformation Identification. arXiv 2022, arXiv:2103.00242. [Google Scholar]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Dong, Y.; He, D.; Wang, X.; Jin, Y.; Ge, M.; Yang, C.; Jin, D. Unveiling implicit deceptive patterns in multi-modal fake news via neuro-symbolic reasoning. Proc. AAAI Conf. Artif. Intell. 2024, 38, 8354–8362. [Google Scholar] [CrossRef]
- Tufchi, S.; Yadav, A.; Ahmed, T. A comprehensive survey of multimodal fake news detection techniques: Advances, challenges, and opportunities. Int. J. Multimed. Inf. Retr. 2023, 12, 28. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Mesbah, M. Deep Learning Techniques for Enhancing the Efficiency of Security Patch Development. In Proceedings of the Advances in Computer Science and Ubiquitous Computing; Park, J.S., Camacho, D., Gritzalis, S., Park, J.J., Eds.; Springer: Singapore, 2025; pp. 199–205. [Google Scholar]
- Shahbazi, Z.; Jalali, R.; Shahbazi, Z. Enhancing Recommendation Systems with Real-Time Adaptive Learning and Multi-Domain Knowledge Graphs. Big Data Cogn. Comput. 2025, 9, 124. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Shahbazi, Z.; Nowaczyk, S. Enhancing Air Quality Forecasting Using Machine Learning Techniques. IEEE Access 2024, 12, 197290–197299. [Google Scholar] [CrossRef]
- Herasimenka, A.; Wang, X.; Schroeder, R. Promoting Reliable Knowledge about Climate Change: A Systematic Review of Effective Measures to Resist Manipulation on Social Media. arXiv 2024, arXiv:2410.23814. [Google Scholar]
- Villela, H.F.; Corrêa, F.; Ribeiro, J.S.d.A.N.; Rabelo, A.; Carvalho, D.B.F. Fake news detection: A systematic literature review of machine learning algorithms and datasets. J. Interact. Syst. 2023, 14, 47–58. [Google Scholar] [CrossRef]
- Mostafa, M.; Almogren, A.S.; Al-Qurishi, M.; Alrubaian, M. Modality deep-learning frameworks for fake news detection on social networks: A systematic literature review. ACM Comput. Surv. 2024, 57, 1–50. [Google Scholar] [CrossRef]
- Zheng, C.; Su, X.; Tang, Y.; Li, J.; Kassem, M. Retrieve-Enhance-Verify: A Novel Approach for Procedural Knowledge Extraction from Construction Contracts via Large Language Models. SSRN 4883720. 2022. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4883720 (accessed on 19 May 2025).
- Popat, K.; Mukherjee, S.; Yates, A.; Weikum, G. Declare: Debunking fake news and false claims using evidence-aware deep learning. arXiv 2018, arXiv:1809.06416. [Google Scholar]
- Ruchansky, N.; Seo, S.; Liu, Y. CSI: A hybrid deep model for fake news detection. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 797–806. [Google Scholar]
- Guo, H.; Cao, J.; Zhang, Y.; Guo, J.; Li, J. Rumor detection with hierarchical social attention network. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 943–951. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Research Problem | Methodology | Contribution |
|---|---|---|---|
| Shu et al. (2024) [22] | Real-time misinformation detection | Transformer-based NLP on social media streams | Showed BERT outperforms traditional classifiers |
| Wang et al. (2023) [23] | Interpretable detection models | Symbolic logic + neural networks | Improved explainability for multimodal misinformation |
| Tufchi et al. (2024) [24] | Detecting AI-generated tweets | NLP on TweepFake dataset | Distinguishes synthetic tweets from authentic ones |
| Chen et al. (2024) [25] | Framing-based misinformation | Large Language Models + framing theory | Detected factual distortions through framing patterns |
| Shahbazi et al. (2025) [26] | Domain knowledge graph | Cross-platform YouTube/Twitter analysis | Identified polarization and content segregation |
| Freiling et al. (2023) [27] | Corrective behavior | Two-wave panel survey + SEM | Activism and anger fuel misinformation correction |
| Wang et al. (2024) [28] | Intervention effectiveness | Systematic review | Evaluated strategies to resist climate misinformation |
| Villela et al. (2023) [29] | Fake news detection with AI | Literature review of NLP/ML tools | Mapped state-of-the-art detection techniques |
| Mostafa et al. (2024) [30] | Health misinformation filtering | ML/NLP review in healthcare | Assessed accuracy and limitations of models |
| Zhang et al. (2022) [31] | Expert-driven detection | Text-mining + human- in-the-loop ML | Increased expert efficiency in flagging false claims |
| Label | Sample Post | Annotation Rationale |
|---|---|---|
| Factual | “According to NOAA, 2023 was the hottest year on record globally”. | Verified against NOAA climate data; contains accurate attribution and context. |
| Misleading | “Wind turbines cause more pollution than coal when you include manufacturing”. | Based on partial truth but distorts impact; lacks full life-cycle comparison. |
| False | “CO2 is not a greenhouse gas, that’s just a myth pushed by the UN”. | Contradicts established climate science; claim refuted by IPCC and multiple sources. |
| Field | Description |
|---|---|
| Platform | Twitter, Reddit, Facebook, YouTube, TikTok |
| Time Range | January 2023–February 2025 |
| Total Posts Collected | 97,542 |
| Annotated Posts | 10,000 (human-labeled) |
| Labels | Factual, Misleading, False |
| Language | English (other languages filtered) |
| Sampling Criteria | Minimum 10 engagements (likes/comments/shares); includes climate-related keywords and hashtags |
| Labeling Source | Verified by IFCN partners, ClimateFeedback.org, Snopes, and expert annotators |
| Metric | Value | Data Type | Tools | Comments |
|---|---|---|---|---|
| Total Posts Collected | 1,050,000 | Text | Twitter API, Reddit API, YouTube API | Cross-Platform Sources |
| Average Daily Data Volume | −11.7 GB/day | Text + Metadata | Scrapy, BeautifulSoup | Including multimedia metadata |
| API Success Rate | 91.4% | Text + Metadata | Tweepy, PRAW | Limited by rate- limiting policies |
| Web-Scraping Efficiency | 86.2% | Text + Metadata | Selenium + Headless Chrome | Used where APIs were limited |
| Metadata Completeness | 95.6% | Text + Metadata | Custom Metadata Parser | Timestamps, Likes, Shares, etc. |
| Platform Breakdown | Tw: 52% Rd: 28% YT: 20% | Text + Metadata | - | Twitter was the most effective |
| Time Span | January–March 2025 | Date Range | - | Period of observation |
| Step | Time per 10k Record | Accuracy | Tools | Description |
|---|---|---|---|---|
| Text Normalization | 2.5 s | 99.1% | spaCy NLTK | Lowercasing, Stemming, Punctuation removal |
| Language Detection | 1.2 s | 97.8% | langdetect | Filtered for English French Spanish |
| Relevance Filtering | 3.1 s | 91.3% | TF-IDF BERT | Matched against climate-related keywords |
| Region Tagging | 2.9 s | 88.7% | GeoText | Based on IP, hashtags and mentions |
| Spam/Bot Removal | 4.4 s | 93.8% | Botometer Regex | Detected based on pattern and frequency |
| Hashtag Normalization | 2.2 s | 96.1% | Custom scripts | Standardized for semantic alignment |
| Model | P | R | F1 | Accuracy | Avg. Time | Data Source | Training Data Size | Explain Ability Tool |
|---|---|---|---|---|---|---|---|---|
| Majority Class Baseline | 72.0% | 0.0% | 0.0% | 72.0% | - | - | - | None |
| RoBERTa | 91.3% | 89.6% | 90.4% | 90.8% | 1.3 s | Twitter Reddit | 75 k labeled samples | SHAP |
| BERT | 89.7% | 87.4% | 88.5% | 89.2% | 1.6 s | Reddit YouTube | 80 k samples | LIME |
| GPT-3 (fine tuned) | 93.1% | 91.5% | 92.3% | 92.8% | 2.0 s | All sources | 100 k samples | OpenAI Tools |
| Ensemble (Voting) | 94.0% | 92.7% | 93.3% | 93.5% | 2.4 s | All sources | Combined | LIME + SHAP |
| Hyperparameter | Value |
|---|---|
| Learning Rate | 2 × 10−5 |
| Optimizer | AdamW |
| Batch Size | 16 |
| Epochs | 10 |
| Dropout Rate | 0.3 |
| Max Sequence Length | 256 |
| Tokenizer | RoBERTa Byte-Pair Encoding (BPE) |
| Loss Function | Weighted Cross-Entropy |
| Label Smoothing | 0.1 |
| Cross-Validation | 5-fold stratified CV |
| Metric | Value | Technique Used | Data Source | Notes |
|---|---|---|---|---|
| Positive Feedback Sentiment for Fact-based Content | 63.7% | VADER BERT | Twitter Reddit | Shows support |
| Negative Sentiment | 21.5% | TextBlob | YouTube | Correlates with flagged misinfo |
| Trust Score Improvement | +34.4% | Weighted Feedback | Platform Feedback | post-flag training loop integration |
| Misinfo Narrative Detection | 87.3% | BERTopic | Reddit Threads | Top clusters: ‘Climate Hoax’, ‘Carbon Scam’ |
| Forecast Accuracy (2 weeks) | 86.5% | LSTM Neural Net | Combined | Trendline matched with real data |
| Flag to Resolution Time Alert Notification | 13 h Avg. | Alert Pipeline | Internal Log | Resolution after |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shahbazi, Z.; Jalali, R.; Shahbazi, Z. AI-Driven Framework for Evaluating Climate Misinformation and Data Quality on Social Media. Future Internet 2025, 17, 231. https://doi.org/10.3390/fi17060231
Shahbazi Z, Jalali R, Shahbazi Z. AI-Driven Framework for Evaluating Climate Misinformation and Data Quality on Social Media. Future Internet. 2025; 17(6):231. https://doi.org/10.3390/fi17060231
Chicago/Turabian StyleShahbazi, Zeinab, Rezvan Jalali, and Zahra Shahbazi. 2025. "AI-Driven Framework for Evaluating Climate Misinformation and Data Quality on Social Media" Future Internet 17, no. 6: 231. https://doi.org/10.3390/fi17060231
APA StyleShahbazi, Z., Jalali, R., & Shahbazi, Z. (2025). AI-Driven Framework for Evaluating Climate Misinformation and Data Quality on Social Media. Future Internet, 17(6), 231. https://doi.org/10.3390/fi17060231