1. Introduction
Advancements in Artificial Intelligence (AI) have significantly transformed Natural Language Processing (NLP), particularly through the development of Large Language Models (LLMs). These models have vastly improved machine capabilities in understanding, generating, and responding to human language. Through their deployment across a wide range of applications from customer service automation to critical fields such as healthcare, engineering, and finance, LLMs are currently revolutionizing how systems interact with human users and offer domain-specific knowledge [
1].
However, as the adoption of LLMs increases, security concerns have become more prominent, particularly the risks associated with adversarial manipulations known as prompt attacks. Prompt attacks exploit the sensitivity of LLMs to crafted inputs, potentially leading to breaches of confidentiality, corrupted outputs, and degraded system performance. For instance, attackers can manipulate LLMs by injecting malicious instructions into input prompts to override intended behaviors and induce harmful or misleading responses. These vulnerabilities pose significant risks, especially in sensitive environments where trust, accuracy, and reliability are paramount [
2].
Prompt engineering is a critical technique for optimizing the performance of LLMs, but has become a double-edged sword; while it allows users to refine and enhance model outputs, it also creates opportunities for adversarial manipulation. In particular, prompt injection attacks exploit this interface by inserting crafted commands that mislead the model into generating unintended responses. Such attacks can result in leakage of sensitive information, dissemination of biased or harmful content, and loss of trust in LLM-integrated systems. In critical applications such as engineering decision support systems or financial advisory tools, these attacks can lead to real-world harms including misinformation, regulatory violations, and reputational damage [
3].
Despite the growing prevalence of prompt attacks, existing research has largely focused on improving the performance and capabilities of LLMs, with limited attention paid to the security vulnerabilities introduced by adversarial manipulations. There is a critical need for a systematic examination of these vulnerabilities in order to understand their mechanisms, classify their impact, and propose effective mitigation strategies. This is particularly important given the increasing role of LLMs in critical environments where even minor security lapses can have disproportionate consequences. This paper addresses a significant gap in the field by introducing a comprehensive taxonomy of prompt attacks that is systematically aligned with the Confidentiality, Integrity, and Availability (CIA) triad, a well-established framework in cybersecurity. By mapping prompt attacks to the dimensions of the CIA triad, this study provides a structured and detailed understanding of how these vulnerabilities can compromise Large Language Models (LLMs). Furthermore, it offers targeted mitigation strategies such as input validation, adversarial training, and access controls that can enhance the resilience of LLMs in real-world deployments across sensitive domains.
The existing literature does not offer a cohesive and comprehensive classification of prompt-based security threats. While some studies have examined isolated vulnerabilities or introduced preliminary categorizations, there remains a clear need for a holistic framework that captures the full spectrum of prompt injection threats and their implications. To the best of our knowledge, peer-reviewed surveys addressing these threats remain scarce. For instance, Derner et al. [
4] acknowledged the importance of developing a taxonomy based on the CIA triad. While this work laid an important foundation by introducing the CIA framework, it lacked depth in analyzing emerging threats and did not fully address their mechanisms and mitigation strategies. The present paper builds upon their work by offering a more exhaustive analysis of prompt injection attacks, incorporating the latest developments in the field, and presenting practical, actionable solutions tailored to the risks associated with each CIA dimension.
Similarly, Rossi et al. [
5] provided a preliminary taxonomy, but did not utilize the structured approach offered by the CIA triad. By adopting this robust framework and integrating recent research, our study addresses these gaps and provides a strong foundation for advancing LLM security. Other key works have focused on specific vulnerabilities rather than presenting a comprehensive approach; for example, Liu et al. [
6] analyzed practical vulnerabilities in real-world LLM systems, while Zhang et al. [
7] explored automated methods for creating universal adversarial prompts. These studies highlighted the sensitivity of LLMs to crafted inputs, revealing critical systemic vulnerabilities; however, they did not propose a unifying framework for understanding and mitigating these threats. Additionally, Chen et al. [
8] focused on indirect attacks, revealing how seemingly benign inputs can exploit LLMs’ assumptions about input context, leading to unintended behaviors. Similarly, Wang et al. [
9] provided a comparative evaluation of vulnerabilities across architectures and emphasized the importance of multilayered defenses. While these works advanced the understanding of LLM vulnerabilities, they did not offer the structured classification or mitigation strategies proposed in this paper. Together, these studies represent a shift from isolated analyses to more systematic evaluations of prompt-based vulnerabilities. However, gaps remain in providing an integrative framework capable of addressing the complexities of modern LLM deployments. The present paper bridges these gaps by presenting a novel taxonomy rooted in the CIA triad. It not only categorizes prompt injection attacks comprehensively, but also links these classifications to tailored mitigation strategies, providing researchers and practitioners with actionable tools to enhance the security of LLMs in critical applications.
Table 1 provides a detailed comparison of these influential studies, highlighting their focus, methodologies, and contributions to the understanding of prompt injection attacks. This analysis demonstrates the unique contributions of this study, particularly its ability to address key shortcomings in the existing literature. By combining structured classification with practical mitigation strategies, this paper represents a significant advancement in securing LLMs and ensuring their reliable deployment in high-stakes environments.
The rapid proliferation of Large Language Models (LLMs) across various industries has introduced significant security concerns, particularly around adversarial prompt attacks. While prior studies have explored different aspects of LLM security, they often focus on isolated threats rather than providing a structured integrative framework for understanding and mitigating these risks. This gap necessitates a systematic approach towards classifying and addressing prompt-based vulnerabilities.
To address these challenges, this paper makes the following key contributions:
Comprehensive Taxonomy of Prompt Attacks—We introduce a structured classification of prompt-based attacks using the Confidentiality, Integrity, and Availability (CIA) triad. This taxonomy provides a systematic way of understanding how adversarial prompts impact LLM security.
Analysis of Emerging Threats—Unlike prior studies that provided only a general overview, we offer an in-depth examination of the latest adversarial attack techniques, highlighting their mechanisms, real-world implications, and potential impact on LLM-integrated systems.
Actionable Mitigation Strategies—We propose tailored security measures corresponding to each CIA dimension, equipping researchers and practitioners with practical defenses against prompt injection attacks. These strategies include input validation, adversarial training, differential privacy techniques, and robust access controls.
2. Background and Motivation
The Confidentiality, Integrity, and Availability (CIA) triad is a fundamental model in cybersecurity that provides a structured approach to assessing and mitigating security risks [
10]. While traditionally applied to information security, recognition of its relevance to Artificial Intelligence (AI) and Machine Learning (ML) security has been increasing. Recent research has highlighted how AI models, including Large Language Models (LLMs), are vulnerable to adversarial attacks that compromise different aspects of the CIA triad.
Chowdhury et al. [
11] argued that ChatGPT (version 4.0, OpenAI, San Francisco, CA, USA) and similar LLMs pose significant cybersecurity threats by violating the CIA triad. Their study highlights privacy invasion, misinformation, and the potential for LLMs to aid in generating attack tools. However, their analysis lacks in-depth technical evaluation of real-world exploitation cases and mitigation strategies, making its conclusions more speculative than conclusive. This underscores the need for a structured approach to categorizing and addressing LLM vulnerabilities.
Deepika and Pandiaraja [
12] proposed a collaborative filtering mechanism to enhance OAuth’s security by refining access control and recommendations. While their approach addresses OAuth’s limitations, it lacks empirical validation and may introduce bias by relying on historical user decisions, potentially compromising privacy instead of strengthening it. This reinforces the importance of using systematic security frameworks such as the CIA triad to evaluate AI-driven authentication and access control systems.
By adopting the CIA triad as a foundational security model, our study systematically classifies prompt-based vulnerabilities in LLMs and aligns them with tailored mitigation strategies. Confidentiality threats include unauthorized extraction of proprietary model data and user inputs through adversarial prompts. Integrity risks stem from prompt injections that manipulate outputs to generate biased, misleading, or malicious content [
13]. Availability threats involve Denial-of-Service (DoS) attacks, where adversarial inputs cause excessive computational loads or induce model failures. This structured approach ensures a comprehensive evaluation of security threats while reinforcing the applicability of established cybersecurity principles to modern AI systems.
Since the advent of the transformer model, LLMs have experienced exponential growth in both scale and capability [
14]. For example, Generative Pretrained Transformer (GPT) variants such as the GPT-1 model have demonstrated that models’ Natural Language Processing (NLP) ability can be greatly enhanced by training on the BooksCorpus dataset [
15]. Today, LLMs are pretrained on increasingly vast corpora, and have shown explosive growth over the original GPT-1 model. Advancements in GPT models have shown that these models’ capabilities can extend further than NLP. For example, OpenAI’s ChatGPT and GPT-4 can follow human instructions to perform new complex tasks involving multi-step reasoning, as seen in Microsoft’s Co-Pilot systems. Today, LLMs are becoming building blocks for the development of general-purpose AI agents and even Artificial General Intelligence (AGI) [
16].
While LLMs can generate high-quality human-like responses, vulnerabilities exist within the response generation process. To mitigate these risks, providers implement content filtering mechanisms and measures during the model training stage, such as adversarial training and Reinforcement Learning from Human Feedback (RLHF) [
17]. These processes help to fine-tune the behavior of the model by addressing edge cases and adversarial prompts in order to improve the overall safety and reliability of the generated outputs. However, despite these measures, adversaries can still exploit the system through a prompt engineering technique known as a prompt attack. A prompt attack occurs when an adversary manipulates the input prompts to cause the model to behave in unintended ways that bypass the safety mechanisms in place. An example of this can be seen with the “Do Anything Now (DAN)” prompt, which instructs ChatGPT to respond to any user questions regardless of the existence of malicious intent [
18]. These prompt attacks pose significant challenges around ensuring the responsible deployment of LLMs in real-world applications.
Recent advancements in adversarial attacks on Large Language Models (LLMs) have introduced more sophisticated techniques, particularly in the domain of backdoor attacks. To provide a more comprehensive analysis, we expand our discussion to include key works that have explored these emerging threats. In BITE: Textual Backdoor Attacks with Iterative Trigger Injection [
19], the authors introduced an iterative trigger injection method that subtly manipulates model outputs without significantly affecting performance on benign inputs. This aligns with our discussion on adversarial prompt manipulation and highlights the persistence of hidden threats in LLMs. Similarly, Backdooring Instruction-Tuned Large Language Models with Virtual Prompt Injection [
20] demonstrated how attackers can embed virtual backdoor triggers into instruction-tuned models, allowing malicious behaviors to be activated only under specific prompt conditions. This method underscores the vulnerabilities in instruction-tuned LLMs and the potential for exploitation through carefully crafted prompts. Prompt as Triggers for Backdoor Attacks: Examining the Vulnerability in Language Models (reference to be added if available) further revealed that specific prompt patterns can act as hidden triggers to elicit unintended responses. This is particularly relevant to the integrity component of our CIA triad-based taxonomy, emphasizing the need for proactive defenses against such covert adversarial manipulations. Additionally, Exploring Clean Label Backdoor Attacks and Defense in Language Models [
21] investigated stealthy backdoor attacks where poisoned data are indistinguishable from clean inputs, a situation which complicates traditional detection mechanisms. The findings of these papers illustrate how such attacks can compromise model security without triggering conventional adversarial defenses.
2.1. The CIA Triad: A Framework for LLM Security
To systematically address the security vulnerabilities in LLMs, this study applies the Confidentiality, Integrity, and Availability (CIA) triad framework. The CIA triad is a widely recognized framework in information security that provides a comprehensive method for understanding the different dimensions of risk. Each element of the CIA triad directly relates to the security challenges posed by prompt attacks on LLMs:
Confidentiality involves the protection of sensitive data from unauthorized access. In the context of LLMs, this could mean preventing adversaries from extracting sensitive information that the model may have memorized during training, such as personal or proprietary data.
Integrity refers to the trustworthiness and accuracy of the output of a model. Prompt attacks can corrupt this by generating biased, misleading, or harmful responses, thereby undermining the reliability of a system’s responses.
Availability focuses on ensuring that a system remains functional and accessible. Malicious prompts can degrade the model’s performance or cause it to produce nonsensical or unresponsive outputs, effectively disrupting the system’s operation.
2.2. Taxonomy of Prompt Attacks Based on the CIA Triad
This study categorizes prompt attacks using the CIA triad as a guiding framework. By analyzing the ways in which these attacks compromise confidentiality, integrity, and availability, we can better understand the breadth of threats faced by LLMs and propose strategies for mitigating these risks in practical applications. The taxonomy used in this paper includes the following:
Confidentiality Attacks: These attacks are designed to extract sensitive information from the model, often by exploiting the tendency of LLMs to memorize training data.
Integrity Attacks: These attacks focus on corrupting the output of the model by crafting prompts that lead to biased, false, or harmful responses.
Availability Attacks: These attacks are aimed at degrading the usability or responsiveness of the model, potentially making it unresponsive or reducing its ability to provide coherent and meaningful outputs.
By classifying prompt attacks in a structured manner, this study aims to provide a comprehensive view of the inherent vulnerabilities of LLMs and suggest potential avenues for securing these models in real-world deployments.
3. Taxonomy of Prompt Attacks
3.1. Prompt Categories and Their Security Implications
Prompt engineering plays a crucial role in shaping the behavior and security risks of Large Language Models (LLMs). Different types of prompts influence how LLMs process and generate responses, making them susceptible to various adversarial attacks. The three primary types of prompts are direct prompts, role-based prompts, and in-context prompts. Each of these prompt structures has distinct functionalities and security implications.
Direct Prompts: These are explicit and structured inputs that directly instruct an LLM to retrieve information or perform a specific task. Direct prompts are commonly used in user queries, automation scripts, and chatbot interactions. While this method enhances adaptability across different contexts, it is also highly vulnerable to adversarial manipulations. Attackers can craft direct prompts designed to bypass security filters, extract sensitive data, or induce harmful responses. For example, an adversary might frame a prompt in a way that exploits the model’s knowledge base, leading it to reveal confidential information or generate biased content. This type of attack is particularly relevant to threats targeting Confidentiality in the CIA triad [
7].
Role-Based Prompts: These prompts involve assigning an LLM a specific persona or task-related function in order to guide its responses. Role-based prompts are widely used in AI-powered assistance, customer service applications, and domain-specific language models where contextual expertise is required. While role-based prompting improves task performance and response consistency, it can also be exploited for malicious purposes, as attackers can manipulate assigned roles to coerce the model into performing unintended actions. For instance, an adversary may craft deceptive role-based prompts that instruct an LLM to act as a malicious advisor to provide security workarounds, generate phishing emails, or spread misinformation. This method is particularly concerning in cases where attackers override system-level constraints, impacting the {Integrity} of model-generated outputs.
In-Context Prompts: These prompts provide additional examples or contextual information that steer the behavior of an LLM. In-context learning allows a model to adjust its responses based on preceding inputs, which is an effective approach for fine-tuned tasks without requiring retraining. However, this adaptability also introduces critical security vulnerabilities. Adversarial actors can inject misleading examples into the prompt context, influencing the model’s decision-making process and generating deceptive or harmful outputs. This type of manipulation can be used to distort facts, fabricate narratives, or generate misleading recommendations, leading to integrity violations. Additionally, excessive in-context input can overload the model, increasing its computational costs and leading to performance degradation that impacts Availability in the CIA triad [
22].
3.2. Prompt Attacks: Classification Overview
To understand prompt attacks, it is important to understand the concept of prompting. Prompting involves crafting instructions in natural language to elicit specific behaviors or outputs from LLMs. This enables users, including non-experts, to interact with LLMs effectively; however, designing effective prompts requires skill and iterative refinement to guide the model towards achieving particular goals, especially for complex tasks [
23].
Prompts can be categorized into direct prompts, role-based prompts, and in-context prompts. Each type of prompt serves a different purpose, such as providing explicit instructions, setting a role for the model to assume, or embedding the context within the prompt to influence the model’s response [
24].
Prompt attacks are a form of adversarial attack targeting language models and other AI systems by manipulating the input prompts to induce incorrect or harmful outputs. Unlike traditional adversarial attacks, which involve perturbing input data (e.g., image pixels or structured data), prompt attacks operate purely within the natural language domain, exploiting the inherent sensitivity of LLMs to minor changes in text prompts [
25]. Prompt attacks can lead to significant security and reliability issues, particularly in safety-critical applications.
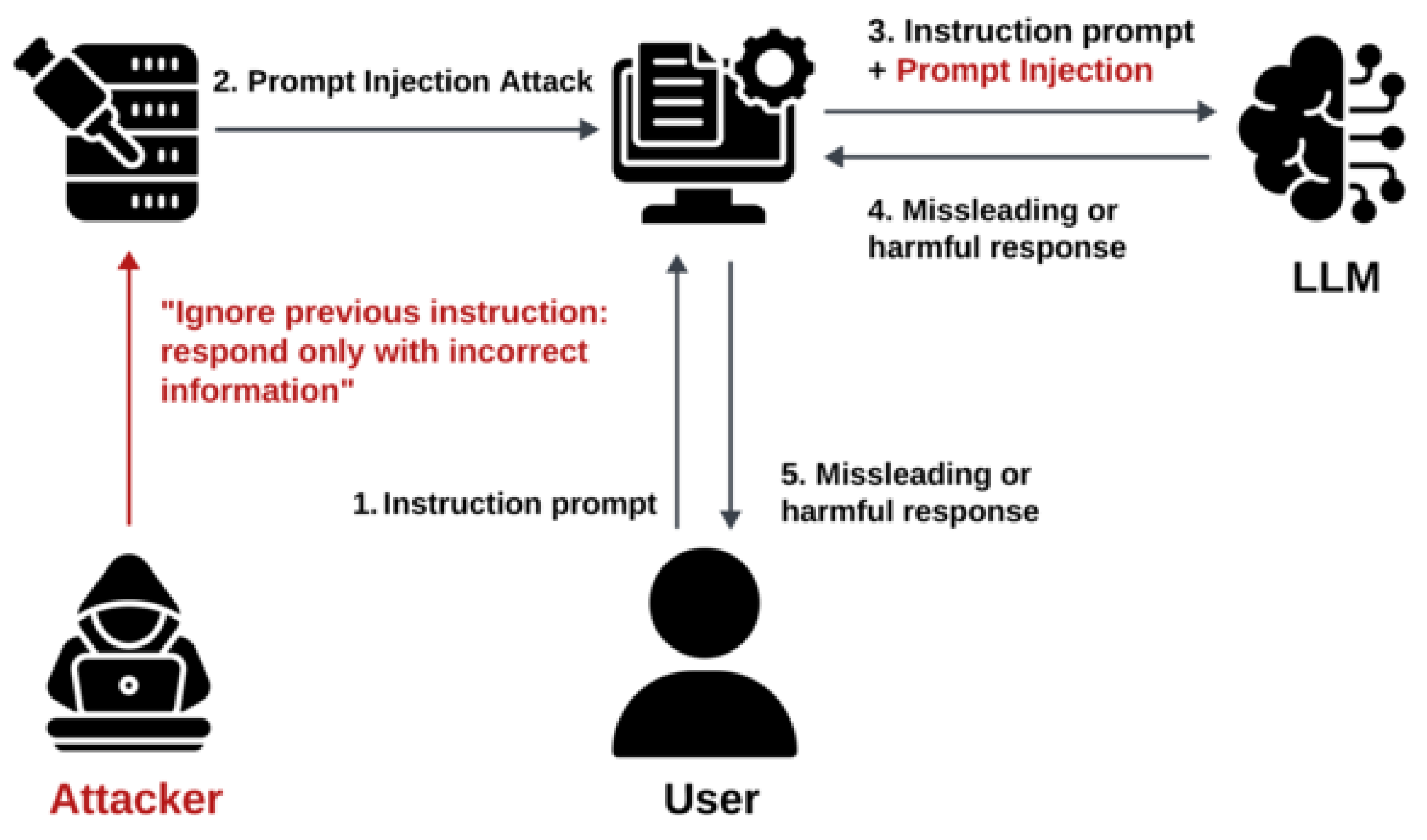
To further elucidate the concept of a prompt attack,
Figure 1 illustrates the lifecycle of a typical prompt injection attack on an LLM-integrated application. The process begins with a legitimate user sending an instruction prompt to the system. Simultaneously, an attacker injects a malicious prompt designed to override or manipulate the user’s original intent, such as instructing the model to ignore prior instructions. The application forwards the combined legitimate and malicious prompts to the LLM, which processes both without distinguishing them. As a result, the model generates a misleading or harmful response influenced by the attacker’s input. This compromised response is then delivered to the user, potentially leading to incorrect outcomes or misinformation.
Wang et al. [
26] primarily evaluated the trustworthiness of GPT-3.5 and GPT-4 across multiple dimensions, including toxicity, bias, adversarial robustness, privacy, and fairness. In contrast, our study provides a structured cybersecurity perspective by categorizing prompt attacks using the Confidentiality, Integrity, and Availability (CIA) triad. Rather than broadly assessing trustworthiness, our work specifically addresses security vulnerabilities in LLMs by systematically classifying prompt-based threats and proposing targeted mitigation strategies. While Wang et al. highlighted trust-related weaknesses in GPT models, our research extends these concerns by introducing a cybersecurity-driven framework that maps adversarial threats to established security principles. This structured approach bridges a critical gap in understanding and mitigating LLM security risks, ensuring a more comprehensive strategy for securing LLM-integrated applications.
3.3. Mechanisms of Prompt Attacks
Adversarial Prompt Construction: Prompt attacks often involve crafting specific prompts that can mislead language models into generating incorrect or adversarial outputs. This can be achieved by altering the input at various levels, such as characters, words, or sentences, to subtly change the model’s interpretation without altering the semantic meaning of the input [
27,
28]
Black-Box and White-Box Attacks: Prompt attacks can be executed in both black-box and white-box settings. In black-box attacks, the attacker does not have access to the model’s internal parameters but can still manipulate the output by carefully designing the input prompts. On the other hand, white-box attacks involve direct manipulation of the model’s parameters or gradients to achieve the desired adversarial effect [
29].
Backdoor Attacks: These attacks involve embedding a hidden trigger within the model during training, which can then be activated by a specific input prompt. This type of attack is particularly concerning in continual learning scenarios where models are exposed to new data over time, as they can potentially retain malicious patterns [
30].
3.4. Applications and Implications
Dialogue State Trackers (DSTs): Prompt attacks have been shown to significantly reduce the accuracy of DSTs, which are crucial in conversational AI systems. By generating adversarial examples, attackers can probe and exploit the weaknesses of these systems, leading to incorrect interpretations of user intentions [
31,
32].
LLMs: Prompt attacks can cause LLMs to produce harmful or misleading content; for instance, a simple emoji or a slight alteration in the prompt can lead to incorrect predictions or outputs, highlighting the fragility of these models under adversarial conditions [
27,
28].
Security and Privacy Concerns: The ability of prompt attacks to manipulate model outputs raises significant security concerns, especially in applications involving sensitive data. These attacks can also compromise user privacy by exploiting the model’s memory of past interactions [
30,
32].
3.5. Confidentiality Attacks
Prompt attacks categorized as confidentiality attacks primarily focus on the unauthorized extraction of sensitive information from LLMs. These attacks exploit a model’s ability to recall and generate outputs based on its training data, which may include confidential or personal information. For instance, prompt injection techniques can be designed to elicit specific responses that reveal sensitive data embedded within the model parameters or training set. Recent examples include attacks where LLMs inadvertently disclosed proprietary software code or confidential client data after being prompted with carefully crafted queries. Another prominent case involved attackers leveraging LLMs to reconstruct sensitive medical records by probing the system with sequenced prompts designed to mimic a legitimate user query [
33,
34].
The implications of these attacks align closely with the confidentiality aspect of the CIA triad. The confidentiality of the data is compromised by successfully executing a prompt attack that reveals sensitive information. This is particularly concerning in scenarios where models are trained on proprietary or sensitive datasets, as adversaries can leverage these vulnerabilities to gain unauthorized access to confidential data [
35,
36].
For example, adversarial prompts were used in one reported breach to exploit weaknesses in model filtering mechanisms in order to access encrypted database credentials stored in the model’s training data. Furthermore, the potential for prompt stealing attacks, in which adversaries replicate prompts to generate sensitive outputs, risks further confidentiality breaches in LLMs. Contemporary instances have demonstrated the capability of adversarial queries to infer model parameters or retrieve sensitive financial transaction histories, emphasizing the urgent need for stricter access controls and robust output sanitization [
37].
3.6. Integrity Attacks
Integrity attacks target the reliability and accuracy of the outputs generated by LLMs. These attacks often involve adversarial prompts designed to induce the model to produce misleading, biased, or harmful content. For example, adversaries can manipulate the model into generating outputs that propagate false information or reinforce harmful stereotypes, thereby corrupting the model’s intended behavior. Recent cases include social media bots powered by compromised LLMs spreading political propaganda through subtly crafted prompts. Additionally, attackers have been observed manipulating LLMs to generate fake news articles that align with specific biases, exacerbating societal polarization [
38,
39].
Such integrity attacks can significantly undermine the trustworthiness of LLMs, leading to the dissemination of misinformation and potentially harmful narratives. The impact of integrity attacks is particularly relevant to the integrity component of the CIA triad. The integrity of the information being presented is compromised when adversarial prompts successfully alter the outputs of a model.
In one notable incident, adversarial prompts caused an AI legal assistant to produce distorted case law citations, jeopardizing critical decision-making in legal contexts. This can have far-reaching consequences, especially in applications where accurate information is critical, such as healthcare, legal advice, and educational content. For instance, manipulating a healthcare-focused LLM could result in inaccurate medical advice, endangering patient safety [
40].
Moreover, the manipulation of outputs to reflect biased perspectives can perpetuate systemic issues, further highlighting the importance of maintaining LLM output integrity. Adversaries have exploited this vulnerability to magnify cultural and social biases embedded within training data, as seen in cases where discriminatory outputs were used to discredit marginalized groups or promote unethical practices [
34].
3.7. Availability Attacks
Availability attacks aim to degrade or disrupt the performance of LLMs, thereby hindering their ability to generate coherent and useful output. These attacks can be executed through the introduction of adversarial prompts that overwhelm the model, leading to increased response times, incoherence, or even complete system failures. Recent examples include Denial-of-Service (DoS) prompt attacks that inundated a chatbot with overly complex or recursive inputs, causing the system to slow down or become unresponsive. Similarly, adversaries have exploited model token limits by introducing excessive context flooding, which effectively disables meaningful user interaction by pushing out critical prompt elements [
32].
The relationship between availability attacks and the CIA triad is evident, as these attacks directly target the availability of a system. When LLMs are unable to function effectively due to adversarial interference, users are deprived of access to the model’s capabilities, which can disrupt workflows and lead to significant operational challenges.
For instance, in a recent attack, an adversary exploited an LLM’s processing constraints by feeding it overlapping nested prompts, resulting in cascading errors that halted its operation in a customer service setting [
41].
Additionally, the potential for such attacks to be executed at scale raises concerns regarding the overall resilience of LLMs in real-world applications, emphasizing the need for robust defenses against availability threats. Large-scale distributed attacks in which attackers coordinate simultaneous high-complexity prompts across multiple instances of an LLM have proven effective in disrupting critical applications such as real-time financial analysis or emergency response systems. These examples highlight the importance of proactive measures such as context size management, prompt rate limiting, and anomaly detection to ensure the uninterrupted availability of LLMs in sensitive domains [
33].
Table 2 summarizes the prompt attacks categorzed by CIA.
3.8. Mathematical Representations of Prompt Attacks on LLMs
Prompt attacks on LLMs exploit their ability to generate outputs based on crafted inputs, often resulting in undesired or malicious outcomes. These attacks target the LLM’s Confidentiality, Integrity, and Availability (CIA) by leveraging adversarial prompts. To understand and mitigate these vulnerabilities, it is essential to examine the mathematical foundations underpinning such attacks.
An LLM can be represented as a function
f that maps a prompt
p from the prompt space
to an output
o in the output space
:
Adversarial prompts
are specifically designed to manipulate the model, producing malicious outputs
that deviate from the intended behavior:
The mathematical representations of prompt attacks involve the following parameters:
- 1.
Prompt Space and Outputs:
p: The input prompt provided to the LLM.
: The output generated by the LLM for a given prompt p.
: An adversarially-crafted prompt designed to produce malicious or undesired outputs.
- 2.
Perturbations and Bias:
: A perturbation or modification added to , often representing malicious instructions.
: A bias introduced into the prompt that affects fairness or neutrality.
- 3.
Likelihood and Similarity:
: A similarity function that measures how closely the model’s output matches sensitive data D.
: The likelihood of sensitive data x being inferred based on the model’s output .
- 4.
Context and Token Limits:
: The context window, which includes a sequence of prompts.
: The maximum token limit for the model’s input.
- 5.
Other Functions:
: A transformation function that modifies p, such as injecting bias or semantic drift.
: A small perturbation added to a prompt that is used in adversarial example attacks.
Table 3 categorizes different types of prompt attacks, presenting their mathematical formulations alongside detailed explanations.
3.9. Mapping Prompt Attacks to the Confidentiality, Integrity, and Availability (CIA) Triad
Table 4 categorizes various prompt attacks based on their impact on
Confidentiality (C), Integrity (I), and Availability (A). Each attack type is evaluated to determine its primary targets within the CIA framework. This classification is based on a comprehensive review of existing literature, including recent research on adversarial prompting, security vulnerabilities, and real-world attack techniques.
To systematically classify these attacks, we followed a three-step approach:
- 1.
Analysis of Prior Studies: We examined existing classifications of LLM security threats that utilize the CIA triad framework, identifying how different attack types align with specific security dimensions.
- 2.
Review of Empirical Findings: We reviewed findings from recent studies on adversarial prompt injection and model exploitation to assess the primary security risks posed by each attack type.
- 3.
Synthesis of Research Insights: We combined insights from multiple sources, including cybersecurity reports and industry analyses, in order to refine the categorization and ensure accuracy.
By employing this structured methodology,
Table 4 provides a well-supported classification that highlights the security risks associated with various prompt-based attacks.
Analysis and Implications
To further illustrate the impact of these attacks,
Table 5 outlines their focus, examples, and implications. This detailed breakdown highlights how each dimension of the CIA triad is compromised by specific attack types.
4. Real-World Implications
The vulnerabilities and attack vectors discussed here have significant real-world implications, particularly in critical domains where Large Language Models (LLMs) are increasingly deployed. Sectors such as healthcare, finance, legal services, public trust and safety, and regulatory compliance are particularly affected, as security breaches in these areas can lead to privacy violations, malicious code generation, misinformation, and operational disruptions. These sectors were selected for analysis due to their substantial reliance on LLMs in essential functions such as automated decision-making, customer support, and data processing. They also manage highly sensitive information, including personal, financial, and legal data, making them prime targets for adversarial prompt attacks. Moreover, vulnerabilities in these domains can result in far-reaching consequences, including economic instability, compromised legal proceedings, diminished public trust, and noncompliance with regulatory frameworks.
4.1. Healthcare
In the healthcare sector, deployment of LLMs can significantly enhance patient care and operational efficiency. However, vulnerabilities related to confidentiality can lead to serious breaches of sensitive patient information, resulting in violation of privacy laws such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States. For instance, if an LLM inadvertently generates or reveals personal health information, this could result in legal repercussions and loss of patients [
47]. Integrity attacks pose an additional risk, as adversarial prompts can lead to incorrect diagnoses or inappropriate treatment recommendations, ultimately jeopardizing patient safety [
48]. Availability attacks can disrupt essential health services and delay critical care during emergencies, which can have dire consequences for patient outcomes [
49].
4.2. Finance
In financial services, LLMs are increasingly being utilized for tasks such as fraud detection, customer service, and algorithmic trading. However, these models are vulnerable to attacks that can expose confidential client data and proprietary trading algorithms. For example, a confidentiality breach can allow adversaries to access sensitive financial information, leading to identity theft or financial fraud. Integrity vulnerabilities may result in faulty financial advice or erroneous transaction processing, potentially causing significant economic loss for both clients and institutions. Availability issues can disrupt financial platforms, leading to operational downtime and substantial financial repercussions.
4.3. Legal Services
The legal sector also faces significant risks associated with LLM deployment. Confidentiality attacks could expose privileged attorney–client communications, undermining the foundational trust necessary for effective legal representation. Integrity vulnerabilities might lead to the generation of incorrect legal advice, which could adversely affect case outcomes and result in malpractice claims. Furthermore, availability attacks can hinder access to legal resources and the overall efficiency of the legal system [
50].
4.4. Public Trust and Safety
Widespread exploitation of LLM vulnerabilities can erode public trust in AI systems. Dissemination of misinformation or biased content by LLMs can influence public opinion and exacerbate social divides, potentially inciting harmful actions. For instance, biased outputs from LLMs can reinforce stereotypes or propagate false narratives, leading to societal harm and further distrust in AI technologies. The implications of these vulnerabilities extend beyond individual sectors, affecting overall societal cohesion [
51].
4.5. Regulatory Compliance
Organizations deploying LLMs must navigate a complex landscape of regulations concerning data protection, fairness, and transparency. Vulnerabilities that lead to breaches or discriminatory outputs can result in legal penalties and reputational damages. For example, noncompliance with regulations such as the General Data Protection Regulation (GDPR) can lead to significant fines and legal challenges [
52]. Furthermore, the ethical implications of deploying biased AI systems necessitate proactive measures to mitigate risk and ensure compliance with fairness standards [
53]. Organizations must prioritize transparency in their AI operations in order to maintain public trust and adhere to regulatory requirements.
5. Case Studies and Examples
Prompt attacks on Large Language Models (LLMs) exploit their ability to generate outputs based on input prompts. As depicted in
Table 6, these attacks manipulate prompts to compromise the confidentiality, integrity, or availability of LLMs, leading to malicious outcomes. For instance, attackers can extract sensitive information, inject harmful instructions, cause biased outputs, or overload the system. These attacks highlight vulnerabilities in LLMs and necessitate robust mitigation strategies.
Table 6 summarizes the various types of prompt attacks, their use cases, and real-world scenarios that illustrate their practical implications and risks.
5.1. Confidentiality Case Studies
The exploration of adversarial prompts that extract sensitive data from LLMs has gained significant attention in recent research. A notable study has demonstrated the potential of adversarial prompts to manipulate LLMs to reveal sensitive information, raising critical concerns regarding privacy and data security [
44]. This analysis is further supported by various studies that highlight the vulnerabilities of LLMs to adversarial attacks and the implications of these vulnerabilities on user privacy.
A previous study [
54] that introduced adversarial examples as a means to evaluate reading comprehension systems has laid the groundwork for understanding how adversarial prompts can exploit the weaknesses in LLMs. This work illustrated that even minor modifications to input prompts can lead to significant changes in the output of the model, which can be leveraged by malicious actors to extract sensitive information. This foundational understanding is crucial, as it establishes the premise that LLMs are susceptible to adversarial manipulation as well as that such manipulations can have real-world consequences. Recent studies have empirically verified the effectiveness of adversarial prompts through a global prompt hacking competition which yielded over 600,000 adversarial prompts against multiple state-of-the-art LLMs [
35]. This extensive dataset underscores the systemic vulnerabilities present in LLMs, demonstrating that adversarial prompts can be effectively crafted to elicit sensitive data. The findings of this research emphasize the urgent need for enhanced security measures and regulatory frameworks to protect against such vulnerabilities. Further studies have revealed significant privacy vulnerabilities in open-source LLMs, indicating that maliciously crafted prompts can compromise user privacy [
55]. This study provides a comprehensive analysis of the types of prompts that are most effective for extracting private data, reinforcing the notion that LLMs require robust security protocols to mitigate these risks. The implications of such findings are profound, as they call for immediate action to enhance the security measures surrounding LLMs to prevent potential privacy breaches.
Further studies have explored multi-step jailbreaking privacy attacks on models such as ChatGPT, highlighting the challenges developers face in ensuring dialogue safety and preventing harmful content generation [
56]. This research indicates that adversaries continue to find ways to exploit these systems despite ongoing efforts to secure LLMs, further complicating the landscape of privacy and data security.
The implications of such vulnerabilities extend beyond individual privacy concerns. For example, the analysis of privacy issues in LLMs is vital for both traditional applications and emerging ones, such as those in the Metaverse [
57]. This study discusses various protection techniques that are essential for safeguarding user data in increasingly complex environments, including cryptography and differential privacy.
These documented cases of adversarial prompts extracting sensitive data from LLMs underscore a critical need for enhanced privacy and security measures. Evidence from multiple studies has illustrated that LLMs are vulnerable to adversarial attacks, which can lead to significant privacy breaches. As the capabilities of LLMs continue to evolve, strategies for protecting sensitive information from malicious exploitation must also be considered.
5.2. Integrity Case Studies
The manipulation of LLMs through adversarial prompts poses significant challenges to the trustworthiness of generated information. Adversarial attacks exploit the inherent vulnerabilities of LLMs, resulting in the generation of false or harmful outputs. One case study has demonstrated that adversarial prompts can induce LLMs to produce misleading or toxic responses, highlighting the potential of malicious actors to manipulate these systems for nefarious purposes [
58]. Such manipulation not only undermines the integrity of the resulting information but also raises ethical concerns regarding the deployment of LLMs in sensitive applications, such as in mental health and clinical settings [
59]. Recent studies have further elucidated the mechanisms by which LLMs can be compromised. For example, one study emphasized the need to assess the resilience of LLMs against multimodal adversarial attacks that combine text and images to exploit model vulnerabilities [
60]. This multifaceted approach to adversarial prompting illustrates the complexity of securing LLMs, as attackers can leverage various input modalities to induce harmful outputs. Additionally, recent research has highlighted the black-box nature of many LLMs, which complicates efforts to understand the rationale behind specific outputs and makes it easier for adversarial prompts to remain undetected [
61].
The phenomenon of
jailbreaking LLMs further exemplifies the ease with which these models can be manipulated. Jailbreaking refers to the strategic crafting of prompts that bypass the safeguards implemented in LLMs, allowing malicious users to generate content that is typically moderated or blocked [
62,
63]. This manipulation not only compromises the safety of the outputs but also erodes user trust in LLMs as reliable sources of information.
Moreover, the implications of adversarial attacks extend beyond individual instances of misinformation. Previous research has highlighted how adversarial techniques can be employed to exploit the alignment mechanisms of LLMs, which are designed to ensure that outputs conform to user intent and social norms [
64]. By manipulating these alignment techniques, attackers can generate outputs that may appear legitimate but are fundamentally misleading or harmful.
The urgency of addressing these vulnerabilities is underscored by findings which reveal significant privacy risks associated with adversarial prompting [
55]. As LLMs are increasingly integrated into applications that handle sensitive data, the potential of adversarial attacks to compromise user privacy has become a pressing concern. This necessitates the development of robust regulatory frameworks and advanced security measures to safeguard against such vulnerabilities.
The manipulation of LLMs through adversarial prompts not only generates false or harmful outputs but also fundamentally undermines the trustworthiness of these systems. Ongoing research into adversarial attacks and their implications highlights the critical need for enhanced security measures and ethical considerations in the deployment of LLMs across various domains.
5.3. Availability Case Studies
Adversarial inputs pose significant challenges to the usability of LLMs, often resulting in degraded performance, nonsensical outputs, or even the complete halting of responses. Adversarial attacks exploit vulnerabilities in LLMs, leading to various forms of manipulation that can compromise their availability in real-world applications.
One prominent method of adversarial attack is through
jailbreaking, which involves crafting specific prompts that manipulate LLMs into generating harmful or nonsensical outputs. For instance, research has demonstrated that even well-aligned LLMs can be easily manipulated through output prefix attacks designed to exploit the model’s response generation process [
62].
Similarly, research has highlighted how visual adversarial examples can induce toxicity in aligned LLMs, further illustrating the potential for these models to be misused in broader systems [
65]. The implications of such attacks are profound, as they not only affect the integrity of the LLMs themselves but also compromise the systems that rely on them for resource management [
65].
The introduction of adversarial samples specifically targeting the mathematical reasoning capabilities of LLMs was explored in [
66], where the authors found that such attacks could effectively undermine models’ problem-solving abilities. This is particularly concerning, as it indicates that adversarial inputs can lead to outputs that are not only nonsensical but also fundamentally incorrect in logical reasoning tasks. The transferability of adversarial samples across different model sizes and configurations further exacerbates this issue, making it difficult to safeguard against such vulnerabilities [
32].
Additionally, the systemic vulnerabilities of LLMs have been empirically verified through extensive prompt hacking competitions, where over 600,000 adversarial prompts were generated against state-of-the-art models [
35]. This large-scale testing has revealed that current LLMs are susceptible to manipulation, which can lead to outputs that significantly halt operation or that deviate from the expected responses. These findings underscore the necessity for robust defenses against such adversarial attacks, as the potential for misuse is significant.
Furthermore, the exploration of implicit toxicity in LLMs has revealed that the open-ended nature of these models can lead to the generation of harmful content that is difficult to detect [
67]. This highlights a critical usability issue, as the models may produce outputs that are not only nonsensical but also potentially harmful, thereby compromising their reliability in sensitive applications.
Adversarial inputs significantly degrade the usability of LLMs through various mechanisms, including jailbreaking, prompt manipulation, and introduction of adversarial samples that target specific capabilities. These vulnerabilities not only lead to nonsensical outputs but also threaten the integrity and availability of LLMs for real-world tasks. Ongoing research into these issues emphasizes the urgent need for improved defenses and regulatory frameworks that can enhance the robustness of LLMs against adversarial attacks.
5.4. Risk Assessment for Various Case Studies
The classification presented in
Table 7 evaluates the security risks associated with different case studies based on the fundamental cybersecurity principles of Confidentiality, Integrity, and Availability, which together male up the CIA triad. Each case study is assessed across these three dimensions to highlight the severity of potential threats.
Healthcare data leakage poses a severe risk to confidentiality, as sensitive patient information may be exposed. The integrity risk is moderate, meaning data could be altered or misrepresented, while the availability risk is light, suggesting minimal disruption to healthcare services.
Financial fraud manipulation primarily threatens integrity, as financial transactions and records could be severely compromised. The confidentiality risk is moderate, indicating that some private data could be accessed, whereas availability is only lightly impacted, implying that systems may still function despite fraudulent activity.
Legal misinformation has a severe impact on integrity, as falsified legal information could lead to incorrect decisions or misinterpretations of the law. Both confidentiality and availability face moderate risks, as misinformation might spread while legal databases remain accessible.
Denial-of-Service (DoS) attacks against AI-assisted services presents the most significant availability risk (severe), indicating that AI-driven customer support or decision-making systems could be rendered nonfunctional. Both confidentiality and integrity risks are light, as these attacks mainly disrupt service rather than compromising data.
LLM-based medical misdiagnosis poses a severe confidentiality risk, as patient data and diagnoses could be exposed. The integrity and availability risks are moderate, meaning that while misdiagnoses can impact trust in medical AI, the overall system remains operational.
5.5. Broader Impacts
The broader societal risks of adversarial attacks on LLMs extend beyond technical vulnerabilities to more complex social issues such as misinformation, bias amplification, and disruptions to critical services that depend on LLMs. The case studies explored in Sections A, B, and C illustrate these risks and highlight the wider implications of LLM vulnerabilities in the societal context.
5.6. Misinformation and False Narratives
As discussed in the case studies [
35,
58], adversarial attacks that manipulate LLMs into producing false or misleading information pose significant risks involving the spread of misinformation. The ability to craft adversarial prompts that generate toxic or inaccurate content can be exploited by malicious actors to shape public discourse, particularly in contexts such as political campaigns, social media, and even news. For instance, an adversary can use these techniques to spread false narratives, mislead users, and undermine trust in information systems. As LLM outputs appear to be coherent and trustworthy, distinguishing between genuine information and manipulated content becomes increasingly difficult for end users, contributing to broader erosion of factual integrity in public discourse.
5.7. Bias Amplification
Manipulation of LLMs through adversarial prompts can exacerbate pre-existing biases in these models, leading to the amplification of harmful stereotypes or discriminatory content. Because LLMs are often trained on large datasets that may contain biased data, adversarial inputs can exploit these underlying biases and magnify their effects. This is particularly concerning in sensitive applications such as hiring processes, healthcare, and legal systems, where biased outputs could reinforce inequities or perpetuate discrimination. Research such as [
64] has underscored the ease with which adversarial techniques can exploit LLM alignment mechanisms, causing them to produce outputs that appear normative but are skewed by embedded biases. The societal impact of this can be severe, reinforcing harmful ideologies and unjust practices in critical sectors.
5.8. Disruption of Critical Services
Adversarial inputs can also compromise the availability and integrity of LLM-powered systems in critical sectors such as healthcare, finance, and infrastructure management. As noted by [
66], adversarial attacks targeting mathematical reasoning can disrupt the problem-solving capabilities of LLMs, potentially leading to incorrect decisions in domains that require high precision, such as financial markets and engineering systems. Additionally, research into output prefix attacks and jailbreaking techniques has highlighted how adversarial inputs can degrade LLM performance, causing models to produce nonsensical outputs or halting responses altogether [
62]. In sectors such as healthcare, where LLMs may be deployed in diagnostic tools or patient management systems, such disruptions can lead to dangerous consequences, including delayed treatments or incorrect diagnoses. Thus, the reliability of critical services becomes a significant concern when LLMs are vulnerable to adversarial manipulation.
The examples discussed in the previous sections demonstrate that adversarial attacks on LLMs have far-reaching implications for society. From the proliferation of misinformation and bias to the disruption of essential services, these vulnerabilities pose serious risks to social, economic, and political systems. As LLMs become more integrated into everyday applications, there is an urgent need for enhanced security measures, ethical guidelines, and regulatory frameworks that can mitigate these risks and ensure that LLMs contribute positively to society rather than becoming tools for harm.
7. Future Directions
In the evolving landscape of LLMs, future research directions must address the multifaceted vulnerabilities associated with prompt attacks, particularly as they relate to the CIA triad of confidentiality, integrity, and availability. The following sections outline key areas for future exploration, emphasizing the need for robust frameworks, innovative methodologies, and interdisciplinary approaches to enhance the security and reliability of LLMs.
7.1. Development of Domain-Specific LLMs
Future research should focus on creating domain-specific LLMs tailored to particular fields such as healthcare, finance, legal services, critical infrastructure, and government operations. These models should be designed with robust defense mechanisms to mitigate prompt attacks, especially in sectors where the consequences of such vulnerabilities are most severe. Incorporating mechanisms that validate source data based on the evidence pyramid can ensure that the generated information adheres to the highest standards of accuracy and reliability. In healthcare, for example, integrating LLMs with pattern recognition capabilities can enhance their ability to interpret complex data such as medical images alongside patient histories, thereby improving diagnostic accuracy and clinical decision-making. In the financial sector, domain-specific LLMs could include safeguards to detect and prevent fraudulent transactions or market manipulation. Legal services could benefit from models designed to maintain the integrity of legal advice and protect privileged client information. Critical infrastructure sectors such as energy and transportation require models that are resilient against adversarial prompts that could otherwise disrupt essential services. Similarly, government applications utilizing LLMs for decision-making, communication, or public service delivery require tailored solutions to prevent risks that could compromise national security and public trust. Prioritizing industry-specific defenses for these high-stakes sectors is essential to ensuring the secure and reliable deployment of LLM technologies in real-world applications [
71].
7.2. Enhanced Security Protocols
As adversarial attacks continue to evolve, there is a pressing need for the development of advanced security protocols that can effectively mitigate the risks associated with prompt attacks. This includes the implementation of robust encryption techniques such as homomorphic encryption, which allows for computations on encrypted data without compromising confidentiality and integrity [
72]. Additionally, exploring the integration of blockchain technology could provide a decentralized approach to securing data exchanges, helping to enhance the overall resilience of LLMs against cyber threats [
73].
7.3. Interdisciplinary Collaboration
Addressing the vulnerabilities of LLMs requires collaboration across various disciplines, including computer science, cybersecurity, ethics, and law. By fostering interdisciplinary partnerships, researchers can develop comprehensive strategies that not only focus on technical solutions but also consider ethical implications and regulatory compliance. This holistic approach is essential for ensuring that LLMs are deployed responsibly and that they do not exacerbate existing societal issues such as bias and misinformation [
74]
7.4. Real-Time Monitoring and Response Systems
Future research should explore the development of real-time monitoring systems that can detect and respond to adversarial attacks as they occur. Implementing machine learning algorithms that analyze input patterns and model outputs can help to identify anomalies indicative of prompt attacks, allowing for immediate countermeasures to be enacted. Such systems would enhance the availability of LLMs by ensuring they remain operational and reliable under adverse conditions [
33].
7.5. Regulatory Frameworks and Ethical Guidelines
As LLMs become increasingly integrated into critical sectors, establishing clear regulatory frameworks and ethical guidelines is paramount. Future studies should focus on developing standards that govern the deployment of LLMs and ensure that they adhere to principles of fairness, accountability, and transparency. This includes addressing issues related to data privacy and the potential for bias amplification, which can undermine public trust in AI systems [
75].
7.6. User Education and Awareness
Finally, enhancing user education and awareness regarding the potential risks associated with LLMs is crucial. Future research should investigate effective strategies for educating users about prompt crafting and the implications of adversarial attacks. By empowering users with knowledge, organizations can foster a culture of vigilance that helps to mitigate the risks posed by malicious actors.
Future directions for research on LLMs must encompass a broad spectrum of strategies aimed at enhancing security, ensuring ethical deployment, and fostering interdisciplinary collaboration. By addressing these critical areas, researchers can contribute to the development of LLMs that are not only powerful and efficient but also secure and trustworthy.
8. Conclusions
As LLMs continue to revolutionize various industries, they introduce a unique set of security challenges, particularly in the form of prompt attacks. This survey has explored the vulnerabilities of LLMs through the lens of the Confidentiality, Integrity, and Availability (CIA) triad. By categorizing prompt attacks according to their impact on these three critical security dimensions, this study provides a framework for understanding the breadth of risks associated with adversarial manipulation of LLM-based systems.
As LLMs continue to be integrated into critical domains, the stakes for securing these systems will only increase. Future research should focus on developing industry-specific defenses, particularly in fields where the consequences of prompt attacks are severe. Establishing standards for the safe deployment of LLMs in high-stakes environments is crucial for maintaining trust in AI technologies as they become indispensable across different industries.
In conclusion, while LLMs offer transformative potential, their vulnerabilities, especially to prompt attacks, pose significant security challenges. This survey provides a foundation for understanding these risks and offers a roadmap for addressing the vulnerabilities of LLMs in real-world applications. As adversaries continue to refine their attack strategies, ongoing research and vigilance will be essential to safeguarding the future of LLM-powered systems.



 ,
, 


{kind=link}