1. Introduction
1.1. Background on GDPR
The General Data Protection Regulation (GDPR), officially Regulation (EU) 2016/679, is a comprehensive data protection law that came into effect on 25 May 2018. It was established by the European Union (EU) to strengthen and unify data protection for all individuals within the EU and the European Economic Area (EEA) [
1]. Moreover, the GDPR addresses the export of personal data outside the EU and EEA regions, thereby extending its reach globally due to its extraterritorial applicability [
2]. More specifically, Article 3 [
3] of the GDPR defines its territorial scope, significantly extending the reach of EU data protection law beyond its borders. This has critical implications for the global development and deployment of large language models (LLMs), which often process vast amounts of personal data across jurisdictions. The Regulation applies under the “establishment” criterion when a data controller or processor operates within the EU and under the “targeting” criterion when non-EU organizations offer goods or services to individuals in the EU or monitor their behavior. Even companies with no physical presence in the EU may still fall within the GDPR’s scope if their activities involve EU individuals, and the Regulation further applies where Member State law is relevant under public international law. Given the cross-border nature of AI and LLMs, the GDPR is a crucial regulatory framework in shaping global AI governance.
The primary objectives of the GDPR are to give individuals control over their personal data, simplify the regulatory environment for international business by unifying data protection within the EU, and enhance organizational accountability for data protection [
4]. Its key principles require that personal data is processed lawfully, fairly, and transparently; that data is collected for specified, explicit, and legitimate purposes; that only the data necessary for those purposes is processed (data minimization); that personal data is accurate and kept up to date; that data is stored only as long as necessary; and that all processing is carried out securely, with the data controller being accountable for ensuring compliance [
5].
In addition, the GDPR grants several rights to individuals (data subjects). These rights include the Right of Access (Article 15) [
6], which allows individuals to obtain confirmation of whether their personal data is being processed and to access that data along with information about its processing; the Right to Rectification (Article 16) [
7], which enables individuals to correct inaccurate personal data; the Right to Erasure, or “Right to be Forgotten” (Article 17) [
8], which permits individuals to request the deletion of their personal data under certain conditions; the Right to Restrict Processing (Article 18) [
9], which allows individuals to request limitations on how their data is processed; the Right to Data Portability (Article 20) [
10], which gives individuals the right to receive their personal data in a structured, commonly used, and machine-readable format and to transmit it to another controller; the Right to Object (Article 21) [
11], which enables individuals to object to the processing of their personal data for certain purposes such as direct marketing; and the Rights Related to Automated Decision-Making (Article 22) [
12], which protect individuals from decisions based solely on automated processing, including profiling, that have legal or similarly significant effects.
Organizations (both data controllers and processors) are obligated to implement appropriate technical and organizational measures to ensure and demonstrate compliance with the GDPR. This includes, among other measures, conducting Data Protection Impact Assessments (DPIAs) for high-risk processing activities (Article 35) [
13], appointing Data Protection Officers (DPOs) in certain cases (Articles 37–39) [
14,
15,
16], and adhering to the principles of data protection by design and by default (Article 25) [
17]. Non-compliance with the GDPR can result in significant penalties, with fines reaching up to 4% of a company’s annual global turnover or €20 million, whichever is higher [
18]. Since its enforcement, numerous high-profile cases have underscored the regulation’s stringent enforcement. Moreover, the GDPR has influenced data protection laws worldwide and serves as a benchmark for countries updating their privacy regulations, as seen with the California Consumer Privacy Act (CCPA) in the United States, Brazil’s General Data Protection Law (LGPD), and Japan’s Act on the Protection of Personal Information (APPI).
1.2. Overview of Large Language Models (LLMs)
Large Language Models (LLMs) are advanced artificial intelligence models designed to understand, generate, and manipulate human language in a way that closely mimics human communication [
19]. They leverage deep learning techniques—particularly neural networks with transformer architectures—to process and generate text [
20]. The introduction of the Transformer model by Vaswani et al. in 2017 revolutionized natural language processing (NLP) by enabling models to capture long-range dependencies in text more effectively than recurrent neural networks (RNNs) [
20]. Building on this foundation, models such as BERT (Bidirectional Encoder Representations from Transformers) [
21], GPT-2 [
22], GPT-3 [
23], and the more recent GPT-4 [
24] have significantly advanced AI capabilities in language understanding and generation.
LLMs are pre-trained on massive datasets that include a wide array of internet text, books, articles, and other publicly available content [
25]. This extensive pre-training allows them to learn complex linguistic patterns, semantics, and world knowledge. As a result, LLMs can perform a variety of tasks, such as producing coherent and contextually relevant text, translating text between languages, responding to queries based on provided context, condensing long documents into concise summaries, and determining the sentiment expressed in text [
23,
26,
27,
28,
29].
1.3. Real-World Implementation Examples
Although fully documented GDPR compliance cases for LLMs remain relatively scarce, a few noteworthy examples indicate industry movement toward addressing the Right to Erasure in practice. OpenAI, for instance, has introduced user controls allowing individuals to request deletion of conversation logs, which are then excluded from subsequent training updates [
30]. Nonetheless, it remains unclear how effectively these logs can be “unlearned” from the core model parameters, as current unlearning methods often require resource-intensive retraining [
31]. Similarly, Google has responded to EU regulatory pressures by refining its data usage policies and quarantining user data when erasure requests are granted [
32].
Preliminary evidence suggests that while user-facing deletion controls and opt-outs reduce the volume of retained data, selectively removing or editing data that has already shaped an LLM’s internal parameters poses significant technical hurdles. Indeed, many solutions focus on filtering model outputs rather than permanently eliminating learned representations [
30,
31]. Until more robust machine unlearning techniques achieve scalability and third-party validation, practical implementations of the Right to Erasure in large-scale LLMs will likely remain partial, relying on procedural measures (e.g., privacy policies, segmentation of training data, and post-deployment filtering) rather than guaranteed removal of all personal information from model weights.
Moreover, LLMs are increasingly integrated into applications across various domains. In healthcare, they assist in diagnostics, facilitate patient communication, and summarize medical records [
33]. In finance, they analyze market sentiment, automate customer service, and aid in fraud detection [
34]. In the education sector, LLMs provide personalized tutoring and language learning support [
35], while in customer service they power chatbots and virtual assistants to efficiently handle inquiries [
36].
Despite their impressive capabilities, LLMs raise several concerns related to data privacy, security, and ethical considerations. For instance, these models may inadvertently memorize and reproduce personal or sensitive information present in their training data, potentially leading to privacy breaches [
37]. Recent work on securing sensitive data in LLMs has proposed comprehensive trust frameworks that incorporate adaptive output control and user trust profiling to dynamically manage the disclosure of sensitive information [
38]. Such approaches emphasize the necessity of embedding trust mechanisms into LLMs, especially in domains where data sensitivity is paramount. They can also inherit and amplify biases found in the training data, resulting in discriminatory or offensive outputs [
39]. Furthermore, the black-box nature of LLMs makes it challenging to interpret their decision-making processes, complicating accountability and trust [
40]. Finally, the methods used to collect and process data for training LLMs may conflict with legal requirements regarding consent and data minimization, posing further challenges to legal compliance [
41,
42].
1.4. Feasibility and Scalability of Privacy-Preserving Techniques
Implementing privacy safeguards for LLMs exceeding 100 billion parameters poses daunting computational hurdles. Differential privacy (DP) methods, such as DP-SGD, require computing and clipping per-sample gradients, which becomes prohibitively expensive at scale [
43,
44]. Even when feasible, DP often incurs notable utility losses, with some large-model experiments showing a 10–20% accuracy gap versus non-private baselines [
44]. Machine unlearning faces similar challenges: fully retraining a gigantic model to “forget” a single dataset is prohibitively time-consuming, and approximate fine-tuning approaches risk degrading unrelated functionality [
45]. Many real-world deployments thus rely on partial solutions, like filtering user-specific outputs rather than fully erasing internal representations [
46].
Recent work suggests potential mitigations. For instance, a Mixture-of-Experts approach allows selectively “removing” or retraining only an expert sub-module, decreasing the scope of full-model updates [
47]. Likewise, selective DP applies noise only to truly sensitive training steps, reducing overhead and preserving more utility [
48]. While these techniques show promise on smaller to medium-scale benchmarks, the path to seamless, large-scale unlearning and high-utility differential privacy remains an open research area. Efforts continue to balance stringent privacy requirements with practical computational costs and minimal accuracy loss.
Practical Examples of Machine Unlearning and Bias Mitigation. Recent studies have investigated techniques for selectively removing or “unlearning” personal data from trained machine learning models to comply with regulations such as the GDPR’s Right to Erasure. Golatkar et al. (2020) presented methods for selective forgetting in deep neural networks, demonstrating effective data removal with minimal degradation in model performance on image classification tasks [
49]. Bourtoule et al. (2021) proposed a systematic approach for machine unlearning, employing modular architectures to efficiently delete specific training instances without significant retraining overhead [
31]. In terms of bias mitigation, empirical analyses have highlighted effective techniques for debiasing large pretrained language models. For example, Bartl et al. (2020) provided evidence that targeted fine-tuning significantly reduces gender-based stereotypes in language models like BERT [
50]. Additionally, Kaneko and Bollegala (2021) introduced efficient debiasing methods for contextualized embeddings, achieving measurable decreases in biases while preserving the overall effectiveness of the embeddings [
51]. These studies collectively underscore the potential and current challenges in developing practical technical solutions to enhance privacy and fairness in machine learning applications.
These concerns necessitate a careful examination of the intersection between LLMs and data protection laws to ensure that the deployment of such technologies aligns with legal and ethical standards.
1.5. Thesis Statement
This paper examines the challenges in complying with GDPR articles like deletion (Article 17) [
8], access (Article 15) [
6], and decision-making (Article 22) [
12] with LLMs.
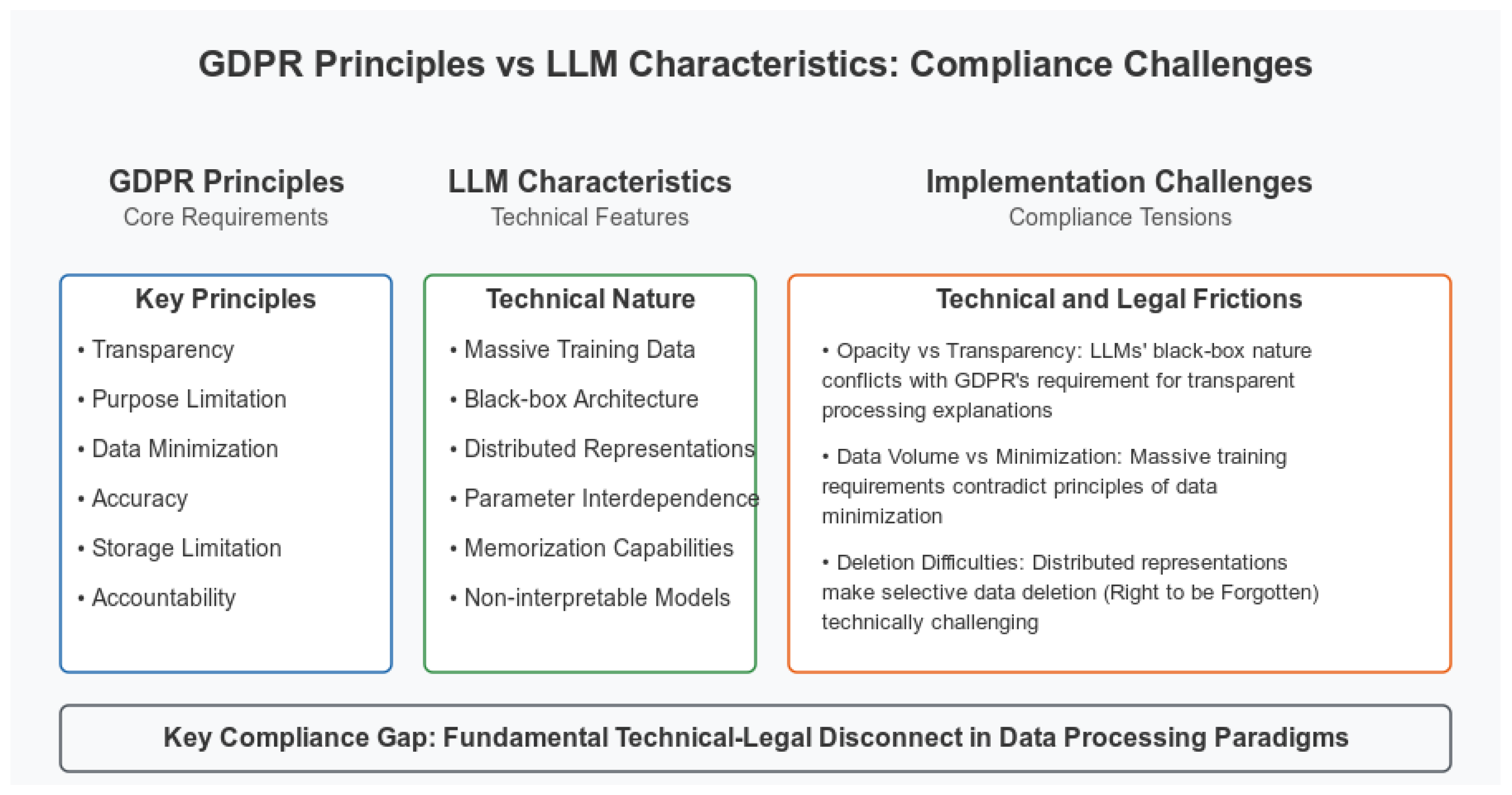
The diagram above (
Figure 1) contrasts key GDPR principles such as transparency and accountability, alongside core LLM features, demonstrating significant compliance tensions between technical and legal paradigms.
1.6. Distinction Between Personal and Non-Personal Data
One of the critical challenges in developing and deploying Large Language Models (LLMs) under GDPR is the ability to clearly distinguish between personal and non-personal data. LLMs are typically trained on massive, heterogeneous datasets drawn from a variety of sources—such as websites, social media, and digital archives—that often contain a mix of both types of information. This data aggregation makes it challenging to identify and segregate personal data, especially when much of the input is unstructured and context-dependent.
For example, personal identifiers may not be explicitly present; rather, they can appear as quasi-identifiers (such as postal codes, birthdates, or behavioral patterns) that, when combined with other data, reveal an individual’s identity. Furthermore, the unstructured nature of much of the training data means that sophisticated natural language processing (NLP) tools are required to detect personal information hidden in nuanced contexts. The context in which data appears is also important; a common name like “John” might not be considered personal in isolation but could become personally identifiable when paired with other details such as a location or occupation.
Additionally, once personal data is ingested into an LLM during training, it is transformed into abstract, high-dimensional representations stored in the model’s parameters. While these representations are not readily interpretable, evidence suggests that LLMs can sometimes memorize specific details, raising concerns that personal data may be inadvertently reproduced in outputs. Organizations are exploring several techniques to manage these challenges. Data anonymization methods—such as k-anonymity [
52], l-diversity, or t-closeness—can help reduce the risk of re-identification, although achieving true anonymization in large, complex datasets remains difficult. Advances in automated data classification using machine learning and NLP have also shown promise in detecting and flagging personal information, even though such systems are not infallible and may yield both false positives and negatives.
Other strategies include data minimization practices, which involve limiting the collection and processing of personal data to what is strictly necessary, as well as employing human oversight to review flagged data that automated tools may miss. In addition, privacy-preserving techniques like federated learning can help keep personal data localized and separate from the centralized datasets used to train models, while differential privacy can be applied to introduce statistical noise that protects individual data points without significantly affecting model performance.
The implications of these challenges are significant. Failure to properly distinguish and handle personal data can lead to serious GDPR violations, with risks including unlawful processing, data breaches, and substantial fines. Moreover, strict privacy-preserving measures may sometimes degrade model performance by reducing the diversity or representativeness of training data. Therefore, robust data governance and accountability frameworks are essential. Organizations must not only track and manage the data used in LLM training but also ensure that they are in full compliance with data protection regulations. Ultimately, a clear understanding of what constitutes personal data—and the application of advanced techniques to minimize associated privacy risks—is key to balancing compliance with the need to maintain the utility of LLMs.
1.7. Data Protection
GDPR emphasizes data protection through principles such as data minimization, purpose limitation, and ensuring data integrity and confidentiality [
5]. These principles require that personal data is processed only for legitimate purposes, kept accurate and up-to-date, and protected against unauthorized access and breaches [
1].
LLMs are typically trained on extensive datasets that often include personal data scraped from diverse sources such as the internet, books, and articles [
22,
37]. During training, these models ingest and transform vast amounts of data, which may inadvertently include sensitive information. Moreover, the ability of LLMs to generate text based on learned patterns can lead to the unintentional disclosure of personal information [
37].
Ensuring data protection in LLMs is challenging for several reasons. First, the requirement for large datasets to achieve high performance may conflict with the GDPR principle of processing only the necessary data. Second, the diverse applications of LLMs make it difficult to restrict data usage to specific, predefined purposes. To mitigate these risks, various privacy-preserving techniques have been developed. A recent narrative review provides a comprehensive overview of methods such as differential privacy, federated learning, homomorphic encryption, and secure multi-party computation, specifically in the context of generative AI and LLMs [
53]. These techniques not only mitigate risks like model inversion and membership inference attacks but also align technical safeguards with evolving legal requirements. Finally, protecting the integrity and confidentiality of data within the high-dimensional parameter spaces of LLMs is technically complex [
39,
54].
To mitigate these risks, organizations can anonymize training data to prevent the identification of individuals, incorporate differential privacy techniques during training to limit the influence of any single data point, and employ federated learning to train models without centralizing personal data [
54,
55].
1.8. Right to Erasure and LLMs
Article 17 [
8] of the GDPR, known as the “Right to Erasure” or “Right to be Forgotten”, allows individuals to request the deletion of their personal data under specific conditions [
8]. This right is intended to give individuals control over their personal information and to ensure that outdated or irrelevant data is removed from processing systems [
4].
Implementing the Right to Erasure in the context of LLMs is particularly challenging. Once trained, the model parameters encapsulate the information learned during training, making it difficult to remove specific data points without retraining the entire model. In addition, the aggregation of data across numerous sources complicates the identification and extraction of individual data points [
31,
37]. Potential solutions include developing machine unlearning techniques that enable models to “forget” specific data without complete retraining, retraining the model from scratch while excluding the data subject’s information, or designing modular model architectures where specific data segments can be isolated and removed [
31,
56]. However, these approaches remain in early stages and require further research to be practical for large-scale LLMs [
41,
42].
1.9. Right of Access and LLMs
Article 15 [
6] of the GDPR grants individuals the right to obtain confirmation about whether their personal data is being processed, to access that data, and to receive additional information about the processing activities [
6]. This right is crucial for transparency and for empowering individuals to understand how their data is used.
For LLMs, the Right of Access poses significant challenges. Personal data used in training is embedded within the model’s parameters in a non-transparent manner, which makes direct access difficult. Moreover, retrieving specific data points from models trained on vast datasets is not straightforward [
31,
37]. Potential solutions include developing model auditing tools to detect personal data within the models, providing query-based access to allow individuals to receive outputs related to their data, or publishing transparency reports that detail data sources and processing activities without revealing individual data points [
40,
41,
42].
1.10. Right to Rectification and LLMs
Article 16 [
7] of the GDPR provides individuals with the right to have inaccurate personal data corrected or completed. This ensures that data controllers maintain accurate and up-to-date information about data subjects.
Rectification in LLMs is challenging because, once trained, the models lack mechanisms to update or correct specific data points without comprehensive retraining easily. Personal data within these models is often intertwined with other information, making isolated corrections difficult. While methods such as fine-tuning with corrected data, continuous learning frameworks, or modular updates have been proposed, each approach has its limitations. Fine-tuning may not fully eliminate residual inaccuracies if the model retains influences from the original data, and retraining large-scale models is resource-intensive. Consequently, significant advancements in model architecture and training methodologies are needed to effectively implement the Right to Rectification in LLMs [
23,
37,
39,
41,
42,
55,
56].
1.11. Automated Decision-Making and Profiling
Article 22 [
12] of the GDPR restricts decisions based solely on automated processing, including profiling, thereby ensuring that affected individuals have the right to human intervention, the opportunity to express their views, and the possibility to contest such decisions. LLMs are increasingly employed in automated decision-making across sectors such as finance, healthcare, and human resources due to their capability to process and generate human-like text, making them suitable for tasks like credit scoring, medical diagnostics, and employee evaluations [
19].
However, several challenges complicate GDPR compliance in this area. First, the inherent opacity of LLMs makes it difficult to explain how specific inputs lead to particular decisions [
40]. In addition, these models can inherit and even amplify biases from their training data, potentially leading to unfair or discriminatory outcomes [
39]. Finally, the complexity of determining responsibility for decisions made by autonomous models further compounds the accountability issues [
1].
To address these challenges, organizations are exploring multiple strategies. The implementation of explainable AI (XAI) techniques can help provide understandable explanations for decisions made by LLMs. At the same time, bias mitigation methods are being employed to detect and reduce biases in both training data and model outputs. Additionally, incorporating human oversight into critical decision-making processes is essential to ensure compliance with GDPR’s requirement for human intervention. Finally, establishing robust consent frameworks that clearly inform individuals about automated decision-making processes can further enhance transparency and accountability [
1,
19,
39,
40].
1.12. Data Minimization and Purpose Limitation
GDPR mandates that personal data collected must be adequate, relevant, and limited to what is strictly necessary for the intended purposes [
5]. Moreover, data should be collected for specified, explicit, and legitimate purposes, and should not be further processed in a manner incompatible with those purposes [
1].
LLMs, however, require vast amounts of data covering a wide array of topics and sources to achieve high performance [
22,
25]. This broad data collection can conflict with the principles of data minimization and purpose limitation, as the data used for training may extend far beyond what is strictly necessary for a specific application [
39]. In practice, the challenge lies in balancing the need for large, diverse datasets against the GDPR’s requirements. Organizations are addressing this by curating training data selectively, developing models tailored for specific purposes, and implementing robust data governance frameworks that closely monitor data collection, usage, and retention [
1,
19,
39].
1.13. Data Protection by Design and by Default
Article 25 of the GDPR requires that data controllers implement data protection measures from the very beginning of designing data processing systems, ensuring that by default only the personal data necessary for each specific purpose is processed [
17]. This principle calls for the proactive integration of privacy measures throughout the development lifecycle.
In the case of LLMs, integrating data protection by design poses significant challenges. The intricate and complex architectures of these models make it difficult to seamlessly embed data protection measures. Moreover, LLMs often require continuous updates with new data, complicating the consistent maintenance of data protection standards. There is also a delicate balance between enhancing data protection and maintaining model performance, as robust privacy measures may sometimes adversely impact functionality [
22,
39,
54].
To mitigate these issues, organizations are adopting a range of strategies. Techniques such as differential privacy, federated learning, and homomorphic encryption are being utilized to safeguard personal data during both training and inference phases. Additionally, designing models with modular components that can incorporate privacy measures independently, and integrating automated compliance tools into the development lifecycle, are promising approaches to ensure that data protection is woven into the fabric of the model from the outset.
Potential Solutions
To effectively implement data protection by design in LLMs, organizations can adopt the following approaches:
Privacy-Preserving Techniques: Utilizing methods such as differential privacy, federated learning, and homomorphic encryption to protect personal data during training and inference [
54,
55].
Modular Design: Designing models with modular components that can incorporate data protection measures independently [
56].
Automated Compliance Tools: Integrating tools that automatically enforce data protection policies throughout the model development and deployment lifecycle [
41,
42].
These measures facilitate the integration of data protection principles into the core design of LLMs, ensuring compliance with GDPR from the ground up [
17].
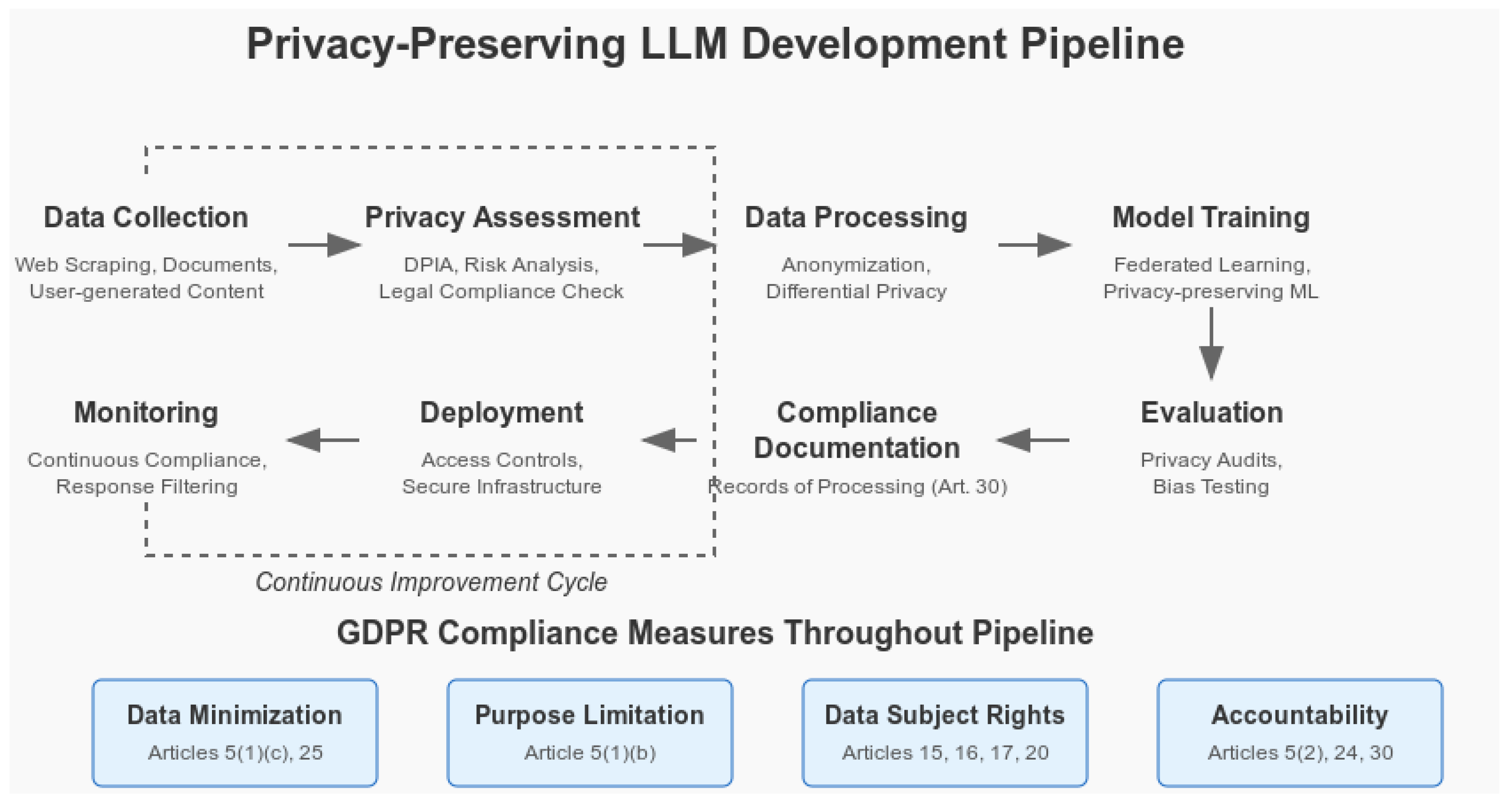
Figure 2 illustrates a comprehensive Privacy-Preserving LLM Development Pipeline with integrated GDPR compliance measures. The diagram visually maps out the end-to-end process—from data collection and privacy assessment to data processing, model training, evaluation, compliance documentation, deployment, and continuous monitoring. By embedding privacy-preserving techniques and automated compliance checks at each stage, the figure reinforces the modular design and integrated approach needed to meet GDPR requirements in LLM development.
1.14. Records of Processing Activities
1.14.1. GDPR’s Requirement for Records of Processing Activities
Article 30 of the GDPR mandates that data controllers and processors maintain detailed records of all personal data processing activities [
57]. These records should include information about the data categories, processing purposes, data recipients, and data retention periods [
1].
1.14.2. Challenges with LLMs
Maintaining comprehensive records of processing activities for LLMs is challenging due to:
Scale and Complexity: The vast scale and complexity of data processing in LLMs make it difficult to document all activities accurately [
25].
Dynamic Data Sources: LLMs often integrate data from numerous, dynamic sources, complicating the tracking of data provenance and processing steps [
22].
Model Updates: Frequent model updates and retraining cycles necessitate continuous record-keeping, which can be resource-intensive [
55].
1.14.3. Potential Solutions
To effectively manage records of processing activities in LLMs, organizations can implement:
Automated Documentation Tools: Leveraging tools that automatically generate and update processing records based on data ingestion and model training activities [
41,
42].
Comprehensive Data Logging: Establishing robust data logging mechanisms that capture detailed information about data sources, processing purposes, and data transformations [
25].
Regular Audits: Conducting periodic audits to ensure that records of processing activities are accurate, up-to-date, and compliant with GDPR requirements [
1].
These strategies enhance the ability to maintain accurate and comprehensive records, thereby facilitating GDPR compliance [
57].
1.15. The European Union’s Artificial Intelligence Act (AI Act)
The EU’s Artificial Intelligence Act (AI Act), officially adopted on 13 June 2024, introduces a harmonized regulatory framework for AI systems across the European Union [
58]. In addition to the current regulation, earlier studies have provided an AI security perspective on the proposed requirements. For instance, Kalodanis et al. have examined the applicability of the AI Act’s technical requirements to high-risk systems, highlighting the gap between the regulatory mandates and available AI security countermeasures [
59]. Their work reinforces the need for an integrated framework to evaluate AI system security within the context of the new regulatory landscape.
Key provisions relevant to Large Language Models (LLMs) include several requirements. First, AI systems operating in high-risk areas must meet stringent data quality standards, ensuring that training datasets are accurate, representative, and free of bias. This aligns closely with GDPR principles by ensuring data used by AI systems is both relevant and fair. In addition, transparency obligations require that AI systems interacting with users disclose their AI nature, making it clear when individuals are engaging with an automated system. Organizations must document and share detailed information about the functioning of their AI systems, thus enhancing traceability and explainability. Furthermore, the Act mandates the establishment of compliance frameworks: providers must maintain detailed technical documentation, register high-risk AI systems in an EU database, and conduct ongoing monitoring and reporting to mitigate risks related to data accuracy, bias, and safety.
For LLMs, these provisions have significant implications. Providers must clearly disclose when users are interacting with an AI system and ensure that risk management practices, including comprehensive risk assessments, are in place. Data governance is also critical: training data must meet high standards of quality and fairness to avoid perpetuating biases, and human oversight is required especially in critical decision-making contexts such as recruitment or credit assessments. Organizations need to navigate the overlaps between the AI Act and GDPR, ensuring compliance with both sets of regulations. This involves maintaining detailed technical documentation for each AI system and implementing robust risk management and human oversight measures to ensure that AI systems are deployed in a safe, transparent, and ethically sound manner.
In summary, the AI Act represents a significant step toward making AI systems, including LLMs, safer and more transparent by mandating robust risk management, human oversight, and detailed documentation. Organizations must proactively align their AI development and deployment practices with these new regulations to ensure full compliance and to foster ethical and fair AI practices within the EU [
58].
1.16. Comparative Analysis: GDPR vs. AI Act Interactions
The European Union’s General Data Protection Regulation (GDPR) and the forthcoming Artificial Intelligence Act (AI Act) are complementary yet distinct frameworks. While the GDPR establishes technology-neutral, principles-based rules to protect personal data, the AI Act adopts a risk-tiered, system-focused approach to ensure AI systems are safe and ethical by design. Importantly, the AI Act is implemented “without prejudice” to the GDPR, meaning that organizations must comply with both regimes when processing personal data with AI. The AI Act classifies AI systems based on risk—from banned applications (unacceptable risk) to high-risk systems (e.g., those used in employment, healthcare, or law enforcement) that must meet strict requirements for risk management, transparency, and oversight [
58]. In contrast, the GDPR governs all personal data processing based on principles such as lawfulness, fairness, transparency, and data minimization, ensuring robust data subject rights [
60]. Together, these regulations aim to safeguard both technological integrity and individual privacy. Sectors such as healthcare and recruitment face dual compliance challenges. Healthcare AI systems must satisfy the AI Act’s requirements for risk management and technical documentation while also adhering to the GDPR’s strict rules for processing sensitive health data [
61]. Similarly, recruitment AI tools must balance the AI Act’s bias mitigation and transparency measures with GDPR mandates on lawful processing and non-discrimination [
62]. Adopting a “GDPR-first” approach—where robust data protection forms the foundation for additional AI-specific controls—is widely recommended as a strategy to achieve an integrated framework for trustworthy AI. In summary, the GDPR and the AI Act together promote a vision of trustworthy AI that ensures both system safety and the protection of fundamental rights. Despite challenges in aligning their differing approaches, integrated compliance strategies can enable organizations to meet both sets of obligations without compromising innovation or privacy.
1.17. Balancing Compliance and Innovation
The intersection of GDPR and LLMs highlights significant challenges in aligning advanced AI technologies with stringent data protection regulations. The core GDPR principles of transparency, accountability, and data protection often conflict with the technical nature of LLMs, which inherently obscure data processing activities and make individual data point manipulation difficult. Addressing these challenges requires a multifaceted approach that combines technological innovations, robust governance frameworks, and ongoing collaboration between technologists and legal experts. By implementing privacy-preserving techniques, enhancing model interpretability, and establishing comprehensive documentation practices, organizations can better navigate the complexities of GDPR compliance in the realm of Large Language Models.
4. Discussion
Navigating the complex intersection of the GDPR and Large Language Models (LLMs) requires recommendations that target policymakers, industry practitioners, and the research community. The overall goal is to bridge the gap between regulatory requirements and technological capabilities, ensuring that LLM deployment aligns with data protection and privacy standards.
Critical Legal Interpretations and Implications for Developers. Recent regulatory discussions underscore ongoing uncertainties in applying GDPR to Large Language Model (LLM) training. For instance, the Hamburg Commissioner for Data Protection and Freedom of Information warns that high-dimensional embeddings may still be re-identifiable, casting doubt on whether mere pseudonymization or anonymization suffices [
84]. Similarly, the European Data Protection Board’s
Opinion 28/2024 highlights divergent national stances on whether broad web-scraping for AI training constitutes a legitimate interest, urging a case-by-case assessment of both necessity and proportionality [
62]. Legal commentators further note that authorities like the Garante (Italian DPA) increasingly scrutinize the extent of user consent when publicly available data is re-purposed for commercial LLMs [
85]. In contrast, certain industry perspectives argue that data subjects’ rights over passively collected training data may be limited under existing privacy doctrines [
86], leaving developers with inconsistent guidance. As a result, and given the lack of definitive Court of Justice of the EU rulings on LLM-specific data removal thresholds, risk management for AI developers hinges on conservative data governance and robust documentation [
87] until courts and regulators clarify these grey areas.
Regulators are encouraged to update existing GDPR guidelines to address the unique challenges posed by LLMs, providing clearer definitions and standards for data processing practices specific to AI and machine learning. In addition, it is important to develop AI-specific regulations that complement GDPR by focusing on issues such as model transparency, accountability, and ethical AI development. International cooperation is also essential to harmonize data protection laws, thereby facilitating standardized frameworks that support global AI deployments.
Clear guidelines should be established regarding data deletion and rectification in the context of LLMs, including acceptable methods for machine unlearning and conditions under which retraining is required. Transparency reporting is another key area; organizations should be mandated to publish regular reports detailing their data processing activities, the sources of training data, and the measures taken to ensure compliance with GDPR. Such reporting not only enhances accountability but also builds trust with stakeholders.
From an industry perspective, it is advisable for organizations to embed privacy-by-design strategies throughout the AI development lifecycle. This means integrating data protection measures from the very beginning of model design and maintaining these considerations during development, training, and deployment. In parallel, organizations should adopt transparent data processing practices and maintain comprehensive documentation to support accountability. The use of Explainable AI (XAI) techniques can further help in making model behaviors and decision-making processes more understandable.
Investing in privacy-preserving technologies such as differential privacy, federated learning, and homomorphic encryption is crucial for safeguarding personal data during both training and inference. Regular Data Protection Impact Assessments (DPIAs) are recommended to identify and mitigate potential risks associated with data processing. Robust data governance frameworks that oversee data collection, usage, retention, and deletion must be established, and comprehensive records of processing activities should be maintained in accordance with GDPR requirements.
Practical applications of high-risk AI systems further underscore the challenges of aligning advanced AI technologies with regulatory and ethical standards. A recent study on AI-based lie detection for border control systems illustrates the complex interplay between technical performance, ethical concerns, and strict regulatory compliance under the EU AI Act [
88]. By evaluating real-world case studies such as iBorderCtrl and AVATAR, the study emphasizes the necessity for rigorous risk assessments and tailored security controls in high-stakes environments.
Preliminary Quantitative Assessments and Simulation Results. Preliminary evaluations of privacy-preserving LLMs highlight notable trade-offs between privacy and model performance. For instance, training with differential privacy (DP) often reduces accuracy and even amplifies biases: Bagdasaryan et al. (2019) report that DP-SGD can significantly lower overall accuracy and disproportionately hurt underrepresented classes [
81]. On text generation tasks, DP also tends to degrade quality (e.g., a strong privacy setting
only modestly reduced a GPT-2 model’s BLEU score from about 66.8 to 64.6 [
89]). Recent techniques seek to mitigate such losses. Shi et al. (2022) propose *Selective* DP, which protects only sensitive tokens and yields a much better privacy–utility trade-off: in experiments, Selective-DPSGD roughly halved the perplexity increase caused by DP (bringing test perplexity down to 160 from DP-SGD’s 306, versus 61 with no privacy) at equivalent privacy levels [
48]. Meanwhile, modular *machine unlearning* methods improve the efficiency of data removal from trained models. Bourtoule et al. (2021) introduced a “SISA” training strategy that accelerates retraining after deletion requests by 2–5× with minimal impact on accuracy [
31]—for example, SISA achieved about 4.6× faster unlearning on a Purchase dataset model and 2.4× on SVHN, and even a 1.36× speed-up for ImageNet-scale models (with only minor accuracy degradation). These results illustrate that privacy enhancements (whether during training or post-hoc) do incur performance costs, but careful design (e.g., SDP and SISA) can substantially narrow the gap while upholding strong privacy guarantees.
Proposed Framework for GDPR-Aligned LLM Governance
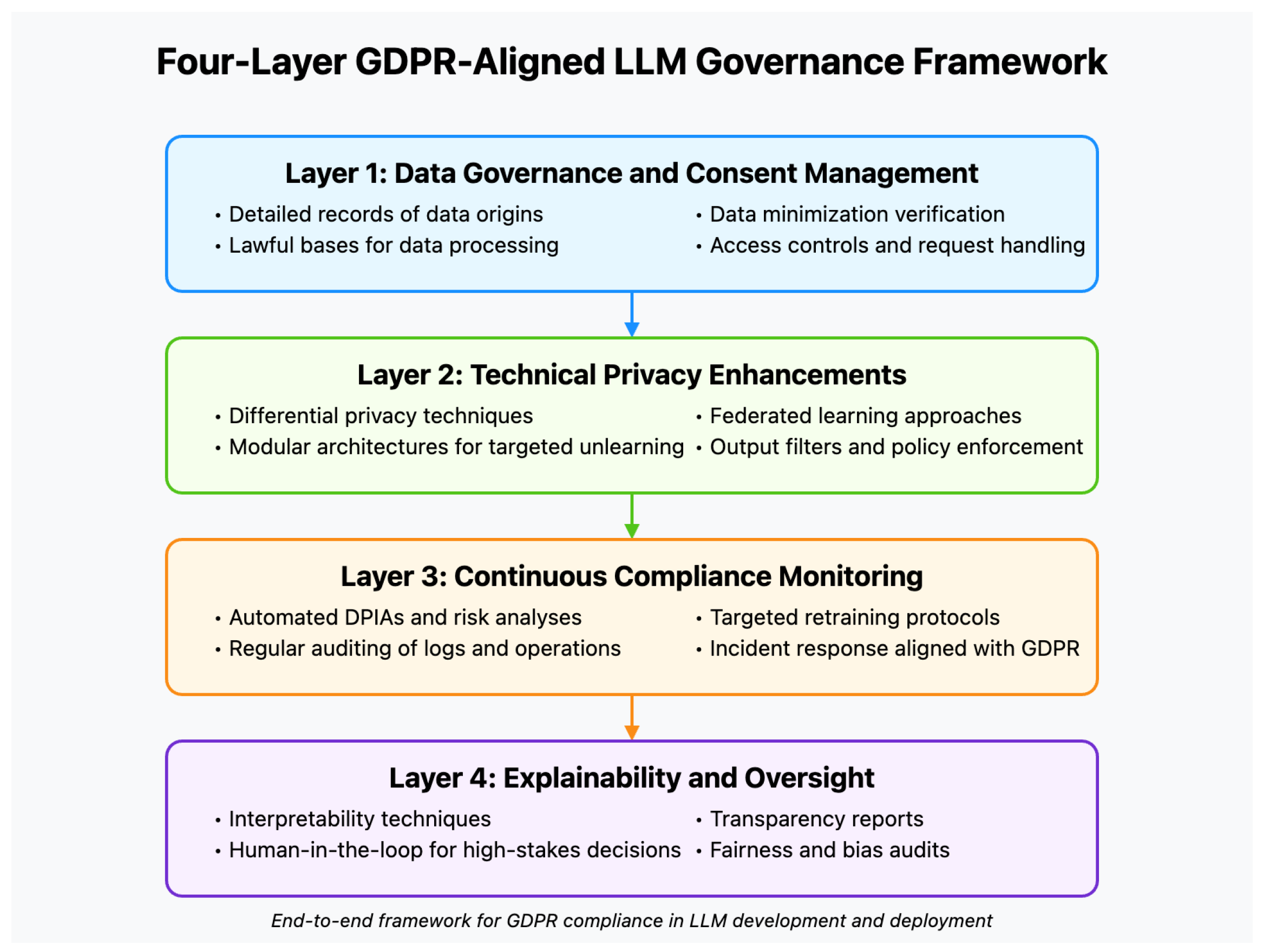
Bridging the gap between GDPR obligations and the technical realities of Large Language Models (LLMs) requires an approach that addresses data governance, technical safeguards, continuous compliance, and transparency. We propose a four-layer governance model that integrates existing regulatory guidance with novel conceptual contributions to align LLM development and deployment with GDPR. This model synthesizes the expectations of multiple Data Protection Authorities (DPAs) and reflects GDPR’s core principles of lawfulness, fairness, and accountability, while providing practical mechanisms for end-to-end compliance.
The first layer, “Data Governance and Consent Management”, focuses on creating a robust foundation before any training or deployment of the model. This involves maintaining detailed records of data origins, especially where personal data may be present, as well as establishing lawful bases for data processing (such as explicit consent or legitimate interest). It also requires verifying that the training data collected is fit for purpose, thereby fulfilling the principle of data minimization and ensuring that only what is strictly necessary is used. Strong access controls and organizational policies are put in place so that sensitive data remains protected and so that any relevant GDPR obligations—such as handling data subject requests—can be efficiently managed.
The second layer, “Technical Privacy Enhancements”, addresses the safeguards needed during training and inference. Here, developers may rely on techniques such as differential privacy (DP) to ensure that individual data points are not easily traced or reconstructed from the model’s parameters. They can also opt for modular architectures that allow specific segments of data to be selectively unlearned in response to erasure requests, reducing the need for retraining entire large-scale models. Federated learning, when appropriate, helps keep personal data on local devices rather than centralizing it, and encrypted training methods protect raw data against unauthorized disclosures. Furthermore, output filters and policy enforcement mechanisms can be implemented to prevent the inadvertent leakage of personal data in generated outputs.
Because LLMs evolve over time—either by ingesting new data or through model updates—the third layer, “Continuous Compliance Monitoring”, ensures that privacy and compliance obligations are not seen as a one-time project but rather an ongoing effort. Automated systems for data protection impact assessments (DPIAs) and risk analyses can detect emerging threats as the model changes. Regular auditing of training logs, inference requests, and unlearning operations helps verify that privacy measures are functioning as intended. In addition, targeted retraining protocols allow developers to respond efficiently to specific requests for erasure or rectification. If a data subject wishes to remove their personal data from the model, well-defined retraining or unlearning methods can be applied to address that need without unduly disrupting the model’s functionality. This continuous monitoring framework extends to incident response plans that align with GDPR’s breach notification requirements, ensuring swift containment and remediation of any data leak or privacy lapse.
Finally, the fourth layer, “Explainability and Oversight”, targets the transparency of the model’s decisions and the establishment of human review for high-stakes scenarios. Because LLMs can act as black boxes, it is crucial to incorporate techniques for interpretability, such as saliency mappings or model distillation, that provide insight into how certain inputs affect outputs. In settings like finance, healthcare, or legal decision-making, there should be a mandatory human-in-the-loop stage to fulfill the GDPR requirement of allowing data subjects to contest automated decisions that have significant effects on them. This layer also involves publishing periodic transparency reports, informing stakeholders about model performance, known biases, and any privacy incidents. In addition, audits focusing on fairness and bias can help detect and mitigate discriminatory outcomes, thus upholding GDPR’s principle of non-discrimination and fostering public trust.
Taken together, these four layers operate in tandem to deliver a comprehensive governance model for GDPR-aligned LLM development. By embedding privacy controls throughout the entire lifecycle, developers can more effectively manage evolving legal obligations, particularly in high-risk application domains, and demonstrate a proactive approach to safeguarding individual rights. This end-to-end framework helps to meet the complexities of personal data definitions, legitimate interests, and unlearning feasibility, thereby supporting a “GDPR-first” culture of compliance that remains sensitive to the unique challenges posed by large-scale AI systems. As shown in
Figure 4, our proposed governance framework divides LLM compliance into four interconnected layers. The first layer focuses on data governance practices and lawful bases for data collection, ensuring that all personal information is gathered under appropriate conditions and thoroughly documented. Building on this foundation, the second layer deploys technical mechanisms such as differential privacy and modular unlearning to safeguard personal data throughout the model’s training and inference stages. The third layer underscores the importance of continuous monitoring through regular audits, automated risk analyses, and protocols for retraining or incident response in alignment with GDPR. Finally, the fourth layer highlights the role of transparency and accountability mechanisms—such as interpretability techniques, human oversight for high-stakes decisions, fairness evaluations, and public reporting—in fostering trust and compliance in AI-driven systems.
Future research should focus on developing scalable machine unlearning techniques to efficiently remove specific data points without necessitating complete retraining. Enhancing model interpretability remains a key priority, with efforts aimed at creating more intuitive and effective XAI tools. Modular model architectures that facilitate easier updates and corrections are also a promising area for further study. Standardizing data portability mechanisms, investigating advanced bias detection and mitigation techniques, and integrating privacy-preserving machine learning into standard AI pipelines will further support compliance with GDPR. Additionally, there is a need for comprehensive regulatory frameworks that evolve with technological advancements, as well as cross-disciplinary collaboration among technologists, legal experts, ethicists, and policymakers to create holistic solutions. Finally, the development of benchmark datasets specifically designed to assess the privacy and compliance aspects of LLMs, along with the exploration of ethical AI development practices, can guide organizations toward deploying LLMs in a manner that is both responsible and compliant.
5. Conclusions
The intersection of GDPR and LLMs presents a unique set of technical, legal, and ethical challenges. As LLMs continue to evolve and be integrated into various sectors, their compliance with data protection laws like GDPR becomes increasingly complex [
90]. The core GDPR principles of transparency, accountability, and data protection often conflict with the technical characteristics of LLMs, which obscure data processing activities and make it difficult to manipulate individual data points.
Our analysis shows that addressing these challenges will require a multifaceted approach, combining advancements in technology, improvements in data governance frameworks, and ongoing collaboration between legal experts, policymakers, and technologists. Organizations need to invest in privacy-preserving techniques such as differential privacy, federated learning, and anonymization, while also ensuring compliance with GDPR’s requirements for transparency and accountability through explainable AI (XAI) methods and robust documentation practices.
Moreover, the inherent biases within LLMs, stemming from the large-scale and diverse data they are trained on, highlight the need for ethical AI development. Organizations must adopt ethical guidelines, promote fairness, and implement bias mitigation strategies to ensure that AI outputs do not reinforce societal prejudices. These efforts are essential not only for GDPR compliance but also for fostering public trust in AI systems.
Future research and policy development should focus on scalable solutions for managing personal data in LLMs, ensuring that rights such as the Right to Erasure and Right to Access are effectively upheld. Additionally, regulatory frameworks like the EU’s Artificial Intelligence Act (AI Act) will play a crucial role in shaping the future of AI, providing clearer guidelines and promoting responsible innovation in the field of LLMs.
In conclusion, the successful alignment of LLMs with GDPR will require ongoing collaboration, innovation, and adaptability. As AI technologies continue to advance, legal and regulatory frameworks must evolve alongside them, ensuring that the benefits of LLMs are realized without compromising data protection and individual rights. By bridging the gap between technological capabilities and stringent data protection standards, we can create a more transparent, accountable, and ethically sound future for AI systems.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}