
Dynamic Storage Optimization for Communication between AI Agents


Abstract
1. Introduction
- Template Layer: Optional. Offers partial views of the concept’s fields, enabling its use for various purposes where only subsets of fields are necessary.
- Versioning Layer: Optional. Manages requests for evolving the concept’s structure.
- Instruction Layer: Optional. Provides information on the concept’s purpose and usage.
- Naming Layer: Optional. Offers user-friendly labels for concept fields.
- Restriction Layer: Core. Contains cross-field validation rules for a concept.
- Validation Layer: Core. Stores rules to determine whether a given value can be stored in a particular field.
- Defaults Layer: Core. Provides default values for the concept’s fields, ensuring consistency.
- Encoding Layer: Core. Specifies how the fields of a concept are encoded, guiding AI agents on data parsing or encoding during transmission.
- Connection Layer: Core. Stores addresses of complex concepts declared in the structural layer, enabling retrieval of definitions from decentralized storage.
- Structural Layer: Core. Defines the fields of a message, including their names and data types, which may be primitive (e.g., string, number) or complex (e.g., another concept).
2. Use Case
- Traffic Signal Controller AI:
- –
- Ontology Concept: TrafficSignalStatus.
- –
- Fields: SignalID (string), Status (string: “Red”, “Yellow”, “Green”), Timestamp (datetime).
- –
- Description: The traffic signal controller AI updates the status of each traffic signal in real time. These data are encoded and transmitted using the TrafficSignalStatus concept defined in the ontology.
- Autonomous Vehicle AI:
- –
- Ontology Concept: VehicleStatus.
- –
- Fields: VehicleID (string), Location (GPS coordinates), Speed (numeric), Destination (GPS coordinates).
- –
- Description: Autonomous vehicles periodically share their status, including their current location and speed. This information is structured according to the VehicleStatus concept.
- Public Transportation System AI:
- –
- Ontology Concept: BusArrivalEstimate.
- –
- Fields: BusID (string), RouteID (string), EstimatedArrivalTime (datetime).
- –
- Description: The public transportation system provides real-time updates on bus arrival times, allowing other agents to adjust traffic management strategies accordingly.
- Emergency Response Unit AI:
- –
- Ontology Concept: EmergencyEvent.
- –
- Fields: EventID (string), Location (GPS coordinates), Severity (string: “Low”, “Medium”, “High”), Description (string).
- –
- Description: In case of an incident, the emergency response unit broadcasts information about the event, including the location and severity. Other agents, such as traffic signal controllers and autonomous vehicles, prioritize emergency response routes.
- The Traffic Signal Controller AI detects a change in the signal status at a major intersection and updates the TrafficSignalStatus concept.
- Autonomous vehicles approaching the intersection receive the updated TrafficSignalStatus, adjust their speed, and plan their routes accordingly.
- A bus on the public transportation system calculates its updated arrival time due to the traffic signal change and updates the BusArrivalEstimate concept.
- An emergency occurs nearby, and the Emergency Response Unit AI broadcasts an EmergencyEvent concept. The Traffic Signal Controller AI and Autonomous Vehicle AI reprioritize routes to clear the way for emergency vehicles.
- The data exchanged among these AI agents are stored and retrieved from a decentralized storage system (e.g., IPFS, Tendermint Cosmos, or Hyperledger Fabric), ensuring fast and reliable communication.
3. Related Works
4. Materials and Methods
4.1. Concept Sizes
4.2. Peer-to-Peer Configurations
4.2.1. Infrastructure Topology
4.2.2. Storage Engines

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Values |
|---|---|
| Network setup | Default | Cluster |
| Topology (peers count) | 2 | 4 | 8 |
| Concept size (properties count) | | | |
| Operation | Read | Write |
| Datastore engine | BadgerDS, FlatFs, Lowpower Profile |
| Warm-up iterations | 5 (each running for 10 s) |
| Execution iterations | 10 (each running for 30 s) |
4.2.3. Public Blockchain
4.2.4. Infrastructure Topology
4.2.5. Storage Engines
4.2.6. Permissioned Blockchain
4.2.7. Infrastructure Topology
4.2.8. Storage Engines
| Parameter | Values |
|---|---|
| Topology (peers count) | 2 | 4 | 8 |
| Concept size (properties count) | | | |
| Operation | Read | Write |
| Block size | Half | Double |
| Transaction pool | Half | Double |
| Datastore engine | GolevelDB | CouchDB |
| Warm-up iterations | 5 (each running for 10 s) |
| Execution iterations | 10 (each running for 30 s) |
4.3. Hardware Configuration
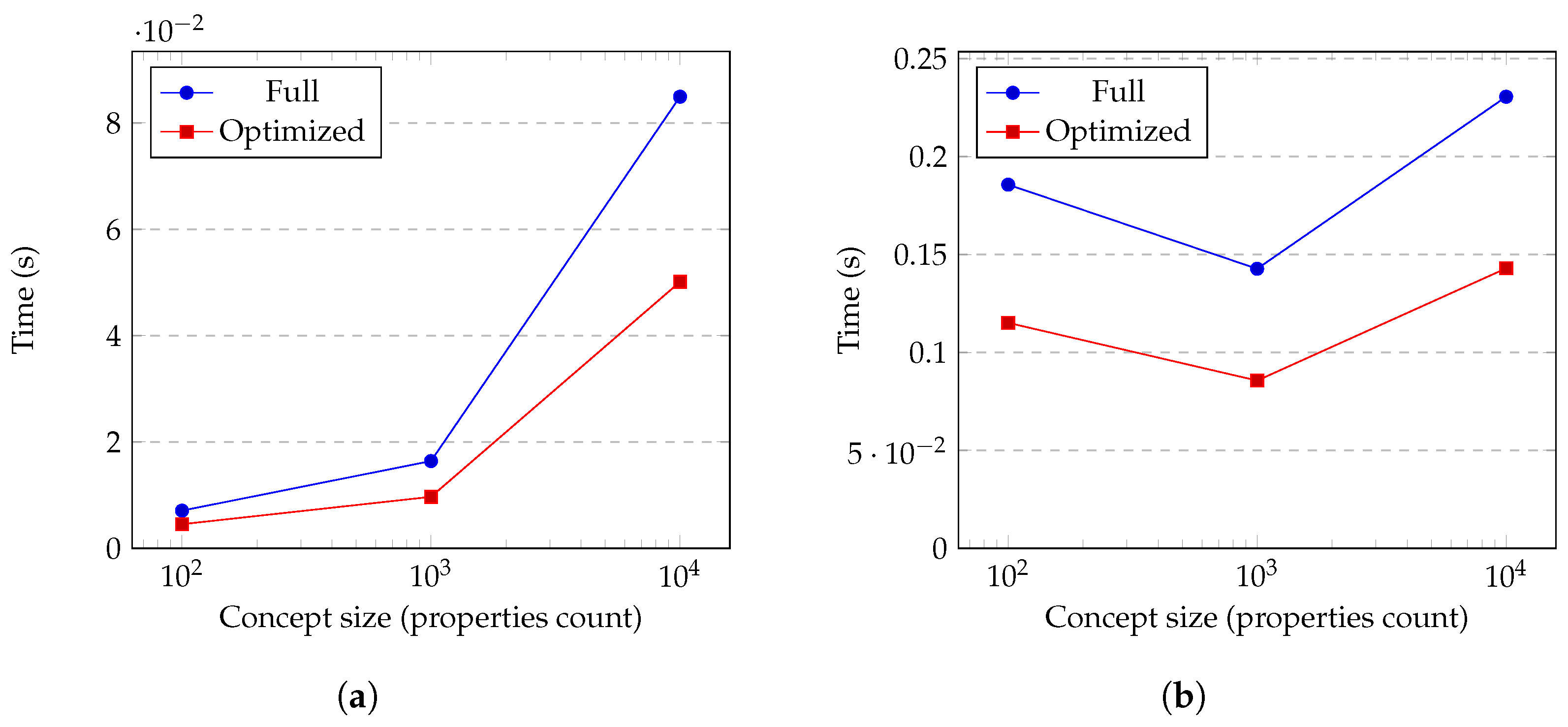
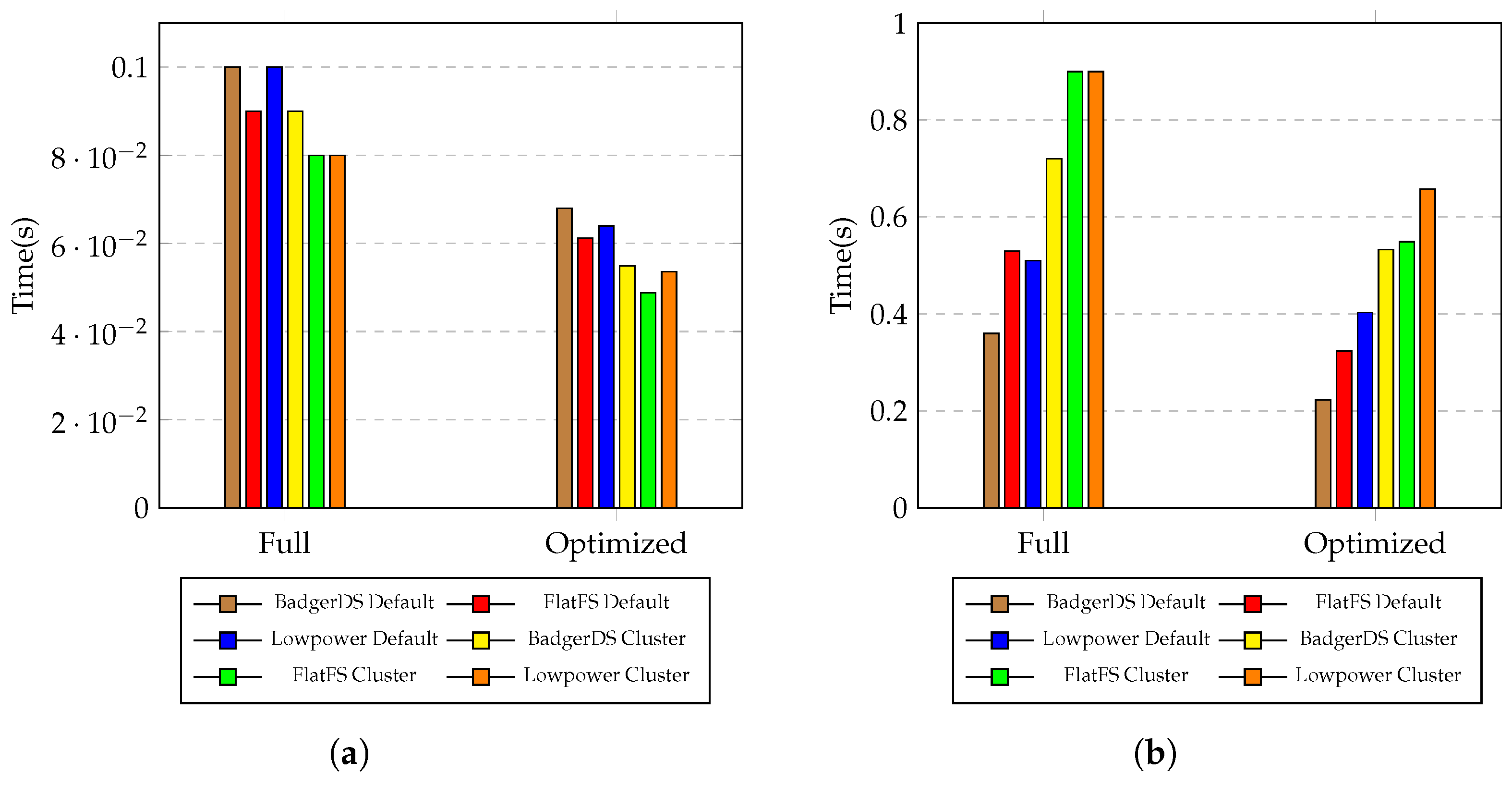
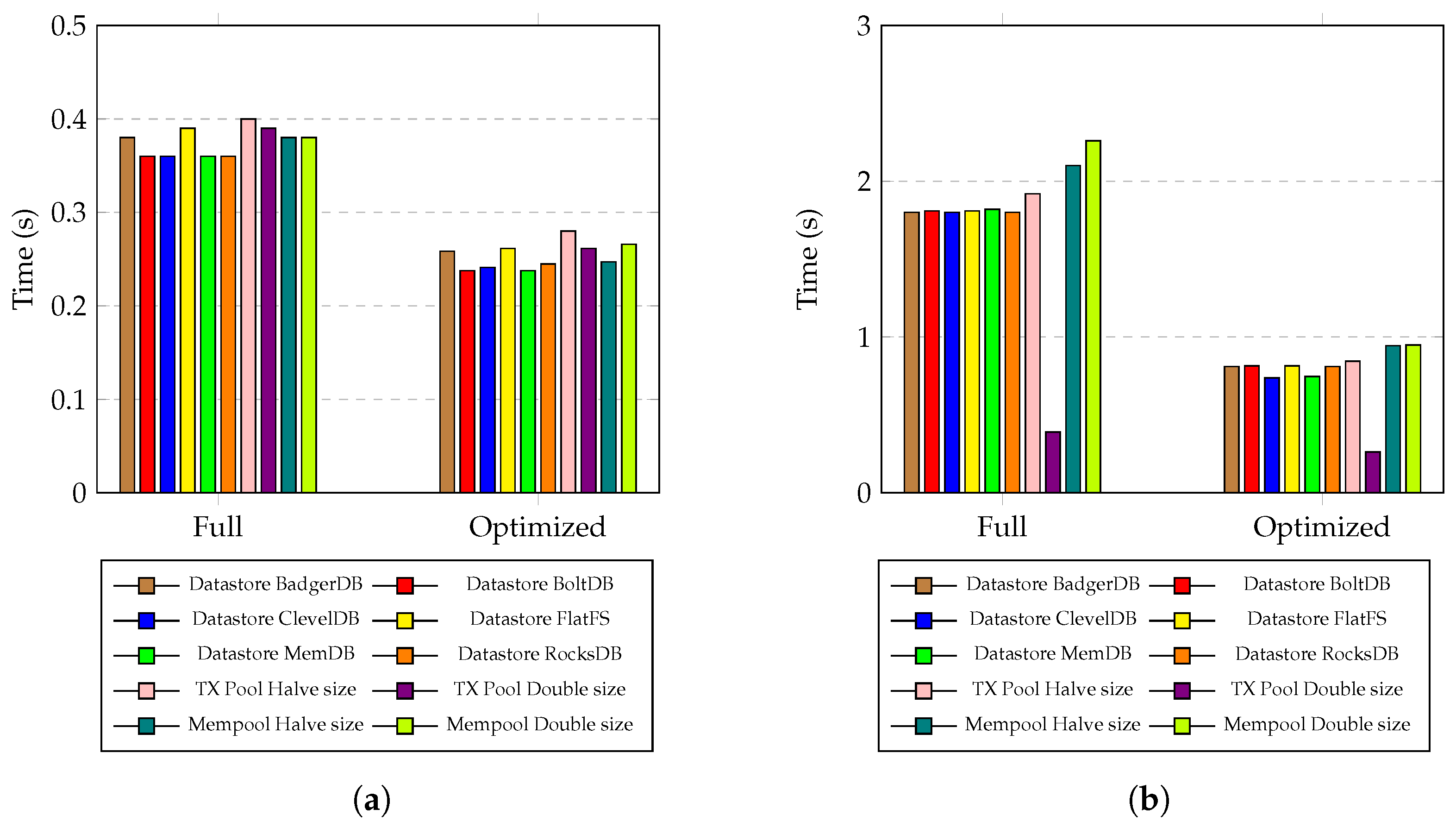
5. Results
6. Discussion
Future Research
- Performance Optimization: Further investigation into optimization methodologies could enhance the efficacy of AI agent communication in decentralized systems. This may include investigating ways to improve scalability, reduce resource bottlenecks, and accelerate data transfer rates among agents.
- Security and Privacy Considerations: As decentralized systems raise security and privacy concerns, future research could focus on developing robust protocols that safeguard confidential data during communication among AI agents. This could involve looking at privacy-preserving protocols, access control systems, and encryption techniques.
- Integration with Emerging Technologies: Given the rapid rate at which new technologies are developing, it would be advantageous to look into how the proposed communication model can integrate with technologies such as edge computing, the Internet of Things (IoT), or federated learning. This could enable AI bots to collaborate and communicate effectively under difficult conditions.
- Real-World Deployment and Case Studies: Case studies and real-world implementations can be conducted to obtain useful information on the suitability and effectiveness of the proposed communication model. This could involve applying the model in particular industries or enterprises and evaluating how well it functions, how user-friendly it is, and how it influences choices.
- Standardization and Interoperability: To facilitate widespread adoption and smooth communication among AI bots from different platforms or organizations, future research could also focus on standardizing communication protocols and promoting interoperability. This may involve developing common ontologies, semantic mappings, and communication protocols in order to facilitate smooth integration and cooperation among AI agents.By pursuing these research avenues, we can improve AI agents’ capabilities in decentralized environments, encouraging their use across a range of industries and advancing the field of AI communication.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hassanzadeh, P.; Atyabi, F.; Dinarvand, R. The significance of artificial intelligence in drug delivery system design. Adv. Drug Deliv. Rev. 2019, 151, 169–190. [Google Scholar] [CrossRef]
- Mitchell, M. Debates on the nature of artificial general intelligence. Science 2024, 383, eado7069. [Google Scholar] [CrossRef] [PubMed]
- Fei, N.; Lu, Z.; Gao, Y.; Yang, G.; Huo, Y.; Wen, J.; Lu, H.; Song, R.; Gao, X.; Xiang, T.; et al. Towards artificial general intelligence via a multimodal foundation model. Nat. Commun. 2022, 13, 3094. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Song, K.; Tan, X.; Li, D.; Lu, W.; Zhuang, Y. HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace. arXiv 2023, arXiv:2303.17580. [Google Scholar]
- Hao, R.; Hu, L.; Qi, W.; Wu, Q.; Zhang, Y.; Nie, L. ChatLLM Network: More brains, More intelligence. arXiv 2023, arXiv:2304.12998. [Google Scholar]
- Masterman, T.; Besen, S.; Sawtell, M.; Chao, A. The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey. arXiv 2024, arXiv:2404.11584. [Google Scholar]
- Gupta, R.; Kumari, A.; Tanwar, S. Fusion of blockchain and artificial intelligence for secure drone networking underlying 5G communications. Trans. Emerg. Telecommun. Technol. 2021, 32, e4176. [Google Scholar] [CrossRef]
- Morgan, J. Yesterday’s Tomorrow Today: Turing, Searle and the Contested Significance of Artificial Intelligence; Routledge: London, UK, 2018. [Google Scholar]
- Zekai, Ş. Significance of artificial intelligence in science and technology. J. Intell. Syst. Theory Appl. 2018, 1, 1–4. [Google Scholar]
- Salah, K.; Rehman, M.H.U.; Nizamuddin, N.; Al-Fuqaha, A. Blockchain for AI: Review and open research challenges. IEEE Access 2019, 7, 10127–10149. [Google Scholar] [CrossRef]
- Tara, A.; Turesson, H.K.; Natea, N.; Kim, H.M. An Evaluation of Storage Alternatives for Service Interfaces Supporting a Decentralized AI Marketplace. IEEE Access 2023, 11, 116919–116931. [Google Scholar] [CrossRef]
- Tara, A.; Taban, N.; Vasiu, C.; Zamfirescu, C. A Decentralized Ontology Versioning Model Designed for Inter-operability and Multi-organizational Data Exchange. In Artificial Intelligence in Intelligent Systems; Silhavy, R., Ed.; Springer: Cham, Switzerland, 2021; pp. 617–628. [Google Scholar]
- Birr, T.; Pohl, C.; Younes, A.; Asfour, T. AutoGPT+P: Affordance-based Task Planning with Large Language Models. arXiv 2024, arXiv:2402.10778. [Google Scholar]
- Chen, W.; Su, Y.; Zuo, J.; Yang, C.; Yuan, C.; Chan, C.; Yu, H.; Lu, Y.; Hung, Y.; Qian, C.; et al. AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors. arXiv 2023, arXiv:2308.10848. [Google Scholar]
- Guo, X.; Huang, K.; Liu, J.; Fan, W.; Vélez, N.; Wu, Q.; Wang, H.; Griffiths, T.L.; Wang, M. Embodied LLM Agents Learn to Cooperate in Organized Teams. arXiv 2024, arXiv:2403.12482. [Google Scholar]
- Gao, S.; Dwivedi-Yu, J.; Yu, P.; Tan, X.E.; Pasunuru, R.; Golovneva, O.; Sinha, K.; Celikyilmaz, A.; Bosselut, A.; Wang, T. Efficient Tool Use with Chain-of-Abstraction Reasoning. arXiv 2024, arXiv:2401.17464. [Google Scholar]
- Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. Training Verifiers to Solve Math Word Problems. arXiv 2021, arXiv:2110.14168. [Google Scholar]
- Liu, N.; Chen, L.; Tian, X.; Zou, W.; Chen, K.; Cui, M. From LLM to Conversational Agent: A Memory Enhanced Architecture with Fine-Tuning of Large Language Models. arXiv 2024, arXiv:2401.0277. [Google Scholar]
- Liu, X.; Yu, H.; Zhang, H.; Xu, Y.; Lei, X.; Lai, H.; Gu, Y.; Ding, H.; Men, K.; Yang, K.; et al. AgentBench: Evaluating LLMs as Agents. arXiv 2023, arXiv:2308.03688. [Google Scholar]
- Tian, Y.; Yang, X.; Zhang, J.; Dong, Y.; Su, H. Evil Geniuses: Delving into the Safety of LLM-based Agents. arXiv 2024, arXiv:2311.11855. [Google Scholar]
- Golchin, S.; Surdeanu, M. Time Travel in LLMs: Tracing Data Contamination in Large Language Models. arXiv 2024, arXiv:2308.08493. [Google Scholar]
- Tagde, P.; Tagde, S.; Bhattacharya, T.; Tagde, P.; Chopra, H.; Akter, R.; Kaushik, D.; Rahman, M.H. Blockchain and artificial intelligence technology in e-Health. Environ. Sci. Pollut. Res. 2021, 28, 52810–52831. [Google Scholar] [CrossRef] [PubMed]
- Lopes, V.; Alexandre, L.A. An overview of blockchain integration with robotics and artificial intelligence. arXiv 2018, arXiv:1810.00329. [Google Scholar] [CrossRef]
- Hussien, H.M.; Yasin, S.M.; Udzir, N.I.; Ninggal, M.I.H.; Salman, S. Blockchain technology in the healthcare industry: Trends and opportunities. J. Ind. Inf. Integr. 2021, 22, 100217. [Google Scholar] [CrossRef]
- Rana, S.K.; Rana, S.K.; Nisar, K.; Ag Ibrahim, A.A.; Rana, A.K.; Goyal, N.; Chawla, P. Blockchain technology and Artificial Intelligence based decentralized access control model to enable secure interoperability for healthcare. Sustainability 2022, 14, 9471. [Google Scholar] [CrossRef]
- Krittanawong, C.; Aydar, M.; Virk, H.U.H.; Kumar, A.; Kaplin, S.; Guimaraes, L.; Wang, Z.; Halperin, J.L. Artificial intelligence-powered blockchains for cardiovascular medicine. Can. J. Cardiol. 2022, 38, 185–195. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.; Sharma, P.K.; Yoon, B.; Shojafar, M.; Cho, G.H.; Ra, I.H. Convergence of blockchain and artificial intelligence in IoT network for the sustainable smart city. Sustain. Cities Soc. 2020, 63, 102364. [Google Scholar] [CrossRef]
- English, M.; Auer, S.; Domingue, J. Block chain technologies & the semantic web: A framework for symbiotic development. In Computer Science Conference for University of Bonn Students; Lehmann, J., Thakkar, H., Halilaj, L., Asmat, R., Eds.; 2016; pp. 47–61. Available online: https://www.semanticscholar.org/paper/Block-Chain-Technologies-%26-The-Semantic-Web-%3A-A-for-English-Auer/2fd37fed17e07c4ec04caefe7dcbcb16670fa2d8 (accessed on 7 June 2023).
- Graux, D.; Sejdiu, G.; Jabeen, H.; Lehmann, J.; Sui, D.; Muhs, D.; Pfeffer, J. Profiting from kitties on Ethereum: Leveraging blockchain RDF data with SANSA. In Proceedings of the SEMANTiCS Conference, Vienna, Austria, 8–12 October 2018. [Google Scholar]
- Hoffman, M.R.; Ibáñez, L.D.; Fryer, H.; Simperl, E. Smart papers: Dynamic publications on the blockchain. In Proceedings of the European Semantic Web Conference, Crete, Greece, 3–7 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 304–318. [Google Scholar]
- Kim, H.M.; Laskowski, M.; Nan, N. A First Step in the Co-Evolution of Blockchain and Ontologies: Towards Engineering an Ontology of Governance at the Blockchain Protocol Level. arXiv 2018, arXiv:1801.02027. [Google Scholar] [CrossRef]
- Sikorski, J.J.; Haughton, J.; Kraft, M. Blockchain technology in the chemical industry: Machine-to-machine electricity market. Appl. Energy 2017, 195, 234–246. [Google Scholar] [CrossRef]
- Sicilia, M.Á.; Visvizi, A. Blockchain and OECD data repositories: Opportunities and policymaking implications. Library Hi Tech 2018, 37, 30–42. [Google Scholar] [CrossRef]
- Le-Tuan, A.; Hingu, D.; Hauswirth, M.; Le-Phuoc, D. Incorporating blockchain into rdf store at the lightweight edge devices. In International Conference on Semantic Systems; Springer: Cham, Switzerland, 2019; pp. 369–375. [Google Scholar]
- Ibáñez, L.D.; Fryer, H.; Simperl, E.P.B. Attaching Semantic Metadata to Cryptocurrency Transactions. In Proceedings of the DeSemWeb@ISWC, Vienna, Austria, 21–22 October 2017. [Google Scholar]
- Cano-Benito, J.; Cimmino, A.; García-Castro, R. Towards blockchain and semantic web. In Proceedings of the International Conference on Business Information Systems, Hannover, Germany, 14–17 June 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 220–231. [Google Scholar]
- Kruijff, J.d.; Weigand, H. Understanding the blockchain using enterprise ontology. In Proceedings of the International Conference on Advanced Information Systems Engineering, Essen, Germany, 12–16 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 29–43. [Google Scholar]
- Cano-Benito, J.; Cimmino, A.; García-Castro, R. Benchmarking the efficiency of RDF-based access for blockchain environments. In Proceedings of the SEKE, Pittsburgh, PA, USA, 9–11 July 2020; pp. 554–559. [Google Scholar]
- Ruta, M.; Scioscia, F.; Ieva, S.; Capurso, G.; Di Sciascio, E. Supply chain object discovery with semantic-enhanced blockchain. In Proceedings of the 15th ACM Conference on Embedded Network Sensor Systems, Delft, The Netherlands, 6–8 November 2017; pp. 1–2. [Google Scholar]
- ECLASS Technical-Specification. Available online: https://eclass.eu/support/technical-specification/data-model/iso-13584-32-ontoml (accessed on 7 June 2023).
- Costa, D.; Bezemer, C.P.; Leitner, P.; Andrzejak, A. What’s wrong with my benchmark results? studying bad practices in JMH benchmarks. IEEE Trans. Softw. Eng. 2019, 47, 1452–1467. [Google Scholar] [CrossRef]



| Parameter | Values |
|---|---|
| Topology (peers count) | 2 | 4 | 8 |
| Concept size (properties count) | | | |
| Operation | Read | Write |
| Memory pool | Half | Double |
| Transaction pool | Half | Double |
| Datastore engine | GolevelDB, BadgerDB, BoltDB, ClevelDB, RocksDB, MemDB |
| Warm-up iterations | 5 (each running for 10 s) |
| Execution iterations | 10 (each running for 30 s) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tara, A.; Turesson, H.K.; Natea, N. Dynamic Storage Optimization for Communication between AI Agents. Future Internet 2024, 16, 274. https://doi.org/10.3390/fi16080274
Tara A, Turesson HK, Natea N. Dynamic Storage Optimization for Communication between AI Agents. Future Internet. 2024; 16(8):274. https://doi.org/10.3390/fi16080274
Chicago/Turabian StyleTara, Andrei, Hjalmar K. Turesson, and Nicolae Natea. 2024. "Dynamic Storage Optimization for Communication between AI Agents" Future Internet 16, no. 8: 274. https://doi.org/10.3390/fi16080274
APA StyleTara, A., Turesson, H. K., & Natea, N. (2024). Dynamic Storage Optimization for Communication between AI Agents. Future Internet, 16(8), 274. https://doi.org/10.3390/fi16080274