
A Novel Traffic Classification Approach by Employing Deep Learning on Software-Defined Networking

 ,
,  , , ,
, , ,  and
and
Abstract
1. Introduction
- We have developed four classifiers with DL algorithms to evaluate which offers better results based on two open datasets. Specifically, we used the Gated Recurrent Unit (GRU), Bidirectional Gated Recurrent Unit (BiGRU), Long Short-Term Memory(LSTM), and Bidirectional Long Short-Term Memory (BiLSTM) algorithms. In related work, we observed a lack of classifiers that specifically use GRU, BiGRU, and BiLSTM algorithms for multiclass traffic classification in SDNs.
- The classifiers aim to improve the SDN performance and security by using the traffic flow to identify application types and attacks in five classes: Multimedia, VoIP, Instant message, File transfer, and Attacks. One of the main innovations of our approach lies in integrating attack detection into the classification process, thus addressing a gap identified in the related work. The experiments demonstrate the accuracy of detecting different application types and attacks, such as Denial of Service (DoS), Distributed Denial of Service (DDoS), Brute-force-attack, Exploitation (R2L), Web_attack, Botnet, and Probe.
- The selection of features based on analysis of the SDN controllers and sequence length enabled an appropriate generalization of deep learning models. This choice facilitates implementing classifiers in SDN with any controller because northern interfaces can obtain the selected features, thus reducing the complexity of model training, improving traffic classification accuracy, and decreasing the associated computational cost.
2. Related Work
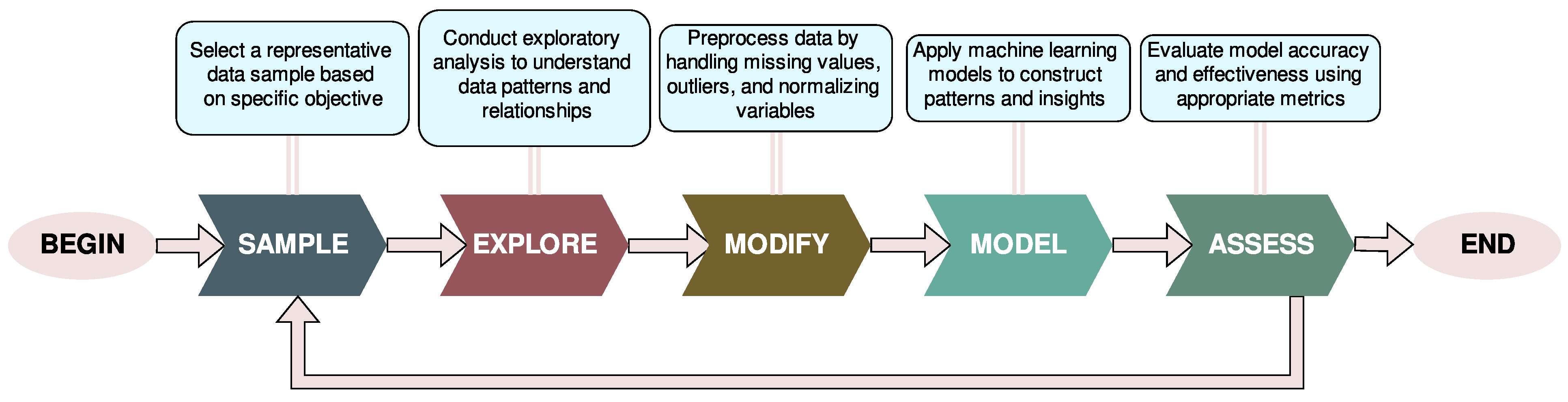
3. Materials and Methods
3.1. Sample
3.2. Explore
3.3. Modify
3.3.1. Data Cleaning
3.3.2. Label Encoding
3.3.3. Data Scaling
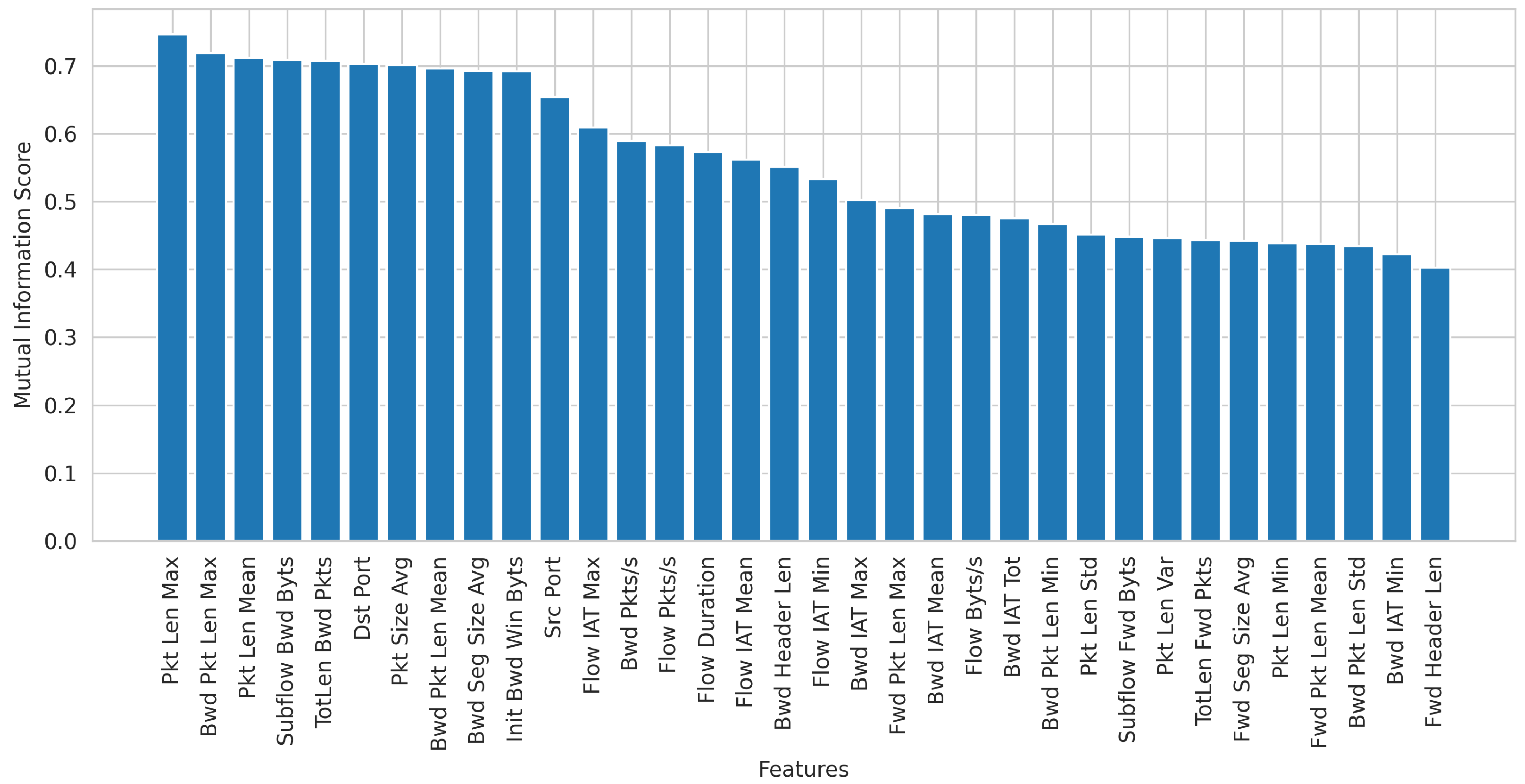
3.3.4. Feature Selection
3.4. Model
3.4.1. Hardware and Software Environment
3.4.2. Deep Learning Model Selection
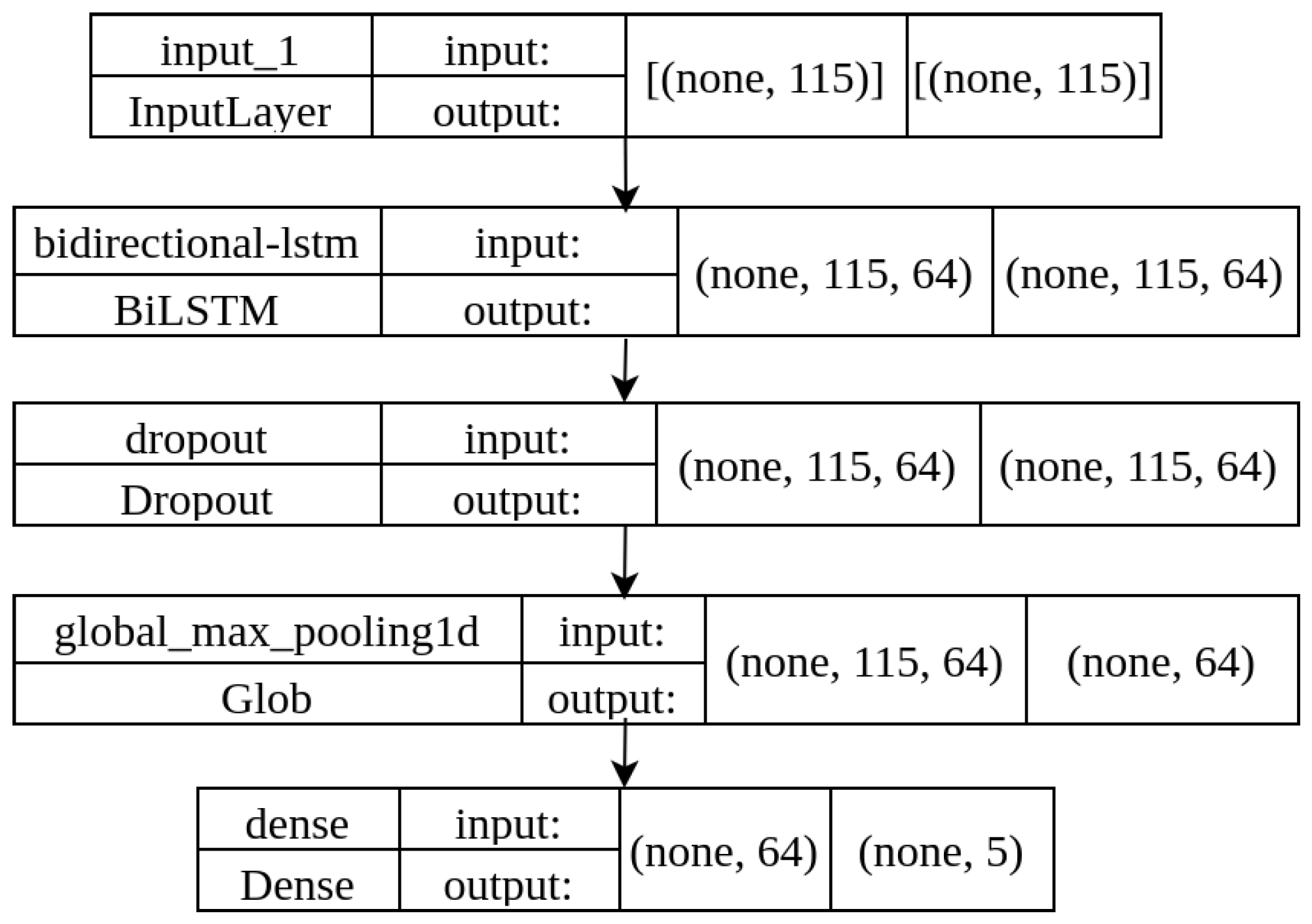
- GRU: These are variants of LSTM networks that incorporate a forgetting gate. Unlike LSTMs, GRUs have fewer parameters due to the absence of an output gate. Despite this difference, GRUs offer similar accuracy to LSTMs [40]. In addition, it has been observed that GRUs can offer computationally more efficient performance in certain scenarios. Figure 3 shows the architecture of the GRU model.
- BiGRU is a model that adds a future layer in the opposite direction of the data sequence. This network uses two hidden layers to extract past and future information connected to a single output layer. This bidirectional structure aids an RNN in removing more information, consequently enhancing the learning process’s performance [41]. Figure 4 shows the architecture of the BiGRU model.
- LSTM: It is a variant of RNNs that can perform computations based on time sequences, allowing the processing of recent data and data that occurred at distant time steps in the series. Unlike a simple RNN algorithm, LSTMs can assess the significance of data, even when there are many time steps between them, making them ideal for learning long-term relationships [42]. Figure 5 shows the architecture of the LSTM model.
- BiLSTM: This model employs two LSTMs, one of which processes the sequence forward and the other in reverse. Through this bidirectional process, BiLSTM increases the amount of information available to the network, which can be valuable in traffic classification problems where comprehending relationships between various traffic features is essential [43]. Figure 6 shows the architecture of the BiLSTM model.
3.4.3. Definition of Hyperparameters
3.5. Assess
- Accuracy is the model’s precision in predicting accurate outcomes, calculated by dividing the number of accurate predictions by the total number of predictions.
- Precision indicates how precise the model is in identifying positive cases. It is calculated by dividing the number of correctly classified positive instances by the total number of cases classified as positive.
- Recall is the proportion of positive cases correctly identified by dividing the number of correctly classified positive instances by the total number of positive cases.
- F1-Score aims to achieve a balanced performance in classifying positive and negative cases. It is a combined measure of precision and recall that balances both metrics. This metric was helpful because there was an imbalance in the classes.
4. Results and Discussion
4.1. Sequence Length Analysis Results
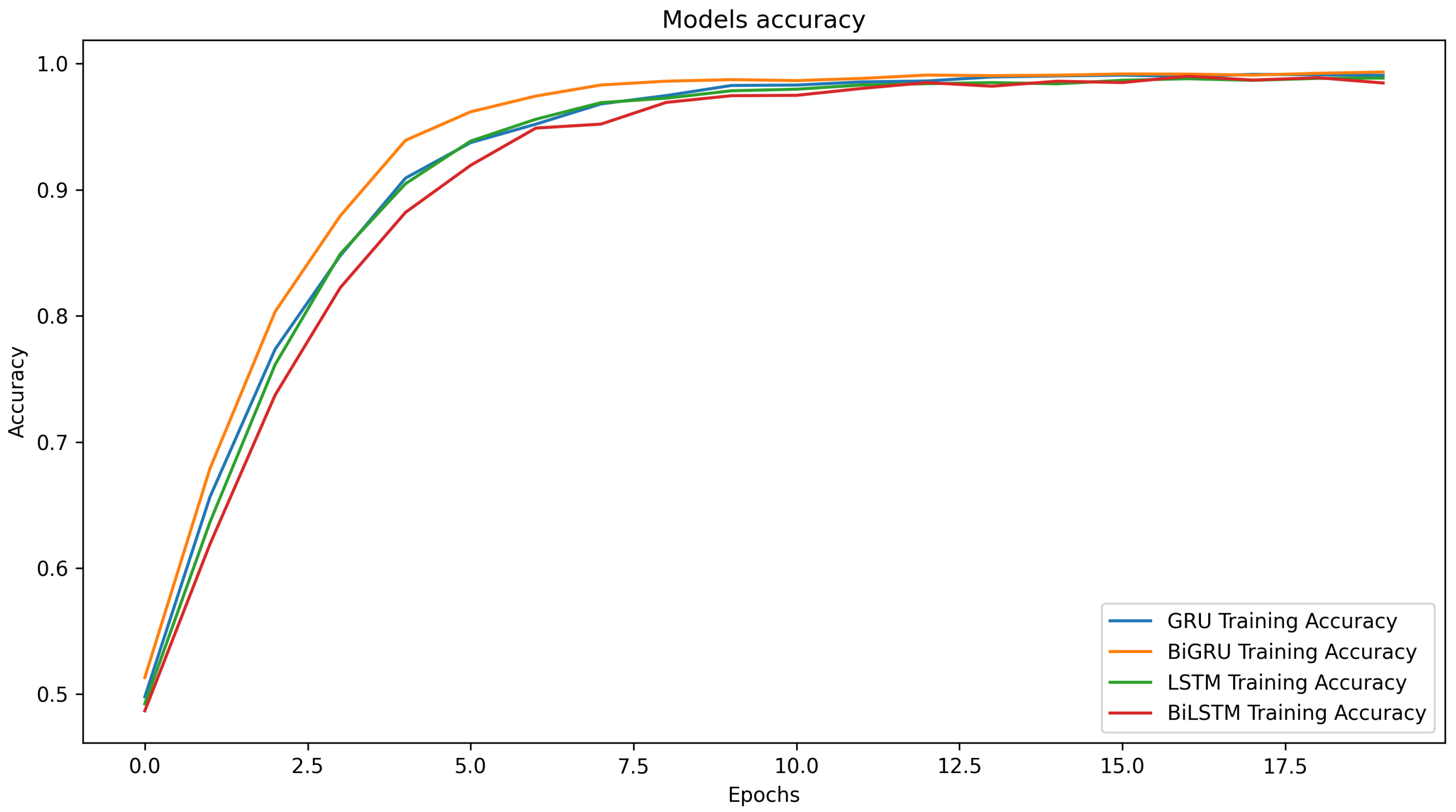
4.2. Evaluation of the Classifiers
4.3. Discussion
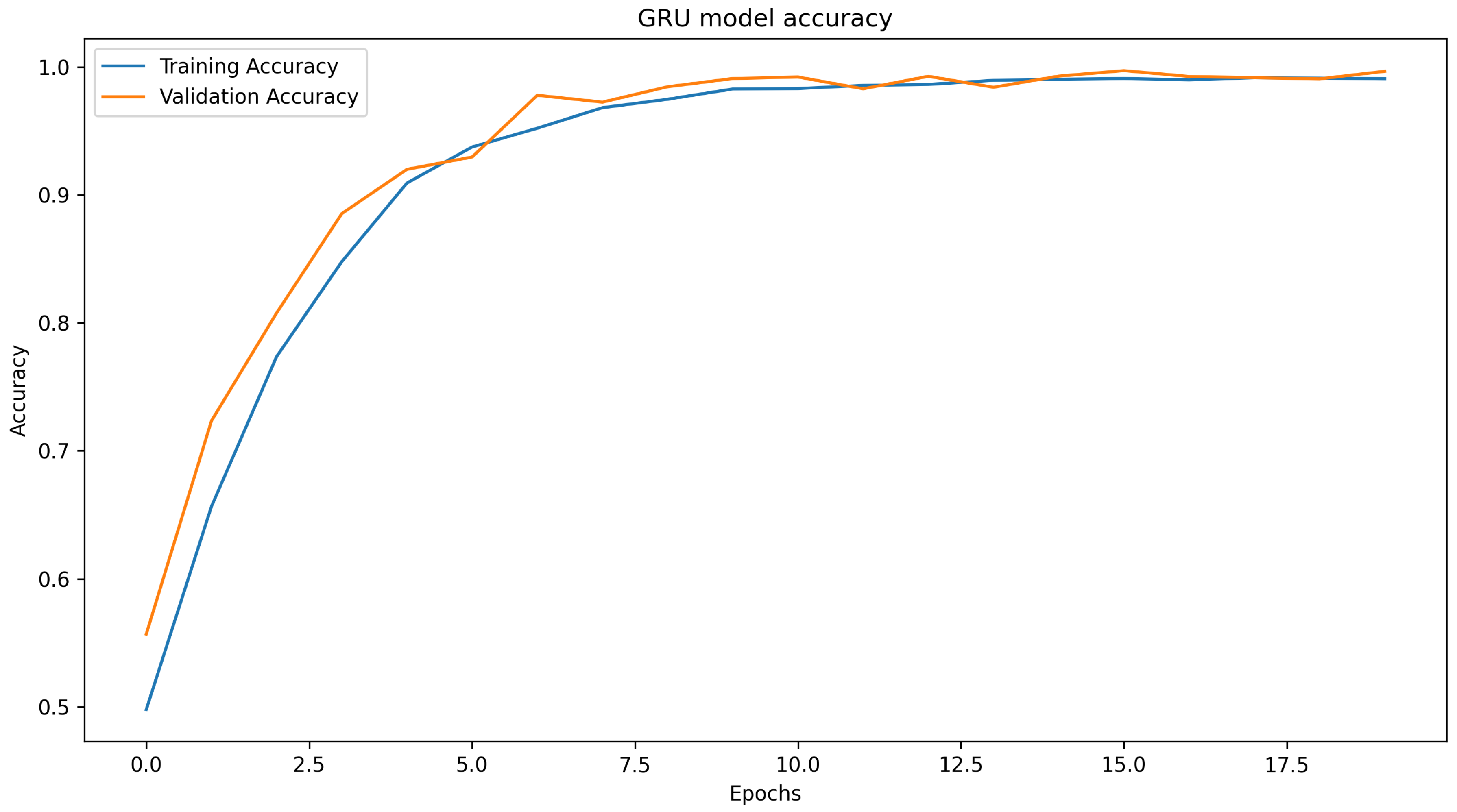
4.3.1. GRU Model
4.3.2. BiGRU Model
4.3.3. LSTM Model
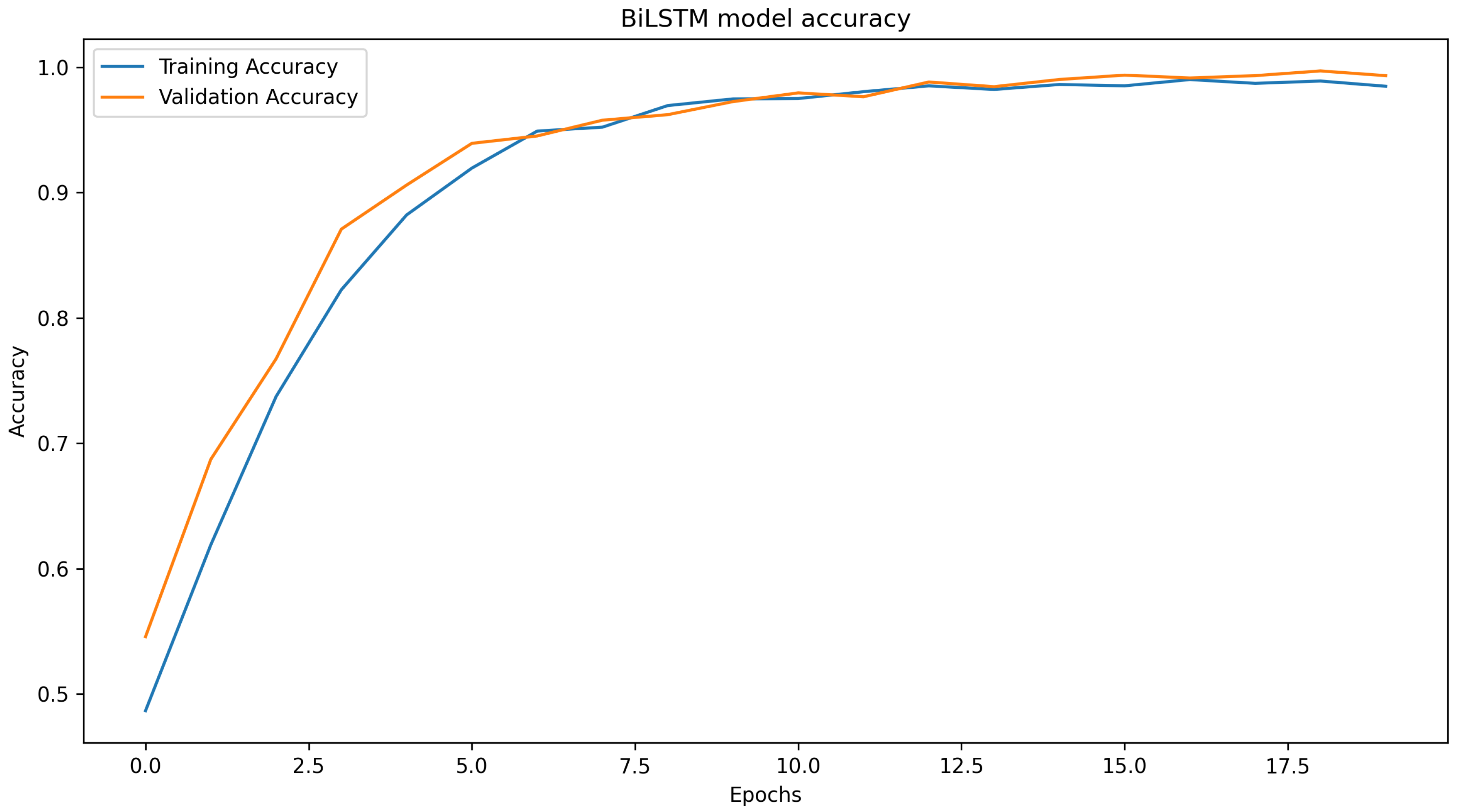
4.3.4. BiLSTM Model
4.4. Comparative Assessment of Model Performance
4.5. Comparison with Previous Research
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| CIC | Canadian Institute for Cybersecurity |
| DPI | Deep Packet Inspection |
| DNN | Deep Neural Network |
| GAN | Generative Adversarial Network |
| ISP | Internet Service Providers |
| LSTM | Long Short-Term Memory |
| BiLSTM | Bidirectional Gated Recurrent Unit |
| GRU | Gated Recurrent Unit |
| BiGRU | Bidirectional Long Short-Term Memory |
| ML | Machine Learning |
| DL | Deep Learning |
| MLP | Multilayer Perceptron |
| NFV | Network Function Virtualization |
| QoS | Quality of Service |
| RNN | Recurrent Neural Network |
| SAE | Stacked Autoencoder |
| SDN | Software-Defined Networking |
| VAE | Variational Autoencoder |
References
- Cisco. Cisco Annual Internet Report (2018–2023); Technical Report; Cisco: San Jose, CA, USA, 2018–2023; Available online: www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/white-paper-c11-741490.html (accessed on 1 April 2024).
- Belkadi, O.; Vulpe, A.; Laaziz, Y.; Halunga, S. ML-Based Traffic Classification in an SDN-Enabled Cloud Environment. Electronics 2023, 12, 269. [Google Scholar] [CrossRef]
- Ayoubi, S.; Limam, N.; Salahuddin, M.A.; Shahriar, N.; Boutaba, R.; Estrada-Solano, F.; Caicedo, O.M. Machine Learning for Cognitive Network Management. IEEE Commun. Mag. 2018, 56, 158–165. [Google Scholar] [CrossRef]
- Clark, D.D.; Partridge, C.; Ramming, J.C.; Wroclawski, J.T. A Knowledge Plane for the Internet. In Proceedings of the 2003 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, SIGCOMM’03, New York, NY, USA, 25–29 August 2003; pp. 3–10. [Google Scholar] [CrossRef]
- Trois, C.; Del Fabro, M.D.; de Bona, L.C.E.; Martinello, M. A Survey on SDN Programming Languages: Toward a Taxonomy. IEEE Commun. Surv. Tutor. 2016, 18, 2687–2712. [Google Scholar] [CrossRef]
- Kreutz, D.; Ramos, F.M.V.; Veríssimo, P.E.; Rothenberg, C.E.; Azodolmolky, S.; Uhlig, S. Software-Defined Networking: A Comprehensive Survey. Proc. IEEE 2015, 103, 14–76. [Google Scholar] [CrossRef]
- Xie, J.; Yu, F.R.; Huang, T.; Xie, R.; Liu, J.; Wang, C.; Liu, Y. A Survey of Machine Learning Techniques Applied to Software Defined Networking (SDN): Research Issues and Challenges. IEEE Commun. Surv. Tutor. 2019, 21, 393–430. [Google Scholar] [CrossRef]
- Moore, A.W.; Papagiannaki, K. Toward the Accurate Identification of Network Applications. In Passive and Active Network Measurement; Dovrolis, C., Ed.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 41–54. [Google Scholar]
- Nguyen, T.T.; Armitage, G. A survey of techniques for internet traffic classification using machine learning. IEEE Commun. Surv. Tutor. 2008, 10, 56–76. [Google Scholar] [CrossRef]
- Finsterbusch, M.; Richter, C.; Rocha, E.; Muller, J.A.; Hanssgen, K. A Survey of Payload-Based Traffic Classification Approaches. IEEE Commun. Surv. Tutor. 2014, 16, 1135–1156. [Google Scholar] [CrossRef]
- Li, G.; Dong, M.; Ota, K.; Wu, J.; Li, J.; Ye, T. Deep Packet Inspection Based Application-Aware Traffic Control for Software Defined Networks. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Nunez-Agurto, D.; Fuertes, W.; Marrone, L.; Macas, M. Machine Learning-Based Traffic Classification in Software-Defined Networking: A Systematic Literature Review, Challenges, and Future Research Directions. IAENG Int. J. Comput. Sci. 2022, 49, 1002–1015. [Google Scholar]
- Fan, Z.; Liu, R. Investigation of machine learning based network traffic classification. In Proceedings of the 2017 International Symposium on Wireless Communication Systems (ISWCS), Bologna, Italy, 28–31 August 2017; pp. 1–6. [Google Scholar]
- Tahaei, H.; Afifi, F.; Asemi, A.; Zaki, F.; Anuar, N.B. The rise of traffic classification in IoT networks: A survey. J. Netw. Comput. Appl. 2020, 154, 102538. [Google Scholar] [CrossRef]
- Hayes, M.; Ng, B.; Pekar, A.; Seah, W.K.G. Scalable Architecture for SDN Traffic Classification. IEEE Syst. J. 2018, 12, 3203–3214. [Google Scholar] [CrossRef]
- Selvi, D.K.T.; Thamilselvan, R. Deep Learning Based Traffic Classification In Software Defined Networking—A Survey. Int. J. Sci. Technol. Res. 2020, 9, 2034–2041. [Google Scholar]
- Md. Zaki, F.A.; Chin, T.S. FWFS: Selecting Robust Features Towards Reliable and Stable Traffic Classifier in SDN. IEEE Access 2019, 7, 166011–166020. [Google Scholar] [CrossRef]
- Wang, P.; Ye, F.; Chen, X.; Qian, Y. Datanet: Deep Learning Based Encrypted Network Traffic Classification in SDN Home Gateway. IEEE Access 2018, 6, 55380–55391. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, X.; Li, F.; He, Q.; Huang, M. Deep learning–based network application classification for SDN. Trans. Emerg. Telecommun. Technol. 2018, 29, e3302. [Google Scholar] [CrossRef]
- Lim, H.K.; Kim, J.B.; Kim, K.; Hong, Y.G.; Han, Y.H. Payload-Based Traffic Classification Using Multi-Layer LSTM in Software Defined Networks. Appl. Sci. 2019, 9, 2550. [Google Scholar] [CrossRef]
- Chang, L.H.; Lee, T.H.; Chu, H.C.; Su, C.W. Application-Based Online Traffic Classification with Deep Learning Models on SDN Networks. Adv. Technol. Innov. 2020, 5, 216–229. [Google Scholar] [CrossRef]
- Abdulazzaq, S.; Demirci, M. A Deep Learning Based System for Traffic Engineering in Software Defined Networks. Int. J. Intell. Syst. Appl. Eng. 2020, 8, 206–213. [Google Scholar] [CrossRef]
- Chiu, K.C.; Liu, C.C.; Chou, L.D. CAPC: Packet-Based Network Service Classifier With Convolutional Autoencoder. IEEE Access 2020, 8, 218081–218094. [Google Scholar] [CrossRef]
- Wang, P.; Wang, Z.; Ye, F.; Chen, X. ByteSGAN: A semi-supervised Generative Adversarial Network for encrypted traffic classification in SDN Edge Gateway. Comput. Netw. 2021, 200, 108535. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, X.; Yang, J. Deep Learning-Based Encrypted Network Traffic Classification and Resource Allocation in SDN. J. Web Eng. 2021, 20, 2319–2334. [Google Scholar] [CrossRef]
- Setiawan, R.; Ganga, R.R.; Velayutham, P.; Thangavel, K.; Sharma, D.K.; Rajan, R.; Krishnamoorthy, S.; Sengan, S. Encrypted Network Traffic Classification and Resource Allocation with Deep Learning in Software Defined Network. Wirel. Pers. Commun. 2022, 127, 749–765. [Google Scholar] [CrossRef]
- Ahn, S.; Kim, J.; Park, S.Y.; Cho, S. Explaining Deep Learning-Based Traffic Classification Using a Genetic Algorithm. IEEE Access 2021, 9, 4738–4751. [Google Scholar] [CrossRef]
- Jang, Y.; Kim, N.; Lee, B.D. Traffic classification using distributions of latent space in software-defined networks: An experimental evaluation. Eng. Appl. Artif. Intell. 2023, 119, 105736. [Google Scholar] [CrossRef]
- Azevedo, A.; Santos, M. KDD, semma and CRISP-DM: A parallel overview. In Proceedings of the IADIS European Conference on Data Mining, Amsterdam, The Netherlands, 24–26 July 2008; pp. 182–185. [Google Scholar]
- Elsayed, M.S.; Le-Khac, N.A.; Jurcut, A.D. InSDN: A Novel SDN Intrusion Dataset. IEEE Access 2020, 8, 165263–165284. [Google Scholar] [CrossRef]
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A. Characterization of Encrypted and VPN Traffic using Time-related Features. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy—ICISSP, Rome, Italy, 19–21 February 2016; pp. 407–414. [Google Scholar] [CrossRef]
- Lashkari, A.H.; Gil, G.D.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of Tor Traffic using Time based Features. In Proceedings of the 3rd International Conference on Information Systems Security and Privacy—ICISSP, Porto, Portugal, 19–21 February 2017; Volume 1, pp. 253–262. [Google Scholar] [CrossRef]
- Chuang, H.M.; Liu, F.; Tsai, C.H. Early Detection of Abnormal Attacks in Software-Defined Networking Using Machine Learning Approaches. Symmetry 2022, 14, 1178. [Google Scholar] [CrossRef]
- Garcia, C.; Leite, D.; Škrjanc, I. Incremental Missing-Data Imputation for Evolving Fuzzy Granular Prediction. IEEE Trans. Fuzzy Syst. 2020, 28, 2348–2362. [Google Scholar] [CrossRef]
- Wang, H.; Bah, M.J.; Hammad, M. Progress in Outlier Detection Techniques: A Survey. IEEE Access 2019, 7, 107964–108000. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- George, B. A study of the effect of random projection and other dimensionality reduction techniques on different classification methods. Baselius Res. 2017, 18, 201769. [Google Scholar]
- Nuñez-Agurto, D.; Fuertes, W.; Marrone, L.; Benavides-Astudillo, E.; Vásquez Bermúdez, M. Traffic Classification in Software-Defined Networking by Employing Deep Learning Techniques: A Systematic Literature Review. In Technologies and Innovation, 9th International Conference, CITI 2023, Guayaquil, Ecuador, 13–16 November 2023; Springer: Cham, Switzerland, 2023; pp. 67–80. [Google Scholar]
- Deng, H.; Zhang, L.; Shu, X. Feature memory-based deep recurrent neural network for language modeling. Appl. Soft Comput. 2018, 68, 432–446. [Google Scholar] [CrossRef]
- Cao, X.; Zhong, Y.; Zhou, Y.; Wang, J.; Zhu, C.; Zhang, W. Interactive Temporal Recurrent Convolution Network for Traffic Prediction in Data Centers. IEEE Access 2018, 6, 5276–5289. [Google Scholar] [CrossRef]
- Li, H.; He, E.; Kuang, C.; Yang, X.; Wu, X.; Jia, Z. An Abnormal Traffic Detection Based on Attention-Guided Bidirectional GRU. In Proceedings of the 2022 IEEE 22nd International Conference on Communication Technology (ICCT), Nanjing, China, 11–14 November 2022; pp. 1300–1305. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Xu, H.; Sun, L.; Fan, G.; Li, W.; Kuang, G. A Hierarchical Intrusion Detection Model Combining Multiple Deep Learning Models With Attention Mechanism. IEEE Access 2023, 11, 66212–66226. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Alazab, M.; Srinivasan, S.; Pham, Q.V.; Padannayil, S.K.; Simran, K. A Visualized Botnet Detection System Based Deep Learning for the Internet of Things Networks of Smart Cities. IEEE Trans. Ind. Appl. 2020, 56, 4436–4456. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Classification Objective | Model Input | Model Output | Accuracy |
|---|---|---|---|---|
| [18] | QoS-aware | Automatic by algorithm | 15 applications | MLP: 97.14% SAE: 99.14% CNN: 99.30% |
| [19] | QoS-aware | Automatic by algorithm | 10 classes | SAE: >90.00% |
| [20] | Application-aware | Automatic by algorithm | 8 applications | ML-LSTM: 97.14% |
| [21] | Application-aware | 4 features | 6 applications | CNN: 93.35% MLP: 93.21% SAE: 93.13% |
| [22] | QoS-aware | 23 features | 3 classes | CNN: 96.00% DNN: 94.00% |
| [23] | Application-aware | Flow features selected by autoencoders | 24 applications | CNN+autoencoder: 97.42% CNN: 96.03% DNN: 94.36% |
| [24] | Application-aware | Automatic by algorithm | 15 applications | GAN: 93.18% CNN: 93.30% |
| [25] | Application-aware | Automatic by algorithm | 5 classes | CNN: 98.85% LSTM: 99.22% SAE: 98.74% |
| [26] | QoS-aware | Automatic by algorithm | 20 applications | MLP, CNN and SAE: >90.00% |
| [27] | QoS-aware | 20 features | 8 classes | ResNet: 97.24% |
| [28] | QoS-aware | 6 features | 6 classes | VAE: 89.00% |
| Dataset | Content | Samples |
|---|---|---|
| ICSX VPN–nonVPN | AIM chat | 1033 |
| BitTorrent | 777 | |
| Email Client | 6976 | |
| Facebook Audio | 62,544 | |
| Facebook Chat | 2285 | |
| Facebook Video | 1226 | |
| FTPS | 2045 | |
| Gmail Chat | 1053 | |
| Hangouts Audio | 72,397 | |
| Hangouts Chat | 4033 | |
| Hangouts Video | 2882 | |
| ICQ | 1131 | |
| Netflix | 2084 | |
| SCP | 9546 | |
| SFTP | 449 | |
| Skype Audio | 27,756 | |
| Skype Chat | 6703 | |
| Skype File | 42,640 | |
| Skype Video | 1594 | |
| Spotify | 1498 | |
| Vimeo | 1752 | |
| VoIP Buster | 6217 | |
| YouTube | 2962 | |
| InSDN | DDoS | 121,942 |
| DoS | 53,616 | |
| Probe | 98,129 | |
| Brute-force-attack | 1405 | |
| Exploitation (R2L) | 17 | |
| Web_attack | 192 | |
| Botnet | 164 |
| Class | Content | Total Samples | Selected Samples |
|---|---|---|---|
| Multimedia | Facebook Video, Hangouts Video, Skype Video, Netflix, Vimeo, YouTube | 12,500 | 10,000 |
| VoIP | Facebook Audio, Hangouts Audio, Skype Audio, VoIP Buster | 168,914 | 10,000 |
| Instant message | AIM Chat, Facebook Chat, Gmail Chat, Hangouts Chat, ICQ, Skype Chat | 16,238 | 10,000 |
| File transfer | FTPS, SCP, SFTP, Skype File | 54,680 | 10,000 |
| Attack | DDoS, DoS, Probe, Brute-force-attack, Exploitation (R2L), Web_attack, Botnet | 275,515 | 10,000 |
| No. | Feature Name | No. | Feature Name | No. | Feature Name |
|---|---|---|---|---|---|
| 1 | Flow ID | 29 | Fwd IAT Std | 57 | ECE Flag Cnt |
| 2 | Src IP | 30 | Fwd IAT Max | 58 | Down/Up Ratio |
| 3 | Src Port | 31 | Fwd IAT Min | 59 | Pkt Size Avg |
| 4 | Dst IP | 32 | Bwd IAT Tot | 60 | Fwd Seg Size Avg |
| 5 | Dst Port | 33 | Bwd IAT Mean | 61 | Bwd Seg Size Avg |
| 6 | Protocol | 34 | Bwd IAT Std | 62 | Fwd Byts/b Avg |
| 7 | Timestamp | 35 | Bwd IAT Max | 63 | Fwd Pkts/b Avg |
| 8 | Flow Duration | 36 | Bwd IAT Min | 64 | Fwd Blk Rate Avg |
| 9 | Tot Fwd Pkts | 37 | Fwd PSH Flags | 65 | Bwd Byts/b Avg |
| 10 | Tot Bwd Pkts | 38 | Bwd PSH Flags | 66 | Bwd Pkts/b Avg |
| 11 | TotLen Fwd Pkts | 39 | Fwd URG Flags | 67 | Bwd Blk Rate Avg |
| 12 | TotLen Bwd Pkts | 40 | Bwd URG Flags | 68 | Subflow Fwd Pkts |
| 13 | Fwd Pkt Len Max | 41 | Fwd Header Len | 69 | Subflow Fwd Byts |
| 14 | Fwd Pkt Len Min | 42 | Bwd Header Len | 70 | Subflow Bwd Pkts |
| 15 | Fwd Pkt Len Mean | 43 | Fwd Pkts/s | 71 | Subflow Bwd Byts |
| 16 | Fwd Pkt Len Std | 44 | Bwd Pkts/s | 72 | Init Fwd Win Byts |
| 17 | Bwd Pkt Len Max | 45 | Pkt Len Min | 73 | Init Bwd Win Byts |
| 18 | Bwd Pkt Len Min | 46 | Pkt Len Max | 74 | Fwd Act Data Pkts |
| 19 | Bwd Pkt Len Mean | 47 | Pkt Len Mean | 75 | Fwd Seg Size Min |
| 20 | Bwd Pkt Len Std | 48 | Pkt Len Std | 76 | Active Mean |
| 21 | Flow Byts/s | 49 | Pkt Len Var | 77 | Active Std |
| 22 | Flow Pkts/s | 50 | FIN Flag Cnt | 78 | Active Max |
| 23 | Flow IAT Mean | 51 | SYN Flag Cnt | 79 | Active Min |
| 24 | Flow IAT Std | 52 | RST Flag Cnt | 80 | Idle Mean |
| 25 | Flow IAT Max | 53 | PSH Flag Cnt | 81 | Idle Std |
| 26 | Flow IAT Min | 54 | ACK Flag Cnt | 82 | Idle Max |
| 27 | Fwd IAT Tot | 55 | URG Flag Cnt | 83 | Idle Min |
| 28 | Fwd IAT Mean | 56 | CWE Flag Count | 84 | Label |
| No. | Feature Name | Description |
|---|---|---|
| 1 | Flow Duration | Duration of the flow in Microsecond |
| 2 | Flow Pkts/s | Number of flow bytes per second |
| 3 | Flow Byts/s | Number of flow packets per second |
| 4 | Fwd Pkts/s | Number of forward packets per second |
| 5 | Bwd Pkts/s | Number of backward packets per second |
| Flow Duration | Flow Pkts/s | Flow Byts/s | Fwd Pkts/s | Bwd Pkts/s | |
|---|---|---|---|---|---|
| count | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 |
| mean | −2.387424 | 1.136868 | −5.400557 | −7.389644 | −2.273737 |
| std | 1.000010 | 1.000010 | 1.000010 | 1.000010 | 1.000010 |
| min | −5.253012 | −1.000130 | −4.345196 | −5.722901 | −1.127359 |
| 25% | −5.200939 | −9.993990 | −4.344642 | −5.722901 | −1.126813 |
| 50% | −4.405559 | −9.982524 | −4.342988 | −5.714464 | −1.125122 |
| 75% | −4.341171 | −9.591224 | −4.287239 | −5.707213 | −1.089045 |
| max | 2.576183 | 4.561686 | 1.236910 | 3.544473 | 4.542805 |
| Component | Description |
|---|---|
| Processor | AMD Ryzen Threadrippe 2920X |
| Main board | ASUS ROG Zenith Extreme Alpha |
| RAM | 64 GB Crucial Ballistix DDR4-3000 |
| GPU | 16 GB Phantom Gaming X Radeon VII |
| SSD | 500 GB Crucial SSD M.2 NVMe |
| HDD | 3 TB Western Digital HDD Purple |
| Activation Function | Loss Function | Bath Size | Optimization Algorithm | Input Layer | No. Epochs |
|---|---|---|---|---|---|
| Sigmoid | Categorical crossentropy | 16 | Adam | 64 | 20 |
| Algorithm | Sequence Length | Training Accuracy | Test Accuracy | Training Time (s) |
|---|---|---|---|---|
| GRU | 50 | 0.9711 | 0.9744 | 244 |
| BiGRU | 50 | 0.9824 | 0.9492 | 382 |
| LSTM | 50 | 0.9639 | 0.9582 | 229 |
| BiLSTM | 50 | 0.9607 | 0.6023 | 424 |
| GRU | 75 | 0.9894 | 0.9834 | 251 |
| BiGRU | 75 | 0.9900 | 0.9553 | 390 |
| LSTM | 75 | 0.9825 | 0.9782 | 317 |
| BiLSTM | 75 | 0.9859 | 0.8644 | 540 |
| GRU | 115 | 0.9927 | 0.9955 | 339 |
| BiGRU | 115 | 0.9904 | 0.9854 | 626 |
| LSTM | 115 | 0.9853 | 0.9951 | 382 |
| BiLSTM | 115 | 0.9843 | 0.8777 | 646 |
| Algorithm | Accuracy | Precision | Recall | F1-Score | Training Time (s) | GPU Utilization (%) |
|---|---|---|---|---|---|---|
| GRU | 0.9965 | Class 0: 1.00 Class 1: 1.00 Class 2: 1.00 Class 3: 1.00 Class 4: 1.00 | Class 0: 0.94 Class 1: 0.99 Class 2: 0.93 Class 3: 0.99 Class 4: 0.98 | Class 0: 0.97 Class 1: 0.99 Class 2: 0.96 Class 3: 1.00 Class 4: 0.99 | 339 | 28 |
| BiGRU | 0.9860 | Class 0: 1.00 Class 1: 1.00 Class 2: 1.00 Class 3: 1.00 Class 4: 1.00 | Class 0: 0.94 Class 1: 0.98 Class 2: 0.85 Class 3: 0.95 Class 4: 0.86 | Class 0: 0.97 Class 1: 0.99 Class 2: 0.92 Class 3: 0.97 Class 4: 0.92 | 626 | 45 |
| LSTM | 0.9963 | Class 0: 1.00 Class 1: 1.00 Class 2: 1.00 Class 3: 1.00 Class 4: 1.00 | Class 0: 0.94 Class 1: 0.99 Class 2: 0.88 Class 3: 0.99 Class 4: 0.98 | Class 0: 0.97 Class 1: 0.99 Class 2: 0.94 Class 3: 1.00 Class 4: 0.99 | 389 | 33 |
| BiLSTM | 0.9932 | Class 0: 0.99 Class 1: 0.93 Class 2: 0.97 Class 3: 0.99 Class 4: 0.91 | Class 0: 0.73 Class 1: 0.70 Class 2: 0.64 Class 3: 0.70 Class 4: 0.80 | Class 0: 0.84 Class 1: 0.80 Class 2: 0.77 Class 3: 0.82 Class 4: 0.85 | 646 | 48 |
| Ref. | Algorithm | Accuracy | Number of Features |
|---|---|---|---|
| Proposed | GRU BiGRU LSTM BiLSTM | 99.65% 98.60% 99.63% 99.32% | 5 |
| [18] | ML-LSTM SAE CNN | 97.14% 99.14% 99.30% | Automatic by algorithm |
| [19] | SAE | >90.00% | Automatic by algorithm |
| [20] | ML-LSTM | 97.14% | Automatic by algorithm |
| [21] | CNN MLP SAE | 93.35% 93.21% 93.13% | 4 |
| [22] | CNN DNN | 96.00% 94.00% | 23 |
| [23] | CNN+autoencoder CNN DNN | 97.42% 96.03% 94.36% | Flow features selected by autoencoders |
| [24] | GAN CNN | 93.18% 93.30% | Automatic by algorithm |
| [25] | CNN LSTM SAE | 98.85% 99.22% 98.74% | Automatic by algorithm |
| [26] | MLP, CNN and SAE | >90.00% | Automatic by algorithm |
| [27] | ResNet | 97.24% | 20 |
| [28] | VAE | 89.00% | 6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nuñez-Agurto, D.; Fuertes, W.; Marrone, L.; Benavides-Astudillo, E.; Coronel-Guerrero, C.; Perez, F. A Novel Traffic Classification Approach by Employing Deep Learning on Software-Defined Networking. Future Internet 2024, 16, 153. https://doi.org/10.3390/fi16050153
Nuñez-Agurto D, Fuertes W, Marrone L, Benavides-Astudillo E, Coronel-Guerrero C, Perez F. A Novel Traffic Classification Approach by Employing Deep Learning on Software-Defined Networking. Future Internet. 2024; 16(5):153. https://doi.org/10.3390/fi16050153
Chicago/Turabian StyleNuñez-Agurto, Daniel, Walter Fuertes, Luis Marrone, Eduardo Benavides-Astudillo, Christian Coronel-Guerrero, and Franklin Perez. 2024. "A Novel Traffic Classification Approach by Employing Deep Learning on Software-Defined Networking" Future Internet 16, no. 5: 153. https://doi.org/10.3390/fi16050153
APA StyleNuñez-Agurto, D., Fuertes, W., Marrone, L., Benavides-Astudillo, E., Coronel-Guerrero, C., & Perez, F. (2024). A Novel Traffic Classification Approach by Employing Deep Learning on Software-Defined Networking. Future Internet, 16(5), 153. https://doi.org/10.3390/fi16050153