
Stance Detection in the Context of Fake News—A New Approach †



Abstract
1. Introduction
2. Literature Review
2.1. Fake News
2.2. Stance Detection
3. Fake News Challenge Contributions
3.1. Talos Intelligence (1st Place)
- Similarities assessed through word count, 2-g, and 3-g (an n-gram is a contiguous sequence of n items from a given sample of text or speech). The items can be phonemes, syllables, letters, words, or base pairs according to the application. The 2-g and 3-g are specific types of n-grams in natural language processing and computational linguistics. For example, the 2-g of “The cat sat on the mat” would be “The cat”, “cat sat”, “sat on”, “on the”, “the mat”, and so on) comparisons.
- Similarities calculated after applying term frequency–inverse document frequency (TF-IDF).
- Weighting and Singular Value Decomposition (SVD) to these counts.
- BoW: Bag of words uni-grams.
- NNF: Non-Negative Matrix Factorization.
- LSI: Latent Semantic Indexing.
- LSA: Latent Semantic Analysis.
- PPDB: Paraphrase Detection based on Word Embeddings.
3.2. University College London (UCL) Machine Reading (3rd Place)
- Pandas—Data analysis.
- Scikit-learn—Machine learning toolkit used for the following:
- Text processing.
- Feature selection.
- Model training.
- Cross-validation.
- Seaborn—Data charting.
3.3. Other Solutions
4. The Proposed Method and FNC Analysis
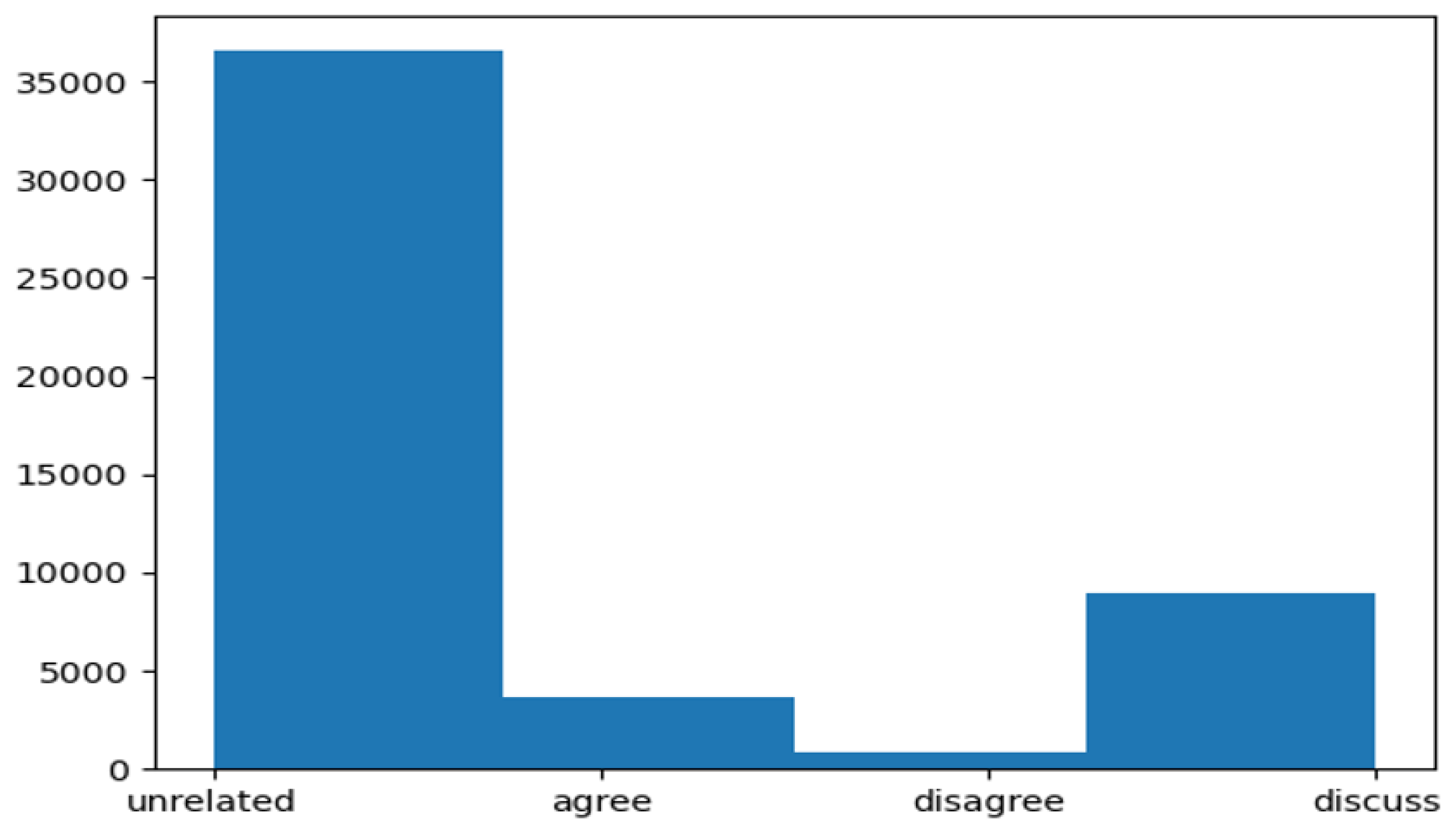
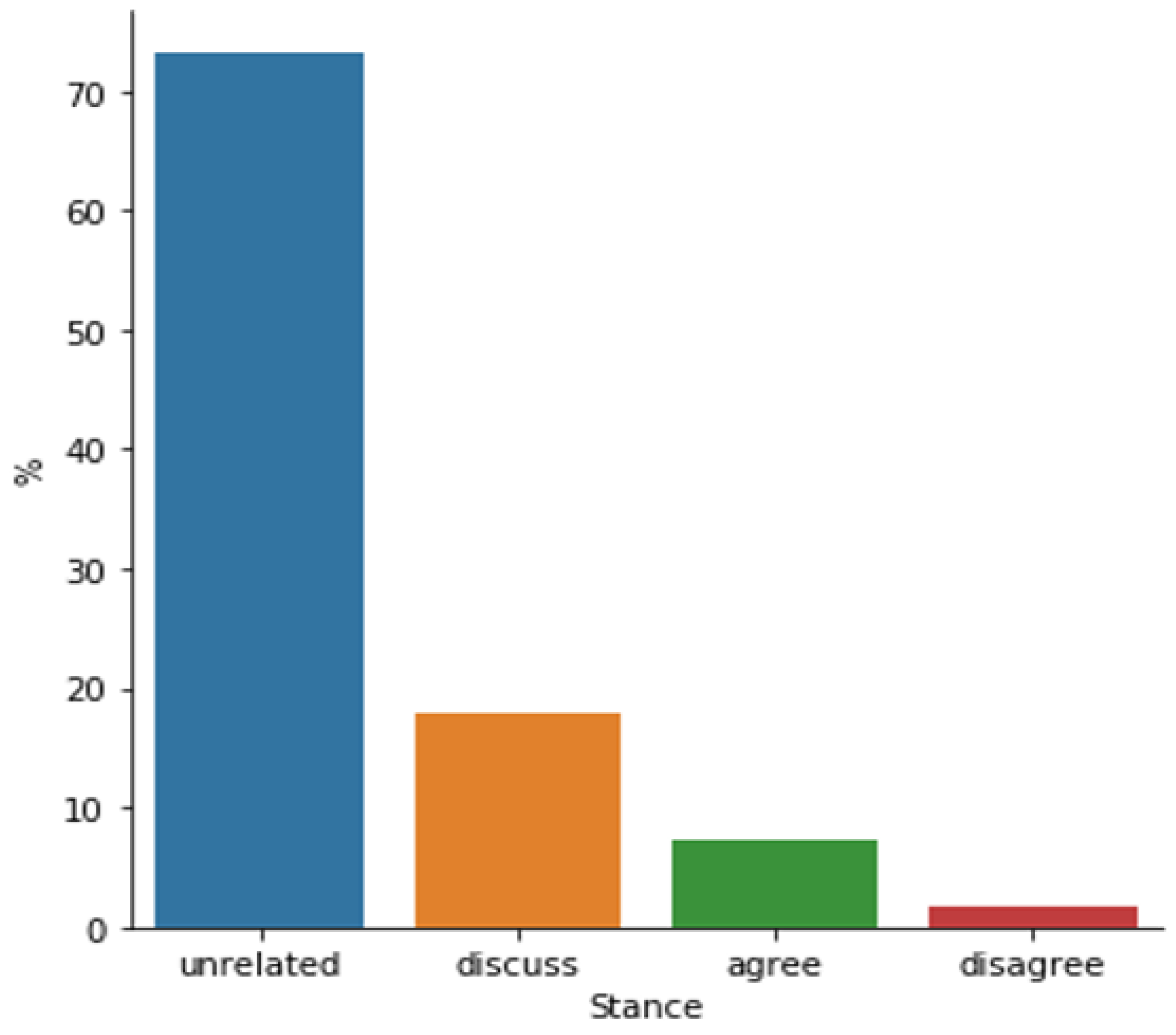
4.1. FNC Dataset
- train_bodies.csv
- train_stances.csv
- compeition_test_bodies.csv
- compeition_test_stances.csv
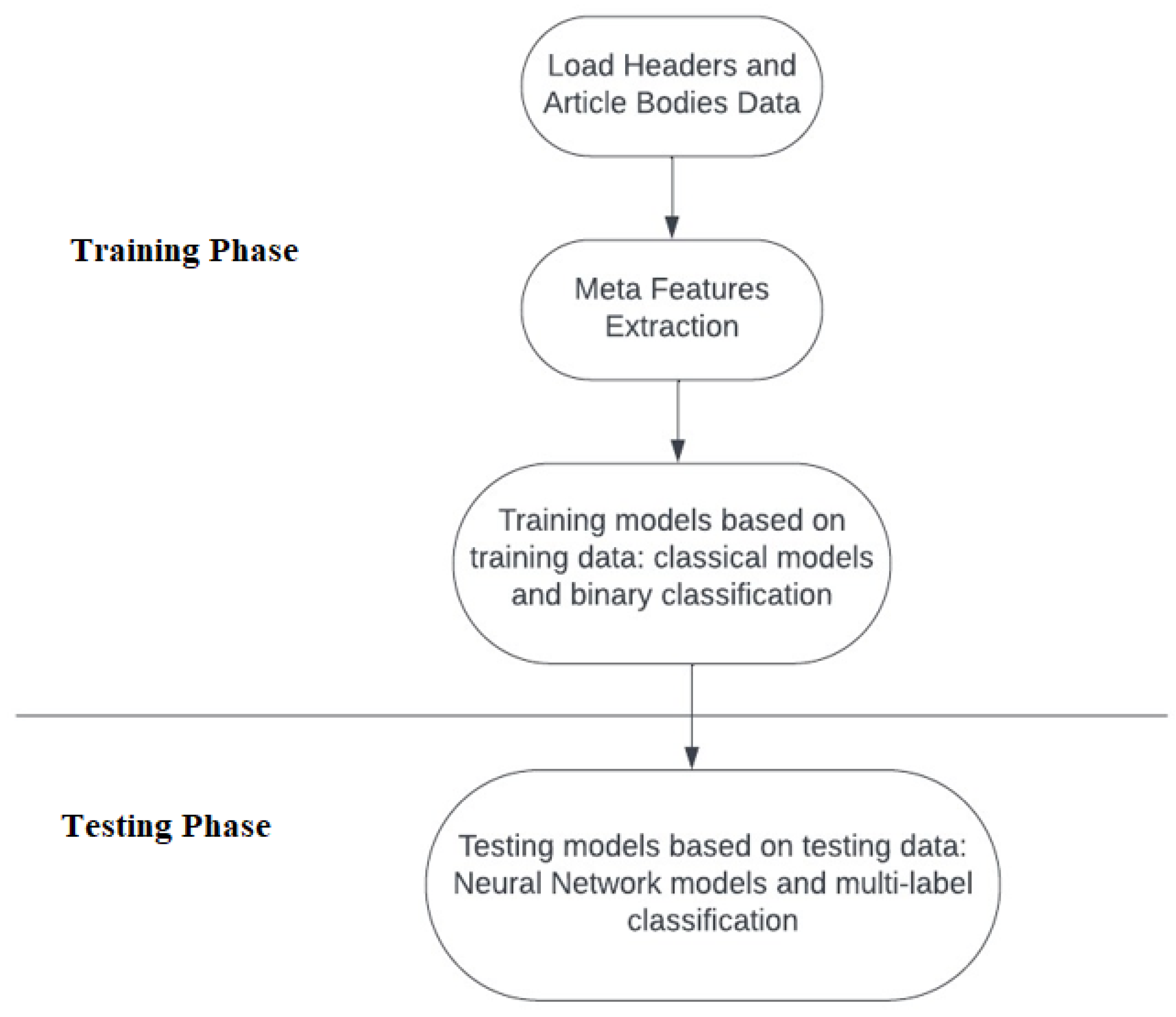
4.2. Pipeline of the Proposed Method
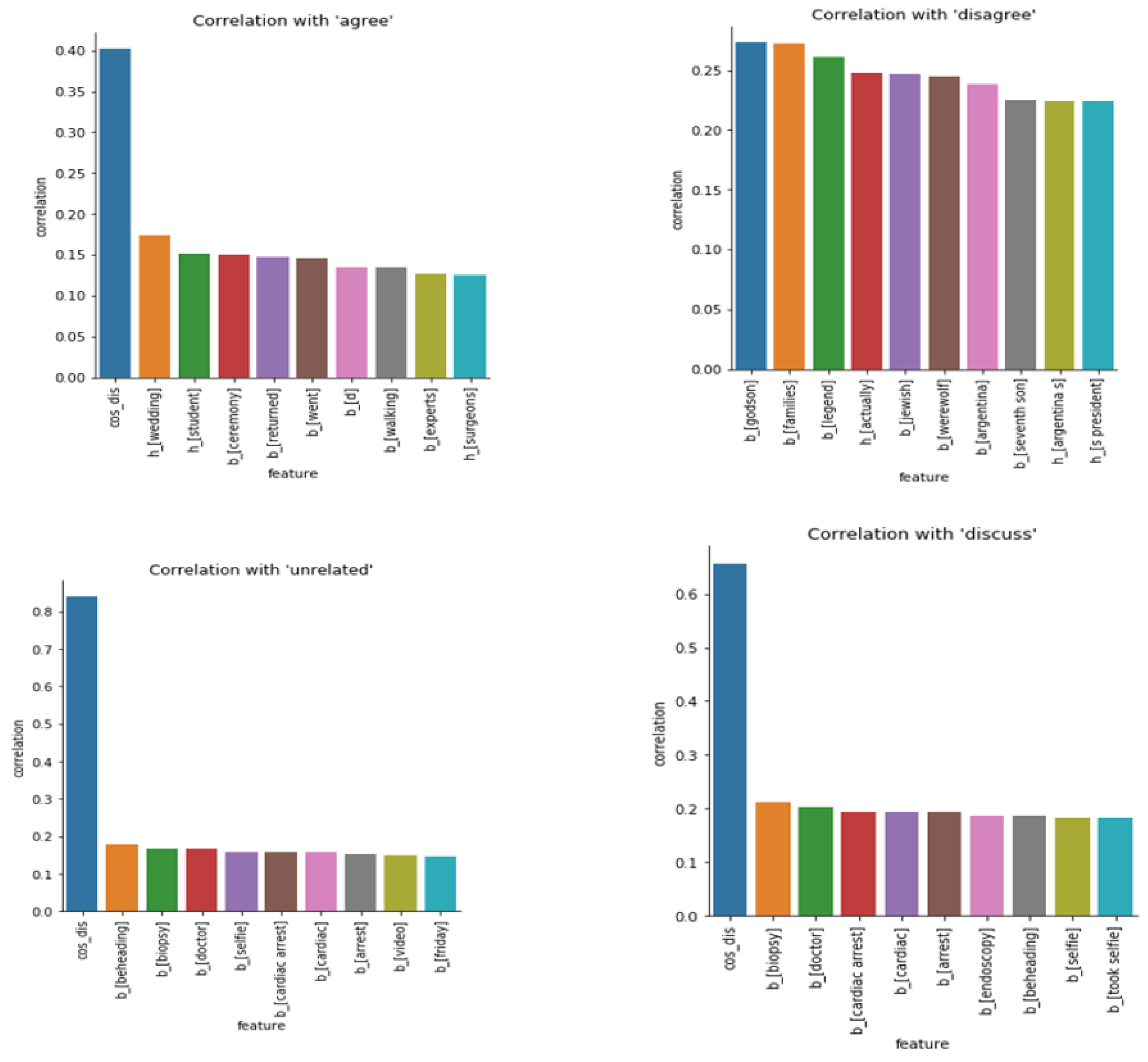
4.2.1. First Stage: Text-Based Meta Features and Classical Learning Models
4.2.2. Second Stage: Pre-Trained Embeddings-Based Neural Network Model, Multi-Label Classification
4.2.3. A Hybrid Multi-Stage Approach
- The first one is adopting a multi-stage approach rather than a single-stage approach to build the final learning model. Typically, the first stage involves meta features with classical classifiers.
- The second trend in significant submissions used several examples of meta features extracted from headlines and/or article bodies. We used several features mentioned in those previous submissions, such as cosine similarity or other similarity metrics between headline and body, TF-IDF, Bag of Words, N-grams, and text summarizations.
- The third trend is using Neural Network (NN) models and also pre-trained embeddings. In our experiments, we used Glove, but other embeddings should be evaluated and compared as well. Previous literature showed that some embedding models can perform better based on the dataset and the domain. We are also planning to use sentence transformers, as they showed significant accuracy in recent literature.
- Individual classifiers in the first stage will classify input text as either related or un-related. Second-stage NN models will classify input text into either agree, disagree, or discuss.
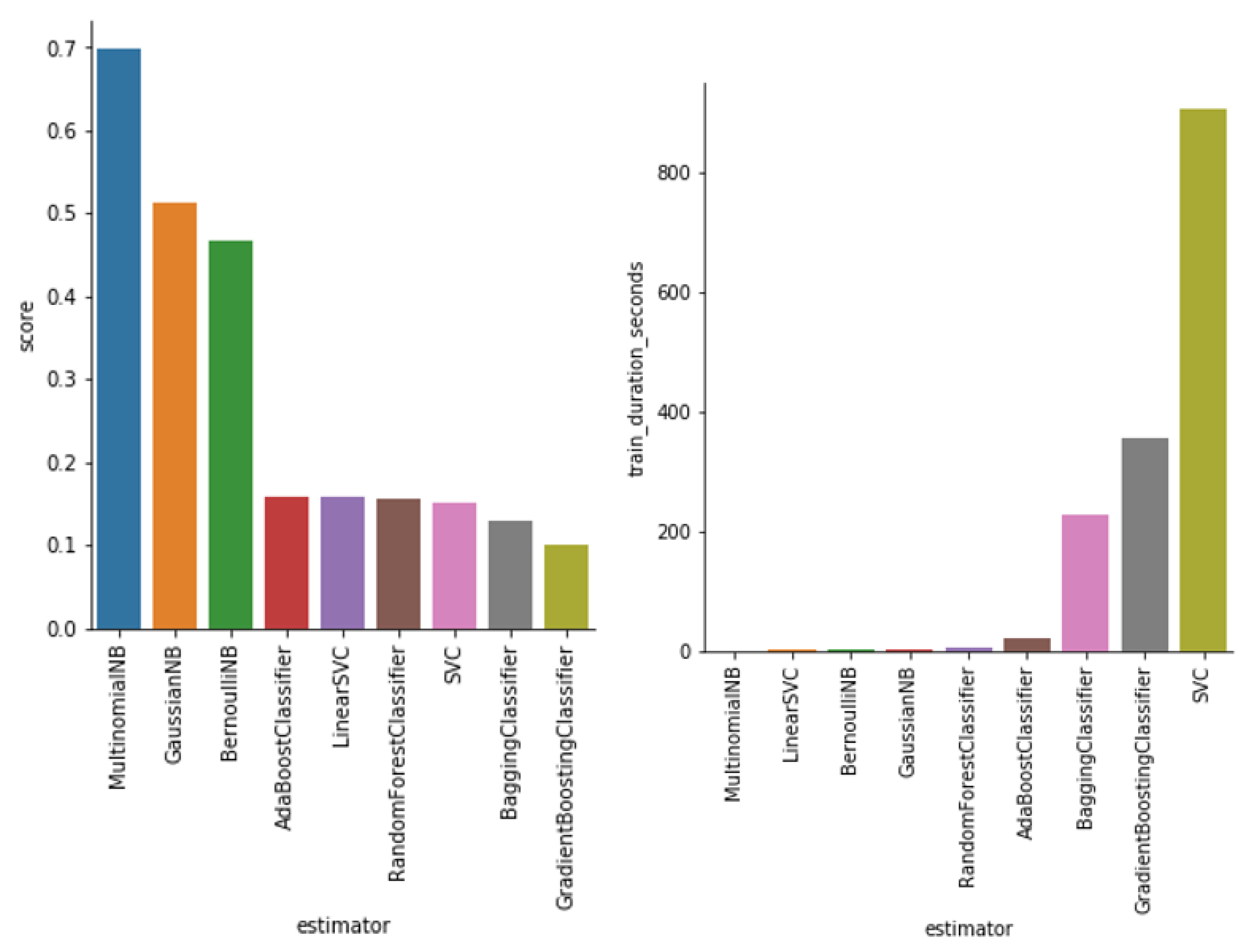
5. Experiments and Results
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| OSNs | Online Social Networks |
| NLP | Natural Language Processing |
| FNC | Fake News Challenge |
| DL | Deep learning |
| CNN | Convolutional Neural Networks |
| GRU | Gated recurrent unit |
| MLP | Multi-Layer Perceptron |
| BiLSTM | Bidirectional long and short-term memory |
| MVNN | Multi-domain Visual Neural Network |
| BAG | Block Artifact Grids |
| PCA | Principal Component Analysis |
| COOC | Cooccurrence |
| LSA | Latent Semantic Analysis |
| DCN | Deep convolutional neural networks |
| LF | Lexical features |
| GBDT | Gradient-boosted decision trees |
| TF-IDF | Frequency–inverse document frequency |
| SVD | Singular Value Decomposition |
| DRM | Deep recurrent model |
| NN | Neural Network |
References
- Kaplan, A.M.; Haenlein, M. Users of the world, unite! The challenges and opportunities of Social Media. Bus. Horiz. 2010, 53, 59–68. [Google Scholar] [CrossRef]
- Cha, M.; Haddadi, H.; Benevenuto, F.; Gummadi, K.P. Measuring user influence in Twitter: The million follower fallacy. In Proceedings of the International AAAI Conference on Web and Social Media, Washington, DC, USA, 23–26 May 2010; Volume 4. No. 1. [Google Scholar]
- Papacharissi, Z. Affective Publics: Sentiment, Technology, and Politics; Oxford University Press: Oxford, UK, 2015. [Google Scholar]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Lazer, D.M.; Baum, M.A.; Benkler, Y.; Berinsky, A.J.; Greenhill, K.M.; Menczer, F.; Zittrain, J.L. The science of fake news. Science 2018, 359, 1094–1096. [Google Scholar] [CrossRef]
- Metzger, M.J.; Flanagin, A.J. Credibility and trust of information in online environments: The use of cognitive heuristics. J. Pragmat. 2013, 59, 210–220. [Google Scholar] [CrossRef]
- Sundar, S.S. The MAIN Model: A Heuristic Approach to Understanding Technology Effects on Credibility; Metzger, M.J., Flanagin, A.J., Eds.; MacArthur Foundation Digital Media and Learning: Cambridge, MA, USA, 2007; pp. 73–100. [Google Scholar]
- Anand, P.; Walker, M.; Abbott, R.; Tree, J.E.F.; Bowmani, R.; Minor, M. Cats Rule and Dogs Drool!: Classifying Stance in Online Debate. In Proceedings of the 2nd Workshop on Computational Approaches to Subjectivity and Sentiment Analysis (WASSA 2.011), Portland, OR, USA, 11–17 June 2011; pp. 1–9. [Google Scholar]
- Hasan, K.S.; Ng, V. Stance Classification of Ideological Debates: Data, Models, Features, and Constraints. In Proceedings of the Sixth International Joint Conference on Natural Language Processing, Nagoya, Japan, 14–19 October 2013; pp. 1348–1356. [Google Scholar]
- Qiu, M.; Sim, Y.; Smith, N.A.; Jiang, J. Modeling User Arguments, Interactions, and Attributes for Stance Prediction in Online Debate Forums. In Proceedings of the 2015 SIAM International Conference on Data Mining, Vancouver, BC, Canada, 30 April–2 May 2015; pp. 855–863. [Google Scholar]
- Walker, M.; Anand, P.; Abbott, R.; Grant, R. Stance Classification Using Dialogic Properties of Persuasion. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Montréal, QC, Canada, 3–8 June 2012; pp. 592–596. [Google Scholar]
- Zhang, Q.; Yilmaz, E.; Liang, S. Ranking-Based Method for News Stance Detection. In Proceedings of the Web Conference, Lyon, France, 23–27 April 2018; pp. 41–42. [Google Scholar]
- Mohammad, S.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. Semeval-2016 Task 6: Detecting Stance in Tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 31–41. [Google Scholar]
- Riedel, B.; Augenstein, I.; Spithourakis, G.P.; Riedel, S. A simple but tough-to-beat baseline for the Fake News Challenge stance detection task. arXiv 2017, arXiv:1707.03264. [Google Scholar]
- Thorne, J.; Chen, M.; Myrianthous, G.; Pu, J.; Wang, X.; Vlachos, A. Fake News Detection Using Stacked Ensemble of Classifiers; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017. [Google Scholar]
- Bourgonje, P.; Schneider, J.M.; Rehm, G. From clickbait to fake news detection: An approach based on detecting the stance of headlines to articles. In Proceedings of the 2017 EMNLP Workshop: Natural Language Processing Meets Journalism, Copenhagen, Denmark, 7 September 2017; pp. 84–89. [Google Scholar]
- Hanselowski, A.; PVS, A.; Schiller, B.; Caspelherr, F.; Chaudhuri, D.; Meyer, C.M.; Gurevych, I. A retrospective analysis of the fake news challenge stance detection task. arXiv 2018, arXiv:1806.05180. [Google Scholar]
- Bhatt, G.; Sharma, A.; Sharma, S.; Nagpal, A.; Raman, B.; Mittal, A. Combining neural, statistical and external features for fake news stance identification. In Proceedings of the Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 1353–1357. [Google Scholar]
- Slovikovskaya, V. Transfer learning from transformers to fake news challenge stance detection (FNC-1) task. arXiv 2019, arXiv:1910.14353. [Google Scholar]
- Schütz, M.; Schindler, A.; Siegel, M.; Nazemi, K. Automatic Fake News Detection with Pre-trained Transformer Models. In Proceedings of the Pattern Recognition, ICPR International Workshops and Challenges (ICPR 2021), Virtual Event, 10–15 January 2021; Del Bimbo, A., Cucchiara, R., Sclaroff, S., Farinella, G.M., Mei, T., Bertini, M., Escalante, H.J., Vezzani, R., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2021; Volume 12667. [Google Scholar] [CrossRef]
- Li, Q.; Zhou, W. Connecting the Dots Between Fact Verification and Fake News Detection. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 1820–1825. [Google Scholar] [CrossRef]
- Segura-Bedmar, I.; Alonso-Bartolome, S. Multimodal Fake News Detection. Information 2022, 13, 284. [Google Scholar] [CrossRef]
- Dedeepya, P.; Yarrarapu, M.; Kumar, P.P.; Kaushik, S.K.; Raghavendra, P.N.; Chandu, P. Fake News Detection on Social Media Through a Hybrid SVM-KNN Approach Leveraging Social Capital Variables. In Proceedings of the 2024 3rd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 2–4 July 2024; pp. 1168–1175. [Google Scholar] [CrossRef]
- Dev, D.G.; Bhatnagar, V.; Bhati, B.; Gupta, M.; Nanthaamornphong, A. LSTMCNN: A hybrid machine learning model to unmask fake news. Heliyon 2024, 10, e25244. [Google Scholar] [CrossRef]
- Zeng, X.; La Barbera, D.; Roitero, K.; Zubiaga, A.; Mizzaro, S. Combining Large Language Models and Crowdsourcing for Hybrid Human-AI Misinformation Detection. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’24), Washington, DC, USA, 14–18 July 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 2332–2336. [Google Scholar] [CrossRef]
- Alsmadi, I.; Alazzam, I.; Al-Ramahi, M. Stance Detection in the Context of Fake News. In Proceedings of the Annual IDeaS Conference: Disinformation, Hate Speech, and Extremism, CMU, Online, 12–13 July 2021. [Google Scholar]
- Fake News Challenge Stage 1 (Fnc-I): Stance Detection. 2017. Available online: http://www.fakenewschallenge.org/ (accessed on 1 October 2023).
- Rubin, V.L.; Chen, Y.; Conroy, N.K. Deception Detection for News: Three Types of Fakes. Proc. Assoc. Inf. Sci. Technol. 2015, 52, 1–4. [Google Scholar] [CrossRef]
- Bedi, A.; Pandey, N.; Khatri, S.K. A Framework to Identify and Secure the Issues of Fake News and Rumours in Social Networking. In Proceedings of the 2019 2nd International Conference on Power Energy, Environment and Intelligent Control (PEEIC), Greater Noida, India, 18–19 October 2019; pp. 70–73. [Google Scholar]
- De Oliveira, N.R.; Medeiros, D.S.; Mattos, D.M. A Sensitive Stylistic Approach to Identify Fake News on Social Networking. IEEE Signal Process. Lett. 2020, 27, 1250–1254. [Google Scholar] [CrossRef]
- Ajao, O.; Bhowmik, D.; Zargari, S. Fake News Identification on Twitter with Hybrid Cnn and Rnn Models. In Proceedings of the 9th International Conference on Social Media and Society, Copenhagen, Denmark, 18–20 July 2018; pp. 226–230. [Google Scholar]
- Boididou, C.; Papadopoulos, S.; Dang-Nguyen, D.-T.; Boato, G.; Kompatsiaris, Y. The Certh-Unitn Participation@ Verifying Multimedia Use 2015. In Proceedings of the MediaEval 2015 Workshop, Wurzen, Germany, 14–15 September 2015. [Google Scholar]
- Boididou, C.; Andreadou, K.; Papadopoulos, S.; Dang-Nguyen, D.-T.; Boato, G.; Riegler, M.; Kompatsiaris, Y. Verifying Multimedia Use at Mediaeval 2016. In Proceedings of the MediaEval 2016 Workshop, Hilversum, The Netherlands, 20–21 October 2016. [Google Scholar]
- Gupta, A.; Lamba, H.; Kumaraguru, P.; Joshi, A. Faking Sandy: Characterizing and Identifying Fake Images on Twitter During Hurricane Sandy. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 729–736. [Google Scholar]
- Chen, M.; Lai, Y.; Lian, J. Using Deep Learning Models to Detect Fake News about COVID-19. ACM Trans. Internet Technol. 2023, 23, 2. [Google Scholar] [CrossRef]
- Qi, P.; Cao, J.; Yang, T.; Guo, J.; Li, J. Exploiting Multi-Domain Visual Information for Fake News Detection. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 518–527. [Google Scholar]
- Dementieva, D.; Kuimov, M.; Panchenko, A. Multiverse: Multilingual Evidence for Fake News Detection. J. Imaging 2023, 9, 77. [Google Scholar] [CrossRef]
- Zhou, X.; Wu, J.; Zaiane, O.R. SAFE: Similarity-Aware multi-modal Fake news detection. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Singapore, 11–14 May 2020; Springer: Cham, Switzerland, 2020; pp. 354–367. [Google Scholar]
- Qi, P.; Cao, J.; Yang, T.; Guo, J.; Li, J. Exploiting multi-domain visual information for fake news detection. In Proceedings of the IEEE International Conference on Data Engineering (ICDE), Beijing, China, 8–11 November 2021; pp. 1598–1609. [Google Scholar]
- Mishra, A.; Sadia, H. A Comprehensive Analysis of Fake News Detection Models: A Systematic Literature Review and Current Challenges. Eng. Proc. 2023, 59, 28. [Google Scholar] [CrossRef]
- Singh, M.; Ahmed, J.; Alam, A.; Raghuvanshi, K.; Kumar, S. A comprehensive review on automatic detection of fake news on social media. Multimed. Tools Appl. 2023, 83, 47319–47352. [Google Scholar] [CrossRef]
- Nikumbh, D.; Thakare, A. A Comprehensive review of fake news detection on social media: Feature engineering, feature fusion, and future research directions. Int. J. Syst. Innov. 2023, 7, 6. [Google Scholar]
- Popat, K.; Mukherjee, S.; Strötgen, J.; Weikum, G. Where the Truth Lies: Explaining the Credibility of Emerging Claims on the Web and Social Media. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 1003–1012. [Google Scholar]
- Ferreira, W.; Vlachos, A. Emergent: A Novel Data-Set for Stance Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1163–1168. [Google Scholar]
- Borges, L.; Martins, B.; Calado, P. Combining Similarity Features and Deep Representation Learning for Stance Detection in the Context of Checking Fake News. J. Data Inf. Qual. 2019, 11, 1–26. [Google Scholar] [CrossRef]
- Shang, J.; Shen, J.; Sun, T.; Liu, X.; Gruenheid, A.; Korn, F.; Lelkes, Á.D.; Yu, C.; Han, J. Investigating Rumor News Using Agreement-Aware Search. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 2117–2125. [Google Scholar]
- Umer, M.; Imtiaz, Z.; Ullah, S.; Mehmood, A.; Choi, G.S.; On, B.-W. Fake News Stance Detection Using Deep Learning Architecture (Cnn-Lstm). IEEE Access 2020, 8, 156695–156706. [Google Scholar] [CrossRef]
- Hardalov, M.; Arora, A.; Nakov, P.; Augenstein, I. A survey on stance detection for mis-and disinformation identification. arXiv 2021, arXiv:2103.00242. [Google Scholar]
- Jiang, Y.; Petrak, J.; Song, X.; Bontcheva, K.; Maynard, D. Team Bertha von Suttner at SemEval-2022 Task 4: Multi-modal Stance Detection using Visual and Textual Cues. In Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022), Seattle, WA, USA, 14–15 July 2022; pp. 416–424. [Google Scholar]
- Zotova, E.; Agerri, R.; Nuñez, M.; Rigau, G. Multilingual Stance Detection in Tweets: The Catalonia Independence Corpus. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; European Language Resources Association: Paris, France, 2020; pp. 1368–1375. [Google Scholar]
- Guo, Z.; Zhang, Q.; Ding, F.; Zhu, X.; Yu, K. A Novel Fake News Detection Model for Context of Mixed Languages through Multiscale Transformer. IEEE Trans. Comput. Soc. Syst. 2023, 11, 5079–5089. [Google Scholar] [CrossRef]
- Sean, B.; Pan, Y. Talos Targets Disinformation with Fake News Challenge Victory. 2017. Available online: https://blog.talosintelligence.com/2017/06/talos-fake-news-challenge.html (accessed on 1 February 2021).
- Hanselowski, A.; Avinesh, P.V.S.; Schiller, B.; Caspelherr, F. Description of the System Developed by Team Athene in the FNC-1. 2017. Available online: https://github.com/hanselowski/athene_system/blob/master/system_description_athene.pdf (accessed on 13 August 2024).
- Zhang, Q.; Liang, S.; Lipani, A.; Ren, Z.; Yilmaz, E. From stances’ imbalance to their hierarchical representation and detection. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; ACM: New York, NY, USA, 2019; pp. 2323–2332. [Google Scholar]
- Altheneyan, A.; Alhadlaq, A. Big Data ML-Based Fake News Detection Using Distributed Learning. IEEE Access 2023, 11, 29447–29463. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Approach | Weighted Accuracy |
|---|---|---|
| Riedel et al. [14] | MLP + BoW | 81.72% |
| Bhatt et al. [18] | DRM + NE + n-gram + BoW | 83.08% |
| Borges et al. [45] | RNN + Neural attention | 83.38% |
| Sean et al. [52] | DCN + GBDT + LF | 82.02% |
| Hanselowski et al. [53] | EL-MLP | 81.97% |
| Paper | Approach | Weighted Accuracy |
|---|---|---|
| Riedel et al. [14] | MLP + BoW | 81.72% |
| Bhatt et al. [18] | DRM + NE + n-gram + BoW | 83.08% |
| Borges et al. [45] | RNN + Neural attention | 83.38% |
| Sean et al. [52] | DCN + GBDT + LF | 82.02% |
| Hanselowski et al. [53] | EL-MLP | 81.97% |
| Proposed approach | Two-Stages, hybrid, meta features | 86.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsmadi, I.; Alazzam, I.; Al-Ramahi, M.; Zarour, M. Stance Detection in the Context of Fake News—A New Approach. Future Internet 2024, 16, 364. https://doi.org/10.3390/fi16100364
Alsmadi I, Alazzam I, Al-Ramahi M, Zarour M. Stance Detection in the Context of Fake News—A New Approach. Future Internet. 2024; 16(10):364. https://doi.org/10.3390/fi16100364
Chicago/Turabian StyleAlsmadi, Izzat, Iyad Alazzam, Mohammad Al-Ramahi, and Mohammad Zarour. 2024. "Stance Detection in the Context of Fake News—A New Approach" Future Internet 16, no. 10: 364. https://doi.org/10.3390/fi16100364
APA StyleAlsmadi, I., Alazzam, I., Al-Ramahi, M., & Zarour, M. (2024). Stance Detection in the Context of Fake News—A New Approach. Future Internet, 16(10), 364. https://doi.org/10.3390/fi16100364