
An Imbalanced Sequence Feature Extraction Approach for the Detection of LTE-R Cells with Degraded Communication Performance


Abstract
1. Introduction
- Based on the principle of shapelet transformation, this paper designed a neural network structure that can extract morphological features of sequence data by transforming CNN neural networks.
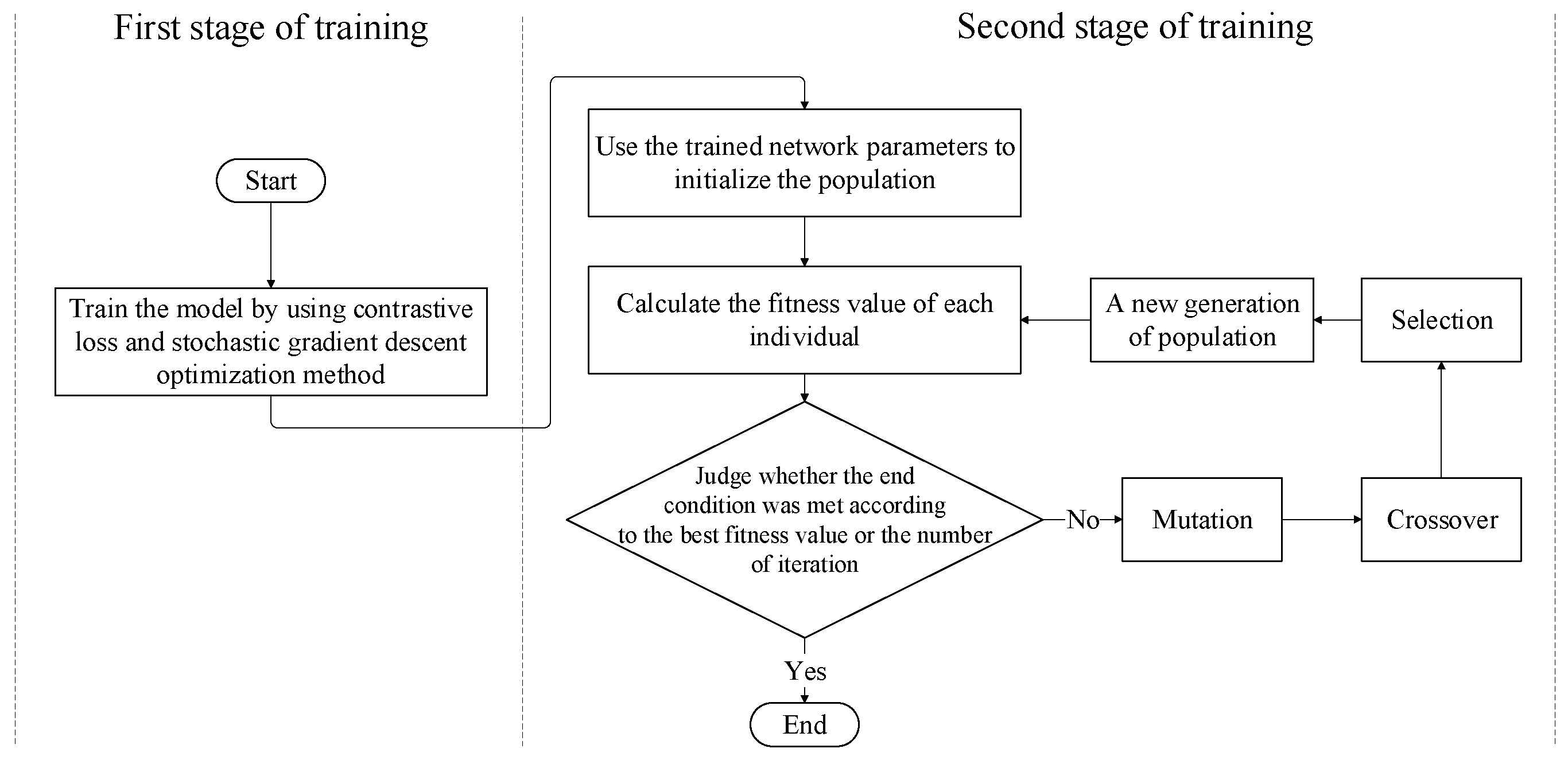
- In the detection of LTE-R cells with degraded communication performance, considering the class imbalanced problem, a two-stage training method is proposed to make the features extracted by the trained feature extraction network meet Fisher criterion as much as possible.
- By using machine learning methods, the mapping relationship between the drive test data and the abnormal release rate of LTE-R core communication services was established, which provides a powerful tool for the operation and maintenance of LTE-R network.
2. Related Work
2.1. Abnormal Wireless Communication Performance Detection
2.2. Imbalanced Data Classification
3. Preliminaries
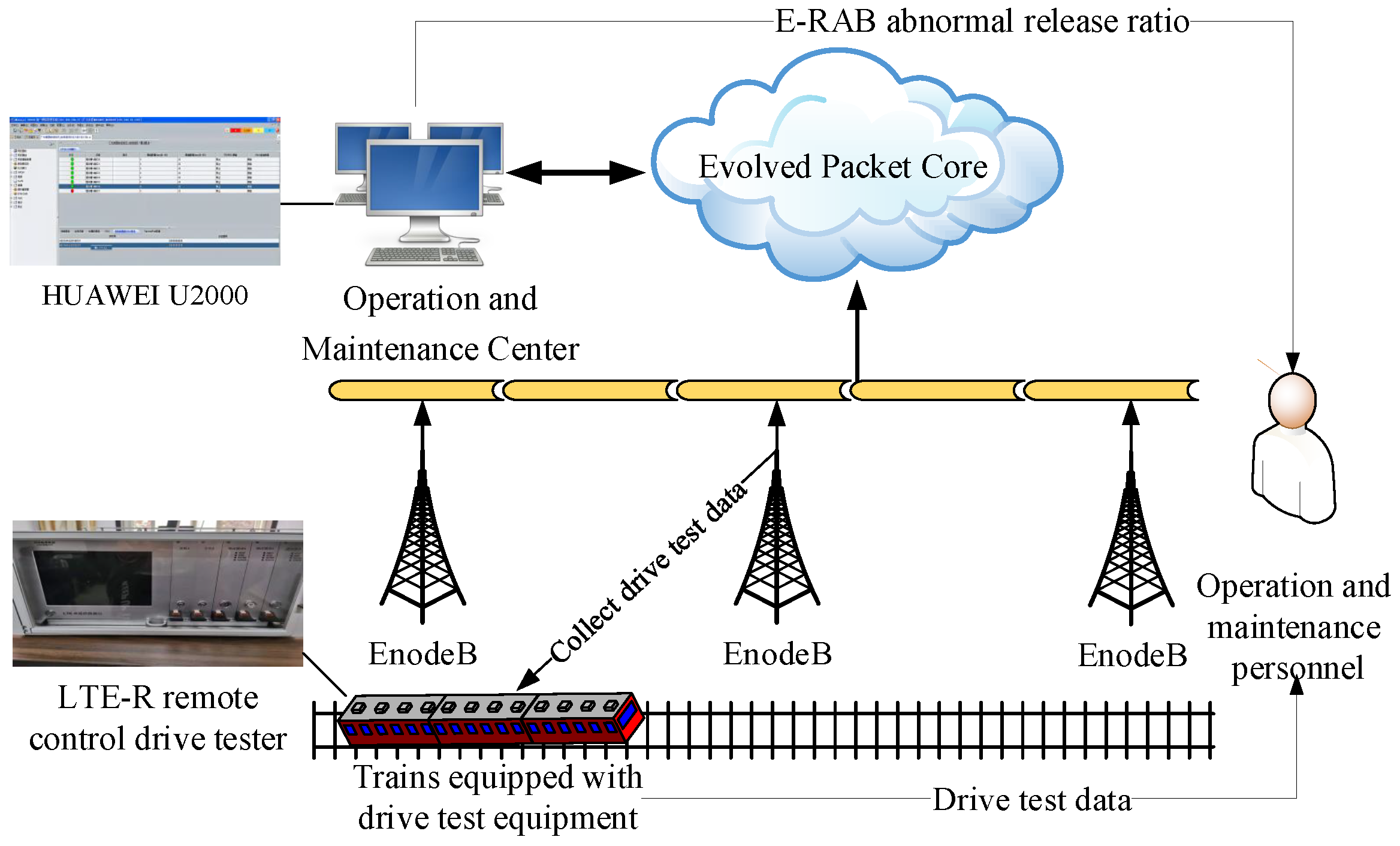
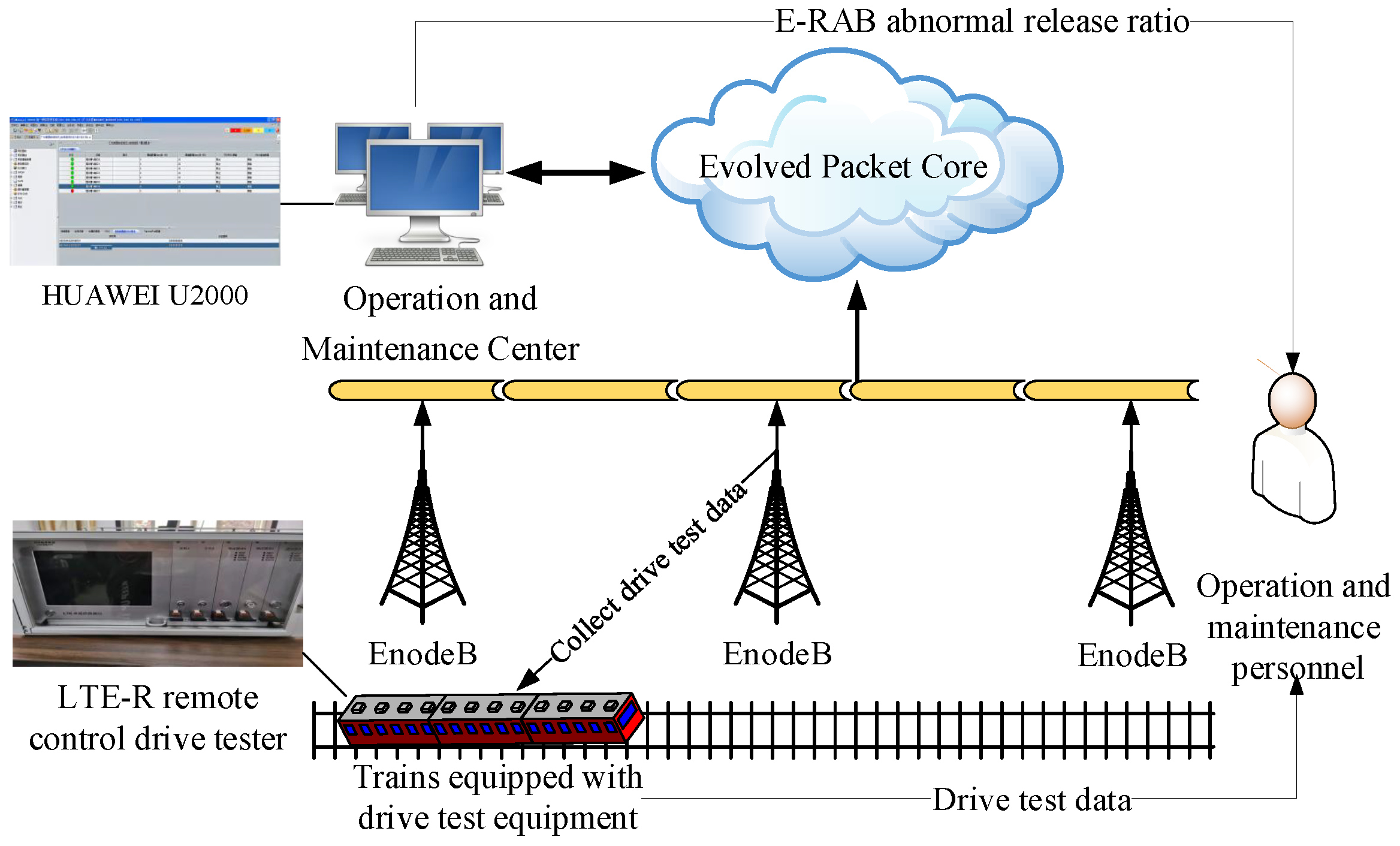
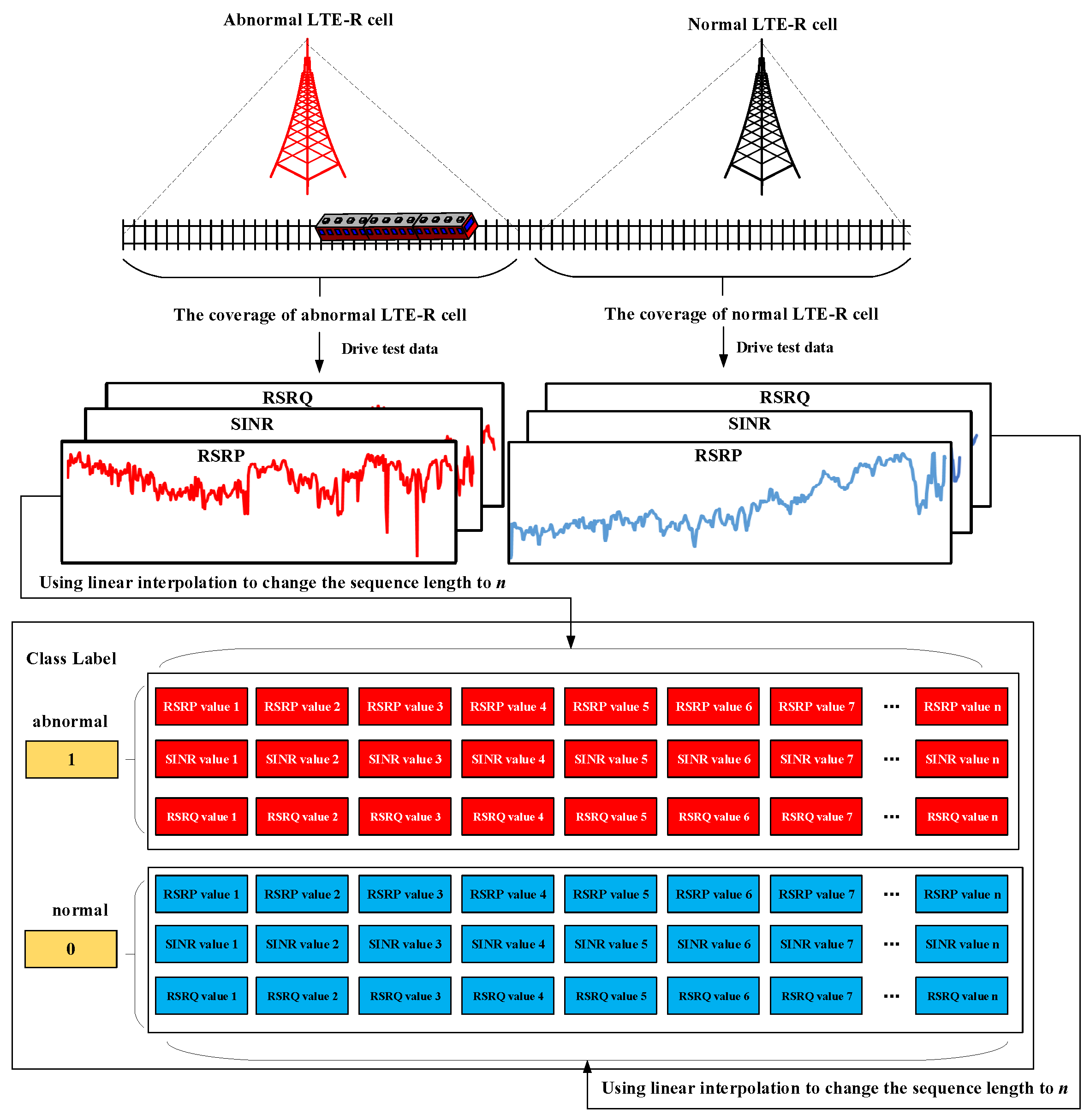
3.1. Data Description
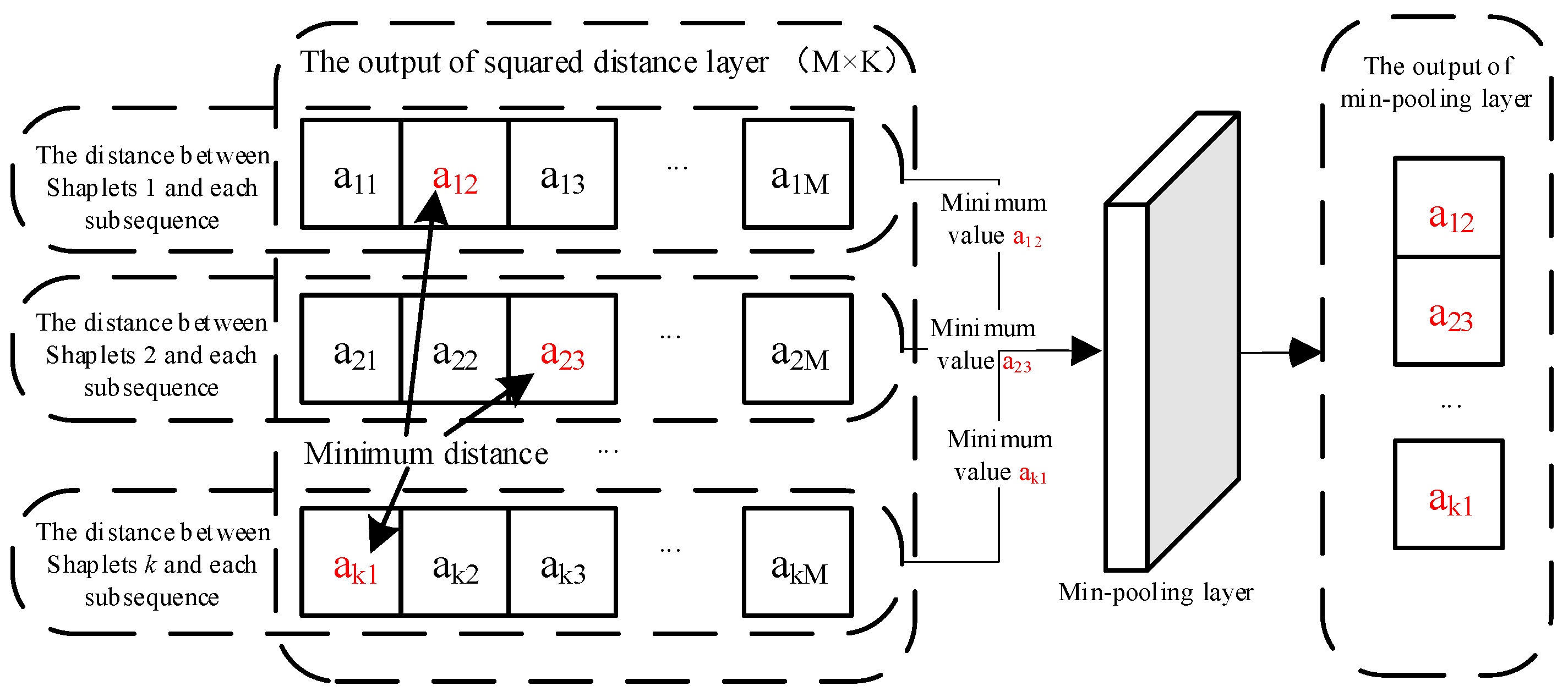
3.2. Shapelet and Shapelet Transformation
4. Methodology
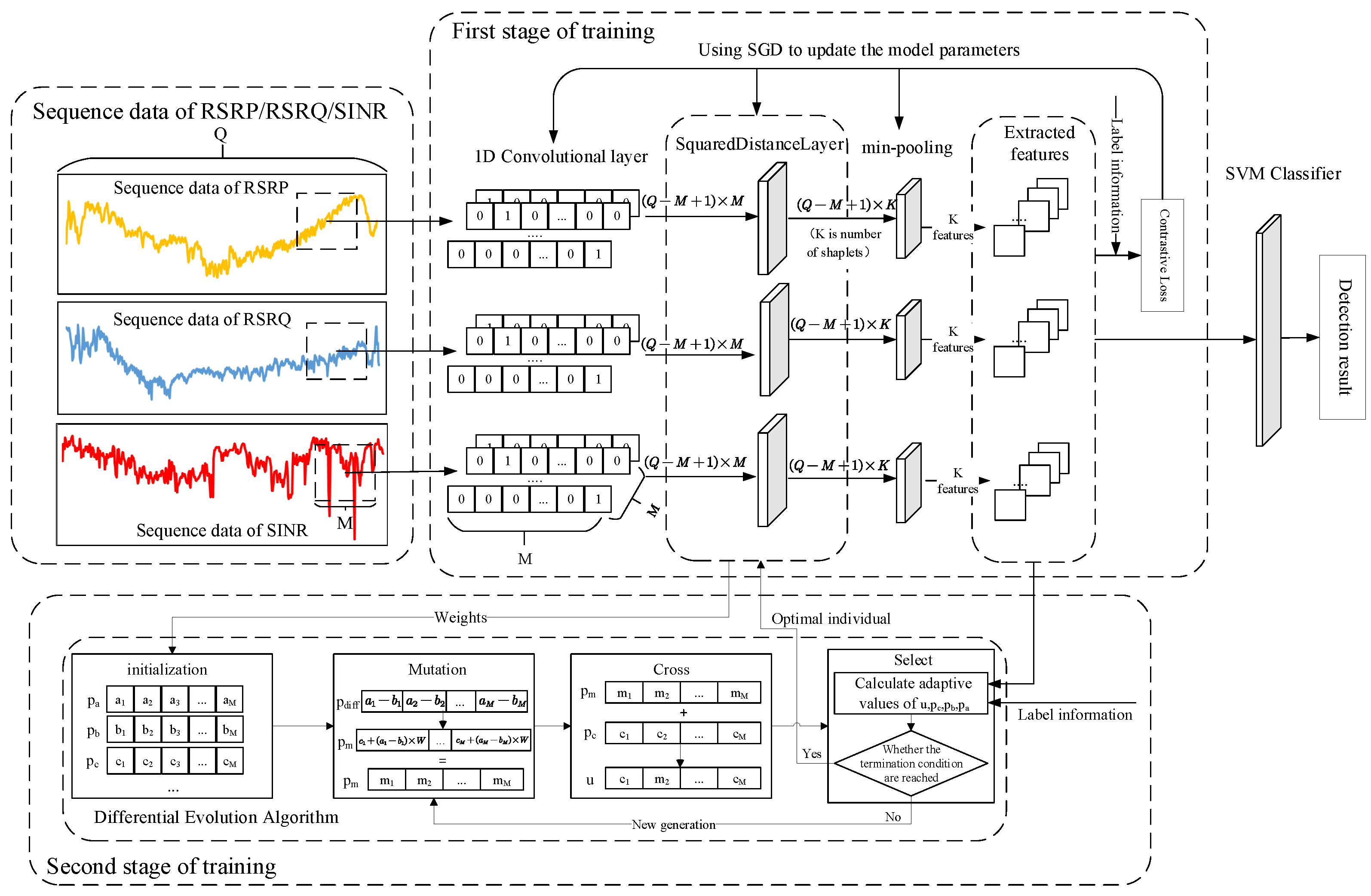
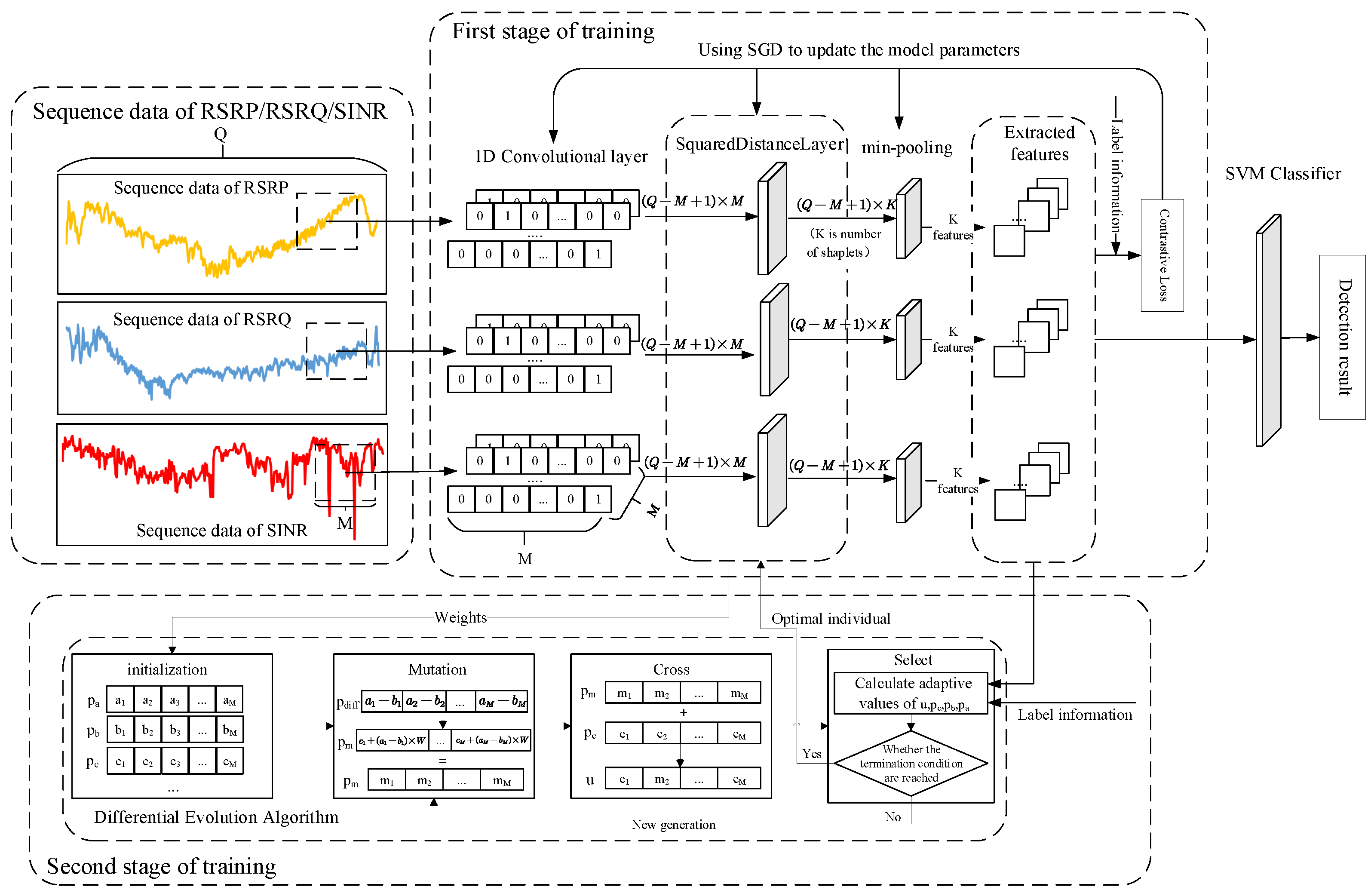
4.1. The Overall Framework of Our Approach
4.2. A Feature Extraction Network-Based CNN
- One-dimensional convolutional layer.Convolutional layers perform discrete convolution operations on input data through convolutional kernels, thereby extracting the features of the input data. Multiple convolution kernels can be used to extract different features of input data. Assuming that is a one-dimensional convolutional kernel, is a data record and is the result of one-dimensional convolutional. The j-th element of y is as shown in Formula (2).where N denotes the dimensions of the data record and M denotes the size of the convolutional kernel.
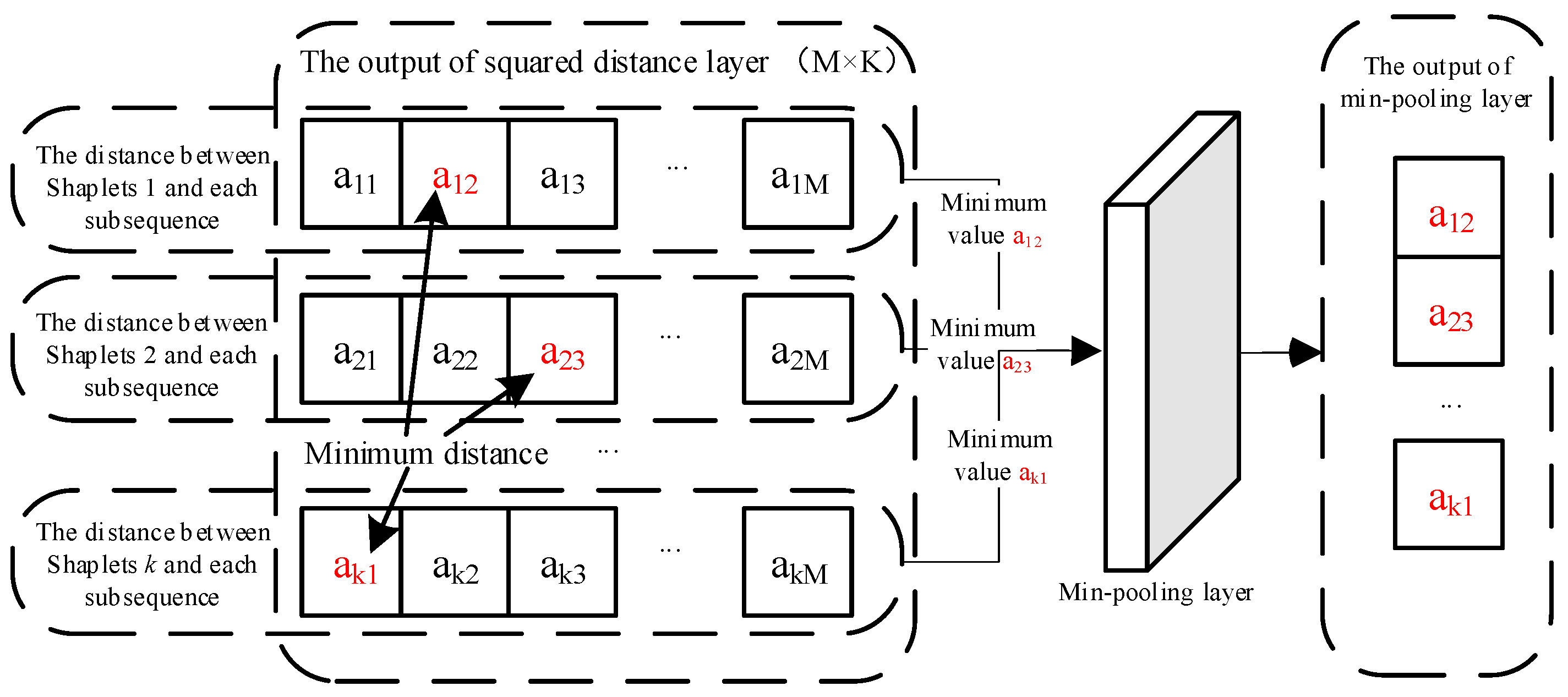
- Pooling layersIn CNNs, pooling layers are used to reduce the size of feature maps while expanding the receptive fields of the next-level neural networks. There are several types of pooling layers, including mean pooling, max pooling, stochastic pooling, and min pooling.
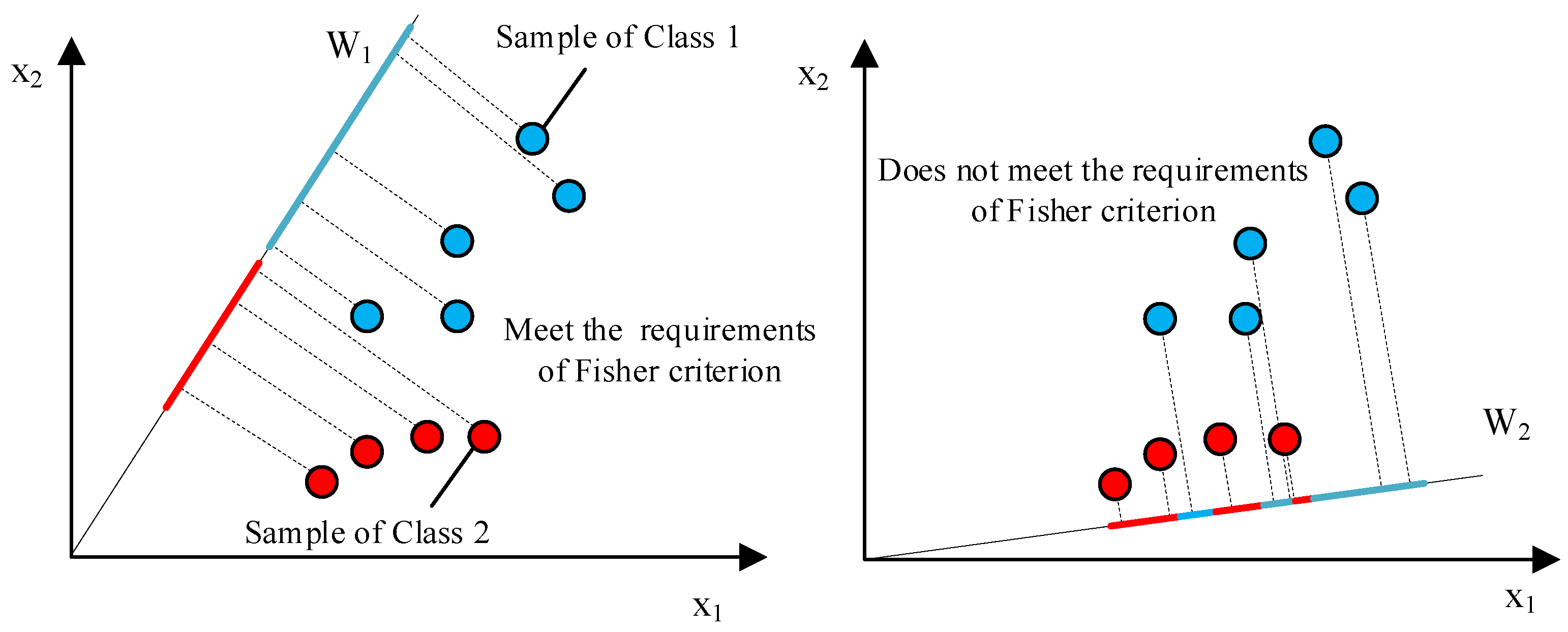
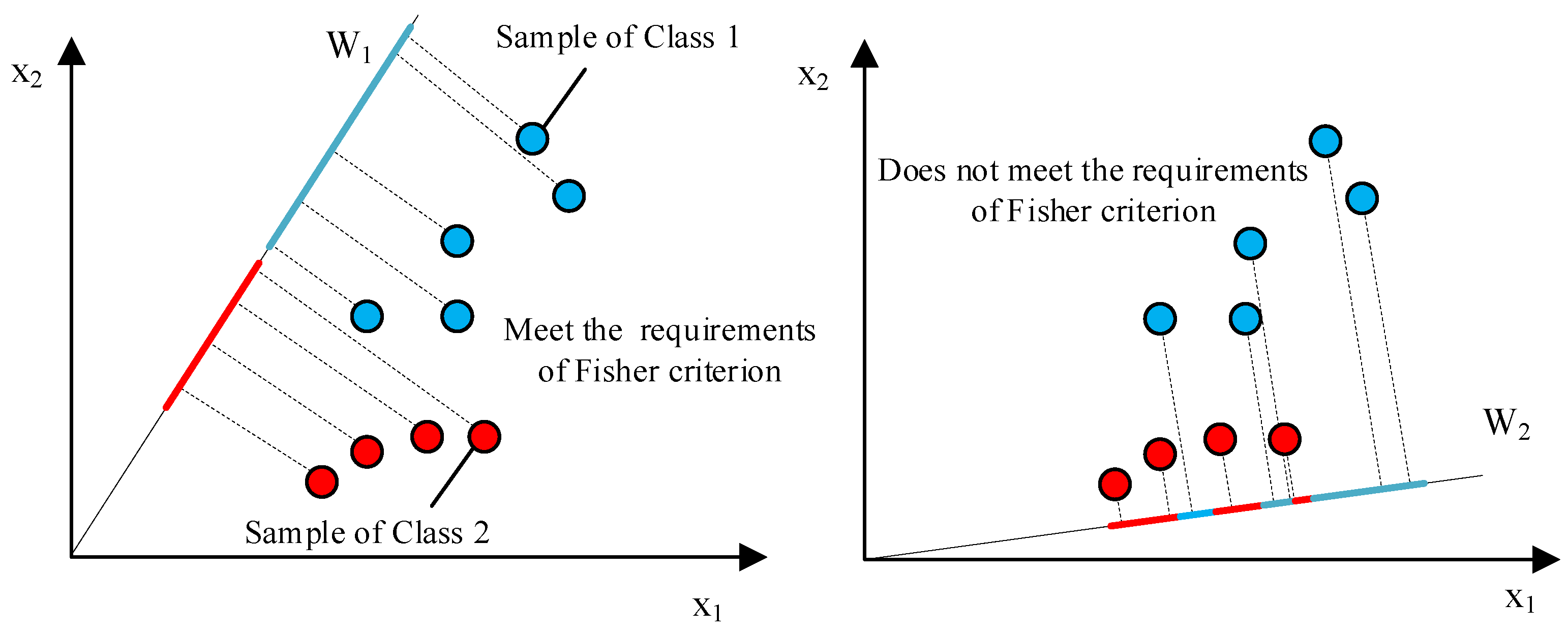
4.3. Optimization Objective for the Feature Extraction of Imbalanced Sequences
- Within-class scatter.Considering that the problem studied in this paper is a binary classification problem and assuming that the two classes are and , then is the number of samples in class . So, the within-class scatter matrix of class is as shown in Formula (4).In (4), is the mean vector of . The overall within-class scatter matrix is as shown in Formula (5).The trace of is the overall within-class scatter of and . Assuming that is a matrix, is the element of at row i and column j and represents the trace of . The trace of is as shown in Formula (6).
- Between-class scatter.The between-class scatter matrix between and is as shown in Formula (7).The trace of is the between-class scatter between and .
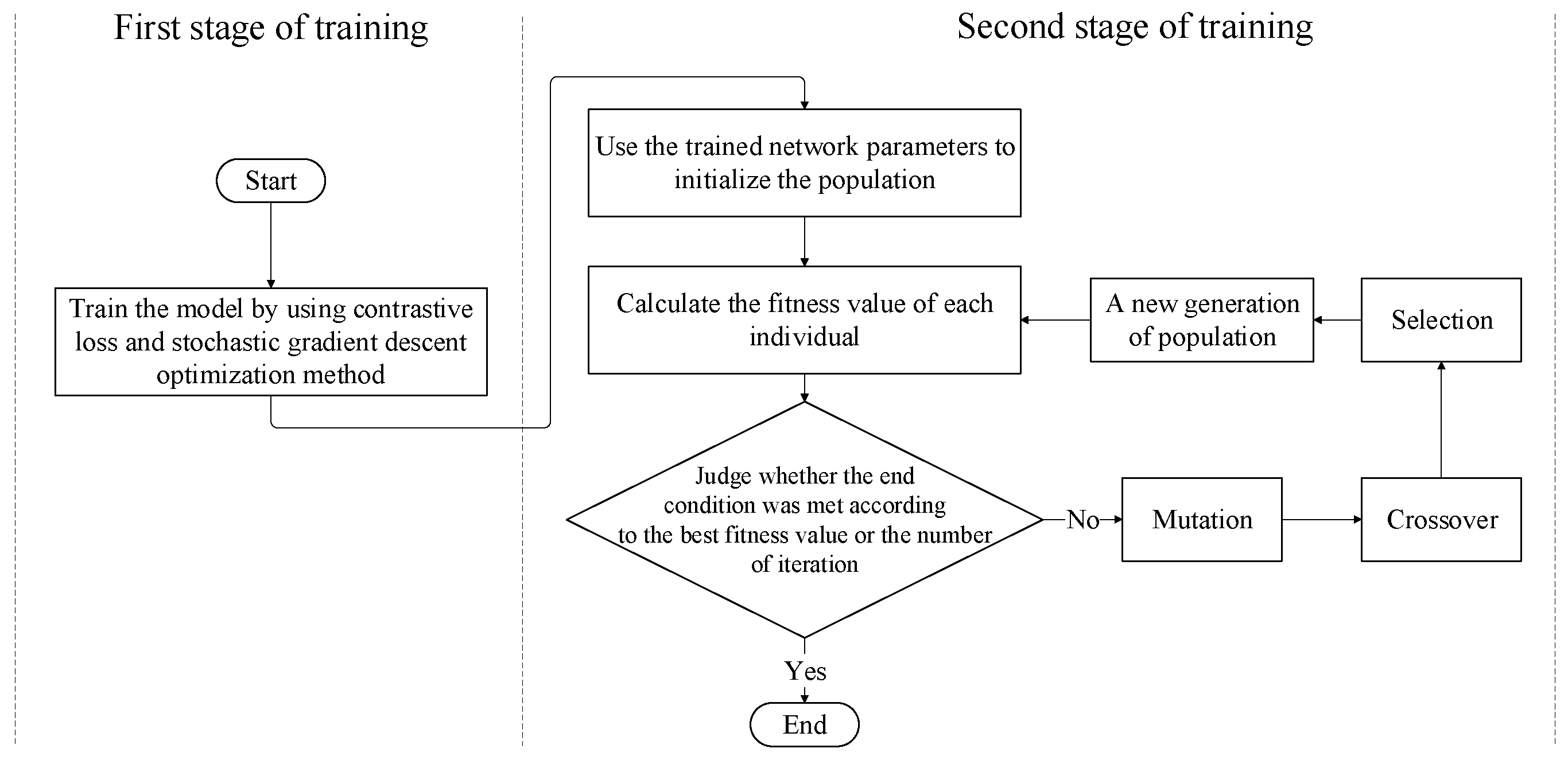
4.4. Model Training
5. Experiments and Discussion
5.1. Experimental Data
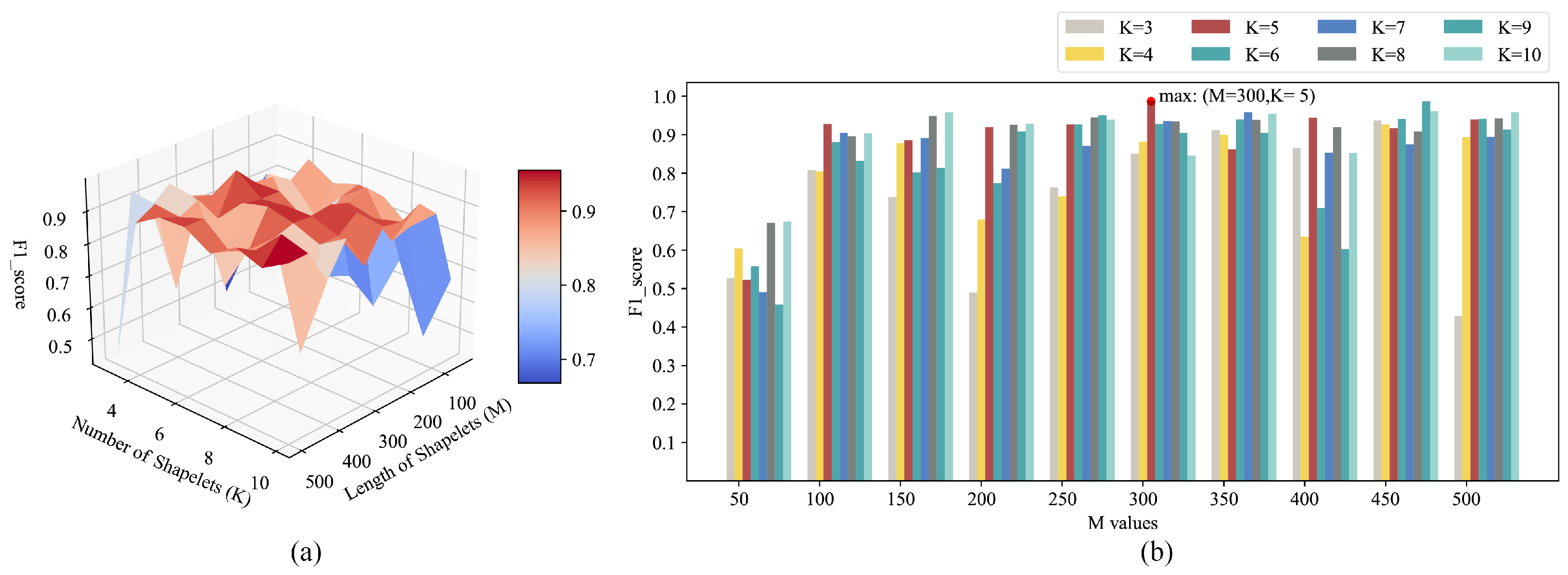
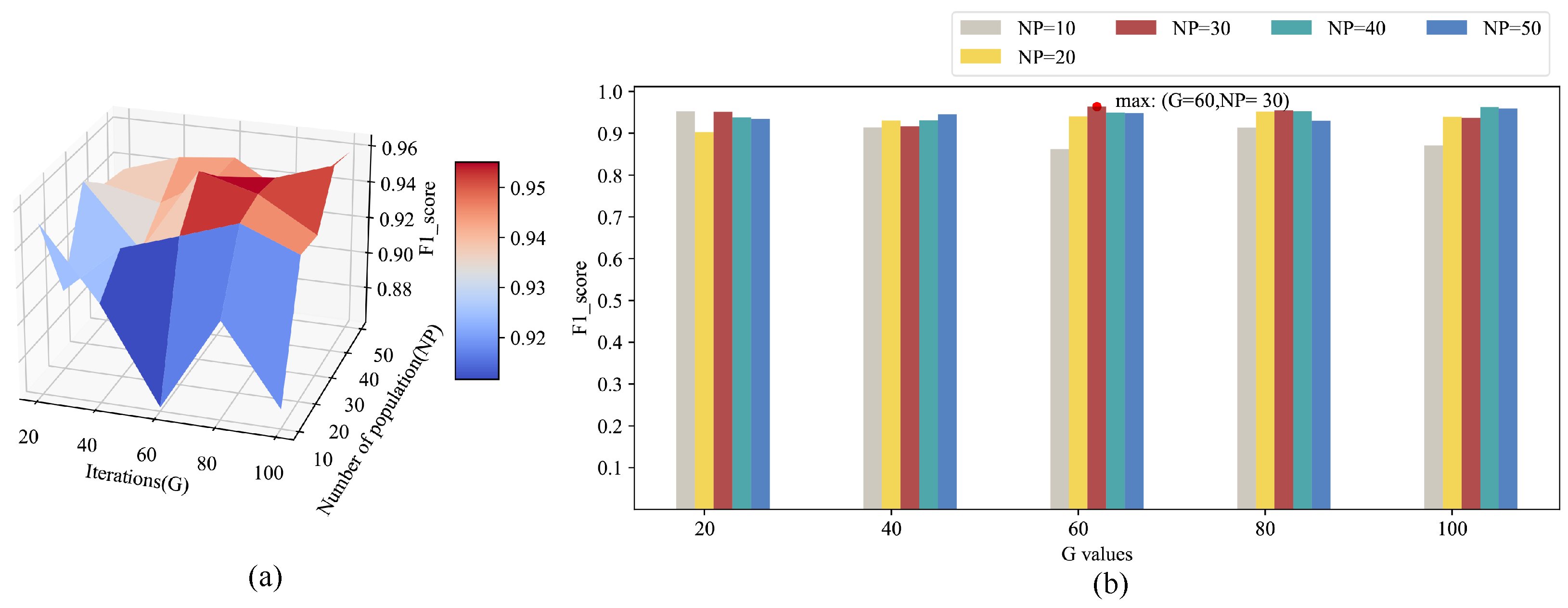
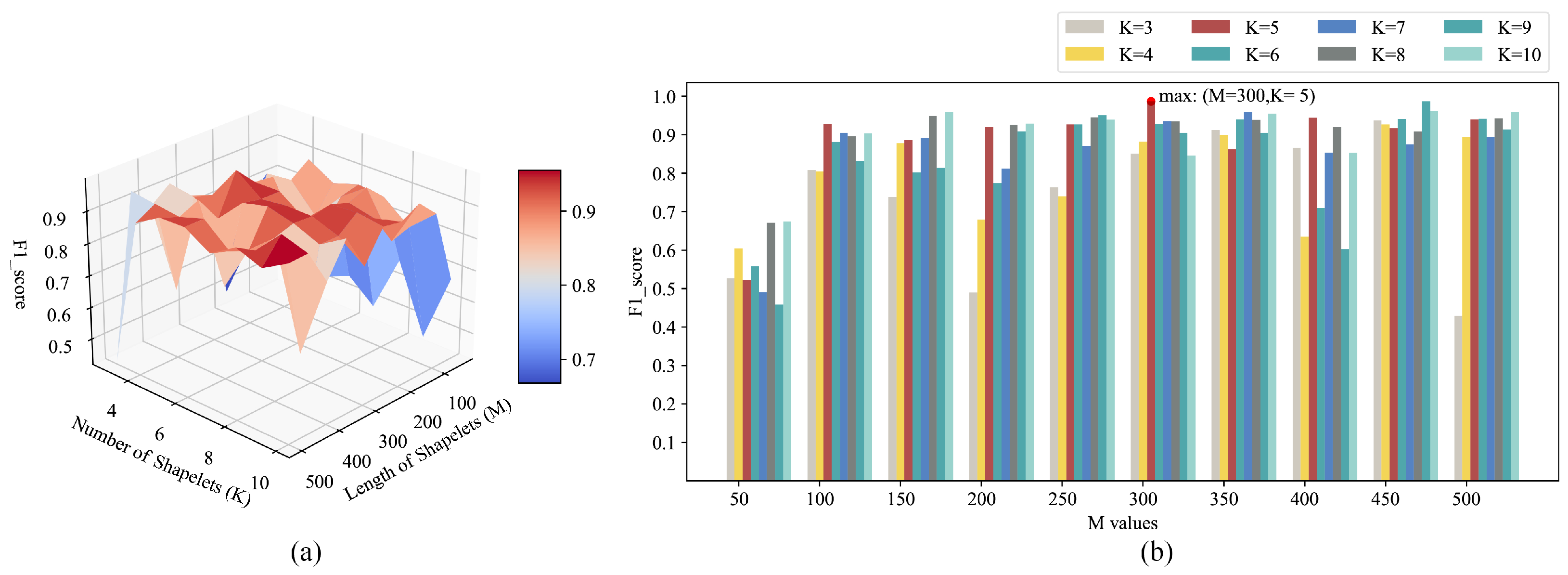
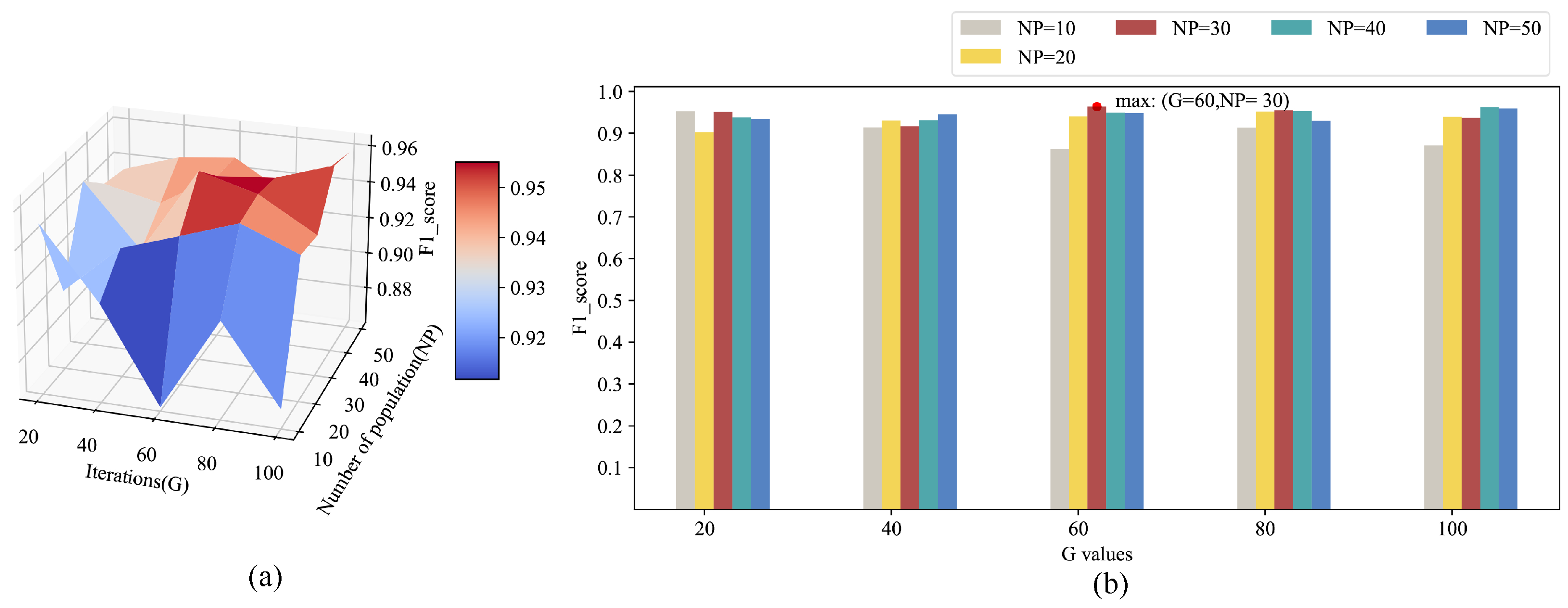
5.2. Experiment Settings
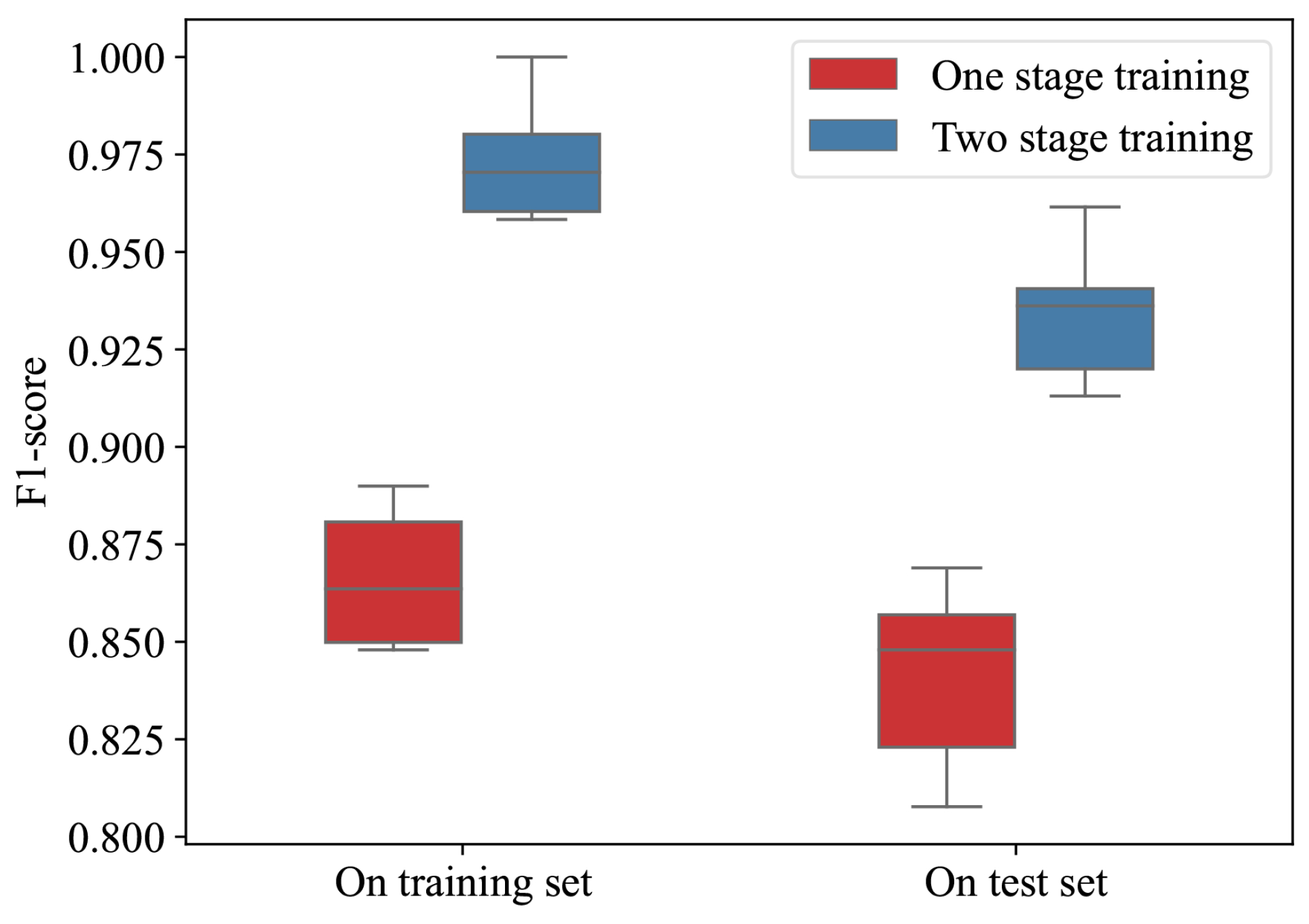
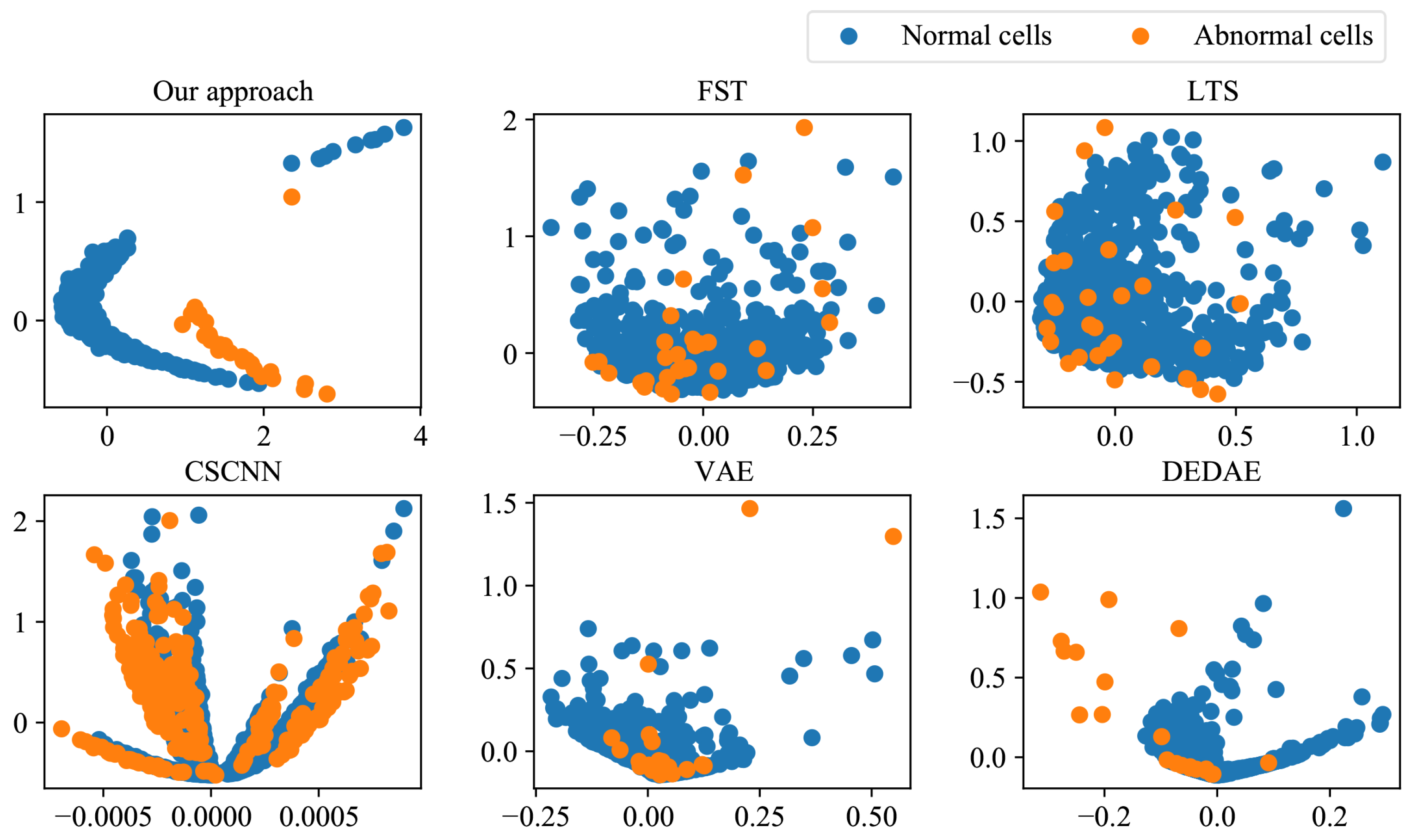
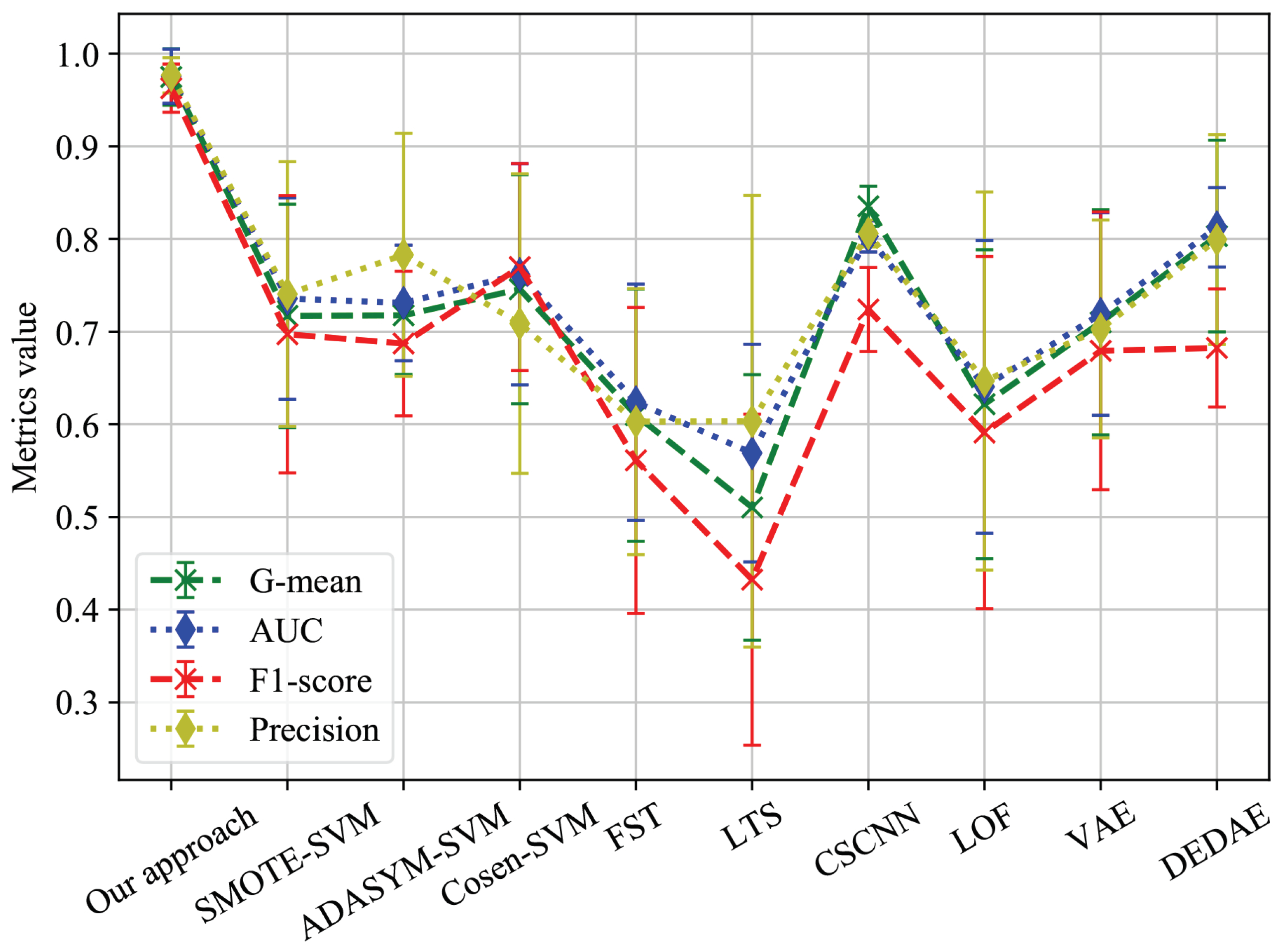
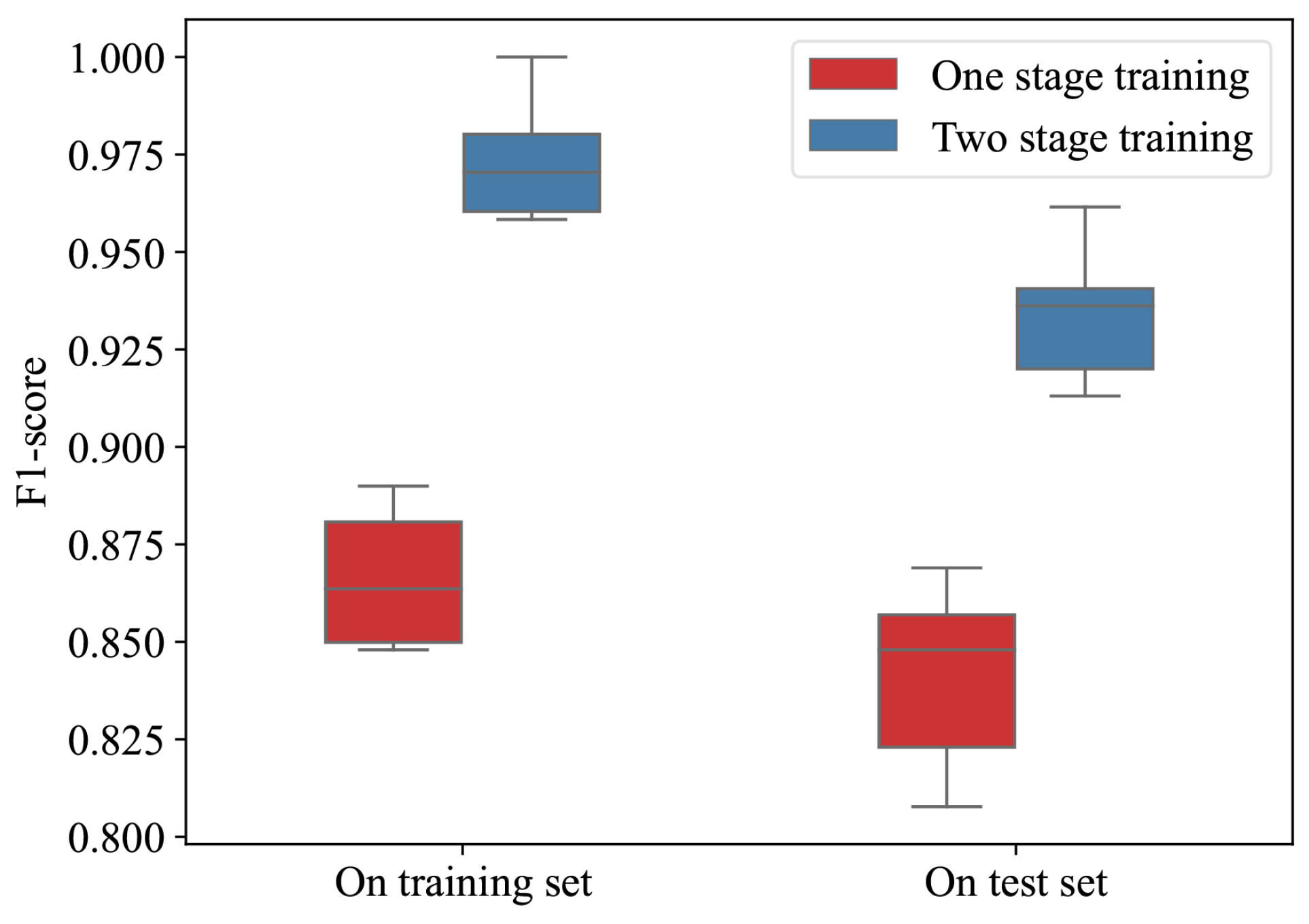
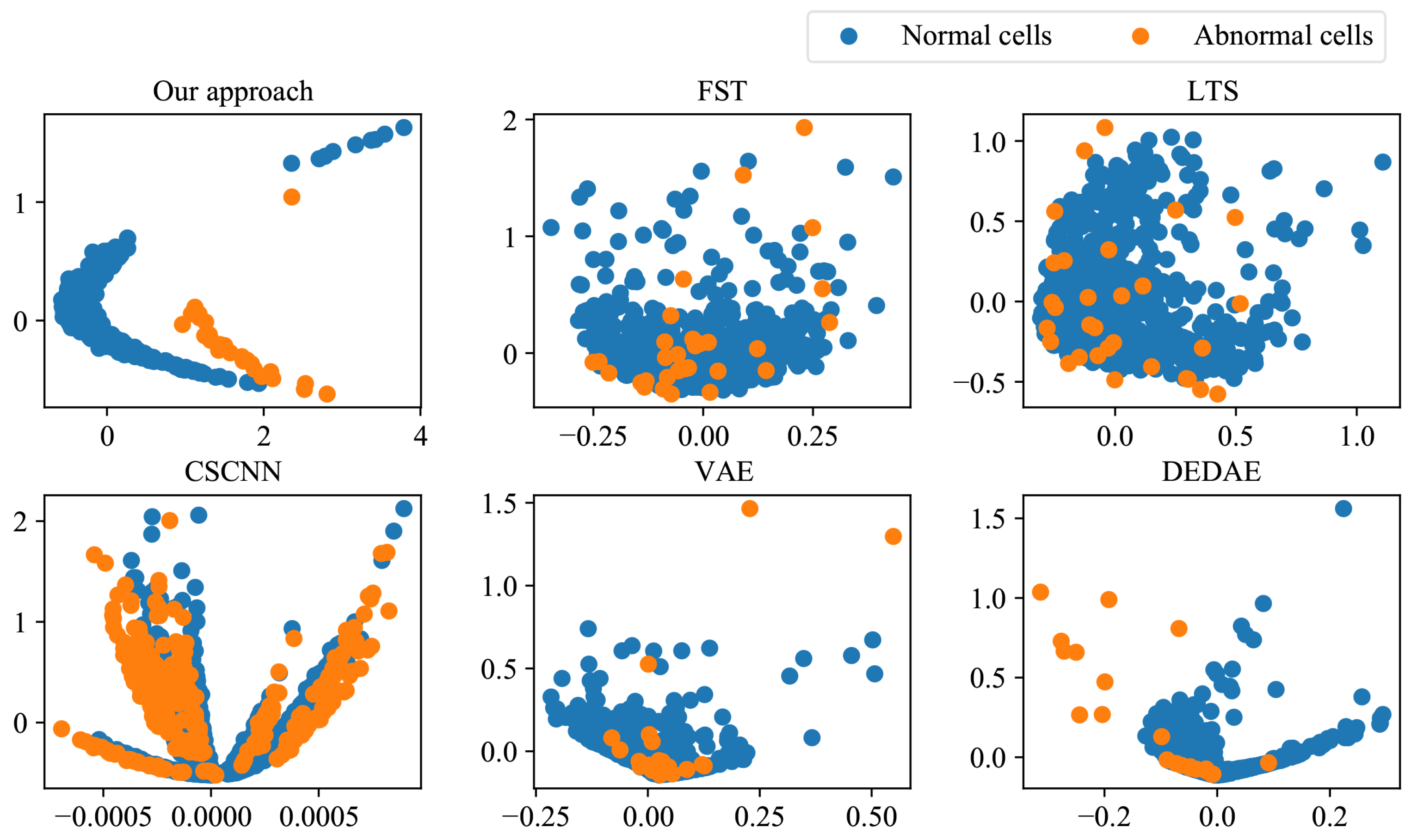
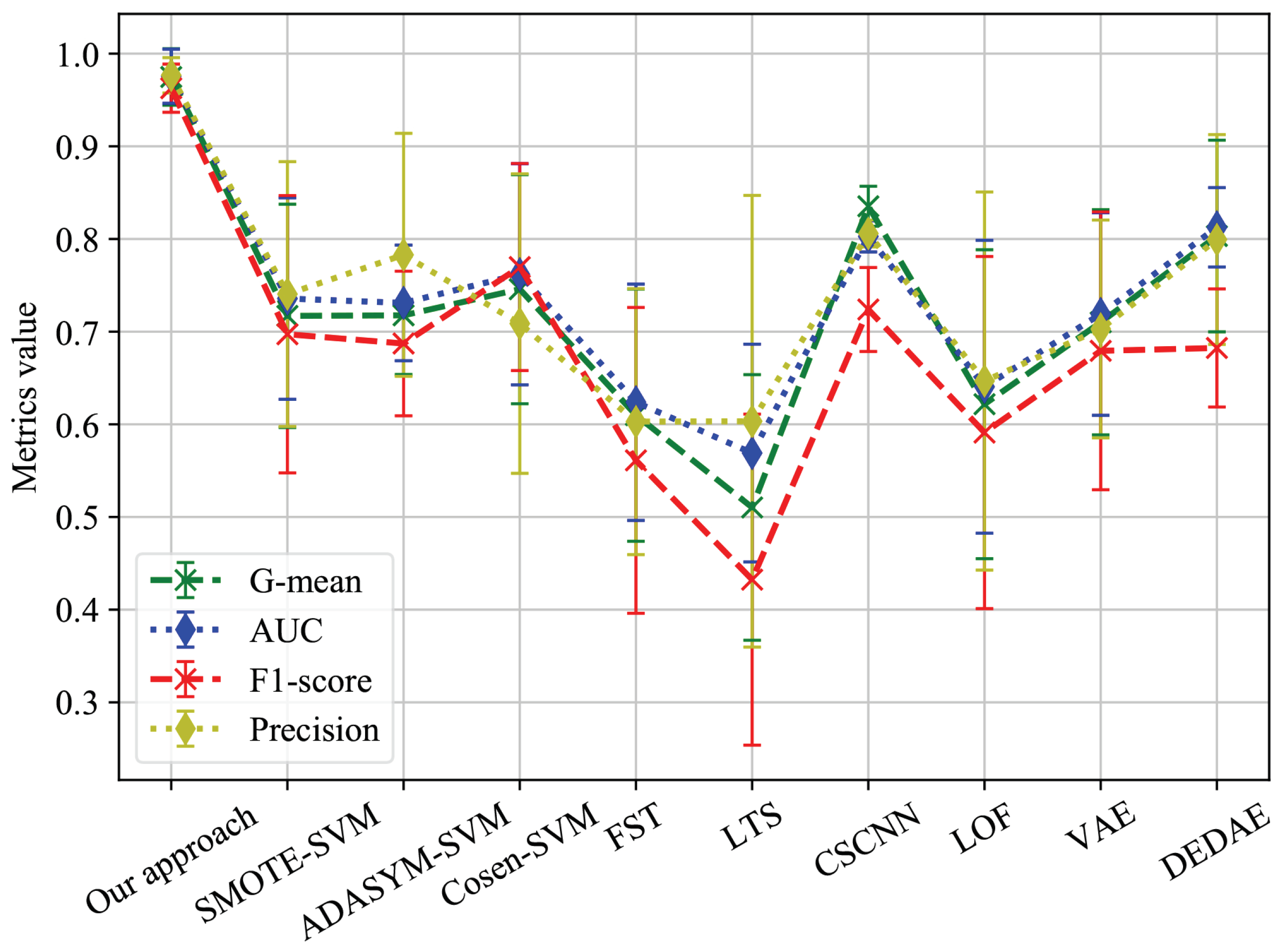
5.3. Comparison and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Meng, Z. Design and implementation of a coal-dust removal device for heavy-haul railway tunnels. Transp. Saf. Environ. 2020, 2, 283–291. [Google Scholar] [CrossRef]
- Qu, J.; Liu, F.; Ma, Y.; Fan, J. Temporal-spatial Collaborative Prediction for LTE-R Communication Quality Based on Deep Learning. IEEE Access 2020, 8, 94817–94832. [Google Scholar] [CrossRef]
- Qu, J.; Liu, F.; Ma, Y. A dual encoder DAE neural network for imbalanced binary classification based on NSGA-3 and GAN. Pattern Anal. Appl. 2022, 25, 17–34. [Google Scholar] [CrossRef]
- Chernogorov, F.; Ristaniemi, T.; Brigatti, K.; Chernov, S. N-gram analysis for sleeping cell detection in LTE networks. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Chernov, S.; Cochez, M.; Ristaniemi, T. Anomaly detection algorithms for the sleeping cell detection in LTE networks. In Proceedings of the 2015 IEEE 81st Vehicular Technology Conference (VTC Spring), Glasgow, UK, 11–14 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–5. [Google Scholar]
- Miao, D.; Qin, X.; Wang, W. Anomalous cell detection with kernel density-based local outlier factor. China Commun. 2015, 12, 64–75. [Google Scholar] [CrossRef]
- Safaei, M.; Ismail, A.S.; Chizari, H.; Driss, M.; Boulila, W.; Asadi, S.; Safaei, M. Standalone noise and anomaly detection in wireless sensor networks: A novel time-series and adaptive Bayesian-network-based approach. Softw. Pract. Exp. 2020, 50, 428–446. [Google Scholar] [CrossRef]
- Premkumar, M.; Sundararajan, T. DLDM: Deep learning-based defense mechanism for denial of service attacks in wireless sensor networks. Microprocess. Microsyst. 2020, 79, 103278. [Google Scholar] [CrossRef]
- Regin, R.; Rajest, S.; Singh, B. Fault detection in wireless sensor network based on deep learning algorithms. EAI Endorsed Trans. Scalable Inf. Syst. 2021, 8, e8. [Google Scholar] [CrossRef]
- Kuadey, N.A.E.; Maale, G.T.; Kwantwi, T.; Sun, G.; Liu, G. DeepSecure: Detection of distributed denial of service attacks on 5G network slicing—Deep learning approach. IEEE Wirel. Commun. Lett. 2021, 11, 488–492. [Google Scholar] [CrossRef]
- Aljebreen, M.; Alrayes, F.S.; Maray, M.; Aljameel, S.S.; Salama, A.S.; Motwakel, A. Modified Equilibrium Optimization Algorithm with Deep Learning-Based DDoS Attack Classification in 5G Networks. IEEE Access 2023, 11, 108561–108570. [Google Scholar] [CrossRef]
- Dahiya, D. DDoS attacks detection in 5G networks: Hybrid model with statistical and higher-order statistical features. Cybern. Syst. 2023, 54, 888–913. [Google Scholar] [CrossRef]
- Aghbashlo, M.; Peng, W.; Tabatabaei, M.; Kalogirou, S.A.; Soltanian, S.; Hosseinzadeh-Bandbafha, H.; Mahian, O.; Lam, S.S. Machine learning technology in biodiesel research: A review. Prog. Energy Combust. Sci. 2021, 85, 100904. [Google Scholar] [CrossRef]
- Huan, W.; Lin, H.; Lie, H.; Zhou, Y.; Wang, Y. Anomaly Detection Method Based On Clustering Undersampling And Ensemble Learning. Space Sci. Technol. 2020, 2022, 980–984. [Google Scholar]
- Jing, X.Y.; Zhang, X.; Zhu, X.; Wu, F.; You, X.; Gao, Y.; Shan, S.; Yang, J.Y. Multiset feature learning for highly imbalanced data classification. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 139–156. [Google Scholar] [CrossRef] [PubMed]
- Phua, C.; Alahakoon, D.; Lee, V. Minority report in fraud detection: Classification of skewed data. ACM SIGKDD Explor. Newsl. 2004, 6, 50–59. [Google Scholar] [CrossRef]
- Laurikkala, J. Instance-based data reduction for improved identification of difficult small classes. Intell. Data Anal. 2002, 6, 311–322. [Google Scholar] [CrossRef]
- Farshidvard, A.; Hooshmand, F.; MirHassani, S. A novel two-phase clustering-based under-sampling method for imbalanced classification problems. Expert Syst. Appl. 2023, 213, 119003. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the International Conference on Intelligent Computing, Hefei China, 23–26 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1322–1328. [Google Scholar]
- Islam, A.; Belhaouari, S.B.; Rehman, A.U.; Bensmail, H. KNNOR: An oversampling technique for imbalanced datasets. Appl. Soft Comput. 2022, 115, 108288. [Google Scholar] [CrossRef]
- Khreich, W.; Khosravifar, B.; Hamou-Lhadj, A.; Talhi, C. An anomaly detection system based on variable N-gram features and one-class SVM. Inf. Softw. Technol. 2017, 91, 186–197. [Google Scholar] [CrossRef]
- Wang, K.; An, J.; Yu, Z.; Yin, X.; Ma, C. Kernel local outlier factor-based fuzzy support vector machine for imbalanced classification. Concurr. Comput. Pract. Exp. 2021, 33, e6235. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, Y.; Lv, C.; Wang, T. Anomaly credit data detection based on enhanced Isolation Forest. Int. J. Adv. Manuf. Technol. 2022, 122, 185–192. [Google Scholar] [CrossRef]
- Zhang, C.; Tan, K.C.; Li, H.; Hong, G.S. A cost-sensitive deep belief network for imbalanced classification. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 109–122. [Google Scholar] [CrossRef] [PubMed]
- Geng, Y.; Luo, X. Cost-sensitive convolutional neural networks for imbalanced time series classification. Intell. Data Anal. 2019, 23, 357–370. [Google Scholar] [CrossRef]
- An, J.; Cho, S. Variational autoencoder based anomaly detection using reconstruction probability. Spec. Lect. IE 2015, 2, 1–18. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In Proceedings of the International Conference on Information Processing in Medical Imaging, Boone, NC, USA, 25–30 June 2017; Springer: Cham, Switzerland, 2017; pp. 146–157. [Google Scholar]
- Cheng, Z.; Wang, S.; Zhang, P.; Wang, S.; Liu, X.; Zhu, E. Improved autoencoder for unsupervised anomaly detection. Int. J. Intell. Syst. 2021, 36, 7103–7125. [Google Scholar] [CrossRef]
- Wang, Z.; Peng, C.; Zhang, Y.; Wang, N.; Luo, L. Fully convolutional siamese networks based change detection for optical aerial images with focal contrastive loss. Neurocomputing 2021, 457, 155–167. [Google Scholar] [CrossRef]
- Jiao, Y.; Yang, K.; Song, D.; Tao, D. Timeautoad: Autonomous anomaly detection with self-supervised contrastive loss for multivariate time series. IEEE Trans. Netw. Sci. Eng. 2022, 9, 1604–1619. [Google Scholar] [CrossRef]
- Oproiu, M.; Boldan, V.; Marghescu, I. Effects of using carrier aggregation with three component carriers in a mobile operator’s network. In Proceedings of the 2016 International Conference on Communications (COMM), Bucharest, Romania, 9–10 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 169–172. [Google Scholar]
- Ye, L.; Keogh, E. Time series shapelets: A new primitive for data mining. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 947–956. [Google Scholar]
- Chen, T.; Luo, C.; Li, L. Intriguing properties of contrastive losses. Adv. Neural Inf. Process. Syst. 2021, 34, 11834–11845. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Pant, M.; Zaheer, H.; Garcia-Hernandez, L.; Abraham, A. Differential Evolution: A review of more than two decades of research. Eng. Appl. Artif. Intell. 2020, 90, 103479. [Google Scholar]
- Gao, S.; Wang, K.; Tao, S.; Jin, T.; Dai, H.; Cheng, J. A state-of-the-art differential evolution algorithm for parameter estimation of solar photovoltaic models. Energy Convers. Manag. 2021, 230, 113784. [Google Scholar] [CrossRef]
- Singh, D.; Kaur, M.; Jabarulla, M.Y.; Kumar, V.; Lee, H.N. Evolving fusion-based visibility restoration model for hazy remote sensing images using dynamic differential evolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Ren, L.; Zhao, D.; Zhao, X.; Chen, W.; Li, L.; Wu, T.; Liang, G.; Cai, Z.; Xu, S. Multi-level thresholding segmentation for pathological images: Optimal performance design of a new modified differential evolution. Comput. Biol. Med. 2022, 148, 105910. [Google Scholar] [CrossRef] [PubMed]
- Ramadhan, N.G. Comparative Analysis of ADASYN-SVM and SMOTE-SVM Methods on the Detection of Type 2 Diabetes Mellitus. Sci. J. Inform. 2021, 8, 276–282. [Google Scholar] [CrossRef]
- Iranmehr, A.; Masnadi-Shirazi, H.; Vasconcelos, N. Cost-sensitive support vector machines. Neurocomputing 2019, 343, 50–64. [Google Scholar] [CrossRef]
- Rakthanmanon, T.; Keogh, E. Fast shapelets: A scalable algorithm for discovering time series shapelets. In Proceedings of the 2013 SIAM International Conference on Data Mining, Austin, TX, USA, 2–4 May 2013; SIAM: Philadelphia, PA, USA, 2013; pp. 668–676. [Google Scholar]
- Grabocka, J.; Schilling, N.; Wistuba, M.; Schmidt-Thieme, L. Learning time-series shapelets. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 392–401. [Google Scholar]
- Hemalatha, P.; Amalanathan, G.M. FG-SMOTE: Fuzzy-based Gaussian synthetic minority oversampling with deep belief networks classifier for skewed class distribution. Int. J. Intell. Comput. Cybern. 2021, 14, 270–287. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Terminal Type | Communication Service | QCI Value |
|---|---|---|
| Terminal of train operation control | Train control data transmission service | 1 |
| Emergency call | 1 | |
| The cab-integrated radio communication equipment | Transmission dispatching order | 2 |
| Wireless train number calibration | 2 | |
| In-vehicle speech | 2 | |
| Handheld mobile station | Emergency call | 1 |
| Speech call | 3 | |
| Train video surveillance system | Video Surveillance | 4 |
| Layer Type | Input Shape | Output Shape |
|---|---|---|
| Input layer | (None, 500, 1) | (None, 500, 1) |
| 1D convolutional layer | (None, 500, 1) | (None, 101, 400) |
| Squared distance layer | (None, 101, 400) | (None, 101, 7) |
| Min pooling layer | (None, 101, 7) | (None, 7) |
| Data Properties | Property Values |
|---|---|
| Sequence length | 500 |
| Dataset size | 2554 |
| Normal data size | 2470 |
| Abnormal data size | 84 |
| Training set size | 1788 |
| Test set size | 766 |
| Imbalance ratio | 29.4 |
| Name | G-Mean | AUC | F1 Score | Precision |
|---|---|---|---|---|
| SMOTE-SVM | 0.7194 ± 0.1048 | 0.7238 ± 0.1079 | 0.7041 ± 0.1194 | 0.6862 ± 0.1028 |
| ADASYM-SVM | 0.7063 ± 0.1035 | 0.7095 ± 0.1066 | 0.6919 ± 0.1195 | 0.6595 ± 0.0857 |
| Cosen-SVM | 0.6835 ± 0.1360 | 0.6929 ± 0.1339 | 0.6658 ± 0.1637 | 0.6483 ± 0.1385 |
| FST | 0.5231 ± 0.0058 | 0.5333 ± 0.005 | 0.4788 ± 0.0009 | 0.501 ± 0.0026 |
| LTS | 0.5294 ± 0.0001 | 0.5292 ± 0.0001 | 0.5262 ± 0.0087 | 0.5195 ± 0.0007 |
| CSCNN | 0.8448 ± 0.0332 | 0.8564 ± 0.0277 | 0.7439 ± 0.0263 | 0.7741 ± 0.0309 |
| LOF | 0.6217 ± 0.1667 | 0.6405 ± 0.158 | 0.5911 ± 0.19 | 0.6467 ± 0.204 |
| VAE | 0.7101 ± 0.1215 | 0.719 ± 0.1093 | 0.6793 ± 0.1499 | 0.7029 ± 0.1175 |
| DEDAE | 0.8032 ± 0.1034 | 0.8126 ± 0.0428 | 0.6824 ± 0.0637 | 0.7994 ± 0.1132 |
| Our approach | 0.9863 ± 0.0092 | 0.9864 ± 0.0091 | 0.9799 ± 0.0004 | 0.9872 ± 0.0181 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, J.; Qi, C.; Meng, H. An Imbalanced Sequence Feature Extraction Approach for the Detection of LTE-R Cells with Degraded Communication Performance. Future Internet 2024, 16, 30. https://doi.org/10.3390/fi16010030
Qu J, Qi C, Meng H. An Imbalanced Sequence Feature Extraction Approach for the Detection of LTE-R Cells with Degraded Communication Performance. Future Internet. 2024; 16(1):30. https://doi.org/10.3390/fi16010030
Chicago/Turabian StyleQu, Jiantao, Chunyu Qi, and He Meng. 2024. "An Imbalanced Sequence Feature Extraction Approach for the Detection of LTE-R Cells with Degraded Communication Performance" Future Internet 16, no. 1: 30. https://doi.org/10.3390/fi16010030
APA StyleQu, J., Qi, C., & Meng, H. (2024). An Imbalanced Sequence Feature Extraction Approach for the Detection of LTE-R Cells with Degraded Communication Performance. Future Internet, 16(1), 30. https://doi.org/10.3390/fi16010030