
FREDY: Federated Resilience Enhanced with Differential Privacy
 , , , , ,
, , , , ,
Abstract
:1. Introduction
- We introduce FREDY, a knowledge transfer federated learning framework which offers PATE’s privacy-preserving technique in a federated learning setting. From a federated learning standpoint, multiple teachers are trained in a federated manner and then the FL server queries the teachers and aggregates their outputs in order to label public data and thus train a student model on these data. We evaluate FREDY on two benchmark datasets, namely CIFAR10 and MNIST.
- We implement a membership inference attack model and perform inference attacks to several student models that are trained with different noise addition values, showing its robustness and the privacy preservation ability of our proposed method.
2. Related Work and Backround
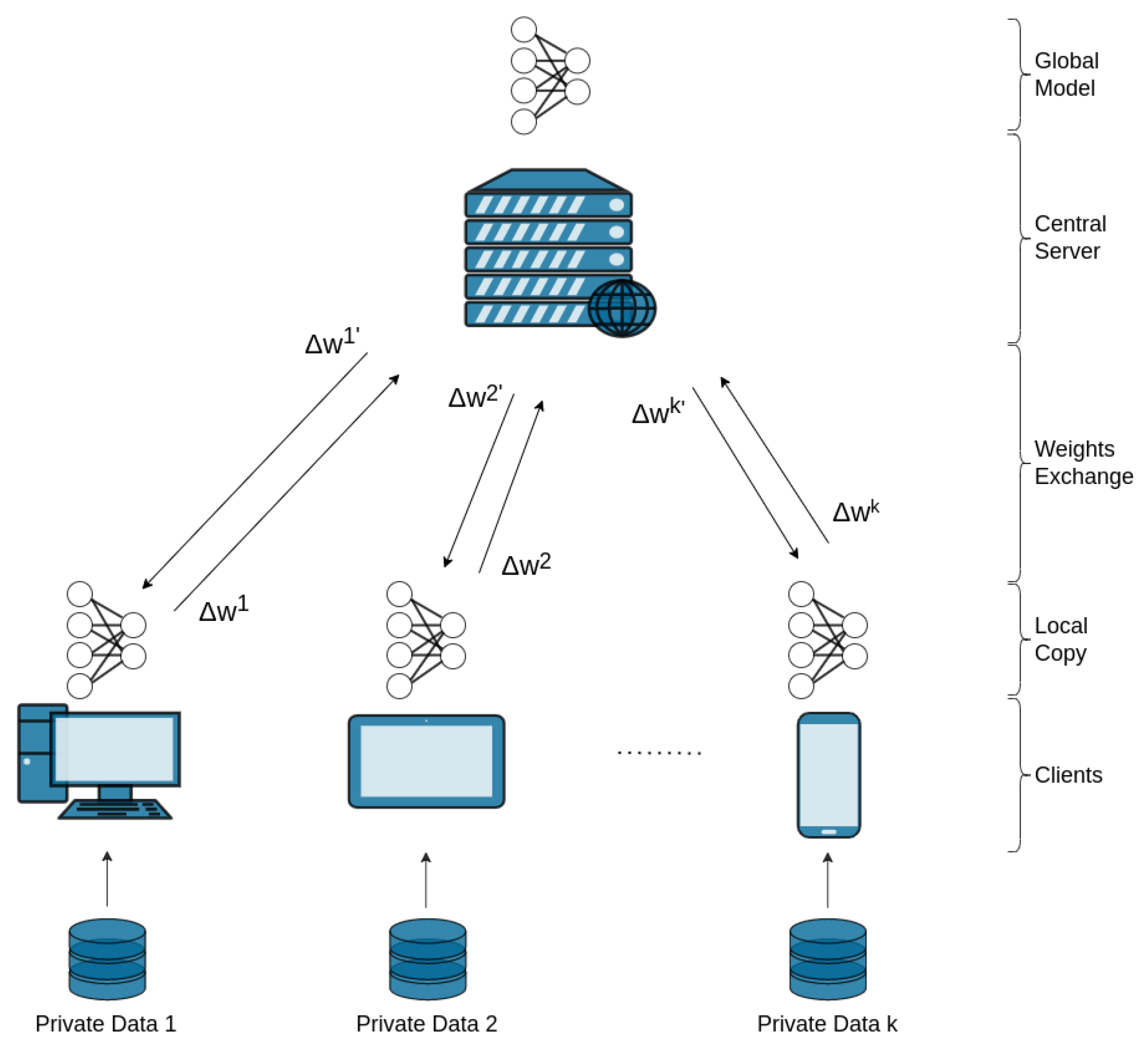
2.1. Federated Learning
2.2. Membership Inference Attack Models
- Black-box Attack: An adversarial has black-box access to a target model meaning that it has information about the training data distribution and the black-box queries on the target model. For example, the attacker queries the target model and obtains only the raw prediction probability of the input data [42,43,44,45,46,47].
2.3. Knowledge Transfer Frameworks
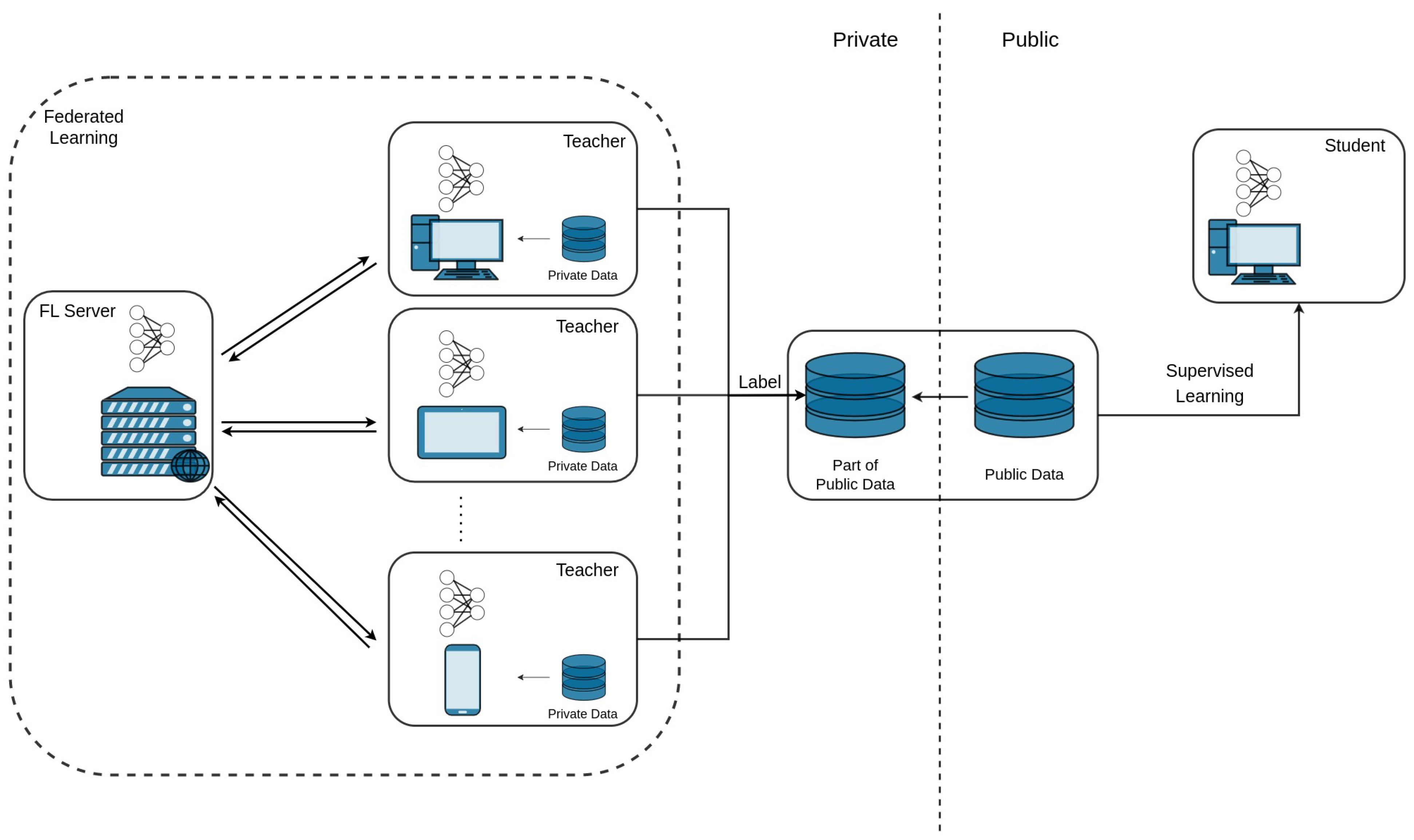
3. Proposed Framework
3.1. Design Overview
| Algorithm 1 Training Procedure of FREDY |
|
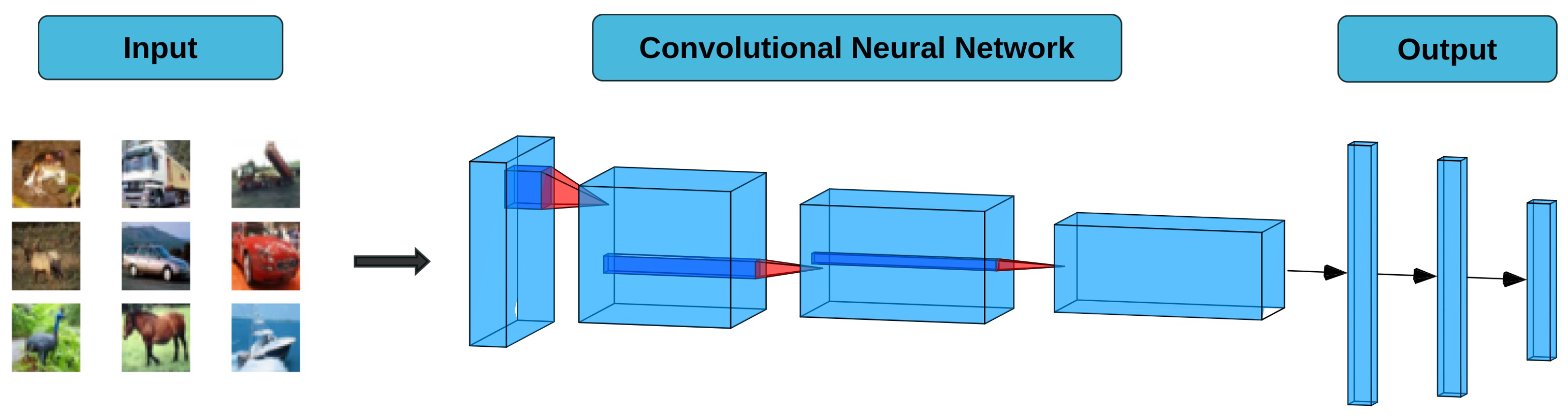
3.2. Teachers Model Training
3.3. Student Model Training
4. Experiments
4.1. Datasets
4.2. Models
4.3. Metrics
- Accuracy. Number of samples correctly identified as either truly positive or truly negative out of the total number of samples.
- Precision. Number of samples correctly identified as positive out of the total samples identified as positive.
- Recall. Number of samples correctly identified as positive out of the total actual positives.
- F1-Score. The harmonic average of the precision and recall measures the effectiveness of identification when just as much importance is given to recall as to precision.
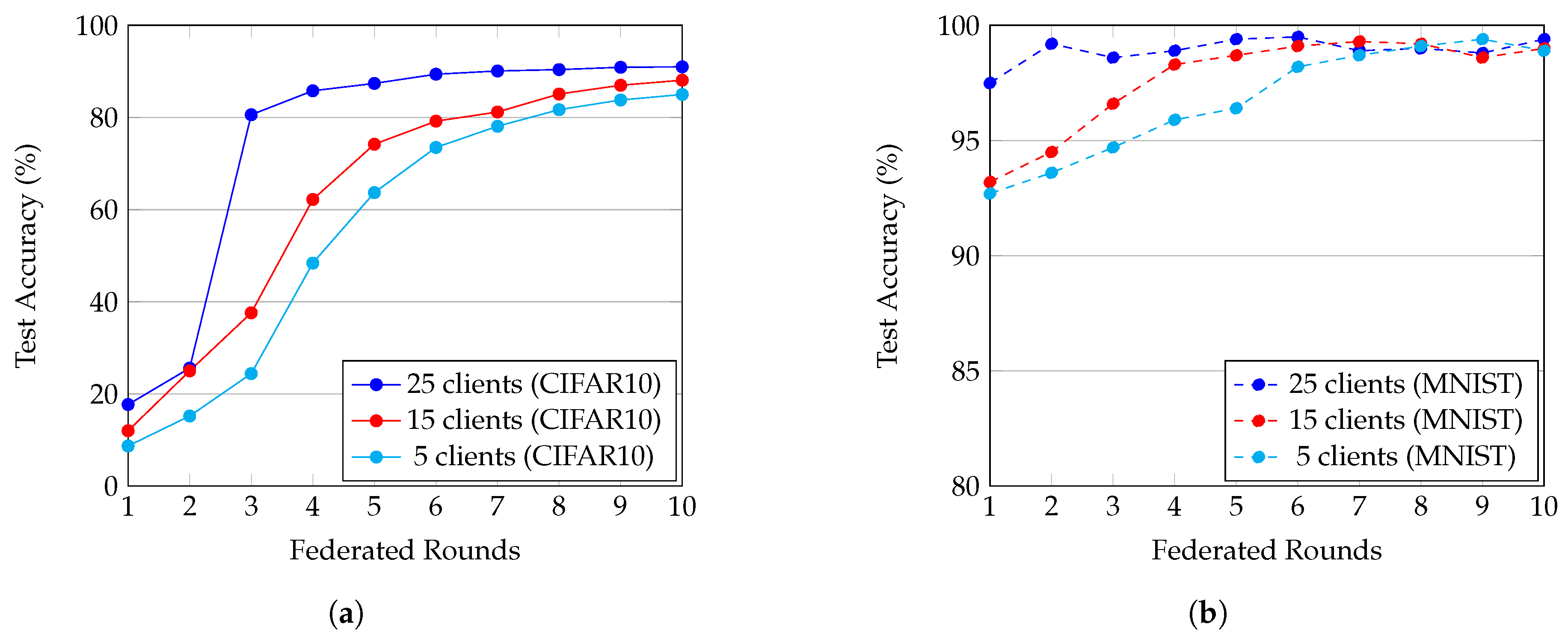
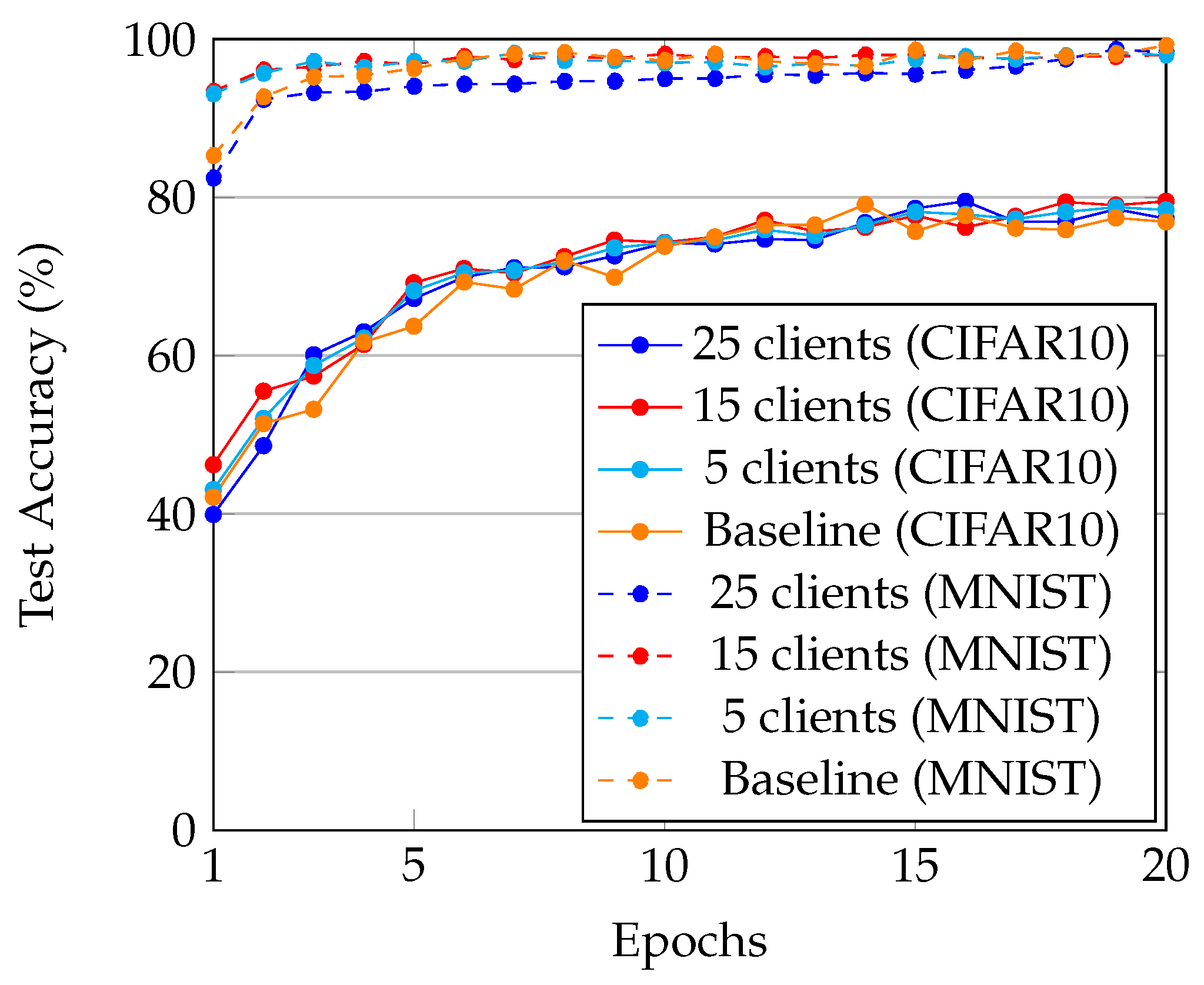
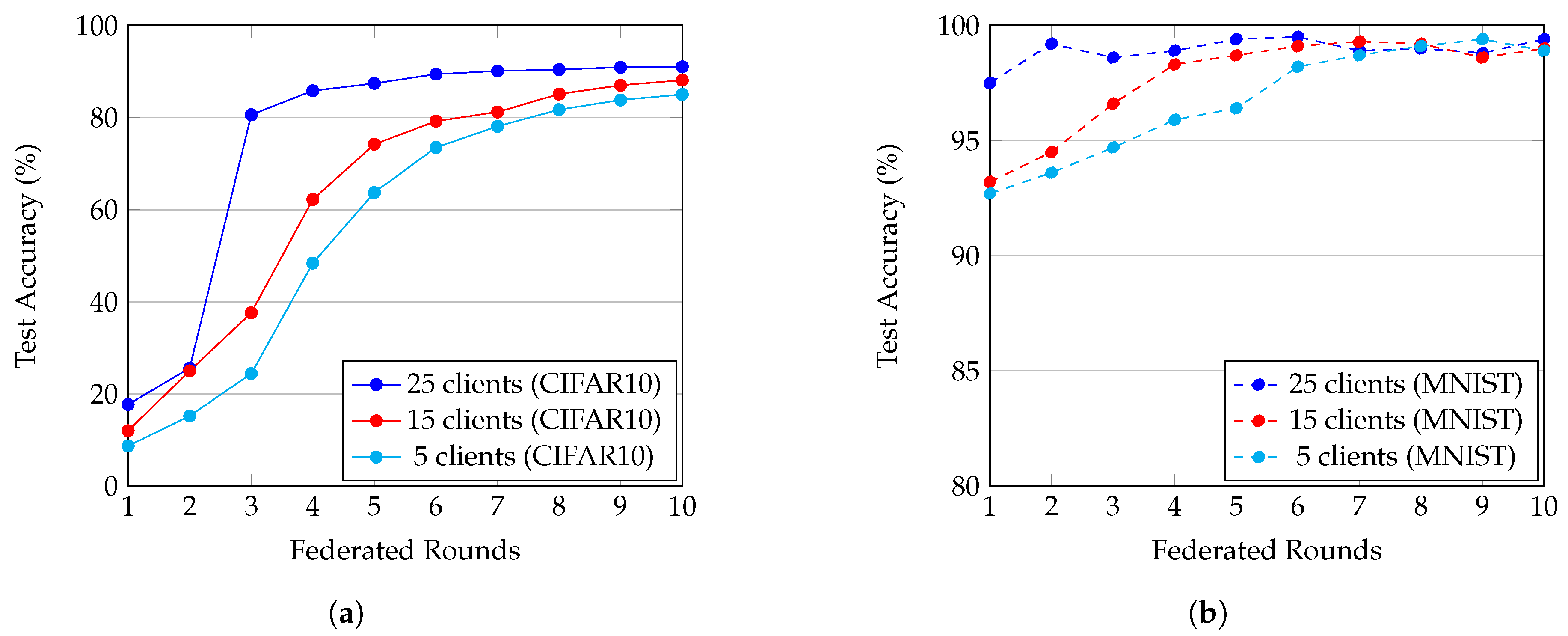
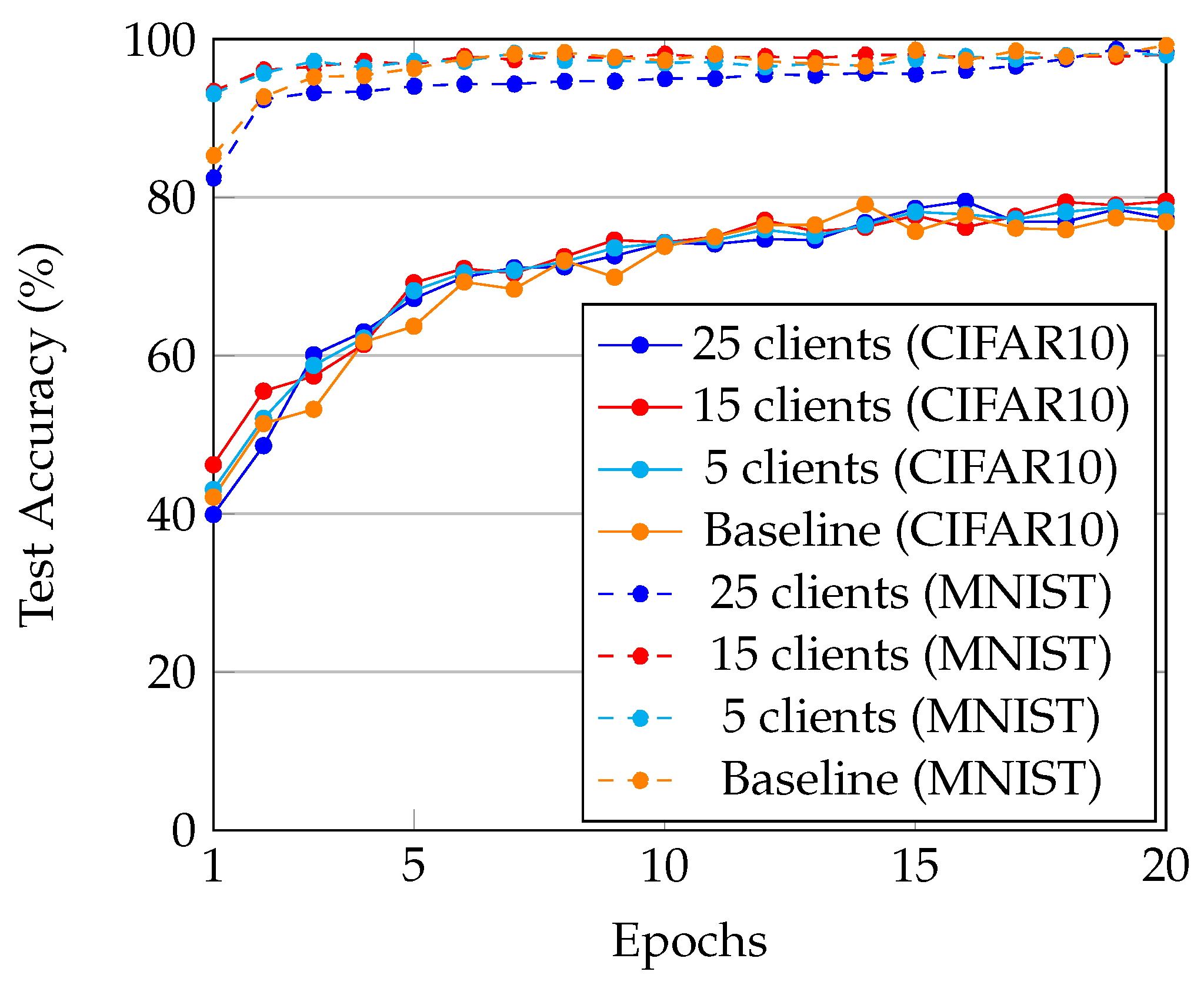
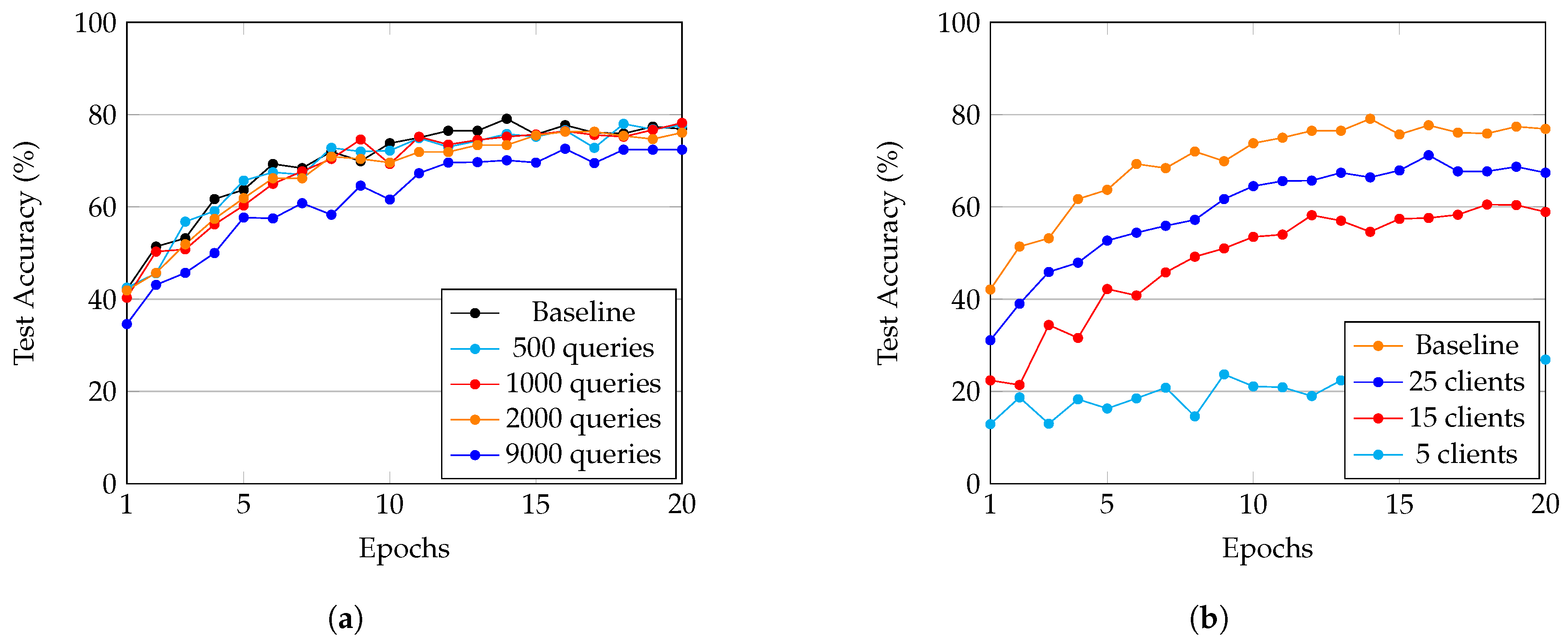
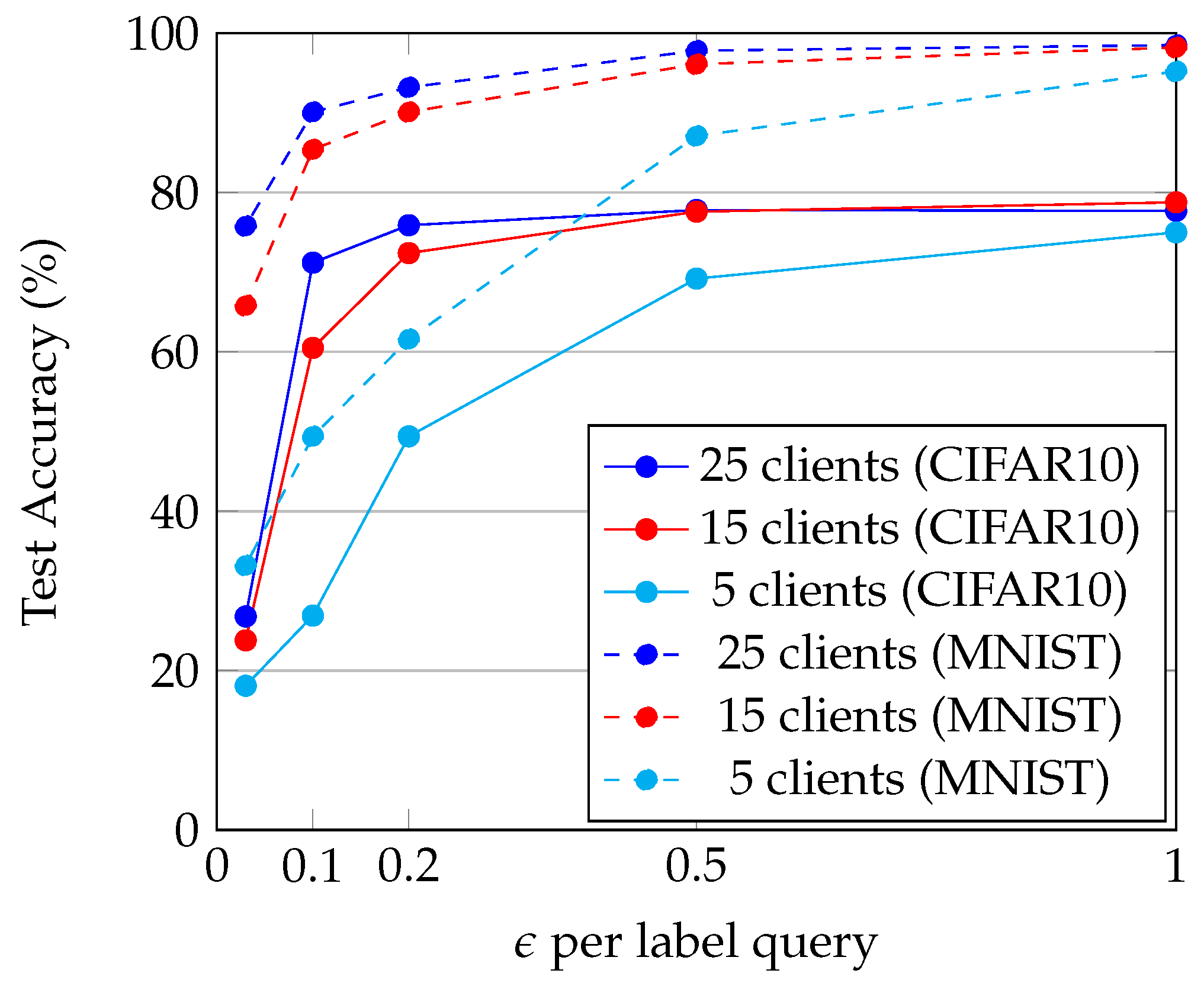
4.4. Performance Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| FL | Federated Learning |
| IoT | Internet of Things |
| ML | Machine Learning |
| PATE | Private Aggregation of Teacher Ensembles |
| SGD | Stochastic Gradient Descent |
References
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016. [Google Scholar]
- Dwork, C.; Roth, A. The Algorithmic Foundations of Differential Privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Rivest, R.L.; Dertouzos, M.L. On data banks and privacy homomorphisms. Found. Secur. Comput. 1978, 4, 169–180. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Seif, M.; Tandon, R.; Li, M. Wireless Federated Learning with Local Differential Privacy. In Proceedings of the IEEE International Symposium on Information Theory, ISIT 2020, Los Angeles, CA, USA, 21–26 June 2020; pp. 2604–2609. [Google Scholar] [CrossRef]
- Lee, J.; Clifton, C. How Much Is Enough? Choosing ϵ for Differential Privacy. In Proceedings of the Information Security, 14th International Conference, ISC 2011, Xi’an, China, 26–29 October 2011; pp. 325–340. [Google Scholar] [CrossRef]
- Anastasakis, Z.; Psychogyios, K.; Velivassaki, T.; Bourou, S.; Voulkidis, A.; Skias, D.; Gonos, A.; Zahariadis, T. Enhancing Cyber Security in IoT Systems using FL-based IDS with Differential Privacy. In Proceedings of the 2022 Global Information Infrastructure and Networking Symposium (GIIS), Argostoli, Greece, 26–28 September 2022; pp. 30–34. [Google Scholar] [CrossRef]
- Phong, L.T.; Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-Preserving Deep Learning via Additively Homomorphic Encryption. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1333–1345. [Google Scholar] [CrossRef]
- Gentry, C. A Fully Homomorphic Encryption Scheme. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2009. [Google Scholar]
- Zhao, C.; Zhao, S.; Zhao, M.; Chen, Z.; Gao, C.Z.; Li, H.; Tan, Y. Secure Multi-Party Computation: Theory, practice and applications. Inf. Sci. 2019, 476, 357–372. [Google Scholar] [CrossRef]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar] [CrossRef]
- Wang, K.; Fu, Y.; Li, K.; Khisti, A.; Zemel, R.S.; Makhzani, A. Variational Model Inversion Attacks. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual. 6–14 December 2021; pp. 9706–9719. [Google Scholar]
- Gong, N.Z.; Liu, B. Attribute Inference Attacks in Online Social Networks. ACM Trans. Priv. Secur. 2018, 21, 1–30. [Google Scholar] [CrossRef]
- Juuti, M.; Szyller, S.; Marchal, S.; Asokan, N. PRADA: Protecting Against DNN Model Stealing Attacks. In Proceedings of the IEEE European Symposium on Security and Privacy, EuroS&P 2019, Stockholm, Sweden, 17–19 June 2019; pp. 512–527. [Google Scholar] [CrossRef]
- Shen, Y.; He, X.; Han, Y.; Zhang, Y. Model Stealing Attacks Against Inductive Graph Neural Networks. In Proceedings of the 43rd IEEE Symposium on Security and Privacy, SP 2022, San Francisco, CA, USA, 22–26 May 2022; pp. 1175–1192. [Google Scholar] [CrossRef]
- Steinhardt, J.; Koh, P.W.; Liang, P. Certified Defenses for Data Poisoning Attacks. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 3517–3529. [Google Scholar]
- Zhang, X.; Zhu, X.; Lessard, L. Online Data Poisoning Attacks. In Proceedings of the 2nd Annual Conference on Learning for Dynamics and Control, L4DC 2020, Online Event, Berkeley, CA, USA, 11–12 June 2020; pp. 201–210. [Google Scholar]
- Quiring, E.; Arp, D.; Rieck, K. Forgotten Siblings: Unifying Attacks on Machine Learning and Digital Watermarking. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy, EuroS&P 2018, London, UK, 24–26 April 2018; pp. 488–502. [Google Scholar] [CrossRef]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H.; Zhang, R.; Zhou, Y. A hybrid approach to privacy-preserving federated learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security, London, UK, 15 November 2019; pp. 1–11. [Google Scholar]
- Kaissis, G.A.; Makowski, M.R.; Rückert, D.; Braren, R.F. Secure, privacy-preserving and federated machine learning in medical imaging. Nat. Mach. Intell. 2020, 2, 305–311. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Ma, X.; Chen, C.; Sun, L.; Zhao, J.; Yang, Q.; Philip, S.Y. Privacy and robustness in federated learning: Attacks and defenses. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–21. [Google Scholar] [CrossRef]
- Salem, A.; Zhang, Y.; Humbert, M.; Berrang, P.; Fritz, M.; Backes, M. ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models. In Proceedings of the 26th Annual Network and Distributed System Security Symposium, NDSS 2019, San Diego, CA, USA, 24–27 February 2019. [Google Scholar]
- Long, Y.; Bindschaedler, V.; Wang, L.; Bu, D.; Wang, X.; Tang, H.; Gunter, C.A.; Chen, K. Understanding Membership Inferences on Well-Generalized Learning Models. arXiv 2018, arXiv:1802.04889. [Google Scholar]
- Long, Y.; Wang, L.; Bu, D.; Bindschaedler, V.; Wang, X.; Tang, H.; Gunter, C.A.; Chen, K. A Pragmatic Approach to Membership Inferences on Machine Learning Models. In Proceedings of the IEEE European Symposium on Security and Privacy, EuroS&P 2020, Genoa, Italy, 7–11 September 2020; pp. 521–534. [Google Scholar] [CrossRef]
- Song, C.; Raghunathan, A. Information Leakage in Embedding Models. arXiv 2020, arXiv:2004.00053. [Google Scholar]
- Hayes, J.; Melis, L.; Danezis, G.; Cristofaro, E.D. LOGAN: Membership Inference Attacks Against Generative Models. Proc. Priv. Enhancing Technol. 2019, 2019, 133–152. [Google Scholar] [CrossRef]
- Gupta, U.; Stripelis, D.; Lam, P.K.; Thompson, P.M.; Ambite, J.L.; Steeg, G.V. Membership Inference Attacks on Deep Regression Models for Neuroimaging. arXiv 2021, arXiv:2105.02866. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership Inference Attacks Against Machine Learning Models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, SP 2017, San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar] [CrossRef]
- Papernot, N.; Abadi, M.; Erlingsson, Ú.; Goodfellow, I.J.; Talwar, K. Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 10 June 2022).
- Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečnỳ, J.; Mazzocchi, S.; McMahan, B.; et al. Towards federated learning at scale: System design. Proc. Mach. Learn. Syst. 2019, 1, 374–388. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 739–753. [Google Scholar]
- Wang, T.; Kerschbaum, F. Robust and undetectable white-box watermarks for deep neural networks. arXiv 2019, arXiv:1910.14268. [Google Scholar]
- Sablayrolles, A.; Douze, M.; Schmid, C.; Ollivier, Y.; Jégou, H. White-box vs black-box: Bayes optimal strategies for membership inference. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5558–5567. [Google Scholar]
- Leino, K.; Fredrikson, M. Stolen memories: Leveraging model memorization for calibrated white-box membership inference. In Proceedings of the 29th USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020. [Google Scholar]
- Wu, D.; Qi, S.; Qi, Y.; Li, Q.; Cai, B.; Guo, Q.; Cheng, J. Understanding and defending against White-box membership inference attack in deep learning. Knowl.-Based Syst. 2023, 259, 110014. [Google Scholar] [CrossRef]
- Jia, J.; Salem, A.; Backes, M.; Zhang, Y.; Gong, N.Z. Memguard: Defending against black-box membership inference attacks via adversarial examples. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 259–274. [Google Scholar]
- Mehnaz, S.; Li, N.; Bertino, E. Black-box model inversion attribute inference attacks on classification models. arXiv 2020, arXiv:2012.03404. [Google Scholar]
- Truex, S.; Liu, L.; Gursoy, M.E.; Yu, L.; Wei, W. Demystifying membership inference attacks in machine learning as a service. IEEE Trans. Serv. Comput. 2019, 14, 2073–2089. [Google Scholar] [CrossRef]
- Liew, S.P.; Takahashi, T. FaceLeaks: Inference attacks against transfer learning models via black-box queries. arXiv 2020, arXiv:2010.14023. [Google Scholar]
- Bai, Y.; Chen, D.; Chen, T.; Fan, M. Ganmia: Gan-based black-box membership inference attack. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Zhang, Y.; Zhou, H.; Wang, P.; Yang, G. Black-box based limited query membership inference attack. IEEE Access 2022, 10, 55459–55468. [Google Scholar] [CrossRef]
- Pan, Y.; Ni, J.; Su, Z. FL-PATE: Differentially Private Federated Learning with Knowledge Transfer. In Proceedings of the IEEE Global Communications Conference, GLOBECOM 2021, Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Kiefer, J.; Wolfowitz, J. Stochastic Estimation of the Maximum of a Regression Function. Ann. Math. Stat. 1952, 23, 462–466. [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Beutel, D.J.; Topal, T.; Mathur, A.; Qiu, X.; Fernandez-Marques, J.; Gao, Y.; Sani, L.; Kwing, H.L.; Parcollet, T.; Gusmão, P.P.d.; et al. Flower: A Friendly Federated Learning Research Framework. arXiv 2020, arXiv:2007.14390. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameter | Value |
|---|---|
| Federated rounds (n) | 10 |
| Teacher epochs () | 10 |
| Student epochs () | 20 |
| Learning rate () | |
| Weight decay (w) | |
| Batch size (B) | 32 |
| Optimizer |
| Model | Attack Performance | ||||
|---|---|---|---|---|---|
| Accuracy | Recall | Precision | F1-Score | ||
| Baseline | - | 0.71 | 0.71 | 0.78 | 0.70 |
| FREDY (Ours) | 1.0 | 0.68 | 0.68 | 0.69 | 0.67 |
| 0.5 | 0.57 | 0.57 | 0.57 | 0.52 | |
| 0.2 | 0.50 | 0.49 | 0.49 | 0.46 | |
| 0.1 | 0.49 | 0.49 | 0.49 | 0.45 | |
| Model | Queries | Student Convergence Time (s) | |
|---|---|---|---|
| Baseline | - | - | 32.9 |
| FREDY (ours) | 0.2 | 2000 | 33.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anastasakis, Z.; Velivassaki, T.-H.; Voulkidis, A.; Bourou, S.; Psychogyios, K.; Skias, D.; Zahariadis, T. FREDY: Federated Resilience Enhanced with Differential Privacy. Future Internet 2023, 15, 296. https://doi.org/10.3390/fi15090296
Anastasakis Z, Velivassaki T-H, Voulkidis A, Bourou S, Psychogyios K, Skias D, Zahariadis T. FREDY: Federated Resilience Enhanced with Differential Privacy. Future Internet. 2023; 15(9):296. https://doi.org/10.3390/fi15090296
Chicago/Turabian StyleAnastasakis, Zacharias, Terpsichori-Helen Velivassaki, Artemis Voulkidis, Stavroula Bourou, Konstantinos Psychogyios, Dimitrios Skias, and Theodore Zahariadis. 2023. "FREDY: Federated Resilience Enhanced with Differential Privacy" Future Internet 15, no. 9: 296. https://doi.org/10.3390/fi15090296
APA StyleAnastasakis, Z., Velivassaki, T.-H., Voulkidis, A., Bourou, S., Psychogyios, K., Skias, D., & Zahariadis, T. (2023). FREDY: Federated Resilience Enhanced with Differential Privacy. Future Internet, 15(9), 296. https://doi.org/10.3390/fi15090296