1. Introduction
Information-centric networking (ICN) has received significant interest and attention in recent years as a promising paradigm for network communication. ICN introduces a shift in focus from the traditional host-centric model to a content-centric approach. Named-based routing and in-network caching are two key features of ICN that have contributed to its growing popularity and adoption in various domains.
Researchers have explored the potential applications of ICN in diverse areas such as the Internet of Things (IoTs), where the efficient dissemination and retrieval of data is crucial for IoT devices to interact and exchange information [
1]. In the context of the Internet of Vehicles (IoVs), ICN can enable efficient content delivery, facilitate real-time communication, and support intelligent transportation systems [
2]. Furthermore, in the realm of 5G networks, ICN has been investigated for its potential to enhance content delivery, reduce latency, and improve overall network performance [
3]. ICN has also been explored in software-defined networking (SDN) environments, offering flexibility, scalability, and efficient resource management [
4].
One of the fundamental challenges in ICN is the effective caching of content across the network. Caching reduces latency, minimizes network congestion, and improves content delivery efficiency. However, it is a complex task due to the limited cache space available at each router and the potentially vast number of items distributed throughout the network. Researchers have been actively investigating caching strategies and policies to optimize cache performance.
In recent years, deep reinforcement learning (DRL) has allowed significant advancements in decision making, particularly in caching decisions. Numerous studies (see [
5,
6]) have demonstrated the exceptional performance of DRL in solving caching problems. Researchers have adopted deep Q-learning network architectures, such as multi-layer perceptron (MLP) and convolutional neural networks (CNNs), to replace traditional Q-tables. However, MLP and CNN architectures struggle to effectively utilize the neighbourhood information in arbitrary graph data, such as network topologies and knowledge graphs. While CNNs have been extensively optimized for the processing of Euclidean space data such as images and grids, they face challenges when dealing with graph-structured data. This limitation hampers their ability to capture the relational information necessary for efficient caching decision making.
Graph neural networks (GNNs) offer distinct advantages over traditional MLP and CNN architectures, as they are purpose-built to handle graph-structured data and excel in non-Euclidean spaces. This unique capability has made GNNs a popular choice in a wide range of domains that involve data represented as arbitrary graphs [
7]. Notably, GNNs have demonstrated remarkable success in network routing optimization [
8], where the underlying graph structure captures the intricate relationships between network nodes and facilitates efficient path planning. Additionally, in the domain of traffic prediction [
9], GNNs leverage the graph structures of road intersections and their connectivity to forecast traffic flow patterns accurately.
Moreover, recent research has highlighted the remarkable generalization capabilities of GNNs [
10]. GNNs can generalize effectively over different network topologies, allowing them to adapt to various environments and scenarios. This has been substantiated by studies such as [
11,
12,
13], which have showcased the impressive generalization performance of GNNs across diverse network architectures.
The inherent suitability of GNNs for graph-structured data and their exceptional generalization capabilities make them an ideal choice in tackling complex problems in network-related domains. In the context of our research, leveraging the power of GNNs allows us to capture the intricate relationships and dependencies present in network caching scenarios, ultimately enhancing the network caching performance.
This paper aims to enhance the caching performance in the SDN-ICN scenario by leveraging DRL and GNN. Specifically, we introduce a GNN–double deep Q-network [
14] (GNN-DDQN) caching agent within the SDN controller. The SDN controller provides a real-time and comprehensive view of the traffic situation in the SDN-ICN environment, while the network nodes are equipped with caching capabilities. The GNN-DDQN agent determines optimal caching decisions for individual nodes by considering the traffic conditions at each time step. The controller then communicates these decisions to the respective nodes, enabling them to update their cache stores accordingly.
The contributions of this paper are as follows.
We develop a statistical model to generate users’ preferences. Initially, we employ matrix factorization based on the Neural Collaborative Filtering Model [
15] to learn content and user embeddings using the real-world dataset MovieLens100K [
16]. Next, we employ a Gaussian mixture model to cluster users and content based on their embeddings. Subsequently, we employ a statistical model to generate the request behaviour of each user group.
We introduce a GNN-DDQN agent within the SDN-ICN scenario. Incorporating a GNN in DRL is advantageous as GNNs excel in modelling graph-structured data, enabling nodes to engage in cooperative caching and enhancing the overall caching performance. Additionally, with only a single forward pass through the neural network, the GNN-DDQN agent can make caching decisions for all nodes in the network at each time step.
We extensively evaluate the proposed caching scheme through simulations across various scenarios. These scenarios include different numbers of items, cache sizes, and network topologies, such as GEANT [
17], ROCKETFUEL [
18], TISCALI [
19], and GARR [
19]. Notably, our proposed caching scheme outperforms the state-of-the-art DRL-based caching strategy. Furthermore, it exhibits a significant performance advantage over several benchmark caching schemes (Leave Copy Down (LCD), Probabilistic Caching (PROB_CACHE), Cache Less for More (CL4M), and Leave Copy Everywhere (LCE) [
20,
21,
22,
23]). The evaluations demonstrate the robustness of our proposed strategy to simulation parameters and variations in network topology.
It is worth noting that GNN-DDQN has several advantages.
Computational Efficiency: GNN-DDQN is computationally efficient, requiring only one DRL agent to make caching decisions for all network nodes in a single forward pass.
Multi-Action Capability: GNN-DDQN enables the agent to take multiple actions for each network node at each time step, demonstrating strong performance even with the incorporation of multi-actions.
Applicability: GNN-DDQN can be applied in various real-world scenarios.
- −
Content Delivery Networks (CDNs): Our proposed caching scheme can be employed within CDNs to improve caching decisions at edge nodes.
- −
Mobile Edge Computing (MEC): Our caching scheme can benefit MEC environments by strategically caching frequently accessed content at edge servers.
- −
Internet Service Providers (ISPs): By deploying our scheme, ISPs can enhance their caching infrastructure, effectively reducing the bandwidth requirements for popular content and providing faster access to frequently accessed data for their subscribers.
- −
Video Streaming Platforms: By caching popular videos at appropriate network nodes, our algorithm can reduce buffering times and enhance the overall streaming experience for users.
However, there are also limitations to consider.
Scalability: GNN-DDQN may face challenges in terms of scalability when dealing with a large number of network nodes. With only one SDN controller monitoring the entire network traffic, it may experience high latency, impacting the overall performance of the caching algorithm.
Overfitting and Underfitting: GNN-DDQN, as with other deep learning algorithms, may suffer from overfitting or underfitting, depending on various factors.
The rest of this paper is organized as follows.
Section 2 overviews related work.
Section 3 and
Section 4 present our system model and proposed methodology.
Section 5 shows the experimental results.
Section 6 concludes the paper.
2. Related Work
Classical caching placement algorithms commonly used in the literature include LCE, LCD, PROB_CACHE, and CL4M [
20,
21,
22,
23]. LCE involves copying content at any cache between the serving and receiving nodes, while LCD caches content in the immediate neighbourhood of the serving node in the receiver’s direction. PROB_CACHE probabilistically caches content on a path, considering various factors. CL4M aims to place content in nodes with high graph-based centrality. In addition to placement algorithms, traditional caching replacement algorithms such as Least Recently Used (LRU), Least Frequently Used (LFU), and First-In-First-Out (FIFO) are commonly employed [
24,
25]. LRU discards the least recently accessed content, LFU replaces the least frequently used content first, and FIFO evicts the first item inserted in the cache. However, these traditional algorithms are often considered inefficient, yielding poorer performance than deep learning-based caching algorithms.
DRL-based caching algorithms have demonstrated remarkable achievements in recent years [
26,
27]. In [
5], the authors developed a deep Q-network (DQN)-based caching algorithm designed explicitly for mobile edge networks. The application of DRL in the Internet of Vehicles (IoV) field has also gained substantial attention. As the demand for computation and entertainment in autonomous driving and vehicular scenarios increases, researchers have been actively advancing caching strategies to enhance the user experience.
In [
28], the authors propose CoCaRL, a caching strategy leveraging DRL and a multi-level federated learning framework. They utilize a DDQN [
14] to optimize the cache hit ratio of local roadside units (RSUs), neighbour RSUs, and cloud data centers in vehicular networks. Their approach also incorporates federated learning to enable decentralized model training. Another study [
29] introduces a quality of experience (QoE)-driven RSU caching model based on DRL. Their caching algorithm addresses the growing demand for time-sensitive short videos in a 5G-based IoV scenario. The reward in their DRL model is defined as the ratio of the number of videos interesting to each user to the total number of videos stored in the RSU. Furthermore, in [
6], the authors design a DQN-based strategy to optimize joint computing and edge caching in a three-layer IoV-ICN network architecture, encompassing vehicles, edges, and cloud layers. In [
30], the authors proposed a social-aware vehicular edge computing architecture to efficiently deliver popular content to end-users in vehicular social networks. They introduce a social-aware graph pruning search algorithm to assign content consumer vehicles to the shortest path with the most relevant content providers. Additionally, they utilize a DRL method to optimize content distribution across the network. In [
31], the authors develop an IoV-specific edge caching model that enables collaborative content caching among mobile vehicles and considers varying content popularity and channel conditions. Additionally, the framework empowers each vehicle agent to make caching decisions based on environmental observations autonomously. In [
32], the authors proposed a spatial–temporal correlation approach to predict content popularity in the IoV. They introduce a DRL-based multi-agent caching strategy, where each RSU is an independent agent, to optimize caching decisions. In [
33], the authors investigate joint computation offloading, data caching, transmission path selection, subchannel assignment, and caching management in the IoV-based environment. Dynamic online algorithms such as the Simulated Annealing Genetic Algorithm (SAGA) and DQN are adopted to minimize the content access latency.
In addition to DRL, GNNs have emerged as another effective approach in addressing caching problems. One notable application of GNNs in caching is presented in [
34]. The authors introduce a GNN-based caching algorithm to optimize the cache hit ratio in a named data networking (NDN) context. Their approach involves two key steps. First, they utilize a 1D-CNN to predict the popularity of content in each node. Subsequently, a GNN is employed to propagate the content popularity predictions among neighbouring nodes. Finally, each node makes caching decisions based on node-level caching probability ranking. Leveraging the message-passing capabilities of GNNs, their caching approach outperforms the CNN-based caching algorithm, leading to improved caching performance in the NDN scenario. Moreover, in [
35], the authors propose GNN-GM to enhance the caching performance in NDN. In this work, a GNN is utilized to predict users’ ratings of unviewed movies within a bipartite graph representation. Leveraging the accurate rating predictions achieved by GNN, the proposed approach achieves a higher cache hit ratio compared to state-of-the-art caching schemes. The successful application of GNNs in these studies highlights their efficacy in addressing caching challenges. By leveraging the GNN’s ability to capture complex dependencies and propagate information across nodes, these approaches demonstrate improved caching performance and provide valuable insights for the optimization of cache hit ratios in various network scenarios.
The integration of DRL and GNN has additionally emerged as a growing trend, delivering numerous benefits. The authors in [
36] employ dynamic graph convolutional networks (GCNs) and RL for long-term traffic flow prediction. They represent traffic flow as a graph, where each station is a node and directed weighted edges are used to indicate traffic flow occurrence. A graph convolutional policy network (GCPN) model generates dynamic graphs at each time step, and the RL agent receives a reward if the generated graph closely resembles the target graph. The paper further utilizes a GCN and long short-term memory (LSTM) to extract spatial and temporal features from the generated dynamic graph sequences, enabling traffic flow prediction in future time steps. Another study [
37] introduces the Inductive Heterogeneous Graph Multi-Agent Actor–Critic (IHG-MA) algorithm for traffic signal control. The traffic network is modelled as a heterogeneous graph, with each traffic signal controller considered an agent. An inductive GNN algorithm is applied to learn the embeddings of the agents and their neighbours. The learned representations are then fed into an actor–critic network to optimize traffic control. Additionally, [
38] proposes an innovative approach using a GCN and DQN for the multi-agent cooperative control of connected autonomous vehicles (CAVs). Each CAV is treated as an agent, and a GCN is utilized to extract embeddings for each agent. These representations are then fed into a Q-network to determine the actions of each agent, facilitating effective cooperative control among the CAVs. Furthermore, in an SDN-based scenario, [
13] presents a centralized agent that leverages DRL and GNNs to optimize routing strategies. They utilize a GNN to model the network and DRL to calculate the Q-value of an action. By embedding routing paths into node representations and feeding them into the Q-network, they evaluate various routing strategies and select the optimal one when a traffic demand is issued. In [
39], the authors propose a method that combines prediction, caching, and offloading techniques to optimize computation in 6G-enabled IoV. The prediction method is based on a spatial–temporal graph neural network (STGNN), the caching decision method is realized using the simplex algorithm, and the offloading method is based on Twin Delayed Deterministic Policy Gradient (TD3).
These studies demonstrate the efficacy of combining DRL and GNNs in tackling various issues, including traffic prediction, traffic signal control, the cooperative control of autonomous vehicles, routing optimization in SDN scenarios, and caching in IoV environments. By leveraging the respective strengths of DRL and GNNs, these approaches enable intelligent decision making and enhance performance in intricate systems. We are confident that the amalgamation of DRL and GNNs can similarly bring advantages to caching in the SDN-ICN context.
3. System Model
In this section, we present the system architecture of our proposed caching scheme and provide a comprehensive overview of the key components. We also define the concept of content popularity. Furthermore, we develop a user preference model based on real-world data from the MovieLens100K dataset [
16]. Important notations used throughout the paper are listed in
Table 1.
3.1. System Architecture
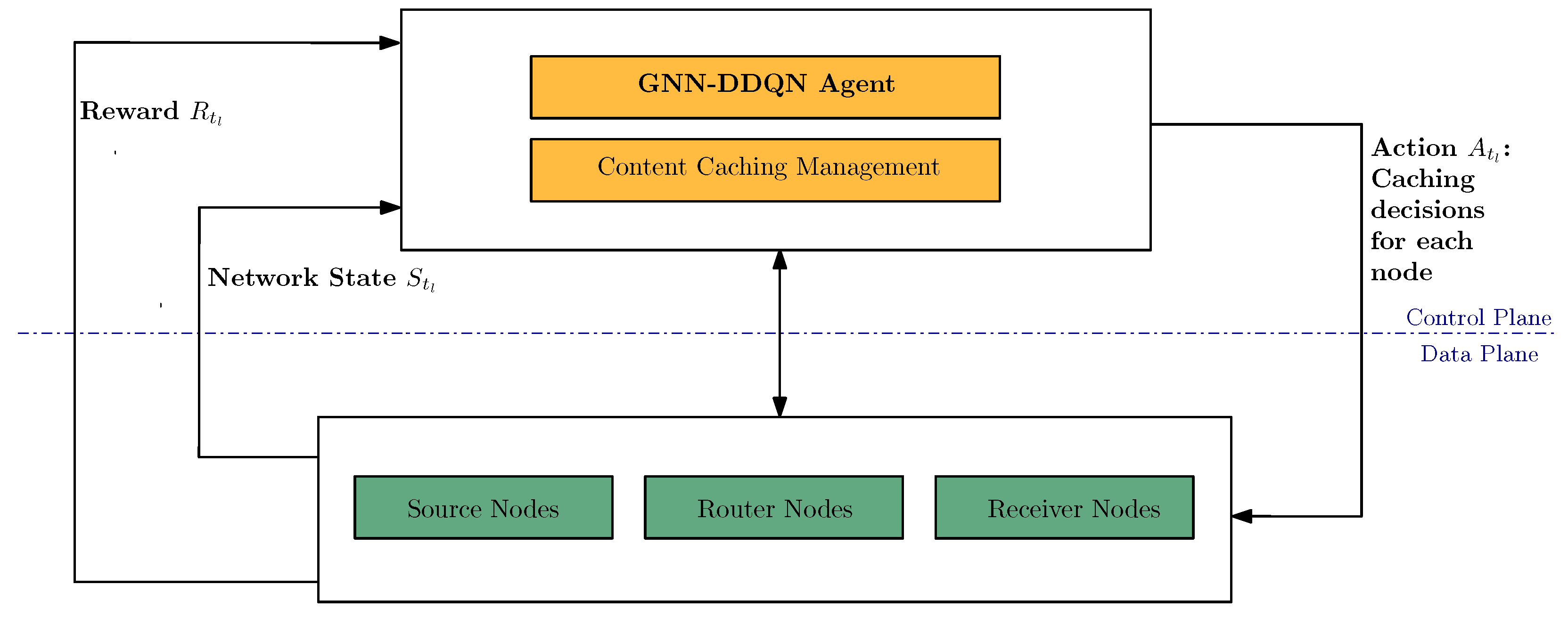
We propose an intelligent caching strategy in an SDN-based ICN (SDN-ICN) architecture, as depicted in
Figure 1. The SDN-ICN architecture separates the control plane from the data plane, and the OpenFlow protocol facilitates the data transfer between them. We introduce the GNN-DDQN [
14,
40] agent responsible for making caching decisions in the control plane. The data plane comprises network nodes that perform caching actions.
Figure 1 illustrates the control plane, consisting of two modules: (i) the GNN-DDQN agent module, which plays a crucial role in caching decisions for ICN nodes in the data plane; and (ii) the content caching management module, which handles the content caching of each ICN node. We assume that the data plane’s network topology consists of
N ICN nodes, denoted as
.
The data plane encompasses ICN nodes, each fulfilling specific roles: (i) source nodes responsible for content publication without caching capabilities, (ii) receiver nodes accountable for sending requests to source nodes, also without caching capabilities, and (iii) router nodes responsible for forwarding requests and data packets across the network. Instead of assuming that all router nodes have the caching capability, we consider only some of them to have this. These router nodes equipped with caching capabilities have a cache capacity of z, defined as the number of content items.
The network contains C distinct content items, represented by the set . We assume that an experimental time round can be divided into T slots of equal duration, denoted by . To indicate whether a node caches content at time step , we employ a binary variable , where , , and . Specifically, if and only if node caches content at time step , implying that content is available at node during the time interval between and .
In the SDN-ICN architecture, the controller can see the network’s traffic. Therefore, at each time step , the GNN-DDQN agent observes the network state , which encompasses information about the network’s status during the time interval between and . Subsequently, the GNN-DDQN agent performs content caching predictions at the node level, denoted as , and communicates the recommended content to be cached to each router node with caching capabilities. When a router node with caching capabilities receives a request packet for content within this period, it can fulfill the request directly if the requested content is cached or forward the request to the source node. At the subsequent time step , a set of rewards is sent to the GNN-DDQN agent. Specifically, represents the rewards of all nodes at time step . Furthermore, represents the set of rewards for each content item received by node at time step .
3.2. Content Popularity and User Preference
In a realistic computer network, users exhibit preferences for specific types of content, leading to varying request frequencies. We develop a statistical model that incorporates content popularity and user preferences to simulate this network traffic. In our network, receiver nodes correspond to users, and we denote the users as . Our objective is to determine the probability distribution , which represents the likelihood of a request for the content by the user.
Content popularity refers to the probability distribution of requesting the
content within the network, represented by
. Research studies [
41] have shown that the content popularity in a network can be modelled using a Zipfian distribution,
where
is a skewness factor with a value of 0.8.
User preference refers to the relationship between users and content items. In our study, we employ collaborative filtering [
15,
42] to capture user preferences. Collaborative filtering is a popular recommendation system technique that predicts a user’s preference by identifying users with similar tastes based on their historical behaviours. Collaborative filtering has two primary approaches: the neighbourhood-based method and the latent factor method. The neighbourhood-based method identifies similar users or items based on their historical preferences and recommends items that similar users or items have liked. On the other hand, the latent factor method discovers latent factors that represent underlying characteristics of users and items and uses these factors to predict user preferences. In our case, we utilize matrix factorization, a latent factor method, to extract the latent factors of users and content items. By decomposing the user–item interaction matrix into lower-dimensional matrices, we can represent users and items in terms of these latent factors. Subsequently, we calculate user preferences by analyzing the relationships between users and content items derived from matrix factorization.
To capture the user–content relation, we construct a matrix M with dimensions , where C represents the number of content items and U represents the number of users. Each element in the matrix corresponds to the relationship between content and user . This relationship can be based on various factors, such as ratings given by the user, the time spent on the content, or any other relevant metric. We utilize trainable embedding layers to process the user–content matrix further to generate embedding vectors for each content item and user. Specifically, for each content item , we apply an embedding layer that maps it to a continuous vector representation , where e denotes the dimensionality of the embedding. Similarly, for each user , we employ an embedding layer to obtain the embedding vector .
Our research uses the well-known MovieLens100K dataset [
16] as a real-world dataset for our experiments. This dataset consists of user ratings for movies and is widely used in evaluating recommendation systems. We focus on learning embedding vectors for 943 users and 1682 content items within this dataset.
To obtain user and content embeddings, we employ a matrix factorization technique combined with a neural network architecture inspired by the works [
15,
42]. Our model consists of two trainable embedding layers, one for users and another for content items. These layers enable the learning of dense and low-dimensional representations that capture users’ and content’s underlying characteristics and preferences. The next step in our model involves computing the element-wise product of the content and user embedding vectors. This element-wise product represents the interaction between a specific content item and a user. Subsequently, the resulting products are fed into a linear layer with an activation function. For a given content embedding
and a user embedding
, the output is computed as follows:
in this equation,
denotes the sigmoid activation function,
represents a trainable matrix, and ⊙ signifies the element-wise product. To train the matrix factorization model, we minimize the binary cross-entropy (BCE) loss between the ground truth values
and the predicted values
. It is worth mentioning that we label
as 1 if the
user has provided a rating for the
content item, and 0 otherwise. The key training parameters for the Neural Collaborative Filtering (NCF) model are summarized in
Table 2.
In order to fit the number of content items and users in our network, all users and content items in the dataset are divided into groups. If the content embeddings are close to each other, we cluster them into groups, and users are grouped in the same way. We utilize a Gaussian mixture model (GMM) to cluster the embedding vectors, and then compute a representative embedding for each group by taking the element-wise mean.
Since the inner product
captures the correlation between content
and a user
, we apply the softmax function on the inner products to obtain the probability
for given content
. This probability represents the preference of user
for content
. Inspired by the works [
43,
44], we calculate the joint probability
of content
being requested by user
as follows:
where
represents the content popularity, while
reflects the preference of user
for content
. Combining these probabilities establishes a link between the user preference and content popularity.
It is important to note that our approach differs from the methods proposed in [
43,
44], as we obtain user and content embeddings from a real-world dataset. Furthermore, we consider the inner products of the learned user embeddings and content embeddings to measure their associations, enabling us to capture the relationships between users and content meaningfully.
4. Proposed Methodology
This section presents our GNN-DDQN agent, which incorporates a GNN as the Q-network within the DDQN framework [
14]. DDQN improves upon the original DQN algorithm [
40] by mitigating Q-value overestimation and enhancing the overall performance.
The GNN-DDQN agent predicts Q-values based on the observed state and the chosen action at each time step . The predicted Q-value is denoted as . The objective of the agent is to learn an optimized policy that maximizes the expected Q-value . This section describes the state space, action space, and reward function used in our DDQN. Additionally, we explain the GNN architecture employed to map network states to action rewards for each node. Finally, we provide an overview of the GNN-DDQN agent, including its key components and functionality.
4.1. State Space
The network state captures the state of each network node at time step . Each node’s state feature vector at time step is represented by , where C is the total number of items in the network.
The state of a network node at time step consists of three components:
1st component: The number of requests for each content item that have traversed the node during the previous time interval ( to ). This count is stored only for the requested content in receiver nodes, cached content in router nodes, and published content in source nodes.
2nd component: The cache storage of the node, represented by a binary variable for each content item . A value of 1 indicates that the node caches the content during the previous time interval, while a value of 0 is used otherwise.
3rd component: The content publication of the node is also represented by a binary variable for each content item . A value of 1 indicates that the node has published the content during the previous time interval, while a value of 0 is used otherwise.
4.2. Action Space
At a time step
, each node
can choose
z out of
C content items to cache. We record its cache scheme in a binary tuple,
where 1 means to ‘cache’ and 0 means to ‘not cache’, and the sum of all entries cannot exceed the assumed router’s cache size
z. We also use
to denote the cache scheme of all nodes such that,
and refer to it as the agent’s action at the time step
. When the agent takes action
at time step
, the node
caches content according to
, which can be used to satisfy the request in the future.
4.3. Reward Function
Our objective is to maximize the cache hit ratio. Thus, we use cache hits as the agent’s reward, denoted as
, which includes the cache hits of each node. For a node
at time step
, its cache hits for each content item are
. Let us assume that a node
’s reward sum for all content at time step
is
; then, the objective function can be formulated as follows:
this objective aims to maximize the cache hit ratio for the stored content while ensuring that the number of content items stored in a node does not exceed
z if it is a router node with caching capability and zero otherwise. We apply this constraint because only router nodes with caching capability can cache content, while other nodes, such as source and receiver nodes, can only distribute or receive content.
4.4. GNN Architecture
Our methodology utilizes a GNN for node-level Q-value predictions. The model architecture, depicted in
Figure 2, operates on a network graph consisting of node embeddings and an adjacency matrix.
The GNN takes as input the graph structure data , where represents the set of nodes, denotes the set of edges, and represents the network state. With this input, the GNN model generates Q-value predictions for each action of every node, allowing us to estimate the outcome of each action through a single forward propagation of the GNN model.
For the GNN architecture, our approach utilizes four GraphSage layers [
45]. Each layer has different hidden embedding dimensions, specifically 1024, 512, 256, and
C. GraphSage is an inductive framework that leverages sampling and aggregation techniques to generate node embeddings. It allows for efficient embedding generation even for previously unseen data. By incorporating four GraphSage layers, we can aggregate information from up to four-hop neighbouring nodes at each step. This enables the GNN to capture the network structure and traffic patterns, resulting in more informative node embeddings for Q-value prediction.
The aggregation process in GraphSage is described by the equation
where
represents the one-hop neighbours of node
v, and
is the embedding of node
u at the previous
step. In each step, the GNN aggregates the embeddings of the one-hop neighbours of a node
v from the previous step to obtain
. The aggregation function
is typically permutation-invariant, meaning that it is not affected by the ordering of the aggregated embeddings. In our approach, we use a mean aggregator, which calculates the element-wise mean of the vectors
.
After the aggregation step, the GNN performs concatenation by combining the embeddings of each central node from the previous
step with the embeddings of its neighbouring nodes from the current
step. The concatenated embeddings are then fed into a fully connected layer with a nonlinear activation function:
where
represents a learned matrix specific to the
step,
denotes the rectified linear activation function (ReLU), and
corresponds to the embedding of the central node
v at the
step. The CONCAT operation refers to the concatenation of the embeddings
and
.
4.5. The GNN-DDQN Agent
The GNN-DDQN agent operates based on the procedure described in Algorithm 1. In the beginning, we initialize a replay buffer P, a Q-network (Q) implemented as a GNN with randomly generated parameters , and a target Q-network () with the same network architecture and parameters as Q. Each episode corresponds to a complete round of experimentation, and the time is divided into T slots. The GNN-DDQN agent takes actions at each time step, denoted as (starting from , as represents the initial point of the experimentation).
To balance exploration and exploitation, we utilize an
-greedy exploration strategy [
40]. This strategy involves randomly selecting actions with a probability of
and selecting the action with the highest expected Q-value with a probability of
. The purpose is to encourage initial exploration and gradually decrease exploration over time. We employ an exponential decay strategy for
, starting with an initial value of
and decaying to a minimum value of
with a decay rate of 0.01, denoted as
.
Since each router with caching capability has a cache size of
z, the GNN-DDQN agent selects
z actions for each node at each time step. It chooses the top
z actions with the highest Q-values for each node during greedy action selection. For random actions, it randomly selects
z actions for each node. It is crucial to emphasize that the agent precisely chooses
z actions for each node at every time step. However, it only executes these actions for router nodes with caching capabilities, excluding others.
| Algorithm 1 GNN-DDQN Agent Operation |
Input: number of episodes E, batch size B, target network update step K, replay buffer capacity R, epsilon start , epsilon end , epsilon decay , number of steps k, discount factor
- 1:
Initialize replay buffer P with capacity R - 2:
Initialize Q-network with random weights - 3:
Initialize target -network with weights - 4:
fordo - 5:
for do - 6:
Randomly pick - 7:
- 8:
- 9:
for do - 10:
if then - 11:
Randomly select z actions - 12:
else - 13:
Select z actions with the highest - 14:
end if - 15:
end for - 16:
Take action , get reward and next state - 17:
Store transition into P - 18:
Randomly sample B transitions from P - 19:
Use Equation ( 10) to compute - 20:
Perform a gradient descent step on with respect to the network parameters , where is computed in Equation ( 9) - 21:
Update every K steps - 22:
end for - 23:
end for
|
At time step , the GNN-DDQN agent interacts with the environment by taking action and receiving a reward and the subsequent state at time step . The rewards, denoted by , are node-level rewards, where each node has C rewards corresponding to different actions. The newly generated transition is then stored in the replay buffer P.
We train the Q-network by randomly sampling a batch of transitions
from the replay buffer
P. The Q-network is trained using gradient descent on a loss function
, which measures the discrepancy between the predicted Q-values and the target Q-values. For the sampled transitions
, the loss function is defined as follows:
where
is defined as follows:
and
is defined as follows:
where
represents the ground truth Q-values. If the episode terminates at transition
,
is equal to
. Otherwise, it is computed as the sum of
and the discounted expected reward of the next state. To estimate the expected future reward, the Q-network selects the top
z greedy actions based on state
, and the corresponding Q-values are computed using the target Q-network
. The discount factor
determines the importance of long-term rewards and is typically between 0 and 1. To ensure that each action taken at the next time step contributes equally, the sum of the expected long-term rewards is divided by
z. To focus the loss contribution on routers with caching capabilities, a mask is applied in Equation (
9). Nodes without caching capabilities are assigned a mask value of 0, while routers with caching capabilities have a mask value of 1.
To maintain the training stability, the parameters of the Q-network Q are periodically copied to the target Q-network every K steps. This helps to reduce the potential for the overestimation of the Q-values during training.
The key training parameters for the GNN-DDQN model are summarized in
Table 3.
5. Experimentation and Results
In this section, we present simulation results to demonstrate the effectiveness of the proposed caching strategy in various network scenarios. To conduct these experiments, we utilized Icarus [
46], a Python-based ICN caching simulator that comprehensively evaluates different caching strategies. Not bound to any specific architecture, such as content-centric networking (CCN) or named data networking (NDN), Icarus provides functionalities for more generalized ICN.
We employed the LRU strategy as the caching replacement policy for all our experiments. Moreover, the content popularity and user preference distributions mentioned in
Section 3.2 were considered.
Table 4 lists the key simulation parameters used. We followed the recommendations from a previous study [
47] and set the internal and external link delays to 2 milliseconds (ms) and 34 ms, respectively, for all network topologies.
The experiments involved a set of distinct content, ranging from 600 to 1000, uniformly distributed among all source nodes in the network. The router’s cache size varied from 1 to 4, denoting the number of content items that it could store. Each experiment consisted of a warm-up phase with 2000 requests, followed by 4000 requests that were measured to evaluate the performance of different caching schemes. User requests followed a Poisson distribution with a mean of 100 requests per second.
We divided each experiment into T segments, each representing 10 s. We conducted 600 experiments for each caching scenario and calculated the average evaluation metrics based on the results of the last 200 experiments.
The evaluation of different caching strategies relied on four key metrics.
Cache Hit Ratio (CHR): The cache hit ratio represents the percentage of requests that can be fulfilled by retrieving data packets from the cache in the router nodes,
where
refers to the count of
packets that are successfully satisfied by retrieving the corresponding
packet from the router’s cache. On the other hand,
represents the count of
packets that cannot be fulfilled by the cache and require fetching from external sources. An
packet carries the name of the requested content and is transmitted from the receiver node, while a
packet contains the requested content itself and can serve as a response to the corresponding
packet.
Average Latency Time (ALT): The average latency time represents the average delay between the moment that a user sends an
packet and the moment that it receives the corresponding
packet,
where
I denotes the total number of user requests.
represents the travel time of the
packet from the receiver node to the node that fulfills the request, while
denotes the travel time of the responding
packet.
Average Path Stretch (APS): The average path stretch measures the average increase in path length for each user request,
where
I represents the total number of user requests.
denotes the receiver node that sends the request,
refers to the node that responds to the request, and
represents the source node that publishes the requested content.
denotes the number of hops travelled by the
request, while
represents the shortest path from the receiver to the source.
Average Link Load (ALL): The average link load represents the average ratio of the total link load to the total number of links in the network,
where
L denotes the total number of links in the network, and
represents the link load of the specific link
l.
The caching performance of our proposed GNN-DDQN scheme was evaluated and compared with the state-of-the-art caching scheme MLP-DDQN. MLP-DDQN, which has been extensively studied in various research works [
5,
6], was used as a baseline for comparison. We adapted the MLP-DQN framework to incorporate the DDQN technique to ensure a fair comparison. The MLP-DDQN agent consisted of four linear layers with dimensions of 1024, 512, 256, and
C.
There are some differences between the state representations of the MLP-DDQN agent and our proposed GNN-DDQN approach. In the MLP-DDQN agent, the first component of the state representation includes the number of requests for each content item passed through each node, covering all types of nodes (receivers, routers, and sources). This provides more general traffic-related information to assist the MLP agent in making predictions, as it lacks the ability to gather neighbouring information as in the GNN approach.
Additionally, we compared our caching strategy with classical caching algorithms, including LCD, PROB_CACHE, LCE, and CL4M. These algorithms served as additional baselines to assess the performance of our proposed approach.
5.1. Effect of Content Item Number
This section examines the impact of the number of content items on caching performance. The number of content items ranged from 600 to 1000.
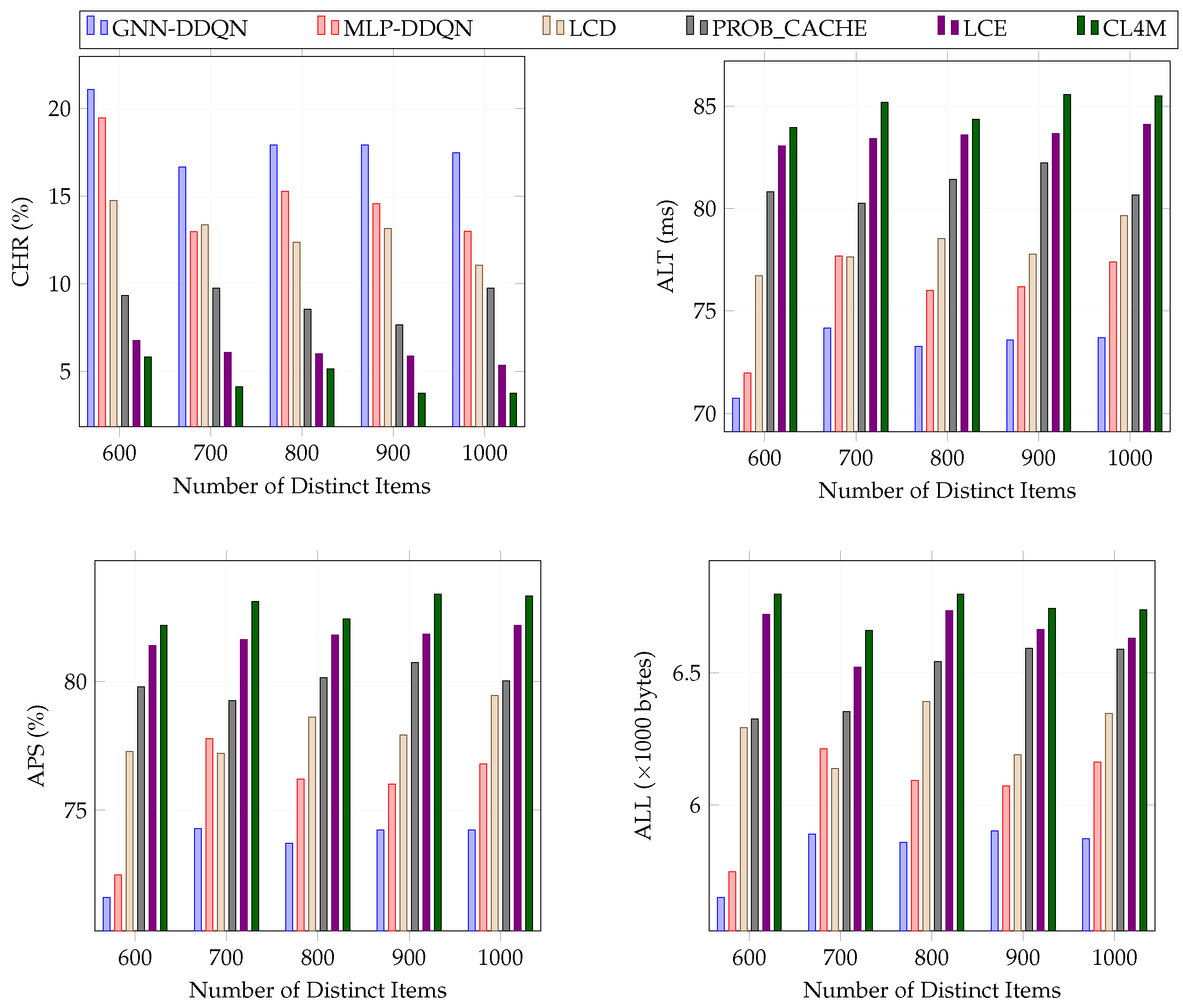
Figure 3 illustrates how the caching performance varied with the number of items in the GEANT [
17] network, where routers with caching capability had a uniform cache size of one item. The GEANT network is a well-known real-world topology comprising 53 nodes and 74 edges. Within the network are 13 source nodes responsible for content production, 32 router nodes, and 8 receiver nodes that initiate requests. However, it is worth noting that only router nodes with a degree higher than 2 have cache capabilities, which amounts to 19 nodes in this case.
Figure 3 demonstrates that GNN-DDQN consistently outperformed all other caching strategies across different numbers of distinct content items. GNN-DDQN achieved a maximum improvement of 34.42% in CHR, 4.76% in ALT, 3.77% in APS, and 5.21% in ALL compared to MLP-DDQN. On average, GNN-DDQN surpassed LCD and PROB_CACHE by 41.33% and 103.92% in CHR, respectively. It also achieved significantly lower ALT, APS, and ALL than LCD and PROB_CACHE. Furthermore, the performance gap between GNN-DDQN and LCE and CL4M was even more pronounced regarding all evaluation metrics.
Overall, GNN-DDQN consistently exhibited exceptional caching performance regardless of the number of content items. Its superiority over MLP-DDQN stemmed from its ability to facilitate cooperative caching among neighbouring router nodes. By efficiently utilizing the caching space of all router nodes, GNN-DDQN enhanced the network performance. Additionally, GNN-DDQN outperformed traditional caching algorithms by quickly capturing user preferences and proactively placing popular content on appropriate router nodes. Consequently, the cache hit ratio improved, alleviating network traffic congestion.
5.2. Effect of Cache Size
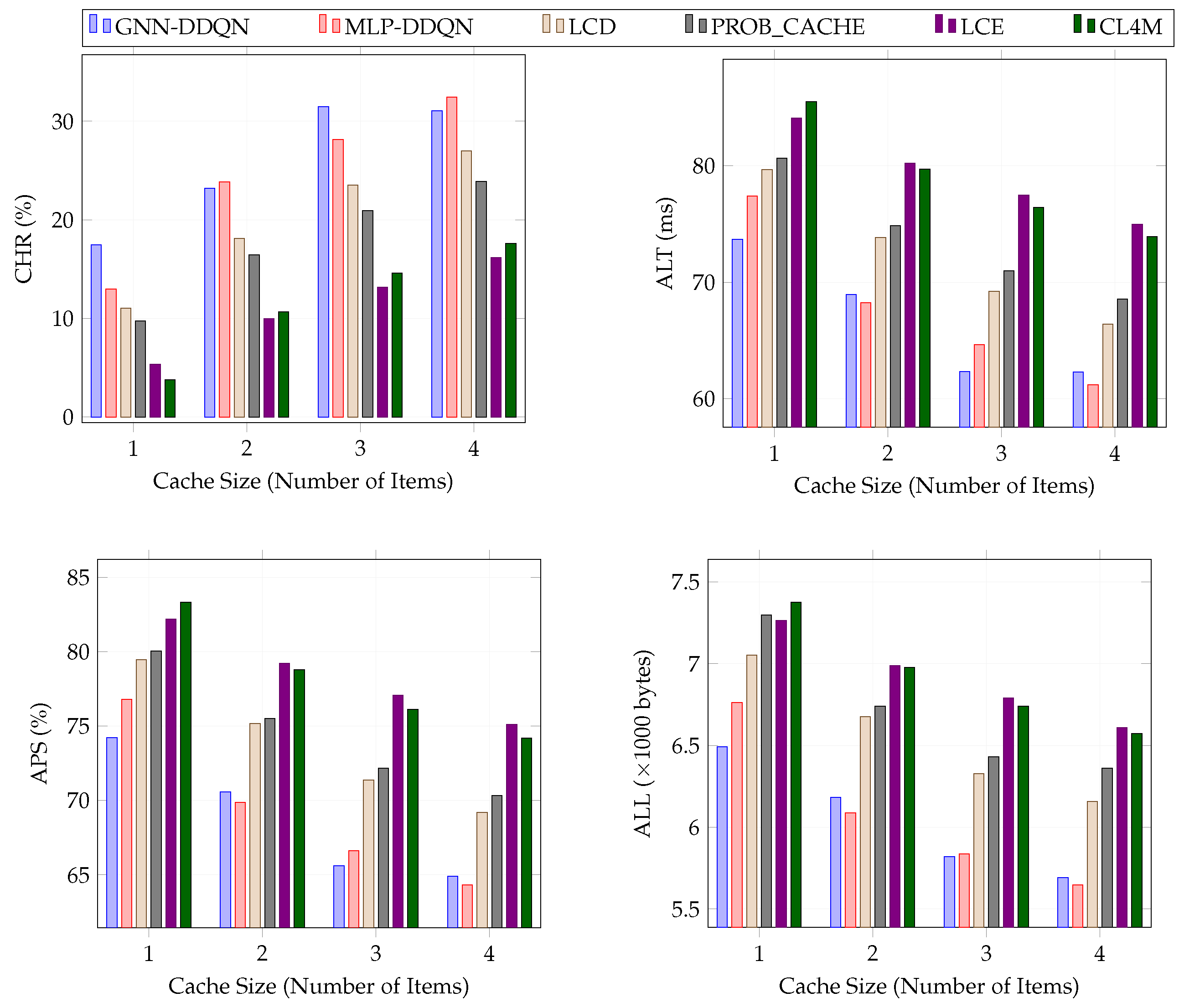
This section investigates the performance of different caching schemes across various router cache sizes, defined as the number of content items.
Figure 4 presents the caching performance of GNN-DDQN, MLP-DDQN, LCD, PROB_CACHE, LCE, and CL4M under different caching scenarios. The router cache sizes ranged from 1 to 4, while the number of content items was fixed at 1000.
GNN-DDQN exhibited a substantial performance advantage over MLP-DDQN when the cache size was limited to one item. For cache sizes of two and four, GNN-DDQN and MLP-DDQN performed similarly. However, when the cache size was set to three items, GNN-DDQN outperformed MLP-DDQN by achieving an 11.87% higher CHR, 3.57% lower ALT, 1.54% APS, and 2.20% lower ALL.
Significantly, regardless of the router cache size, GNN-DDQN consistently reduced the latency time by at least 14.96%, 29.88%, 92.20%, and 76.37% compared to LCD, PROB_CACHE, LCE, and CL4M, respectively. The advantages of GNN-DDQN stem from its ability to predict popular content in advance and proactively cache them.
5.3. Effect of Network Topology
To further evaluate the effectiveness of the proposed caching scheme, we conducted experiments on different network topologies, namely ROCKETFUEL [
18], TISCALI [
19], and GARR [
19]. The aim was to assess the robustness of the caching scheme in diverse network environments.
Table 5 presents the distribution of each network topology’s source, router, and receiver nodes. It is important to note that, in the TISCALI network, only router nodes with a degree higher than 6 possess caching capabilities, resulting in 36 router nodes equipped with cache functionality.
This section evaluates the caching performance of different strategies in the ROCKETFUEL, TISCALI, and GARR network topologies. The experiments were conducted with an item number of 1000, and all routers with caching capabilities had a uniform cache size of one item. The results are summarized in
Table 6.
Across all network topologies, GNN-DDQN consistently outperformed the other strategies. Specifically, in ROCKETFUEL, GNN-DDQN achieved a 2.89% higher CHR than MLP-DDQN. In TISCALI, the margin became even more significant, with GNN-DDQN achieving a 25.72% higher CHR than MLP-DDQN. These results highlight the superior caching performance of GNN-DDQN, particularly in large networks such as ROCKETFUEL and TISCALI.
Furthermore, GNN-DDQN demonstrated a significant margin over MLP-DDQN and other traditional caching schemes in the GARR network. This further emphasizes the robustness and effectiveness of GNN-DDQN across various network topologies.
6. Conclusions
In this paper, we introduced GNN-DDQN, an intelligent caching scheme designed for the SDN-ICN scenario. GNNs have gained significant attention recently for their ability to handle graph-structured data. Leveraging this capability, we applied GNNs to process network topologies, enabling cooperative caching among nodes and promoting a wider variety of cached content. By integrating GNNs into DRL, our proposed approach empowered the DRL agent to make caching decisions for all nodes in the network with only one forward pass through the neural network. This integration not only streamlined the caching decision-making process but also harnessed the power of GNN-DRL synergy in optimizing the caching strategies.
Firstly, we generated user preferences for content based on a real-world dataset. This step ensured that the evaluation reflected realistic user behaviour and content demand patterns. Next, we developed a GNN-DDQN agent within the SDN controller, enabling the agent to make intelligent caching decisions for all router nodes equipped with caching capabilities in the ICN network. Finally, we compared the performance of our proposed GNN-DDQN caching scheme with the state-of-the-art MLP-DDQN strategy and several classical benchmark caching schemes, including LCD, PROB_CACHE, CL4M, and LCE. The extensive evaluation revealed that GNN-DDQN consistently outperformed MLP-DDQN in most scenarios. Notably, in the best-case scenario, GNN-DDQN achieved a remarkable 34.42% higher CHR, a 4.76% lower ALT, a 3.77% lower APS, and a 5.21% lower ALL compared to MLP-DDQN. Furthermore, GNN-DDQN demonstrated superior performance compared to classical caching schemes. To assess the robustness of our proposed scheme, we conducted experiments on benchmark network topologies, including GEANT, ROCKETFUEL, TISCALI, and GARR. GNN-DDQN consistently delivered outstanding performance across these diverse network topologies, reinforcing its reliability and applicability in real-world scenarios.
Some potential directions for future research include the following.
Latency Consideration: Investigating the latency of the SDN controller and exploring techniques to mitigate the latency issue when dealing with a large number of network nodes.
IoV-Based Environment: Integrating the proposed caching strategy in an IoV environment. This may involve studying the unique characteristics of vehicular networks and exploring how the methodology can be adapted to optimize content caching and delivery in such dynamic and mobile scenarios.









{kind=link}
{kind=link}
{kind=link}
{kind=link}