
Self-Healing in Cyber–Physical Systems Using Machine Learning: A Critical Analysis of Theories and Tools

 ,
,  ,
,  ,
,  and
and
Abstract
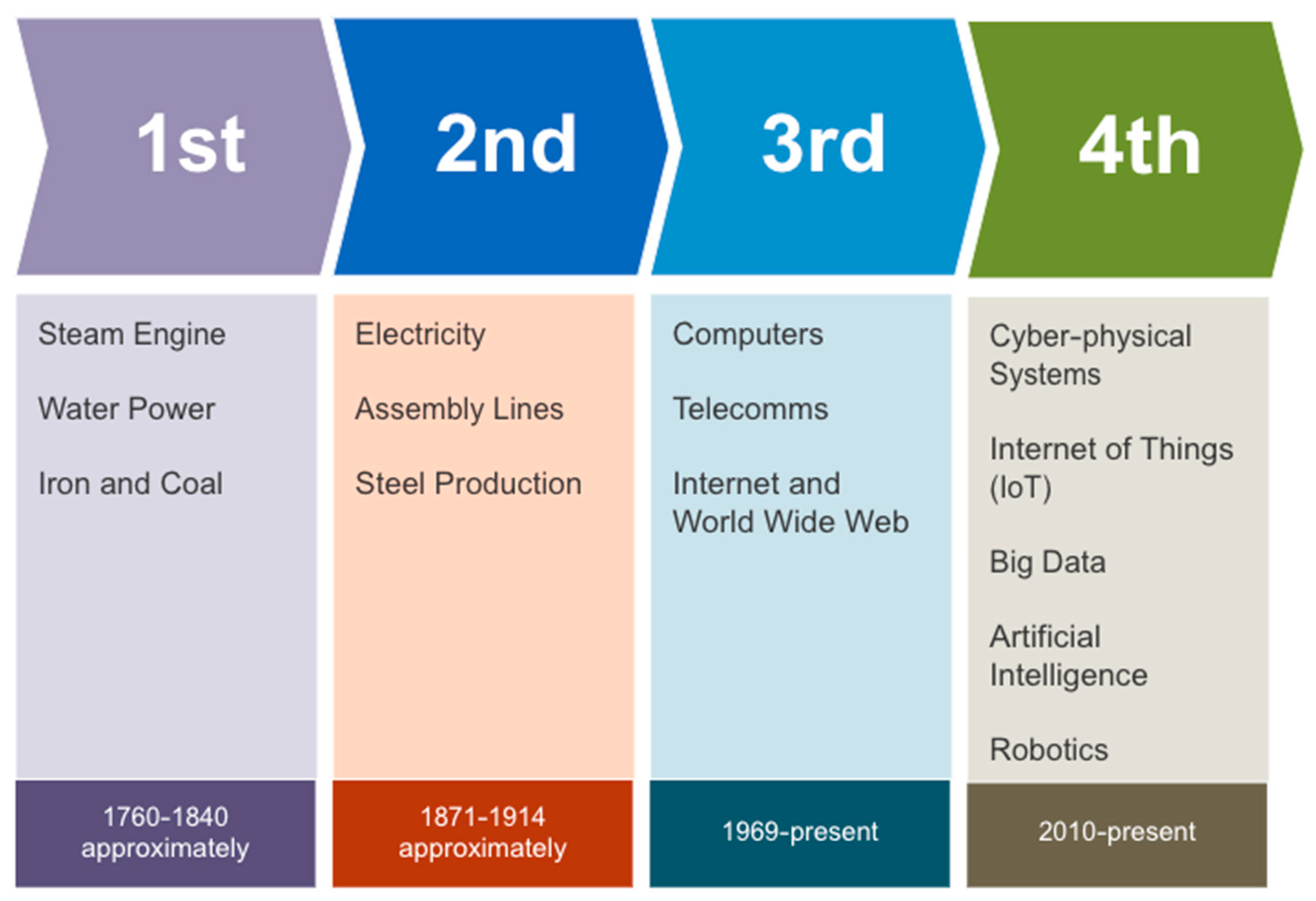
1. Introduction
- This paper aims to enhance knowledge by highlighting current trends in the area of study;
- The main objective of this paper is to identify the latest machine-learning tools, methods, and algorithms for integrating self-healing functionality into cyber–physical systems;
- The self-healing capability of cyber-physical systems will be evaluated concerning state-of-the-art techniques, and machine-learning tools and methods in implementing self-healing functions will be explored;
- The existing literature will be critically reviewed to identify current tools, methods, algorithms, classification models, frameworks, networks, and architectures currently deployed for a self-healing approach.
2. Self-Healing Theories
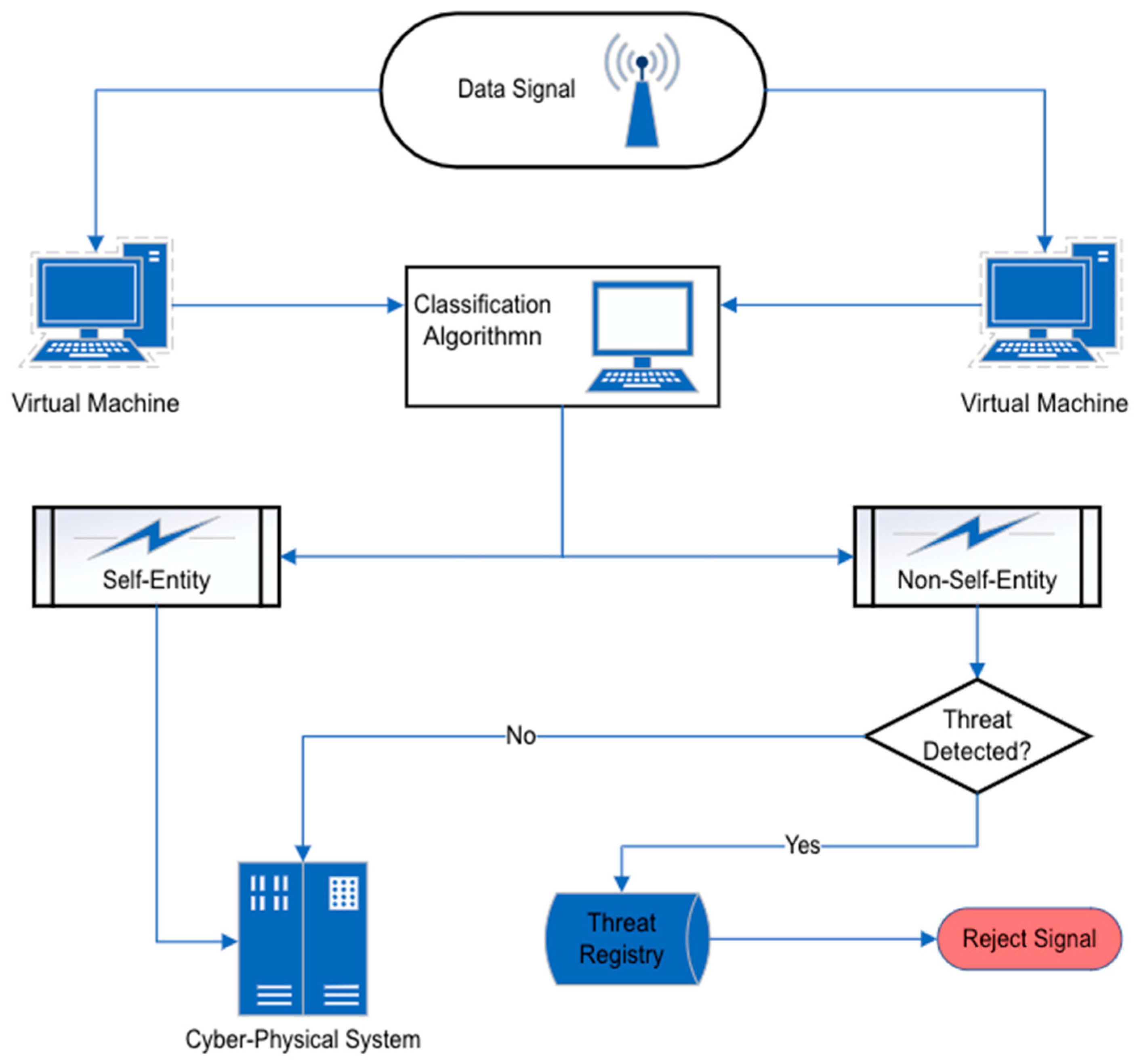
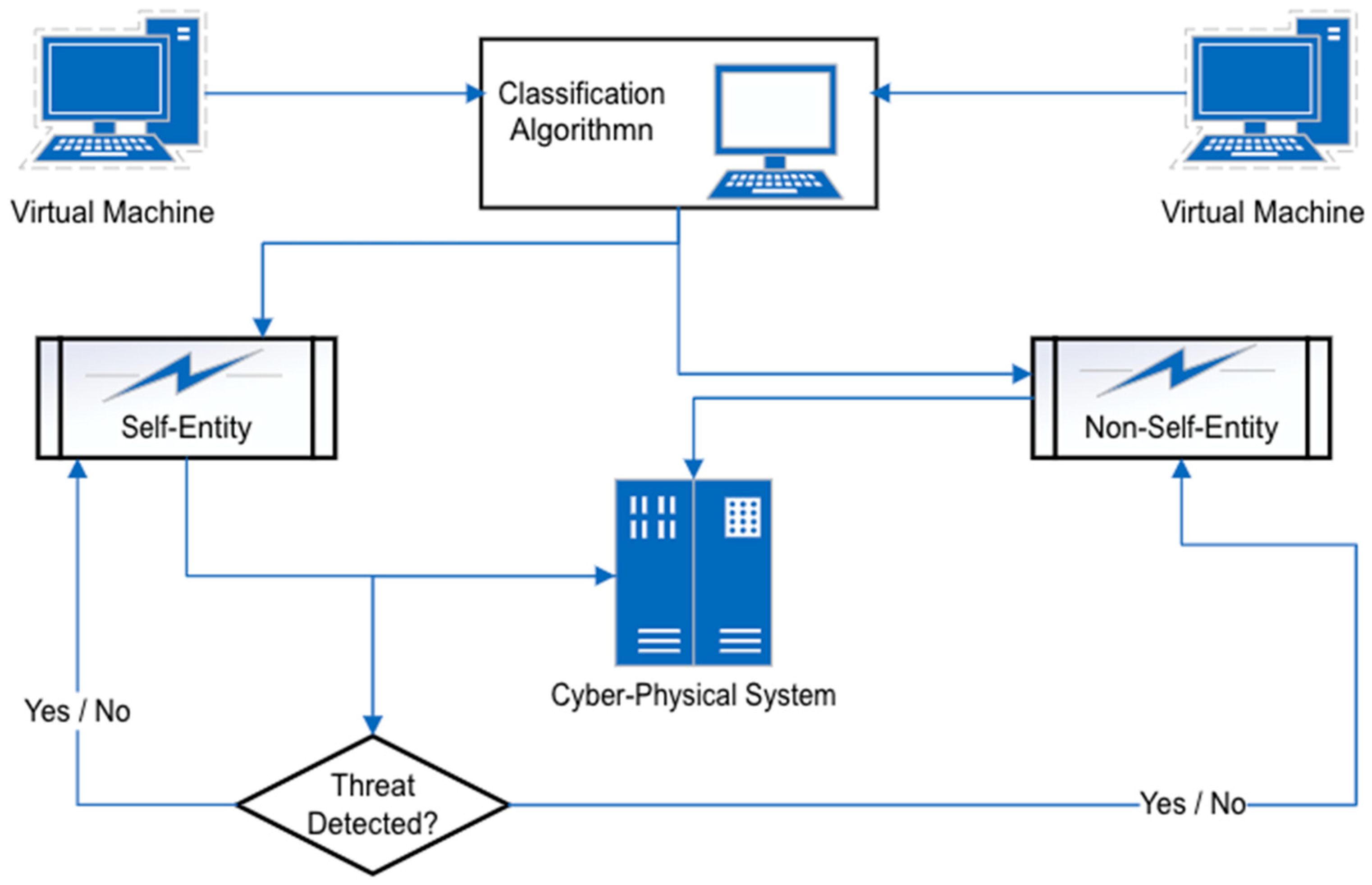
2.1. Negative and Positive Selection
2.2. Danger Theory
- New event analysis: When a new event is detected, it should be added to the timeline, and the dangerous pattern should be checked;
- Danger signal procession: When a danger signal is detected, the system must decide if any pattern can be related to the danger signal and then act accordingly;
- Warning signal processing: When a warning arrives from other hosts that carry information about a danger signal and related dangerous sequence of events, a host’s timeline should be checked to verify that it does not have a similar dangerous sequence of events.
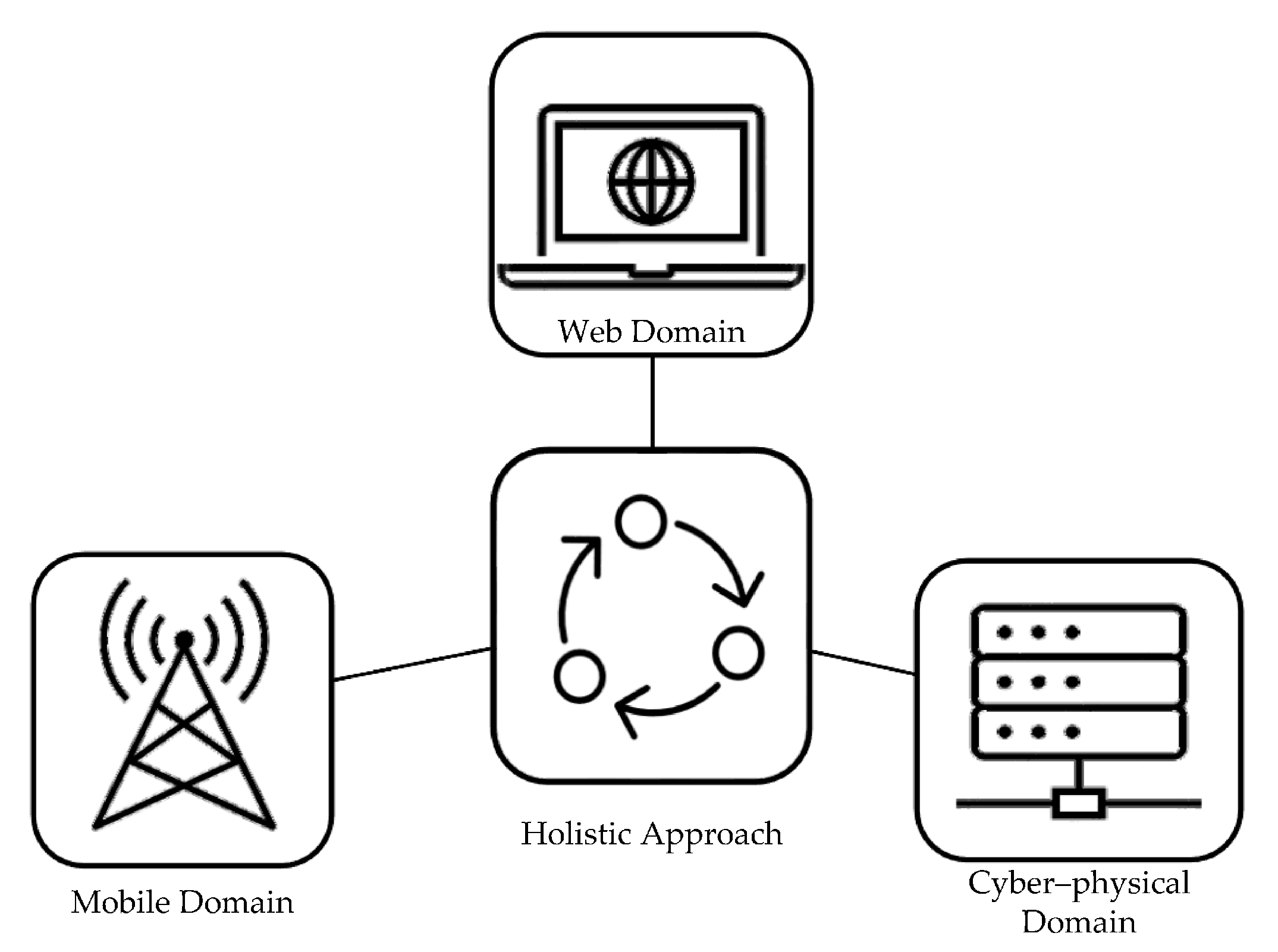
2.3. Holistic Self-Healing Theory
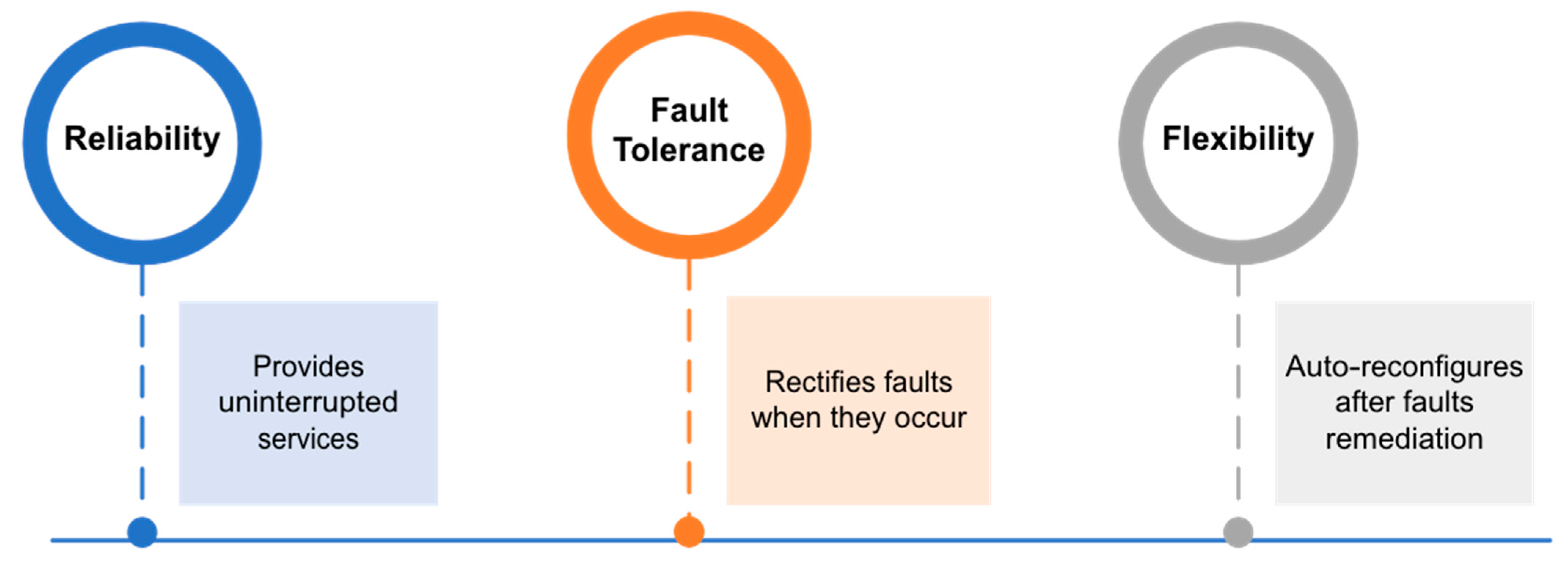
3. Self-Healing for Cyber-Physical Systems
- Provision of self-configuration resources by reinstalling newer versions of obsolete dependencies of the system’s software and offers management of errors through self-healing;
- Automatically schedules resource provisioning and optimises QoS without the need for human intervention;
- Provides algorithms for four-phased approaches of monitoring, analysis, planning, and execution of the QoS values. These four phases are triggered through corresponding alerts to aid the preservation of the system’s efficiency;
- Reduces the breach of service level agreement (SLA) and increases the QoS expectation of the user by improving the availability and reliability of services.
- Detection of overloaded transmission lines in the power network;
- Identify buses that have overloaded transmission lines connected to them;
- Identification of the busbar that has the highest reserve capacity and that can then serve as a viable option for a power restoration strategy;
- Identification of the nearest distribution generator to the overloaded transmission line;
- Identification of the termination point of the overloaded lines;
- Establishment of line connection using the references of the reserve busbar index.
- Monitoring and adaptation: It must be responsive to unforeseen attacks;
- Redundancy, decoupling, and modularity: It must have a decentralised structure to prevent the threats from spreading to the other constituent parts of the network or the system’s host;
- Focusing: The system must be able to focus resources where they are most needed to prevent the overuse of resources, which may be counterintuitive to the task of shoring up the system’s resilience;
- Diverse at the edge and simple at the core: The system should be able to utilise shared protocols through simply defined processes. Still, it should also retain an element of diversity to circumvent widespread attack threats.
- The system’s architecture;
- The available datasets;
- Profile scope;
- Profile features;
- Feature distribution or subset;
- Understandability.
- Manufacturing: In a manufacturing environment, production lines and equipment must always be operational and available to ensure maximum output. Self-healing mechanisms can detect and respond to faults or failures automatically, thereby minimising downtime and reducing the need for manual intervention;
- Transportation: Transportation systems, such as trains, planes, and automobiles, rely on sensors and other technology to monitor and control their operations. Self-healing mechanisms can detect faults or failures and take corrective action to ensure the system’s safety;
- Power grids: Power grids are critical infrastructure that must always be operational to ensure reliable access to electricity. Self-healing mechanisms can detect and respond to faults or failures, preventing cascading failures and reducing the impact of outages;
- Healthcare: Healthcare systems rely on technology to monitor and provide critical care. Self-healing mechanisms can ensure that these systems are always operational, minimising the risk of disruption that could compromise patient safety;
- Internet of Things (IoT): IoT devices are becoming increasingly common in homes, businesses, and public spaces. Self-healing mechanisms can detect and respond to faults or failures, ensuring these devices remain operational and connected to the Internet.
4. Self-Healing Approaches
- Redundancy: Redundancy involves having duplicate components or systems that can take over if the primary system fails. For example, if one node fails in a computer cluster, another node can take over and continue processing the request;
- Automated recovery: Automated recovery involves setting up automated processes to detect and resolve problems. For example, a computerised process can restart a server or move its workload to another server if it goes down;
- Predictive maintenance: Predictive maintenance involves using sensors and data analytics to predict when a system is likely to fail and proactively take action to prevent the failure from occurring. For example, an aircraft engine can be monitored for signs of wear and tear, and maintenance can be scheduled before failure occurs;
- Machine learning: Machine learning involves using algorithms to analyse data and learn patterns that can be used to detect and resolve problems. For example, machine algorithms can analyse network traffic and detect anomalies that may indicate security breaches;
- Fault tolerance: Fault tolerance involves designing systems that can continue to operate even if one or more components fail. For example, a database cluster can be designed to replicate data across multiple nodes. If one node fails, then other nodes can continue providing data access.
- Log data: This contains information about the system events, such as error messages and other data that can be used to diagnose problems;
- Performance metrics: This includes data derived from CPU utilisation, memory usage, network latency, and input/output disk;
- Configuration data: Includes data related to the system’s configuration changes and parameters;
- Environment data: Identifies the issues relating to environmental conditions, such as overheating and excessive humidity.
- User behaviour data: These data identify patterns in the system’s user behaviours, such as the response times or the frequency of errors.
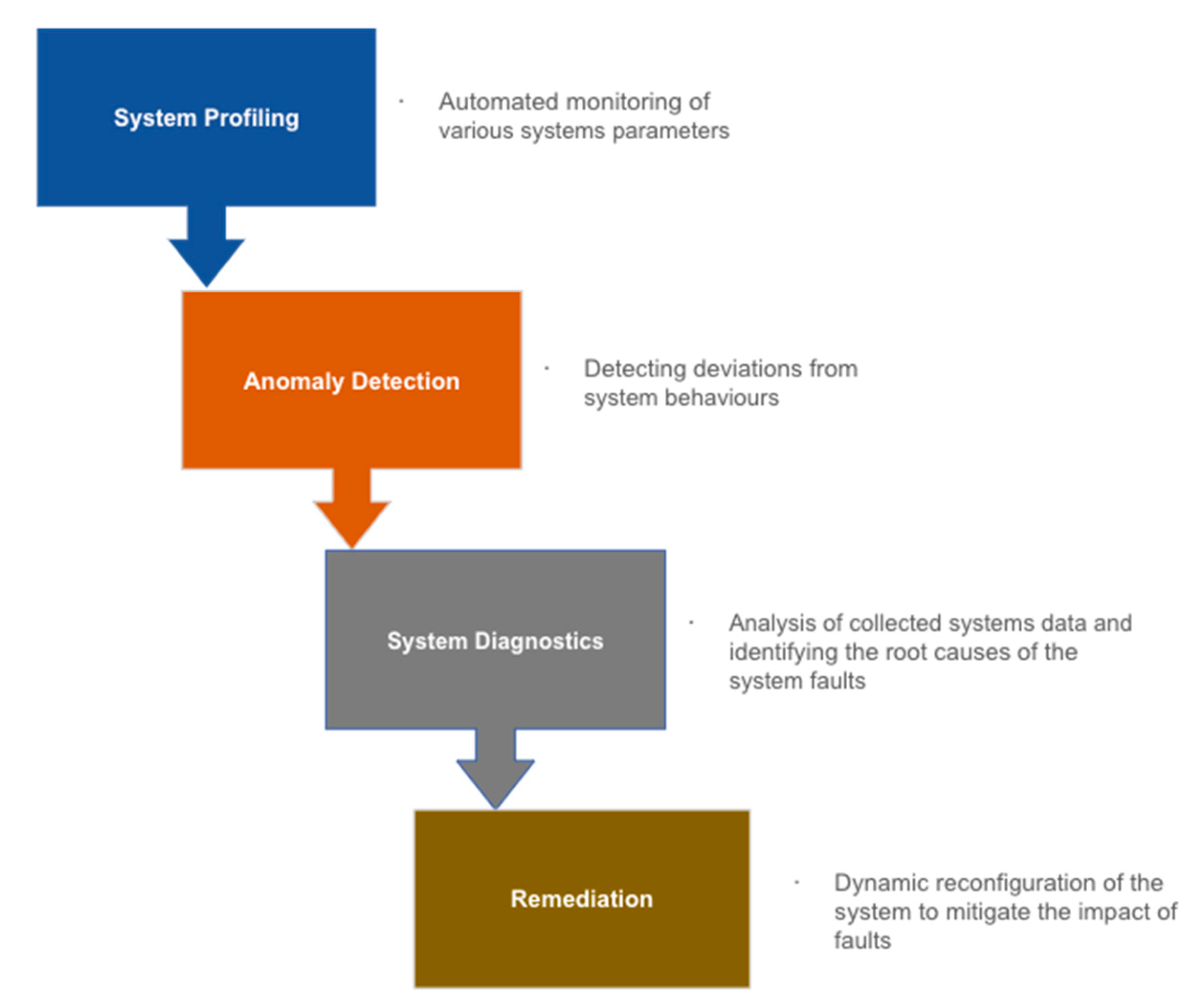
4.1. Self-Healing Models and Frameworks
- Quick detection of system faults;
- Redistribution of network resources to protect the system;
- Reconfiguration of the system to maintain service, irrespective of the situation;
- Minimal interruption of service during reconfiguration or self-healing period.
4.1.1. Twin Model
4.1.2. QoS Model
4.1.3. Auto-Regressive Moving Average with Exogenous Input Model
4.2. Network Architecture
- Redundancy: The network should be designed with redundant components to minimise the impact of failures by providing fail-safe functionality to the system;
- Automation: The network should be automated to reduce the need for manual intervention and speed up the recovery process;
- Monitoring: The network should have robust monitoring capabilities to detect and diagnose issues as soon as they occur;
- Resiliency: The network should be designed to be resilient to common failures, such as power outages, hardware failures, and software bugs;
- Security: The network should be designed with safety in mind to mitigate attacks that could cause outages
4.2.1. Strategy Network
- Perception layer: This layer monitors the network to detect failures and anomalies. Strategies in this layer include using sensors to monitor network traffic, analysing system logs, and applying ML techniques to identify abnormal patterns;
- Analysis layer: This layer is responsible for analysing the data collected by the perception layer to identify the root cause of failures. Strategies in this layer include using ML algorithms to analyse the data and identify patterns that indicate the cause of a failure;
- Planning layer: This layer is responsible for developing a plan to address the identified failures. Strategies in this layer include using ML algorithms to determine the optimal recovery strategy and selecting the appropriate recovery mechanism;
- Execution layer: This layer is responsible for executing the recovery plan. Strategies in this layer include using automation to execute the recovery plan and providing feedback to the other layers to optimise the recovery process;
- Knowledge layer: This layer stores and manages knowledge about the network and the recovery process. Strategies in this layer include using databases to store information about the network topology and previous failures and using algorithms to learn from previous failures and improve the self-healing process.
4.2.2. Valuation Network
4.2.3. Fast Decision Network
4.2.4. Virtual Machine
- Isolation: A VM can isolate applications and services from each other. If one application or service experiences a failure, it can be restarted within the VM without affecting the other applications or services running on the same physical machine;
- Redundancy: Multiple VMs can be deployed to provide redundancy for critical applications or services. If one VM fails, another can take over its workload to ensure continuity of service;
- Rapid provisioning: VMs can quickly be configured to meet changing workload demands. The proposed method enables the network to scale up or down as needed by utilising shared operation and spare nodes in each neural network layer, ensuring performance and availability are maintained;
- Testing and validation: VMs can test and validate self-healing mechanisms before they are deployed in a production environment. Implementing these approaches can help ensure the effectiveness of the tools without causing unintended consequences.
4.2.5. Phasor Measurement Unit
- Real-time monitoring: PMUs can be used to monitor the state of the power grid in real-time, providing high-resolution data on voltage, current, and frequency. This data can be used to detect and diagnose faults and other anomalies in the grid;
- Fault detection and isolation: PMUs can detect faults in the power grid, such as short circuits or equipment failures, by analysing electrical quantities’ magnitude and phase angle. PMUs can identify the location and the extent of the fault;
- Restoration: PMUs can be used to facilitate the repair of power after a fault has occurred. By providing real-time data on the state of the grid, PMUs can help operators quickly identify the source of the fault and take steps to restore power;
- Protection: PMUs can be used to protect critical equipment and infrastructure. By monitoring the state of the power grid in real-time, PMUs can detect abnormal conditions and trigger protective measures, such as tripping circuit breakers or isolating faulty equipment.
- Intrusion detection system (IDS): Relies on the PMU network logs and phasor measurements to detect different classes of abnormal events within the network;
- Intrusion mitigation system (IMS): Once the IDS detects an anomaly, the generated alerts from AMS are delivered through a publisher–subscriber interface; for appropriate remedial action to be taken;
- Alert management system (AMS): Generates alerts based on anomaly rules defined in IDS and forwards the alert to the IMS if abnormal events are detected for onward remedial actions by the IMS.
4.2.6. Mesh-Type Configuration Network
4.2.7. Agent Architecture
- Sensing: Agents can monitor the system and gather data about its current state. The data may include system performance metrics, error logs, and other relevant information;
- Diagnosis: Agents use data gathered during the sensing phase to analyse the system’s current state and identify any faults or errors. Various techniques can be employed to achieve this, such as comparing current data to historical trends or utilising machine-learning algorithms to detect and pinpoint abnormal behaviours;
- Decision-making: Once a fault or error has been detected, agents must decide how to respond. In such scenarios, the process may involve selecting from a predetermined set of response options, such as restarting a process or diverting traffic to a backup system;
- Action: Agents take action to resolve the fault or error using pre-define or adaptive responses. This process may involve coordinating with other agents to initiate a synchronised response or adjusting the system configuration to prevent future occurrences;
- Learning: Agents continually learn from their experiences and adapt their behaviour over time to improve effectiveness. To adapt effectively, agents may need to adjust their response strategies based on the outcomes of past responses and update their system models using new data.
4.2.8. Host Intrusion Detection System on IoT
4.2.9. Multi-Area Microgrid
4.3. Machine-Learning Algorithms
4.3.1. Monte Carlo Tree Search
4.3.2. Deep Learning
4.3.3. Intensive Learning
4.3.4. Multi-Layer Perceptron (MLP)
4.3.5. Supervised Knowledge-Based Algorithm
- Knowledge acquisition: Expert knowledge is collected and formalised in a knowledge base, which typically includes rules or heuristics for diagnosing faults;
- Data acquisition: Data are collected from the system, including sensor data, performance metrics, and other relevant information;
- Model training: The SKBA is trained using the knowledge base and the available data. The model is then used to detect and diagnose faults in the system based on the input data.
- Detect the overloaded transmission lines in the power network;
- Identify the affected buses that have overloaded transmission lines connected;
- Identify the busbar with the highest reserve capacity factor to serve as a candidate for the restoration strategy;
- Identify the nearest distributed generator located near the overloaded transmission line;
- Identify the overloaded line termination;
- Establish line connectivity using the highest reserve capacity busbar index.
4.3.6. Artificial Immune System
- Negative selection: When an anomaly is detected based on the classifying entities being part of the “non-self” originating system;
- Positive selection: When an anomaly is detected based on the classification of the “self” originating system;
- Danger theory: This approach raises the alarm if a harmful signal is detected, regardless of whether the entity is of “self” or of “non-self” of the originating system.
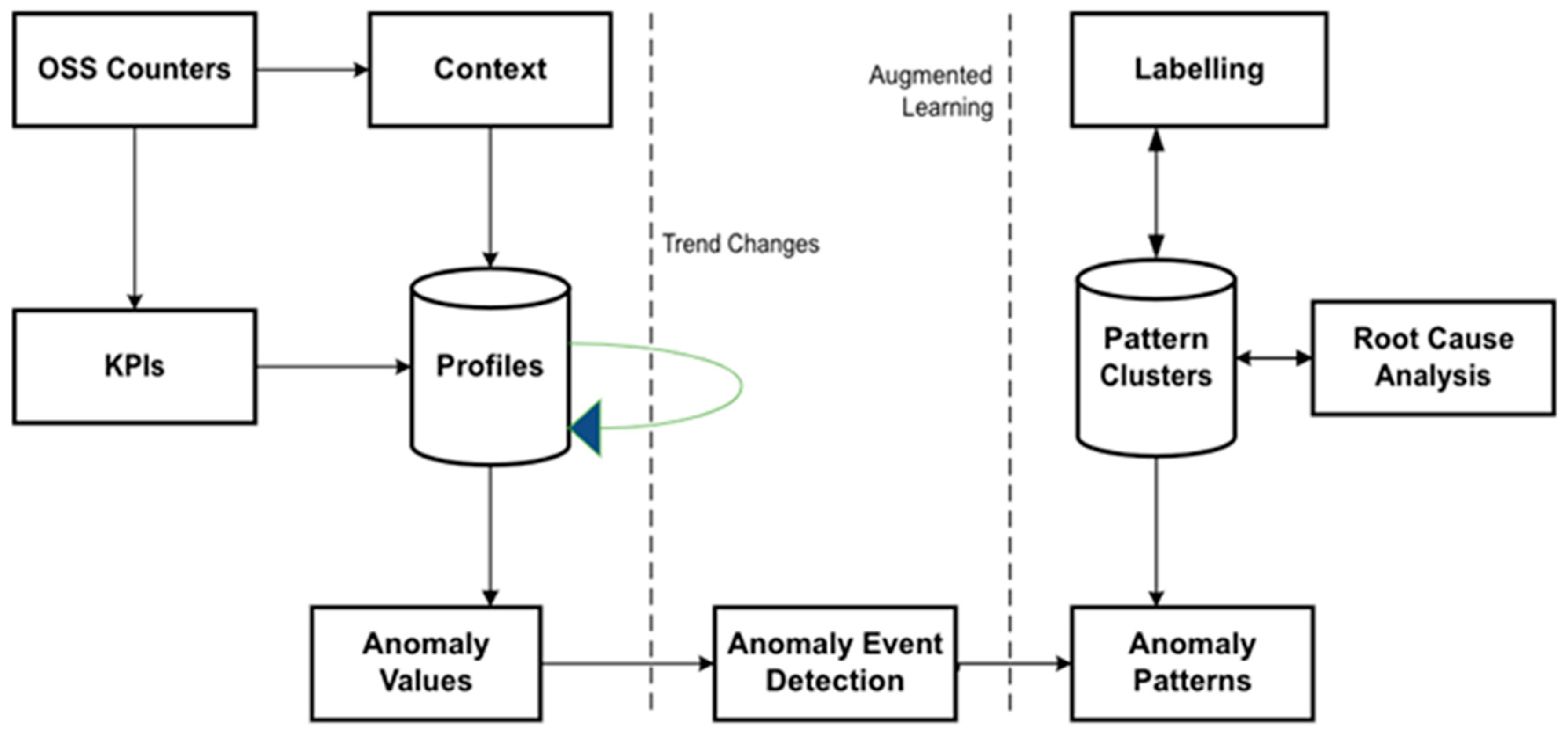
4.3.7. Behavioural Modelling Intrusion Detection System
4.3.8. Genetic Algorithm
4.3.9. Hybrid Calibration Algorithm
4.3.10. Dynamic Event Detection Algorithm
4.3.11. Support Vector Machine
4.3.12. Naïve Bayes
4.3.13. Random Forest
4.3.14. DBSCAN
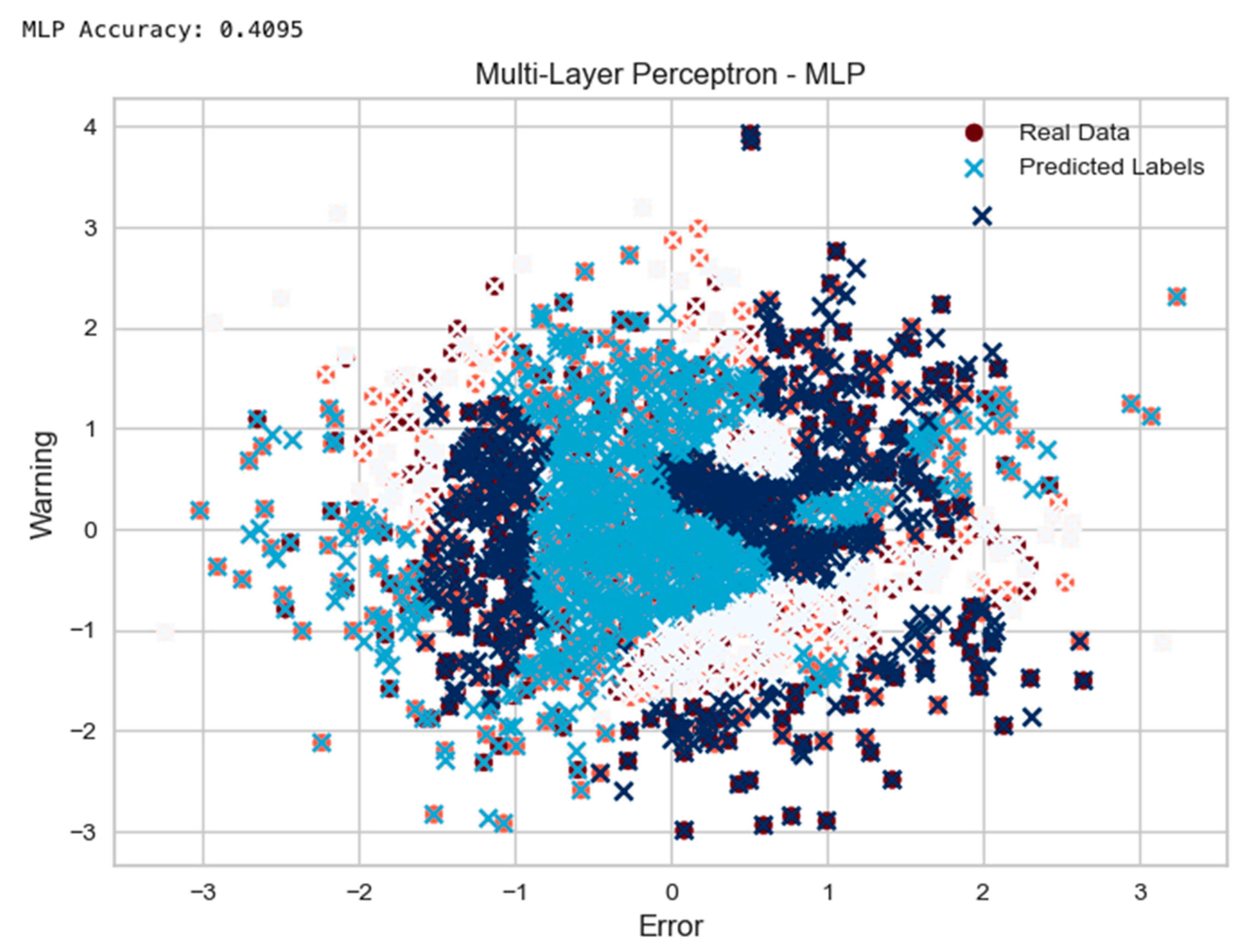
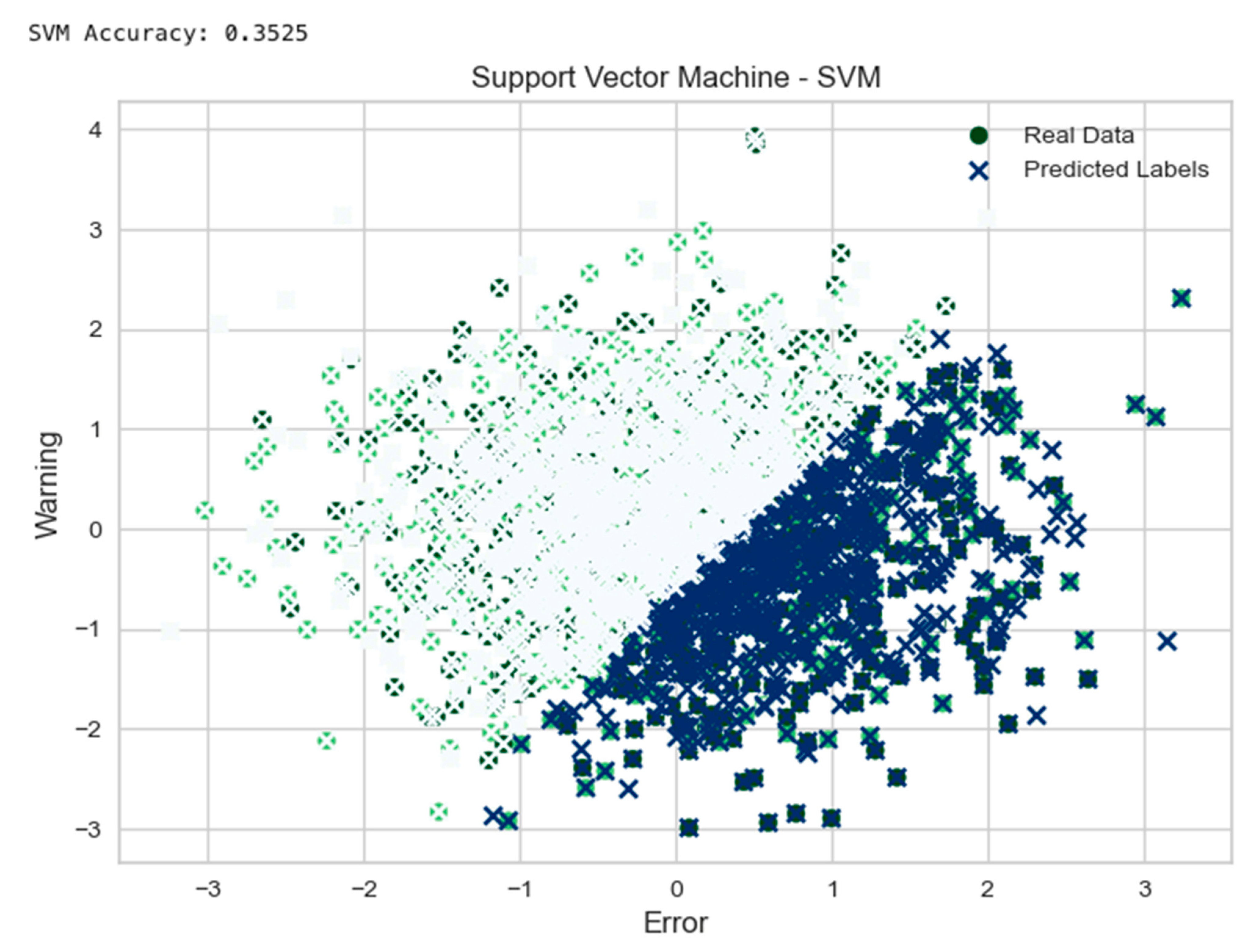
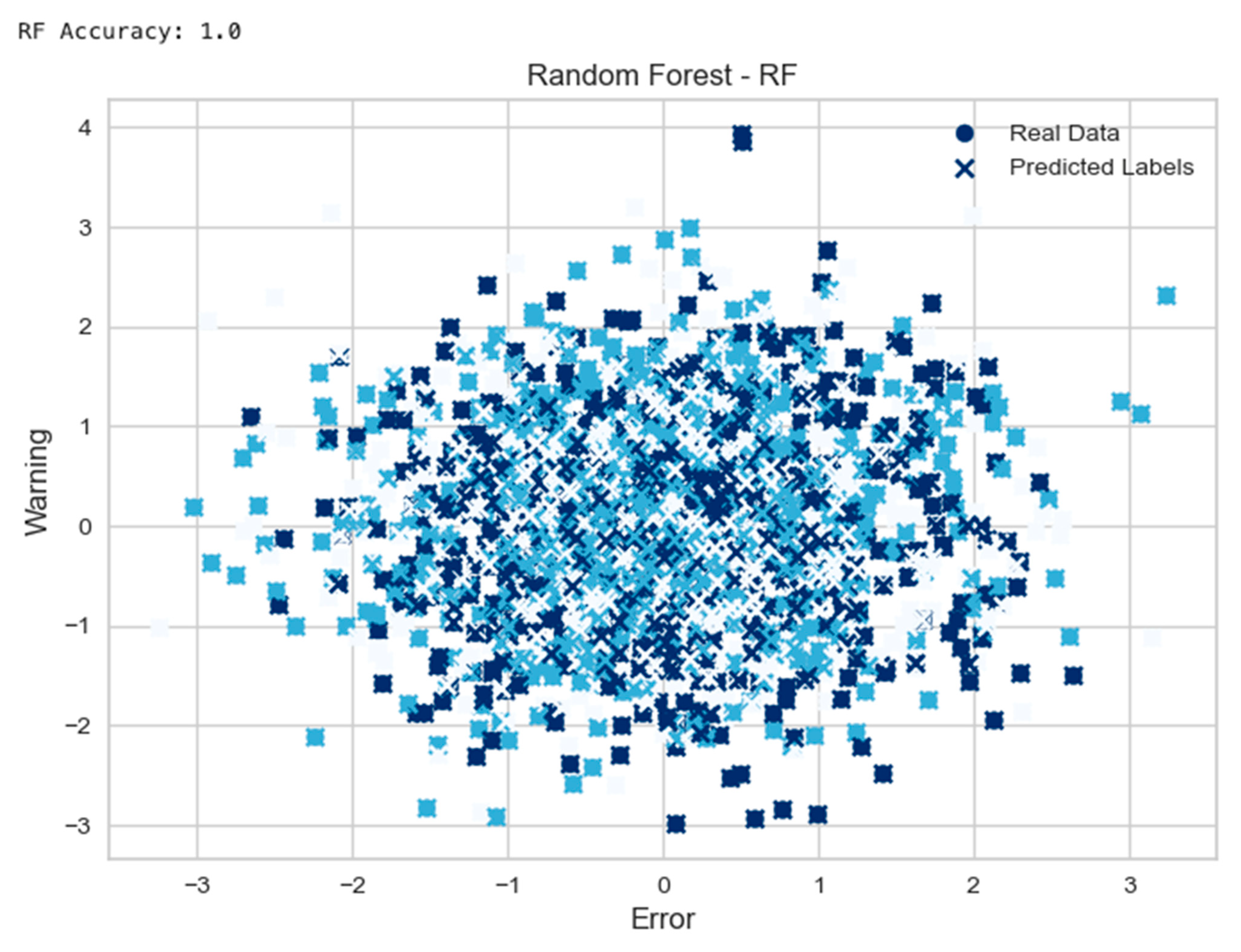
5. Analytical Comparison of MLP, SVM, and RF in Classifying Error in Simulated CPSs
5.1. Breakdown of What the Models Chart Plots Represent
5.2. Experiment Method
- Sample Data:
- 1.1
- A random seed for reproducibility was set.
- 1.2
- The number of samples as “num_samples” is defined.
- 1.3
- Random data were generated using “np.random.randn” with dimensions “num_samples” by 2.
- 1.4
- Random labels ranging from 0 to 2 using “np.random.randint” for “num_samples” times were generated.
- Saving the Data to a CSV File:
- 2.1
- A pandas DataFrame called “df” with columns named “Error”, “Warning”, and “Label” was created.
- 2.2
- The DataFrame was saved to a CSV file and specified by “csv_file” using the “to_csv” function.
- Loading the Data from the CSV File:
- 3.1
- The CSV file was read into a pandas DataFrame called “df_loaded”.
- 3.2
- The “Error” and “Warning” columns were extracted from “df_loaded” and assigned to “data_loaded”.
- 3.3
- The “Label” column was extracted from “df_loaded” and set to “labels_loaded”.
- Multi-Layer Perceptron (MLP) Example:
- 4.1
- The function “mlp_self_healing” was defined to train an MLPClassifier model on the “data” and “labels”.
- 4.2
- Prediction using the trained MLP model and calculating the accuracy was performed.
- 4.3
- The “real” data were randomly generated, and predicted labels were plotted into a scatter chart.
- Support Vector Machine (SVM) Example:
- 5.1
- The function “svm_self_healing” was defined to train an SVC model with a linear kernel on the “data” and “labels”.
- 5.2
- Prediction using the trained SVM model and calculating the accuracy was performed.
- 5.3
- The “real” data were randomly generated, and predicted labels were plotted into a scatter chart.
- Random Forest Example:
- 6.1
- The function “random_forest_self_healing” was defined to train a RandomForestClassifier model with 100 estimators on the “data” and “labels”.
- 6.2
- Perform prediction using the trained random forest model and calculate the accuracy was performed.
- 6.3
- The “real” data were randomly generated, and predicted labels were plotted into a scatter chart.
- Calling the Self-Healing Approaches Using the Loaded Data:
- 7.1
- The “mlp_self_healing” function with “data_loaded” and “labels_loaded” was invoked.
- 7.2
- The “svm_self_healing” function with “data_loaded” and “labels_loaded” was invoked.
- 7.3
- The “random_forest_self_healing” function with “data_loaded” and “labels_loaded” was invoked.
- Preparing the Data for PyCaret:
- 8.1
- Pandas DataFrame called “df_pycaret” was created by concatenating “data_loaded” and “labels_loaded” along the columns.
- 8.2
- The column names (“Error”, “Warning”, “Label”) were set.
- Initialising PyCaret Classification Setup:
- 9.1
- PyCaret “setup” function to initialise the classification task with “df_pycaret” as the dataset and “Label” as the target variable was used.
- Comparing Models and Select the Best One:
- 10.1
- PyCaret’s “compare_models” function was used to compare the performance of the available models (MLP, SVM, RF).
- 10.2
- The best-performing model based on the comparison was selected.
- Evaluation of the Performance of the Best Model:
- 11.1
- PyCaret’s “evaluate_model” function was used to evaluate the performance of the best model selected in the previous step.
- Model: The name or identifier of the model.
- Accuracy: The proportion of correctly classified instances by the model.
- AUC: The Area Under the Receiver Operating Characteristic (ROC) curve measures the model’s ability to distinguish between classes.
- Recall: Also known as sensitivity or true positive rate, it represents the proportion of true positive predictions out of all actual positive instances.
- Prec.: Short for precision, it indicates the proportion of true positive predictions out of all predicted positive instances.
- F1: The harmonic mean of precision and recall provides a balanced model performance measure.
- Kappa: Cohen’s kappa coefficient assesses the agreement between the model’s predictions and the actual classes, considering the agreement by chance.
- MCC: Matthews Correlation Coefficient, a measure of the quality of binary classifications.
- TT (Sec): The time taken by the model to make predictions (in seconds).
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, J.; Li, H. Cyber-Physical Systems: A Comprehensive Review. IEEE Access 2021, 9, 112003–112033. [Google Scholar]
- El Fallah Seghrouchni, A.; Beynier, A.; Gleizes, M.P.; Glize, P. A review on self-healing systems: Approaches, properties, and evaluation. Eng. Appl. Artif. Intell. 2021, 99, 104220. [Google Scholar]
- Hahsler, M.; Piekenbrock, M.; Thiel, S.; Kuhn, R. Review of Cyber-Physical Systems for Autonomous Driving: Approaches, Challenges, and Tools. Sensors 2021, 21, 1577. [Google Scholar]
- Subashini, S.; Kavitha, V. A survey on security issues in cyber-physical systems. J. Netw. Comput. Appl. 2016, 68, 1–22. [Google Scholar]
- Sejdić, E.; Djouani, K.; Mouftah, H.T. A Survey on Fault Diagnosis in Cyber-Physical Systems. ACM Comput. Surv. 2020, 53, 1–36. [Google Scholar]
- Zhang, J.; Yang, J.; Sun, H. Security and Privacy in Cyber-Physical Systems: A Survey. ACM Trans. Cyber-Phys. Syst. 2019, 3, 1027–1070. [Google Scholar]
- Samuel, S.R.; Madria, S.K. Cyber-Physical Systems Security: A Survey. J. Netw. Comput. Appl. 2020, 150, 102520. [Google Scholar]
- Mahdavinejad, M.; Al-Fuqaha, A.; Oh, S. Cyber-Physical Systems: A Survey. J. Syst. Archit. 2018, 90, 60–91. [Google Scholar]
- Omar, T.; Ketseoglou, T.; Naffaa, O.; Marzvanyan, A.; Carr, C. A Precoding Real-Time Buffer Based Self-Healing Solution for 5G Networks. J. Comput. Commun. 2021, 9, 1–23. [Google Scholar] [CrossRef]
- Schneider, K.P.; Laval, S.; Hansen, J.; Melton, R.B.; Ponder, L.; Fox, L.; Hart, J.; Hambrick, J.; Buckner, M.; Baggu, M.; et al. A Distributed Power System Control Architecture for Improved Distribution System Resiliency. IEEE Access 2021, 7, 9957–9970. [Google Scholar] [CrossRef]
- Cai, W.; Yu, L.; Yang, D.; Zheng, Y. Research on Risk Assessment and Strategy Dynamic Attack and Defence Game Based on Twin Model of power distribution network. In Proceedings of the 7th Annual IEEE International Conference on Cyber Technology in Automation, Control, and Intelligent Systems, Honolulu, HI, USA, 31 July–4 August 2017; pp. 684–689. [Google Scholar]
- Gill, S.S.; Chana, I.; Singh, M.; Buyya, R. RADAR: Self-Configuring and Self-Healing in Resource Management for Enhancing Quality of Cloud Services. J. Concurr. Comput. Exp. 2016, 31, 1–29. [Google Scholar] [CrossRef]
- Degeler, V.; French, R.; Jones, K. Self-Healing Intrusion Detection System Concept. In Proceedings of the 2016 IEEE 2nd International Conference on Big Data Security on Cloud (BigdataSecurity), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS), New York, NY, USA, 9–10 April 2016; pp. 351–356. [Google Scholar]
- Samir, A.; Pahl, C. Self-Adaptive Healing for Containerized Cluster Architectures with Hidden Markov Models. In Proceedings of the 2019 Fourth International Conference on Fog and Mobile Edge Computing (FMEC), Rome, Italy, 10–13 June 2019; pp. 66–73. [Google Scholar]
- Wyers, E.J.; Qi, W.; Franzon, P.D. A Robust Calibration and Supervised Machine Learning Reliability Framework for Digitally Assisted Self-Healing RFIC (Radio Frequency Integrated Circuit). In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1138–1141. [Google Scholar]
- Mehmet, C. Self-Healing Methods in Smart Grids. Int. J. Progress. Sci. Technol. (IJPSAT) 2016, 24, 264–268. [Google Scholar]
- Chen, T.; Bahsoon, R. Self-adaptive and Sensitive-Aware QoS Modelling for Cloud. In Proceedings of the 8th International Symposium on Software Engineering for Adaptive and Self-Managing Systems (SEAMS), Seoul, Republic of Korea, 25–26 May 2020; pp. 43–52. [Google Scholar]
- Sigh, V.K.; Vaughan, E.; Rivera, J. Sharp-Net: Platform for Self-Healing and Attack Resilient PMU Networks. In Proceedings of the 2020 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 16–18 February 2020; pp. 1–5. [Google Scholar]
- Stojanovic, L.; Stojanovic, N. PREMIuM: Big Data Platform for Enabling Self-Healing Manufacturing. In Proceedings of the 2017 International Conference on Engineering, Technology, and Innovation (ICE/ITMC), Madeira Island, Portugal, 27–29 June 2017; pp. 1501–1508. [Google Scholar]
- Berry, T.; Chollot, Y. Reference Architecture for Self-Healing Distribution Networks. In Proceedings of the 2016 IEEE/PES Transmission and Distribution Conference and Exposition (T&D), Dallas, TX, USA, 3–5 May 2016; pp. 1–5. [Google Scholar]
- Khalil, K.; Eldash, O.; Kuma, A.; Bayoumi, M. Self-Healing Approach for Hardware Neural Network Architecture. In Proceedings of the 2019 IEEE 62nd International Midwest Symposium on Circuits and Systems (MWSCAS), Dallas, TX, USA, 4–7 August 2019; pp. 622–625. [Google Scholar]
- Ahmad, I.; Basheri, M.; Iqbal, M.J.; Rahim, A. Performance Comparison of Support Vector Machine, Random Forest and Extreme Learning Machine for Intrusion Detection. IEEE Access 2018, 6, 33789–33795. [Google Scholar]
- Colabianchi, S.; Costantino, F.; Di Gravio, G.; Nonino, F.; Patriarca, R. Discussing Resilience in The Context of Cyber-Physical Systems. Comput. Ind. Eng. 2021, 160, 1075347. [Google Scholar]
- Mohammadi, M.; Rashid, T.A.; Karim, S.H.T.; Aldalwie, A.H.M.; Tho, Q.T.; Bidaki, M.; Rashmani, A.M.; Hosseinzadeh, M. A Comprehensive Survey and Taxonomy of the SVM-Based Intrusion Detection Systems. J. Netw. Comput. Appl. 2021, 178, 102983. [Google Scholar]
- Ali-Tolppa, J.; Kocsis, S.; Schultz, B.; Bodrog, L.; Kajo, M. Self-Healing and Resilience in Future 5G Cognitive Autonomous Networks. In Proceedings of the 2019 ITU Kaleidoscope: Machine Learning for 5G Future (ITU K), Santa Fe, Argentina, 26–28 November 2019; pp. 1–7. [Google Scholar]
- Karim, M.A.; Currie, J.; Lie, T. Dynamic Event Detection Using a Distributed Feature Selection Based Machine Learning Approach in Self-Healing Microgrid. IEEE Trans. Power Syst. 2018, 33, 4706–4718. [Google Scholar] [CrossRef]
- Ahmad, M.; Samiullah, M.; Pirzada, M.J.; Fahad, M. Using ML in Designing Self-Healing OS. In Proceedings of the The Sixth International Conference on Innovative Computing Technology (INTECH 2016), Dublin, Ireland, 24–26 August 2016; pp. 667–671. [Google Scholar]
- Tiwari, S.; Jian, A.; Ahmed, N.M.O.S.; Charu; Alkwai, L.M.; Hamad, S.A.S. Machine Learning-Based Model for Prediction of Power Consumption in Smart Grid-Smart Way Towards Smart City. Expert Syst. 2021, 39, 1–12. [Google Scholar]
- Yang, Q.; Li, W.; de Souza, J.N.; Zomaya, A.Y. Resilient Virtual Communication Networks Using Multi-Commodity Low Based Local Optimal Mapping. J. Netw. Comput. Appl. 2018, 110, 43–51. [Google Scholar] [CrossRef]
- Al-juaifari, M.K.R.; Alshamy, H.M.; Khammas, N.H.A. Power Enhancement Based Link Quality for Wireless Mesh Network. Int. J. Electr. Comput. Eng. (IJECE) 2021, 11, 1388–1394. [Google Scholar]
- Idio, I., Jr.; Rufus, R.; Esterline, A. Artificial Registration of Network Stress to Self-Monitor an Autonomic Computing System. In Proceedings of the SoutheastCon 2017, Charlotte, NC, USA, 30 March–2 April 2017; pp. 1–7. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Muhammad, B.M.S.R.; Raj, S.; Logenthiran, T.; Naayagi, R.T.; Woo, W.L. Self-Healing Network Instigated by Distributed Energy Resources. In Proceedings of the 2017 IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Bengaluru, India, 8–10 November; pp. 1–6.
- Mdini, M.; Simon, G.; Blanc, A.; Lecoeuvre, J. Introducing an Unsupervised Automated Solution for Root Cause Diagnosis in Mobile Networks. IEEE Trans. Netw. Serv. Manag. 2020, 17, 547–561. [Google Scholar]
- Bothe, S.; Masood, U.; Farooq, H.; Imran, A. Neuromorphic AI Empowered Root Cause Analysis of Faults in Engineering Networks. In Proceedings of the 2020 IEEE International Black Sea Conference on Communications and Networking (BLackSeaCom), Odessa, Ukraine, 26–29 May 2020; pp. 1–6. [Google Scholar]
- Keromytis, A.D. The Case for Self-Healing Software. In Aspects of Network and Information Security; IOS Press: Amsterdam, The Netherlands, 2008; pp. 47–55. [Google Scholar]
- Amit, G.; Shabtai, A.; Elovici, Y. A Self-Healing Mechanism for Internet of Things. IEEE Secur. Priv. 2021, 19, 44–53. [Google Scholar] [CrossRef]
- Dorsey, C.; Wang, B.; Grabowski, M.; Merrick, J.; Harrald, J.R. Self-Healing Databases for Predictive Risk Analytics in Safety-Critical Systems. J. Loss Prev. Process Ind. 2020, 63, 104014. [Google Scholar] [CrossRef]
- Joseph, L.; Mukesh, R. To Detect Malware Attacks for Autonomic Self-Heal Approach of Virtual Machines in Cloud Computing. In Proceedings of the 2019 Fifth International Conference on Science Technology Engineering and Mathematics (ICONSTEM), Chennai, India, 14–15 March 2019; pp. 220–231. [Google Scholar]
- Haggi, H.; Sun, W.; Fenton, M.; Brooker, P. Proactive Rolling-Horizon-Based Scheduling of Hydrogen Systems for Resilient Power Grid. IEEE Trans. Ind. Appl. 2022, 58, 1737–1746. [Google Scholar] [CrossRef]
- Hsieh, F. An Efficient Method to Assess Resilience and Robustness Properties of a Class of Cyber Physical Production Systems. Symmetry 2022, 14, 2327. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Principal Topic | Authors |
|---|---|
| 1. Resilience and Risk Assessment | ▪ Cai et al. [11] ▪ Degeler et al. [13] ▪ Samir et al. [14] ▪ Wyers et al. [15] ▪ Gill et al. [12] ▪ Mehmet [16] |
| 2. Self-Healing Approaches and Techniques | ▪ Chen and Bahsoon [17] ▪ Singh et al. [18] ▪ Stojanovic and Stojanovic [19] ▪ Berry and Chollot [20] ▪ Schneider et al. [10] ▪ Khalil et al. [21] ▪ Hsieh [14] ▪ El Fallah Seghrouchni et al. [2] |
| 3. Intrusion Detection and Security | ▪ Degeler et al. [13] ▪ Joseph and Mukesh [9] ▪ Ahmad et al. [22] ▪ Berry and Chollot [20] ▪ Zhang et al. [6] ▪ Subashini and Kavitha [4] ▪ Colabianchi et al. [23] ▪ Mohammadi et al. [24] |
| 4. Machine Learning and Artificial Intelligence | ▪ Bodrog et al. [2] ▪ Ali-Tolppa et al. [25] ▪ Karim et al. [26] ▪ Ahmad et al. [27] ▪ Tiwari et al. [28] ▪ Yang et al. [29] ▪ Al-juaifari et al. [30] ▪ Bothe et al. [Bothe] |
| 5. Fault Diagnosis and Detection | ▪ Singh et al. [18] ▪ Li and Li [1] ▪ Sejdić et al. [5] ▪ Mohammadi et al. [24] |
| 6. Resilience and Robustness | ▪ Idio et al. [31] ▪ Hahsler et al. [3] ▪ Breiman [32] |
| 7. Survey and Overview of Cyber-physical Systems | ▪ Chen and Bahsoon [17] ▪ Subashini and Kavitha [4] ▪ Mahdavinejad et al. [8] ▪ Samuel and Madria [7] ▪ Zhang et al. [6] |
| Self-Healing Machine-Learning Tools | Model and Framework | Twin Model |
| QoS Model | ||
| Auto-Regressive Moving Average with Exogenous Input Model | ||
| Network Architecture | Strategy Network | |
| Valuation Network | ||
| Fast Decision Network | ||
| Intrusion Detection System | ||
| Phasor Measurement Unit | ||
| Agent Architecture | ||
| Host Intrusion Detection System | ||
| Multi-Area Microgrid | ||
| Algorithms | Monte Carlo Tree Search | |
| Artificial Neural Network | ||
| Supervised Knowledge Base Algorithm | ||
| Genetic Algorithm | ||
| Dynamic Detection Algorithm | ||
| Support Vector Machine | ||
| Naive Bayes | ||
| Random Forest | ||
| DBSCAN Algorithm | ||
| Long Short-Term Memory (LSTM) | ||
| Auto-Regressive Moving Average (ARMA) |
| Usage | Algorithms |
|---|---|
| Sensing | • Support Vector Machine (SVM) • Genetic Algorithm • Dynamic Detection Algorithm |
| Mining | • Supervised Knowledge-Based Algorithm • DBSCAN Algorithm |
| Prediction | • Auto-Regressive Moving Average (ARMA) • Long Short-Term Memory (LSTM) • Multi-Layer Perceptron (MLP) • Naïve Bayes |
| Decision | • Monte Carlo Tree Search • Random Forest |
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa | Mcc | TT (S) | |
|---|---|---|---|---|---|---|---|---|---|
| mlp | MLP classifier | 0.3493 | 0.5215 | 0.3493 | 0.3498 | 0.3327 | 0.0201 | 0.0210 | 0.1620 |
| svm | SVM-Linear Kernel | 0.3357 | 0.0000 | 0.3357 | 0.3007 | 0.2735 | 0.0052 | 0.0047 | 0.0670 |
| rf | Random Forest Classifier | 0.3336 | 0.4965 | 0.3336 | 0.3349 | 0.3334 | −0.0002 | −0.0002 | 0.1950 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Johnphill, O.; Sadiq, A.S.; Al-Obeidat, F.; Al-Khateeb, H.; Taheir, M.A.; Kaiwartya, O.; Ali, M. Self-Healing in Cyber–Physical Systems Using Machine Learning: A Critical Analysis of Theories and Tools. Future Internet 2023, 15, 244. https://doi.org/10.3390/fi15070244
Johnphill O, Sadiq AS, Al-Obeidat F, Al-Khateeb H, Taheir MA, Kaiwartya O, Ali M. Self-Healing in Cyber–Physical Systems Using Machine Learning: A Critical Analysis of Theories and Tools. Future Internet. 2023; 15(7):244. https://doi.org/10.3390/fi15070244
Chicago/Turabian StyleJohnphill, Obinna, Ali Safaa Sadiq, Feras Al-Obeidat, Haider Al-Khateeb, Mohammed Adam Taheir, Omprakash Kaiwartya, and Mohammed Ali. 2023. "Self-Healing in Cyber–Physical Systems Using Machine Learning: A Critical Analysis of Theories and Tools" Future Internet 15, no. 7: 244. https://doi.org/10.3390/fi15070244
APA StyleJohnphill, O., Sadiq, A. S., Al-Obeidat, F., Al-Khateeb, H., Taheir, M. A., Kaiwartya, O., & Ali, M. (2023). Self-Healing in Cyber–Physical Systems Using Machine Learning: A Critical Analysis of Theories and Tools. Future Internet, 15(7), 244. https://doi.org/10.3390/fi15070244