
Synonyms, Antonyms and Factual Knowledge in BERT Heads




Abstract
1. Introduction
- We propose a technique for identifying heads that find relationships among words that are in the same semantic field (synonyms or antonyms) or are related by some real-world knowledge;
- We experimentally verify that different types of relations (such as semantics, geography or medicine) are mostly identified by the same heads across different domains;
- We perform an experimental analysis that shows how the behaviour of these heads is correlated to the model performance in simple question-answering tasks (without access to external knowledge sources) using probing datasets;
- We show how semantic knowledge is not strongly influenced by the overall context of the sentence and is robust to different types of prompts and contexts.
2. Background and Related Work
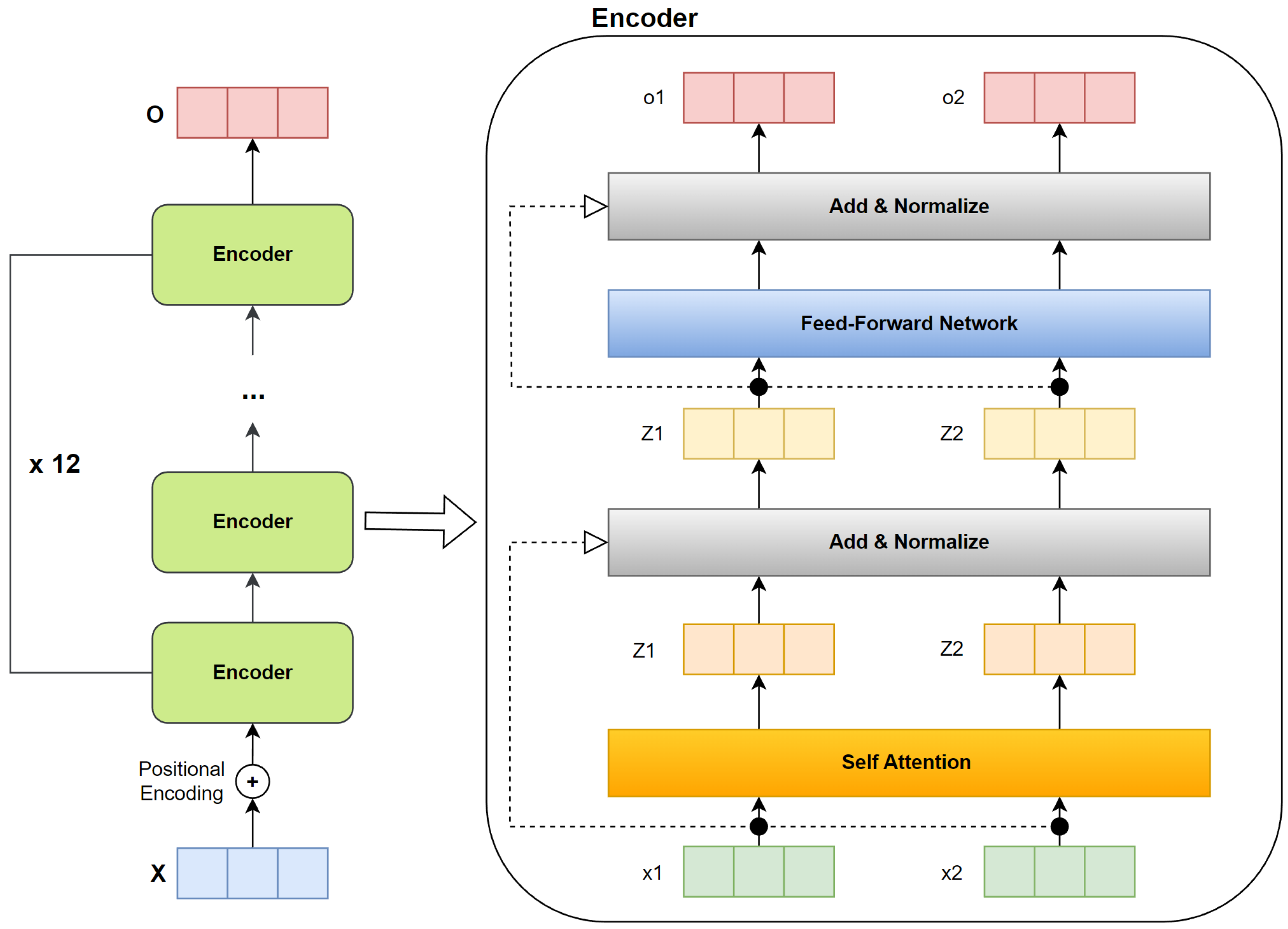
2.1. BERT
2.2. Related Work
3. Methodology
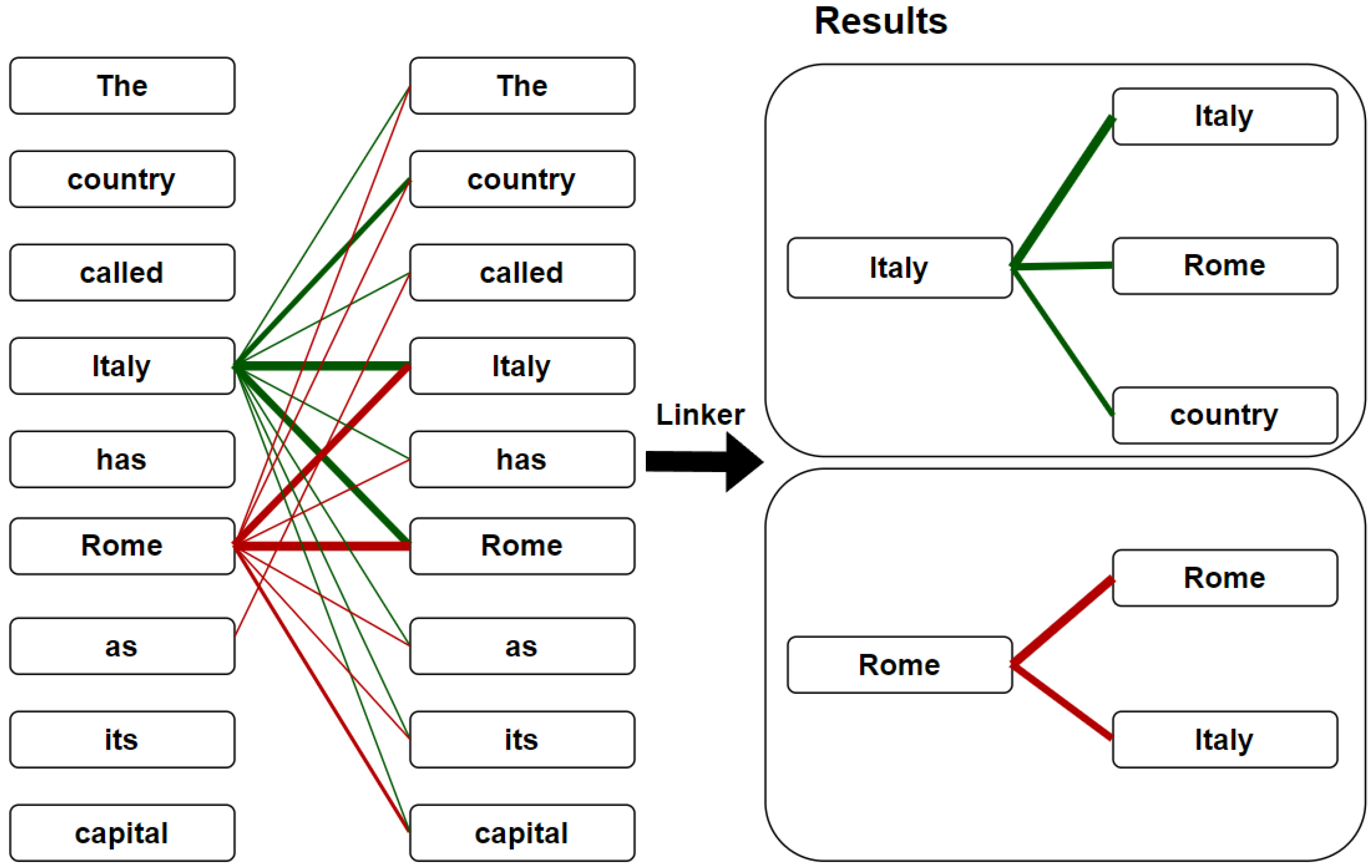
- For each head we have identified, we extract which pairs of tokens have the highest weights assigned by the head. This is conducted with a custom-made algorithm (the Linker Algorithm).
- We compare these pairs of tokens with some ground truth pairs. More specifically, we aim to verify whether a head (or a specific group of heads) is able to capture if two words are related by some semantic or factual knowledge, such as the one between the synonyms important and meaningful, or the state–capital relation between Paris and France. We claim that, if a head gives an high attention weight specifically to these pairs of words considering different examples, then it is able to capture such knowledge.
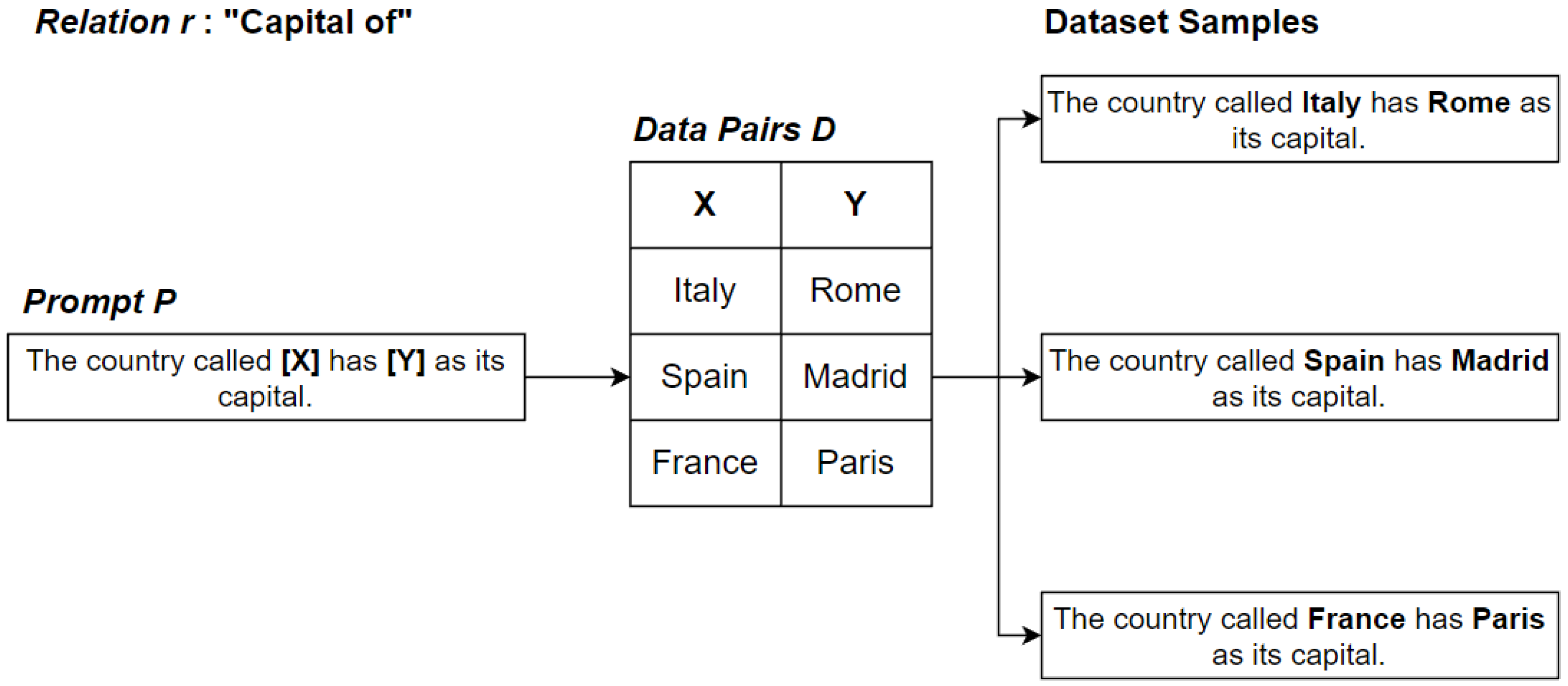
3.1. Dataset Structure
3.2. Self Metric
3.3. Linker Algorithm
3.4. Evaluation Metrics
4. Case Studies
4.1. Semantic Knowledge
- Synonyms: we took the dataset containing synonyms from Kaggle (https://www.kaggle.com/datasets/duketemon/wordnet-synonyms accessed on 26 June 2023), which is based on WordNet [27]. We randomly selected 250 synonym pairs and filled the prompt: “If you would ask me to describe it I could say that it is [X], or, in other words, it is [Y]”, replacing the [X] and [Y] with a word and its synonym. For example, a pair of synonyms is (frigid, cold).
- Antonyms: Similarly to the procedure we used for the Synonyms, we took the WordNet-based antonyms dataset from Kaggle (https://www.kaggle.com/datasets/duketemon/antonyms-wordnet accessed on 26 June 2023) and we randomly selected 250 antonym pairs considering the prompt “You described it as [Y], but I would say that it is the opposite, I would describe it as [X]”, replacing the [X] and [Y] with a word and its antonym. For example, a pair of antonyms is (hot, cold).
4.2. Real-World Factual Knowledge
- States and Capitals: we created a dataset using state–capital pairs that can be commonly found on the Internet. In order to simplify the analysis of the relationship based on attention, we took only the pairs where both capital and nation names were one word long in order to have precise word pairs to compare with the ground truth labels. Thus, we created a dataset of 159 sentences based on the state–capital pairs and the prompt “The country called [X] has the city of [Y] as its capital”. For example, a pair state–capital is (Italy, Rome).
- Locations: we used some entities included in the T-REX dataset [12], containing a state and a well-known place belonging to that state. As we did for the States and Capitals, we consider one-word entities. The dataset is created from 95 sentences and exploits the prompt “[X] is a place of great fame and it is located in the country of [Y]”. For example, a relation location nation is (Catalonia, Spain).
- Belongs to: this dataset is based on the T-REX dataset and contains pairs made by a concept and a more general category to which the concept belongs. It is made by 220 sentences with the prompt “As we all know [X] belongs to the bigger category of [Y]”. For instance, it contains the relation (Champagne, Wine).
- Part of: this dataset contains pairs of sets, into which one is a subset of the other. It contains 260 sentences with the prompt “It has been proven that [X] is a specific part of [Y]”. For example, it contains the relation (Torah, Bible). Although this dataset is quite similar to the previous one (also based on T-REX), please note that we used a completely different prompt for better generalization.
- Medicine: this dataset contains pairs (which are commonly available online) of drugs and medical conditions treated by them. It contains 100 sentences and it exploits the prompt “The medicine [X] is commonly used for the treatment of [Y] and other medical conditions”. For example, it contains the relation (Aspirine, Inflammation).
5. Experimental Settings and Evaluation
- bert-base-uncased (https://huggingface.co/bert-base-uncased accessed on 26 June 2023), a BERT English model insensitive to capital letters [1];
- bert-base-cased (https://huggingface.co/bert-base-cased accessed on 26 June 2023), a BERT English model sensitive to capital letters [1];
- bert-base-multilingual-cased (https://huggingface.co/bert-base-multilingual-cased accessed on 26 June 2023), a multilingual BERT model [1];
- bluebert (https://huggingface.co/bionlp/bluebert_pubmed_uncased_L-12_H-768_A-12 accessed on 26 June 2023), an uncased BERT model training on a generic corpus and on medical documents [2].
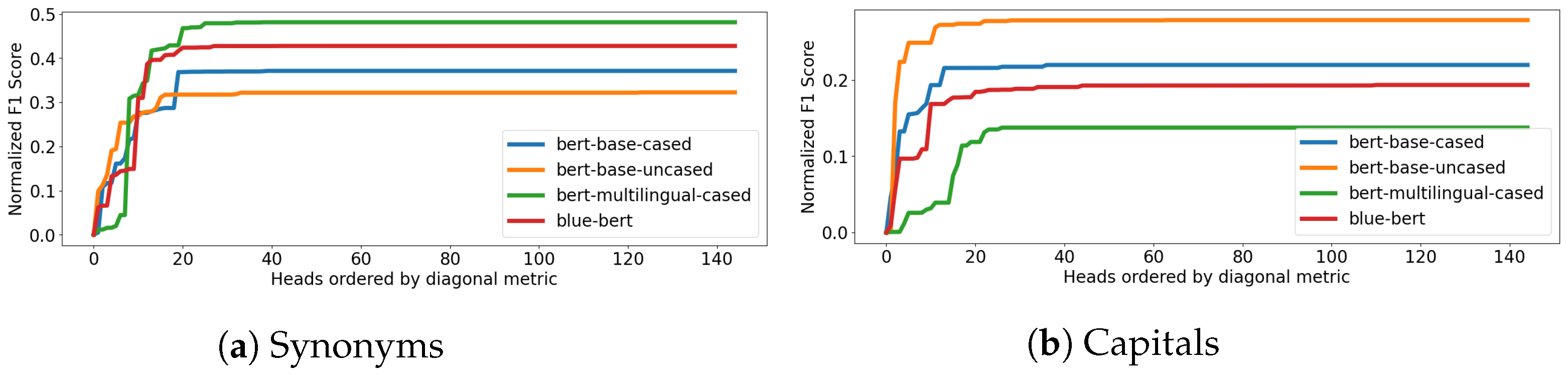
5.1. Experimental Results
5.2. Robustness to Different Prompts
- I could describe it as [X], or, to put it another way, it is [Y].
- If I had to put it into words, I would say it is [X], or, to use a synonym, it is [Y].
- You might call it [X], but I would describe it as [Y]—they are essentially synonyms.
- In my opinion, it is [X], or, to use a similar term, it is [Y].
- If you were to ask me for a word to describe it, I might choose [X], or, to put it synonymously, [Y].
- You used the term [X], but I would argue that it is actually quite the opposite. I would describe it as [Y].
- While you described it as [X], I believe that it is actually the antithesis. I would say it is [Y].
- Your description of it as [X] does not quite fit; I think the antonym is more accurate. I would label it as [Y].
- Although you referred to it as [X], I think there is a more fitting antonym. I would say it is [Y].
- Your characterization of it as [X] does not match my perception; the opposite seems more appropriate. I would describe it as [Y].
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar]
- Peng, Y.; Yan, S.; Lu, Z. Transfer Learning in Biomedical Natural Language Processing: An Evaluation of BERT and ELMo on Ten Benchmarking Datasets. In Proceedings of the 2019 Workshop on Biomedical Natural Language Processing (BioNLP 2019), Florence, Italy, 1 August 2019; pp. 58–65. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Tenney, I.; Das, D.; Pavlick, E. BERT Rediscovers the Classical NLP Pipeline. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Miaschi, A.; Brunato, D.; Dell’Orletta, F.; Venturi, G. Linguistic Profiling of a Neural Language Model. In Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), 8–13 December 2020; International Committee on Computational Linguistics: Cedarville, OH, USA, 2020; pp. 745–756. [Google Scholar]
- Jawahar, G.; Sagot, B.; Seddah, D. What Does BERT Learn about the Structure of Language? In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; Volume 1: Long Papers, pp. 3651–3657. [Google Scholar]
- Lenci, A.; Sahlgren, M.; Jeuniaux, P.; Gyllensten, A.C.; Miliani, M. A comparative evaluation and analysis of three generations of Distributional Semantic Models. Lang. Resour. Eval. 2022, 56, 1269–1313. [Google Scholar] [CrossRef]
- Jiang, Z.; Xu, F.F.; Araki, J.; Neubig, G. How Can We Know What Language Models Know. Trans. Assoc. Comput. Linguist. 2020, 8, 423–438. [Google Scholar] [CrossRef]
- Petroni, F.; Lewis, P.S.H.; Piktus, A.; Rocktäschel, T.; Wu, Y.; Miller, A.H.; Riedel, S. How Context Affects Language Models’ Factual Predictions. In Proceedings of the Conference on Automated Knowledge Base Construction, AKBC 2020, Virtual, 22–24 June 2020; Das, D., Hajishirzi, H., McCallum, A., Singh, S., Eds.; Association of Computational Linguistics: Cedarville, OH, USA, 2020. [Google Scholar] [CrossRef]
- Petroni, F.; Rocktäschel, T.; Riedel, S.; Lewis, P.S.H.; Bakhtin, A.; Wu, Y.; Miller, A.H. Language Models as Knowledge Bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 2463–2473. [Google Scholar] [CrossRef]
- Elazar, Y.; Kassner, N.; Ravfogel, S.; Ravichander, A.; Hovy, E.H.; Schütze, H.; Goldberg, Y. Measuring and Improving Consistency in Pretrained Language Models. Trans. Assoc. Comput. Linguist. 2021, 9, 1012–1031. [Google Scholar] [CrossRef]
- ElSahar, H.; Vougiouklis, P.; Remaci, A.; Gravier, C.; Hare, J.S.; Laforest, F.; Simperl, E. T-REx: A Large Scale Alignment of Natural Language with Knowledge Base Triples. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation, LREC 2018, Miyazaki, Japan, 7–12 May 2018; Calzolari, N., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Hasida, K., Isahara, H., Maegaard, B., Mariani, J., Mazo, H., et al., Eds.; European Language Resources Association (ELRA): Paris, France, 2018. [Google Scholar]
- Rogers, A.; Kovaleva, O.; Rumshisky, A. A Primer in BERTology: What We Know About How BERT Works. Trans. Assoc. Comput. Linguist. 2020, 8, 842–866. [Google Scholar] [CrossRef]
- Clark, K.; Khandelwal, U.; Levy, O.; Manning, C.D. What Does BERT Look at? An Analysis of BERT’s Attention. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, BlackboxNLP@ACL 2019, Florence, Italy, 1 August 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 276–286. [Google Scholar]
- Kovaleva, O.; Romanov, A.; Rogers, A.; Rumshisky, A. Revealing the Dark Secrets of BERT. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 4364–4373. [Google Scholar]
- Vig, J. A Multiscale Visualization of Attention in the Transformer Model. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; Volume 3: System Demonstrations, pp. 37–42. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; NeurIPS Foundation, Inc.: San Diego, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Arici, N.; Gerevini, A.E.; Putelli, L.; Serina, I.; Sigalini, L. A BERT-Based Scoring System for Workplace Safety Courses in Italian. In Proceedings of the AIxIA 2022—Advances in Artificial Intelligence—XXIst International Conference of the Italian Association for Artificial Intelligence, AIxIA 2022, Udine, Italy, 28 November–2 December 2022; Dovier, A., Montanari, A., Orlandini, A., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2022; Volume 13796, pp. 457–471. [Google Scholar]
- Kassner, N.; Dufter, P.; Schütze, H. Multilingual LAMA: Investigating Knowledge in Multilingual Pretrained Language Models. arXiv 2021, arXiv:2102.00894. [Google Scholar]
- Dai, D.; Dong, L.; Hao, Y.; Sui, Z.; Chang, B.; Wei, F. Knowledge Neurons in Pretrained Transformers. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2022; pp. 8493–8502. [Google Scholar] [CrossRef]
- Anelli, V.W.; Biancofiore, G.M.; De Bellis, A.; Di Noia, T.; Di Sciascio, E. Interpretability of BERT Latent Space through Knowledge Graphs. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; CIKM ’22. pp. 3806–3810. [Google Scholar] [CrossRef]
- Putelli, L.; Gerevini, A.E.; Lavelli, A.; Mehmood, T.; Serina, I. On the Behaviour of BERT’s Attention for the Classification of Medical Reports. In Proceedings of the 3rd Italian Workshop on Explainable Artificial Intelligence Co-Located with 21th International Conference of the Italian Association for Artificial Intelligence (AIxIA 2022), Udine, Italy, 28 November–3 December 2022; Musto, C., Guidotti, R., Monreale, A., Semeraro, G., Eds.; CEUR Workshop Proceedings: Aachen, Germany; Volume 3277, pp. 16–30. [Google Scholar]
- Putelli, L.; Gerevini, A.E.; Lavelli, A.; Olivato, M.; Serina, I. Deep Learning for Classification of Radiology Reports with a Hierarchical Schema. In Proceedings of the Knowledge-Based and Intelligent Information & Engineering Systems: 24th International Conference KES-2020, Virtual Event, 16–18 September 2020; Cristani, M., Toro, C., Zanni-Merk, C., Howlett, R.J., Jain, L.C., Eds.; Procedia Computer Science. Elsevier: Amsterdam, The Netherlands, 2020; Volume 176, pp. 349–359. [Google Scholar]
- Putelli, L.; Gerevini, A.E.; Lavelli, A.; Maroldi, R.; Serina, I. Attention-Based Explanation in a Deep Learning Model For Classifying Radiology Reports. In Proceedings of the Artificial Intelligence in Medicine—19th International Conference on Artificial Intelligence in Medicine, AIME 2021, Virtual Event, 15–18 June 2021; Tucker, A., Abreu, P.H., Cardoso, J.S., Rodrigues, P.P., Riaño, D., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2021; Volume 12721, pp. 367–372. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean Shift: A Robust Approach Toward Feature Space Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Ghassabeh, Y.A. On the convergence of the mean shift algorithm in the one-dimensional space. Pattern Recognit. Lett. 2013, 34, 1423–1427. [Google Scholar] [CrossRef]
- Princeton University. Princeton University, About Wordnet. 2010. Available online: https://wordnet.princeton.edu/ (accessed on 26 June 2023).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) Bert-Base-Uncased | ||||||
| Synonyms | Antonyms | Capitals | Locations | Part of | Belogns to | Medical |
| (3,7) | (3,7) | (3,7) | (3,7) | (3,7) | (12,9) | (3,7) |
| (12,9) | (12,9) | (12,9) | (12,9) | (12,9) | (3,7) | (12,9) |
| (4,1) | (11,11) | (2,12) | (2,12) | (2,12) | (2,12) | (2,12) |
| (2,12) | (11,10) | (11,10) | (11,10) | (11,10) | (11,11) | (4,1) |
| (11,10) | (2,12) | (11,11) | (4,1) | (11,10) | (11,10) | (11,10) |
| (b) Bert-Base-Cased | ||||||
| Synonyms | Antonyms | Capitals | Locations | Part of | Belogns to | Medical |
| (12,4) | (12,4) | (12,4) | (12,4) | (12,2) | (12,4) | (12,4) |
| (12,12) | (12,12) | (12,12) | (12,12) | (12,4) | (12,12) | (12,12) |
| (4,8) | (4,8) | (12,3) | (12,3) | (12,3) | (12,3) | (12,3) |
| (12,3) | (12,3) | (4,8) | (4,8) | (4,8) | (11,3) | (4,8) |
| (5,1) | (5,1) | (10,2) | (3,6) | (3,3) | (3,6) | (3,6) |
| Model | Synonyms | Antonyms | Capitals | Locations | ||||
| bert-base-uncased | 0.84 | 0.82 | 0.77 | 0.76 | 0.85 | 0.84 | 0.97 | 0.97 |
| bert-base-cased | 0.84 | 0.80 | 0.76 | 0.76 | 0.87 | 0.86 | 0.94 | 0.94 |
| bert-multilingual-cased | 0.84 | 0.79 | 0.77 | 0.74 | 0.84 | 0.82 | 0.90 | 0.62 |
| bluebert | 0.84 | 0.81 | 0.77 | 0.77 | 0.87 | 0.81 | 0.93 | 0.90 |
| Model | Belongs to | Part of | Medical | |||||
| bert-base-uncased | 0.91 | 0.75 | 0.82 | 0.68 | 0.87 | 0.69 | ||
| bert-base-cased | 0.91 | 0.52 | 0.81 | 0.75 | 0.88 | 0.21 | ||
| bert-multilingual-cased | 0.91 | 0.67 | 0.81 | 0.53 | 0.87 | 0.46 | ||
| bluebert | 0.91 | 0.70 | 0.82 | 0.56 | 0.88 | 0.79 | ||
| (a) Synonyms | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | Prompt 1 | Prompt 2 | Prompt 3 | Prompt 4 | Prompt 5 | |||||
| bert-base-uncased | 0.9 | 0.8 | 0.9 | 0.83 | 0.9 | 0.88 | 0.9 | 0.85 | 0.9 | 0.88 |
| bert-base-cased | 0.88 | 0.83 | 0.90 | 0.80 | 0.90 | 0.78 | 0.90 | 0.85 | 0.90 | 0.88 |
| bert-multilingual-cased | 0.90 | 0.83 | 0.90 | 0.78 | 0.90 | 0.83 | 0.90 | 0.83 | 0.90 | 0.90 |
| bluebert | 0.88 | 0.75 | 0.90 | 0.90 | 0.90 | 0.78 | 0.90 | 0.85 | 0.88 | 0.88 |
| (b) Antonyms | ||||||||||
| Model | Prompt 1 | Prompt 2 | Prompt 3 | Prompt 4 | Prompt 5 | |||||
| bert-base-uncased | 0.9 | 0.8 | 0.9 | 0.83 | 0.9 | 0.88 | 0.9 | 0.85 | 0.9 | 0.88 |
| bert-base-cased | 0.83 | 0.55 | 0.83 | 0.60 | 0.83 | 0.60 | 0.83 | 0.63 | 0.83 | 0.63 |
| bert-multilingual-cased | 0.83 | 0.78 | 0.83 | 0.75 | 0.83 | 0.78 | 0.83 | 0.83 | 0.83 | 0.80 |
| bluebert | 0.80 | 0.80 | 0.80 | 0.78 | 0.80 | 0.78 | 0.80 | 0.78 | 0.80 | 0.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Serina, L.; Putelli, L.; Gerevini, A.E.; Serina, I. Synonyms, Antonyms and Factual Knowledge in BERT Heads. Future Internet 2023, 15, 230. https://doi.org/10.3390/fi15070230
Serina L, Putelli L, Gerevini AE, Serina I. Synonyms, Antonyms and Factual Knowledge in BERT Heads. Future Internet. 2023; 15(7):230. https://doi.org/10.3390/fi15070230
Chicago/Turabian StyleSerina, Lorenzo, Luca Putelli, Alfonso Emilio Gerevini, and Ivan Serina. 2023. "Synonyms, Antonyms and Factual Knowledge in BERT Heads" Future Internet 15, no. 7: 230. https://doi.org/10.3390/fi15070230
APA StyleSerina, L., Putelli, L., Gerevini, A. E., & Serina, I. (2023). Synonyms, Antonyms and Factual Knowledge in BERT Heads. Future Internet, 15(7), 230. https://doi.org/10.3390/fi15070230