
Hybridizing Fuzzy String Matching and Machine Learning for Improved Ontology Alignment



Abstract
1. Introduction
- The development of a novel method that considers both the lexical and semantic features of ontologies in the alignment process to address the limitations of fuzzy string-matching algorithms,
- The use of deep learning and machine learning regression models to improve ontology alignment results, thereby demonstrating the potential of machine learning in enhancing performance in the field of ontology alignment, and
- The accomplishment of a thorough and detailed performance analysis of the proposed method against state-of-the-art alignment systems in the OAEI 2022 ontology alignment challenge.
2. Related Work
3. Preliminaries
3.1. Fuzzy String Matching
3.1.1. Jaro–Winkler
3.1.2. Jaccard Similarity
3.1.3. Levenshtein Distance
3.1.4. Longest Common Subsequence
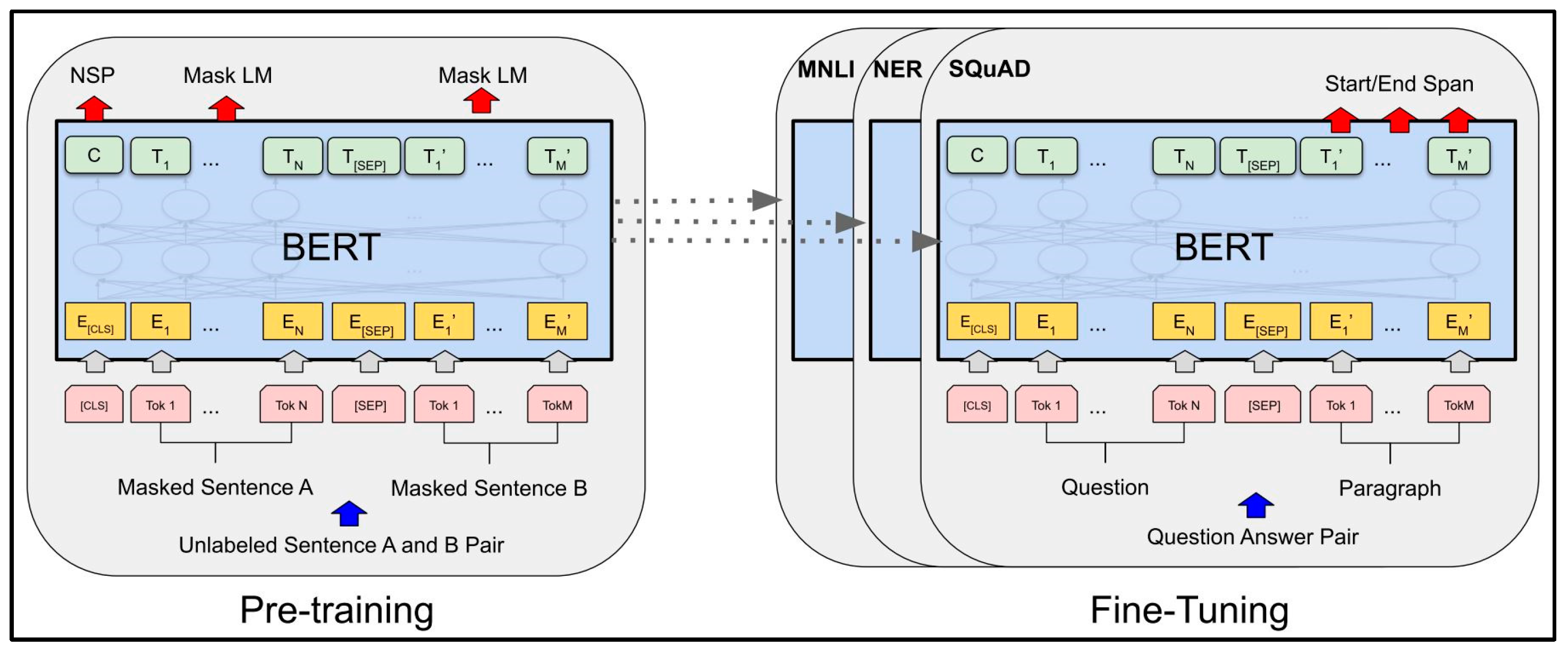
3.2. Bidirectional Encoder Representations from Transformers
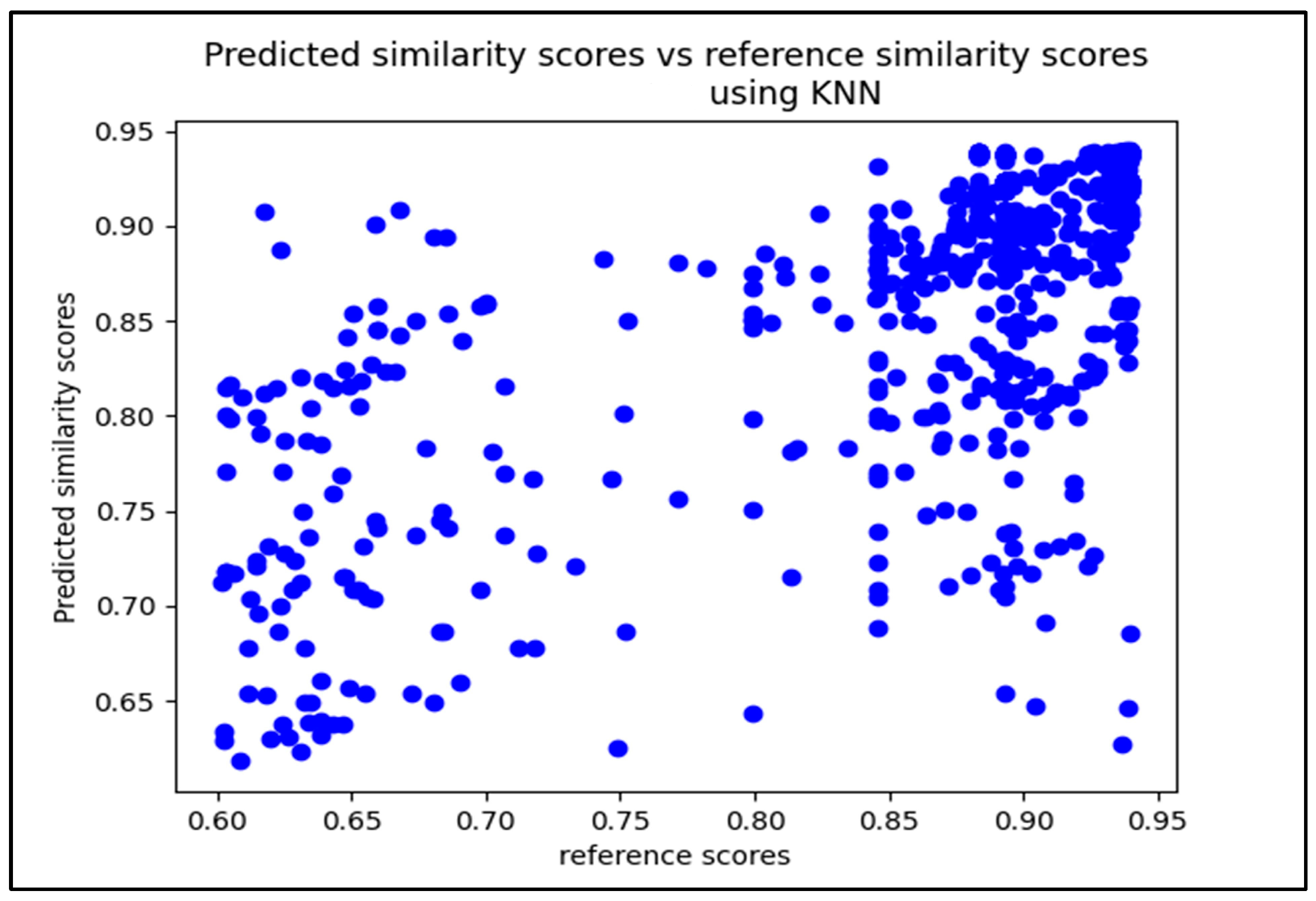
3.3. K-Nearest Neighbour Regression (kNN)
3.4. Support Vector Regression
3.5. Decision Tree Regression
3.6. Evaluation Metrics
3.6.1. Confusion Matrix and Thresholds
3.6.2. Precision
3.6.3. Recall
3.6.4. F1-Score
3.6.5. Accuracy
3.6.6. Mean Square Error (MSE) and Root Mean Square Error (RMSE)
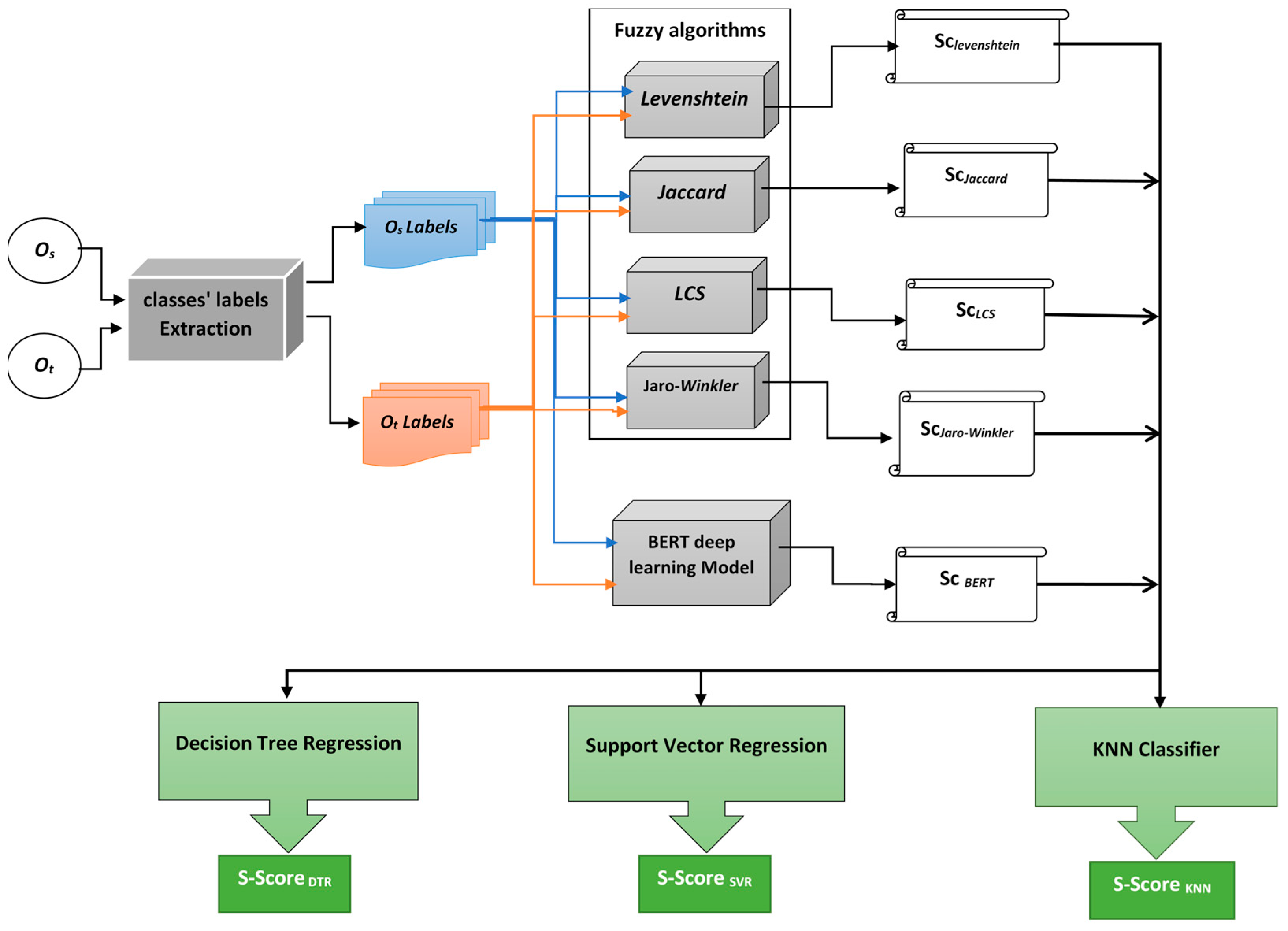
4. Proposed Method
| Algorithm 1: Hybridizing fuzzy string matching and BERT using regression classifiers |
|
5. Experimental Results and Discussion
5.1. Performancee Evaluation of Fuzzy String-Matching Algorithms and BERT
5.2. Performance of SM-kNN, SM-SVR, and SM-DTR Models
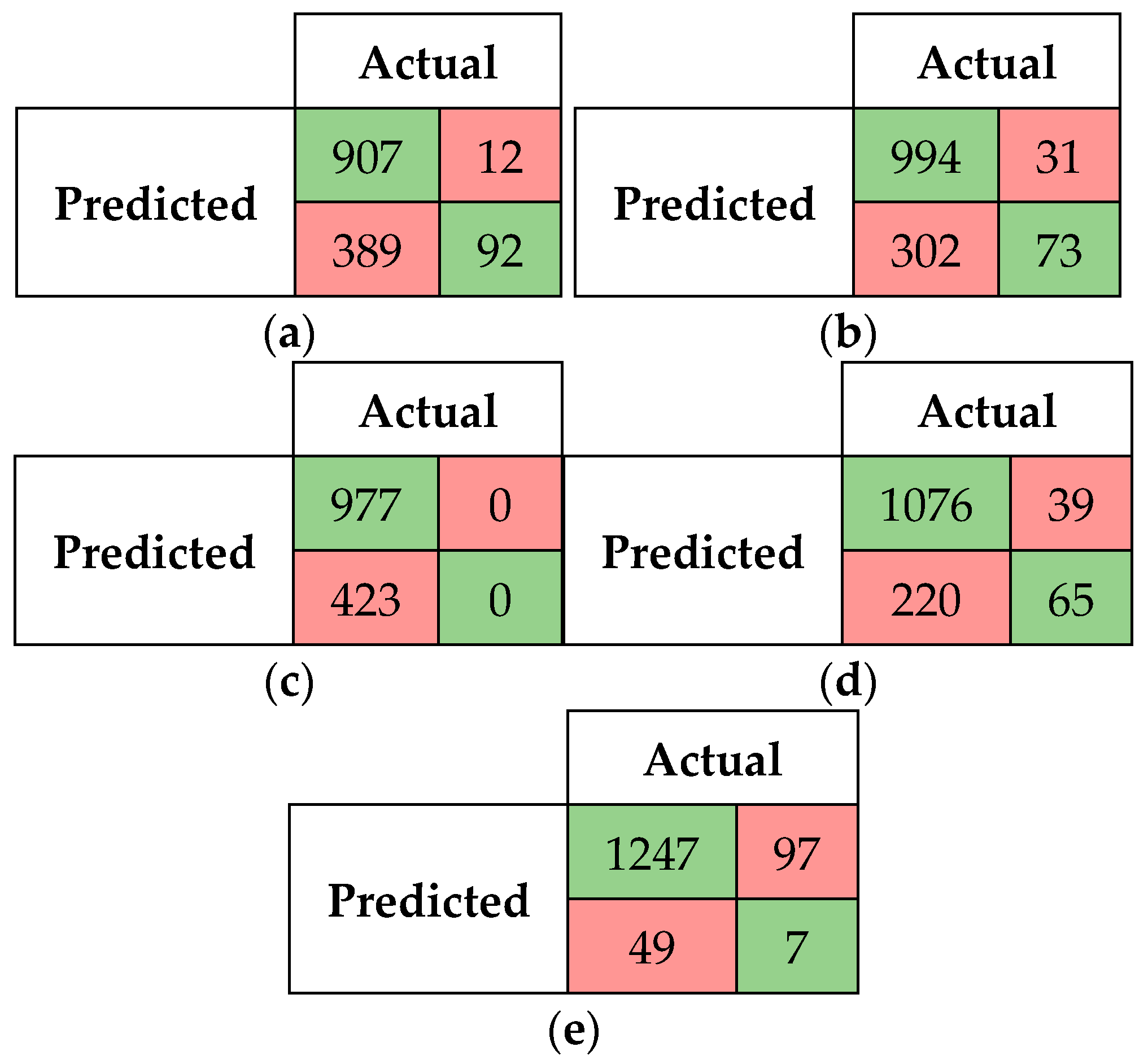
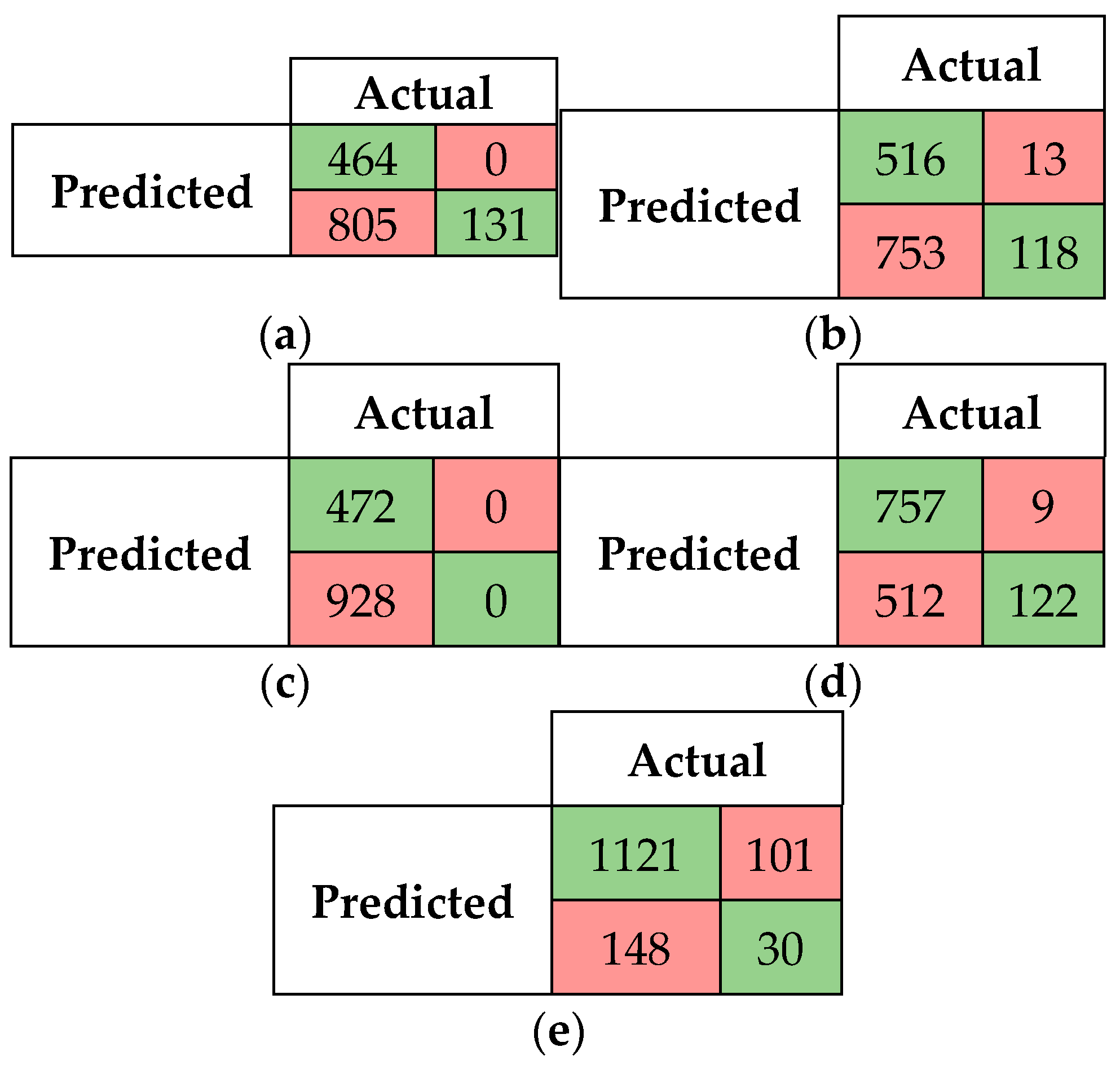
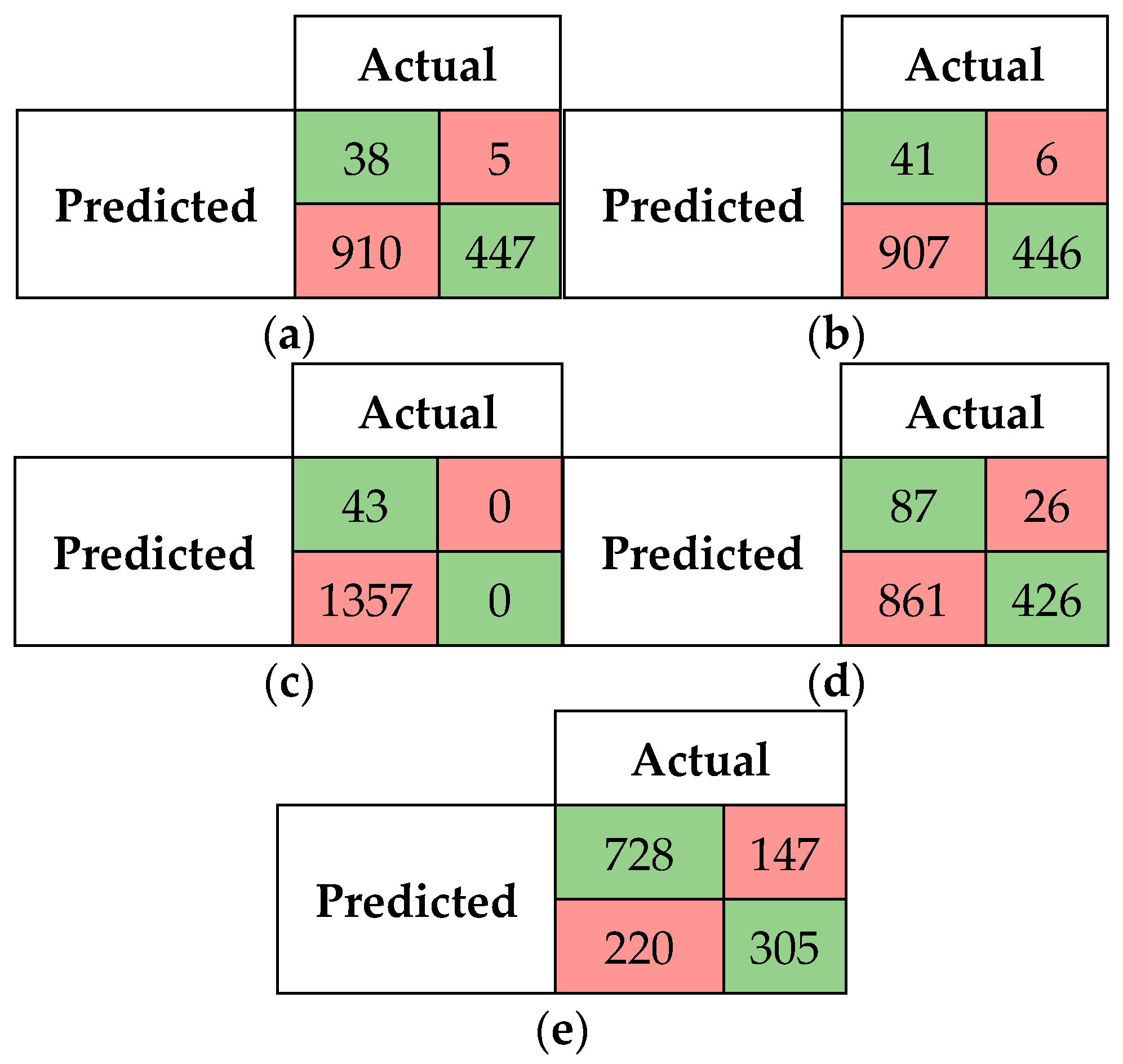
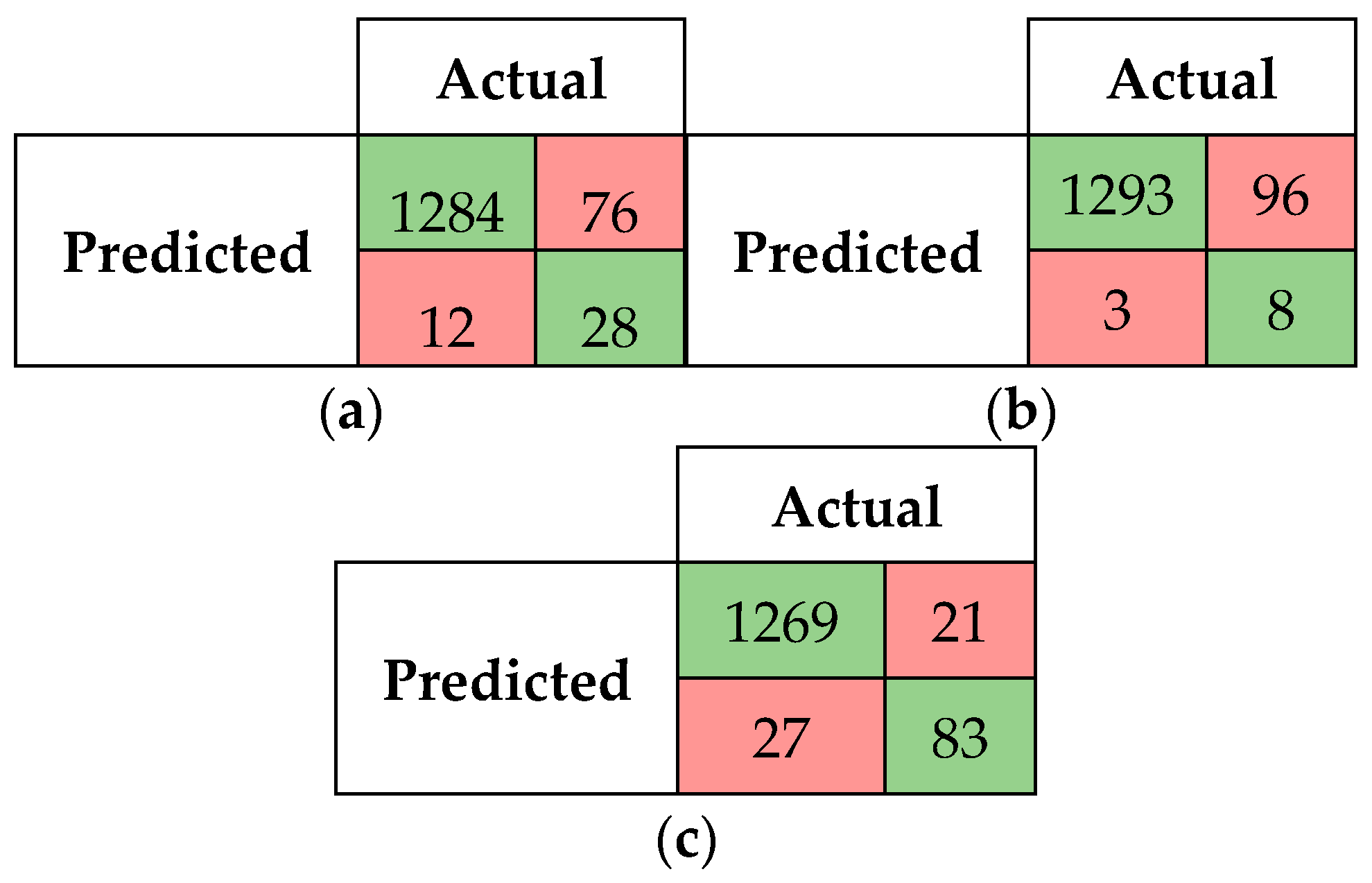
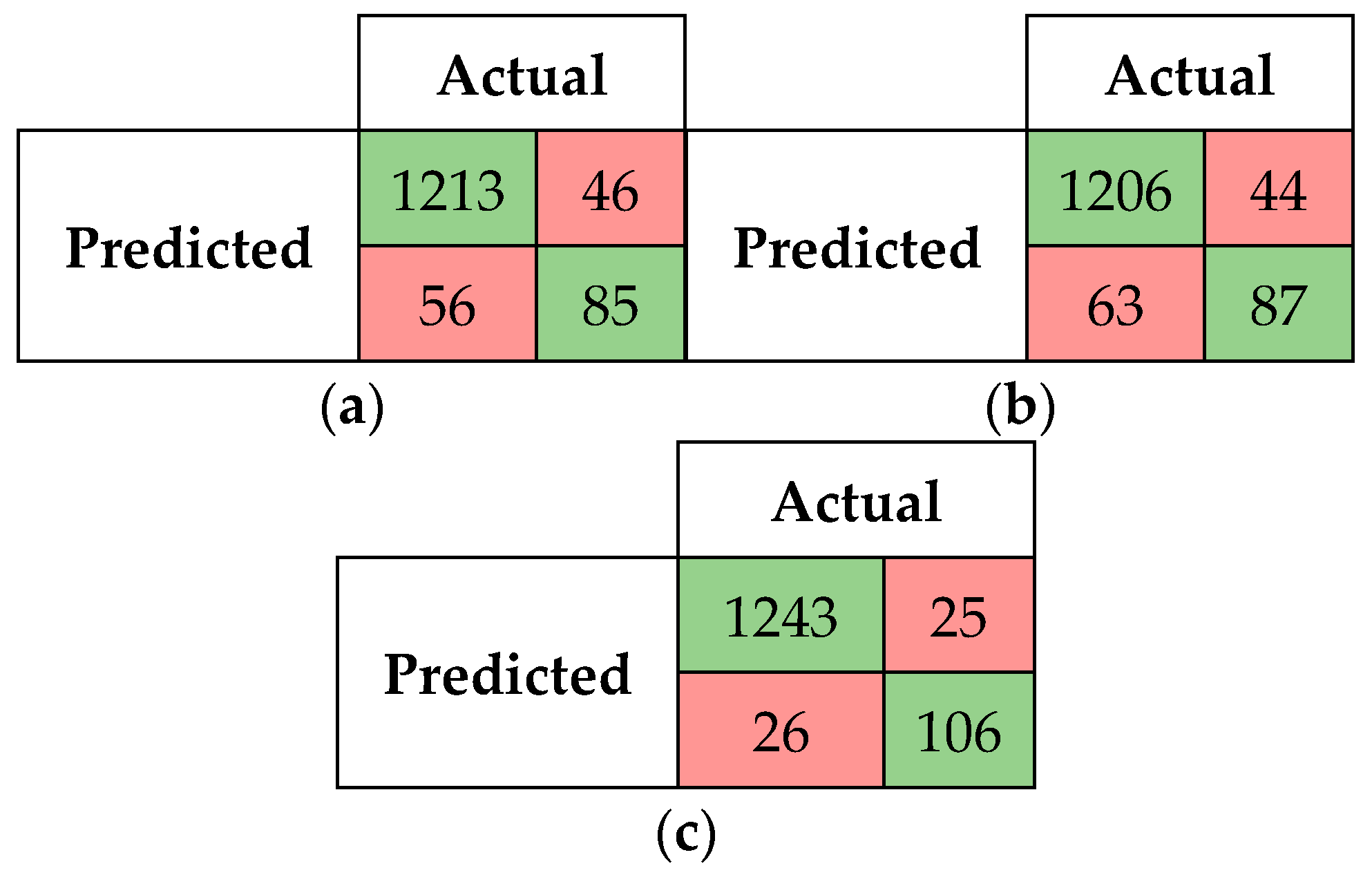
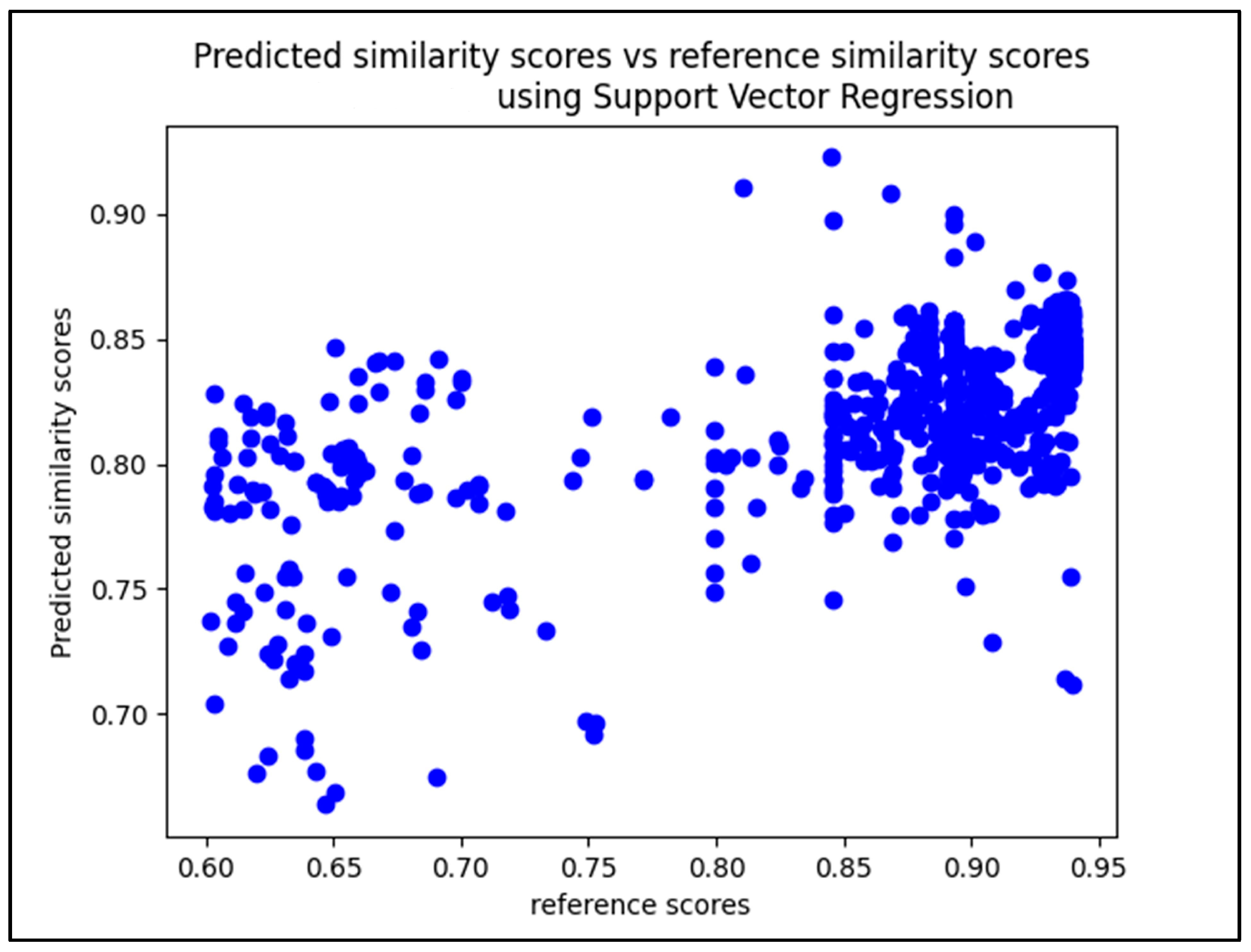
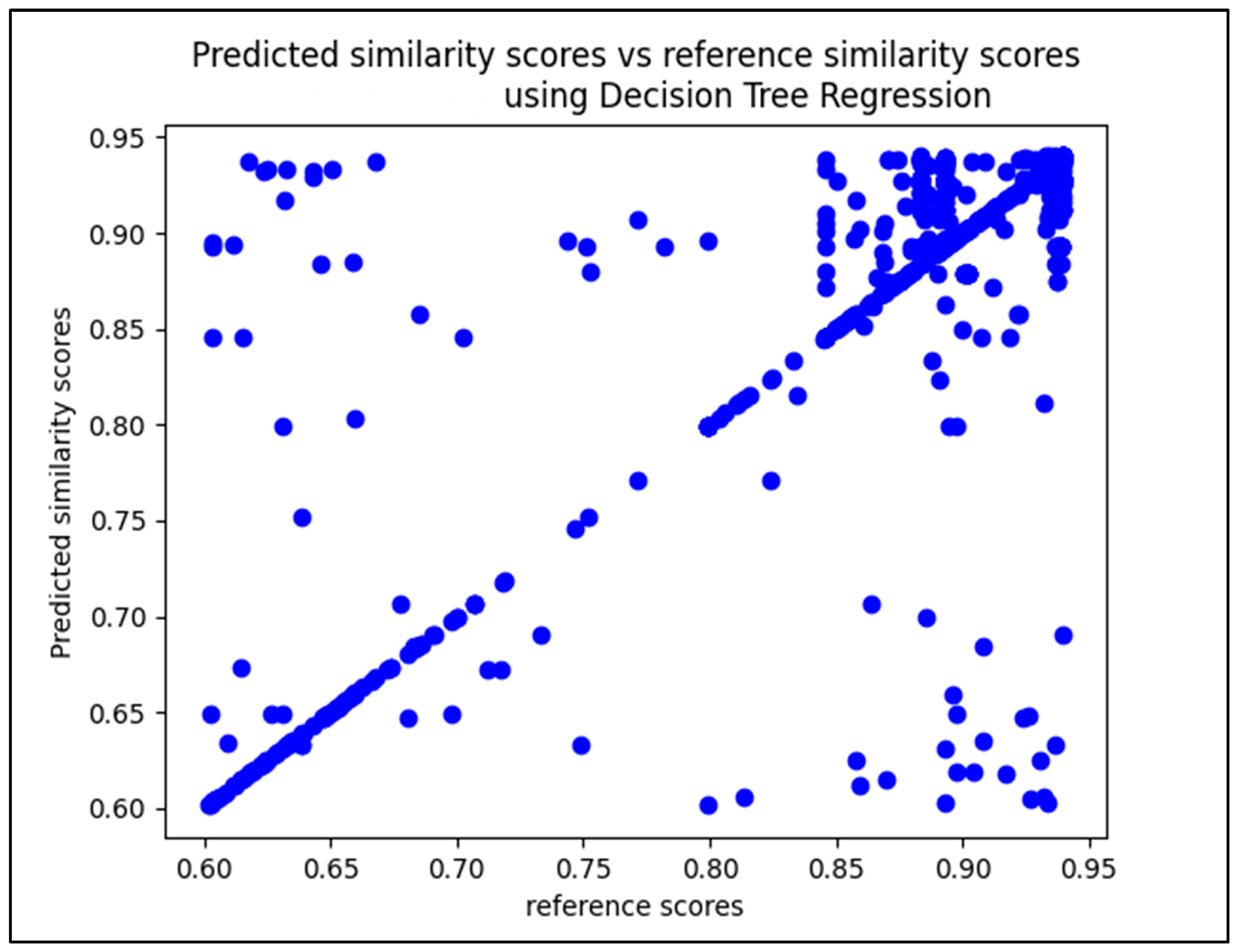
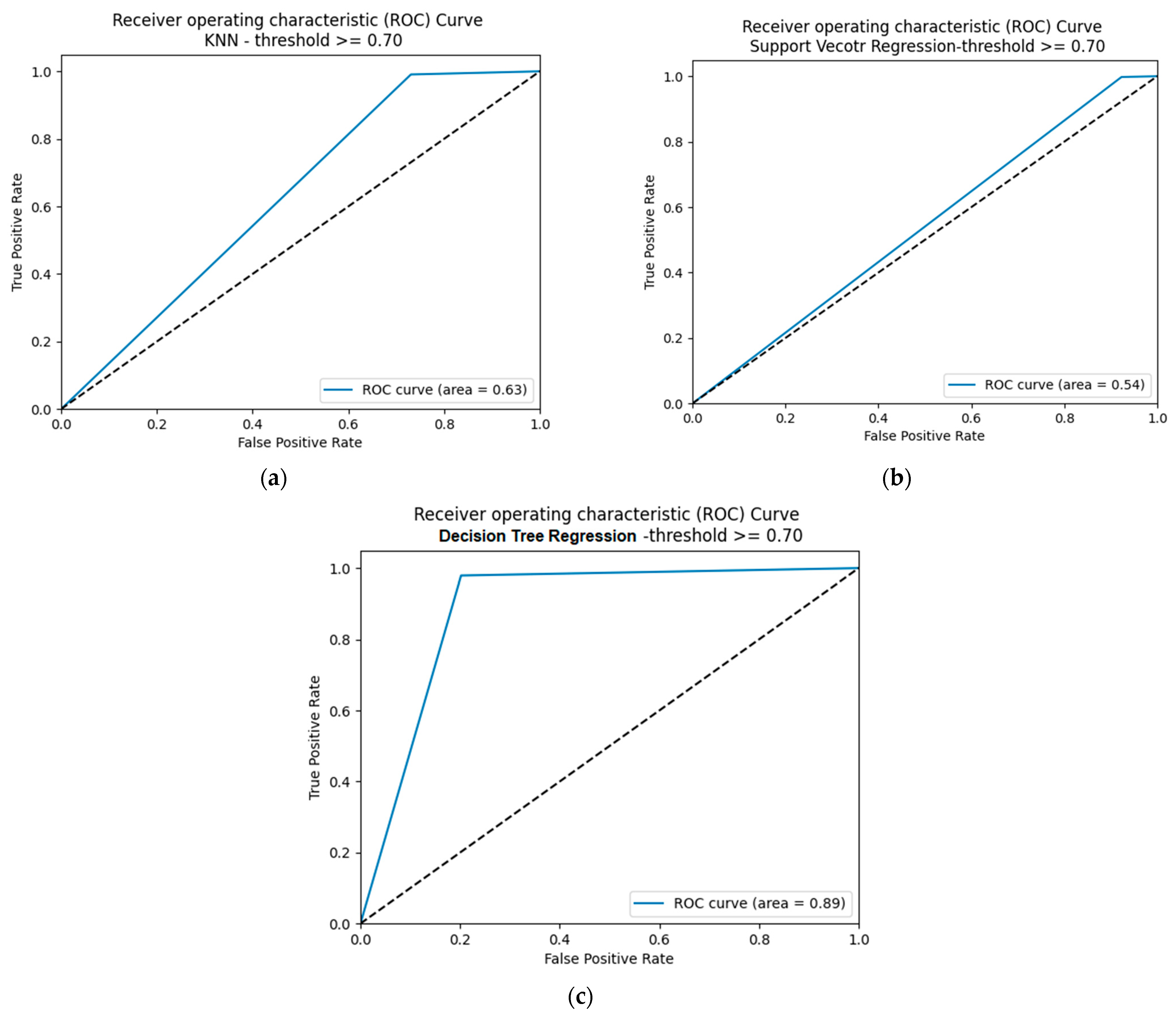
5.2.1. Confusion Matrices and Visual Presentation of the Proposed Model’s Performance
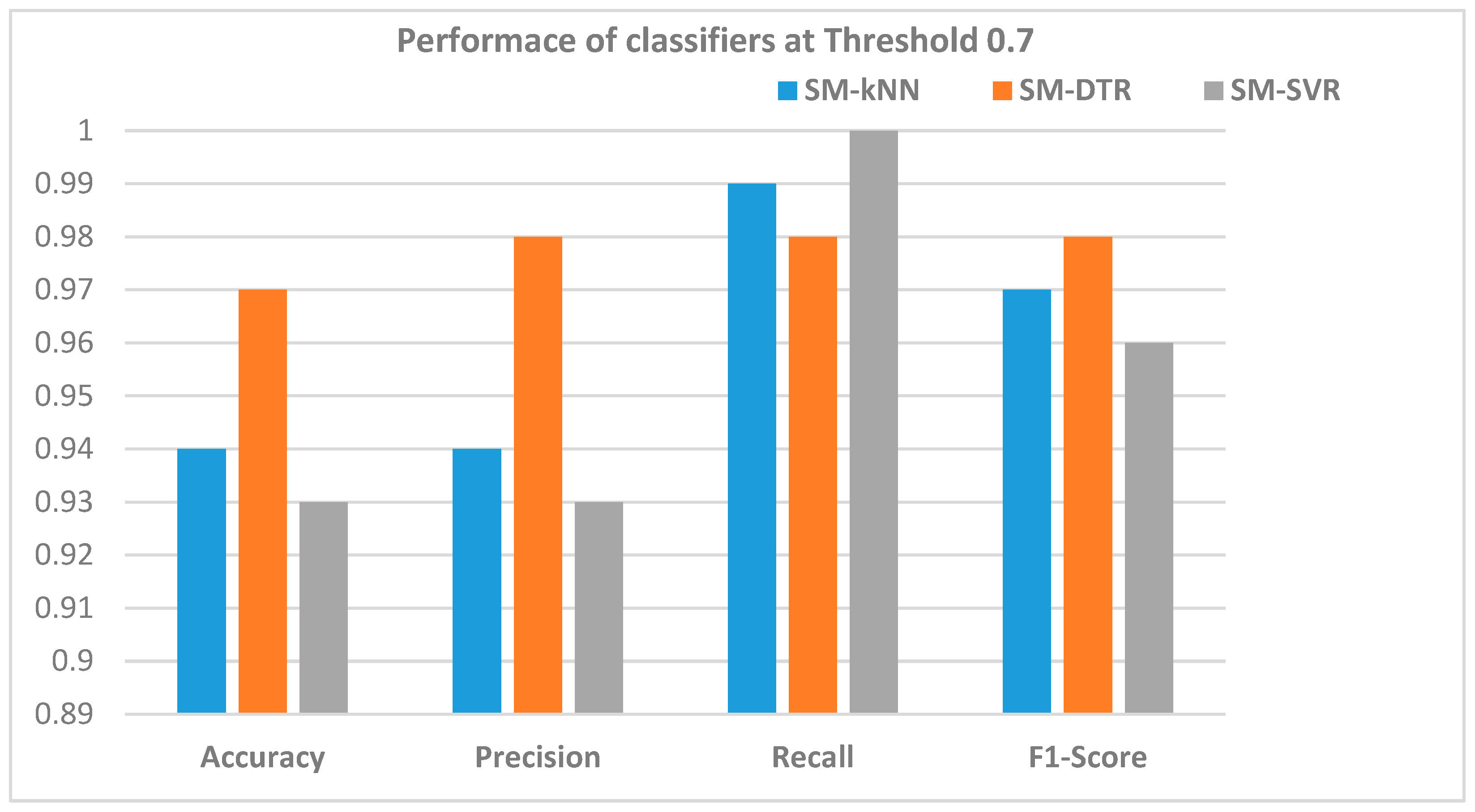
5.2.2. Performance of the SM-kNN, SM-SVR, and SM-DTR Models at Threshold 0.70
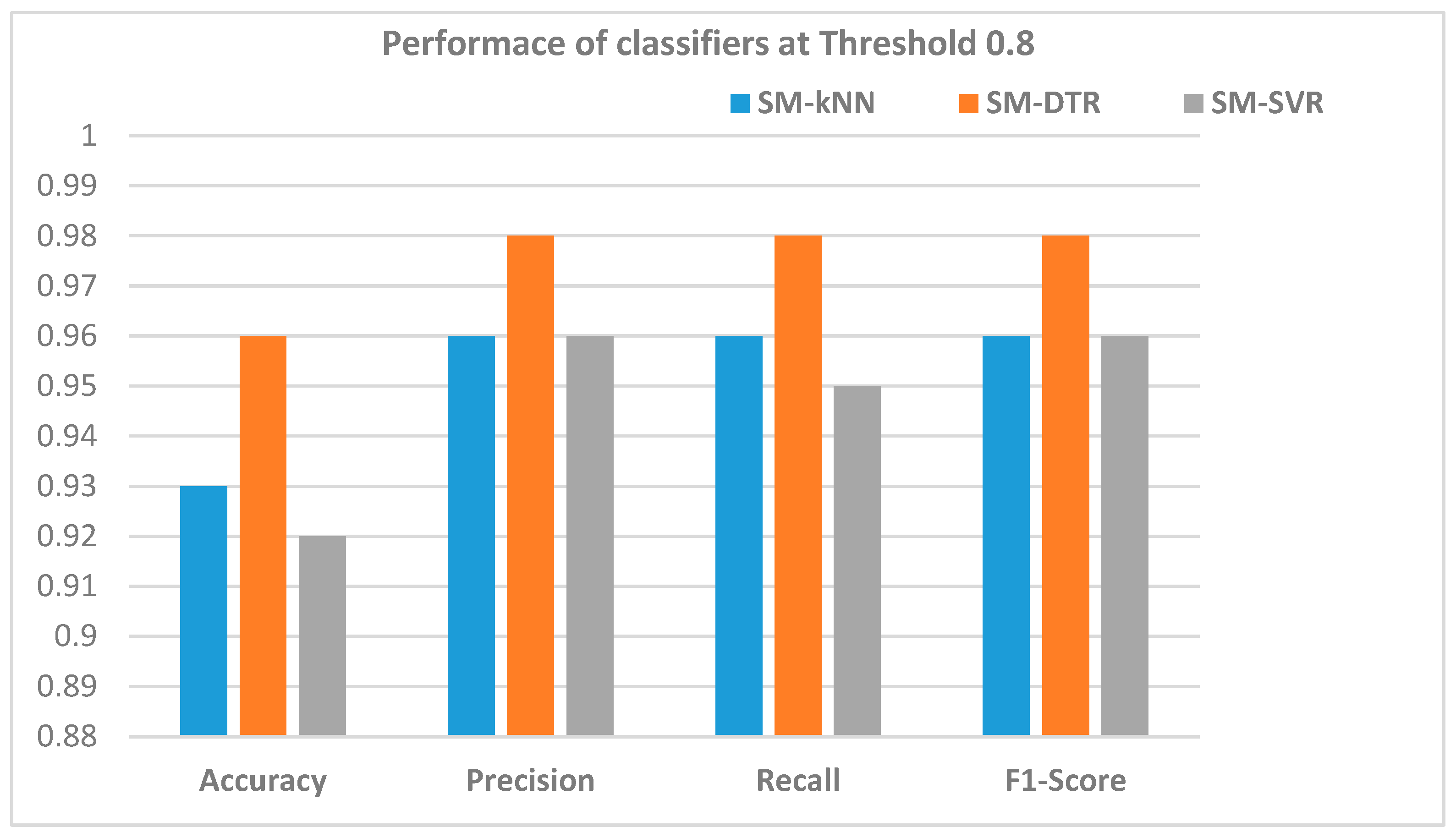
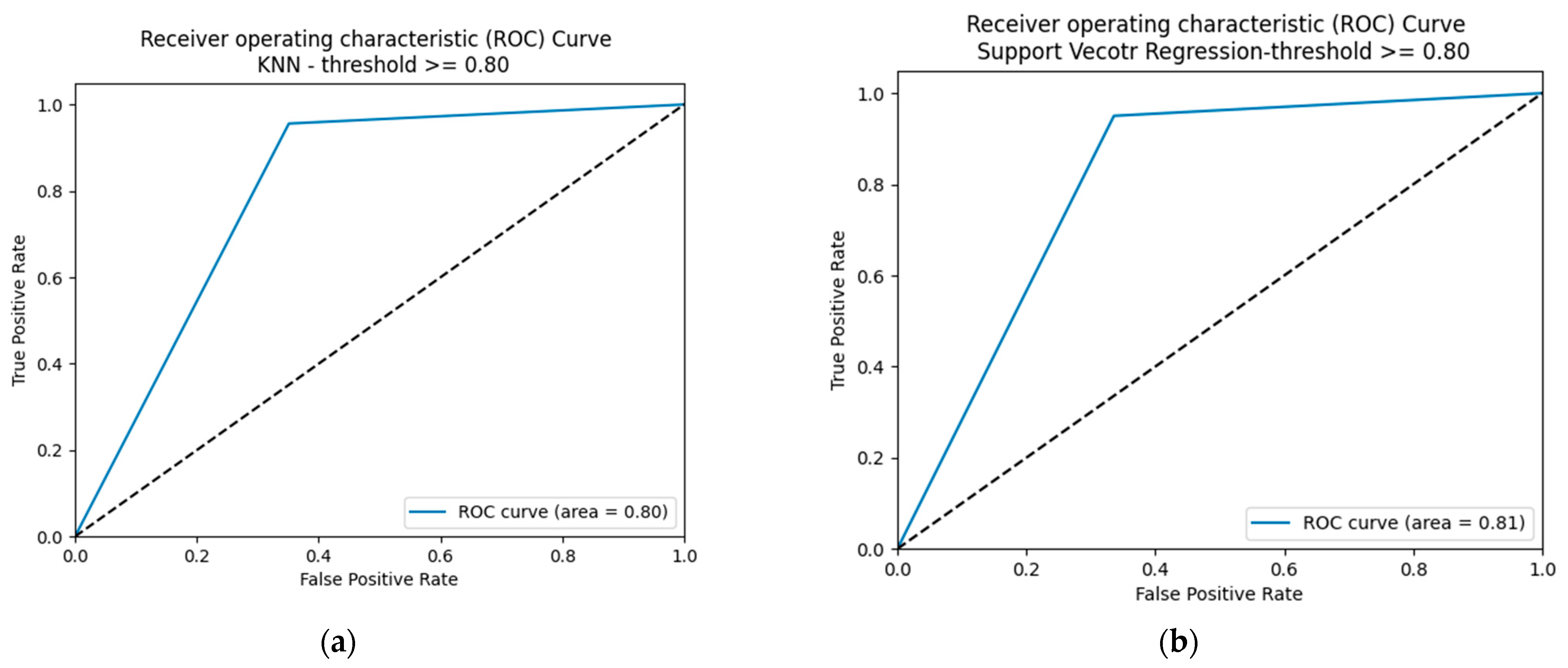
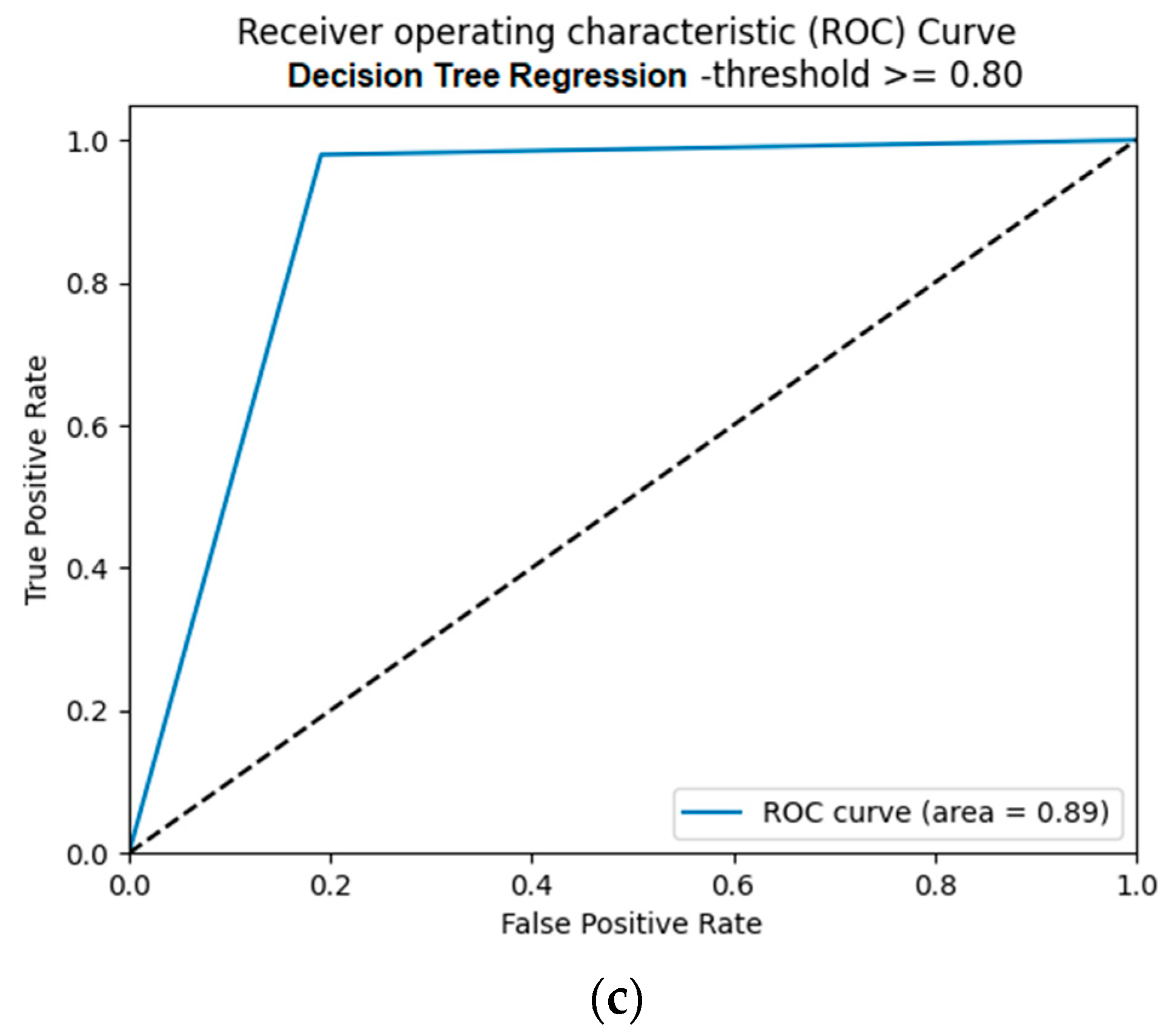
5.2.3. Performance of the SM-kNN, SM-SVR, and SM-DTR Models at Threshold 0.80
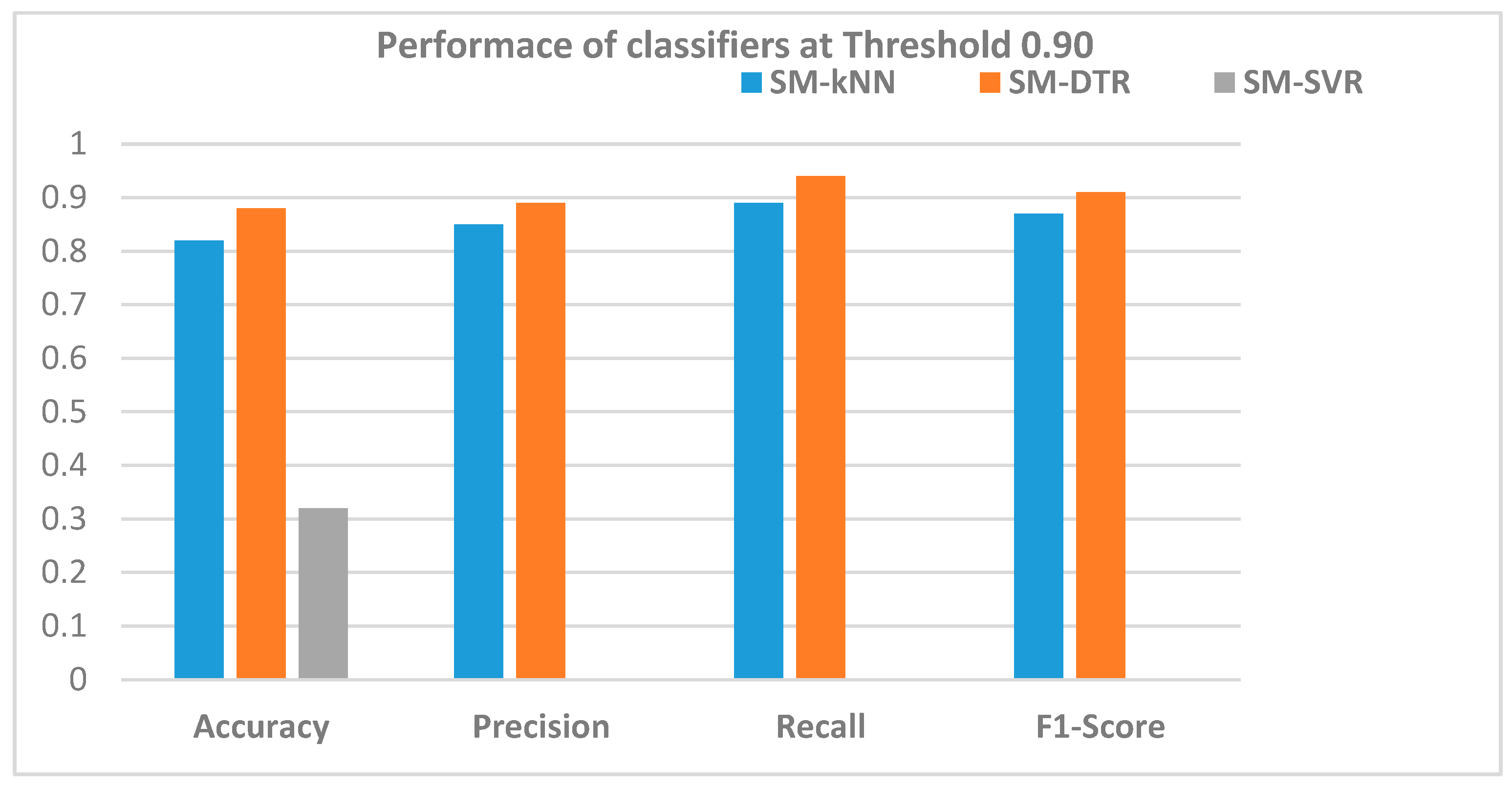
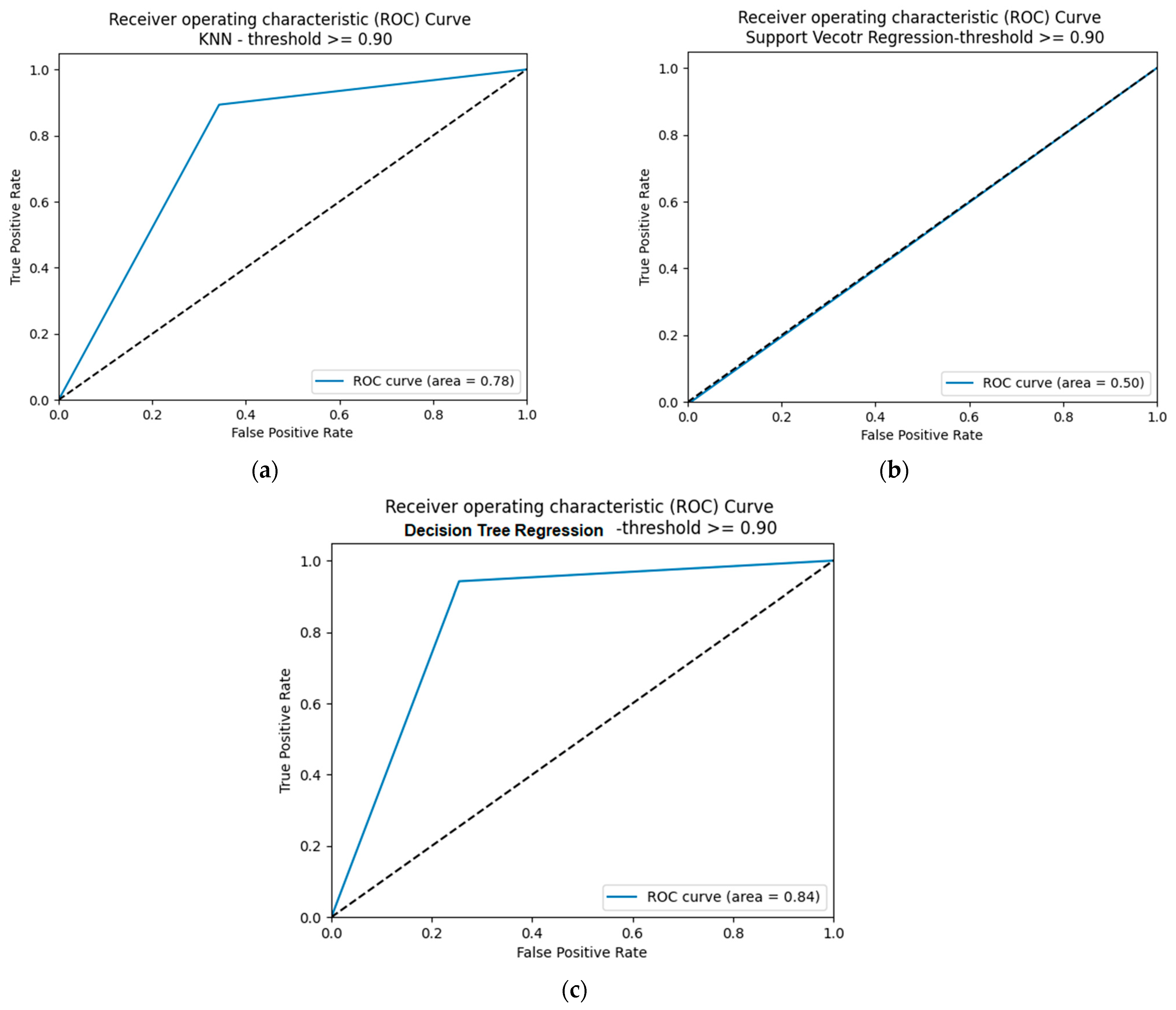
5.2.4. Performance of SM-kNN, SM-SVR, and SM-DTR Models at Threshold 0.90
5.3. Analysis of Error Rates of SM-kNN, SM-SVR, and SM-DTR Models
5.4. Analysis of Processing Time of the SM-kNN, SM-SVR, and SM-DTR Models
6. Comparison of the Proposed Method with State-of-the-Art Alignment Systems
7. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shadbolt, N.; Berners-Lee, T.; Hall, W. The semantic web revisited. IEEE Intell. Syst. 2006, 21, 96–101. [Google Scholar] [CrossRef]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Shojaee-Mend, H.; Ayatollahi, H.; Abdolahadi, A. Developing a mobile-based disease ontology for traditional Persian medicine. Inform. Med. Unlocked 2020, 20, 100353. [Google Scholar] [CrossRef]
- Hu, S.; Wang, H.; She, C.; Wang, J. Agont: Ontology for Agriculture Internet of Things; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Reedoy, A.V.; Dayal, S.B.; Govender, P.; Fonou-Dombeu, J.V. An ontology for smart home design. In Proceedings of the 2021 International Conference on Artificial Intelligence, Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, 5–6 August 2021. [Google Scholar]
- Esbjörn-Hargens, S. An ontology of climate change. J. Integral Theory Pract. 2010, 5, 143–174. [Google Scholar]
- Bouyerbou, H.; Bechkoum, K.; Lepage, R. Geographic ontology for major disasters: Methodology and implementation. Int. J. Disaster Risk Reduct. 2019, 34, 232–242. [Google Scholar] [CrossRef]
- Elsaleh, T.; Enshaeifar, S.; Rezvani, R.; Acton, S.T.; Janeiko, V.; Bermudez-Edo, M. IoT-Stream: A lightweight ontology for internet of things data streams and its use with data analytics and event detection services. Sensors 2020, 20, 953. [Google Scholar] [CrossRef]
- Alsanad, A.A.; Chikh, A.; Mirza, A. A domain ontology for software requirements change management in global software development environment. IEEE Access 2019, 7, 49352–49361. [Google Scholar] [CrossRef]
- Al-Zebari, A.; Zebari, S.; Jacksi, K. Football Ontology Construction using Oriented Programming. J. Appl. Sci. Technol. Trends 2020, 1, 24–30. [Google Scholar] [CrossRef]
- Uschold, M.; Healy, M.J.; Keith, E.W.; Clark, P.; Woods, S. Ontology reuse and application. In Formal Ontology in Information Systems; IOS Press: Amsterdam, The Netherlands, 1998. [Google Scholar]
- Jiménez, A.; Suárez-Figueroa, M.C.; Mateos, A.; Gomez-Perez, A.; Fernandez-Lopez, M. A maut approach for reusing domain ontologies on the basis of the neon methodology. Int. J. Inf. Technol. Decis. Mak. 2013, 12, 945–968. [Google Scholar] [CrossRef]
- Nkisi-Orji, I.; Wiratunga, N.; Massie, S.; Hui, K.-Y.; Heaven, R. Ontology Alignment Based on Word Embedding and Random Forest Classification; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Hughes, T.C.; Ashpole, B.C. The Semantics of Ontology Alignment; Lockheed Martin Advanced Technology Labs: Cherry Hill, NJ, USA, 2004. [Google Scholar]
- Ouali, I.; Ghozzi, F.; Taktak, R.; Sassi, M.S.H.S. Ontology alignment using stable matching. Procedia Comput. Sci. 2019, 159, 746–755. [Google Scholar] [CrossRef]
- Liu, X.; Tong, Q.; Liu, X.; Qin, Z. Ontology matching: State of the art, future challenges, and thinking based on utilized information. IEEE Access 2021, 9, 91235–91243. [Google Scholar] [CrossRef]
- de Lourdes Martínez-Villaseñor, M.; González-Mendoza, M. Fuzzy-Based Approach of Concept Alignment; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Cochez, M. Locality-sensitive hashing for massive string-based ontology matching. In Proceedings of the 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Warsaw, Poland, 11–14 August 2014. [Google Scholar]
- Cheatham, M.; Hitzler, P. String similarity metrics for ontology alignment. In Proceedings of the Semantic Web–Iswc 2013: 12th International Semantic Web Conference, Sydney, Australia, 21–25 October 2013; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Rudwan, M.S.M.; Fonou-Dombeu, J.V. Ontology Reuse: Neural Network-Based Measurement of Concepts Representations and Similarities in Ontology Corpus. In Proceedings of the 2022 International Conference on Artificial Intelligence, Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, 4–5 August 2022. [Google Scholar]
- Rudwan, M.S.M.; Fonou-Dombeu, J.V. Machine Learning Selection of Candidate Ontologies for Automatic Extraction of Context Words and Axioms from Ontology Corpus; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Megdiche, I.; Teste, O.; Trojahn, C. An Extensible Linear Approach For Holistic Ontology Matching; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Chu, S.C.; Xue, X.; Pan, J.S.; Wu, X. Optimizing ontology alignment in vector space. J. Internet Technol. 2020, 21, 15–22. [Google Scholar]
- Patel, A.; Jain, S. A novel approach to discover ontology alignment. Recent Adv. Comput. Sci. Commun. (Former. Recent Pat. Comput. Sci.) 2021, 14, 273–281. [Google Scholar] [CrossRef]
- Liu, W.; Xue, X.; Wu, Z.; Istanda, V. Aggregating Similarity Measures for Optimizing Ontology Alignment. J. Netw. Intell. 2022, 7, 36–44. [Google Scholar]
- Mani, S.; Annadurai, S. An Improved Structural-Based Ontology Matching Approach Using Similarity Spreading. Int. J. Semant. Web Inf. Syst. (IJSWIS) 2022, 18, 1–17. [Google Scholar] [CrossRef]
- Zhou, X.; Lv, Q.; Geng, A. Matching heterogeneous ontologies based on multi-strategy adaptive co-firefly algorithm. Knowl. Inf. Syst. 2023, 65, 2619–2644. [Google Scholar] [CrossRef]
- Şentürk, F.; Aytac, V. A Graph-Based Ontology Matching Framework. New Gener. Comput. 2023, 1–19. [Google Scholar] [CrossRef]
- Bulygin, L. Combining lexical and semantic similarity measures with machine learning approach for ontology and schema matching problem. In Proceedings of the XX International Conference “Data Analytics and Management in Data Intensive Domains”(DAMDID/RCDL’2018), Moscow, Russia, 9–12 October 2018. [Google Scholar]
- Bento, A.; Zouaq, A.; Gagnon, M. Ontology matching using convolutional neural networks. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020. [Google Scholar]
- Faria, D.; Pesquita, C.; Santos, E.; Palmonari, M.; Cruz, I.F.; Couto, F.M. The Agreementmakerlight Ontology Matching System; Springer: Cham, Switzerland, 2013. [Google Scholar]
- Jiménez-Ruiz, E.; Grau, B.C. Logmap: Logic-Based and Scalable Ontology Matching; Springer: Cham, Switzerland, 2011. [Google Scholar]
- Xiang, Y.; Zhang, Z.; Chen, J.; Chen, X.; Lin, Z.; Zheng, Y. OntoEA: Ontology-guided entity alignment via joint knowledge graph embedding. arXiv 2021, arXiv:2105.07688. [Google Scholar]
- Karimi, H.; Kamandi, A. A learning-based ontology alignment approach using inductive logic programming. Expert Syst. Appl. 2019, 125, 412–424. [Google Scholar] [CrossRef]
- Wang, L.L.; Bhagavatula, C.; Neumann, M.; Lo, K.; Wilhelm, C.; Ammar, W. Ontology alignment in the biomedical domain using entity definitions and context. arXiv 2018, arXiv:1806.07976. [Google Scholar]
- Khoudja, M.A.; Fareh, M.; Bouarfa, H. Ontology matching using neural networks: Survey and analysis. In Proceedings of the 2018 International Conference on Applied Smart Systems (ICASS), Medea, Algeria, 24–25 November 2018. [Google Scholar]
- Sun, Y.; Ma, L.; Wang, S. A comparative evaluation of string similarity metrics for ontology alignment. J. Inf. Comput. Sci. 2015, 12, 957–964. [Google Scholar] [CrossRef]
- Cross, V. Semantic Similarity: A Key to Ontology Alignment. 2018. Available online: http://disi.unitn.it/~pavel/om2018/papers/om2018_STpaper1.pdf (accessed on 1 May 2023).
- Santisteban, J.; Tejada-Cárcamo, J. Unilateral Jaccard Similarity Coefficient. 2015. Available online: https://ceur-ws.org/Vol-1393/paper-10.pdf (accessed on 1 May 2023).
- He, Y.; Chen, J.; Antonyrajah, D.; Horrocks, I. BERTMap: A BERT-based ontology alignment system. Proc. AAAI Conf. Artif. Intell. 2022, 36, 5684–5691. [Google Scholar] [CrossRef]
- Neutel, S.; De Boer, M.H.T. Towards Automatic Ontology Alignment using BERT. In Proceedings of the AAAI Spring Symposium: Combining Machine Learning with Knowledge Engineering, Palo Alto, CA, USA, 22–24 March 2021. [Google Scholar]
- He, Y.; Chen, J. Biomedical ontology alignment with BERT. In Proceedings of the 16th International Workshop on Ontology Matching co-located with the 20th International Semantic Web Conference (ISWC 2021), Virtual Event, 25 October 2021. [Google Scholar]
- Bajaj, G.; Nguyen, V.; Wijesiriwardene, T.; Yip, H.Y.; Javangula, V.; Parthasarathy, S.; Sheth, A.; Bodenreider, O. Evaluating Biomedical BERT Models for Vocabulary Alignment at Scale in the UMLS Metathesaurus. arXiv 2021, arXiv:2109.13348. [Google Scholar]
- Keil, J.M. Efficient Bounded Jaro-Winkler Similarity Based Search; Gesellschaft für Informatik: Bonns, Germany, 2019. [Google Scholar]
- Zhang, S.; Hu, Y.; Bian, G. Research on string similarity algorithm based on Levenshtein Distance. In Proceedings of the 2017 IEEE 2nd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 25–26 March 2017. [Google Scholar]
- Bergroth, L.; Hakonen, H.; Raita, T. A survey of longest common subsequence algorithms. In Proceedings of the Seventh International Symposium on String Processing and Information Retrieval, SPIRE 2000, A Curuna, Spain, 27–29 September 2000. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding with Unsupervised Learning. 2018. Available online: https://openai.com/research/language-unsupervised (accessed on 1 May 2023).
- Zhang, Z. Introduction to machine learning: k-nearest neighbors. Ann. Transl. Med. 2016, 4, 218. [Google Scholar] [CrossRef] [PubMed]
- Modaresi, F.; Araghinejad, S.; Ebrahimi, K. A comparative assessment of artificial neural network, generalized regression neural network, least-square support vector regression, and K-nearest neighbor regression for monthly streamflow forecasting in linear and nonlinear conditions. Water Resour. Manag. 2018, 32, 243–258. [Google Scholar] [CrossRef]
- Hu, C.; Jain, G.; Zhang, P.; Schmidt, C.; Gomadam, P.; Gorka, T.S. Data-driven method based on particle swarm optimization and k-nearest neighbor regression for estimating capacity of lithium-ion battery. Appl. Energy 2014, 129, 49–55. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Support Vector Regression. Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Apress: Berkeley, CA, USA, 2015; pp. 67–80. [Google Scholar]
- Pekel, E. Estimation of soil moisture using decision tree regression. Theor. Appl. Climatol. 2020, 139, 1111–1119. [Google Scholar] [CrossRef]
- Swetapadma, A.; Yadav, A. A novel decision tree regression-based fault distance estimation scheme for transmission lines. IEEE Trans. Power Deliv. 2016, 32, 234–245. [Google Scholar] [CrossRef]
- Xue, X.; Yang, C.; Jiang, C.; Tsai, P.-W.; Mao, G.; Zhu, H. Optimizing ontology alignment through linkage learning on entity correspondences. Complexity 2021, 2021, 5574732. [Google Scholar] [CrossRef]
- Hariri, B.B.; Sayyadi, H.; Abolhassani, H.; Esmaili, K.S. Combining Ontology Alignment Metrics Using the Data Mining Techniques. 2006. Available online: https://ceur-ws.org/Vol-210/paper17.pdf (accessed on 1 May 2023).
- Zhu, X.; Zhang, S.; Jin, Z.; Zhang, Z.; Xu, Z. Missing value estimation for mixed-attribute data sets. IEEE Trans. Knowl. Data Eng. 2010, 23, 110–121. [Google Scholar] [CrossRef]
- OAEI. Results—Anatomoy Track. 2022. Available online: http://oaei.ontologymatching.org/2022/results/anatomy/index.html (accessed on 1 April 2023).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Description |
|---|---|
| Os | Source ontology |
| Ot | Target ontology |
| reference | An xml document containing the similarity scores between each pair of classes in Os and Ot |
| osLabels | A document containing the labels of all classes in the source ontology |
| otLabels | A document containing the labels of all classes in the target ontology |
| finalScores | A csv document containing the similarity scores for both fuzzy string-matching algorithms and BERT |
| refAMLFile | A csv documents containing three columns representing the URIs of each pair of classes from Os and Ot and their similarity scores generated by the baseline AML alignment system |
| smKNNScores | A csv document containing the final similarity scores of the alignment by the SM-kNN model |
| smSVRScores | A csv document containing the final similarity scores of the alignment by the SM-SVR model |
| smDTRScores | A csv document containing the final similarity scores of the alignment by the SM-DTR model |
| Algorithm | Sc1 | Sc2 | Sc3 | Sc4 | Sc5 | Sc6 | Sc7 | Sc8 | Sc9 | Sc10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Levenshtein | 0.941176471 | 0.9375 | 0.933333333 | 0.933333333 | 0.933333333 | 0.928571429 | 0.928571429 | 0.928571429 | 0.928571429 | 0.928571429 |
| LCS | 0.941176471 | 0.9375 | 0.933333333 | 0.933333333 | 0.933333333 | 0.928571429 | 0.928571429 | 0.928571429 | 0.928571429 | 0.928571429 |
| Jaccard | 0.94 | 0.94 | 0.93 | 0.93 | 0.93 | 0.93 | 0.93 | 0.93 | 0.93 | 0.93 |
| Jaro–Winkler | 0.960784314 | 0.955555556 | 0.955555556 | 0.955555556 | 0.952380952 | 0.952380952 | 0.952380952 | 0.948717949 | 0.948717949 | 0.944444444 |
| BERT | 1.0000004 | 1.0000002 | 1.0000002 | 1.0000002 | 1.0000002 | 1.0000002 | 1.0000002 | 1.0000002 | 1.0000002 | 1.0000002 |
| AML System | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 |
| Variable Name | LCS | Levenshtein | Jaccard | Jaro–Winkler | BERT |
|---|---|---|---|---|---|
| Precision | 0.969756098 | 0.986942329 | 1 | 0.965022422 | 0.927827381 |
| Recall | 0.766975309 | 0.699845679 | 0.697857143 | 0.830246914 | 0.96219 |
| F1-score | 0.856527359 | 0.818961625 | 0.822044594 | 0.892575695 | 0.94469697 |
| Accuracy | 76.2142857 | 71.3571429 | 69.7857143 | 81.5 | 89.5714286 |
| Variable Name | LCS | Levenshtein | Jaccard | Jaro–Winkler | BERT |
|---|---|---|---|---|---|
| Precision | 0.975425331 | 1 | 1 | 0.988250653 | 0.917348609 |
| Recall | 0.406619385 | 0.365642238 | 0.337142857 | 0.596532703 | 0.88337 |
| F1-score | 0.573971079 | 0.535487594 | 0.504273504 | 0.743980344 | 0.90004014 |
| Accuracy | 45.2857143% | 42.5% | 33.7142857% | 62.7857143% | 82.2142857% |
| Variable Name | LCS | Levenshtein | Jaccard | Jaro–Winkler | BERT |
|---|---|---|---|---|---|
| Precision | 0.872340426 | 0.88372093 | 1 | 0.769911504 | 0.832 |
| Recall | 0.043248945 | 0.040084388 | 0.030714286 | 0.091772152 | 0.76793 |
| F1-score | 0.08241206 | 0.076690212 | 0.05959806 | 0.16399623 | 0.79868349 |
| Accuracy | 34.7857143% | 34.6428571% | 3.0714286% | 36.6428571% | 73.7857143% |
| Variable Name | SM-kNN | SM-DTR | SM-SVR |
|---|---|---|---|
| Precision | 0.94 | 0.98 | 0.93 |
| Recall | 0.99 | 0.98 | 1.0 |
| F1-score | 0.97 | 0.98 | 0.96 |
| Accuracy | 94% | 97% | 93% |
| Variable Name | SM-kNN | SM-DTR | SM-SVR |
|---|---|---|---|
| Precision | 0.96 | 0.98 | 0.96 |
| Recall | 0.96 | 0.98 | 0.95 |
| F1-score | 0.96 | 0.98 | 0.96 |
| Accuracy | 93% | 96% | 92% |
| Variable Name | SM-kNN | SM-DTR | SM-SVR |
|---|---|---|---|
| Precision | 0.85 | 0.89 | 0 |
| Recall | 0.89 | 0.94 | 0 |
| F1-score | 0.87 | 0.91 | 0 |
| Accuracy | 82% | 88% | 32% |
| SM-kNN | SM-DTR | SM-SVR | |
|---|---|---|---|
| MSE | 0.003 | 0.003 | 0.008 |
| RMSE | 0.054 | 0.050 | 0.091 |
| SM-kNN | SM-DTR | SM-SVR |
|---|---|---|
| 0.0045 | 0.0011 | 0.0147 |
| Matcher | Runtime | Precision | F-Measure | Recall |
|---|---|---|---|---|
| ALIN | 374 | 0.984 | 0.852 | 0.752 |
| ATMatcher | 156 | 0.978 | 0.794 | 0.669 |
| LogMap | 9 | 0.917 | 0.881 | 0.848 |
| LogMapBio | 1183 | 0.873 | 0.895 | 0.919 |
| LogMapLite | 3 | 0.962 | 0.828 | 0.728 |
| LSMatch | 20 | 0.952 | 0.761 | 0.634 |
| Matcha | 37 | 0.951 | 0.941 | 0.93 |
| ALIOn | 26134 | 0.364 | 0.407 | 0.46 |
| SEBMatcher | 35602 | 0.945 | 0.908 | 0.874 |
| AMD | 160 | 0.953 | 0.88 | 0.817 |
| StringEquiv | - | 0.997 | 0.766 | 0.622 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rudwan, M.S.M.; Fonou-Dombeu, J.V. Hybridizing Fuzzy String Matching and Machine Learning for Improved Ontology Alignment. Future Internet 2023, 15, 229. https://doi.org/10.3390/fi15070229
Rudwan MSM, Fonou-Dombeu JV. Hybridizing Fuzzy String Matching and Machine Learning for Improved Ontology Alignment. Future Internet. 2023; 15(7):229. https://doi.org/10.3390/fi15070229
Chicago/Turabian StyleRudwan, Mohammed Suleiman Mohammed, and Jean Vincent Fonou-Dombeu. 2023. "Hybridizing Fuzzy String Matching and Machine Learning for Improved Ontology Alignment" Future Internet 15, no. 7: 229. https://doi.org/10.3390/fi15070229
APA StyleRudwan, M. S. M., & Fonou-Dombeu, J. V. (2023). Hybridizing Fuzzy String Matching and Machine Learning for Improved Ontology Alignment. Future Internet, 15(7), 229. https://doi.org/10.3390/fi15070229