
Deep Reinforcement Learning-Based Video Offloading and Resource Allocation in NOMA-Enabled Networks


Abstract
1. Introduction
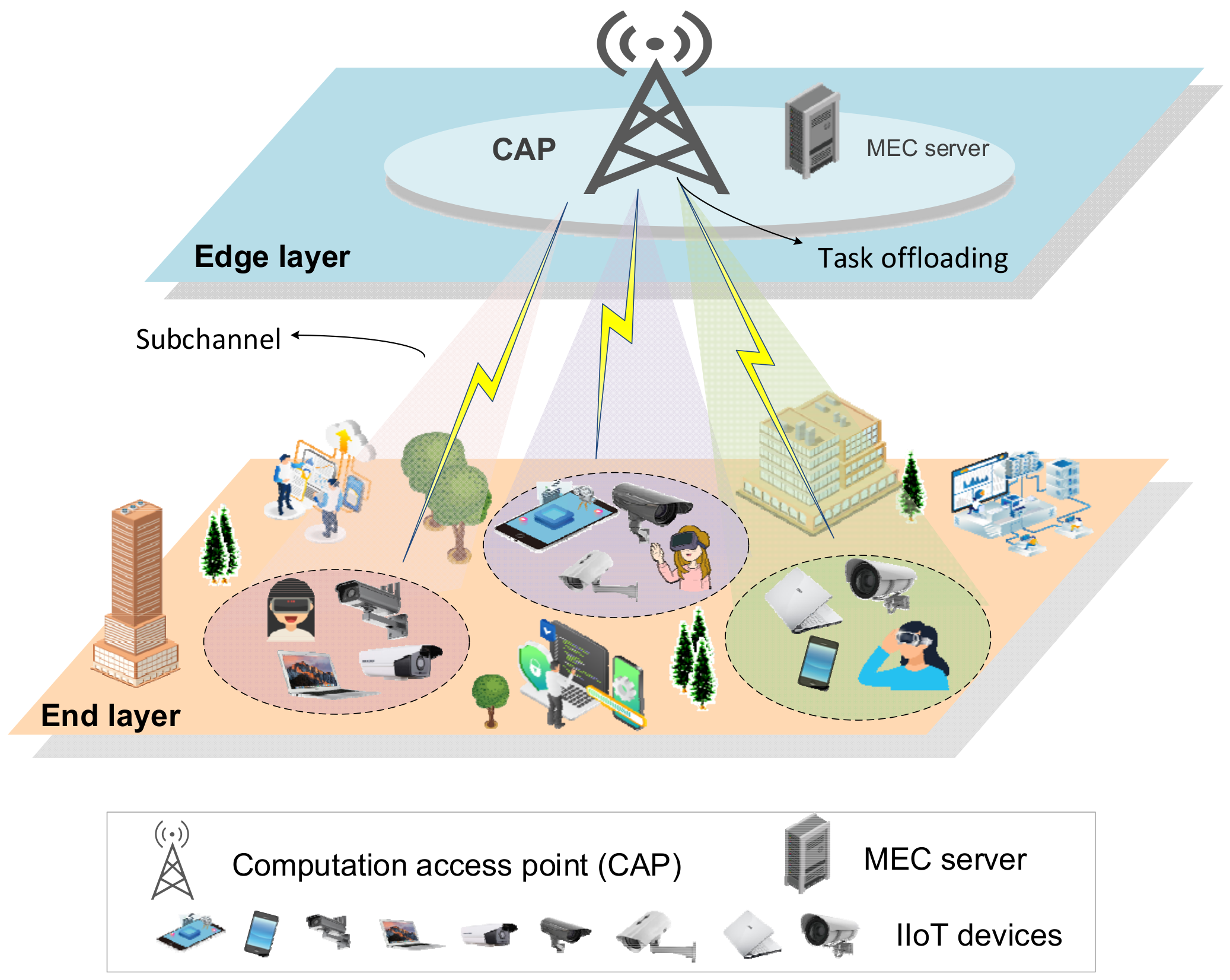
- A two-layer NOMA-enabled video edge scheduling architecture is proposed, where UEs are divided into different clusters of NOMA, and the tasks generated by UEs in the same cluster are offloaded over a common subchannel to improve the offloading efficiency.
- An attempt is made to optimize the QoE of the UE by formulating a cost-minimization problem composed of delay, energy, and accuracy in order to weigh up the relationship between these three parameters.
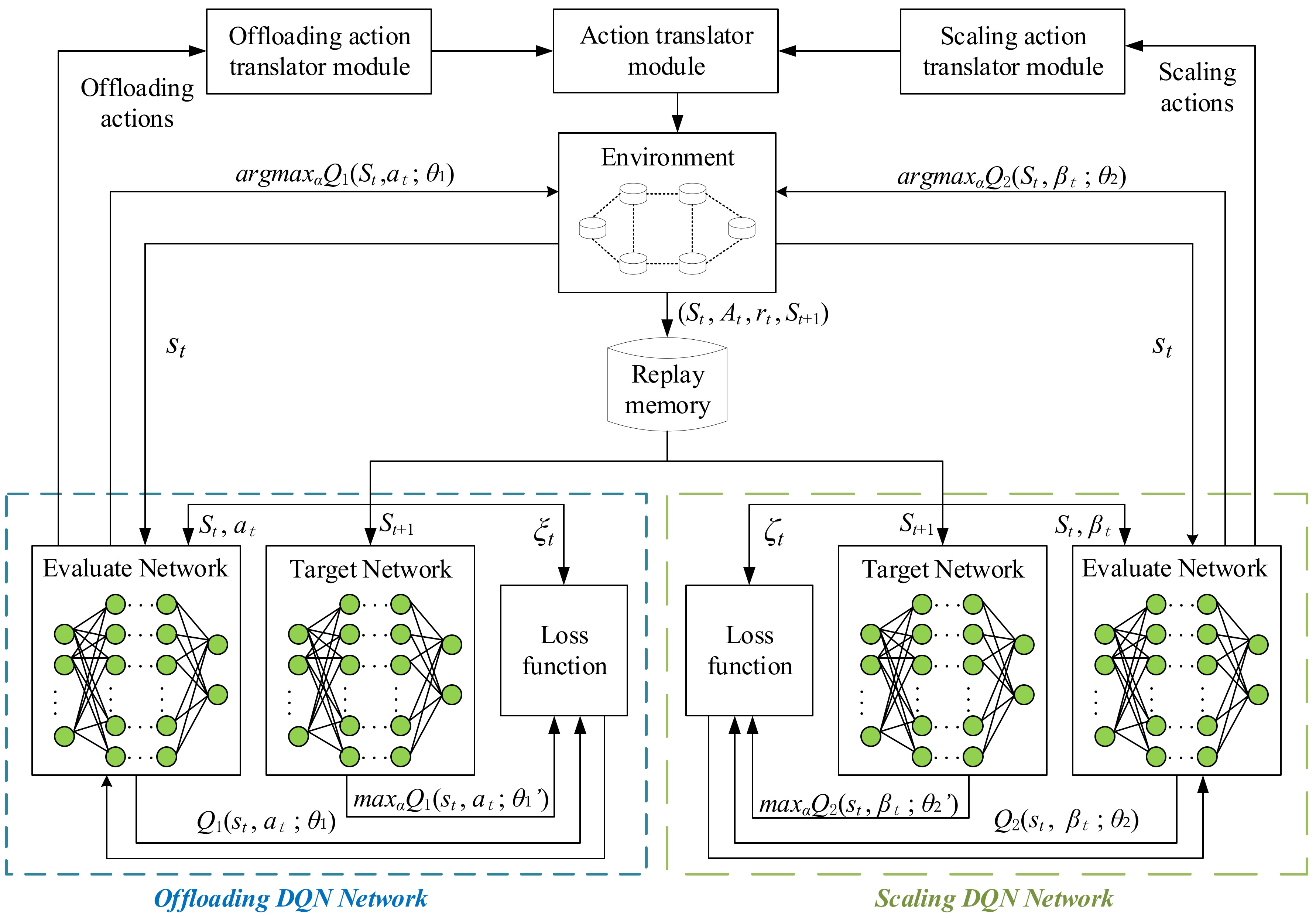
- The JVFRS-TO-RA-DQN algorithm is proposed to solve the joint optimization problem. The JVFRS-TO-RA-DQN algorithm contains two DQN networks; one is used to select offloading and resource allocation action, and the other is used to select video frame resolution scaling action, which effectively overcomes the sparsity of the single-layer reward function and accelerates the training convergence speed.
- The experimental results show that the JVFRS-TO-RA-DQN algorithm can achieve better performance gains in terms of improving video analysis accuracy, reducing total delay, and decreasing energy consumption compared to the other baseline schemes.
2. Related Works
2.1. NOMA-Enabled Task Offloading in MEC Scenarios
2.2. Video Analysis in MEC Scenarios
2.3. Video Offloading Based on DRL
3. System Model
3.1. NOMA-Enabled Transmission Model
3.2. Edge Computation Model
3.3. Problem Formulation
4. Deep Reinforcement Learning-Based Algorithm
4.1. Deep Reinforcement Learning Model
4.1.1. State Space
4.1.2. Action Space
4.1.3. Reward Function
4.2. JVFRS-TO-RA-DQN Algorithm
| Algorithm 1: JVFRS-CO-RA-DQN algorithm | |
| Input: Dm, w, F, γ. | |
| Output: αm, βm. | |
| 1: | Initialize the evaluate network with random weights as θ |
| 2: | Initialize the target networks as a copy of the evaluate network with random weights as θ’ |
| 3: | Initialize replay memory D |
| 4: | Initialize an empty state set |
| 5: | for episode = 1 to Max do |
| 6: | Initialize state Sm,t in Equation (16) |
| 7: | for t < T do |
| 8: | With probability ε to select a random offloading and resource allocation decision αm,t; with probability δ to select a random resolution βm,t |
| 9: | Execute action αm,t, receive a reward ξm,t; execute action βm,t, receive a reward ζm,t |
| 10: | Combine αm,t and βm,t as Am,t, calculate rm,t with ξm,t and ζm,t, and observe the next state Sm,t + 1 |
| 11: | Store interaction tuple {Sm,t, Am,t, rm,t, Sm,t + 1} in D |
| 12: | Sample a random tuple {Sm,t, Am,t, rm,t, Sm,t + 1} from D |
| 13: | Compute the offloading target Q value and the scaling target Q value |
| 14: | Train the offloading target Q value and the scaling target Q value |
| 15: | Perform gradient descent with respect to θ |
| 16: | Update the evaluate Q-network and target Q-network |
| 17: | end for |
| 18: | end for |
5. Experimental Results and Discussion
5.1. Parameter Settings
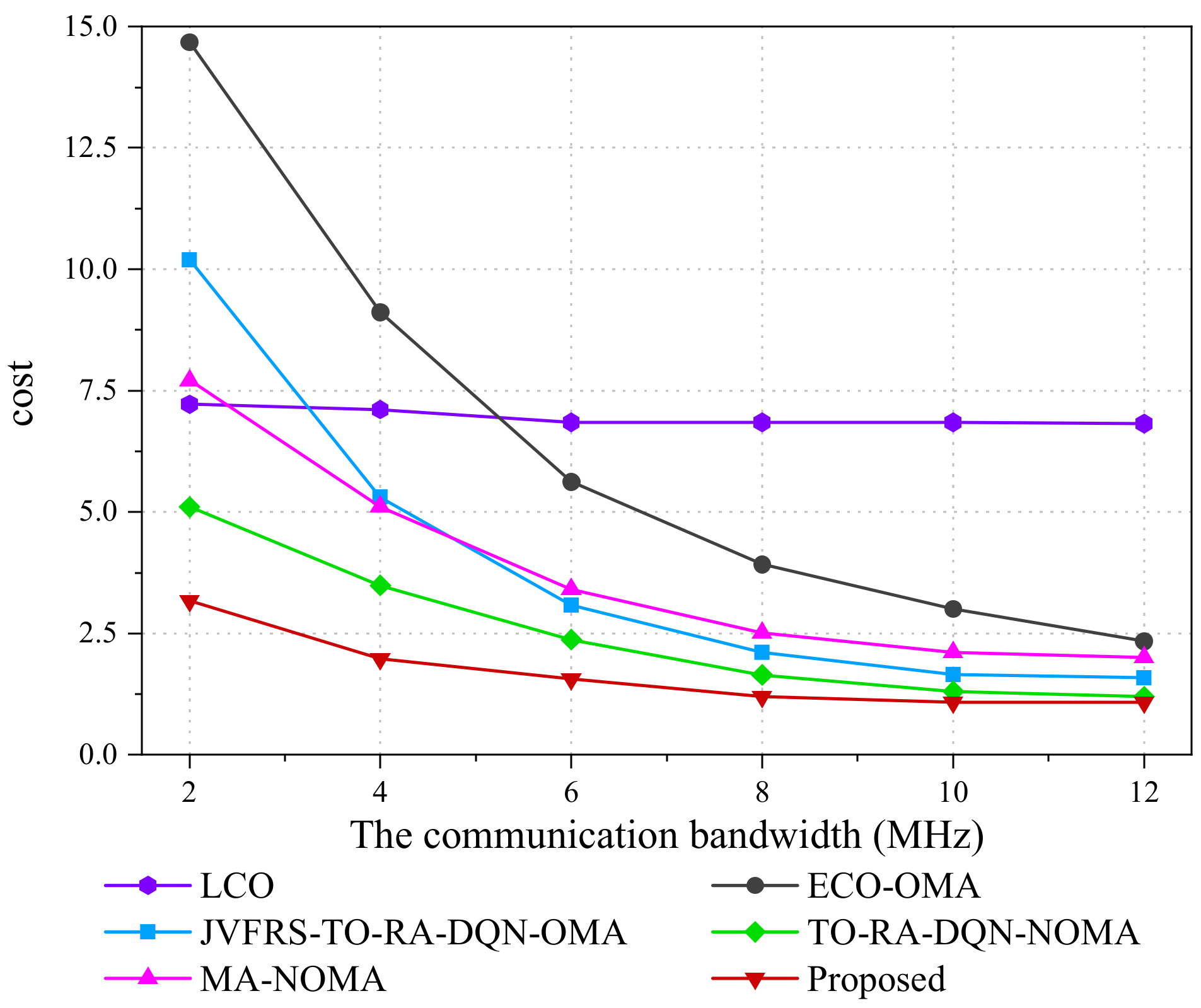
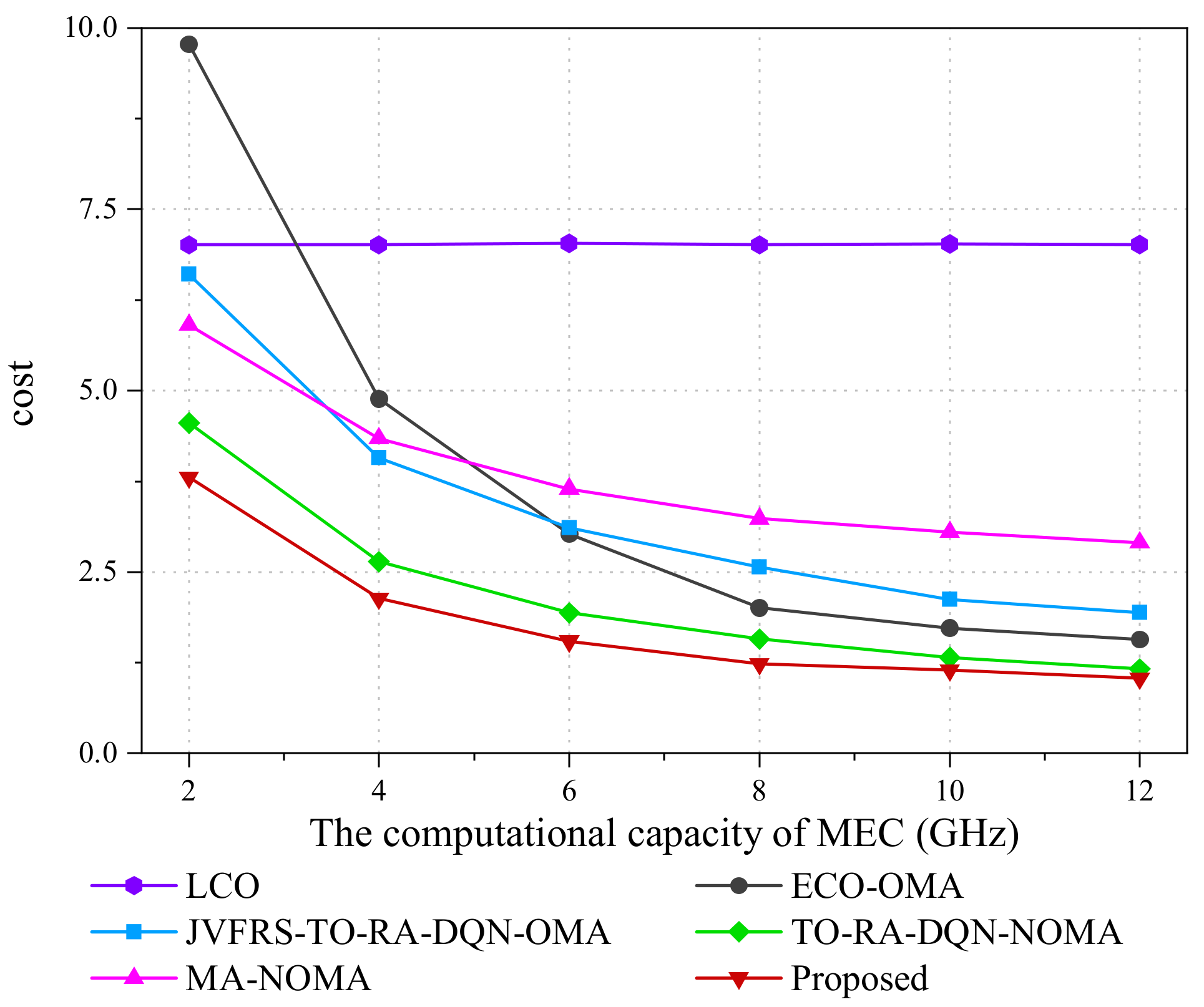
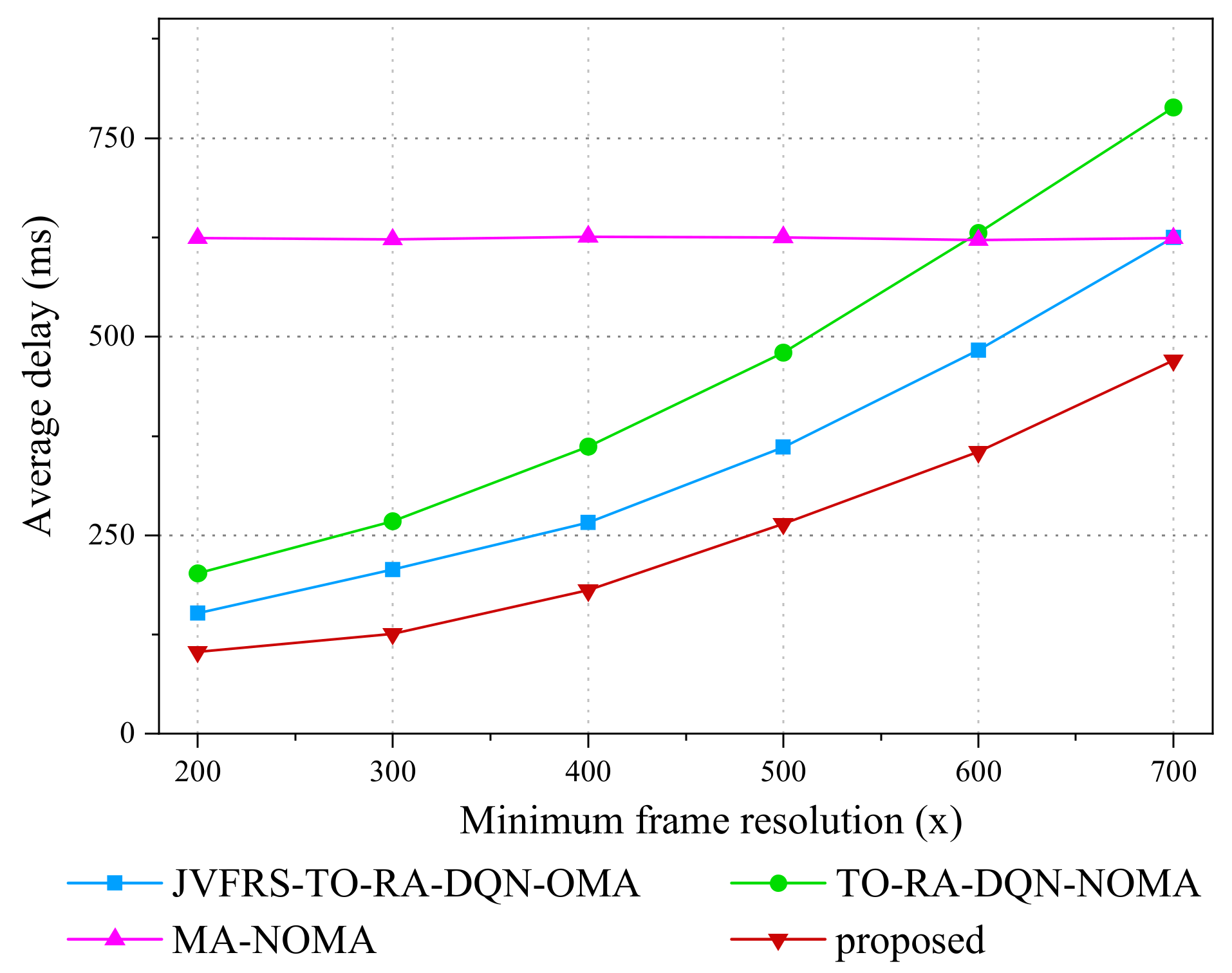
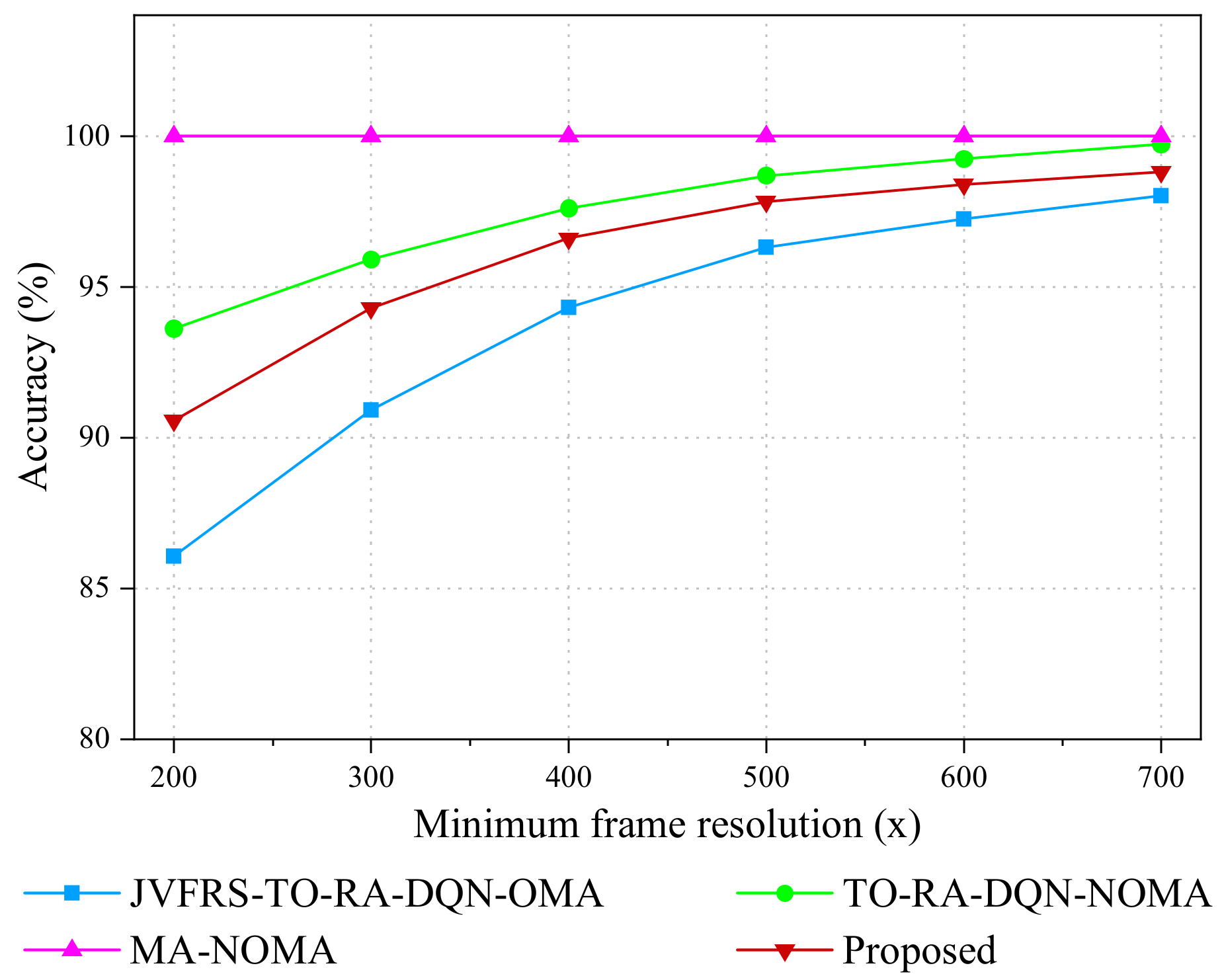
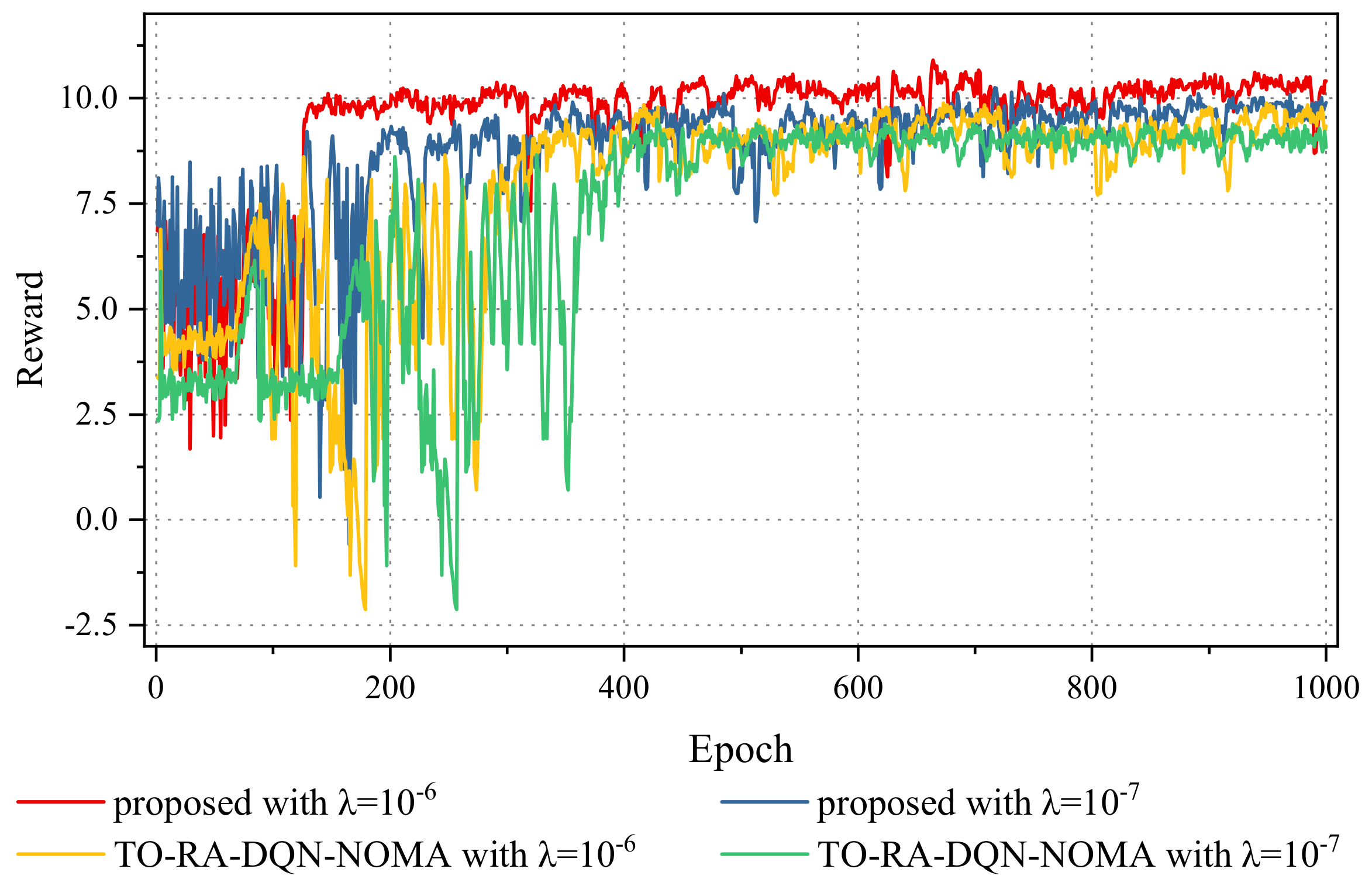
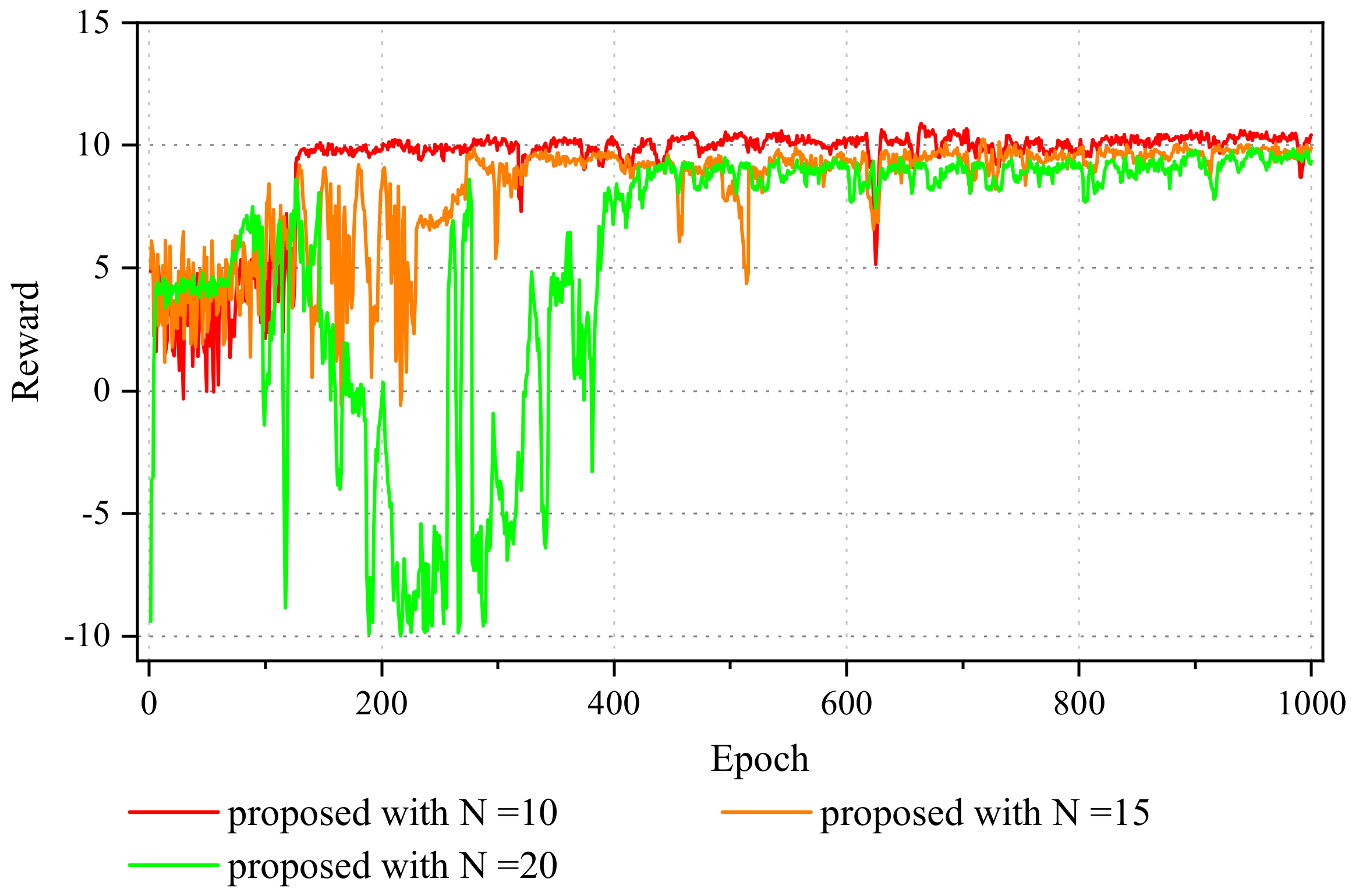
5.2. Result Analysis
- (1)
- Local Computing Only (LCO): the video streams are processed totally at the UEs with ∑n=1 Nxm,n = 0, ∀m ∈ M, which has a fixed video frame resolution.
- (2)
- Edge Computing Only via OMA (ECO-OMA): the video streams are totally offloaded to and processed at the MEC server with xm,n = 1, ∀m ∈ M, n ∈ N, which has a fixed video frame resolution.
- (3)
- JVFRS-TO-RA-DQN via OMA (JVFRS-TO-RA-DQN-OMA): Unlike JVFRS-TO-RA-DQN, task Dm generated by UE m are offloaded to the MEC server through OMA. Each UE has an independent subchannel. We use ym to denote whether task Dm offloaded to the MEC server, ym = 1 denotes that task Dm were offloaded to MEC sever; otherwise, ym = 0.
- (4)
- Task offloading and a resource allocation algorithm based on DQN via NOMA (TO-RA-DQN-NOMA) [50]: Compared with JVFRS-TO-RA-DQN, TO-RA-DQN-NOMA does not consider the change in video frame resolution, which means that it has a fixed video frame resolution.
- (5)
- Maximum accuracy algorithm via NOMA (MA-NOMA) [46]: Compared with JVFRS-TO-RA-DQN, MA-NOMA implements maximum accuracy with the largest frame resolutions in NOMA.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wan, S.; Ding, S.; Chen, C. Edge computing enabled video segmentation for real-time traffic monitoring in internet of vehicles. Pattern Recognit. 2022, 121, 108146. [Google Scholar] [CrossRef]
- Cisco. Annual Internet Report (2018–2023) White Paper. Available online: http://www.cisco.com (accessed on 22 March 2023).
- Luo, Q.; Hu, S.; Li, C.; Li, G.; Shi, W. Resource scheduling in edge computing: A survey. IEEE Commun. Surv. Tutor. 2021, 23, 2131–2165. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, Y.; Zhou, F.; Hu, R.Q. Computation efficiency maximization in OFDMA-based mobile edge computing networks. IEEE Commun. Lett. 2019, 24, 159–163. [Google Scholar] [CrossRef]
- Dai, L.; Wang, B.; Ding, Z.; Wang, Z.; Chen, S.; Hanzo, L. A survey of non-orthogonal multiple access for 5G. IEEE Commun. Surv. Tutor. 2018, 20, 2294–2323. [Google Scholar] [CrossRef]
- Kiani, A.; Ansari, N. Edge computing aware NOMA for 5G networks. IEEE Internet Things J. 2018, 5, 1299–1306. [Google Scholar] [CrossRef]
- Maraqa, O.; Rajasekaran, A.S.; Al-Ahmadi, S.; Yanikomeroglu, H.; Sait, S.M. A survey of rate-optimal power domain NOMA with enabling technologies of future wireless networks. IEEE Commun. Surv. Tutor. 2020, 22, 2192–2235. [Google Scholar] [CrossRef]
- Yan, J.; Bi, S.; Zhang, Y.J.A. Offloading and resource allocation with general task graph in mobile edge computing: A deep reinforcement learning approach. IEEE Trans. Wirel. Commun. 2020, 19, 5404–5419. [Google Scholar] [CrossRef]
- Zhao, Y.; Yang, Z.; He, X.; Cai, X.; Miao, X.; Ma, Q. Trine: Cloud-edge-device cooperated real-time video analysis for household applications. IEEE Trans. Mob. Comput. 2022, 1–13. [Google Scholar] [CrossRef]
- Ran, X.; Chen, H.; Zhu, X.; Liu, Z.; Chen, J. Deepdecision: A mobile deep learning framework for edge video analytics. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1421–1429. [Google Scholar]
- Zhang, H.; Ananthanarayanan, G.; Bodik, P.; Philipose, M.; Bahl, P.; Freedman, M.J. Live video analytics at scale with approximation and delay-tolerance. In Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation, Boston, MA, USA, 27–29 March 2017. [Google Scholar]
- Wang, X.; Han, Y.; Leung, V.C.M.; Niyato, D.; Yan, X.; Chen, X. Convergence of edge computing and deep learning: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, Y.; Huang, X.; Fang, C.; Zhang, P. Ultra-low latency multi-task offloading in mobile edge computing. IEEE Access 2021, 9, 32569–32581. [Google Scholar] [CrossRef]
- Li, Y.; Wang, T.; Wu, Y.; Jia, W. Optimal dynamic spectrum allocation-assisted latency minimization for multiuser mobile edge computing. Digit. Commun. Netw. 2022, 8, 247–256. [Google Scholar] [CrossRef]
- Kuang, Z.; Ma, Z.; Li, Z.; Deng, X. Cooperative computation offloading and resource allocation for delay minimization in mobile edge computing. J. Syst. Archit. 2021, 118, 102167. [Google Scholar] [CrossRef]
- Cui, Q.; Zhao, X.; Ni, W.; Hu, Z.; Tao, X.; Zhang, P. Multi-Agent Deep Reinforcement Learning-Based Interdependent Computing for Mobile Edge Computing-Assisted Robot Teams. IEEE Trans. Veh. Technol. 2022, 72, 6599–6610. [Google Scholar] [CrossRef]
- Sun, Y.; Zhou, S.; Xu, J. EMM: Energy-aware mobility management for mobile edge computing in ultra dense networks. IEEE J. Sel. Areas Commun. 2017, 35, 2637–2646. [Google Scholar] [CrossRef]
- You, C.; Huang, K.; Chae, H.; Kim, B.-H. Energy-efficient resource allocation for mobile-edge computation offloading. IEEE Trans. Wirel. Commun. 2016, 16, 1397–1411. [Google Scholar] [CrossRef]
- Zhou, H.; Jiang, K.; Liu, X.; Leung, V.C.M. Deep reinforcement learning for energy-efficient computation offloading in mobile-edge computing. IEEE Internet Things J. 2021, 9, 1517–1530. [Google Scholar] [CrossRef]
- Zhou, F.; Hu, R.Q. Computation efficiency maximization in wireless-powered mobile edge computing networks. IEEE Trans. Wirel. Commun. 2020, 19, 3170–3184. [Google Scholar] [CrossRef]
- Cheng, Q.; Li, L.; Sun, Y.; Wang, D.; Liang, W.; Li, X.; Han, Z. Efficient resource allocation for NOMA-MEC system in ultra-dense network: A mean field game approach. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Zhu, B.; Chi, K.; Liu, J.; Yu, K.; Mumtaz, S. Efficient offloading for minimizing task computation delay of NOMA-based multiaccess edge computing. IEEE Trans. Commun. 2022, 70, 3186–3203. [Google Scholar] [CrossRef]
- Zhu, H.; Wu, Q.; Wu, X.-J.; Fan, Q.; Fan, P.; Wang, J. Decentralized power allocation for MIMO-NOMA vehicular edge computing based on deep reinforcement learning. IEEE Internet Things J. 2021, 9, 12770–12782. [Google Scholar] [CrossRef]
- Zhong, R.; Liu, X.; Liu, Y.; Chen, Y.; Wang, X. Path design and resource management for NOMA enhanced indoor intelligent robots. IEEE Trans. Wirel. Commun. 2022, 21, 8007–8021. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, M.; Liu, X.; Liu, Y.; Chen, Y.; Cui, S.; Poor, H.V. AI-driven UAV-NOMA-MEC in next generation wireless networks. IEEE Wirel. Commun. 2021, 28, 66–73. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Yang, Z.; Yue, X.; Wang, C.; Chen, Y. Integrated 3c in noma-enabled remote-e-health systems. IEEE Wirel. Commun. 2021, 28, 62–68. [Google Scholar] [CrossRef]
- Naouri, A.; Wu, H.; Nouri, N.A.; Dhelim, S.; Ning, H. A novel framework for mobile-edge computing by optimizing task offloading. IEEE Internet Things J. 2021, 8, 13065–13076. [Google Scholar] [CrossRef]
- Hanyao, M.; Jin, Y.; Qian, Z.; Zhang, S.; Lu, S. Edge-assisted online on-device object detection for real-time video analytics. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–10. [Google Scholar]
- Wang, Y.; Wang, W.; Liu, D.; Jin, X.; Jiang, J.; Chen, K. Enabling edge-cloud video analytics for robotics applications. IEEE Trans. Cloud Comput. 2022. [Google Scholar] [CrossRef]
- Liu, L.; Li, H.; Gruteser, M. Edge assisted real-time object detection for mobile augmented reality. In Proceedings of the 25th Annual International Conference on Mobile Computing and Networking, Los Cabos, Mexico, 21–25 October 2019; pp. 1–16. [Google Scholar]
- Yang, P.; Lyu, F.; Wu, W.; Zhang, N.; Yu, L.; Shen, X.S. Edge coordinated query configuration for low-latency and accurate video analytics. IEEE Trans. Ind. Inform. 2019, 16, 4855–4864. [Google Scholar] [CrossRef]
- Jin, Y.; Liu, J.; Wang, F.; Cui, S. Ebublio: Edge assisted multi-user 360-degree video streaming. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]
- Jiang, B.; He, Q.; Liu, P.; Maharjan, S.; Zhang, Y. Blockchain Empowered Secure Video Sharing With Access Control for Vehicular Edge Computing. IEEE Trans. Intell. Transp. Syst. 2023. [Google Scholar] [CrossRef]
- Lee, D.; Kim, Y.; Song, M. Cost-Effective, Quality-Oriented Transcoding of Live-Streamed Video on Edge-Servers. IEEE Trans. Serv. Comput. 2023. [Google Scholar] [CrossRef]
- Aguilar-Armijo, J.; Timmerer, C.; Hellwagner, H. SPACE: Segment Prefetching and Caching at the Edge for Adaptive Video Streaming. IEEE Access 2023, 11, 21783–21798. [Google Scholar] [CrossRef]
- Chen, N.; Quan, S.; Zhang, S.; Qian, Z.; Jin, Y.; Wu, J.; Li, W.; Lu, S. Cuttlefish: Neural configuration adaptation for video analysis in live augmented reality. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 830–841. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, S.; Chen, Y.; Qian, Z.; Wu, J.; Xiao, M. Joint configuration adaptation and bandwidth allocation for edge-based real-time video analytics. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 257–266. [Google Scholar]
- Chen, J.; Chen, S.; Wang, Q.; Cao, B.; Feng, G.; Hu, J. iRAF: A deep reinforcement learning approach for collaborative mobile edge computing IoT networks. IEEE Internet Things J. 2019, 6, 7011–7024. [Google Scholar] [CrossRef]
- Yan, K.; Shan, H.; Sun, T.; Hu, R.; Wu, Y.; Yu, L.; Zhang, Z.; Quek, T.Q. Reinforcement learning-based mobile edge computing and transmission scheduling for video surveillance. IEEE Trans. Emerg. Top. Comput. 2021, 10, 1142–1156. [Google Scholar]
- Liu, X.; Zhou, L.; Zhang, X.; Tan, X.; Wei, J. Joint Radio Map Construction and Dissemination in MEC Networks: A Deep Reinforcement Learning Approach. Wirel. Commun. Mob. Comput. 2022, 2022, 4621440. [Google Scholar] [CrossRef]
- Yang, P.; Hou, J.; Yu, L.; Chen, W.; Wu, Y. Edge-coordinated energy-efficient video analytics for digital twin in 6G. China Commun. 2023, 20, 14–25. [Google Scholar] [CrossRef]
- Liu, B.; Liu, C.; Peng, M. Resource allocation for energy-efficient MEC in NOMA-enabled massive IoT networks. IEEE J. Sel. Areas Commun. 2020, 39, 1015–1027. [Google Scholar] [CrossRef]
- Kimura, T.; Kimura, T.; Matsumoto, A.; Yamagishi, K. Balancing quality of experience and traffic volume in adaptive bitrate streaming. IEEE Access 2021, 9, 15530–15547. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, S.; Opadere, J.; Han, T. An edge network orchestrator for mobile augmented reality. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 756–764. [Google Scholar]
- Zhao, T.; He, L.; Huang, X.; Li, F. DRL-Based Secure Video Offloading in MEC-Enabled IoT Networks. IEEE Internet Things J. 2022, 9, 18710–18724. [Google Scholar] [CrossRef]
- Chen, X.; Liu, G. Energy-efficient task offloading and resource allocation via deep reinforcement learning for augmented reality in mobile edge networks. IEEE Internet Things J. 2021, 8, 10843–10856. [Google Scholar] [CrossRef]
- Ahn, J.; Lee, J.; Niyato, D.; Park, H.S. Novel QoS-guaranteed orchestration scheme for energy-efficient mobile augmented reality applications in multi-access edge computing. IEEE Trans. Veh. Technol. 2020, 69, 13631–13645. [Google Scholar] [CrossRef]
- Wu, Z.; Yan, D. Deep reinforcement learning-based computation offloading for 5G vehicle-aware multi-access edge computing network. China Commun. 2021, 18, 26–41. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Number of UEs, M | 10 |
| Number of NOMA clusters, k | 4 |
| The distance between the MEC server and UEs | [0, 200] m |
| The total communication bandwidth, W | 12 MHz |
| CPU cycles required for unit bit task, | 100 cycles/bit |
| The computational capacity of the MEC server, F | 10 GHz |
| The computational capacity of the UEs, | [0.4, 2] GHz |
| Average energy consumption threshold, | 15 J |
| Required bits representing one pixel, τ | 24 |
| Maximum transmission power, p | 0.5 W |
| Maximum tolerance time for task, | 30 ms |
| Minimum video frame resolution, | 40,000 px (200 × 200) |
| Constant of the IoT device, | 1 × 10−27 |
| Compression ratio of the video frame for UE, ρm | 74 |
| Discount factor, γ | [0, 1] |
| Batch size, Z | 128 |
| Replay buffer, B | 100 |
| 0–1 Offloading | NOMA | Resolution | Delay and Energy | |
| LCO | × | × | × | √ |
| ECO-OMA | × | × | × | √ |
| JVFRS-TO-RA-DQN-OMA | √ | × | √ | √ |
| TO-RA-DQN-NOMA | √ | √ | × | √ |
| MA-NOMA | √ | √ | √ | × |
| JVFRS-TO-RA-DQN-NOMA | √ | √ | √ | √ |
| LCO | ECO-OMA | JVFRS-TO-RA-DQN-OMA | TO-RA-DQN-NOMA | MA-NOMA | Proposed | |
|---|---|---|---|---|---|---|
| The bandwidth of subchannel (MHz) | 1.2 | 1.2 | 1.2 | 3 | 3 | 3 |
| Average delay (ms) | 644.54 | 801.49 | 323.42 | 251.77 | 409.66 | 167.71 |
| TO-RA-DQN-NOMA | Proposed | |
|---|---|---|
| Learning rate of 10−6 | 95.87% | 98.74% |
| Learning rate of 10−7 | 95.96% | 98.82% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, S.; Wang, Y.; Feng, N.; Wei, Z.; Zhao, J. Deep Reinforcement Learning-Based Video Offloading and Resource Allocation in NOMA-Enabled Networks. Future Internet 2023, 15, 184. https://doi.org/10.3390/fi15050184
Gao S, Wang Y, Feng N, Wei Z, Zhao J. Deep Reinforcement Learning-Based Video Offloading and Resource Allocation in NOMA-Enabled Networks. Future Internet. 2023; 15(5):184. https://doi.org/10.3390/fi15050184
Chicago/Turabian StyleGao, Siyu, Yuchen Wang, Nan Feng, Zhongcheng Wei, and Jijun Zhao. 2023. "Deep Reinforcement Learning-Based Video Offloading and Resource Allocation in NOMA-Enabled Networks" Future Internet 15, no. 5: 184. https://doi.org/10.3390/fi15050184
APA StyleGao, S., Wang, Y., Feng, N., Wei, Z., & Zhao, J. (2023). Deep Reinforcement Learning-Based Video Offloading and Resource Allocation in NOMA-Enabled Networks. Future Internet, 15(5), 184. https://doi.org/10.3390/fi15050184