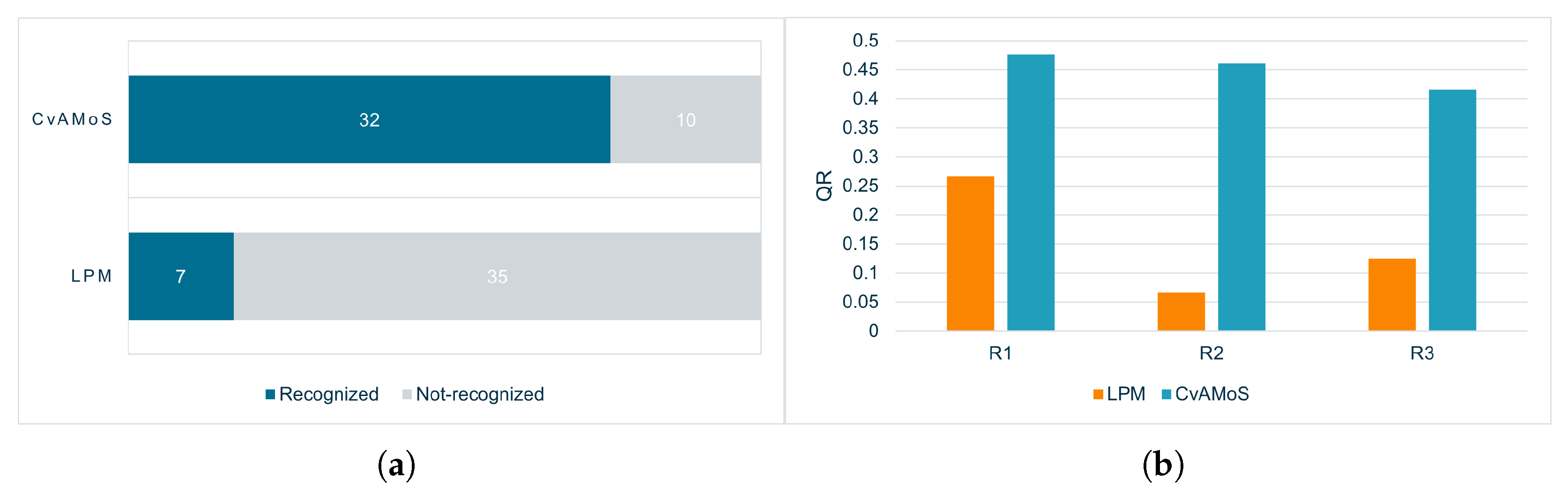
The approach proposed in this paper aims at identifying recurring sequences of activities within a low-level event log (e.g., where activities refer to sensor data), which can be abstracted and interpreted as higher-level activities. The proposed algorithm, called CvAMoS, is a motif search algorithm that focuses on the identification of recurring and variable patterns while considering contextual attributes. CvAMoS is implemented as a Java application and the code is freely available (See the Data Availability Statement for the details).
The origin of the algorithm can be traced to the biology field, more specifically to the quorum Planted Motif Search [
21] (qPMS). qPMS is a method for finding motifs (recurring patterns) in biological sequences of proteins. The algorithm searches for instances of the pattern in the sequences provided as input, such that each motif occurs in most of the sequences, up to a given distance. We have implemented a first extension of this algorithm (called
vAMoS [
9]) that is able to deal with an event log and the concept of traces, together with a more accurate mechanism for the identification and verification of the motifs.
CvAMoS is an extension of
vAMoS, which is enriched with contextual variables. The objective of
CvAMoS is to identify sequences of events that occur frequently in the traces, but introducing the notion of context in the motifs construction.
vAMoS was different from qPMS in a few respects, but in particular for the introduction of the concept of
cost. The cost can be expressed as the similarity, e.g., given two traces and a maximum cost, it is possible to identify common parts of the traces that are similar (up to the cost). The improvement of
CvAMoS with respect to
vAMoS is the distinction between events and contextual events. Contextual events are attributes of a motif, and describe the state of the environment while the motif was recorded.
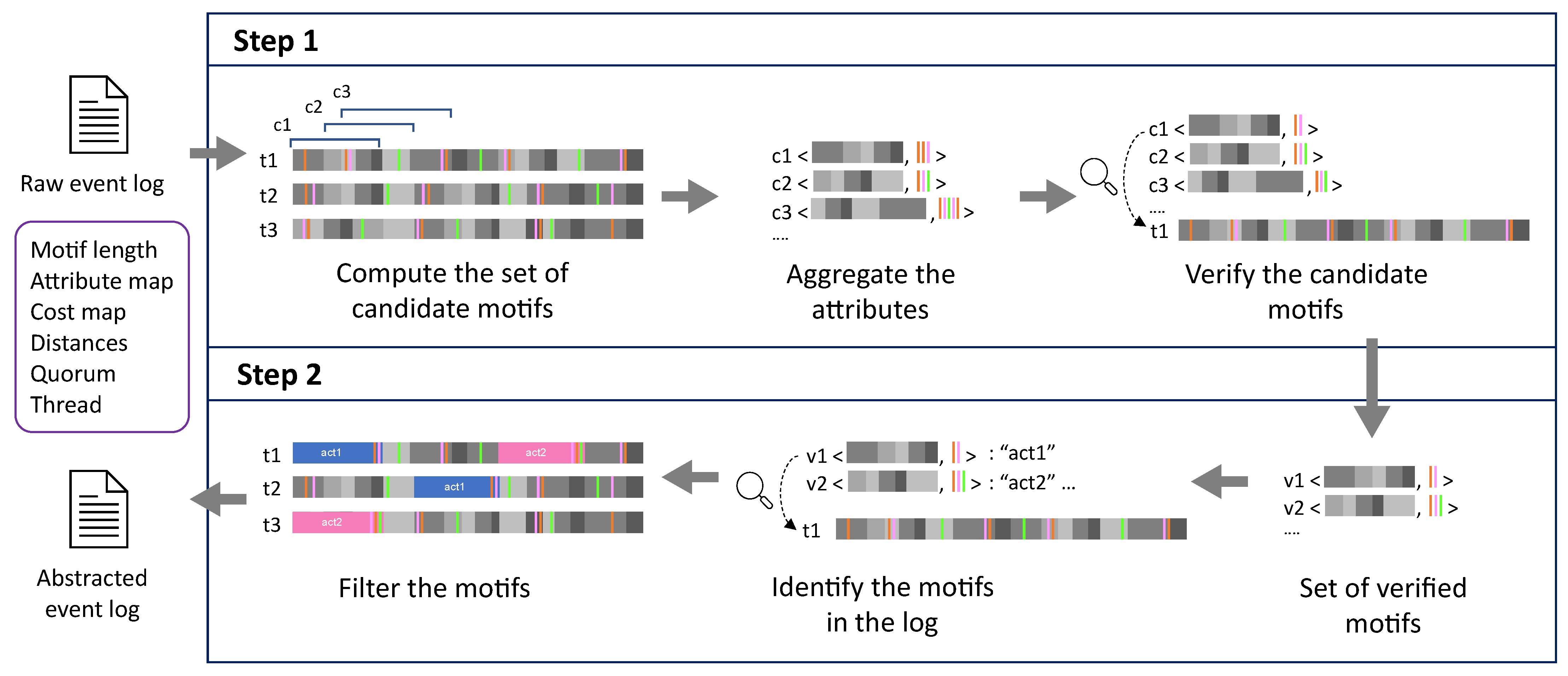
4.2. Step 1: Construction of the Set of Motifs
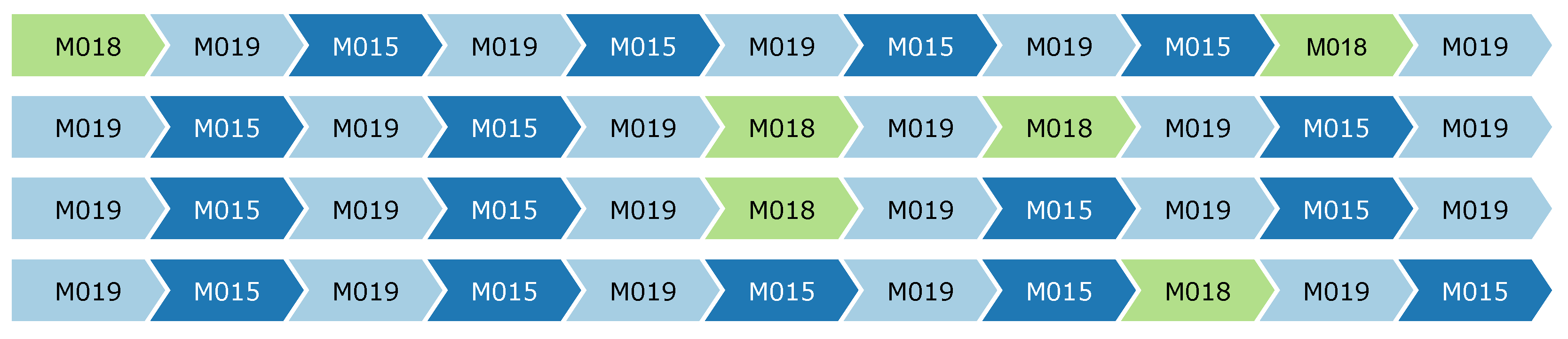
The first step of the approach consists of the construction of the set of motifs that will be then verified. In this paper, a motif is not only a sequence of events, but also considers the context. In the event log, we can distinguish between events referring to the execution of an activity, and events that are referring to the state of the environment, usually in the form of continuous measurement (e.g., temperature, noise level). The former is part of the motif, while the latter belongs to the set of attributes of the given motif (i.e., the context). The information regarding which attributes should be considered as environment and which refer to the execution of activities should be provided by the user in the form of an “attribute map”. Additionally, the attribute map should contain aggregation operators (which indicate how environment attributes are aggregated) as well as the maximum tolerance from the aggregated value.
Definition 5 (Attribute map). An attribute map is a triplet , where is the set of all attribute names (cf. Definition 1), is an aggregation operator, and σ is the maximum approximation tolerance (which is a scalar value). We indicate with the set of all attribute names of , with the aggregation operator associated with attribute name n, and with the σ tolerance associated with attribute name n.
For example, given an activity , the attribute map could be which means that the attribute label temp should be aggregated using the mean, and values with distance 2 from such a mean should be considered as equal.
Therefore, a candidate motif can be defined as follows:
Definition 6 (Candidate Motif). Given a trace , a starting index i, a target motif length such that , and an attribute map , a candidate motif c is defined as a tuple where is the sub-trace, and is the relation mapping all attribute names contained in to the corresponding aggregated values (according to the respective aggregation function in ) computed over .
Considering again the example from the previous definition, the component of a candidate motif would contain the mean value of all the temp attribute values computed on all events in the sub-trace.
Definition 7. Given an event log , a motif length , and an attribute map , we call the set of all candidate motifs that can be seen on all traces part of . To compute all motifs an iterative approach can be adopted, by iterating all traces and extracting all possible motifs for each trace (i.e., all possible sub-traces of length ).
During the construction of a candidate motif, several attributes sharing the same attribute name are identified. However, the following verification task requires a single value for each attribute name. The aggregation operator, defined in the attribute map (see Definition 5), serves this purpose. Hence, these attribute values are aggregated according to the attribute map. A candidate motif, therefore, includes the attribute values already aggregated.
The candidate motifs now need to be verified. The verification establishes whether a candidate motif can be considered an actual motif, by checking the requirements of distance, activity cost, attribute cost, and quorum. The motif must appear in a given percentage of traces (quorum), up to a certain dissimilarity (distance), according to the interchangeability relations provided by the user (costs), and according to the context defined by the attributes.
The activity cost is a relation indicating the similarity (or dissimilarity) between pairs of activities: the cost value can be used to indicate whether two activities can be performed interchangeably or not (i.e., whether one is an acceptable replacement of the other).
Definition 8 (Activity Cost Relation). The relation indicates the extent of the interchangeability of two activities. For example, given two activities if is close to 0, then and are interchangeable (i.e., they are equivalent); if the value is close to 1 it means they are not.
The relation is expected to be provided by the user since it is heavily domain dependent. If the user does not specify a cost for a certain pair of activities, a cost of 1 is assumed.
The capability of setting activity costs is particularly relevant every time an activity is mapped by, for example, two proximity sensors that are physically very close to each other. In this setting, these will usually be triggered simultaneously and therefore could be considered interchangeable. Another example of how this concept can be applied is to consider two activities that are completely unrelated and cannot be performed in the same context. In this case, it would be appropriate to assign a cost value close to 1 to reflect that these activities cannot be interchanged.
The cost relation is used to compute the distance. The distance function quantifies the similarity between two traces. The distance is firstly computed in terms of activities and then in terms of attributes. The activity distance can be defined as follows:
Definition 9 (Activity distance).
Given two traces and with the same length (i.e., ) and given the relation, the activity distance between and is defined as the sum of the costs for each pair of activities of the respective traces: To check the similarity between the activities in the motif and the activities in the sub-trace, CvAMoS implements the Hamming distance as a distance function, by computing the number of positions at which the corresponding activities are different. The cost map is used by this function to evaluate the similarity. The activity distance tackles the problem of the variability of the behaviors, meaning that there could be a slightly different configuration in how the same behavior appears in different instances, and this difference is tolerated by the distance. If the activity distance is within an acceptable threshold, the attribute distance is checked.
Definition 10 (Attribute Distance).
Given two traces and and given an attribute map . Let us call with and the application of operator o on the attribute values names n of trace t. The attribute distance between the two traces is defined as: The attribute distance between two traces is calculated by comparing the values of their set of attributes, and quantifying the difference between these values. To simplify, the distance between two attribute values, sharing the same attribute name, is computed as the absolute difference between these values, but considering the maximum approximation tolerance. Accordingly, the attribute distance between two traces is the sum of these differences. Only differences that exceed the tolerance value are included in the attribute distance calculation.
Definition 11 (Overall Distance).
Given two traces and , given an attribute map , an activity cost , a maximum activity cost , and a maximum attribute cost , the distance between the two traces is defined as: It follows from the above that two traces can be considered similar if their activity distance is less than the given threshold and their attributes must match too (according to the tolerance) within the respective distance .
We can slightly adapt this definition to compare traces and candidate motifs too:
Definition 12.
Given a trace t and a candidate motif , given the attribute map used to construct c, the activity cost , a maximum activity cost and a maximum attribute cost , we can verify whether the candidate motif is verified by the trace with the following: The last concept to be discussed is the quorum. The quorum is the minimum relative amount of traces in which the candidate motif must appear in order to be considered as an actual motif. Since the objective is to look for recurrent sequences, the quorum value allows defining how recurrent the motif should be to be considered relevant. With this, we can now define a motif:
Definition 13 (Motif, or verified motif).
Given an event log and candidate motif , a maximum activity cost and attribute cost , an activity cost relation , and a quorum q, we call c motif (
or verified motif),
if In other words, to verify whether a candidate motif is indeed a motif, we check in all the traces of the event log if there is at least one sub-trace (of the same length as the motif) that matches it in terms of both activities and attributes, according to the two distance thresholds provided
,
(as described in Equation (
1)). If the amount of traces containing the motif satisfies the quorum
q, the candidate motif is returned as a motif.
Definition 14 (Set of motifs). We call the set of all motifs. This set comprises all candidate motifs that are verified (cf. Definition 13).
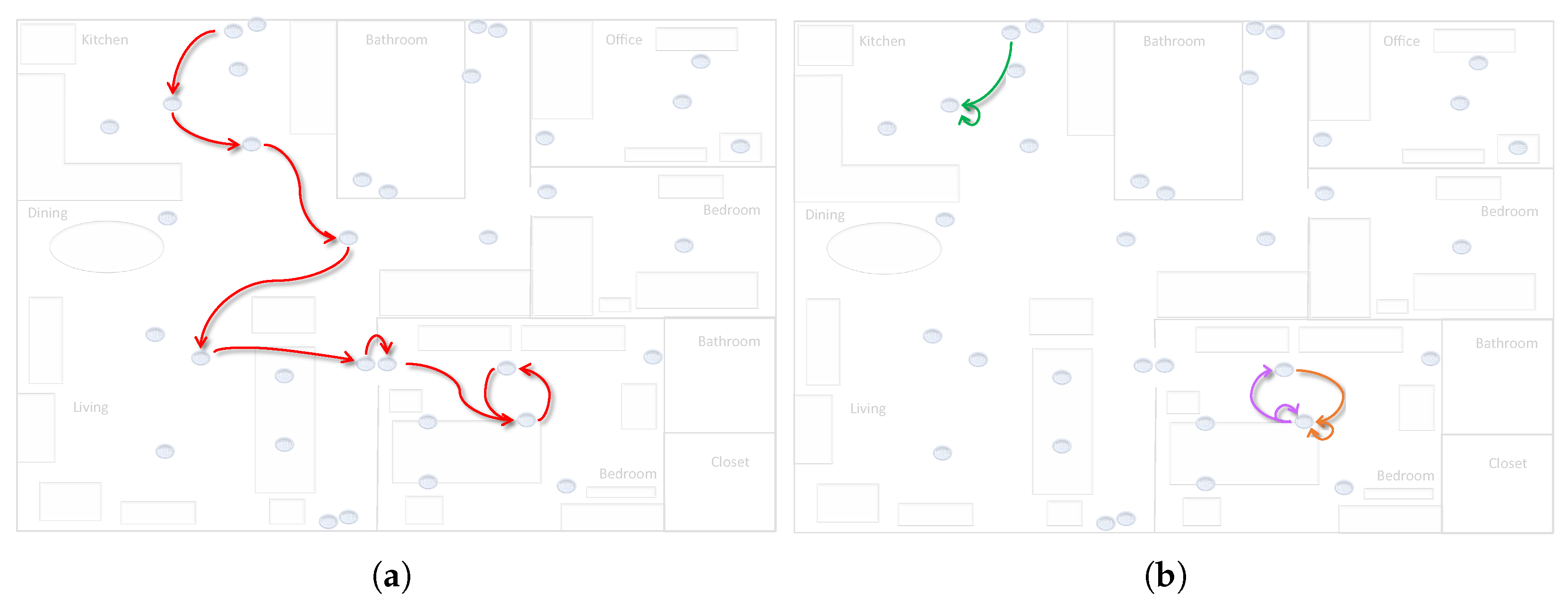
Algorithm 1 describes in detail the procedure for the verification of a set of candidates motifs: for each candidate motif the number of traces where it appears is computed (lines 4–9) by checking each possible sub-trace (with same length as the candidate motif) of each trace in the log (lines 4–5). If the candidate motif is contained in a trace (i.e., its activity distance is less than a parameter, cf. line 6), then their attributes are verified (line 7). If the distance between the attributes is less than the attribute distance parameter, a counter is incremented by the multiplicity of the trace in the log (line 8) and the procedure can skip to the next trace (line 9). If the number of traces containing the candidate motif satisfies the quorum, then the candidate motif becomes verified and hence it is added to the list of motifs to be returned (lines 11–12).
| Algorithm 1: Verification of candidates motifs. |
 |
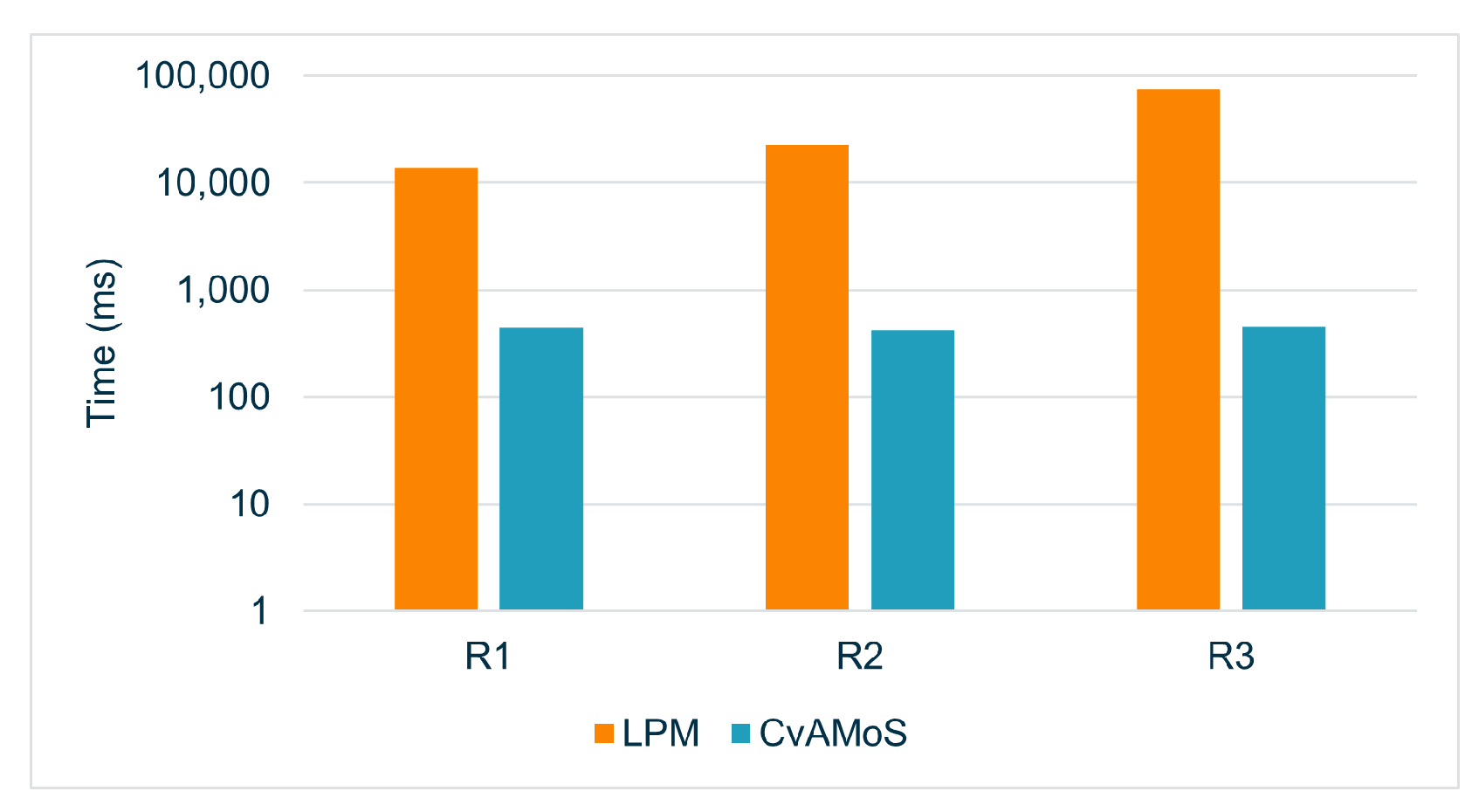
The algorithm has linear complexity, meaning that the amount of time required for the algorithm to complete increases in direct proportion to the size of the input data. In this case, it is given by the number of events in the event log times the size of the set of candidate motifs. The current implementation of CvAMoS exports the list of verified motifs in an XES file.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














