

Prediction of Energy Production Level in Large PV Plants through AUTO-Encoder Based Neural-Network (AUTO-NN) with Restricted Boltzmann Feature Extraction




Abstract
1. Introduction
2. Related Works
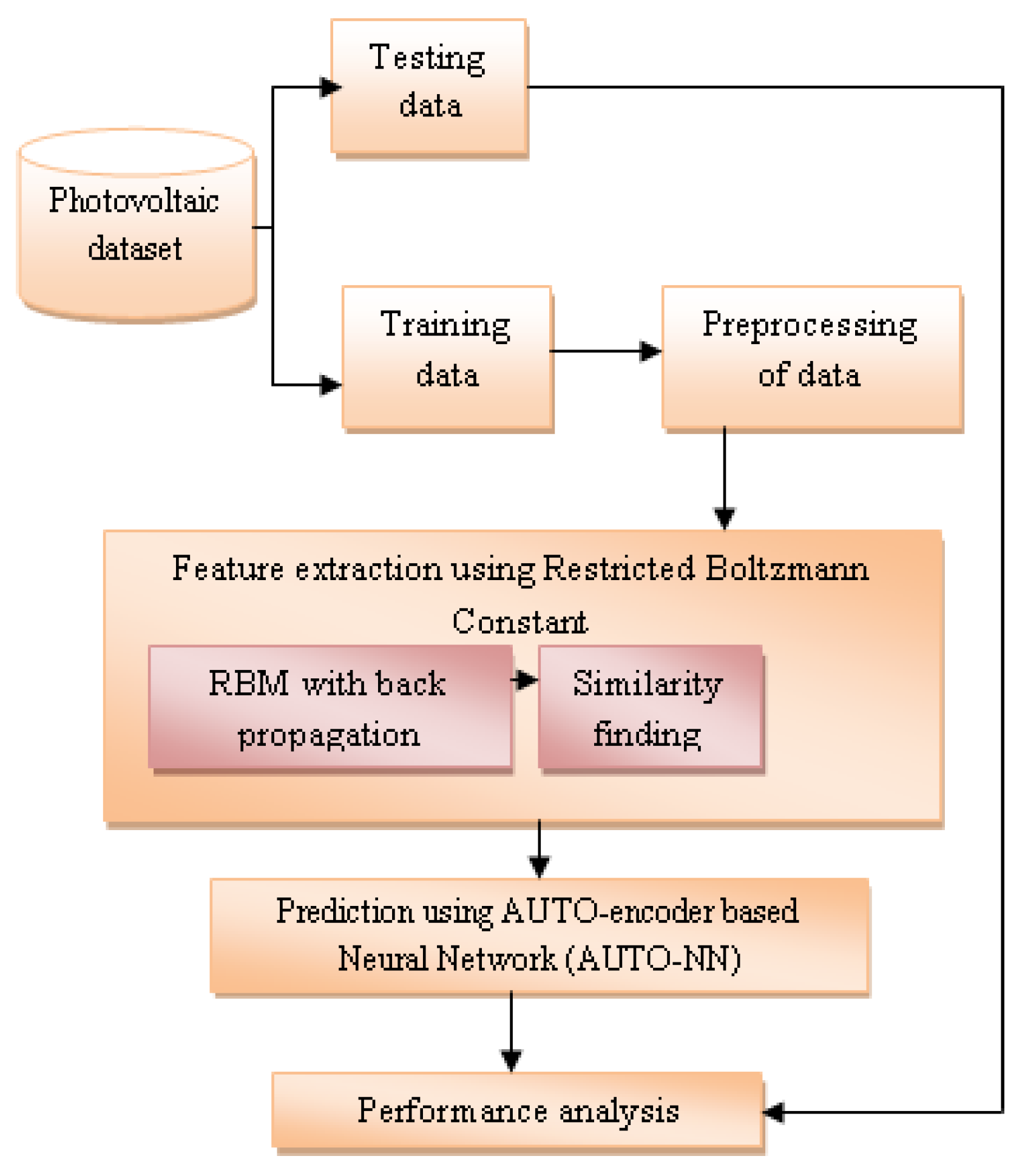
3. Proposed Model
3.1. Dataset Description
3.2. Preprocessing of Training Data
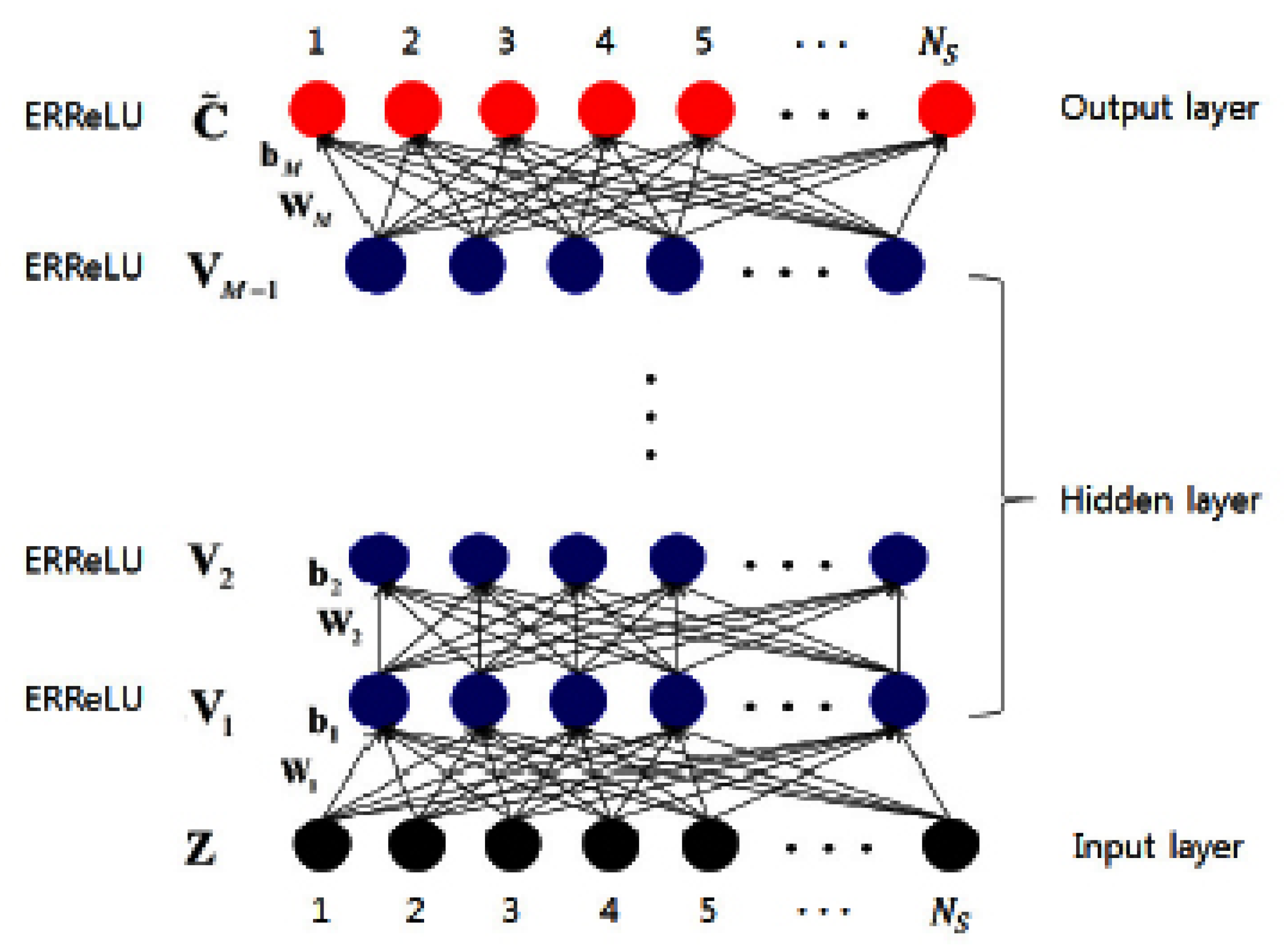
3.3. Feature Extraction Using Restricted Boltzmann Machine
3.4. Similarity Finding
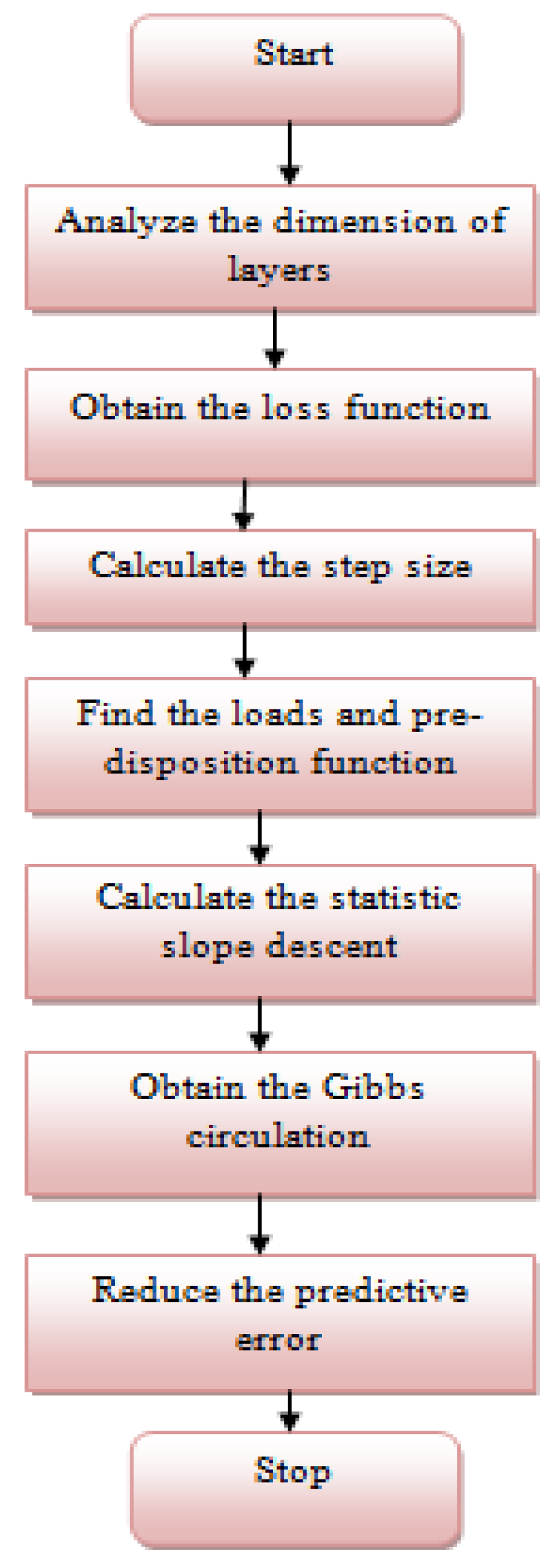
| Algorithm 1: AUTO-encoder-based Neural Network (AUTO-NN) Algorithm |
| In: Rx(t), x = 1,2,…n Out: Out_x(t), out = 1,2,…K and (K + 1)_t of every Out_x(t), For lay = 0 to lay-1 do Ki(hi) = Direct(hi) + ki For every lay do Initiate {u,v{h<-discrimate (low) and discrimate (low)} Find the weight (wei)<-0 Disc(sample),{low, high} For wei (k); k = 1,2…N(iteration) K > s = {{a1,b1},{a2,b2,}…{an,bn}} K becomes shrouded layer (sh) Sh = {1,2,…HH}.g where g = x(t) Compute fx(t) Update fx(t) as concealed unit I(t) = fx(t) < concealed units then Foundation = testing else foundation = concealed units end if end for |
3.5. Similarity Updating
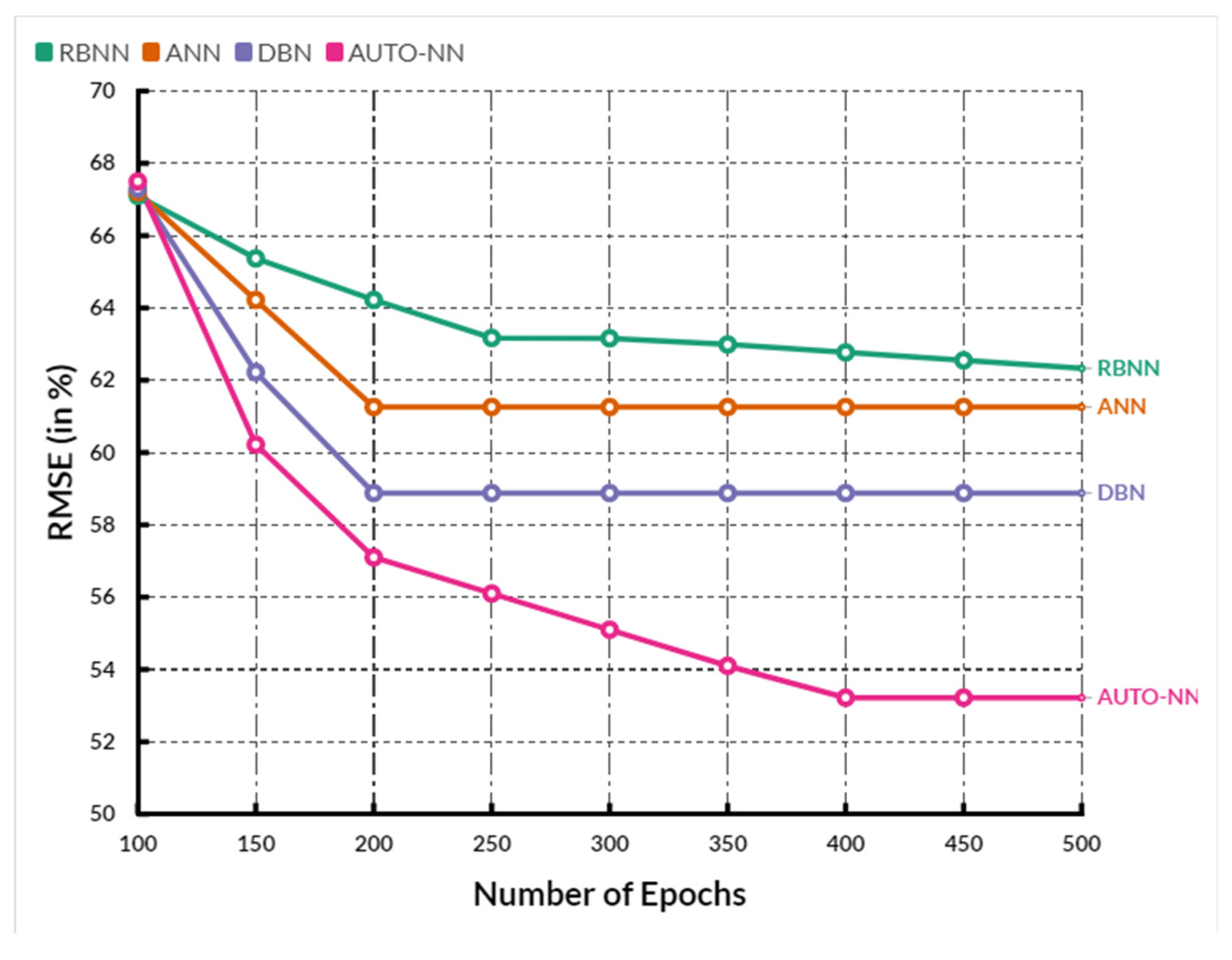
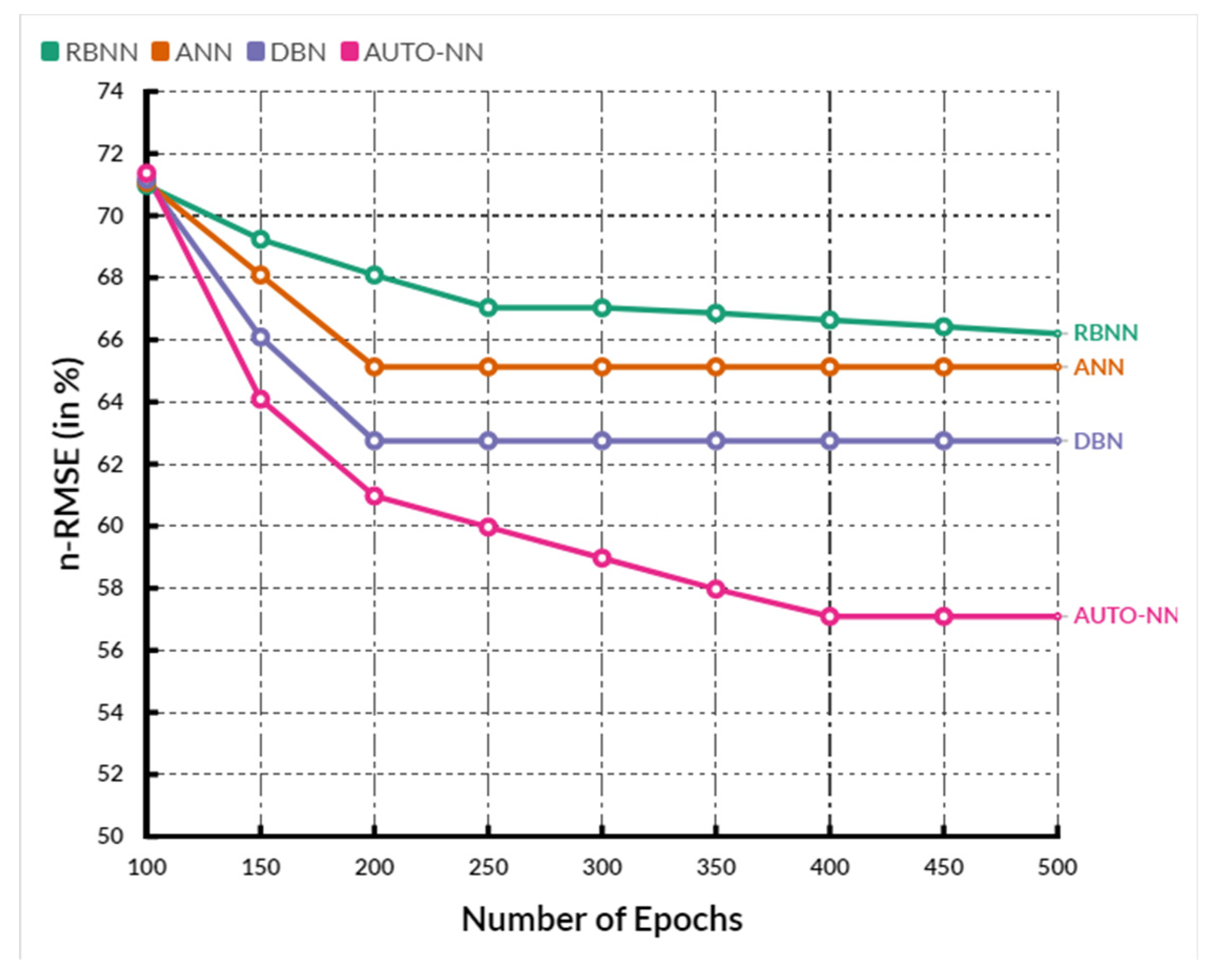
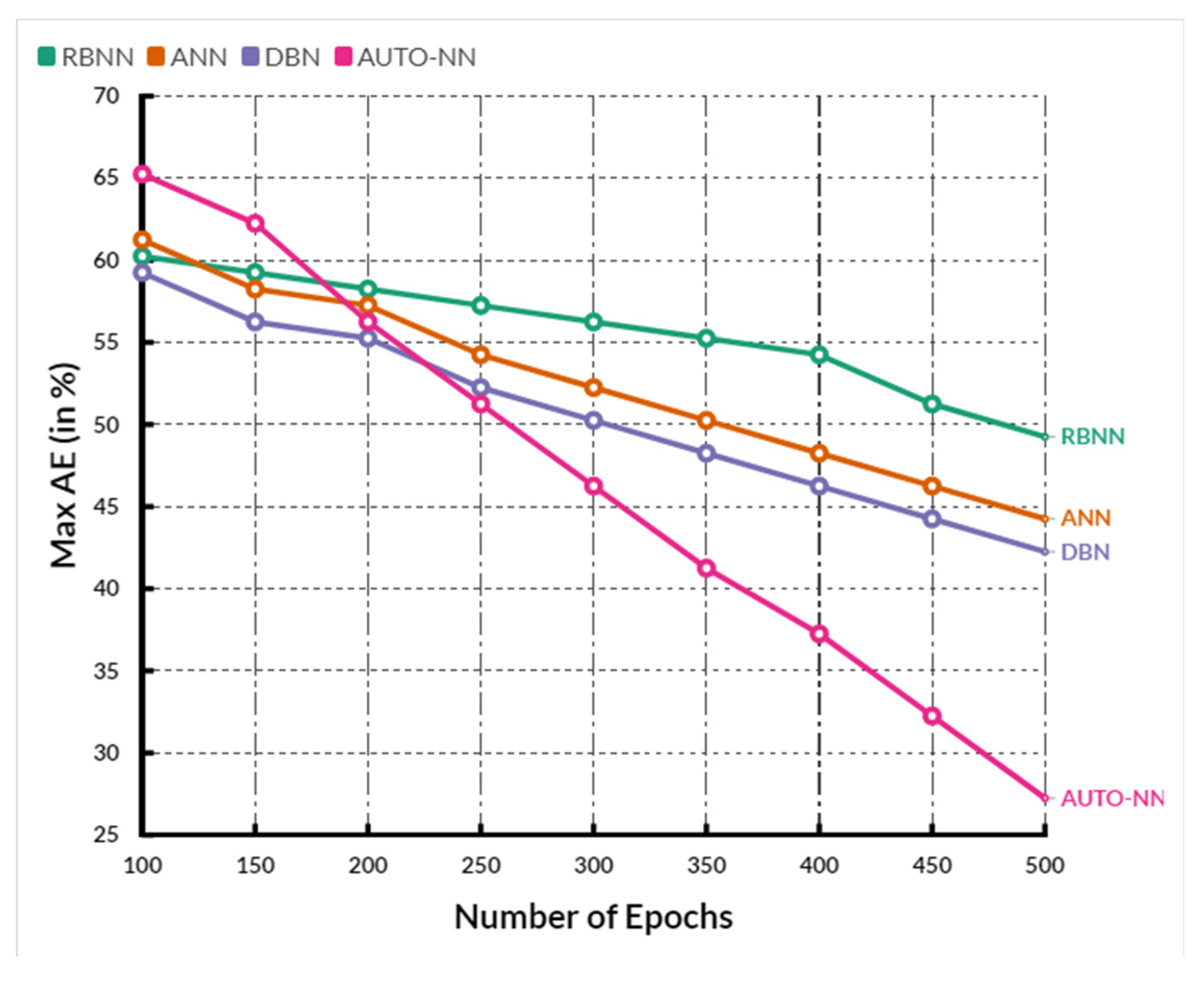
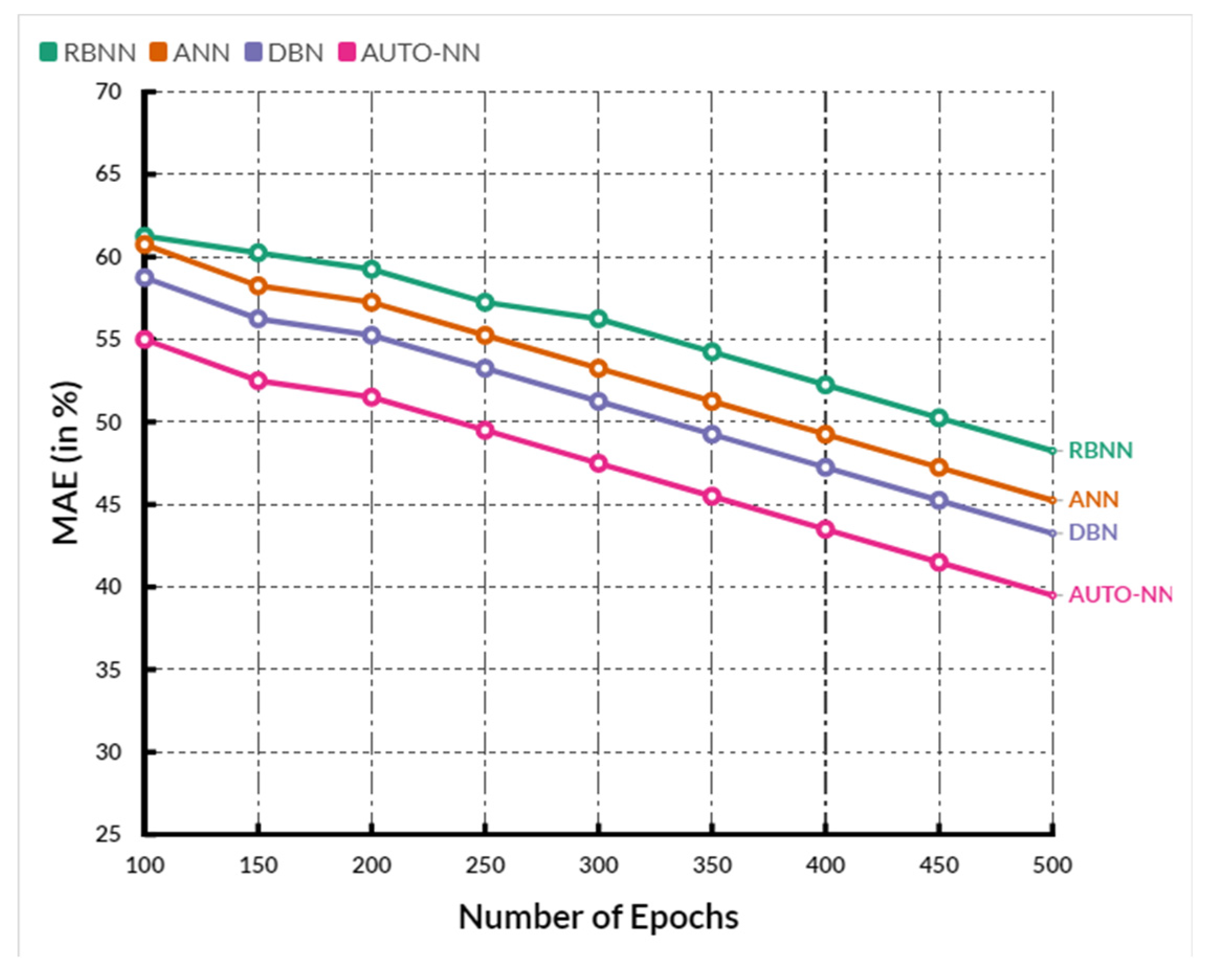
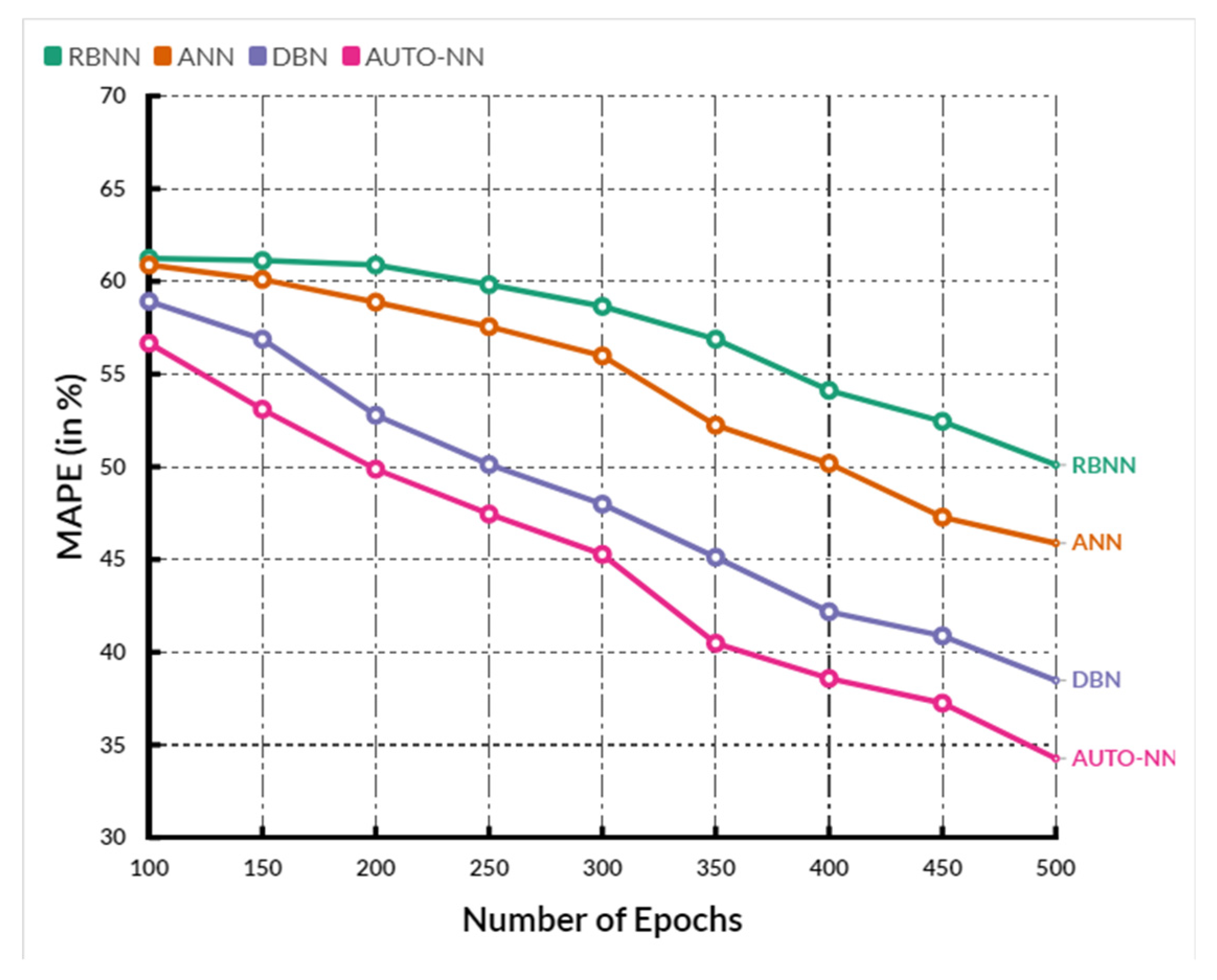
4. Comparative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Durrani, S.P.; Balluff, S.; Wurzer, L.; Krauter, S. Photovoltaic Yield Prediction Using an Irradiance Forecast Model Based on Multiple Neural Networks. J. Mod. Power Syst. Clean Energy 2018, 6, 255–267. [Google Scholar] [CrossRef]
- El-Baz, W.; Tzscheutschler, P.; Wagner, U. Day-ahead Probabilistic PV Generation Forecast for Buildings Energy Management Systems. Sol. Energy 2018, 171, 478–490. [Google Scholar] [CrossRef]
- Ibrahim, I.A.; Khatib, T. A novel hybrid model for hourly global solar radiation prediction using random forests technique and firefly algorithm. Energy Convers. Manag. 2017, 138, 413–425. [Google Scholar] [CrossRef]
- Lave, M.; Hayes, W.; Pohl, A.; Hansen, C.W. Evaluation of Global Horizontal Irradiance to Plane-of-Array Irradiance Models at Locations Across the United States. IEEE J. Photovolt. 2015, 5, 597–606. [Google Scholar] [CrossRef]
- Marzouq, M.; El Fadili, H.; Zenkouar, K.; Lakhliai, Z.; Amouzg, M. Short term solar irradiance forecasting via a novel evolutionary multi-model framework and performance assessment for sites with no solar irradiance data. Renew. Energy 2020, 157, 214–231. [Google Scholar] [CrossRef]
- VanDeventer, W.; Jamei, E.; Thirunavukkarasu, G.S.; Seyedmahmoudian, M.; Soon, T.K.; Horan, B.; Mekhilef, S.; Stojcevski, A. Short-term PV power forecasting using hybrid GASVM technique. Renew. Energy 2019, 140, 367–379. [Google Scholar] [CrossRef]
- Shamshirband, S.; Mohammadi, K.; Yee, P.L.; Petković, D.; Mostafaeipour, A. A comparative evaluation for identifying the suitability of extreme learning machine to predict horizontal global solar radiation. Renew. Sustain. Energy Rev. 2015, 52, 1031–1042. [Google Scholar] [CrossRef]
- Wu, L.; Huang, G.; Fan, J.; Zhang, F.; Wang, X.; Zeng, W. Potential of kernel-based nonlinear extension of Arps decline model and gradient boosting with categorical features support for predicting daily global solar radiation in humid regions. Energy Convers. Manag. 2019, 183, 280–295. [Google Scholar] [CrossRef]
- Zhu, H.; Li, X.; Sun, Q.; Nie, L.; Yao, J.; Zhao, G. A Power Prediction Method for Photovoltaic Power Plant Based on Wavelet Decomposition and Artificial Neural Networks. Energies 2015, 9, 11. [Google Scholar] [CrossRef]
- Yin, W.; Han, Y.; Zhou, H.; Ma, M.; Li, L.; Zhu, H. A novel non-iterative correction method for short-term photovoltaic power forecasting. Renew. Energy 2020, 159, 23–32. [Google Scholar] [CrossRef]
- Yagli, G.M.; Yang, D.; Gandhi, O.; Srinivasan, D. Can We Justify Producing Univariate Machine-learning Forecasts with Satellite-derived Solar Irradiance? Appl. Energy 2020, 259, 114122. [Google Scholar] [CrossRef]
- Nespoli, A.; Ogliari, E.; Leva, S.; Pavan, A.M.; Mellit, A.; Lughi, V.; Dolara, A. Day-Ahead Photovoltaic Forecasting: A Comparison of the Most Effective Techniques. Energies 2019, 12, 1621. [Google Scholar] [CrossRef]
- Hernández, L.; Baladrón, C.; Aguiar, J.M.; Carro, B.; Sánchez-Esguevillas, A.; Lloret, J. Artificial neural networks for short-term load forecasting in microgrids environment. Energy 2014, 75, 252–264. [Google Scholar] [CrossRef]
- Logeshwaran, J.; Shanmugasundaram, R.N. Enhancements of Resource Management for Device to Device (D2D) Communication: A Review. In Proceedings of the 2019 Third International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud)(I-SMAC), Palladam, India, 12–14 December 2019; IEEE: Piscataway, NJ, USA; pp. 51–55. [Google Scholar]
- Hernandez, L.; Baladrón, C.; Aguiar, J.M.; Carro, B.; Sanchez-Esguevillas, A.J.; Lloret, J. Short-Term Load Forecasting for Microgrids Based on Artificial Neural Networks. Energies 2013, 6, 1385–1408. [Google Scholar] [CrossRef]
- Logeshwaran, J.; Rex, M.J.; Kiruthiga, T.; Rajan, V.A. FPSMM: Fuzzy probabilistic based semi morkov model among the sensor nodes for realtime applications. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 7–8 December 2017; IEEE: Piscataway, NJ, USA; pp. 442–446.
- Hernández, L.; Baladron, C.; Aguiar, J.M.; Calavia, L.; Carro, B.; Sánchez-Esguevillas, A.; Pérez, F.; Fernández, A.; Lloret, J. Artificial Neural Network for Short-Term Load Forecasting in Distribution Systems. Energies 2014, 7, 1576–1598. [Google Scholar] [CrossRef]
- Nguyen, A.-T.; Taniguchi, T.; Eciolaza, L.; Campos, V.; Palhares, R.; Sugeno, R.M. Fuzzy Control Systems: Past, Present and Future. IEEE Comput. Intell. Mag. 2019, 14, 56–68. [Google Scholar] [CrossRef]
- Yin, L.; Cao, X.; Liu, D. Weighted fully-connected regression networks for one-day-ahead hourly photovoltaic power forecasting. Appl. Energy 2023, 332, 120527. [Google Scholar] [CrossRef]
- Cui, Y.; Chen, Z.; He, Y.; Xiong, X.; Li, F. An algorithm for forecasting day-ahead wind power via novel long short-term memory and wind power ramp events. Energy 2023, 263, 125888. [Google Scholar] [CrossRef]
- Li, P.; Gao, X.; Li, Z.; Zhou, X. Effect of the temperature difference between land and lake on photovoltaic power generation. Renew. Energy 2022, 185, 86–95. [Google Scholar] [CrossRef]
- Tamoor, M.; Habib, S.; Bhatti, A.R.; Butt, A.D.; Awan, A.B.; Ahmed, E.M. Designing and Energy Estimation of Photovoltaic Energy Generation System and Prediction of Plant Performance with the Variation of Tilt Angle and Interrow Spacing. Sustainability 2022, 14, 627. [Google Scholar] [CrossRef]
- Wu, Y.-K.; Lai, Y.-H.; Huang, C.-L.; Phuong, N.T.B.; Tan, W.-S. Artificial Intelligence Applications in Estimating Invisible Solar Power Generation. Energies 2022, 15, 1312. [Google Scholar] [CrossRef]
- Ibrahim, M.; Alsheikh, A.; Awaysheh, F.M.; Alshehri, M.D. Machine Learning Schemes for Anomaly Detection in Solar Power Plants. Energies 2022, 15, 1082. [Google Scholar] [CrossRef]
- Sittón-Candanedo, I.; Alonso, R.S.; García, Ó.; Gil, A.B.; Rodríguez-González, S. A Review on Edge Computing in Smart Energy by means of a Systematic Mapping Study. Electronics 2019, 9, 48. [Google Scholar] [CrossRef]
- Kim, T.; Ko, W.; Kim, J. Analysis and Impact Evaluation of Missing Data Imputation in Day-ahead PV Generation Forecasting. Appl. Sci. 2019, 9, 204. [Google Scholar] [CrossRef]
- Hartono, D.; Hastuti, S.H.; Balya, A.A.; Pramono, W. Modern energy consumption in Indonesia: Assessment for accessibility and affordability. Energy Sustain. Dev. 2020, 57, 57–68. [Google Scholar] [CrossRef]
- Tian, Z.; Si, B.; Shi, X.; Fang, Z. An application of Bayesian Network approach for selecting energy efficient HVAC systems. J. Build. Eng. 2019, 25, 100796. [Google Scholar] [CrossRef]
- Tian, W.; Yang, S.; Li, Z.; Wei, S.; Pan, W.; Liu, Y. Identifying informative energy data in Bayesian calibration of building energy models. Energy Build. 2016, 119, 363–376. [Google Scholar] [CrossRef]
- Amasyali, K.; El-Gohary, N.M. A review of data-driven building energy consumption prediction studies. Renew. Sustain. Energy Rev. 2018, 81, 1192–1205. [Google Scholar] [CrossRef]
- Somu, N.; MR, G.R.; Ramamritham, K. A deep learning framework for building energy consumption forecast. Renew. Sustain. Energy Rev. 2021, 137, 110591. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Oliveto, G. Riprap incipient motion for overtopping flows with machine learning models. J. Hydroinformatics 2020, 22, 749–767. [Google Scholar] [CrossRef]
- Seyedzadeh, S.; Rahimian, F.; Rastogi, P.; Glesk, I. Tuning machine learning models for prediction of building energy loads. Sustain. Cities Soc. 2019, 47, 101484. [Google Scholar] [CrossRef]
- Hernandez, L.; Baladron, C.; Aguiar, J.M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J.; Chinarro, D.; Gomez-Sanz, J.J.; Cook, D. A multi-agent system architecture for smart grid management and forecasting of energy demand in virtual power plants. IEEE Commun. Mag. 2013, 51, 106–113. [Google Scholar] [CrossRef]
- Canada, N.R. High-Resolution Solar Radiation Datasets. 2017. Available online: http://www.nrcan.gc.ca/energy/renewable-electricity/solar-photovoltaic/18409 (accessed on 10 November 2022).
- Shamsi, P.; Xie, H. Preemptive control: A paradigm in supporting high renewable penetration levels. In Proceedings of the North American Power Symposium (NAPS), Denver, CO, USA, 18–20 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–5. [Google Scholar]
- Logeshwaran, J.; Ramkumar, M.; Kiruthiga, T.; Sharanpravin, R. The role of integrated structured cabling system (ISCS) for reliable bandwidth optimization in high-speed communication network. ICTACT J. Commun. Technol. 2022, 13, 2635–2639. [Google Scholar]
- Fu, S.; Zhang, Z.; Jiang, Y.; Chen, J.; Peng, X.; Zhao, W. An Automatic RF-EMF Radiated Immunity Test System for Electricity Meters in Power Monitoring Sensor Networks. Ad Hoc Sens. Wirel. Netw. 2021, 50, 173–192. [Google Scholar]
- Balasubramaniam, S.; Kumar, K.S. Fractional Feedback Political Optimizer with Prioritization-Based Charge Scheduling in Cloud-Assisted Electric Vehicular Network. Ad Hoc Sens. Wirel. Netw. 2022, 52, 173–198. [Google Scholar]
- Visser, L.; AlSkaif, T.; van Sark, W. Operational day-ahead solar power forecasting for aggregated PV systems with a varying spatial distribution. Renew. Energy 2022, 183, 267–282. [Google Scholar] [CrossRef]
- Jain, A.; Verma, C.; Kumar, N.; Raboaca, M.S.; Baliya, J.N.; Suciu, G. Image Geo-Site Estimation Using Convolutional Auto-Encoder and Multi-Label Support Vector Machine. Information 2023, 14, 29. [Google Scholar] [CrossRef]
- Khan, W.; Walker, S.; Zeiler, W. Improved solar photovoltaic energy generation forecast using deep learning-based ensemble stacking approach. Energy 2022, 240, 122812. [Google Scholar] [CrossRef]
- Thapa, K.; Seo, Y.; Yang, S.H.; Kim, K. Semi-Supervised Adversarial Auto-Encoder to Expedite Human Activity Recognition. Sensors 2023, 23, 683. [Google Scholar] [CrossRef]
- Ren, Y.; Yao, X.; Liu, D.; Qiao, R.; Zhang, L.; Zhang, K.; Jin, K.; Li, H.; Ran, Y.; Li, F. Optimal design of hydro-wind-PV multi-energy complementary systems considering smooth power output. Sustain. Energy Technol. Assess. 2022, 50, 101832. [Google Scholar] [CrossRef]
- Rodríguez, F.; Azcárate, I.; Vadillo, J.; Galarza, A. Forecasting intra-hour solar photovoltaic energy by assembling wavelet based time-frequency analysis with deep learning neural networks. Int. J. Electr. Power Energy Syst. 2022, 137, 107777. [Google Scholar] [CrossRef]
- Gao, X.; Deng, F.; Zheng, H.; Ding, N.; Ye, Z.; Cai, Y.; Wang, X. Followed The Regularized Leader (FTRL) prediction model based photovoltaic array reconfiguration for mitigation of mismatch losses in partial shading condition. IET Renew. Power Gener. 2022, 16, 159–176. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Advantages | Drawbacks |
|---|---|---|
| Sittón-Candanedo et al. [25] | The highly recommended energy projects in fuel consumption are the modern energy availability, particularly for low individuals as well as remote regions | Renewable energy is critical to the long-term viability of energy and the environment |
| Kim, T et al. [26] | The learning algorithm was used to determine which buildings’ major refrigerants should be installed | Impact Evaluation of Missing Data Imputation in Day-ahead PV Generation Forecasting The Bayesian network analysis was used to predict the most electricity main refrigerants |
| D. Hartono et al. [27] | The proposed model indicated that data-driven techniques, including load projections, energy consumption profiles, and retrofit solutions, have indeed been widely utilized in the energy domain | The data-driven methodologies for monitoring energy and costs were examined. These observations backed up the overall validity of data-driven architecture. |
| Z. Tian et al. [28] | The ANNs concept was shown to be the majority accepted in applications ranging from force forecast to retrofit resolution. | SVM models were frequently utilized for extensive construction liveliness analyses |
| W. Tian et al. [29] | This research looked into the predictive ranges, pre-processing stage methodologies, machine learning classification algorithms, and assessment key metrics. | Here the analytical information has various ways of estimating energy use in buildings. It is a little complex to estimate the values. |
| K. Amasyali et al. [30] | In terms of panel size, the majority of the research examined were using a smart prediction of PV energy | There have been two types of building structures of prediction. Hence the energy scattering occurs easily. |
| N. Somu et al. [31] | The authors introduced a novel infrastructure machine learning method (ResNet) to predict the forecasting of the energy on more accurate values. | The benchmark energy modeling model to create the needed periodical collected information for every property |
| M. Najafzadeh et al. [32] | A hybrid methodology for simulating power usage in various spatiotemporal qualities by disciplines’ expertise with neural networks | The ‘hidden’ effects of the urban environment which are not represented in the actual building computation, a deep residual program was built |
| S. Seyedzadeh et al. [33] | The thickness of hidden units in ResNet can understand the relationships among demand in nearby buildings | Obtaining data and information beginning a physics-induced form took more time |
| Luis Hernández et al. [34] | The SVM, MARS, and RF models were used to forecast the approaches dens metric Froude score there at the impending movement of riprap particles | The prediction failure occurs in degradation monitoring. This could also prevent streams from degradation |
| N. R. Canada et al. [35] | The performance of the machine learning model that can predict indoor thermal comfort in buildings was assessed | The PV energy prediction in a timely manner. Hence it does not provide a periodical update about the prediction. |
| P. Shamsi et al. [36] | The ANNs paradigm has a faster computational effort than the other ML mode studied throughout the investigation | Researchers also concluded that with complicated datasets supporting high renewable penetration levels |
| J. Logeshwaran et al. [37] | The current state of knowledge introduced a genuine needs disparity in the existing energy in the basic of integrated structured cabling systems | The scattering loss and other cabling problems are not addressed properly. |
| Shisheng Fu et al. [38] | This model can be identified as improving a precise long-term hourly prediction for the period consumed energy | Renewable electricity consumers were experiencing a significant drop in forecasting without accuracy. |
| Balasubramaniam S et al. [39] | Energy can be transferred to a particular place or element, but it is something that cannot be created or destroyed | Focusing on energy and every variation of each model would be too broad and complex |
| Visser, L et al. [40] | Some of the main sources of global warming are derived from thermal processes due to the exchange reaction of CO2. | The transfer of CO2 from energy conversion is essentially non-existent |
| Tamoor, M et al. [41] | Conversion of thermal energy from other forms of energy can be given with high efficiency | A certain amount of energy is always wasted in a thermal way, which is similar to friction and process |
| Khan, W et al. [42] | The minimum approximation point is reached, and the process is reversed to go in the opposite direction. | The process has maximum efficiency as this environment is not practical |
| Li, P et al. [43] | the variation in density that has thermal energy to perform the work, and the efficiency of this variation is less than one hundred percent | It should be noted that heat energy is specific because it cannot be converted into other energy |
| Ren, Y et al. [44] | Thermal energy represents a peculiarly disordered or chaotic energy that is distributed without a particular continuity. | The multitude of situations available to the group of particles that make up the systematic mechanism |
| Rodríguez, F et al. [45] | All matter that alters or produces changes in its environment contains energy. | In all kinds of activities undertaken, energy is of utmost importance |
| Gao, X et al. [46] | Everything from electrical appliances to electric vehicles requires fuel to run. It combines blocks of chemical energy. | When placed in contact with a particular hot element, are converted into thermal energy and then into kinetic energy |
| Parameter | RBNN | ANN | DBN | AUTO-NN |
|---|---|---|---|---|
| RMSE (Root Mean Square Error) | 64.00 | 62.20 | 60.52 | 58.72 |
| nRMSE (Normalized Root Mean Square Error) | 67.48 | 66.58 | 64.74 | 62.72 |
| MAE (Mean Absolute Error) | 57.26 | 56.20 | 51.16 | 48.66 |
| MaxAE (Maximum Absolute Error) | 53.48 | 51.66 | 50.54 | 48.04 |
| MAPE (Mean Absolute Percentage Error) | 57.96 | 54.12 | 48.96 | 46.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramesh, G.; Logeshwaran, J.; Kiruthiga, T.; Lloret, J. Prediction of Energy Production Level in Large PV Plants through AUTO-Encoder Based Neural-Network (AUTO-NN) with Restricted Boltzmann Feature Extraction. Future Internet 2023, 15, 46. https://doi.org/10.3390/fi15020046
Ramesh G, Logeshwaran J, Kiruthiga T, Lloret J. Prediction of Energy Production Level in Large PV Plants through AUTO-Encoder Based Neural-Network (AUTO-NN) with Restricted Boltzmann Feature Extraction. Future Internet. 2023; 15(2):46. https://doi.org/10.3390/fi15020046
Chicago/Turabian StyleRamesh, Ganapathy, Jaganathan Logeshwaran, Thangavel Kiruthiga, and Jaime Lloret. 2023. "Prediction of Energy Production Level in Large PV Plants through AUTO-Encoder Based Neural-Network (AUTO-NN) with Restricted Boltzmann Feature Extraction" Future Internet 15, no. 2: 46. https://doi.org/10.3390/fi15020046
APA StyleRamesh, G., Logeshwaran, J., Kiruthiga, T., & Lloret, J. (2023). Prediction of Energy Production Level in Large PV Plants through AUTO-Encoder Based Neural-Network (AUTO-NN) with Restricted Boltzmann Feature Extraction. Future Internet, 15(2), 46. https://doi.org/10.3390/fi15020046