
HeFUN: Homomorphic Encryption for Unconstrained Secure Neural Network Inference




Abstract
:1. Introduction
- Firstly, existing HE schemes only support addition and multiplication, while other operators, such as comparison, are not readily available and are usually replaced by evaluating expensive (high-degree) polynomial approximation [9,10]. Hence, current HE-based SNNI frameworks cannot practically evaluate non-linear activation functions, e.g., function, which are widely adopted in NNs.
- Secondly, in all existing HE schemes, ciphertexts contain noise, which will be accumulated after running homomorphic operations, and at some point, the noise present in a ciphertext may become too large, and the ciphertext is no longer decryptable. A family of HE supporting a predetermined number of homomorphic operators is called leveled HE (LHE). LHE is widely adopted in SNNI frameworks (LHE-based SNNI frameworks). Therefore, an inherent drawback of existing LHE-based SNNI frameworks is that they limit the depth of NNs.
- Thirdly, LHE-based SNNI suffers from huge computational overhead. The computational cost of LHE, for example, grows dramatically with the number of levels of multiplication that the scheme needs to support. This means LHE-based SNNI is impractical in the case of deep NNs (equivalent to a very large multiplication level). Interestingly, naturally reduces the size of LHE schemes’ parameters, hence significantly reducing computational overhead (details in Section 5.3).
- We proposed a novel iLHE-based protocol, , that can exactly evaluate the function solely based on HE, which achieves better communication rounds than current HE-MPC hybrid frameworks. The analysis is presented in Section 5.1.
- We proposed a novel iLHE-based protocol, , that refreshes noise in ciphertexts to enable arbitrary depth of the circuit. also reduces HE parameters’ size, hence significantly reducing computation time. Considering the ciphertext refreshing purpose, outperforms bootstrapping in relation to computation time (we detail this in Section 5.2). Furthermore, our protocol deviates from Gentry’s bootstrapping technique, so we bypass the circular security requirement.
- We build a new iLHE-based framework for SNNI, named , which uses to evaluate the activation function and use to refresh intermediate neural network layers.
- We provide security proofs for the proposed protocols. All proposed protocols, i.e., and , are proven to be secure in the semi-honest model using the simulation paradigm [21]. Our framework, , is created by composing sequential protocols. The security proof of the framework is provided based on modular sequential composition [22].
- Experiments show that outperform previous HE-based SNNI frameworks. Particularly, we achieve higher accuracy and better inference time.

{kind=link}
| Approach | Framework | Security | Accuracy | Efficiency | ||||
|---|---|---|---|---|---|---|---|---|
| Circuit Privacy | Comparable Accuracy a | Non-Linear | Unbounded | Non-Interactive b | SIMD | Small HE Params c | ||
| LHE | CryptoNets | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ |
| CryptoDL | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | |
| BNormCrypt | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | |
| Faster-CryptoNets | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | |
| HCNN | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | |
| E2DM | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | |
| LoLa | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | |
| CHET | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | |
| SEALion | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | |
| nGraph-HE | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | |
| FHE | FHE-DiNN | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ | ✓ |
| TAPAS | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ | ✓ | |
| SHE | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ | ✓ | |
| MPC | DeepSecure | ✗ | ✗ | ✓ | ✓ | ✗ | - | - |
| XONN | ✗ | ✗ | ✓ | ✓ | ✗ | - | - | |
| GarbledNN | ✗ | ✗ | ✓ | ✓ | ✗ | - | - | |
| QUOTIENT | ✗ | ✓ | ✓ | ✓ | ✗ | - | - | |
| Chameleon | ✗ | ✓ | ✓ | ✓ | ✗ | - | - | |
| ABY3 | ✗ | ✓ | ✓ | ✓ | ✗ | - | - | |
| SecureNN | ✗ | ✓ | ✓ | ✓ | ✗ | - | - | |
| FalconN | ✗ | ✓ | ✓ | ✓ | ✗ | - | - | |
| CrypTFlow | ✗ | ✓ | ✓ | ✓ | ✗ | - | - | |
| Crypten | ✗ | ✓ | ✓ | ✓ | ✗ | - | - | |
| HE-MPC hybrid | Gazelle | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
| MP2ML | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | |
| iLHE | nGraph-HE2 | ✗ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
| HeFUN (this work) | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | |
2. Related Works
2.1. LHE-Based SNNI
2.2. TFHE-Based SNNI
2.3. MPC-Based SNNI
2.4. HE-MPC Hybrid SNNI
3. Cryptographic Preliminaries
3.1. Notation
3.2. Homomorphic Encryption
3.3. Threat Model and Security
- Correctness: For any ’s input and ’s input , the probability that, at the end of the protocol, outputs and outputs is 1.
- Security:
- −
- Corrupted : For that follows the protocol, there exists a simulator such that where denotes the view of in the execution of (the view includes the ’s input, randomness, and the message received during the protocol), and denotes the ultimate output received at the end of Π.
- −
- Corrupted : For that follows the protocol, there exists a simulator such that where denotes the view of in the execution of and denotes the ultimate output received at the end of Π.
4. HeFUN: An iLHE-Based SNNI Framework
4.1. Problem Statement
4.2. : Homomorphic Evaluation Protocol
| Protocol 1 : Homomorphic evaluation protocol |
Input : Secret key Input : Public key , ciphertext Output :
|
- 1.
- Pick ;
- 2.
- Output .
- 1.
- Pick ;
- 2.
- Output .
4.3. : Refreshing Ciphertexts
| Protocol 2 : Ciphertext refreshing protocol |
Input : Secret key Input : Public key , Output :
|
- 1.
- Pick ;
- 2.
- Output .
- 1.
- Pick ;
- 2.
- Output .
4.4. Protocol
| Protocol 3 framework |
Input : Data , secret key Input : public key , trained weights and biases with Output : , where is function.
|
4.5.
- Permuting two vectors with the same permutation preserves element-wise addition:
- Permute two vectors with the same permutation and preserve their dot product:
- Permute a vector, and every column in a matrix with the same permutation preserves the vector–matrix product:where denotes that we apply the permutation to every column of .
- In vector–matrix multiplication, (only) permutation of a matrix by column leads to the same permutation on the result.
| Protocol 4 : Homomorphic permutation |
Input: ciphertext , permutation Output:
|
| Protocol 5 framework |
Input : Data , secret key Input : public key , trained weights and biases with Output : , where is function.
|
- 1.
- Pick with ;
- 2.
- Output .
5. Experiments
- Compared to current HE-MPC frameworks, requires less communication rounds in evaluating the activation function (Section 5.1).
- Compared to existing bootstrapping procedures, is much faster (Section 5.2).
- Compared to current LHE-based frameworks, outperforms the current LHE-based approach in terms of accuracy and inference time (Section 5.3).
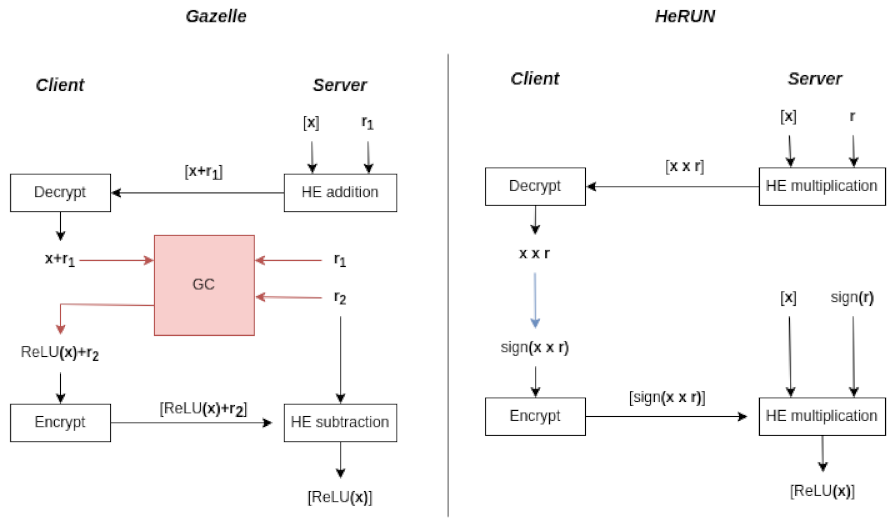
5.1. Comparison with Hybrid HE-MPC Approach
- Conversion from HE to MPC: The server additively blinds with a random mask and sends the masked ciphertext to the client.
- MPC circuit evaluation: The client decrypts . Then, the client (holds ) and the server (holds and a randomness ) run GC to compute without leaking to the server and and to the client. Finally, the client sends to the server.
- Conversion from MPC to HE: The server homomorphically subtracts and obtains .
5.2. Experimental Results
5.3. Comparison between and LHE (CryptoNets)
5.3.1. Experimental Setup
5.3.2. Dataset and NN Setup
- Small NN:
- −
- Convolution layer: The input image is 28 × 28. 5 kernels, each in size, with a stride of 2 and no padding. The output is a tensor.
- −
- Activation function: This layer applies the approximate activation function to each input value. It is a square function in CryptoNets, and the function in .
- −
- Fully connected layer: It connects the 845 incoming nodes to 100 outgoing nodes.
- −
- Activation function: It is the square function in CryptoNets, and the function in .
- −
- Fully connected layer: It connects the 100 incoming nodes to 10 outgoing nodes (corresponding to 10 classes in the MNIST dataset).
- −
- Activation function: It is the sigmoid activation function.
- Large NN:
- −
- Convolution layer: It contains 5 kernels, each in size, with a stride of 2 and no padding. The output is a tensor.
- −
- Activation function: It is the square function in CryptoNets, and the function in .
- −
- Fully connected layer: It connects the 845 incoming nodes to 300 outgoing nodes.
- −
- Activation function: It is the square function in CryptoNets, and the function in .
- −
- Fully connected layer: It connects the 300 incoming nodes to 100 outgoing nodes.
- −
- Activation function: It is the square function in CryptoNets, and the function in .
- −
- Fully connected layer: connects the 100 incoming nodes to 10 outgoing nodes.
- −
- Activation function: It is the sigmoid activation function.
5.3.3. HE Parameter
5.3.4. Experimental Results
6. Discussion on Security of
6.1. Model Extraction Attack
6.2. Fully Private SNNI
7. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- OpenAI. ChatGPT. 2023. Available online: https://chat.openai.com (accessed on 3 November 2023).
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar]
- Lee, E.; Lee, J.W.; No, J.S.; Kim, Y.S. Minimax approximation of sign function by composite polynomial for homomorphic comparison. IEEE Trans. Dependable Secur. Comput. 2021, 19, 3711–3727. [Google Scholar] [CrossRef]
- Cheon, J.H.; Kim, D.; Kim, D. Efficient homomorphic comparison methods with optimal complexity. In Advances in Cryptology–ASIACRYPT 2020, Proceedings of the 26th International Conference on the Theory and Application of Cryptology and Information Security, Daejeon, Republic of Korea, 7–11 December 2020; Proceedings, Part II 26; Springer: Cham, Switzerland, 2020; pp. 221–256. [Google Scholar]
- Boemer, F.; Costache, A.; Cammarota, R.; Wierzynski, C. nGraph-HE2: A high-throughput framework for neural network inference on encrypted data. In Proceedings of the 7th ACM Workshop on Encrypted Computing & Applied Homomorphic Cryptography, London, UK, 11 November 2019; pp. 45–56. [Google Scholar]
- Gilad-Bachrach, R.; Dowlin, N.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 201–210. [Google Scholar]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the Forty-First Annual ACM Symposium on Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009; pp. 169–178. [Google Scholar]
- Podschwadt, R.; Takabi, D.; Hu, P.; Rafiei, M.H.; Cai, Z. A survey of deep learning architectures for privacy-preserving machine learning with fully homomorphic encryption. IEEE Access 2022, 10, 117477–117500. [Google Scholar] [CrossRef]
- Juvekar, C.; Vaikuntanathan, V.; Chandrakasan, A. GAZELLE: A low latency framework for secure neural network inference. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 1651–1669. [Google Scholar]
- Boemer, F.; Cammarota, R.; Demmler, D.; Schneider, T.; Yalame, H. MP2ML: A mixed-protocol machine learning framework for private inference. In Proceedings of the 15th International Conference on Availability, Reliability and Security, Virtual Event, 25–28 August 2020; pp. 1–10. [Google Scholar]
- Lehmkuhl, R.; Mishra, P.; Srinivasan, A.; Popa, R.A. Muse: Secure inference resilient to malicious clients. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Virtual Event, 11–13 August 2021; pp. 2201–2218. [Google Scholar]
- Chen, S.; Fan, J. SEEK: Model extraction attack against hybrid secure inference protocols. arXiv 2022, arXiv:2209.06373. [Google Scholar]
- Yao, A.C.C. How to generate and exchange secrets. In Proceedings of the 27th Annual Symposium on Foundations of Computer Science (Sfcs 1986), Toronto, ON, Canada, 27–29 October 1986; pp. 162–167. [Google Scholar]
- Mohassel, P.; Rindal, P. ABY3: A mixed protocol framework for machine learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 35–52. [Google Scholar]
- Goldreich, O. Foundations of Cryptography: Volume 2, Basic Applications; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Canetti, R. Security and composition of multiparty cryptographic protocols. J. Cryptol. 2000, 13, 143–202. [Google Scholar] [CrossRef]
- Fan, J.; Vercauteren, F. Somewhat Practical Fully Homomorphic Encryption. Cryptology ePrint Archive. 2012. Available online: https://eprint.iacr.org/2012/144 (accessed on 13 November 2023).
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic encryption for arithmetic of approximate numbers. In Advances in Cryptology–ASIACRYPT 2017, Proceedings of the 23rd International Conference on the Theory and Applications of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; Proceedings, Part I 23; Springer: Cham, Switzerland, 2017; pp. 409–437. [Google Scholar]
- Hesamifard, E.; Takabi, H.; Ghasemi, M. CryptoDL: Deep neural networks over encrypted data. arXiv 2017, arXiv:1711.05189. [Google Scholar]
- Chabanne, H.; De Wargny, A.; Milgram, J.; Morel, C.; Prouff, E. Privacy-Preserving Classification on Deep Neural Network. Cryptology ePrint Archive. 2017. Available online: https://eprint.iacr.org/2017/1114 (accessed on 13 November 2023).
- Chou, E.; Beal, J.; Levy, D.; Yeung, S.; Haque, A.; Fei-Fei, L. Faster cryptonets: Leveraging sparsity for real-world encrypted inference. arXiv 2018, arXiv:1811.09953. [Google Scholar]
- Al Badawi, A.; Jin, C.; Lin, J.; Mun, C.F.; Jie, S.J.; Tan, B.H.M.; Nan, X.; Aung, K.M.M.; Chandrasekhar, V.R. Towards the alexnet moment for homomorphic encryption: Hcnn, the first homomorphic cnn on encrypted data with gpus. IEEE Trans. Emerg. Top. Comput. 2020, 9, 1330–1343. [Google Scholar] [CrossRef]
- Jiang, X.; Kim, M.; Lauter, K.; Song, Y. Secure outsourced matrix computation and application to neural networks. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 1209–1222. [Google Scholar]
- Brutzkus, A.; Gilad-Bachrach, R.; Elisha, O. Low latency privacy preserving inference. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 812–821. [Google Scholar]
- Dathathri, R.; Saarikivi, O.; Chen, H.; Laine, K.; Lauter, K.; Maleki, S.; Musuvathi, M.; Mytkowicz, T. CHET: An optimizing compiler for fully-homomorphic neural-network inferencing. In Proceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation, Phoenix, AZ, USA, 22 June 2019; pp. 142–156. [Google Scholar]
- van Elsloo, T.; Patrini, G.; Ivey-Law, H. SEALion: A framework for neural network inference on encrypted data. arXiv 2019, arXiv:1904.12840. [Google Scholar]
- Boemer, F.; Lao, Y.; Cammarota, R.; Wierzynski, C. nGraph-HE: A graph compiler for deep learning on homomorphically encrypted data. In Proceedings of the 16th ACM International Conference on Computing Frontiers, Alghero, Italy, 30 April–2 May 2019; pp. 3–13. [Google Scholar]
- Smart, N.P.; Vercauteren, F. Fully homomorphic SIMD operations. Des. Codes Cryptogr. 2014, 71, 57–81. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Chillotti, I.; Gama, N.; Georgieva, M.; Izabachène, M. TFHE: Fast fully homomorphic encryption over the torus. J. Cryptol. 2020, 33, 34–91. [Google Scholar] [CrossRef]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks. In Advances in Neural Information Processing Systems 29 (NIPS 2016); Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Bourse, F.; Minelli, M.; Minihold, M.; Paillier, P. Fast homomorphic evaluation of deep discretized neural networks. In Advances in Cryptology–CRYPTO 2018, Proceedings of the 38th Annual International Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2018; Proceedings, Part III 38; Springer: Cham, Switzerland, 2018; pp. 483–512. [Google Scholar]
- Sanyal, A.; Kusner, M.; Gascon, A.; Kanade, V. TAPAS: Tricks to accelerate (encrypted) prediction as a service. In Proceedings of the International Conference on Machine Learning. PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4490–4499. [Google Scholar]
- Lou, Q.; Jiang, L. SHE: A fast and accurate deep neural network for encrypted data. Adv. Neural Inf. Process. Syst. 2019, 32, 10035–10043. [Google Scholar]
- Clet, P.E.; Stan, O.; Zuber, M. BFV, CKKS, TFHE: Which One is the Best for a Secure Neural Network Evaluation in the Cloud? In Applied Cryptography and Network Security Workshops, Proceedings of the ACNS 2021 Satellite Workshops, AIBlock, AIHWS, AIoTS, CIMSS, Cloud S&P, SCI, SecMT, and SiMLA, Kamakura, Japan, 21–24 June 2021; Proceedings; Springer: Cham, Switzerland, 2021; pp. 279–300. [Google Scholar]
- Rouhani, B.D.; Riazi, M.S.; Koushanfar, F. Deepsecure: Scalable provably-secure deep learning. In Proceedings of the 55th Annual Design Automation Conference, San Francisco, CA, USA, 24–29 June 2018; pp. 1–6. [Google Scholar]
- Riazi, M.S.; Samragh, M.; Chen, H.; Laine, K.; Lauter, K.; Koushanfar, F. XONN: XNOR-based oblivious deep neural network inference. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 1501–1518. [Google Scholar]
- Ball, M.; Carmer, B.; Malkin, T.; Rosulek, M.; Schimanski, N. Garbled Neural Networks Are Practical. Cryptology ePrint Archive. 2019. Available online: https://eprint.iacr.org/2019/338 (accessed on 13 November 2023).
- Ng, L.K.; Chow, S.S. SoK: Cryptographic Neural-Network Computation. In Proceedings of the 2023 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–24 May 2023; pp. 497–514. [Google Scholar]
- Shamir, A. How to share a secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Micali, S.; Goldreich, O.; Wigderson, A. How to play any mental game. In Proceedings of the Nineteenth ACM Symposium on Theory of Computing (STOC), New York, NY, USA, 25–27 May 1987; pp. 218–229. [Google Scholar]
- Mohassel, P.; Zhang, Y. SecureML: A system for scalable privacy-preserving machine learning. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 19–38. [Google Scholar]
- Patra, A.; Schneider, T.; Suresh, A.; Yalame, H. ABY2. 0: Improved Mixed-Protocol Secure Two-Party Computation. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Virtual Event, 11–13 August 2021; pp. 2165–2182. [Google Scholar]
- Agrawal, N.; Shahin Shamsabadi, A.; Kusner, M.J.; Gascón, A. QUOTIENT: Two-party secure neural network training and prediction. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 1231–1247. [Google Scholar]
- Riazi, M.S.; Weinert, C.; Tkachenko, O.; Songhori, E.M.; Schneider, T.; Koushanfar, F. Chameleon: A hybrid secure computation framework for machine learning applications. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, Incheon, Republic of Korea, 4–8 June 2018; pp. 707–721. [Google Scholar]
- Wagh, S.; Gupta, D.; Chandran, N. SecureNN: 3-Party Secure Computation for Neural Network Training. Proc. Priv. Enhancing Technol. 2019, 2019, 26–49. [Google Scholar] [CrossRef]
- Wagh, S.; Tople, S.; Benhamouda, F.; Kushilevitz, E.; Mittal, P.; Rabin, T. Falcon: Honest-majority maliciously secure framework for private deep learning. arXiv 2020, arXiv:2004.02229. [Google Scholar] [CrossRef]
- Kumar, N.; Rathee, M.; Chandran, N.; Gupta, D.; Rastogi, A.; Sharma, R. CrypTFlow: Secure tensorflow inference. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 336–353. [Google Scholar]
- Knott, B.; Venkataraman, S.; Hannun, A.; Sengupta, S.; Ibrahim, M.; van der Maaten, L. Crypten: Secure multi-party computation meets machine learning. Adv. Neural Inf. Process. Syst. 2021, 34, 4961–4973. [Google Scholar]
- Demmler, D.; Schneider, T.; Zohner, M. ABY-A framework for efficient mixed-protocol secure two-party computation. In Proceedings of the NDSS, San Diego, CA, USA, 8–11 February 2015. [Google Scholar]
- Halevi, S.; Shoup, V. Algorithms in helib. In Advances in Cryptology–CRYPTO 2014, Proceedings of the 34th Annual Cryptology Conference, Santa Barbara, CA, USA, 17–21 August 2014; Proceedings, Part I 34; Springer: Cham, Switzerland, 2014; pp. 554–571. [Google Scholar]
- Lee, J.W.; Kang, H.; Lee, Y.; Choi, W.; Eom, J.; Deryabin, M.; Lee, E.; Lee, J.; Yoo, D.; Kim, Y.S.; et al. Privacy-preserving machine learning with fully homomorphic encryption for deep neural network. IEEE Access 2022, 10, 30039–30054. [Google Scholar] [CrossRef]
- Benaissa, A.; Retiat, B.; Cebere, B.; Belfedhal, A.E. TenSEAL: A library for encrypted tensor operations using homomorphic encryption. arXiv 2021, arXiv:2104.03152. [Google Scholar]
- Lou, Q.; Jiang, L. Hemet: A homomorphic-encryption-friendly privacy-preserving mobile neural network architecture. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 7102–7110. [Google Scholar]
- Lyubashevsky, V.; Peikert, C.; Regev, O. On ideal lattices and learning with errors over rings. In Advances in Cryptology–EUROCRYPT 2010, Proceedings of the 29th Annual International Conference on the Theory and Applications of Cryptographic Techniques, French Riviera, 30 May–3 June 2010; Proceedings 29; Springer: Cham, Switzerland, 2010; pp. 1–23. [Google Scholar]
- Cheon, J.H.; Kim, D.; Kim, D.; Lee, H.H.; Lee, K. Numerical method for comparison on homomorphically encrypted numbers. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Kobe, Japan, 8–12 December 2019; pp. 415–445. [Google Scholar]
- Lee, E.; Lee, J.W.; Kim, Y.S.; No, J.S. Optimization of homomorphic comparison algorithm on rns-ckks scheme. IEEE Access 2022, 10, 26163–26176. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) fully homomorphic encryption without bootstrapping. ACM Trans. Comput. Theory (TOCT) 2014, 6, 1–36. [Google Scholar] [CrossRef]
- Mishra, P.; Lehmkuhl, R.; Srinivasan, A.; Zheng, W.; Popa, R.A. Delphi: A cryptographic inference system for neural networks. In Proceedings of the 2020 Workshop on Privacy-Preserving Machine Learning in Practice, Virtual Event, 9–13 November 2020; pp. 27–30. [Google Scholar]
- Al Badawi, A.; Polyakov, Y. Demystifying Bootstrapping in Fully Homomorphic Encryption. Cryptology ePrint Archive. 2023. Available online: https://eprint.iacr.org/2023/149 (accessed on 13 November 2023).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 8024–8035. [Google Scholar]
- Albrecht, M.; Chase, M.; Chen, H.; Ding, J.; Goldwasser, S.; Gorbunov, S.; Halevi, S.; Hoffstein, J.; Laine, K.; Lauter, K.; et al. Homomorphic encryption standard. In Protecting Privacy through Homomorphic Encryption; Springer: Cham, Switzerland, 2021; pp. 31–62. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Samaria, F.S.; Harter, A.C. Parameterisation of a stochastic model for human face identification. In Proceedings of 2nd IEEE Workshop on Applications of Computer Vision, Sarasota, FL, USA, 5–7 December 1994; pp. 138–142. [Google Scholar]
- Tramèr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing machine learning models via prediction APIs. In Proceedings of the 25th USENIX security symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016; pp. 601–618. [Google Scholar]
- Carlini, N.; Jagielski, M.; Mironov, I. Cryptanalytic extraction of neural network models. In Proceedings of the Annual International Cryptology Conference, Barbara, CA, USA, 17–21 August 2020; pp. 189–218. [Google Scholar]
- Aïvodji, U.; Gambs, S.; Ther, T. Gamin: An adversarial approach to black-box model inversion. arXiv 2019, arXiv:1909.11835. [Google Scholar]
- Bekman, T.; Abolfathi, M.; Jafarian, H.; Biswas, A.; Banaei-Kashani, F.; Das, K. Practical black box model inversion attacks against neural nets. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bilbao, Spain, 13–17 September 2021; pp. 39–54. [Google Scholar]

| 1 | 1 | 1 |
| 1 | 0 | 0 |
| 1 | −1 | −1 |
| −1 | 1 | −1 |
| −1 | 0 | 0 |
| −1 | −1 | 1 |
| Depth | Runtime (s) | N | Level | |||
|---|---|---|---|---|---|---|
| DoubleR-CKKS | Bootstrapping | DoubleR-CKKS | Bootstrapping | DoubleR-CKKS | Bootstrapping | |
| 1 | 0.04 | 11.85 | 16,384 | 65,536 | 1 | 22 |
| 2 | 0.05 | 12.71 | 16,384 | 65,536 | 2 | 23 |
| 4 | 0.07 | 14.69 | 16,384 | 65,536 | 4 | 25 |
| 8 | 0.10 | 17.39 | 32,768 | 65,536 | 8 | 29 |
| 16 | 0.19 | 22.51 | 65,536 | 65,536 | 16 | 37 |
| Security Level | N | L | q (Bit Length) | |
|---|---|---|---|---|
| CryptoNets | 128 | 16,384 | 5 | 420 |
| 128 | 16,384 | 3 | 320 | |
| CryptoNets | 128 | 16,384 | 7 | 520 |
| 128 | 16,384 | 3 | 320 |
| CryptoNets | HeFUN | CryptoNets | HeFUN | ||
|---|---|---|---|---|---|
| Accuracy (%) | 98.15 | 98.31 | 98.52 | 99.16 | |
| Inference times (s) | Encoding+Encryption | 0.008 | 0.007 | 0.011 | 0.007 |
| Convolution | 0.503 | 0.395 | 0.829 | 0.395 | |
| Activation 1 a | 0.008 | 0.028 | 0.012 | 0.028 | |
| Fully connected 1 | 1.121 | 0.812 | 2.138 | 0.812 | |
| Activation 2 | 0.008 | 0.029 | 0.012 | 0.029 | |
| Fully connected 2 | 0.065 | 0.102 | 0.408 | 0.102 | |
| Activation 3 | - | - | 0.011 | 0.029 | |
| Fully connected 3 | - | - | 0.073 | 0.098 | |
| Decryption + Decoding | 0.002 | 0.001 | 0.003 | 0.001 | |
| Total | 1.715 | 1.374 | 3.497 | 1.501 | |
| CryptoNets | HeFUN | CryptoNets | HeFUN | ||
|---|---|---|---|---|---|
| Accuracy (%) | 95.19 | 96.66 | 96.87 | 97.43 | |
| Inference times (s) | Encoding+Encryption | 0.009 | 0.007 | 0.013 | 0.007 |
| Convolution | 0.695 | 0.425 | 0.991 | 0.435 | |
| Activation 1 a | 0.008 | 0.027 | 0.012 | 0.028 | |
| Fully connected 1 | 1.583 | 1.115 | 3.171 | 1.115 | |
| Activation 2 | 0.009 | 0.030 | 0.012 | 0.030 | |
| Fully connected 2 | 0.065 | 0.102 | 0.408 | 0.102 | |
| Activation 3 | - | - | 0.011 | 0.029 | |
| Fully connected 3 | - | - | 0.081 | 0.102 | |
| Decryption + Decoding | 0.002 | 0.001 | 0.003 | 0.001 | |
| Total | 2.361 | 1.707 | 5.248 | 1.849 | |
| Depth | Encryption | Decryption | Multiplication | Addition | |||
|---|---|---|---|---|---|---|---|
| Ciphert-Plain | Cipher-Cipher | Ciphert-Plain | Cipher-Cipher | ||||
| CryptoNets | L a | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 1 | 1 | 3 | 1 | 0 | 1 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, D.T.K.; Duong, D.H.; Susilo, W.; Chow, Y.-W.; Ta, T.A. HeFUN: Homomorphic Encryption for Unconstrained Secure Neural Network Inference. Future Internet 2023, 15, 407. https://doi.org/10.3390/fi15120407
Nguyen DTK, Duong DH, Susilo W, Chow Y-W, Ta TA. HeFUN: Homomorphic Encryption for Unconstrained Secure Neural Network Inference. Future Internet. 2023; 15(12):407. https://doi.org/10.3390/fi15120407
Chicago/Turabian StyleNguyen, Duy Tung Khanh, Dung Hoang Duong, Willy Susilo, Yang-Wai Chow, and The Anh Ta. 2023. "HeFUN: Homomorphic Encryption for Unconstrained Secure Neural Network Inference" Future Internet 15, no. 12: 407. https://doi.org/10.3390/fi15120407
APA StyleNguyen, D. T. K., Duong, D. H., Susilo, W., Chow, Y.-W., & Ta, T. A. (2023). HeFUN: Homomorphic Encryption for Unconstrained Secure Neural Network Inference. Future Internet, 15(12), 407. https://doi.org/10.3390/fi15120407