
An Artificial Neural Network Autoencoder for Insider Cyber Security Threat Detection

 , ,
, ,  and
and 
Abstract
:1. Introduction
1.1. Insider Threats Attacks
1.2. Security Information and Event Management Attack
- Due to centralized logging, when an insider threat is detected and alerted, security analysts cannot find out how and where to start an intruder search. Meanwhile, the attack goes deep into the network before being detected, and incident forensics are ineffective.
- The SIEM tools protect against most external threats, and they are defenseless against insider threats.
- The SIEM tools generally are not accurate for a particular security threat event. Mostly, they fail to detect the actual occurrence of an event.
- The SIEM tools are difficult to control and manage.
- Predefined correlation rules make the SIEM system unable to detect new attack techniques.
1.3. User Behavior Analysis and User and Entity Behavior Analysis Attack
1.4. Contribution of the Paper
- Developing a more effective and sophisticated insider cyber security threat detection based on a combination of the SIEM and UEBA solutions;
- The improvement of the detection of insider threats with unknown signatures that are mainly focused on situations that involve compromising user accounts.
2. Related Works
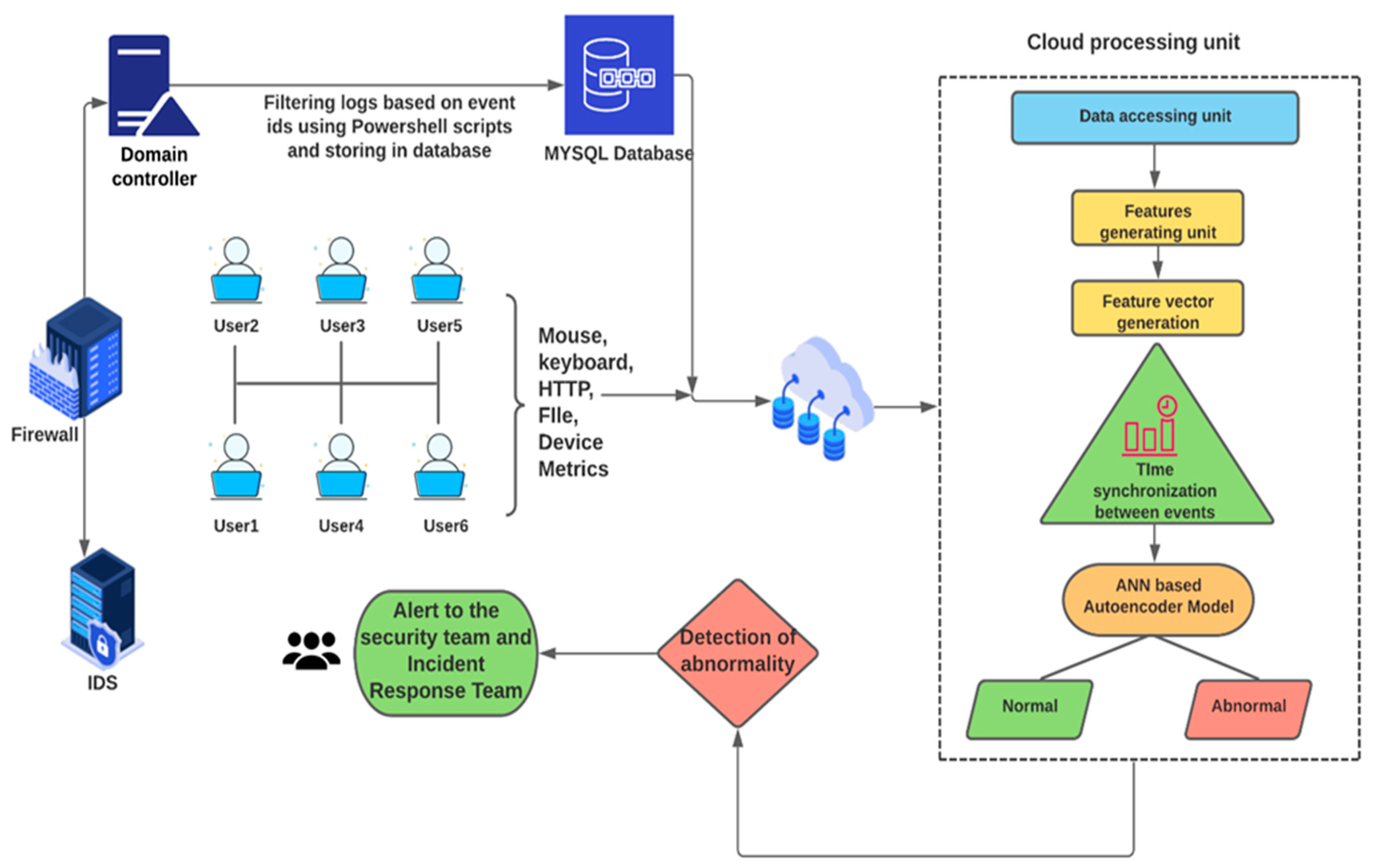
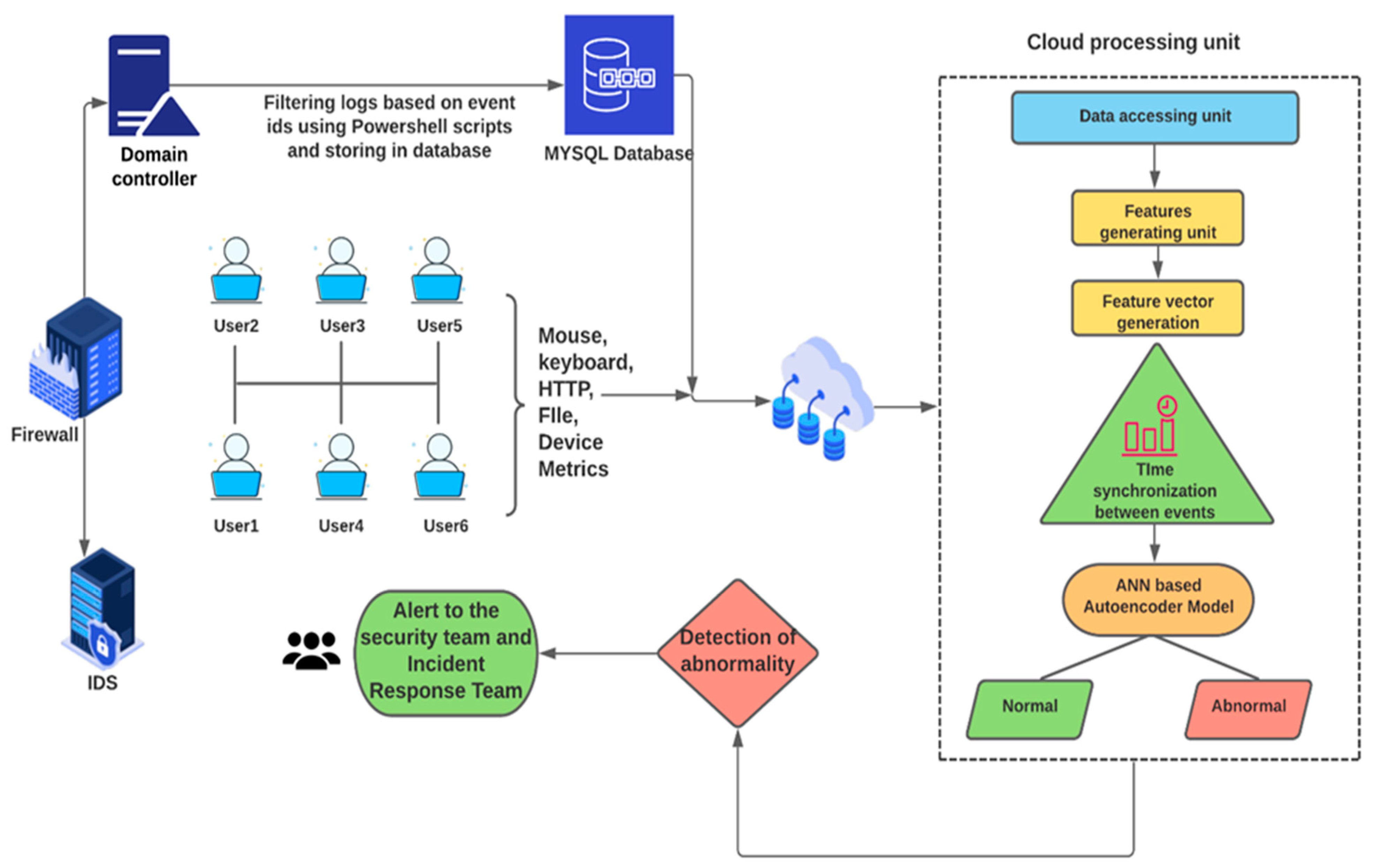
3. Proposed Architecture for User and Entity Behavior Analysis
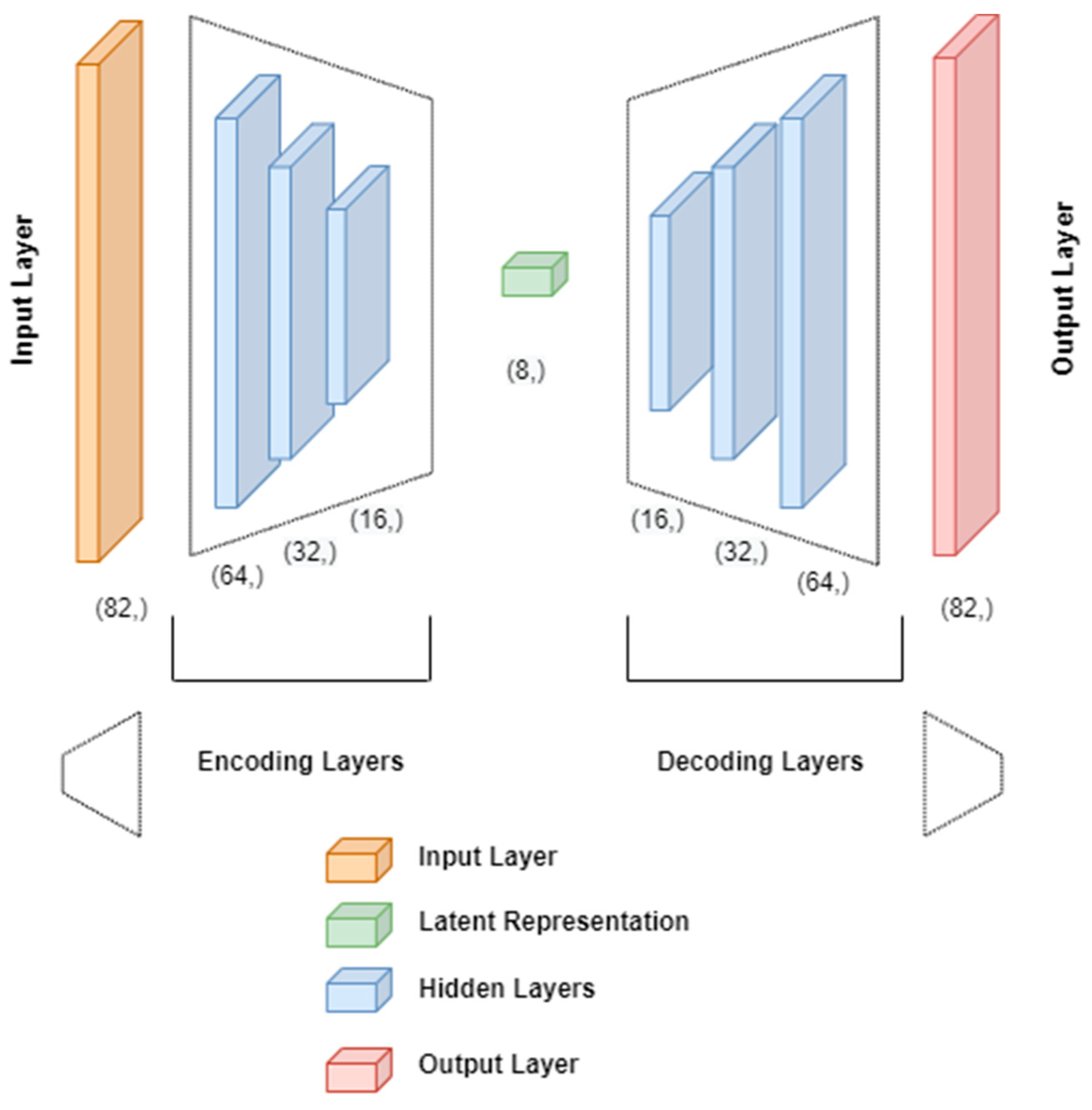
3.1. Proposed System Architecture
- Perform a user and entity behavior analysis with the capability of detecting insider threats.
- Provide a solution for detecting and storing nonregular intervals of intrusion data in time.
- Provide a solution for collecting different system device metric information (such as the activity of the keyboard, mouse, processor, etc.), which will be used for detecting anomaly user behavior.
- Provide a solution that overcomes the general disadvantages of the UBA approach.
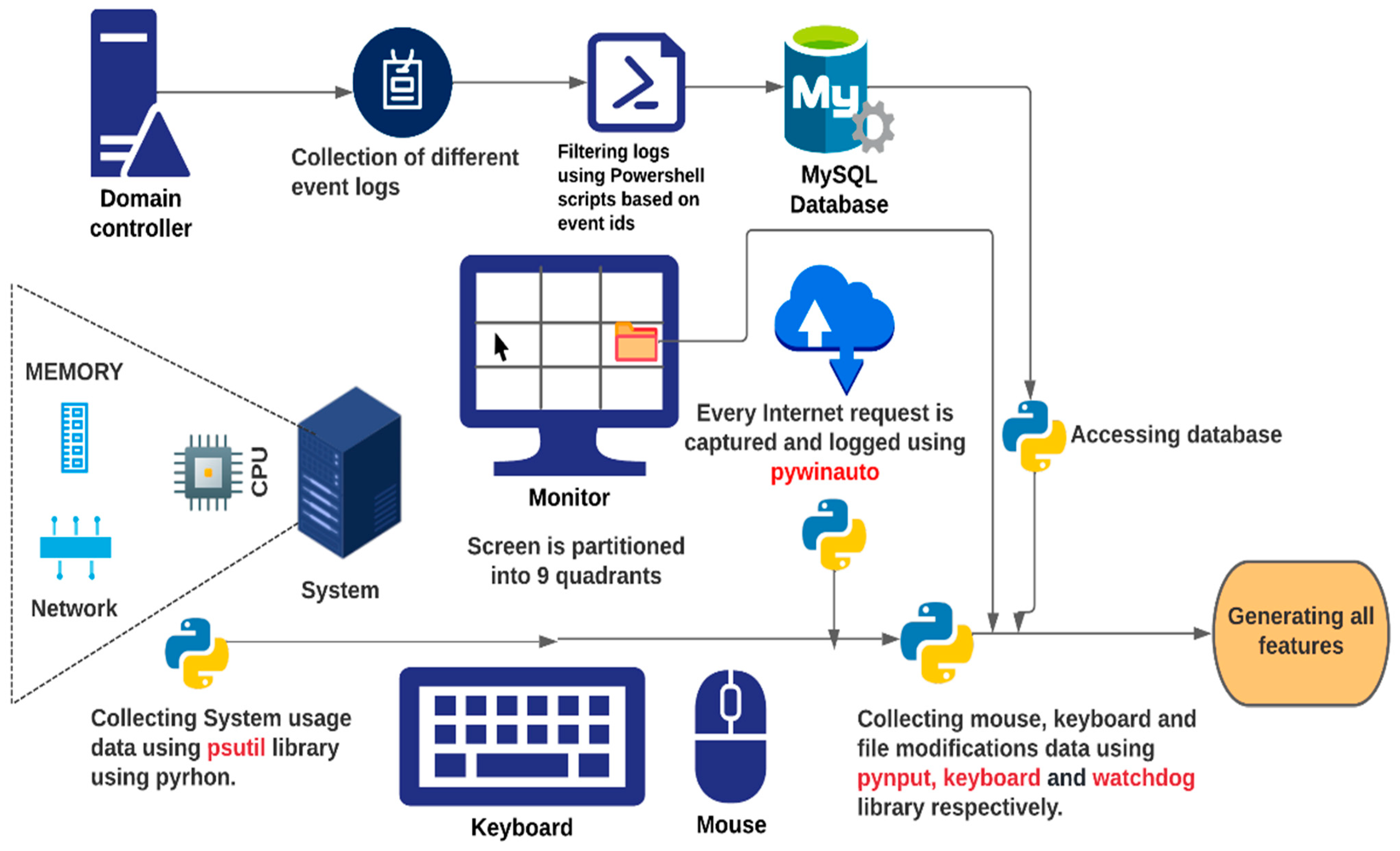
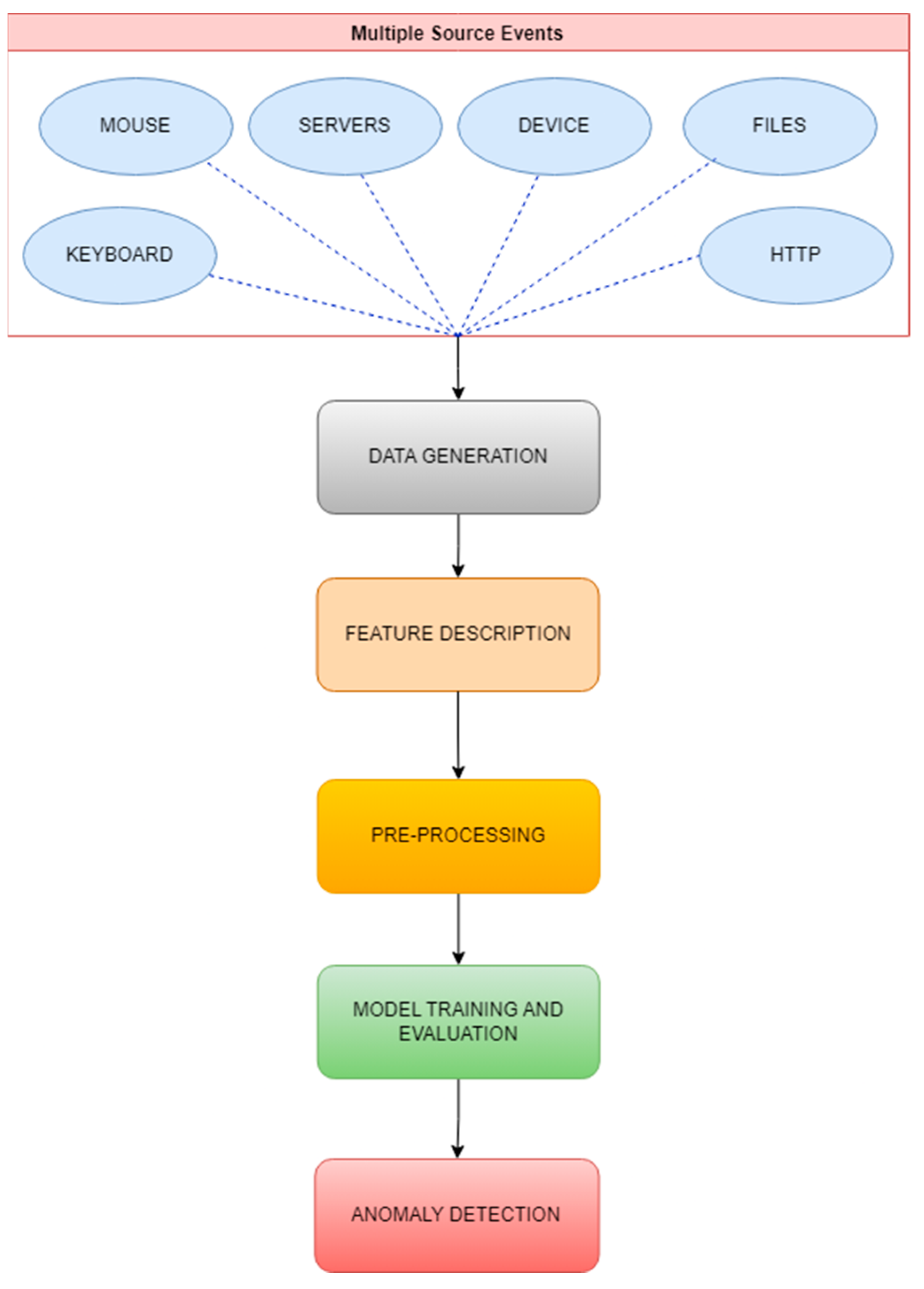
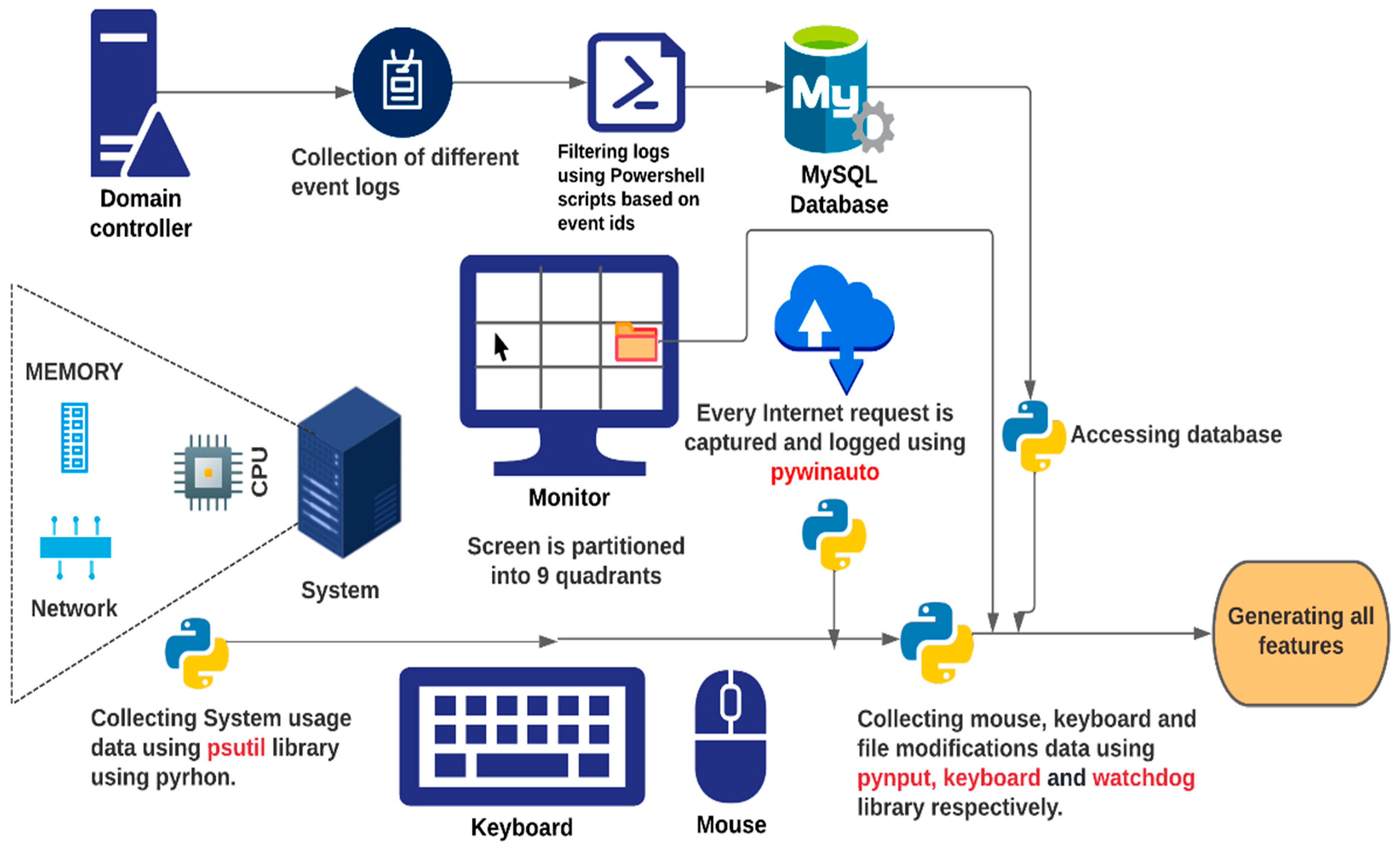
3.2. Data Generation
3.2.1. Keyboard-Related Data
- Keystroke timestamps;
- The number of keystrokes;
- Keystroke press and release time;
- Keyboard-related application data transferred in the foreground.
3.2.2. Mouse-Related Data
- Two-dimensional (x, y) coordinates representing the location of the cursor;
- Mouse clicks (left, right, and center click);
- Mouse cursor movements on the entire screen.
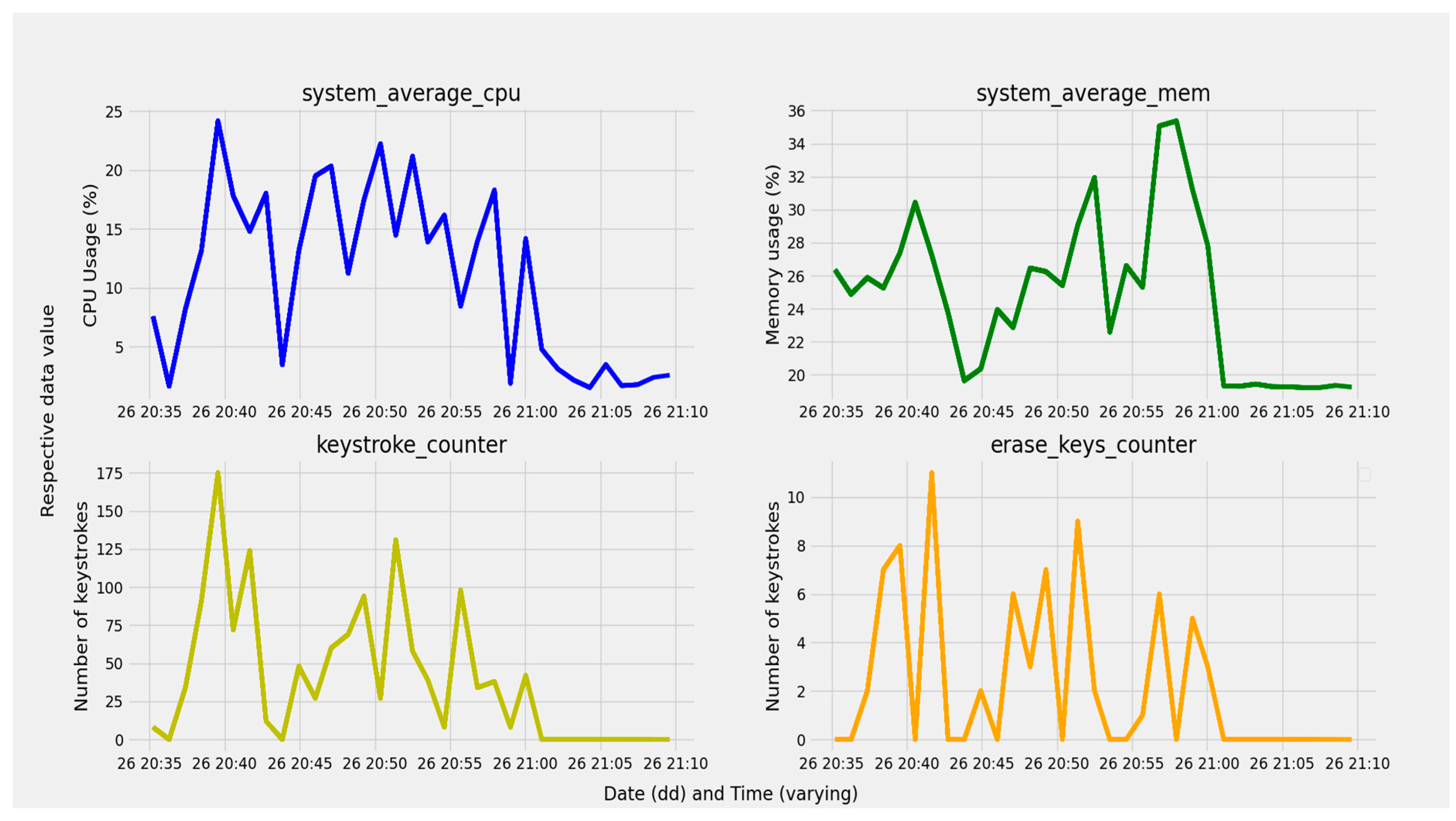
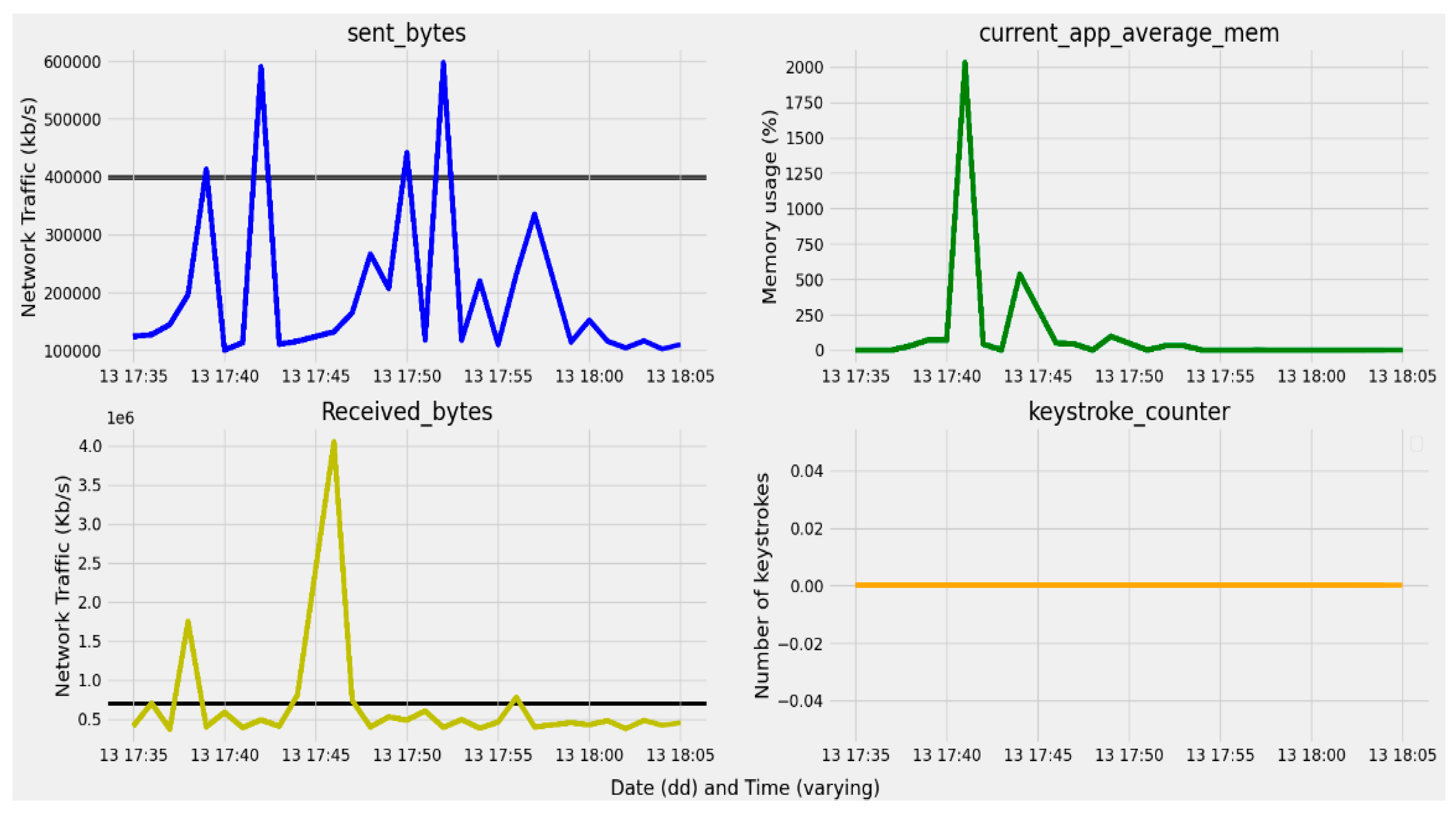
3.2.3. Device Applications and Resource Usage Data
- The number of active applications;
- The current foreground application name;
- The amount of CPU usage by each process;
- The application in the foreground (%);
- The total CPU usage (%);
- The amount of memory used by the foreground process and application (%);
- The total memory usage (%);
- Bytes received;
- Bytes sent;
- The number of processes of the application in the foreground.
3.2.4. Log-on and Log-off Activity-Related Data
- 4624—successful log-on,
- 4625—failed log-on,
- 4648—log-on with explicitly mentioning credentials,
- 4672—new log-on with special privileges.
3.2.5. File-System-Related Data
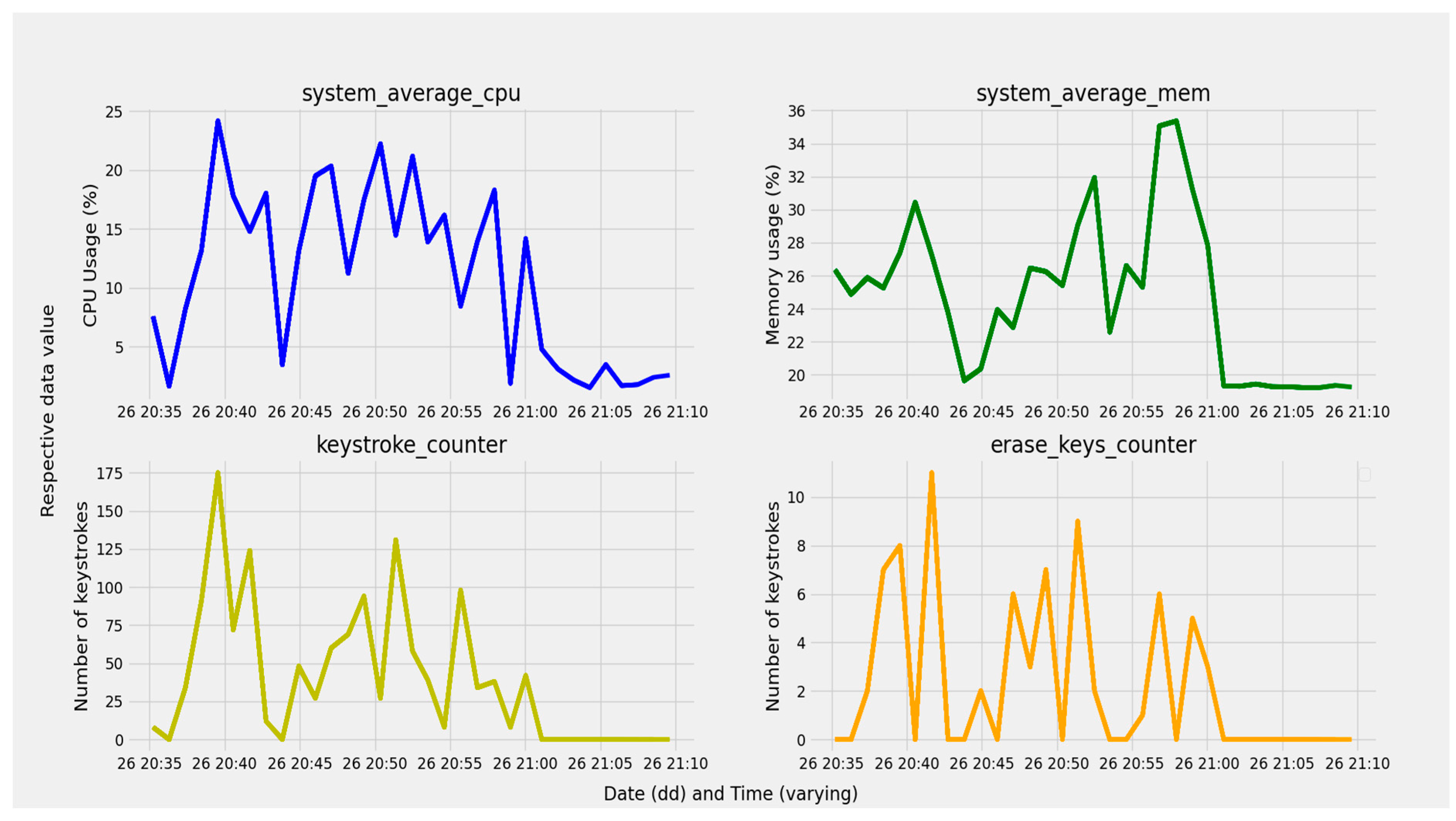
3.2.6. The CPU and Memory Usage
3.2.7. Internet Browsing Data
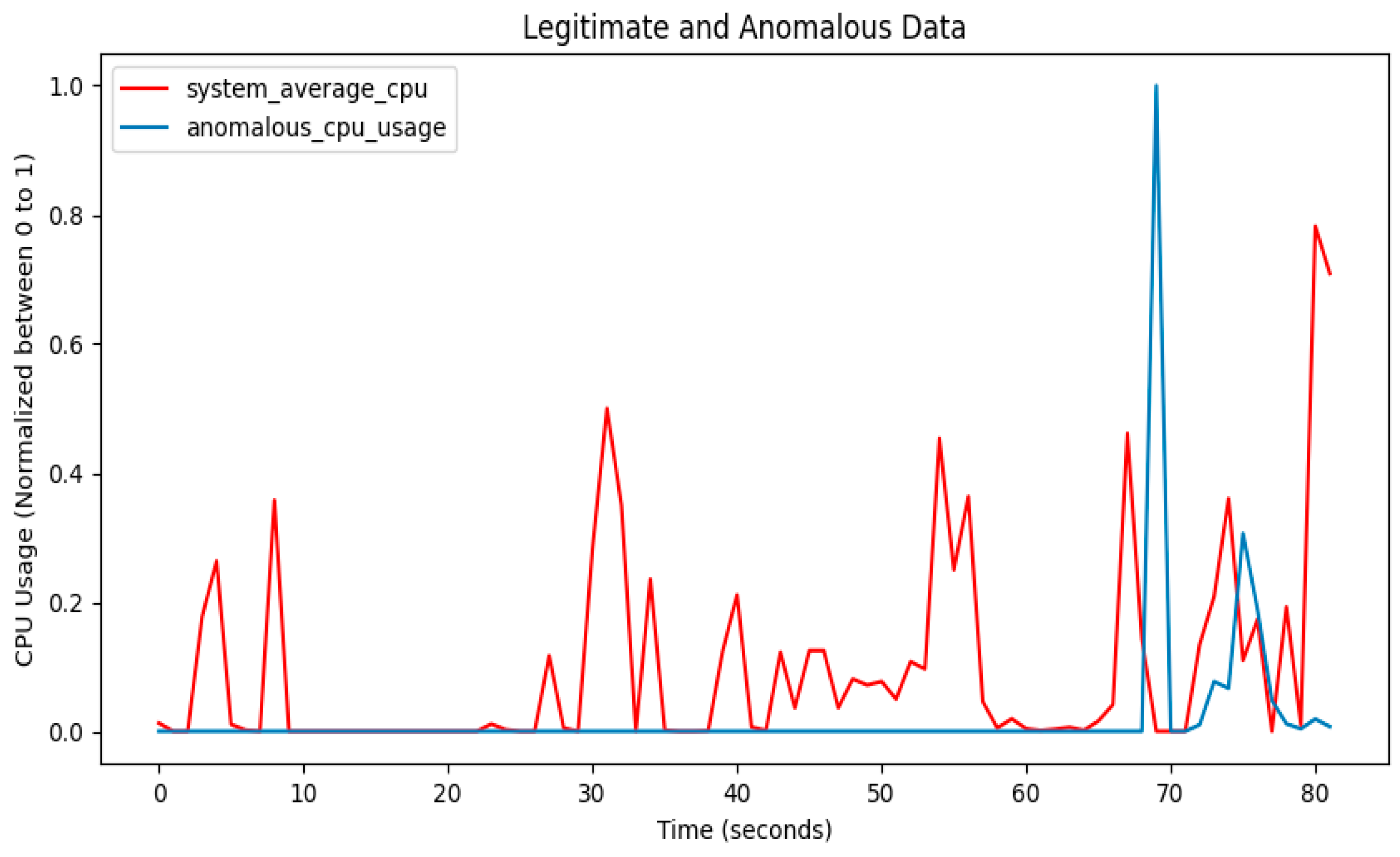
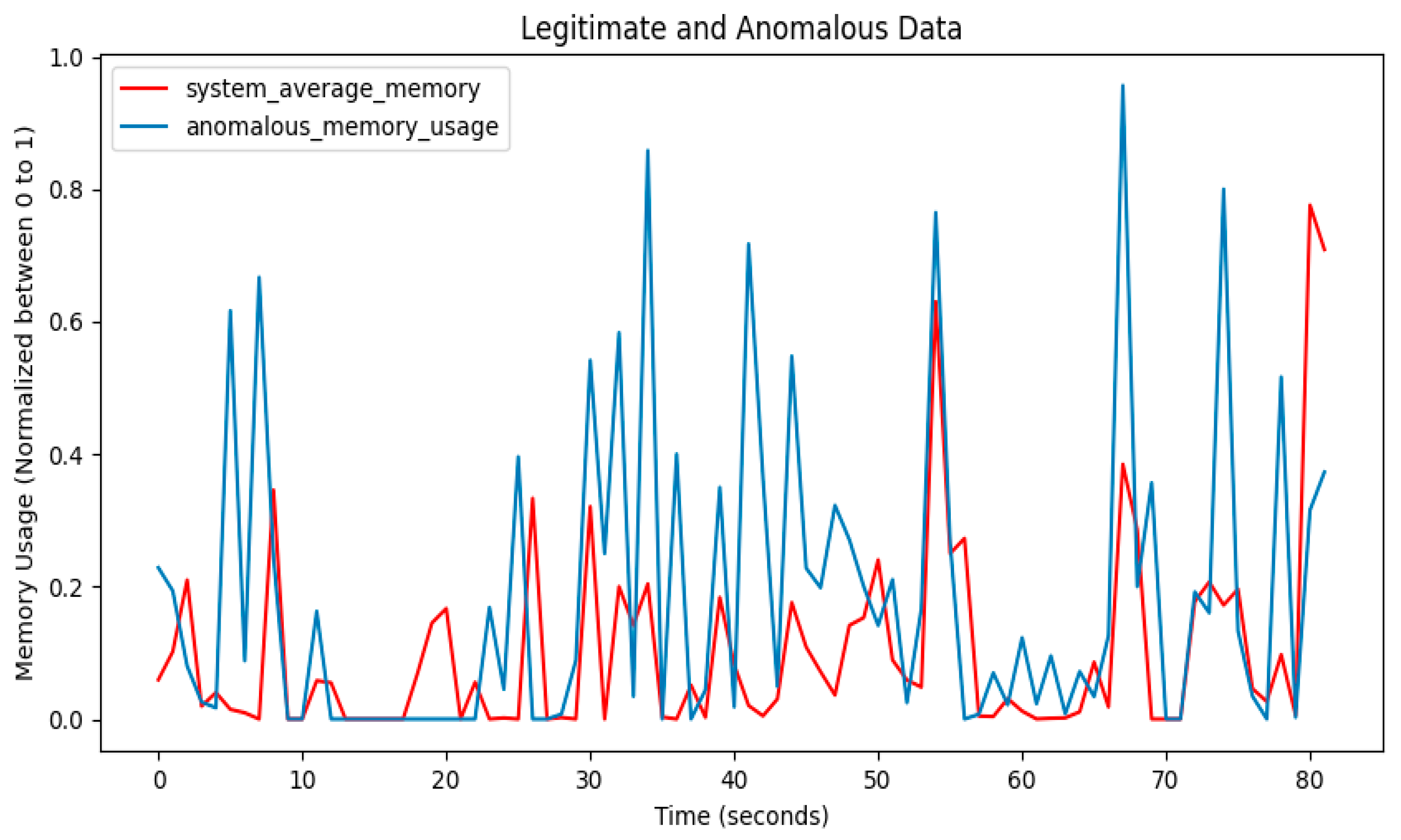
3.2.8. Anomaly-Related Data
3.3. Feature Description
3.4. Preprocessing Phase
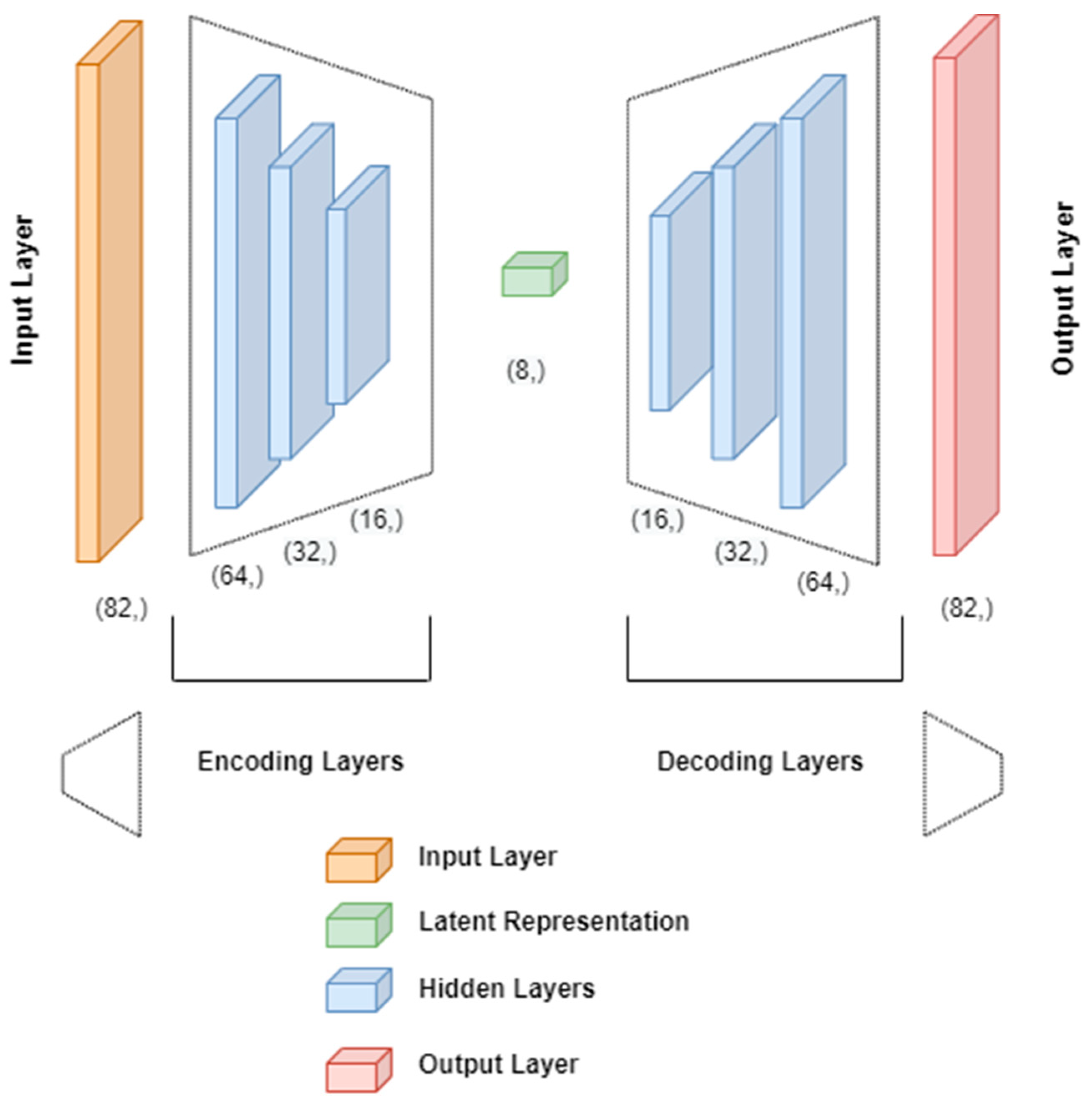
3.5. Model Training
- Loss function parameter: among different loss functions, the MSE loss function (defined in the next section) fits best for the problem tackled by the proposed algorithm, since the proposed approach deals with continuous values.
- Activation function parameter: for all the layers except the last layer, the ReLu activation function defined in Equation (2) is used. For the last ANN layer, sigmoid function (3) is used, as the output values need to be in the range of [0,1].
- Optimizer parameter: the Adaptive Moment Estimation (ADAM) optimizer function is used to scale the magnitude of weight updates in order to minimize the network loss function.
- The reason for choosing this specific optimizer is the fact that it is developed based on the drawbacks of other optimizers such as Adadelta (stochastic gradient-based optimization algorithm), root mean square propagation (RMSprop), etc.
- Batch size parameter: this parameter also provides a major contribution to the model’s performance and needs to be lower than the lowest analyzed dataset size. For this approach, 120 is taken as the batch size according to the training set, CPU/GPU capability, etc.
- Shuffle parameter: is set to false, as analysis is performed with continuous time series data. By setting it to false, this parameter helps in randomizing the data, which further enables the discretization of the analyzed data.
- Restore_best_weights parameter: is set to True. The primary motive of a model is to select the best weights that provide a solution; therefore, this parameter selects the best weights from the previous epoch and updates accordingly.
3.6. Evaluation of the Model
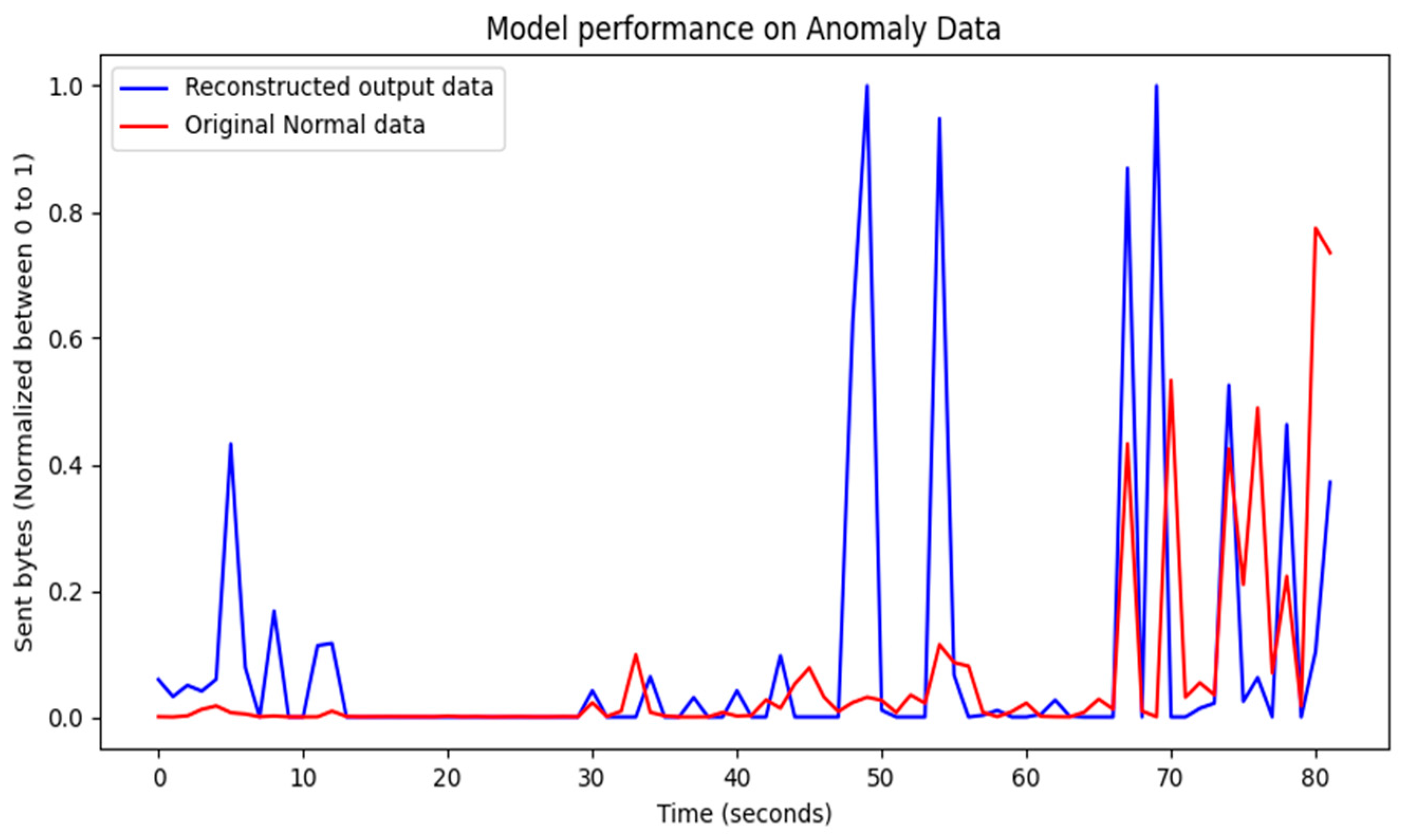
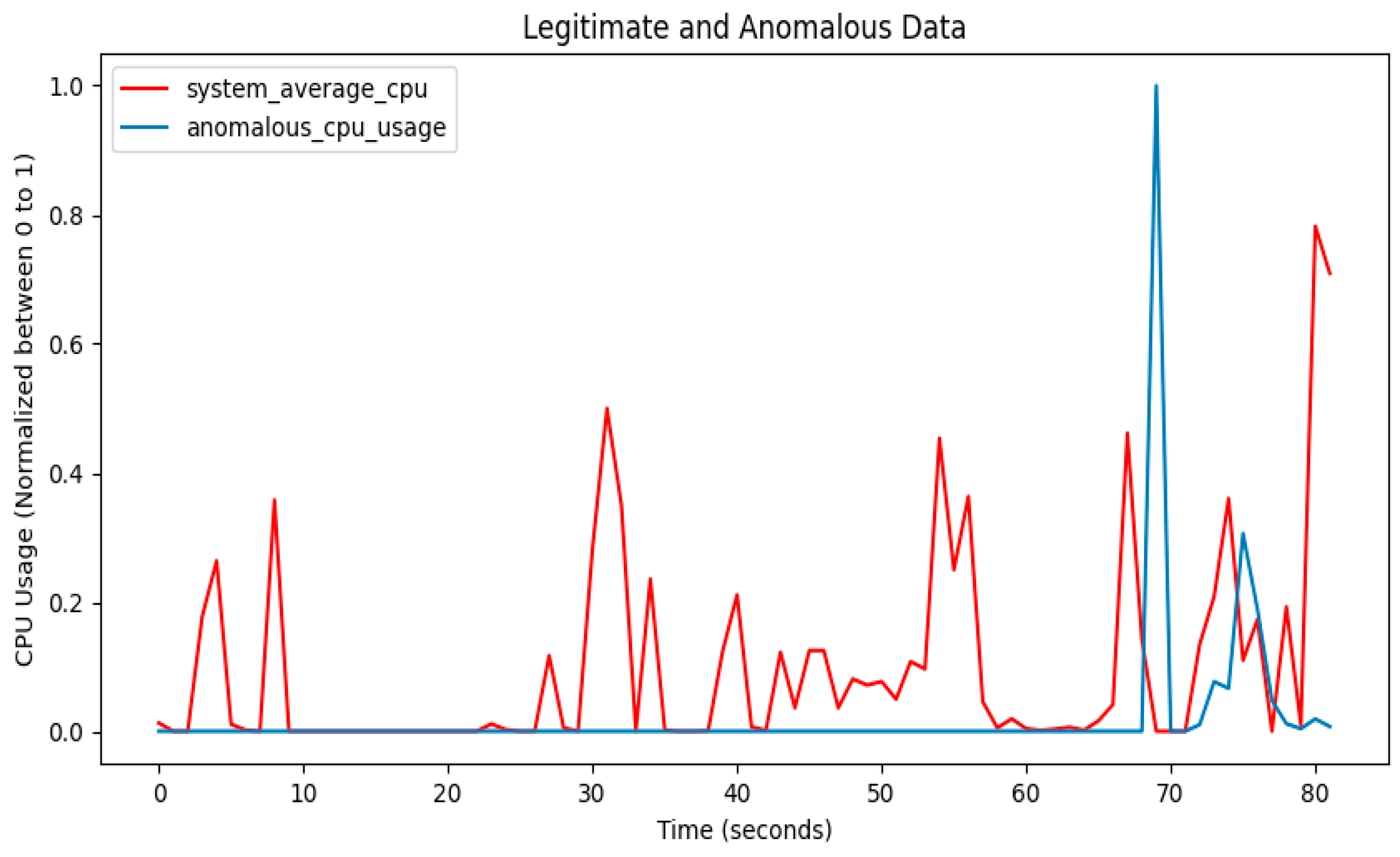
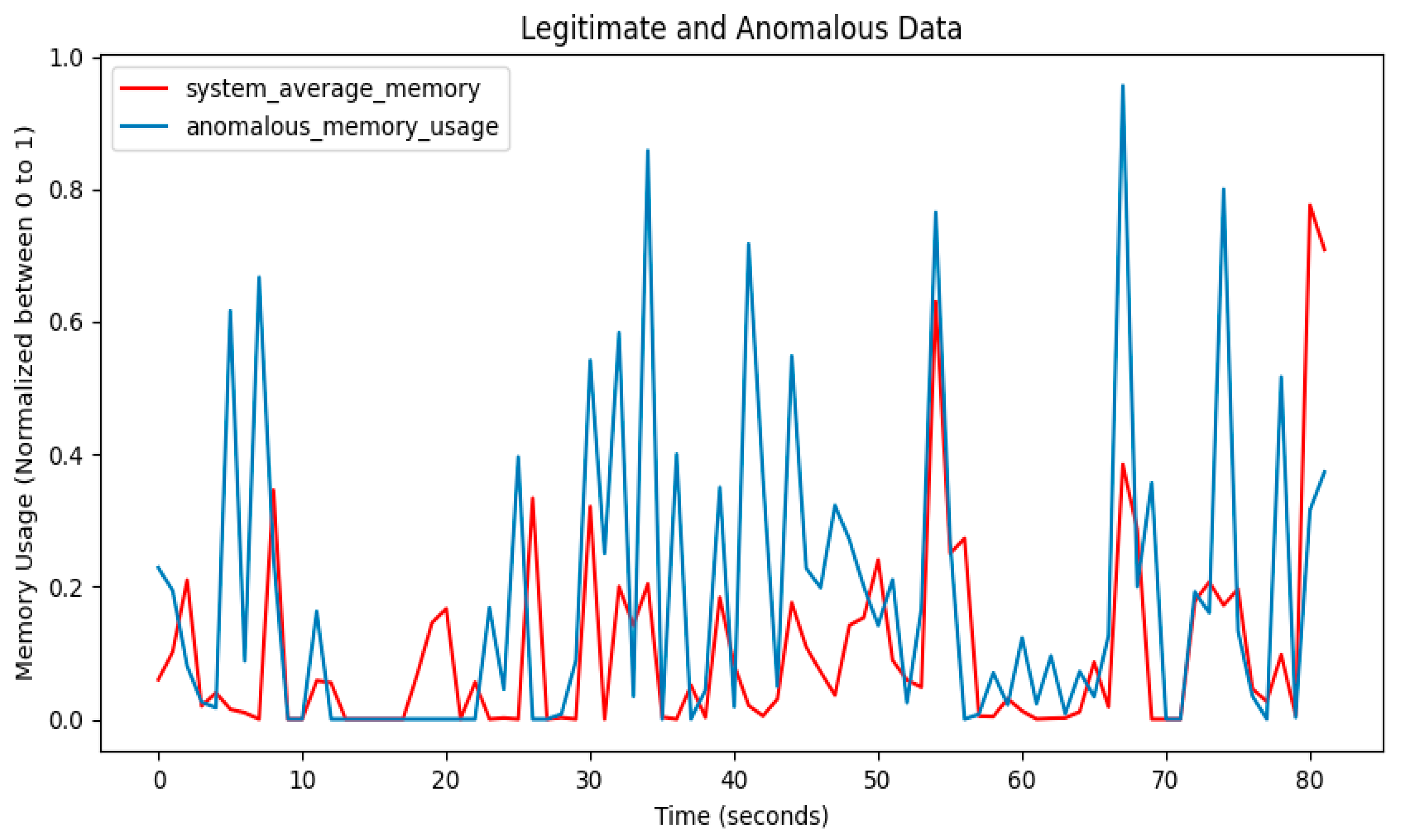
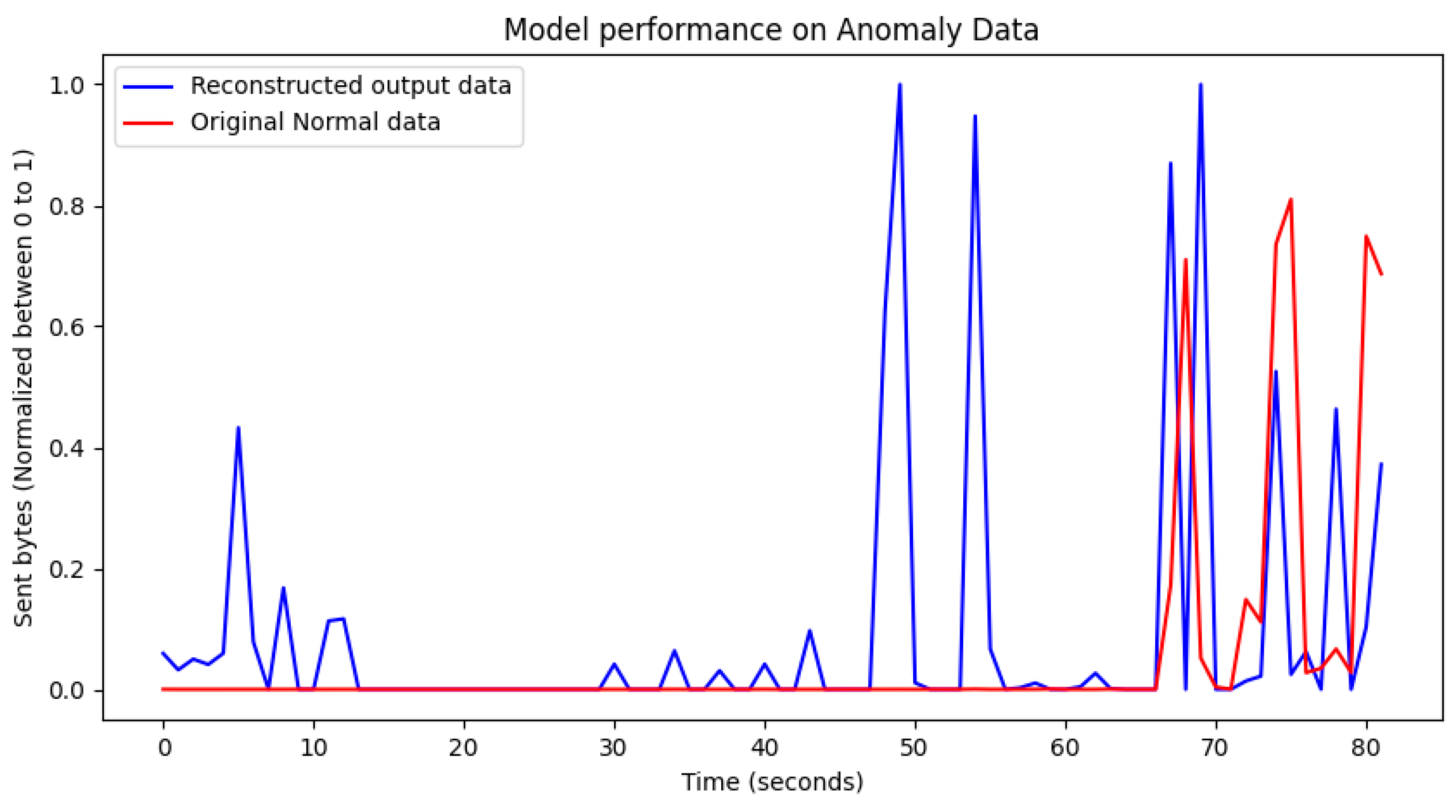
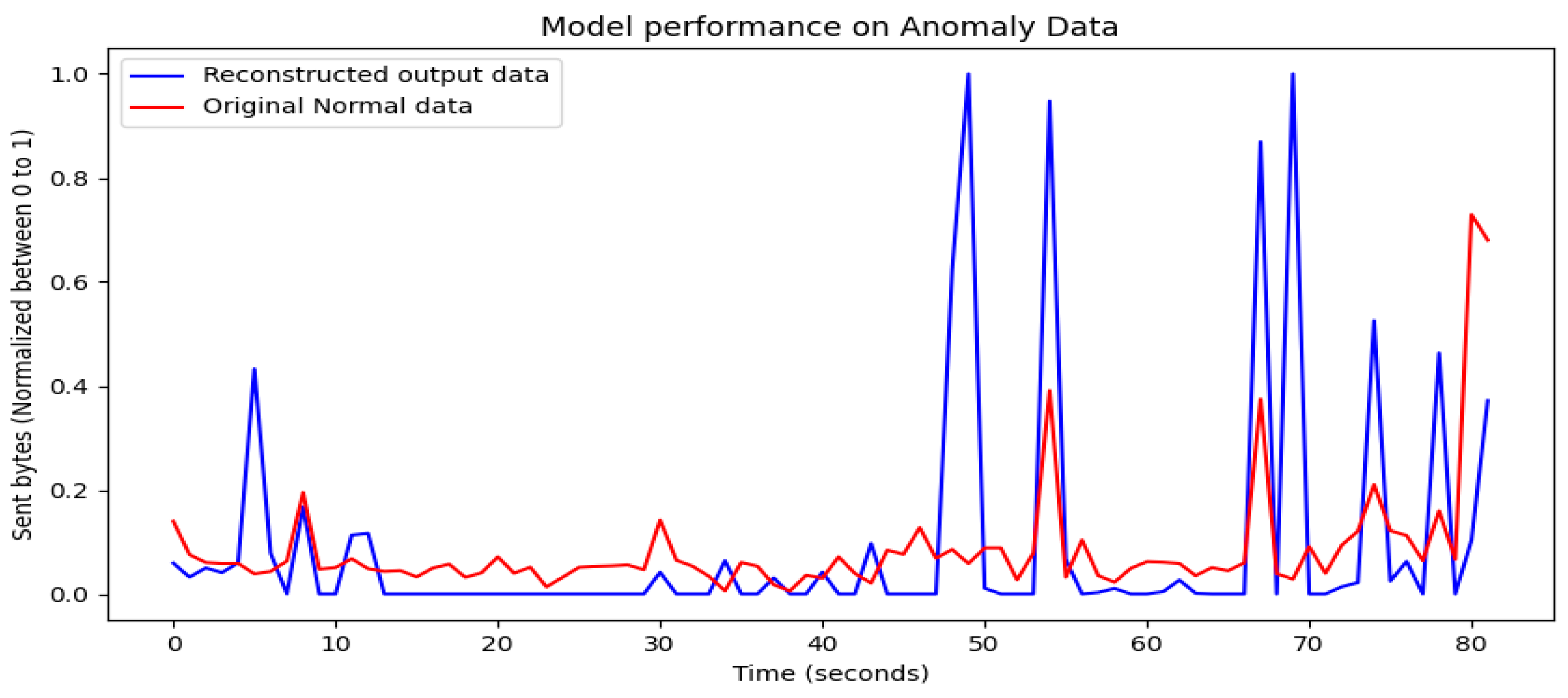
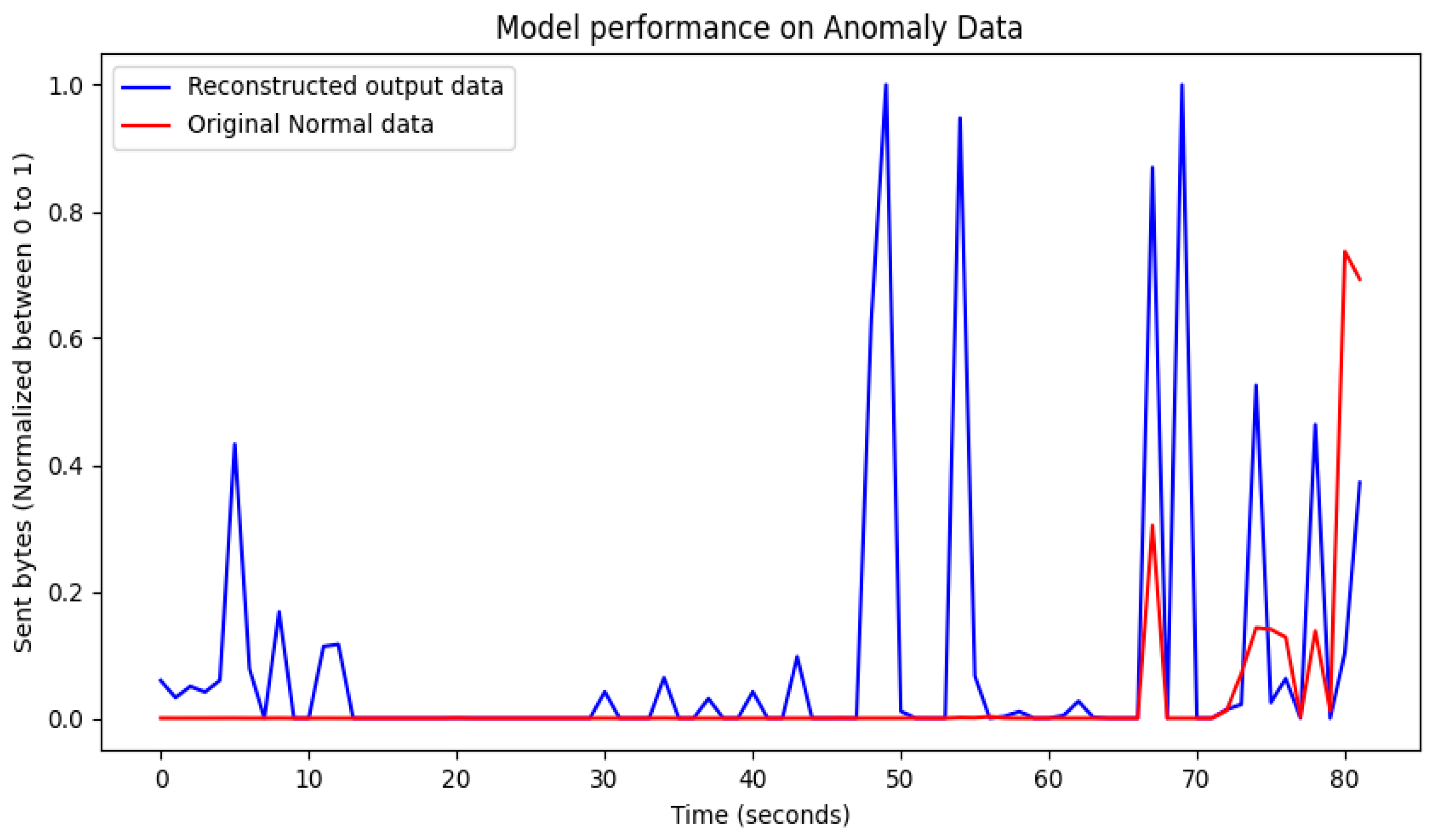
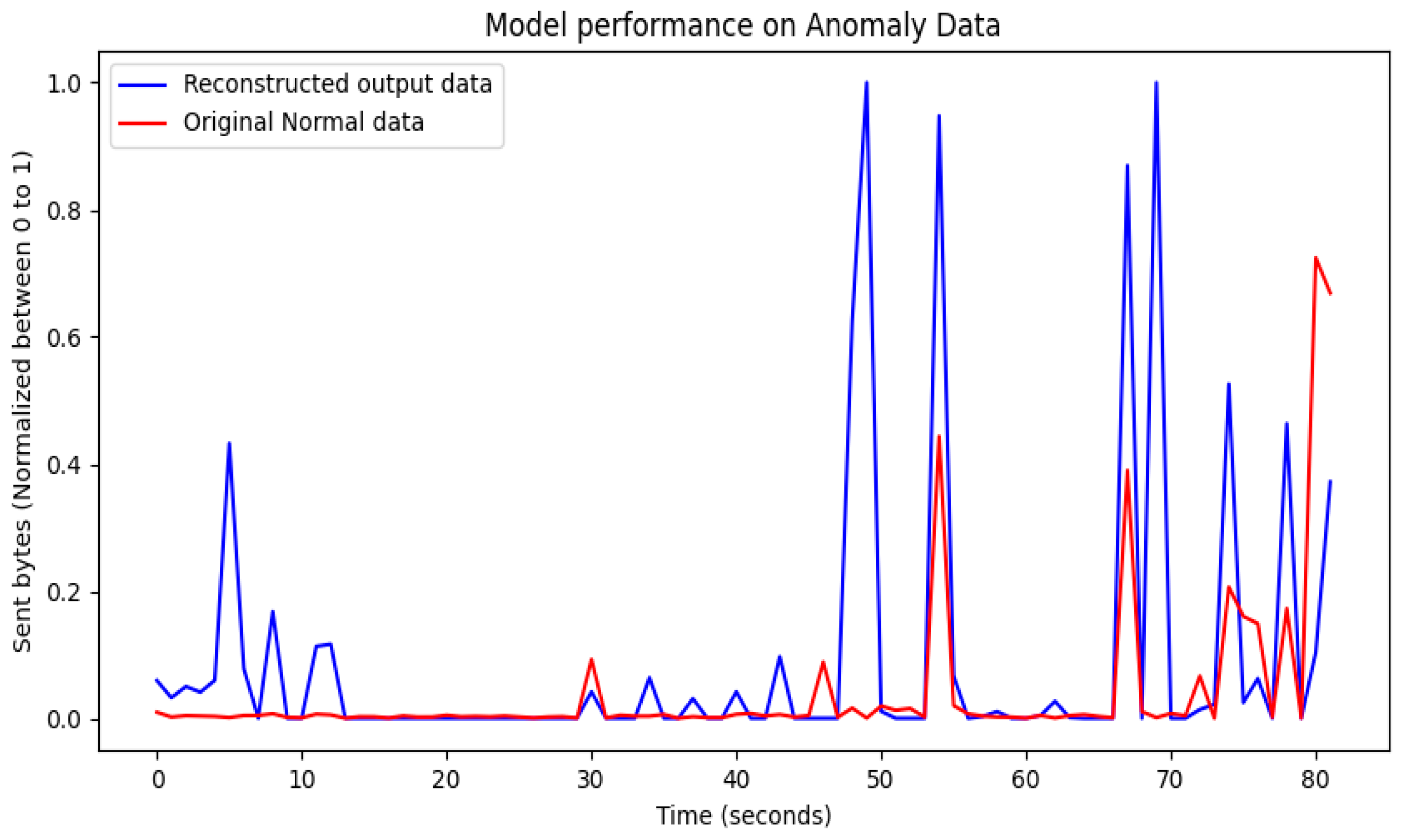
3.7. Anomaly Detection
4. Performance Results of Threat Intrusion Monitoring
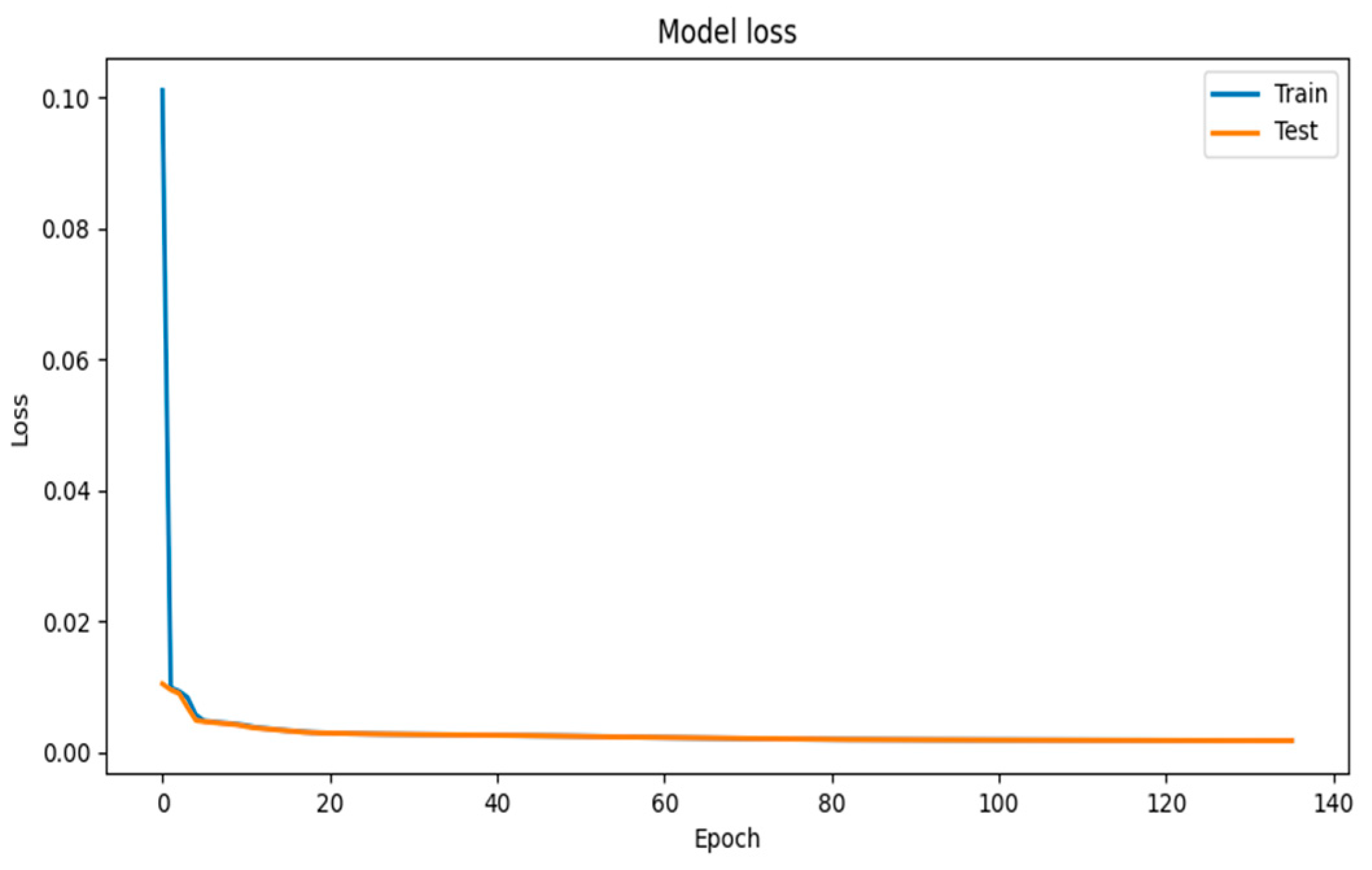
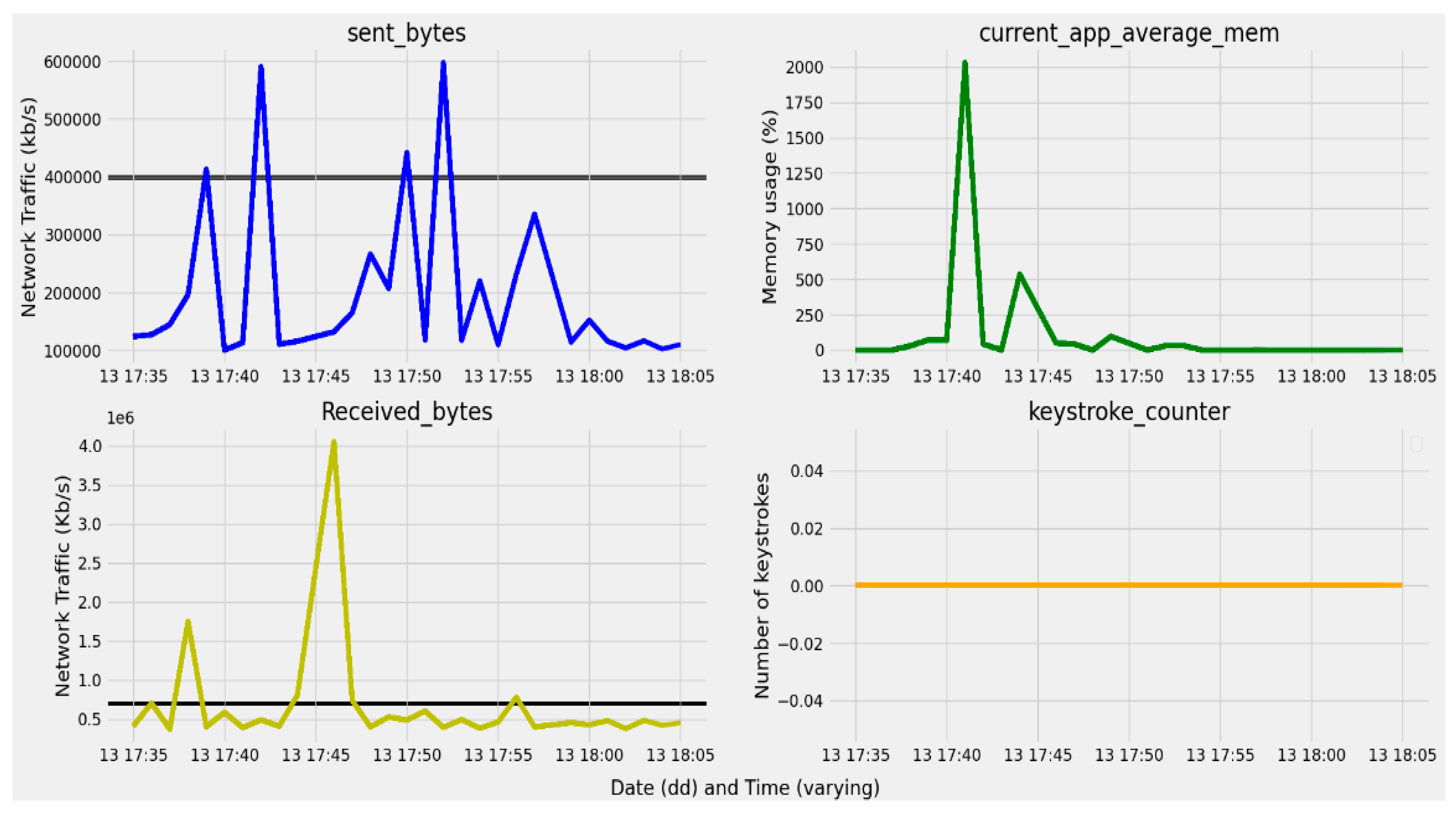
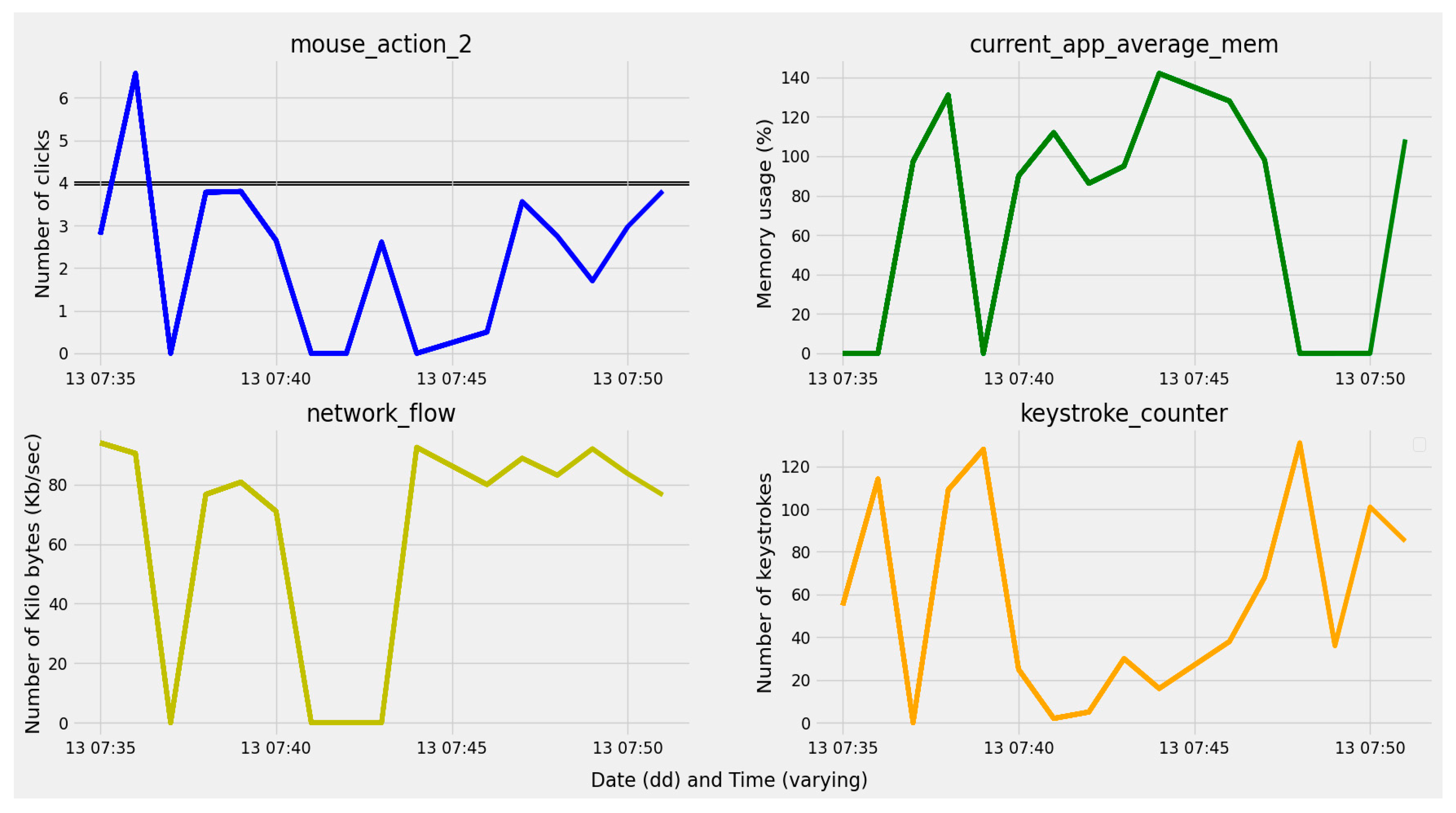
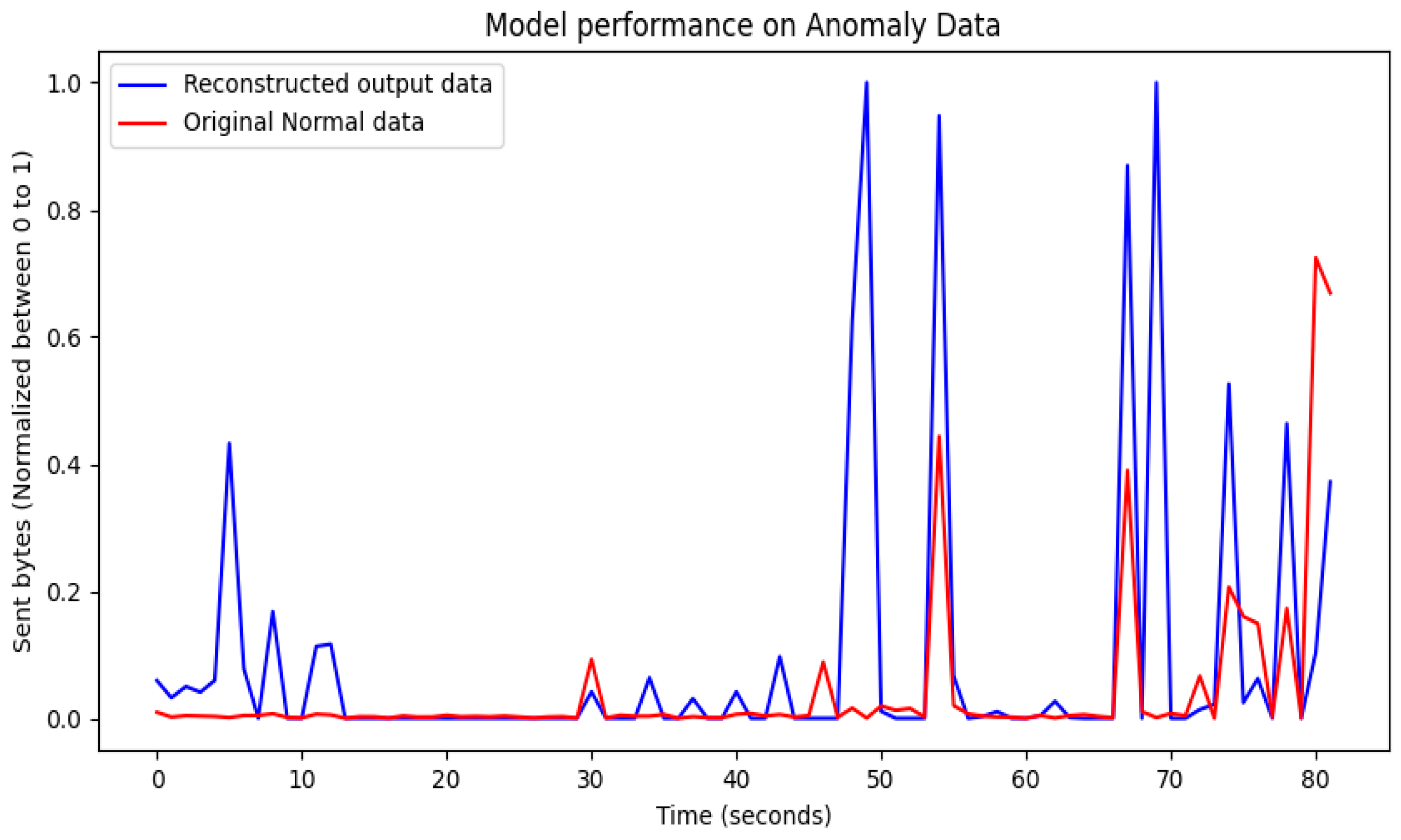
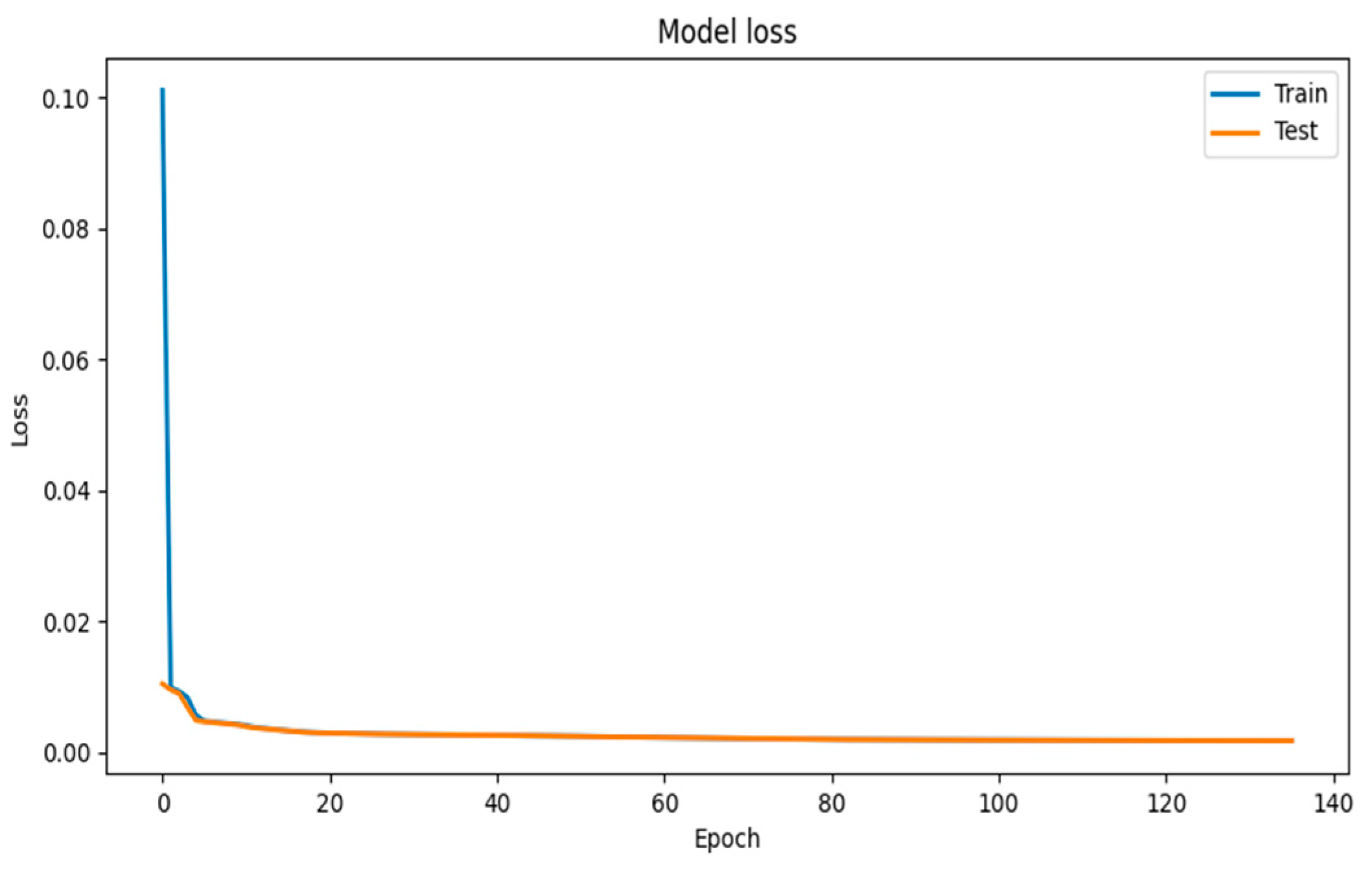
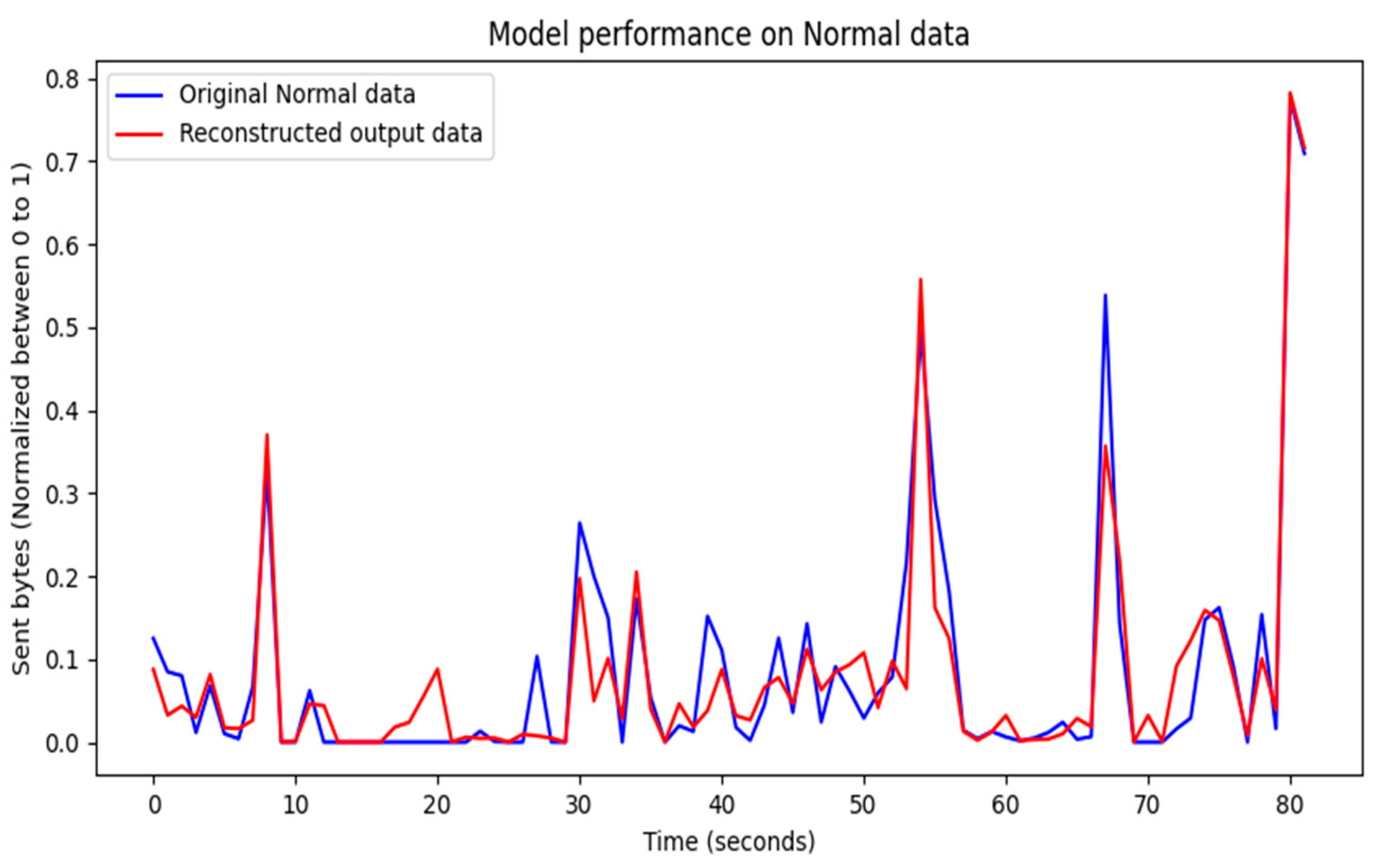
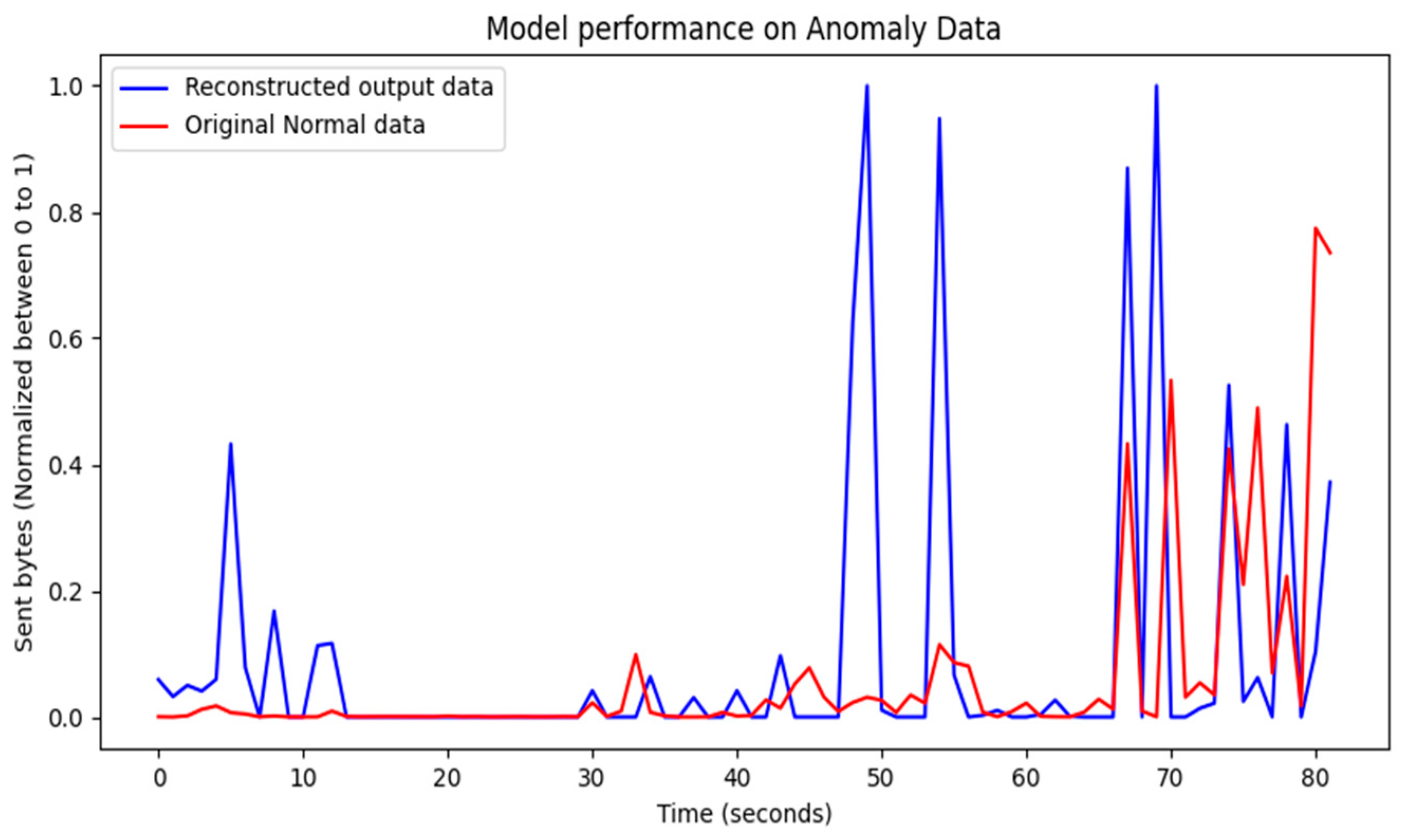
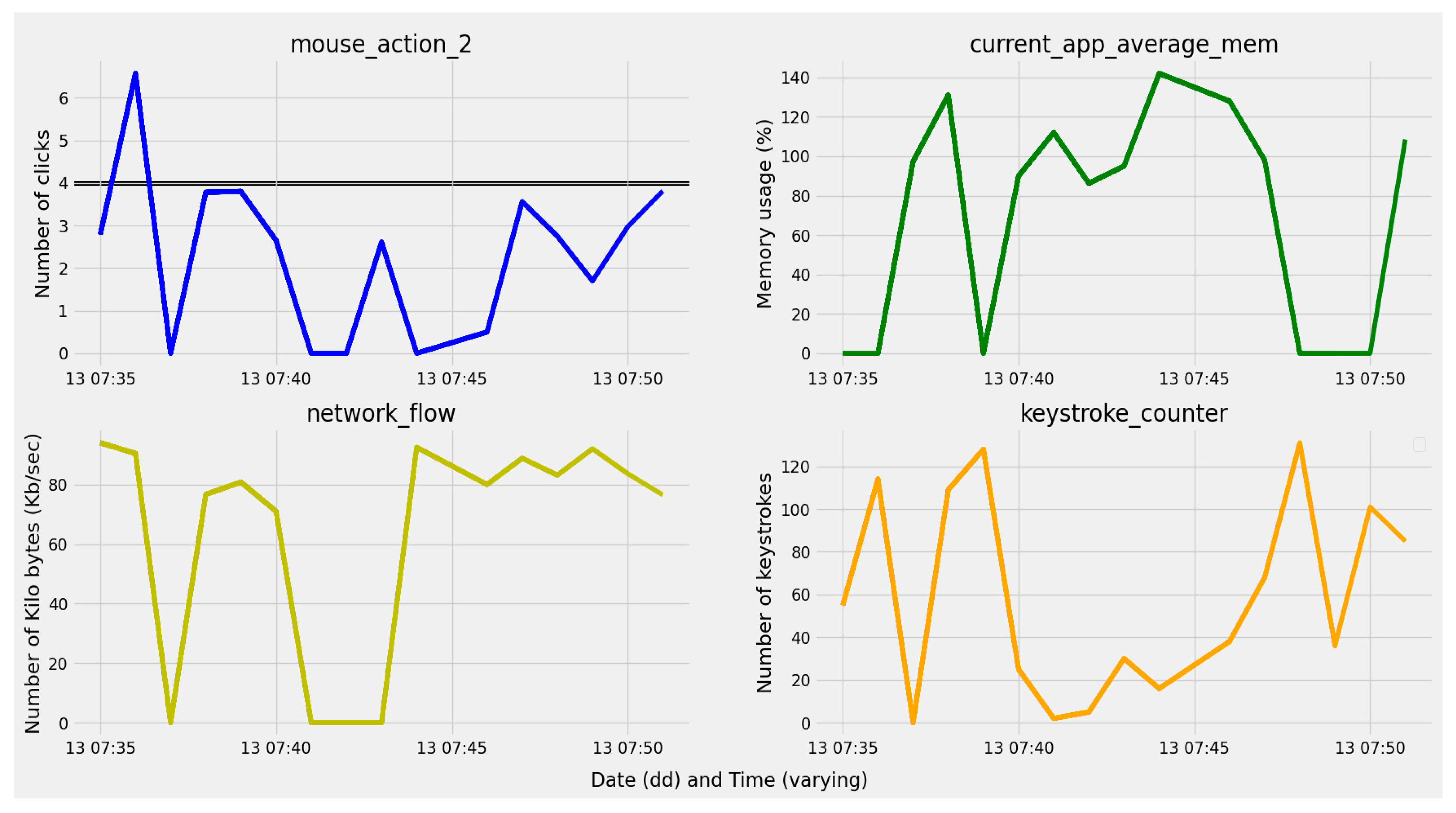
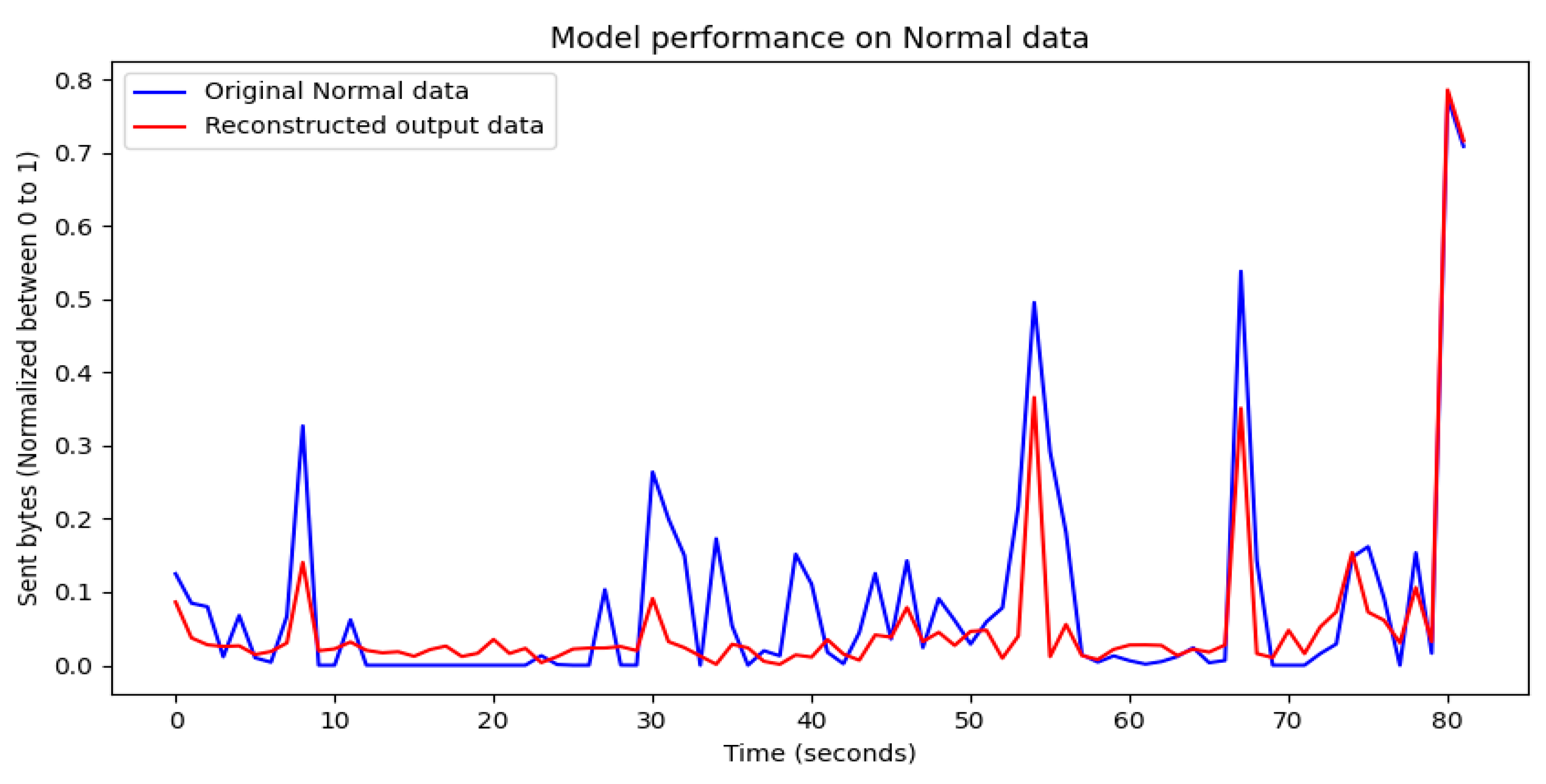
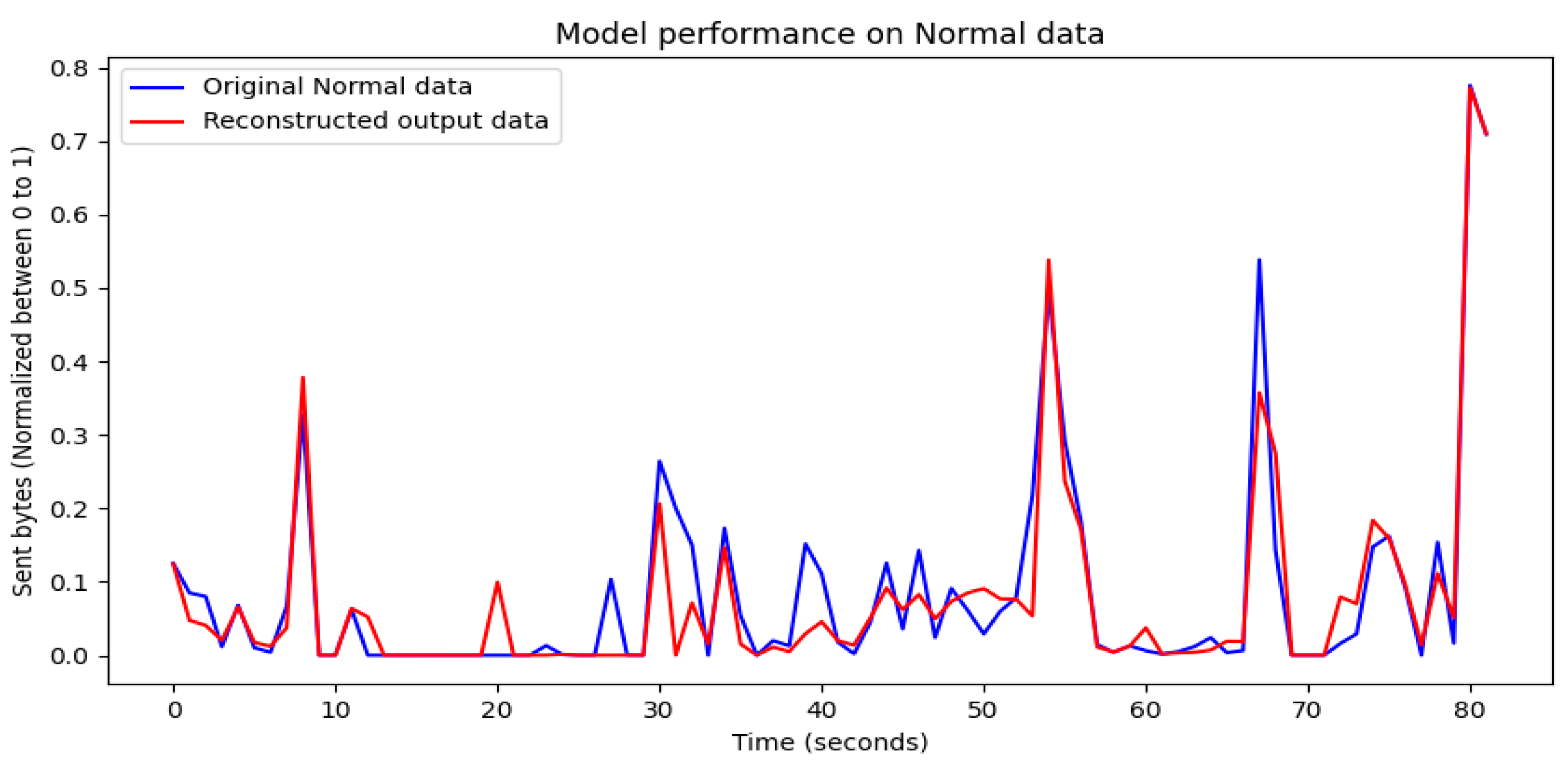
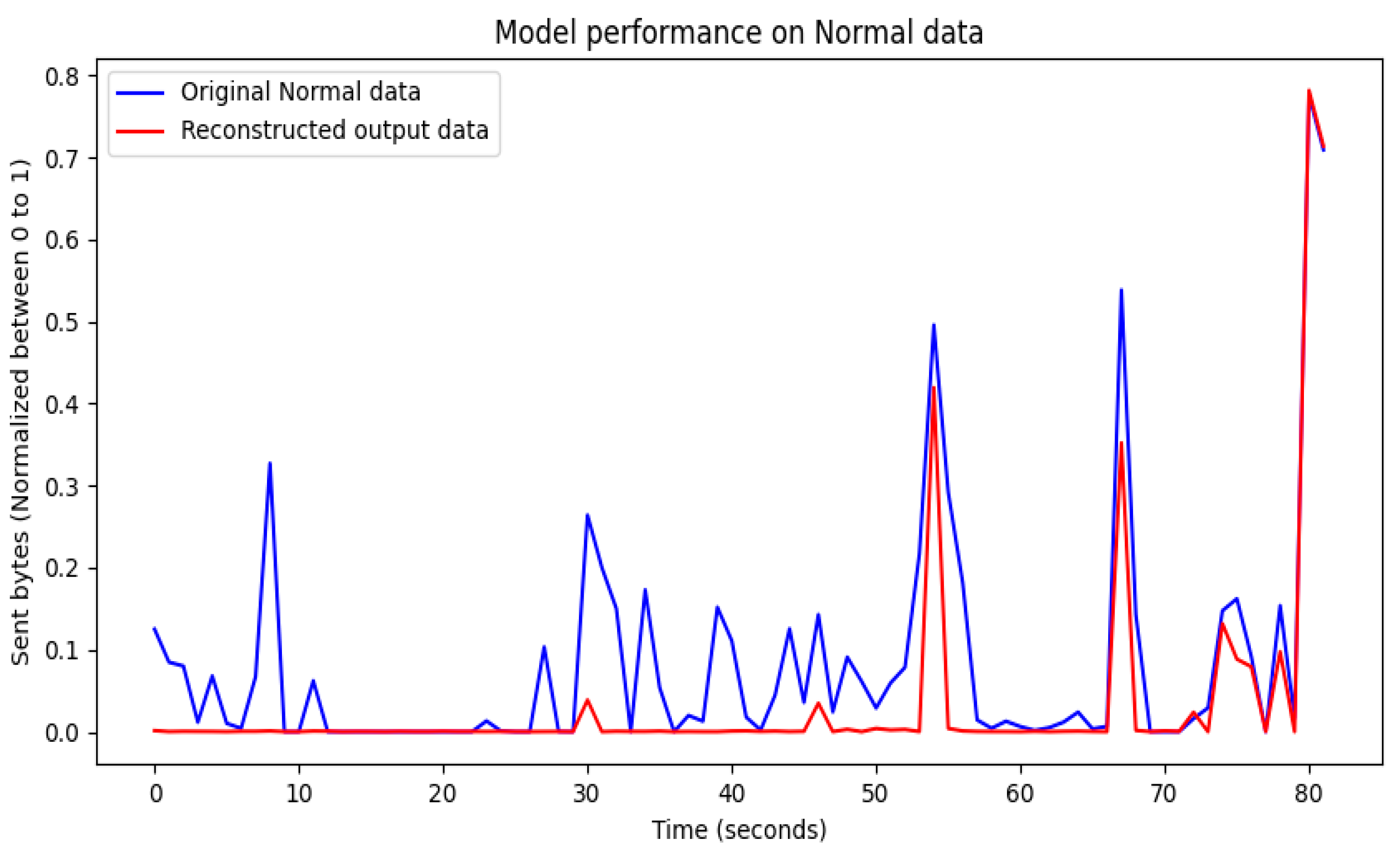
4.1. Visualization of Model Training Results
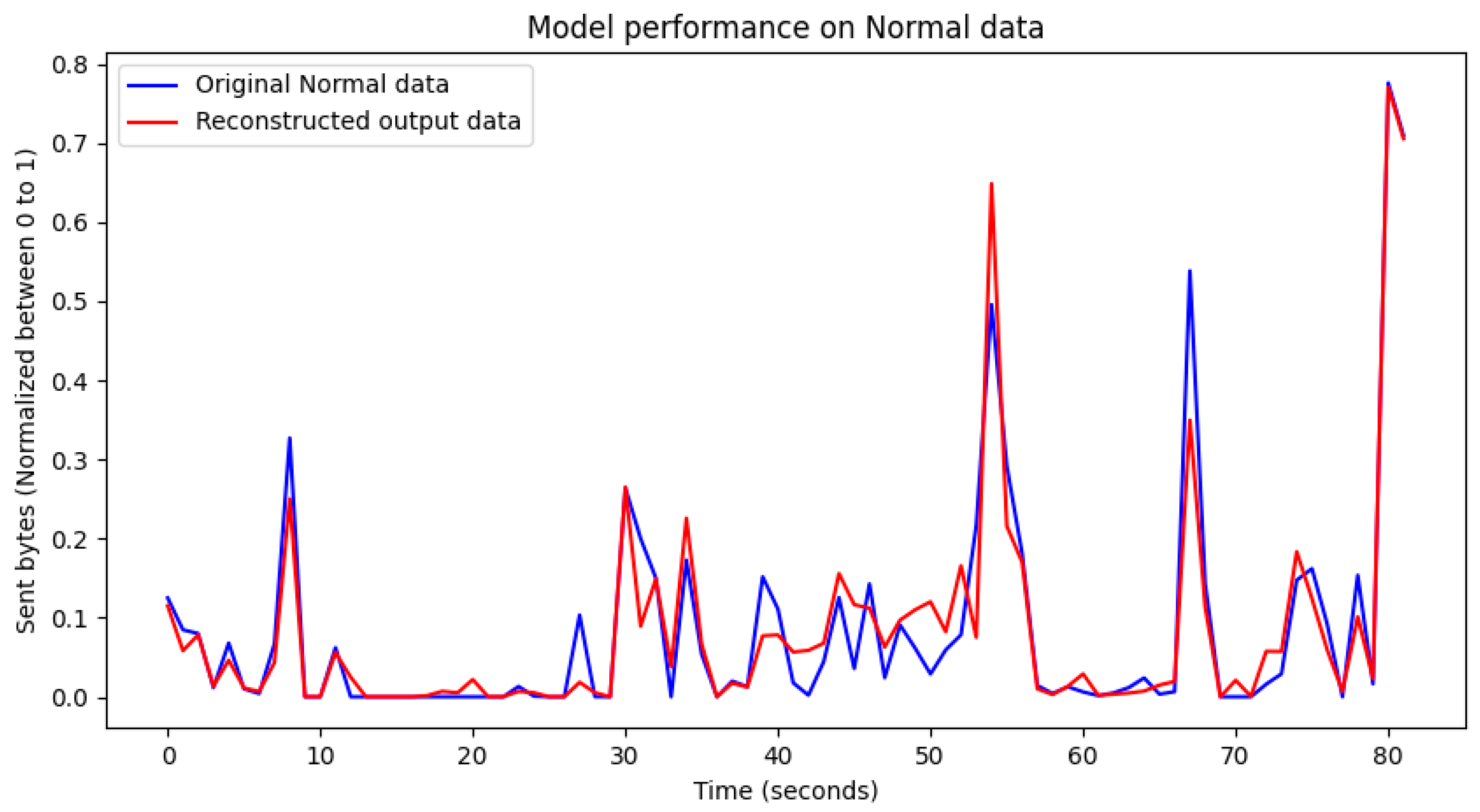
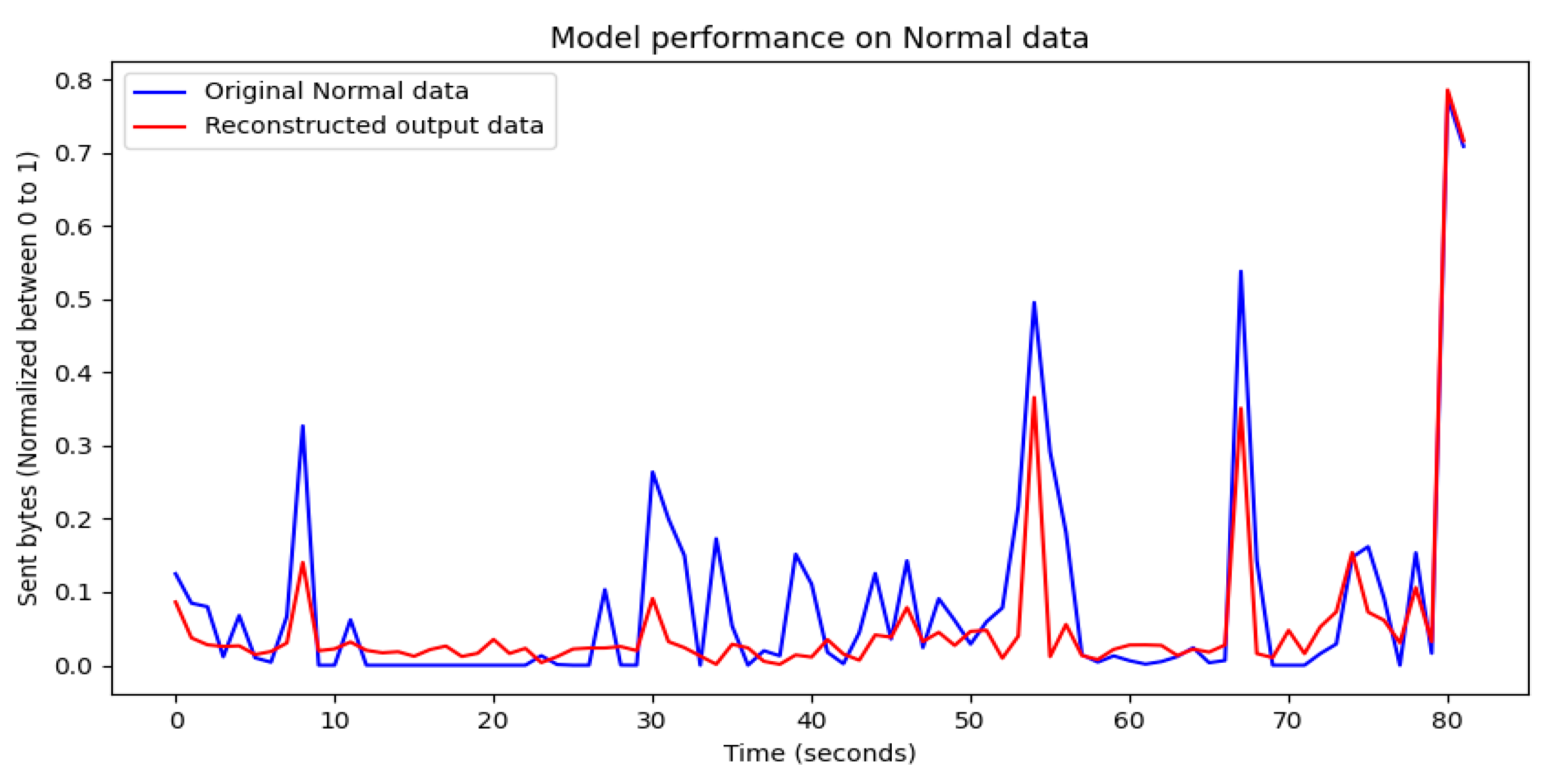
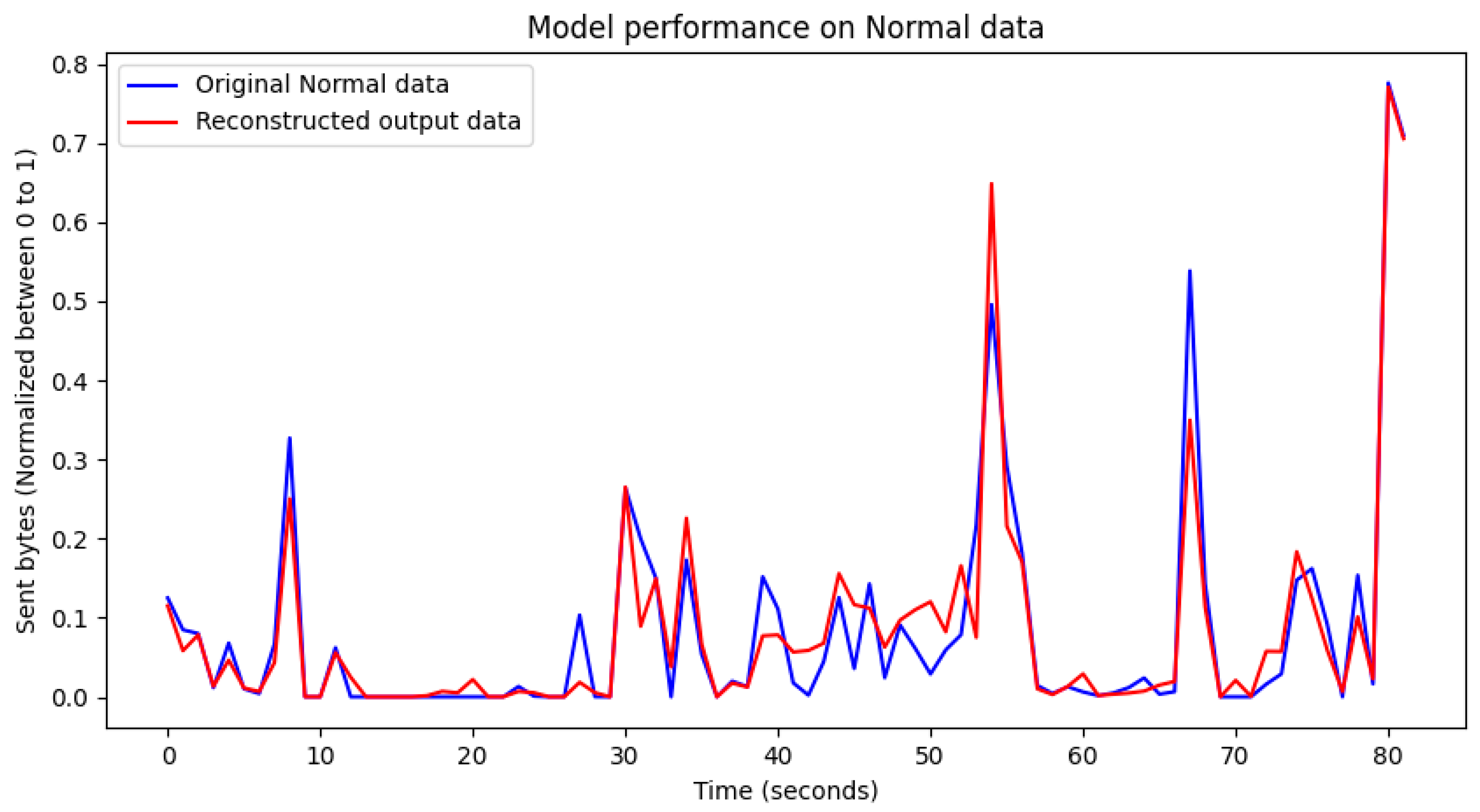
4.2. Evaluation of Model Training Results
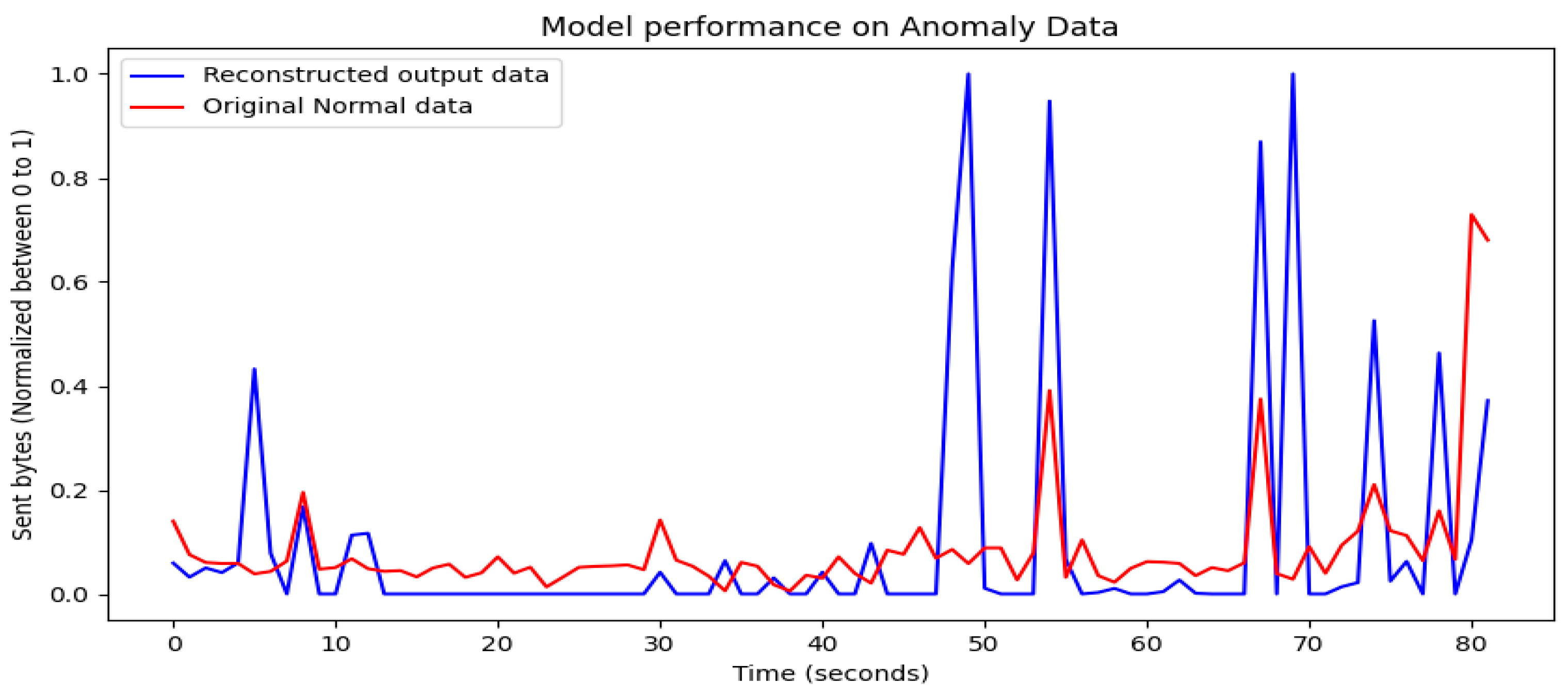
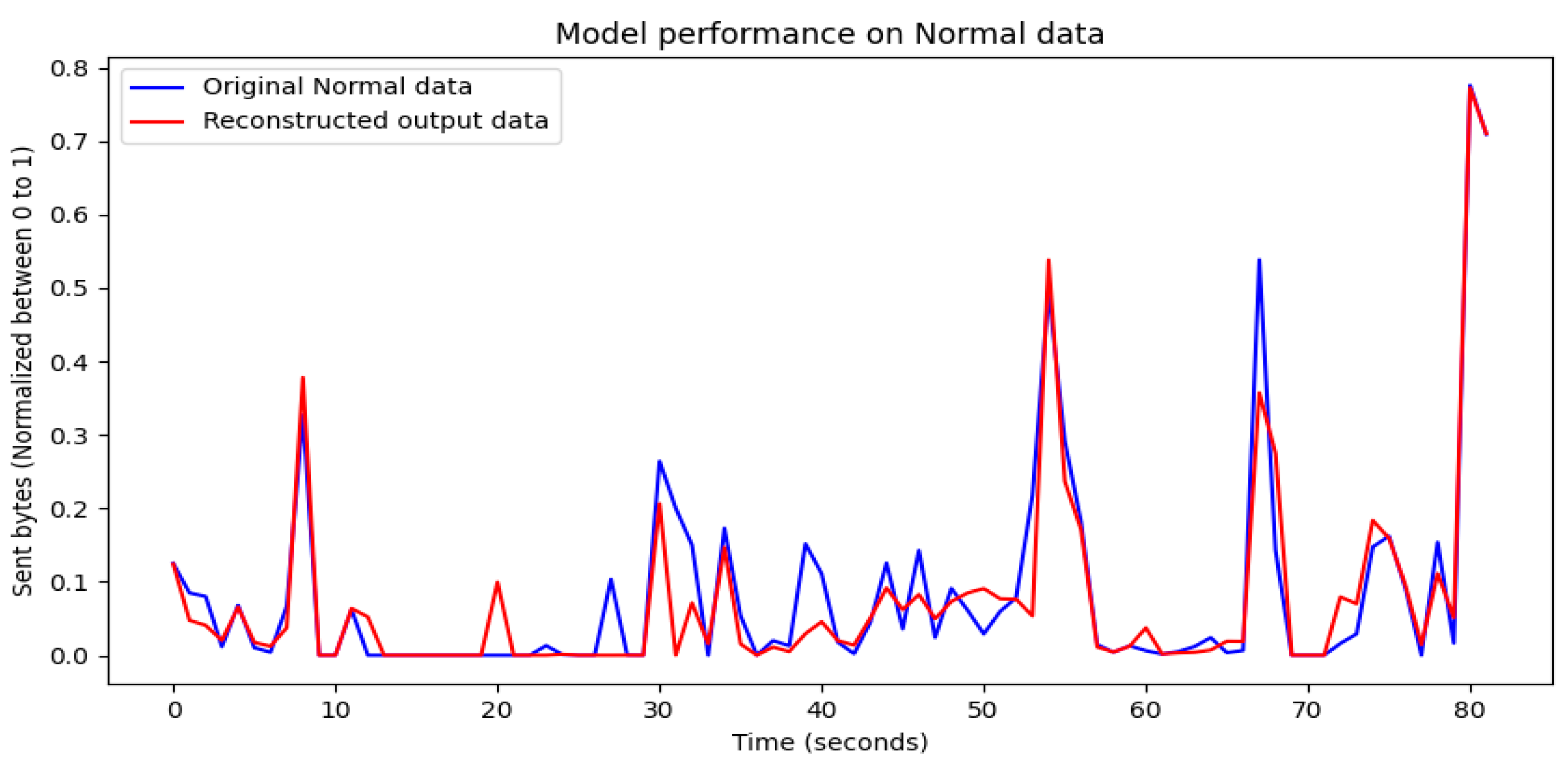
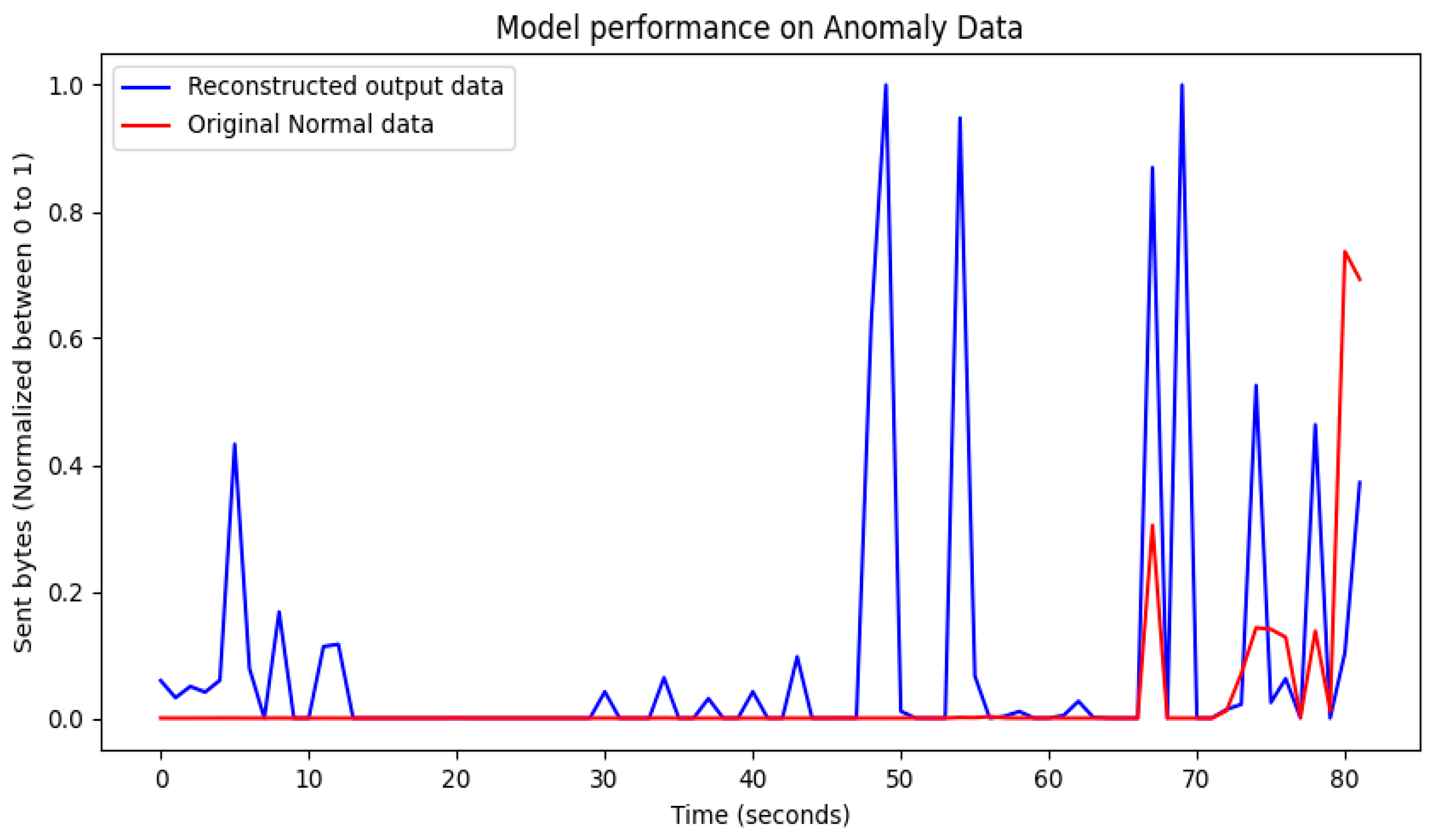
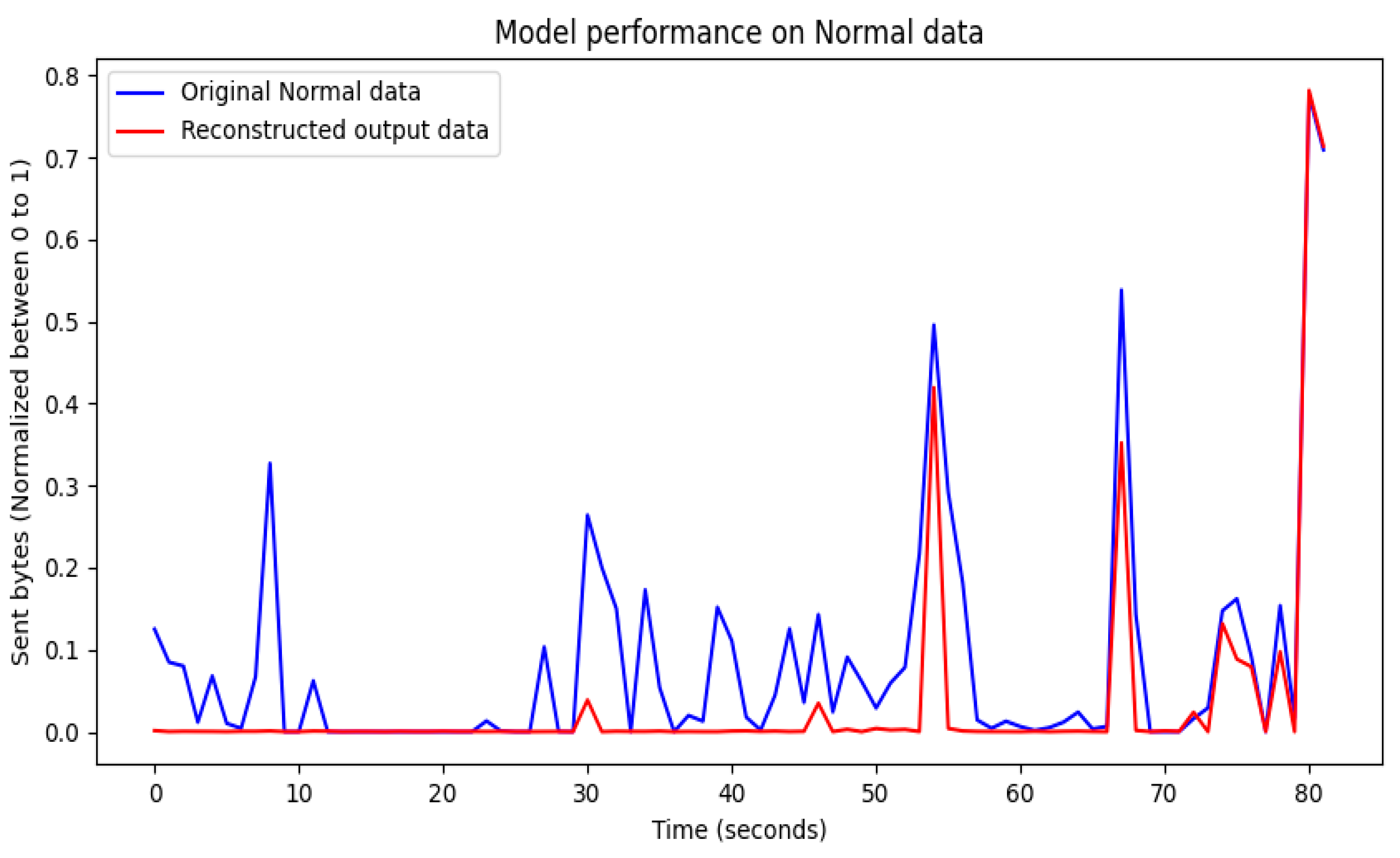
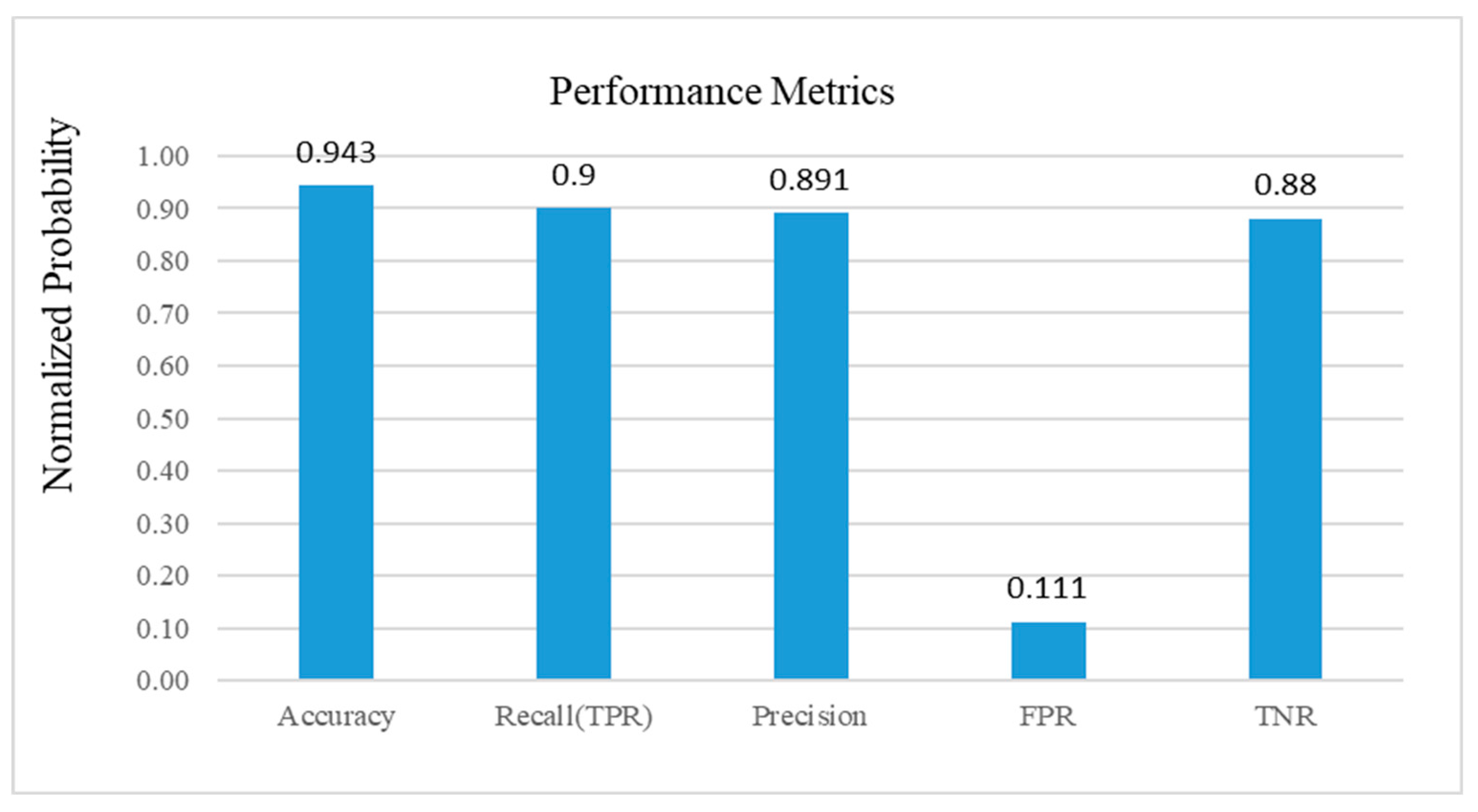
4.3. Performance Results
5. Discussion
5.1. Impact of Tuning Parameters on Threat Detection
5.1.1. The Impact of the Combination of the Loss Function and Optimizer Type
5.1.2. Impact of Batch Size and Number of Epochs
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- IBM. What Is a Zero-Day Exploit? Available online: https://www.ibm.com/topics/zero-day (accessed on 8 September 2023).
- BBC News. Russian Nuclear Scientists Arrested for ‘Bitcoin Mining Plot’. 9 February 2018. Available online: https://www.bbc.com/news/world-europe-43003740 (accessed on 8 June 2023).
- Ikeda, S. 250 Million Microsoft Customer Service Records Exposed; Exactly How Bad Was It? CPO Magazine. Available online: https://www.cpomagazine.com/cyber-security/250-million-microsoft-customer-service-records-exposed-exactly-how-bad-was-it/(accessed on 8 June 2023).
- Thompson, N.; Barrett, B. How Twitter Survived Its Biggest Hack—And Plans to Stop the Next One. WIRED, 20 September 2020. Available online: https://news.hitb.org/content/how-twitter-survived-its-biggest-hack-and-plans-stop-next-one(accessed on 8 June 2023).
- Petters, J. What Is SIEM? A Beginner’s Guide. 15 June 2020. Available online: https://www.varonis.com/blog/what-is-siem (accessed on 8 June 2023).
- Cassetto, O. What Is UBA, UEBA, & SIEM? Security Management Terms Defined. Exabeam, 13 July 2017. Available online: https://www.exabeam.com/siem/uba-ueba-siem-security-management-terms-defined-exabeam/(accessed on 8 June 2023).
- Rajasekaran, A.S.; Maria, A.; Rajagopal, M.; Lorincz, J. Blockchain Enabled Anonymous Privacy-Preserving Authentication Scheme for Internet of Health Things. Sensors 2022, 23, 240. [Google Scholar] [CrossRef] [PubMed]
- Warner, J. User Behavior Analytics (UBA/UEBA): The Key to Uncovering Insider and Unknown Security Threats. 9 May 2019. Available online: https://www.exabeam.com/ueba/user-behavior-analytics/#:~:text=Unknown%20Security%20Threats-,User%20Behavior%20Analytics%20(UBA%2FUEBA)%3A%20The%20Key%20to%20Uncovering,Insider%20and%20Unknown%20Security%20Threats&text=User%20Behavior%20Analytics%20was%20defined,detect%20anomalies%20and%20malicious%20behavior (accessed on 8 June 2023).
- What Is SIEM? Microsoft Security, Microsoft 2023. Available online: https://www.microsoft.com/en-us/security/business/security-101/what-is-siem (accessed on 23 October 2023).
- Shashanka, M.; Shen, M.-Y.; Wang, J. User and entity behavior analytics for enterprise security. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016. [Google Scholar] [CrossRef]
- Eberle, W.; Graves, J.; Holder, L. Insider Threat Detection Using a Graph-Based Approach. J. Appl. Secur. Res. 2010, 6, 32–81. [Google Scholar] [CrossRef]
- Gavai, G.; Sricharan, K.; Gunning, D.; Hanley, J.; Singhal, M.; Rolleston, R. Supervised and Unsupervised methods to detect Insider Threat from Enterprise Social and Online Activity Data. JoWUA 2015, 6, 47–63. [Google Scholar]
- Kim, J.; Park, M.; Kim, H.; Cho, S.; Kang, P. Insider Threat Detection Based on User Behavior Modeling and Anomaly Detection Algorithms. Appl. Sci. 2019, 9, 4018. [Google Scholar] [CrossRef]
- de Andrade, D.C. Recognizing Speech Commands Using Recurrent Neural Networks with Attention. Towards Data Science, 27 December 2018. Available online: https://towardsdatascience.com/recognizing-speech-commands-using-recurrent-neural-networks-with-attention-c2b2ba17c837(accessed on 16 June 2023).
- Lu, J.; Wong, R.K. Insider Threat Detection with Long Short-Term Memory. In Proceedings of the Australasian Computer Science Week Multiconference, New York, NY, USA, 29–31 January 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Nasir, R.; Afzal, M.; Latif, R.; Iqbal, W. Behavioral Based Insider Threat Detection Using Deep Learning. IEEE Access 2021, 9, 143266–143274. [Google Scholar] [CrossRef]
- Veeramachaneni, K.; Arnaldo, I.; Korrapati, V.; Bassias, C.; Li, K. AI^2: Training a Big Data Machine to Defend. In Proceedings of the 2016 IEEE 2nd International Conference on Big Data Security on Cloud (Big Data Security), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS), New York, NY, USA, 9–10 April 2016; pp. 49–54. [Google Scholar] [CrossRef]
- Rashid, T.; Agrafiotis, I.; Nurse, J.R.C. A New Take on Detecting Insider Threats. In Proceedings of the 8th ACMCCS International Workshop on Managing Insider Security Threats, Vienna, Austria, 24–28 October 2016. [Google Scholar] [CrossRef]
- Sharma, B.; Pokharel, P.; Joshi, B. User Behavior Analytics for Anomaly Detection Using LSTM Autoencoder—Insider Threat Detection. In Proceedings of the 11th International Conference on Advances in Information Technology (IAIT2020), Bangkok, Thailand, 1–3 July 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Killourhy, K.S.; Maxion, R.A. Comparing anomaly-detection algorithms for keystroke dynamics. In Proceedings of the 2009 IEEE/IFIP International Conference on Dependable Systems & Networks, Lisbon, Portugal, 29 June–2 July 2009; pp. 125–134. [Google Scholar] [CrossRef]
- Park, Y.; Molloy, I.M.; Chari, S.N.; Xu, Z.; Gates, C.; Li, N. Learning from Others: User Anomaly Detection Using Anomalous Samples from Other Users; Springer: Berlin/Heidelberg, Germany, 2015; pp. 396–414. [Google Scholar] [CrossRef]
- Wang, X.; Tan, Q.; Shi, J.; Su, S.; Wang, M. Insider Threat Detection Using Characterizing User Behavior. In Proceedings of the 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC), Guangzhou, China, 18–21 June 2018; pp. 476–482. [Google Scholar] [CrossRef]
- Jawed, H.; Ziad, Z.; Khan, M.M.; Asrar, M. Anomaly detection through keystroke and tap dynamics implemented via machine learning algorithms. Turk. J. Electr. Eng. Comput. Sci. 2018, 26, 1698–1709. [Google Scholar] [CrossRef]
- Chen, Y.; Nyemba, S.; Malin, B. Detecting Anomalous Insiders in Collaborative Information Systems. IEEE Trans Dependable Secur. Comput. 2012, 9, 332–344. [Google Scholar] [CrossRef]
- Parveen, K.H.P.; Weger, Z.R.; Thuraisingham, B.; Khan, L. Supervised Learning for Insider Threat Detection Using Stream Mining. In Proceedings of the 2011 IEEE 23rd International Conference on Tools with Artificial Intelligence, Boca Raton, FL, USA, 7–9 November 2011. [Google Scholar]
- Pierini, A.; Trotta, G. Juicy-Potato. 2019. Available online: https://github.com/ohpe/juicy-potato (accessed on 23 June 2023).
- Thisisnzed. Anywhere. 2023. Available online: https://github.com/thisisnzed/Anywhere (accessed on 23 June 2023).
- Sánchez, P.M.S.; Valero, J.M.J.; Zago, M.; Celdrán, A.H.; Maimó, L.F.; Bernal, E.L.; Bernal, S.L.; Valverde, J.M.; Nespoli, P.; Galindo, J.P.; et al. BEHACOM—A dataset modelling users’ behaviour in computers. Data Brief 2020, 31, 105767. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference Number | Behavior- Based (U/EBA) Approach | Algorithm | Dataset | Features Considered | Device and Entities Behavioral Analysis |
|---|---|---|---|---|---|
| [23] | Yes | Multiclass SVM | Custom-made dataset | Keystrokes and tap dynamics | No |
| [22] | Yes | Supervised and unsupervised (one-class SVM) | 1998 Lincoln Laboratory intrusion detection dataset | Time, user ID, machine IP, command, argument, path | No |
| [19] | Yes | LSTM autoencoder | CERT dataset | Device, email, HTTP, file, log-on activity | Yes |
| [24] | Yes | K-nearest neighbors and PCA | RUU dataset | Window touches, new processes, running processes, and applications on the system | Yes |
| [21] | No | Local outlier factor | Multiple datasets | Keyboard data, emails, log access | No |
| Proposed approach | Yes | ANN-based autoencoder | Custom-made dataset | Keystroke, mouse, file, HTTP, resource consumption, device usage (central processing unit (CPU), random access memory (RAM), network) | Yes |
| Feature Domain | Feature | Description |
|---|---|---|
| Mouse | click_speed_aveage_N | Set of features that depict the average time to complete a click using the mouse in (ms). Clicks (0—left, 1—right, 2—left double, 3—middle). |
| click_speed_stddev_N | Set of features that depict the standard deviation in time to complete a click using the mouse in (ms). Clicks (0—left, 1—right, 2—left double, 3—middle). | |
| mouse_action_counter_N | Set of features that depict the number of events respective to each type of action. Actions (Clicks (0—left, 1—right, 2—left double, 3—middle, 4—mouse movement, 5—drag or selection, 6—scroll)). | |
| mouse_position_histogram_N | Set of features that depict the number of events that occurred in each quadrant of the screen, where the screen is divided into 3 × 3 matrix, i.e., 9 quadrants. | |
| mouse_movement_direction_ histogram_N | Set of features that represent the number of mouse movement events in each direction (8 directions). | |
| mouse_average_movement_ duration | Average time of the mouse movements in (ms). | |
| mouse_average_movement_ speed | The standard deviation in the time of the mouse movements in (ms). | |
| mouse_average_movement_ speed_direction_N | Set of features that depict the histogram of movement average speeds per direction. | |
| Keyboard | keystroke_counter | Total number of key strokes generated by the user. |
| erase_keys_counter | Number of times the user pressed “backspace” and “delete”. | |
| erase_keys_percentage | Percentage of erased keys over total keys. | |
| press_press_average_interval | The average time between two successive key strokes in (ms). | |
| press_press_stddev_interval | Standard deviation in the time between two successive key strokes. | |
| press_release_average_interval | The average time between press and release of all the key strokes in (ms). | |
| press_release_stddev_interval | Standard deviation in the time between the press and release of all the key strokes in (ms). | |
| keystrokes_key_Ki | Set of features that depict the number of key y-strokes per key. Ki is the key in the set of keys and is meant to be recorded. | |
| press_release_average_Ki | Set of features that depict the average time between press and release of all the key strokes in keys set in (ms). | |
| Application | active_apps_average | The average number of active applications. |
| current_app | Executable name of the application in the foreground. | |
| penultimate_app | Penultimate application’s executable name in foreground. | |
| changes_between_apps | The number of changes between different foreground applications. | |
| current_app_foreground_time | Amount of time the current application has been in the foreground. | |
| current_app_average_processes | The average number of processes of the current application in the foreground. | |
| current_app_stddev_processes | The standard deviation in the number of processes of the current application in the foreground. | |
| Resource Consumption (Device) | current_app_average_cpu | The average amount of CPU used by the current application (%). |
| current_app_stddev_cpu | The standard deviation in the CPU used by the current application (%). | |
| system_average_cpu | The average amount of the system’s total CPU capacity used (%). | |
| system_stddev_cpu | The standard deviation in the system’s total CPU capacity used (%). | |
| current_app_average_mem | The average amount of memory used by the current application (%). | |
| current_app_stddev_mem | The standard deviation in the memory used by the current application (%). | |
| system_average_mem | The average amount of total system memory capacity used (%). | |
| system_stddev_mem | The standard deviation in total system memory capacity used (%). | |
| received_bytes | The number of bytes received through the network interfaces of the device. | |
| sent_bytes | The number of bytes sent using the network interfaces of the device. | |
| HTTP and File | URL | URLs visited by the user. These will be classified as 0—normal and 1—malicious. |
| File_modifications | Any read and write operations performed by escalating privileges are classified as 1 and 0 if not. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saminathan, K.; Mulka, S.T.R.; Damodharan, S.; Maheswar, R.; Lorincz, J. An Artificial Neural Network Autoencoder for Insider Cyber Security Threat Detection. Future Internet 2023, 15, 373. https://doi.org/10.3390/fi15120373
Saminathan K, Mulka STR, Damodharan S, Maheswar R, Lorincz J. An Artificial Neural Network Autoencoder for Insider Cyber Security Threat Detection. Future Internet. 2023; 15(12):373. https://doi.org/10.3390/fi15120373
Chicago/Turabian StyleSaminathan, Karthikeyan, Sai Tharun Reddy Mulka, Sangeetha Damodharan, Rajagopal Maheswar, and Josip Lorincz. 2023. "An Artificial Neural Network Autoencoder for Insider Cyber Security Threat Detection" Future Internet 15, no. 12: 373. https://doi.org/10.3390/fi15120373
APA StyleSaminathan, K., Mulka, S. T. R., Damodharan, S., Maheswar, R., & Lorincz, J. (2023). An Artificial Neural Network Autoencoder for Insider Cyber Security Threat Detection. Future Internet, 15(12), 373. https://doi.org/10.3390/fi15120373