
End-to-End Service Availability in Heterogeneous Multi-Tier Cloud–Fog–Edge Networks


Abstract
:1. Introduction
1.1. Evolution and Significance of Multi-Level Communication Networks
1.2. The Imperative of High Availability
1.3. Objective and Contributions of the Paper
2. Related Works
- Architectures and methodologies for integrating cloud, fog, and edge layers into unified platforms for seamless operation and resource orchestration, e.g., OpenFog Consortium reference architecture [2], multi-access edge computing standards of the European Standards Organization [3], fog computing and networking theory, practice, and applications [4].
- Management and virtualization techniques to dynamically allocate resources across discrete layers, e.g., software-defined networking approaches [5].
- Most existing analytical models focus on reliability within isolated tiers rather than end-to-end availability across systems. For example, the authors of [2,3,4,12,13,14] assessed the reliability of individual cloud, edge, or fog tiers but did not study overall system availability. This fails to account for cascading failures between interdependent layers.
- Leveraging Markov chains to create an analytical model of availability spanning edge, fog, and cloud tiers;
- Accounting for inter-tier dependencies and cascading failures in an integrated system-level model;
- Providing a flexible approach adaptable to different multi-tier architectures, including sublayers;
- Enabling quantitative availability target setting based on user specifications;
- Striking a balance between model simplicity, mathematical tractability, and practical fidelity.
- The methodology enables quantitative availability target setting during design, which most of the literature lacks. This ties modeling to user requirements.
3. Materials and Methods
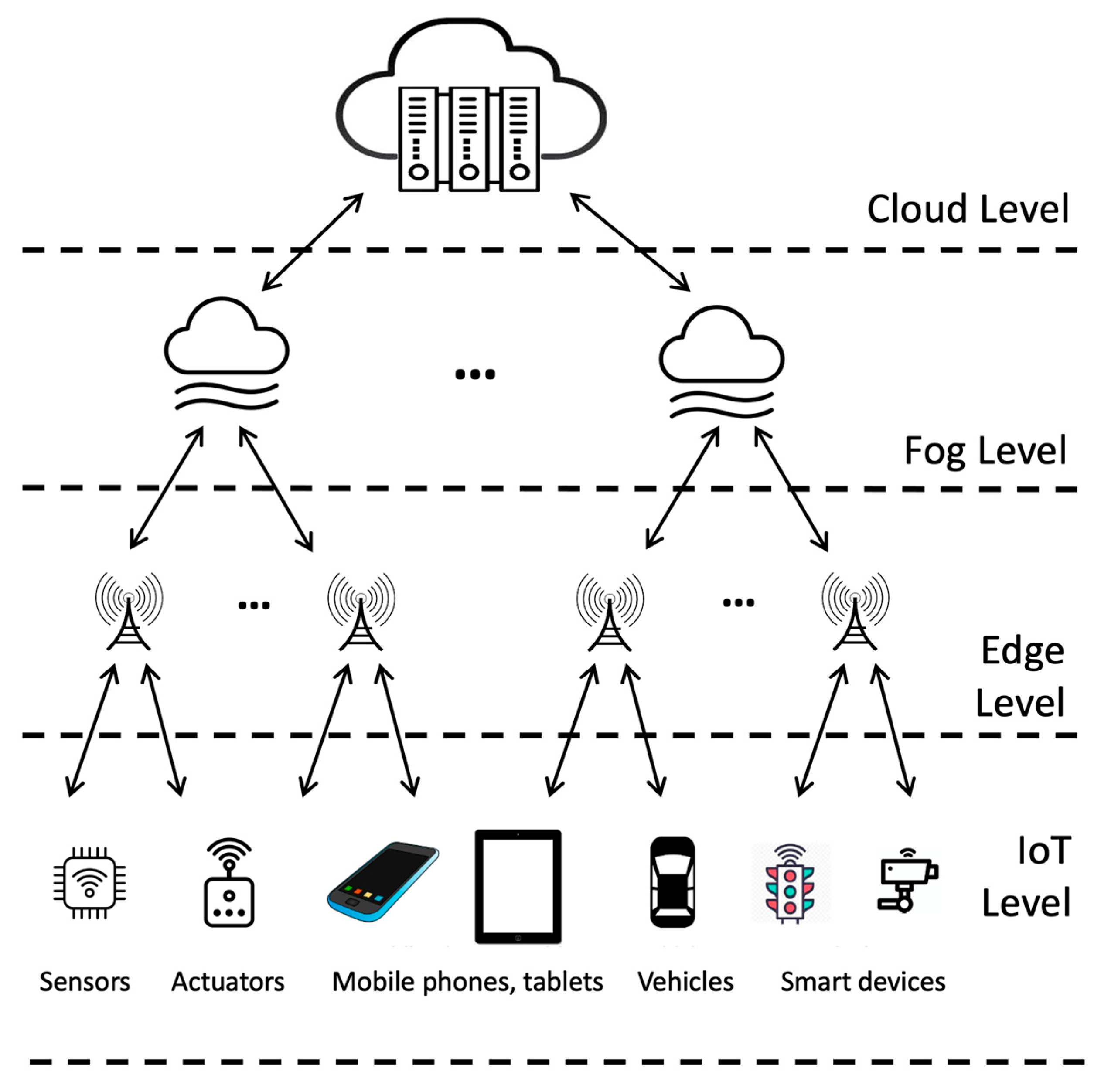
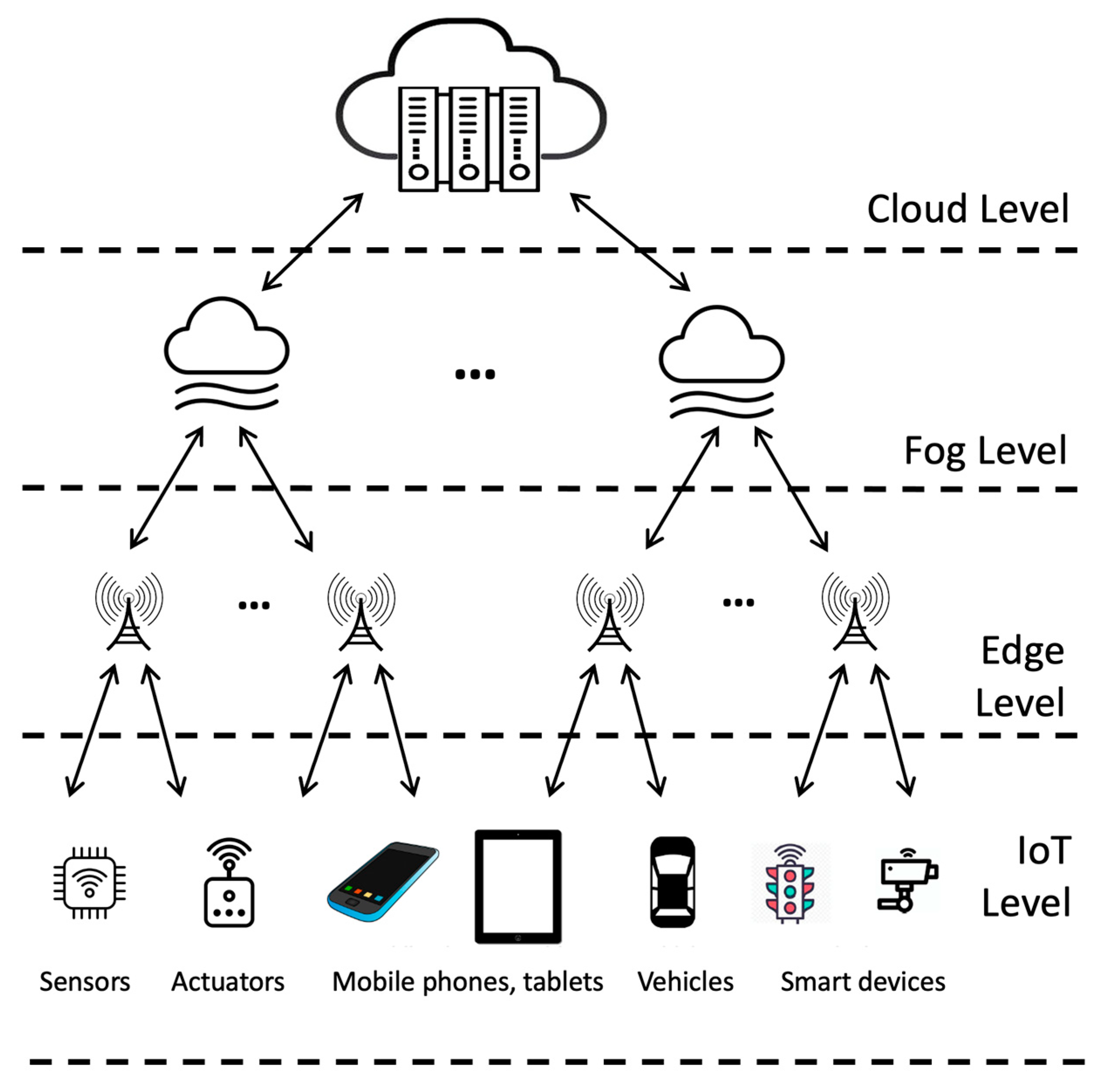
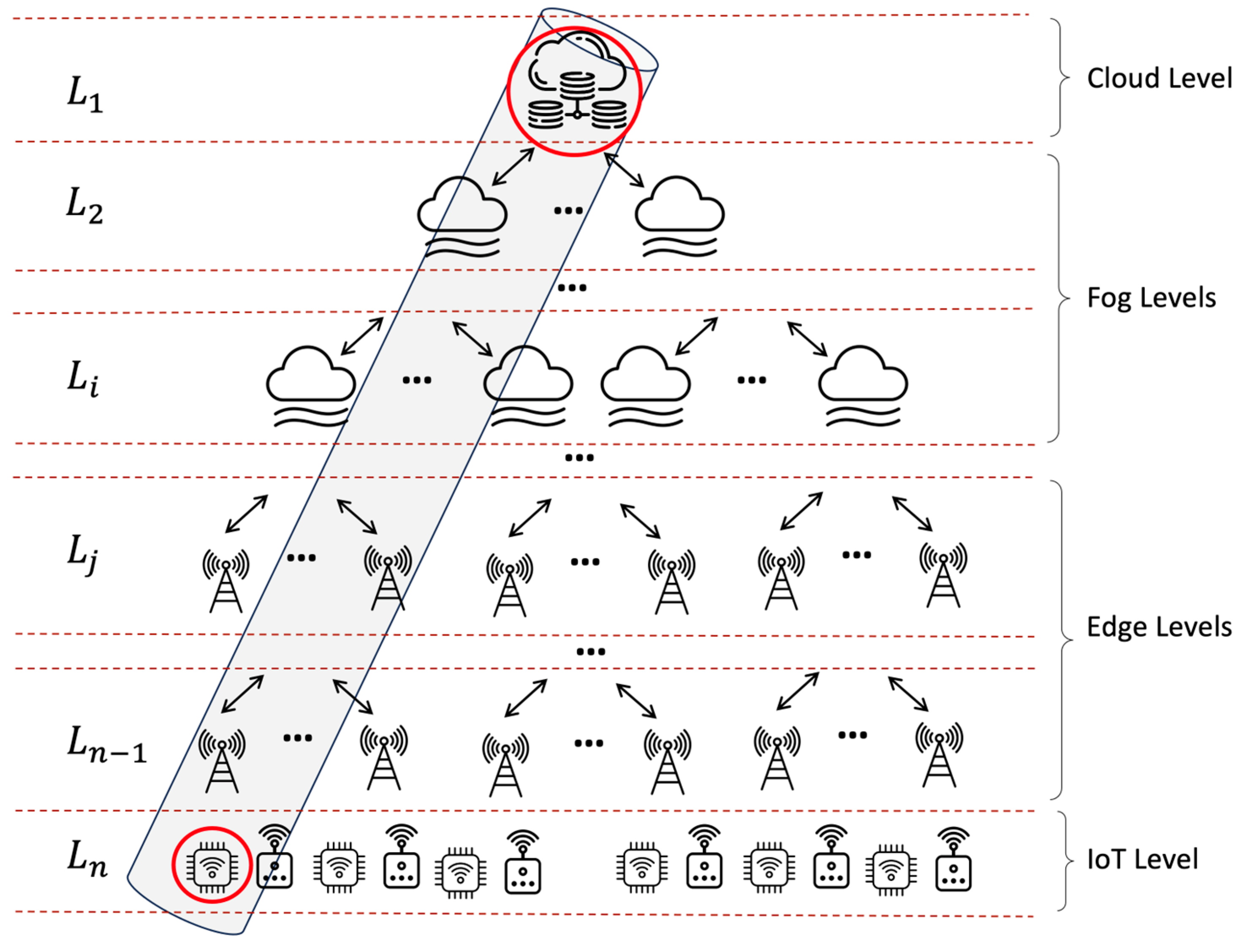
3.1. Traditional Three-Level Cloud–Fog–Edge Architecture
- Smart Agriculture:
- -
- IoT—Sensors monitor soil moisture, crop growth parameters, weather, and livestock vitals.
- -
- Edge—Gateways in fields pre-process sensor data and activate irrigation.
- -
- Fog—Local farm servers aggregate data and optimize water/fertilizer levels.
- -
- Cloud—Cloud services analyze long-term trends and provide global monitoring.
- Smart Retail:
- -
- IoT—RFID tags track inventory. Point-of-sale and shopping apps capture purchase data.
- -
- Edge—Store servers filter noise and detect localized trends.
- -
- Fog—Regional servers identify buying behaviors and optimize pricing.
- -
- Cloud—Central cloud analyzes worldwide sales and shopping habits.
- Industrial Automation:
- -
- IoT—PLCs, sensors, and actuators control production processes and machinery.
- -
- Edge—Local control systems modulate manufacturing lines in real time.
- -
- Fog—Plantwide monitoring and control systems enhance coordination.
- -
- Cloud—Global cloud optimizes manufacturing operations and schedules.
- Smart Energy Utilities:
- -
- IoT—Smart meters monitor household electricity usage. Grid sensors track power levels.
- -
- Edge—Neighborhood-level servers balance local loads.
- -
- Fog—Regional systems regulate distribution across substations.
- -
- Cloud—Cloud analyzes usage patterns and controls cross-region transmission.
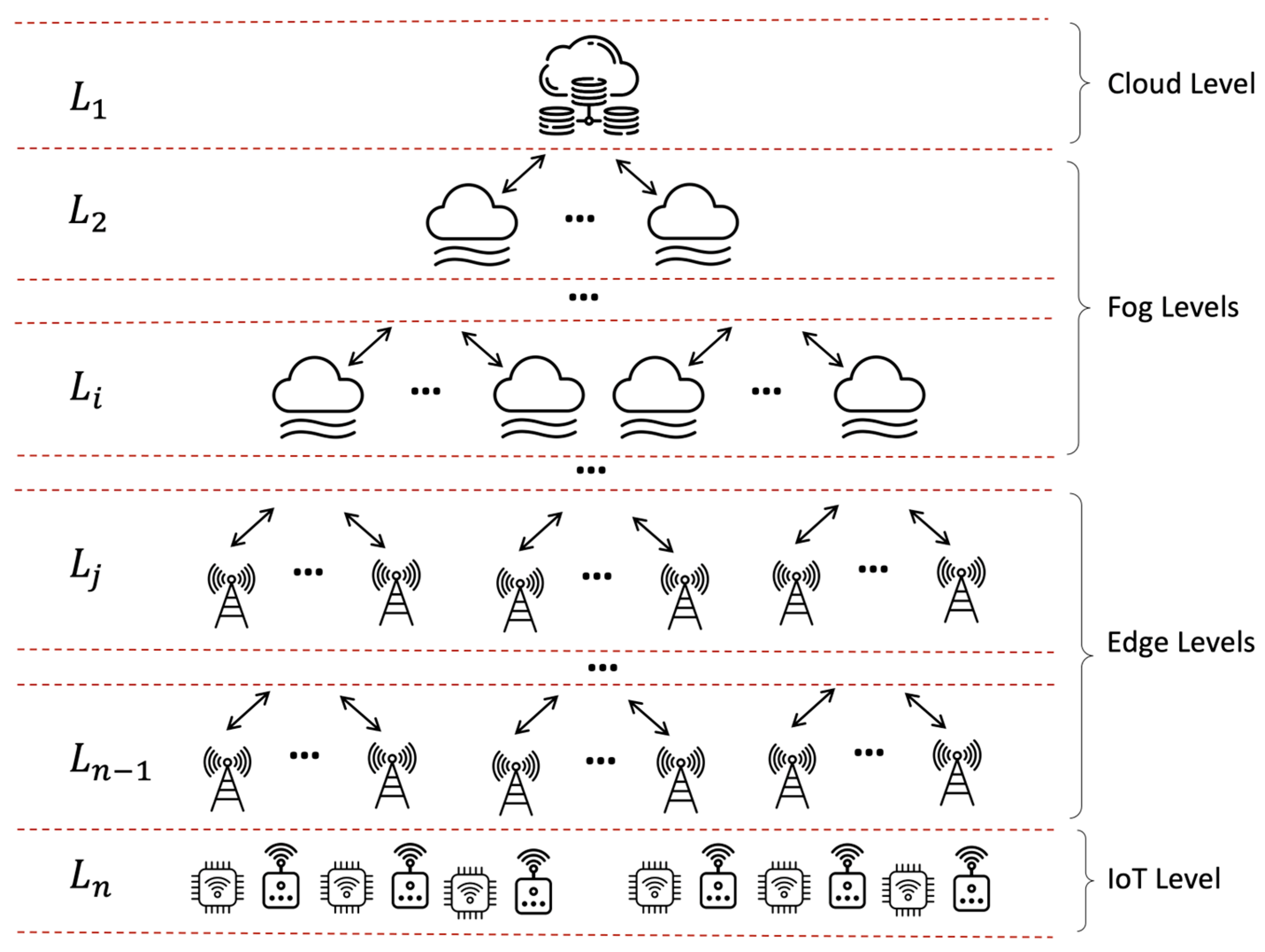
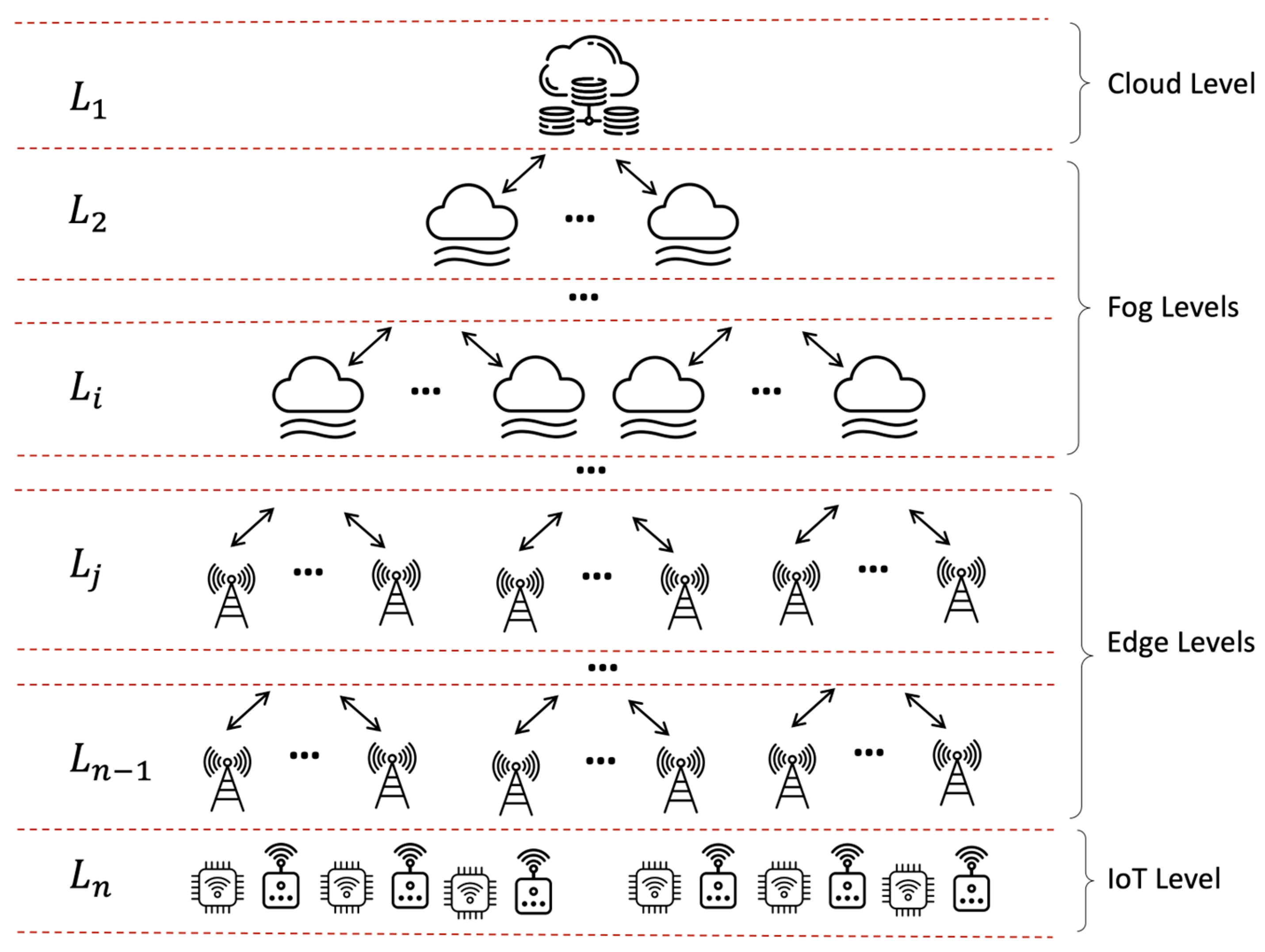
3.2. Multi-Tier Systems
- Smart City. A metropolitan area can have multiple tiers of fog infrastructure. A neighborhood fog layer of gateways and micro data centers connects into a wider city-level fog system for broader connectivity and storage, managed by a municipal IT department. Both feed into a regional cloud data center.
- Private 5G Network. For a large corporate campus or industrial site, Wi-Fi can provide a lower fog tier for indoor/short-range wireless access. 5G small cells overlay this to cover the extended campus. A central on-premises private 5G core integrates the radio access network with internal IT systems and an optional public cloud service.
- Retail Chain. Point-of-sale devices and inventory sensors in stores form the edge layer. In-store servers and networking comprise the fog layer. Regional distribution centers provide a second tier of fog resources. The central enterprise cloud contains core business systems and analytics.
- Environmental Monitoring. A first tier of simple sensors monitors local conditions like temperature. More advanced gateways aggregate data from clusters of these devices over a wider area. Periodic drone flights act as temporary fog hotspots to backhaul data. The cloud provides centralized data historian capabilities.
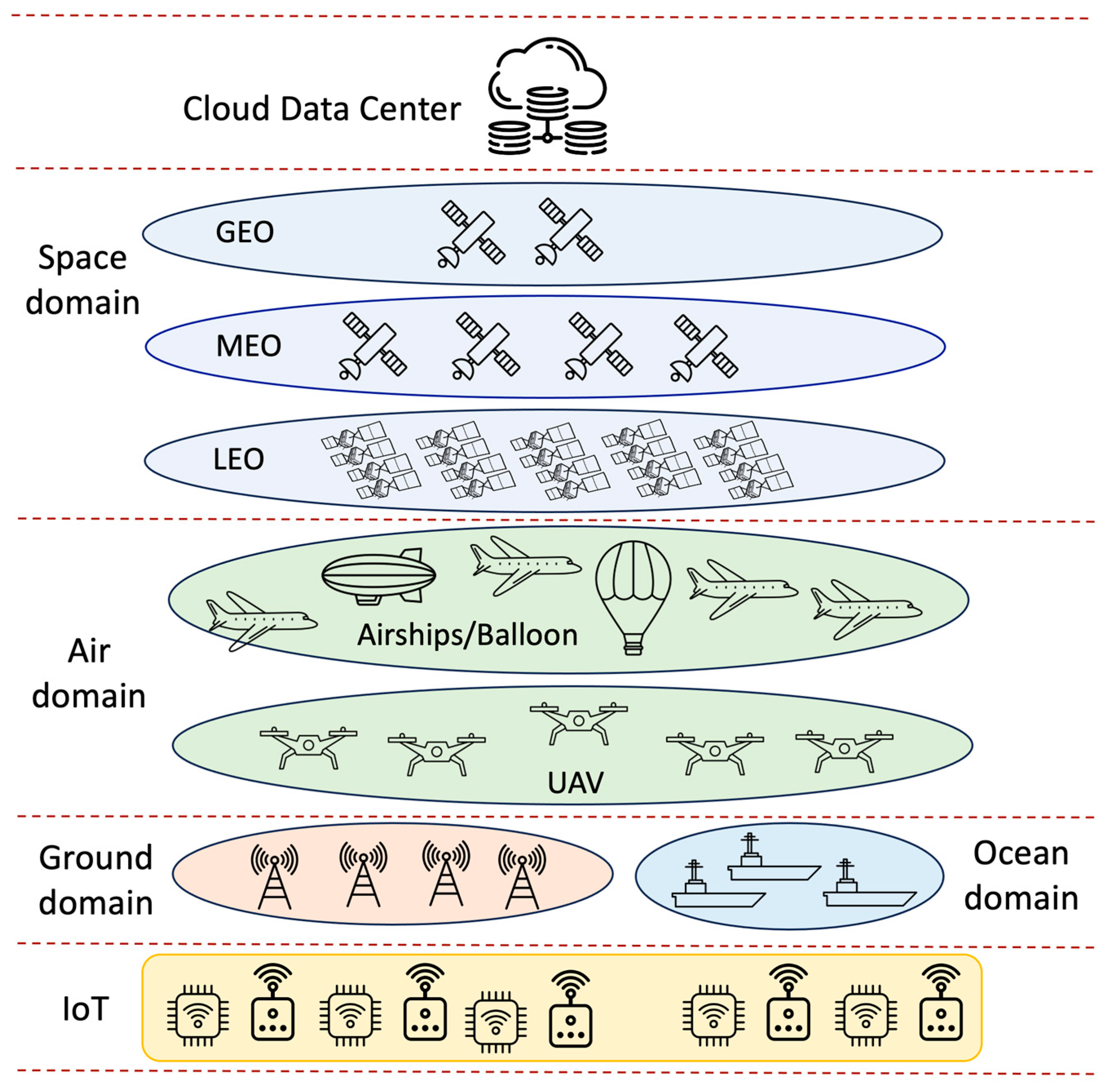
- Cloud Level. The cloud represents the most abstract and vast digital storage and computational capacities. In the context of SAGIN, it includes:
- Space. Ground-based control centers for space objects can interface with cloud platforms to handle vast amounts of data from satellites, ensuring global coverage and communication with remote satellites.
- Air. Major control centers for managing large-scale aerial operations, such as fleets of drones or aircraft, rely on cloud infrastructure for coordination and data analysis.
- Ground and Ocean. Large data centers, tasked with handling terrestrial and marine data, connect directly to the cloud.
- Fog Level. Fog computing acts as an intermediate processing layer, residing closer to data sources:
- Space. Nearby satellite clusters can communicate and process data in a local fog network before sending data down to Earth or to another satellite cluster.
- Air. Aircraft and high-altitude drones can have onboard fog computing systems to process data in real time before sending essential data to the ground or the cloud.
- Ground. Infrastructure like cellular towers or regional data hubs. For the marine context, surface vessels or buoy systems can have fog systems to handle localized oceanic data.
- Edge Level. This level is closer to the data source and often responsible for more immediate, time-sensitive computations:
- Space. Satellites, especially those in low Earth orbits, are edge devices gathering and sometimes processing data before sending data to the ground or across the satellite network.
- Air. Individual drones or low-altitude aircraft can act as edge devices, making real-time decisions based on immediate data, like adjusting flight paths for obstacles.
- Ground. Roadside units (RSUs) in intelligent transportation systems, regional communication hubs, and even individual buildings in smart cities operate at the edge level.
- Ocean. Submarines or deep-sea drones equipped with sensors and communication tools act as edge devices, processing underwater data in real time.
- IoT Level. This is the level at which data are primarily gathered.
- Space. There is not a direct IoT equivalent in space in the traditional sense. However, individual sensors on satellites that pick up specific types of data can be seen as IoT devices.
- Air. Sensors on drones or aircraft, which gather data like atmospheric conditions, camera feeds, etc., are the IoT devices of the air segment.
- Ground. In a smart city, for example, traffic cameras, environmental sensors, or even devices in our homes are all IoT devices. In intelligent transportation systems, vehicular onboard units (OBU) operate at this level.
- Ocean. Primary sensors placed on the ocean floor, those attached to marine animals for tracking, or sensors on floating buoys fall under the IoT level.
- These systems can dynamically adapt to different scenarios, allowing for customized deployments based on specific geographic or operational requirements.
- Additional tiers can lead to reduced data travel distances and, consequently, lower latency, which is crucial for applications demanding near instantaneous responses.
- By adding or removing tiers based on demand, multi-tier systems can be seamlessly scaled up or down, accommodating fluctuating data volumes and processing needs.
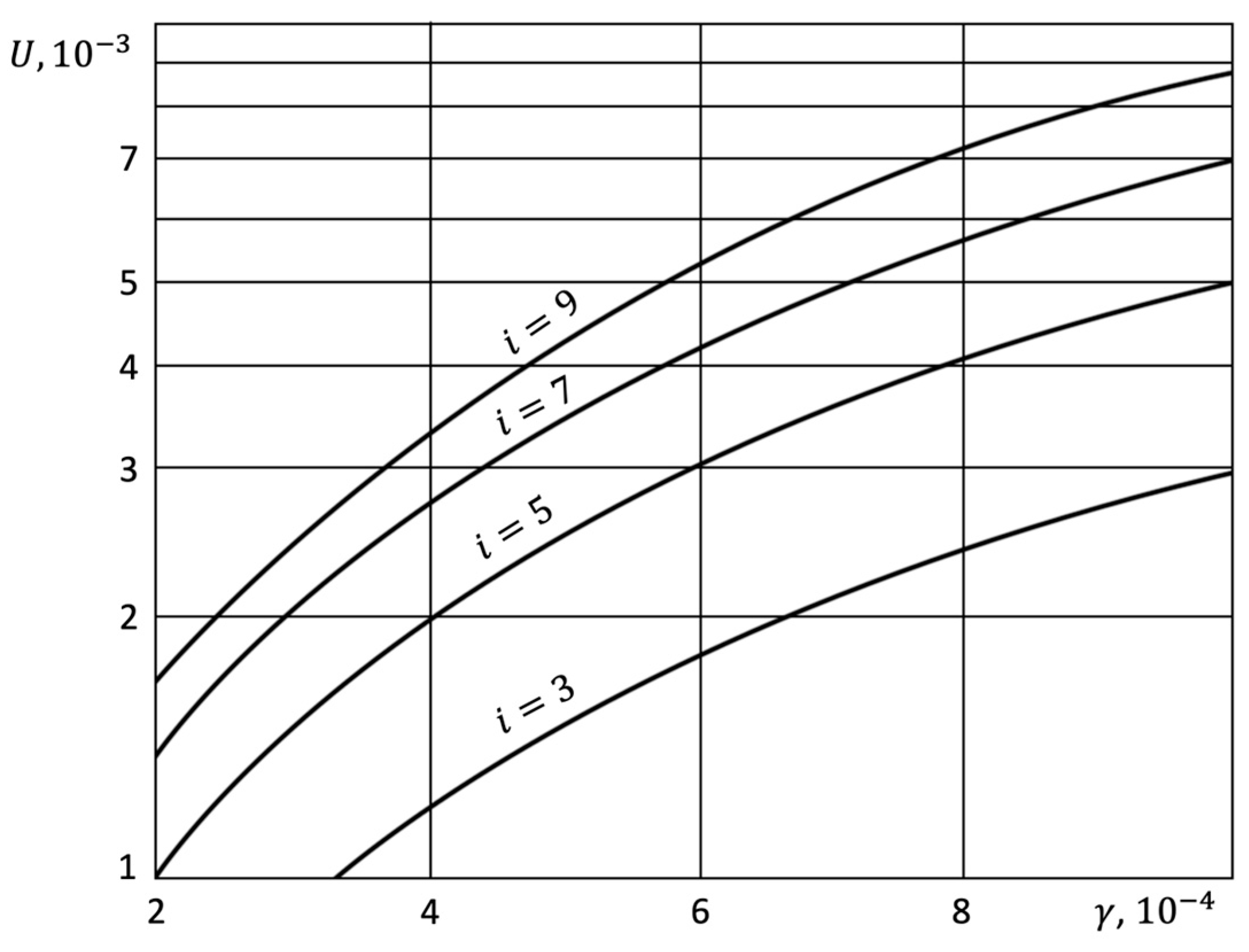
4. Results
- Latency refers to the time it takes for a packet of data to move from the source to the destination. In geographically distributed networks, this is influenced by the number of tiers the data have to traverse and the nature of those tiers (terrestrial, aerial, or orbital).
- Throughput is the amount of data that can be transferred within a given time frame. It is influenced by the bandwidth and capacity of each tier.
- Availability is the likelihood that the system or service is operational and accessible when needed. It is directly correlated with the system’s reliability.
- Error rate is the frequency at which errors occur during data transmission or processing. In multi-level systems, errors can arise from factors like signal interference, hardware malfunctions, or software glitches.
- As the number of connected devices grows, ensuring consistent QoS and reliability can become challenging.
- Effective communication and coordination between tiers are essential, especially in dynamic scenarios.
- External factors like space weather for satellite tiers, physical obstructions for aerial tiers, or terrestrial network congestion can pose challenges.
- refers to the amount of time a system, service, or component is operational and available to perform its intended function. Uptime is essentially the period when a system is functioning without any interruptions.
- represents the duration when a system, service, or component is not operational due to planned maintenance, unplanned outages, or failures. It is the period when the system is not available for its intended purpose.
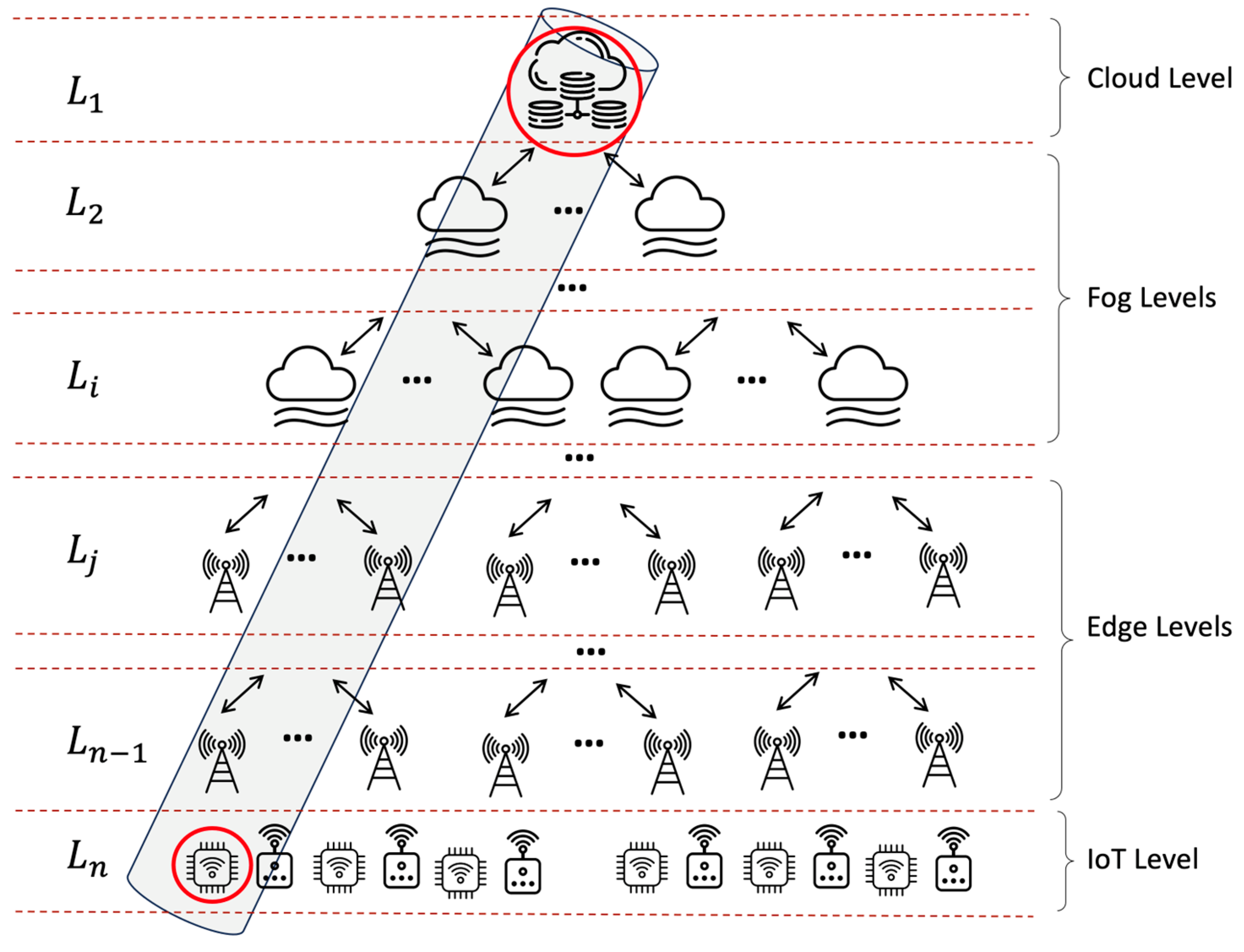
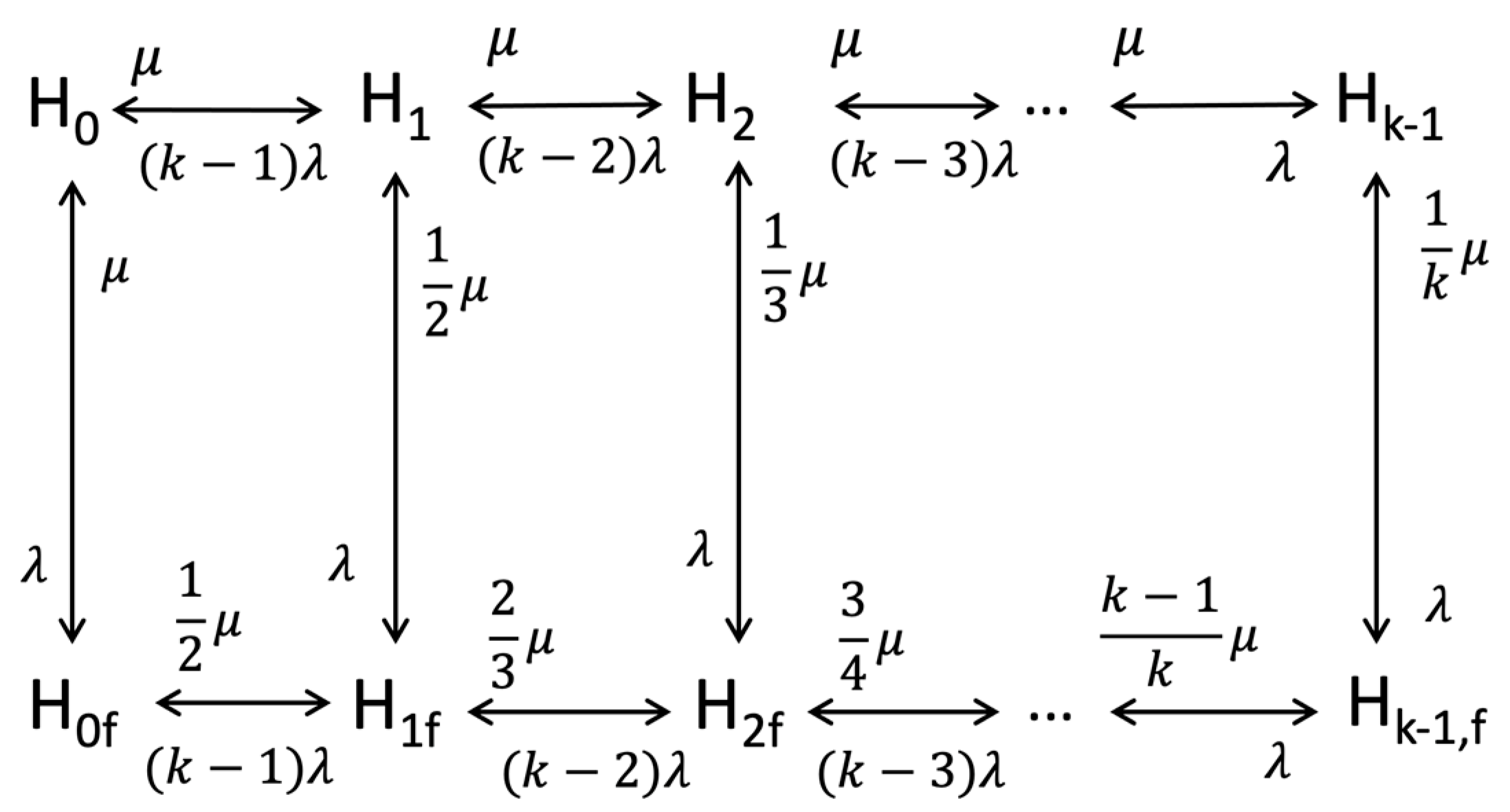
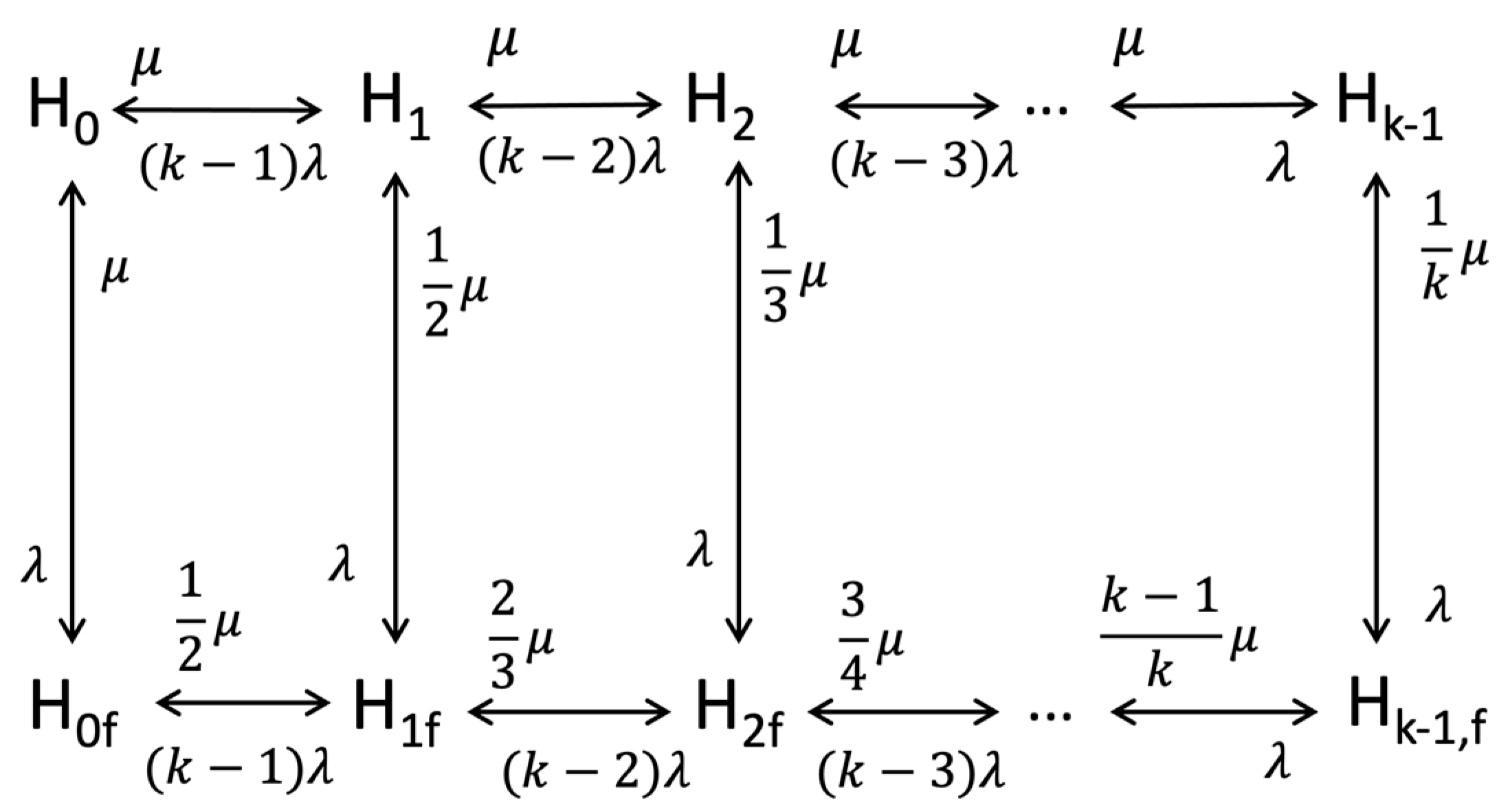
- Assessing the local availability between an endpoint device and its connected node at the lowest tier using a dedicated two-state Markov chain model representing up and down states. This local availability reflects reliability just for the specific endpoint’s channel, disregarding other endpoints.
- Iteratively applying the same Markov model at each higher tier to quantify the availability of nodes providing dedicated service to the tier below. Failures of other nodes at a given tier are assumed to not affect service to the endpoint.
- Taking the product of the local availability values at each tier to derive the overall end-to-end availability for the selected endpoint and service. This combines reliability along the hierarchical service provisioning path.
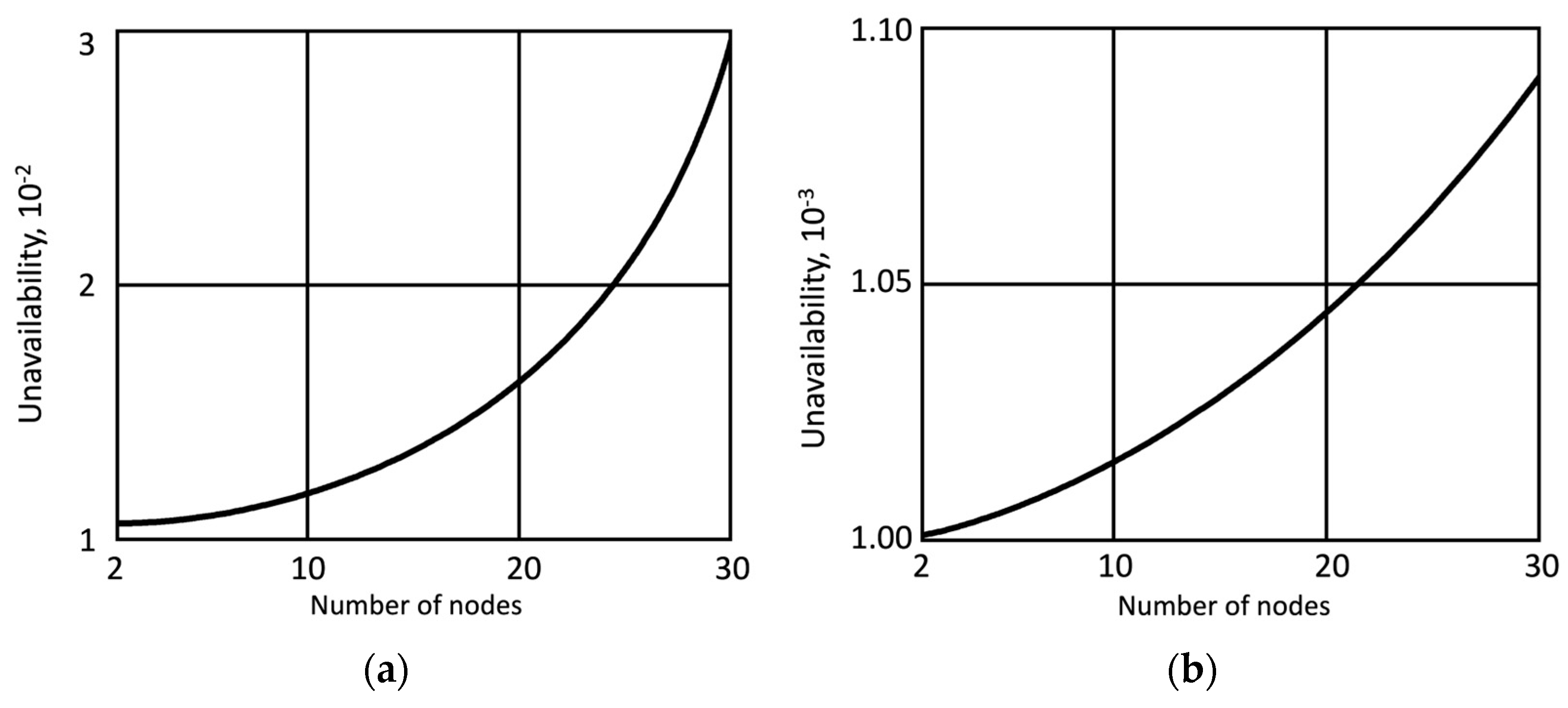
- -
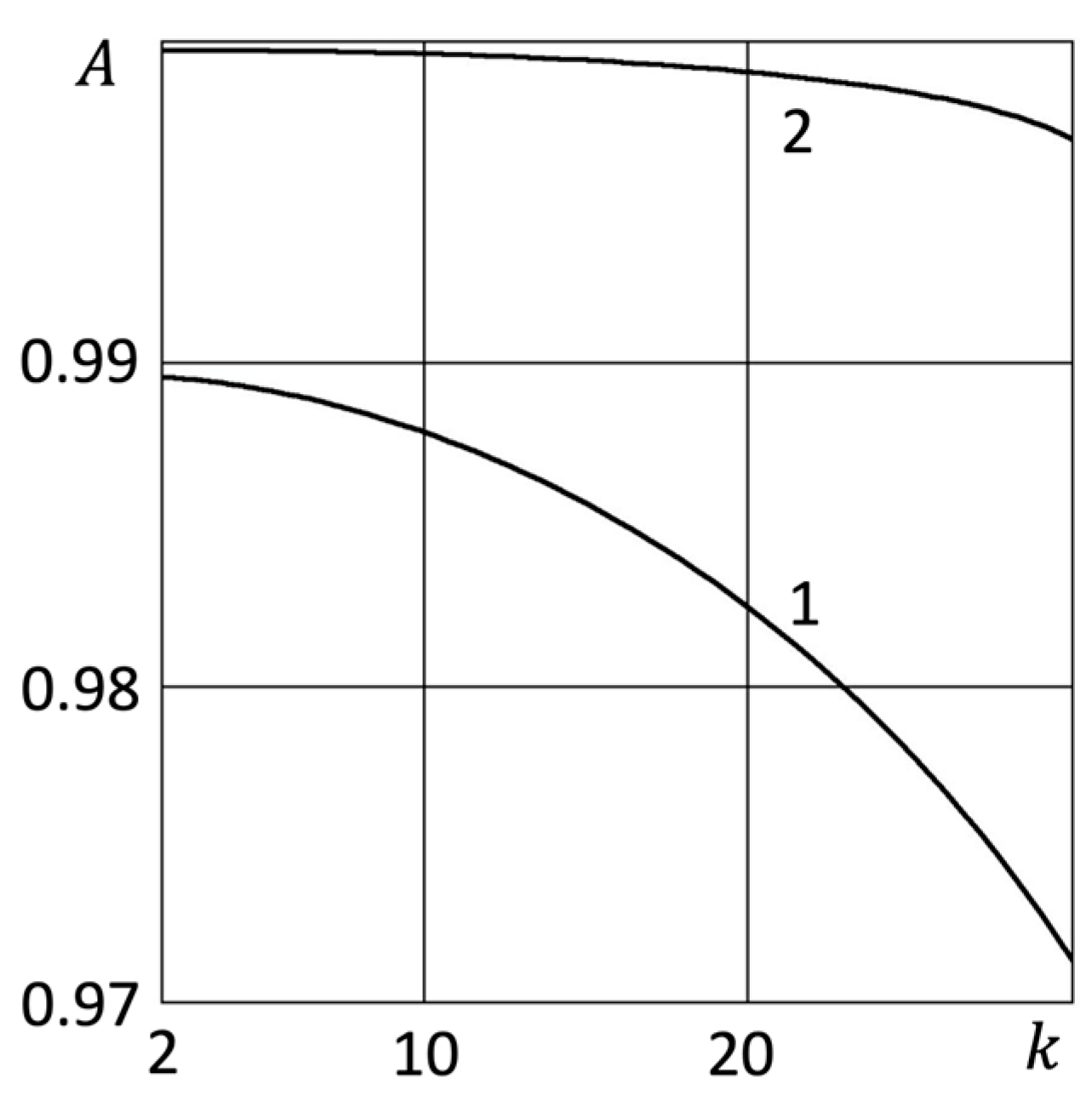
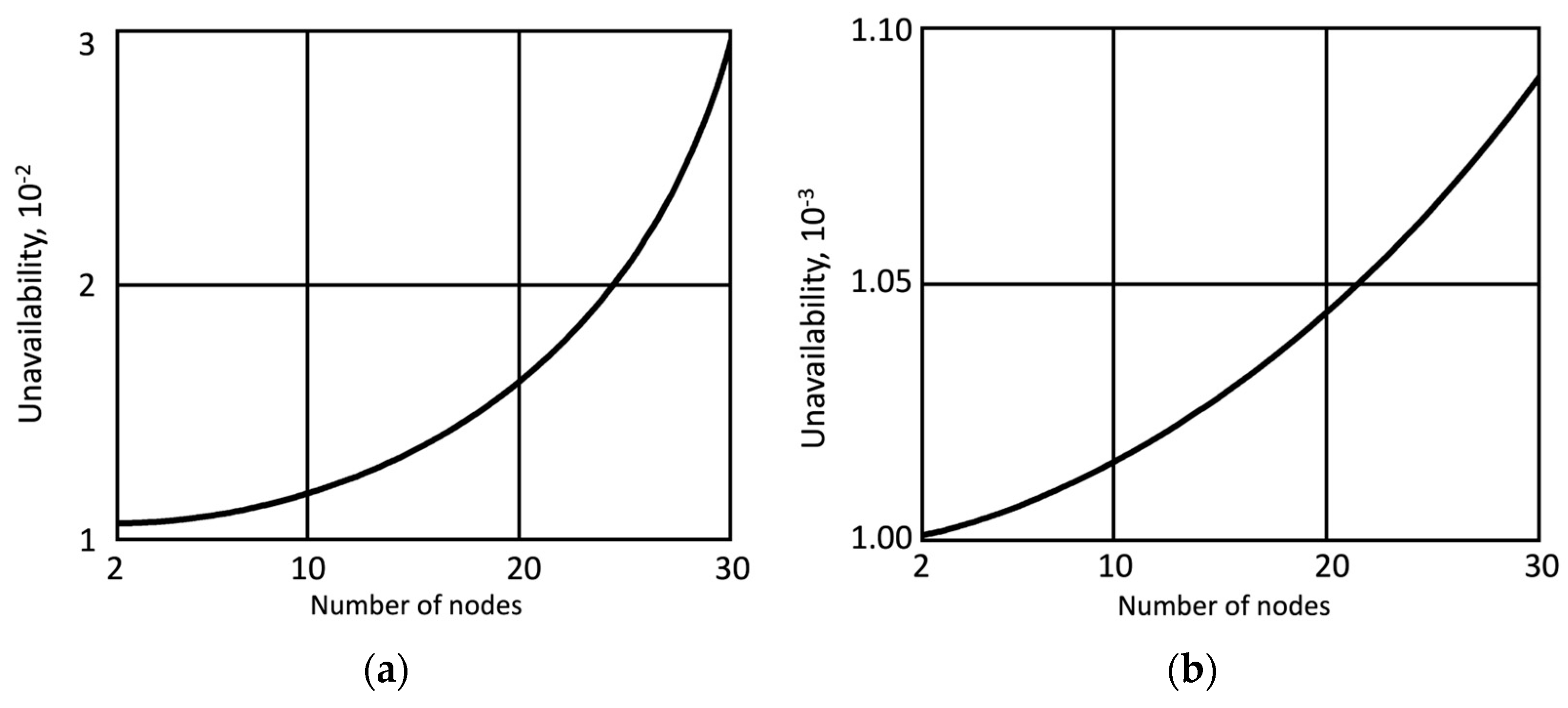
- Tier 1 (IoT): 10 nodes, = 0.01
- -
- Tier 2 (Edge): 15 nodes, = 0.02
- -
- Tier 3 (Fog): 5 nodes, = 0.005
- -
- Tier 4 (Cloud): Availability = 99.95%
5. Discussion
- The Markov chain inherently assumes that the future state depends only on the current state and not on the sequence of states that preceded it. This “memoryless” property might not always be representative of real-world systems, especially if there are underlying patterns or dependencies that span across multiple states.
- As the number of states and transitions increases in the system, the complexity of the Markov chain model can grow exponentially. This state explosion can make the model computationally intensive and challenging to manage and interpret.
- In rapidly evolving systems, transition probabilities might not remain constant over time. If these probabilities change and the model is not correspondingly updated, the predictions and availability calculations could be off the mark.
- While the approach focuses on the availability of individual connections in isolation, real-world systems often have intricate interdependencies. Ignoring these can lead to an over- or underestimations of system availability.
- The accuracy of the Markov chain model is heavily reliant on the accuracy and completeness of the input data. Inaccurate or incomplete data can lead to misleading results.
- Markov chains work with discrete state spaces. If the system has continuous or hybrid states, using a straightforward Markov chain model could be restrictive.
- For vast multi-tier systems with numerous nodes and connections, the model might become unwieldy, especially if each connection is to be analyzed in detail.
- The proposed model might oversimplify some aspects of the system, especially if there are nuances or subtleties that do not fit neatly into the Markov chain framework.
6. Conclusions
- -
- The standard Markov chain assumes time-homogeneous transition probabilities. Extension to semi-Markov or time-dependent Markov models could capture temporal variations in failure and repair processes. This could improve the accuracy in non-stationary environments.
- -
- Individual tier Markov models could be integrated into larger system-level availability models to account for cascading failures between interdependent tiers. Hybrid modeling approaches could also couple Markov chains with complementary simulation, machine learning, or network science techniques.
- -
- As multi-tier systems evolve, the Markov model should be dynamically updated to reflect changes in transition probabilities and topology. Adaptive Markov chains and reinforcement learning methods could enable self-reconfiguring availability models.
- -
- While the methodology is generalizable, adapting the Markov model with reliability data and attributes tailored to specific applications and sectors (e.g., telecom, power grid, healthcare) could improve its fidelity.
- -
- Availability and security are interlinked. Extending the model to account for the impact of threats like cyber attacks on availability could be highly relevant.
Funding
Data Availability Statement
Conflicts of Interest
References
- Saeik, F.; Avgeris, M.; Spatharakis, D.; Santi, N.; Dechouniotis, D.; Violos, J.; Leivadeas, A.; Athanasopoulos, N.; Mitton, N.; Papavassiliou, S. Task offloading in Edge and Cloud Computing: A survey on mathematical, artificial intelligence and control theory solutions. Comput. Netw. 2021, 195, 108177. [Google Scholar] [CrossRef]
- OpenFog Consortium Architecture Working Group. OpenFog Reference Architecture for Fog Computing; OpenFog Consortium: Piscataway, NJ, USA, 2017; Available online: https://site.ieee.org/denver-com/files/2017/06/OpenFog_Reference_Architecture_2_09_17-FINAL-1.pdf (accessed on 30 August 2023).
- Sabella, D.; Hechwartner, R.; Scarrone, E.; Shailendra, S.; Song, J.; Flynn, B.; Ishaq, A.; Velez, L.; Gazda, R.; Jieun, L. Enabling Multi-Access Edge Computing in Internet-of-Things: How to Deploy ETSI MEC and oneM2M; White Paper No. 59; ETSI: Sophia Antipolis, France, 2023; Available online: https://www.etsi.org/images/files/ETSIWhitePapers/ETSI-WP59-Enabling-Multi-access-Edge-Computing-in-iot.pdf (accessed on 30 August 2023).
- Zomaya, A.; Abbas, A.; Khan, S. (Eds.) Fog Computing: Theory and Practice; John Wiley & Sons: Hoboken, NJ, USA, 2020. [Google Scholar]
- Al-Qamash, A.; Soliman, I.; Abulibdeh, R.; Saleh, M. Cloud, Fog, and Edge Computing: A Software Engineering Perspective. In Proceedings of the 2018 International Conference on Computer and Applications (ICCA), Beirut, Lebanon, 25–27 April 2018; pp. 276–284. [Google Scholar] [CrossRef]
- Skarlat, O.; Nardelli, M.; Schulte, S.; Dustdar, S. Towards QoS-Aware Fog Service Placement. In Proceedings of the 2017 IEEE 1st International Conference on Fog and Edge Computing (ICFEC), Madrid, Spain, 14–15 May 2017; pp. 89–96. [Google Scholar] [CrossRef]
- Mahmud, R.; Srirama, S.N.; Ramamohanarao, K.; Buyya, R. Quality of Experience (QoE)-Aware Placement of Applications in Fog Computing Environments. J. Parallel Distrib. Comput. 2019, 132, 190–203. [Google Scholar] [CrossRef]
- Mas, L.; Vilaplana, J.; Mateo, J.; Solsona, F.; Rius, A.; Melià-Seguí, J. A Queuing Theory Model for Fog Computing. J. Supercomput. 2022, 78, 11138–11155. [Google Scholar] [CrossRef]
- Vilaplana, J.; Solsona, F.; Teixidó, I.; Abella, J.; Rius, A. A Queuing Theory Model for Cloud Computing. J. Supercomput. 2014, 69, 492–507. [Google Scholar] [CrossRef]
- Panigrahi, S.K.; Goswami, V.; Apat, H.K.; Mund, G.B.; Das, H.; Barik, R.K. PQ-Mist: Priority Queueing-Assisted Mist–Cloud–Fog System for Geospatial Web Services. Mathematics 2023, 11, 3562. [Google Scholar] [CrossRef]
- Bai, Y.; Zhang, H.; Fu, Y. Reliability Modeling and Analysis of Cloud Service Based on, Complex Network. In Proceedings of the 2016 Prognostics and System Health Management Conference (PHM-Chengdu), Chengdu, China, 19–21 October 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Shahid, M.A.; Alam, M.M.; Su’ud, M.M. Achieving Reliability in Cloud Computing by a Novel Hybrid Approach. Sensors 2023, 23, 1965. [Google Scholar] [CrossRef] [PubMed]
- Alshammari, S.T.; Albeshri, A.; Alsubhi, K. Integrating a High-Reliability Multicriteria Trust Evaluation Model with Task Role-Based Access Control for Cloud Services. Symmetry 2021, 13, 492. [Google Scholar] [CrossRef]
- Chiang, M.-L.; Huang, Y.-F.; Hsieh, H.-C.; Tsai, W.-C. Highly Reliable and Efficient Three-Layer Cloud Dispatching Architecture in the Heterogeneous Cloud Computing Environment. Appl. Sci. 2018, 8, 1385. [Google Scholar] [CrossRef]
- Panicucci, S.; Nikolakis, N.; Cerquitelli, T.; Ventura, F.; Proto, S.; Macii, E.; Makris, S.; Bowden, D.; Becker, P.; O’Mahony, N.; et al. A Cloud-to-Edge Approach to Support Predictive Analytics in Robotics Industry. Electronics 2020, 9, 492. [Google Scholar] [CrossRef]
- Peniak, P.; Bubeníková, E.; Kanáliková, A. Validation of High-Availability Model for Edge Devices and IIoT. Sensors 2023, 23, 4871. [Google Scholar] [CrossRef] [PubMed]
- Behera, S.R.; Panigrahi, N.; Bhoi, S.K.; Sahoo, K.S.; Jhanjhi, N.Z.; Ghoniem, R.M. Time Series-Based Edge Resource Prediction and Parallel Optimal Task Allocation in Mobile Edge Computing Environment. Processes 2023, 11, 1017. [Google Scholar] [CrossRef]
- Abba Ari, A.A.; Djedouboum, A.C.; Gueroui, A.M.; Thiare, O.; Mohamadou, A.; Aliouat, Z. A Three-Tier Architecture of Large-Scale Wireless Sensor Networks for Big Data Collection. Appl. Sci. 2020, 10, 5382. [Google Scholar] [CrossRef]
- Stan, O.P.; Enyedi, S.; Corches, C.; Flonta, S.; Stefan, I.; Gota, D.; Miclea, L. Method to Increase Dependability in a Cloud-Fog-Edge Environment. Sensors 2021, 21, 4714. [Google Scholar] [CrossRef]
- Alsowail, R.A.; Al-Shehari, T. A Multi-Tiered Framework for Insider Threat Prevention. Electronics 2021, 10, 1005. [Google Scholar] [CrossRef]
- Mora-Gimeno, F.J.; Mora-Mora, H.; Marcos-Jorquera, D.; Volckaert, B. A Secure Multi-Tier Mobile Edge Computing Model for Data Processing Offloading Based on Degree of Trust. Sensors 2018, 18, 3211. [Google Scholar] [CrossRef] [PubMed]
- Abdulsalam, Y.S.; Hedabou, M. Security and Privacy in Cloud Computing: Technical Review. Future Internet 2022, 14, 11. [Google Scholar] [CrossRef]
- Ayedh, M.A.T.; Wahab, A.W.A.; Idris, M.Y.I. Systematic Literature Review on Security Access Control Policies and Techniques Based on Privacy Requirements in a BYOD Environment: State of the Art and Future Directions. Appl. Sci. 2023, 13, 8048. [Google Scholar] [CrossRef]
- Aldea, C.L.; Bocu, R.; Solca, R.N. Real-Time Monitoring and Management of Hardware and Software Resources in Heterogeneous Computer Networks through an Integrated System Architecture. Symmetry 2023, 15, 1134. [Google Scholar] [CrossRef]
- González, I.; Calderón, A.J.; Portalo, J.M. Innovative Multi-Layered Architecture for Heterogeneous Automation and Monitoring Systems: Application Case of a Photovoltaic Smart Microgrid. Sustainability 2021, 13, 2234. [Google Scholar] [CrossRef]
- Fraser, I.J.; Müller, M.; Schwarzkopf, J. Transparency for Multi-Tier Sustainable Supply Chain Management: A Case Study of a Multi-tier Transparency Approach for SSCM in the Automotive Industry. Sustainability 2020, 12, 1814. [Google Scholar] [CrossRef]
- Hamdan, S.; Ayyash, M.; Almajali, S. Edge-Computing Architectures for Internet of Things Applications: A Survey. Sensors 2020, 20, 6441. [Google Scholar] [CrossRef]
- Gomes, E.; Costa, F.; De Rolt, C.; Plentz, P.; Dantas, M. A Survey from Real-Time to Near Real-Time Applications in Fog Computing Environments. Telecom 2021, 2, 489–517. [Google Scholar] [CrossRef]
- Huynh, L.N.T.; Pham, Q.-V.; Pham, X.-Q.; Nguyen, T.D.T.; Hossain, M.D.; Huh, E.-N. Efficient Computation Offloading in Multi-Tier Multi-Access Edge Computing Systems: A Particle Swarm Optimization Approach. Appl. Sci. 2020, 10, 203. [Google Scholar] [CrossRef]
- Costa, D.G.; Vasques, F.; Portugal, P.; Aguiar, A. A Distributed Multi-Tier Emergency Alerting System Exploiting Sensors-Based Event Detection to Support Smart City Applications. Sensors 2020, 20, 170. [Google Scholar] [CrossRef] [PubMed]
- Jaiswal, R.; Davidrajuh, R.; Rong, C. Fog Computing for Realizing Smart Neighborhoods in Smart Grids. Computers 2020, 9, 76. [Google Scholar] [CrossRef]
- Alam, M.S.; Kurt, G.K.; Yanikomeroglu, H.; Zhu, P.; Đào, N.D. High Altitude Platform Station Based Super Macro Base Station Constellations. IEEE Commun. Mag. 2021, 59, 103–109. [Google Scholar] [CrossRef]
- Lu, Y.; Wen, W.; Igorevich, K.K.; Ren, P.; Zhang, H.; Duan, Y.; Zhu, H.; Zhang, P. UAV Ad Hoc Network Routing Algorithms in Space–Air–Ground Integrated Networks: Challenges and Directions. Drones 2023, 7, 448. [Google Scholar] [CrossRef]
- Liao, Z.; Chen, C.; Ju, Y.; He, C.; Jiang, J.; Pei, Q. Multi-Controller Deployment in SDN-Enabled 6G Space–Air–Ground Integrated Network. Remote Sens. 2022, 14, 1076. [Google Scholar] [CrossRef]
- Qiu, Y.; Niu, J.; Zhu, X.; Zhu, K.; Yao, Y.; Ren, B.; Ren, T. Mobile Edge Computing in Space-Air-Ground Integrated Networks: Architectures, Key Technologies and Challenges. J. Sens. Actuator Netw. 2022, 11, 57. [Google Scholar] [CrossRef]
- Cui, H.; He, H.; Zhou, J.; Li, Q.; Wang, Q.; Niu, J.; Zhang, Y. Space-Air-Ground Integrated Network (SAGIN) for 6G: Requirements, Architecture and Challenges. China Commun. 2022, 19, 90–108. [Google Scholar] [CrossRef]
- Xu, Q.; Su, Z.; Li, R. Security and Privacy in Artificial Intelligence-Enabled 6G. IEEE Netw. 2022, 36, 188–196. [Google Scholar] [CrossRef]
- Trivedi, K.; Bobbio, A. Reliability and Availability Engineering: Modeling, Analysis, and Applications; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Rubino, G.; Sericola, B. Markov Chains and Dependability Theory; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Bauer, E.; Adams, R. Reliability and Availability of Cloud Computing; Wiley-IEEE Press: Hoboken, NJ, USA, 2012. [Google Scholar]
- Federal Aviation Administration. Reliability, Maintainability, and Availability (RMA) Handbook; FAA-HDBK-006A; Federal Aviation Administration: Washington, DC, USA, 2008.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Location | Functionality | Communication |
|---|---|---|---|
| Cloud Level | Data centers that can be continents away from the data source. | Houses vast computational resources, data storage, and advanced analytics tools. Ideal for complex operations and long-term data storage. | Primarily communicates with the fog layer, receiving aggregated or processed data, and sending back processed insights or commands. |
| Fog Level | Typically within the local network infrastructure, e.g., in gateways, routers, and local network nodes. | Offers intermediate processing capabilities, often handling tasks like data aggregation, preliminary analytics, and local storage. It can offload some of the immediate processing needs from the edge while filtering and reducing the amount of data sent to the cloud. | Acts as a two-way bridge, communicating with the cloud for more advanced processing or updates and with the edge to receive raw data or to send immediate commands. |
| Edge Level | Typically located close to the data source, possibly within the same premises or even embedded within devices. | Immediate processing of data: because of the proximity to the data source, edge devices can process data almost instantly, making them crucial for time-sensitive applications. Decentralized decision-making: they can make on-the-spot decisions based on the data they collect, without necessarily having to send it to a centralized system. | Primarily communicates with nearby devices or systems. Can send summarized or processed data back to the fog or cloud layers for further processing or storage. Suitable for intermittent connectivity—not always required to be online. |
| IoT Level | Integrated into our daily environment, from our homes and workplaces to public spaces. These are the endpoints of data collection. | Raw data collection: IoT devices primarily function as data collectors, sensing changes in their environment and reporting them. Limited processing: Some IoT devices have the ability to minimally process data, deciding what is worth sending forward in the network hierarchy. | IoT devices usually communicate data to the edge level, which might be a local gateway or processing unit. This communication might be continuous or event-driven (i.e., only when a change is detected). Uses low-power communication protocols like Zigbee, LoRaWAN, or BLE (Bluetooth Low Energy) for short-range transmissions. |
| Layer of Space Domain | Proximity | Characteristics and Functions | Applications |
|---|---|---|---|
| LEO Layer | Closest to the Earth, typically at altitudes between 160 and 2000 km. | Quick data transmission due to low latency, high-resolution Earth imaging. Often involves constellations for continuous global coverage. | Internet service in remote areas, Earth observation, space research, and scientific studies. |
| MEO Layer | Occupying a mid-range altitude, typically between 2000 and 35,786 km. | Acts as a bridge between the closeness of LEO and the wide coverage of GEO, balancing latency and coverage. | Primarily home to global navigation satellite systems (GNSS) like GPS, GLONASS, and Galileo. Also utilized for certain communication purposes, especially in areas lacking infrastructure. |
| GEO Layer | Positioned at an altitude of exactly 35,786 km above the equator. | Provides a fixed view of a particular region of the Earth, facilitating continuous coverage of that region. | Ideal for stable communication links, TV broadcasting, weather monitoring, surveillance, and defense systems. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kabashkin, I. End-to-End Service Availability in Heterogeneous Multi-Tier Cloud–Fog–Edge Networks. Future Internet 2023, 15, 329. https://doi.org/10.3390/fi15100329
Kabashkin I. End-to-End Service Availability in Heterogeneous Multi-Tier Cloud–Fog–Edge Networks. Future Internet. 2023; 15(10):329. https://doi.org/10.3390/fi15100329
Chicago/Turabian StyleKabashkin, Igor. 2023. "End-to-End Service Availability in Heterogeneous Multi-Tier Cloud–Fog–Edge Networks" Future Internet 15, no. 10: 329. https://doi.org/10.3390/fi15100329
APA StyleKabashkin, I. (2023). End-to-End Service Availability in Heterogeneous Multi-Tier Cloud–Fog–Edge Networks. Future Internet, 15(10), 329. https://doi.org/10.3390/fi15100329