

An Enhanced Minimax Loss Function Technique in Generative Adversarial Network for Ransomware Behavior Prediction


Abstract
:1. Introduction
- We propose an enhanced GAN’s generator loss function technique called Bi-Gradual Minimax, by incorporating a gradual up-weighting coefficient into the probability estimation calculation, which decreases the distance between the real and artificial distributions.
- We propose an improved GAN-based data augmentation module by incorporating the enhanced loss function in (1) into the GAN network, which generates artificial attack patterns that compensate for pre-encryption data insufficiency.
- We train an early detection model by training an LSTM estimator using the augmented dataset generated in (2), which improved the detection accuracy during the early pre-encryption phase of ransomware attacks.
2. Related Works
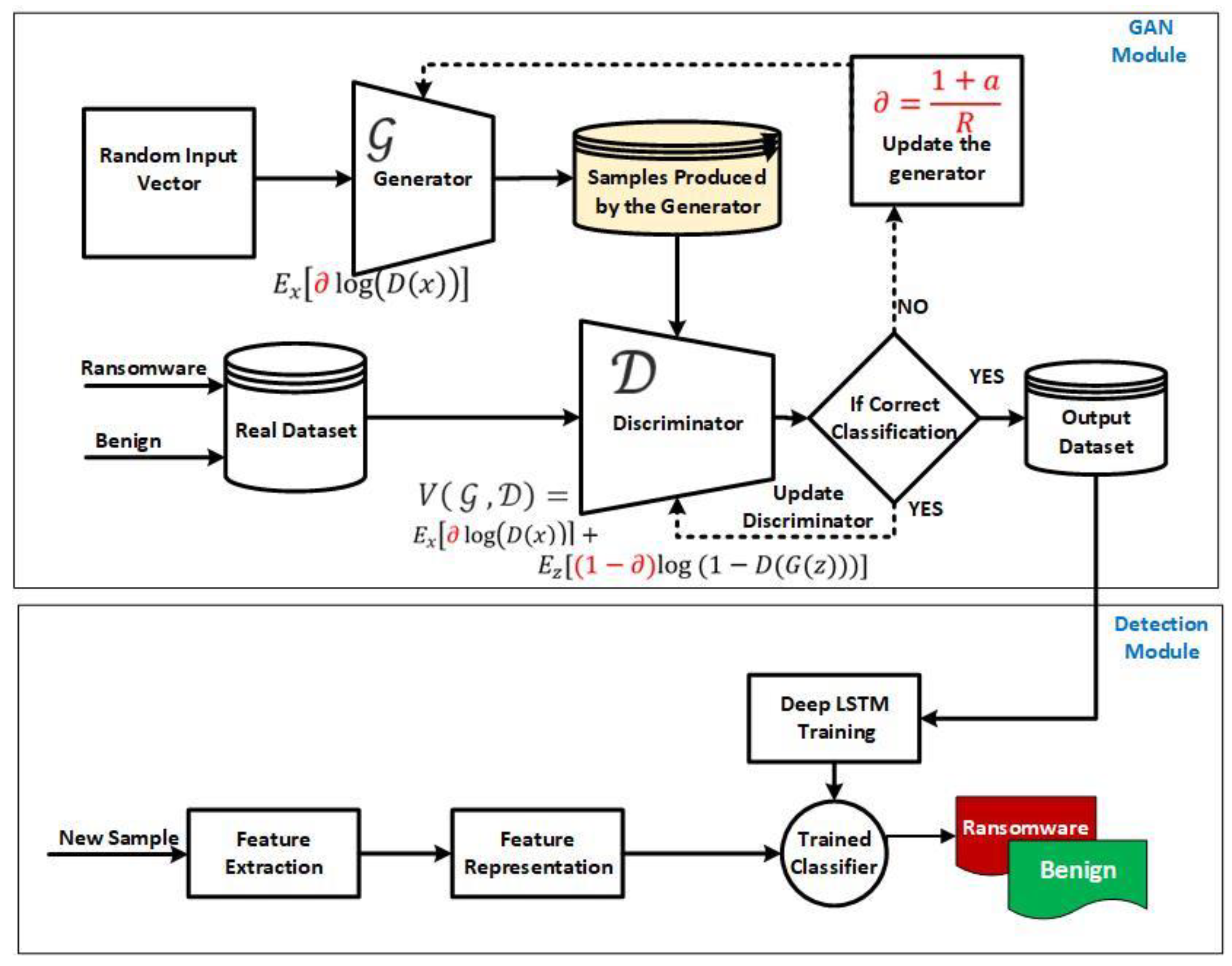
3. The Methodology
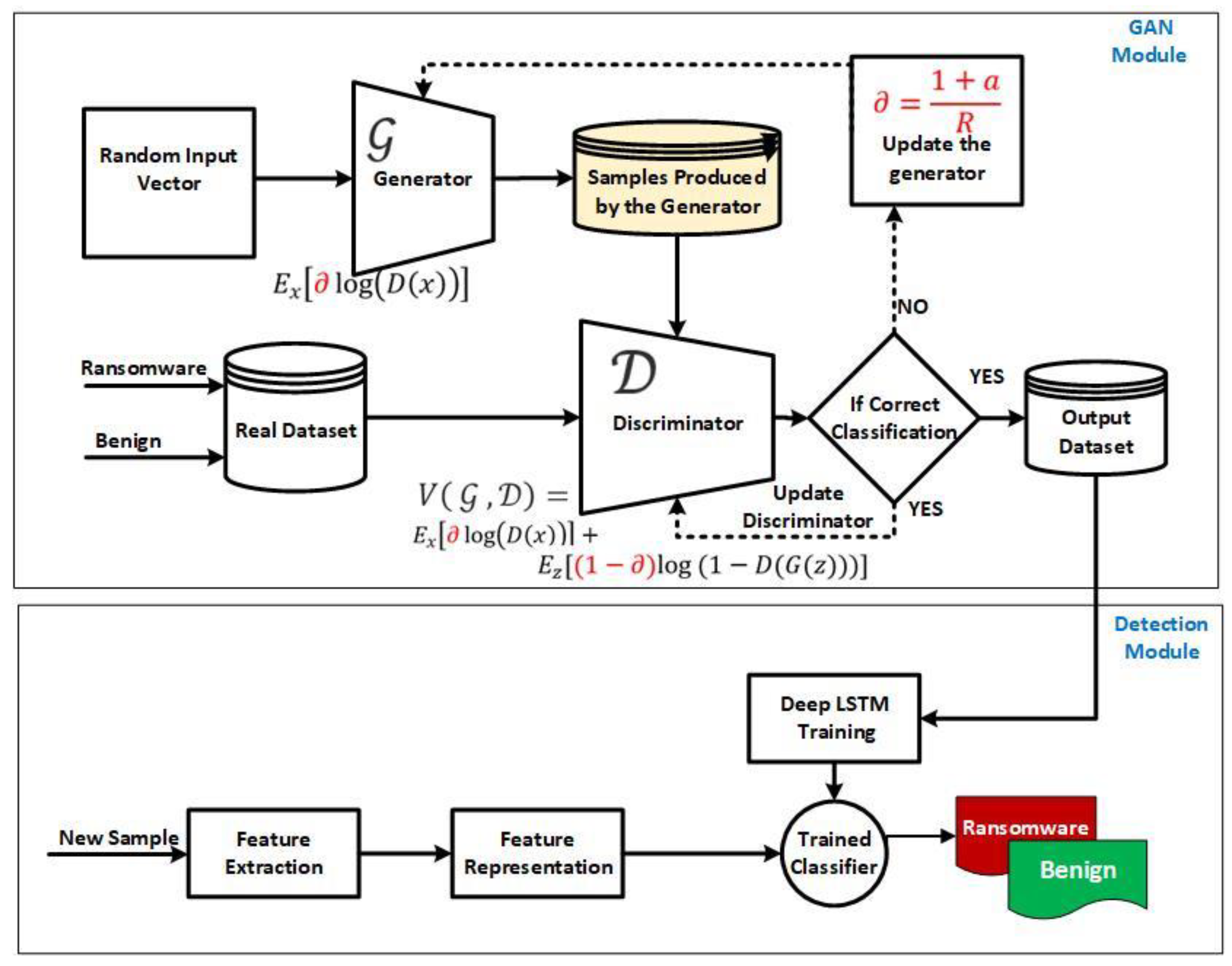
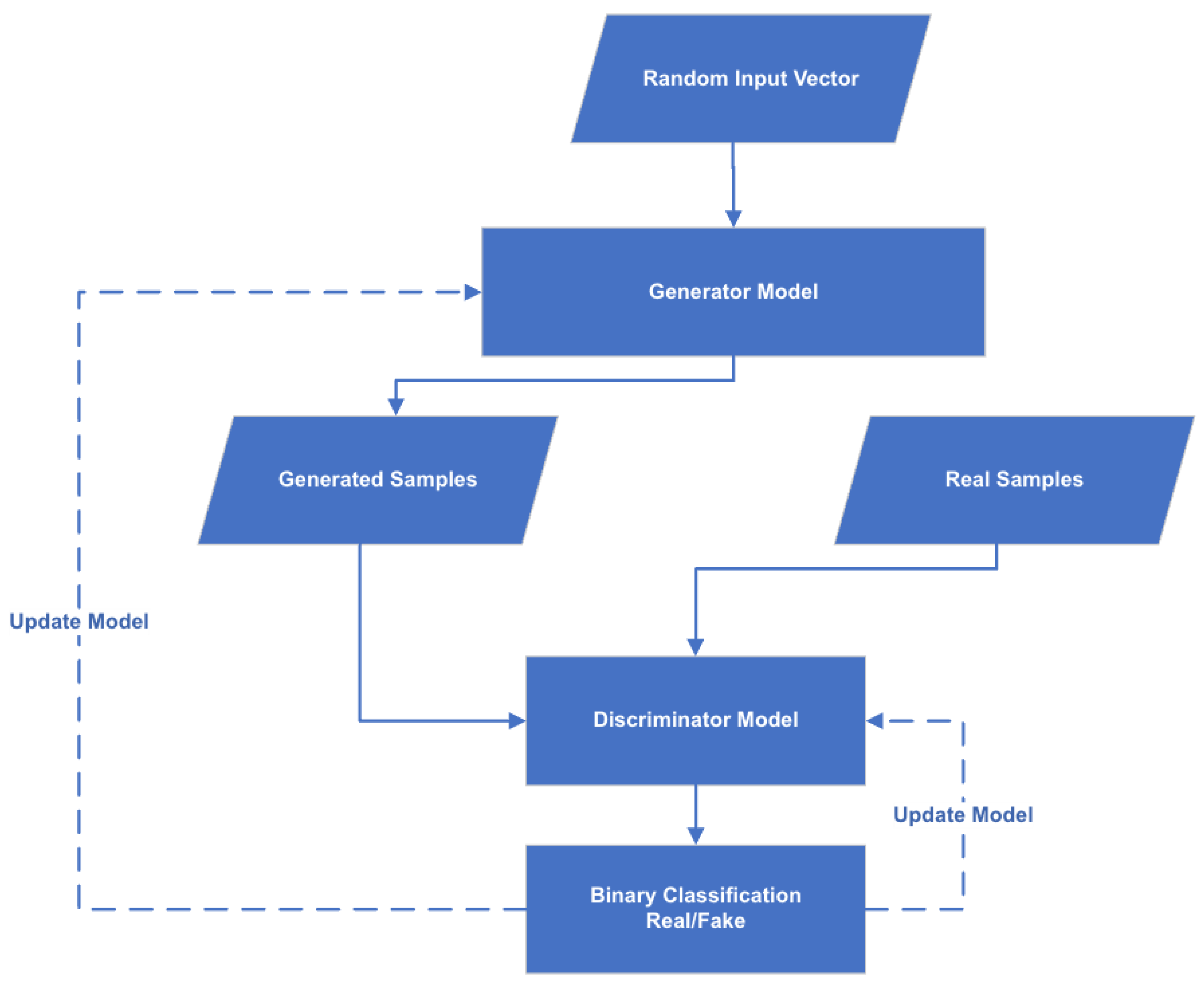
3.1. The Improved Generative Adversarial Network Model for Ransomware Early Detection
3.1.1. Phase 1: The Enhanced Bi-Gradual Minimax Function of the Generative Adversarial Network
The Enhanced Bi-Gradual Minimax Loss Function
3.1.2. Phase 2: The Early Detection Module
4. Results and Discussion
4.1. Experimental Facilities
4.2. Corpus of Crypto-Ransomware Binaries
4.3. Data Engineering
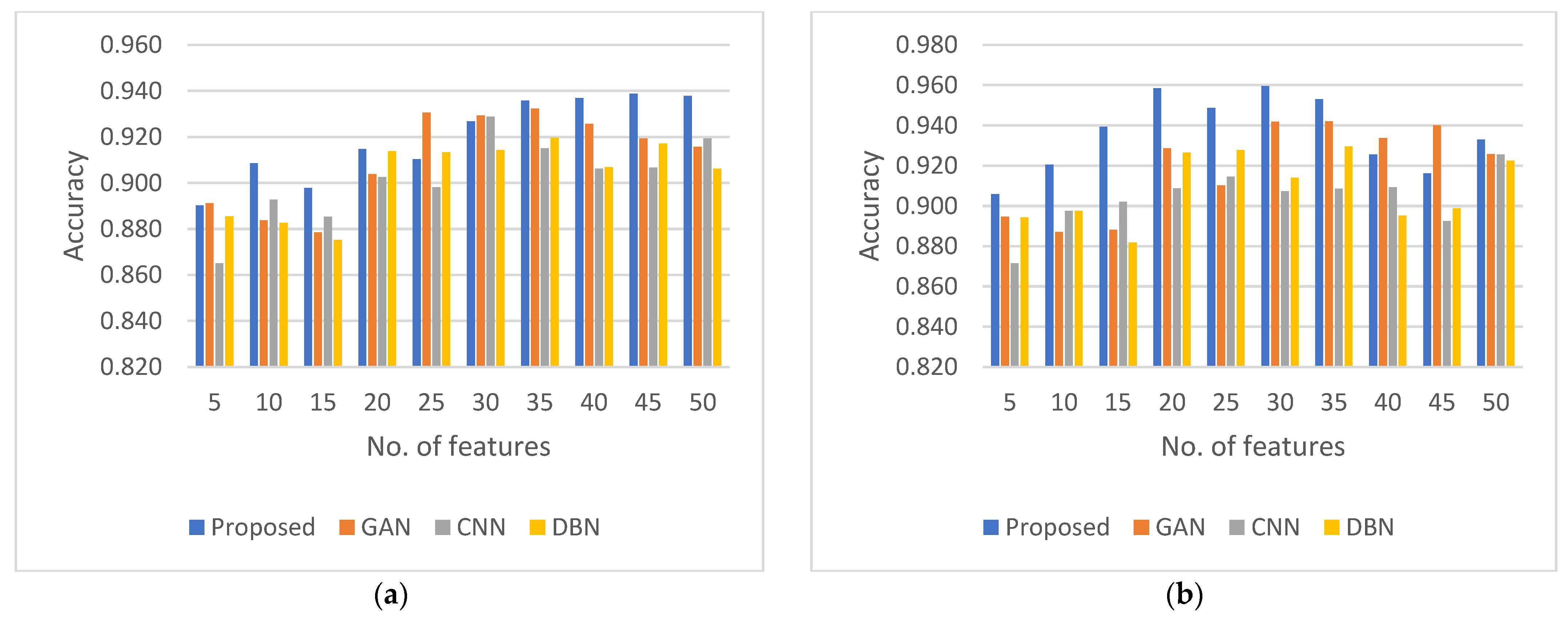
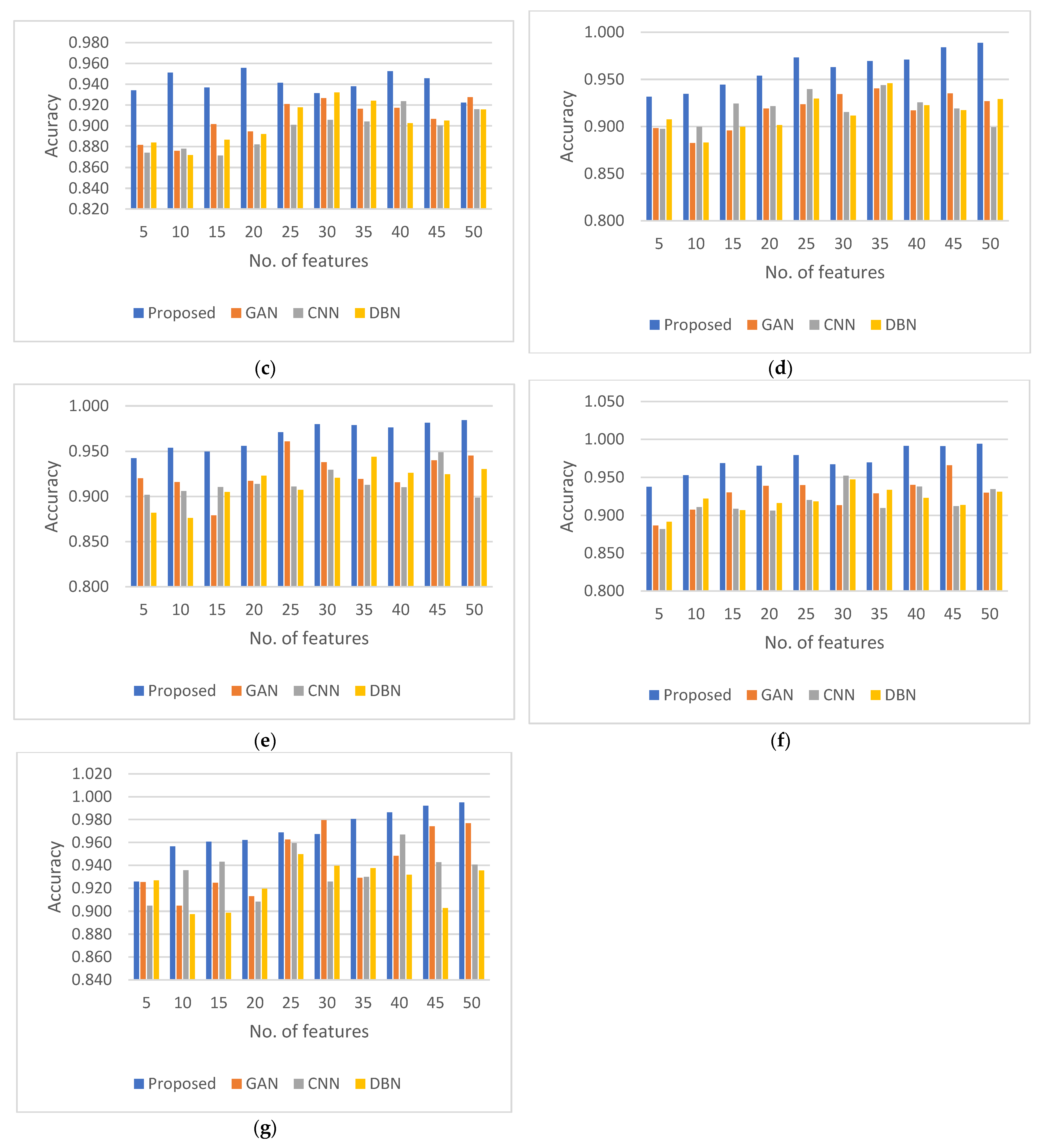
4.4. Feature Selection
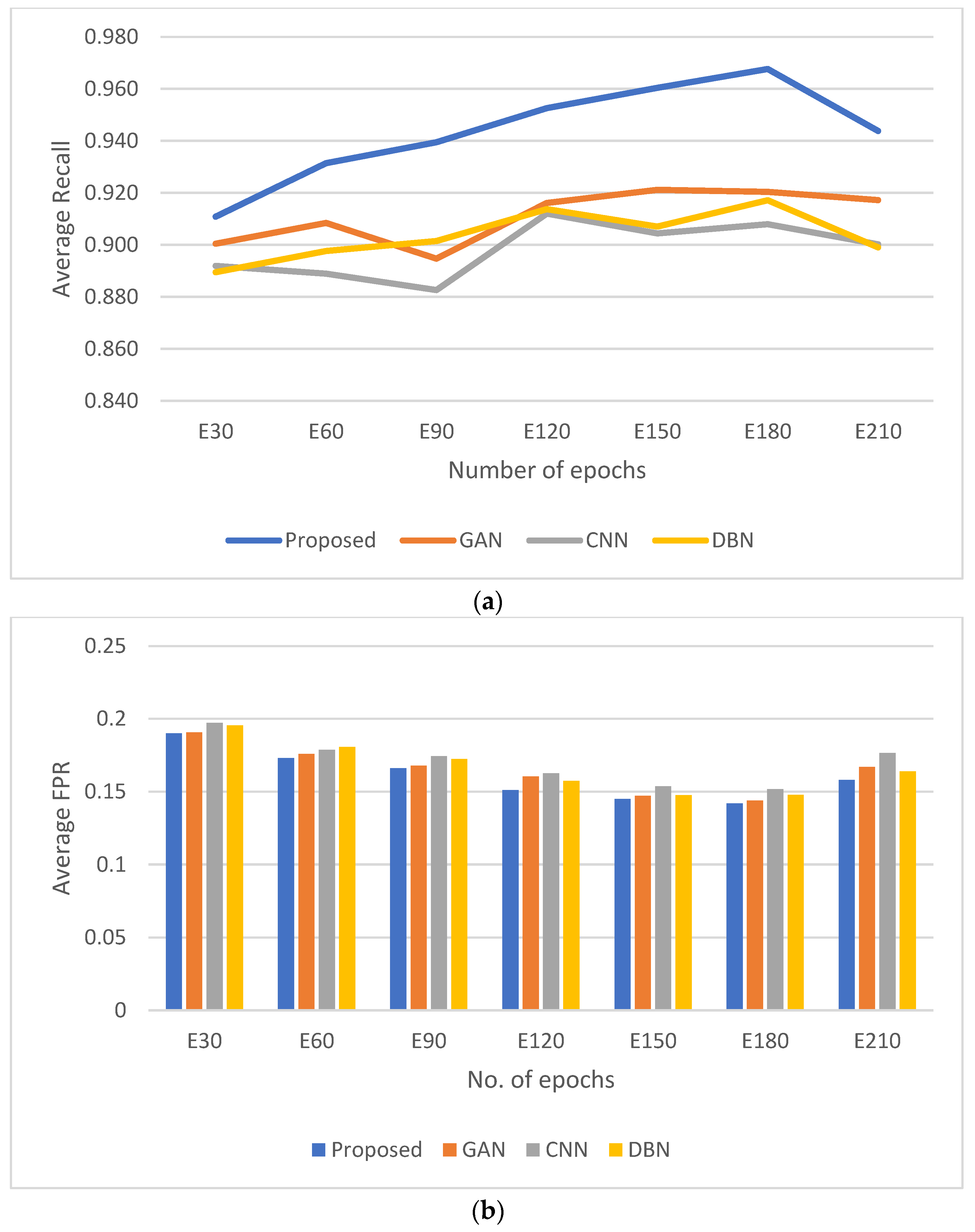
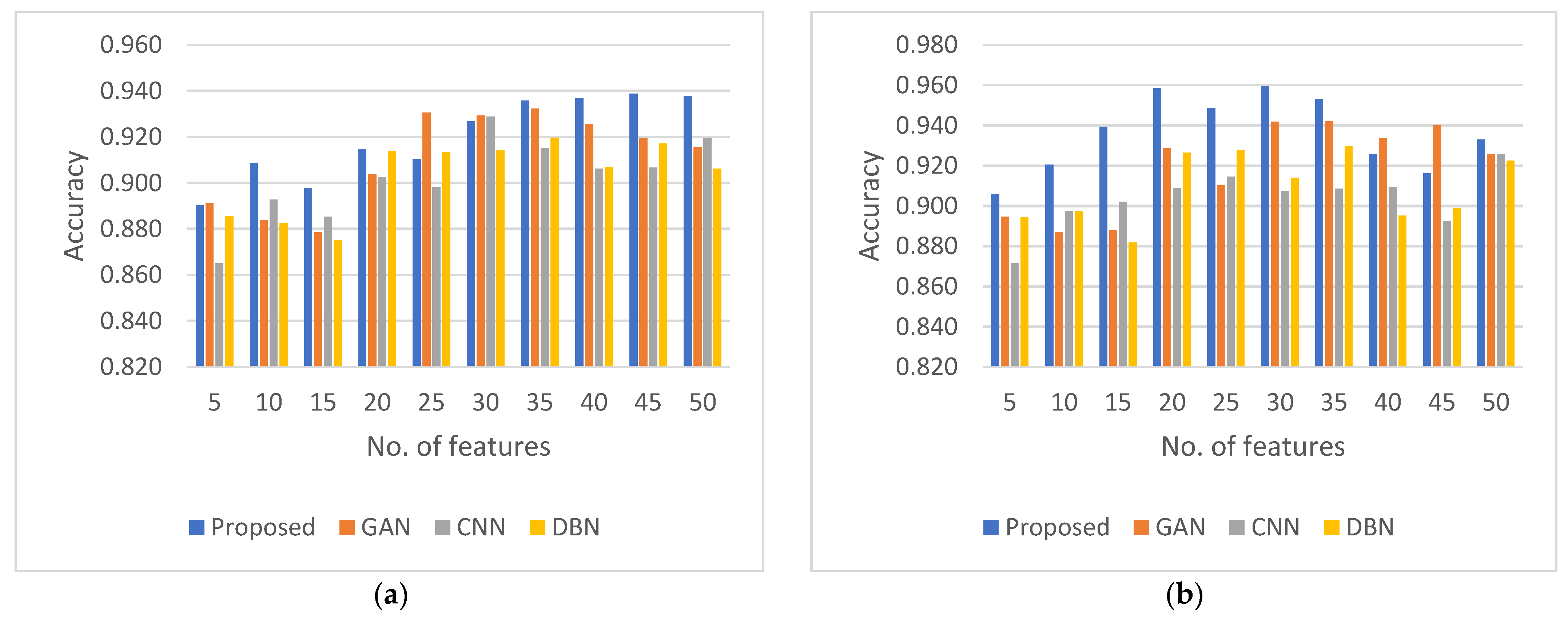
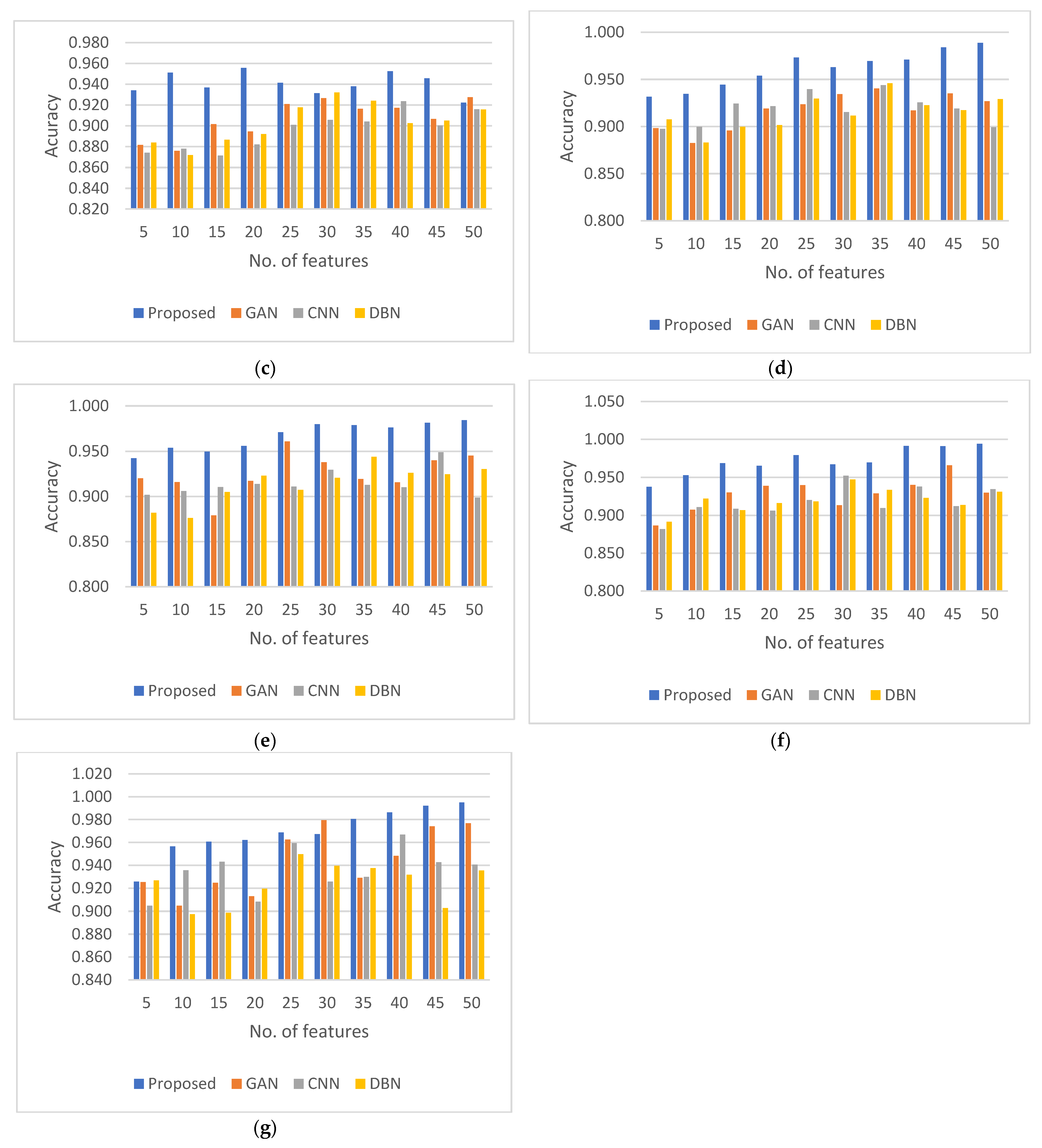
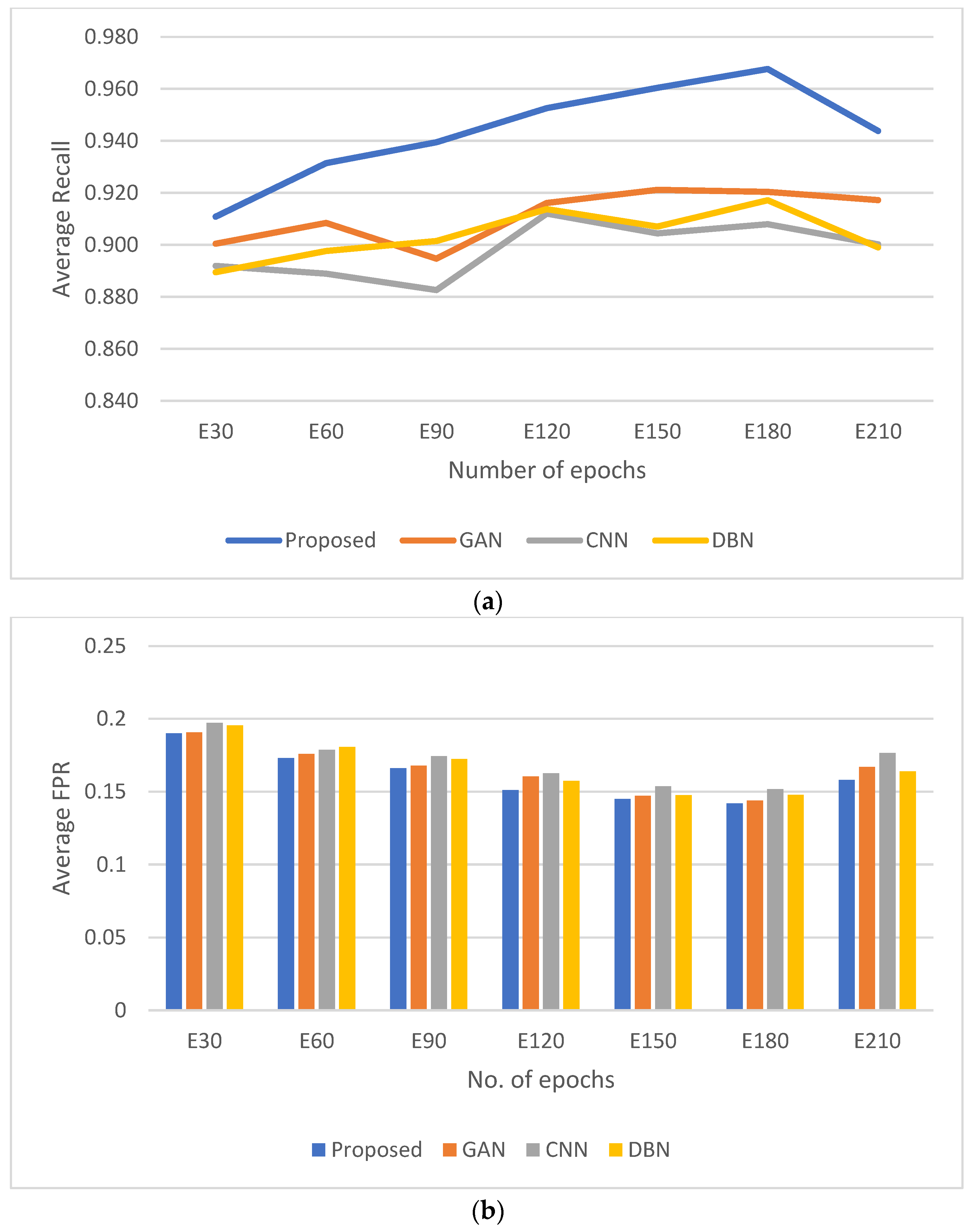
4.5. Compilation and Comparison of Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Urooj, U.; Maarof, M.A.B.; Al-rimy, B.A.S. A proposed adaptive pre-encryption crypto-ransomware early detection model. In Proceedings of the 2021 3rd International Cyber Resilience Conference (CRC), Langkawi Island, Malaysia, 29–31 January 2021. [Google Scholar]
- Ahmed, Y.A.; Huda, S.; Al-Rimy, B.A.S.; Alharbi, N.; Saeed, F.; Ghaleb, F.A.; Ali, I.M. A weighted minimum redundancy maximum relevance technique for ransomware early detection in industrial IoT. Sustainability 2022, 14, 1231. [Google Scholar] [CrossRef]
- Assaggaf, A.M.A.; Al-Rimy, B.A.; Ismail, N.L.; Al-Nahari, A. Development of Graph-Based Knowledge on Ransomware Attacks Using Twitter Data. In Proceedings of the International Conference on Data Science and Emerging Technologies, Virtual, 20–21 December 2022; Springer: Berlin/Heidelberg, Germany. [Google Scholar]
- Olaimat, M.N.; Maarof, M.A.; Al-rimy, B.A.S. Ransomware anti-analysis and evasion techniques: A survey and research directions. In Proceedings of the 2021 3rd International Cyber Resilience Conference (CRC), Langkawi Island, Malaysia, 29–31 January 2021. [Google Scholar]
- Ahmed, Y.A.; Koçer, B.; Huda, S.; Al-Rimy, B.A.S.; Hassan, M.M. A system call refinement-based enhanced Minimum Redundancy Maximum Relevance method for ransomware early detection. J. Netw. Comput. Appl. 2020, 167, 102753. [Google Scholar] [CrossRef]
- Al-rimy, B.A.S.; Maarof, M.A.; Shaid, S.Z.M. Crypto-ransomware early detection model using novel incremental bagging with enhanced semi-random subspace selection. Future Gener. Comput. Syst. 2019, 101, 476–491. [Google Scholar] [CrossRef]
- Al-Rimy, B.A.S.; Maarof, M.A.; Alazab, M.; Alsolami, F.; Shaid SZ, M.; Ghaleb, F.A.; Al-Hadhrami, T.; Ali, A.M. A pseudo feedback-based annotated TF-IDF technique for dynamic crypto-ransomware pre-encryption boundary delineation and features extraction. IEEE Access 2020, 8, 140586–140598. [Google Scholar] [CrossRef]
- Al-rimy, B.A.S.; Maarof, M.A.; Prasetyo, Y.A.; Shaid SZ, M.; Ariffin AF, M. Zero-day aware decision fusion-based model for crypto-ransomware early detection. Int. J. Integr. Eng. 2018, 10. [Google Scholar] [CrossRef]
- Al-rimy, B.A.S.; Maarof, M.A.; Shaid, S.Z.M. A 0-day aware crypto-ransomware early behavioral detection framework. In Recent Trends in Information and Communication Technology: Proceedings of the 2nd International Conference of Reliable Information and Communication Technology (IRICT 2017), Johor Bahru, Malaysia, 23–24 April 2017; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Gazzan, M.; Sheldon, F.T. Opportunities for Early Detection and Prediction of Ransomware Attacks against Industrial Control Systems. Future Internet 2023, 15, 144. [Google Scholar] [CrossRef]
- Gazzan, M.; Alqahtani, A.; Sheldon, F.T. Key Factors Influencing the Rise of Current Ransomware Attacks on Industrial Control Systems. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 27–30 January 2021. [Google Scholar]
- Alqahtani, A.; Sheldon, F.T. A survey of crypto ransomware attack detection methodologies: An evolving outlook. Sensors 2022, 22, 1837. [Google Scholar] [CrossRef]
- Urooj, U.; Al-Rimy, B.A.S.; Zainal, A.; Ghaleb, F.A.; Rassam, M.A. Ransomware Detection Using the Dynamic Analysis and Machine Learning: A Survey and Research Directions. Appl. Sci. 2022, 12, 172. [Google Scholar] [CrossRef]
- Aboaoja, F.A.; Zainal, A.; Ghaleb, F.A.; Al-rimy, B.A.S. Toward an ensemble behavioral-based early evasive malware detection framework. In Proceedings of the 2021 International Conference on Data Science and Its Applications (ICoDSA), Virtual, 10–11 April 2021. [Google Scholar]
- Moti, Z.; Hashemi, S.; Karimipour, H.; Dehghantanha, A.; Jahromi, A.N.; Abdi, L.; Alavi, F. Generative adversarial network to detect unseen internet of things malware. Ad. Hoc. Netw. 2021, 122, 102591. [Google Scholar] [CrossRef]
- Yinka-Banjo, C.; Ugot, O.-A. A review of generative adversarial networks and its application in cybersecurity. Artif. Intell. Rev. 2020, 53, 1721–1736. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, Y.; Pei, S.; Zhuge, J.; Chen, J. Adversarial examples detection for XSS attacks based on generative adversarial networks. IEEE Access 2020, 8, 10989–10996. [Google Scholar] [CrossRef]
- Wang, C.; Xu, C.; Yao, X.; Tao, D. Evolutionary generative adversarial networks. IEEE Trans. Evol. Comput. 2019, 23, 921–934. [Google Scholar] [CrossRef]
- Li, H.; Zhou, S.; Yuan, W.; Li, J.; Leung, H. Adversarial-example attacks toward android malware detection system. IEEE Syst. J. 2019, 14, 653–656. [Google Scholar] [CrossRef]
- Lu, Y.; Li, J. Generative adversarial network for improving deep learning based malware classification. In Proceedings of the 2019 Winter Simulation Conference (WSC), National Harbor, MD, USA, 8–11 December 2019. [Google Scholar]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Mastropietro, O.; Lamb, A.; Arjovsky, M.; Courville, A. Adversarially learned inference. arXiv 2016, arXiv:1606.00704. [Google Scholar]
- Uehara, M.; Sato, I.; Suzuki, M.; Nakayama, K.; Matsuo, Y. Generative adversarial nets from a density ratio estimation perspective. arXiv 2016, arXiv:1610.02920. [Google Scholar]
- Haloui, I.; Gupta, J.S.; Feuillard, V. Anomaly detection with Wasserstein GAN. arXiv 2018, arXiv:1812.02463. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Barua, S.; Erfani, S.M.; Bailey, J. FCC-GAN: A fully connected and convolutional net architecture for GANs. arXiv 2019, arXiv:1905.02417. [Google Scholar]
- Li, M.; Lin, J.; Meng, C.; Ermon, S.; Han, S.; Zhu, J.Y. Efficient spatially sparse inference for conditional gans and diffusion models. Adv. Neural Inf. Process. Syst. 2022, 35, 28858–28873. [Google Scholar] [CrossRef]
- Torfi, A.; Fox, E.A.; Reddy, C.K. Differentially private synthetic medical data generation using convolutional GANs. Inf. Sci. 2022, 586, 485–500. [Google Scholar] [CrossRef]
- Hoang, T.-N.; Kim, D. Detecting in-vehicle intrusion via semi-supervised learning-based convolutional adversarial autoencoders. Veh. Commun. 2022, 38, 100520. [Google Scholar] [CrossRef]
- Le Guernic, C.; Legay, A. Ransomware and the Legacy Crypto API. In Proceedings of the Risks and Security of Internet and Systems: 11th International Conference (CRiSIS 2016), Roscoff, France, 5–7 September 2016; Revised Selected Papers. Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Christensen, J.B.; Beuschau, N. Ransomware Detection and Mitigation Tool. Master’s Thesis, Technical University of Denmark, Kongens Lyngby, Denmark, 2017. [Google Scholar]
- Chen, Z.-G.; Kang, H.S.; Yin, S.N.; Kim, S.R. Automatic Ransomware Detection and Analysis Based on Dynamic API Calls Flow Graph. In Proceedings of the International Conference on Research in Adaptive and Convergent Systems, Krakow, Poland, 20–23 September 2017; ACM: Krakow, Poland, 2017; pp. 196–201. [Google Scholar]
- Sgandurra, D.; Muñoz-González, L.; Mohsen, R.; Lupu, E.C. Automated Dynamic Analysis of Ransomware: Benefits, Limitations and use for Detection. arXiv 2016, arXiv:1609.03020. [Google Scholar]
- Ioanid, A.; Scarlat, C.; Militaru, G. The Effect of Cybercrime on Romanian SMEs in the Context of Wannacry Ransomware Attacks. In Proceedings of the 12th European Conference on Innovation and Entrepreneurship ECIE 2017, Paris, France, 21–22 September 2017. [Google Scholar]
- Pandey, S.K.; Mehtre, B.M. Performance of malware detection tools: A comparison. In Proceedings of the 2014 IEEE International Conference on Advanced Communication, Control and Computing Technologies, ICACCCT 2014, Ramanathapuram, India, 8–10 May 2014; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2015. [Google Scholar]
- Zhang, X.; Wang, J.; Zhu, S. Dual Generative Adversarial Networks Based Unknown Encryption Ransomware Attack Detection. IEEE Access 2022, 10, 900–913. [Google Scholar] [CrossRef]
- Yadav, P.; Menon, N.; Ravi, V.; Vishvanathan, S.; Pham, T.D. EfficientNet convolutional neural networks-based Android malware detection. Comput. Secur. 2022, 115, 102622. [Google Scholar] [CrossRef]
- Su, X.; Shi, W.; Qu, X.; Zheng, Y.; Liu, X. DroidDeep: Using Deep Belief Network to characterize and detect android malware. Soft Comput. 2020, 24, 6017–6030. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Epochs | E30 | E60 | E90 | E120 | E150 | E180 | E210 | |
|---|---|---|---|---|---|---|---|---|
| Features | ||||||||
| 5 | 0.890 | 0.906 | 0.934 | 0.932 | 0.942 | 0.938 | 0.926 | |
| 10 | 0.908 | 0.920 | 0.951 | 0.935 | 0.954 | 0.953 | 0.957 | |
| 15 | 0.898 | 0.939 | 0.937 | 0.944 | 0.950 | 0.969 | 0.961 | |
| 20 | 0.915 | 0.959 | 0.956 | 0.954 | 0.956 | 0.965 | 0.962 | |
| 25 | 0.910 | 0.949 | 0.941 | 0.973 | 0.971 | 0.979 | 0.969 | |
| 30 | 0.927 | 0.960 | 0.931 | 0.963 | 0.980 | 0.967 | 0.967 | |
| 35 | 0.936 | 0.953 | 0.938 | 0.970 | 0.979 | 0.970 | 0.981 | |
| 40 | 0.937 | 0.925 | 0.953 | 0.971 | 0.976 | 0.991 | 0.986 | |
| 45 | 0.939 | 0.916 | 0.946 | 0.984 | 0.981 | 0.991 | 0.992 | |
| 50 | 0.938 | 0.933 | 0.922 | 0.989 | 0.984 | 0.994 | 0.995 | |
| # of Epochs | Total Training Time (Seconds) |
|---|---|
| 30 | 70 s |
| 60 | 132 s |
| 90 | 189 s |
| 120 | 253 s |
| 150 | 307 s |
| 180 | 369 s |
| 210 | 431 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gazzan, M.; Sheldon, F.T. An Enhanced Minimax Loss Function Technique in Generative Adversarial Network for Ransomware Behavior Prediction. Future Internet 2023, 15, 318. https://doi.org/10.3390/fi15100318
Gazzan M, Sheldon FT. An Enhanced Minimax Loss Function Technique in Generative Adversarial Network for Ransomware Behavior Prediction. Future Internet. 2023; 15(10):318. https://doi.org/10.3390/fi15100318
Chicago/Turabian StyleGazzan, Mazen, and Frederick T. Sheldon. 2023. "An Enhanced Minimax Loss Function Technique in Generative Adversarial Network for Ransomware Behavior Prediction" Future Internet 15, no. 10: 318. https://doi.org/10.3390/fi15100318
APA StyleGazzan, M., & Sheldon, F. T. (2023). An Enhanced Minimax Loss Function Technique in Generative Adversarial Network for Ransomware Behavior Prediction. Future Internet, 15(10), 318. https://doi.org/10.3390/fi15100318