
Clinical Screening Prediction in the Portuguese National Health Service: Data Analysis, Machine Learning Models, Explainability and Meta-Evaluation

 ,
,  ,
,  ,
,  ,
,  ,
,
Abstract
1. Introduction
- a characterisation of 3 years SNS24 calls;
- a thorough comparison of different Machine Learning models to select the most appropriate clinical pathway;
- a comprehensive analysis of the results including classification and execution time performance, per class error analysis, explainability of decisions and experts’ meta-evaluation.
2. Related Work
3. Materials and Methods
3.1. Materials
3.1.1. Three-Month Data
3.1.2. Three-Year Data
3.1.3. Features under Analysis
3.2. Methods
3.2.1. Data Characterisation
3.2.2. Pathway Prediction
3.2.3. Experiment Organisation
4. Results
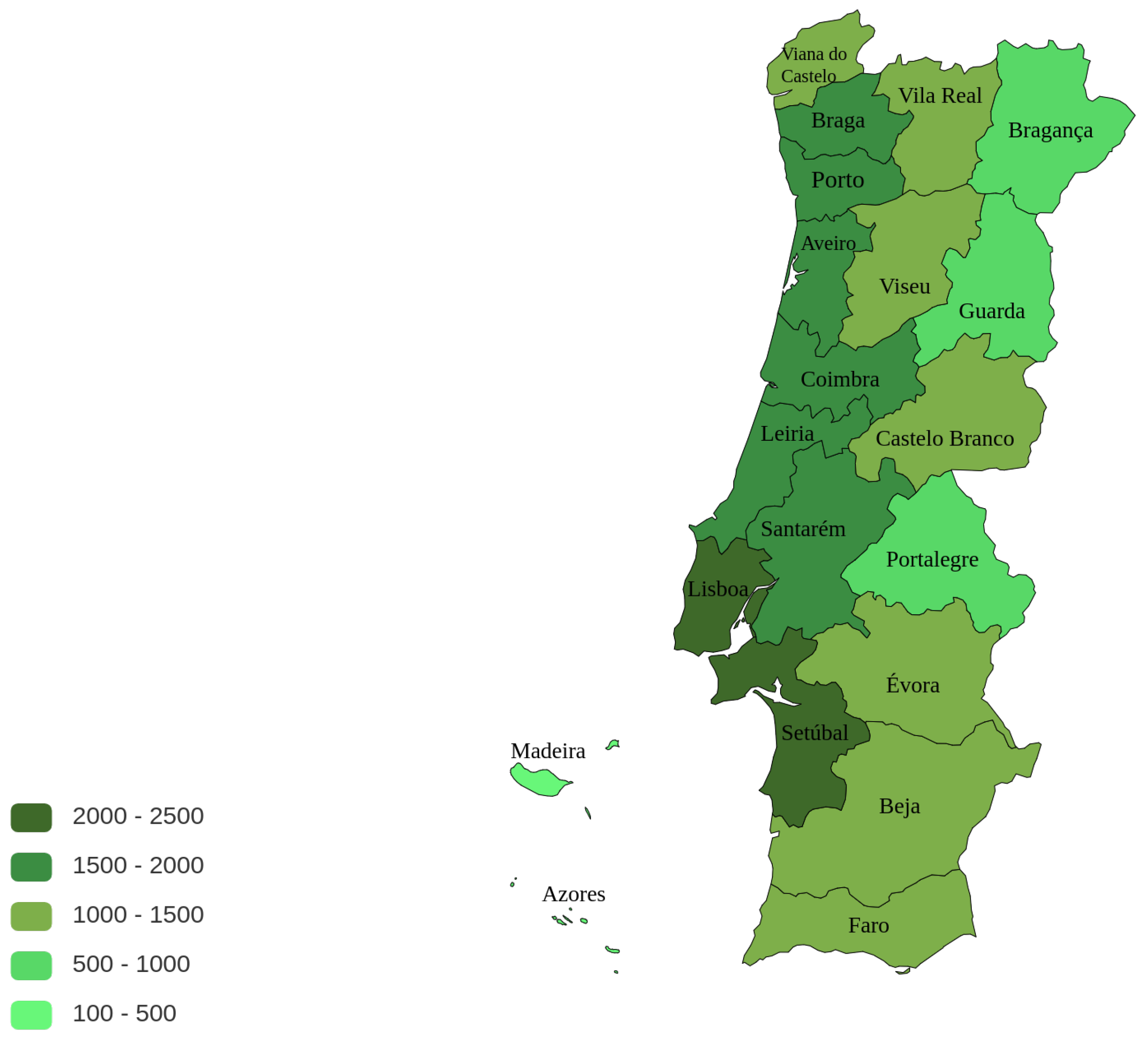
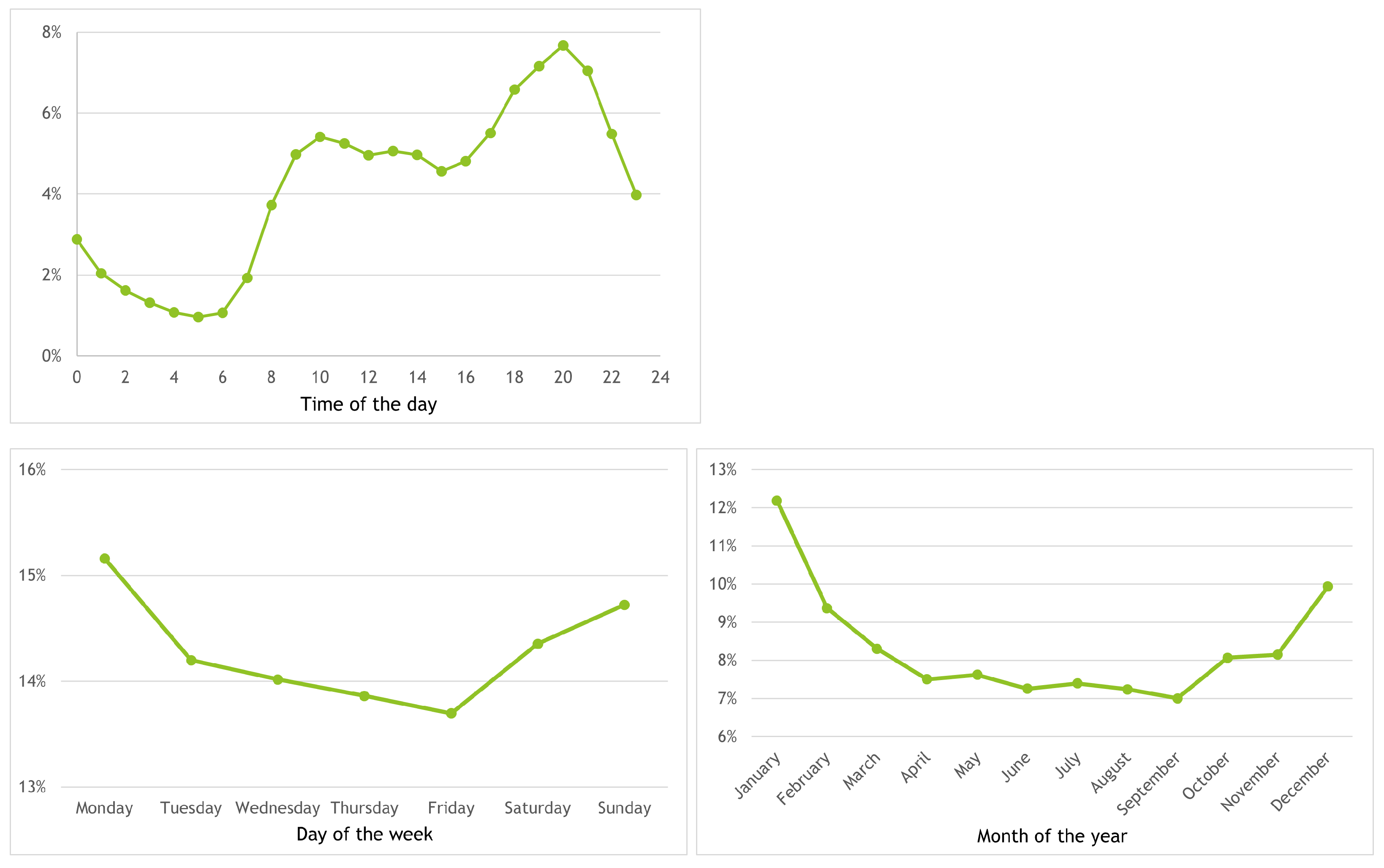
4.1. Data Characterisation: Main Findings
4.2. Evaluation of Prediction Models
5. Error Analysis, Explainability and Meta-Evaluation
5.1. Error Distribution by Class
5.2. Explainability
- derrame ocular à direita há 2 semanas aprox. e prurido ocular desde ontemright eye effusion 2 weeks ago approx. and itchy eyes since yesterday
- Congestão nasal, tosse com expectoração não eficaz e secreções oculares amarelas há 24 horasNasal congestion, coughing ineffective sputum and yellow eye secretions for 24 h

5.3. Meta-Evaluation
- Palpitações, hiperventilação há 1 horaPalpitations, hyperventilation 1 h ago
- refere prurido anal há 1 horareports anal itching 1 h ago
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| AUC | Area Under the Learning Curve |
| BERT | Bidirectional Encoder Representations from Transformers |
| CNN | Convolution Neural Network |
| DGS | Directorate General of Health |
| DL | Deep Learning |
| DNN | Deep Neural Networks |
| HiSAN | Hierarchical Self-Attention Network |
| INEM | National Medical Emergency Institute |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| NN | Neural Network |
| PIC | Poison Information Center |
| SNS | Serviço Nacional de Saúde (Portuguese National Health Service) |
| SNS24 | Portuguese National Health Line |
| SPMS | Serviços Partilhados do Ministério da Saúde |
| SVM | Support-Vector Machines |
Appendix A. Clinical Pathways and Performance of 2017–2018 Models

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 3 Years | 2017 | 2018 | 2019 | |||||
|---|---|---|---|---|---|---|---|---|
| Clinical Pathway | abs. | % | abs. | % | abs. | % | abs. | % |
| Cough | 275,291 | 10.68 | 62,986 | 9.22 | 89,707 | 10.43 | 122,598 | 11.86 |
| Nausea and vomiting problem | 191,716 | 7.44 | 60,116 | 8.80 | 59,289 | 6.89 | 72,311 | 6.99 |
| Abdominal pain | 161,461 | 6.26 | 43,430 | 6.36 | 52,612 | 6.12 | 65,419 | 6.33 |
| Oropharynx problem | 130,999 | 5.08 | 32,850 | 4.81 | 41,822 | 4.86 | 56,327 | 5.45 |
| Rash | 125,142 | 4.86 | 35,691 | 5.22 | 41,695 | 4.85 | 47,756 | 4.62 |
| Flu syndrome | 109,880 | 4.26 | 24,486 | 3.58 | 43,567 | 5.07 | 41,827 | 4.04 |
| Diarrhea | 98,092 | 3.81 | 30,020 | 4.39 | 30,870 | 3.59 | 37,202 | 3.60 |
| Urinary problem | 91,910 | 3.57 | 23,457 | 3.43 | 30,696 | 3.57 | 37,757 | 3.65 |
| Body temperature change problem | 90,630 | 3.52 | 25,335 | 3.71 | 30,931 | 3.60 | 34,364 | 3.32 |
| Chest pain | 87,098 | 3.38 | 22,587 | 3.31 | 29,118 | 3.39 | 35,393 | 3.42 |
| Migrain | 85,846 | 3.33 | 22,799 | 3.34 | 28,008 | 3.26 | 35,039 | 3.39 |
| Eye problem | 68,546 | 2.66 | 18,272 | 2.67 | 23,313 | 2.71 | 26,961 | 2.61 |
| Ear problem | 66,928 | 2.60 | 18,322 | 2.68 | 22,058 | 2.56 | 26,548 | 2.57 |
| Pregnancy problem, puerperium | 57,781 | 2.24 | 15,932 | 2.33 | 19,942 | 2.32 | 21,907 | 2.12 |
| Dizziness problem | 53,564 | 2.08 | 10,848 | 1.59 | 19,306 | 2.24 | 23,410 | 2.26 |
| Face problem | 52,851 | 2.05 | 14,356 | 2.10 | 17,555 | 2.04 | 20,940 | 2.03 |
| Skin integrity problem | 52,327 | 2.03 | 13,396 | 1.96 | 17,689 | 2.06 | 21,242 | 2.05 |
| Women’s health problem | 51,568 | 2.00 | 13,635 | 2.00 | 17,251 | 2.01 | 20,682 | 2.00 |
| Head and neck problem | 50,916 | 1.98 | 13,844 | 2.03 | 17,142 | 1.99 | 19,930 | 1.93 |
| Nasal problem | 49,464 | 1.92 | 12,430 | 1.82 | 16,572 | 1.93 | 20,462 | 1.98 |
| Nonspecific problem | 48,585 | 1.88 | 16,876 | 2.47 | 14,881 | 1.73 | 16,828 | 1.63 |
| Low back pain problem | 48,222 | 1.87 | 8766 | 1.28 | 16,930 | 1.97 | 22,526 | 2.18 |
| Blood pressure problem | 42,491 | 1.65 | 11,075 | 1.62 | 14,782 | 1.72 | 16,634 | 1.61 |
| Anxiety problem | 41,300 | 1.60 | 11,321 | 1.66 | 14,086 | 1.64 | 15,893 | 1.54 |
| Lower limb—ankle foot | 37,583 | 1.46 | 10,004 | 1.46 | 12,556 | 1.46 | 15,023 | 1.45 |
| Toxic sub ingestion problem | 35,355 | 1.37 | 10,549 | 1.54 | 12,221 | 1.42 | 12,585 | 1.22 |
| Allergy problem | 31,034 | 1.20 | 7976 | 1.17 | 10,435 | 1.21 | 12,623 | 1.22 |
| Lower limb—hip | 29,300 | 1.14 | 7968 | 1.17 | 9350 | 1.09 | 11,982 | 1.16 |
| Upper limb—shoulder collarbone arm | 25,469 | 0.99 | 6779 | 0.99 | 8380 | 0.97 | 10,310 | 1.00 |
| Constipation problem | 24,851 | 0.96 | 8181 | 1.20 | 8260 | 0.96 | 8410 | 0.81 |
| Lower limb—knee | 24,700 | 0.96 | 6327 | 0.93 | 8289 | 0.96 | 10,084 | 0.98 |
| Diabetes problem | 23,157 | 0.90 | 7139 | 1.04 | 7982 | 0.93 | 8036 | 0.78 |
| Crying child problem (0–1 year) | 22,068 | 0.86 | 6545 | 0.96 | 7332 | 0.85 | 8191 | 0.79 |
| Respiratory problem | 21,821 | 0.85 | 5585 | 0.82 | 7528 | 0.88 | 8708 | 0.84 |
| Geriatric problem | 21,241 | 0.82 | 6688 | 0.98 | 6879 | 0.80 | 7674 | 0.74 |
| Stool color change problem | 20,723 | 0.80 | 3359 | 0.49 | 7727 | 0.90 | 9637 | 0.93 |
| Upper limb—wrist hand | 17,374 | 0.67 | 4665 | 0.68 | 5783 | 0.67 | 6926 | 0.67 |
| Finger problem | 16,599 | 0.64 | 4020 | 0.59 | 5593 | 0.65 | 6986 | 0.68 |
| Men’s health problem | 16,272 | 0.63 | 4258 | 0.62 | 5435 | 0.63 | 6579 | 0.64 |
| Vaccination reaction problem | 11,073 | 0.43 | 3234 | 0.47 | 3531 | 0.41 | 4308 | 0.42 |
| Depression problem | 10,980 | 0.43 | 3315 | 0.49 | 3588 | 0.42 | 4077 | 0.39 |
| Burn problem | 9287 | 0.36 | 2682 | 0.39 | 3164 | 0.37 | 3441 | 0.33 |
| Breast problem | 8775 | 0.34 | 2338 | 0.34 | 2980 | 0.35 | 3457 | 0.33 |
| Fainting or lipothymia problem | 8500 | 0.33 | 1686 | 0.25 | 3130 | 0.36 | 3684 | 0.36 |
| Foreign body problem | 8479 | 0.33 | 2394 | 0.35 | 2865 | 0.33 | 3220 | 0.31 |
| Emergency | 7272 | 0.28 | 1236 | 0.18 | 2835 | 0.33 | 3201 | 0.31 |
| Breastfeeding problem | 4436 | 0.17 | 1323 | 0.19 | 1534 | 0.18 | 1579 | 0.15 |
| Asthma or wheezing problem | 3618 | 0.14 | 904 | 0.13 | 1195 | 0.14 | 1519 | 0.15 |
| Elbow problem | 1819 | 0.07 | 445 | 0.07 | 608 | 0.07 | 766 | 0.07 |
| Solar exposure problem | 1550 | 0.06 | 447 | 0.07 | 502 | 0.06 | 601 | 0.06 |
| Crisis adaptation problem | 663 | 0.03 | 124 | 0.02 | 226 | 0.03 | 313 | 0.03 |
| Measles problem | 576 | 0.02 | 257 | 0.04 | 207 | 0.02 | 112 | 0.01 |
| Heat problem | 334 | 0.01 | 102 | 0.01 | 156 | 0.02 | 76 | 0.01 |
| TOTAL | 2,577,517 | – | 683,360 | – | 860,093 | – | 1,034,064 | – |
| SVM | CNN | ||||||
|---|---|---|---|---|---|---|---|
| Clinical Pathway | Prec | Rec | F1 | Prec | Rec | F1 | Sup |
| Cough | 0.818 | 0.835 | 0.826 | 0.843 | 0.829 | 0.836 | 122,598 |
| Nausea and vomiting problem | 0.779 | 0.831 | 0.804 | 0.803 | 0.864 | 0.832 | 72,311 |
| Abdominal pain | 0.771 | 0.781 | 0.776 | 0.807 | 0.807 | 0.807 | 65,419 |
| Oropharynx problem | 0.769 | 0.712 | 0.740 | 0.793 | 0.741 | 0.766 | 56,327 |
| Rash | 0.875 | 0.906 | 0.890 | 0.888 | 0.897 | 0.892 | 47,756 |
| Flu syndrome | 0.586 | 0.634 | 0.609 | 0.562 | 0.663 | 0.608 | 41,827 |
| Diarrhea | 0.842 | 0.780 | 0.810 | 0.846 | 0.826 | 0.836 | 37,202 |
| Urinary problem | 0.897 | 0.873 | 0.885 | 0.897 | 0.880 | 0.888 | 37,757 |
| Body temperature change problem | 0.730 | 0.764 | 0.747 | 0.742 | 0.762 | 0.752 | 34,364 |
| Chest pain | 0.836 | 0.836 | 0.836 | 0.847 | 0.853 | 0.850 | 35,393 |
| Migrain | 0.735 | 0.761 | 0.748 | 0.801 | 0.796 | 0.798 | 35,039 |
| Eye problem | 0.916 | 0.922 | 0.919 | 0.929 | 0.932 | 0.931 | 26,961 |
| Ear problem | 0.889 | 0.844 | 0.866 | 0.905 | 0.867 | 0.886 | 26,548 |
| Dizziness problem | 0.728 | 0.727 | 0.727 | 0.777 | 0.807 | 0.791 | 23,410 |
| Low back pain problem | 0.843 | 0.812 | 0.827 | 0.849 | 0.842 | 0.846 | 22,526 |
| Pregnancy problem, puerperium | 0.827 | 0.693 | 0.754 | 0.811 | 0.700 | 0.752 | 21,907 |
| Skin integrity problem | 0.665 | 0.645 | 0.655 | 0.656 | 0.654 | 0.655 | 21,242 |
| Face problem | 0.736 | 0.780 | 0.757 | 0.725 | 0.804 | 0.763 | 20,940 |
| Women’s health problem | 0.796 | 0.836 | 0.816 | 0.804 | 0.831 | 0.817 | 20,682 |
| Nasal problem | 0.706 | 0.730 | 0.717 | 0.710 | 0.757 | 0.733 | 20,462 |
| Head and neck problem | 0.775 | 0.811 | 0.793 | 0.788 | 0.826 | 0.806 | 19,930 |
| Nonspecific problem | 0.346 | 0.437 | 0.386 | 0.375 | 0.408 | 0.391 | 16,828 |
| Blood pressure problem | 0.788 | 0.773 | 0.780 | 0.834 | 0.780 | 0.806 | 16,634 |
| Anxiety problem | 0.761 | 0.711 | 0.735 | 0.738 | 0.745 | 0.742 | 15,893 |
| Lower limb—ankle foot | 0.777 | 0.760 | 0.768 | 0.755 | 0.787 | 0.771 | 15,023 |
| Allergy problem | 0.766 | 0.580 | 0.660 | 0.769 | 0.573 | 0.657 | 12,623 |
| Toxic sub ingestion problem | 0.836 | 0.852 | 0.844 | 0.842 | 0.849 | 0.846 | 12,585 |
| Lower limb—hip | 0.648 | 0.735 | 0.689 | 0.654 | 0.745 | 0.696 | 11,982 |
| Upper limb—shoulder collarbone arm | 0.738 | 0.801 | 0.768 | 0.759 | 0.819 | 0.788 | 10,310 |
| Lower limb—knee | 0.819 | 0.692 | 0.750 | 0.830 | 0.692 | 0.755 | 10,084 |
| Stool color change problem | 0.731 | 0.754 | 0.742 | 0.745 | 0.703 | 0.723 | 9637 |
| Respiratory problem | 0.571 | 0.633 | 0.601 | 0.582 | 0.653 | 0.616 | 8708 |
| Constipation problem | 0.757 | 0.779 | 0.768 | 0.735 | 0.832 | 0.780 | 8410 |
| Crying child problem (0–1 Year) | 0.671 | 0.493 | 0.568 | 0.667 | 0.498 | 0.570 | 8191 |
| Diabetes problem | 0.845 | 0.613 | 0.711 | 0.821 | 0.641 | 0.720 | 8036 |
| Geriatric problem | 0.447 | 0.474 | 0.460 | 0.453 | 0.462 | 0.457 | 7674 |
| Finger problem | 0.664 | 0.733 | 0.697 | 0.689 | 0.711 | 0.700 | 6986 |
| Upper limb—wrist hand | 0.724 | 0.644 | 0.682 | 0.757 | 0.658 | 0.704 | 6926 |
| Men’s health problem | 0.831 | 0.797 | 0.813 | 0.845 | 0.794 | 0.819 | 6579 |
| Vaccination reaction problem | 0.743 | 0.697 | 0.719 | 0.747 | 0.676 | 0.710 | 4308 |
| Depression problem | 0.767 | 0.647 | 0.702 | 0.783 | 0.632 | 0.700 | 4077 |
| Breast problem | 0.702 | 0.812 | 0.753 | 0.714 | 0.800 | 0.755 | 3457 |
| Burn problems | 0.862 | 0.840 | 0.851 | 0.853 | 0.853 | 0.853 | 3441 |
| Fainting or lipothymia problem | 0.647 | 0.688 | 0.667 | 0.701 | 0.720 | 0.710 | 3684 |
| Foreign body problem | 0.675 | 0.684 | 0.679 | 0.675 | 0.651 | 0.663 | 3220 |
| Emergency | 0.437 | 0.083 | 0.140 | 0.413 | 0.114 | 0.179 | 3201 |
| Breastfeeding problem | 0.595 | 0.505 | 0.547 | 0.597 | 0.457 | 0.518 | 1579 |
| Asthma or wheezing problem | 0.576 | 0.257 | 0.355 | 0.577 | 0.275 | 0.372 | 1519 |
| Elbow problem | 0.565 | 0.621 | 0.592 | 0.664 | 0.599 | 0.630 | 766 |
| Solar exposure problem | 0.565 | 0.759 | 0.648 | 0.585 | 0.582 | 0.584 | 601 |
| Crisis adaptation problem | 1.000 | 0.006 | 0.013 | 0.000 | 0.000 | 0.000 | 313 |
| Measles problems | 0.706 | 0.107 | 0.186 | 0.800 | 0.071 | 0.131 | 112 |
| Heat problems | 0.333 | 0.079 | 0.128 | 0.000 | 0.000 | 0.000 | 76 |
| minimum | 0.333 | 0.006 | 0.013 | 0.000 | 0.000 | 0.000 | |
| maximum | 1.000 | 0.922 | 0.919 | 0.929 | 0.932 | 0.931 | |
| average | 0.725 | 0.671 | 0.677 | 0.712 | 0.674 | 0.683 | |
| stdev | 0.136 | 0.213 | 0.199 | 0.185 | 0.224 | 0.212 | |
References
- Mackway-Jones, K.; Marsden, J.; Windle, J. Emergency Triage: Manchester Triage Group; John Wiley & Sons: New York, NY, USA, 2013. [Google Scholar]
- Veladas, R.; Yang, H.; Quaresma, P.; Gonçalves, T.; Vieira, R.; Sousa Pinto, C.; Martins, J.P.; Oliveira, J.; Cortes Ferreira, M. Aiding Clinical Triage with Text Classification. In Proceedings of the EPIA Conference on Artificial Intelligence; Springer: New York, NY, USA, 2021; pp. 83–96. [Google Scholar]
- Yang, H.; Gonçalves, T.; Quaresma, P.; Vieira, R.; Veladas, R.; Pinto, C.S.; Oliveira, J.; Ferreira, M.C.; Morais, J.; Pereira, A.R.; et al. Clinical Trial Classification of SNS24 Calls with Neural Networks. Future Internet 2022, 14, 130. [Google Scholar] [CrossRef]
- Kavuluru, R.; Rios, A.; Lu, Y. An empirical evaluation of supervised learning approaches in assigning diagnosis codes to electronic medical records. Artif. Intell. Med. 2015, 65, 155–166. [Google Scholar] [CrossRef] [PubMed]
- Marafino, B.J.; Boscardin, W.J.; Dudley, R.A. Efficient and sparse feature selection for biomedical text classification via the elastic net: Application to ICU risk stratification from nursing notes. J. Biomed. Inform. 2015, 54, 114–120. [Google Scholar] [CrossRef] [PubMed]
- Mujtaba, G.; Shuib, L.; Idris, N.; Hoo, W.L.; Raj, R.G.; Khowaja, K.; Shaikh, K.; Nweke, H.F. Clinical text classification research trends: Systematic literature review and open issues. Expert Syst. Appl. 2019, 116, 494–520. [Google Scholar] [CrossRef]
- Shickel, B.; Tighe, P.J.; Bihorac, A.; Rashidi, P. Deep EHR: A survey of recent advances in deep learning techniques for electronic health record (EHR) analysis. IEEE J. Biomed. Health Inform. 2017, 22, 1589–1604. [Google Scholar] [CrossRef] [PubMed]
- Shao, Y.; Taylor, S.; Marshall, N.; Morioka, C.; Zeng-Treitler, Q. Clinical text classification with word embedding features vs. In bag-of-words features. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2874–2878. [Google Scholar]
- Mustafa, A.; Rahimi Azghadi, M. Automated Machine Learning for Healthcare and Clinical Notes Analysis. Computers 2021, 10, 24. [Google Scholar] [CrossRef]
- Funkner, A.A.; Yakovlev, A.N.; Kovalchuk, S.V. Data-driven modeling of clinical pathways using electronic health records. Procedia Comput. Sci. 2017, 121, 835–842. [Google Scholar] [CrossRef]
- Elbattah, M.; Molloy, O.; Zeigler, B.P. Designing Care Pathways Using Simulation Modeling and Machine Learning. In Proceedings of the 2018 Winter Simulation Conference (WSC), Gothenburg, Sweden, 9–12 December 2018; pp. 1452–1463. [Google Scholar] [CrossRef][Green Version]
- Almeida, J.R.; Silva, J.F.; Sierra, A.P.; Matos, S.; Oliveira, J.L. Leveraging Clinical Notes for Enhancing Decision-Making Systems with Relevant Patient Information. In Proceedings of the Biomedical Engineering Systems and Technologies; Ye, X., Soares, F., De Maria, E., Gómez Vilda, P., Cabitza, F., Fred, A., Gamboa, H., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 521–540. [Google Scholar]
- Aggarwal, C.C.; Clustering, C.R.D. Algorithms and Applications; Springer: New York, NY, USA, 2014. [Google Scholar]
- Gómez, D.; Rojas, A. An empirical overview of the no free lunch theorem and its effect on real-world machine learning classification. Neural Comput. 2016, 28, 216–228. [Google Scholar] [CrossRef] [PubMed]
- Mascio, A.; Kraljevic, Z.; Bean, D.; Dobson, R.; Stewart, R.; Bendayan, R.; Roberts, A. Comparative analysis of text classification approaches in electronic health records. arXiv 2020, arXiv:2005.06624. [Google Scholar]
- Stein, R.A.; Jaques, P.A.; Valiati, J.F. An analysis of hierarchical text classification using word embeddings. Inf. Sci. 2019, 471, 216–232. [Google Scholar] [CrossRef]
- Kadhim, A.I. Survey on supervised machine learning techniques for automatic text classification. Artif. Intell. Rev. 2019, 52, 273–292. [Google Scholar] [CrossRef]
- Baker, S.; Korhonen, A.L.; Pyysalo, S. Cancer Hallmark Text Classification Using Convolutional Neural Networks. In Proceedings of the Fifth Workshop on Building and Evaluating Resources for Biomedical Text Mining (BioTxtM 2016), Osaka, Japan, 11–16 December 2016. [Google Scholar] [CrossRef]
- Flores, C.A.; Figueroa, R.L.; Pezoa, J.E. Active Learning for Biomedical Text Classification Based on Automatically Generated Regular Expressions. IEEE Access 2021, 9, 38767–38777. [Google Scholar] [CrossRef]
- Gao, S.; Alawad, M.; Young, M.T.; Gounley, J.; Schaefferkoetter, N.; Yoon, H.J.; Wu, X.C.; Durbin, E.B.; Doherty, J.; Stroup, A.; et al. Limitations of Transformers on Clinical Text Classification. IEEE J. Biomed. Health Inform. 2021, 25, 3596–3607. [Google Scholar] [CrossRef] [PubMed]
- Markus, A.F.; Kors, J.A.; Rijnbeek, P.R. The role of explainability in creating trustworthy artificial intelligence for health care: A comprehensive survey of the terminology, design choices, and evaluation strategies. J. Biomed. Inform. 2021, 113, 103655. [Google Scholar] [CrossRef]
- Amann, J.; Blasimme, A.; Vayena, E.; Frey, D.; Madai, V.I. Explainability for artificial intelligence in healthcare: A multidisciplinary perspective. BMC Med. Inform. Decis. Mak. 2020, 20, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Yang, T. Word Embedding for Understanding Natural Language: A Survey. In Guide to Big Data Applications; Springer International Publishing: Cham, Switzerland, 2018; pp. 83–104. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019, Volume 1 (Long and Short Papers); Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Akbik, A.; Blythe, D.; Vollgraf, R. Contextual String Embeddings for Sequence Labeling. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; Association for Computational Linguistics: Santa Fe, NM, USA, 2018; pp. 1638–1649. [Google Scholar]
- Souza, F.; Nogueira, R.; Lotufo, R. BERTimbau: Pretrained BERT models for Brazilian Portuguese. In Proceedings of the 9th Brazilian Conference on Intelligent Systems, BRACIS, Rio Grande do Sul, Brazil, 20–23 October 2020. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1746–1751. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Scikit-learn. Available online: https://scikit-learn.org/stable/ (accessed on 7 December 2022).
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 7 December 2022).
- Pytorch. Available online: https://pytorch.org/ (accessed on 7 December 2022).
- Python. Available online: https://www.python.org/ (accessed on 7 December 2022).
- ELI5. Available online: https://eli5.readthedocs.io/en/latest/index.html (accessed on 7 December 2022).
- Dhar, P. The carbon impact of artificial intelligence. Nat. Mach. Intell. 2020, 2, 423–425. [Google Scholar] [CrossRef]
- Bannour, N.; Ghannay, S.; Névéol, A.; Ligozat, A.L. Evaluating the carbon footprint of NLP methods: A survey and analysis of existing tools. In Proceedings of the EMNLP, Workshop SustaiNLP, Online, 7–11 November 2021. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]










| Contact Reason | Clinical Pathway |
|---|---|
| Rinorreira transparente, tosse produtiva e febre há 3d. Transparent rhinorrhea, productive cough and fever 3d. | Cough |
| Dor Abdominal e nauseas há 15 dias, agravamento hoje Abdominal pain and nausea for 15 days, worse today | Nausea and vomiting pr. |
| Dor supraumbilical há cerca de alguns dias Supraumbilical pain for about a few days | Abdominal pain |
| Congestão nasal há 24 h. Nasal congestion for 24 h. | Oropharynx problem |
| Foliculite purulenta face, tronco, braços e pernas desde 3a feira Purulent folliculitis face, corpo since Tuesday | Rash |
| desde dia 21 tosse seca provoca o vomito, mialgias since the 21st dry cough causes vomiting, myalgias | Flu syndrome |
| Sangue nas fezes e diarreia ha 5 h Blood in stool and diarrhea for 5 h | Diarrhea |
| Lombalgias e hematuria há 72 h. Low back pain and hematuria 72 h ago. | Urinary problem |
| Episódios de febre e extremidades cianosadas há 18 h Episodes of fever and cyanotic extremities for 18 h | Body temp. change pr. |
| Dor na região costal algumas vezes Pain in the rib area sometimes | Chest pain |
| Accuracy | Pred Time (ms) | |||||||
|---|---|---|---|---|---|---|---|---|
| SVM | CNN | SVM | CNN | |||||
| Training Set | Top 1 | Top 3 | Top 5 | Top 1 | Top 3 | Top 5 | ||
| 3 months | 0.743 | 0.927 | 0.959 | 0.631 | 0.775 | 0.804 | 14.82 | 12.31 |
| 2017 | 0.755 | 0.932 | 0.963 | 0.772 | 0.931 | 0.961 | 54.32 | 12.41 |
| 2018 | 0.766 | 0.938 | 0.968 | 0.780 | 0.937 | 0.964 | 54.57 | 12.50 |
| 2017–2018 | 0.768 | 0.940 | 0.969 | 0.782 | 0.940 | 0.967 | 92.48 | 14.19 |
| SVM | CNN | |||||
|---|---|---|---|---|---|---|
| Training Set | Prec | Rec | F1 | Prec | Rec | F1 |
| 3 months | 0.754 | 0.743 | 0.745 | 0.657 | 0.632 | 0.642 |
| 2017 | 0.761 | 0.755 | 0.755 | 0.776 | 0.772 | 0.772 |
| 2018 | 0.768 | 0.766 | 0.765 | 0.782 | 0.780 | 0.779 |
| 2017–2018 | 0.771 | 0.768 | 0.768 | 0.785 | 0.783 | 0.782 |
| SVM | CNN | ||||||
|---|---|---|---|---|---|---|---|
| Clinical Pathway | Prec | Rec | F1 | Prec | Rec | F1 | Sup |
| Cough | 0.818 | 0.835 | 0.826 | 0.843 | 0.829 | 0.836 | 122,598 |
| Nausea and vomiting | 0.779 | 0.831 | 0.804 | 0.803 | 0.864 | 0.832 | 72,311 |
| Abdominal pain | 0.771 | 0.781 | 0.776 | 0.807 | 0.807 | 0.807 | 65,419 |
| Oropharynx problem | 0.769 | 0.712 | 0.740 | 0.793 | 0.741 | 0.766 | 56,327 |
| Rash | 0.875 | 0.906 | 0.890 | 0.888 | 0.897 | 0.892 | 47,756 |
| Flu syndrome | 0.586 | 0.634 | 0.609 | 0.562 | 0.663 | 0.608 | 41,827 |
| Diarrhea | 0.842 | 0.780 | 0.810 | 0.846 | 0.826 | 0.836 | 37,202 |
| Urinary problem | 0.897 | 0.873 | 0.885 | 0.897 | 0.880 | 0.888 | 37,757 |
| Body temp change pr. | 0.730 | 0.764 | 0.747 | 0.742 | 0.762 | 0.752 | 34,364 |
| Chest pain | 0.836 | 0.836 | 0.836 | 0.847 | 0.853 | 0.850 | 35,393 |
| average (10 most freq) | 0.790 | 0.795 | 0.792 | 0.803 | 0.812 | 0.807 | |
| stdev (10 most freq) | 0.088 | 0.080 | 0.082 | 0.096 | 0.072 | 0.083 | |
| Fainting or lipothymia | 0.647 | 0.688 | 0.667 | 0.701 | 0.720 | 0.710 | 3684 |
| Foreign body problem | 0.675 | 0.684 | 0.679 | 0.675 | 0.651 | 0.663 | 3220 |
| Emergency | 0.437 | 0.083 | 0.140 | 0.413 | 0.114 | 0.179 | 3201 |
| Breastfeeding problem | 0.595 | 0.505 | 0.547 | 0.597 | 0.457 | 0.518 | 1579 |
| Asthma or wheezing | 0.576 | 0.257 | 0.355 | 0.577 | 0.275 | 0.372 | 1519 |
| Elbow problem | 0.565 | 0.621 | 0.592 | 0.664 | 0.599 | 0.630 | 766 |
| Solar exposure pr. | 0.565 | 0.759 | 0.648 | 0.585 | 0.582 | 0.584 | 601 |
| Crisis adaptation pr. | 1.000 | 0.006 | 0.013 | 0.000 | 0.000 | 0.000 | 313 |
| Measles problem | 0.706 | 0.107 | 0.186 | 0.800 | 0.071 | 0.131 | 112 |
| Heat problem | 0.333 | 0.079 | 0.128 | 0.000 | 0.000 | 0.000 | 76 |
| average (10 least freq) | 0.610 | 0.379 | 0.395 | 0.501 | 0.347 | 0.379 | |
| stdev (10 least freq) | 0.176 | 0.300 | 0.260 | 0.282 | 0.287 | 0.280 | |
| minimum (full data) | 0.333 | 0.006 | 0.013 | 0.000 | 0.000 | 0.000 | |
| maximum (full data) | 1.000 | 0.922 | 0.919 | 0.929 | 0.932 | 0.931 | |
| average (full data) | 0.725 | 0.671 | 0.677 | 0.712 | 0.674 | 0.683 | |
| stdev (full data) | 0.136 | 0.213 | 0.199 | 0.185 | 0.224 | 0.212 | |
| SVM | CNN | ||||||
|---|---|---|---|---|---|---|---|
| Cough | Flu | Other | Cough | Flu | Other | ||
| Cough | 102,339 | 9271 | 10,988 | Cough | 101,603 | 10,636 | 10,359 |
| Flu | 7821 | 26,522 | 7484 | Flu | 7157 | 27,748 | 6922 |
| Other | 14,989 | 9432 | 991,171 | Other | 11,728 | 11,015 | 994,040 |
| Clinical Pathway | Total | e-g | e-s | e-c | g-s | g-c | s-c |
|---|---|---|---|---|---|---|---|
| Cough | 10 | 2 | 4 | 5 | 5 | 5 | 9 |
| Nausea and vomiting problem | 9 | 2 | 4 | 3 | 3 | 3 | 8 |
| Abdominal pain | 10 | 5 | 5 | 6 | 6 | 7 | 9 |
| Oropharynx problem | 9 | 4 | 6 | 7 | 3 | 4 | 9 |
| Rash | 8 | 1 | 2 | 3 | 4 | 4 | 7 |
| Flu syndrome | 10 | 3 | 7 | 8 | 4 | 3 | 8 |
| Diarrhea | 9 | 1 | 2 | 3 | 4 | 4 | 9 |
| Urinary problem | 10 | 7 | 8 | 7 | 9 | 10 | 9 |
| Body temperature change problem | 10 | 3 | 7 | 7 | 5 | 3 | 7 |
| Chest pain | 9 | 5 | 7 | 8 | 7 | 6 | 9 |
| Sub-total (10 most frequent) | 94 | 33 | 52 | 57 | 50 | 49 | 84 |
| Fainting or lipothymia | 10 | 3 | 6 | 5 | 5 | 4 | 7 |
| Foreign body problem | 10 | 8 | 6 | 5 | 8 | 7 | 8 |
| Emergency | 7 | 3 | 2 | 2 | 2 | 0 | 6 |
| Breastfeeding problem | 10 | 0 | 6 | 7 | 3 | 2 | 9 |
| Asthma or wheezing problem | 9 | 0 | 6 | 6 | 0 | 0 | 8 |
| Elbow problem | 10 | 4 | 2 | 3 | 2 | 3 | 9 |
| Solar exposure problem | 8 | 6 | 5 | 6 | 4 | 5 | 8 |
| Crisis adaptation problem | 8 | 0 | 6 | 6 | 0 | 0 | 9 |
| Measles problem | 10 | 0 | 6 | 6 | 0 | 0 | 10 |
| Heat problem | 10 | 1 | 7 | 6 | 0 | 0 | 8 |
| Sub-total (10 least frequent) | 92 | 25 | 52 | 52 | 24 | 21 | 82 |
| TOTAL | 186 | 58 | 104 | 109 | 74 | 70 | 166 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gonçalves, T.; Veladas, R.; Yang, H.; Vieira, R.; Quaresma, P.; Infante, P.; Sousa Pinto, C.; Oliveira, J.; Cortes Ferreira, M.; Morais, J.; et al. Clinical Screening Prediction in the Portuguese National Health Service: Data Analysis, Machine Learning Models, Explainability and Meta-Evaluation. Future Internet 2023, 15, 26. https://doi.org/10.3390/fi15010026
Gonçalves T, Veladas R, Yang H, Vieira R, Quaresma P, Infante P, Sousa Pinto C, Oliveira J, Cortes Ferreira M, Morais J, et al. Clinical Screening Prediction in the Portuguese National Health Service: Data Analysis, Machine Learning Models, Explainability and Meta-Evaluation. Future Internet. 2023; 15(1):26. https://doi.org/10.3390/fi15010026
Chicago/Turabian StyleGonçalves, Teresa, Rute Veladas, Hua Yang, Renata Vieira, Paulo Quaresma, Paulo Infante, Cátia Sousa Pinto, João Oliveira, Maria Cortes Ferreira, Jéssica Morais, and et al. 2023. "Clinical Screening Prediction in the Portuguese National Health Service: Data Analysis, Machine Learning Models, Explainability and Meta-Evaluation" Future Internet 15, no. 1: 26. https://doi.org/10.3390/fi15010026
APA StyleGonçalves, T., Veladas, R., Yang, H., Vieira, R., Quaresma, P., Infante, P., Sousa Pinto, C., Oliveira, J., Cortes Ferreira, M., Morais, J., Pereira, A. R., Fernandes, N., & Gonçalves, C. (2023). Clinical Screening Prediction in the Portuguese National Health Service: Data Analysis, Machine Learning Models, Explainability and Meta-Evaluation. Future Internet, 15(1), 26. https://doi.org/10.3390/fi15010026