1. Introduction
Facial expressions are one of the most important ways in which humans can effectively communicate their emotional states and intentions [
1,
2]. The research on facial expression recognition has been enhanced, as more and more researchers focus their attention on the problem in the field of facial expression recognition. Automatic analysis techniques for facial expressions are being used in more and more fields, such as medical care, driver fatigue, robot interaction, and student classroom state analysis [
3,
4,
5,
6,
7]. The changing needs have also given rise to many problems in different scenarios, and in the past period, the algorithms have been iterated continuously in FER-related problems [
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18], and eventually, these algorithms have achieved good results. Meanwhile, in order to meet the requirements of different experiments, some datasets have been generated, such as CK+ [
19], FER2013 [
20], FERPLUS [
21], etc.
The construction of previous facial expression recognition systems is mainly divided into three steps: face detection, feature extraction, and expression recognition [
22]. In dealing with facial expression recognition, the Dlib detector [
23] is commonly used for face detection under various noise conditions. It can correct the images containing faces so that the images perform accurate face alignment. For face feature extraction, due to increasing computational power in recent years, researchers have designed many deep neural network algorithms to extract these geometric and appearance features [
24,
25]. ResNet [
26] is frequently seen in recent methods used for feature extraction. The feature maps obtained from the feature extractor are fed into the classifier used to match expression classes in facial expression recognition. Meanwhile, the great increase in arithmetic power has largely accelerated the development of deep learning [
27,
28] and the research process of problems in the field of face recognition.
Traditional facial expression recognition methods [
29,
30] use manually extracted features such as the Histogram of oriented Gradients (HOG) [
31], Local Binary Patterns (LBP) [
32] and scale-invariant feature transformations (SIFT) [
33] to deal with FER [
34,
35,
36]. However, these methods usually have disadvantages, such as a long time spent, high cost, and poor portability. Compared with the traditional methods, deep learning methods can learn more deep features, such as rotation angle changes and changes caused by illumination. Additionally, due to the rapid development of the Internet in recent years, large-scale datasets can be obtained from challenging real-world scenarios in a relatively easier way [
37,
38]. Deep learning methods benefit from these advantages and are more popular among researchers. Information on some datasets commonly used for facial expression recognition is shown in
Table 1.
Despite the great success of facial expression recognition, there are still some challenges, such as the noise generated by intra-class differences unrelated to expressions and the problem of overfitting due to insufficient training data caused by too small a dataset. Further, first, there are large intersubject differences in faces in the dataset due to age, gender, and race [
22]. Intra-class differences become larger because of these uncertainties. The intra-class variance unrelated to expression recognition is shown in
Figure 1. Second, experiments on deep neural networks require a large amount of training data. Insufficient training data can easily lead to overfitting of the model. Finally, directly using the global face as the input of the neural network will lose local detailed feature information [
39]. Ekman [
40] studied facial parts to find out the most important regions for human perception by masking the key parts, and the regions around the eyes and mouth are highly correlated with FER. From Kotsia et al. [
41], based on Gabor features and human observer synthesis analysis of obscured FER, the masked mouth affects the accuracy of FER more than the masked eyes. Inspired by this, we propose a Dual Path Feature Fusion and Stacked Attention Network (DPSAN) to address the challenges of noise generated by intra-class differences unrelated to expression recognition in FER and the challenges of overfitting due to insufficient training data. DPSAN consists of a dual path feature fusion module and a stacked attention module. Based on studies related to the symmetry of facial expressions [
11,
16], we segment four regions from the aligned face image, left eye, right eye, left half of the mouth, and right half of the mouth. The four key regions are used to reduce the effects of irrelevant intra-class differences, such as facial contour and hairstyle. Additionally, the effect of noise from occlusions, such as the partial occlusion of the left or right eye, is reduced based on the symmetry of facial expression features in local regions. Meanwhile, existing ensemble learning studies show [
42] that the combination of multiple networks outperforms a single network. Therefore, we designed a Dual path feature fusion module. The dual path feature fusion module of DPSAN divides the face image feature extraction into global and local face features for extraction. The dual path feature fusion module fuses the global and local features extracted using the two updated ResNet18 [
43]. By combining the global and local features, this module is used to overcome the noise caused by intra-class differences unrelated to expression recognition, and to increase the data to alleviate the problem of insufficient data. Additionally, multi-scale expression details are introduced in this module to improve the generalization ability of the model by adjusting the size of the local region to match the size of the global face image. Second, we design a stacked attention module for compressing the feature maps, reducing redundant data and supervising DPSAN, and also refine the global features via the local features of faces, enabling the model to learn more meaningful weights from both local- and global-based feature maps. In summary, our contributions are summarized as follows:
We propose a DPSAN model to address the challenge of noise generated by intra-class differences in FER that are not related to expression recognition, and the challenge of overfitting due to insufficient training data.
The dual path feature fusion module is able to segment the critical regions in the face and combine the local feature information with the global feature information. This can reduce the noise impact from intra-class differences in FER that are not related to facial expressions. Additionally, it can alleviate the overfitting problem caused by insufficient data. The stacked attention module is used to compress the feature maps and learn more meaningful weights from the local- and global-based feature maps.
We perform extensive validation of our model on the dataset. The experimental results show that DPSAN outperforms previous state-of-the-art methods on the commonly used CK+ and FERPLUS datasets (93.26% on CK+, 87.63% on FERPLUS).
The rest of this paper is organized as follows. In
Section 2, we review the literature related to the development of techniques related to facial expression recognition. In
Section 3, we describe the research methodology in detail. In
Section 4, we describe the experimental setup and provide a discussion of the experimental results. Finally, in
Section 5, we conclude the paper and give an outlook on future work.
2. Related Work
Deep learning and Attention in FER: With the rapid development of computer vision in recent years, deep learning solutions are increasingly used to handle challenging tasks in FER compared to traditional manual feature extraction solutions. Meanwhile, traditional CNNs pay insufficient attention to important channel features and important regions of images, which restrict the accuracy of facial expression recognition. However, with the proposed attention, the model will give more attention and weight to important channels and regions, which is a good improvement to the deficiency of the original traditional model. Many existing models of deep learning and attention have achieved good performance. Li et al. [
11] proposed a convolutional neural network with attention (ACNN) to automatically perceive blocked face regions and focus primary attention on unblocked expression regions for judgment. Wang et al. [
16] proposed a regional attention network (RAN) to recognize the occlusion of facial regions. Wang et al. [
15] proposed a self-cure network (SCN) to suppress bad data such as obscured face images in many large datasets, which prevents the network from overfitting incorrectly labeled samples.
Facial Landmark in FER: The purpose of facial landmark detection is to identify the location of distinguishable key points on a human face. Currently, with the combination of facial landmark detection and deep learning techniques, such as face recognition [
15,
20], facial expression recognition [
13,
31], and face tracking [
17], great progress has been made in the application of facial landmark detection, which has also facilitated the research of many accurate facial landmark detectors. Many accurate and widely used facial landmark detectors have been proposed, such as [
4,
11,
14,
45]. Using these excellent detectors, researchers are able to better utilize facial landmarks as informative features in solving FER tasks.
Ensemble learning in FER: Previous studies on ensemble learning have amply demonstrated that the combination of multiple networks outperforms individual networks [
42]. When implementing network combinations, two key factors should be considered: (1) to ensure complementarity among multiple networks, we can increase the diversity of networks; and (2) choosing the right combination strategy can provide more effective assistance in aggregating committee networks [
22]. For the second point, each member of the committee network can be combined at the feature level and at the decision level, respectively. For the aggregation of features, concatenating features obtained in different network paths is the most commonly used strategy [
12,
46]. For the decision level, there are several most frequently used rules, such as simple averaging, majority voting, and weighted averaging. Yovel et al. [
39] showed that people could effectively access the information displayed by facial expressions through two paths: local regions of the face and the whole face.
Compared with previous methods, our proposed method is very effective in reducing the interference of irrelevant intra-class differences using a unique four key region segmentation method. Additionally, the method has good robustness due to the fixed region cropping approach. Comparing previous methods on the same dataset, the proposed method in this paper effectively expands the data volume via cropping segmentation to obtain detailed information in local paths while better meeting the experimental requirements of the dataset. The dual path feature fusion module and stacked attention module designed in this paper can make better use of contextual information and also focus more attention on more important regions.
3. Methods
3.1. Overview
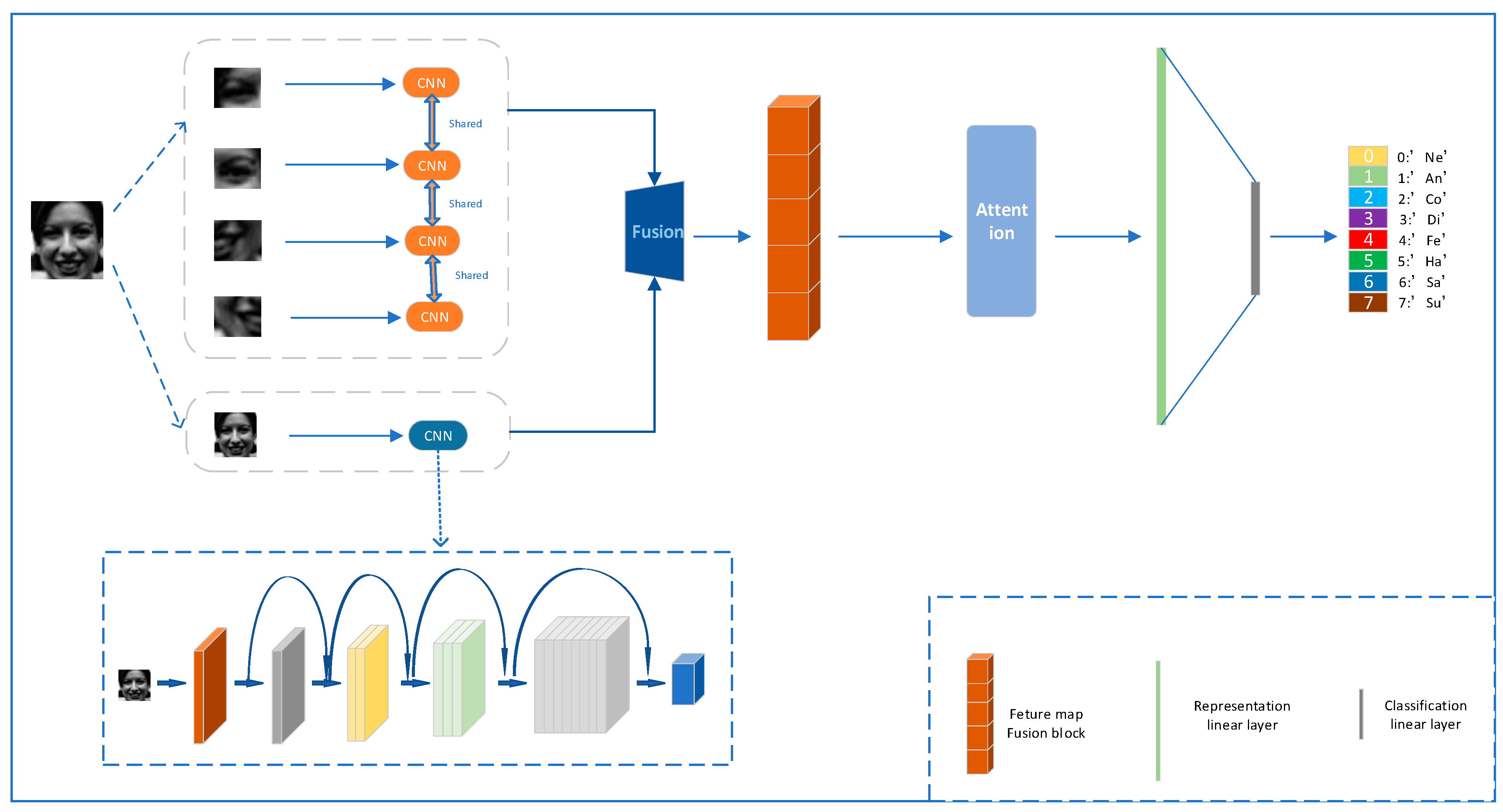
As shown in
Figure 2, first, the face image is segmented using the segmentation method to segment four local image regions. The face key region segmentation method can extract more local details, and the size of each region image is resized to be equal to the size of the global input image via scaling. Then, the global image and the four local image regions are input to the updated ResNet18 for feature extraction in the global path and local path, respectively. The general structure of the updated ResNet18 is shown in the dashed rectangle at the lower left corner, and a more detailed structure is shown in
Figure 3. After completing the feature extraction, the global image feature map is fused with the local image feature map. After that, the fused feature maps are fed into the stacked attention module (SA). The SA module can learn features from different regions and complete the weighting of different channels by re-estimating the importance of each feature. The image segmentation method is shown in
Figure 4. The details of the structure of the stacked attention module are shown in
Figure 5.
The model consists of two main parts. One is the dual path feature fusion module, which performs segmentation, feature extraction, and feature fusion on the input face image. The other is the SA module, which weights each channel of the feature map according to its contribution to the classification result. The detailed process of the first module is as follows. First, the model segments the local area of the base image, and compresses and scales the size of the local area image and the size of the base image; and then the scaled image is used as the input to the network. The dual path feature fusion network concatenates the features extracted from the four local regions with the features of the complete face image and outputs the fused feature map. The main role of the SA module is to calculate the importance of the feature maps of each layer and compress the irrelevant information. Finally, the classification of expressions is output from the linear connectivity layer.
Figure 2 illustrates the DPSAN framework.
DPSAN is used with one global image and four local image regions as inputs. These five parts are input to two ResNet18, and the features are extracted and represented as five sets of feature maps. Then, DPSAN merges the global feature maps and the four sets of local feature maps into one set of feature maps. The advantage of this processing is that the fused feature maps have both the global information of the facial image and local information that can be easily ignored. The SA module calculates the weights for each channel of the feature map. The weighted features contain all the key information that we are interested in that is beneficial to FER. The classification layer after the stacked attention module aims to classify the face images into their corresponding facial expression classes. The softmax loss is used to optimize the DPSAN model.
3.2. Face Image Segmentation and Dual Path Feature Fusion Module
The face image segmentation and dual path feature extraction module firstly segment the input base image, crop it to obtain four local regions, and then extract the global features and local features from the adjusted global image and the four local region images through the dual path, respectively. The advantage of dual path feature extraction is that the global information is obtained along with the local detail information, thus complementing the information ignored by the global information. Then, the global features and the local part of the features are fused, which can make the feature representation more adequate and complete.
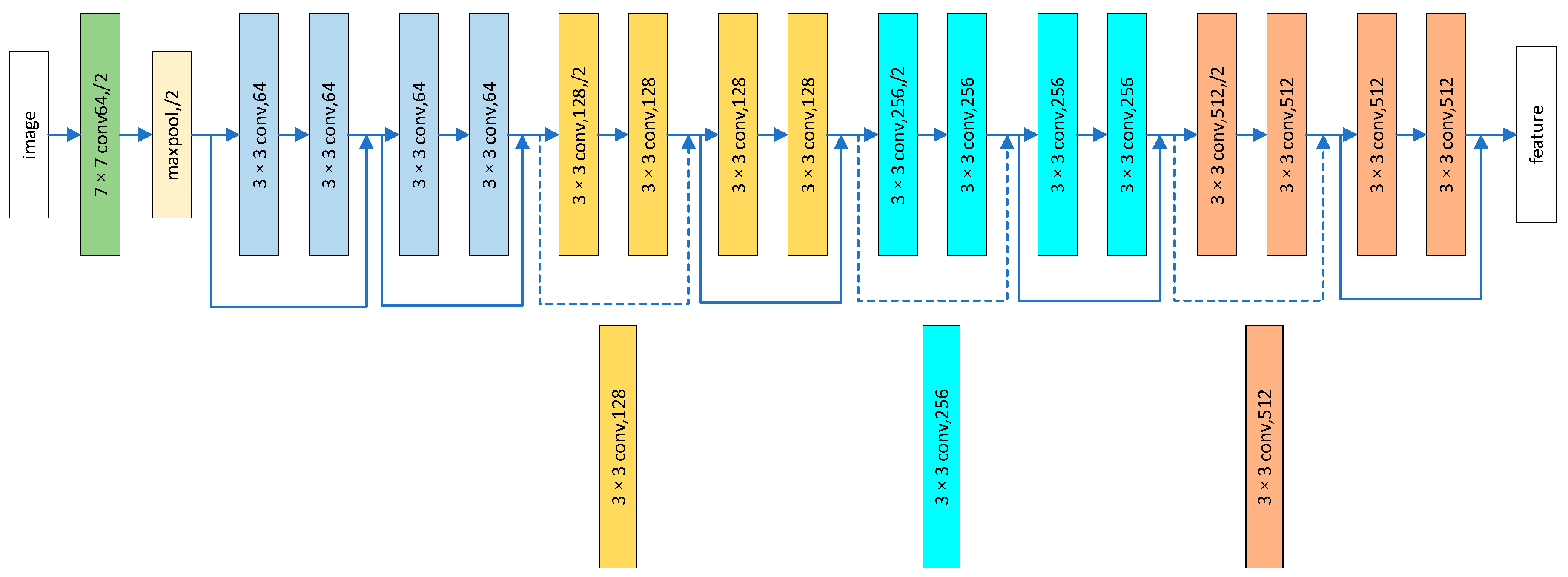
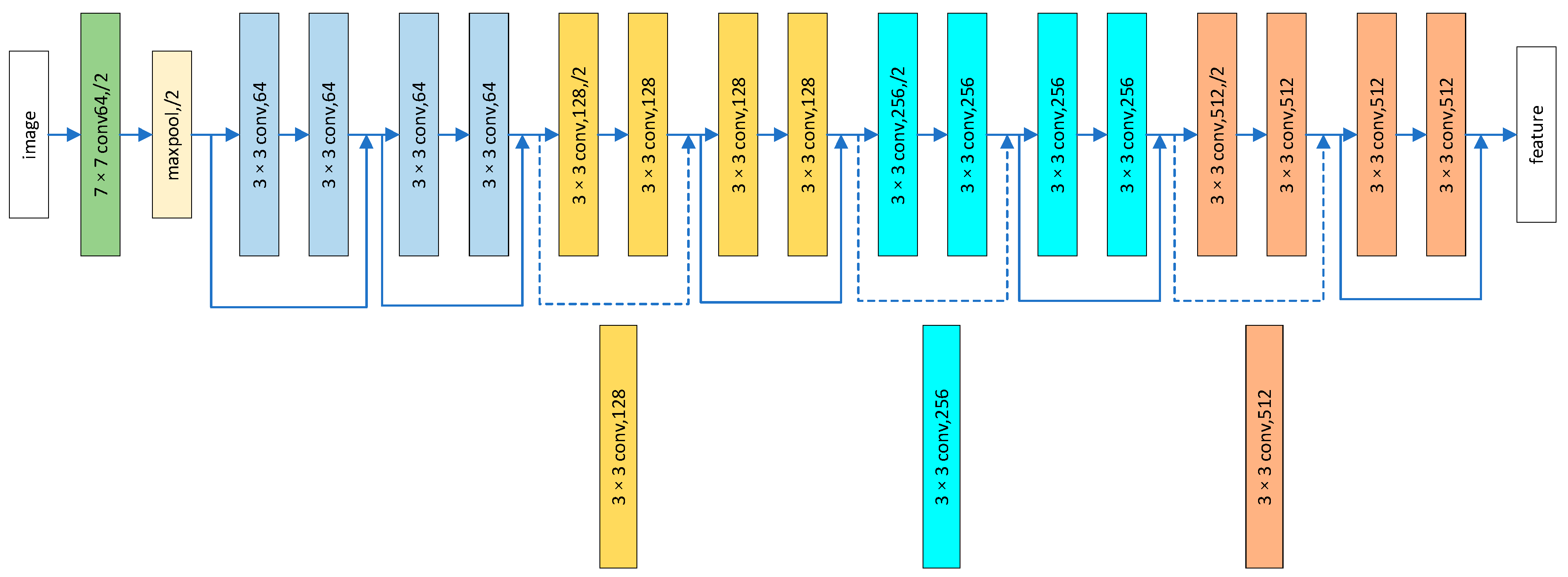
We extract feature information from the base face image and the local image regions, using the updated ResNet18 network. The detailed information on the updated ResNet18 is given in
Figure 3. In the updated ResNet18, the avg-pool layer and the FC layer in the structure are removed in this paper to facilitate the computation and fusion of features later. For the segmentation methods, specifically, we propose three methods for face region segmentation for comparison, and then we select a better method from them to segment the global image and obtain the local block.
Comparison and selection of face key region segmentation schemes. With the study conducted by Ekman [
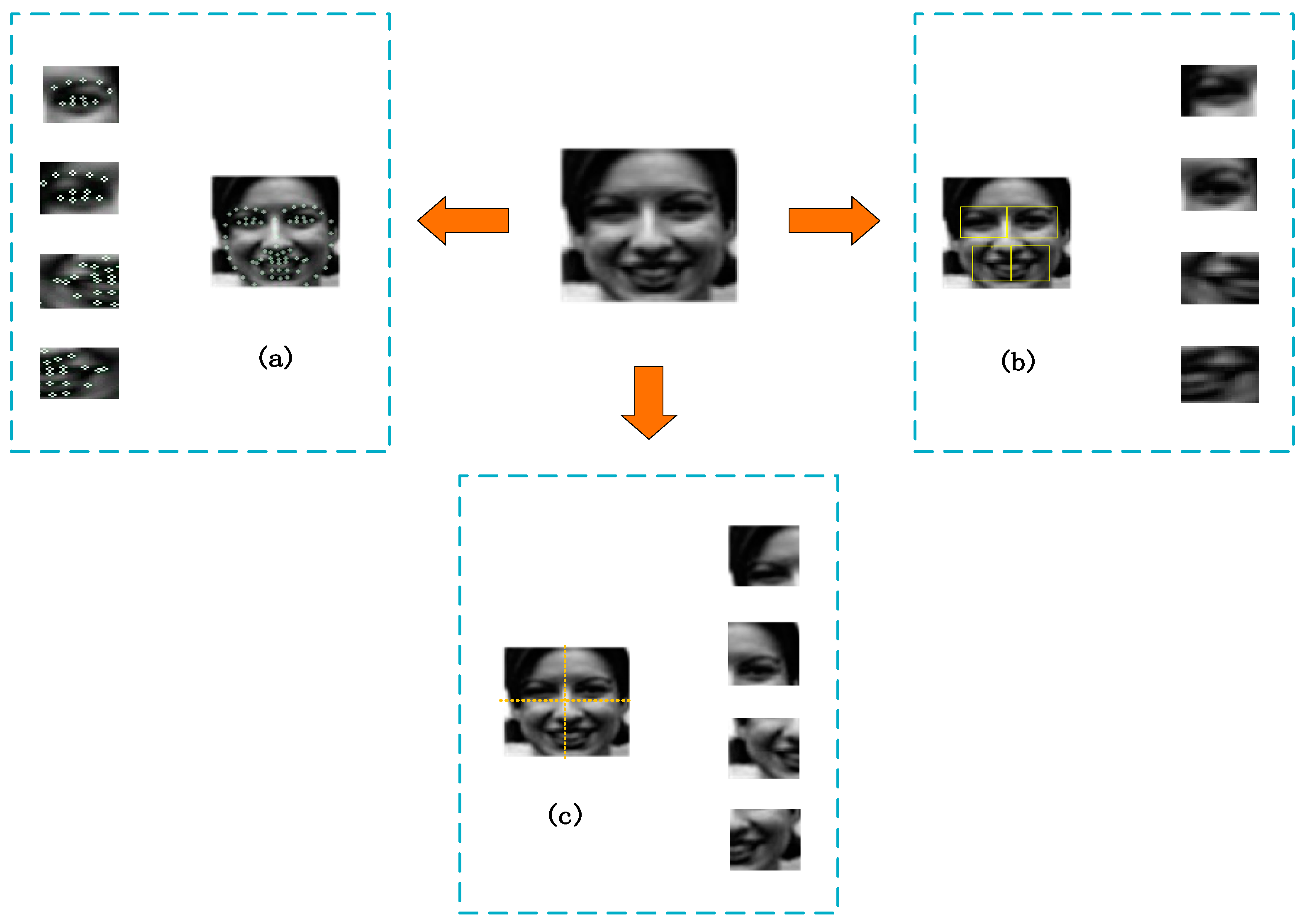
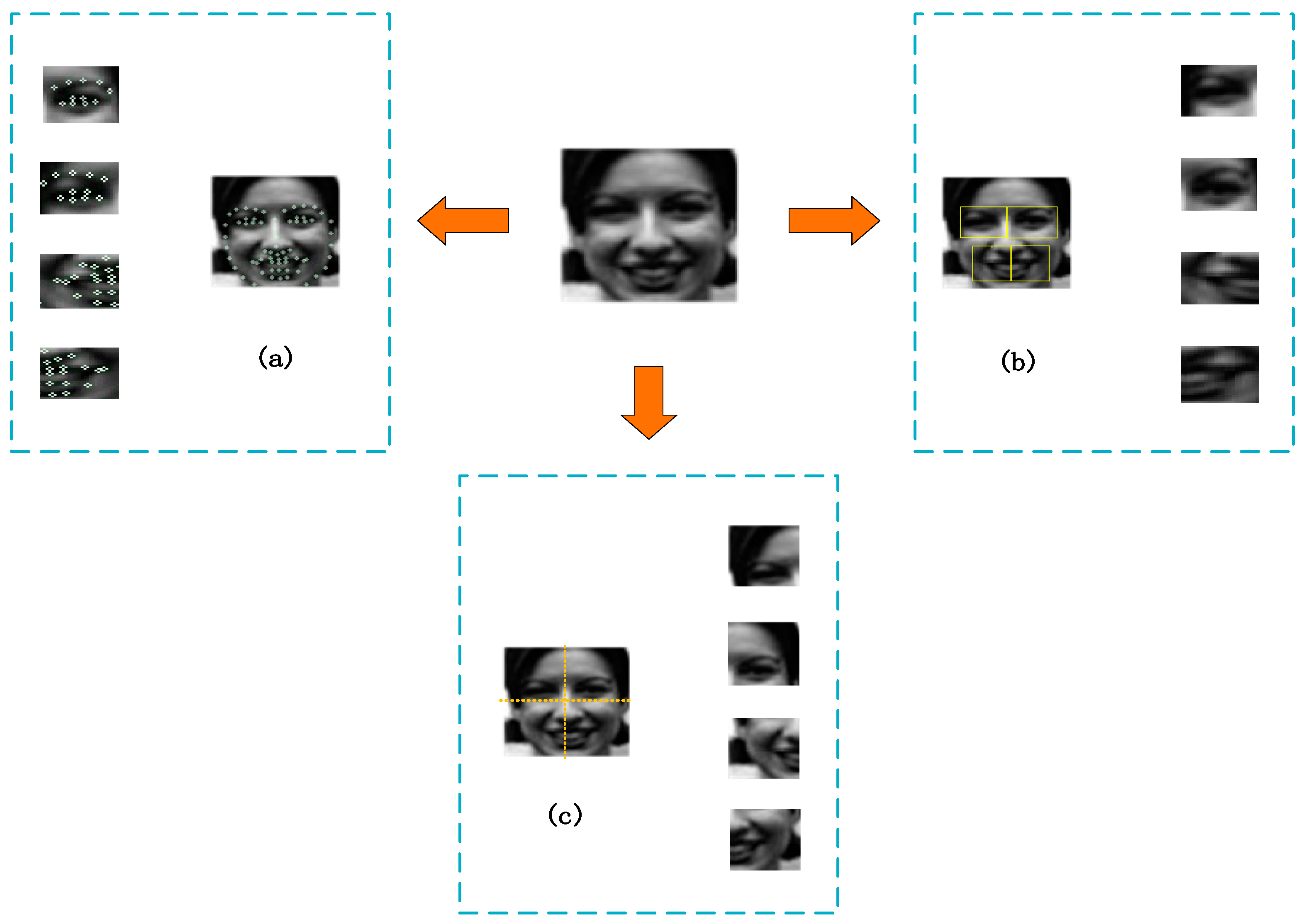
40] on facial parts, this paper extracts the features of specific regions related to facial expressions, which contribute to FER. First, we use Dlib, which is popular among researchers, to detect facial regions. Then, the eyes, nose, and left half of the mouth, along with the right half of the mouth, are selected from the facial regions as patches that are highly relevant to FER.
Figure 4 shows the different methods for the selection of facial regions. The three methods are as follows:
- (1)
Forty-two-point cropping method based on face: (a) After we read and studied many papers, we used the method from [
47] to detect 68 landmark points in the facial image after selection. Then, we selected 42 points that could completely cover the eyes, nose, left half of the mouth, and right half of the mouth. (b) Eleven point pairs are selected around the eyes, and the maximum and minimum coordinates of each eye are calculated as rectangular boundaries. We select a total of 20 points around the mouth, with 12 points each for the left and right half of the mouth, of which four points are duplicated. The two local regions are divided by the four points located in the middle for the left and right half of the mouth, and then the maximum and minimum coordinates of the left and right parts of the mouth are calculated as the rectangular boundaries, respectively. The image of the segmented region is shown in
Figure 4.
- (2)
Crop method based on four regions of the face: The local area of the face image is relatively regular. Four face images can be dropped at a key fixed location and the coordinates of the rectangular frame can be directly calculated to obtain four local blocks.
- (3)
Four-equivalent cropping method based on face image: The fixed size of the input face image is 96 × 96. The midpoint coordinates of the length and width of the face image are calculated and divided directly into four local blocks, with a size of 48 × 48.
After region segmentation, the next step is to extract features from the global image and local image regions. Since the features of the global image tend to ignore the attention to local detail features, considering the different attentions to the highly correlated local region image and the global structure image, the DPSAN in this paper introduces two paths: the local path network (LPN) and the global path network (GPN). First, the local region face images and global face images are resized to 96 × 96. As shown in
Figure 2, the LPN consists of local blocks with the resized four sets of local face images as the input. The GPN consists of only the resized global face images as the global input patches. Then, the five sets of feature maps are combined into one set. The LPN is designed to focus on highly relevant detailed information that is ignored by the global patches. The Dlib face detector is commonly used to locate faces in images. For images containing only faces detected using the Dlib detector, a face region segmentation module is required to obtain four regions. In this paper, details are given in
Figure 2.
As shown in
Figure 2, four local regions of the eyes, nose, left half of the mouth, and right half of the mouth are selected from the original image and resized to 96 × 96. Using only global images or local images will ignore some associated information in the face image. Feature fusion of the global image and local image regions leads to a better performance. DPSAN considers both the global face and local face blocks. First, considering the difference in information between the global and local images, this paper encodes the feature maps of global face and local face blocks in two ResNet18 separately so that DPSAN obtains facial expression information from the local features and global features, respectively, and refines the contextual information that may be overlooked. Second, ensemble learning studies show that multiple network combinations outperform individual network structures, and acquiring features from different scales globally and locally can also help the network to learn more diverse information related to expressions. The images of the global face regions and local face blocks are input into two ResNet18, and the final feature map of 5 × 512 × 21 × 21 is obtained after transformation.
3.3. Stacked Attention Module
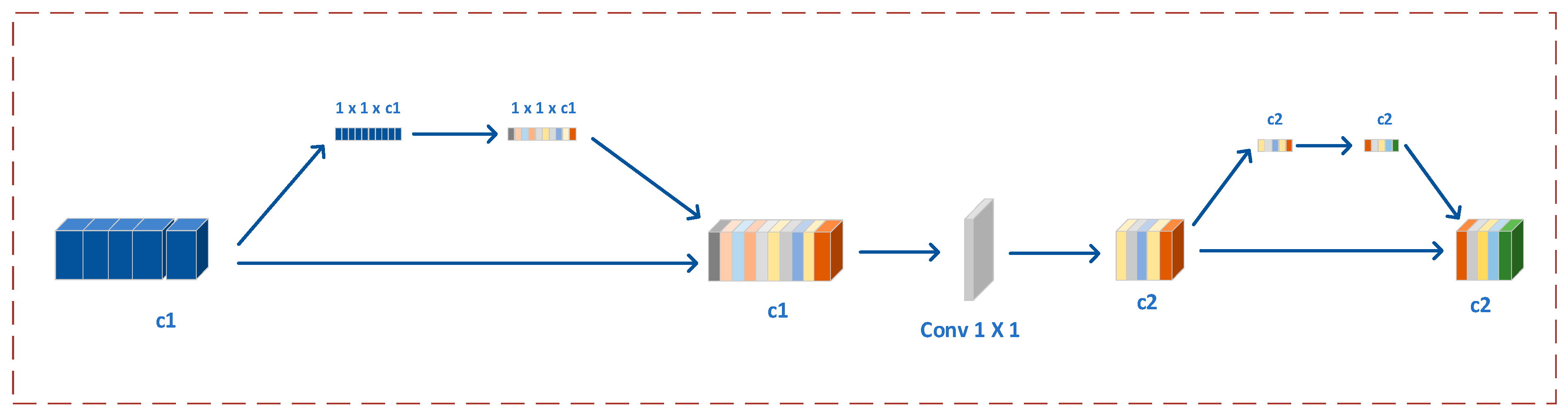
The stacked attention (SA) module computationally assigns different weights to each channel feature map with the purpose of learning weights that are more meaningful for expression recognition from the fused local and global feature maps. This module compresses the fused feature maps and filters out redundant information. In this paper, we embed SA after the dual path feature fusion module based on two ResNet18 networks to automatically reweight the whole feature map. Our proposed SA consists of two channel attentions and a 1 × 1 Conv. The detailed structure of the SA is shown in
Figure 5.
The role of channel attention is to assign weights to different channels of the feature map. In the SA module, a fused feature map
is first computed with
and
as the inputs. Then, a
is sequentially obtained after a channel attention map
[
48], with
being computed with the feature map
as input. After a
convolutional neural network calculation, another channel attention map,
, is used to calculate
, as shown in
Figure 5. The functions of the SA module are described as follows.
where
is the feature map extracted from the global path in the dual path fusion module based on the ResNet18 network,
is the feature map extracted from the local path,
is the channel attention network, and ⊗ indicates multiplication.
is the output after the first channel attention calculation, and
is defined as the final output.
For the facial expression feature maps, the weights learned for each channel dimension are different. In the process of facial expression recognition, features are extracted from each local region and global image. By weighting each channel feature, we can assign different weights to the feature maps from the four different regional images and the global image, thus weighting the fused overall feature map. The detailed structure of SA is shown in
Figure 5.
There are two steps in SA. The first step is to use the attention network to learn weights to represent the importance of the feature maps, and then merge the five groups of feature maps into one group. After our validation, the feature maps obtained with only one channel attention are too large for direct classification and do not facilitate back-propagation. The features extracted from the global and local regions are too large, and these data need to be compressed and further learned. Therefore, in the next step, a 1 × 1 convolution and another attention network are used to reduce the feature map dimensions and reweight their importance to facilitate the next step of encoding them into feature vectors corresponding to facial expressions.
3.4. Loss Function
In the experiments of this paper, to compare the difference between the predicted labels and the real labels, and to minimize the differences between them, we use the cross-entropy loss function. This function is as follows:
where
denotes the indicator variable, and the value of
is 1 if the true label of sample
is equal to
; otherwise,
is 0.
is the predicted probability that the observed sample
belongs to category
.
3.5. Summary
In order to improve the accuracy of facial expression recognition, this paper proposes improvements to the problems of insufficient attention to local detail features and irrelevant noise interference that exist in the previous FER models. First, we propose a dual path approach to segment the global face image and to extract local detail features to complement the global features via local paths, which improves the problem of insufficient attention to local features in the previous FER models and ignores the interference of irrelevant information for expression recognition. Second, we also propose the SA module to calculate the importance of each channel feature map in the fused feature map and also compress redundant data to improve the computational efficiency of DPSAN.
4. Experiment
In our experiments, we will use two public datasets, the CK+ dataset and the FERPLUS dataset. Then, the effectiveness and robustness of DPSAN will be demonstrated through experiments on these two datasets. Then, DPSAN is compared with some of the latest methods available on the CK+ and FERPLUS public datasets, respectively, to demonstrate the advancedness of DPSAN. We also designed ablation experiments to demonstrate the effectiveness of each module in DPSAN by splitting the dual path feature module and the stacked attention module in separate comparison experiments.
4.1. Datasets
Two public datasets, CK+ [
19] and FERPLUS [
21], will be used in the experiments, and the experimental data on these two datasets will be used to analyze and evaluate our proposed method. These two datasets contain many different numbers of face images. In
Figure 6, we show some examples of differently labeled images from these two datasets. The public datasets of facial expressions used in the paper are used in accordance with the official requirements of the datasets. In accordance with these official statements, we have cited the corresponding literature in the paper.
The extended Cohn-Kanade (CK+) [
19] dataset is the most widely used dataset in studies of facial expression recognition. One hundred and twenty-three subjects were included in the CK+ dataset, in which 593 video sequences were recorded. Based on the Facial Action Coding System (FACS), the peak expressions in the 327 video sequences of 118 subjects were labeled with seven basic expression labels, which were happy, angry, sad, disgusted, fearful, surprised, and contempt. Additionally, the first frame image in the video sequence was usually used as the neutral expression, which is the eighth basic expression label.
The FER2013 [
20] dataset was first introduced in the 2013 ICML challenge. This dataset is a dataset automatically collected from the web using the Google search engine without any constraints. The dataset contains a large number of facial expression images, which are adjusted and cropped to a resized image size of 48 ∗ 48. The FER2013 dataset consists of 28,709 training images, 3589 test images, and 3589 validation images. The dataset FERPLUS [
21] used in our experiments relabeled the original images in the FER2013 dataset and added the emotion label of light contempt. Additionally, each image had 10 taggers, and the labeled data allowed us to better estimate the emotional probability distribution of each face image. The eight emotion labels in the FERPLUS dataset were happiness, disgust, fear, sadness, anger, surprise, neutrality, and contempt, where the contempt tag is newly added.
4.2. Implementation Details
Pytorch [
49] and TensorFlow [
50] are both excellent open source frameworks in deep learning. Our experiments use the Pytorch framework to implement DPSAN. Previous experiments have demonstrated that ResNet18 [
43] can show excellent performance in deep learning, so two ResNet18 networks are used for feature extraction in the dual path feature fusion block of DPSAN. The batch size is set to 8, the maximum number of iterations is 1200, the learning rate is 0.0001, the Stochastic Gradient Descent (SGD) is used to optimize the network parameters, and finally, all other parameters are set to default values. Regarding the hardware parameters in the experiments, the DPSAN experiments were performed on an RTX 2080Ti GPU with 11 GB of RAM.
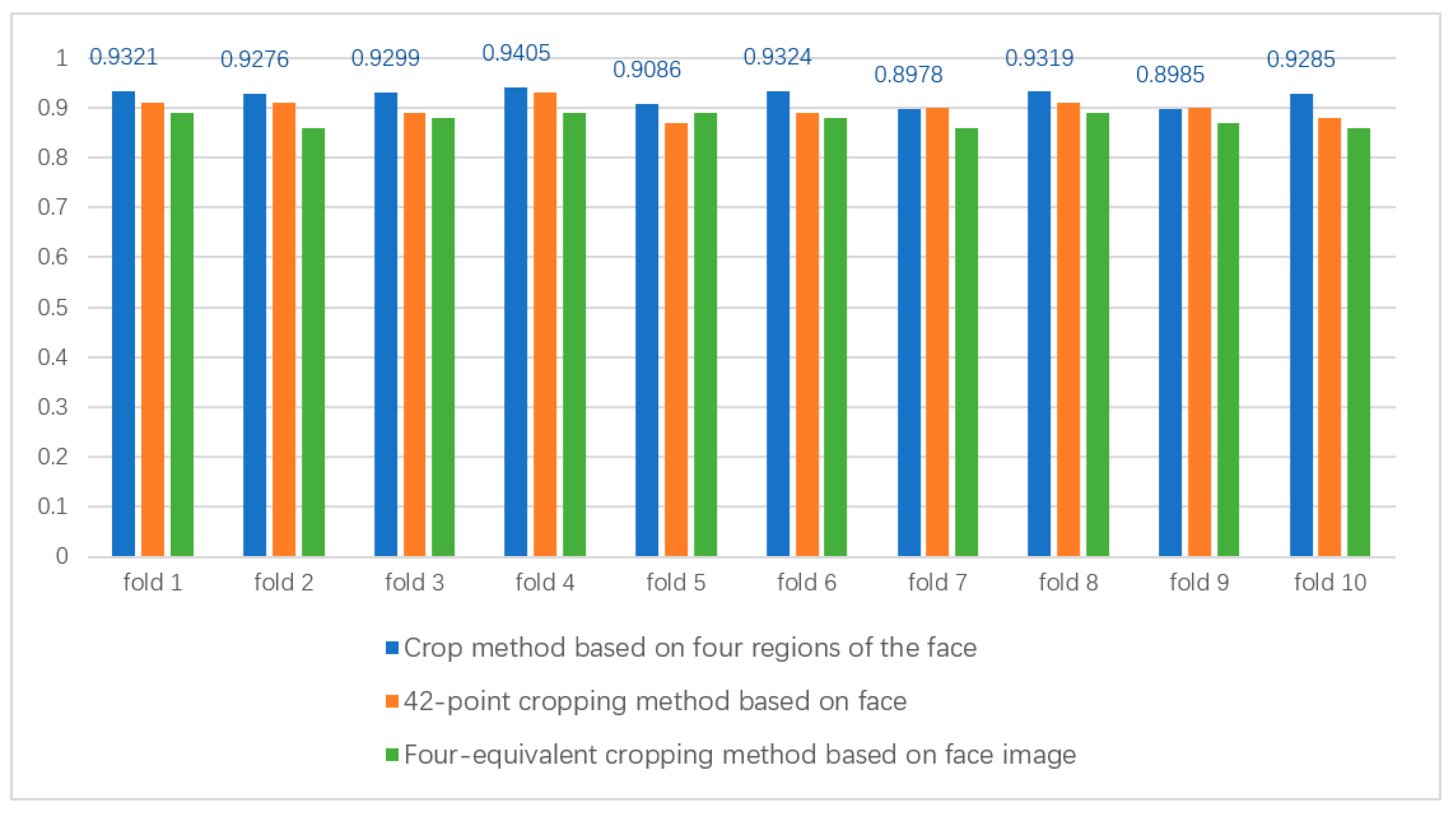
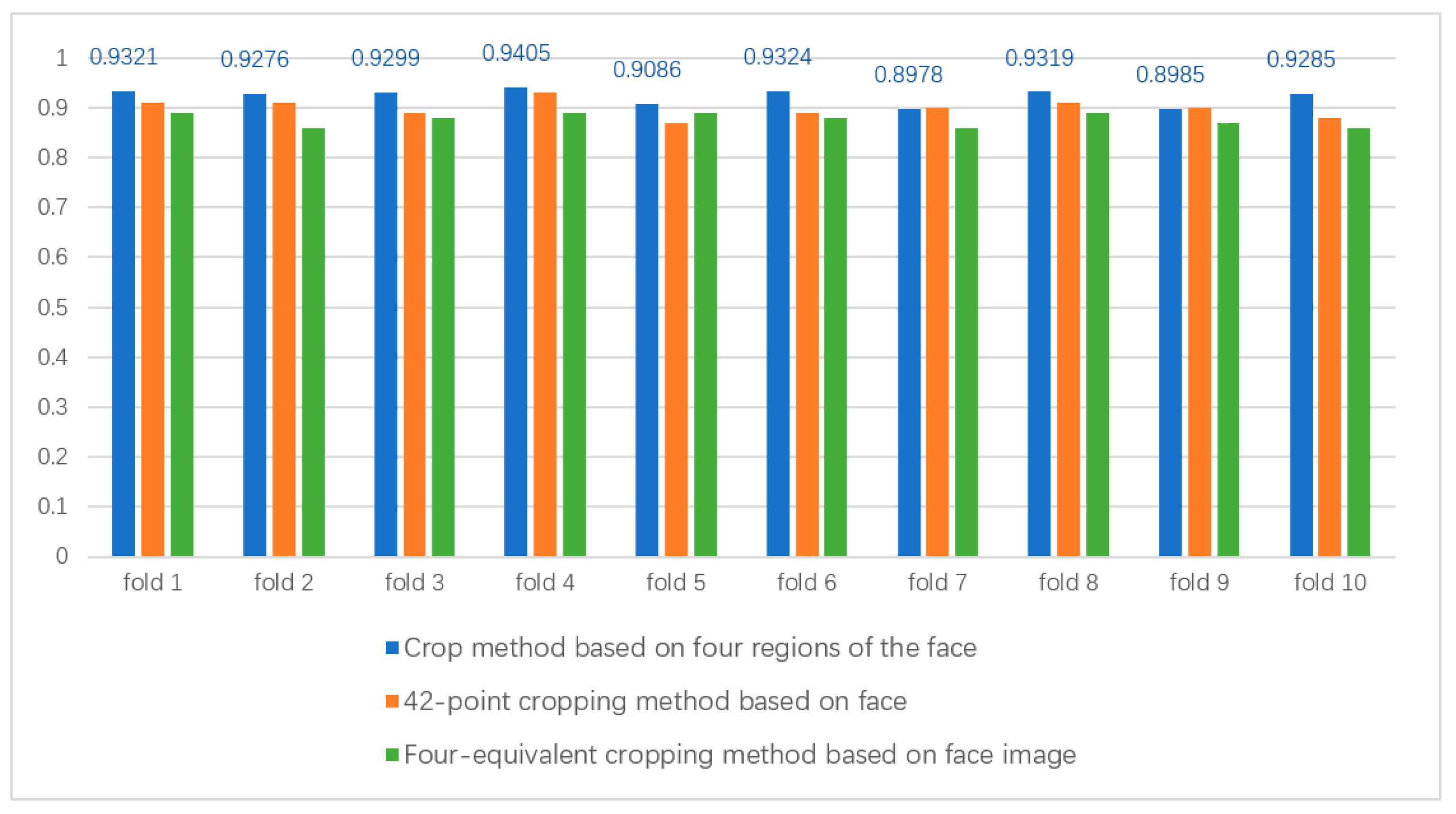
In order to improve the computational efficiency in the experiment, we designed some operations that can increase the computational speed. For the CK+ dataset, since the original image size in this dataset is 640 × 490, the information in the image has some information that is irrelevant for FER. For the global face image, we use the Dlib face detector to crop out the face image and resize the cropped image to 96 × 96, which can exclude the intra-class differences irrelevant to facial expressions and reduce the computational effort at the same time. For the local region blocks, we also cropped the left eye, right eye, left half of the mouth, and right half of the mouth from the original image and resized these regions of interest to 96 × 96. After the above operations, we evaluated the accuracy and speed of the three cropping methods via 10-fold cross-validation on the CK+ dataset. These are the crop method based on 42 points of the face, the crop method based on four fixed regions of the face, and the crop method based on four equal parts of the face image. The local area images cropped using the three methods are adjusted to the same size in the experiments. The parameter settings in the experiments are kept the same as the default settings. We show the results of the three cropping methods in
Figure 7, and the data show that the cropping method based on the fixed four regions of the face can obtain the regional information related to facial expression recognition faster and more effectively. First, compared with the four-equivalent cropping method based on face image, the cropping method based on four fixed regions of the face can obtain the FER-related region information more effectively; meanwhile, compared with the cropping method based on 42 points of the face, the cropping method based on four fixed regions of the face can obtain the FER-related region information faster because the cropping is performed almost instantaneously. More importantly, the face fixed four region-based cropping method 10-fold cross-validation is also higher than the previous two, in terms of accuracy. Therefore, the experimental cropping method used in the dual path feature fusion module is based on the face fixed four regions cropping method.
Previous ensemble learning studies have shown that the combination of multiple networks can learn more effective information from images due to a single network. Good results have been obtained for integration learning in many areas of research, such as [
51,
52,
53]. One of the feature combinations for emotion recognition in [
46] is fc5 VGG13 + fc7 VGG16 + pool ResNet, which has the disadvantage of the network and parameter size being too large and not easy to train. Our experiments select two ResNet18 for feature extraction, where four local regions share the same ResNet18, thus achieving improved computational efficiency while enabling local region images to provide more effective feature information for facial expression recognition. Meanwhile, due to the excessive number of features obtained from the dual path feature fusion module, the feature vector created by these features is relatively inefficient and difficult to train after only one channel attention network. So, we add a
convolution here, which reduces the number of parameters. The stacked attention module allows for reweighting the importance of each channel in the feature map while compressing the feature map and reducing the number of parameters through a
convolution and another channel attention network.
4.3. Comparison of DPSAN on the CK+ dataset
Combining the characteristics of the CK+ dataset, we first extracted the first frame from each sequence on the CK+ dataset as a natural neutral expression while labeling the last three frames of the sequence with the peak expression as one of the seven basic emotions. Then, the global face image is cropped using the dlib face cropper, and four local image regions of the eyes, nose, left half of the mouth, and right half of the mouth are segmented using the face key region segmentation method. The cropped images are then resized to reset the image size to 96 × 96 pixels. Since the CK+ dataset does not provide a specified training and validation set, we choose the 10-fold cross-validation scheme for training and validation. Finally, the average cross-validation recognition accuracy of 10 times is taken as the result. In this paper, we show the accuracy of the validation set of the CK+ dataset in
Figure 7, and the selected method is labeled with the data in
Figure 7.
In
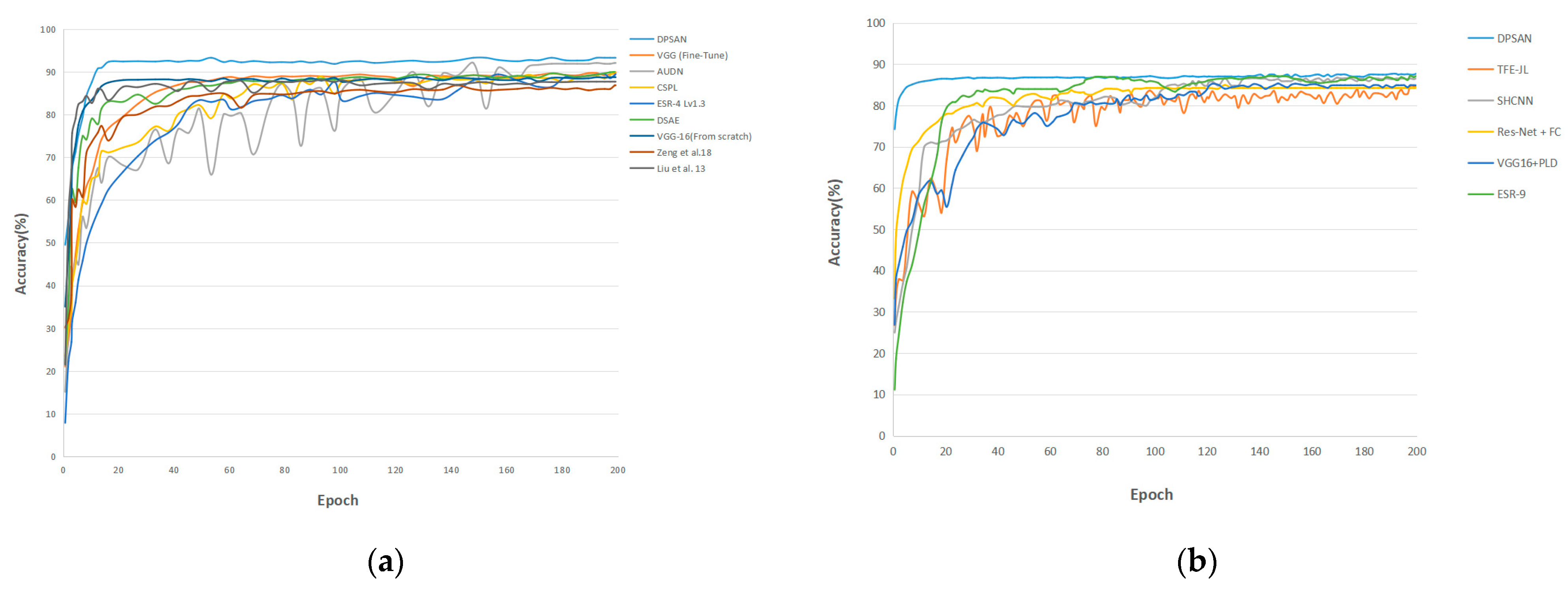
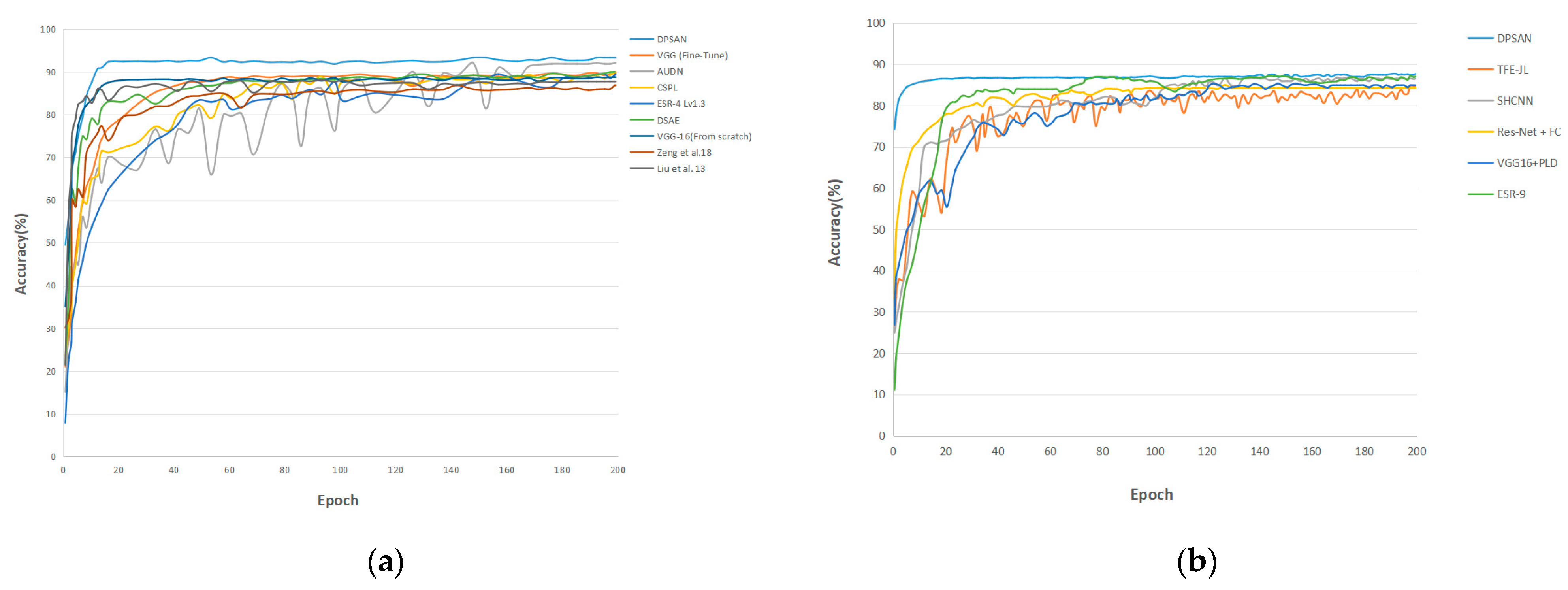
Table 2, this paper compares DPSAN with a variety of state-of-the-art methods on CK+. Among them, the accuracy of AUDN and VGG (Fine-Tune) is 92.05% and 89.90%, respectively, our proposed DPSAN reaches 93.26%, and the data in the table show that DPSAN outperforms these state-of-the-art methods. The results of DPSAN compared to other methods on the CK+ dataset are shown in (a) of
Figure 8.
4.4. Comparison of DPSAN on the FERPLUS Dataset
FERPLUS is an extension of the original FER dataset. In order to better test the recognition effect of DPSAN in the real environment in the field, this paper conducts training validation on the FERPLUS dataset. Since the image size in the FERPLUS dataset is 48 × 48, the image size is resized to 96 × 96 pixels in this paper. The DPSAN model is faster than CK+ on the FERPLUS dataset, so the initial learning rate is set to 0.1, and it is updated by multiplying it by 0.75 after every 10 cycles. Other settings remain the same as CK+.
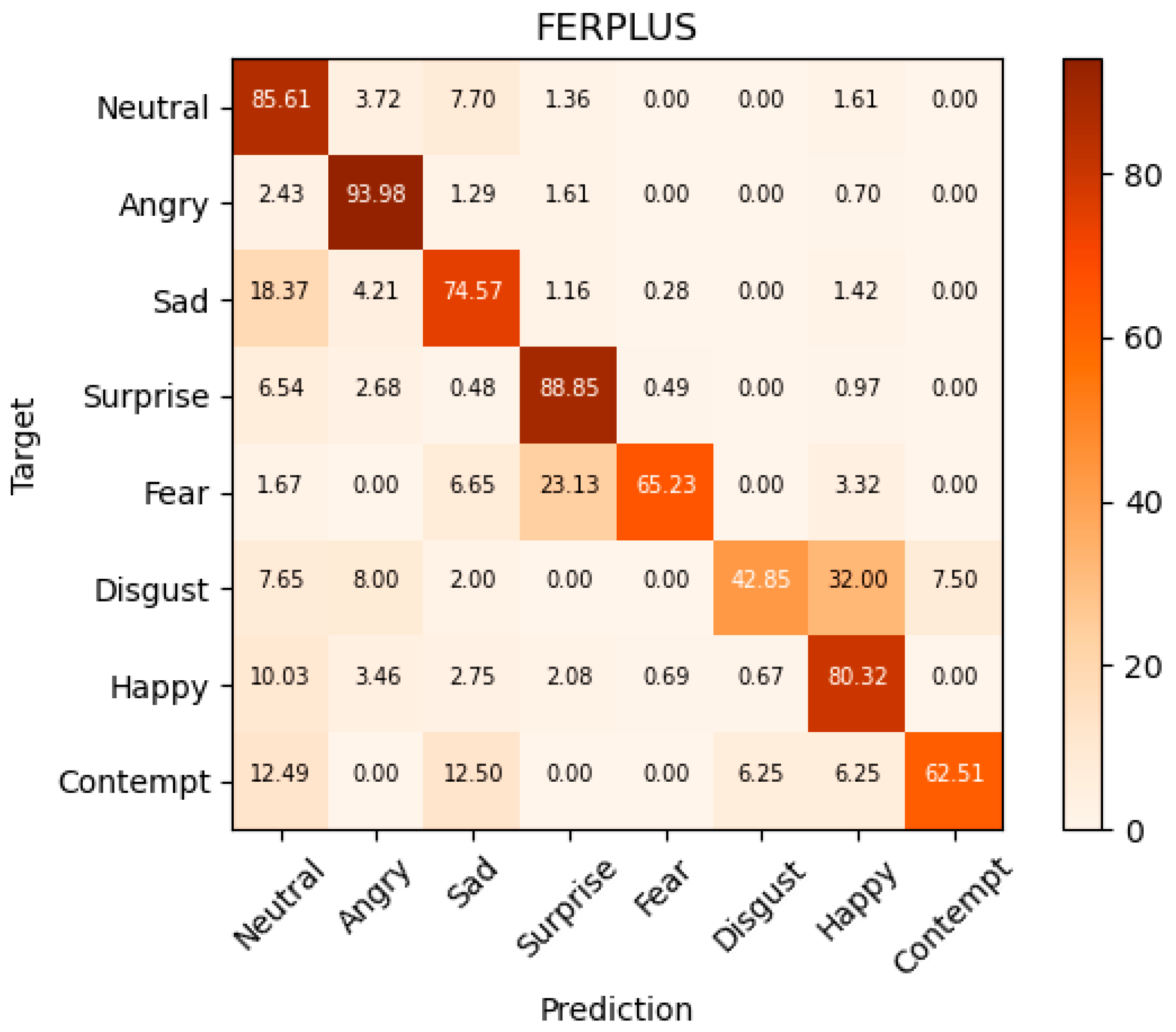
We show the results of the DPSAN comparison experiments on the FERPLUS dataset in
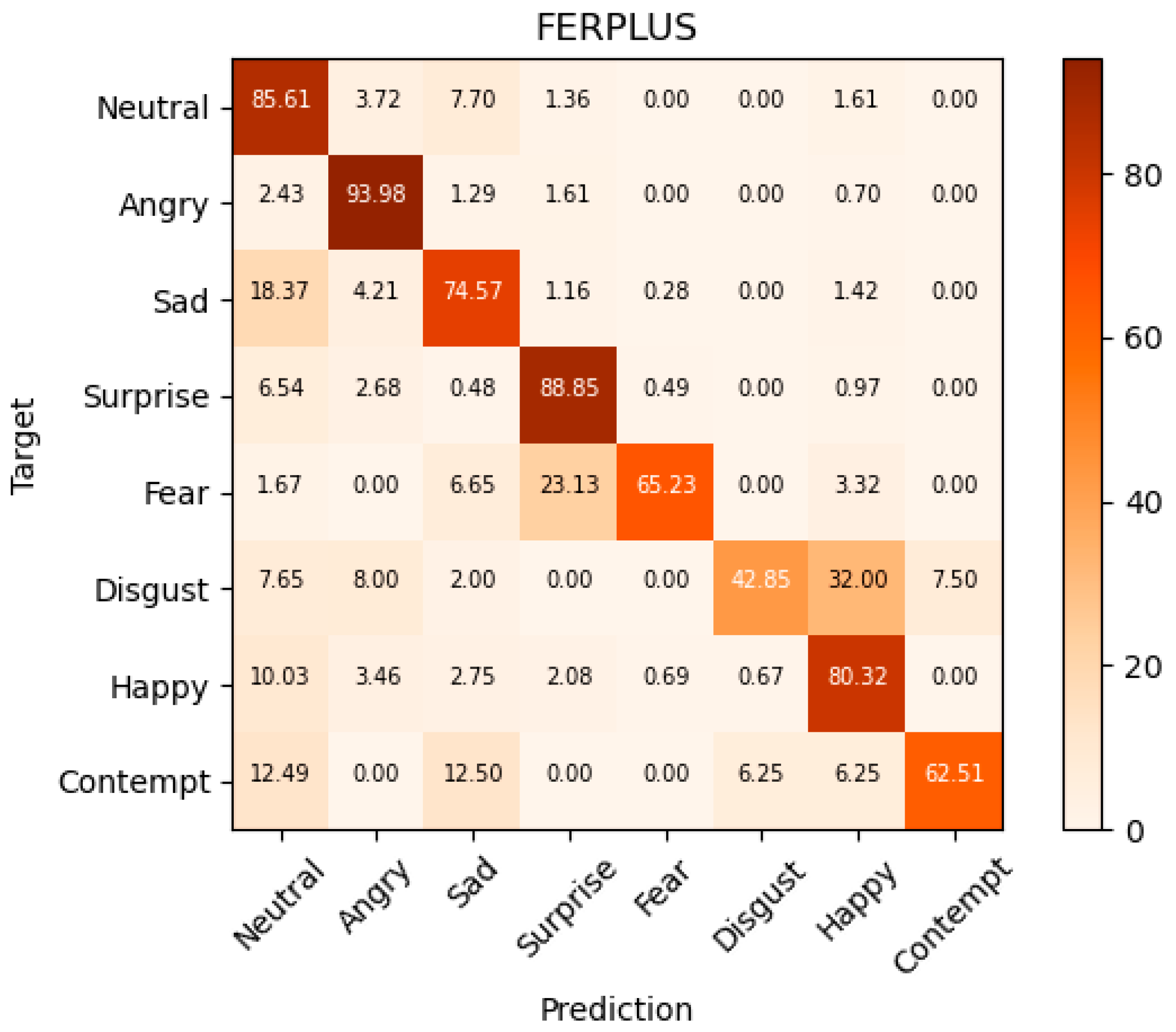
Table 3. In this paper, we compare DPSAN with various state-of-the-art methods successively. Additionally, we show the confusion matrix of DPSAN sentiment prediction on the FERPLUS dataset in
Figure 9. By comparing DPSAN with multiple advanced methods on FERPLUS, where the accuracy of ESR-9 and SHCNN is 87.15% [
14] and 86.5% [
57], respectively, the accuracy of the DPSAN proposed in this paper is 87.63%, which shows that the effectiveness of our DPSAN on FERPLUS is up to the current advanced level. The results of DPSAN with other methods on the FERPLUS dataset are shown in (b) of
Figure 8.
4.5. Ablation Experiments
In order to fully investigate the effectiveness of each module of DPSAN, an ablation experiment is designed in this paper to verify the effects of two modules, the dual path feature fusion module and the SA module, on FER.
The baseline model global path network (GN) is designed in the experiment. This model only takes the global image as input and generates a feature map through a ResNet18 shown in
Figure 3, and then classifies the expressions via a classifier. In order to demonstrate the advantages of the dual path feature fusion module and the SA module, two groups of comparative experiments are designed; the comparison between the dual path network (DPN) and GN, and the comparison between DPN and DPSAN.
First, to demonstrate that dual path networks can reduce model overfitting and have better accuracy stability over different data, a DPN model is experimentally designed. The DPN model has one more local path than the GN model, which takes the global image and local image blocks as input and is compared with GN for both accuracy and standard deviation. Second, to demonstrate the advantages of the SA module, DPN is compared with DPSAN, in which DPN lacks the stacked attention module. By comparing the two, the superiority of DPSAN in both accuracy and standard deviation can be demonstrated.
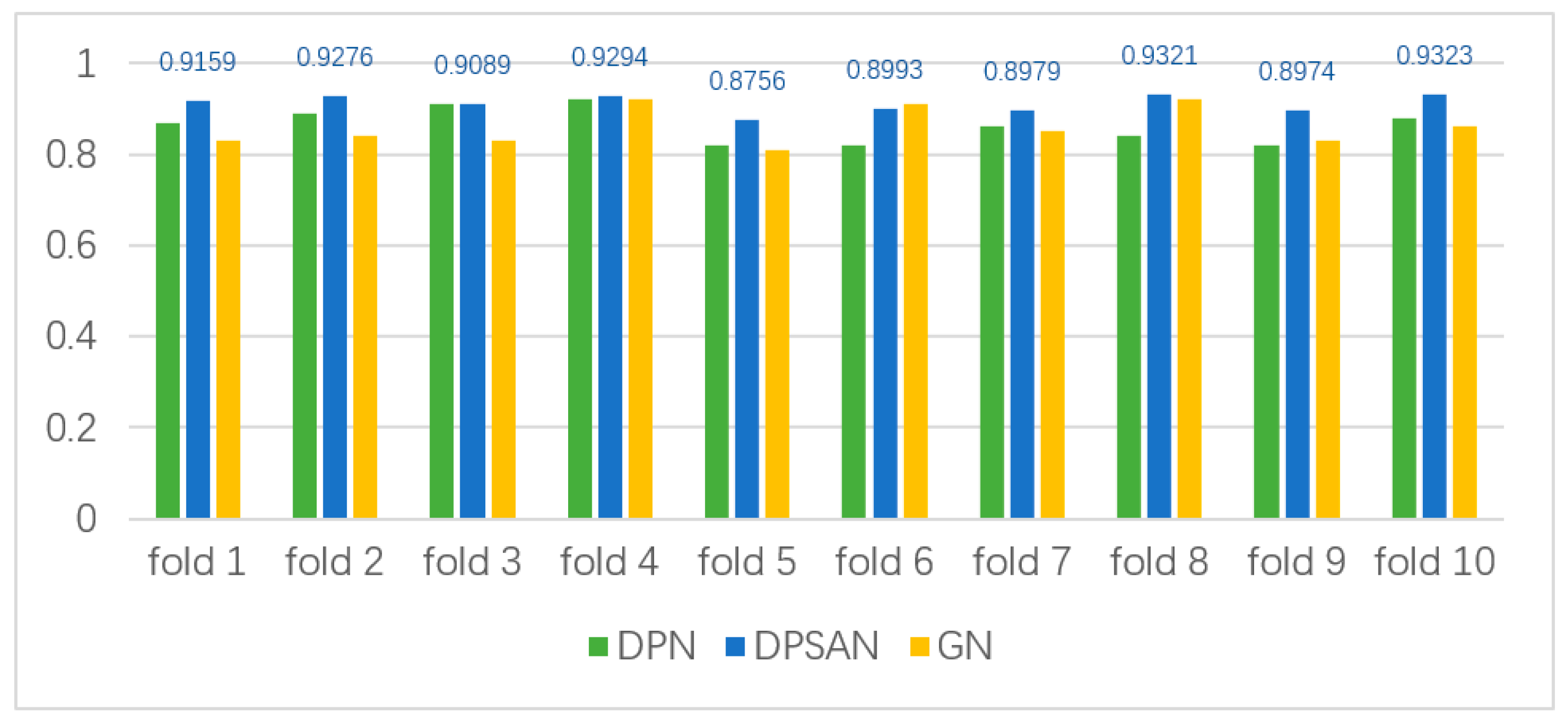
The histogram of the comparison between the two groups of experiments is shown in
Figure 10. We annotated the experimental data of DPSAN. From
Figure 10, it can be roughly seen that the accuracy of GN fluctuates a lot in 10-fold cross-validation, while DPN fluctuates less, indicating that it is less stable than DPN; and at the same time, the advantage of accuracy is too small. The performance of DPSAN clearly exceeds that of the baseline, i.e., GN. The experimental results are shown in
Table 4.
(1) DPN VS. GN: DPN and GN were compared in the experiments to demonstrate the benefits of adding a local path. The combined results in
Figure 10 and
Table 4 can now show that GN performs slightly better than DPN in terms of accuracy in certain folds. However, the standard deviation calculated by DPN is much smaller than the results of GN, which is more stable than GN, and which also indicates that DPN can introduce multi-scale expression details by adding local paths in facial expression recognition through region segmentation, and that it can complement the detailed attributes ignored by the global image features and effectively avoid overfitting. The reduction in the standard deviation shows that combining local details and global feature mapping can well suppress intra-class differences.
Additionally, considering the different contributions of local regions and global images to the FER problem, these features need to be re-weighted. Here, we design the stacked attention module.
(2) DPSAN VS. DPN: Experiments were conducted to compare DPSAN and DPN to validate the benefits of overlaying the attention module. As shown in
Table 4, the accuracy of DPSAN improved by 4.03% on the CK+ dataset. As shown in
Figure 10, DPSAN outperforms DPN and GN in almost all folds. The comparative experimental data in
Table 4 show that the SA module in DPSAN can effectively reassign the weights of each feature map based on its contribution to FER.
Through two sets of ablation experiments, the following conclusions can be drawn. First, it can be demonstrated that the dual path feature fusion module in the DPSAN model is effective and can effectively suppress the intra-class variance, but it leads to a slight decrease in recognition accuracy. Second, DPSAN achieves good results after the addition of the stacked attention module. The model achieves a large improvement on the CK+ dataset, and the accuracy improves from 89.76% to 93.26%, which indicates that the stacked attention module is an important contributing module of DPSAN, and also proves the effectiveness and advancement of the proposed stacked attention module.
5. Conclusions
In this paper, we propose a network model DPSAN for facial expression recognition. A dual path feature fusion module and a stacked attention module are designed in this paper. The model utilizes more detailed information that is ignored by the global image, reduces the effect of intra-class differences that are not related to expression recognition, and also expands the size of the experimental dataset.
The dual path feature fusion module designed in this paper by combining the global and local features can be used to reduce the impact of noise caused by intra-class differences unrelated to expression recognition, and to increase the data to alleviate the problem of insufficient data. In order for DPSAN to learn key features more effectively, compress features, and reduce the number of parameters, a stacked attention module is designed in the model and it achieves better results in terms of the accuracy of FER. Finally, the analysis of ablation experiments shows that both the dual path network and the stacked attention module are important modules of DPSAN. Experiments under two dataset evaluation protocols show that DPSAN achieves the performance of other state-of-the-art methods. At the same time, due to the presence of some images in the CK+ and FERPLUS datasets that do not have obvious expression features or images with relatively obvious intra-class differences, these factors can make it difficult for the image algorithm to obtain a very good performance gain at once. Therefore, the accuracy improvement obtained by DPSAN is meaningful when compared with the accuracy improvement obtained using other methods.
There are also shortcomings in this paper. In the experiments, our model only considers expression recognition on a pure dataset of face expressions without occlusions. However, in real scenarios, face images may be obscured by glasses, masks, and many other occlusions. Especially in the current global epidemic, wearing masks has become the norm in people’s lives, and these occlusions can affect the accuracy of expression recognition. So, how to improve the accuracy of facial expression recognition under the condition of partial occlusions, such as mask occlusion and glasses occlusion, will be one of the major challenges to overcome in our research in the future.
In our future work, we will further investigate the following perspectives in order to reduce the impact of occlusion on expression recognition. First, we will consider the use of spatial attention for obtaining the feature information of unobscured regions and more important regions in face images from a global perspective. Second, considering the advantage of local paths to capture more details in this paper, we will consider segmenting the occluded face image into several local regions for feature extraction. Finally, we will consider using both channel attention and spatial attention to give higher weights to the features of important regions spatially and to the features of important channels spatially, so as to reduce the effect of occlusion on expression recognition.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}