1. Introduction
Machine learning (ML) is consistently one of the most-applied computing disciplines in the current technological era and has become the norm synonymous with artificial intelligence (AI). The popularity of ML and its widespread use in many applications has led it to become a must for every business or organization intending to gain an edge over their competitors. Deep learning (DL) is a subset of ML. The differentiation between the two lies in the number of layers in the architecture of artificial neural networks. A deep neural network has more than one hidden layer. Contrariwise, an artificial neural network like Support Vector Machine (SVM) has only one hidden layer [
1]. DL has seen steady adoption because of its performance over traditional state-of-the-art ML algorithms used in different fields, particularly image processing [
2,
3]. A popular example of a DL framework is TensorFlow, which has support for scalability in training DL models in a distributed manner, capable of scaling across 200 workers [
4]. However, the distributed inference aspect in TensorFlow has yet to be tested so far.
Nowadays, researchers no longer solely implement DL-based image processing on high-performance hardware. Researchers have experimented with low-cost, low-power embedded devices such as Raspberry Pi and Nvidia Jetson Nano. These include an AI traffic control system, face recognition systems, as well as an integrated smart CCTV system [
5,
6,
7]. The computational power of Raspberry Pi was barely sufficient for training ML models. Some researchers have opted to use a pre-trained model that was trained using powerful hardware before deployment on Raspberry Pi [
8]. Thus, Raspberry Pi is mostly limited to prototyping DL inference operations as an embedded device rather than training DL models.
Raspberry Pi (Pi) is a single-board computer (SBC) designed and manufactured by the Raspberry Pi Foundation in the United Kingdom. Compared to a standard mid-end desktop which typically costs around US$500 to US$600, the latest Pi 4 Model B (Pi 4B) costs just US$35 for the base 2 GB RAM model. Its low cost makes it appealing among IoT hobbyists and it is used for prototyping embedded systems in research. Pi 4B is powered by a Broadcom BCM2711 system-on-a-chip (SoC), comprising four Cortex-A72 cores at a clock speed of 1.5 GHz and two to eight gigabytes of LPDDR4-3200 RAM, depending on the model variant. In contrast to previous generations of Pi, Pi 4B includes the addition of two USB 3.0 ports which allow for faster forms of storage to be used, such as an external HDD or even an external SSD in place of the traditional microSD card. Pi 4B runs on its customized version of the Debian operating system named Raspberry Pi OS, even though it supports other Linux operating systems such as Ubuntu and Arch Linux ARM.
However, DL inference performance benchmarks for Pi 4B are lacking, as most research papers focus on prototyping AI systems using Pi 4B. This is especially important as Pi is increasingly replacing traditional computers in prototyping systems. The choice of choosing a base system for prototyping depends on the computational complexity of the prototype system itself. In a scenario where researchers plan to implement a prototype system, the choice for the base system would be rigorously evaluated to determine whether it fulfills the requirements set out for prototyping. As Pi 4B is touted to be faster than its predecessor, the performance gap between Pi and a conventional computer may be reduced. Most ML and DL benchmarks carried out with the previous generation of Pi (3B) could quickly become obsolete and irrelevant. Thus, there is a need to re-investigate the performance difference between Pi 4B and a conventional x86 desktop computer to ensure performance review results are up to date. There is also a need to study the improvement of the enhancements for Pi 4B in lessening the performance gap between Pi 4B and a conventional x86 desktop computer. Given its low cost, the increase in the competitiveness of the Pi 4B against powerful and modern hardware could also increase its appeal for prototyping.
Other than enhancing Pi’s performance through software tweaks, the clustering of multiple Pis is also known to improve performance in heavy processing workloads and offers somewhat competitive performance for certain workloads [
9,
10,
11]. Despite the existence of the research mentioned in earlier papers implementing Pi clusters, there is very little to no information about the performance evaluation of Pi clusters in DL inference. This also forms another research gap to further investigate how well Pi SBCs perform in many aspects via system comparisons and scalability tests. To the best of the authors’ knowledge, the closest attempt to distributed DL inference was by using the Apache Spark clustering framework via Spark MLlib. However, this framework only encompasses traditional ML paradigms which limit flexibility in implementing the distributed DL system [
12]. Such a limitation would disallow the implementation of novel, state-of-the-art DL models into a distributed system. For context, Apache Spark supports only a popular set of classification, regression, and clustering algorithms such as random forest and linear SVM. Its closest classifier is multilayer perceptron, though customizability is limited to the number of layers rather than the entire neural network structure.
Apache Spark is a data processing engine suite designed for distributed processing and data analytics. It is incorporated into the Hadoop ecosystem by working with or replacing Hadoop MapReduce. Intermediate operation results in Spark are stored as resilient distributed datasets (RDDs), which use RAM. By using RDDs, processing operations can be up to 100 times faster compared to MapReduce, as there are no intermediate disk I/O operations that limit the processing speed. However, this comes at the cost of memory space for Spark jobs, which necessitates the use of high-capacity RAM. While the impact of using a Spark cluster for inference tasks in MLlib is already known, as seen in [
12], there is no information on the impact of using a Spark cluster for distributed inference in other DL frameworks outside MLlib. DL frameworks, such as TensorFlow and PyTorch, offer superior versatility and customizability regarding the creation and testing of a DL model. Moreover, MLlib is concerned with traditional ML paradigms and not DL, as per the focus of this paper. Thus, there is a need to investigate the performance difference between using a Spark cluster versus a single system for inference tasks outside of the MLlib framework.
To reiterate, the entire scope of this paper first encompasses the study on the effectiveness of distributed inference using Spark TensorFlow Distributor, which is achieved by investigating the performance difference between using a single Pi and a 2-node Pi cluster. Identifying the performance difference between a single system and a 2-node cluster is crucial in understanding the effectiveness of distributed inference versus a single system, as the relatively novel Spark TensorFlow Distributor is experimentally trialed for this study as opposed to Spark MLlib which is proven to scale in ML tasks. So far, Spark MLlib remains in use as the preferred option for scalable ML with the Spark clustering framework and it is interesting to know whether distributed DL inference with Spark TensorFlow Distributor would show potential to compete against MLlib not just in the customizability aspect, but also in terms of performance scalability. Second, the performance gap between Pi 4B and a standard mid-end desktop in inference tasks involving lightweight and standard DL models will be identified. In contrast to standard DL models, lightweight models require significantly less processing power for inference, which is suitable for resource-constrained systems. However, these models are less accurate than their novel DL counterparts in most tasks. In the interest of fairness, both lightweight and standard DL models are included to investigate the performance gap between the two systems. In addition, this comparison may help discover a relationship between using lightweight or standard DL models. Through the identification of the performance gap, an estimation of Pi 4B’s DL performance can be made for reference when setting up DL prototype systems using Pi 4B. Third, the performance of the enhanced Pi 4B will be studied and compared against the standard unaltered Pi 4B and its 2-node Spark cluster counterpart in TensorFlow inference tasks. This aspect evaluates the impact of the enhancements on the Pi 4B and determines the more effective approach to increasing the DL performance of the Pi 4B. So far, TensorFlow is the only DL library that officially supports the Spark clustering framework via Spark TensorFlow Distributor for scalable DL. The use of TensorFlow Lite for this study was originally considered, but it was revealed that the Spark TensorFlow Distributor, which interfaces both Spark and TensorFlow, only supports the standard version of TensorFlow. Thus, it was not possible to use TensorFlow Lite with Spark TensorFlow Distributor.
The rest of the paper is organized as follows.
Section 2 presents the related work that serves as motivation to investigate the DL performance of the Pi 4B, distributed or otherwise.
Section 3 presents the evaluation metrics used, the procedure of the experiments, environment configuration, test systems, software used for carrying out the experiments of this study, and the implementation of the Spark cluster.
Section 4 details the experimental results and the results of the enhanced Pi.
Section 5 discusses the results and hypotheses and the performance gap of the Pi 4B relative to other systems.
Section 6 details the contribution and suggestions of this work, as well as possible future works.
3. Methodology
3.1. Evaluation Metrics
This section outlines and explores the performance metrics that were used for evaluation in the experiments. Most of the performance metrics are chosen from the research paper reviews in
Section 2, though interpretations of the metrics may be different depending on the context of the research scope and objective.
The metrics chosen for the experiments are execution time, frames per second (FPS), and speedup. Their respective equations are shown in
Table 2. Execution time is defined as “a period in which an event is actively operating” [
17]. It is the time taken to complete an execution job. Execution time as a performance metric has been used in many papers involving processing applications, as with [
14,
16] reviewed earlier in
Section 2. Execution time is used as the primary performance metric in this study because this metric well represents the real-world processing performance for an application or a system, as opposed to the theoretical on-paper performance measures such as GFLOPS. In this paper, this term is synonymous with model inference time.
The definition of frames per second is perhaps best defined as the number of image frames rendered in one second, which is commonly used for videos and for benchmarking graphics performance in video games. This is the case as videos are essentially a continuous sequence of image frames. However, there are multiple interpretations of this metric. For example, Ref. [
18] defined it as the “measure of fluidness of movement”, as higher FPS relates to smoother and more fluid motion in videos and games alike. Instead of merely focusing on video camera fluidity and smoothness, FPS is also used as a metric for inference speed in object detection and recognition, especially in [
19], where the authors benchmarked ZF’s in-house ProAI SBC against the NVIDIA Jetson Nano and a Dell laptop with a dedicated NVIDIA Quadro P2000 workstation GPU. This specific metric is used for the experiment where rendering frames that have undergone face detection highly depend on the inference speed of the face detection model, rather than the FPS as captured by the camera. For this study, the former is used since DL model inference related to face detection processes a series of frames that are captured by a source before being returned as another set of frames.
Speedup is defined as “the ratio of the performance improvement on different input sizes between two systems processing the same problem” [
20]. Speedup is a metric used to measure the effectiveness of a configuration versus some baseline configuration for a processing job, as found in [
15,
20]. Besides being used in clustering versus single node scenarios, as per the case of Pi 4B versus the 2-node Pi 4B Spark cluster, it is also used for comparing the performance difference between different system configurations, processing models, and software settings. This specific metric is used for measuring the effectiveness of distributed inference using Spark TensorFlow Distributor, the effectiveness of the enhancements on the Pi, and the performance gap between systems, which are the scopes of this study.
3.2. Neural Network Models & Datasets Used
The first experiment used the ImageNetV2 [
21] and CIFAR10 [
22] datasets for evaluating the inference performance in image classification for every system stated in
Section 3.6. ImageNetV2 was chosen as it is considered the benchmark dataset for classification models. CIFAR10 was chosen to complement it as a simpler and smaller dataset in contrast to the complex nature of ImageNetV2. The next experiment deals with face detection performance using the WIDER FACE [
23] image dataset, which was the face detection benchmark dataset for the second experiment. Convolutional neural networks (CNN) such as Inceptionv3 and its lightweight counterpart, MobileNetV3, were used for image classification for all system configurations in the first experiment, whereas RetinaFace, YOLOface, and Multi-task Cascaded Convolutional Network (MTCNN) were used solely for face detection in the second and third experiments.
Nowadays, there are a wide variety of CNN architectures for different use cases. Newer CNN architectures can classify datasets with a high number of labels, such as ImageNet, at higher accuracy, as with InceptionV3. InceptionV3 is the newest version of the Inception neural network model and contains a different neural network structure as opposed to its predecessors. It is pre-trained on the ImageNet dataset, which saves the hassle of transfer learning, as inference can be done on the test set of the ImageNet dataset directly. It is one of the best image classification models in terms of accuracy and is therefore chosen for the experiment to investigate the performance trade-off for the testing accuracy gained. MTCNN [
24], RetinaFace [
25], and YOLOface [
26] are other CNN architectures optimized for face detection. YOLOface is a version of the YOLOv3 CNN model trained on the WIDER FACE dataset, and it obtains higher accuracy than YOLOv3 in detecting faces. MTCNN is different and is comprised of 3 components. As explained in [
27], the first component is the Proposal Network (P-Net) which generates candidate windows that help in classifying images as ‘face’ or a ‘non-face’. These candidate windows are used to estimate bounding boxes on face locations. The second component, the Refine Network (R-Net), is intended to reject false candidate windows. Finally, the Output Network (O-Net) outputs the facial landmarks’ positions based on the results of the two previous components. RetinaFace is a recent state-of-the-art face detection architecture that uses feature pyramid networks that are based on the concept of convolution seen in CNNs. Notably, it achieved one of the highest accuracies in the WIDER FACE dataset at 91.4%.
Table 3 summarizes the datasets and models used in Experiments 1 to 3. The use of common lightweight face detection models such as the Haar-Cascade algorithm and SSD for Experiments 2 and 3 was not considered, as the intended focus was solely on comparing state-of-the-art, high-accuracy face detection models on Pi against the rest of the system configurations for the coverage of this research.
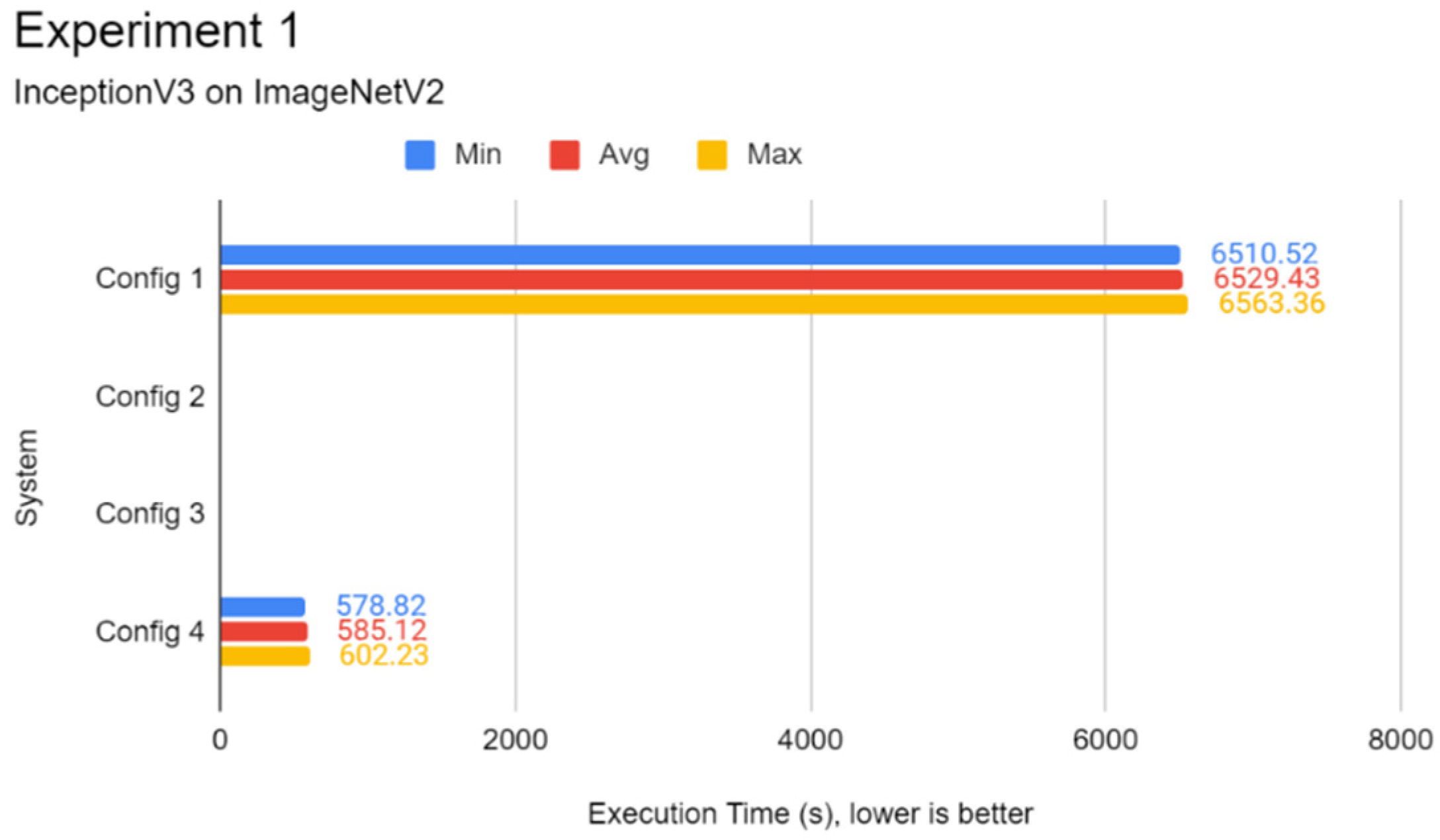
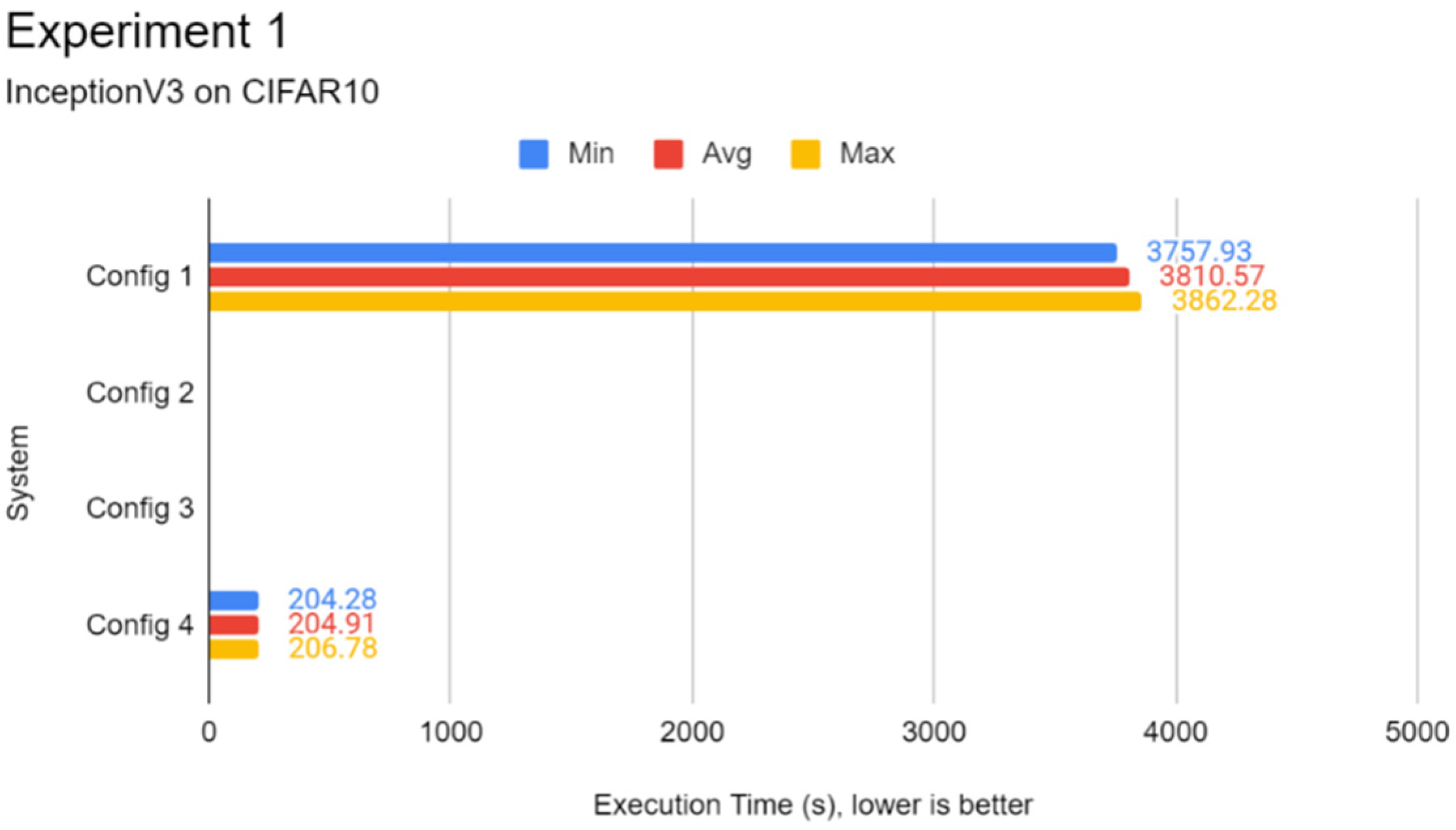
For Experiment 1, the datasets used were the ImageNetV2 test set and the CIFAR10 test split. The ImageNetV2 dataset is a specialised test set that follows the original ImageNet2012 dataset with the same label space, each comprising 10 test images per class. It is comprised of 10,000 test images which can be paired with an existing model that is pre-trained on the ImageNet2012 dataset for running inference. The CIFAR10 test split is comprised of 10,000 images which are 32 × 32 in resolution and are coloured. For consistency reasons, test splits for these two datasets were chosen as the goal was to evaluate the performance across every system configuration rather than evaluating the neural network models used in this paper.
For Experiment 2, the WIDER FACE dataset [
23], which is a face detection benchmark containing faces taken from the WIDER dataset, was used. The official recommended dataset split is 40% for training, 10% for validation, and 40% for testing. Its
test split dataset contains 16,097 images, which are similar in size to the
train split. Originally, the plan was to use the
test split for executing inference on the WIDER FACE dataset. But during the experiment, the time taken was exorbitantly long for low-end devices where it required almost a week to complete inference on a single iteration on the Pi 4B. Hence, the decision was taken to reduce the dataset size to the
validation split, which contained 3220 images.
For Experiment 3, the experiment captured frames continuously in a real-time face detection test.
3.3. Experiment 1: Image Classification Inference Test
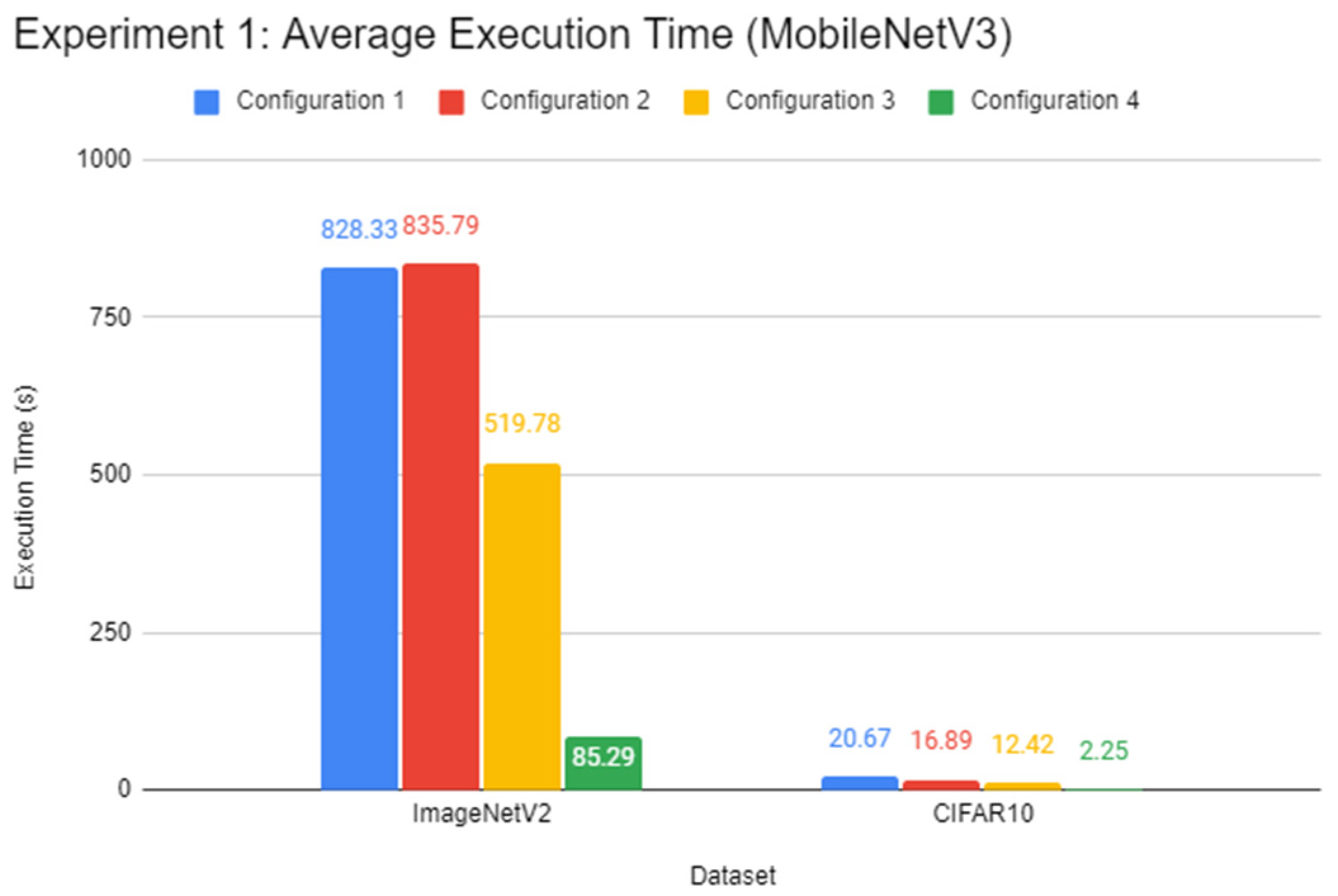
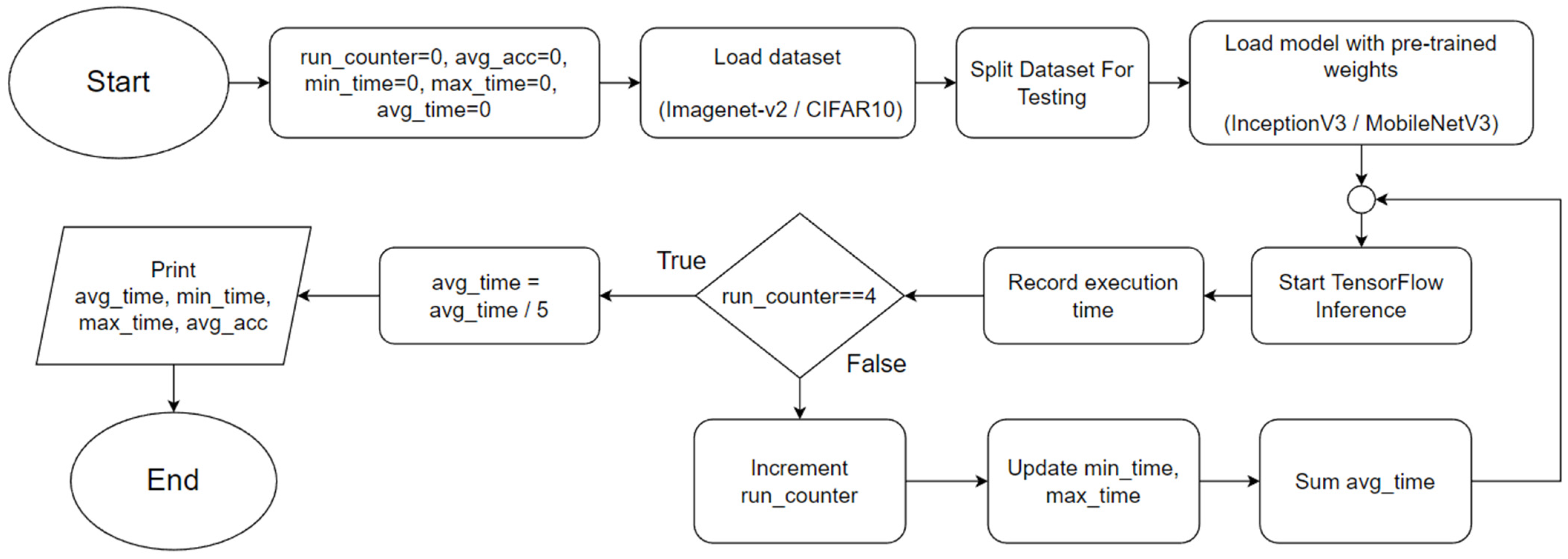
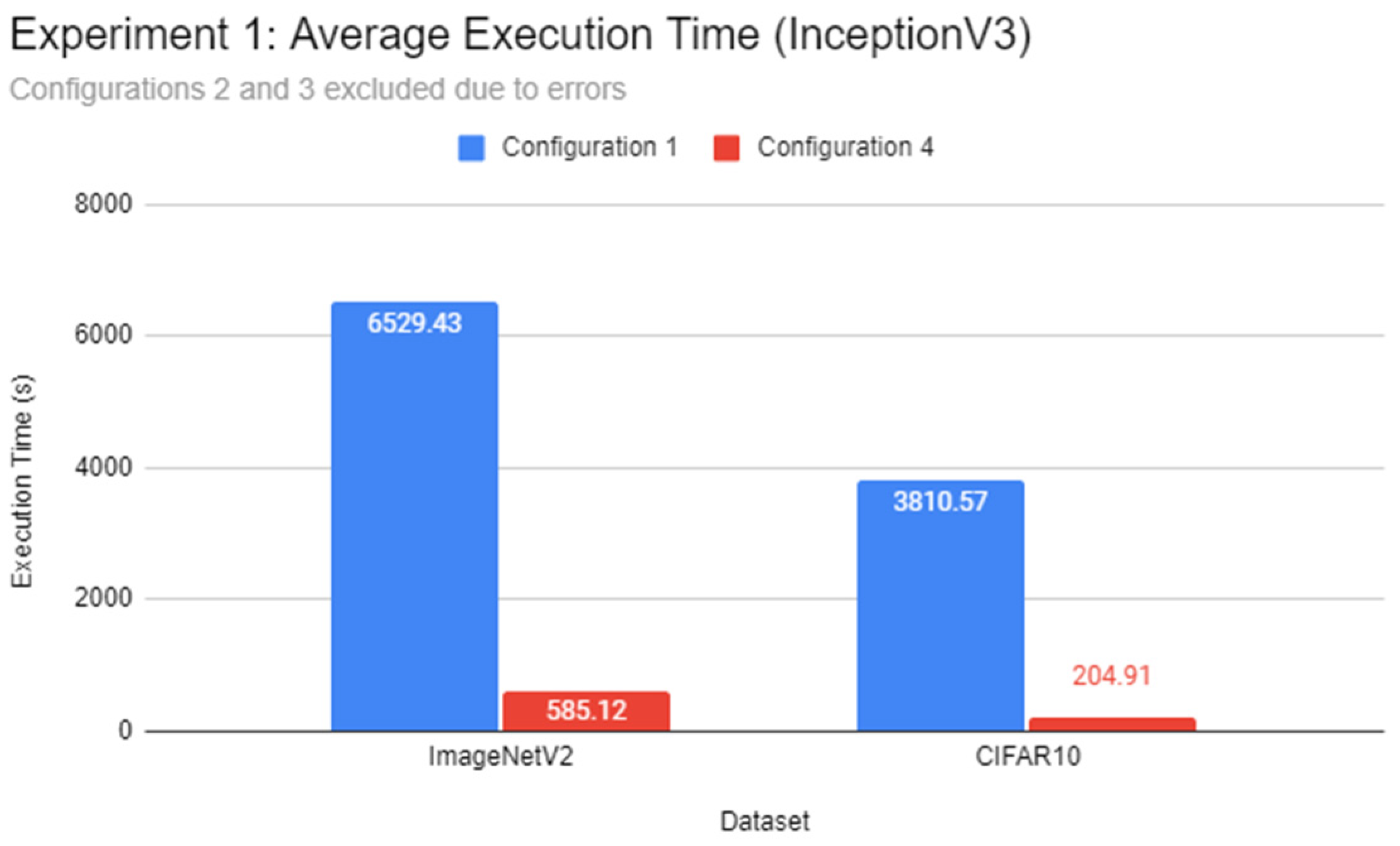
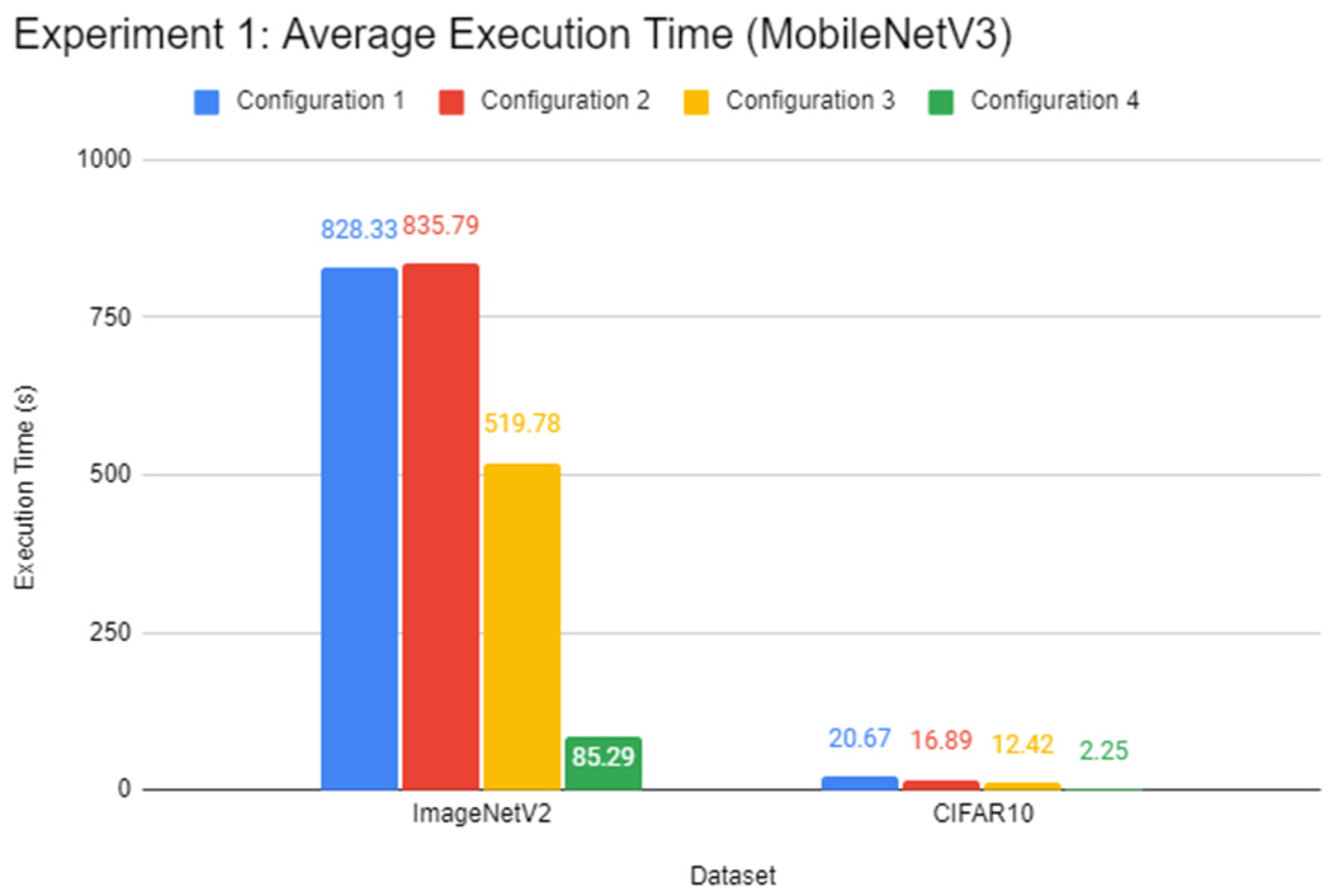
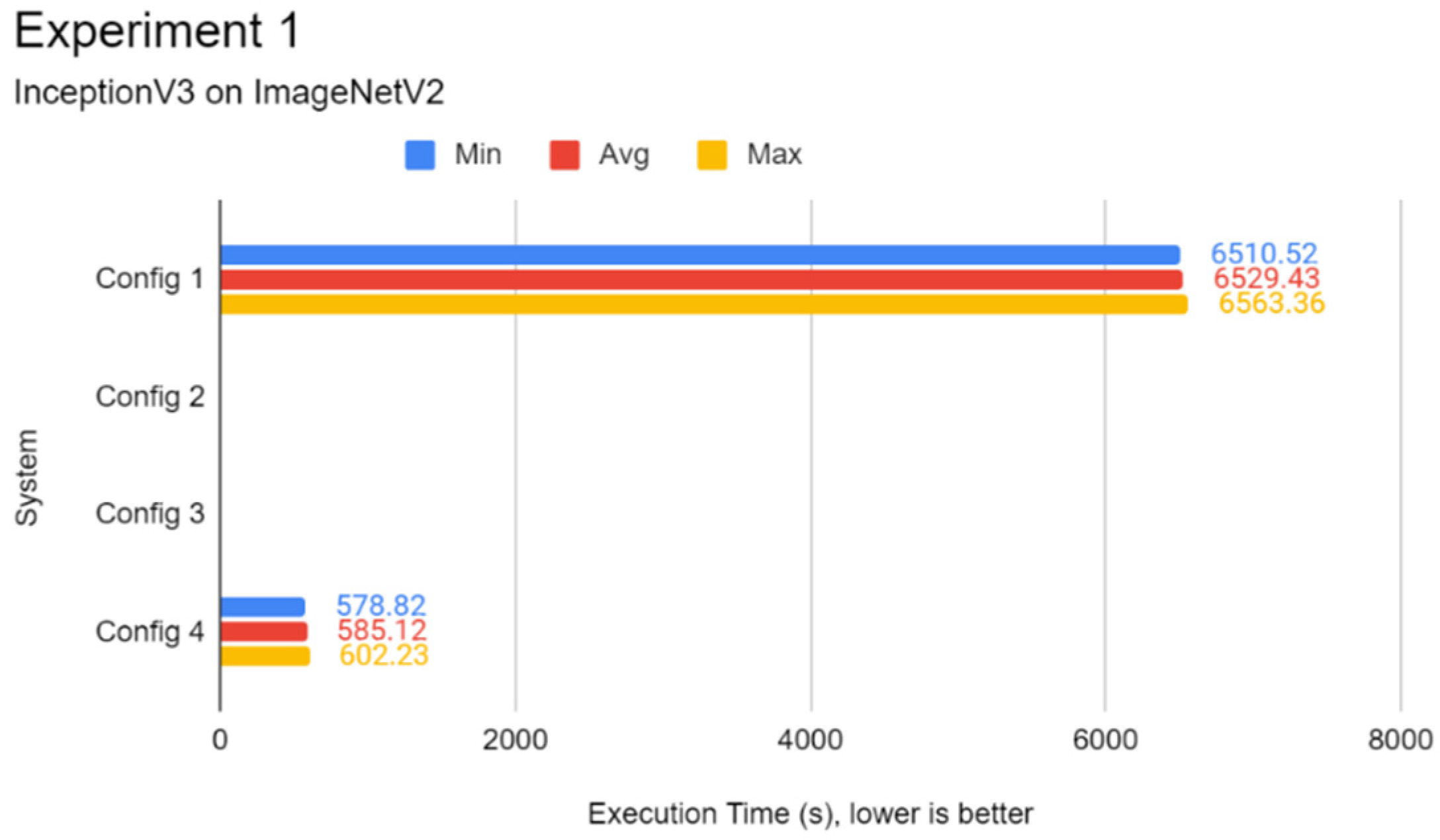
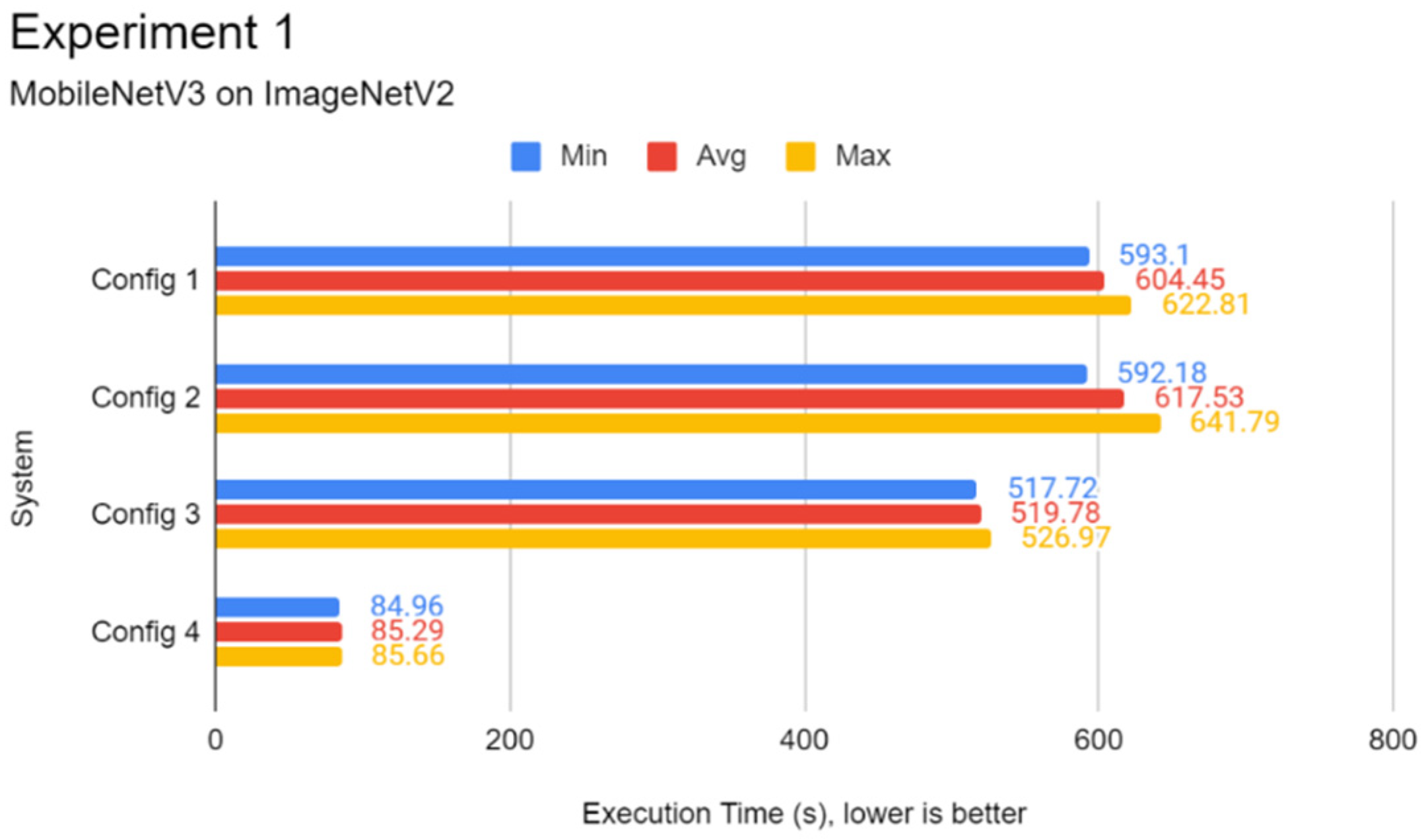
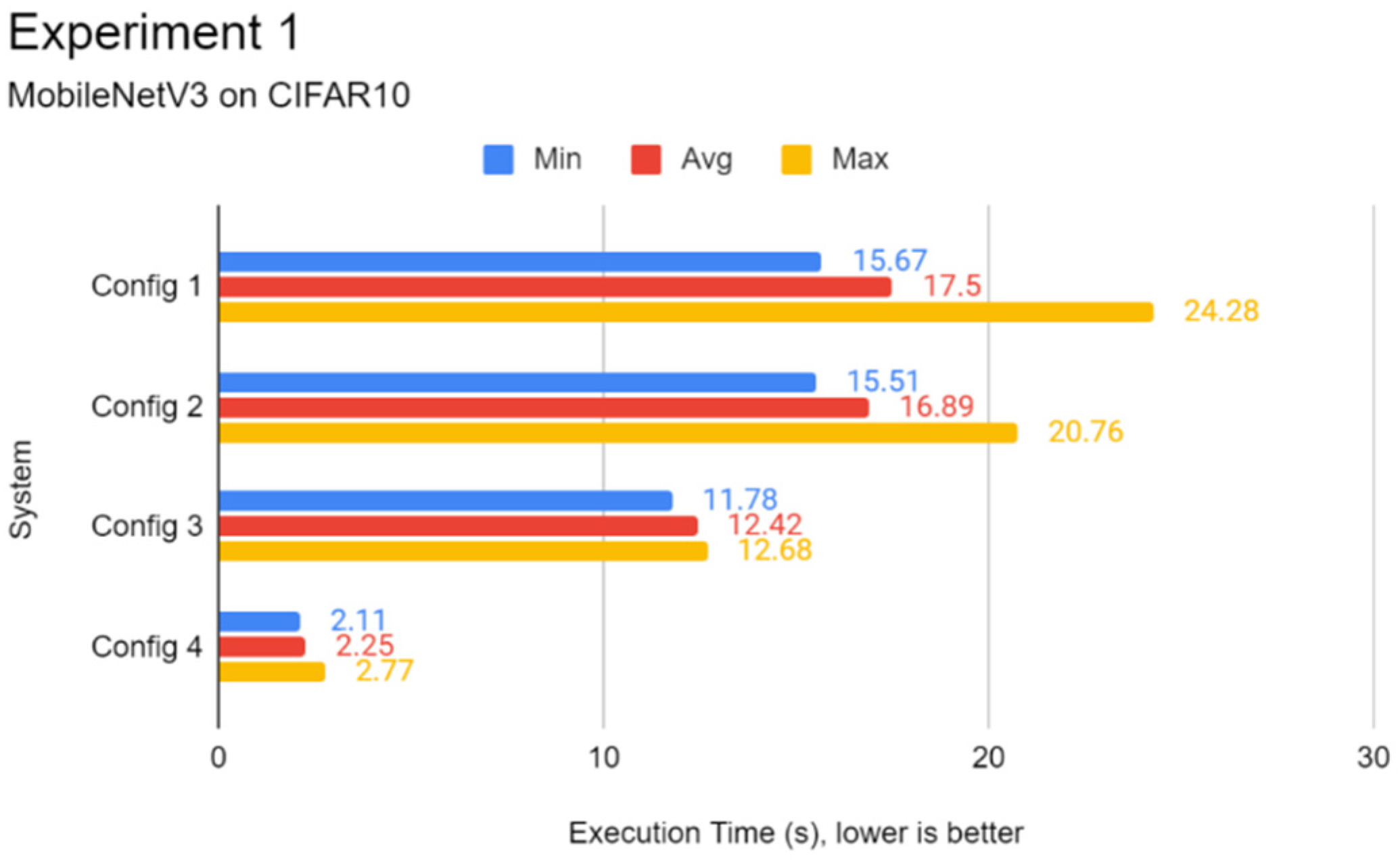
In this experiment, a comparison of the inference speed in classifying images from the ImageNetV2 test set and the test split of CIFAR10 was done across every system configuration on both pre-trained Inception-v3 and MobileNetV3 models. This experiment serves to evaluate the general image classification inference performance of all systems.
Since Python works best with 2 executors in Spark as per the findings in [
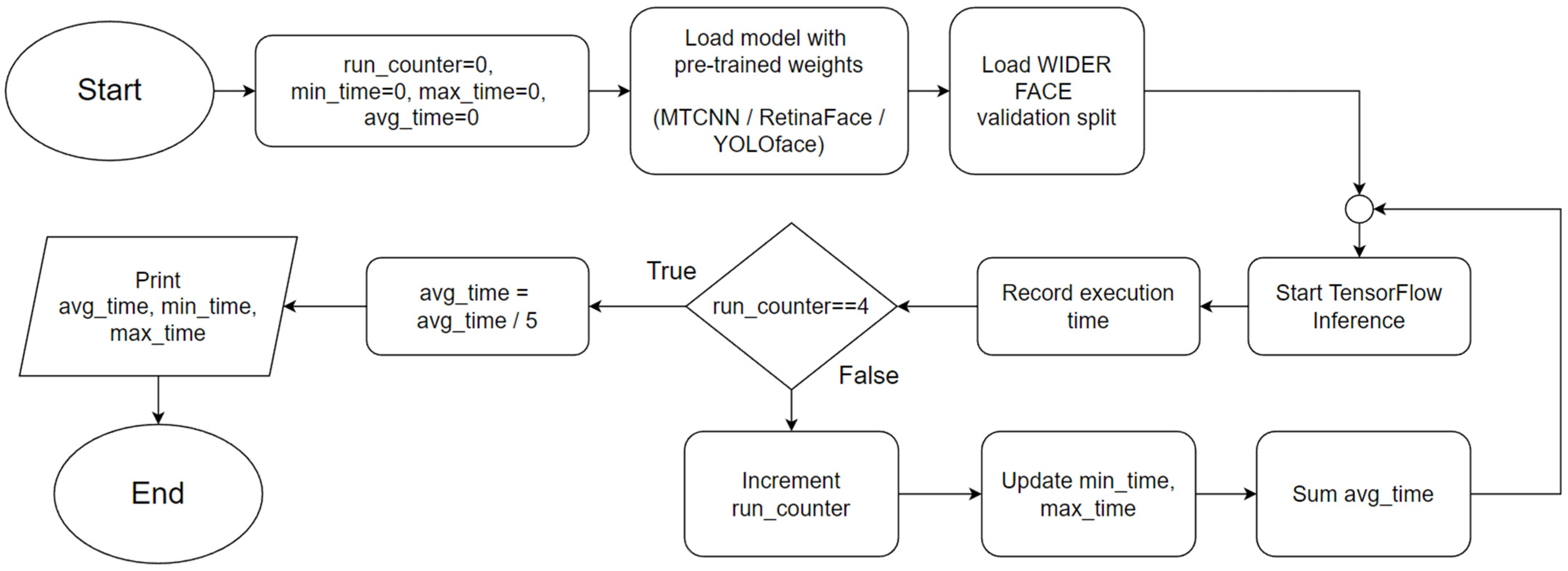
12], and TensorFlow has official support only on Python, this experiment was carried out by running programs coded in Python. Each different program resulted in TensorFlow importing a different testing dataset, ImageNetV2 or CIFAR10, and the same applied to the loading of a pre-trained model, Inception-v3 or MobileNetV3. By running either program, TensorFlow would evaluate the model on the dataset and output its accuracy and the time taken for executing inference on the entire test dataset (the execution time), of which both were recorded at the end of each run. Each configuration was automatically run 5 times to produce consistent results and to reduce the likelihood of outliers. Minimum, maximum, and average values for execution time were recorded over 5 runs and then averaged into a single result. The flowchart for the Python program used in Experiment 1 is shown in
Figure 1. Distributed versions of the programs are also included for use by the cluster systems.
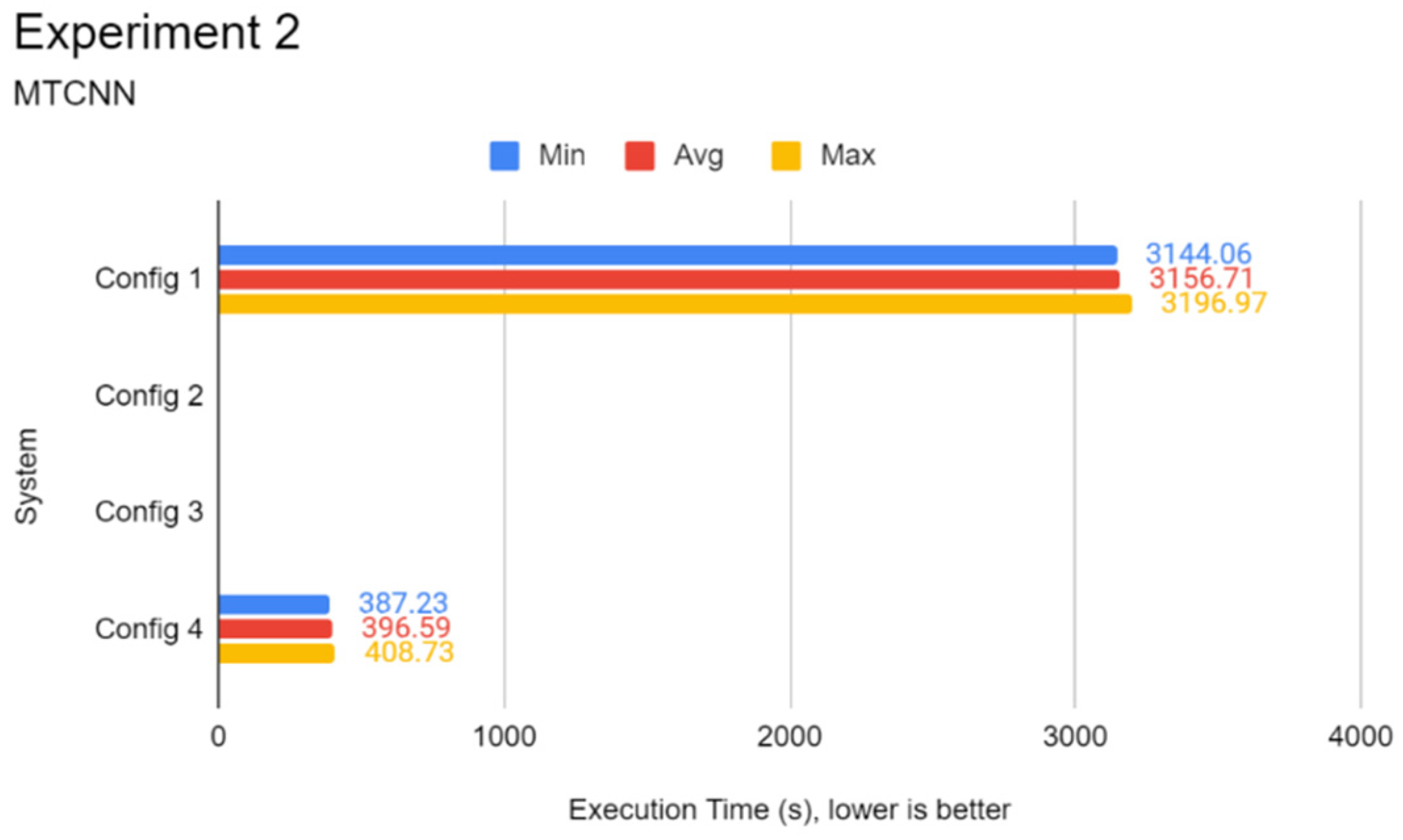
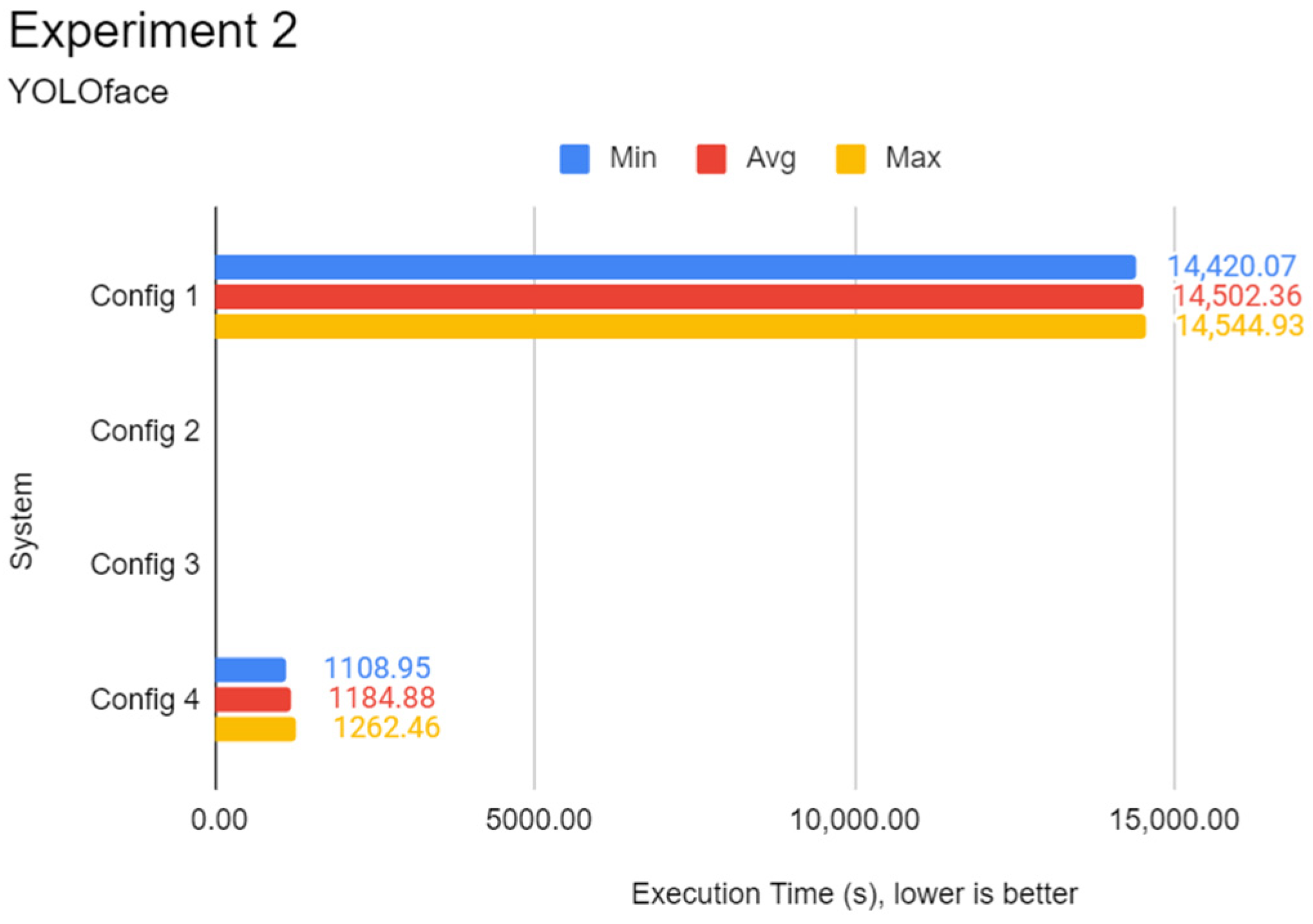
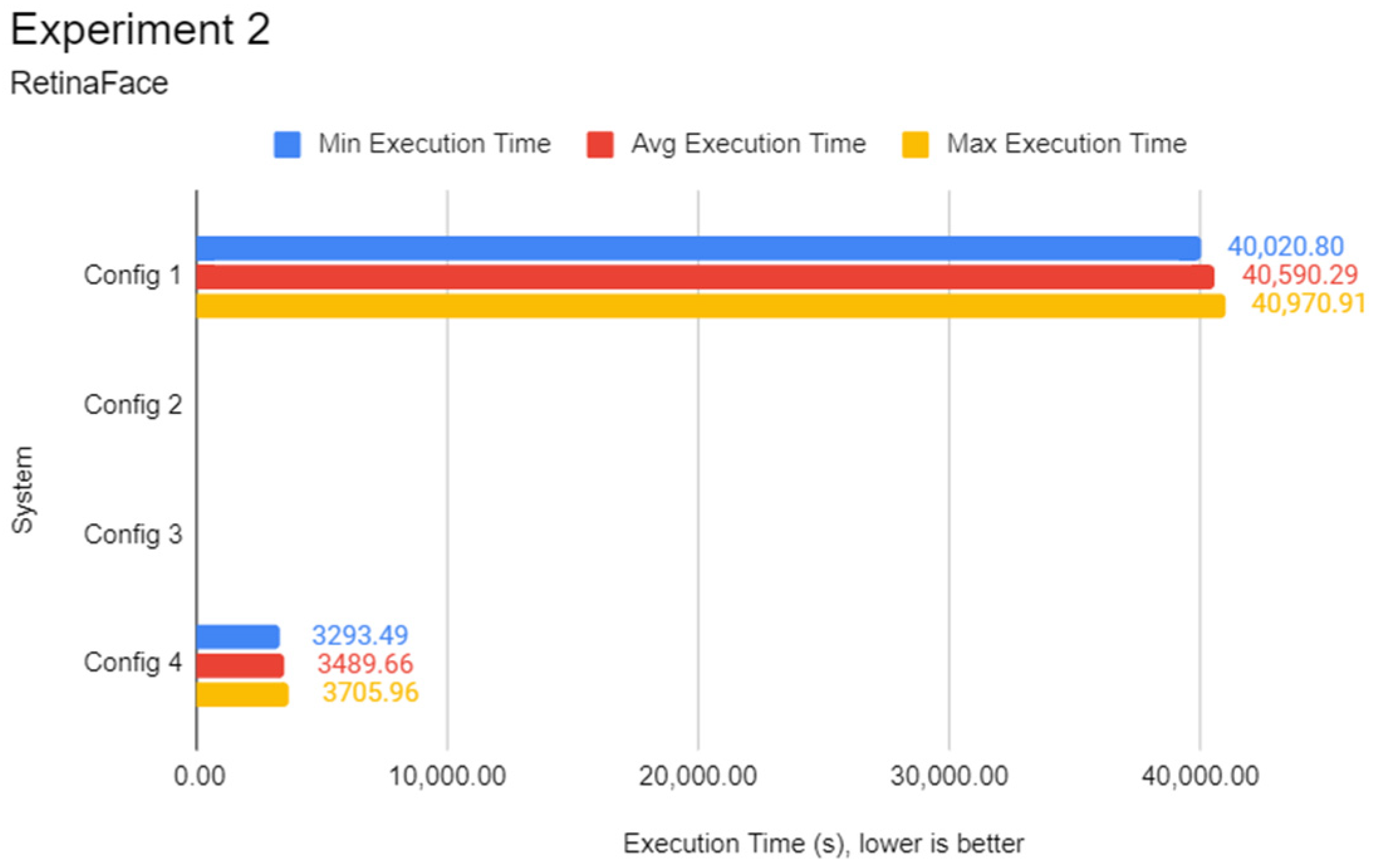
3.4. Experiment 2: Face Detection Test
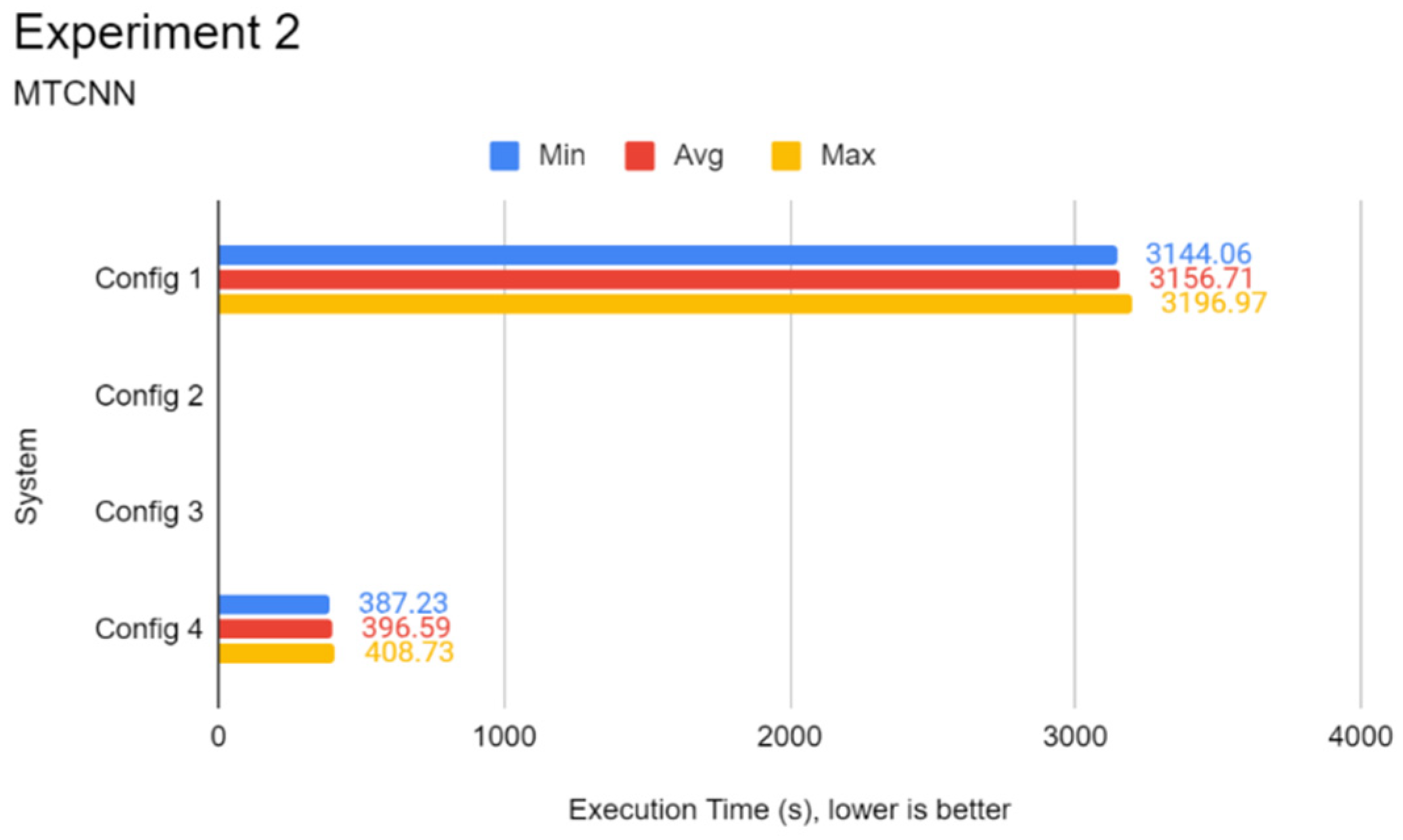
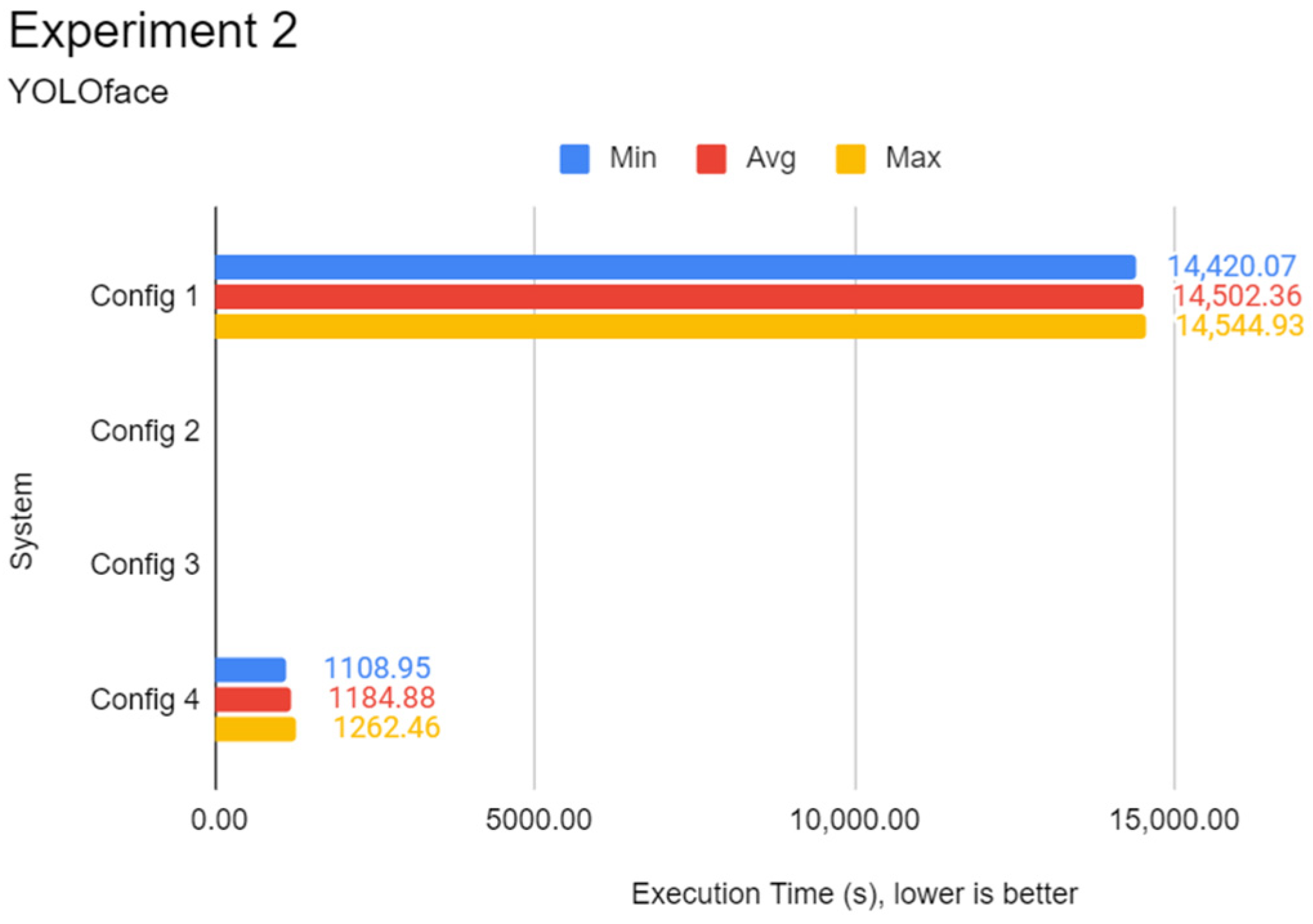
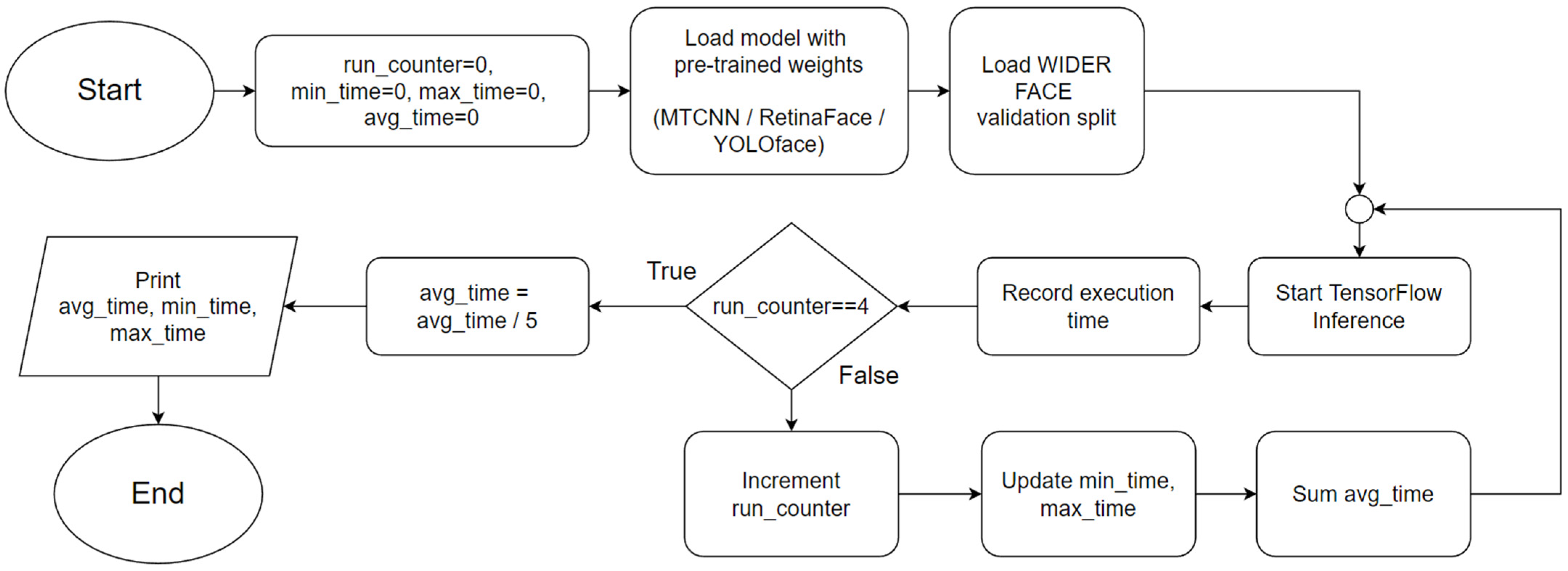
This experiment focuses on evaluating the inference performance of every system in face detection on a fixed dataset. Unlike the first experiment, CNN architectures such as Inception-v3 and MobileNetV3 are not used as they are architected with image classification tasks in mind. Instead, CNN architectures specialised in face detection such as RetinaFace, YOLOface, and MTCNN are used in this experiment on the WIDER FACE image dataset.
The procedures are identical to Experiment 1, except that Python programs coded specifically for this experiment initialise only the WIDER FACE
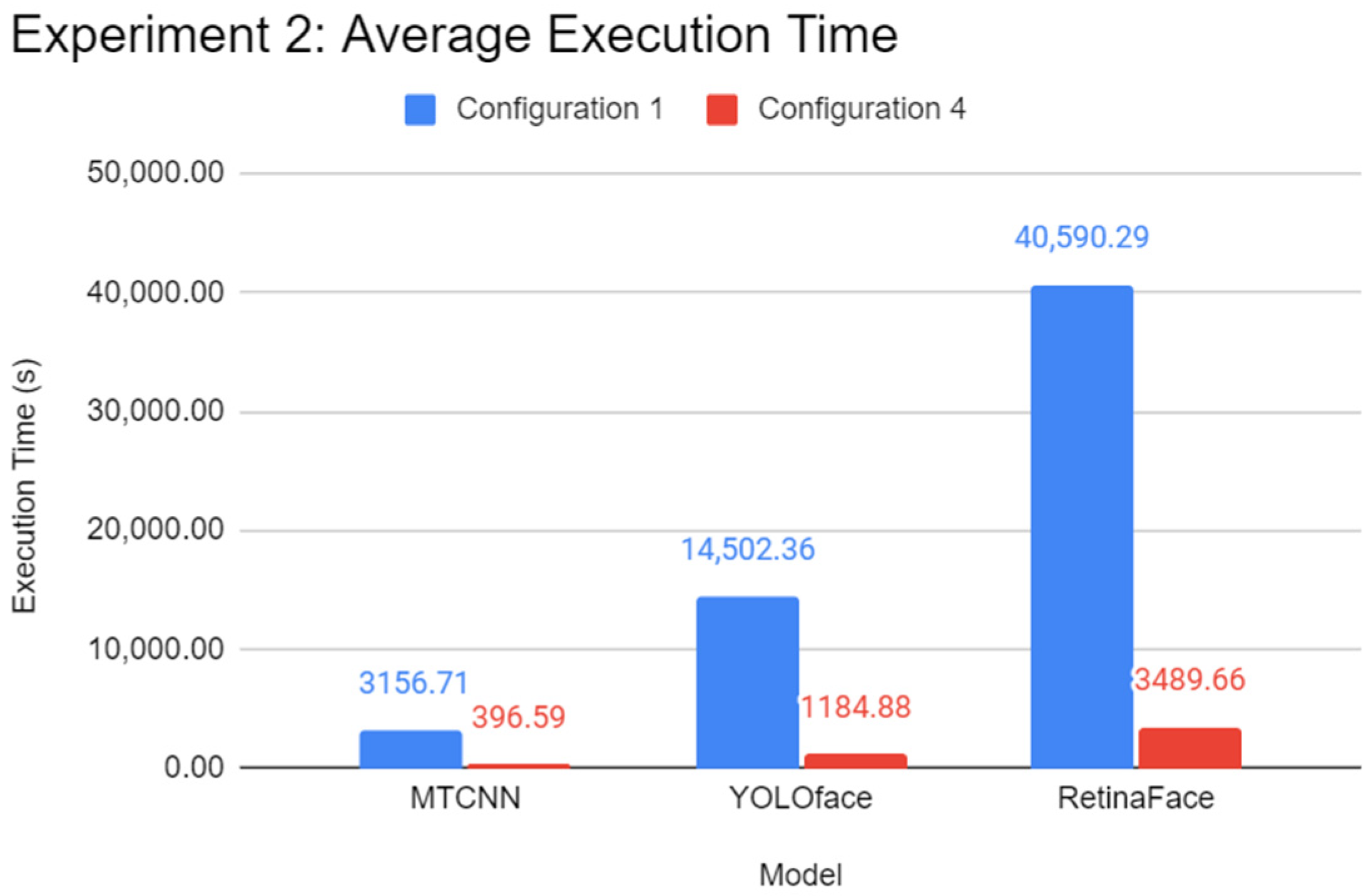
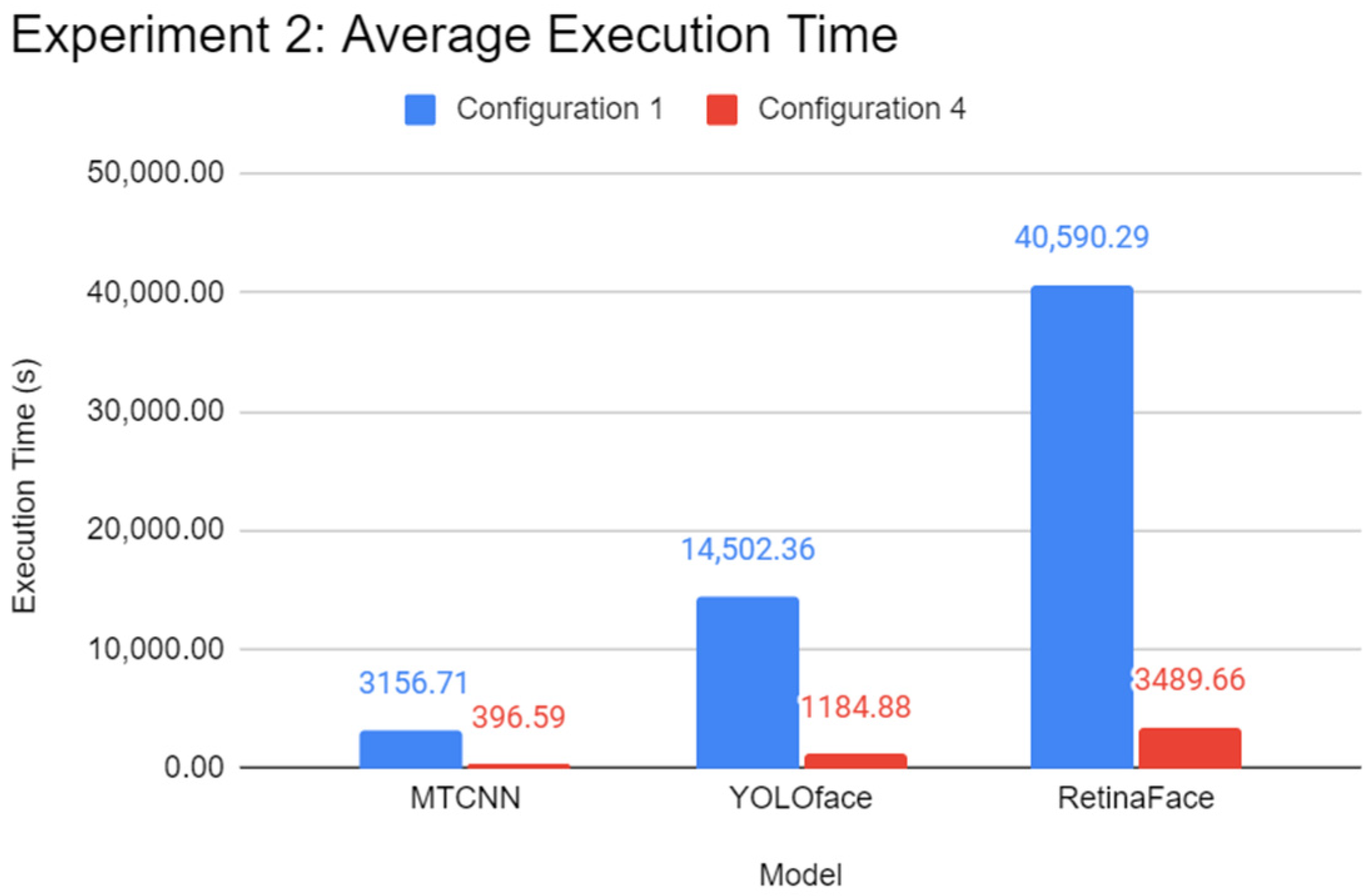
validation dataset split. One of three Python programs contains a different face detection model, which can be RetinaFace, YOLOface, or MTCNN. Like Experiment 1, each Python program would be automatically run five times, the results recorded, and the next program with undocumented results chosen for subsequent testing until the results for every program were tested, respectively. RetinaFace was chosen as it is currently one of the most accurate face detection models available. YOLOface is essentially YOLOv3 trained on the WIDER FACE training dataset. MTCNN is a well-known face detection model with high detection accuracy and was chosen as the model benchmark for this experiment. Likewise, execution time was used as the sole primary metric for this experiment.
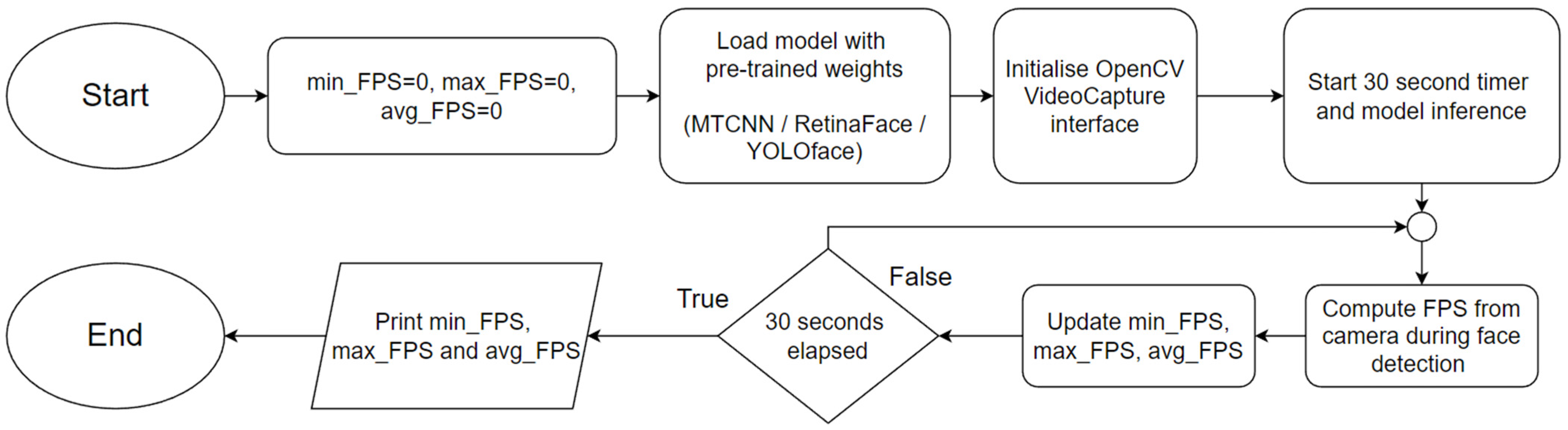
Figure 2 shows the flowchart for the program used in Experiment 2.
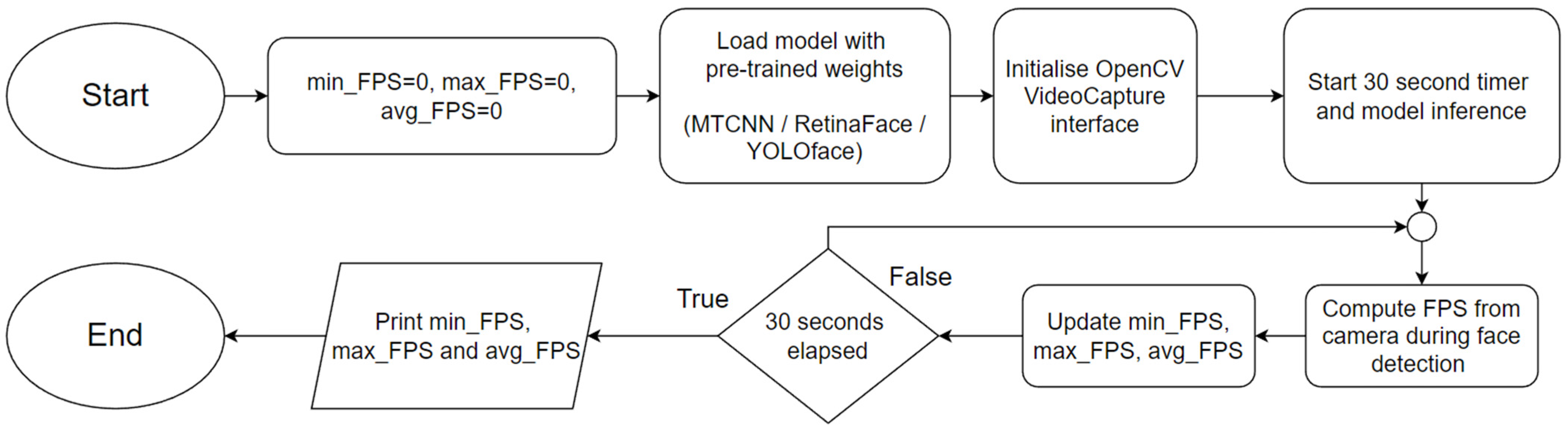
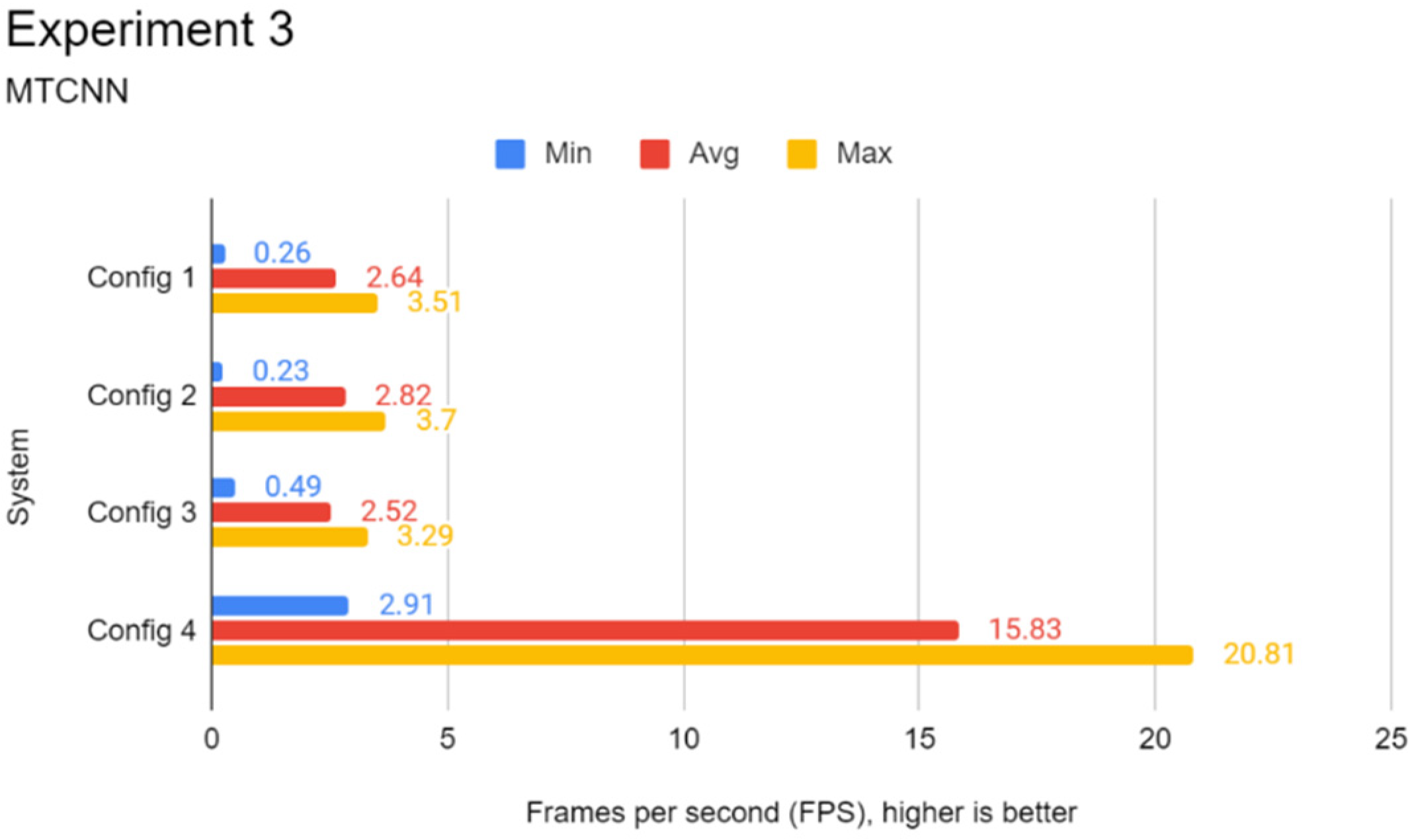
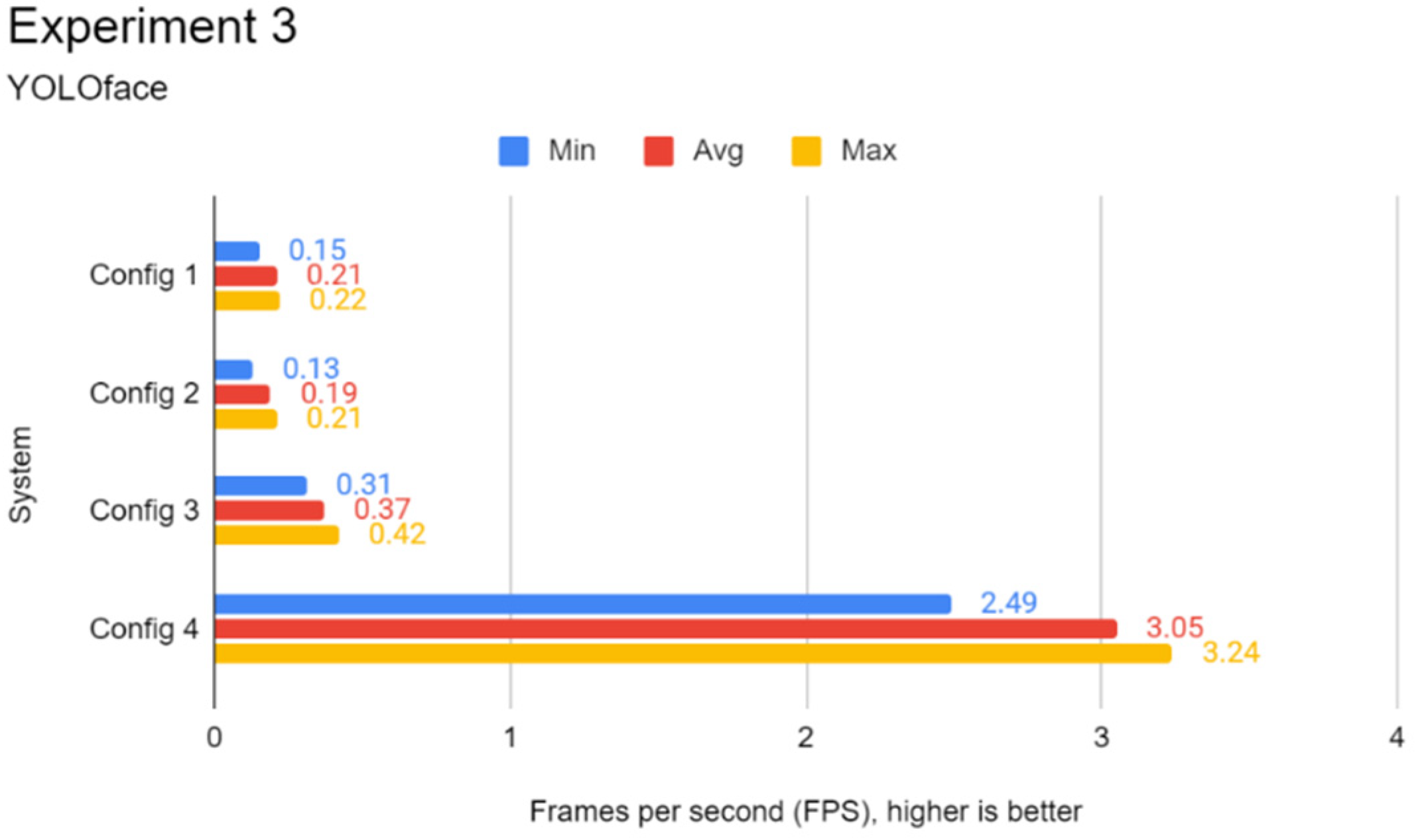
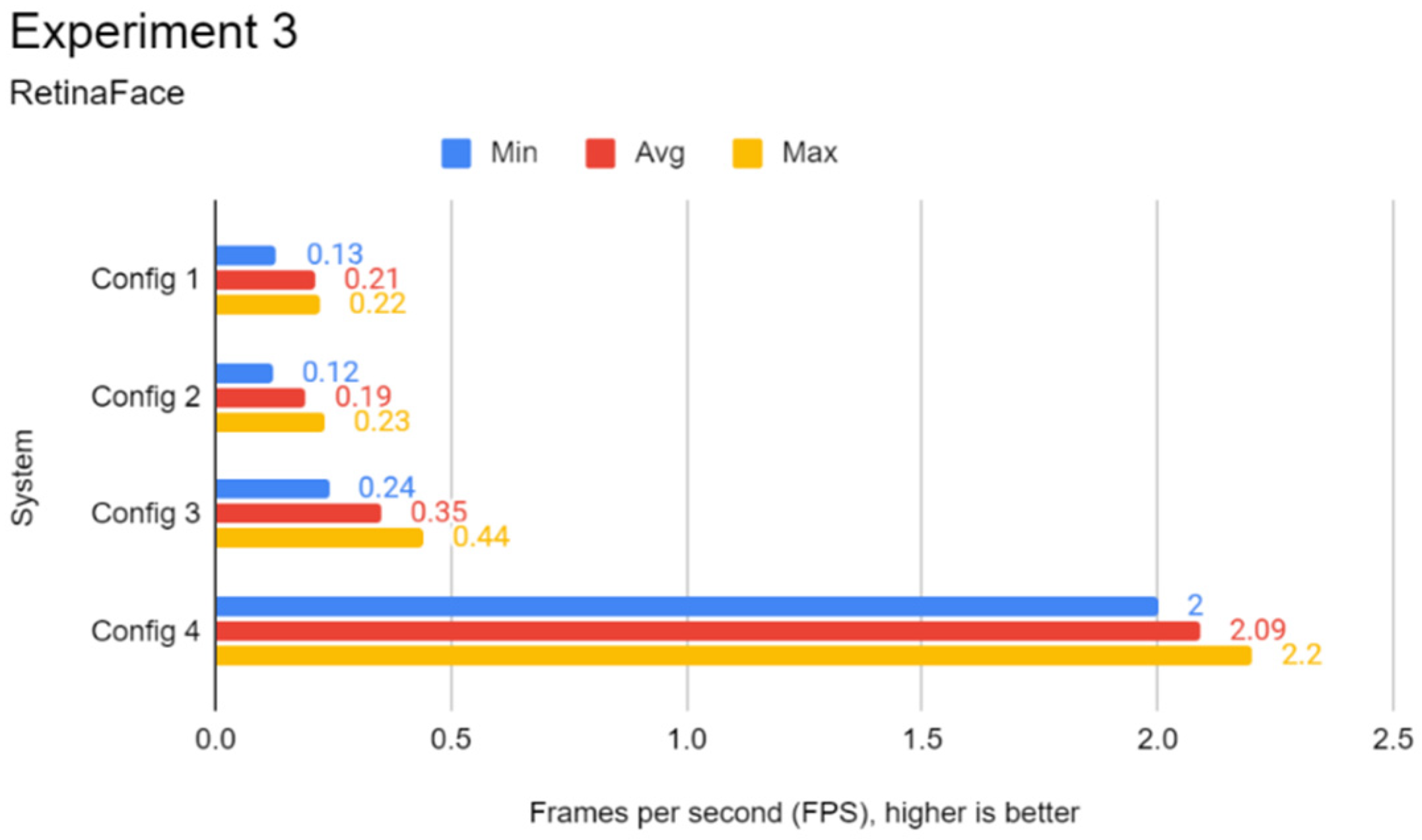
3.5. Experiment 3: Real-Time Face Detection Test
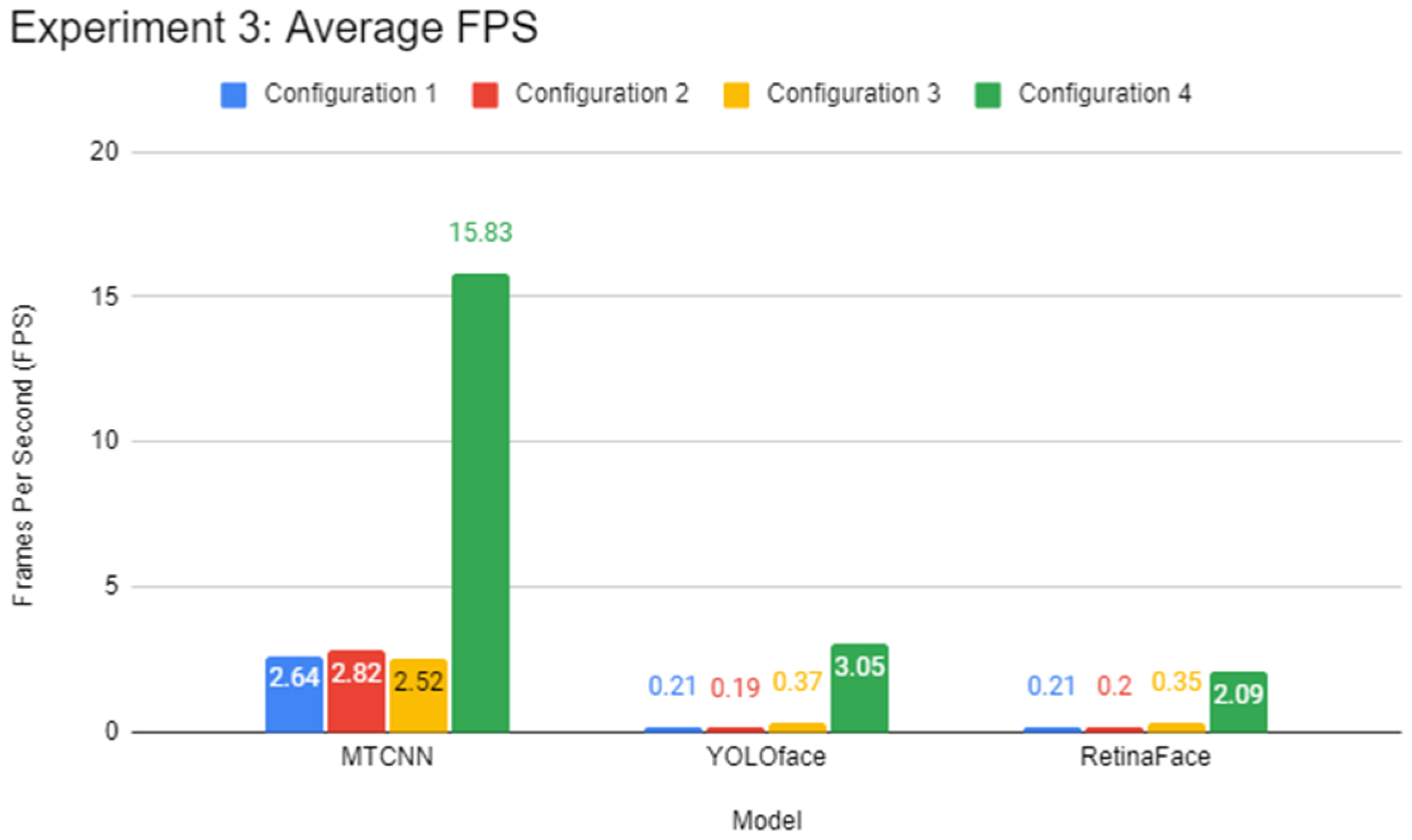
This experiment focuses on evaluating the performance of every configuration in face detection in real-time. Similar to Experiment 2, RetinaFace, YOLOface, and MTCNN were used as the face detection models for this experiment. The additional processing workload from rendering the frames from a video source poses a challenge to systems with weak processing hardware such as the Pi. As most recognition systems capture frames and process them in real-time, this experiment provides a good simulation of deploying the Pi in a production environment.
This experiment involved the use of the Redmi Note 5 Pro smartphone as a USB camera for real-time face detection. To clarify, frames were captured from the USB camera in real-time via OpenCV instead of using a dataset. Inference via a face detection model was then carried out on the captured frames via TensorFlow. Like Experiment 2, multiple Python programs were coded specifically for this experiment, utilising different face detection models to process the captured frames from the videos from OpenCV. When one of the chosen programs was launched, OpenCV would capture frames from the USB camera video footage continuously and the chosen model would carry out the inference on each of these video frames using either of the three face detection models. This experiment focused on camera FPS, which is retrieved directly from OpenCV. As the processing part of the face detection is performed on the systems and not on the phone camera itself, it is a good way to gauge the real-world performance of the systems if the face detection models are applied for production.
For this experiment, the procedure differed from the previous two experiments. Before the experiment began, the lead author was positioned in front of the USB camera, capturing the lead author from shoulders up. First, the procedure for this experiment involved launching one of the said programs. The lead author’s face would move side-to-side for 30 s. At the end of each run, the average FPS was recorded.
Figure 3 shows the flowchart for Experiment 3.
3.6. Environment Configuration
This section explains the environmental configuration of all hardware and virtualized systems, as well as their respective system configurations used for the experiments. The hardware used in the experiments consisted of two Pi 4 Model B SBCs, a desktop computer with a dedicated GPU, and a Redmi Note 5 Pro smartphone for the USB camera. Two Pi 4 Model B SBCs that were similar in specifications were included in the experiment to evaluate the SBC’s performance in both standalone and clustered configurations. This was done in consideration of the findings in [
12,
16], which have shown diminishing performance returns with higher node counts. Thus, two nodes should eliminate any factor of diminishing performance gains, and it allows for evaluating the effectiveness of distributed inference. Four-gigabyte variants of the Pi 4 SBC were used for this experiment, and both used identical Class 10 microSD cards for storage. Like previous researchers, Raspberry Pi OS was used (formerly Raspbian) for these SBCs, as it is optimized for them. The lead author’s desktop computer was included in the experiment for virtualizing two low-end x86 virtual machines (VMs) as well as to act as a reference for the performance of other configurations. This system has 32 GB of DDR4 memory to cope with the worst memory-intensive operations possible such as running multiple VMs. Storage for the VMs and for the main machine was provided by a 256 GB Corsair MP510 solid-state drive (SSD). Windows 10 runs on the host system.
The Redmi Note 5 Pro was used to provide the USB webcam input via the Droidcam app on Android. The Redmi Note 5 Pro is connected to every system configuration used in the experiment through the v4l2loopback module in Linux, creating virtual cameras in the system configurations used. Based on the hardware used for the experiment, 4 configurations were set up as summarized in
Table 4.
3.7. Apache Spark: Standalone with HDFS, Cluster Setup & Job Execution
Spark is a data processing engine designed to replace or complement Hadoop’s MapReduce processing engine. The research experiments made use of the latest Spark version (3.2.1) for clustering multiple nodes and for single-node use. Configurations 2 and 3 ran Spark in standalone cluster deployment mode alongside the Hadoop Distributed File System (HDFS) which runs as a background service. As for Hadoop’s HDFS, the research experiments made use of Hadoop version 3.3.1. The replication factor for HDFS was set to the number of nodes, which in this case was 2.
Much like Hadoop and Spark-on-YARN, a Spark Standalone cluster has a master node in charge of coordinating and distributing all Spark jobs to all workers or working nodes of that cluster. To ease the entry of hostnames as worker nodes into the Spark environment file, the local IP addresses of the nodes for Configurations 2 and 3 were mapped to their respective hostnames in the /etc/hosts file, as these configurations use Linux operating systems, and this process was repeated in every node. As Spark requires Secure Shell (SSH) access, SSH fingerprints in the form of Rivest-Shamir-Adleman (RSA) keys were created on the master node. These keys were then placed in the worker nodes to verify and trust the master node. It is worth noting that a Spark node can be both a master and a worker at the same time. The hostnames of the nodes, which now map to their local IP addresses, were entered into the ‘workers’ file located under the Spark configuration folder. For checking whether all nodes were configured properly for Spark cluster use, the web UI for Spark was accessed via ‘(hostname): 8080’ in a web browser which displays the status of all nodes, including the master node.
For all cluster systems, the following environment variables were set in the .bashrc file, as seen in
Figure 4. These environment variables were required by Spark. As Spark is built on Java, using a compatible Java Development Kit (JDK) version was required. During initial testing, newer versions of JDK such as 14 and 17 failed to work, and thus the decision to revert to JDK 11 was made as it is the longest supported stable JDK version compatible with Spark at the time of writing. Since Configuration 2 runs on ARM architecture, an ARM64 version of the JDK developed by the open-source community (OpenJDK) was used in place of the traditional AMD64 architecture found in modern computers, which was also used for Configuration 3. The Spark folder containing all important binaries and configuration files was in the home directory of the user account for each cluster system. For Spark to use Python, ‘PYSPARK_PYTHON’ would have used the system’s default Python version, which was kept exactly at 3.8.10 across every node to prevent compatibility issues. The ‘SPARK_WORKER_CORES’ was set to the maximum number of cores available for a worker node, which in this case is 4 for Configuration 2 and ‘2’ for Configuration 3, as the Pi 4B is powered by a quad-core Broadcom SoC. Configuration 3 uses two cores from the host system for virtualization. ‘SPARK_WORKER_MEMORY’ was set to the total memory of the node minus 1 GB, which was 3 GB for both cluster systems to offer the best clustering performance and stability. Although ‘JAVA_HOME’ was already set in the .bashrc file, Spark mandated the JAVA_HOME environment variable in the Spark environment file, as it would refuse to launch without it declared and set. The value of the ‘SPARK_MASTER_HOST’ parameter varies for Configurations 2 and 3, as it was set to the local IP address of the master node for each of the Configurations.
For launching cluster-optimized versions of the programs used for the experiments, the spark-submit command was used to execute a SparkContext-containing Python program for the experiments, which was suited for experimenting.
3.8. Enhancement Methodology for Pi 4B
This section outlines a combination of enhancements that have a significant speedup impact on the Pi to further evaluate the effectiveness of these combined enhancements in contrast to a stock Pi. The enhancements consist of using the SSD, overclocking, and disabling the graphical user interface of the Pi. Initially, the use of neural accelerators such as the Intel Neural Compute Stick was considered. However, due to budget constraints, it was not possible to obtain such devices for testing their effectiveness. The authors highly recommend the use of neural accelerators for the Pi 4B to improve its DL performance where available.
The Pi 4B has two hi-speed USB 2.0 ports and 2 super-speed USB 3.0 ports which allow the use of external storage solutions such as an external hard drive, flash drive, or even an SSD. The enhancement trials the use of SSD instead of the traditional Class 10 microSD card storage, which has inferior read and write speeds compared to the SSD. The SSD used in this test was a 120 GB Kingston A400 running off a 2.5-inch SATA-to-USB cable, as per
Figure 5. The contents of the microSD card were cloned to the SSD using the ‘SD Card Copier’ program available in Raspberry Pi OS. During testing, it was found that using the USB 3.0 port for the SSD draws a significant amount of power from the Pi 4B, preventing the use of other peripherals such as the wireless network interface chip. Thus, the decision was made to stick to USB 2.0 for operability.
Typically, increasing the clock speed of the processor allows for more processing operations to be done in a second. This act of increasing clock speeds beyond designated specifications is called overclocking. To date, this has been the most effective method in increasing the processing performance of a system on all devices such as computers and smartphones. However, not every device allows overclocking access as it might void the warranty of a device. Overclocking on the Pi is achieved by setting a frequency beyond 1500 MHz in the config.txt file in the boot directory of the Raspberry Pi OS, which is the stock maximum permissible frequency of the Pi. For this paper, the clock speed was set to 1800 MHz with an overvoltage setting of 6 to help with stability. It was impossible to attempt a higher clock speed as the system failed to stabilise long enough for all tests to be complete.
By default, the Raspberry Pi OS includes a graphical user interface (or termed ‘desktop environment’ in the Linux community) based on the Lightweight X Desktop Environment (LXDE). However, there is still a motivation to know whether the standalone Pi will perform considerably better without the additional workload imposed by the rendering of LXDE, as the computing resource on the Pi is scarce. The ‘sudo systemctl set-default multi-user.target’ command was used to prevent the display server from being launched. This prevents the loading of graphical elements onto the screen and by extension, LXDE will not be loaded. The command forces the system to use a command-line interface.
6. Conclusions
In summary, the findings of this research paper have successfully addressed the need to investigate the use of the TensorFlow framework for Spark cluster systems, which to the authors’ knowledge is one of the earliest findings based on the suggestion of fellow researchers. The performance difference between a 2-node Pi 4B Spark cluster and a Pi 4B has been studied successfully. For the time being, it is currently not advised to use a Pi 4B cluster for distributed DL because of the state of immaturity in DL frameworks beyond SparkML like TensorFlow, as confirmed by the lack of performance scalability in inference tasks seen in the results. The authors believe these findings will motivate fellow researchers and the TensorFlow team to pursue a scalable distributed inference solution that will allow multiple low-end devices to perform in tandem, especially in an age where semiconductor shortage is rampant, and hopefully, such a solution shall eliminate the status quo of SparkML as the preferred distributed ML framework.
Through the experiments, the performance gap between a Pi and a standard mid-end system in inference tasks was also identified. The differences lie between 6 to 15 times, depending on the complexity of the DL model. It was found that using a lightweight DL model can help reduce the performance deficit between powerful systems and low-end embedded devices like the Pi 4B as opposed to complex models. Therefore, low-end embedded devices can carry out lightweight DL inference competitively with their more powerful counterparts. In the experiments of this report, the Pi 4B could keep up with the VM cluster in lightweight inference most of the time while falling behind on heavier tasks, which is possibly attributed to a hardware-level architecture difference. The use of state-of-the-art face detection models, which can achieve extremely high accuracies, requires an ample amount of processing power. The authors highly recommend lightweight, CPU-optimised neural network models for simple DL applications.
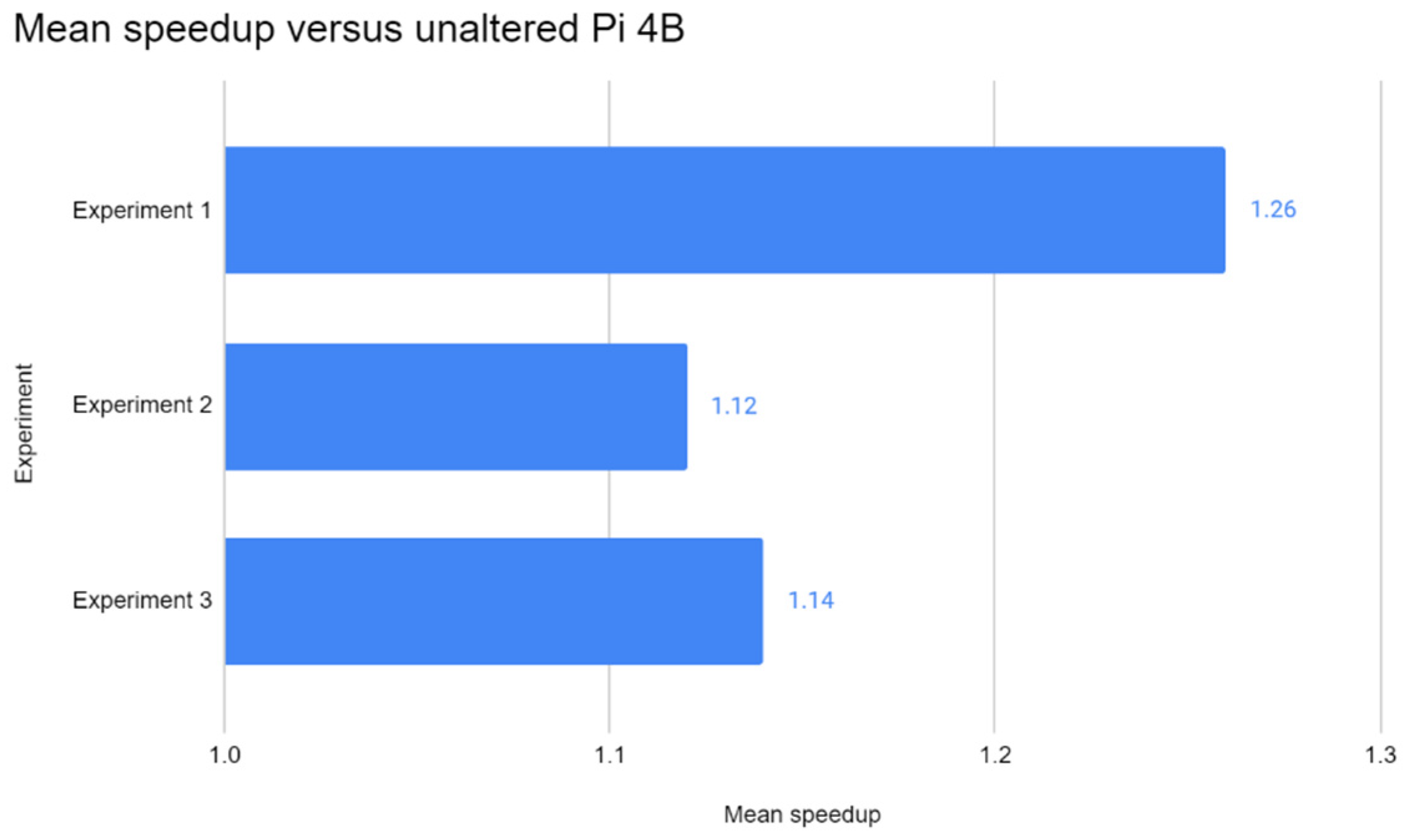
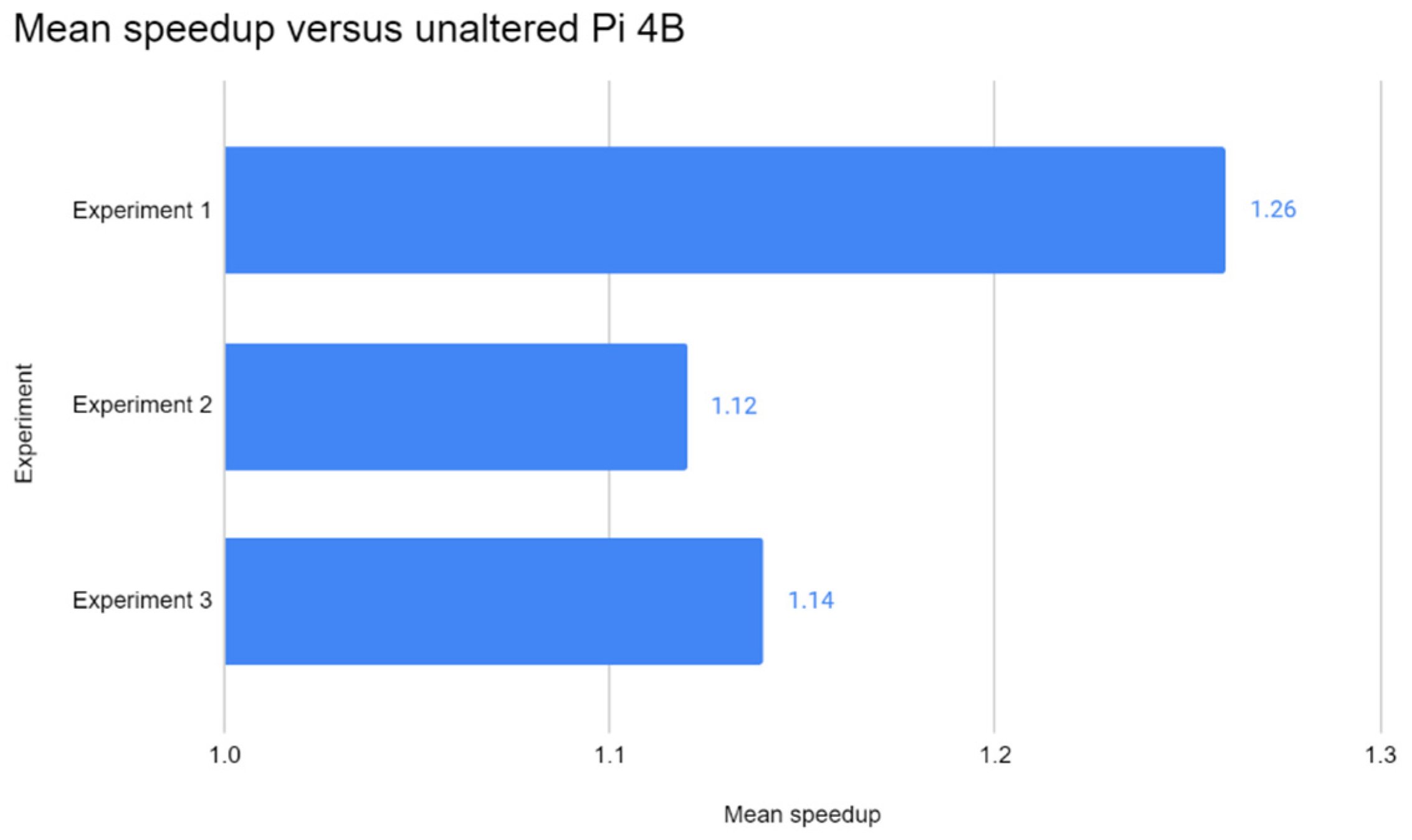
This paper has also optimised the Pi 4B, and results have shown that the enhancement helped the Pi perform 17% faster on average than its standalone and 2-node cluster counterparts, albeit with the addition of the SSD. However, the use of SSD may not have made a major impact on the image processing performance of the Pi. For those seeking to optimise the Pi, the switch to SSD is not mandatory for performance gains—in fact, it increases the price–performance proposition of the Pi. Until distributed inference solutions are available, the concept of distributed DL inference remains a theoretical concept for the time being, and optimising remains key to increasing the performance of the Pi. Undoubtedly, the computational power of a single Pi 4B would still suffice in lightweight ML and DL inference tasks, as seen through the results of the experiments.
The authors would like to remind the reader that the Pi is a general-purpose embedded device suitable for nearly every use case. Thus, the lack of neural acceleration is to be expected, as DL is not Pi’s major use case. For those opting for an embedded device for more complex DL inference tasks, the better price–performance option would be an AI-accelerated SBC such as the Nvidia Jetson Nano at
$149, as it outperforms the Pi 4B by a huge margin as per the results in [
13]. Alternatively, a neural accelerator such as an Intel Neural Computing Stick can also help boost the DL performance of the Pi, as seen in [
14]. If an embedded system is not the primary focus and where permissible, a low-cost PC with AI acceleration via a single powerful discrete GPU is also recommended. If hardware solutions are not an option, lightweight ML/DL models in TensorFlow can readily be converted into the TensorFlow Lite versions to further improve inference speed. Progress on distributed inference for cluster systems needs to be made for the feasibility of low-end device clusters to come to fruition. Before that, the ideal cluster deployment mode for PySpark jobs must be implemented in place of the less-reliable client mode. Regarding the previous statement, the authors also suggest that the Apache Spark development team and the TensorFlow development team collaborate in addressing this specific scope of distributed systems, which may be niche by nature but will enable low-cost distributed DL inference that will suffice as a viable alternative to a single powerful system for such purposes.
Additional work on investigating the benefits of using the Spark TensorFlow Distributor is required, as model inference seems to be ineffective. Future work in this study would be to verify the performance benefits of distributed training of DL models using Spark TensorFlow Distributor. Instead of using a Pi cluster, a distributed system containing multiple GPUs would be used for this investigation. A performance comparison between Spark MLlib and Spark TensorFlow Distributor by training models of identical architecture should also be considered for investigating the use of DL frameworks outside the Spark ecosystem. Other DL frameworks, like PyTorch, could be trialled against TensorFlow in investigating the ideal scalable DL framework.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}