1. Introduction
As an exploration and innovation of the financial market, the futures market plays an essential role in risk diversification, price discovery, and hedging that cannot be replaced by the spot market [
1]. In China, the steel industry has been an essential support for various industries such as agriculture, transportation, and architecture. Currently, China is the world’s largest steel producer and trader, and the launch of rebar futures is of great significance to the progress of the Chinese futures market and steel industry. Since its listing on the Shanghai Futures Exchange (SHFE) in 2009, rebar futures have become one of the most active futures, with its trading volume ranking first among the steel-related futures for many years. On the one hand, rebar futures provides market participants with an effective tool for reducing market risk by establishing a profit and loss hedging mechanism by employing the futures and spot markets. On the other hand, steel enterprises can have access to corresponding market price information so they could rationally arrange their steel production and operation activities. Therefore, the study of price-movement-direction forecasting of the rebar futures market has become an essential issue for many scholars, market investors, and steel-related companies.
In the last few decades, numerous scholars have developed practical approaches in exploring financial forecasting, such as the traditional econometric methods and artificial intelligence technologies. Among those approaches, Autoregressive Integrated Moving Average (ARIMA) is one of the most commonly used traditional econometric models [
2,
3]. However, when referring to the nonlinear characteristics of time series data in financial markets, traditional analysis methods might be unable to show favorable forecasting ability [
4,
5]. With the development and successful application of artificial intelligence, many machine learning methods, such as Artificial Neural Network (ANN) [
6,
7], Support Vector Machines (SVM) [
8,
9], and Random Forest (RF) [
10,
11], have been evidenced to be capable of producing excellent performances for financial time series forecasting. For instance, an ANN-based model was proposed by Kara et al. for daily price-movement prediction in the stock market, and it generated great forecasting accuracy [
12]. Hao et al. adopted a novel SVM-based method to predict stock price trends by extracting financial news texts, and the results showed that their proposed model was more robust than the benchmark methods [
13]. Ballings et al. successfully predicted the stock price direction by applying an RF-based method [
14].
Recently, since Chen and Guestrin first proposed the eXtreme Gradient Boosting (XGBoost) algorithm in 2016 [
15], an increasing number of researchers have implemented it to solve the forecasting task, and great accuracies have been produced in many applications [
16,
17]. The most remarkable advantage of XGBoost is that the prediction accuracy and computing speed are significantly enhanced compared to the traditional gradient boosting algorithms [
18,
19,
20]. In the field of financial markets, Huang et al. predicted the intradaily market trends using an XGBoost-based method, and it successfully produced satisfactory forecasting performance [
21,
22,
23]. Chen et al. built an XGBoost-based portfolio construction method to forecast the price movement of stock market, and the experiment results indicated that their proposed method outperformed all the benchmarks by evaluating the trading returns and transaction risks [
24]. However, there are a limited number of studies in the literature that report on the futures market prediction by using the XGBoost method. Hence, this paper fills the gap and applies XGBoost in the rebar futures price prediction to investigate whether XGBoost could be employed as an efficient method and whether it is superior to the machine learning algorithms that other researchers have applied.
Nevertheless, when using the machine-learning-based methods, training and testing data often have a problem of data imbalance in the model learning process, resulting in unsatisfied classification performance of the minority class samples [
25,
26]. Therefore, classification tasks with imbalanced data categories in machine learning have received increasing attention in academic and practical applications. To solve this problem, the Synthetic Minority Oversampling Technique (SMOTE) [
27], which is an improved random oversampling method, has been extensively adopted. For the class-imbalanced data, the training dataset of minority categories could be oversampled by the SMOTE, which aims to solve the unbalanced class distribution problem of the studied data [
28]. In academics, the efficiency of the SMOTE technique for enhancing classification accuracy of minority categories has been successfully applied and proved by many scholars [
29,
30]. Therefore, in this research, the SMOTE technique is integrated with the XGBoost model to predict the price-movement direction of rebar futures.
For the simulation trading in financial markets, how to design trading strategies and determine various trading parameters has drawn much attention from market participants. However, because of the extraordinary high leverage and risk of futures trading, other than a great return, trading risk should also be an essential indicator in the futures market, while it is generally overlooked by researchers. Therefore, different from the literature reports that considered only the return as the objective function, we propose to implement a multiobjective optimization approach for optimizing the pre-designed trading rule by considering both the trading return and the trading risk. Recent optimization studies have shown that the application of the Nondominated Sorting Genetic Algorithm II (NSGA-II) algorithm [
31], which is one of the well-known multiobjective optimization algorithms, has been successfully expanded in many application fields. For example, Raad et al. optimized the design of an urban water distribution system using an NSGA-II-based method, intending to find a tradeoff between system cost and reliability [
32]. Cao et al. focused on optimizing spatial multiobjective land use, and they applied an NSGA-II-based method to generate the best compromise solutions among minimum conversion costs, maximum accessibility, and maximum compatibilities among land uses [
33]. Feng et al. developed a multiobjective optimization algorithm based on the NSGA-II algorithm to find a reasonable allocation of medical resources [
34]. To improve the trading performance of the proposed approach, the objective functions, including the accumulated return and maximum drawdown, are both optimized using NSGA-II to search for the best parameter combination of the pre-designed trading rule.
Additionally, in recent years, hybrid methods have been extensively applied widely in research, and their empirical results demonstrated that those hybrid algorithms generally performed better than one part of the single model [
35,
36,
37,
38]. It provides us with an idea to forecast the movement and to perform trading simulation by a hybrid approach that integrates the XGBoost, SMOTE, and NSGA-II.
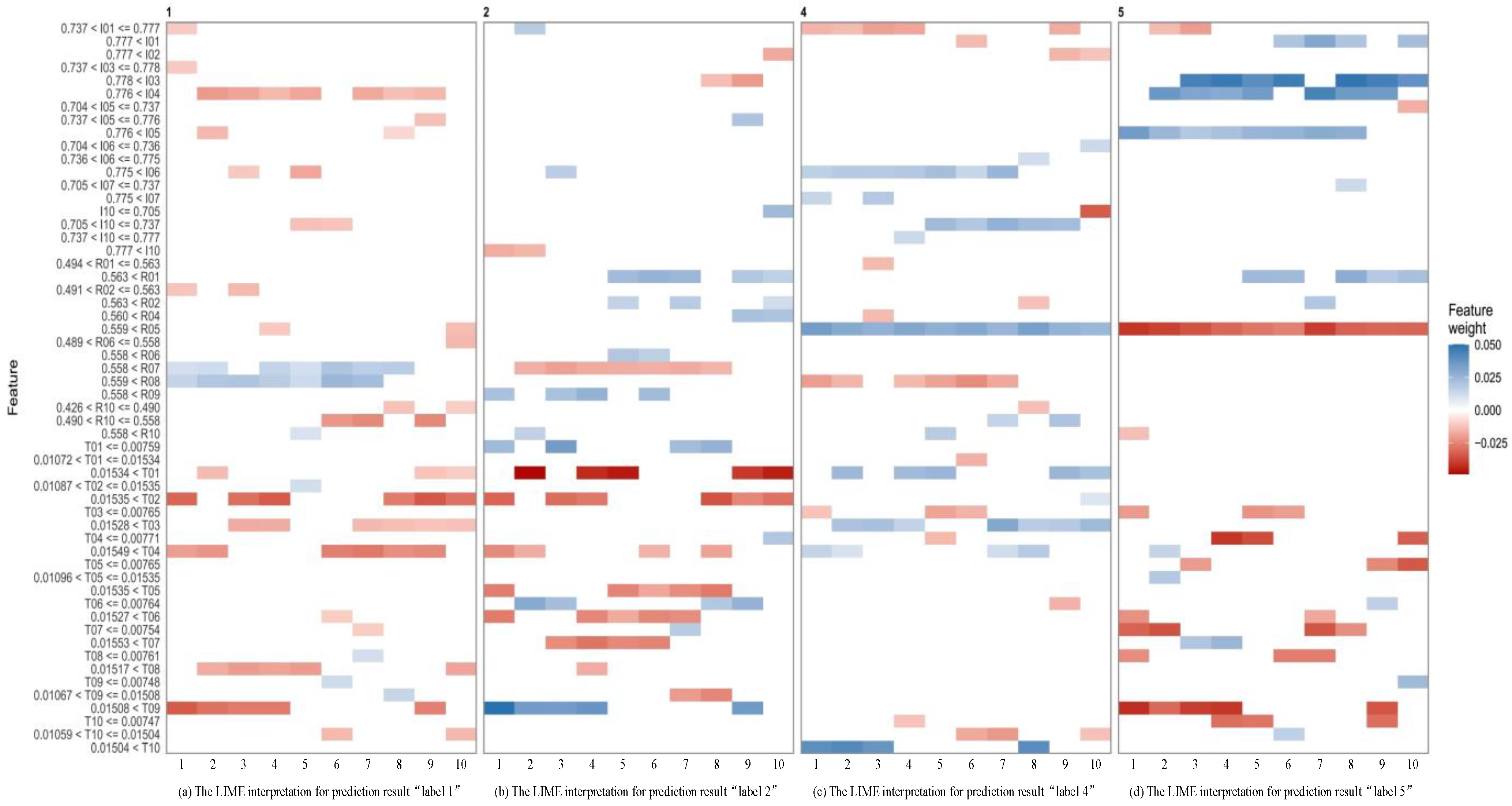
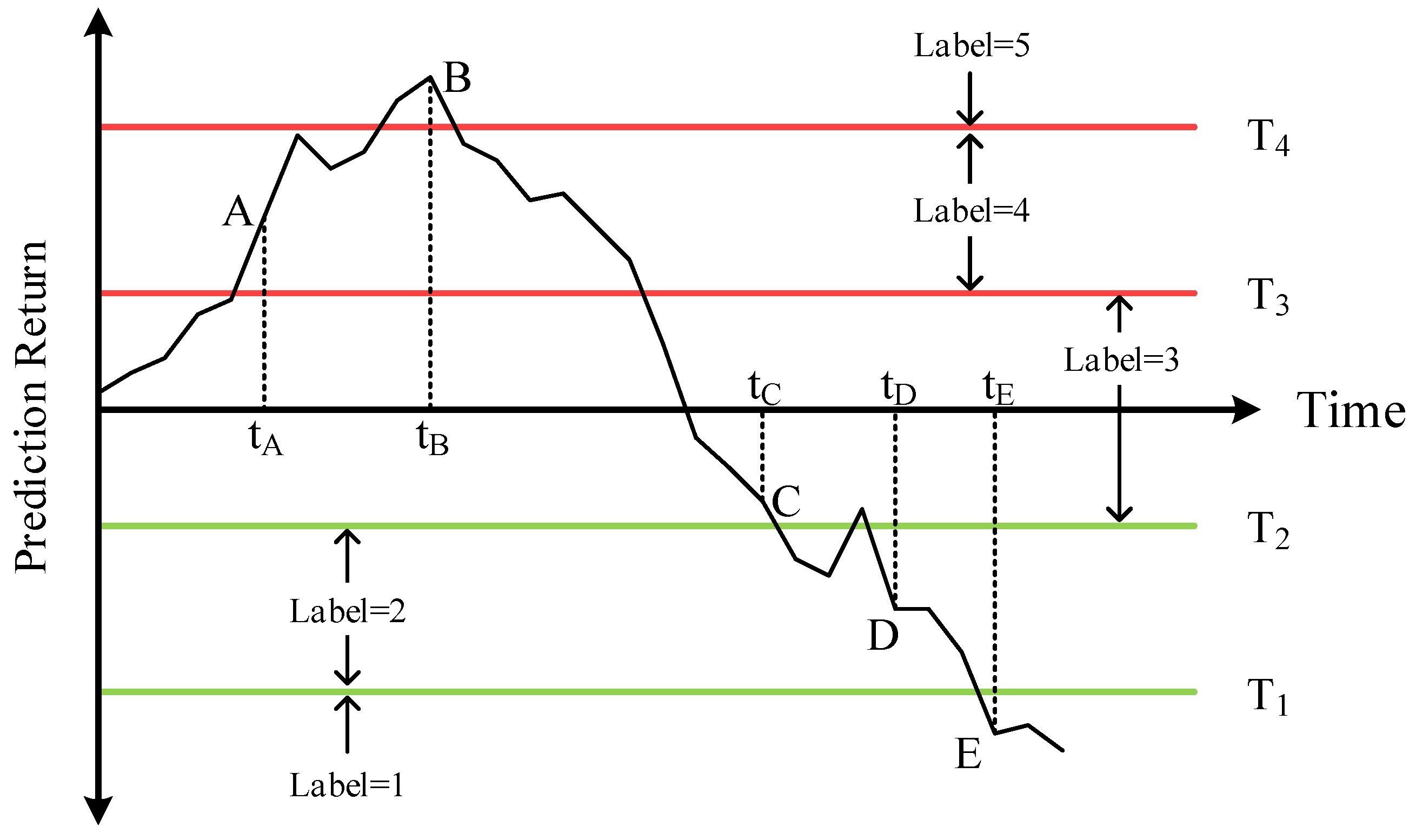
In summary, the main procedures of the method proposed in this research are as follows. First, the proposed approach collects and pre-processes the historical high-frequency data of the Chinese rebar futures. Second, the whole dataset is divided into several consecutive in-sample and out-of-sample periods, with the predicted labels divided into multiple categories of magnitude. Third, the training samples with smaller ratios are oversampled using the SMOTE for producing the balanced training datasets. Next, an XGBoost-based multiclass direction prediction model is trained for price direction change forecasting. Meanwhile, NSGA-II is employed to optimize the simulation trading rule. At last, Local Interpretable Model-agnostic Explanations (LIME) is employed for an explanation of the proposed method by analyzing the contributions of each feature on the multiclass labels. To validate the efficiency of the proposed approach, several performance evaluation indicators and a group of benchmark methods are designed and used to investigate their classification and trading results.
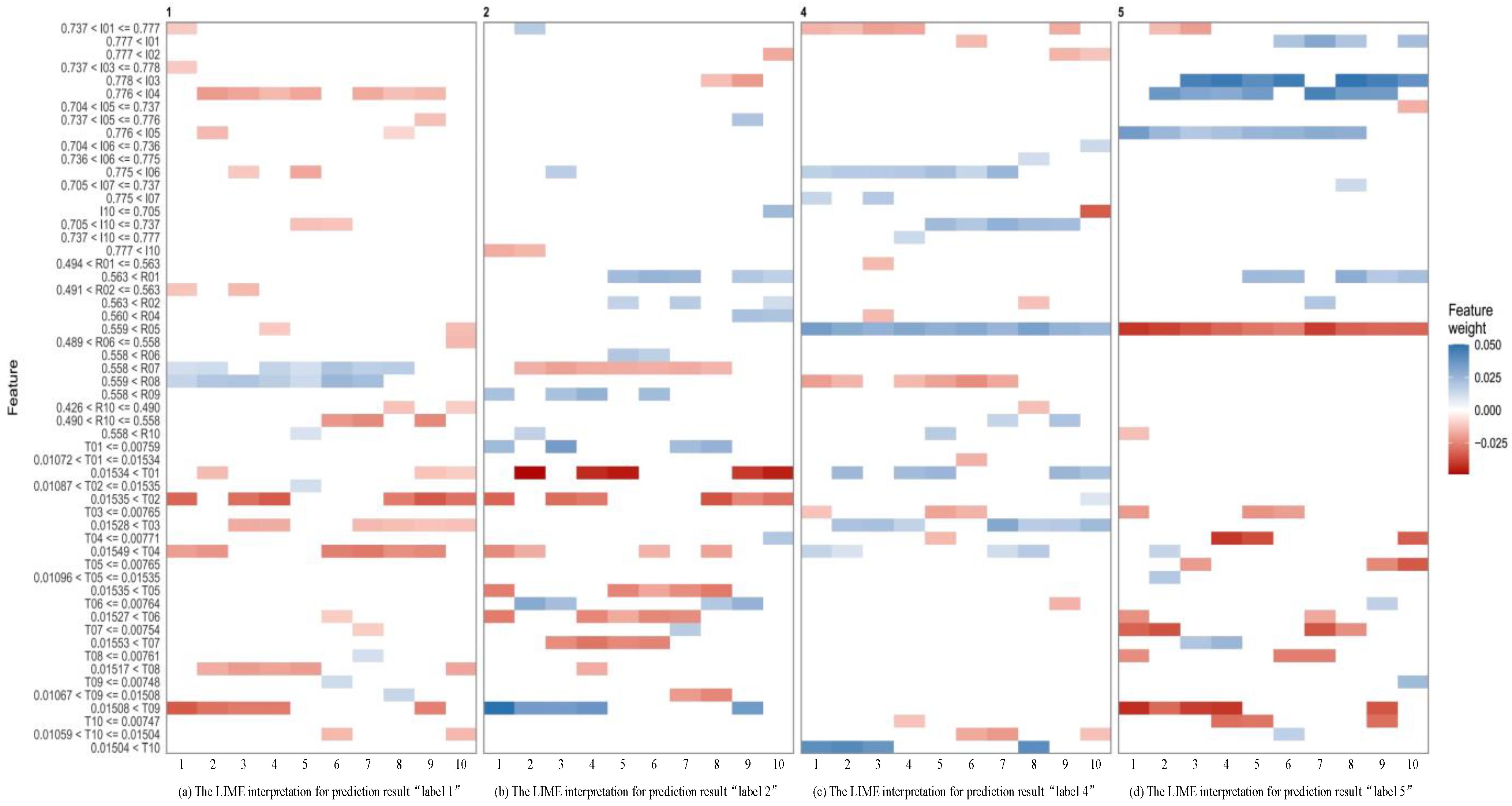
In short, this paper contains mainly the following three contributions: (1) A novel multi-classification method is proposed to forecast the price-movement direction, and to perform simulation trading of rebar futures in the Chinese futures market. (2) The SMOTE technique is adopted to overcome the class imbalance problem in the original training dataset, which further enhances the prediction performance of the classification model. (3) A sophisticated trading rule for high-frequency trading of rebar futures is designed, and the trading parameters are optimized using NSGA-II by considering trading profits and trading risks. (4) The LIME method is adopted to explain how the proposed method performed movement direction predictions for rebar futures prices quantitatively.
The rest of this paper is structured as follows. In
Section 2, we introduce some basic background about the relevant algorithms used in this research.
Section 3 explains the main structure of the proposed approach. The empirical data, design, and optimization of trading rule, evaluation metrics, and benchmark models are provided in
Section 4. The experimental results are reported and discussed in
Section 5. At last,
Section 6 summarizes the conclusion of this research.
3. Proposed Approach
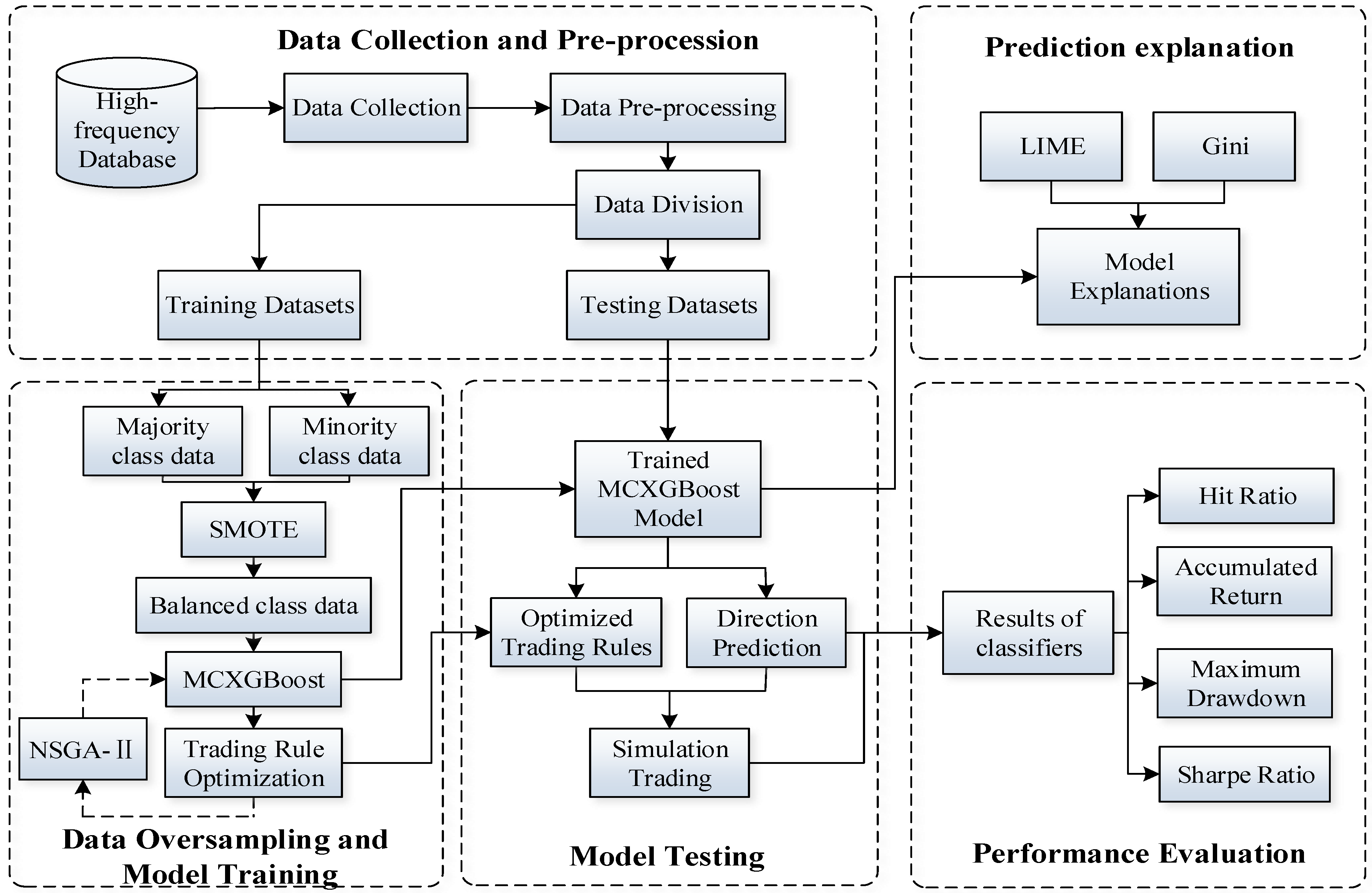
For direction prediction and simulation trading of the rebar futures, a multiclassification method, which combines XGBoost, SMOTE, and NSGA-II, is proposed in this research. The main structure of the proposed approach is presented in
Figure 1, with its specific procedures summarized in the following steps:
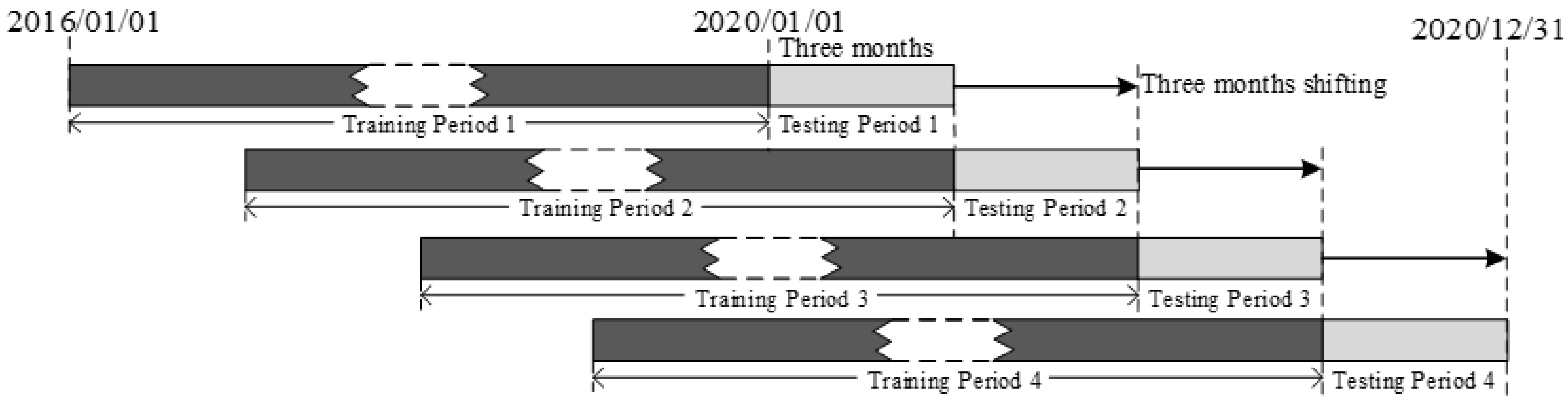
At first, 5 min historical trading data of the rebar futures are collected from databases. After timeframe transformation, the 1-h interval trading data are generated and normalized. Then, the entire dataset is divided into four consecutive experimental datasets. Each subdataset consists of a training period and a testing period.
In the second step, the proposed approach uses the SMOTE technique to generate the class-balanced training datasets. Then, XGBoost is adopted to construct a multiclassification forecasting model using the balanced datasets. Meanwhile, NSGA-II is incorporated for parameters optimization of the pre-designed trading rule. The multiobjective optimization is performed to achieve the Pareto optimal solution for two objectives, including the maximization of accumulated return and minimization of the maximum drawdown.
In the third step, the optimized XGBoost model and trading rule are selected for price-movement-direction prediction and trading simulation of rebar futures in four consecutive testing periods.
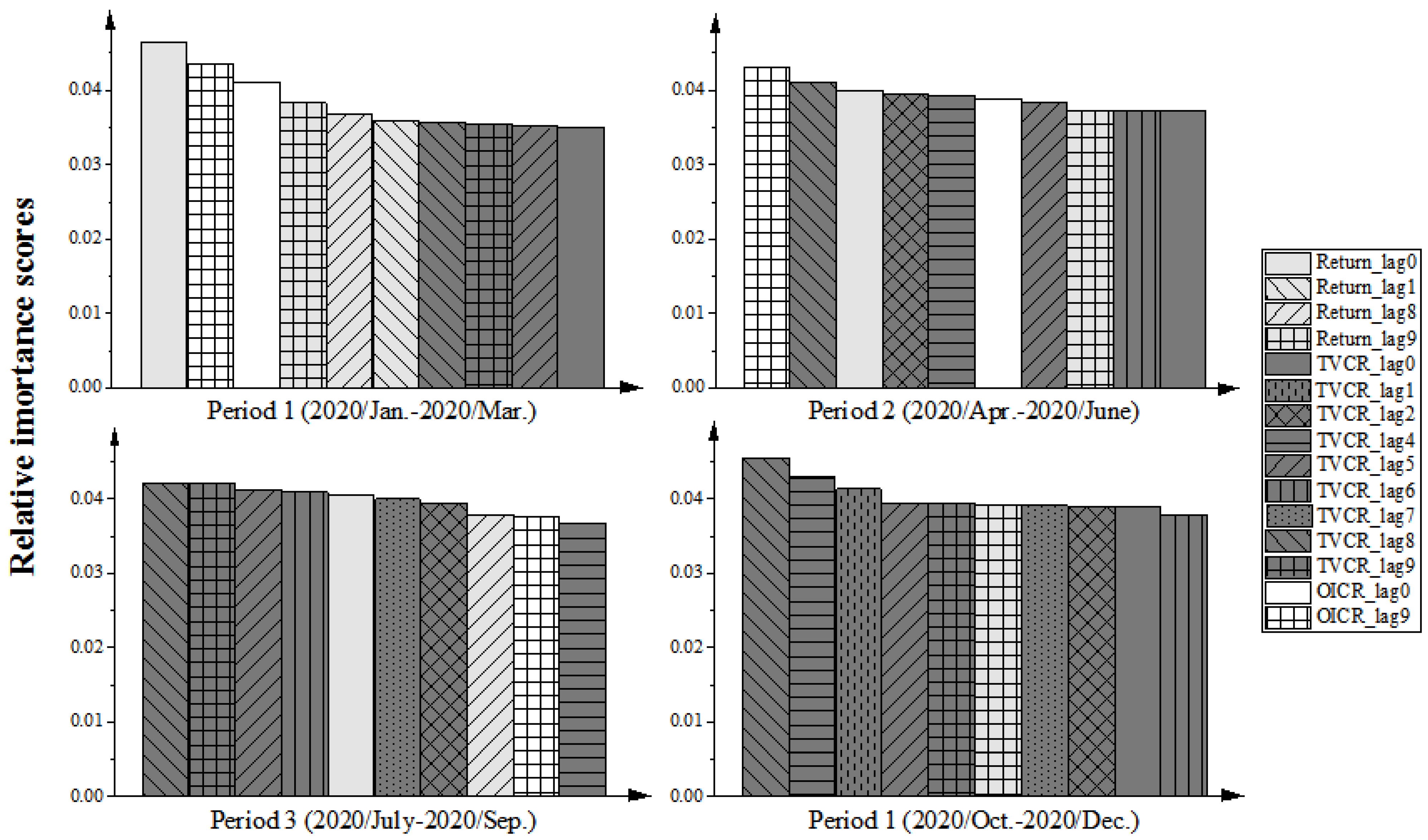
In the fourth step, LIME is adopted to explain how the XGBoost made multiclassification predictions for rebar futures price direction.
In the final step, evaluation measures are employed to judge the prediction and trading performances of all methods from the perspective of direction prediction accuracy, profitability, and trading risk.
6. Conclusions
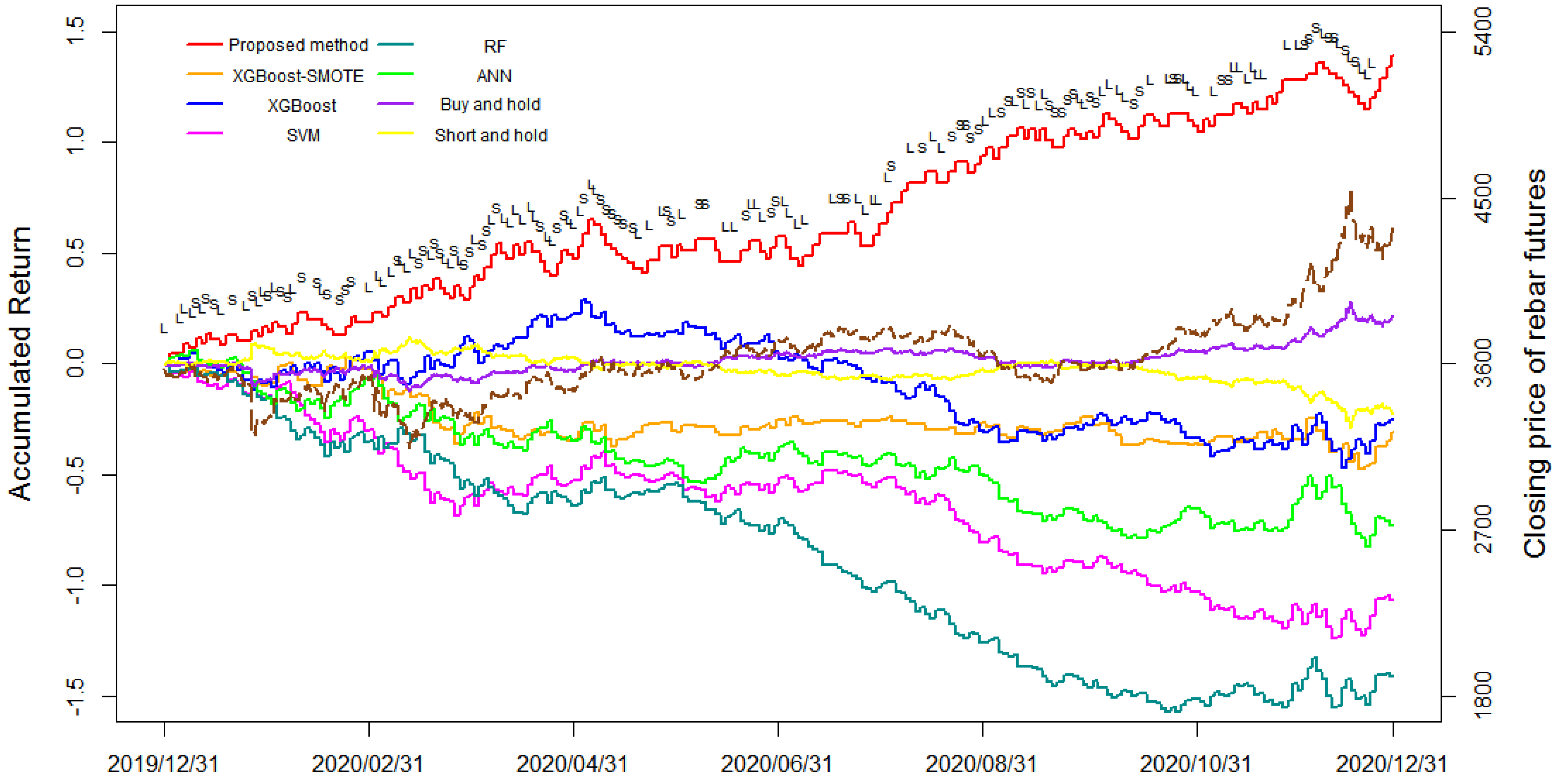
In this research, a novel integration approach based on a combination of XGBoost, SMOTE, and NSGA-II is developed to predict and trade on rebar futures. In the proposed model, the training datasets of minority classes are oversampled by the SMOTE technique to overcome the problem of the class imbalance, and XGBoost is adopted for the rebar futures price direction prediction using the oversampled training data. Then, NSGA-II is employed to search for the Pareto optimal solution of the trading rule parameters by efficiently allocating accumulated returns and maximum drawdown. The proposed approach produced an average hit ratio of 53.98% and an average return of 34.9% over the four testing periods. The proposed method also performed well in terms of the accumulated return of the entire one-year simulation trading with the value of 1.395. Furthermore, the maximum drawdown and Sharpe ratio of the proposed method reached 0.135 and 3.6574, respectively, which were superior to all the benchmark methods. Based on the experimental results comparison of the proposed method and benchmarks, it demonstrates that the proposed method XGBoost-SMOTE-NSGA-II successfully enhances the direction prediction accuracy and profitability, and generates the best return–risk ratio results among all the investigated methods. In summary, according to the outstanding direction prediction and simulation trading performances, it demonstrates that the proposed XGBoost-SMOTE-NSGA-II method can be utilized as an effective decision-making system for both investors and regulators engaged in the rebar futures market.
In this paper, we propose a high-frequency direction prediction and simulation trading model for rebar futures that combines the XGBoost, SMOTE and NSGA-II algorithms. The LIME algorithm is adopted to explain the prediction results of the proposed method. There are some research directions to be further expanded. For instance, in this research, historical transaction data from ten periods are utilized for five periods-ahead movement prediction, different time frames of historical data could be further considered as input features for prediction performance comparison. Moreover, this research develops an integrated approach based on the historical price data of rebar futures for direction forecasting. However, the sentiment and behavior of investors in the futures market could have an impact on the movement of futures prices. Therefore, other researchers may take into account the influence of investors’ sentiment features to improve the model prediction and trading accuracy. Moreover, scholars could employ other machine-learning algorithms as the multiclassification models, such as Random Forest [
53], CatBoost, and LightGBM. Moreover, scholars can also try other methods to solve the imbalance sample problem, such as the Generative Adversarial Networks (GAN) [
54], LoRAS [
55], or the improved algorithms of SMOTE [
56].








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}