
A Multi-View Framework to Detect Redundant Activity Labels for More Representative Event Logs in Process Mining


Abstract
:1. Introduction
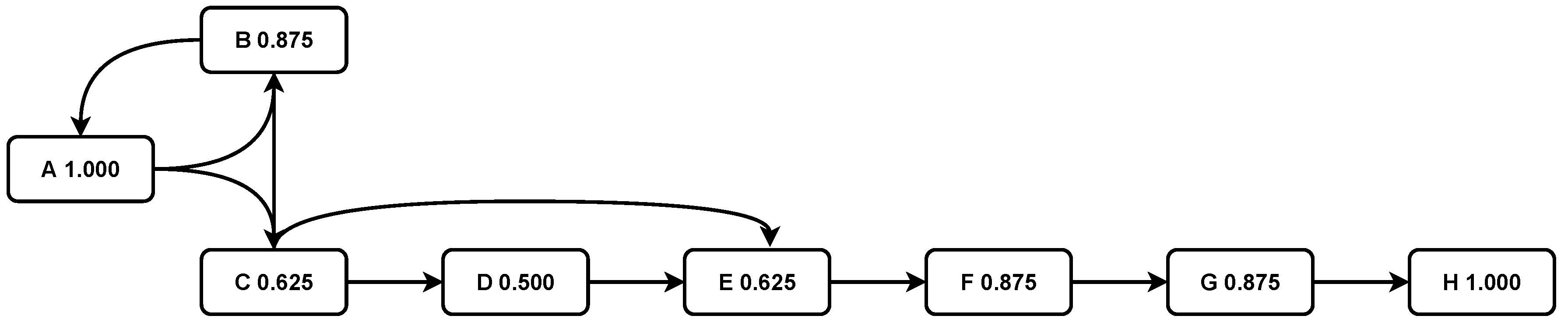
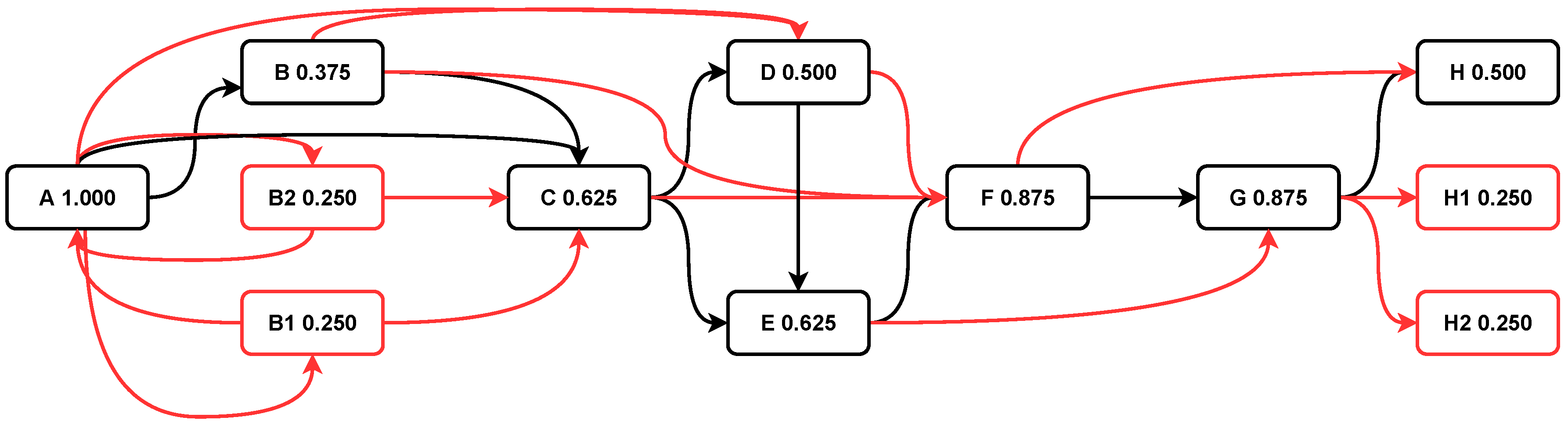
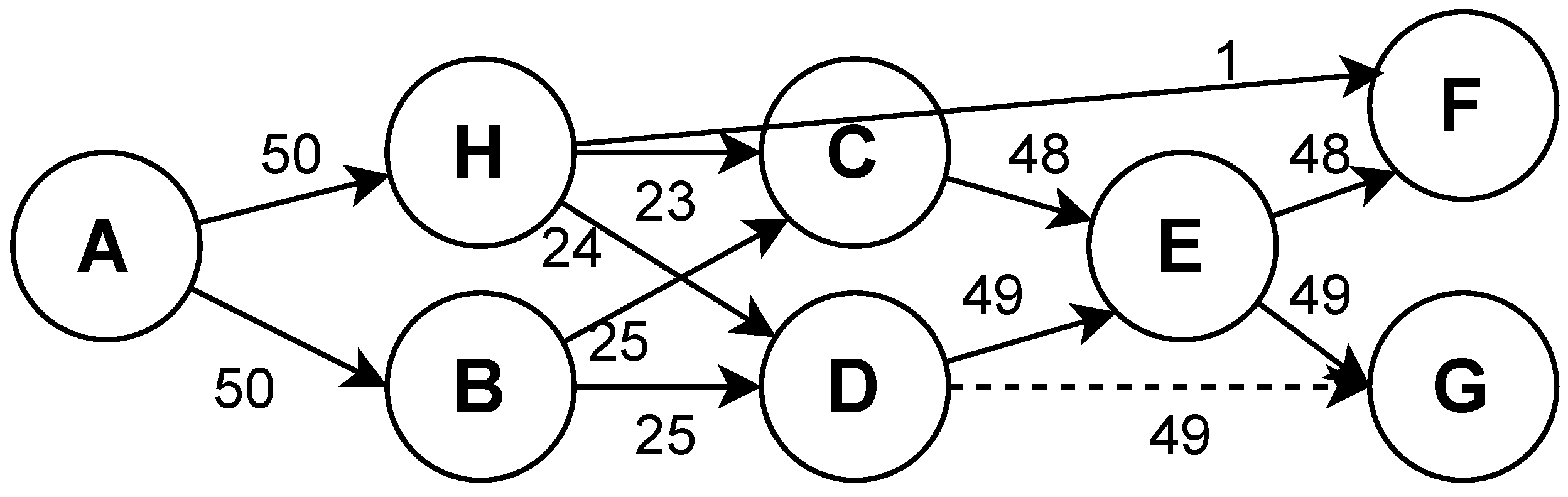
1.1. Motivating Example
1.2. Contributions of This Paper
- For the purpose of improving the quality of event logs, a novel data preprocessing framework is proposed for process mining.
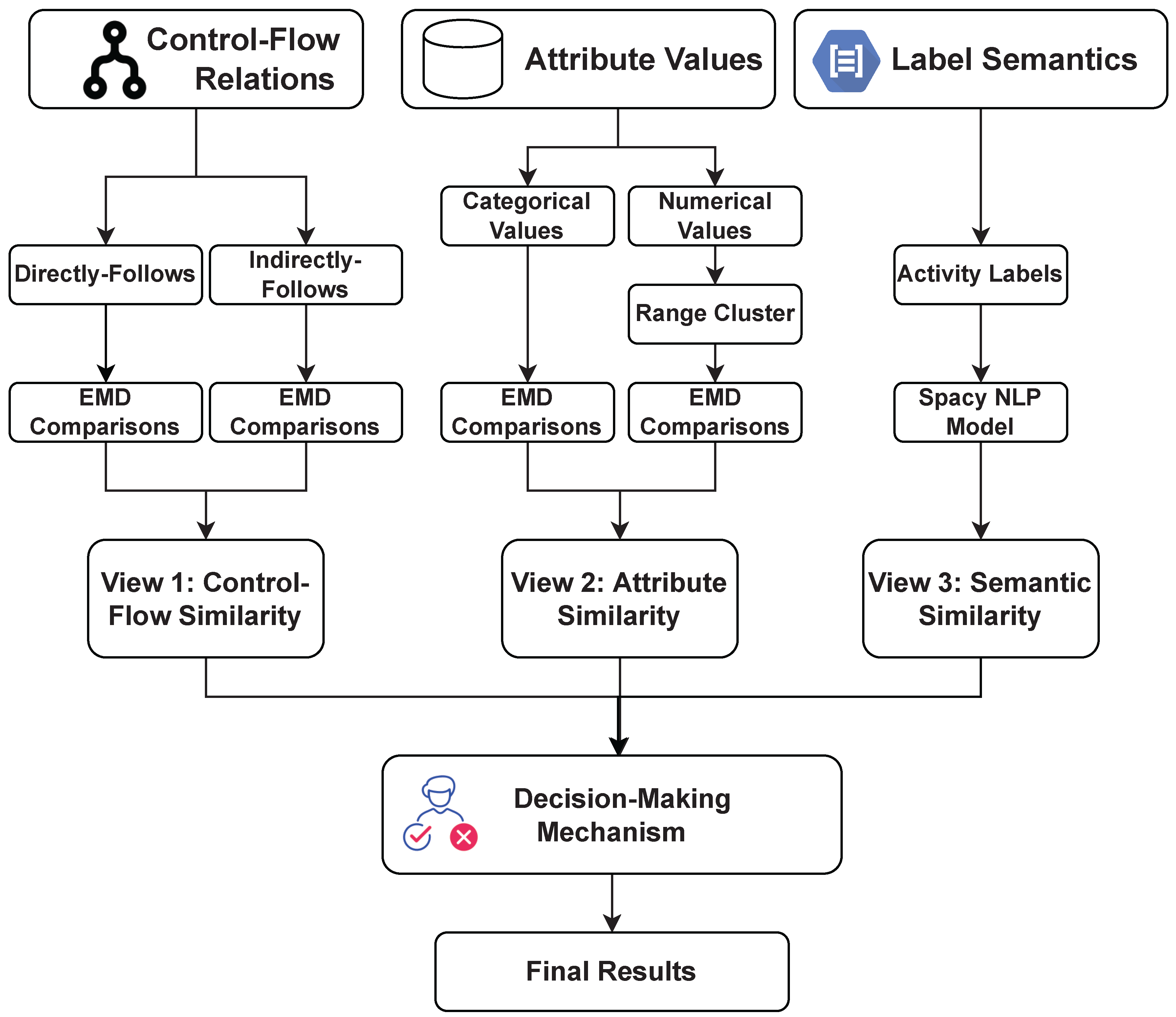
- A multi-view framework is proposed to detect redundant activity labels in event logs. In particular, our framework integrates control–flow relations, attribute values, and label semantic information in event logs. In terms of the control–flow relation (i.e., the ordering of activities), we adopt the Earth Mover’s Distance (EMD) statistical method to compare the directly-follows and indirectly-follows relations of different activity labels. In terms of the attribute value (i.e., categorical or numerical values of recorded activity labels), activity labels are first clustered and followed by EMD to compare the value’s distribution. We assess labels’ semantic similarity by using the pre-trained NLP model as another view. A consensus is guided by a decision-making mechanism to integrate the results produced from multiple views.
- Experiments on publicly available datasets under various settings show that our framework can accurately detect redundant activity labels even when the redundant activity labels are infrequent and contain numerical values as attributes compared with the existing state-of-the-art approach.
- A case study in the healthcare domain using the 5-year EMR dataset collected from two local health districts (LHDs) in Sydney, Australia [18], further demonstrates that our framework can be used as a preprocessing tool in real-life event logs.
2. Related Work
2.1. Process Discovery Algorithms
2.2. Event Log Quality
3. Preliminaries
Problem Definition
- Directly-follows relation: holds if there is a trace and such that and and .
- Indirectly-follows relation: holds if there is a trace and and such that and and .
4. A Multi-View Detecting Framework
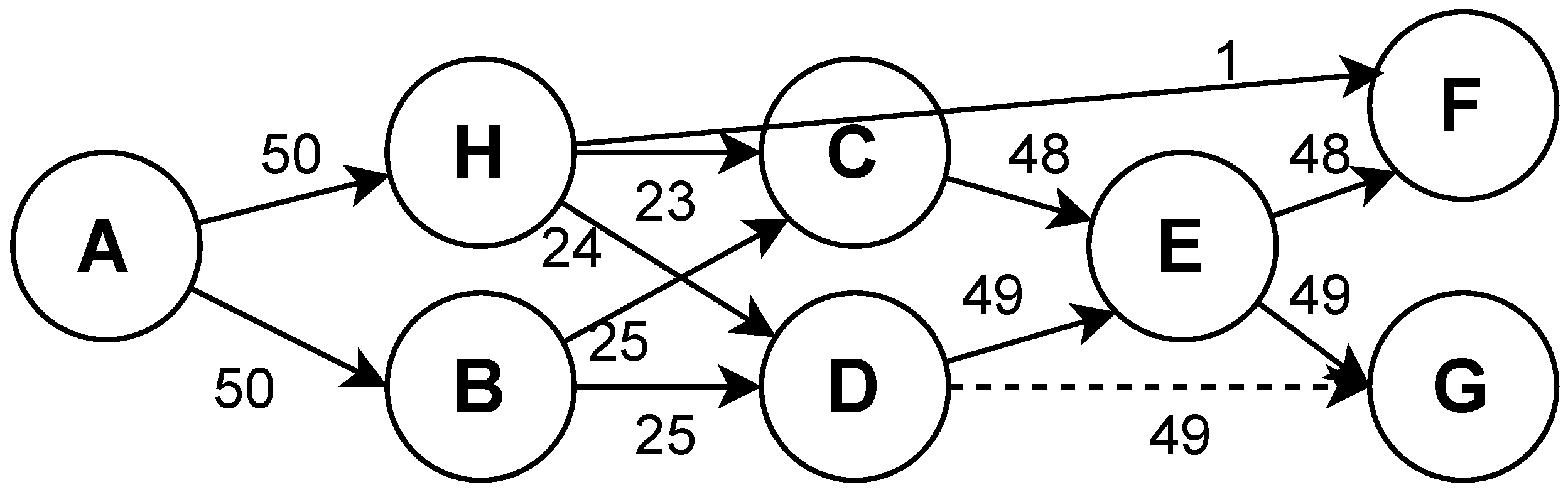
4.1. Earth Mover’s Distance
- Non-negativity flow: .
- Sent and receive flow should not exceed weights in P and Q:
- -
- , ;
- -
- , .
- All weights possible have to be sent:
4.2. View 1: Measuring Control–Flow Similarity
| Algorithm 1: Directly-Follows Similarity |
 |
4.3. View 2: Measuring Attribute Value Similarity
| Algorithm 2: Attribute Value Similarity |
 |
4.4. View 3: Measuring Semantic Similarity
4.5. Decision-Making Mechanism: Majority Voting
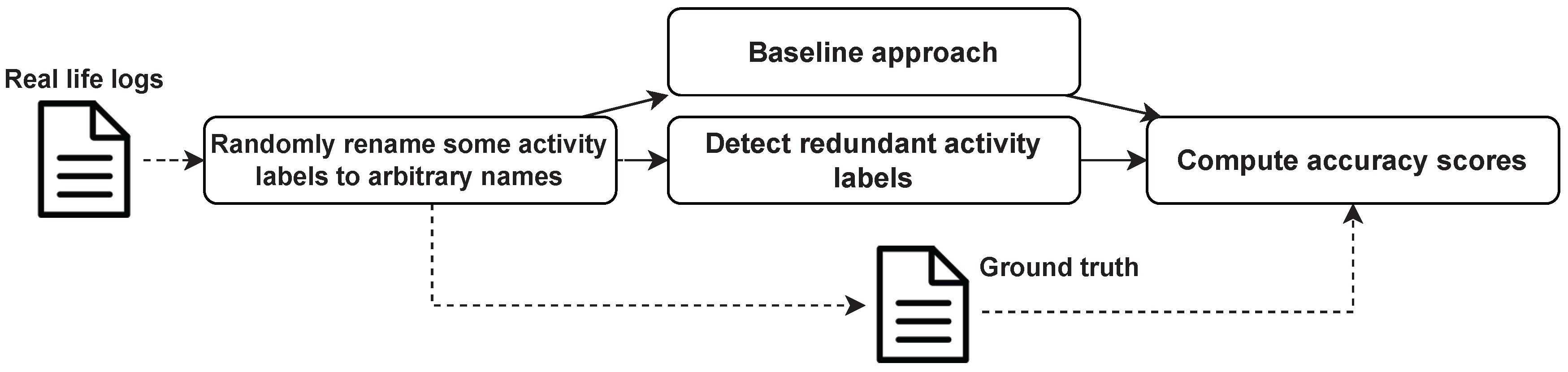
5. Evaluation
- Hospital Billing log (https://doi.org/10.4121/uuid:76c46b83-c930-4798-a1c9-4be94dfeb741 (accessed 7 April 2022)): An event log records processes related to billing medical services provided by a Dutch hospital.
- Sepsis log (https://doi.org/10.4121/uuid:915d2bfb-7e84-49ad-a286-dc35f063a460 (accessed 7 April 2022)): An event log records treatment processes of sepsis patients from a Dutch hospital.
- Helpdesk (https://doi.org/10.4121/uuid:0c60edf1-6f83-4e75-9367-4c63b3e9d5bb (accessed 7 April 2022)): An event log contains the ticketing management process of the help desk in a software company in Italy.
- BPI Challenge 2012 (https://doi.org/10.4121/uuid:3926db30-f712-4394-aebc-75976070e91f (accessed 7 April 2022)): An event log of a loan application process in a Dutch financial institute.
5.1. Comparing with The Existing Method
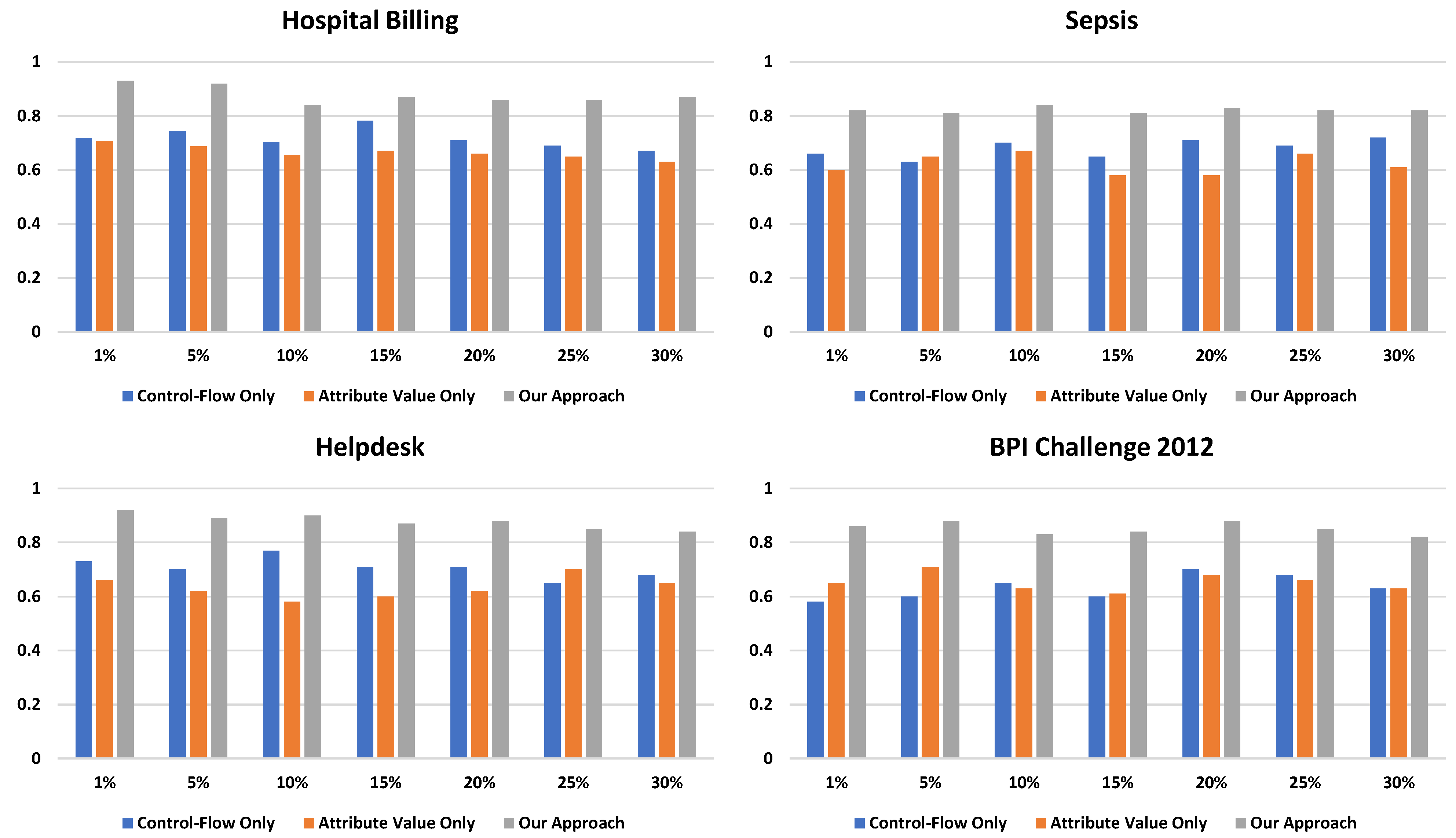
5.2. Further Analysis of Our Proposed Framework
- Control–Flow Only: the baseline only relies on the control–flow similarity to detect redundant activity labels.
- Attribute Value Only: the baseline only relies on the attribute similarity to detect redundant activity labels.
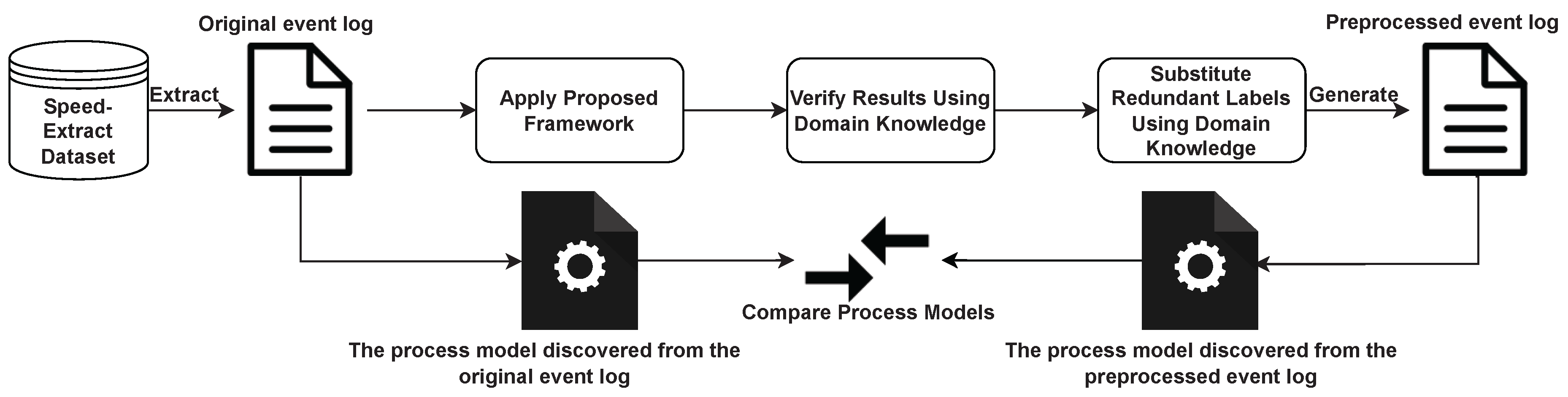
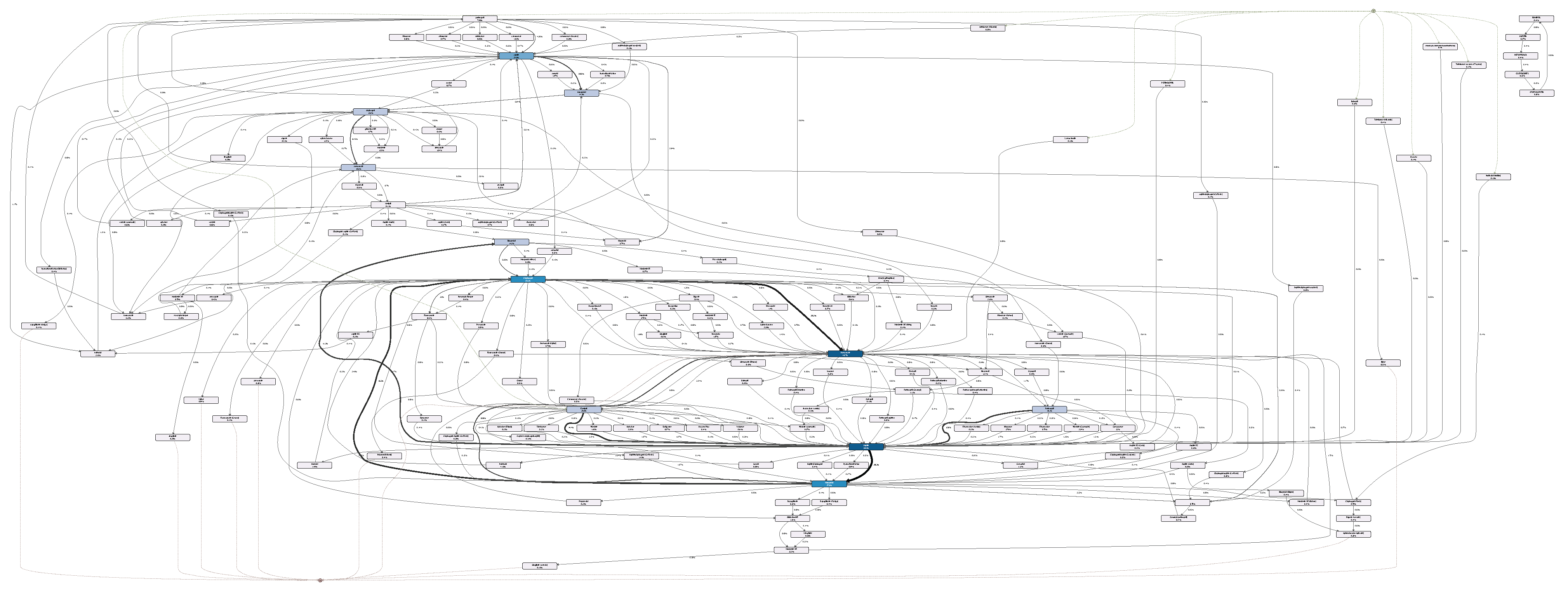
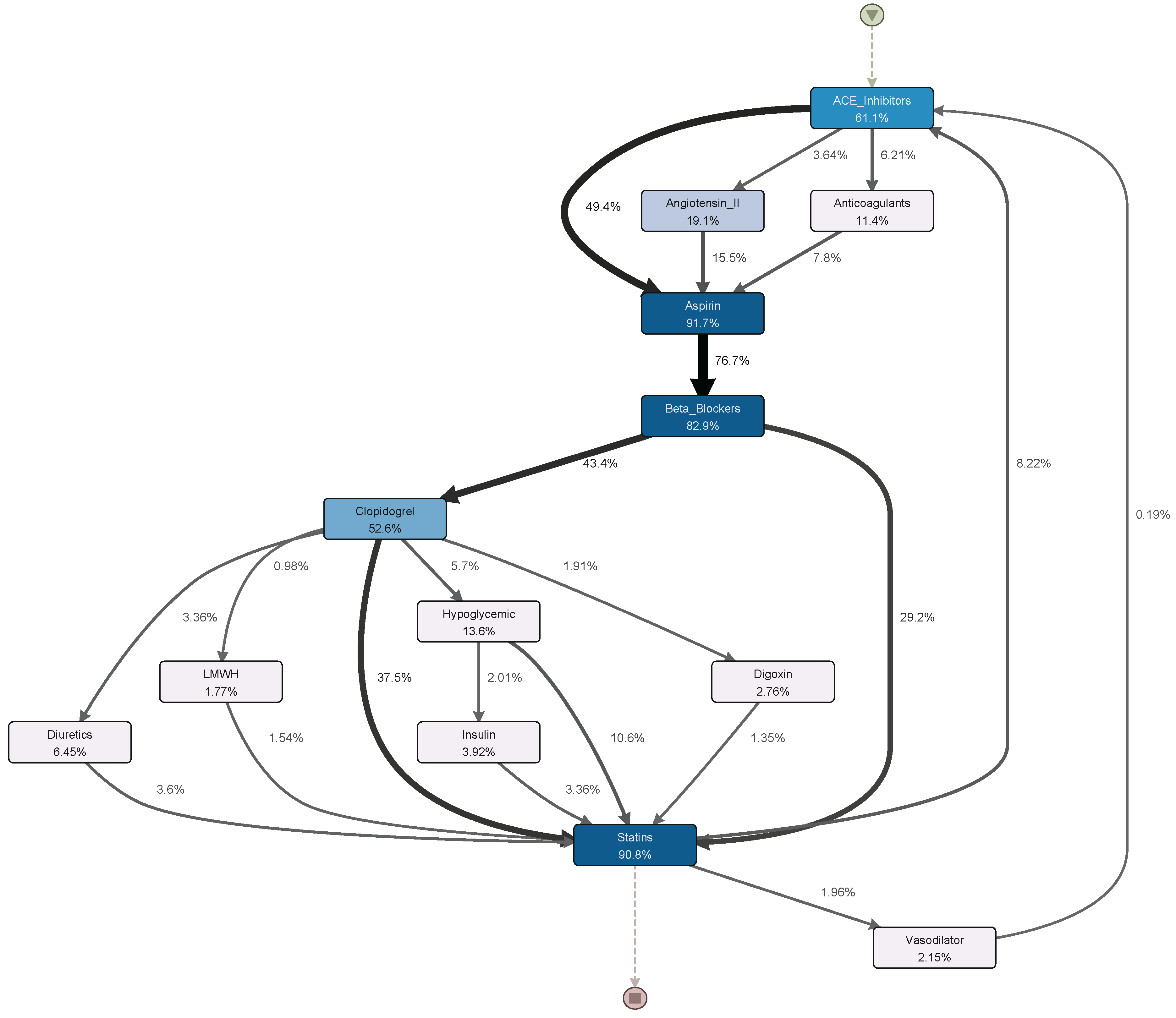
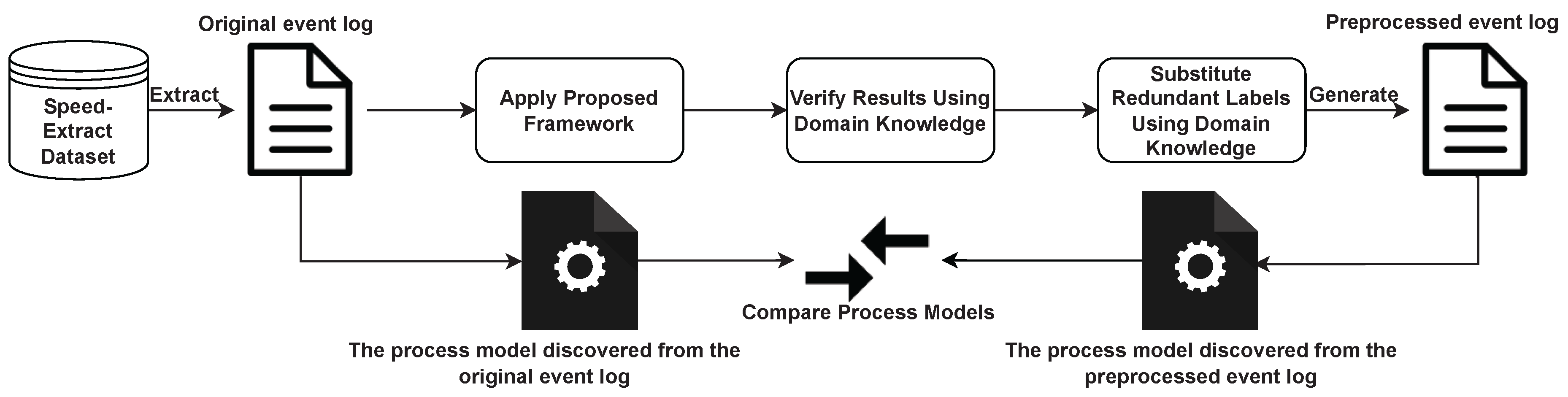
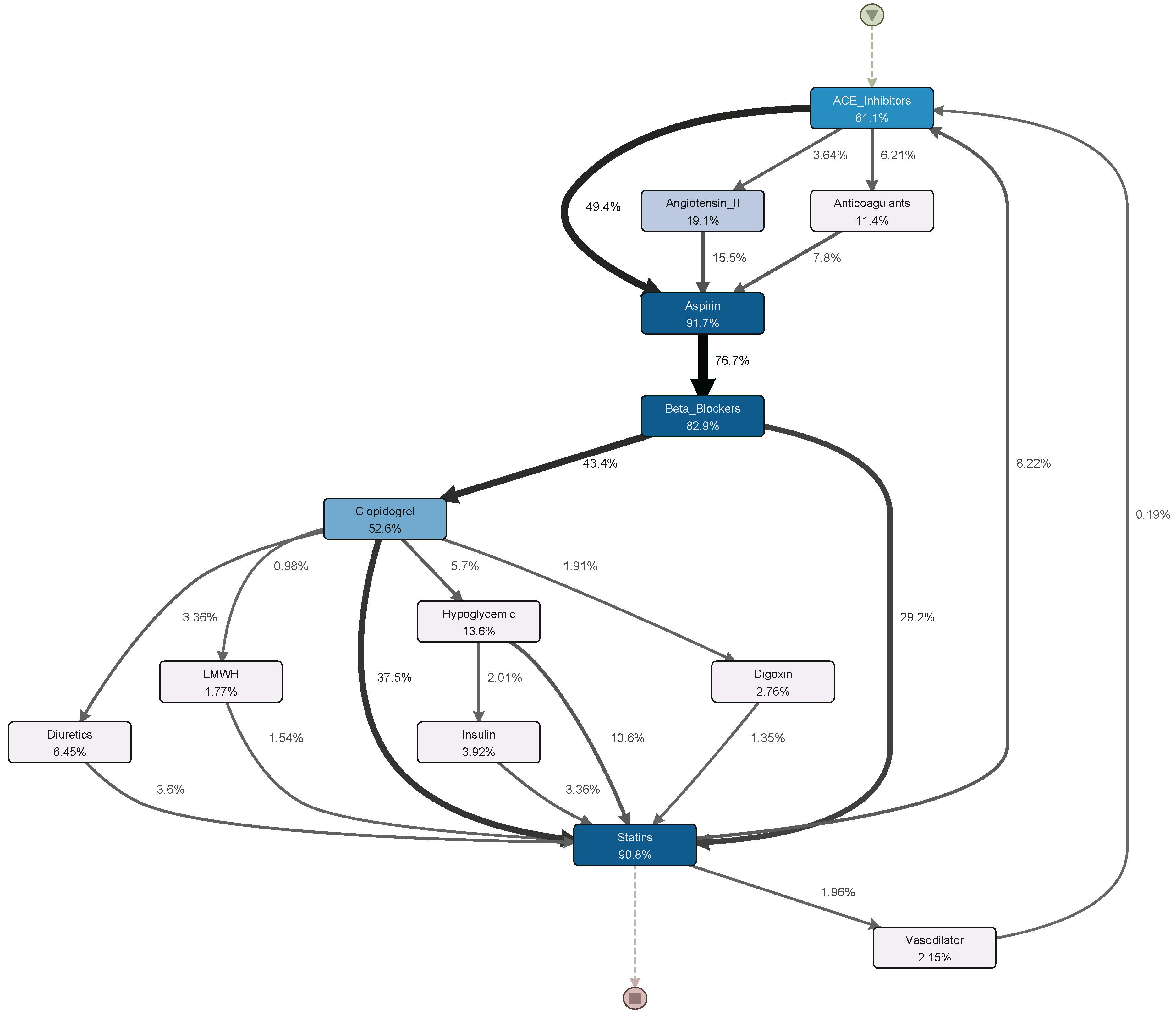
6. Real-Life Case Study
6.1. Event Log Construction
6.2. Result and Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| EMR | Electronic Medical Records |
| MIMIC-III | Medical Information Mart for Intensive Care-III |
| EMD | Earth Mover’s Distance |
| LHD | Local Health District |
| NLP | Natural Language Processing |
| ACS | Acute Coronary Syndrome |
| STEMI | ST-elevation Myocardial Infarction |
| ICD | International Classification of Diseases |
Appendix A. Notations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| L | the event log |
| t | the trace |
| A | set of activities |
| e | the event |
| the function that obtains attribute values recorded for an event e | |
| the directly follows relation | |
| the indirectly follows relation | |
| the long distance measure | |
| the strong indirectly follows relation | |
| G | the directly follows graph |
| the post-set | |
| the pre-set | |
| P | the probability distribution |
| D | the ground distance between clusters |
| the EMD between two probability distributios |
References
- Van Der Aalst, W. Data science in action. In Process Mining; Springer: Berlin/Heidelberg, Germany, 2016; pp. 3–23. [Google Scholar]
- Marin-Castro, H.M.; Tello-Leal, E. Event Log Preprocessing for Process Mining: A Review. Appl. Sci. 2021, 11, 10556. [Google Scholar] [CrossRef]
- Wen, L.; Wang, J.; van der Aalst, W.M.; Huang, B.; Sun, J. Mining process models with prime invisible tasks. Data Knowl. Eng. 2010, 69, 999–1021. [Google Scholar] [CrossRef]
- Maggi, F.M.; Bose, R.; van der Aalst, W.M. Efficient discovery of understandable declarative process models from event logs. In Proceedings of the International Conference on Advanced Information Systems Engineering, Gdansk, Poland, 25–29 June 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 270–285. [Google Scholar]
- Mans, R.S.; Van der Aalst, W.M.; Vanwersch, R.J. Process Mining in Healthcare: Evaluating and Exploiting Operational Healthcare Processes; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Weijters, A.; Ribeiro, J. Flexible heuristics miner (FHM). In Proceedings of the 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011; pp. 310–317. [Google Scholar]
- Augusto, A.; Conforti, R.; Dumas, M.; La Rosa, M.; Polyvyanyy, A. Split miner: Automated discovery of accurate and simple business process models from event logs. Knowl. Inf. Syst. 2019, 59, 251–284. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Lu, Y.; Tam, C.; Poon, S. Process Mining to Discover and Preserve Infrequent Relations in Event Logs: An Application to Understand the Laboratory Test Ordering Process Using the MIMIC-III Dataset. In Proceedings of the Australasian Conference on Information Systems (ACIS), Sydney, Australia, 6–10 December 2021; pp. 30–41. [Google Scholar]
- Van Der Aalst, W.; Adriansyah, A.; De Medeiros, A.K.A.; Arcieri, F.; Baier, T.; Blickle, T.; Bose, J.C.; Van Den Brand, P.; Brandtjen, R.; Buijs, J.; et al. Process mining manifesto. In Proceedings of the International Conference on Business Process Management, Clermont-Ferrand, France, 30 August–2 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 169–194. [Google Scholar]
- Suriadi, S.; Andrews, R.; ter Hofstede, A.H.; Wynn, M.T. Event log imperfection patterns for process mining: Towards a systematic approach to cleaning event logs. Inf. Syst. 2017, 64, 132–150. [Google Scholar] [CrossRef]
- Sadeghianasl, S.; ter Hofstede, A.H.; Wynn, M.T.; Suriadi, S. A contextual approach to detecting synonymous and polluted activity labels in process event logs. In Proceedings of the OTM Confederated International Conferences On the Move to Meaningful Internet Systems, Rome, Italy, 10–14 September 2012; Springer: Berlin/Heidelberg, Germany, 2019; pp. 76–94. [Google Scholar]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Li-Wei, H.L.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Sadeghianasl, S.; ter Hofstede, A.H.; Suriadi, S.; Turkay, S. Collaborative and interactive detection and repair of activity labels in process event logs. In Proceedings of the 2020 2nd International Conference on Process Mining (ICPM), Padua, Italy, 5–8 October 2020; pp. 41–48. [Google Scholar]
- Sadeghianasl, S.; Ter Hofstede, A.H.; Wynn, M.T.; Turkay, S.; Myers, T. Process Activity Ontology Learning From Event Logs Through Gamification. IEEE Access 2021, 9, 165865–165880. [Google Scholar] [CrossRef]
- Lu, Y.; Chen, Q.; Poon, S.K. A Deep Learning Approach for Repairing Missing Activity Labels in Event Logs for Process Mining. Information 2022, 13, 234. [Google Scholar] [CrossRef]
- Günther, C.W.; Rozinat, A. Disco: Discover Your Processes. BPM (Demos) 2012, 940, 40–44. [Google Scholar]
- Mannhardt, F.; Blinde, D. Analyzing the Trajectories of Patients with Sepsis Using Process Mining; RADAR+ EMISA@ CAiSE: 2017 Springer: Berlin/Heidelberg, Germany, 2017; pp. 72–80. [Google Scholar]
- Tam, C.S.; Gullick, J.; Saavedra, A.; Vernon, S.T.; Figtree, G.A.; Chow, C.K.; Cretikos, M.; Morris, R.W.; William, M.; Morris, J.; et al. Combining structured and unstructured data in EMRs to create clinically-defined EMR-derived cohorts. BMC Med Inform. Decis. Mak. 2021, 21, 91. [Google Scholar] [CrossRef]
- Van der Aalst, W.; Weijters, T.; Maruster, L. Workflow mining: Discovering process models from event logs. IEEE Trans. Knowl. Data Eng. 2004, 16, 1128–1142. [Google Scholar] [CrossRef]
- Wen, L.; Van Der Aalst, W.M.; Wang, J.; Sun, J. Mining process models with non-free-choice constructs. Data Min. Knowl. Discov. 2007, 15, 145–180. [Google Scholar] [CrossRef]
- Leemans, S.J.; Fahland, D.; van der Aalst, W.M. Discovering block-structured process models from event logs containing infrequent behaviour. In Proceedings of the International Conference on Business Process Management, Beijing, China, 26–30 August 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 66–78. [Google Scholar]
- Conforti, R.; Dumas, M.; García-Bañuelos, L.; La Rosa, M. BPMN Miner: Automated discovery of BPMN process models with hierarchical structure. Inf. Syst. 2016, 56, 284–303. [Google Scholar] [CrossRef] [Green Version]
- Buijs, J.C.; Van Dongen, B.F.; van Der Aalst, W.M. On the role of fitness, precision, generalization and simplicity in process discovery. In Proceedings of the OTM Confederated International Conferences On the Move to Meaningful Internet Systems, Rome, Italy, 10–14 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 305–322. [Google Scholar]
- Fox, F.; Aggarwal, V.R.; Whelton, H.; Johnson, O. A data quality framework for process mining of electronic health record data. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics (ICHI), New York, NY, USA, 4–7 June 2018; pp. 12–21. [Google Scholar]
- Mans, R.S.; van der Aalst, W.M.; Vanwersch, R.J.; Moleman, A.J. Process mining in healthcare: Data challenges when answering frequently posed questions. In Process Support and Knowledge Representation in Health Care; Springer: Berlin/Heidelberg, Germany, 2012; pp. 140–153. [Google Scholar]
- Bose, R.J.C.; Mans, R.S.; van der Aalst, W.M. Wanna improve process mining results? In Proceedings of the 2013 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Singapore, 16–19 April 2013; pp. 127–134. [Google Scholar]
- Van Der Aalst, W. Process mining: Overview and opportunities. ACM Trans. Manag. Inf. Syst. (TMIS) 2012, 3, 1–17. [Google Scholar] [CrossRef]
- Conforti, R.; La Rosa, M.; Ter Hofstede, A.H.; Augusto, A. Automatic repair of same-timestamp errors in business process event logs. In Proceedings of the International Conference on Business Process Management, Seville, Spain, 13–18 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 327–345. [Google Scholar]
- Sim, S.; Bae, H.; Choi, Y. Likelihood-based multiple imputation by event chain methodology for repair of imperfect event logs with missing data. In Proceedings of the 2019 International Conference on Process Mining (ICPM), Aachen, Germany, 24–26 June 2019; pp. 9–16. [Google Scholar]
- Alharbi, A.; Bulpitt, A.; Johnson, O. Improving pattern detection in healthcare process mining using an interval-based event selection method. In Proceedings of the International Conference on Business Process Management, Barcelona, Spain, 10–15 September 2017; Springer:: Berlin/Heidelberg, Germany, 2017; pp. 88–105. [Google Scholar]
- van der Aa, H.; Gal, A.; Leopold, H.; Reijers, H.A.; Sagi, T.; Shraga, R. Instance-based process matching using event-log information. In Proceedings of the International Conference on Advanced Information Systems Engineering, Essen, Germany, 12–16 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 283–297. [Google Scholar]
- Klinkmüller, C.; Weber, I.; Mendling, J.; Leopold, H.; Ludwig, A. Increasing recall of process model matching by improved activity label matching. In Business Process Management; Springer: Berlin/Heidelberg, Germany, 2013; pp. 211–218. [Google Scholar]
- Dijkman, R.; Dumas, M.; Van Dongen, B.; Käärik, R.; Mendling, J. Similarity of business process models: Metrics and evaluation. Inf. Syst. 2011, 36, 498–516. [Google Scholar] [CrossRef] [Green Version]
- Richter, F.; Zellner, L.; Azaiz, I.; Winkel, D.; Seidl, T. LIProMa: Label-independent process matching. In Proceedings of the International Conference on Business Process Management, Vienna, Austria, 1–6 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 186–198. [Google Scholar]
- Koschmider, A.; Ullrich, M.; Heine, A.; Oberweis, A. Revising the Vocabulary of Business Process Element Labels. International Conference on Advanced Information Systems Engineering; Springer: Berlin/Heidelberg, Germany, 2015; pp. 69–83. [Google Scholar]
- Mendling, J.; Reijers, H.A.; Recker, J. Activity labeling in process modeling: Empirical insights and recommendations. Inf. Syst. 2010, 35, 467–482. [Google Scholar] [CrossRef] [Green Version]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The earth mover’s distance as a metric for image retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Assent, I.; Wenning, A.; Seidl, T. Approximation techniques for indexing the earth mover’s distance in multimedia databases. In Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006; p. 11. [Google Scholar]
- Zhang, M.; Liu, Y.; Luan, H.; Sun, M.; Izuha, T.; Hao, J. Building earth mover’s distance on bilingual word embeddings for machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Brockhoff, T.; Uysal, M.S.; van der Aalst, W.M. Time-aware Concept Drift Detection Using the Earth Mover’s Distance. In Proceedings of the 2020 2nd International Conference on Process Mining (ICPM), Padua, Italy, 5–8 October 2020; pp. 33–40. [Google Scholar]
- Guo, Q.; Wen, L.; Wang, J.; Yan, Z.; Philip, S.Y. Mining invisible tasks in non-free-choice constructs. In Proceedings of the International Conference on Business Process Management, Rio de Janeiro, Brazil, 18–22 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 109–125. [Google Scholar]
- Johnson, S.C. Hierarchical clustering schemes. Psychometrika 1967, 32, 241–254. [Google Scholar] [CrossRef]
- Faloutsos, C.; Ranganathan, M.; Manolopoulos, Y. Fast subsequence matching in time-series databases. Acm Sigmod Rec. 1994, 23, 419–429. [Google Scholar] [CrossRef] [Green Version]
- Sturges, H.A. The choice of a class interval. J. Am. Stat. Assoc. 1926, 21, 65–66. [Google Scholar] [CrossRef]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710, Doklady Akademii Nauk SSSR, V163 No4 845–848 1965. [Google Scholar]
- Honnibal, M.; Montani, I. spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing. Appear 2017, 7, 411–420. [Google Scholar]
- Ruta, D.; Gabrys, B. Classifier selection for majority voting. Inf. Fusion 2005, 6, 63–81. [Google Scholar] [CrossRef]
- Berti, A.; Van Zelst, S.J.; van der Aalst, W. Process mining for python (PM4Py): Bridging the gap between process-and data science. arXiv 2019, arXiv:1905.06169. [Google Scholar]
- Switaj, T.L.; Christensen, S.; Brewer, D.M. Acute coronary syndrome: Current treatment. Am. Fam. Physician 2017, 95, 232–240. [Google Scholar] [PubMed]
- Chew, D.P.; Scott, I.A.; Cullen, L.; French, J.K.; Briffa, T.G.; Tideman, P.A.; Woodruffe, S.; Kerr, A.; Branagan, M.; Aylward, P.E. National Heart Foundation of Australia and Cardiac Society of Australia and New Zealand: Australian clinical guidelines for the management of acute coronary syndromes 2016. Med. J. Aust. 2016, 205, 128–133. [Google Scholar] [CrossRef]







| Event Log | Number of Traces | Number of Trace Variants | Number of Events | Number of Attributes | Number of Activity Labels |
|---|---|---|---|---|---|
| Hospital Billing | 100,000 | 1020 | 451,359 | 1105 | 18 |
| Sepsis | 1050 | 846 | 15,214 | 26 | 16 |
| Helpdesk | 4580 | 226 | 21,348 | 22 | 14 |
| BPI Challenge 2012 | 13,087 | 4366 | 262,200 | 69 | 24 |
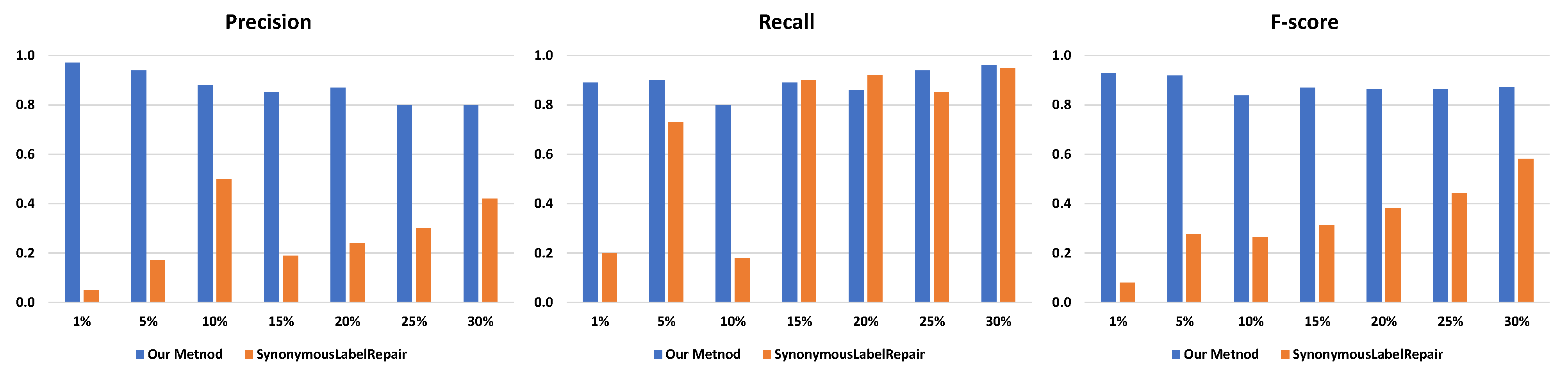
| Event Log | Number of Redundant Activity Labels | Precision | Recall | F-Score | |||
|---|---|---|---|---|---|---|---|
| Ours | Baseline | Ours | Baseline | Ours | Baseline | ||
| 5254 (1%) | 0.97 | 0.05 | 0.89 | 0.20 | 0.93 | 0.08 | |
| 21,693 (5%) | 0.94 | 0.17 | 0.90 | 0.73 | 0.92 | 0.28 | |
| 44,890 (10%) | 0.88 | 0.5 | 0.80 | 0.18 | 0.84 | 0.26 | |
| Hospital Billing | 66,368 (15%) | 0.85 | 0.19 | 0.89 | 0.90 | 0.87 | 0.31 |
| 90,273 (20%) | 0.87 | 0.24 | 0.86 | 0.92 | 0.86 | 0.38 | |
| 112,840 (25%) | 0.80 | 0.30 | 0.94 | 0.85 | 0.86 | 0.44 | |
| 135,480 (30%) | 0.80 | 0.42 | 0.96 | 0.95 | 0.87 | 0.58 | |
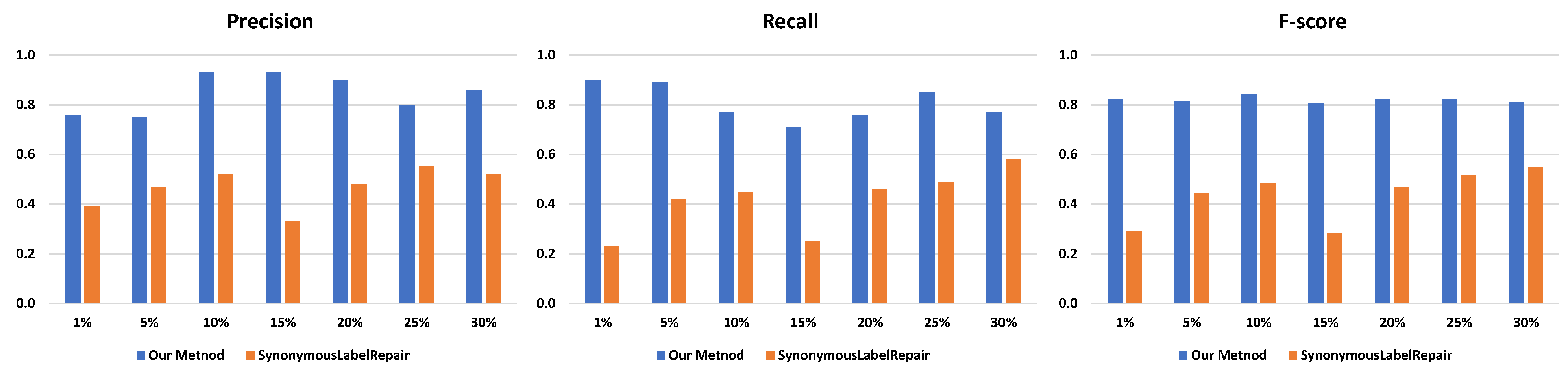
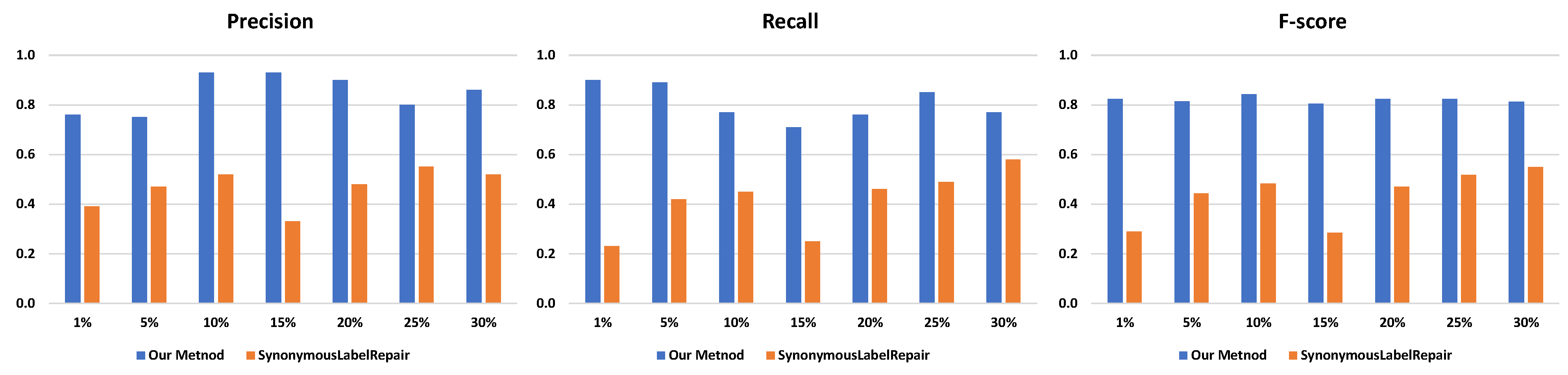
| 180 (1%) | 0.76 | 0.39 | 0.90 | 0.23 | 0.82 | 0.29 | |
| 745 (5%) | 0.75 | 0.47 | 0.89 | 0.42 | 0.81 | 0.44 | |
| 1569 (10%) | 0.93 | 0.52 | 0.77 | 0.45 | 0.84 | 0.47 | |
| Sepsis | 2327 (15%) | 0.93 | 0.33 | 0.71 | 0.25 | 0.81 | 0.29 |
| 3086 (20%) | 0.90 | 0.48 | 0.76 | 0.46 | 0.83 | 0.47 | |
| 3844 (25%) | 0.80 | 0.55 | 0.85 | 0.49 | 0.82 | 0.51 | |
| 4605 (30%) | 0.86 | 0.52 | 0.77 | 0.58 | 0.82 | 0.55 | |
| Event Log | Number of Redundant Activity Labels | Control–Flow Only | Attribute Value Only | Our Framework |
|---|---|---|---|---|
| 5254 (1%) | 0.72 | 0.71 | 0.93 | |
| 21,693 (5%) | 0.74 | 0.69 | 0.92 | |
| 44,890 (10%) | 0.70 | 0.66 | 0.84 | |
| Hospital Billing | 66,368 (15%) | 0.78 | 0.67 | 0.87 |
| 90,273 (20%) | 0.71 | 0.66 | 0.86 | |
| 112,840 (25%) | 0.69 | 0.65 | 0.86 | |
| 135,480 (30%) | 0.67 | 0.63 | 0.87 | |
| 180 (1%) | 0.66 | 0.60 | 0.82 | |
| 745 (5%) | 0.63 | 0.55 | 0.81 | |
| 1569 (10%) | 0.70 | 0.67 | 0.84 | |
| Sepsis | 2327 (15%) | 0.65 | 0.58 | 0.81 |
| 3086 (20%) | 0.71 | 0.58 | 0.83 | |
| 3844 (25%) | 0.69 | 0.66 | 0.82 | |
| 4605 (30%) | 0.72 | 0.61 | 0.82 | |
| 213 (1%) | 0.73 | 0.66 | 0.92 | |
| 1067 (5%) | 0.70 | 0.62 | 0.89 | |
| 2135 (10%) | 0.77 | 0.58 | 0.90 | |
| Helpdesk | 3202 (15%) | 0.71 | 0.60 | 0.87 |
| 4270 (20%) | 0.71 | 0.62 | 0.88 | |
| 5337 (25%) | 0.65 | 0.70 | 0.85 | |
| 6404 (30%) | 0.68 | 0.65 | 0.84 | |
| 2622 (1%) | 0.58 | 0.65 | 0.86 | |
| 13,110 (5%) | 0.60 | 0.71 | 0.88 | |
| 26,220 (10%) | 0.65 | 0.63 | 0.83 | |
| BPI Challenge 2012 | 39,330 (15%) | 0.60 | 0.61 | 0.84 |
| 52,440 (20%) | 0.70 | 0.68 | 0.88 | |
| 65,550 (25%) | 0.68 | 0.66 | 0.85 | |
| 78,660 (30%) | 0.63 | 0.63 | 0.82 |
| Event Log | Number of Redundant Activity Labels | F-Score (the Original Log | Average F-Score (the Logs with Redundant Activity Labels) | Average F-Score (the Repaired Logs) |
|---|---|---|---|---|
| 5254 (1%) | 0.75 | 0.69 | 0.73 | |
| 21,693 (5%) | 0.75 | 0.64 | 0.72 | |
| 44,890 (10%) | 0.75 | 0.62 | 0.70 | |
| Hospital Billing | 66,368 (15%) | 0.75 | 0.59 | 0.69 |
| 90,273 (20%) | 0.75 | 0.55 | 0.67 | |
| 112,840 (25%) | 0.75 | 0.53 | 0.67 | |
| 135,480 (30%) | 0.75 | 0.51 | 0.66 | |
| 180 (1%) | 0.77 | 0.74 | 0.75 | |
| 745 (5%) | 0.77 | 0.72 | 0.74 | |
| 1569 (10%) | 0.77 | 0.66 | 0.72 | |
| Sepsis | 2327 (15%) | 0.77 | 0.64 | 0.70 |
| 3086 (20%) | 0.77 | 0.61 | 0.70 | |
| 3844 (25%) | 0.77 | 0.60 | 0.68 | |
| 4605 (30%) | 0.77 | 0.57 | 0.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Q.; Lu, Y.; Tam, C.S.; Poon, S.K. A Multi-View Framework to Detect Redundant Activity Labels for More Representative Event Logs in Process Mining. Future Internet 2022, 14, 181. https://doi.org/10.3390/fi14060181
Chen Q, Lu Y, Tam CS, Poon SK. A Multi-View Framework to Detect Redundant Activity Labels for More Representative Event Logs in Process Mining. Future Internet. 2022; 14(6):181. https://doi.org/10.3390/fi14060181
Chicago/Turabian StyleChen, Qifan, Yang Lu, Charmaine S. Tam, and Simon K. Poon. 2022. "A Multi-View Framework to Detect Redundant Activity Labels for More Representative Event Logs in Process Mining" Future Internet 14, no. 6: 181. https://doi.org/10.3390/fi14060181
APA StyleChen, Q., Lu, Y., Tam, C. S., & Poon, S. K. (2022). A Multi-View Framework to Detect Redundant Activity Labels for More Representative Event Logs in Process Mining. Future Internet, 14(6), 181. https://doi.org/10.3390/fi14060181