1. Introduction
Knowledge graphs use graphs as the underlying model for representing data, and they are typically used for large-scale data integration and analysis, although the exact meaning of the term is debatable (see e.g., [
1,
2,
3] for further discussion around definitions of knowledge graphs). Knowledge graphs have become a popular concept due the development of a new generation of Web and Enterprise applications (where data needed to be integrated in a more simplified way), advances in NoSQL graph databases (where graph data could be stored and managed at scale), and enhanced learning (where graph data structures have been proved to improve machine learning techniques). Knowledge graphs have witnessed attraction both in the scientific community and industry [
4]. They are particularly used in large organisations to break down data silos and make data more accessible by lowering the bar for business analysts to perform advanced data retrieval and analysis. Companies such as Google, Amazon, and Facebook utilise machine learning and graph analytics over knowledge graphs to improve their core products, for example for providing better search results and product recommendations.
The idea of integrating data using a graph format, and eventually extracting knowledge from it, existed for many decades and led to various graph-based data models, such as directed edge-labelled graphs, heterogeneous graphs, and property graphs [
2]. The Resource Description Framework (RDF), which is the data model for the Semantic Web, is based on directed edge-labelled graphs. The use of Semantic Web technologies for creating knowledge graphs both for industrial (e.g., [
5,
6]) and public data (e.g., [
7,
8]) is a natural and active line of research. This is because, firstly, the knowledge graph paradigm encompasses many of the core and long-standing ideas of the Semantic Web domain [
9]. Secondly, with the use of ontologies and linked data technologies, the Semantic Web utilises an open approach based on a wide range of standards and formal logic for representing, integrating, sharing, accessing, and reasoning over the data. Knowledge in a semantic knowledge graph could be exploited in various ways using deductive and inductive approaches. Deductive approaches concern extracting knowledge using entailment and reasoning through logical axioms and rules. RDFS and OWL enrich RDF with formal semantics, making deductive knowledge extraction possible [
10]. Inductive approaches concern deriving knowledge through analysing generalised patterns in a knowledge graph. These include graph analytics, embedding, and graph neural networks. Graph analytics uses techniques such as centrality, community, connectivity, and node similarity [
11,
12] and also utilises graph query languages [
13]. In embedding, a knowledge graph is embedded into a vector space so that it can be used for various machine learning tasks such as training for classification, regression, recommendation, etc. [
14], while the graph neural network approaches model a neural network based on the topology of the knowledge graph [
15].
Creating and maintaining knowledge graphs is not a trivial task, where several aspects need to be taken into consideration such as data modelling, transformation, and reconciliation [
3]. With respect to the purpose of the implementation, the actors involved, the domain, the data sources, etc., pipelines used for knowledge graph creation could greatly vary. In the Semantic Web domain, the overall process usually includes mapping source data onto an ontology/schema, translating it to RDF format, and subsequently publishing the resulting data through APIs. Organisations store considerable amounts of data in (semi-)structured format, such as in relational databases, CSV files, etc., and publish data on the Web in other (semi-)structured formats, such as XML, JSON, etc. These require mapping languages and engines to transform [
16], integrate, and feed data into knowledge graphs, while for unstructured data, such as free text and PDF documents, natural language processing and information extraction techniques are required for knowledge graph creation [
17].
Since a considerable amount of industrial and public data is in (semi-)structured format, in this study (based on [
18]), we explore knowledge graph creation within the Semantic Web domain, specifically from (semi-)structured data, through a systematic literature review. The review takes into account four prominent publication venues, namely,
Extended Semantic Web Conference, International Semantic Web Conference, Journal of Web Semantics, and
Semantic Web Journal. We highlight the challenges, limitations, and lessons learned. Our goal is to answer the following questions:
What are the publication statistics on the state of the art techniques for knowledge graph creation from (semi-)structured data?
What are the key techniques, and associated technical details, for the creation of knowledge graphs from (semi-)structured data?
What are the main limitations, lessons learned, and issues of the identified knowledge graph construction techniques?
The rest of this paper is organised as follows. In
Section 2, related work is presented, while
Section 3 sets the background.
Section 4 introduces the method and execution of the study and
Section 5 presents the results. Finally,
Section 6 discusses the results, while
Section 7 concludes the paper.
2. Related Work
In this paper, we focus on research related to knowledge graph creation and publication within the Semantic Web domain, while other aspects, such as knowledge graph refinement [
19], embedding [
14], querying [
13], and quality [
20] fall outside the scope of this paper.
Pereira et al. [
21] provide a review of linked data in the context of the educational domain. The study highlights the tools, vocabularies, and datasets being used for knowledge graphs. For tools, they find that the D2RQ platform [
22] is the most used for mapping data to RDF, and Openlink Virtuoso [
23] and Sesame [
24] (now RDF4J [
25]) are the most frequently used tools for storage. Regarding the vocabularies, the Dublin Core vocabulary [
26] is the most used. Some of the challenges mentioned are related to data interlinking, data integration, and schema matching. Barbosa et al. [
27] provide a review of tools for linked data publication and consumption. The study highlights the supported processes and serialisation formats and provides an evaluation. Key takeaways from the review include: most of the studies focus on the use of tools for machine access; few solutions exist for the preparation phase, including licence specification and selection of datasets for reuse; and no tool was found to support all steps of the data publication process.
Avila-Garzon [
28] surveys applications, methodologies, and technologies used for linked open data. The main findings from this survey include: most of the studies focus on the use of Semantic Web technologies and tools in the context of specific domains, such as biology, social sciences, research, and libraries and education; there is a gap in research for a consolidated and standardised methodology for managing linked open data; and there is a lack of user-friendly interfaces for querying datasets. Penteado et al. [
29] survey methodologies used for the creation of linked open government data, including common steps, associated tools and practices, quality assessment validations, and evaluation of the methodology. Key takeaways from this study include: phases are described with different granularity levels for the creation process, but in general, they can be classified into specification, modelling, conversion, publication, exploitation, and maintenance; there are different tools, and each tool is often only used for one phase; and, the assessment of the methodologies mostly focus on specific aspects and not the methodologies as a whole.
Other relevant related works, more focused on specific aspects, include:
Feitosa et al. [
30] provide a review of the best practices used for linked data. This study finds that the use of best practices is mostly motivated by having standard practices, integrability, and uniformity, and that the most used best practice is the reuse of vocabularies.
Pinto and Parreiras [
31] provide a review of the applications of linked data for corporate environments. The study finds that enterprises experience the same challenges as linked open data initiatives. Semantic Web technologies may be complex and require highly specialised teams.
Ali and Warraich [
32] provide a review of linked data initiatives in the library domain, and they find that there are technical challenges in the selection of ontologies and link maintenance of evolving data.
Such studies on knowledge graph creation in the context of the Semantic Web focus on a specific application domain or on specific aspect, such as tools, technologies, etc.; however, no study appears to take a generic approach (irrespective of the application domain or specific aspects) to the knowledge graph creation process.
3. Background
This section focuses on what constitutes knowledge graph creation, in the context of (semi-)structured data. The knowledge graph creation process involves several phases. Depending on different factors, such as focus, intent, data sources, actors involved, etc., different phases with varying sub-tasks need to be undertaken [
2,
3,
33,
34]. The order of phases presented in this section is not to be taken as the ”right” order of action, as it is not always necessary to be finished with one phase before another one starts, and different situations may motivate different orders. Methodologies used may be based bottom–up or top–down [
35] or may involve pay-as-you-go approaches [
36]. The phases presented below are based on existing literature [
2,
3,
33,
34] and also based on the work carried out as part of this review.
3.1. Ontology/Schema Development
In general, an ontology can be described as a formal definition of the concepts and their relations over a given domain, ranging from simple vocabularies to complex logic-based formalisms. In the context of knowledge graphs, the term is closely related to the schema of the knowledge graph, which can be described using an ontology. In the context of this paper, we use ontology, vocabulary, and schema interchangeably. Ontologies can be created either by defining concepts and relations through domain analysis, or through analysing the available data [
2]. These are often referred to as the top–down and bottom–up approaches, respectively [
37]. The top–down approach is traditionally done manually, while the bottom–up approach can be done automatically and semi-automatically.
Regarding the top–down approach, it usually starts with obtaining an overview of the given domain through reading papers and books, interviewing experts, etc. The knowledge from this phase is then used to further formalise the ontology, until a specification of the ontology is obtained. The task of formalising a given domain may be substantial, depending on the domain to be modelled. An agile methodology is therefore often employed [
38]. This can be obtained using competency questions throughout the development process [
39], meaning that the ontology is incrementally developed by adding concepts based on questions the ontology has to answer. Other methods include using ontology design patterns [
40], which enable the reuse of existing ontology designs and modelling templates. Regarding the bottom–up approach, automatic and semi-automatic approaches are often used to extract information from the given input data in order to model the ontology. These methods also relate to the approaches for automatically integrating data into a knowledge graph. The techniques may involve measuring the relevancy of entities in the data, based on count, or relations, through patterns [
41].
It is also possible to combine the two approaches by using some information from the top–down approach as a basis for the further development of an ontology with the bottom–up approach, which is often described as the middle–out approach [
37]. Such approaches allow validation of intermediate results, similarly to the bottom–up approach [
2].
3.2. Data Preprocessing
Preprocessing of the data is of high relevance, especially since the data may be of poor quality. There are different tasks involved in data preprocessing, including (i) enrichment, i.e., adding additional information to the data, (ii) reconciliation, i.e., correctly matching entities from different sources, and (iii) cleaning, i.e., improving the quality of the data. Rahm et al. [
42] classify data quality problems in data sources, differentiating between single- and multi-source and between schema- and instance-level.
Schema-level problems refer to the overall schema for the data source and may affect several data instances at once. Single-source problems are related to the poor schema design and lack of integrity constraints. This includes uniqueness violation, illegal values, violated attribute dependencies, etc. For multi-source, the problems are related to translation and integration between schemas. Schema integration problems may occur when matching entities with respect to naming and structural features. Naming problems may occur when the same object has different names or different objects have the same name. Structural problems may be the difference in data types, different integrity constraints, etc. Instance-level problems refer to the problems happening at instance level in the data. Instance-level problems cannot be prevented at the schema level. Single source problems, at the instance level, may be spelling error, duplicates, etc. Multi-source problems, at the instance level, may be contradicting values for objects, different use of units, different use of aggregation, etc.
To resolve the mentioned problems, Rahm et al. [
42] mention several phases, which include data analysis, definition of transformation workflow and mapping rules, verification, transformation, and backflow of cleaned data. Several tools exist for the execution of data cleaning, including spreadsheet software, command line interface (CLI) tools, programming languages, and complex systems designed to be used for interactive data cleaning and transformation [
43,
44].
3.3. Data Integration
In this section, we describe the different data integration methods that exist for integrating (semi-)structured data into knowledge graphs. Data integration methods include manual integration and mapping-based integration.
Manual integration of data into a knowledge graph involves manually defining the entities of the knowledge graph directly from the source. This can be done either by writing the code directly in the given language or through a dedicated editor [
45]. Some knowledge graphs on the Web are created through manual data integration, such as Wikidata [
46]. The human interaction in this data integration process comes at a high cost compared to other approaches. However, this usually ensures high quality, where each statement in the knowledge graph can be manually verified as being correctly mapped to its corresponding concept.
Mapping-based approaches allow for integrating data from (semi-)structured sources, such as relational databases: CSV, JSON, XML, etc. Data are mapped through rules onto a graph or a graph view (a view of the data source, in graph format) [
47]. The mapping can be done either directly or through custom statements. Direct mapping involves mapping data directly from its source. For table-structured data, a standard direct mapping involves the creation of a triple for each non-empty, non-header cell, where the subject is represented by the row, the predicate is represented by the column, and the object is represented by the value of the cell. Direct mapping from relational databases to RDF has been standardised by the W3C [
48]. The flexibility of being able to create dedicated tables through SQL queries makes this a productive approach for knowledge graph creation. Direct mapping from tree-structured data, e.g., XML or JSON, is often not desirable, since this will only produce a mirroring of the data. Custom mapping involves defining statements about how data are to be mapped from its source [
49]. This enables specifying how columns and rows are to be mapped. The mapping language R2RML [
50] is a W3C standard that defines mapping from relational databases to RDF. Building upon this language, other languages have been proposed for mapping from other data structures. RML [
51] is one of the well-known languages for mapping data also from CSV, XML, and JSON. Other languages such as FnO [
52] enable defining transformations for the data to be mapped and integrating them with the aforementioned custom mapping languages.
Mapping from other knowledge graphs is also an option. This can either be done by manually recreating the target knowledge graph or by querying the target knowledge graph to obtain a sub-graph of it. This is typically done using SPARQL CONSTRUCT queries [
53]. This approach usually also includes the necessity of aligning the schema/ontology of the graphs. An aspect to consider when mapping data onto a knowledge graph is whether to fully integrate the data onto the graph model or only make a graph view of the data. Fully integrating the data, often referred to as Extract–Transform–Load (ETL), does require the data to be updated from time to time. On the other hand, Ontology-Based Data Access (OBDA) techniques based on data virtualisation [
16] enable a graph view of the data without materialising it by using query rewriting techniques. This means data are kept in their original place and format, and queries are specified using ontological concepts and relationships and rewritten to the query language of the underlying database system(s).
3.4. Quality and Refinement
Knowledge graph quality and refinement refers to how a knowledge graph may be assessed and subsequently improved. There are numerous frameworks and methods for both assessing and refining knowledge graphs [
3,
19,
20]. Zaveri et al. [
20] provide a survey of approaches for evaluating and assessing the quality of linked data, identifying 18 different interlinked quality dimensions as briefly described in the following.
Accessibility quality describes the quality aspects concerning how a knowledge graph may be accessed and how well it supports the user to easily retrieve data from it:
Availability describes the degree a knowledge graph and its contents are available for interaction (e.g., through a SPARQL endpoint).
Licensing concerns whether a knowledge graph has a license published with it (human-readable and machine-readable format).
Interlinking describes the degree that entities, referring to the same real-world concept, are linked to each other [
54].
Security refers to the degree the knowledge graph is secured through verification of confidentiality in the communication between the consumers and the knowledge graph itself.
Performance relates to how well the knowledge graph may handle latency, throughput, and scalability.
Intrinsic quality refers to the quality dimensions that are internal to the knowledge graph. These dimensions refer to quality dimensions that are independent of the user context:
Syntactic validity describes the degree to which the knowledge graph content follows syntactic rules [
55].
Semantic accuracy refers to the degree to which a knowledge graph correctly represents real-world facts semantically.
Consistency refers to how well a knowledge graph is free of contradictions in the information contained in it.
Conciseness describes the degree to which a knowledge graph only contains relevant information [
56].
Completeness concerns how complete a knowledge graph is in comparison to all the required information.
Contextual quality refers to quality dimensions that usually depend on the context of the implemented knowledge graph [
20]:
Relevancy describes the extent it is possible to obtain relevant knowledge from a knowledge graph for the task at hand.
Trustworthiness refers to how trustworthy the information contained in a knowledge graph is subjectively accepted to be correct.
Understandability refers to the extent the information contained in a knowledge graph can be used and interpreted by users without ambiguity [
57].
Timeliness refers to how well a knowledge graph is up to date based on the real-world facts [
58].
Representational quality refers to the dimensions describing the design aspects of the knowledge graph:
Representational conciseness refers to the extent to which information is concisely represented in a knowledge graph.
Interoperability refers to the extent to which a knowledge graph represents data with respect to the existing relevant vocabularies for the subject domain [
57].
Interpretability refers to how well a knowledge graph is technically capable of providing information in an appropriate serialisation and whether a machine is capable of processing the data.
Versatility refers to which extent a knowledge graph is capable of being used in different representations and in different languages.
Tim Berners-Lee described a five-star rating scheme [
59], where datasets could be awarded stars with the following criteria: data are available on the Web under an open license (1 star) in (semi-)structured format (2 stars) and a non-proprietary open format (3 stars) using open standards from the W3C (4 stars) and linked to other data (5 stars). This was extended to a seven-star scheme [
60]: data are provided with an explicit schema (6 stars), and data are validated against the schema (7 stars). There is also a five-star rating scheme for the vocabulary use with the following criteria: there is dereferencable human-readable information about the used vocabulary (1 star); the information is available as machine-readable explicit axiomatization of the vocabulary (2 stars); the vocabulary is linked to other vocabularies (3 stars); metadata about the vocabulary are available (4 stars); the vocabulary is linked to other vocabularies (5 stars) [
61].
Regarding the knowledge graph refinement, several approaches exist [
19], particularly in terms of completion and error detection. These methods can be categorised as either external or internal, i.e., whether external sources are being used for the process or not. Internal methods usually use machine learning or probabilistic methods, while external methods focus on using external data, such as Wikipedia or another knowledge graph [
19].
3.5. Publication
Several aspects need to be taken into consideration when publishing a knowledge graph on the Web. These include aspects around how the knowledge graph will be hosted and what data will be accessible. In the context of the Semantic Web, Heath and Bizer [
62] describe different methods for publishing linked data on the Web. Linked data may be published directly through static RDF/XML files, RDF embedded into HTML files, a wrapper over existing applications or APIs, relational databases, and triplestores. In addition to having published the knowledge graph, the publisher may also provide tools for accessing the data, such as SPARQL endpoints, data dumps, and search engines. Some publishers also provide documentation pages for concepts [
63], or even visualisation tools for the given graph [
64].
FAIR principles (findability, accessibility, interoperability, and reusability) [
65], initially proposed for the publication of scientific data, are highly relevant for knowledge graph publication. The FAIR principles ensure that data can be easily found and accessed through the Web and they can easily be explored and reused by others, and these principles include requirements such as links to other datasets, provenance and licensing metadata, and the use of widely deployed vocabularies. Often with the publication of data on the Web, it is preferable to define a licence for the data. The W3C standard vocabulary Open Digital Rights Language (ODRL) [
66] allows for defining permission, prohibition, and obligation statements of data, and it can be easily integrated in an RDF serialisation format. The vocabulary allows for modelling common licences such as the Apache [
67] or Creative Commons [
68] licenses, and it enables a standardised format for licensing linked data on the Web.
Other aspects relevant for knowledge graph publication are URI strategy and context and versioning [
2]. The identity of instances in the model is also of relevance. Having a consistent URI or IRI strategy is important for easily finding the right instance on the Web and keeping it non-changing. Facts contained in the graph may only hold within a certain context, e.g., within a specific time period or domain. There are several ways of applying context to knowledge graphs, such as through reification (adding information directly to the edges) and higher arity representations [
69].
5. Results
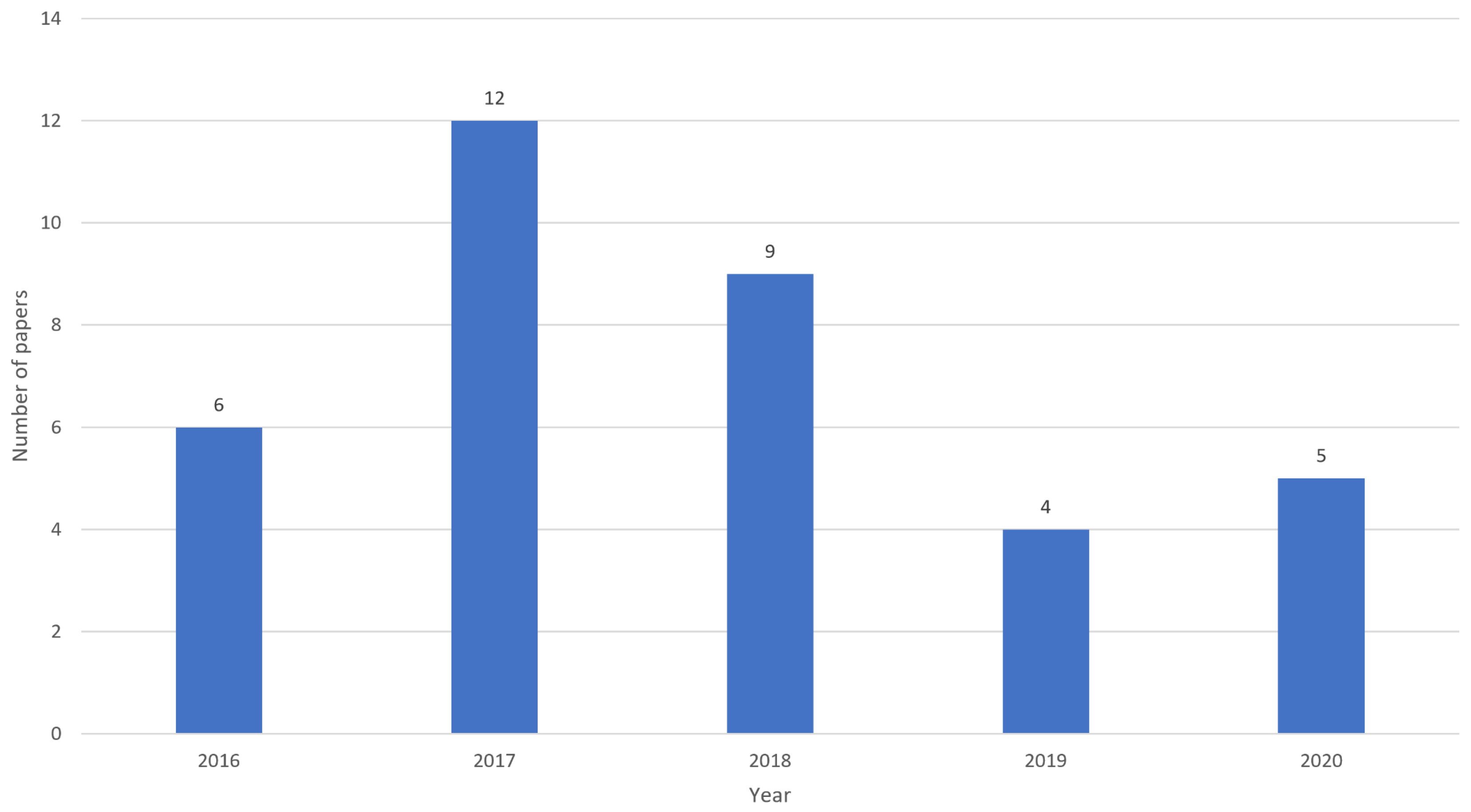
In this section, the results from the review are presented, highlighting the key takeaways. The publication statistics are shown in
Figure 1, depicting the publication counts from each year. The numbers vary across the years. It can be seen that there is a clear high in 2017, with a low in 2019. This is in line with the growth in number of RDF graphs in the linked open data cloud over time as presented by Hitzler [
9]. We also see that there is a minor increase from 2019 to 2020.
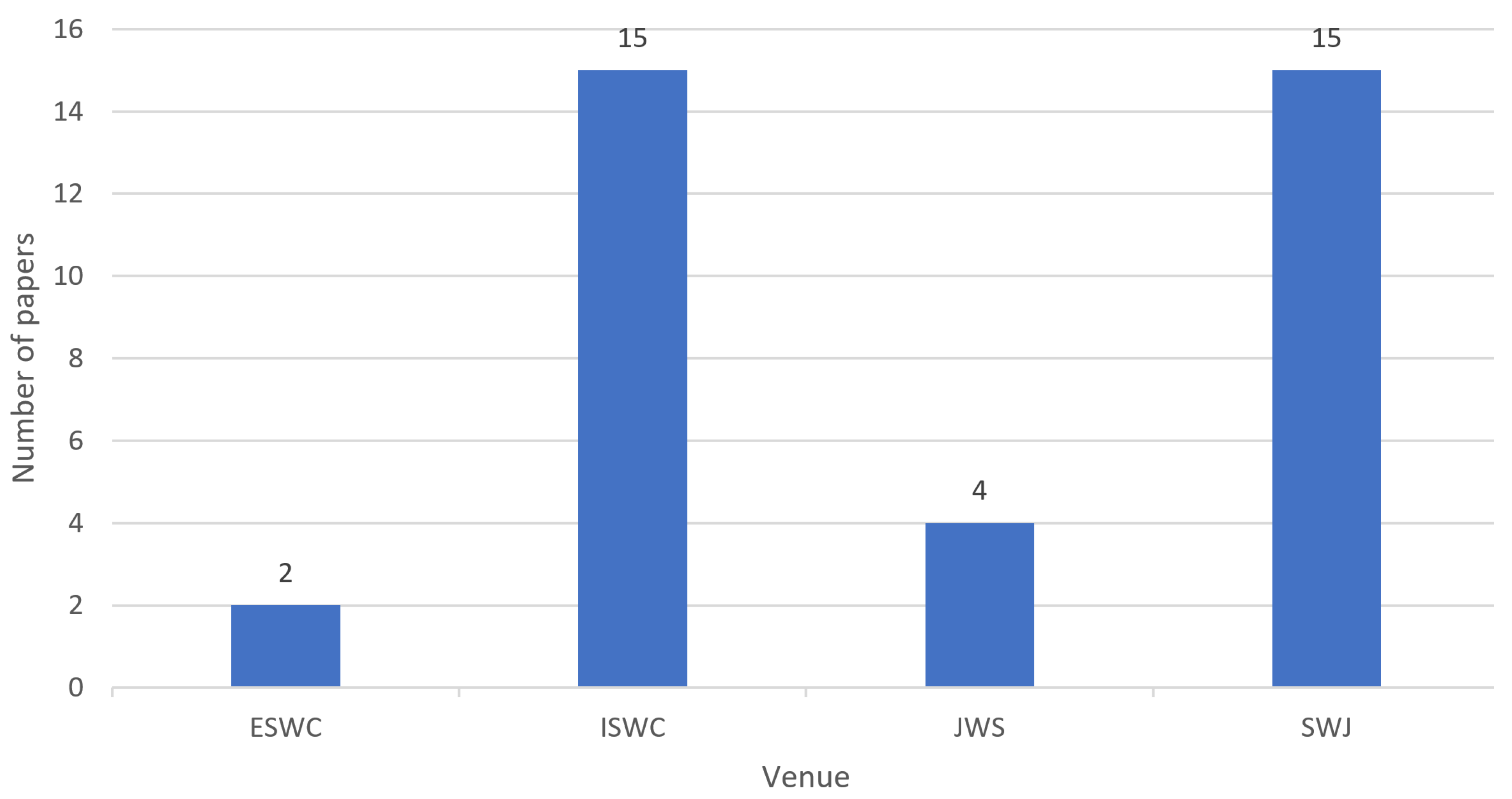
The number of papers per venue is shown in
Figure 2. There is a clear gap between two groups of venues, namely between ISWC and SWJ publications on one hand, and ESWC and JWS publications on the other hand. Even though the sample size and variance are not of great consideration, it may give an indication on the focus of each venue.
Regarding the domains, we see that domains such as history, culture, government, medicine, and bibliography provide a comparatively higher number of studies, while there is a spectrum of domains including art, education, climate, media (see
Table 1). This indicates that research on knowledge graphs for the Semantic Web may be more popular for the public sector compared to the industry. One reason for this could be that industry could be reluctant to share data openly, while published industrial research focuses around the tools and processes (e.g., [
5,
6]) rather than the knowledge graphs themselves as the main contributions.
5.1. Technical Analysis
In this section, we provide an analysis of the selected works from a technical perspective in terms of their contributions, phases undertaken, and resources used.
5.1.1. Contributions
The main contribution for each paper is the publication of a dedicated knowledge graph, often together with other artefacts developed (e.g., tools and ontologies). Some works include additional contributions to achieve their goal in their respective domains. These contributions include:
The work by Achichi et al. [
78] (#9) discusses contributions in terms of tools made for evaluation, data generation, construction, linking, and alignment.
The work by Kiesling et al. [
79] (#10) discusses contribution in terms of a specific ETL framework to build knowledge graphs.
The work by Knoblock et al. [
80] (#11) discusses contributions in terms of tools developed to support the processes of mapping and validation.
It should also be mentioned that several of the other papers do contribute with other specific tools. For example, Soylu et al. [
77] (#8) provide a platform to explore and utilise the given knowledge graph. Pinto et al. [
103] (#34) describe a Java application, developed for the data mapping in a specific project. It is also published as open source code to be modified and used. Even though the count of studies contributing additional tools is low, it does indicate that there is still room for development and that existing tools do not always seem fit.
Regarding the sizes of the knowledge graphs, 12 studies out of the 36 do not provide information on the size of the presented knowledge graphs.
Table 2 presents the sizes of the knowledge graph for each study. We see that [
83] (#14) is the study reporting the biggest knowledge graph, containing data from GitHub, while [
105] (#36) reports the lowest, containing metadata about Web API’s. The size difference highlights the applicability of knowledge graph technologies. Regarding the quality, only 19 of the studies report on knowledge graph quality based on the five to seven-star scheme, while only five of them report on the quality of the vocabulary (see
Table 2).
5.1.2. Phases
We earlier categorised phases for knowledge graph construction into ontology development, data preprocessing, data integration, quality and refinement, and data publication. During the review process, we collected various tasks that fall under these categories.
Table 3 presents these tasks, the number of studies using them, studies including one or more of these tasks, and the phases they belong to.
Although there are several tasks mentioned for each phase, these are often sparsely used as seen from
Table 3. Ontology reuse, URI/IRI strategy, data linking, RDF transformation, and publication are the top mentioned tasks, as these could be seen among the common tasks; however, we also see other relevant phases such as evaluation and versioning, although these are not as frequent. This discrepancy could be due to the nature of the problem and solution and the extent of the work undertaken. For example, the work by Buyle et al. [
75] (#6) uses a virtualisation-based approach; hence, there is no need for RDF transformation; this could apply to other tasks such as ontology modelling, data cleaning, and enrichment. A lack of tasks such as evaluation, versioning, and validation, however, is largely connected to the focus and completeness of the work.
The tasks listed are self-explanatory to a large extent. Enrichment refers to the completion of missing information or improving the precision of information available in the knowledge graph through external and internal data using knowledge graph completion techniques [
111]. Data linking, in this paper, is a broader term referring to linking entities in the same knowledge graph or with entities in other graphs, and matching entity information against a set of canonical entities (i.e., reconciliation). Validation is a task used to check mostly the semantic and syntactic validity of the knowledge graph. For example, SHACL [
112] is used to validate the shape of a knowledge graph, while ontological reasoning is used to check the logical consistency of a knowledge graph.
5.1.3. Resources
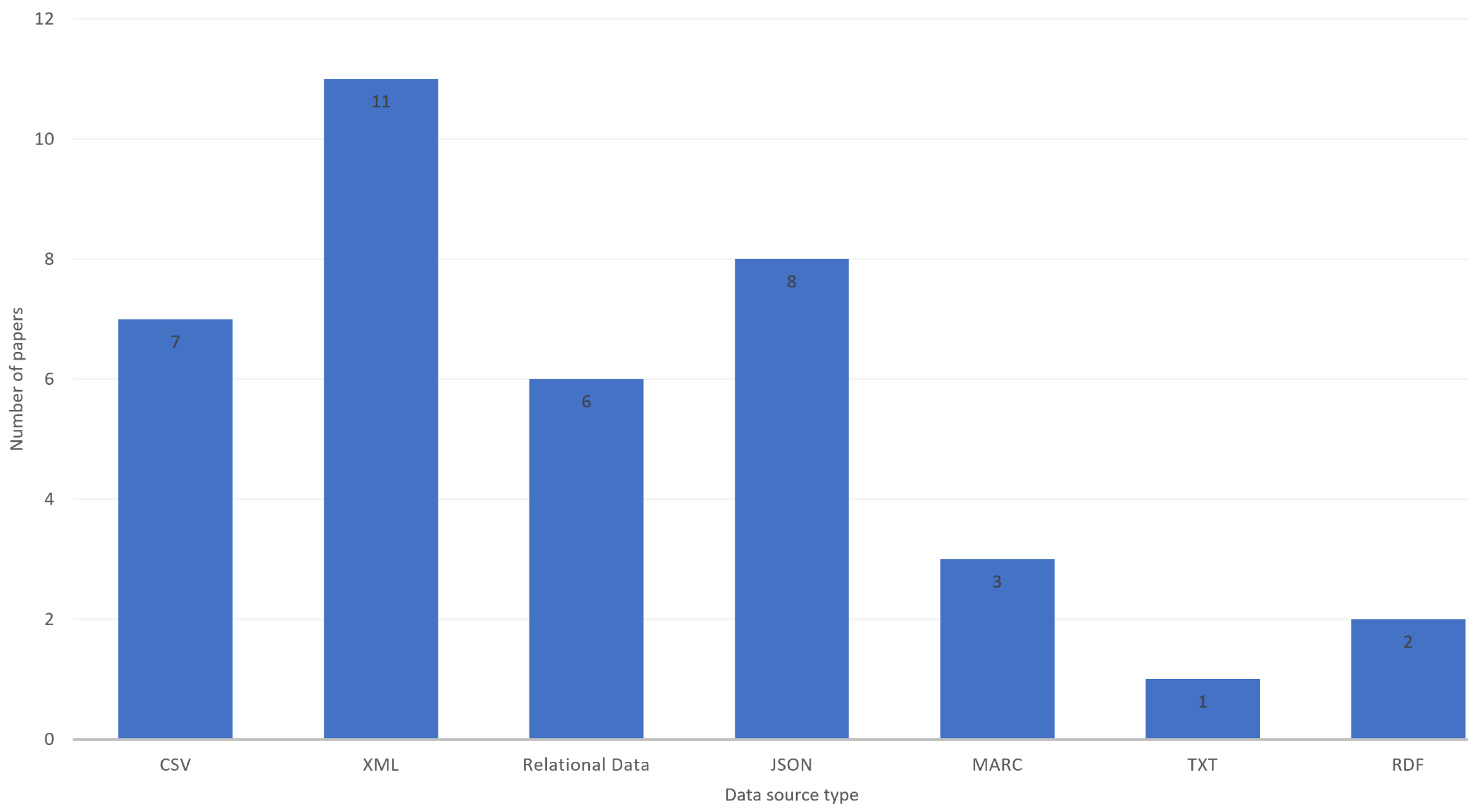
There are in total seven different data source types mentioned, as shown in
Figure 3. There is a diverse set of data source types. The XML format is the most common type of source, indicating that much of the data may be taken from sources available on the Web. We also see JSON, CSV, and relational data are much utilised. The JSON format is typically seen in API sources and may be an easy target for knowledge graph transformation without needing much preprocessing.
Regarding the tools used, an account is given in
Table 4. We observe that most of the listed artefacts are mentioned once and show a discrepancy in the creation of knowledge graphs; a large portfolio of tools are available (see Dominik et al. [
113] for knowledge graph generation tools from XML and relational databases). Useful tools such as SWI Prolog [
114] and languages such as SHACL are scarcely referenced. Heavily referenced tools include the triple stores Jena TDB (and Fuseki) [
115] and OpenLink Virtuoso [
23], together with other tools and languages such as SILK [
116] for linking data, Pubby [
117] for publishing, and XLST [
118] as a mapping language. In addition to the two mentioned databases, it appears that there is a wide variety of needs and preferences for different knowledge graphs.
Considering the ontologies and vocabularies used, an account is given for the most used ontologies in
Table 5. We observe there is a frequent use of metadata ontologies for describing the different datasets. This may probably be due to the fact that the creators of the knowledge graphs are actually interested in following the good practice of describing their data, but it may also be because it becomes more relevant when the data contained come from another source. We also see that on the other side, reusing already defined classes and properties, from, e.g., Schema.org or DBPedia, is not common.
Regarding the specific methodologies used in creation of the knowledge graphs, there were few examples of reusing existing frameworks, both for the whole creation process and also just for the ontology development, even though there are many frameworks available. From all of the 36 chosen primary studies, only Carriero et al. [
82] (#13) mention using the eXtreme Design methodology in development of the ontology. Other than this, some studies, such as Achichi et al. [
78] (#9), mention the development of tools for the creation process as a framework but do not label it as a dedicated methodology.
5.2. Adoption
In this section, we present how the resulting knowledge graphs are published and exploited as well as the limitations, lessons learned, and issues reported in the studies.
5.2.1. Publishing and Exploitation
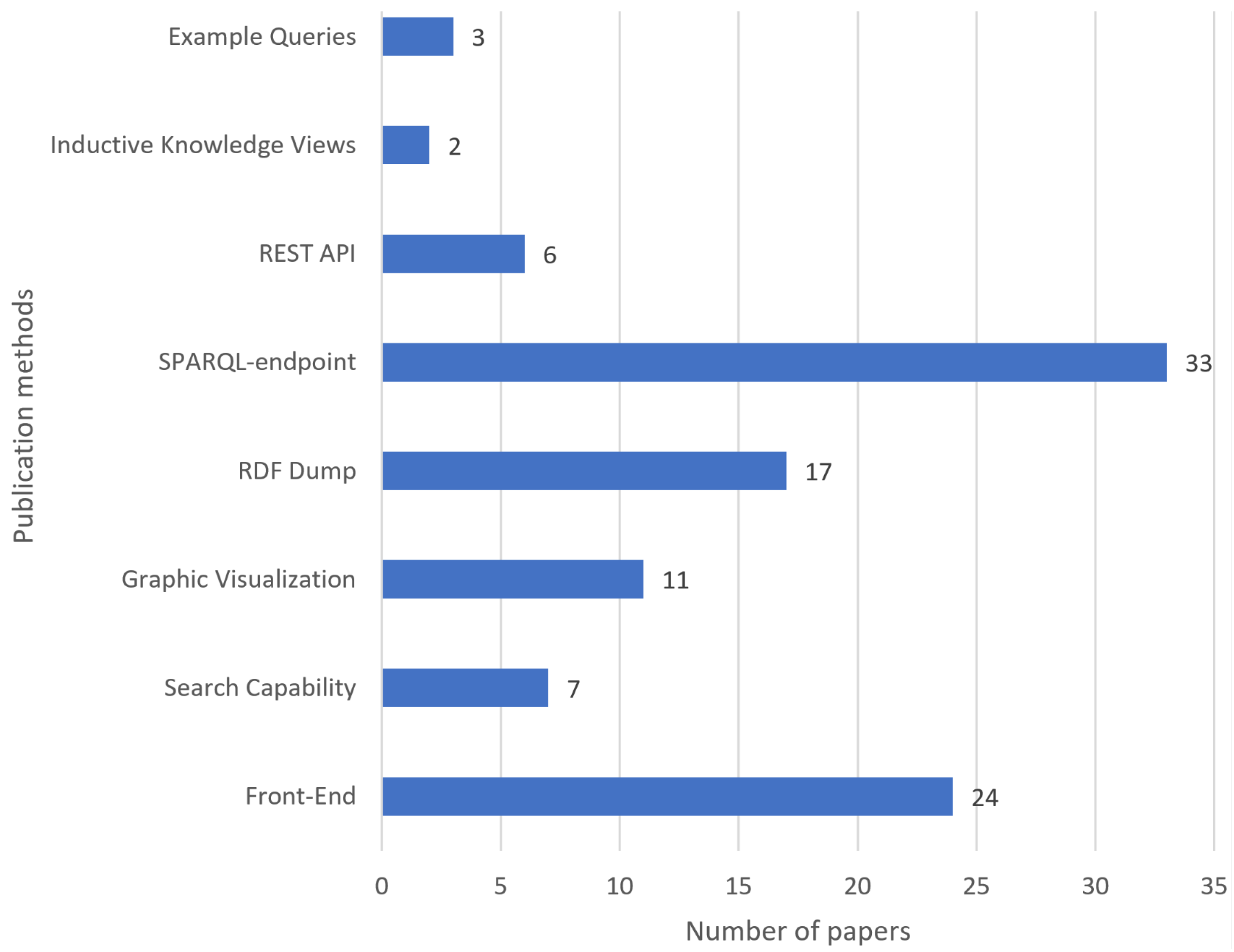
A SPARQL endpoint is the most used publication method, but we also see that the majority of the publications provide a front-end (see
Figure 4). However, an interesting observation is that even though knowledge graphs do provide a unique way for data aggregation and analysis, very few of the papers provide autogenerated analytics for common metrics and data views. Even fewer provide any type of tutorial to utilise the knowledge graph. These aspects do limit the utilisation of the potential of knowledge graph features. In
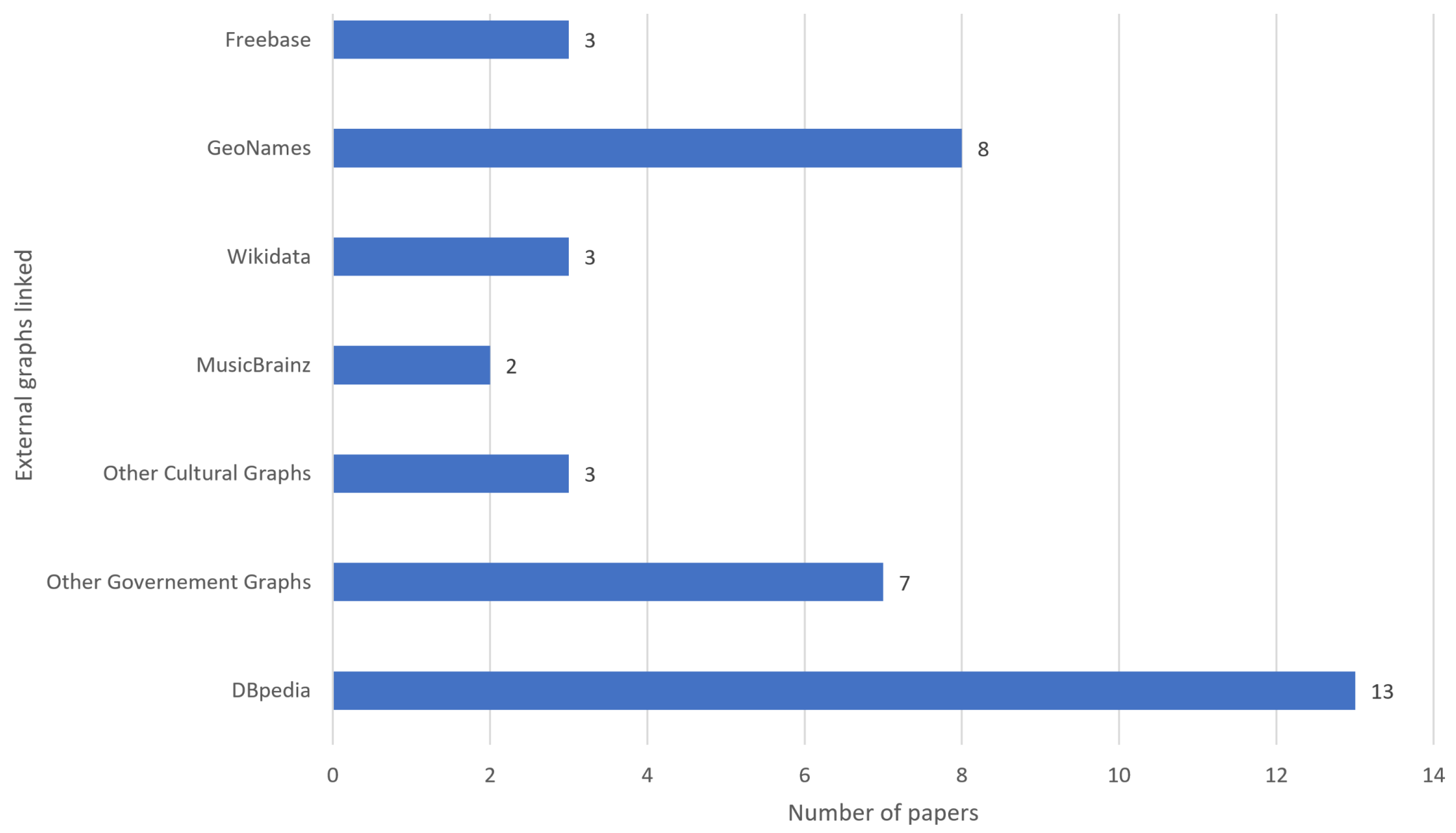
Figure 5, we have an overview of some of the most used external knowledge graphs and types of knowledge graphs that have been linked to (not including the ones with the smallest count). DBpedia appears the most popular knowledge graph.
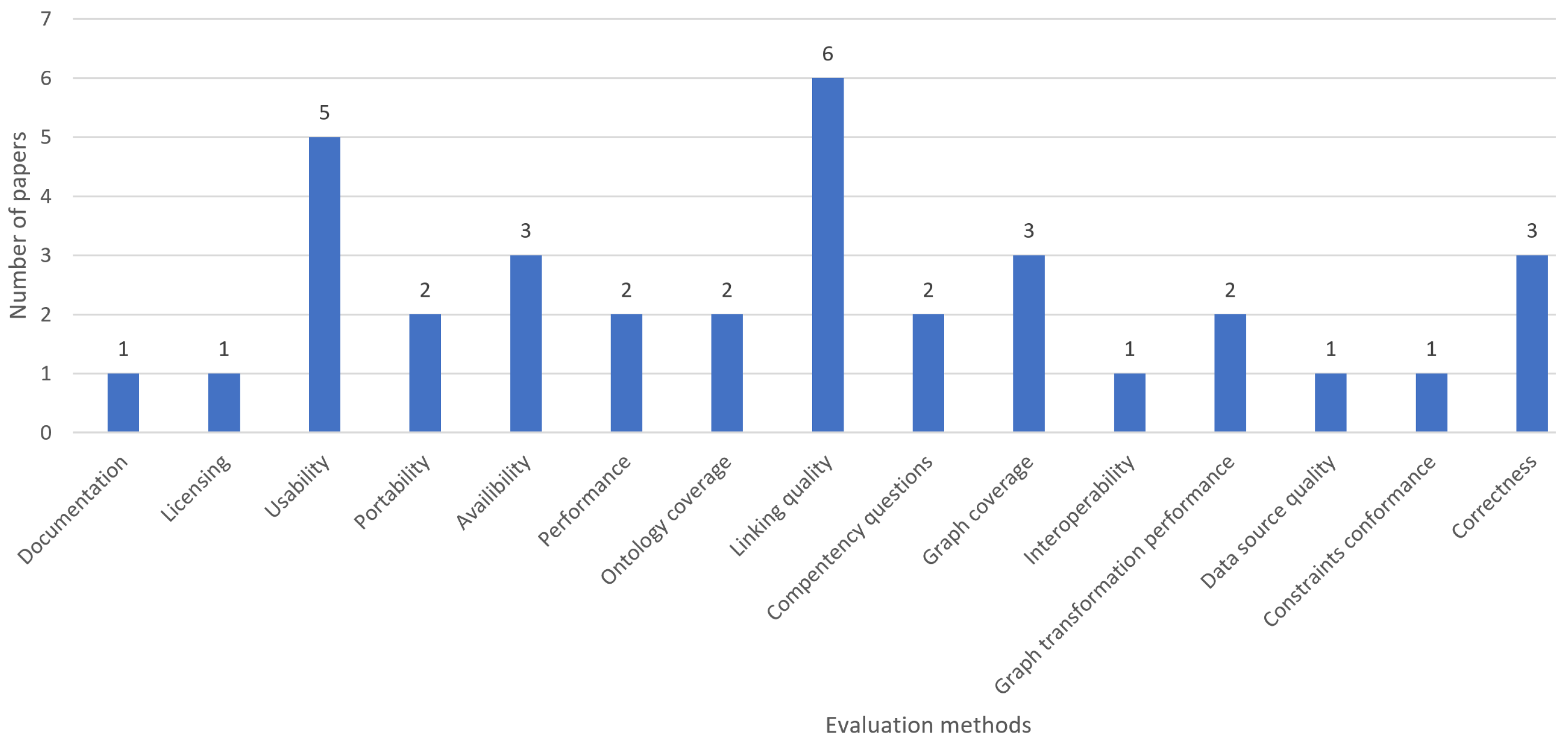
Figure 6 provides an overview on how knowledge graphs are evaluated in the reviewed works. We see that linking quality to other graphs is of high interest, together with usability. Based on the technical and semantic capabilities of knowledge graphs, it is interesting to see that metrics such as correctness, graph coverage, and ontology coverage are infrequently mentioned.
Key observations regarding the employed use cases include:
Only two studies [
77,
78] (#8 and #9) provide descriptions of use cases with advanced analytics, utilising the semantic and technical potential of knowledge graphs.
Six studies provide sample queries for the respective knowledge graph.
Twelve studies mention a use case from an external party.
Seven studies mention use cases done by the authors themselves.
Four studies mention potential use cases, without having an actual performed use case presented.
In total, 28 studies provide a use case, proving that usability of the graphs is of interest. However, like previously mentioned, the focus does not seem to include full utilisation of the knowledge graph capabilities.
5.2.2. Limitations and Lessons Learned
There is a wide variety of limitations reported. The limitations presented are related to the process used to generate the knowledge graph and the associated tools/systems. This then is often linked to future work, which also gives an insight into the primary focus of the research.
Reported limitations are listed in
Table 6. We see that more data are needed to be integrated in several cases, and there is a lack of tools for exploration, showing that there is still room for improvement in this area. The limitations related to linking to the other knowledge graphs and vocabulary coverage show that there is still work to do to support these core aspects.
We also extracted lessons learned from the reviewed works, and the frequent ones include:
Publishing the knowledge graph in an alternative data format, e.g., CSV, helped those not familiar with graph technologies consume the data more easily.
Metadata helped understandability.
Publishing the vocabulary helped linking.
Using a transformation pipeline made the process more maintainable.
Users were more familiar with JSON, which helped bridge the gap between JSON-LD and RDF.
Standard vocabulary helped understandability.
Interlinking unveiled unknown analytics.
Rest API made the knowledge graph more understandable.
GitHub helped tracking data when mapping to RDF.
Data cleaning was important.
Validation was important to make vocabulary use understandable.
Use of experts helped data quality.
Linking to other graphs helped derive structural concepts.
Keeping track of sub-graphs can be difficult.
Having many sub-graphs resulted in several vocabularies.
Errors related to the automation of RDF mapping were out-weighted by the potential for improvement.
Vocabulary lookup services helped matching vocabularies.
Vocabularies may be prone to subjectivity.
Several lessons learned related to making the knowledge graphs easier to use for non-experts were reported, which seems an important focus in many of the studies. Other than this, many of the mentions relate to specifics, such as handling of sub-graphs, or that GitHub helped tracking data in the mapping process. Even though these mentions can only be related to the respective primary study, they are valuable in pointing out issues that may be occurring in the future for other knowledge graph producers and motivate the developments of new solutions and tools.
Even though issues are expected when transforming data, few issues were reported, including:
Five studies mention issues with poor quality of the data source, in terms of, e.g., missing data, duplicate data, and erroneous data.
Buyle et al. [
75] (#6) report an unstable SPARQL endpoint.
Carriero et al. [
82] (#13) report that the URI strategy made some of the data ambiguous.
Daga et al. [
96] (#27) report erroneous language classification in the graph based on user-provided country of origin.
Khrouf et al. [
97] (#28) report that blank nodes create issues when updating the knowledge graph.
Rietveld et al. [
99] (#30) report that the automated mapping pipeline gave erroneous results.
Dojchinovski et al. [
104] (#35) report that linking via string matching gave errors.
The reported issues are quite different, and the low count indicates that they are exclusive to their respective reports. However, some of the issues, such as trouble with URI strategy, updates, and automation are expected depending on the domain. The higher mention of data source quality issues also may be expected, but it does highlight the importance of preprocessing tools and the whole RDF transformation pipeline in general.
6. Discussion
The number of studies published on knowledge graphs creation (as a contribution) in the selected venues constitutes a minor fragment of papers published in those venues. This indicates that there is a limited interest for resource and application studies resulting in knowledge graphs, and this limits their adoption and exploitation. This lack of attention becomes even more evident between different venues. Resource and application studies documenting the knowledge graph creation process along with the resulting knowledge graphs, software and data resources used as well as lessons learned and emerging issues are essential for guiding the research in this area. A similar discrepancy also occurs at a larger scale between studies focusing on public data sources and commercial/industrial data sources. The fact that the review largely included public knowledge graphs makes it hard for the community to assess the quality of knowledge graphs developed in the industry.
An interesting observation was the reuse of ontologies and infrequent mention of the development of new ontologies. As many as 35 of the 36 chosen studies report on reuse and the selection process of other existing vocabularies. Another interesting observation was transforming data into KG by directly transforming the original schema into an ontology. Based on the previously described ontology development methods, this may be seen as using a bottom–up approach, since the decision on ontology reuse was guided by the data and not the domain. This may be due to fact that ontology development is a demanding task; however, the ontologies used closely follow the underlying data, and hence, its model may indicate problems regarding the quality of knowledge graphs developed, since for example, a relational schema is developed with different considerations in mind compared to an ontology.
Out of the 36 studies, 16 mentioned some way of data preprocessing of the data source before mapping to RDF. The most mentioned was data cleaning, with 14 mentions. This shows the importance, also for structured sources, of data preprocessing. An interesting observation however is that this process in not always mentioned in the current published literature (e.g., [
2,
3,
33,
34]). The data sources mentioned throughout the reviewed literature are diverse, including XML, JSON, CSV, and relational databases, demanding data preprocessing and hence tools for supporting common preprocessing tasks.
Given the publication methods reported, the focus of the studies appears to be on the direct publishing of knowledge graphs and not on providing more complex views. Most of the studies provide a SPARQL endpoint for the published knowledge graph, which enables the possibility to extract deductive knowledge. However, more complex views, providing inductive knowledge, were low in numbers. Utilising the full features of knowledge graphs could motivate the adoption of the technology. There is considerable research available on this area (e.g., [
2,
11,
13,
14,
15]). Similarly, quality of the knowledge graphs is also a sparsely developed area; some dimensions such as linking quality and usability are often used, while others such as performance and ontology coverage are less used. It is often not clear if all the necessary evaluations are conducted, raising questions on the practical use of the resulting knowledge graphs.
The limitations, issues, and lessons learned give an insight into what the authors of the studies saw as areas for potential improvement. There is a great variety in all aspects, underpinning the complexity of knowledge graph creation. One of the key elements concerns the lack of knowledge and skills on Semantic Web technologies, which is a concern not only for consumers of the knowledge graphs but also for developers, since it could be a challenge for public and private organisations to find skilled staff in this area. For example, Soylu et al. [
77] reported that the use of a RESTful approach helped non-Semantic Web developers to use the data more easily. Therefore, end user tools supporting knowledge graph consumption and various tasks related to knowledge graph construction are essential. Finally, low data source quality is also worth mentioning, since this makes the construction and use of the knowledge graphs a challenge. Particularly, public entities are required to publish more and more data openly; however, quality of the data published is a challenge that has to be addressed.
7. Conclusions
In this paper, we reported a systematic review, focusing on four selected venues, namely Extended Semantic Web Conference, International Semantic Web Conference, Journal of Web Semantics, and Semantic Web Journal. The goal was to obtain an overview over publication statistics, technical details, and issues and limitations within knowledge graph creation for the Semantic Web. Regarding the validity of results, the arguably smaller scope of venues can be considered a limitation. The venues were chosen based on general citation count and the relevancy of publications within the scope. We see that the count of studies, within the given time frame, was as much as 36 studies. Given the fact that the chosen venues are of high relevance within the Semantic Web domain and have strict review processes, the sample of studies should give a relevant and valid view for the addressed research questions.
From the research statistics, we see that the interest in knowledge graph publication in the Semantic Web domain, throughout the four years reported, had a decrease from the first two years to the last two years, and had its peak in 2017. From the technical details, the main observations were that:
The main phases in the construction process reported were ontology development, the RDF mapping process, and publication.
There is a big diversity in sources, tools, and phases reported, with 11 data source types, more than 20 sub-phases, and more than 40 tools and languages used.
There was a big focus on publication; 24 out of 36 studies reported a front end for the exploration of the knowledge graph.
Few studies reported the use of advanced knowledge processing, i.e., inductive knowledge such as embedding, analytics, etc.
There was little focus on the evaluation phase; most of the evaluation tasks described were qualitative and not within a dedicated phase.
Regarding the reported issues, limitations, and lessons learned, a great variety was reported, but many aspects were within the same category. The main findings were:
There were frequent mentions of limitations related to tools.
Many of the lessons learned were related to making knowledge graph technologies more approachable to non-experts.
Poor data quality is often reported to be an issue.
Regarding the future work, literature reviews focusing explicitly on the tools and methodologies for creating knowledge graphs with the goal of consolidating the landscape would be one direction. This is because the findings from the review showed that knowledge graph construction in the Semantic Web domain is of high complexity with a very fragmented tool portfolio. The scope of this review was on the creation of knowledge graphs from (semi-)structured data sources; there is still room for reviews with a larger scope. Apart from extending the selected venues, another interesting direction would be to do a similar review for knowledge graph construction from unstructured data sources.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}