1. Introduction
Numerous visual investigations, including object tracking [
1,
2], person identification [
3], face recognition [
4,
5], and crowd understanding [
6], depend on head detection. Locating every person and counting them is crucial in many security and emergency-management scenarios in restaurants, conference centers, and subway stations. The occlusion of the target body part, however, limits the ability to detect people. Face detection also seems to be helpless when the person is facing away from the camera. These factors make head detection more suitable for locating and counting people than person detection and face detection. However, the wide variations in body attitudes, orientations, occlusions, and lighting conditions make this task a remarkable challenge even today.
Without taking into account the characteristics of head detection, many current methods view head detection as a specific case of generic object detection. CNN-based object detectors, represented by Faster-RCNN [
7], SSD [
8], YOLO [
9], and their variants, have significantly improved performance of generic object detection. Generally, these methods use learned models or predetermined anchors to predict proposals first, and then they extract the features of the chosen proposals for additional classification and regression. However, these methods deal with candidate boxes separately. Furthermore, they only extract features from the appearance near the objects’ region of interest, ignoring a lot of the context information, such as object–scene relationships and object–object similarity in the same lighting condition. Consequently, it is challenging to apply these models directly to head detection, especially in complex scenes.
To address these problems, Vu et al. [
10] introduce a context-aware method for detecting heads. Initially, this model predicts candidate boxes. The context-aware model then explicitly creates relationships between people using a pairwise model and establishes object–scene relations by learning a global CNN model. Their context-aware model achieves impressive performance compared with traditional models, for instance, DPM [
11]. The context-aware model, however, has a number of drawbacks, including the following: (1) capturing global context by repeated convolution layers is difficult to optimize [
12]; (2) as the quantity of targets rises, the computational complexity of the model is amplified exponentially; and (3) local context information surrounding objects is ignored.
After that, Li et al. [
13] present HeadNet, which achieves much better performance. In order to obtain local context information, HeadNet estimates similarity around the object and combines the results from layers with various receptive fields. However, there are three issues with HeadNet: (1) the local context estimate is computationally sophisticated; (2) the merge strategy is based on prior statistical analysis; and (3) long-range dependency is underutilized.
In this paper, to tackle the problems mentioned above, we propose a novel one-stage head detector called Context Refinement Network (CRN), which refines both the local and global context without any prior knowledge and identifies heads via their center points in the images. People’s heads perform similar features in the same environment, which is the motivation behind our method, and contextual information can increase classification accuracy. We introduce two context-refinement modules called the global context refinement module (GRM) and the local context refinement module (LRM), respectively. GRM captures the global context by explicitly establishing long-distance dependencies between pixels of the feature map. In addition, the global context can be further refined by fusing feature maps from different stages. Then, LRM is designed to obtain the local context around objects by enlarging the receptive field through multi-scale dilated convolution while maintaining a low computational complexity.
Our model outperformed other models with a 93.89% AP on the Brainwash dataset and an 83.4% AP on the HollywoodHeads dataset.
The following is a summary of our contributions:
We designed a one-stage head detector, namely, Context Refinement Network (CRN), which is end-to-end trainable without any artificial priors.
We present the global context refinement module (GRM), which creates long-range dependencies between heads to improve the global context.
We propose a local context refinement module (LRM) with a multi-scale architecture to refine the local context.
Our proposed head detector significantly improve the performance on the Brainwash and the HollywoodHeads datasets.
3. Our Approach
Our network architecture and work flow are firstly described in this section. The use of a multi-level feature map to capture a more precise global context is then demonstrated. Last but not least, we present the local context refinement module, which aids in obtaining an aggregated multi-scale context to improve the overall performance.
3.1. One-Stage Object Detector
Refer to the overall network architecture shown in
Figure 1. In our neural network, similar to CenterNet [
18], we regard a head as a center point, that is, the center of the bounding box. For objective comparison with most existing methods, our framework adopts ResNet50 [
31] as the backbone. This model is trained on the ImageNet dataset. As in HeadNet [
13], SANM [
32], and FPN [
33], all layers after conv5 are removed. We denote the activated feature generated by each stage as
. In relation to the input image,
have strides of
, and their channel numbers are
, respectively. We design a top-down pyramidal structure with GRM, which will be discussed below, to restore resolution from higher stage levels in order to capture high-quality relations between objects. The dimension of final output feature map from a series of GRMs is
. After that, a context-aware module is exploited to fuse the local context information around objects without changing the dimension of the feature map. Finally, three parallel branches are used to estimate the head heatmap, bounding box sizes, and head center offsets, respectively. Each branch is implemented by applying a
convolution to generate the final targets.
3.1.1. Heatmap Branch
The heatmap aims to estimate the position of the head center. In particular, for our problem, the shape of the heatmap is
. The value of a location in the heatmap is anticipated to be 1 if it corresponds to the ground-truth head center and 0 for background pixels. As the distance between the heatmap location and the head center increases, the response within the radius exponentially decays, and the background outside the radius is 0. Following [
34], we set the radius of each head center point to a constant 2.
For each ground truth box
, the center of it is
, where
and
. Then its location on the headmap can be computed by dividing the output stride; here, the output stride is set to 4. Therefore,
. After that, the heatmap target value at the location
is obtained as follows:
Here, is the indicator function, which is 1 if the distance between position and the object location is less than or equal to the radius, and 0 otherwise. N stands for the number of heads, and is the standard deviation related to the radius. Specifically, .
The heatmap’s loss function is the pixel-wise focal loss [
16]:
where
and
are predetermined parameters, and
is the predicted heatmap.
3.1.2. Box Size Branch and Offset Branch
The width and height of the target box are regressed at each position by the box size branch. The offset branch, meanwhile, aims to address the discretization issue brought on by the output stride. We denote box size branch output
and offset branch output
. The dimensions of these two outputs both are
. For each ground truth box
, its box size is
and the offset is
. Then, we use
losses for the box size branch and offset branch as follows:
where
and
denote the predicted box size and offset at the corresponding location, respectively.
3.1.3. Loss Function
The following is a definition of CRNet loss:
where the three hyper-parameters
,
, and
are used to balance the weights of three branches.
3.2. Global Context Refinement Module
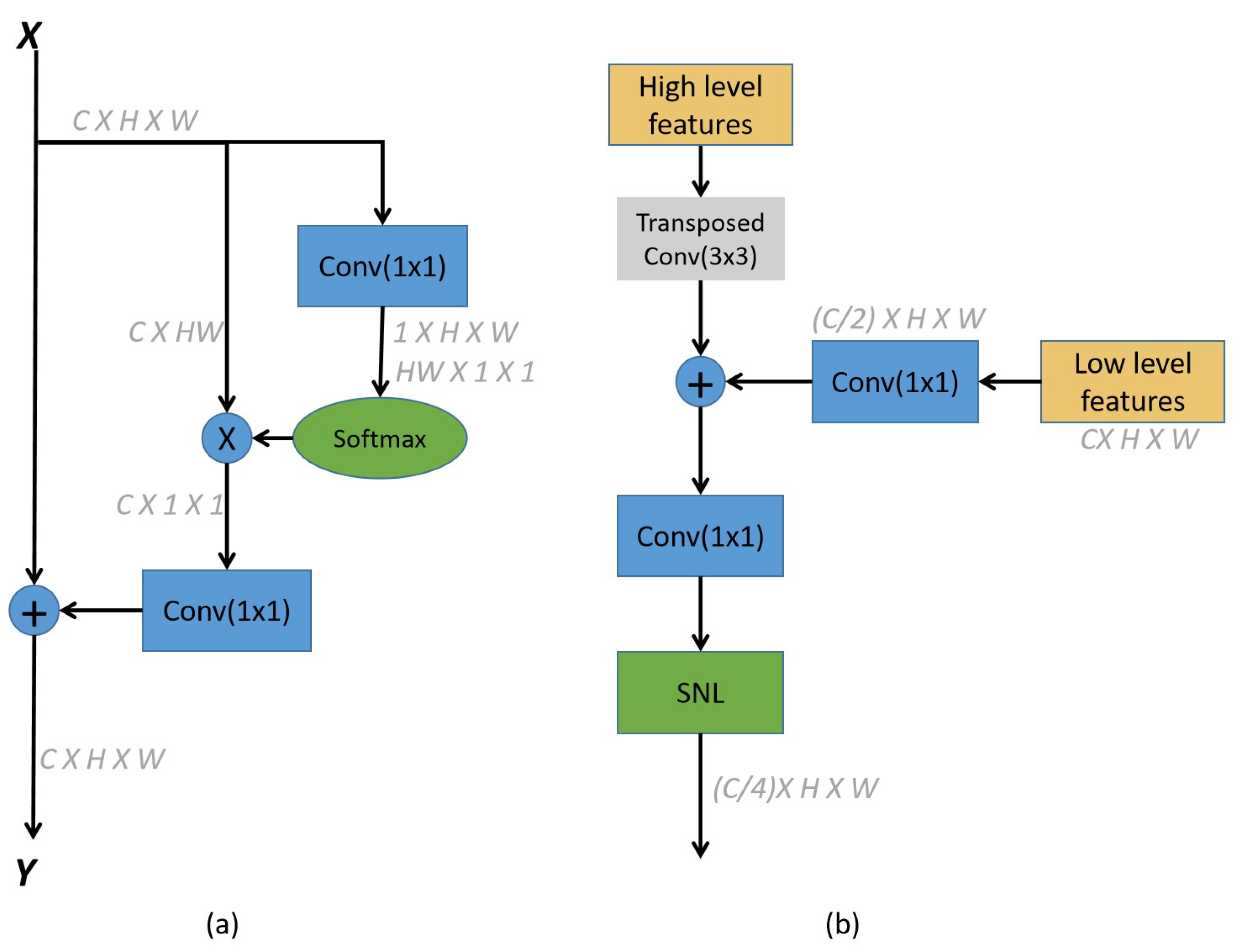
The standard Non-local (NL) [
30] is responsible for reinforcing the features of the query location by assembling features from other locations. The SNL [
12] block is the simplified version of NL, which aims to compute a global attention map and shares this attention map for all query positions. SNL has a lower computation cost than and similar performance to NL. In
Figure 2a, the detailed structure of the SNL block is illustrated. We denote
as a feature map whose height is
H and width is
W.
and
represent the input and output of the SNL, respectively. The process of SNL block can be formulated as follows:
where
i is the query position’s index and
j traverses all possible positions. Furthermore,
and
denote linear transformation matrices, which are both
conv.
When a feature map enters the SNL, the SNL first reduces the number of channels to 1 before using softmax for the global system to obtain a response map. The matrix multiplication for the features of the original input, which is the process of modeling long-range dependencies between each pair of points, is then performed using the response graph. Additionally, the multiplication results are added to the original input element-wise, resembling a residual structure. The reason why SNL can generate the response map with only one channel is that [
12] discovered that the response maps of different query positions in NL are similar, so we only need to learn one to replace the others, thus greatly reducing the computational complexity.
Lin et al. [
33] point out that, in the deep ConvNet, high-resolution maps have low-level features that hurt their representational capacity, while low-resolution maps have stronger semantics but coarser spatial representation ability. We rely on a certain architecture, the global context refinement module (GRM), which refines the global context via a top-down pathway and lateral connections in order to obtain a global context with strong representational ability and precise spatial positioning.
Figure 2b depicts the basic block architecture of the GRM.
All the low-level features go through a convolutional layer to shrink the channel’s dimensions. On account of the limited capability of the bilinear upsampling, our model applies a transposed convolution to upsample the resolution of high-level features by a factor of 2 (). Then, using element-wise addition, the low-level feature map with reduced dimensions is combined with the corresponding upsampled feature map. For fused features, although parameters of SNL are much less than those of NL, we further reduce the channel dimensions through a convolution for less computational complexity. Finally, the output feature map of is used as the input of the SNL to obtain the refined global context by building long-range dependencies between similar pixels. We denote as the output as the GRM block which merges feature maps of and . In particular, is denoted as the first GRM block, which is only related to and has no upsampling or element-wise addition operator.
3.3. Local Context Refinement Module
Due to the perspective principle, the sizes of heads are different in pictures, even though the actual size difference is small. This situation of objects with different scales give rise to different sizes of local context ranges. A partial remedy is to use multi-scale convolution and apply larger kernel convolutions such as
or
to expand receptive field, which, however, requires additional memory and computation cost. We advocate instead the use of dilated convolution, inspired of impressive work in image segmentation [
35,
36,
37]. The process of constructing dilated convolution consists of inserting zeros between each pixel in the convolutional kernel.
There are three main advantages of dilated convolution: (1) For a dilated convolution kernel with size
and dilation rate
r, the size of its receptive field is
larger than that of a conventional convolution with the same kernel size. (2) If the stride of a dilated convolution is 1, it can maintain the resolution of input feature maps. (3) The dilated convolution matches the calculation amount of a standard convolution with the same kernel size. For instance, a dilated convolution whose kernel size is
and dilation rate is
has the same size receptive field as a standard convolution whose kernel size is
, but without any change in Flops as a
convolution. In particular, in standard convolution, the dilation rate
. As shown in
Figure 3, we apply multi-scale dilation convolution with four branches with rates
. Each of them has
and
to maintain the resolution of the input feature map. Additionally, we fuse them by adding their feature maps point-wise for refining the local context. After that, we use a residual architecture to prevent difficult training. Eventually, the feature map of LRM is passed through three parallel heads.
4. Experiments and Analysis
We detail the specifics of our experiments’ execution in this section and examine the results. Datasets and evaluation metrics are first introduced. Next, we go into detail about how the experiments are conducted. We then use ablation studies to assess the efficiency of our method. Finally, our network is evaluated against the most advanced detectors on the public dataset.
4.1. Dataset and Evaluation Metrics
We conduct extensive research on the Brainwash [
38] and HollywoodHeads [
10] head detection datasets. The Brainwash dataset contains 82,906 labeled head boxes across 11,917 images. There are 10,917 total images in the training set, 500 images in the verification set, and 500 images in the test set. It is a large dataset obtained from crowd scenes utilizing video footage at a fixed interval. The HollywoodHeads dataset is the largest dataset currently used for head detection. It consists of 224,740 images from 21 Hollywood movies, with 369,846 heads in total. The training, validation, and test sets contain 216,719, 6719, and 1302 annotated images, respectively.
The evaluation metric adopted in testing is the standard average precision (AP). Furthermore, the IoU threshold is 0.5.
4.2. Implementation Details
Pre-trained weights from ImageNet are utilized as the model’s initial parameters, and we adopt Adam as the optimizer, setting the initial learning rate to . The training batchsize is set to 32 (on 2 Nividia 3060 GPUs). Furthermore, we set the max training epochs to 65 and 20 for the Brainwash and HollywoodHeads datasets, respectively.
We limit the input size of images to during the training phase. For the data augmentation, random horizontal flips, random scaling from 0.6 to 1.3, random cropping, and color jittering are used in this implementation.
At inference time, all test samples are resized to
. Following [
18], we first extract the peaks of the heatmaps whose responses are greater than or equal to the connected pixels around them by using a
max pooling operation. We then keep the top 100 peaks as the head center points. The number of points is further filtered using a confidence threshold, which we set to 0.05 in the test phase. Let
P be one of the detected head center points with the heatmap location
. The detected score of
P is
, and its prediction bounding box can be produced as follows:
where
and
.
4.3. Ablation Analysis
Considering that the output form and loss function of our model are the same as CenterNet [
18], and the model architecture is similar, we adopt CenterNet as the baseline. Following the original CenterNet [
18], we set the three hyper-parameters
,
, and
to 1,
, and 1, respectively, in Equation (
4) and set
and
to 1 and 2 in Equation (
1). For fair comparison, we employ ResNet50 instead of Dla34 [
39] as the backbone relative to the standard CenterNet. In particular, the upsampling operator of CenterNet(ResNet50) is three deconvolution layers. We use the same settings to achieve a fair comparison during the training stage. For instance, the initialization of the parameters is the same for all models, and the input size is
.
Table 1 presents the ablation experiment’s outcomes. We can see that our GRM and LRM can each outperform the baseline model in terms of AP by 2.29% and 1.04%, respectively. On the Brainwash test dataset, using LRM and GRM simultaneously can even improve performance by 2.71% over the benchmark model.
Figure 4 displays the precision recall (PR) curves of the ablation analysis of CRNet at IoU 0.5 on the Brainwash dataset. These results show that LRM and GRM can effectively improve the performance of the head detector.
Additionally, we further compare the influence of the number of GRM blocks used in CRNet by successively adding GRM
,
,
, and
on the CRNet without LRM. As indicated in
Table 2, GRM is applied to all four stages for the best outcome.
Another observation from
Table 2 is that the absolute improvement of adding GRM on
is the smallest. One possible explanation is that although the representation ability is strong in the global context at the high stage, the spatial representation ability is weak due to the large receptive field.
Furthermore, we display qualitative results of GRM on the Brainwash test set. We exploit Grad-CAM [
40] to visualize the class activation map (CAM) [
41] for SNL blocks from different GRMs in
Figure 5. Input images and the CAMs of the
,
,
, and
are displayed in order from left to right. The CAM will highlight the area that has more influence on the result. The greater the contribution of the area to the final result, the more the area will be highlighted. It can be clearly seen that the process of the global context of images is refined step by step. In
Figure 5, from left to right, almost all head center points become clearer and more accurate. The ability of GRM to obtain the global context and gradually refine the global context by combining features from various resolutions is demonstrated by this process. It can be determined from the last row in the figure that even the completely occluded head (left bottom) can be recalled through the refined global context, which is nearly impossible using the local context.
We also experiment with various configurations of dilation rates on our model with GRM to find an optimal combination of LRM. The results in
Table 3 show that multi-scale dilated convolution can have a positive effects in the results, and the configuration of
is the best combination of dilation rates for our experiments.
4.4. Performance Evaluation
According to the ablation studies above, we adopt GRM on the outputs of all stages and a multi-scale dilated convolution with dilatation rates of
. Finally, we evaluate the performance of our detector against several other representative detectors, including SSD, Faster-RCNN, TINY [
42], and the existing methods for head detection, such as HeadNet [
13] and SANM [
32].
Table 4 offers a summary of the results from the Brainwash dataset. We provide some examples in
Figure 6. These examples indicate that our model has good performance in densely populated scenes and small target detection.
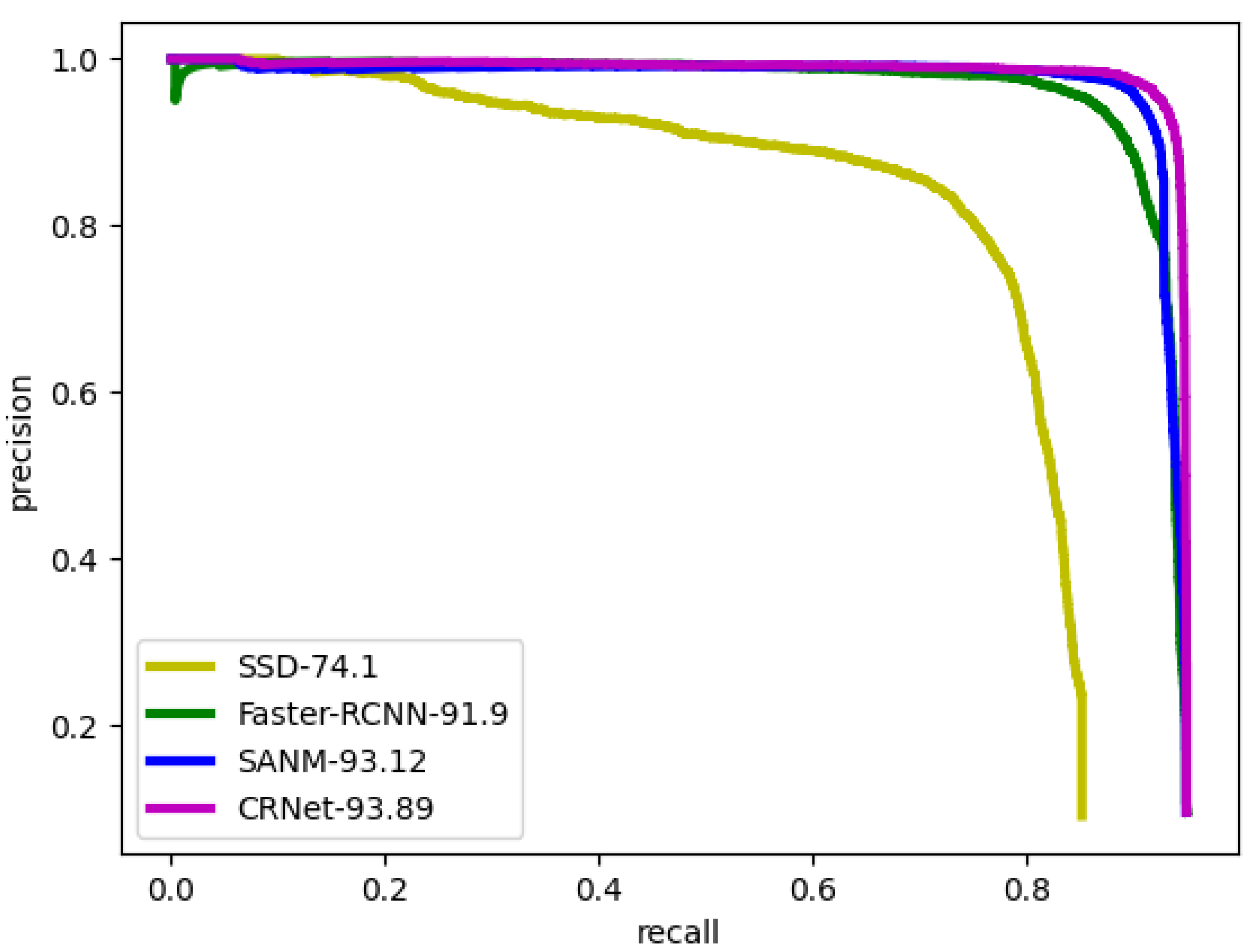
Figure 7 compares CRNet with other head detectors that show good performance by plotting the PR curves at IoU 0.5 on the Brainwash dataset. Our method shows a better performance than other detectors, which proves the superiority of our proposed model. A competitive performance is obtained when we test our model on HollywoodHeads as well. In
Table 5, the outcomes for HollywoodHeads are presented.
Figure 8 presents the qualitative results of our method on the HollywoodHeads dataset.
In terms of running time, we use a Ubuntu platform with one NVIDIA 3060 GPU and an Intel Xeon CPU E5-2697 v2 @ 2.70GHz to test the running speeds of different algorithms. At the same time, we also test the effect of LRM and GRM on the running speed of our model. As shown in
Table 6, our model achieves a good balance between precision and speed. Furthermore, as expected, LRM and GRM do not have a very large negative impact on the operating speed.
5. Conclusions and Future Work
Although head detection is a fundamental and important task, the current approaches fall short in terms of their ability to extract useful local and global contexts. We suggest CRNet, which is a one-stage detector for head detection, as a remedy for this issue. CRNet identifies heads via their center points in the images, without any anchor design, avoiding the need for prior statistical analysis. Because we associate heads with their center points, the similarity between points replaces the similarity between head proposals, and the computational costs become irrelevant to the number of targets. In order to extract the global context better and improve the classification ability, we introduce the global context refinement module (GRM). The GRM establishes long-range dependencies between pixels through SNL. SNL is much easier to optimize than the previous approach to obtaining global contexts through the use of repeated convolution layers [
12]. In addition, we enhance the global context by fusing output feature maps of different GRMs. Furthermore, a multi-scale dilated convolution layer is also used to refine the local context around the center point of the head. The computational complexity of the dilated convolution with a dilation rate greater than 1 is less than that of a conventional convolution with the same receptive field. The results of our experiments demonstrate that our proposed method achieves state-of-the-art performance on two public datasets. The running time test proves that our method achieves a good balance in terms of speed and accuracy. In future work, we intend to expand our framework to other visual fields, such as human crowd counting and face detection. At the same time, inspired by the latest progress in deep learning technology, in future work, we will explore the differences in our models’ performance caused by different backbones, especially ViT backbones [
44].










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}