1. Introduction
Recently, cloud computing has been recognized as an innovative strategy to increase cloud provider (CP) profit while satisfying a diverse range of consumers worldwide. Cloud computing is predicated on the idea that consumers can use CP’s computing resources while having to pay for them [
1,
2,
3]. Long-term success of cloud computing necessitates numerous technological, economic, and data security advancements. It is critical, in particular, to establish a proper mechanism that provides sufficient incentives for CPs to provide their computing resources for client sharing. Market-driven cloud computing is a viable approach for addressing the issue of client and CP incentives. In the cloud market, CPs lease their computing resources (CRs) temporarily to clients all over the world [
1,
4,
5,
6]. Access to CRs is often unpredictable, unlike the supply of more common goods. Furthermore, when working in an online environment such as the cloud, a task may fail for a variety of reasons, including software bugs, hardware failure, and insufficient resources. According to the Google cloud status dashboard [
7], infrastructure problems caused YouTube and Gmail to be down for an hour on 14 December 2020. When tasks fail, the customer’s Quality of Service (QoS) suffers dramatically. As a result, it is critical to take actions that can assist in compensating and protecting clients when task failure occurs [
6,
7,
8,
9]. Due to task failure, the availability of CRs is unknown. CPs cannot typically provide a good service with a guarantee to meet their clients’ expectations. From the perspective of a CP, it is mandatory to gain maximum profit, which can be obtained by serving the clients’ requests within the agreed upon deadline. To prevent a penalty for a delay, a deadline constraint should be met. Consequently, CPs need to be ready for any CR failure that could cause a violation the deadline constraint. Furthermore, CPs should take steps to lower customer queue wait times. To address this issue, we proposed a novel method that ensures the QoS of all requests while drastically reducing resource waste. In addition, CPs need to take action to shorten the time that customers must wait in line. However, earlier research has not addressed the needs and applications for fault-tolerant computing, as well as fundamental subjects, components, and trading metrics in the context of fault tolerance in the cloud. This paper investigates fault tolerance in the cloud market in a straightforward manner. To that end, we study short-term trading in the cloud market, where trade takes place between the CP (a monopoly supplier) and multiple clients. In this market, each client comes to an arrangement, known as a contract, with the CP. The contract specifies the following key elements:
Clients in the cloud market rent CRs in real time and on demand through an auction. Clients compete for CRs, and through pre-defined contracts, CPs insure clients from the uncertainty of future supply. The main concern of this research is to boost CPs’ profit. Cloud market data information is typically erratic. Information about the cloud market includes service demand, supply, and customer bids. This problem is formulated as a profit maximization problem. The following are the main contributions:
A new modeling and solution technique is proposed to handle task failure for clients. In this work, we tackle the problem of profit maximization in cloud markets under stochastic network information. Clients’ satisfaction is guaranteed by providing the committed number of CRs to guarantee the QoS for clients. The CP reserves a few CRs to deal with machine failure, and new requests are served based on an auction policy that guarantees the availability of CRs.
Under stochastic network information, we extract the optimal number of CRs that can be used to replace failed CRs.
We study the CP’s profit and QoS constraints for clients under stochastic cloud market information.
The remainder of this article is organized as follows: First, the related work and our contributions to the paper are introduced in
Section 2. Next, the cloud market is presented in
Section 3. We describe the proposed fault-tolerant trading scheme in
Section 4. Then, we present some of the performed tests and show the performance of the trading scheme under different conditions with our scheme in
Section 5. Finally, the article is concluded in
Section 6.
2. Related Work
Trading is disrupted when machines fail in the cloud market, decreasing consumer confidence in online purchases. It is possible for any machine, process, or part of a network to malfunction. The result is dissatisfied customers who are less likely to return and less likely to shop online in the future. The success of CR trading depends on the efficient handling of faults through the creation of new fault tolerance mechanisms to safeguard customers from any potential outages. A CP can still satisfy the request even if some of the CRs fail thanks to the fault-tolerant scheme employed [
10,
11]. A new scheme for replacing failed machines is proposed in [
12]. The main concern of the proposed scheme is improving the reliability of cloud services based on the replication-based fault tolerance method. The three components of the proposed methodology are the selection of a host server, the optimization of the placement of virtual machines, and the selection of a recovery strategy.
The authors of [
13] propose a new scheme to optimize cloud-based reliability in a versatile and adaptable manner. A peer-to-peer checkpointing method was used, which allows clients’ consistency points and levels to be optimized in light of each one’s unique needs and the full range of data center resources. In [
14], the authors propose a new scheme for dealing with machine failure by migrating a job to new machines if the current set of machines are unable to finish the job. To identify the most suitable replacement virtual machines (VMs) for a failed task, the authors of [
15] propose a new resource-aware virtual machine migration technique. A CP selects the most appropriate target virtual machines by keeping an eye on resource utilization and job arrival rate. In [
16], the authors propose a new model to allocate transfer and compression rate to each virtual machine in order to reduce job migration time. To manage job migration, geometric programming was used. This requires allocation of transfer rate to these VMs, which is usually done such that either the total migration time and/or total downtime is minimized without considering the penalty imposed for the service downtime during migration.
In order to determine whether or not CRs are alive, the majority of today’s methods, such as system layer heart beating, rely on a single, unreliable detector. Regardless of the nature of the fault being detected, there is a minimum amount of time that must elapse before the results of a single unreliable detector can be trusted. There are, however, other detectors that can find many faults much faster. Considering the need for rapid fault detection in cloud computing environments, the authors in [
17] propose an online liveness fault detection mechanism that integrates existing detectors. In [
18], the authors propose a new scheme to manage resources in the cloud market and to reduce the service level agreement violation, cost, energy usage, and time using fuzzy logic. In [
19], various techniques and architecture of fault tolerance systems are discussed. The authors describe the procedures of handling failure in the cloud market. In [
20], the authors introduce a fault-tolerant framework for highly efficient cloud-based computing. To speed up the execution of computationally intensive programs, the authors suggest using process level redundancy (PLR) techniques. Previous research on fault tolerance in the cloud is summarized in [
21]. Recent cloud-based environments have introduced novel difficulties in improving fault tolerance while also presenting novel opportunities for the creation of novel strategies, architectures, and standards. In [
22], the authors suggest a new scheme for calculating the deadline miss rate in the cloud market. The proposed scheme’s main aim is to maximize the CP’s profit by using the proposed method for multi-server configuration. The authors suggest a new scheme in [
23] for service pricing that takes into account the consumer perceived value. The suggested scheme enables CPs to accurately estimate supply and demand in the cloud market. Furthermore, the method determines the best multi-server configuration to maximize the CP’s profit. Authors propose new models for cloud service revenue and costs in [
24]. The trading cloud resources problem was formulated as a profit optimization problem, and a heuristic method based on a grouped grey wolf optimizer (GWO) was proposed to extract the optimal multi-server setup for a given client demand. In [
25], the authors analyzed a deadline constraint that may affect the profit of CPs. Furthermore, a new mathematical model was proposed to analyze the relationship between customer satisfaction and the revenues of CPs.
It can be noticed from the previous discussion that in the cloud market there are different motivations for clients and the CP. These motivations for both sides should be evaluated and appropriately addressed so that a more thorough CRs trading algorithm can be developed, which might serve to offer both parties with sufficient incentives to stay and engage with the cloud, leading to a sustainable system. However, the majority of past research has come from either the incentive for clients or the CP to solve this issue. In contrast, this work attempts to investigate the CRs trading problem in cloud computing by addressing the key motives for both parties, namely, maximizing CP profit and meeting client expectations.
When figuring out the CRs redundancy strategy in the cloud market, many state-of-the-art methods fail to consider the issue of the network’s potentially enormous resource consumption. Moreover, traditional approaches could not adjust to the market shift toward CR failure in the cloud. With this in mind, we propose a novel adaptive fault-tolerant scheme, distinct from existing approaches, in which the optimal number of CRs to be used for replacing a failed CR is calculated at each system epoch. Scalability is achieved by grouping customers into manageable clusters and having a central CP oversee all trading activity for each group. For the trading of CRs, our scheme can be implemented with little to no additional infrastructure. In the event of CRs failure, the job can continue to run thanks to migration strategies proposed in the literature. Nonetheless, shoddy migrations lengthen the migration process, cause disruptions in service, and reduce application performance.
3. The Cloud Market and Problem Formulation
We consider a cloud market with one CP and multiple clients. The CP owns K CRs to serve clients. Depending on CR availability and the demand for CRs, the CP serves clients. In the cloud market, we consider short-term CR trading, where the CP leases the CRs to clients on an availability basis. The main motivation for adopting short-term CR trading is that CR availability changes randomly due to the uncertainty and variability of service demand.
denotes the availability of
ith CR at time
.
= 1 indicates the
ith CR and is not used by any client at time
. The supply of service is defined as the total number of CRs that are used to serve clients. Service supply at time
can be expressed as follows:
The size of total supply
at time
can be expressed as follows:
where
N is the maximum number of CRs that the CP may utilize to support the cloud market customers. Due to the uncertainty of clients’ demand for service,
changes randomly across both time and CRs. The demand for service at time
can be represented as follows:
where
is the number of CRs required by
ith client, and
is the number of requests in the cloud market. Total demand
for service can be represented as follows:
In the cloud market, the demand and supply functions are independent over time. Each CR can be used by only one client. Function represents CR availability. For ith CR, is the idle probability and 1- is the busy probability.
3.1. Overview of Cloud Market
In the cloud computing market, contracts between a CP and its customers are typically short-term. Contract theory is used in our work to create contracts between the CP and clients. The following are some of the provisions of the contract:
The CP agrees to deliver the agreed CRs to the client within the allotted time frame. In exchange for the ith client’s potential utility loss, the CP should pay a penalty . The client only makes a request to rent CRs when needed, and if there are multiple clients with the same need, they must bid against one another to receive the service. The winner receives immediate access to the service at a price determined by market competition and client valuations in real time.
3.2. Contract Structure in the Cloud Market
From the customer’s point of view, there are a number of goals that might be defined, but the most appealing feature is the ability to successfully serve their requests at low cost within the deadline. Nonetheless, customers will move to another CP if request execution consistently falls behind schedule. To avoid delays in satisfying client requests, our scheme has taken steps to address CR failure, such as replacing failed CRs and migrating jobs to new machines. In the cloud market, the contract for
ith client at time
can be written as follows:
where
is the
ith client payment, and
is the CP’s penalty for CR failure. The revenue earned by the CP after completing the contract for the
ith client is calculated as follows:
Thus, when accepting a contract for the
ith client, the CP’s revenue collected is determined by the CP’s penalty and the payment made by the
ith client. The CP’s penalty is calculated as follows:
where
is the number of failed machines in the system, and
is the unit punishing price for a CR. Clients achieve certain benefits from using CRs. A client’s valuation on a specific CR represents the client’s benefit from using CRs. Client satisfaction is determined by service quality, which reflects how good or effective the CR is, and by a user-specific preference, which reflects how efficiently a client can use CRs and how urgently a client requires CRs.
4. Computing Resources Trading Based on a Fault Tolerance Scheme
Our scheme allows a client’s request to be migrated to a new CR if execution is not possible on the present machine. The CP should guarantee the QoS for clients.
Definition 1. For any request, the CP assigns the requested number of CRs to serve the request from the pool of available CRs. The CP receives the reward for serving the request if the request is successfully completed before the deadline.
The CP’s primary objective is to maximize profit by utilizing CRs as much as possible while minimizing the chance of deadline violation. However, if the demand for the service is high, the risk of CR failure increases dramatically, which may result in contract violation and a reduction in client satisfaction. Furthermore, frequent CR failures prohibit the CP from meeting clients’ cloud expectations, which inevitably harms the CP’s reputation, resulting in economic loss in the long run. In this regard, the CP’s primary concern is to ensure that all requests are served on time. Obviously, the main concern of the CP is maximizing its profit as follows:
where
is the simulation time, and
is the requests arrival rate. We assume that the arrival rate of clients’ requests follows a Poisson distribution with arrival rate
λ. The service rate for an incoming request is assumed to be exponentially distributed with service rate μ. These assumptions reflect some of the reality of trading applications. To ensure that clients receive a high quality service, a CP must keep a certain number of CRs on hand in case of CR failure. The CP should consider the failure probability for each machine when keeping certain number of CRs. As a result, and because service demand changes over time, the CP requires a policy to protect clients from machine failure. In our work, a state-dependent policy based on Markov decision processing (MDP) is proposed to model CRs trading in the cloud market. We integrate the CP’s penalty for CR failure in the MDP model. An MDP algorithm is used to extract the optimal management policy that maximizes the CP’s profit for given cloud market state
. The optimal trading policy will be extracted to select the set of possible service requests that maximize the net profit for the CP. The net profit
is computed as follows:
All requests that do not generate extra profit are rejected by the CP. Generally, the sensitivity of clients’ payments to the number of failed CRs can be approximated by the cost of penalty for CR failure:
where
is the number of failed CRs.
is a measure of the change in client willingness to pay in the cloud market based on the number of failed CRs. In order to maximize profit, the CP must respond to fluctuations in service demand by adjusting the price of services and the number of CRs dealing with machine failure. The sensitivity of the CP’s revenue to the number of failed CRs can be represented as follows:
The cost of machine failure is a linear function of
and it is computed as follows:
Substituting (9) in (10), the CP’s net revenue is maximized when number of failed machines equals the root of:
Newton’s method of successive linear approximations is used [
26,
27] to find the root of Equation (12). The new number of failed machines
at each iteration step t is computed as follows:
Approximating the derivative in Equation (13) at step t.
Substituting (14) in (13), the expected number of failed machines is represented as follows:
The expected number of failed machines at step t can be extracted using the following Algorithm 1:
| Algorithm 1 Finding the optimal number of failed machines at step t. |
| Input: , , and .
|
Output: The optimal number of that dedicated to replace failed CRs. - 1:
Arbitrarily initialize; - 2:
if CR-Failure() - 3:
{ - 4:
while - 5:
{ - 6:
- 7:
- 8:
} - 9:
return ; - 10:
} - 11:
End
|
Given a good initial approximation, the time complexity of Newton’s method to compute a root of a function with -digit precision is O((log )F()) where F() is the cost of calculating with -digit precision.
Definition 2. Any request from any client is accepted if the number of free CRs is sufficient to serve the request and the CP is capable of meeting the QoS requirments for the request.
5. Results, Analysis, and Discussion
In this section, we evaluate our proposed security scheme (FS) against an intolerance scheme (IS) in which a failed task is re-added to the waiting queue. Profit and end-to-end delay are the performance metrics used in the comparison. To gauge our scheme’s efficacy, we looked at how well it improves a CP’s profits while cutting down on client request waiting times. An adequate number of replicates were performed, and the results were averaged to ensure a 95% level of confidence and relative errors of less than 5%. We looked at how the proposed scheme (FS) performs using a variety of settings for the parameters. We examined the performance under different parameter settings.
Table 1 shows the parameters used to evaluate the proposed scheme.
Although some CRs may have failed, our scheme will continue to process requests from clients. Customers who are unhappy with their service because of machine failure are more likely to consider switching to a different CP, thereby reducing the profits of the CP.
Figure 1 depicts the effect of CR failure on the profit of the CP. The figure displays the results of our method (FS) and the intolerance scheme (IS). In the experiment, we took the profit at various percentage values of failed CRs. Clearly, as the number of failed machines increases in the cloud market, the profit of the CP decreases significantly. Fortunately, our technique keeps serving clients if some of the CRs fail. The FS moves failed requests into some CRs that are part of a pool of CRs ready to replace any failed CR. The IS, on the other hand, re-adds the failed requests to the queue and begins looking for available CRs. Because it serves all requests in-service, our scheme outperforms the IS in terms of profit.
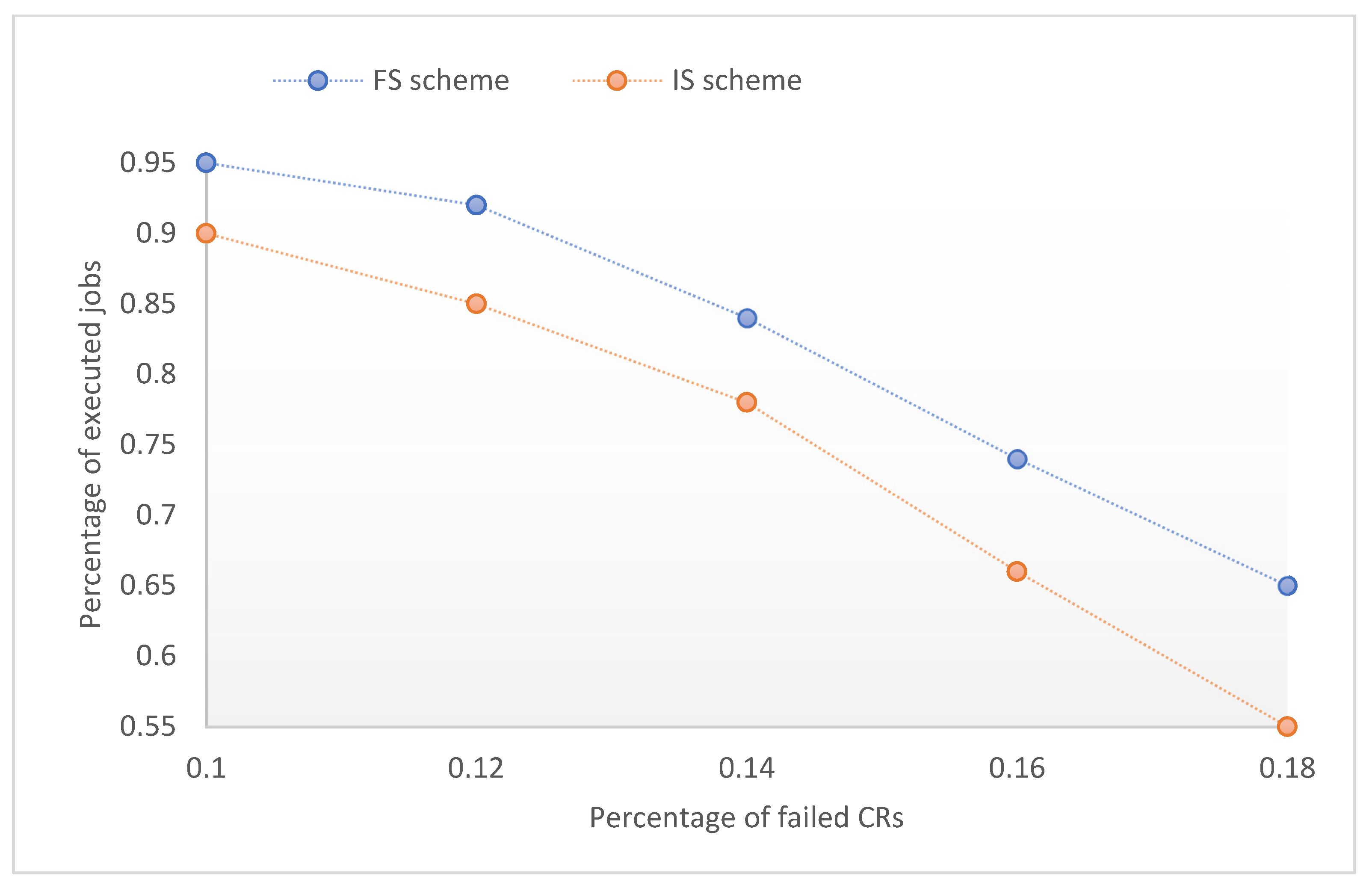
Figure 2 shows a comparison between our suggested scheme and the IS for the percentage of completed jobs. As the proportion of failed CRs rises, the percentage of jobs that are successfully completed falls for both schemes. The system’s capacity to deal with rising client demand is constrained by failed CRs. Instead of canceling them, jobs that have failed are executed by CRs that are dedicated to replication in our system. If a CR in service fails, the CP can decide which CR should take over the failed task. The CP can increase the number of requests it can fulfill by replacing failed CRs. However, the IS places the failed tasks in a queue, which increases the wait time for clients and decreases the proportion of successfully completed jobs.
Figure 3 depicts the size of the replication pool and the number of CRs set aside to replace failed CRs. It is obvious that as more CRs in the cloud market fail, the pool size grows as well. The CP requires more machines to satisfy client requests and perform replication tasks as there are more and more CRs failing.
Figure 4 displays the replication pool size as a function of the penalty for CR failure. It is evident that when the penalty cost rises, the pool size expands to minimize additional losses caused by machine failure. As more CRs fail, the CP requires more machines to serve client requests and complete replication activities. On the other hand, as shown in
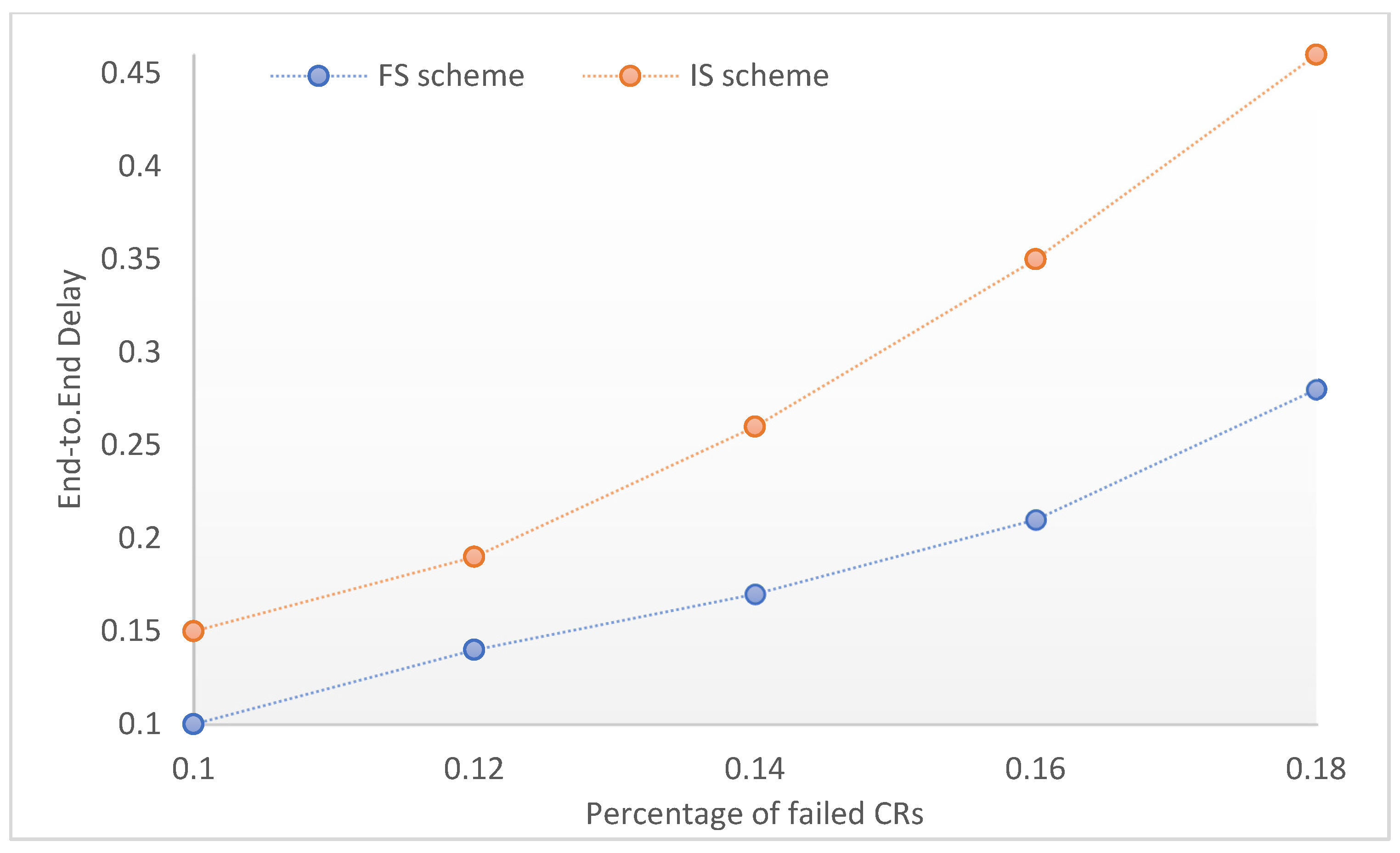
Figure 5, we compare the delay in our suggested scheme and the IS. The simulated scenario used to measure the delay of requests in the two schemes clearly shows that the delay increases significantly as the percentage of failed machines increases. Because of the replication pool, which is utilized to replace failed CRs and greatly reduce the delay, our technique surpasses the IS in terms of latency.
6. Conclusions and Future Work
CP’s profit can be improved significantly by handling the QoS requirements of clients effectively. Because cloud services are prone to a range of failures, fault tolerance issues must be considered while developing new strategies to address all cloud market needs. In order to reduce resource waste while accommodating CR failure and increasing CSP profit, these strategies must strike a compromise between competing objectives.
We proposed a new scheme that keep the services provided by the CP performing regardless of faults. In our scheme, the optimal number of CRs dedicated to replacing failed CRs is extracted. Newtown method is adopted for specifying the optimal size of replication pool. The proposed model moves the request into new CR for the pool of CRs if a machine fails to perform the task. This action minimizes the waiting time for clients and reduce the total migration time significantly. Current strategies for establishing fault tolerance in the cloud market do not take into account computing the appropriate size of CRs allocated to handle any partial failure in the market.
When the replication of failed CRs is used by the FS instead of the IS, the profit of the CP is greatly enhanced and the waiting time for clients is reduced. In the future, we plan to compute the time complexity of the proposed approach and compare it to alternative fault-tolerant schemes in terms of additional performance metrics such as request blocking probability. Furthermore, we will evaluate our technique with a verification tool to test its resilience against various faults and show that it optimizes CP profit under various conditions.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}