1. Introduction
Taxonomic semantic class labeling is a procedure for extracting a common semantic label for a set of conceptually related lexemes. The automation of taxonomic labeling can be exploited in many applications, as it can represent tacit knowledge and infer ontological relations, which is important for various subsequent natural language processing (NLP) tasks and applications [
1]. In lexicology, taxonomic semantic labels enable better standardization of lexical descriptions and allow the construction of “pseudo-definitions”—compact descriptions of the lexical conceptual content.
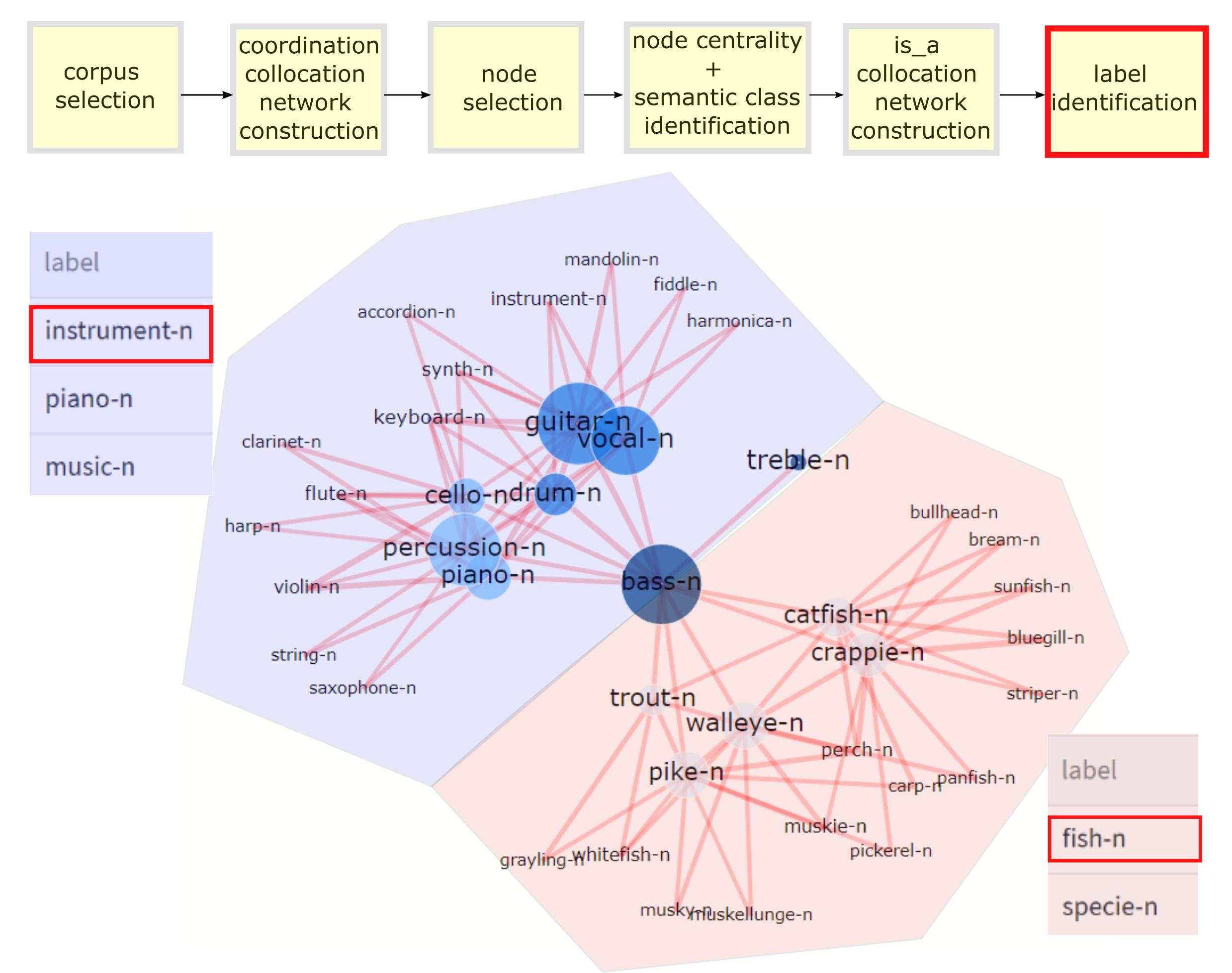
However, the automatic creation of taxonomic labels for a lexeme or a set of lexemes is a non-trivial task with multi-class classification and multi-label classification procedures. One of the major multi-class classification problems of this task is related to the polysemous structure of a lexeme. Namely, an ambiguous word can have multiple senses or acquire new meanings that are often not even semantically related. For instance, the noun bass can be labeled as a species of fish or as an instrument.
Moreover, for a set of lexemes representing a semantic class, taxonomic labeling derives a target semantic class label as a result of the categorial relation
is_a shared with all semantic class members [
2]. For instance, the set of source lexemes
banana,
apple,
mango, and
pear could be labeled as
fruit or
plants, while the community of lexemes
banana,
apple,
cookie,
icecream, and
sandwich should be labeled as
snack. Taxonomic semantic class labeling, in this sense, is a kind of generalization of a semantic field determined by the semantic scope of associated lexical units using a more abstract term that can taxonomically represent its semantic class.
From the perspective of cognitive linguistics [
3] and cognitive grammar [
4], these two lexical phenomena, word disambiguation and taxonomic labeling, can be seen as mutually supportive tasks. The meaning of a word is always profiled in relation to other words through a process of semantic framing and syntactic–semantic construal [
3] (Chapter 2). This means that conceptually similar words tend to form a radial network [
3] (Chapter 3), invoked by a certain semantic frame [
3] (Chapter 10). Using this theoretical background, we can assume that a source lexeme can be disambiguated by identifying the associated lexical networks that form a semantic field [
5]. We can hypothesize that the clustered lexemes can be utilized to label related prototypical semantic frames as categorizations. Additionally, we can suppose that these semantic processes employ particular syntactic constructions.
The Construction Grammar Conceptual Network (ConGraCNet) [
5] semantic class labeling method proposed in this paper introduces the procedure to identify clustered lexical fields of a source lexeme node as a semantic class and reveal their taxonomic labels. It is based on the use of syntactic dependencies to analyze information structures in a text. The use of syntactic dependencies is an established approach that has been shown to be effective in a wide range of applications. Syntactic dependencies refer to the relationships between words in a sentence, such as the subject–verb relationship or the direct object–verb relationship. These relationships can be represented using a graph, where each word is represented as a node and the dependencies between words are represented as edges between nodes. One of the main advantages of using syntactic dependencies is that they provide a structured representation of the conceptual relationships between words in a sentence, which can be used to extract valuable information and make inferences about the meaning of the sentence. This is particularly useful in natural language processing tasks such as summarization and information extraction, which involve analyzing the structure of a sentence and identifying the main subjects and objects in a sentence, the manner, time, aspect of the process, etc. From the perspective of lexical semantics, syntactic dependencies can help in disambiguating words and phrases, as we have shown in our previous work on ConGraCNet, making it easier to determine the semantic potential of a word and its categorical structures. Although similar in function, knowledge databases and ontologies are a type of knowledge representation that contains top-down organized logical descriptions of the concepts and relationships in a given domain. Ontologies are typically used in the semantic web to provide a standardized way of representing and reasoning about the meaning of concepts and relationships. However, they do not represent the synchronic or diachronic dynamic knowledge description extracted from the usage. Thus, while ontologies can be used to infer the labeling of concepts and sense communities, syntactic dependency graphs may be more effective for analyzing dynamic, cross-cultural knowledge.
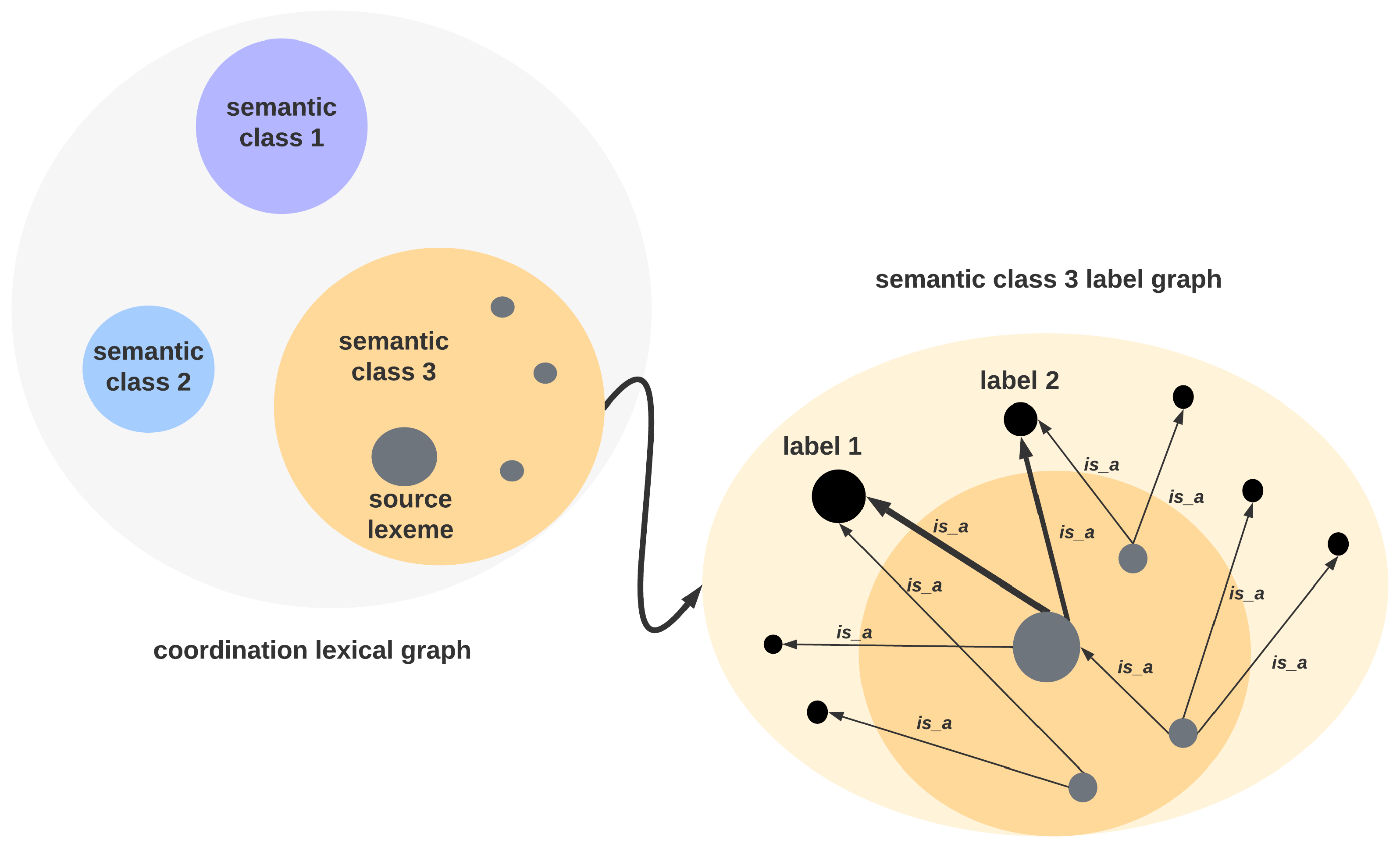
In this paper, we introduce a sequential lexical graph analysis procedure that is employed both for (a) extracting the most fitting conceptual generalizations of a group of related lexemes and for (b) representing the taxonomic label for a semantic class of a given lexeme. In particular, the proposed method exploits the syntactic–semantic dependency relations coordination and|or and categorization is_a and projects their network structure into conceptual similarity and taxonomic relation embedding graph layers, respectively. The proposed approach capitalizes on syntactic–semantic dependency relations and projects them into graph layers to achieve its desired outcomes.
The ConGraCNet coordination-based graph method for semantic association analysis [
5] underlying the labeling task, reveals the polysemous nature of lexical concepts by using coordination
and/or syntactic construction. The obtained graph of associative lexemes for a source lexeme is clustered into subgraphs that reveal the semantic classes of the source lexeme in a corpus. Building from this informational structure of lexical subgraphs, two additional graphs are constructed to capture the taxonomic relations of the subgraph semantic domains: one based on the collocates of the
is_a dependency relation and the other based on the hypernym relation from available commonsense knowledge bases such as Wordnet [
6]. Finally, graph analysis is performed to identify a set of corresponding label candidates representing the abstract semantic features of the associated lexemes in the semantic class. The proposed ConGraCNet multilayered method is an effective way of semantic analysis that reveals the polysemous nature of lexical concepts and provides a cognitive linguistic approach to understanding the semantic meanings of lexical concepts and their taxonomic relations.
We present examples from different corpora and describe the construction of lexical graphs and the process of candidate selection based on collocation and centrality measures, particularly the Semi-Local Integration (
) centrality [
7]. The accompanying ConGraCNet web app [
8] integrates manually annotated lexicons and semi-automatic corpus resources and methods. The app is available as a semantic resource in the EmoCNet project [
9].
The aim of this paper is to (i) present a graph-based method for labeling the taxonomic semantic class of associative concepts; (ii) present a semantic resource for web applications that integrates manually annotated lexicons and semi-automatic corpus techniques. We make the following contributions:
A graph-based approach to the lexical task of labeling semantic classes, which are formed as associative lexical communities related to a polysemous lexeme, using a combination of coordination and is_a syntactic–semantic lexical relations;
A related graph-based method that incorporates the knowledge base with a built-in hierarchical structure, such as the WordNet hypernym relation, to assign hypernym labels to semantic classes;
A web app implementation of the graph-based labeling algorithm.
Relying on the graph clustering and centrality measures from multiple syntactic embedding layers, we demonstrate the relevance of the proposed method, showing how and why it can be used to modify the taxonomic labeling outcome. The “why question” is especially relevant in the context of understanding the underlying cognitive processes that take place while creating abstract categorization of conceptual content. Additionally, the explainable nature of the procedure is in contrast to the growing number of computationally superior black-box models that produce non-transparent results without the possibility to explain the complex algorithmic processes. That being said, we also envisage the possibility of engaging the syntactic-dependency graph procedures in computationally extensive methods such as graph neural networks (GNN), with the possible benefit of creating semantically more transparent and controllable procedures for taxonomic labeling.
Moreover, our method can be produced on a relatively smaller set of corpora, as it is specially designed to be able to infer and represent the specificity of the corpora. We also show how the proposed method can be used to compare corpora and identify the differences in their taxonomic labeling, as well as to analyze the relative composition of the taxonomic labels for each lexeme in a given corpus. The results demonstrate that the proposed method is able to identify the most fitting taxonomic labels for a given lexeme and, more importantly, to identify the relevance of a given label in a given context. The paper begins with a description of related work,
Section 2. The labeling method is described in
Section 3 and then discussed in
Section 4, where we also define future research directions. Conclusions are drawn in
Section 5.
Relation to Our Previous Work
Some of the early research on labeling associative lexical communities was covered in [
10] and in the conference paper [
11]. Label graph construction and label assignment have been considerably elaborated by the selection of dependencies and the application of the
measure [
7]. As explained in detail in
Section 3, both the weights assigned to the edges in the label graph and the identification of the most appropriate label candidates reflect multiple underlying graph-theoretic features, including the collocation measures of the syntactic–semantic dependency relations
and/or and
is_a, as well as the centrality properties of the graphs modeling the lexical sense communities.
2. Related Work
Models for the computational representation of lexical–semantic knowledge have their origins in methods and resources that can be broadly divided into two categories.
Top-down curated knowledge databases such as WordNet [
6] and its counterparts in other languages [
12] form the basis for computational lexicons and the contextualization of paradigmatic hypernymy relations. WordNet lexical synsets, and later VerbNet [
13], PropBank [
14], BabelNet [
15], and VerbAtlas [
16] encode lexical semantic knowledge using word senses as units of meaning. A major problem with Wordnet is the top-down structure of curated resource creation, which inevitably leads to less granularity and the static nature of the inventories.
This class of resources also includes Common-Sense Knowledge (CSK) databases, which store descriptions of a set of common and generic facts or views about a set of concepts, including
is_a relations. They describe the general information that people use to describe, differentiate, and reason about concepts. ConceptNet [
17,
18] is one of the largest such resources, incorporating data from the original MIT Open Mind Common Sense project. Unlike WordNet, which distinguishes the meanings of a given lemma, the terms in ConceptNet are ambiguous, which can lead to confusion in lexical–semantic hypernym relationships for concepts denoted by ambiguous words (e.g.,
bass as an instrument vs. a species of fish).
On the other hand, bottom-up approaches to semantic labeling rely on the extraction of semantic features from the idea that conceptually similar words are used in syntagmatic similar contexts [
19] and the use of corpus-based syntactic pattern analysis [
20,
21].
The underlying idea is to analyze the prototypical syntagmatic patterns of words used in large corpora and assign meaning on a contextual basis through prototypical sentence patterns. Automatic approaches such as those of [
22,
23,
24] use syntactic patterns for automatic extraction of concept descriptions.
A radically different bottom-up approach is based on vector space models of lexical representations that view concepts as geometric vectors whose dimensions are qualitative features [
25] and other similar methods such as Latent Semantic Analysis [
26], Latent Dirichlet Allocation [
27], embeddings of words [
28,
29,
30], and word senses [
31,
32,
33]. Most of the recent approaches have been modified with the introduction of the open-source bidirectional machine learning framework that uses the surrounding text to determine the context of words. These models allow for direct similarity computation, but the knowledge does not explicitly define the concepts and the relations between vector representations are not ontologically organized. Moreover, there is growing concern about the capacity of neural networks to be understood in a transparent way. As automated machine learning models become increasingly complex, many people are anxious about their use and believe it is necessary to create models that can easily be interpreted or explained [
34,
35,
36]. In this respect, there are also some efforts to extract tacit human knowledge [
37,
38,
39,
40,
41].
Finally, there are mixed methods that use resources and methods from different approaches, such as the semagram-based knowledge model, which consists of 26 semantic relations and integrates features from different sources [
42], or the multilingual label propagation scheme introduced in [
43], which leverages word embeddings and the multilingual information from a knowledge database. Additionally, an interesting unsupervised procedure with the aim to reconstruct associative knowledge and emotional profiles in the text is the Textual Forma Mentis Network (TFMN), which utilizes syntactic parsing and psychological cognitive reflection to uncover how people structure and perceive knowledge with a combination of network science, psycholinguistics, and Big Data [
44].
In our earlier work [
5,
10], we introduced the graph method for distinguishing lexical senses, theoretically based on the notions of cognitive construction grammar that syntactic constructions construe a semantic value invoked by a semantic frame, and practically designed using a graph-based analysis of syntactic dependencies within a large corpus. As part of the ConGraCNet application developed to integrate data from various NLP pipelines, lexical dictionaries, and sentiment dictionaries, the method has shown perspective results, for example in the study of linguistic emotion expressions and the conceptual analysis of cultural framings [
10,
45,
46,
47,
48]. This procedure is the basis of the taxonomic lexical labeling procedure introduced in this article.
4. Results and Discussion
In the previous sections, we have shown that dependency-based lexical graph analysis can be used to construct a taxonomic structure of polysemous lexemes. This unsupervised graph method depends on a number of corpus linguistic and graph analysis parameters, including the selection of a corpus, the extraction of syntactic dependencies, and the measures used for ranking label candidates.
In particular, the proposed method exploits the syntactic–semantic dependency relations coordination and|or and categorization is_a and projects their network structure into conceptual similarity and taxonomic relation embedding graph layers, respectively.
The results show that the proposed method is able to identify the most appropriate taxonomic labels for a given lexeme and, more importantly, to determine the relevance of a given label in a given context. We demonstrate that the proposed method is not a black-box technique, as we have shown how graph clustering and centrality measures from multiple embedding layers can be used to change the result of taxonomic labeling in restrictive and non-restrictive settings. Moreover, our method can be produced on a relatively smaller set of corpora, as it is specifically designed to infer and represent the specificity of the corpora. In this section, we also show how the proposed method can be used to compare two corpora and identify the differences in their taxonomic labeling, as well as analyze the relative composition of taxonomic labels for each lexeme in a given corpus.
Expanding our previous work on taxonomic labeling with the enhanced multilayered graph procedure, we demonstrate how the centrality measure can be used to emphasize the integration of nodes in the graph for the propagation of the most appropriate labels.
This approach can be very useful in avoiding the propagation of erroneous labels from noisy data. Additionally, the graph-based method provides an efficient solution for the identification of the most suitable labels for an entire taxonomic tree, which is often a complex task. This method can also be used to identify the most appropriate labels for a given set of taxonomic data, which can be used to generate a more accurate and comprehensive taxonomic map. The representation of the results can be obtained using the web application that currently supports concept analysis in three languages (English, Italian, Croatian) and several corpora.
An important feature of this procedure is the possibility to control the amount of semantic meronymy (part–whole) of the taxonomic candidates by using the process of co-mapping the cluster relationships between label graph in the
layer and the underlying
embedding layer. Namely, if we want the labels to reflect less of the meronymic feature relative to the source lexeme
s, we include label candidates that are not necessarily members of the FoF
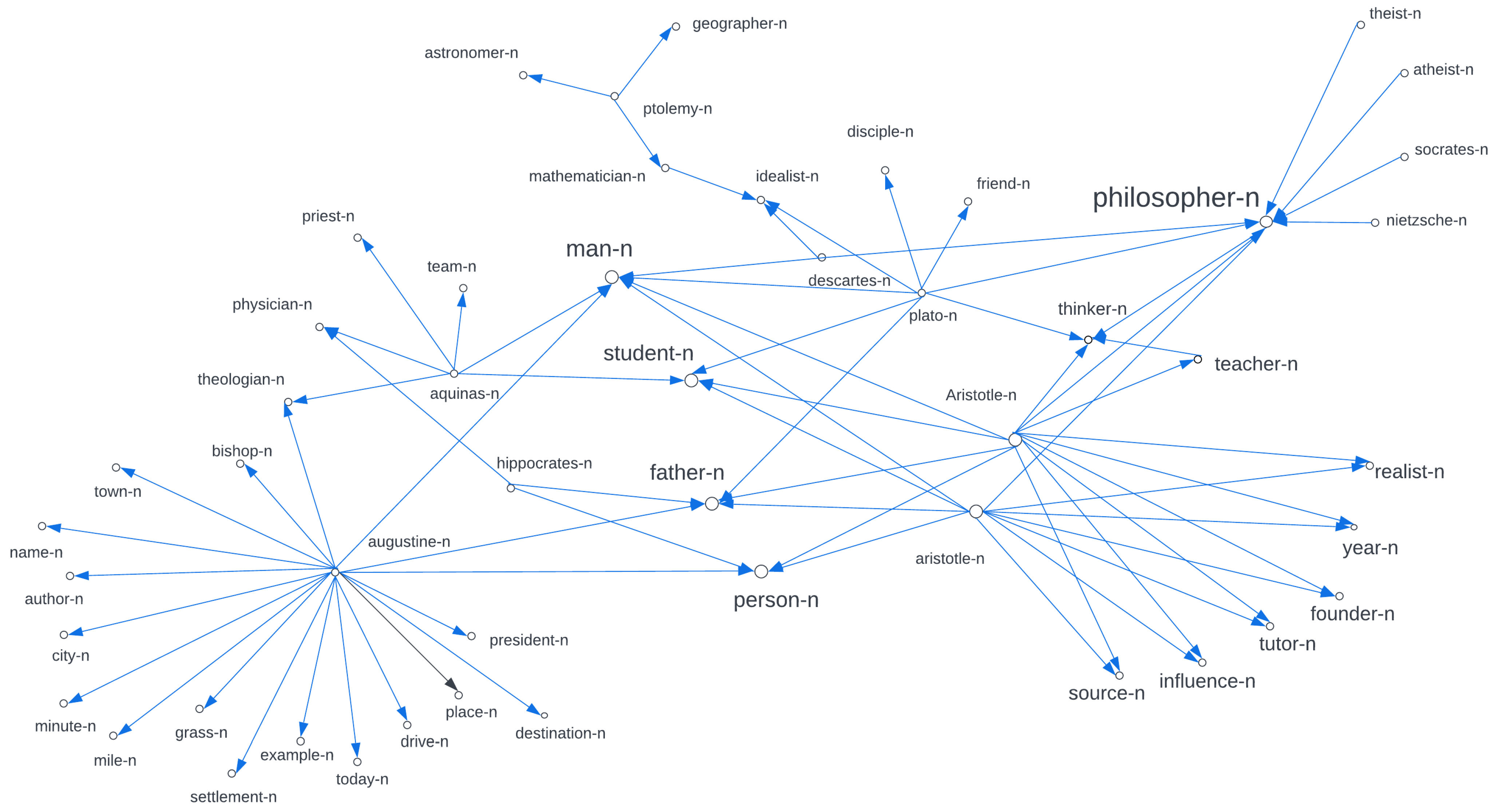
graph. In this way, we weaken the similarity and partonomy relationships of the semantic field used to identify conceptual abstraction used for labeling. For instance,
Table 2 presents top-ranked label candidates, constructed without the restrictions to match with FoF
lexical members. Two best label candidates, in this case, are
philosopher-n and
man-n. Alternatively, if only labels included in the FoF
are permitted, we get the community labels
philosopher-n and
socrates-n, as shown in
Table 3. This difference shows that a more abstract lexeme
man-n is presented in a more permissive label graph, as expected. By weakening the similarity and partonomy relationships of the semantic field used to identify conceptual abstractions for labeling, we can control the amount of semantic abstractness ascribed to the construction of the label graph.
By using the non-restrictive settings we can also notice the smaller relative score difference between the top candidates, in
Table 2, as opposed to the restrictive procedure shown in
Table 3 where the label candidate
philosopher-n is many times more prominent than other candidates in a restrictive setting. In conclusion, the non-restrictive setting should be chosen for open taxonomic labeling, while the restrictive setting produces a clearer candidate for the taxonomic representation of a semantic class, as it widens the score difference between the top candidates.
Moreover, the candidate labels for abstract source concepts of a semantic class do not always exactly match the part–whole pattern, and some of them express the conventional metaphorical patterns of conceptual mapping with candidates being ontologically more distant. For example, the label candidates for the first coordination cluster of the source lexeme
love-n, FoF
, consisting of lexemes:
respect-n,
affection-n,
friendship-n,
admiration-n,
trust-n,
appreciation-n,
loyalty-n, and
companionship-n, are shown in
Table 4 and
Table 5.
It is clear that the non-restrictive option in
Table 4 produces candidates that match the metaphorical definition of
love-n. For instance, “love is a key” is a conceptual metaphor used in expressions such as “love is a key (that can open many doors)” [
51]. However, if we want a formal classification, we would opt for the restrictive procedure with the results shown in
Table 5, such as “love is a relationship”. Finally, we can also exclude lexical items in the community FoF
to get the labels shown in
Table 6.
The results of these tables can be seen to represent different levels of abstraction.
Table 4 is the most general and abstract, while
Table 6 is the most specific and precise. The choice of which level to use will depend on the purpose it is being used for. For example, if one were trying to classify a sentiment as either positive or negative they would likely choose the more precise labels from
Table 6. On the other hand, if someone was trying to give an overview of a concept, then they may opt for less precise labels such as those found in
Table 4.
This procedure, coupled with an additional investigation of ontological similarity performed at the level of the FoF network, can be used to extract the metaphorical collocations with the is_a constructions.
This raises a discussion about the qualitative difference between part–whole patterns of taxonomic labeling and conventional metaphorical patterns used as a proxy for labeling a semantic domain. The part–whole pattern implies that one concept is directly derived from another concept. However, conventional metaphorical patterns suggest that two concepts are related in some way, but the relationship is not necessarily literal. For example, with the label candidates for love-n, respect-n can be seen as a part of love, as it is typically included in an understanding of what love means, while heart-n may be seen more as a metaphor for love rather than being a direct part of it. Therefore, when considering the labels for abstract source concepts of a semantic class, it is important to consider the question of whether the conventional metaphorical patterns of conceptual mapping can be used as labels for a semantic class, even when they may seem ontologically distant. Especially, if it could be argued that these labels reflect our culture’s use of metaphors to explain complex concepts such as love.
Furthermore, it is important to consider the context of the source concept when choosing the most appropriate candidate labels for semantic classes. This can help in understanding how metaphors are used to convey meaning and how they are expressed in language. For example, a metaphor such as “love is a key” implies that love opens up opportunities and possibilities, while “love is a relationship” expresses a more intimate connection between two people. Considering this context can help to identify which of these two relations is used to convey the semantic domain of a source concept.
The discussion of the efficacy of these two approaches to the construction of label graphs for semantic classes is ongoing. It is clear that the restrictive approach produces more accurate labels, as it makes use of a taxonomically defined and controllable set of lexemes that reduce ambiguity. On the other hand, the value of a non-restrictive approach is that it allows for greater flexibility, reflecting construal nuances in meaning between different text corpora. The measure-dependent propagation features need to be further analyzed in our future work, including the possibility to extract metaphoric mapping using the syntactic dependency is_a.
In our future work, we plan to implement the syntactic is_a relation for other languages. In particular, we are developing a Universal Dependency based tagging construction adapted to the language-specific grammatical expression of the is_a relation. An important aspect of developing a Universal Dependency based tagging construction is the consideration of language-specific rules. For example, some languages may require an additional level of specificity when it comes to specifying which elements are in the is_a relation. This could be done through specific verb conjugations or other syntactic cues. Furthermore, depending on the language, different kinds of syntactic constructions may be needed for expressing the is_a relation accurately. It is essential to consider these nuances when developing a Universal Dependency-based tagging construction. Additionally, it is important to keep in mind that there may be cultural and regional differences in how certain languages express particular concepts and ideas, so this should also be taken into account when creating a tagging system.
The informational advantage of corpus-based taxonomic semantic class labeling is the representation of corpus-specific taxonomic structures for a set of associated lexemes. However, this can also be a disadvantage for smaller corpora with a sparse set of syntactic patterns forming an is_a representation. One way to address this issue is to use a thesaurus-based approach, which involves using a pre-existing database of word relationships. These databases can provide a richer set of syntactic patterns and enable us to better analyze the measure-dependent propagation features.
On the other hand, there are some drawbacks associated with this enrichment. For one, the knowledge databases store the prototypical knowledge, while, in a constantly changing cultural environment, new ideas are emerging and their links to established concepts are liable to be reorganized. In practice, WordNet might be unable to capture or show all the subtle aspects of conceptual associations that could be found in a specific corpus-based semantic class labeling. Additionally, if the thesaurus does not contain all relevant words related to a particular concept, then it will not be able to accurately represent that concept in relation to other concepts.
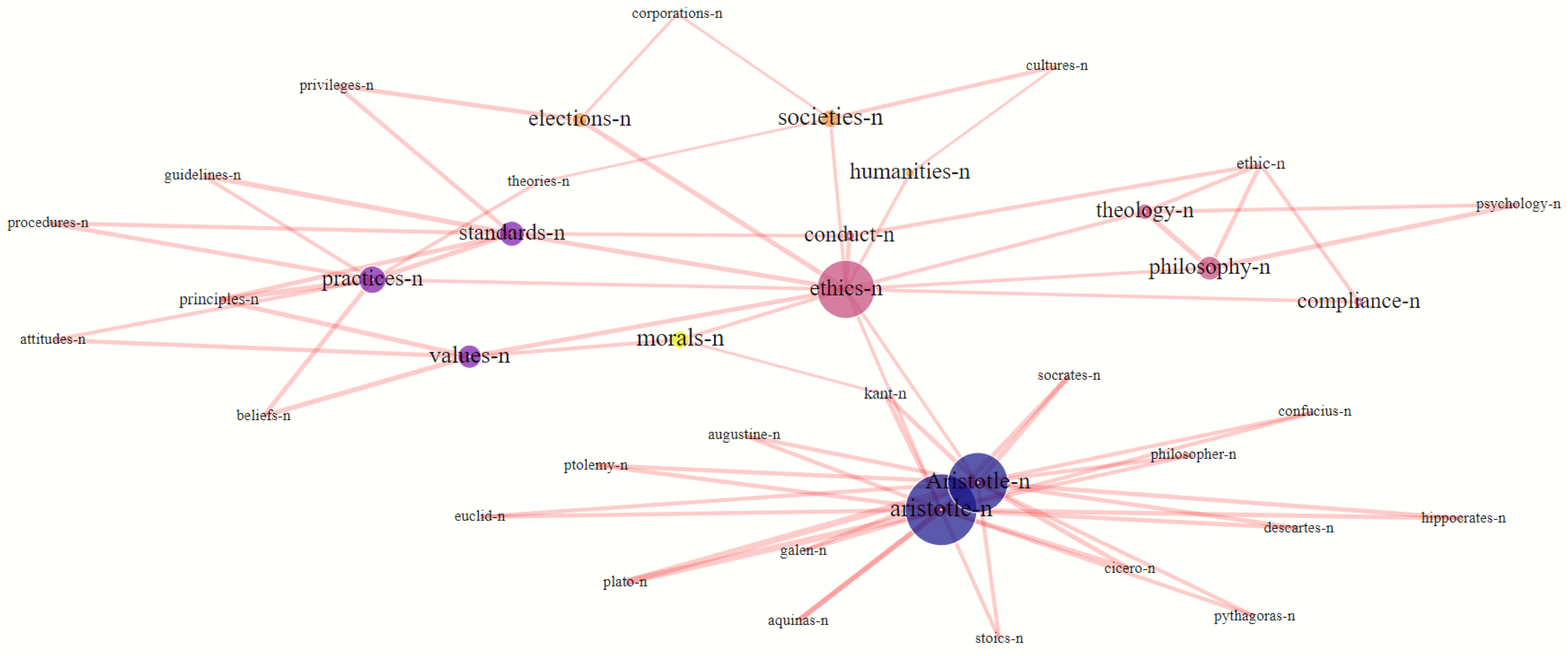
For the comparison of
is_a dependency labels and WordNet hypernym labels, see
Table 1, which shows the prediction of hypernym labels for the related senses of the source lexeme
ethics-n for both methods of label propagation based on the same FoF
graph. The example shows the typical results obtained with this procedure, with a high level of semantic class abstraction provided by the synset candidates. For instance, the first semantic class with various philosophers is labeled dynasty.n.01, while the very abstract semantic class
standards-n, values-n, etc. yields the even more abstract synset label
belief.n.01. This exemplifies the overall validity of providing hypernym synsets for taxonomic semantic labeling.
One of the main advantages of the WordNet hypernym graph algorithm is the symbolic categorical assignment of lexical nodes to a class within a structured taxonomy. This allows semantic enrichment of the associated lexical communities obtained by unsupervised bottom-up graph classification method and results in a set of synsets with well-defined and curated top-down knowledge relations. The hypernym graph abstracts the categories of lexical communities using WordNet dictionary knowledge relative to the data provided by a large web corpus. This results in a comparable corpus-based representation of lexical usage given the same set of graph parameters.
For example,
Table 7 shows the labeling of communities based on the English Timestamped newsfeed 2014–2019 corpus. Both corpora yield a set of sense clusters that abstract
anger-n in a comparatively similar sense of distinct strong feeling
emotion.n.01, associated in particular with
violence, insecurity, intolerance, resentment, and
sadness.
Another advantage of using WordNet is the ability to find corresponding hypernym structures in many languages via the Open Multilingual WordNet library [
12]. The results of the comparative translation equivalent of the concept
anger-n in Croatian, concept
ljutnja-n, calculated on the basis of the Croatian hrWac corpus (hrWac) [
58,
59] are presented in
Table 8.
The cross-linguistic comparison yields a commensurable and yet culturally specific insight into the associative conceptual matrix of the lexeme ljutnja, which indicates a somewhat different picture than its English translation equivalent. The lexeme ljutnja in hrWac also displays the aggressive features of anger, but is more abstractly associated with states and emotions experienced when one is not well or does not achieve the desired goal, as well as with the quality of having no strength or power.
We can argue that corpus-based taxonomic labeling graph procedures highlight usage-based and cultural differences in the semantic processing of the same lexical concept. These features provide a transparent and consistent approach to intra-and cross-cultural analysis of the semantic lexical potential for a given source word.
As a drawback of the method, it should be noted that the lexical sparseness of WordNet hypernym relations hinders the full scope of mapping. Nevertheless, the structure of the coordination layer subgraphs can be compensated to some extent by the association of more frequent noun lexemes, which provide a more conventional abstract categorical label for an associated sense of a source lexeme.
In terms of extending the knowledge-base approach to labeling, although the WordNet labeling results show perspective results, in our future work we plan to integrate other knowledge databases with similar semantic relations, such as Conceptnet and Wikipedia, and compare the results with corpus-based word is_a category and category is_a word syntax dependency. This is an interesting prospect and could potentially lead to a more comprehensive approach to labeling. For example, integrating Conceptnet could provide the ability to link words with more nuanced relationships than WordNet, such as “related concepts”. This could be useful for creating more complex labels that capture the nuances in language.
Additionally, Wikipedia integration could add another layer of contextual information, allowing for labels that are based on topics rather than just individual words. Ultimately, this type of knowledge-based approach could lead to better performance in downstream tasks such as text classification and sentiment analysis.
Finally, in light of the new state-of-the-art methodologies, we plan to introduce the described dependency layers within a graph-to-graph Transformer [
60], which has shown possibilities for integration of dependency layers into sequence-based language modeling, as well as experiment with building graph neural network language models [
61]. The integration of dependency layers into sequence-based language modeling is a promising area for further exploration. This could enable the development of models that are more capable of capturing the syntactic and semantic nuances of natural language, as well as better represent structures such as long-distance dependencies. Additionally, building graph neural network language models has been shown to improve the performance of natural language understanding tasks by leveraging structural information from input lexical graphs. Such models could potentially provide even greater flexibility in terms of integrating both syntactic and semantic information. Finally, it would be interesting to explore how these new state-of-the-art methods can be used to create systems that are able to generate natural language outputs that accurately reflect the underlying structure of an input lexical graph.









{kind=link}
{kind=link}
{kind=link}
{kind=link}