
Recursive Feature Elimination for Improving Learning Points on Hand-Sign Recognition




Abstract
1. Introduction
2. Related Works
2.1. Hand-Sign Detection
2.2. Mediapipe for Feature Extraction
2.3. Feature Selection
2.4. Performance Evaluation
3. Methodology
3.1. Research Design
3.2. Datasets
3.3. Data Pre-Processing
3.3.1. Data Augmentation
3.3.2. Train–Test Split
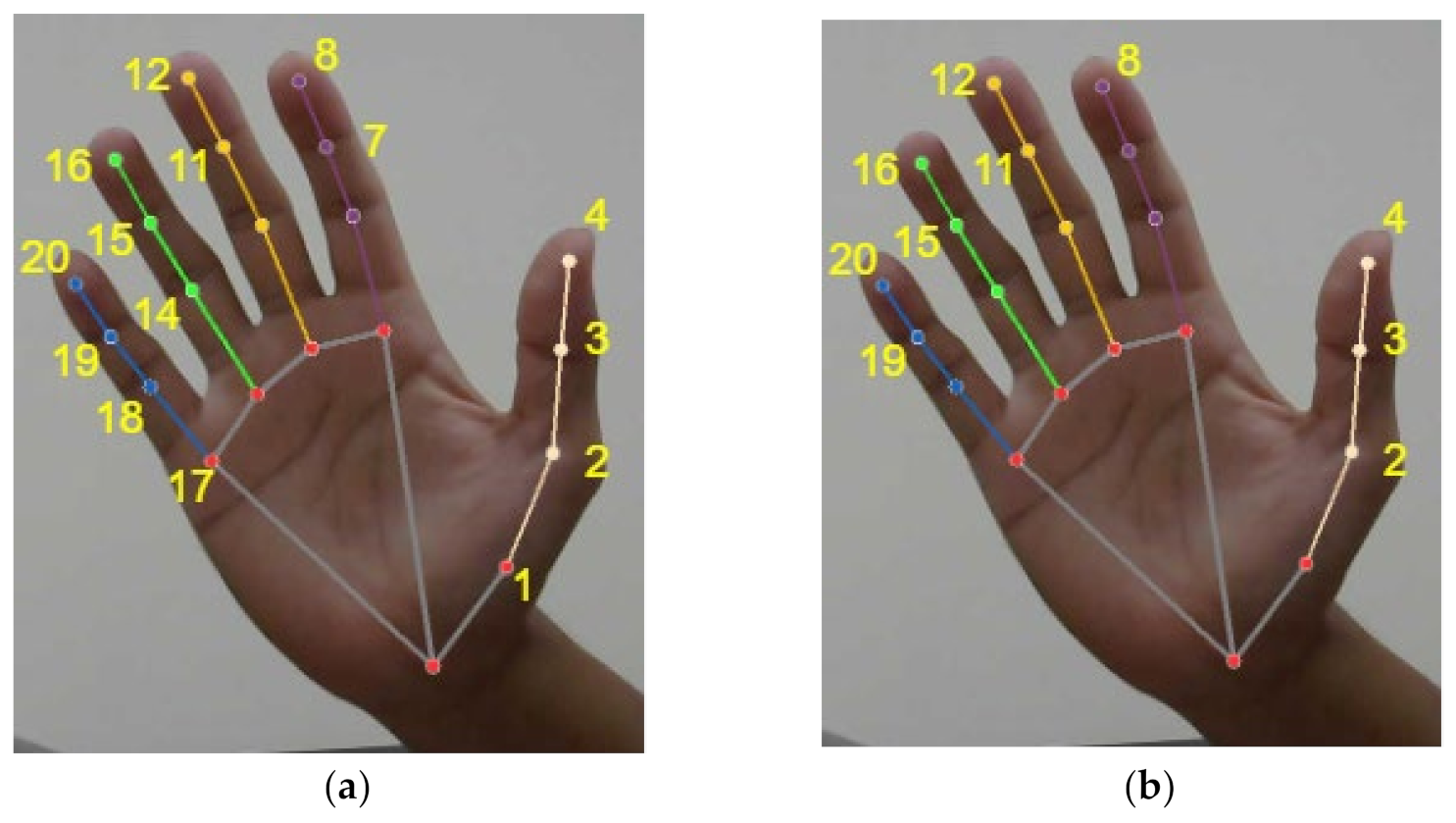
3.4. Hand Landmark Detection and Extraction
3.5. Feature Selection Method
| Algorithm 1: Random Forest-Recursive Feature Elimination. |
 |
3.6. Training Steps
| Algorithm 2: Model Training Steps. |
| inputs: training, testing, and validation set |
| The selected feature sets Fs15 and Fs10 |
| Initialization: initialize untrained model m1, m2, and m3 |
| output: trained model m1, m2, and m3 |
| 1 train m1 using the original training and testing set |
| 2 evaluate m1 performance using the original validation set |
| 3 reduce the number of features in the dataset to follow Fs15 |
| 4 train m2 using the Fs15 training and testing set |
| 5 evaluate m2 performance using the Fs15 validation set |
| 6 reduce the number of features in the dataset to follow Fs10 |
| 7 train m3 using the Fs10 training and testing set |
| 8 evaluate m3 performance using the Fs10 validation set |
4. Results and Discussion
4.1. Experiment Results
4.1.1. Feature Selection Results
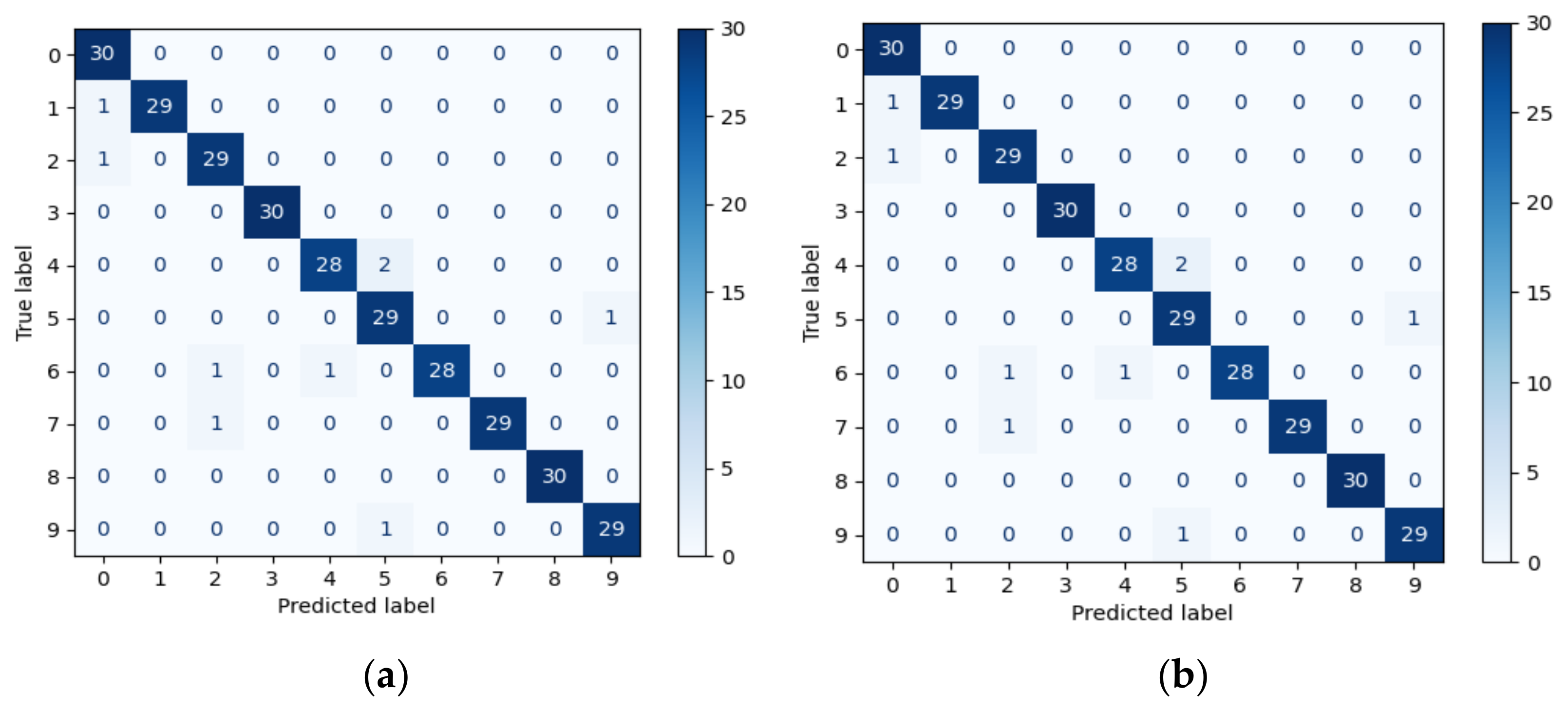
4.1.2. Model Accuracy Results
4.2. Discussion
4.2.1. Feature Selection Result
4.2.2. The Gap between the Validation Accuracy for Dataset 3 and the Other Datasets
4.2.3. Advantages of Our Method Compared to Using CNN
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alom, M.S.; Hasan, M.J.; Wahid, M.F. Digit recognition in sign language based on convolutional neural network and support vector machine. In Proceedings of the 2019 International Conference on Sustainable Technologies for Industry 4.0 (STI), Dhaka, Bangladesh, 24–25 December 2019; pp. 1–5. [Google Scholar]
- Hossain, M.B.; Adhikary, A.; Soheli, S.J. Sign language digit recognition using different convolutional neural network model. Asian J. Res. Comput. Sci. 2020, 6, 16–24. [Google Scholar] [CrossRef]
- Kalam, M.A.; Mondal, M.N.I.; Ahmed, B. Rotation independent digit recognition in sign language. In Proceedings of the 2nd International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 7–9 February 2019; pp. 1–5. [Google Scholar]
- Lin, H.I.; Hsu, M.H.; Chen, W.K. Human hand gesture recognition using a convolution neural network. In Proceedings of the IEEE International Conference on Automation Science and Engineering, New Taipei, Taiwan, 18–22 August 2014; pp. 1038–1043. [Google Scholar]
- Paul, P.; Bhuiya, M.A.U.A.; Ullah, M.A.; Saqib, M.N.; Mohammed, N.; Momen, S. A modern approach for sign language interpretation using convolutional neural network. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Porto, Portugal, 8–11 October 2019; Volume 11672 LNAI, pp. 431–444. [Google Scholar]
- Abiyev, R.H.; Arslan, M.; Idoko, J.B. Sign language translation using deep convolutional neural networks. KSII Trans. Internet Inf. Syst. 2020, 14, 631–653. [Google Scholar] [CrossRef]
- Chakraborty, S.; Bandyopadhyay, N.; Chakraverty, P.; Banerjee, S.; Sarkar, Z.; Ghosh, S. Indian sign language classification (ISL) using machine learning. Am. J. Electron. Commun. 2021, 1, 17–21. [Google Scholar] [CrossRef]
- Rajan, R.G.; Judith Leo, M. American sign language alphabets recognition using hand crafted and deep learning features. In Proceedings of the 5th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020; pp. 430–434. [Google Scholar]
- Shin, J.; Matsuoka, A.; Hasan, M.A.M.; Srizon, A.Y. American sign language alphabet recognition by extracting feature from hand pose estimation. Sensors 2021, 21, 5856. [Google Scholar] [CrossRef] [PubMed]
- Alvin, A.; Shabrina, N.H.; Ryo, A.; Christian, E. Hand gesture detection for sign language using K-nearest neighbor with mediapipe. Ultim. Comput. J. Sist. Komput. 2021, 13, 57–62. [Google Scholar] [CrossRef]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.-L.; Yong, M.G.; Lee, J.; et al. MediaPipe: A Framework for Building Perception Pipelines. 2019. Available online: http://arxiv.org/abs/1906.08172 (accessed on 18 May 2022).
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Assaleh, K.; Shanableh, T.; Zourob, M. Low complexity classification system for glove-based arabic sign language recognition. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Paphos, Cyprus, 23–27 September 2012; Volume 7665 LNCS, pp. 262–268. [Google Scholar]
- Shukor, A.Z.; Miskon, M.F.; Jamaluddin, M.H.; Ali Ibrahim, F.B.; Asyraf, M.F.; Bahar, M.B. Bin a new data glove approach for malaysian sign language detection. In Proceedings of the Procedia Computer Science, Sousse, Tunisia, 5–7 October 2015; Volume 76, pp. 60–67. [Google Scholar]
- Tubaiz, N.; Shanableh, T.; Assaleh, K. Glove-based continuous arabic sign language recognition in user-dependent mode. IEEE Trans. Hum.-Mach. Syst. 2015, 45, 526–533. [Google Scholar] [CrossRef]
- Pan, T.Y.; Tsai, W.L.; Chang, C.Y.; Yeh, C.W.; Hu, M.C. A hierarchical hand gesture recognition framework for sports referee training-based emg and accelerometer sensors. IEEE Trans. Cybern. 2022, 52, 3172–3183. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Li, Y.; Lantz, V.; Wang, K.; Yang, J. A framework for hand gesture recognition based on accelerometer and emg sensors. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2011, 41, 1064–1076. [Google Scholar] [CrossRef]
- Almeida, S.G.M.; Guimarães, F.G.; Ramírez, J.A. Feature extraction in brazilian sign language recognition based on phonological structure and using RGB-D sensors. Expert Syst. Appl. 2014, 41, 7259–7271. [Google Scholar] [CrossRef]
- Chophuk, P.; Pattanaworapan, K.; Chamnongthai, K. Fist american sign language recognition using leap motion sensor. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018; pp. 1–4. [Google Scholar]
- Lai, K.; Konrad, J.; Ishwar, P. A Gesture-driven computer interface using kinect. In Proceedings of the IEEE Southwest Symposium on Image Analysis and Interpretation, Santa Fe, NM, USA, 22–24 April 2012; pp. 185–188.
- Avola, D.; Bernardi, M.; Cinque, L.; Foresti, G.L.; Massaroni, C. Exploiting recurrent neural networks and leap motion controller for the recognition of sign language and semaphoric hand gestures. IEEE Trans. Multimed. 2019, 21, 234–245. [Google Scholar] [CrossRef]
- Bajaj, Y.; Malhotra, P. American sign language identification using hand trackpoint analysis. In Proceedings of the International Conference on Innovative Computing and Communications (Advances in Intelligent Systems and Computing), Delhi, India, 19–20 February 2022; pp. 159–171. [Google Scholar]
- Nai, W.; Liu, Y.; Rempel, D.; Wang, Y. Fast hand posture classification using depth features extracted from random line segments. Pattern Recognit. 2017, 65, 1–10. [Google Scholar] [CrossRef]
- Tharwat, G.; Ahmed, A.M.; Bouallegue, B. Arabic Sign Language Recognition System for Alphabets Using Machine Learning Techniques. J. Electr. Comput. Eng. 2021, 2021, 2995851. [Google Scholar] [CrossRef]
- Gunji, B.M.; Bhargav, N.M.; Dey, A.; Zeeshan Mohammed, I.K.; Sathyajith, S. Recognition of sign language based on hand gestures. J. Adv. Appl. Comput. Math. 2022, 8, 21–32. [Google Scholar] [CrossRef]
- Podder, K.K.; Chowdhury, M.E.H.; Tahir, A.M.; Mahbub, Z.B.; Khandakar, A.; Hossain, M.S.; Kadir, M.A. Bangla sign language (BdSL) alphabets and numerals classification using a deep learning model. Sensors 2022, 22, 574. [Google Scholar] [CrossRef]
- Alsahaf, A.; Petkov, N.; Shenoy, V.; Azzopardi, G. A framework for feature selection through boosting. Expert Syst. Appl. 2022, 187, 115895. [Google Scholar] [CrossRef]
- Mathew, T.E. A logistic regression with recursive feature elimination model for breast cancer diagnosis. Int. J. Emerg. Technol. 2019, 10, 55–63. [Google Scholar]
- Misra, P.; Yadav, A.S. Improving the classification accuracy using recursive feature elimination with cross-validation. Int. J. Emerg. Technol. 2020, 11, 659–665. [Google Scholar]
- Shrivastava, S.; Jeyanthi, P.M.; Singh, S. Failure prediction of Indian Banks using SMOTE, Lasso regression, bagging and boosting. Cogent Econ. Financ. 2020, 8, 1729569. [Google Scholar] [CrossRef]
- Gunduz, H. An efficient stock market prediction model using hybrid feature reduction method based on variational autoencoders and recursive feature elimination. Financ. Innov. 2021, 7, 28. [Google Scholar] [CrossRef]
- Mavi, A. A New dataset and proposed convolutional neural network architecture for classification of american sign language digits. arXiv 2020, arXiv:2011.08927. [Google Scholar]
- Barczak, A.L.C.; Reyes, N.H.; Abastillas, M.; Piccio, A.; Susnjak, T. A new 2D static hand gesture colour image dataset for ASL gestures. Res. Lett. Inf. Math. Sci 2011, 15, 12–20. [Google Scholar]
- Jacob, J. American Sign Language Dataset. 2022. Available online: https://www.kaggle.com/datasets/joannracheljacob/american-sign-language-dataset (accessed on 18 July 2022).
- Priscilla, C.V.; Prabha, D.P. A two-phase feature selection technique using mutual information and XGB-RFE for credit card fraud detection. Int. J. Adv. Technol. Eng. Explor. 2021, 8, 1656–1668. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Image Dimension | Total Number of Images |
|---|---|---|
| Sign Language Digits Dataset (Dataset 1) | 100 × 100 pixels | 2062 |
| American Sign Language Digit Dataset (Dataset 2) | 400 × 400 pixels | 5000 |
| American Sign Language Dataset-Digits Only (Dataset 3) | 422 × 422 pixels | 12,000 |
| Validation Dataset (Dataset 4) | 1280 × 720 pixels and 640 × 480 pixels (full, uncropped image) 100 × 100 pixels (cropped hand image) | 300 |
| Number of Selected Features | Selected Features (Landmark Points) |
|---|---|
| 15 Features | 1, 2, 3, 4, 7, 8, 11, 12, 14, 15, 16, 17, 18, 19, 20 |
| 10 Features | 2, 3, 4, 8, 11, 12, 15, 16, 19, 20 |
| Dataset | Scenario | Features | ||
|---|---|---|---|---|
| Original 21 Features | 15 Features | 10 Features | ||
| Dataset 1 | Training | 95.05% | 98.41% | 98.30% |
| Testing | 91.70% | 93.40% | 93.40% | |
| Validation | 85.00% | 96.00% | 96.30% | |
| Dataset 2 | Training | 99.70% | 100% | 100% |
| Testing | 100% | 100% | 100% | |
| Validation | 96.30% | 97.00% | 97.00% | |
| Dataset 3 | Training | 99.70% | 99.96% | 99.93% |
| Testing | 98.60% | 98.60% | 98.80% | |
| Validation | 72.30% | 84.7% | 88.30% | |
| CNN | Proposed Approach | ||
|---|---|---|---|
| Input | 100 × 100 pixels image | Ten hand landmarks extracted using Mediapipe | |
| Epoch | 30 | 30 | 100 |
| Batch size | 128 | 512 | 512 |
| Training accuracy | 92.79% | 94.3% | 98.3% |
| Testing accuracy | 100% | 90.8% | 93.40% |
| Training time | 1607 s | 62.1 s * | 198.5 s * |
| Validation accuracy | 57.7% | 95.3% | 96.3% |
| Evaluation time | 2.4 s | 1 s | 1 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, R.-C.; Manongga, W.E.; Dewi, C. Recursive Feature Elimination for Improving Learning Points on Hand-Sign Recognition. Future Internet 2022, 14, 352. https://doi.org/10.3390/fi14120352
Chen R-C, Manongga WE, Dewi C. Recursive Feature Elimination for Improving Learning Points on Hand-Sign Recognition. Future Internet. 2022; 14(12):352. https://doi.org/10.3390/fi14120352
Chicago/Turabian StyleChen, Rung-Ching, William Eric Manongga, and Christine Dewi. 2022. "Recursive Feature Elimination for Improving Learning Points on Hand-Sign Recognition" Future Internet 14, no. 12: 352. https://doi.org/10.3390/fi14120352
APA StyleChen, R.-C., Manongga, W. E., & Dewi, C. (2022). Recursive Feature Elimination for Improving Learning Points on Hand-Sign Recognition. Future Internet, 14(12), 352. https://doi.org/10.3390/fi14120352