
Experimenting with Routing Protocols in the Data Center: An ns-3 Simulation Approach



Abstract
:1. Introduction
2. Background and Related Work
2.1. The Sibyl Framework
2.1.1. Sibyl Fat-Tree Experimentation Tools
- VFTGen [18] automatically generates and configures fat-tree topologies for Sibyl. It takes as input the parameters of a fat-tree.
- Sibyl RT Calculator is a tool for generating the expected forwarding tables of the network nodes of a fat-tree, taking into account the routing protocol (e.g., BGP) and the type of test (e.g., Node Failure).
- Sibyl Analyzer is a tool to analyze the results of the experiments using the packets exchanged by the nodes during an experiment.
2.1.2. The Timing Issue
2.2. Fat Tree Networks
3. FRR Port to ns-3 DCE
3.1. Background on ns-3 and DCE
3.2. Previous Work: Quagga Port
3.3. DCE Extensions to Support FRR
3.4. FRR Extensions to Run over DCE
3.5. Helper Class for Running FRR over DCE
3.6. Fat Tree Generator for ns-3 DCE
4. Validation and Experimental Results
4.1. Functional Evaluation
- Running zebra and BGP in a single node: This scenario allows us to test that FRR with zebra and the chosen routing protocol can be loaded and executed in a node.
- Running zebra and BGP in a network: We implemented some scenarios based on Kathará project labs [32], such as BGP Simple Peering and BGP Prefix Filtering, which permit us to test BGP update propagation and filtering among peers, and BGP Multi-homed Stub, which is a more complex scenario.
- Running other routing protocols: Although our focus is on BGP, all the FRR daemons should run on ns-3 DCE. Therefore, we evaluate running OSPF in the same networks from the previous scenario. It is worth mentioning that no particular change was necessary in the OSPF case, and consequently, we expect that other protocols will also work correctly without the need to make further modifications to the implementation; this is reasonable since, by the architecture of FRR, most of the complexity is contained in the zebra daemon.
4.2. Comparison against Sibyl Framework
4.2.1. Experimental Setup
- Bootstrap: The objective is to study the standard behavior of the protocol in the topology when it is started, without any failure.
- Node Failure: This test case is used both to verify that BGP converges after a switch failure, and also to count the number of PDUs that the protocol exchanged for that purpose. The fault can be introduced in any type of switch in the topology, that is, Leaf, Spine or Tof. It is done by shutting down the BGP daemon on the given switch.
- Node Recovery: In this test case, the objective is to count the number of PDUs exchanged by the switches, after one of them fails and is replaced by a new one. Like the previous case, this case can be run on a Leaf, Spine, or Tof. We implement this case by raising the topology without running BGP on the node in question, we wait for it to converge and then we start BGP. This is equivalent to crashing the node and then starting it again.
- Link Failure: This case also has two goals. On the one hand, to verify BGP convergence after a link failure, and on the other hand, to count the number of PDUs for this purpose. The test can be run for both the Leaf–Spine link case and the Spine–Tof link case, simply by pulling down a given interface.
- Link Recovery: This case counts the number of PDUs after a failed link is replaced. That is, the simulation is started and the protocol is expected to converge. Link failure is then caused and the protocol is again expected to converge. Finally, the link is recovered and the new convergence is expected. The number of PDUs that are taken into account are those exchanged in this last phase.
- x is the k_leaf parameter.
- y is the k_top parameter.
- z is the redundancy parameter.
- case represents the test case, which can be link-failure, link-recovery, node-failure, or node-recovery.
- level depends on the case:- If the case is link-failure or link-recovery, level can be leaf-spine or spine-tof, referencing the level where link failure or recovery occurred.- If the case is node-failure or node-recovery, level can be leaf, spine or tof, referencing the level where the failure or recovery of the node occurred.
4.2.2. Execution Environment
- Bootstrap: 10 s.
- Node-failure and link-failure: 20 s. This time allows for the bootstrap to finish and converge, produce the failure in the node or link and then wait again for convergence.
- Node-recovery and link-recovery: 30 s. In this case, after the failure and the convergence, the node or link is recovered and we have to wait again for convergence.
4.2.3. Results
4.3. Theoretical Analysis of BGP Behavior over Selected Scenarios
4.3.1. Case Spine Node Failure
- First note that each leaf needs connectivity information for prefixes; while prefixes are “foreign”, the remaining one is directly connected. When the fails occurs, in the PoD of the fail there are leaf nodes aware of the failure. The BGP process of each leaf node will recalculate the routes and will notice that for every known prefix, one possible next-hop is missing. Consequently, it will send, for each known prefix, a BGP update with the next-hop attribute updated. Thus, we have leafs sending packets (the total number of prefixes in the fabric which have lost a next-hop) through their links. Consequently, the total amount of BGP packets in the PoD of the failure equals .
- The rest of the PoDs learn about the failure through the spine connected to the same plane as the faulty spine, through the corresponding core switch. This spine sends a BGP withdraw containing all the prefixes no longer reachable through the corresponding core switch (all the prefixes inside the PoD with the failure) to all its neighbors ( leaves in this PoD). After that, each leaf recalculate its routes and notice that each prefix received in the withdraw are no longer reachable through one of its next hops. Consequently, it will send, for each of these prefixes, a BGP update to all its neighbors ( spines). Consequently, the total amount of BGP packets in each PoD without a failure equals .
- The faulty spine was connected to core switches. Because the topology considered is multi-plane with , these core nodes have exactly one link with each PoD. After the failure, each core connected with the faulty spine have no longer reachability to the prefixes of the corresponding PoD, and it must send a BGP withdraw for the prefixes of such PoD to all its neighbors ( spines). After that, when a spine connected to these cores receives the withdraw from all of them, it will notice that it no longer has reachability to the prefixes of the given PoD, and it will send the correspondent withdraw upstream to the cores; therefore, a total of two BGP packets traverse every core–spine link. In effect, we have cores, which send and receive one BGP withdraw through all their “live” interfaces (). Consequently, the total amount of BGP packets in the core–spine links equals packets.
4.3.2. Case Leaf Node Failure
5. Performance Analysis
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Number | Execution | PDUs | Execution | PDUs | PDUs |
|---|---|---|---|---|---|---|
| of Nodes | Time | ns-3 | Time | ns-3 | Sibyl | |
| w/o Zebra | w/o Zebra | w Zebra | w Zebra | |||
| 2_2_1_link-failure-leaf-spine | 20 | 1:07.19 | 44 | 1:18.73 | 44 | - |
| 2_2_1_link-failure-spine-tof | 20 | 0:53.28 | 45 | 1:30.77 | 45 | - |
| 2_2_1_link-recovery-leaf-spine | 20 | 0:54.39 | 69 | 1:20.07 | 69 | - |
| 2_2_1_link-recovery-spine-tof | 20 | 1:04.59 | 72 | 1:40.31 | 72 | - |
| 2_2_1_node-failure-leaf | 20 | 0:59.59 | 60 | 1:24.61 | 60 | 60 |
| 2_2_1_node-failure-spine | 20 | 1:01.74 | 56 | 1:40.42 | 56 | - |
| 2_2_1_node-failure-tof | 20 | 1:02.40 | 72 | 1:21.33 | 72 | - |
| 2_2_1_node-recovery-leaf | 20 | 0:52.62 | 96 | 1:03.42 | 96 | - |
| 2_2_1_node-recovery-spine | 20 | 0:58.33 | 160 | 1:50.73 | 160 | - |
| 2_2_1_node-recovery-tof | 20 | 0:55.88 | 168 | 1:19.57 | 168 | - |
| 2_2_2_link-failure-leaf-spine | 10 | 0:37.19 | 16 | 0:46.51 | 16 | - |
| 2_2_2_link-failure-spine-tof | 10 | 0:30.20 | 12 | 0:52.36 | 12 | - |
| 2_2_2_link-recovery-leaf-spine | 10 | 0:33.69 | 29 | 0:32.79 | 29 | - |
| 2_2_2_link-recovery-spine-tof | 10 | 0:32.03 | 26 | 0:32.48 | 24 | - |
| 2_2_2_node-failure-leaf | 10 | 0:34.74 | 28 | 0:50.99 | 28 | 28 |
| 2_2_2_node-failure-spine | 10 | 0:32.22 | 18 | 0:36.68 | 18 | - |
| 2_2_2_node-failure-tof | 10 | 0:34.83 | 24 | 0:50.47 | 24 | - |
| 2_2_2_node-recovery-leaf | 10 | 0:32.05 | 48 | 0:48.94 | 48 | - |
| 2_2_2_node-recovery-spine | 10 | 0:34.10 | 68 | 0:47.40 | 68 | - |
| 2_2_2_node-recovery-tof | 10 | 0:35.70 | 72 | 0:32.06 | 72 | - |
| 4_4_1_link-failure-leaf-spine | 80 | 4:15.53 | 312 | 5:23.27 | 312 | - |
| 4_4_1_link-failure-spine-tof | 80 | 4:15.09 | 427 | 5:10.87 | 427 | - |
| 4_4_1_link-recovery-leaf-spine | 80 | 4:37.03 | 409 | 5:49.97 | 409 | - |
| 4_4_1_link-recovery-spine-tof | 80 | 4:23.28 | 542 | 5:33.42 | 542 | - |
| 4_4_1_node-failure-leaf | 80 | 4:12.73 | 504 | 5:17.12 | 504 | 504 |
| 4_4_1_node-failure-spine | 80 | 4:28.11 | 1128 | 5:57.28 | 904 | - |
| 4_4_1_node-failure-tof | 80 | 4:14.70 | 1568 | 5:39.91 | 1568 | - |
| 4_4_1_node-recovery-leaf | 80 | 4:31.55 | 768 | 6:09.64 | 768 | - |
| 4_4_1_node-recovery-spine | 80 | 4:13.09 | 1808 | 6:00.58 | 1808 | - |
| 4_4_1_node-recovery-tof | 80 | 4:16.72 | 2320 | 6:11.65 | 2320 | - |
| 4_4_2_link-failure-leaf-spine | 40 | 2:11.22 | 96 | 3:03.51 | 96 | - |
| 4_4_2_link-failure-spine-tof | 40 | 2:07.43 | 112 | 3:15.35 | 112 | - |
| 4_4_2_link-recovery-leaf-spine | 40 | 2:20.26 | 145 | 3:29.08 | 145 | - |
| 4_4_2_link-recovery-spine-tof | 40 | 2:07.44 | 162 | 3:10.86 | 162 | - |
| 4_4_2_node-failure-leaf | 40 | 2:10.24 | 248 | 3:08.23 | 248 | 248 |
| 4_4_2_node-failure-spine | 40 | 2:13.89 | 292 | 3:00.28 | 292 | - |
| 4_4_2_node-failure-tof | 40 | 2:06.92 | 672 | 2:59.16 | 672 | - |
| 4_4_2_node-recovery-leaf | 40 | 2:09.55 | 384 | 3:11.17 | 384 | - |
| 4_4_2_node-recovery-spine | 40 | 2:11.83 | 640 | 3:11.03 | 640 | - |
| 4_4_2_node-recovery-tof | 40 | 2:00.63 | 1040 | 3:22.35 | 1040 | - |
| 4_4_4_link-failure-leaf-spine | 20 | 1:05.64 | 72 | 1:16.44 | 72 | - |
| 4_4_4_link-failure-spine-tof | 20 | 1:03.96 | 56 | 1:31.83 | 56 | - |
| 4_4_4_link-recovery-leaf-spine | 20 | 1:12.47 | 97 | 1:19.03 | 97 | - |
| 4_4_4_link-recovery-spine-tof | 20 | 1:10.85 | 78 | 1:32.06 | 78 | - |
| 4_4_4_node-failure-leaf | 20 | 0:58.07 | 120 | 1:44.26 | 120 | 120 |
| 4_4_4_node-failure-spine | 20 | 1:08.24 | 196 | 0:59.93 | 196 | - |
| 4_4_4_node-failure-tof | 20 | 1:07.31 | 224 | 1:30.04 | 224 | - |
| 4_4_4_node-recovery-leaf | 20 | 1:03.67 | 192 | 1:15.28 | 192 | - |
| 4_4_4_node-recovery-spine | 20 | 1:09.48 | 384 | 1:49.51 | 384 | - |
| 4_4_4_node-recovery-tof | 20 | 1:06.60 | 400 | 0:59.46 | 400 | - |
| 6_6_1_link-failure-leaf-spine | 180 | 10:42.61 | 996 | 14:40.34 | 996 | 996 |
| 6_6_1_link-failure-spine-tof | 180 | 10:27.84 | 1529 | 14:17.19 | 1529 | 1529, 1577 |
| 6_6_1_link-recovery-leaf-spine | 180 | 11:11.31 | 1213 | 15:53.67 | 1213 | 1069, 1238 |
| 6_6_1_link-recovery-spine-tof | 180 | 10:55.97 | 1796 | 16:14.04 | 1796 | 1657, 1796 |
| 6_6_1_node-failure-leaf | 180 | 10:41.58 | 1716 | 13:52.94 | 1716 | 1716, 1734 |
| 6_6_1_node-failure-spine | 180 | 10:12.82 | 4704 | 15:13.56 | 4704 | 4704, 4726 |
| 6_6_1_node-failure-tof | 180 | 10:19.49 | 8712 | 14:31.77 | 8712 | 8712, 8808 |
| 6_6_1_node-recovery-leaf | 180 | 10:38.73 | 2592 | 14:44.55 | 2592 | 2592, 3444 |
| 6_6_1_node-recovery-spine | 180 | 10:23.92 | 7872 | 15:32.47 | 7872 | 8686, 9362 |
| 6_6_1_node-recovery-tof | 180 | 9:56.09 | 11,256 | 14:51.07 | 11,256 | 11,190, 11,316 |
| 6_6_2_link-failure-leaf-spine | 90 | 5:08.22 | 288 | 7:25.55 | 288 | 288, 358 |
| 6_6_2_link-failure-spine-tof | 90 | 5:03.01 | 396 | 7:19.56 | 396 | 396, 456 |
| 6_6_2_link-recovery-leaf-spine | 90 | 5:26.72 | 397 | 7:34.14 | 397 | 325, 397 |
| 6_6_2_link-recovery-spine-tof | 90 | 5:26.11 | 500 | 7:43.13 | 500 | 439, 506 |
| 6_6_2_node-failure-leaf | 90 | 5:16.17 | 852 | 7:12.16 | 852 | 852, 858 |
| 6_6_2_node-failure-spine | 90 | 5:09.56 | 1446 | 8:01.95 | 1446 | 1446 |
| 6_6_2_node-failure-tof | 90 | 5:05.01 | 3960 | 7:21.65 | 3960 | 3960 |
| 6_6_2_node-recovery-leaf | 90 | 4:49.43 | 1296 | 7:27.46 | 1296 | 1296, 1926 |
| 6_6_2_node-recovery-spine | 90 | 5:09.29 | 2580 | 7:21.40 | 2580 | 2916, 3247 |
| 6_6_2_node-recovery-tof | 90 | 5:13.78 | 5208 | 7:29.28 | 5208 | 5208, 5310 |
| 6_6_3_link-failure-leaf-spine | 60 | 3:13.01 | 228 | 5:07.65 | 228 | 228 |
| 6_6_3_link-failure-spine-tof | 60 | 3:32.99 | 264 | 4:34.69 | 264 | 264 |
| 6_6_3_link-recovery-leaf-spine | 60 | 3:31.02 | 301 | 5:07.55 | 301 | 253, 301 |
| 6_6_3_link-recovery-spine-tof | 60 | 3:46.15 | 332 | 5:25.22 | 332 | 295, 338 |
| 6_6_3_node-failure-leaf | 60 | 3:28.60 | 564 | 5:30.40 | 564 | 562, 564 |
| 6_6_3_node-failure-spine | 60 | 3:27.40 | 1086 | 4:29.95 | 1086 | 1086 |
| 6_6_3_node-failure-tof | 60 | 3:32.06 | 2376 | 4:37.03 | 2376 | 2376, 2942 |
| 6_6_3_node-recovery-leaf | 60 | 3:26.27 | 864 | 4:54.17 | 864 | 864, 1002 |
| 6_6_3_node-recovery-spine | 60 | 3:24.86 | 1860 | 5:41.32 | 1860 | 1836, 2413 |
| 6_6_3_node-recovery-tof | 60 | 3:25.22 | 3192 | 5:08.39 | 3192 | 3354, 3450 |
| 6_6_6_link-failure-leaf-spine | 30 | 1:46.37 | 168 | 2:14.63 | 168 | 168, 541 |
| 6_6_6_link-failure-spine-tof | 30 | 1:44.24 | 132 | 2:37.48 | 132 | 132 |
| 6_6_6_link-recovery-leaf-spine | 30 | 1:48.37 | 205 | 2:29.47 | 205 | 181, 205 |
| 6_6_6_link-recovery-spine-tof | 30 | 1:47.56 | 164 | 2:32.80 | 164 | 151, 170 |
| 6_6_6_node-failure-leaf | 30 | 1:43.67 | 276 | 2:26.95 | 276 | 276 |
| 6_6_6_node-failure-spine | 30 | 1:47.86 | 726 | 2:39.75 | 726 | 726 |
| 6_6_6_node-failure-tof | 30 | 1:44.04 | 792 | 2:29.69 | 792 | 792 |
| 6_6_6_node-recovery-leaf | 30 | 1:42.01 | 432 | 3:08.22 | 432 | 432 |
| 6_6_6_node-recovery-spine | 30 | 1:46.04 | 1140 | 2:28.39 | 1140 | 1104, 1182 |
| 6_6_6_node-recovery-tof | 30 | 1:45.79 | 1176 | 2:28.30 | 1176 | 1176 |
| 8_8_1_link-failure-leaf-spine | 320 | 21:56.54 | 2288 | 29:13.19 | 2288 | 2288 |
| 8_8_1_link-failure-spine-tof | 320 | 20:06.32 | 3735 | 29:26.26 | 3735 | 3743 |
| 8_8_1_link-recovery-leaf-spine | 320 | 22:56.82 | 2673 | 35:14.27 | 2673 | 2417 |
| 8_8_1_link-recovery-spine-tof | 320 | 22:28.77 | 4218 | 34:43.00 | 4218 | 4218 |
| 8_8_1_node-failure-leaf | 320 | 21:16.01 | 4080 | 30:44.58 | 4080 | 4076, 4080, 4088 |
| 8_8_1_node-failure-spine | 320 | 21:12.30 | 15,152 | 30:26.00 | 15,152 | 15,152, 15,197 |
| 8_8_1_node-failure-tof | 320 | 20:56.05 | 28,800 | 28:37.21 | 28,800 | 28,958, 29,058 |
| 8_8_1_node-recovery-leaf | 320 | 21:26.21 | 6144 | 33:47.08 | 6144 | 8172, 10,228 |
| 8_8_1_node-recovery-spine | 320 | 21:09.10 | 22,816 | 31:55.63 | 22,816 | 22,848 |
| 8_8_1_node-recovery-tof | 320 | 21:26.99 | 34,848 | 30:46.45 | 34,848 | 34,622, 35,076 |
| 8_8_2_link-failure-leaf-spine | 160 | 9:51.76 | 640 | 15:02.54 | 640 | 640 |
| 8_8_2_link-failure-spine-tof | 160 | 9:52.78 | 960 | 14:14.68 | 960 | 960 |
| 8_8_2_link-recovery-leaf-spine | 160 | 10:59.49 | 833 | 16:07.96 | 833 | 705, 855 |
| 8_8_2_link-recovery-spine-tof | 160 | 10:33.65 | 1146 | 14:20.73 | 1146 | 1033, 1154 |
| 8_8_2_node-failure-leaf | 160 | 10:28.93 | 2032 | 14:30.95 | 2032 | 2028, 2032 |
| 8_8_2_node-failure-spine | 160 | 9:56.79 | 4488 | 14:38.23 | 4488 | 4488, 4510 |
| 8_8_2_node-failure-tof | 160 | 10:18.38 | 13,440 | 14:32.53 | 13,440 | 13,440, 13,680 |
| 8_8_2_node-recovery-leaf | 160 | 10:15.41 | 3072 | 15:36.29 | 3072 | 4584 |
| 8_8_2_node-recovery-spine | 160 | 10:05.70 | 7136 | 14:24.24 | 7136 | 7104, 10,439 |
| 8_8_2_node-recovery-tof | 160 | 9:38.98 | 16,416 | 13:43.01 | 16,416 | 16,599, 16,832 |
| 8_8_4_link-failure-leaf-spine | 80 | 4:53.83 | 416 | 7:01.98 | 416 | 416, 447 |
| 8_8_4_link-failure-spine-tof | 80 | 4:51.56 | 480 | 7:02.12 | 480 | 480 |
| 8_8_4_link-recovery-leaf-spine | 80 | 5:18.90 | 513 | 7:16.01 | 513 | 449, 513 |
| 8_8_4_link-recovery-spine-tof | 80 | 5:14.52 | 570 | 7:09.06 | 570 | 521, 578 |
| 8_8_4_node-failure-leaf | 80 | 5:06.75 | 1008 | 6:52.72 | 1008 | 1008, 1024 |
| 8_8_4_node-failure-spine | 80 | 5:02.55 | 2696 | 6:27.52 | 2696 | 2696 |
| 8_8_4_node-failure-tof | 80 | 4:59.97 | 5760 | 6:39.84 | 5760 | 5760 |
| 8_8_4_node-recovery-leaf | 80 | 4:57.09 | 1536 | 6:42.37 | 1536 | 1784, 2278 |
| 8_8_4_node-recovery-spine | 80 | 4:52.50 | 4064 | 7:18.56 | 4064 | 4400, 4802 |
| 8_8_4_node-recovery-tof | 80 | 5:04.17 | 7200 | 6:54.38 | 7200 | 7200 |
| 8_8_8_link-failure-leaf-spine | 40 | 2:31.42 | 304 | 3:19.37 | 304 | 304 |
| 8_8_8_link-failure-spine-tof | 40 | 2:02.31 | 240 | 3:03.47 | 240 | 240 |
| 8_8_8_link-recovery-leaf-spine | 40 | 2:04.05 | 353 | 3:59.65 | 353 | 321, 353 |
| 8_8_8_link-recovery-spine-tof | 40 | 1:54.87 | 282 | 3:36.25 | 282 | 265, 290 |
| 8_8_8_node-failure-leaf | 40 | 2:05.69 | 496 | 3:45.87 | 496 | 496 |
| 8_8_8_node-failure-spine | 40 | 1:56.52 | 1800 | 3:30.05 | 1800 | 1800 |
| 8_8_8_node-failure-tof | 40 | 2:16.27 | 1920 | 3:16.83 | 1920 | 1920 |
| 8_8_8_node-recovery-leaf | 40 | 2:07.44 | 768 | 3:48.72 | 768 | 768, 888 |
| 8_8_8_node-recovery-spine | 40 | 2:21.66 | 2528 | 3:23.44 | 2528 | 2613, 2856 |
| 8_8_8_node-recovery-tof | 40 | 2:09.00 | 2592 | 3:43.65 | 2592 | 2592, 2960 |
| 10_10_1_link-failure-leaf-spine | 500 | 43:21.57 | 4380 | 53:33.93 | 4380 | - |
| 10_10_1_link-failure-spine-tof | 500 | 35:48.74 | 7429 | 52:05.10 | 7429 | - |
| 10_10_1_link-recovery-leaf-spine | 500 | 40:25.85 | 4981 | 1:03:15 | 4981 | - |
| 10_10_1_link-recovery-spine-tof | 500 | 38:10.10 | 8192 | 59:07.93 | 8192 | - |
| 10_10_1_node-failure-leaf | 500 | 36:31.21 | 7980 | 54:41.84 | 7980 | 7980 |
| 10_10_1_node-failure-spine | 500 | 37:16.85 | 37,480 | 53:23.76 | 37,480 | 18,390 |
| 10_10_1_node-failure-tof | 500 | 35:52.55 | 72,200 | 55:32.04 | 72,200 | 36,072 |
| 10_10_1_node-recovery-leaf | 500 | 40:15.09 | 12,000 | 55:27.11 | 12,000 | - |
| 10_10_1_node-recovery-spine | 500 | 36:11.80 | 52,640 | 58:46.43 | 52,640 | - |
| 10_10_1_node-recovery-tof | 500 | 37:35.48 | 84,040 | 54:39.94 | 84,040 | - |
| 10_10_2_link-failure-leaf-spine | 250 | 16:59.57 | 1200 | 23:04.10 | 1200 | 1200 |
| 10_10_2_link-failure-spine-tof | 250 | 17:04.08 | 1900 | 26:00.38 | 1900 | 1900 |
| 10_10_2_link-recovery-leaf-spine | 250 | 18:30.72 | 1501 | 26:21.99 | 1501 | 1301, 1501 |
| 10_10_2_link-recovery-spine-tof | 250 | 18:25.44 | 2192 | 27:09.12 | 2192 | 2011, 2202 |
| 10_10_2_node-failure-leaf | 250 | 17:31.08 | 3980 | 24:08.59 | 3980 | 3980, 3996 |
| 10_10_2_node-failure-spine | 250 | 16:21.09 | 10,810 | 23:40.49 | 10,810 | 10,810, 10,833 |
| 10_10_2_node-failure-tof | 250 | 16:44.71 | 34,200 | 23:44.88 | 34,200 | 34,527, 34,788 |
| 10_10_2_node-recovery-leaf | 250 | 17:46.35 | 6000 | 25:01.38 | 6000 | 6000, 7976 |
| 10_10_2_node-recovery-spine | 250 | 16:41.62 | 15,940 | 24:22.66 | 15,940 | 15,661, 19,401 |
| 10_10_2_node-recovery-tof | 250 | 17:13.10 | 40,040 | 24:49.72 | 40,040 | 41,188, 41,667 |
| 10_10_5_link-failure-leaf-spine | 100 | 6:22.98 | 660 | 8:42.60 | 660 | 660 |
| 10_10_5_link-failure-spine-tof | 100 | 6:14.27 | 760 | 8:32.91 | 760 | 760, 820 |
| 10_10_5_link-recovery-leaf-spine | 100 | 6:52.48 | 781 | 9:46.89 | 781 | 701, 781 |
| 10_10_5_link-recovery-spine-tof | 100 | 6:52.53 | 872 | 10:36.91 | 872 | 811, 882 |
| 10_10_5_node-failure-leaf | 100 | 6:43.43 | 1580 | 8:57.90 | 1580 | 1580 |
| 10_10_5_node-failure-spine | 100 | 6:41.49 | 5410 | 8:41.55 | 5410 | 5410 |
| 10_10_5_node-failure-tof | 100 | 6:34.09 | 11,400 | 8:57.93 | 11,400 | 11,544, 11,550 |
| 10_10_5_node-recovery-leaf | 100 | 6:31.91 | 2400 | 9:57.73 | 2400 | 3180, 2790 |
| 10_10_5_node-recovery-spine | 100 | 6:39.00 | 7540 | 9:25.65 | 7540 | 7510, 7490 |
| 10_10_5_node-recovery-tof | 100 | 6:38.31 | 13,640 | 9:25.54 | 13,640 | 14,798, 15,178 |
| 10_10_10_link-failure-leaf-spine | 50 | 3:09.21 | 480 | 4:35.08 | 480 | 480 |
| 10_10_10_link-failure-spine-tof | 50 | 3:14.54 | 380 | 4:21.50 | 380 | 380 |
| 10_10_10_link-recovery-leaf-spine | 50 | 3:31.83 | 541 | 5:10.14 | 541 | 501, 541 |
| 10_10_10_link-recovery-spine-tof | 50 | 3:15.08 | 432 | 4:37.93 | 432 | 411, 442 |
| 10_10_10_node-failure-leaf | 50 | 3:13.24 | 780 | 4:22.19 | 780 | 780 |
| 10_10_10_node-failure-spine | 50 | 3:11.36 | 3610 | 4:14.41 | 3610 | 3610 |
| 10_10_10_node-failure-tof | 50 | 3:12.86 | 3800 | 4:25.57 | 3800 | 3800 |
| 10_10_10_node-recovery-leaf | 50 | 3:11.31 | 1200 | 4:31.73 | 1200 | 1580, 1582 |
| 10_10_10_node-recovery-spine | 50 | 3:02.23 | 4740 | 5:03.15 | 4740 | 4670, 4710 |
| 10_10_10_node-recovery-tof | 50 | 3:08.48 | 4840 | 4:46.55 | 4840 | 4840, 5540 |
| 12_12_1_link-failure-leaf-spine | 720 | 1:37:58 | 7464 | not enough vRAM | - | |
| 12_12_1_link-failure-spine-tof | 720 | 1:19:03 | 12,995 | not enough vRAM | - | |
| 12_12_1_link-recovery-leaf-spine | 720 | 1:28:55 | 8329 | not enough vRAM | - | |
| 12_12_1_link-recovery-spine-tof | 720 | 1:24:22 | 14,102 | not enough vRAM | - | |
| 12_12_1_node-failure-leaf | 720 | 1:22:40 | 17,244 | not enough vRAM | 13,800 | |
| 12_12_1_node-failure-spine | 720 | 1:19:23 | 78,456 | not enough vRAM | - | |
| 12_12_1_node-failure-tof | 720 | 1:19:27 | 152,352 | not enough vRAM | - | |
| 12_12_1_node-recovery-leaf | 720 | 1:20:34 | 20,736 | not enough vRAM | - | |
| 12_12_1_node-recovery-spine | 720 | 1:20:01 | 104,880 | not enough vRAM | - | |
| 12_12_1_node-recovery-tof | 720 | 1:21:15 | 172,848 | not enough vRAM | - | |
| 12_12_3_link-failure-leaf-spine | 240 | 19:05.59 | 1488 | 25:35.76 | 1488 | 1488 |
| 12_12_3_link-failure-spine-tof | 240 | 19:54.03 | 2208 | 25:56.47 | 2208 | 2208 |
| 12_12_3_link-recovery-leaf-spine | 240 | 21:26.32 | 1777 | 29:01.01 | 1777 | 1585, 1777 |
| 12_12_3_link-recovery-spine-tof | 240 | 20:56.25 | 2486 | 28:28.63 | 2486 | 2317, 2498 |
| 12_12_3_node-failure-leaf | 240 | 19:53.39 | 5724 | 28:19.25 | 4584 | 4580, 4584, 4628 |
| 12_12_3_node-failure-spine | 240 | 19:28.09 | 15,852 | 26:19.43 | 15,852 | 15,929, 16,002 |
| 12_12_3_node-failure-tof | 240 | 19:12.64 | 46,368 | 26:11.43 | 463,68 | 47,227, 57,292 |
| 12_12_3_node-recovery-leaf | 240 | 19:48.84 | 6912 | 26:56.88 | 6912 | 8052, 11,514 |
| 12_12_3_node-recovery-spine | 240 | 19:21.35 | 21,792 | 28:02.68 | 21,792 | 21,797, 23,710, 29,768 |
| 12_12_3_node-recovery-tof | 240 | 19:31.33 | 53,040 | 26:09.66 | 53,040 | 53,926, 54,024 |
| 12_12_4_link-failure-leaf-spine | 180 | 14:05.84 | 1224 | 18:58.75 | 1224 | 1224 |
| 12_12_4_link-failure-spine-tof | 180 | 13:44.66 | 1656 | 18:52.29 | 1656 | 1656, 1680 |
| 12_12_4_link-recovery-leaf-spine | 180 | 14:55.32 | 1441 | 21:11.28 | 1441 | 1297, 1441 |
| 12_12_4_link-recovery-spine-tof | 180 | 15:11.86 | 1862 | 21:08.28 | 1862 | 1741, 1874 |
| 12_12_4_node-failure-leaf | 180 | 14:28.07 | 3852 | 19:42.57 | 3432 | 3430, 3432 |
| 12_12_4_node-failure-spine | 180 | 14:28.08 | 12,684 | 19:42.68 | 12,684 | 12,763, 12,775 |
| 12_12_4_node-failure-tof | 180 | 13:56.64 | 33,120 | 19:12.50 | 33,120 | 33,930, 34,800 |
| 12_12_4_node-recovery-leaf | 180 | 14:16.45 | 5184 | 19:31.86 | 5184 | 5184 |
| 12_12_4_node-recovery-spine | 180 | 13:50.67 | 17,184 | 20:41.04 | 17,184 | - |
| 12_12_4_node-recovery-tof | 180 | 14:33.37 | 38,064 | 19:19.03 | 38,064 | 38,979, 39,312 |
| 12_12_6_link-failure-leaf-spine | 120 | 9:39.02 | 960 | 12:19.99 | 960 | 960, 983 |
| 12_12_6_link-failure-spine-tof | 120 | 8:50.37 | 1104 | 12:47.93 | 1104 | 1104 |
| 12_12_6_link-recovery-leaf-spine | 120 | 10:03.56 | 1105 | 14:16.49 | 1105 | 1009, 1105 |
| 12_12_6_link-recovery-spine-tof | 120 | 10:04.93 | 1238 | 13:47.75 | 1238 | 1165, 1250 |
| 12_12_6_node-failure-leaf | 120 | 9:44.62 | 2700 | 12:41.80 | 2280 | 2278, 2280, 2292 |
| 12_12_6_node-failure-spine | 120 | 9:32.30 | 9516 | 12:41.86 | 9516 | 9516, 9589 |
| 12_12_6_node-failure-tof | 120 | 9:35.47 | 19,872 | 12:30.12 | 19,872 | 20,580, 20,712 |
| 12_12_6_node-recovery-leaf | 120 | 9:15.39 | 3456 | 12:37.12 | 3456 | 3456, 5146 |
| 12_12_6_node-recovery-spine | 120 | 9:27.34 | 12,576 | 13:25.55 | 12,576 | 12,514, 15,936 |
| 12_12_6_node-recovery-tof | 120 | 9:09.30 | 23,088 | 12:53.84 | 23,088 | 23,352, 23,625 |
| 12_12_12_link-failure-leaf-spine | 60 | 4:14.67 | 696 | 5:56.28 | 696 | 696 |
| 12_12_12_link-failure-spine-tof | 60 | 4:04.78 | 552 | 6:10.82 | 552 | 552 |
| 12_12_12_link-recovery-leaf-spine | 60 | 4:41.71 | 769 | 6:56.05 | 769 | 721, 769 |
| 12_12_12_link-recovery-spine-tof | 60 | 4:38.93 | 614 | 6:57.11 | 614 | 589, 626 |
| 12_12_12_node-failure-leaf | 60 | 4:25.29 | 1548 | 6:18.81 | 1128 | 1128 |
| 12_12_12_node-failure-spine | 60 | 4:12.53 | 6348 | 6:08.16 | 6348 | 6348 |
| 12_12_12_node-failure-tof | 60 | 4:11.17 | 6624 | 6:25.72 | 6624 | 6624 |
| 12_12_12_node-recovery-leaf | 60 | 4:22.37 | 1728 | 6:15.41 | 1728 | 1728 |
| 12_12_12_node-recovery-spine | 60 | 4:24.15 | 7968 | 6:31.74 | 7968 | 8162, 9469 |
| 12_12_12_node-recovery-tof | 60 | 4:23.12 | 8112 | 6:25.38 | 8112 | 8112, 8676 |
| 14_14_1_link-failure-leaf-spine | 980 | 2:42:23 | 11,732 | not enough vRAM | - | |
| 14_14_1_link-failure-spine-tof | 980 | 2:32:38 | 20,817 | not enough vRAM | - | |
| 14_14_1_link-recovery-leaf-spine | 980 | 2:40:38 | 12,909 | not enough vRAM | - | |
| 14_14_1_link-recovery-spine-tof | 980 | 2:39:26 | 22,332 | not enough vRAM | - | |
| 14_14_1_node-failure-leaf | 980 | 2:41:23 | 27,398 | not enough vRAM | 21,924 | |
| 14_14_1_node-failure-spine | 980 | 2:40:11 | 146,384 | not enough vRAM | - | |
| 14_14_1_node-failure-tof | 980 | 2:32:28 | 285,768 | not enough vRAM | - | |
| 14_14_1_node-recovery-leaf | 980 | 2:40:42 | 32,928 | not enough vRAM | - | |
| 14_14_1_node-recovery-spine | 980 | 2:42:50 | 188,608 | not enough vRAM | - | |
| 14_14_1_node-recovery-tof | 980 | 2:36:31 | 318,360 | not enough vRAM | - | |
| 14_14_2_link-failure-leaf-spine | 490 | 54:43.59 | 3136 | 59:22.85 | 3136 | - |
| 14_14_2_link-failure-spine-tof | 490 | 52:49.34 | 5292 | 58:15.27 | 5292 | - |
| 14_14_2_link-recovery-leaf-spine | 490 | 56:43.90 | 3725 | 1:02:30 | 3725 | - |
| 14_14_2_link-recovery-spine-tof | 490 | 56:29.84 | 5882 | 1:00:44 | 5882 | - |
| 14_14_2_node-failure-leaf | 490 | 54:45.50 | 14,070 | 1:01:33 | 14,070 | 10,948 |
| 14_14_2_node-failure-spine | 490 | 52:58.71 | 40,782 | 57:15.31 | 40,782 | - |
| 14_14_2_node-failure-tof | 490 | 53:31.63 | 137,592 | 57:16.83 | 13,7592 | - |
| 14_14_2_node-recovery-leaf | 490 | 53:24.08 | 16,464 | 57:33.53 | 16,464 | - |
| 14_14_2_node-recovery-spine | 490 | 53:23.65 | 54,740 | 59:57.35 | 54,740 | - |
| 14_14_2_node-recovery-tof | 490 | 54:33.18 | 15,3720 | 58:34.59 | 153,720 | - |
| 14_14_7_link-failure-leaf-spine | 140 | 12:01.43 | 1316 | 19:57.69 | 1316 | 1336 |
| 14_14_7_link-failure-spine-tof | 140 | 11:36.53 | 1512 | 18:12.65 | 1512 | 1512, 1635 |
| 14_14_7_link-recovery-leaf-spine | 140 | 12:29.71 | 1485 | 21:14.82 | 1485 | 1373, 1485 |
| 14_14_7_link-recovery-spine-tof | 140 | 12:07.47 | 1668 | 20:51.26 | 1668 | 1583, 1682 |
| 14_14_7_node-failure-leaf | 140 | 12:13.42 | 3878 | 19:14.01 | 3108 | 3108, 3150 |
| 14_14_7_node-failure-spine | 140 | 12:02.30 | 15,302 | 19:24.98 | 15,302 | 15,374 |
| 14_14_7_node-failure-tof | 140 | 11:36.70 | 31,752 | 20:30.41 | 31,752 | 32,988, 32,990 |
| 14_14_7_node-recovery-leaf | 140 | 11:37.59 | 4704 | 20:36.14 | 4704 | 5470, 7014 |
| 14_14_7_node-recovery-spine | 140 | 11:53.92 | 19,460 | 19:59.21 | 19,460 | 21,484, 24,662 |
| 14_14_7_node-recovery-tof | 140 | 11:45.48 | 36,120 | 19:06.72 | 36,120 | 37,967, 39,645 |
| 14_14_14_link-failure-leaf-spine | 70 | 5:20.93 | 952 | 9:06.52 | 952 | 952 |
| 14_14_14_link-failure-spine-tof | 70 | 5:16.32 | 756 | 9:00.30 | 756 | 756 |
| 14_14_14_link-recovery-leaf-spine | 70 | 5:50.10 | 1037 | 10:22.86 | 1037 | 981, 1037 |
| 14_14_14_link-recovery-spine-tof | 70 | 5:44.78 | 828 | 10:41.18 | 828 | 799, 842 |
| 14_14_14_node-failure-leaf | 70 | 5:30.51 | 2114 | 9:50.42 | 1540 | 1540, 1552, 1554 |
| 14_14_14_node-failure-spine | 70 | 5:39.92 | 10,206 | 10:21.86 | 10,206 | 10,206, 10,308, 10,350 |
| 14_14_14_node-failure-tof | 70 | 5:32.21 | 10,584 | 9:21.20 | 10,584 | 10,570, 10,584 |
| 14_14_14_node-recovery-leaf | 70 | 5:19.37 | 2352 | 10:15.21 | 2352 | 2730 |
| 14_14_14_node-recovery-spine | 70 | 5:32.34 | 12,404 | 10:15.31 | 12,404 | 12,580, 13,024 |
| 14_14_14_node-recovery-tof | 70 | 5:50.77 | 12,600 | 9:44.88 | 12,600 | 14,406, 14,574 |
| 15_15_1_link-failure-leaf-spine | 1125 | 6:49:52 | 14,370 | not enough vRAM | - | |
| 15_15_1_link-failure-spine-tof | 1125 | 5:10:04 | 25,694 | not enough vRAM | - | |
| 15_15_1_link-recovery-leaf-spine | 1125 | 7:16:43 | 15,721 | not enough vRAM | - | |
| 15_15_1_link-recovery-spine-tof | 1125 | 7:38:04 | 27,437 | not enough vRAM | - | |
| 15_15_1_node-failure-leaf | 1125 | 7:21:43 | 33,705 | not enough vRAM | - | |
| 15_15_1_node-failure-spine | 1125 | 6:57:28 | 193,470 | not enough vRAM | - | |
| 15_15_1_node-failure-tof | 1125 | 7:28:52 | 378,450 | not enough vRAM | - | |
| 15_15_1_node-recovery-leaf | 1125 | 7:14:26 | 40,500 | not enough vRAM | - | |
| 15_15_1_node-recovery-spine | 1125 | 7:06:44 | 245,535 | not enough vRAM | - | |
| 15_15_1_node-recovery-tof | 1125 | 7:06:41 | 418,560 | not enough vRAM | - | |
| 16_16_1_link-failure-leaf-spine | 1280 | not enough vRAM | not enough vRAM | - | ||
| 16_16_1_link-failure-spine-tof | 1280 | not enough vRAM | not enough vRAM | - | ||
| 16_16_1_link-recovery-leaf-spine | 1280 | not enough vRAM | not enough vRAM | - | ||
| 16_16_1_link-recovery-spine-tof | 1280 | not enough vRAM | not enough vRAM | - | ||
| 16_16_1_node-failure-leaf | 1280 | not enough vRAM | not enough vRAM | 32,736 | ||
| 16_16_1_node-failure-spine | 1280 | not enough vRAM | not enough vRAM | - | ||
| 16_16_1_node-failure-tof | 1280 | not enough vRAM | not enough vRAM | - | ||
| 16_16_1_node-recovery-leaf | 1280 | not enough vRAM | not enough vRAM | - | ||
| 16_16_1_node-recovery-spine | 1280 | not enough vRAM | not enough vRAM | - | ||
| 16_16_1_node-recovery-tof | 1280 | not enough vRAM | not enough vRAM | - | ||
| 16_16_8_link-failure-leaf-spine | 160 | 16:09.07 | 1728 | 27:12.65 | 1728 | 1728 |
| 16_16_8_link-failure-spine-tof | 160 | 15:58.80 | 1984 | 23:39.03 | 1984 | 1984 |
| 16_16_8_link-recovery-leaf-spine | 160 | 17:09.07 | 1921 | 27:48.62 | 1921 | 1793, 1991 |
| 16_16_8_link-recovery-spine-tof | 160 | 16:58.23 | 2162 | 26:25.27 | 2162 | 2065, 2178 |
| 16_16_8_node-failure-leaf | 160 | 16:24.14 | 5584 | 24:45.55 | 4064 | 4062, 4064 |
| 16_16_8_node-failure-spine | 160 | 16:31.02 | 23,056 | 23:16.42 | 23,056 | 23,262 |
| 16_16_8_node-failure-tof | 160 | 16:35.37 | 47,616 | 23:58.30 | 47,616 | 48,543, 48,807 |
| 16_16_8_node-recovery-leaf | 160 | 15:59.40 | 6144 | 24:17.76 | 6144 | 8230, 10,174 |
| 16_16_8_node-recovery-spine | 160 | 16:20.55 | 28,480 | 25:01.35 | 28,480 | 29,729, 30,013 |
| 16_16_8_node-recovery-tof | 160 | 16:54.93 | 53,312 | 24:16.86 | 53,312 | 54,467, 56,962 |
| 16_16_16_link-failure-leaf-spine | 80 | 7:09.04 | 1248 | 12:02.83 | 1248 | 1248, 1310 |
| 16_16_16_link-failure-spine-tof | 80 | 7:16.87 | 992 | 11:04.84 | 992 | 992 |
| 16_16_16_link-recovery-leaf-spine | 80 | 7:42.15 | 1345 | 13:31.50 | 1345 | 1281, 1345 |
| 16_16_16_link-recovery-spine-tof | 80 | 7:44.84 | 1074 | 13:39.60 | 1074 | 1041, 1090 |
| 16_16_16_node-failure-leaf | 80 | 7:32.59 | 2768 | 12:06.73 | 2016 | 2016 |
| 16_16_16_node-failure-spine | 80 | 7:27.18 | 15,376 | 11:50.89 | 15,376 | 15,582, 15,596, 15,599 |
| 16_16_16_node-failure-tof | 80 | 7:38.51 | 15,872 | 12:19.22 | 15,872 | 15,376, 15,840, 15,872 |
| 16_16_16_node-recovery-leaf | 80 | 7:29.09 | 3072 | 12:13.98 | 3072 | 3070, 4064 |
| 16_16_16_node-recovery-spine | 80 | 7:21.55 | 18,240 | 13:44.53 | 18,240 | 18,016, 19,074 |
| 16_16_16_node-recovery-tof | 80 | 7:21.64 | 18,496 | 12:05.75 | 18,496 | 19,328, 19,776 |
References
- Cisco. Cisco Global Cloud Index: Forecast and Methodology, 2016–2021; White Paper; Cisco: San Jose, CA, USA, 2018. [Google Scholar]
- Clos, C. A study of non-blocking switching networks. Bell Syst. Tech. J. 1953, 32, 406–424. [Google Scholar] [CrossRef]
- Alberro, L.; Castro, A.; Grampin, E. Experimentation Environments for Data Center Routing Protocols: A Comprehensive Review. Future Internet 2022, 14, 29. [Google Scholar] [CrossRef]
- Bonofiglio, G.; Iovinella, V.; Lospoto, G.; Di Battista, G. Kathará: A container-based framework for implementing network function virtualization and software defined networks. In Proceedings of the NOMS 2018—2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Scazzariello, M.; Ariemma, L.; Caiazzi, T. Kathará: A Lightweight Network Emulation System. In Proceedings of the NOMS 2020—2020 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 20–24 April 2020; pp. 1–2. [Google Scholar] [CrossRef]
- Scazzariello, M.; Ariemma, L.; Battista, G.D.; Patrignani, M. Megalos: A Scalable Architecture for the Virtualization of Network Scenarios. In Proceedings of the NOMS 2020—2020 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 20–24 April 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Ahrenholz, J. Comparison of CORE network emulation platforms. In Proceedings of the 2010—MILCOM 2010 Military Communications Conference, San Jose, CA, USA, 31 October–3 November 2010; pp. 166–171. [Google Scholar] [CrossRef]
- Lantz, B.; Heller, B.; McKeown, N. A Network in a Laptop: Rapid Prototyping for Software-Defined Networks. In Proceedings of the 9th ACM SIGCOMM Workshop on Hot Topics in Networks, Monterey, CA, USA, 20–21 October 2010; Association for Computing Machinery: New York, NY, USA, 2010. Hotnets-IX. [Google Scholar] [CrossRef]
- Caiazzi, T.; Scazzariello, M.; Alberro, L.; Ariemma, L.; Castro, A.; Grampin, E.; Battista, G.D. Sibyl: A Framework for Evaluating the Implementation of Routing Protocols in Fat-Trees. In Proceedings of the NOMS 2022—2022 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 25–29 April 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Lapukhov, P.; Premji, A.; Mitchell, J. Use of BGP for Routing in Large-Scale Data Centers; RFC 7938, RFC Editor; 2016; IETF. Available online: https://datatracker.ietf.org/doc/rfc7938/ (accessed on 9 October 2022).
- White, R.; Hegde, S.; Zandi, S. IS-IS Optimal Distributed Flooding for Dense Topologies. Internet-Draft Draft-White-Distoptflood-03, IETF Secretariat. 2020. Available online: https://datatracker.ietf.org/doc/html/draft-white-distoptflood-03 (accessed on 9 October 2022).
- Przygienda, T.; Sharma, A.; Thubert, P.; Rijsman, B.; Afanasiev, D.; Head, J. RIFT: Routing in Fat Trees. Internet-Draft Draft-Ietf-Rift-Rift-16, IETF Secretariat. 2022. Available online: https://datatracker.ietf.org/doc/draft-ietf-rift-rift/ (accessed on 9 October 2022).
- Aelmans, M.; Vandezande, O.; Rijsman, B.; Head, J.; Graf, C.; Alberro, L.; Mali, H.; Steudler, O. Day One: Routing in Fat Trees (RIFT); Juniper Networks Books: Sunnyvale, CA, USA, 2020. [Google Scholar]
- Quagga. Available online: https://www.quagga.net/ (accessed on 1 August 2022).
- Tazaki, H.; Uarbani, F.; Mancini, E.; Lacage, M.; Camara, D.; Turletti, T.; Dabbous, W. Direct code execution: Revisiting library os architecture for reproducible network experiments. In Proceedings of the Ninth ACM Conference on Emerging Networking Experiments and Technologies, Santa Barbara, CA, USA, 9–12 December 2013; pp. 217–228. [Google Scholar]
- ns-3 Network Simulator. Available online: https://www.nsnam.org (accessed on 30 September 2022).
- ns-3 Direct Code Execution. Available online: https://www.nsnam.org/about/projects/direct-code-execution (accessed on 30 September 2022).
- Caiazzi, T.; Scazzariello, M.; Ariemma, L. VFTGen: A Tool to Perform Experiments in Virtual Fat Tree Topologies. In Proceedings of the IM 2021—2021 IFIP/IEEE International Symposium on Integrated Network Management, Virtual, 17–21 May 2021. [Google Scholar]
- Sibyl Results. Available online: https://gitlab.com/uniroma3/compunet/networks/sibyl-framework/sibyl-results (accessed on 30 September 2022).
- Merkel, D. Docker: Lightweight linux containers for consistent development and deployment. Linux J. 2014, 2014, 2. [Google Scholar]
- Kubernetes. 2021. Available online: https://kubernetes.io/ (accessed on 30 September 2022).
- Azpiroz, S.Y.; Velázquez, F. FRR ns-3 DCE. 2021. Available online: https://gitlab.com/fing-mina/datacenters/frr-ns3 (accessed on 30 September 2022).
- ns-3 Manual. Available online: https://www.nsnam.org/docs/release/3.34/manual/singlehtml/index.html (accessed on 30 September 2022).
- Kaashoek, M.F.; Engler, D.R.; Ganger, G.R.; Briceño, H.M.; Hunt, R.; Mazières, D.; Pinckney, T.; Grimm, R.; Jannotti, J.; Mackenzie, K. Application Performance and Flexibility on Exokernel Systems. In Proceedings of the Sixteenth ACM Symposium on Operating Systems Principles (SOSP’97), Saint Malo, France, 5–8 October 1997; Association for Computing Machinery: New York, NY, USA, 1997; pp. 52–65. [Google Scholar] [CrossRef]
- ns-3 Direct Code Execution (DCE) Documentation. 2021. Available online: https://ns-3-dce.readthedocs.io/en/latest/intro.html (accessed on 30 September 2022).
- White, R.; Zandi, S. IS-IS Support for Openfabric. Internet-Draft Draft-White-Openfabric-07, IETF Secretariat. 2018. Available online: https://datatracker.ietf.org/doc/html/draft-white-openfabric-07 (accessed on 9 October 2022).
- DCE Quagga. Available online: https://www.nsnam.org/docs/dce/manual-quagga/html/getting-started.html (accessed on 30 September 2022).
- Fix Bug in Dce Vasprintf. Available online: https://github.com/direct-code-execution/ns-3-dce/pull/132 (accessed on 30 September 2022).
- Fix Bug in Dce InternalClosedir. Available online: https://github.com/direct-code-execution/ns-3-dce/pull/133 (accessed on 30 September 2022).
- Azpiroz, S.Y.; Velázquez, F. FRR Compilation and Installation Script for ns-3 DCE. 2021. Available online: https://gitlab.fing.edu.uy/proyecto-2021/scripts/-/blob/master/04-install-frr-SUDO (accessed on 30 September 2022).
- Free Range Routing. Available online: https://frrouting.org (accessed on 30 September 2022).
- Kathara-Labs. Available online: https://github.com/KatharaFramework/Kathara-Labs (accessed on 30 September 2022).
- Medhi, D.; Ramasamy, K. Network Routing, Second Edition: Algorithms, Protocols, and Architectures, 2nd ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2017. [Google Scholar]




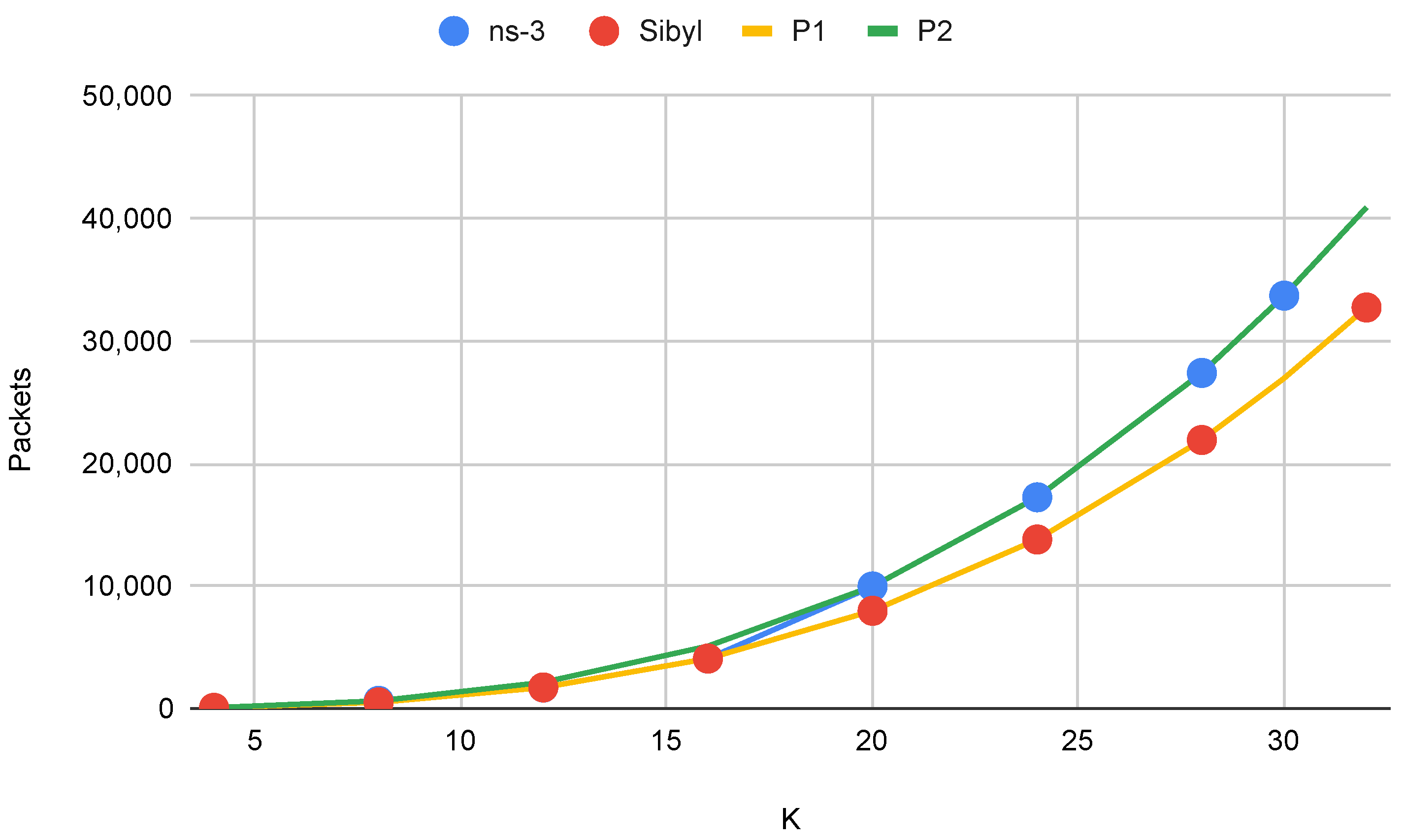
| Scenario | Number | PDUs | PDUs | PDUs |
|---|---|---|---|---|
| of Nodes | ns-3 | ns-3 | Sibyl | |
| w/o Zebra | w Zebra | |||
| 2_2_1_node-failure-leaf | 20 | 60 | 60 | 60 |
| 2_2_2_node-failure-leaf | 10 | 28 | 28 | 28 |
| 4_4_1_node-failure-leaf | 80 | 504 | 504 | 504 |
| 4_4_2_node-failure-leaf | 40 | 248 | 248 | 248 |
| 4_4_4_node-failure-leaf | 20 | 120 | 120 | 120 |
| 6_6_1_link-failure-leaf-spine | 180 | 996 | 996 | 996 |
| 6_6_1_link-recovery-spine-tof | 180 | 1796 | 1796 | 1657, 1796 |
| 10_10_1_node-failure-spine | 500 | 37,480 | 37,480 | 18,390 |
| 12_12_1_node-failure-leaf | 720 | 17,244 | - | 13,800 |
| Proposed Feature | Execution Time | Memory Consumption | Execution Time Improvement |
|---|---|---|---|
| None | 2:50.140 | 705 MB | - |
| Disable IPv6 | 1:44.284 | 705 MB | +38.71% |
| Reduce simu time | 2:18.452 | 705 MB | +18.62% |
| Without zebra | 1:29.786 | 403 MB | +47.23% |
| All together | 1:18.833 | 403 MB | +53.67% |
| Scenario | Number of Nodes | Execution Time in ns-3 | Execution Time in Sibyl |
|---|---|---|---|
| 2_2_1_node-failure-leaf | 20 | 0:59 | 2:2 |
| 4_4_1_node-failure-leaf | 80 | 4:12 | 3:4 |
| 6_6_1_node-failure-leaf | 180 | 10:41 | 6:25 |
| 8_8_1_node-failure-leaf | 320 | 21:16 | 20:49 |
| 10_10_1_node-failure-leaf | 500 | 36:31 | 14:18 |
| 12_12_1_node-failure-leaf | 720 | 1:22:40 | 37:3 |
| 14_14_1_node-failure-leaf | 980 | 2:41:23 | 1:5:31 |
| 15_15_1_node-failure-leaf | 1125 | 7:21:43 | - |
| 16_16_1_node-failure-leaf | 1280 | - | 1:44:58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alberro, L.; Velázquez, F.; Azpiroz, S.; Grampin, E.; Richart, M. Experimenting with Routing Protocols in the Data Center: An ns-3 Simulation Approach. Future Internet 2022, 14, 292. https://doi.org/10.3390/fi14100292
Alberro L, Velázquez F, Azpiroz S, Grampin E, Richart M. Experimenting with Routing Protocols in the Data Center: An ns-3 Simulation Approach. Future Internet. 2022; 14(10):292. https://doi.org/10.3390/fi14100292
Chicago/Turabian StyleAlberro, Leonardo, Felipe Velázquez, Sara Azpiroz, Eduardo Grampin, and Matías Richart. 2022. "Experimenting with Routing Protocols in the Data Center: An ns-3 Simulation Approach" Future Internet 14, no. 10: 292. https://doi.org/10.3390/fi14100292
APA StyleAlberro, L., Velázquez, F., Azpiroz, S., Grampin, E., & Richart, M. (2022). Experimenting with Routing Protocols in the Data Center: An ns-3 Simulation Approach. Future Internet, 14(10), 292. https://doi.org/10.3390/fi14100292