
Spatiotemporal Traffic Prediction Using Hierarchical Bayesian Modeling



Abstract
:1. Introduction
2. Related Works
2.1. Gaussian Processes (GP) Model
2.2. Autoregressive (AR) Model
2.3. Gaussian Predictive Processes (GPP) Model
3. Methodology and Data
3.1. Hierarchical Bayesian Modeling
3.1.1. Gaussian Processes (GP) Model
3.1.2. Autoregressive (AR) Model
3.1.3. Gaussian Predictive Processes (GPP) Model
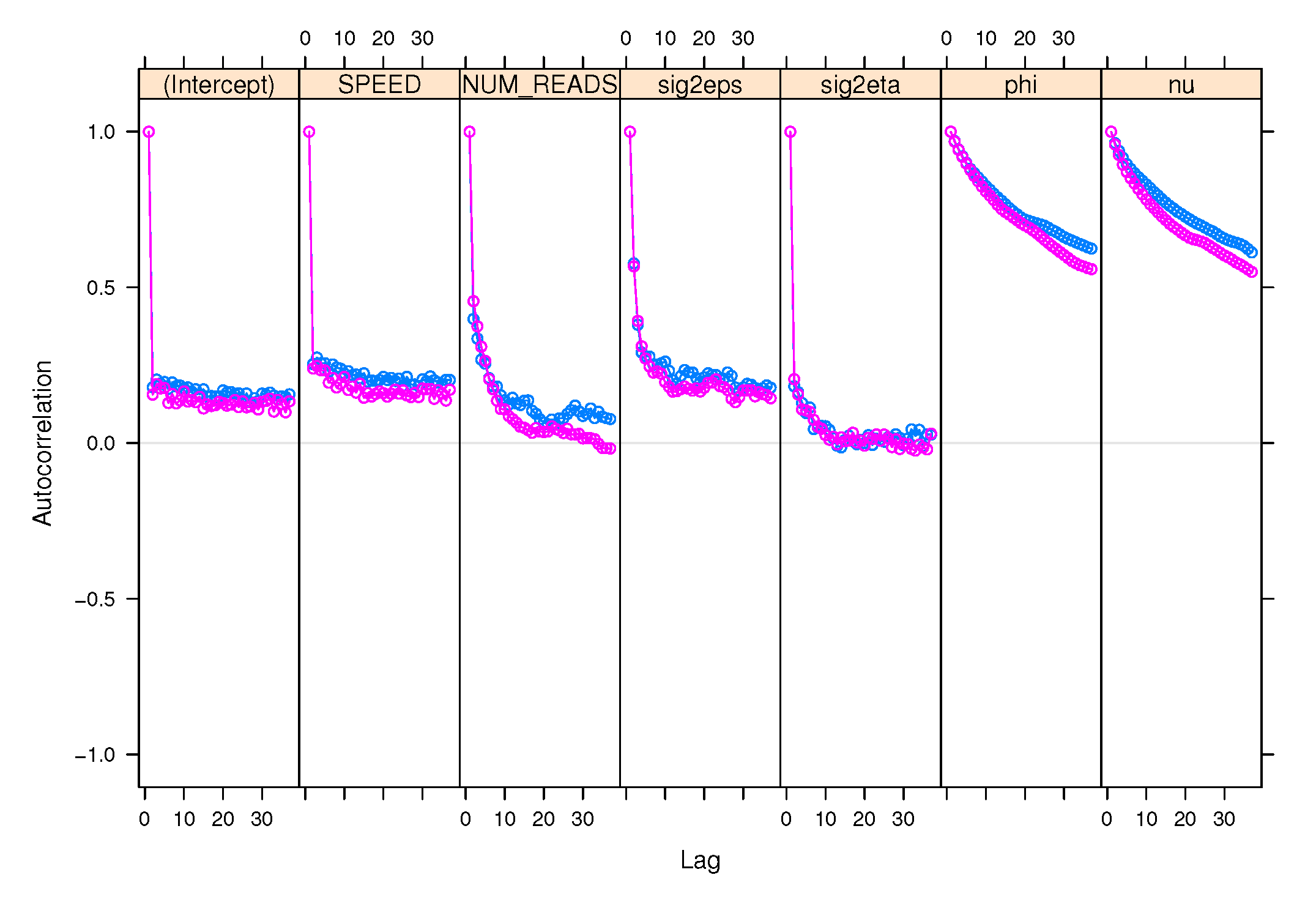
3.1.4. Gibbs Sampler
| Algorithm 1: Gibbs Sampler |
 |
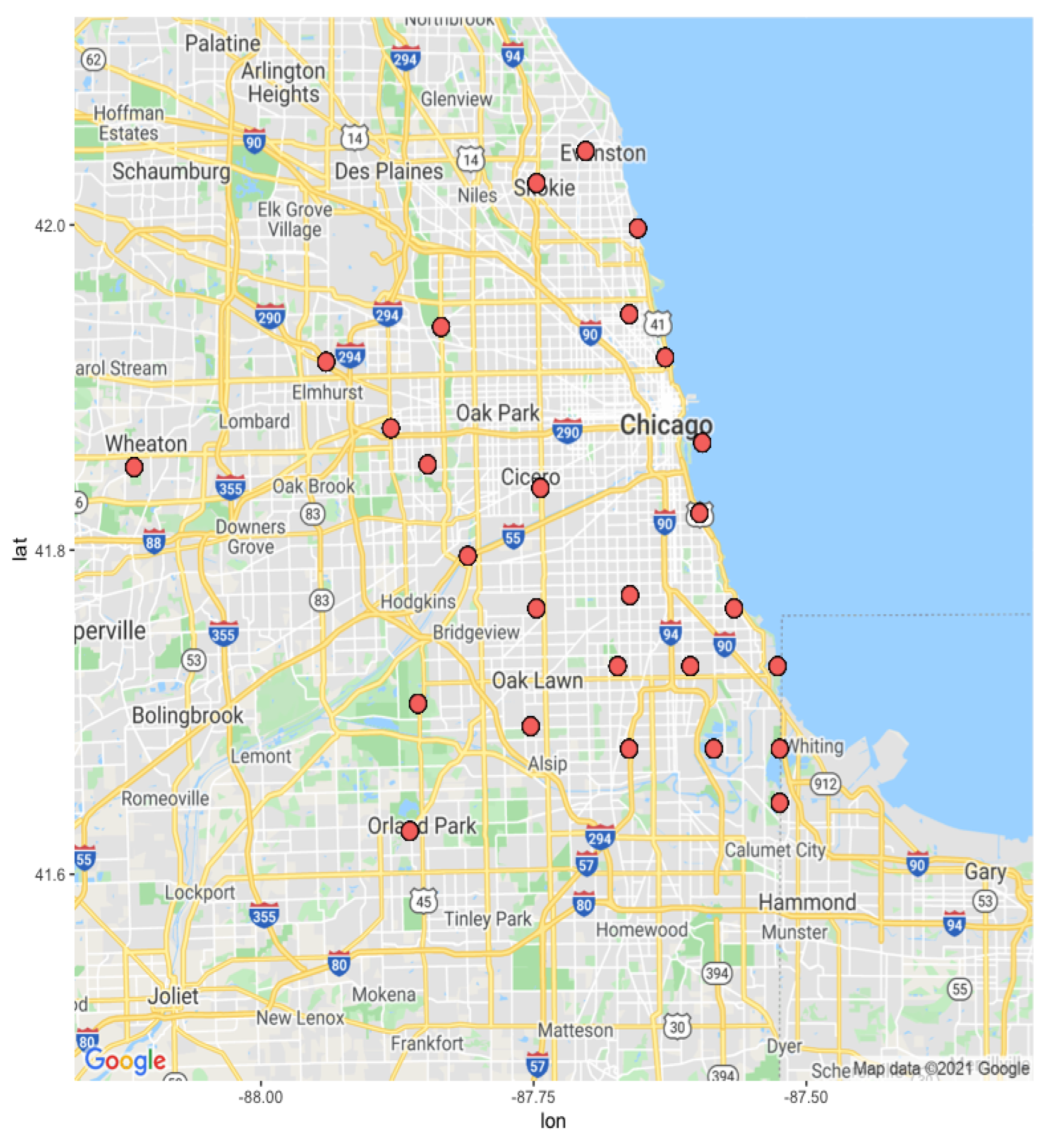
3.2. Study Area and Data Preprocessing
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nguyen-Phuocab, D.Q.; Curriea, G.; De Gruytera, C.; Kimc, I. Modelling the net traffic congestion impact of bus operations in Melbourne. Transp. Res. Part A Policy Pract. 2018, 117, 1–12. [Google Scholar] [CrossRef]
- Chen, X.; He, X.; Xiong, C.; Zhu, Z.; Zhang, L. A Bayesian Stochastic Kriging Optimization Model Dealing with Heteroscedastic Simulation Noise for Freeway Traffic Management. Transp. Sci. 2018. [Google Scholar] [CrossRef]
- Lu, S.H.; Huang, D.; Song, Y.; Jiang, D.; Zhou, T.; Qin, J. St-trafficnet: A spatial-temporal deep learning network for traffic forecasting. Electronics 2020, 9, 1474. [Google Scholar] [CrossRef]
- Gonzalo, R. Transport Gaussian Processes for Regression. arXiv 2020, arXiv:2001.11473. [Google Scholar]
- Alexandre, A.; Filliat, D.; Ibanez-Guzman, J. Modelling stop intersection approaches using gaussian processes. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013. [Google Scholar]
- Fusco, G.; Colombaroni, C.; Isaenko, N. Short-term speed predictions exploiting big data on large urban road networks. Transp. Res. Part C Emerg. Technol. 2016, 73, 183–201. [Google Scholar] [CrossRef]
- Bull, A. NU. CEPAL. ECLAC. In Traffic Congestion: The Problem and How to Deal with it; United Nations Publications: New York, NY, USA, 2006; pp. 1–187. [Google Scholar]
- Sipahi, R.; Niculescu, S.I. A survey of deterministic time delay traffic flow models. IFAC Proc. Vol. 2007, 40, 111–116. [Google Scholar] [CrossRef]
- Rigat, F.; de Gunsty, M.; van Peltz, J. Bayesian modelling and analysis of spatio-temporal neural networks. Bayesian Anal. 2006, 4, 733–764. [Google Scholar]
- Wikle, C.K.; Milliff, R.F.; Nychka, D.; Berlinerr, L.M. Spatiotemporal hierarchical Bayesian modeling tropical ocean surface winds. J. Am. Stat. Assoc. 2001, 96, 382–397. [Google Scholar] [CrossRef] [Green Version]
- Bezener, M.; Hughes, J.; Jones, G. Bayesian spatiotemporal modeling using hierarchical spatial priors, with applications to functional magnetic resonance imaging (with discussion). Bayesian Anal. 2018, 13, 1261–1313. [Google Scholar] [CrossRef]
- Deublein, M.; Schubert, M.; Adey, B.T.; Köhler, J.; Faber, M.H. Prediction of road accidents: A Bayesian hierarchical approach. Accid. Anal. Prev. 2013, 51, 274–291. [Google Scholar] [CrossRef] [PubMed]
- Brogna, G.; Leclere, J.A.Q.; Sauvage, O. Engine noise separation through Gibbs sampling in a hierarchical Bayesian model. Mech. Syst. Signal Process. 2019, 128, 405–428. [Google Scholar] [CrossRef]
- Wikle, C.K. Hierarchical models in environmental science. Int. Stat. Rev. 2003, 71, 181–199. [Google Scholar] [CrossRef]
- Zaslavsky, A.M. Using hierarchical models to attribute sources of variation in consumer assessments of health care. Stat. Med. 2007, 26, 1885–1900. [Google Scholar] [CrossRef]
- Lindgren, F.; Rue, H. Bayesian spatial modelling with R-INLA. J. Stat. Softw. 2015, 63, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Friedman, N.; Koller, D. Being Bayesian about network structure. A Bayesian approach to structure discovery in Bayesian networks. Mach. Learn. 2003, 50, 95–125. [Google Scholar] [CrossRef]
- Bakar, K.S.; Sahu, S.K. spTimer: Spatio-temporal bayesian modelling using R. J. Stat. Softw. 2015, 63, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Smith, B.L.; Williams, B.M.; Oswald, R.K. Comparison of parametric and nonparametric models for traffic flow forecasting. Transp. Res. Part C Emerg. Technol. 2002, 10, 303–321. [Google Scholar] [CrossRef]
- Abdi, J.; Moshiri, B.; Abdulhai, B.; Sedigh, A.K. Short-term traffic flow forecasting: Parametric and nonparametric approaches via emotional temporal difference learning. Neural Comput. Appl. 2013, 23, 141–159. [Google Scholar] [CrossRef]
- Smith, B.L.; Demetsky, M.J. Traffic flow forecasting: Comparison of modeling approaches. J. Transp. Eng. 1997, 123, 261–266. [Google Scholar] [CrossRef]
- Fusco, G.; Colombaroni, C.; Comelli, L.; Isaenko, N. Short-term traffic predictions on large urban traffic networks: Applications of network-based machine learning models and dynamic traffic assignment models. In Proceedings of the 2015 International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Budapest, Hungary, 3–5 June 2015. [Google Scholar]
- Cufoglu, A.; Lohi, M.; Madani, K. Classification accuracy performance of naïve Bayesian (NB), Bayesian networks (BN), lazy learning of Bayesian rules (LBR) and instance-based learner (IB1)-comparative study. In Proceedings of the 2008 International Conference on Computer Engineering & Systems), Washington, DC, USA, 12–14 December 2008. [Google Scholar]
- Cheng, B.; Titterington, D.M. Neural networks: A review from a statistical perspective. Stat. Sci. 1994, 9, 2–30. [Google Scholar]
- Saha, A.; Chakraborty, S.; Chandra, S.; Ghosh, I. Kriging based saturation flow models for traffic conditions in Indian cities. Transp. Res. Part A Policy Pract. 2018, 118, 38–51. [Google Scholar] [CrossRef]
- Selby, B.; Kockelman, K.M. Spatial prediction of traffic levels in unmeasured locations: Applications of universal kriging and geographically weighted regression. J. Transp. Geogr. 2013, 29, 24–32. [Google Scholar] [CrossRef]
- Gentile, M.; Courbin, F.; Meylan, G. Interpolating point spread function anisotropy. Astron. Astrophys. 2013, 123, A1. [Google Scholar] [CrossRef] [Green Version]
- Kotusevski, G.; Hawick, K.A. A Review of Traffic Simulation Software; Massey University: 2009. Available online: http://www.exec-ed.ac.nz/massey/fms/Colleges/College%20of%20Sciences/IIMS/RLIMS/Volume13/TrafficSimulatorReview_arlims.pdf (accessed on 23 August 2021).
- Jones, S.L.; Sullivan, A.J.; Cheekoti, N.; Anderson, M.D.; Malave, D. Traffic Simulation Software Comparison Study; UTCA Report; 2004. Available online: https://docplayer.net/11265523-Traffic-simulation-software-comparison-study.html (accessed on 23 August 2021).
- Wong, K.I.; Yu, S.A. Estimation of origin–destination matrices for mass event: A case of Macau Grand Prix. J. King Saud Univ. -Sci. 2011, 23, 281–292. [Google Scholar] [CrossRef] [Green Version]
- Shirley, K.; Vasilaky, K.; Greatrex, H.; Osgood, D.; Hierarchical Bayes Models for Daily Rainfall Time Series at Multiple Locations from Heterogenous Data Sources. Earth Institute and International Research Institute for Climate and Society. 26 May 2016. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.734.9836&rep=rep1&type=pdf (accessed on 23 August 2021).
- Shuler, K. Bayesian Hierarchical Models for Count Data. Statistical Science, Ph.D. Thesis, University of California, Santa Cruz, Oakland, CA, USA, June 2020. [Google Scholar]
- Normington, J.P. Bayesian Hierarchical Difference-in-Differences Models. Ph.D. Thesis, The University of Minnesota, Minneapolis, MN, USA, December 2019. [Google Scholar]
- McGlothlin, A.E.; Viel, K. Bayesian Hierarchical Models. Am. Med. Assoc. 2018, 320, 2365–2366. [Google Scholar] [CrossRef]
- Sahu, S.K.; Gelfand, A.E.; Holland, D.M. Spatio-temporal modeling of fine particulate matter. J. Agric. Biol. Environ. Stat. 2006, 11, 61–86. [Google Scholar] [CrossRef]
- Datta, A.; Banerjee, S.; Finley, A.O.; Hamm, N.A.S.; Schaap, M. Nonseparable dynamic nearest neighbor Gaussian process models for large spatio-temporal data with an application to particulate matter analysis. Ann. Appl. Stat. 2016, 10, 1286. [Google Scholar] [CrossRef] [PubMed]
- Rodriguesa, F.; Pereiraa, F.C. Heteroscedastic Gaussian processes for uncertainty modeling in large-scale crowdsourced traffic data. Transp. Res. Part C Emerg. Technol. 2018, 95, 636–651. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Yue, Y.; Krishnan, R. Adaptive collective routing using gaussian process dynamic congestion models. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 11–14 August 2013. [Google Scholar]
- Idé, T.; Kato, S. Travel-time prediction using Gaussian process regression: A trajectory-based approach. In Proceedings of the 2009 SIAM International Conference on Data Mining, Sparks, NV, USA, 30 April–2 May 2009. [Google Scholar]
- Neumann, M.; Kersting, K.; Xu, Z.; Schulz, D. Stacked Gaussian process learning. In Proceedings of the 2009 Ninth IEEE International Conference on Data Mining, Miami, FL, USA, 6–9 December 2009. [Google Scholar]
- Cheng, C.A.; Boots, B. Variational inference for Gaussian process models with linear complexity. arXiv 2017, arXiv:1711.10127. [Google Scholar]
- Lu, S.H.; Huang, D.; Song, Y.; Jiang, D.; Zhou, T.; Qin, J. Efficient multiscale Gaussian process regression using hierarchical clustering. arXiv 2015, arXiv:1511.02258. [Google Scholar]
- Chen, P.; Yuan, H.; Shu, X. Forecasting crime using the arima model. In Proceedings of the Fifth International Conference on Fuzzy Systems and Knowledge Discovery, Jinan, China, 18–20 October 2008. [Google Scholar]
- Alghamdi, T.; Elgazzar, K.; Bayoumi, M.; Sharaf, T.; Shah, S. Forecasting traffic congestion using ARIMA modeling. In Proceedings of the 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019. [Google Scholar]
- Chen, C.; Hu, J.; Meng, Q.; Zhang, Y. Short-time traffic flow prediction with ARIMA-GARCH model. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden, Germany, 5–9 June 2011. [Google Scholar]
- He, Z.; Tao, H. Epidemiology and ARIMA model of positive-rate of influenza viruses among children in Wuhan, China: A nine-year retrospective study. Int. J. Infect. Dis. 2018, 74, 61–70. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, Z.; Guo, Y.; Wu, Y., Ma. Short-term traffic speed prediction under different data collection time intervals using a SARIMA-SDGM hybrid prediction model. PLoS ONE 2019, 14, e0218626. [Google Scholar] [CrossRef] [PubMed]
- Nobre, F.F.; Monteiro, A.B.; Telles, P.R.; Williamson, G.D. Dynamic linear model and SARIMA: A comparison of their forecasting performance in epidemiology. Stat. Med. 2018, 20, 3051–3069. [Google Scholar] [CrossRef] [PubMed]
- Banerjee, S.; Gelfand, A.E.; Finley, A.O.; Sang, H. Gaussian predictive process models for large spatial data sets. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2008, 70, 825–848. [Google Scholar] [CrossRef] [Green Version]
- Guhaniyogi, R.; Finley, A.O.; Banerjee, S.; Gelfand, A.E. Adaptive Gaussian predictive process models for large spatial datasets. Environmetrics 2011, 22, 997–1007. [Google Scholar] [CrossRef] [Green Version]
- Paap, R. What are the advantages of MCMC based inference in latent variable models? Stat. Neerl. 2002, 56, 2–22. [Google Scholar] [CrossRef]
- Cressie, N.; Hoboken, C.K.W. Statistics for Spatio-Temporal Data, 2nd ed.; Wiley: Hoboken, NJ, USA, 2011; pp. 1–624. [Google Scholar]
- Davies, S.; Hall, P. Fractal analysis of surface roughness by using spatial data. J. R. Stat. Soc. Ser. B Stat. Methodol. 1999, 61, 3–37. [Google Scholar] [CrossRef]
- Genton, M.G. Classes of kernels for machine learning: A statistics perspective. J. Mach. Learn. Res. 2001, 2, 299–312. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; TMIT Press: Cambridge, MA, USA, 2006; pp. 1–266. [Google Scholar]
- Minasny, B.; McBratney, A.B. The Matérn Function as a General Model for Soil Variograms; Elsevier BV: Amsterdam, The Netherlands, 2005; pp. 192–207. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. SBayesian Data Analysis, 3rd ed.; Chapman and Hall/CRC: New York, NY, USA, 1995. [Google Scholar]
- Johansen, L.; Caluza, B. Deciphering west philippine sea: A plutchik and VADER algorithm sentiment analysis. Indian J. Sci. Technol. 2018, 11, 47. [Google Scholar]
- Džambas, T.; Ahac, S.; Dragčević, V. Numerical prediction of the effect of traffic lights on the vehicle noise at urban street intersections. J. Acoust. Soc. Am. 2008, 123, 3924. [Google Scholar]
- De Myttenaere, A.; Golden, B.; Le Grand, B.; Rossi, F. Mean absolute percentage error for regression models. Neurocomputing 2016, 192, 38–48. [Google Scholar] [CrossRef] [Green Version]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE). Geosci. Model Dev. Discuss. 2014, 7, 1525–1534. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction Error | AR | GP | |||
|---|---|---|---|---|---|
| Matérn | Spherical | Exponential | Gaussian | ||
| MAE | 10.8206 | 7.6839 | 8.1898 | 7.6723 | 41.8726 |
| RMSE | 13.0264 | 9.1833 | 9.7754 | 9.1444 | 53.6856 |
| MAPE | 50.2990 | 37.2477 | 41.5263 | 37.1951 | 201.6881 |
| Prediction Error | AR | GP | |||
|---|---|---|---|---|---|
| Matérn | Spherical | Exponential | Gaussian | ||
| MAE | 9.8014 | 11.4243 | 11.4738 | 11.2184 | 15.2290 |
| RMSE | 10.5591 | 13.1387 | 13.6285 | 12.8379 | 19.1728 |
| MAPE | 41.5620 | 44.5595 | 45.0353 | 44.0292 | 73.0119 |
| Prediction Error | AR | GP | GPP | |||
|---|---|---|---|---|---|---|
| Matérn | Spherical | Exponential | Gaussian | |||
| MAE | 12.1815 | 7.0502 | 7.1497 | 6.9503 | 8.2164 | 6.0661 |
| RMSE | 14.8013 | 8.4186 | 8.6597 | 8.2514 | 10.6448 | 7.7081 |
| MAPE | 62.0773 | 38.5571 | 39.2783 | 38.5146 | 40.7944 | 34.9146 |
| Prediction Error | AR | GP | GPP | |||
|---|---|---|---|---|---|---|
| Matérn | Spherical | Exponential | Gaussian | |||
| MAE | 10.8145 | 9.3554 | 9.3864 | 9.1993 | 11.4445 | 6.1544 |
| RMSE | 11.7616 | 10.8155 | 11.4056 | 10.3655 | 15.9292 | 7.3064 |
| MAPE | 51.0616 | 39.9743 | 40.8310 | 40.0823 | 43.2680 | 30.0583 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alghamdi, T.; Elgazzar, K.; Sharaf, T. Spatiotemporal Traffic Prediction Using Hierarchical Bayesian Modeling. Future Internet 2021, 13, 225. https://doi.org/10.3390/fi13090225
Alghamdi T, Elgazzar K, Sharaf T. Spatiotemporal Traffic Prediction Using Hierarchical Bayesian Modeling. Future Internet. 2021; 13(9):225. https://doi.org/10.3390/fi13090225
Chicago/Turabian StyleAlghamdi, Taghreed, Khalid Elgazzar, and Taysseer Sharaf. 2021. "Spatiotemporal Traffic Prediction Using Hierarchical Bayesian Modeling" Future Internet 13, no. 9: 225. https://doi.org/10.3390/fi13090225
APA StyleAlghamdi, T., Elgazzar, K., & Sharaf, T. (2021). Spatiotemporal Traffic Prediction Using Hierarchical Bayesian Modeling. Future Internet, 13(9), 225. https://doi.org/10.3390/fi13090225