
Text Analysis Methods for Misinformation–Related Research on Finnish Language Twitter




Abstract
1. Introduction
2. Overview of Key Concepts
3. Materials and Methods
3.1. Methodology Issues Related to the Language Used
3.2. Data Collection
3.3. Data Processing
3.4. Word Count Analysis in Atlas.ti 9
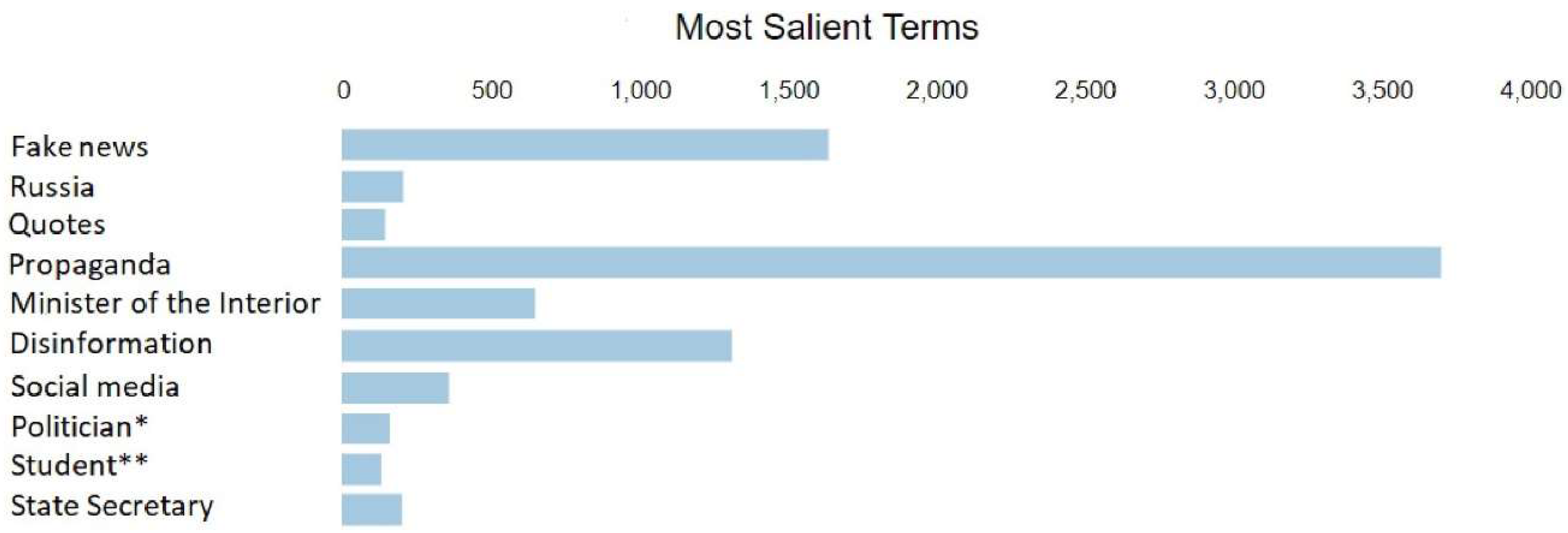
4. Results
4.1. Word Cloud of Tweets
4.2. Topic Model of Tweets
4.3. Word Count Analysis and Clustering
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Choudrie, J.; Banerjee, S.; Kotecha, K.; Walambe, R.; Karende, H.; Ameta, J. Machine learning techniques and older adults processing of online information and misinformation: A covid 19 study. Comput. Human Behav. 2021, 119, 106716. [Google Scholar] [CrossRef]
- EU. Final Report of the High Level Expert Group on Fake News and Online Disinformation. 2018. Available online: https://digital-strategy.ec.europa.eu/en/library/final-report-high-level-expert-group-fake-news-and-online-disinformation (accessed on 10 June 2021).
- Lazer, D.M.J.; Baum, M.A.; Benkler, Y.; Berinsky, A.J.; Greenhill, K.M.; Menczer, F.; Metzger, M.J.; Nyhan, B.; Pennycook, G.; Rothschild, D.; et al. The science of fake news. Science 2018, 359, 1094–1096. [Google Scholar] [CrossRef]
- Shu, K.; Bhattacharjee, A.; Alatawi, F.; Nazer, T.; Ding, K.; Karami, M.; Liu, H. Combating Disinformation in A Social Media Age. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, 1–39. [Google Scholar] [CrossRef]
- Spradling, M.; Straub, J.; Strong, J. Protection from ‘Fake News’: The Need for Descriptive Factual Labeling for Online Content. Futur. Internet 2021, 13, 142. [Google Scholar] [CrossRef]
- Helmstetter, S.; Paulheim, H. Collecting a Large Scale Dataset for Classifying Fake News Tweets Using Weak Supervision. Futur. Internet 2021, 13, 114. [Google Scholar] [CrossRef]
- Carchiolo, V.; Longheu, A.; Malgeri, M.; Mangioni, G.; Previti, M. Mutual Influence of Users Credibility and News Spreading in Online Social Networks. Future Internet 2021, 13, 107. [Google Scholar] [CrossRef]
- Haselton, M.G.; Nettle, D. The paranoid optimist: An integrative evolutionary model of cognitive biases. Personal. Soc. Psychol. Rev. 2006, 10, 47–66. [Google Scholar] [CrossRef] [PubMed]
- Binder, J.R.; Desai, R.H.; Graves, W.W.; Conant, L. Where is the semantic system? A critical review and meta-analysis of 120 functional neuroimaging studies. Cereb Cortex 2009, 19, 2767–2796. [Google Scholar] [CrossRef] [PubMed]
- Fedorenko, E.; Scott, T.L.; Brunner, P.; Coon, W.G.; Pritchett, B.; Schalk, G.; Kanwisher, N. Neural correlate of the construction of sentence meaning. Proc. Natl. Acad. Sci. USA 2016, 113, E6256–E6262. [Google Scholar] [CrossRef]
- Freelon, D.; Wells, C. Disinformation as political communication. Polit. Commun. 2020, 37, 145–156. [Google Scholar] [CrossRef]
- Bradshaw, S.; Howard, P.N.; Kollanyi, B.; Neudert, L.M. Sourcing and automation of political news and information over social media in the United States, 2016–2018. Polit. Commun. 2020, 37, 173–193. [Google Scholar] [CrossRef]
- Bello-Orgaz, G.; Jung, J.J.; Camacho, D. Social big data: Recent achievements and new challenges. Inf. Fusion 2016, 28, 45–59. [Google Scholar] [CrossRef]
- Lytras, M.D.; Visvizi, A.; Jussila, J. Social media mining for smart cities and smart villages research. Soft Comput. 2020, 24, 10983–10987. [Google Scholar] [CrossRef]
- Vatrapu, R.; Mukkamala, R.R.; Hussain, A.; Flesch, B. Social set analysis: A set theoretical approach to big data analytics. IEEE Access 2016, 4, 2542–2571. [Google Scholar] [CrossRef]
- Li, J.; Su, M.H. Real Talk about Fake News: Identity Language and Disconnected Networks of the US Public’s “Fake News” Discourse on Twitter. Soc. Media Soc. 2020, 6. [Google Scholar] [CrossRef]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Soc. Sci. 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Varol, O.; Ferrara, E.; Davis, C.A.; Menczer, F.; Flammini, A. Online Human-Bot Interactions: Detection, Estimation, and Characterization. In Proceedings of the Eleventh International AAAI Conference on Web and Social Media (ICWSM 2017), Montréal, QC, Canada, 15–18 May 2017; pp. 280–289. [Google Scholar]
- EU Institutions Data Flash Eurobarometer 464: Fake News and Disinformation Online. Available online: https://data.europa.eu/data/datasets/s2183_464_eng?locale=en (accessed on 10 June 2021).
- Zakharchenko, A.; Peráček, T.; Fedushko, S.; Syerov, Y.; Trach, O. When Fact-Checking and ‘BBC Standards’ Are Helpless: ‘Fake Newsworthy Event’Manipulation and the Reaction of the ‘High-Quality Media’on It. Sustainability 2021, 13, 573. [Google Scholar] [CrossRef]
- Dann, S. Twitter data acquisition and analysis: Methodology and best practice. In Maximizing Commerce and Marketing Strategies through Micro-Blogging; IGI Global: Hershey, PA, USA, 2015; pp. 280–296. [Google Scholar]
- UN. UN Tackles ‘Infodemic’ of Misinformation and Cybercrime in COVID-19 Crisis|United Nations. Available online: https://www.un.org/en/un-coronavirus-communications-team/un-tackling-%E2%80%98infodemic%E2%80%99-misinformation-and-cybercrime-covid-19 (accessed on 10 June 2021).
- Zeng, J.; Chan, C.H. A cross-national diagnosis of infodemics: Comparing the topical and temporal features of misinformation around COVID-19 in China, India, the US, Germany and France. Online Inf. Rev. 2021. [Google Scholar] [CrossRef]
- Fetzer, J.H. Disinformation: The use of false information. Minds Mach. 2004, 14, 231–240. [Google Scholar] [CrossRef]
- Pal, A.; Banerjee, S. Handbook of Research on Deception, Fake News, and Misinformation Online. In Advances in Media, Entertainment, and the Arts; Chiluwa, I.E., Samoilenko, S.A., Eds.; IGI Global: Hershey, PA, USA, 2019; ISBN 9781522585350. [Google Scholar]
- Fetzer, J.H. Information: Does it have to Be True? Minds Mach. 2004, 14, 223–229. [Google Scholar] [CrossRef]
- Bastick, Z. Would you notice if fake news changed your behavior? An experiment on the unconscious effects of disinformation. Comput. Human Behav. 2021, 116, 106633. [Google Scholar] [CrossRef]
- Tandoc, E.C.; Lim, Z.W.; Ling, R. Defining “Fake News”: A typology of scholarly definitions. Digit. J. 2018, 6, 137–153. [Google Scholar] [CrossRef]
- Tandoc, E.C., Jr.; Thomas, R.J.; Bishop, L. What Is (Fake) News? Analyzing News Values (and More) in Fake Stories. Media Commun. 2021, 9, 110–119. [Google Scholar] [CrossRef]
- UK Parliament Disinformation and ‘fake news’: Interim Report. Available online: https://publications.parliament.uk/pa/cm201719/cmselect/cmcumeds/363/363.pdf (accessed on 28 May 2021).
- Visvizi, A.; Jussila, J.; Lytras, M.D.; Ijäs, M. Tweeting and mining OECD-related microcontent in the post-truth era: A cloud-based app. Comput. Human Behav. 2020, 107, 105958. [Google Scholar] [CrossRef]
- Pan, W.; Fang, J. An Examination of Factors Contributing to the Acceptance of Online Health Misinformation. Front. Psychol. 2020, 12, 524. [Google Scholar] [CrossRef]
- Van Sant, K.; Fredheim, R.; Bergmanis-Korats, G. Abuse of Power: Coordinated Online Harassment of Finnish Government Ministers. Riga: NATO Strategic Communications Centre of Excellence. Available online: https://stratcomcoe.org/pdfjs/?file=/cuploads/pfiles/abuse_of_power_online_harassment_of_fin_ministers_16-03-2021.pdf?zoom=page-fit (accessed on 10 June 2021).
- Mejova, Y.; Weber, I.; Macy, M.W. Twitter: A Digital Socioscope; Cambridge University Press: New York, NY, USA, 2015. [Google Scholar]
- Friese, S. Qualitative Data Analysis with ATLAS.ti; SAGE: Los Angeles, SC, USA, 2019. [Google Scholar]
- Karlsson, F. Finnish: An Essential Grammar; Taylor & Francis e-Library: Abingdon, UK, 2002; ISBN 0-203-18753-9. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Newton, MA, USA, 2009. [Google Scholar]
- Korenius, T.; Laurikkala, J.; Järvelin, K.; Juhola, M. Stemming and lemmatization in the clustering of finnish text documents. In Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management, Washington, DC, USA, 8–13 November 2004; pp. 625–633. [Google Scholar]
- Roesslein, J. Tweepy. Available online: https://docs.tweepy.org/en/stable/ (accessed on 3 May 2021).
- Partanen, A. TweetCollector. Available online: https://github.com/hamk-uas/TweetCollector (accessed on 11 June 2021).
- Twitter Twitter API v2: Early Access. Available online: https://developer.twitter.com/en/docs/twitter-api/early-access (accessed on 11 June 2021).
- Rosen, A. Tweeting Made Easier. Available online: https://blog.twitter.com/en_us/topics/product/2017/tweetingmadeeasier.html (accessed on 7 May 2021).
- Antupis Finnish Lemmatization with Python. Available online: https://antupis.github.io/lemmatization/finnish/2019/06/12/Lemmatizing-finnish-text.html (accessed on 28 May 2021).
- Bakshy, E.; Hofman, J.M.; Mason, W.A.; Watts, D.J. Everyone’s an influencer: Quantifying influence on twitter. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 65–74. [Google Scholar]



{kind=link}
{kind=link}
| Variable Identification | Type | Description |
|---|---|---|
| created_at | String | UTC time when this tweet was created. |
| Text | String | The actual UTF-8 text of the status update. |
| extended_tweet.full_text | String | Untruncated text message when longer than 140 characters. |
| entities.hashtags | array | Represents hashtags that have been parsed out of the tweet text. |
| user.id_srt | String | The string representation of the unique identifier for this user. |
| user.screen_name | String | The screen name, handle, or alias that this user identifies themselves with. screen_names are unique but subject to change. |
| user.description | String | The user-defined UTF-8 string describing their account. |
| Action | Description |
|---|---|
| 1. Remove links | Remove links to reduce unstructured text by removing links. |
| 2. Make all letters lower case. | All letters are converted into lower case because the analysis is case-sensitive. |
| 3. Remove punctuation, digits, and special markers | Removing all punctuation to reduce unstructured text and numbers does not usually change the meaning of the text. Removing special markers, usually @, is commonly used when a user is mentioned. |
| 4. Remove white spaces | All unnecessary white spaces are removed. |
| Action | Inclusion/Exclusion Criteria | Quantity of Data |
|---|---|---|
| 1. Data import from Excel to Atlas.ti | inclusion 16,463 | 16,463 documents (tweets) |
| 2. General terms to the stoplist | general Finnish stop terms 746 in Atlas.ti and other general words and Twitter display names | 47,013 words |
| 3. Wordlist with quantities to Excel spread list | Inclusion criteria minimum 50 tweets per word | 468 words |
| 4. Exclusion | Exclusion of 213 + 37 general words and Twitter display names | 218 words |
| 5. Inclusion | 385 derived or compounded from stem word | 602 words |
| 6. Clustering | Clustering of words | 88 clusters |
| Word | Freq |
|---|---|
| Propaganda | 4804 |
| Valeuutinen | 1676 |
| Disinformaatio | 1500 |
| Suomen | 492 |
| Yleuutiset | 461 |
| mariaohisalo | 421 |
| Leviää | 358 |
| Suomessa | 354 |
| Yle | 354 |
| Russia | 334 |
| Dimmu | 328 |
| Persut | 326 |
| propagandaa | 306 |
| Ylen | 287 |
| Saa | 275 |
| Osa | 268 |
| Media | 267 |
| astatenhunen | 267 |
| Pitää | 266 |
| Mm | 255 |
| Uutisankka | 253 |
| Keronen | 249 |
| Amp | 248 |
| Marinsanna | 244 |
| Hsfi | 225 |
| Twitterissä | 217 |
| Venäjän | 216 |
| Hallituksen | 206 |
| Journalismi | 205 |
| Somessa | 197 |
| Topic 1 | Topic 4 | Topic 7 | Topic 10 | Topic 13 |
| propaganda | propaganda | propaganda | propaganda | propaganda |
| mariaohisalo | disinformaatio | valeuutinen | disinformaatio | valeuutinen |
| somessa | valeuutinen | leviää | yle | hai |
| jaa | marinsanna | persut | mariaohisalo | govt |
| valeuutisia | hai | mariaohisalo | kansainvälistä | disinformaatio |
| linkkejä | lapset | disinformaatio | ritken | sanoin |
| sitaatteja | govt | liittyen | ajoista | mattimuukkonen |
| voida | suomen | opparviainen | vietetään | paikassa |
| alkuperää | pitäisi | sisäministeri | synkistä | vaiennus |
| todistaa | yleisradio | sosiaalisi | kansanmurhien | lakia |
| Topic 2 | Topic 5 | Topic 8 | Topic 11 | Topic 14 |
| propaganda | propaganda | propaganda | propaganda | propaganda |
| valeuutinen | disinformaatio | disinformaatio | valeuutinen | valeuutinen |
| disinformaatio | valeuutinen | vaarallista | russia | leviää |
| mariaohisalo | tuli | päivää | suomen | persut |
| leviää | vihapuhe | levinnyt | propagandaa | kuvaa |
| liittyen | mm | syystä | leviää | govt |
| sosiaalisi | pari | pari | disinformaatio | hai |
| sisäministeri | yle | valheellinen | mariaohisalo | disinformaatio |
| opparviainen | suomen | liandersson | the | somealustoilla |
| propagandaa | kuntavaalit | kuvamanipulaa | opparviainen | kannattajia |
| Topic 3 | Topic 6 | Topic 9 | Topic 12 | Topic 15 |
| propaganda | propaganda | propaganda | propaganda | propaganda |
| valeuutinen | disinformaatio | valeuutinen | astatenhunen | valeuutinen |
| disinformaatio | valeuutinen | lakia | susi | kysymyksiä |
| leviää | yleuutiset | sensuuripykälä | disinformaatio | mariaohisalo |
| yleuutiset | russia | mattimuukkonen | valeuutinen | sanna |
| media | toimii | vaiennus | suomen | leviää |
| ylen | korona | mieltä | syy | keronen |
| mariaohisalo | lapset | sanoin | vihreät | nuorten |
| opparviainen | venäjän | paikassa | mm | hallituksen |
| liittyen | suomessa | rikotaan | amp | suulla |
| Main Clusters in English | Quantity of WordManifestations |
|---|---|
| Keyword clusters | |
| 1. Propaganda (Fin. propaganda) | 5706 |
| 2. Fake news (Fin. valeuutinen or fake news) | 2119 |
| 3. Disinformation (Fin. disinformaatio) | 1991 |
| 4. Hoax (Fin. uutisankka) | 256 |
| 5. Misinformation (Fin. misinformaatio) | 198 |
| 6. Lie, Waddle, Truth, Fact (Fin. vale, valhe, huuhaa, totuus, fakta) | 1274 |
| Theme word clusters | |
| 7. Media | 5692 |
| 8. Politics | 3821 |
| 9. Foreign countries | 2769 |
| 10. Politician | 2101 |
| 11. Finland | 1601 |
| 12. Health (corona, vaccination, virus) | 1538 |
| 13. Social media | 1416 |
| 14. Animals | 520 |
| 15. Children and young people | 507 |
| 16. Movements (Qanon, Isis, Elokapina) | 453 |
| 17. Country and World | 340 |
| 18. School | 290 |
| 19. Police | 253 |
| 20. Researcher and Research | 247 |
| 21. Opposition (Fin. vastaisuus) | 228 |
| 22. Hate Speech | 201 |
| The Content of Three Main Clusters in English | Quantity of Manifestations |
| Clusters | |
| Politics | 3821 |
| Finns Party (Fin. persu, persujen, persut, perussuomalaiset, perussuomalaisten, perussuomalaisiin, ps, ps:n) | 848 |
| The Greens and left-wing greens (Fin. vihreät, vihreat, vihreiden, vihreille, vihreiltä, vihreistä, vihreitä, vihreä, vihreän, vihervasemmisto, vihervasemmiston, vihervasemmisto’lainen) | 564 |
| Right-wing (Fin. äärioikeisto, äärioikeistolainen, äärioikeiston, äärioikeis, äärioikeistolaista, äärioikeistollisten) | 384 |
| Government (Fin. hallituksen, hallitus) | 350 |
| Municipal election, election (Fin. kuntavaaliehdokkaat, kuntavaalien, kuntavaalit, kuntavaalit2021, vaalit, vaaleihin, vaaleissa, vaaleja, vaalien | 297 |
| Left-wing (Fin. vasemmisto, vasemmistolainen, vasemmalla, vasemmistolaisuus, vasemmiston, vasemmistopopulismista) | 259 |
| Communism (Fin. kommunismi, kommunisti, kommunistien, kommunistinen, kommunistisen, kommunistista, kommunistit) | 134 |
| Politicians | 2101 |
| The prime minister (Fin. marin, marinin, marinia, marinista, marinsanna, sanna, pääministeri, pääministeriltä) | 898 |
| Minister of the Interior (Fin. mariaohisalo, ohisalo, ohisalon, ohisalosta, sisäministe, sisäministeri) | 705 |
| Foreign countries | 2769 |
| Russia (Fin. venäjä, venäjän, venäjällä, venäjä’n, venäläinen, venäläispropagandistien, russia, russian, russians) | 867 |
| Trump (Fin. trump, trumpin, trumpia, trumppia) | 409 |
| EU (Fin. eu, eu:n, eu’n, euroopan) | 326 |
| USA (Fin. usa, usa:n, usan, usa:ssa, usassa, usavaalit, yhdysvallat, yhdysvalloissa, yhdysvaltain) | 237 |
| China (Fin. kiina, kiinaa, kiinan, kiinassa, ürümqi) | 225 |
| Sweden (Fin. ruotsin, sek) | 104 |
| Putin (Fin. putin, putinin) | 98 |
| Soviet Union (Fin. neuvostoliitto, neuvostoliiton) | 63 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jussila, J.; Suominen, A.H.; Partanen, A.; Honkanen, T. Text Analysis Methods for Misinformation–Related Research on Finnish Language Twitter. Future Internet 2021, 13, 157. https://doi.org/10.3390/fi13060157
Jussila J, Suominen AH, Partanen A, Honkanen T. Text Analysis Methods for Misinformation–Related Research on Finnish Language Twitter. Future Internet. 2021; 13(6):157. https://doi.org/10.3390/fi13060157
Chicago/Turabian StyleJussila, Jari, Anu Helena Suominen, Atte Partanen, and Tapani Honkanen. 2021. "Text Analysis Methods for Misinformation–Related Research on Finnish Language Twitter" Future Internet 13, no. 6: 157. https://doi.org/10.3390/fi13060157
APA StyleJussila, J., Suominen, A. H., Partanen, A., & Honkanen, T. (2021). Text Analysis Methods for Misinformation–Related Research on Finnish Language Twitter. Future Internet, 13(6), 157. https://doi.org/10.3390/fi13060157