
Person Re-Identification Based on Attention Mechanism and Context Information Fusion



Abstract
1. Introduction
- The method based on feature representation is to perform person ReID tasks by learning a network that can extract significant features of pedestrians. Generally, there are three types of features used for person ReID: global feature, local feature, and auxiliary feature. Zheng et al. [6] regards the pedestrian feature extraction as a classification task, and they train the CNN network by using the pedestrian ID as the label of data. Luo et al. [7] proposed a person ReID network using only global features in order to avoid the excessive complexity of network structure. Ye et al. [8] design a new powerful method called AGW (Attention Generalized mean pooling with Weighted triplet loss), which also uses only the global feature of pedestrians, but achieves competitive results. Wu et al. introduced a reverse attention module to handle the problem that the attention mechanism may lead to the loss of important information [9]. Moreover, some researchers are not satisfied with the information contained in global features, so local feature representation learning is proposed. Zhang et al. [10] apply local feature, and address body misalignment problem by design a two-stream network that uses fine grained semantics. To avoid the problem of missing body parts for pedestrians, Fu et al. propose a Horizontal Pyramid Matching (HPM) approach to make full use of pedestrian body parts [11]. To further improve the robustness of person ReID model, some auxiliary information is used to train the model. For example, Attribute Attention NetWork (AANet) is a novel model that combines person attributes with attribute attention maps [12]. In addition to pedestrian attribute information, viewpoint is also a common auxiliary information. Viewpoint-Aware Loss with Angular Regularization (VA-reID) [13] takes into account not only the viewpoint, but also the relationship between different viewpoints. Another popular solution is to combine multiple features for person ReID. Li et al. [14] learn the global and local characteristics of pedestrians by a multi-scale context awareness network (MSCAN) and spatial transformation network (STN). Guo et al. [15] introduce channel and spatial attention mechanism to learn pedestrian characteristics. Harmonious attention network (HAN) [16] framework is designed to solve the high cost of calculation and lengthy inference process, which applies global-local representation learning and combines attention mechanisms.
- The method based on deep metric learning uses CNN to learn the similarity of different pedestrian images, so that the similarity of the same type of pedestrian images is greater than that of different type of pedestrian images. Increasingly, researchers design different kinds of loss function to guide the feature representation learning. Shi et al. [17] train the network by using triplet loss, triplet loss function can make the relative distance of positive sample pairs smaller than that of negative sample pairs. Cheng et al. [18] improve the triplet loss, taking the absolute distance between positive and negative pedestrian samples into account. Xiao et al. [19] present a method of mining difficult samples, using the most dissimilar positive samples and the most similar negative samples to train the network. The combination of multiple loss function is also a common solution. Ye et al. trained visible thermal person ReID model by combing ranking loss and identity loss [20].
- For the first time, we introduce the ECA attention module in the person ReID task. The ECA attention module increases the accuracy of person ReID tasks while only increasing a few network parameters.
- We design a multi-scale information fusion module, which effectively integrates pedestrian context information and enhances pedestrian feature representation.
- We jointly train the model with MSML and cross entropy loss, so that the robustness of the model is enhanced. Experimental results show that the model we designed performs well on the dataset Market1501 and DukeMTMC-reID, surpasses most mainstream person ReID method in case of only using global feature.
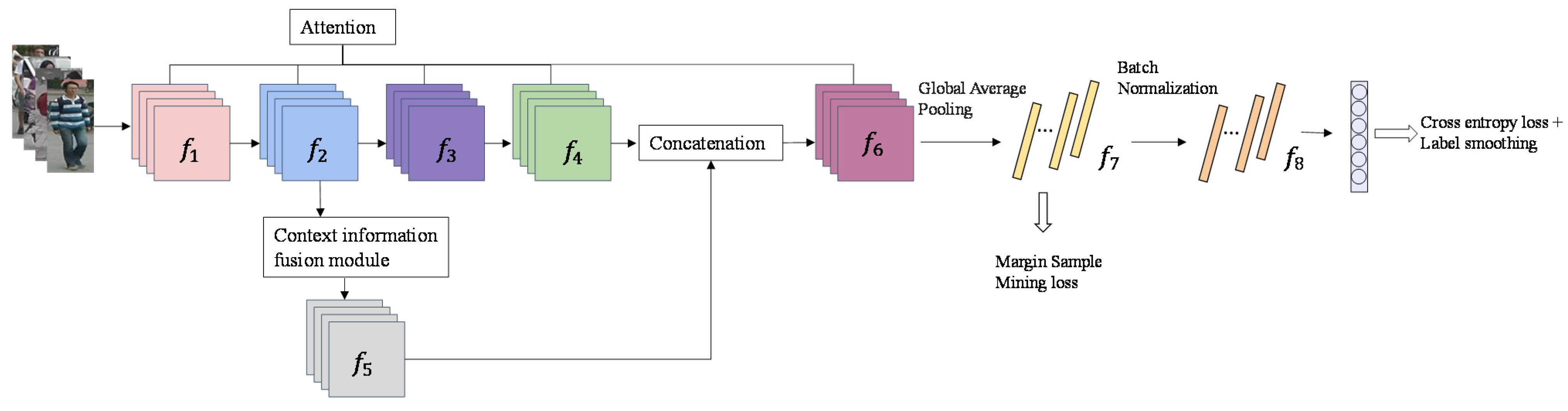
2. Methods
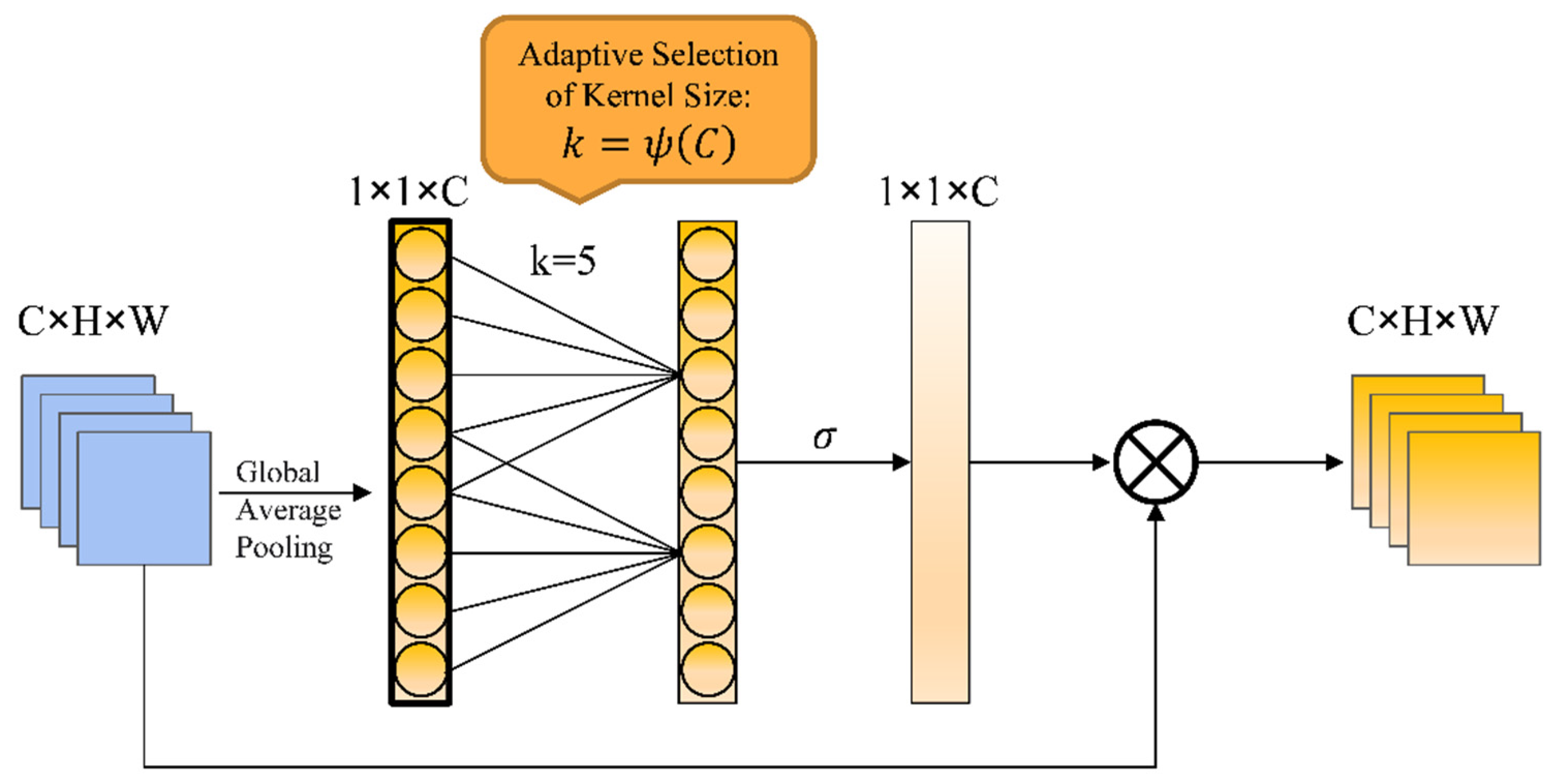
2.1. Channel Attention Module to Improve the Network
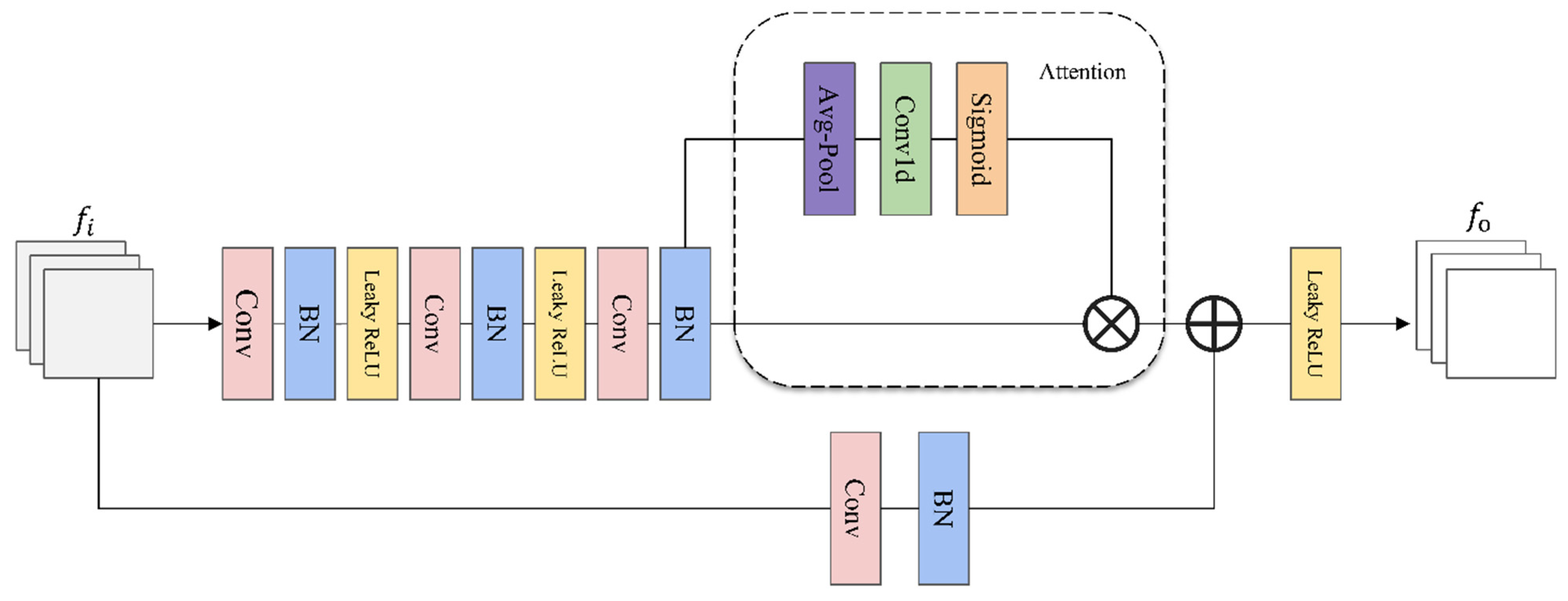
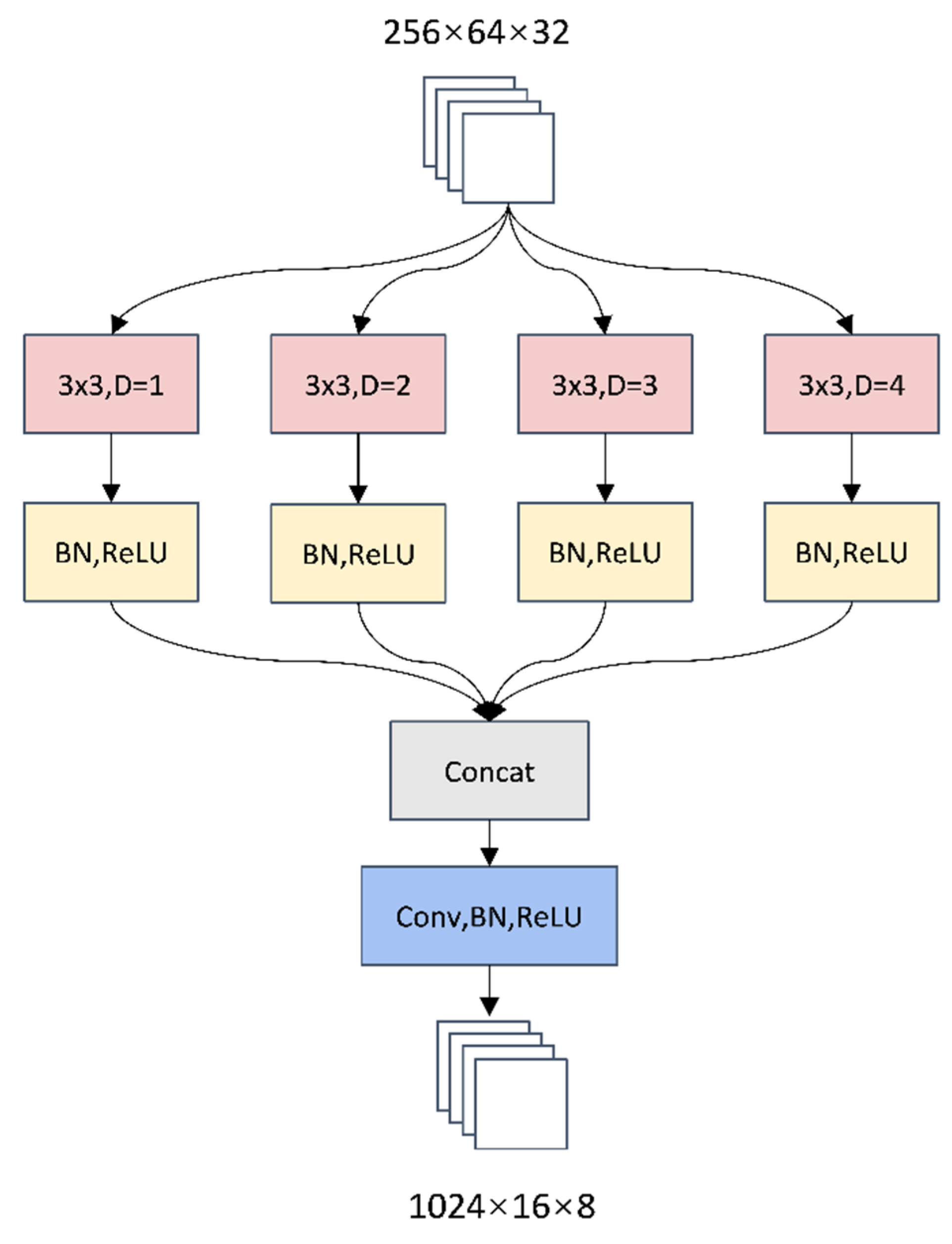
2.2. Multi-Scale Information Fusion Module
2.3. Loss Function
2.3.1. Margin Sample Mining Loss
2.3.2. Cross Entropy Loss
2.3.3. Joint Loss Function
3. Experiment
3.1. Datasets and Evaluation Metrics
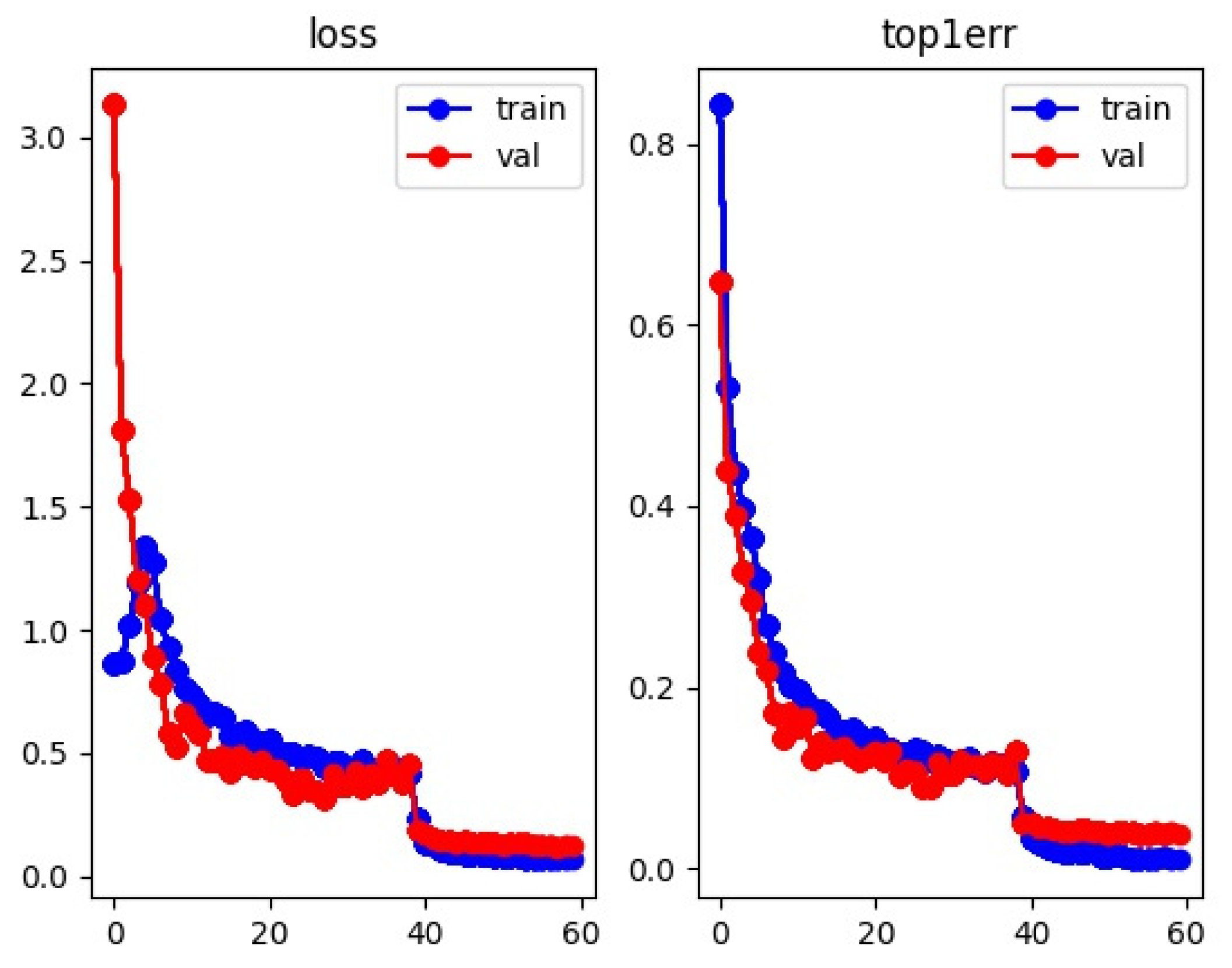
3.2. Experimental Details
3.3. Experimental Results
3.3.1. Ablation Study
3.3.2. Comparison with Mainstream Methods
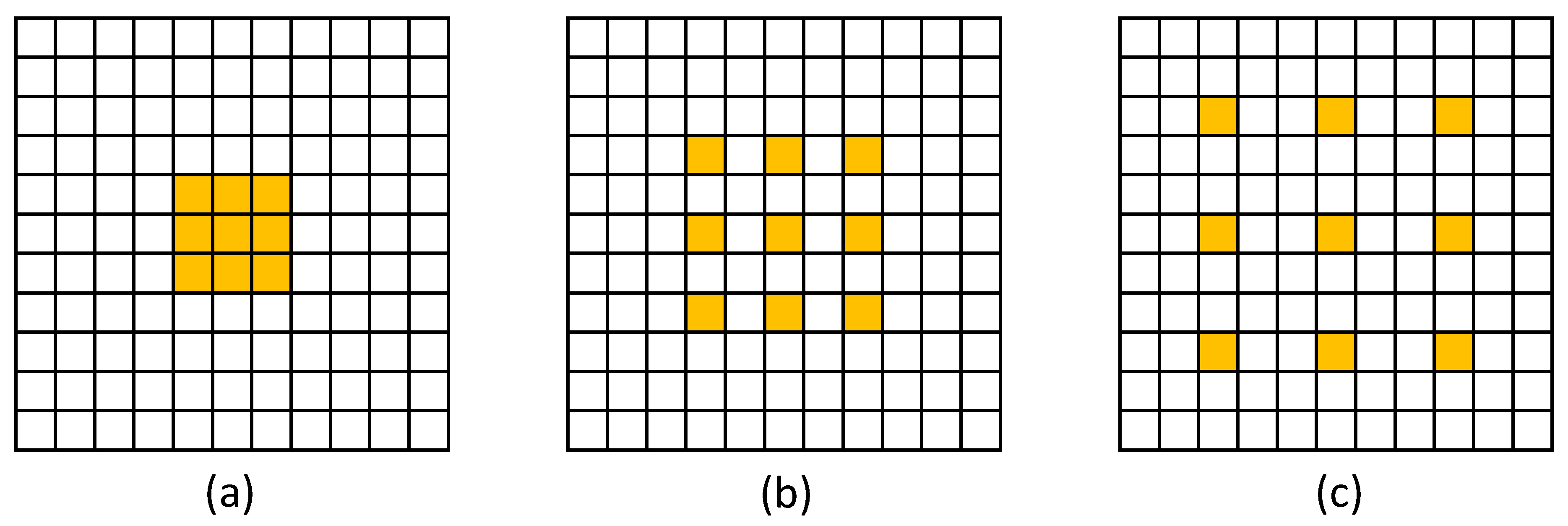
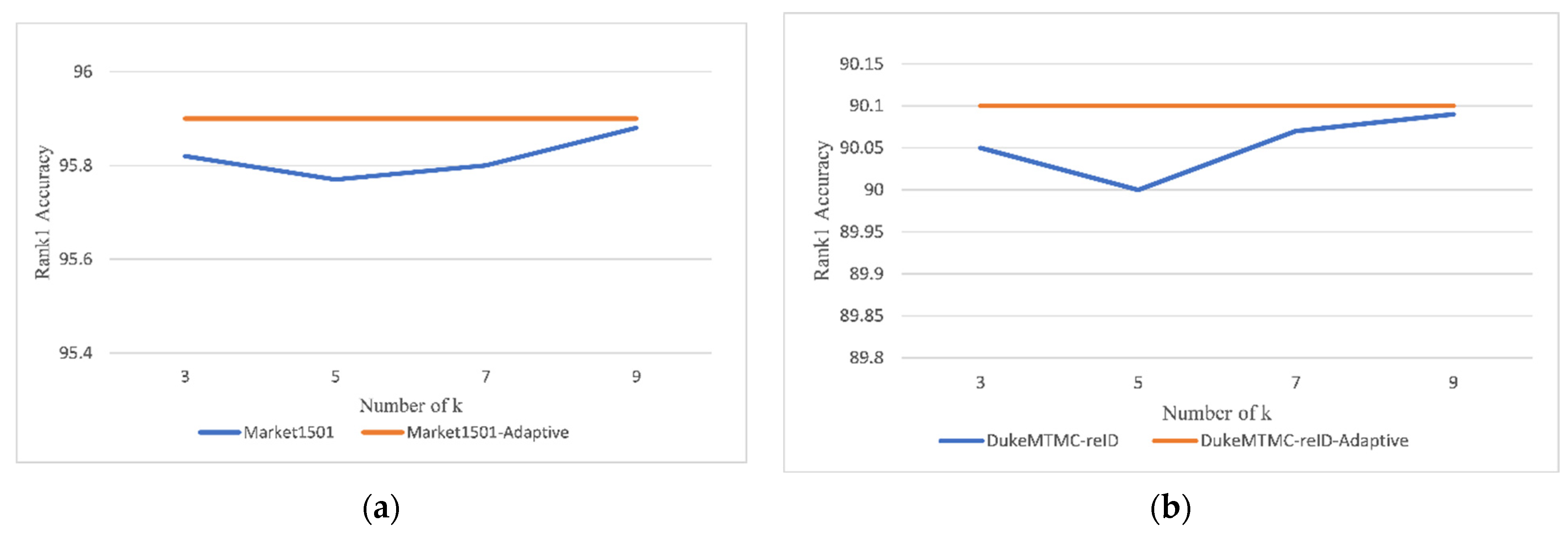
3.3.3. Effect of Kernel Size (k) on Our Model
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, H.; Du, H.; Zhao, Y.; Yan, J. A comprehensive overview of person re-identification approaches. IEEE Access 2020, 8, 45556–45583. [Google Scholar] [CrossRef]
- Jiang, M.; Li, Z.; Chen, J. Person Re-Identification Using Color Features and CNN Features. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 20 March 2019; pp. 460–462. [Google Scholar]
- Zhang, L.; Xiang, T.; Gong, S. Learning a discriminative null space for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June 2016; pp. 1239–1248. [Google Scholar]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person re-identification by local maximal occurrence representation and metric learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 12 June 2015; pp. 2197–2206. [Google Scholar]
- Zhao, R.; Ouyang, W.; Wang, X. Learning mid-level filters for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 28 June 2014; pp. 144–151. [Google Scholar]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person re-identification: Past, present and future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Luo, H.; Jiang, W.; Gu, Y.; Liu, F.; Liao, X.; Lai, S.; Gu, J. A strong baseline and batch normalization neck for deep person re-identification. IEEE Trans. Multimed. 2019, 22, 2597–2609. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. arXiv 2021, arXiv:2001.04193. [Google Scholar]
- Wu, D.; Wang, C.; Wu, Y.; Wang, Q.C.; Huang, D.S. Attention deep model with multi-scale deep supervision for person re-identification. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 70–78. [Google Scholar] [CrossRef]
- Zhang, Z.; Lan, C.; Zeng, W.; Chen, Z. Densely semantically aligned person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 667–676. [Google Scholar]
- Fu, Y.; Wei, Y.; Zhou, Y.; Shi, H.; Huang, G.; Wang, X.; Huang, T. Horizontal pyramid matching for person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 1 February 2019; Volume 33, pp. 8295–8302. [Google Scholar]
- Tay, C.P.; Roy, S.; Yap, K.H. Aanet: Attribute attention network for person re-identifications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7134–7143. [Google Scholar]
- Zhu, Z.; Jiang, X.; Zheng, F.; Guo, X.; Huang, F.; Sun, X.; Zheng, W. Aware Loss with Angular Regularization for Person Re-Identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–8 February 2020; Volume 34, pp. 13114–13121. [Google Scholar]
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Learning deep context-aware features over body and latent parts for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 384–393. [Google Scholar]
- Guo, T.; Wang, D.; Jiang, Z.; Men, A.; Zhou, Y. Deep network with spatial and channel attention for person re-identification. In Proceedings of the 2018 IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018; pp. 1–4. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Scalable Person Re-Identification by Harmonious Attention. Available online: https://link.springer.com/content/pdf/10.1007/s11263-019-01274-1.pdf (accessed on 8 March 2021).
- Shi, H.; Yang, Y.; Zhu, X.; Liao, S.; Lei, Z.; Zheng, W.; Li, S.Z. Embedding deep metric for person re-identification: A study against large variations. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 732–748. [Google Scholar]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person re-identification by multi-channel parts-based cnn with improved triplet loss function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 1335–1344. [Google Scholar]
- Xiao, Q.; Luo, H.; Zhang, C. Margin sample mining loss: A deep learning based method for person re-identification. arXiv 2017, arXiv:1710.00478. [Google Scholar]
- Ye, M.; Lan, X.; Wang, Z.; Yuen, P.C. Bi-directional center-constrained top-ranking for visible thermal person re-identification. IEEE Trans. Inf. Forensics Secur. 2019, 15, 407–419. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Con-ference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global second-order pooling convolutional networks. In Proceedings of the IEEE/CVF Con-ference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3024–3033. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Vedaldi, A. Gather-excite: Exploiting feature context in convolutional neural networks. arXiv 2018, arXiv:1810.12348. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Recalibrating fully convolutional networks with spatial and channel “squeeze and excitation” blocks. IEEE Trans. Med Imaging 2018, 38, 540–549. [Google Scholar] [CrossRef] [PubMed]
- Qilong, W.; Banggu, W.; Pengfei, Z.; Peihua, L.; Wangmeng, Z.; Qinghua, H. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 2818–2826. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13 December 2015; pp. 1116–1124. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 17–35. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–8 February 2020; Volume 34, pp. 13001–13008. [Google Scholar]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking person re-identification with k-reciprocal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017; pp. 1318–1327. [Google Scholar]
- Chen, W.; Chen, X.; Zhang, J.; Huang, K. Beyond triplet loss: A deep quadruplet network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017; pp. 403–412. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Zhao, L.; Li, X.; Zhuang, Y.; Wang, J. Deeply-learned part-aligned representations for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3219–3228. [Google Scholar]
- Xu, J.; Zhao, R.; Zhu, F.; Wang, H.; Ouyang, W. Attention-aware compositional network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 23 June 2018; pp. 2119–2128. [Google Scholar]
- Wang, C.; Zhang, Q.; Huang, C.; Liu, W.; Wang, X. Mancs: A multi-task attentional network with curriculum sampling for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 365–381. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # Image | # ID | # Train | # Validation | # Test |
|---|---|---|---|---|---|
| Market1501 | 32,688 | 1501 | 751 | 751 | 750 |
| DukeMTMC-reID | 36,411 | 1404 | 702 | 702 | 702 |
| Baseline | Baseline + L1 | Baseline + L1 + L2 | Baseline + L1 + L2 + L3 | |
|---|---|---|---|---|
| Rank-1 | 91.8 | 93.1 | 94.5 | 95.2 |
| mAP | 81.8 | 84.7 | 86.1 | 87.1 |
| Baseline | Baseline + L1 | Baseline + L1 + L2 | Baseline + L1 + L2 + L3 | |
|---|---|---|---|---|
| Rank-1 | 82.6 | 85.3 | 86.4 | 88.9 |
| mAP | 70.5 | 74.1 | 76.9 | 78.5 |
| Type | Method | Rank-1 | mAP |
|---|---|---|---|
| Traditional methods | XQDA [4] | 43.0 | 21.7 |
| NPD [3] | 55.4 | 30.0 | |
| Deep metric learning | Quad [33] | 80.0 | 61.1 |
| TriNet [17] | 84.9 | 69.1 | |
| MSML [19] | 85.2 | 69.6 | |
| Local feature | PCB [34] | 92.3 | 77.4 |
| PAN [35] | 81.0 | 63.4 | |
| DSA [10] | 95.7 | 87.6 | |
| HPM [11] | 94.2 | 82.7 | |
| Global-local feature | MSCAN [14] | 80.3 | 57.5 |
| HAN [16] | 93.1 | 89.6 | |
| Auxiliary feature | AACN [36] | 85.9 | 66.9 |
| AANet [12] | 93.9 | 83.4 | |
| Global feature | IDE [6] | 81.9 | 61.0 |
| Mancs [37] | 93.1 | 82.3 | |
| BagTricks [7] | 94.5 | 85.9 | |
| ADMS [9] | 95.5 | 89.0 | |
| Ours | 95.2 | 87.1 | |
| Ours + Re-ranking | 95.9 | 94.5 |
| Type | Method | Rank-1 | mAP |
|---|---|---|---|
| Traditional approaches | XQDA [4] | 31.2 | 17.2 |
| NPD [3] | 46.7 | 27.3 | |
| Deep metric learning | Quad [33] | 73.4 | 58.0 |
| Local feature | PCB [34] | 81.7 | 66.1 |
| PAN [35] | 71.6 | 51.5 | |
| DSA [10] | 86.2 | 74.3 | |
| HPM [11] | 86.6 | 74.3 | |
| Global-local feature | HAN [16] | 84.6 | 81.3 |
| Auxiliary feature | AACN [36] | 76.8 | 59.3 |
| AANet [12] | 87.6 | 74.2 | |
| Global feature | Mancs [37] | 84.9 | 71.8 |
| BagTricks [7] | 86.4 | 76.4 | |
| ADMS [9] | 89.4 | 79.2 | |
| Ours | 88.9 | 78.5 | |
| Ours + Re-ranking | 90.1 | 89.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Zhang, H.; Lei, Z. Person Re-Identification Based on Attention Mechanism and Context Information Fusion. Future Internet 2021, 13, 72. https://doi.org/10.3390/fi13030072
Chen S, Zhang H, Lei Z. Person Re-Identification Based on Attention Mechanism and Context Information Fusion. Future Internet. 2021; 13(3):72. https://doi.org/10.3390/fi13030072
Chicago/Turabian StyleChen, Shengbo, Hongchang Zhang, and Zhou Lei. 2021. "Person Re-Identification Based on Attention Mechanism and Context Information Fusion" Future Internet 13, no. 3: 72. https://doi.org/10.3390/fi13030072
APA StyleChen, S., Zhang, H., & Lei, Z. (2021). Person Re-Identification Based on Attention Mechanism and Context Information Fusion. Future Internet, 13(3), 72. https://doi.org/10.3390/fi13030072