1. Introduction
Noninvasive methods of medical imaging have gained much in popularity with the increasing resolution of image acquisition and new possibilities to acquire volumetric images. These technological changes have led to an increase in the accuracy of patient diagnosis, without the need for invasive checks. There are currently different image segmentation methods, but most of them only consider two-dimensional images. Segmentation involves identifying, individualizing, or isolating one or more regions in the image, based on a uniform characteristic of the region in question. Thus, three-dimensional segmentation, analogous to two-dimensional segmentation, involves isolating a volume. Segmentation can be used in this case, for the automatic or semiautomatic identification of the coronary anatomy in the sequence of images produced by the computed tomography (CT). It can also be used to automatically identify lesions and extract their features, such as geometry or volume.
The mesh-type coronary model can be employed for operations such as determining the degree of blockage of the vessel, determining positive remodeling [
1] (if the vessel has changed shape due to differences in dynamic pressure caused by injury to the vessel), and measuring distances along the vessel. Recent reconstruction models have come to the performance of simulating fluid dynamics [
2,
3]. The problems of three-dimensional reconstruction are the identification of the artifacts introduced by the tomograph and the introduction of a priori knowledge specific to the scanned area.
When it comes to volumetric medical image interpretation, algorithms could help to reduce the variability between observers having different experience levels in searching for features in volumetric images [
4]. Information such as automatic or semiautomatic detection of lesions, plaques, positive remodeling, and calculation of fractional flow reserve (FFR) are targeted for extraction. Once obtained, they can be presented to the specialist in the form of statistics, annotations, and highlights on the model. Vessel segmentation is a prerequisite in the automated pipeline of diagnosis for vascular-related diseases [
5]. Accurate detection of coronary artery diseases (CAD) can be achieved by combining the results of machine learning and image-based morphological feature extraction [
6].
Assigning labels to voxels in biomedical applications has been a cornerstone in medical image processing, with most of the fully automated segmentation techniques being atlas based, in which a set of expert presegmented cases stand as a pillar for high-accuracy results [
7].
The proposed method presented in this paper is a machine learning centerline extraction algorithm that uses a proposed 3D adaptation of the U-NET architecture, which outputs the probability for each voxel of a full volume to be part of a vessel centerline. Additionally, based on an extensive state-of-the-art review, an adapted loss function was proposed to handle sparse annotation, meaning that not all the centerlines are part of the ground truth of the dataset and class imbalance since very few voxels from an entire volume belong to a centerline.
The paper is organized as follows:
Section 2 provides a brief description of the current state of the art methods in coronary centerline extraction, followed by
Section 3 presenting our approach using a 3D-UNET neural network; based on data publicly available, the obtained results are illustrated in
Section 4 and discussed in
Section 5, together with the final conclusions presented in the last section.
2. Related Research
Vessel centerlines can be extracted by either a segmentation and thinning pipeline [
8] or by direct tracking [
8]. The extracted centerlines can serve as input for tracking algorithms for segmenting the required vessel tree. In [
9], the authors proposed Bayesian tracking combined with sphere fitting for segmentation. Vessel branching is performed using statistical models with three categories: locally disconnected vessel (disappearance in some of the slices in the cardiac computed tomography angiography CCTA), locally disconnected branch, and branch occurrence (domain-specific knowledge about coronary vessels). An example of sphere fitting to obtain vessel segmentation starting from centerlines can be seen in Figure 11 from [
9]. In [
10], the lumen segmentation was performed by tracking, using a minimal cost path based on a cost function with prior model information on three measurable parameters: vesselness measure, intensity similarity, and directional information.
Tree-structured segmentation was also achieved in [
11] using the centerline extracted using a deep learning approach. A tree-structured convolutional gated recurrent unit network was trained for tracking segmentation and achieves good results, especially at vessel bifurcations.
Another method for vessel segmentation using a centerline constrained level set method was proposed in [
12]. It improves on two active contour models, Chan–Vase and curve evolution for vessel segmentation, by integrating the centerline into the set evolution, as shown in Figure 13 from [
10]. There are two major categories of vessel and centerline segmentation methods—rule based and machine learning based.
2.1. Rule-Based Centerline Extraction
Dynamic programming of coronary borders was used in [
13] for centerline extraction, with a prior localization of the aorta using the Hough transform, followed by a registration step of the borders in many cross-sectional images.
A fully automated centerline extraction was proposed in [
14]. The pipeline proposed includes preprocessing by multiscale vessel enhancement filtering and then using a tracking algorithm based on an automatic acquisition of an initial point and direction, combined with forward and backward ridge positioning.
Another centerline extractor starting from segmented vessels was described in [
15], in which the authors compute a 3D gradient vector flow field that is then used to compute a timetable of arrival times from one point to another. Combined with a branch tracing algorithm and a measure function for vesselness, the centerlines were extracted in about 16 min of processing time.
2.2. Machine Learning-Based Centerline Extraction
A single voxel wide centerline extraction was implemented in [
16]. It employs a fully convolutional neural network (FCN), which generates distance maps and detects branch endpoints. A distance map is a volume with each voxel representing the probability that a voxel belongs to the centerline, proportional to the distance from the true centerline. Using this information, a minimal path extractor given a root point can extract the centerline tree.
A state-of-the-art convolutional neural network (CNN) for automatic centerline extraction using an orientation classifier was implemented in [
17]. Here, the authors feed the network small patches of size 19 × 19 × 19 (which is a rather small context). The architecture of the network compensates for the small input size by using dilation convolution kernels. The output of the network is a quantized direction of the centerline of the vessel in the patch and also the radius of the vessel. Generating a full centerline relies on an initial point placed anywhere inside the vessel. Using this, a tracking algorithm iteratively feeds patches in the network and constructs the centerline. The tracking stops when the confidence of the output direction is below a given threshold. Due to the nature of the tracking algorithm, it would seem that a CNN with recurrent layers [
18] was a missed opportunity. This work was extended in [
19] by improving bifurcation detection. The bifurcation angle is an important feature in CAD classification [
6].
Machine learning was combined in a hybrid approach with global geometry learning in [
20] in order to improve the connectivity of the result of a CNN. Geometry-aware grouping was also added to improve the continuity of the vessel tree further.
3. Proposed Method
3.1. Neural Network Architecture
The idea for creating a 3D U-Net network came after observing the results of U-Net convolutional networks for biomedical image segmentation [
21], which allowed a fully convolutional neural network to provide a good segmentation even when trained with a small training dataset. Additionally, the belief was further consolidated when observing the results of the U-Net applied for liver segmentation and vessel exclusion [
22], and for retina vessel segmentation, a similar task of centerline segmentation was conducted. The work on retina vessel segmentation was refined many times, in several papers [
23,
24,
25].
A similar extension of the network architecture to 3D was also presented in [
26], for Xenopus kidney segmentation, in which the ground truth segmentation was completed after training using sparse annotation. This is, in a way, similar to the annotation for the dataset used in this paper, where not every vessel is annotated, and the network needs to learn to extrapolate the provided cases. Another variation of the 3D U-Net was introduced in [
27] for multiple organ segmentation tasks.
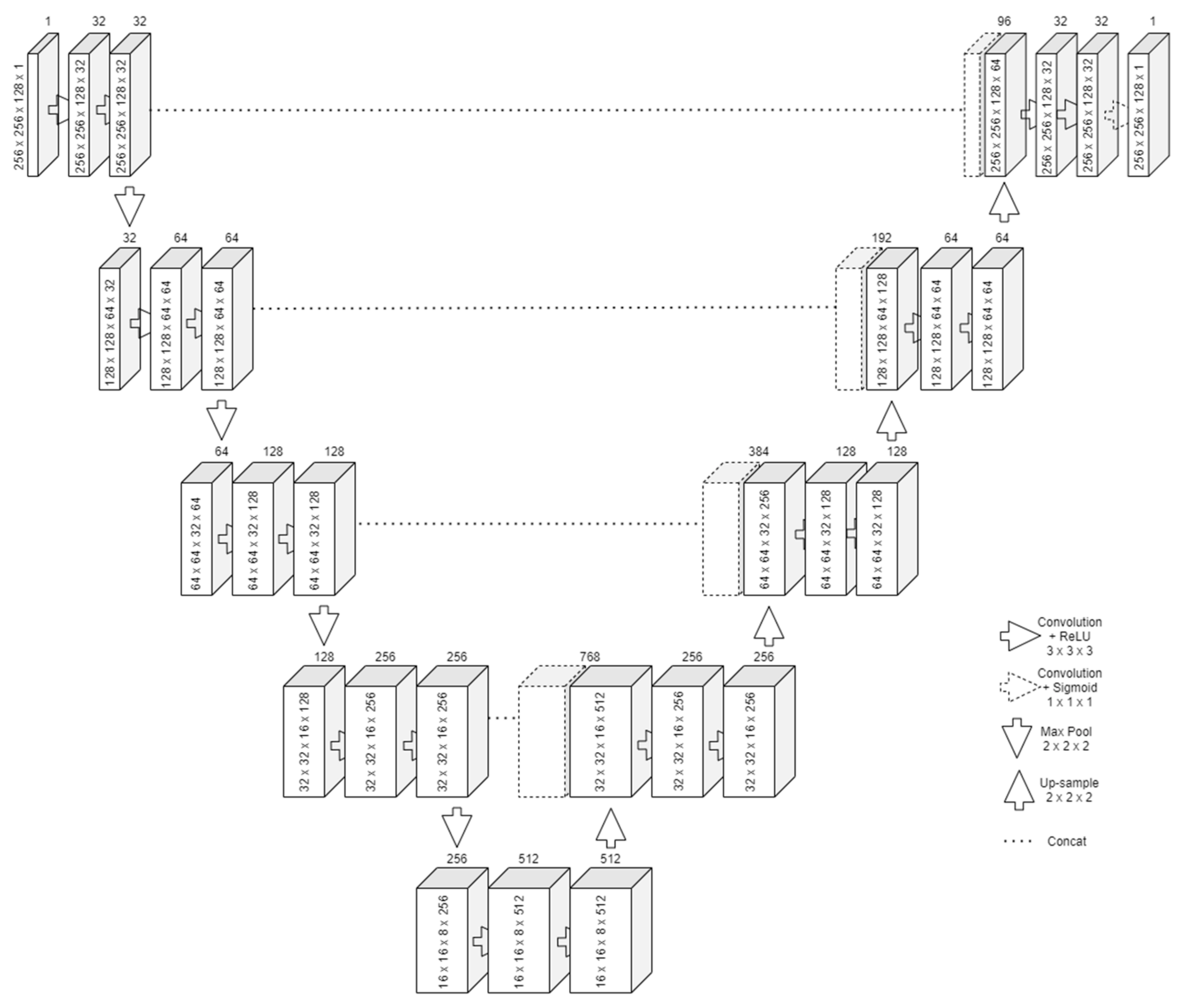
The design of the U-Net follows two important steps, similar to an autoencoder network. The first one is contraction, in which successive rounds of two convolutions and a max pooling to reduce the output size by half are applied on the input, as presented in
Figure 1. For each round, the number of filters for the convolution is doubled. The bottom layer will have the most feature maps but will also be the smallest in size. Its purpose is to learn an encoded representation of what it needs to be segmented. The convolution with 3 × 3 × 3 kernels means that one pixel from all the borders will be lost. To alleviate this problem, padding was employed.
The second one is expansion. Starting from the bottom layer, successive rounds of upsampling, concatenate, and two convolutions (also with padding) are applied. The upsampling resizes the feature vector. Along with the information concatenated from the same-size input of the contraction, the two convolutions can reconstruct the image in its original size. Transposed convolution can be used as an operation instead of upsampling. However, this leads to an increased number of parameters to train.
After the last expansion, another convolution is applied with the number of kernels equal to the number of features to extract. Since centerline extraction aims for binary segmentation, only one last kernel with a sigmoid activation function was required.
The loss function is chosen such that the segmentation behaves similarly to a pixel-wise classification function.
3.2. Resize or Patches
The limited amount of the memory of the GPU puts one in the impossibility of feeding an entire CT volume to a neural network. In 2D images, memory is not a problem, even when working with large batches. In 3D, the equivalent would be as if feeding more than 500 images at once in a network.
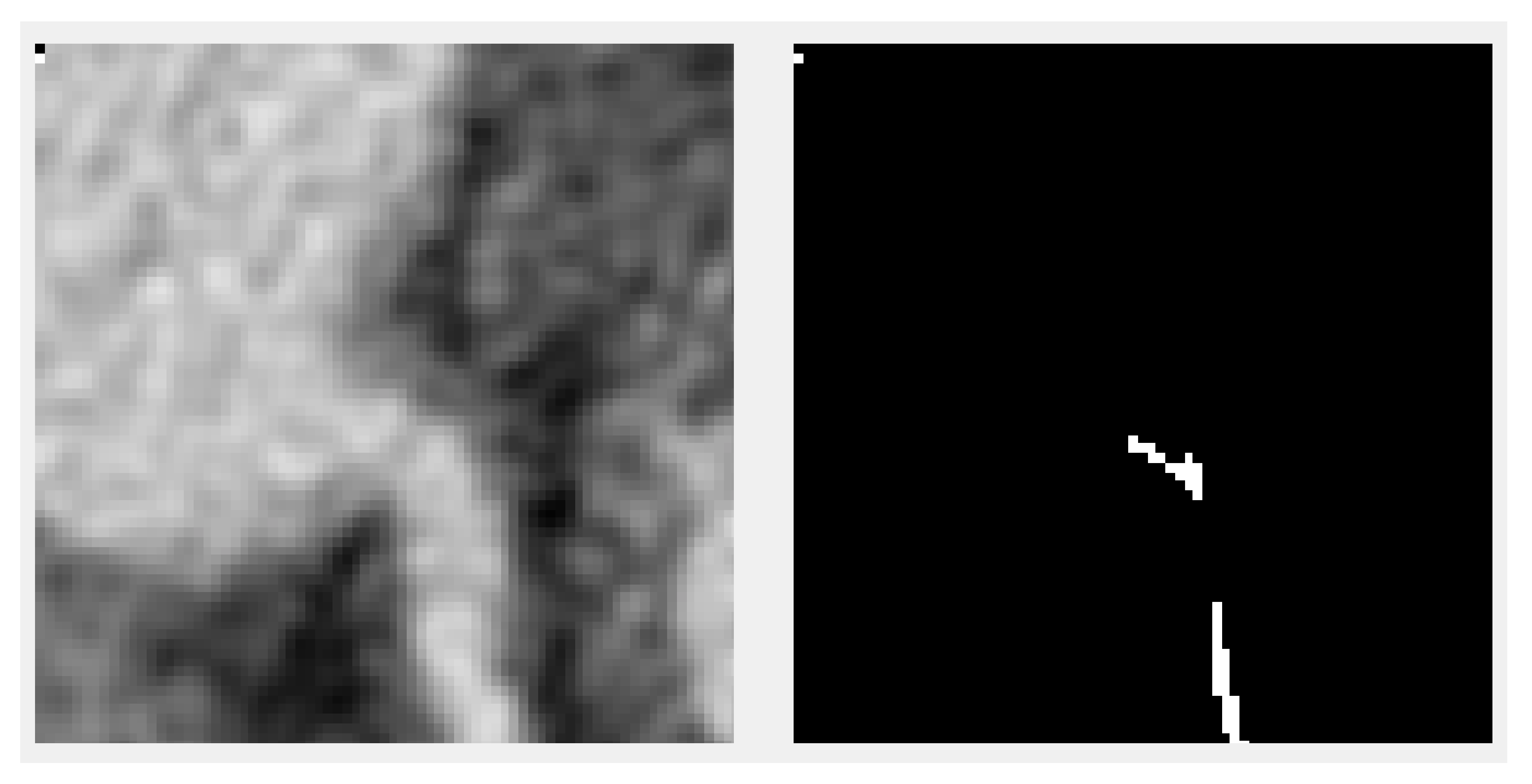
Our first approach was to resize the volumes (and the ground truth) to a volume that would be small enough to fit in the video RAM but large enough not to lose the details needed for segmentation. The first drawback was that the volumes from the benchmark did not come in a standard size. The X- and Y-axis were always of size 512, but the Z-axis ranged from 272 to 388. This meant that the aspect ratio after any resize to a fixed value would not be constant. Another important loss would be the impossibility to have augmentation under the given circumstances since even the 90-degree rotations would cause big ratio changes. The second drawback of this method was the loss of precision when upscaling. Extracting the centerline would imply getting as good a precision as possible since the vessel fitting algorithms that take as input a centerline depend on this accuracy. Upscaling precision loss can be observed in
Figure 2, in which the ground truth centerline is discontinuous and inhomogeneous. Any algorithm without 100% precision would result in something even worse. Training the model using resizing posed problems with the dataset being too small.
A second approach was proposed to divide the input into smaller patches, cutting only small parts of the volume (and the ground truth) and feeding them to the network. An example slice of a patch together with the associated ground truth is shown in
Figure 3. This method does not have any of the downsides of the previous one but introduces a different one—the lack of context. Therefore, a tradeoff is reached between increasing the patch size so that the available contextual information for the model is enough to make a good prediction and the size of the model so that the model is large enough to capture the correlations about where the centerline is positioned and that it should be continuous and also cross the patches.
3.3. Loss Functions
Training neural networks means finding good parameters that make the network approximate a given objective function. For classification tasks, having good accuracy is an objective. For image segmentation tasks, good average pixel-wise classification accuracy could be an objective.
For gradually adjusting weights during the training, a loss function is required. The purpose of the training is to minimize the loss function gradually. A loss function should be chosen to quantify how much and in what direction to adjust the parameters such that on the next iteration, the outputs are closer to the objective.
For image segmentation, numerous loss functions have been proposed in the literature. Some of the existing loss functions for binary segmentation tasks are enumerated here. A new combined loss function that fits the objective of segmenting centerlines is proposed here.
3.3.1. Local Loss
Cross entropy (CE) is defined as follows:
The predicted pixel class is the result of a sigmoid and is interpreted as a probability of belonging to a class. It is then compared with the true class (from the ground truth). Logistic regression is obtained using this loss function.
Weighted cross entropy (WCE) is defined similarly to the cross entropy but adds a coefficient for the positive examples as follows:
It serves in the case of class imbalance in the training dataset. The training might not converge in these cases. The β param controls the expected number of false positives or negatives.
Balanced cross entropy (BCE) is another variation that adds the coefficient for positive examples and the inverted coefficient for negative examples as follows:
Focal loss, introduced in [
28] for dense object detection, aims to reduce the problem of huge class imbalances, in which the cross-entropy loss or any of its variations is not enough to achieve stable training. It downweights the “easy” examples to allow training on the rare events, thus the name of focal loss. It is also derived from the cross entropy but adds a focusing parameter γ.
Another variation called
class balanced focal loss was introduced in [
29].
3.3.2. Global Loss
Dice loss (DL) aims to optimize the F1 score, defined as
which is the harmonic mean between precision and recall. It is considered an overlap measure, as with the Jaccard index. The loss function can be written as
where
and
.
Balanced dice loss (BDL), also known as Tversky loss, adds a
β param to control the expected number of false positives or negatives. It is defined as follows:
3.3.3. Combined Loss Functions
If none of the simple loss functions fits the objective of the neural network, or if the training does not converge, multiple standard loss functions can be combined. An example would be combining a dice coefficient loss with the cross-entropy loss.
To do that, the cross entropy, which outputs individual pixel loss values (called local information), needs to be summed with a loss function on the level of the entire image (called global information). The global loss can be spread to local losses or
the local losses can be averaged.
Distance to the border of the nearest cell (DNC) was introduced for U-Net segmentation in [
21]. It combines cross entropy with an averaged distance function for a positive class to the border of two nearest cells. Morphological operations are applied to the image beforehand to compute the border map in the training dataset. The distance to the cells is defined as
and the loss function as
For the U2-Net segmentation [
27], a loss function combining Lovász–Softmax (an overlap measure) with the focal loss was used.
3.3.4. Proposed Loss Function
None of the above-mentioned loss functions fit the specifics of our dataset. A function to work with sparsely annotated centerlines is needed, meaning that examples would be contradictory, and at the same time, with a huge class imbalance.
The proposed function is a combination between the focal loss and a simple overlap loss. The overlap loss, defined as follows:
which ensures the stability of the training in spite of the contradicting examples. The focal loss was the only loss with enough power to ignore the huge accuracy of choosing the “easy” example. The focal loss was used with the proposed parameters from the original paper γ = 2 and α = 0.25.
3.4. Generating the Full Output
Since the model takes the input in the shape of patches, it cannot make predictions using a full 3D volume. The simple solution employed was to split the input into blocks of the shape of the patch, pass each of the blocks through the model, and recombine the predictions into a full 3D volume again. If the prediction is qualitative, no artifacts are detected at the border of the combined patches when a segmentation threshold is set.
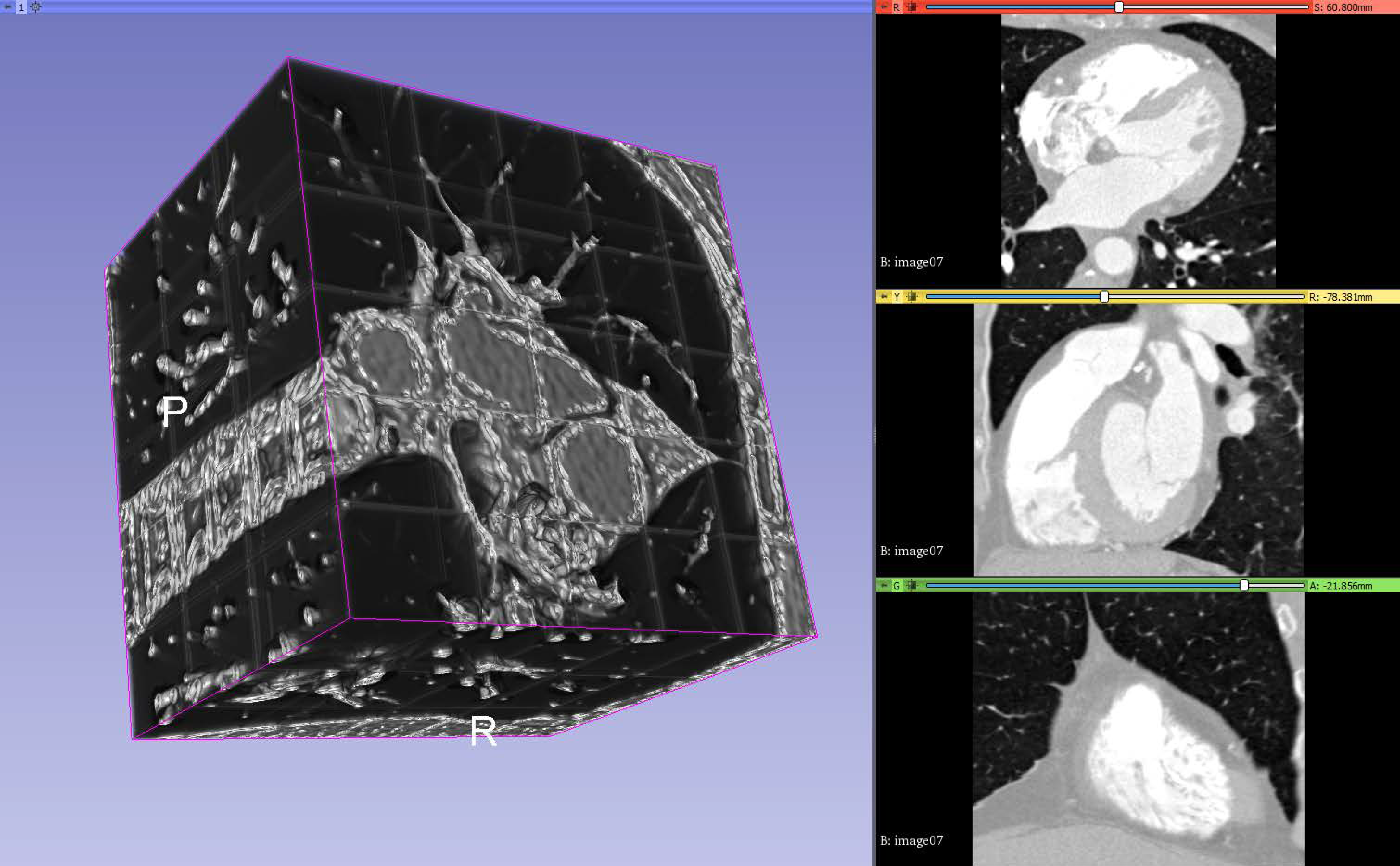
The result is exported as a 3D volume in the same format as the input volumes and generated input masks so that it can be loaded by similar software. One can observe in
Figure 4 the output volume composed of patches, in which the threshold is lowered to make it clear where the patches meet.
4. Experimental Results and Discussion
4.1. Coronary Dataset
To test the implementation of the proposed neural network, we chose the dataset from the Rotterdam Coronary Artery Algorithm Evaluation Framework [
30]. This is a public benchmark to evaluate algorithms for the task of centerline extraction from CCTA data. The training dataset is publicly available, but nonanonymous registering is required. A standardized quantitative method for evaluating the centerline extraction algorithms is also provided [
31].
The dataset is split into a training set and a testing set. The training set consists of 8 volumetric images and the test set consists of 24 volumetric images. All the images have four target vessel descriptions with each containing four reference points (described later). The training set images additionally contain the ground truth in the form of a reference file for the target vessels. This makes it challenging for supervised learning algorithms since many of the vessels are not reported as part of the ground truth. The size and resolution for each training volume are described in
Table 1.
The images are packed in two files. One is a “.mhd” ASCII human-readable header file, which describes volume dimensions (e.g., 512 × 512 × 304), the offset, and element spacing (voxel size in real world). The other is a “.raw” file, which contains the voxel (volume pixel) intensities, expressed in Hounsfield units (HU), following the formula intensity = HU + 1024, with a voxel value of zero corresponding to −1024 HU. The format is Insight Toolkit (ITK) compatible.
The ground truth reference files contain a list of the points that are on the centerline of the vessel. The points are described as x,y,z real-world coordinates, the radius of the vessel at that point, and interobserver variability at that position.
There are three categories for extraction: fully automated, minimal user interaction, and interactive extraction [
32].
For the fully automated method, two points of reference are provided—one inside the distal part of the vessel, which uniquely identifies the vessel to be tracked, and one at a short distance to the starting point of the centerline.
For the minimal user interaction, only one point is allowed but can be chosen from more options, which include the two points described before, a starting point of a centerline, an endpoint of a centerline, and a user-defined point. The first four points are provided with the downloadable data. A vessel tree can be obtained if one starts from the starting point of the centerline. If that is the case, other reference points can be used.
For the interactive extraction, any given number of reference points can be used, even user-defined points by manual clicking.
4.2. Visualization
A 3D slicer (available from [
33]) is a free and open source software platform useful for three-dimensional visualization useful for image-guided therapy (IGT), image processing with registration and interactive segmentation, and medical image informatics. It receives funding support from national health institutes and development support from a large worldwide community of developers with the code available on GitHub (available from [
34]). It is directed by National Alliance for Medical Image Computing (NA-MIC), the Neuroimage Analysis Center (NAC), the National Center for Image-Guided Therapy (NCIGT), etc.
The code compiles cross-platform and it is extensible via plug-ins for different algorithms and applications. It supports python scripting for the customization of the look and workflow.
It supports loading DICOM file format for different types of images such as CT, MRI, nuclear medicine, and microscopy. For usage, it contains functionality supported through modules for different organs and contains a bidirectional interface for integration with medical devices.
A 3D Slicer works with scenes, which are a list of elements to be loaded such as images, volumes, models, transforms, fiducial markers. Element extensions include: vtk (Visualization ToolKit), nrrd (Nearly Raw Raster Data), png (Portable Network Graphics), along with the scene file, which is a mrml (Medical Reality Modeling Language); they are archived into a mrb file (Medical Reality Bundle).
Additionally, 3D Slicer provides an out-of-the-box module called volume rendering, used for visually inspect the input volumes, input masks, and output predictions by overlapping them in a 3D space. It provides presets for easy rendering from volumetric images when trying to catch different aspects of the investigation. A “Shift” control allows the user to tamper with the thresholding for rendering features.
4.3. Experimental Setup
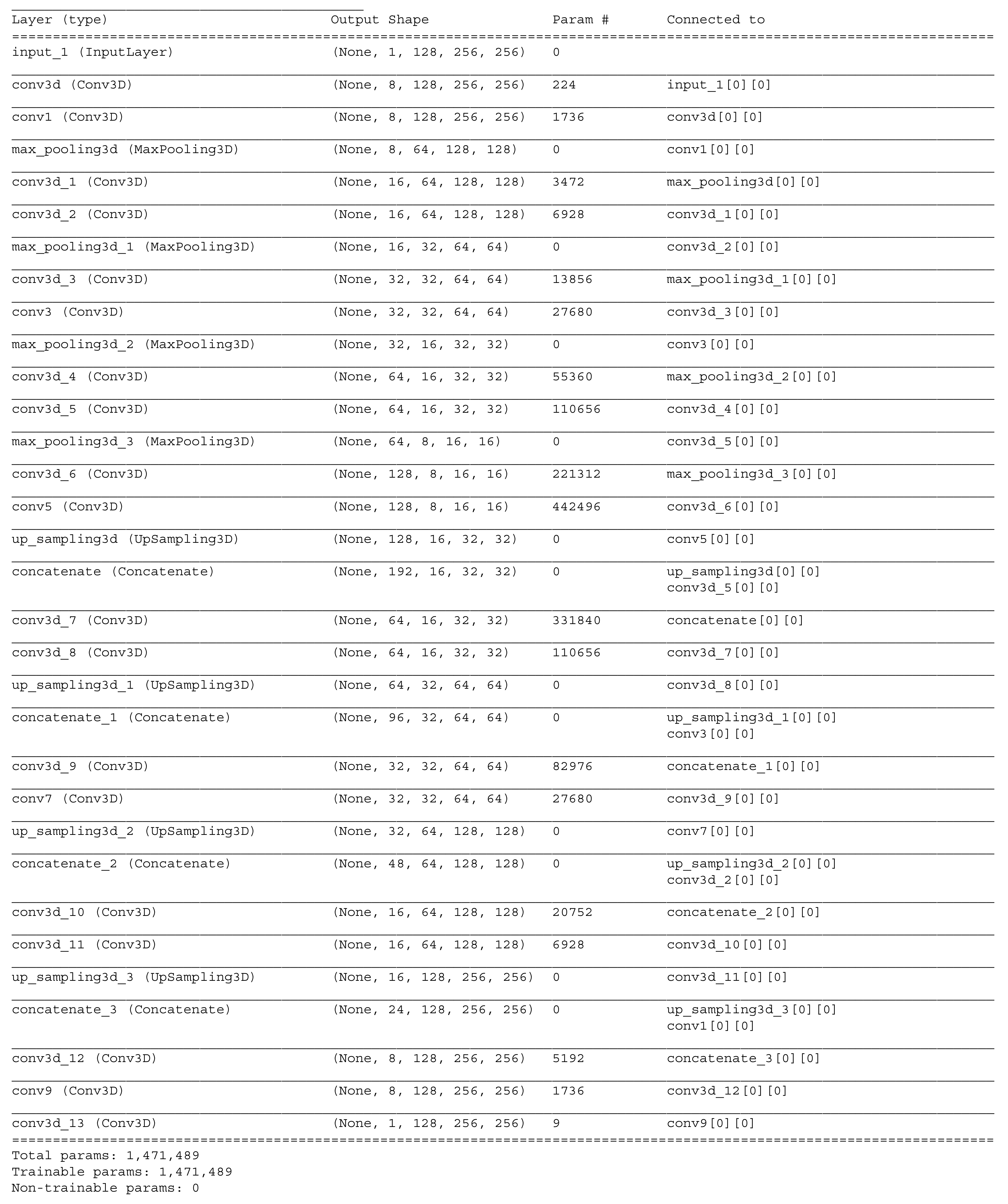
The algorithm was implemented in python using
Tensoflow with
Keras. The full source code is publicly available at [
35]. The provided source code contains the dataset converter and the segmentation algorithm in the form of Python files with executable cells. An example network layout is available in
Figure A4. For loading the dataset, we used the
SimpleITK python library, and for thinning the obtained centerlines, the
skimage package was utilized.
The eight-input volumes with ground truth were split into a training set of seven and a validation set with the remaining volume, leaving one volume out; therefore, the holdout validation was employed. While the number is small, using augmented patches helps reduce the problem of a really small dataset.
The models were trained and tested on an NVIDIA GeForce GTX 1060 with 6GB VRAM. Training required around 8 h on the formerly mentioned video card. The predicting processing time for a patch size input varies between 400 ms and 600 ms, depending on the patch size and model size. For a full volume, this time is multiplied by the number of patches inside a volume. At around 80 patches and 500 ms per patch, the full output is computed in around 40 s. Stitching and postprocessing for saving are negligible in time. The training time makes hyperparameter tuning a strenuous operation, and better configurations can be found by integrating the algorithm into automated design space exploration frameworks. The parameter search space must be more rigidly defined, and the proposed parameters here are a good start.
Following the format of the reference file, we have created a tool to generate a volumetric mask for each input image of the training set, which serves as the ground truth in the supervised learning algorithm. The tool can be parametrized to specify the width in voxels of the centerline. Instead of having a single voxel for one reference point, a cube of a given size is generated, with the center voxel overlapping the centerline. This was found useful in combating the huge class imbalance when working with a single-voxel-wide centerline. The tool outputs the mask in the same format as the input images, with the exception that it can compress the raw data, which is useful when the mask is very sparse. The network will learn centerlines that are thicker than one voxel. A new step of morphological thinning (as described in [
36]) must be applied to convert the output of the network into thin centerlines. The overlap and the accuracy are presented with respect to the wide centerlines, not the thinned ones.
4.4. Training the Network
The training of the proposed U-NET architecture was performed with different configurations for the following parameters:
The hard constraint put on the parameters is given by the limited amount of VRAM of the video card. As an example constraint, if the input path size was increased, the batch size or the number of convolutional kernels in the layers needs to be reduced.
The input patch size is described in voxel dimensions as an (X, Y, Z) pair. The tested patch sizes were 128 × 128 × 96, 128 × 128 × 128, 256 × 256 × 128, 320 × 320 × 64, and 384 × 384 × 48.
The layer reduction is the divisor of the number of convolution kernels (the number of output filters in the convolution) for each convolutional layer. Batch size is the number of input volumes fed to the network before backpropagating the error.
When the ground truth is very sparsely distributed along the volume, many of the patches will not have any parts of the segmentation. As measured by experiment, this tends to make the network fall into a local optimum and to always say that there is never anything to segment in the input volume. To prevent this, for patches of a smaller size, the network is fed only inputs that contain at least one segmented ground truth voxel.
A difficult challenge in biomedical image segmentation is the small number of images available for training neural networks. A way to overcome this problem is to use augmentation.
The
Batchgenerators framework [
37] was used because it provided a wide range of transforms and included spatial augmentation suitable for the 3D input data. The framework allows single or multithreaded computation of the augmented data. An alternative framework that uses the GPU to compute some of the transformations faster is available in [
27].
The following spatial transformations were used: random cropping, elastic deformations, rotation on all axes, scaling, and mirroring on all axes. The following color transformations were added: brightness transformation, gamma transformation, and reverse gamma transformation. Noise transformations were also utilized, including Gaussian noise and Gaussian blur. All the transformations are applied with a probability per input sample.
Only the spatial transformations are applied, with the same parameters, to the ground truth. This is conducted in order to keep the annotation in sync with the input volume. Without augmentations, the dataset was too small for the training to converge.
An alternative to the data augmentation presented above will be the use of synthetic data generated using generative adversarial neural networks (GANs), which were applied for medical imaging with success in increasing the accuracy for liver lesion classification [
38].
4.5. Results
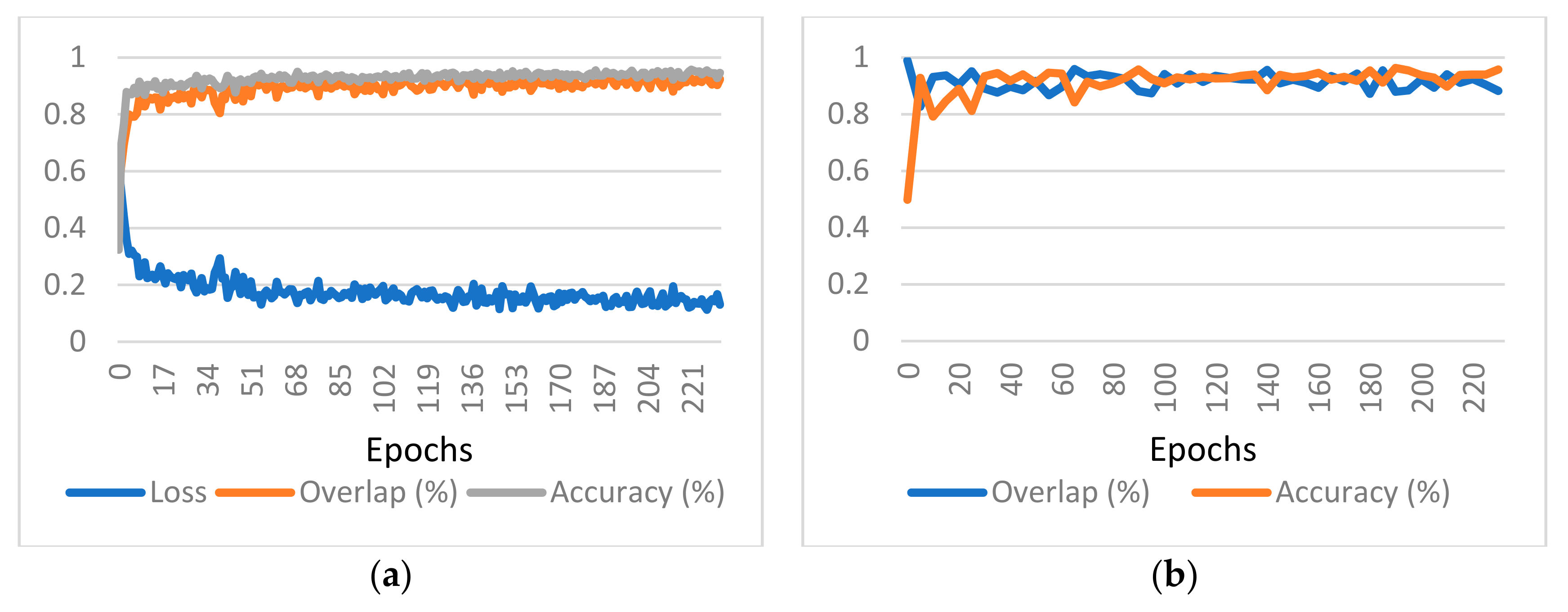
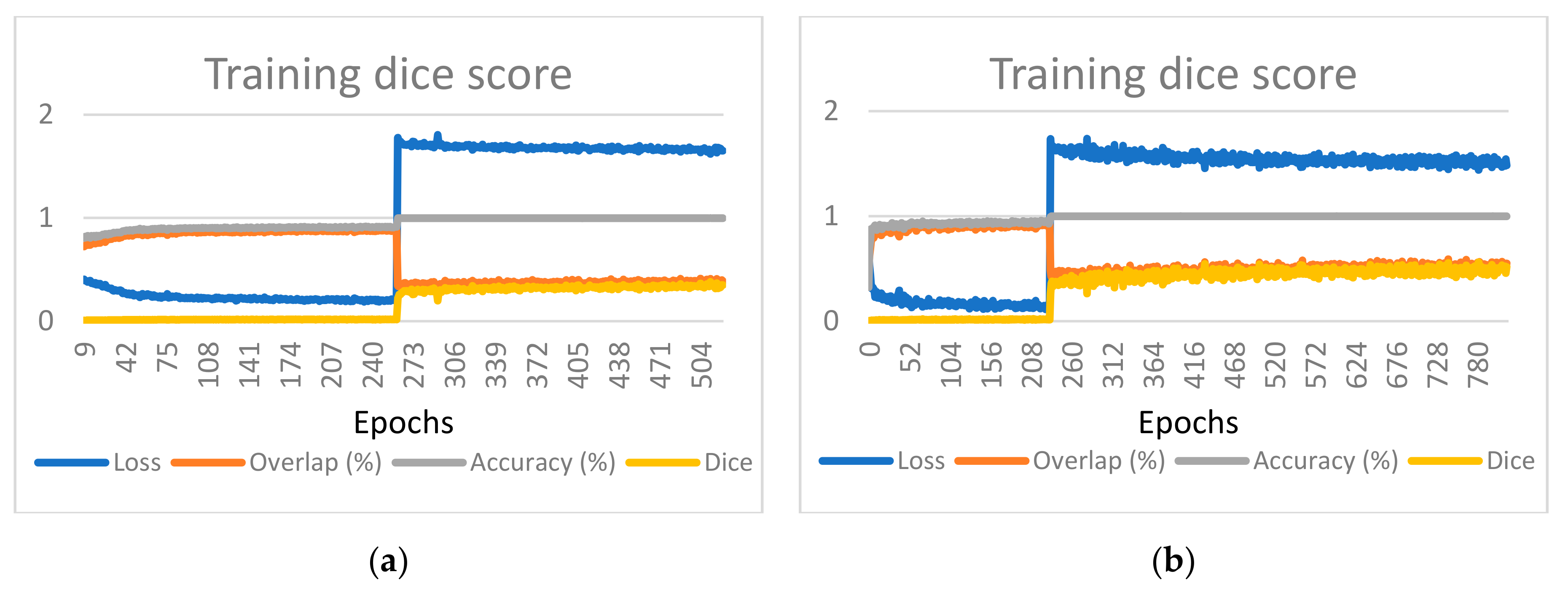
The classical notation of epoch, in which epoch means one pass over the entire training dataset, will no longer apply when working with randomly cut patches. The term epoch is defined here by multiplying the number of volumes in the training set with the largest input volume size divided on each axis with the corresponding patch size, with the result divided by the batch size. As an example, for a patch size 256 × 256 × 128, a maximum size of an input volume of 512 × 512 × 388, and a batch size of 2, the number of input patches considered to be an epoch is 7 × (512/256) × (512/256) × (388/128)/2 = 7 × 2 × 2 × 3/2 = 42. This formula was used as a rough approximation of feeding the entire volumes once through the network. Due to this definition, the results are reported for different epochs given various input patch sizes. For the training dataset, the values for one epoch are computed as the average across all the input patches. For the validation dataset, the values for one epoch are computed by assembling the whole volume from the output patches and comparing it with the whole ground truth.
The overlap and accuracy measures on the validation data are presented in
Table 2. Overlap is defined as the percentage of voxels correctly detected as part of the centerline (analogous to recall), with Equation (11). Accuracy is defined as the percentage of voxels segmented as in the ground truth.
Since the ground truth is presented as sparse centerlines, meaning that only a subset of the coronary vessel tree is annotated, the results cannot be presented using the F1 score or Jaccard index. The number of “false positives” detected by the network will skew the results heavily. Instead, the results are presented in the form of a pair of binary accuracy and overlap (inspired by the results published in [
17]). The graphs provided also include the value of the loss function to demonstrate that the learning converges, as depicted in
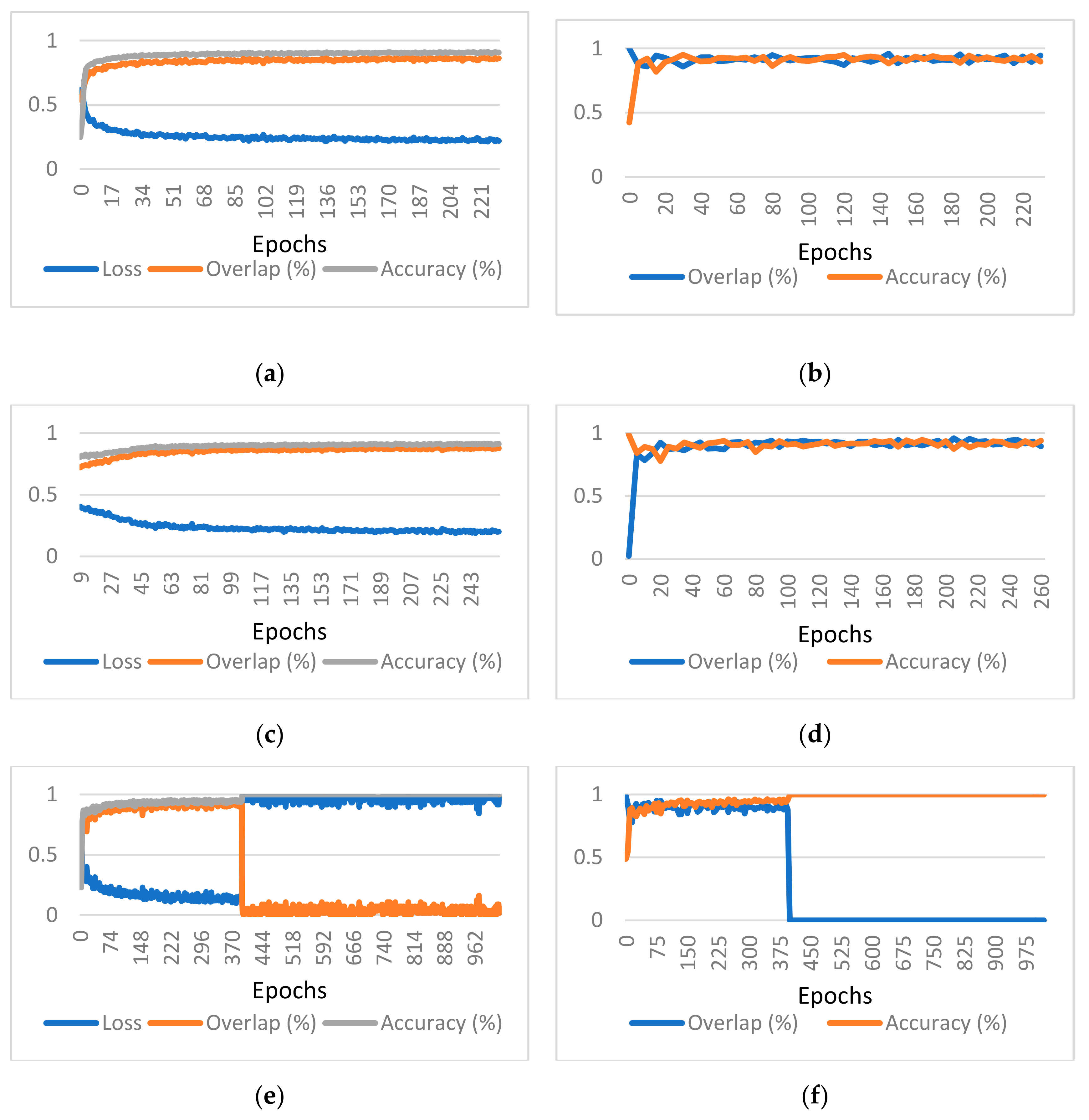
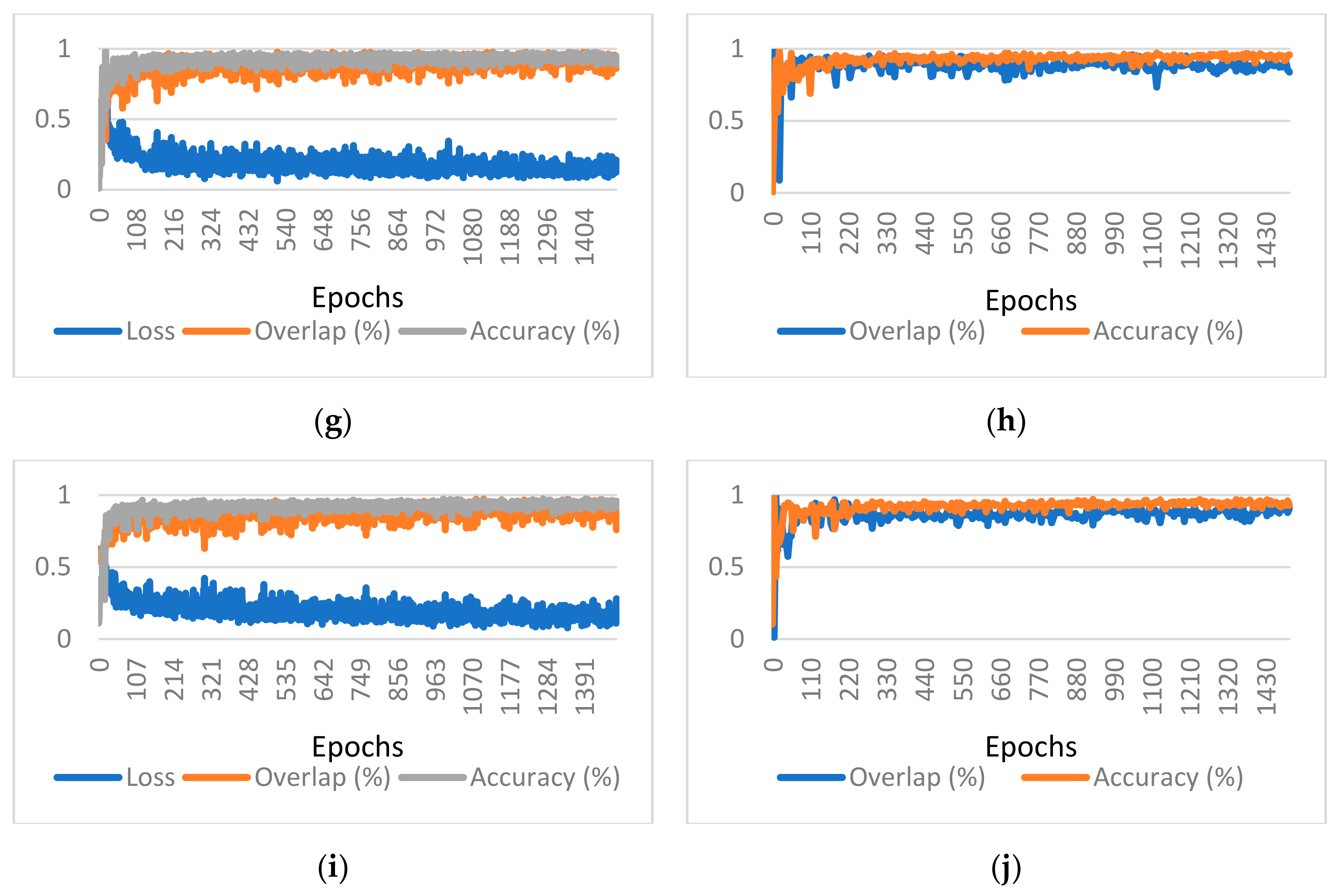
Figure 5 for one of the considered cases. Charts presenting the training and validation evolution for the other configurations can be found in
Appendix A.
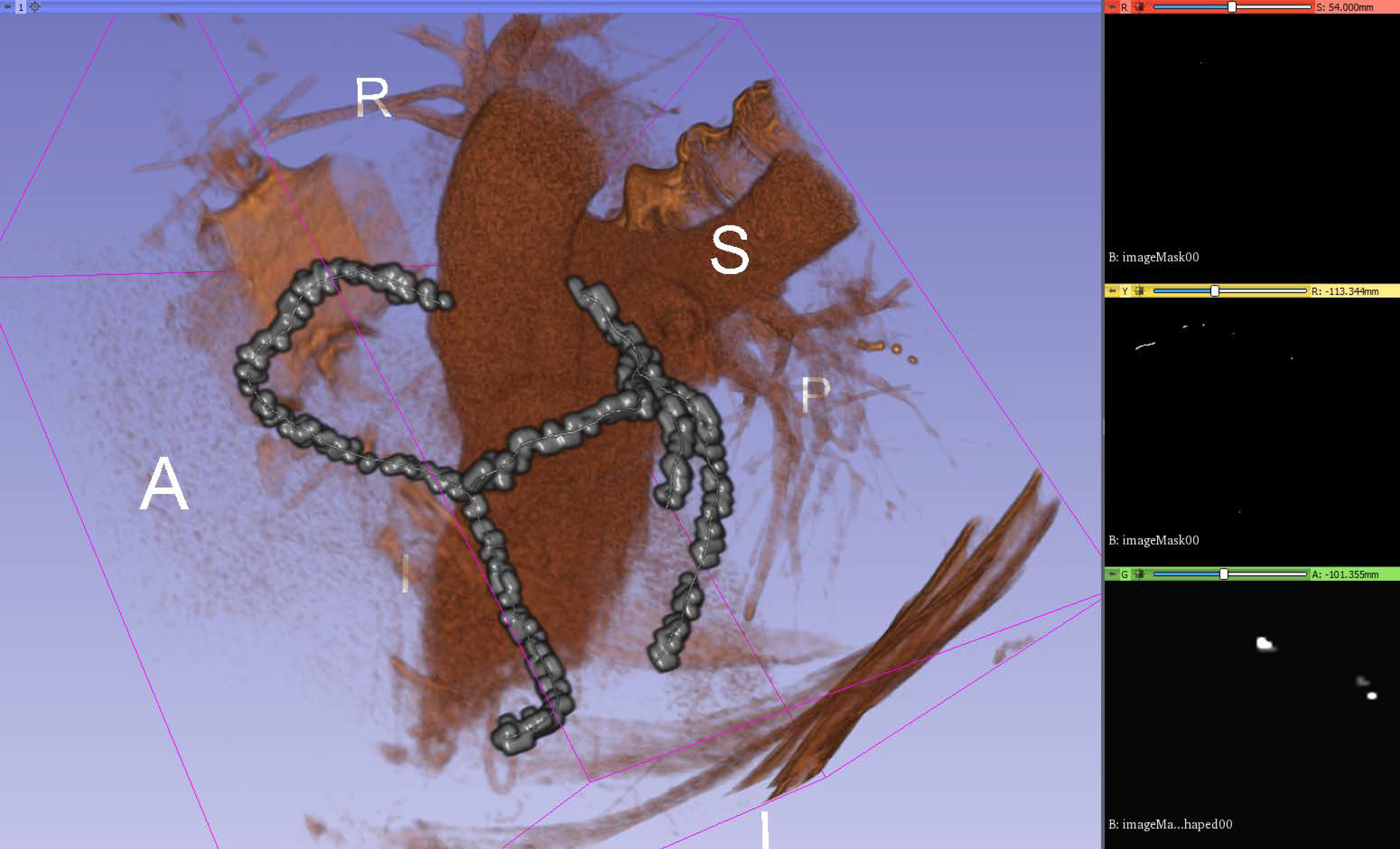
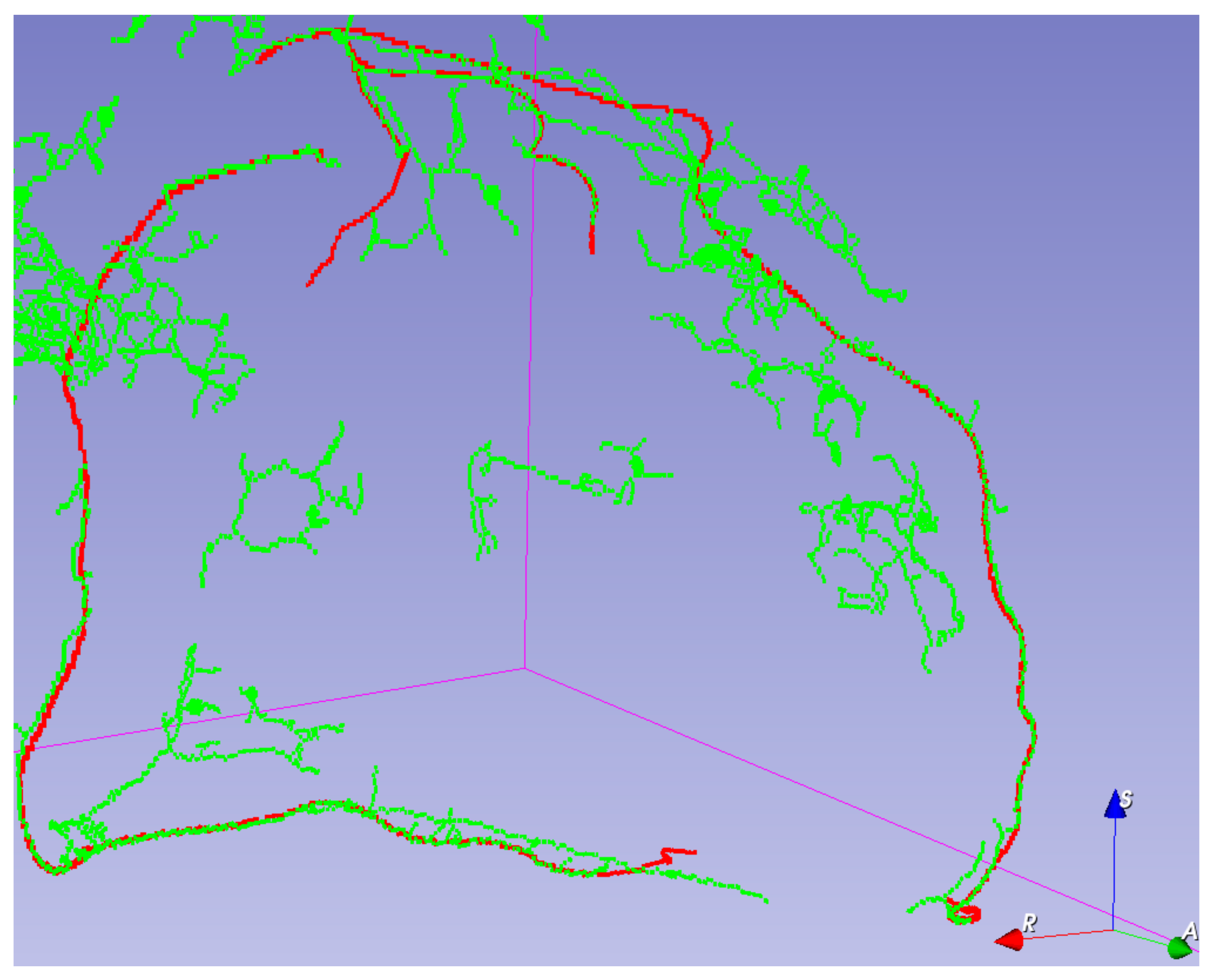
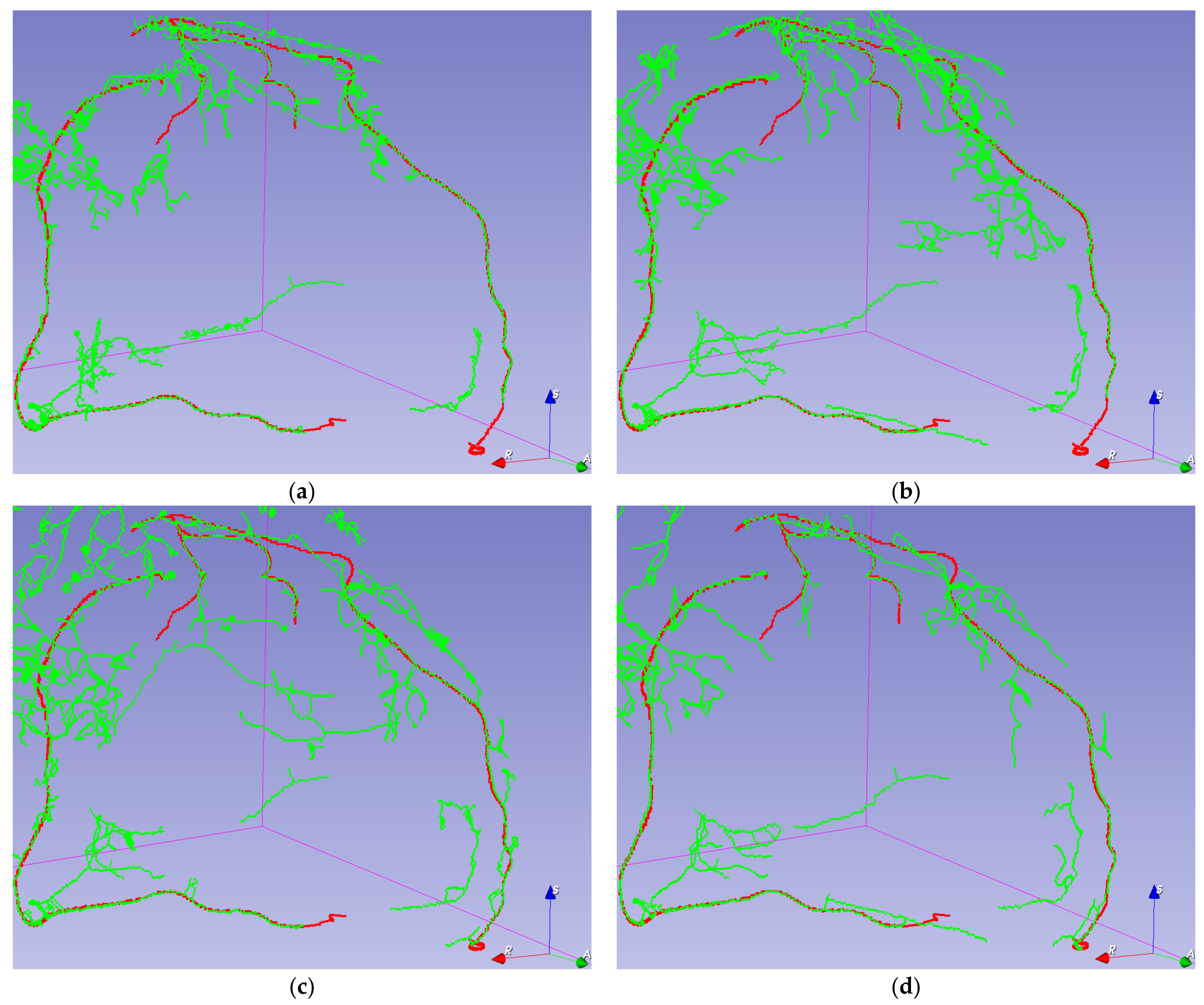
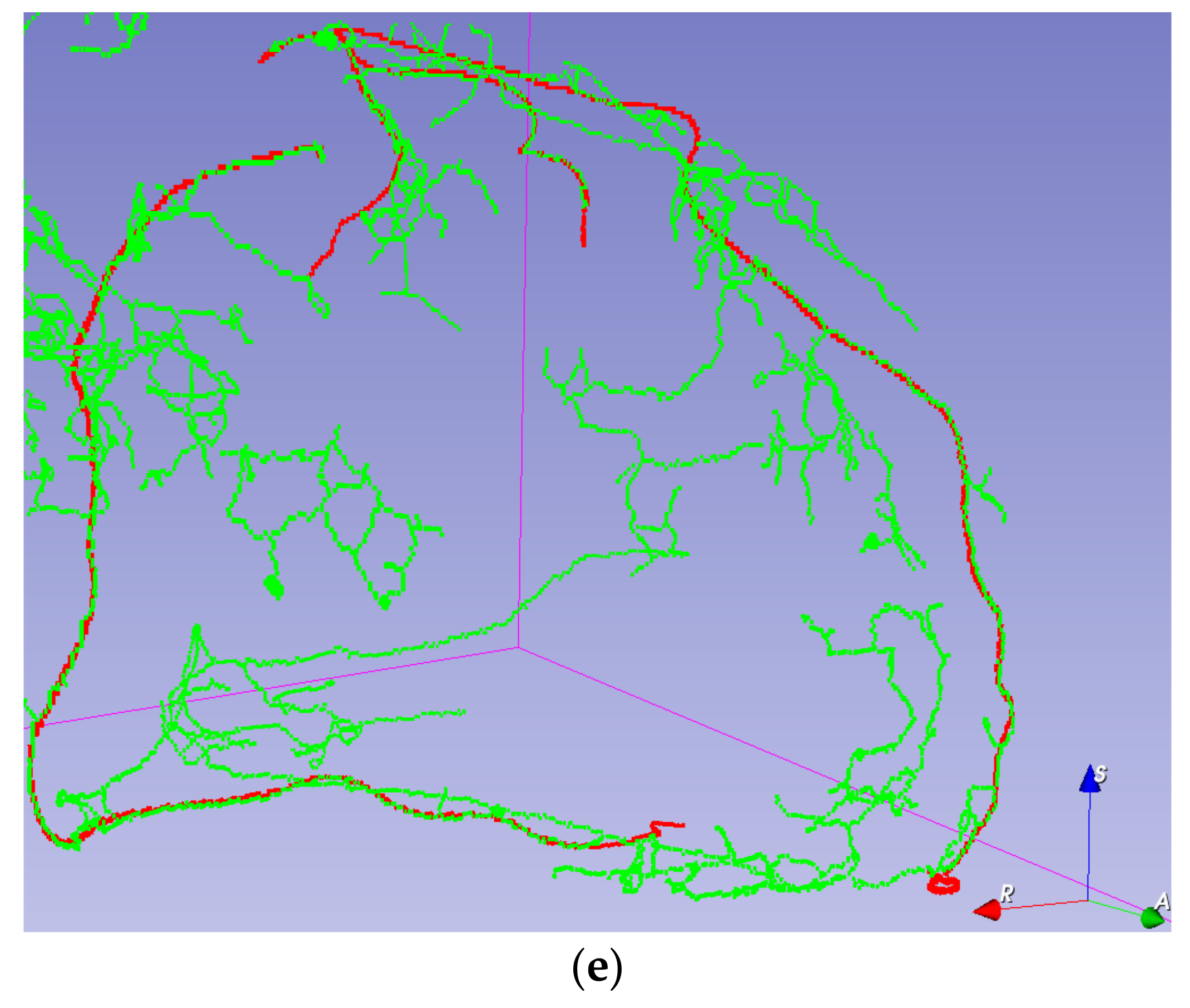
Visual validation for the output volumes is provided, as shown in
Figure 6. The ground truth centerline is depicted in red. The segmentation (after thinning) is seen in green, making it easier to check that the segmentation follows the centerline. Visual validation for other training configurations can be found in
Figure A3.
5. Discussion
As the patch size increases, the clutter created by smaller vessels decreases. This can be explained by the fact that patches without any ground truth are not avoided since the probability of a long run of them is small. The network better learns to discern when the centerline feels relevant. However, this comes with the cost of also partly losing some of the overlap, but this effect could also be explained by losing the homogeneity of size for the Z dimension.
A strong correlation between the patch size and the variance of the training overlap, accuracy, and loss can be observed. This is explained by the smaller number of training examples in an epoch and a greater distortion in the training examples due to augmenting.
It is visible that, as the patch size increases, the number of visual artifacts decreases. We assume that this is due to the network having more contexts to discern which vessels are relevant. Unfortunately, due to constraints on the model size, adding more kernels for bigger patch sizes was not an option.
In the case of patch size 256 × 256 × 128, batch size 1, reduction 2, on epoch 393, the randomness in patch selection made the model fall into a local minimum of favoring the accuracy too much. In
Figure A1, a huge drop in the overlap and a huge rise in the loss value can be detected. The accuracy jumps to almost 100% due to the class imbalance.
Centerline detection seems to be challenging in very low contrast vessels having fuzzy walls.
6. Conclusions
We have provided an open source (available at [
39]) implementation of a 3D U-Net, suitable for segmenting the coronary artery centerline. We have built upon a 2D U-Net-base implementation network, originally designed for retina vessel segmentation, and developed a 3D version capable of segmenting with voxel precision. We have conceived a novel loss function designed to combat two simultaneous problems, usually related to volumetric medical segmentation: huge class imbalance and sparse annotation. Without this loss function, the convergence of the model was not guaranteed even with using augmented inputs. We have built a customizable tool to generate annotated ground truth for the Rotterdam Coronary Artery Centerline Extraction from reference files. We have integrated a 3D augmentation algorithm [
37] with the dataset to combat the problem of very few training examples. Without integrating one, the model would not generalize the centerline extraction. We have demonstrated that the training convergence using a second loss function starting with a network pretrained with another loss function. Without the pretraining, training directly with the second loss function would not converge.
As for future improvements, the existing algorithm could benefit from using transfer learning, which was previously applied for U-Net architectures in [
40], or for medical image classification models [
41]. Even if the training dataset is small for coronary artery centerlines, one can use other segmentation tasks to pretrain the model. Using deconvolution layers instead of upsampling layers in the proposed U-Net architecture may improve the pixel-wise accuracy of the segmentation. The results can be perfected by incorporating a wider training set with data from multiple benchmarks in the same way as in [
14,
16,
17].
Cardiovascular diseases (CVDs), classified as a group of disorders, are the number one cause of death globally [
42]. Automated extraction of information about the coronary artery is one step in the computer-aided diagnosis of CVDs. Based on the extracted centerlines, other methods can be employed for visualizations, artery segmentation, plaque detection, and stenosis evaluation. The proposed method can help in improving the visualization, detection, and segmentation of various features such as soft plaque or calcified plaque if included in a stenosis score processing pipeline.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}