3.1. Problem Presentation and Our Solution
As mentioned above, in Industry 4.0 applications, QR tags are expected to have high positioning accuracy and fine texture semantic segmentation. According to the current research status, the existing instance segmentation algorithms based on deep learning has greater advantages in robustness and can adapt to a variety of complex application scenarios.
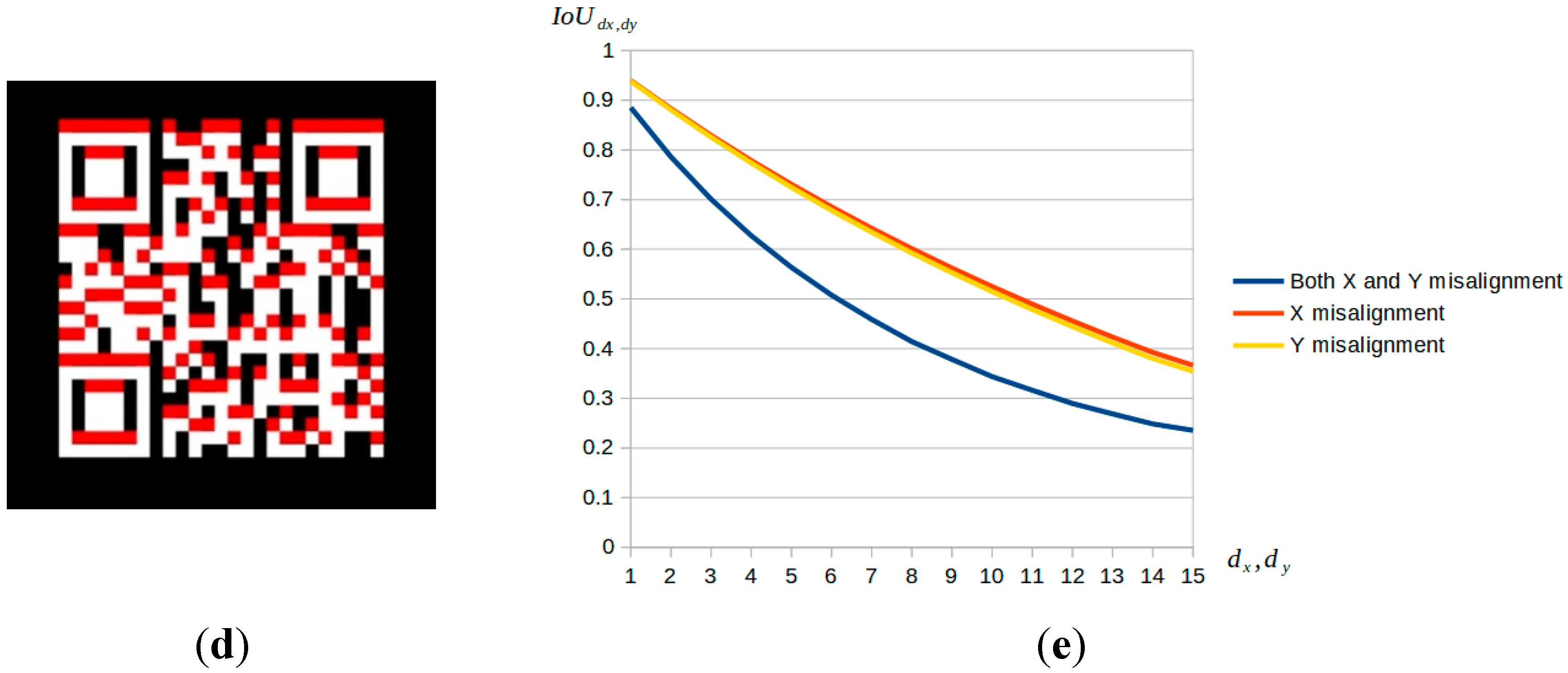
However, instance segmentation is a challenging task, because it requires classification and location at the instance level, while semantic segmentation requires classification at the pixel level. Moreover, QR tag instance segmentation also has special difficulties, which are manifested because QR tags have rich textures, and even small misalignment can cause large IoU reduction. Hence it is difficult for instance segmentation of QR tag. An example of small misalignment causing large IoU reduction problem in QR tag instance segmentation is showed in
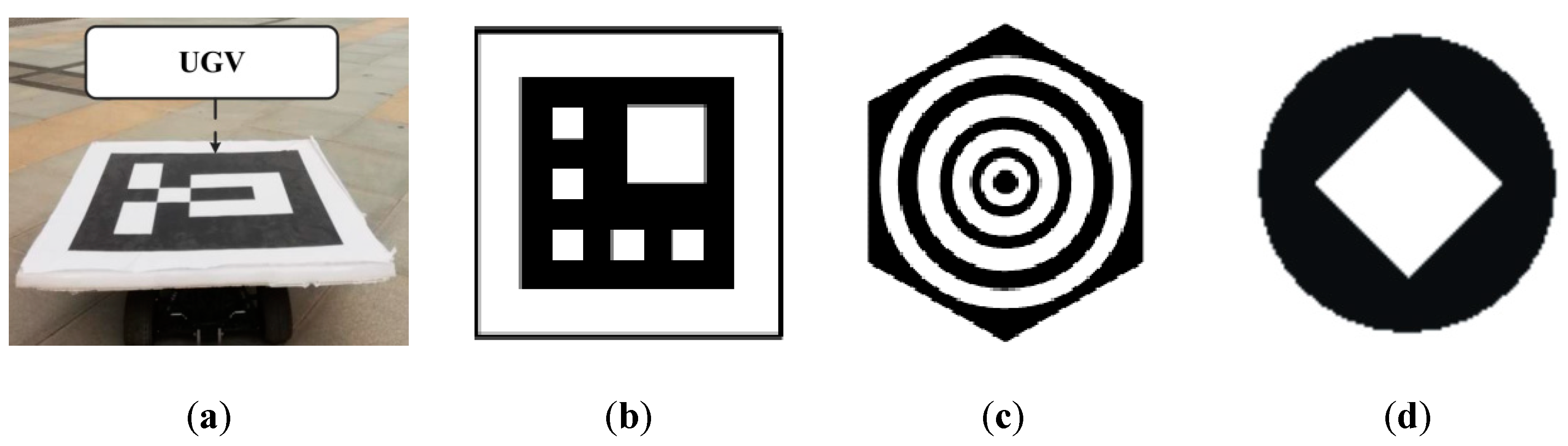
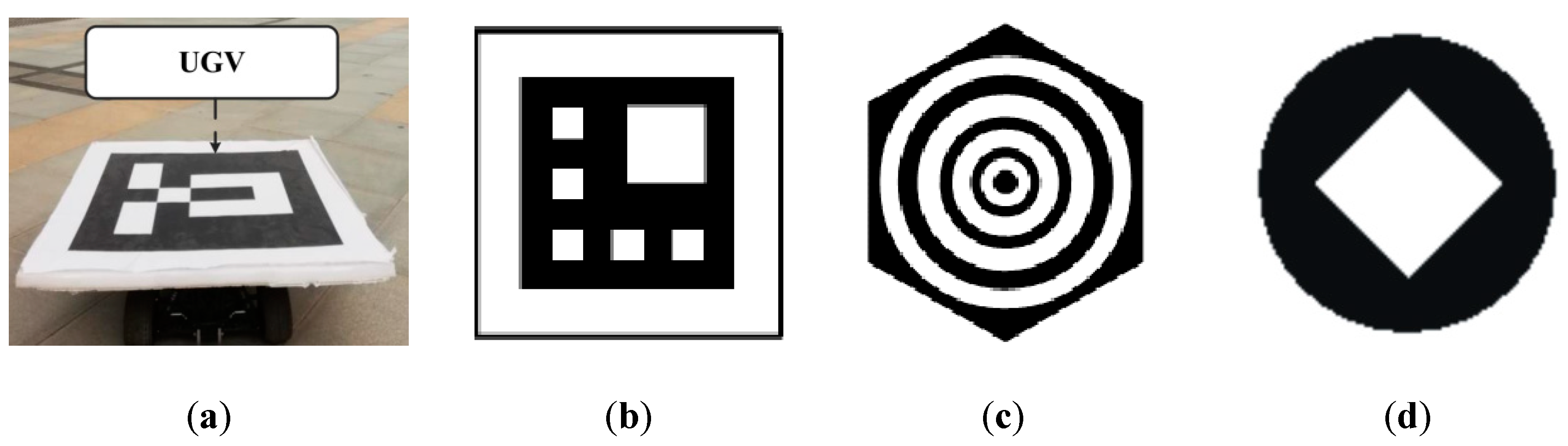
Figure 1. As can be observed a QR code example image with a size of 512 × 512 pixels is illustrated in
Figure 1, the red layer is the predicted output of a neural network (assuming that the output does not have any quality degradation, and is exactly the same as the ground truth image, and it has only misalignment) and white layer is ground truth (GT). Let variables
and
to represent the number of pixel misalignment of neural network prediction result and ground truth (GT) in the x and y directions, and set
to represent the corresponding IoU while
and
pixels misalignment.
Figure 1a–d display
,
, and
, respectively.
Figure 2a shows the
when
, and can also write represented as
. At this time, the offset of predicted output and GT is barely visible to human eyes. But in this case, it turns out that
, and this means the IoU is decrease a lot relative to the change in
. Further, the same situation can be observed for
, and
. As
and
go up,
goes decrease very fast.
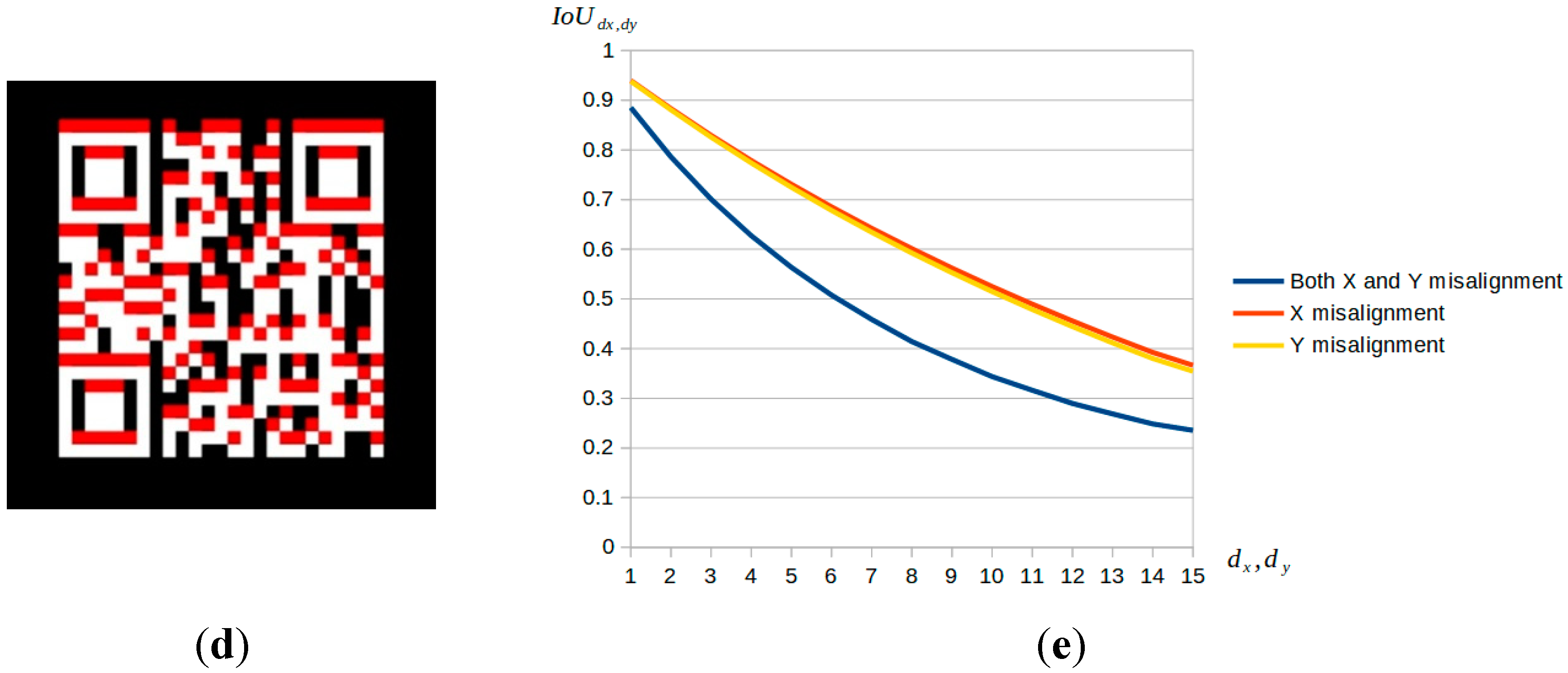
Figure 2e shows the change curve of
while
or
changes. From the three curves, it can be seen that the value of
decreases rapidly with the increase of
or
.
From the above example, we can deduce that, due to the rich texture of the QR tag, misalignment may cause a sharp decrement of IoU. K. He [
29] proved that, in Faster R-CNN, quantization in the RoIPooling layer introduced misalignment between candidate region and the extracted features. Although this may not affect the classification, it has a significant negative effect on predicting pixel-accurate masks.
Hence, it is necessary to find a network that has solved the misalignment problem well as the basis of our research. Mask R-CNN fixed the misalignment problem of Faster R-CNN by using RoiAlign instead of RoIPooling.Therefore, this paper mainly focuses on the research of Mask R-CNN. However, for the segmentation of QR tag instance, Mask R-CNN has the following disadvantages: it is inappropriate to use classification confidence to measure the mask quality since it only serves for distinguishing the semantic categories of proposals, and is not aware of the actual quality and completeness of the instance mask [
69]. However, the quality of the instance mask is quantified as the IoU between the instance mask and its ground truth, this makes the quality of Mask R-CNN’s instance mask very poor.
Figure 2 shows the predicted output of Mask R-CNN model.
In order to enable Mask R-CNN to predict high-quality instance mask, it is necessary to optimize IoU during training period, and also modify existing evaluation methods of the mask quality and modify mask loss.
However, the problem is how can we optimize the IoU in training? It is possible to directly use binary image of candidate region and its ground truth to calculate IoU. The following example will prove that this method is bad.
Figure 3a shows a QR tag image with noise pollution,
Figure 3b exhibits a binary image of
Figure 3a, and
Figure 3c is its ground truth. For QR tags, the effective information part is usually printed in black. In
Figure 3c, the reason why the effective information part of QR tag is shown. Generally speaking, the ground truth will be marked as white and the background marked as black in most data sets. This paper follows this general rule and marks ground truth as white to facilitate the use of this algorithm in other data sets in the future. Therefore, in the binary image showed in
Figure 3b, in order to get the correct value of IoU, it is necessary to invert the gray pixel value during binarization process. The IoU value of
Figure 3b,c is 0.55, where the misalignment
and
are both zero. The reduction of IoU is caused by noise pollution in candidate image, which has no relationship with misalignment. Therefore, low-quality candidate images can lower the value of IoU, disabling it from accurately measuring the completeness of the instance mask, and also making it difficult to obtain a high-quality mask image.
Therefore, when calculating the IoU of candidate areas, methods should be adopted to conduct texture segmentation of the candidate image, so as to obtain high-quality texture image. Then, calculate the IoU with ground truth. In this paper, we propose to add UNet [
30] branch to Mask R-CNN to segment the texture of candidate image and obtain enhanced texture information. After binarization of output image from UNet branch, we calculate the IoU value with ground truth.
Here is an example to illustrate the effect of our proposed adding UNet branch method. For a noise polluted candidate image shown in
Figure 4a, after a pre-trained UNet branch’s prediction, the gray scale image shown in
Figure 4b is obtained, and the image shown in
Figure 4c is then obtained after binarization. Comparing with
Figure 4b and a, it can be seen that the image has removed most influence of noise. It can also be observed that the texture of QR tag is highlighted and the texture enhancement effect is achieved. By calculating the IoU of
Figure 4c and ground truth, and we get
, where
, and the value of
is 0.26 higher than the obtained value by using
Figure 3b. Although there are still some irregular edges and incomplete details compared with ground truth. By using UNet branch texture segmentation, the corresponding IoU of low-quality image and ground truth is greatly improved.
From Ref. [
29] we realize that, previous researches on Mask R-CNN mainly focused on the instance segmentation of natural images. As a precise segmentation mask may not be critical in natural images, Mask R-CNN pays less attention to the quality of the fine texture mask. However, as shown in
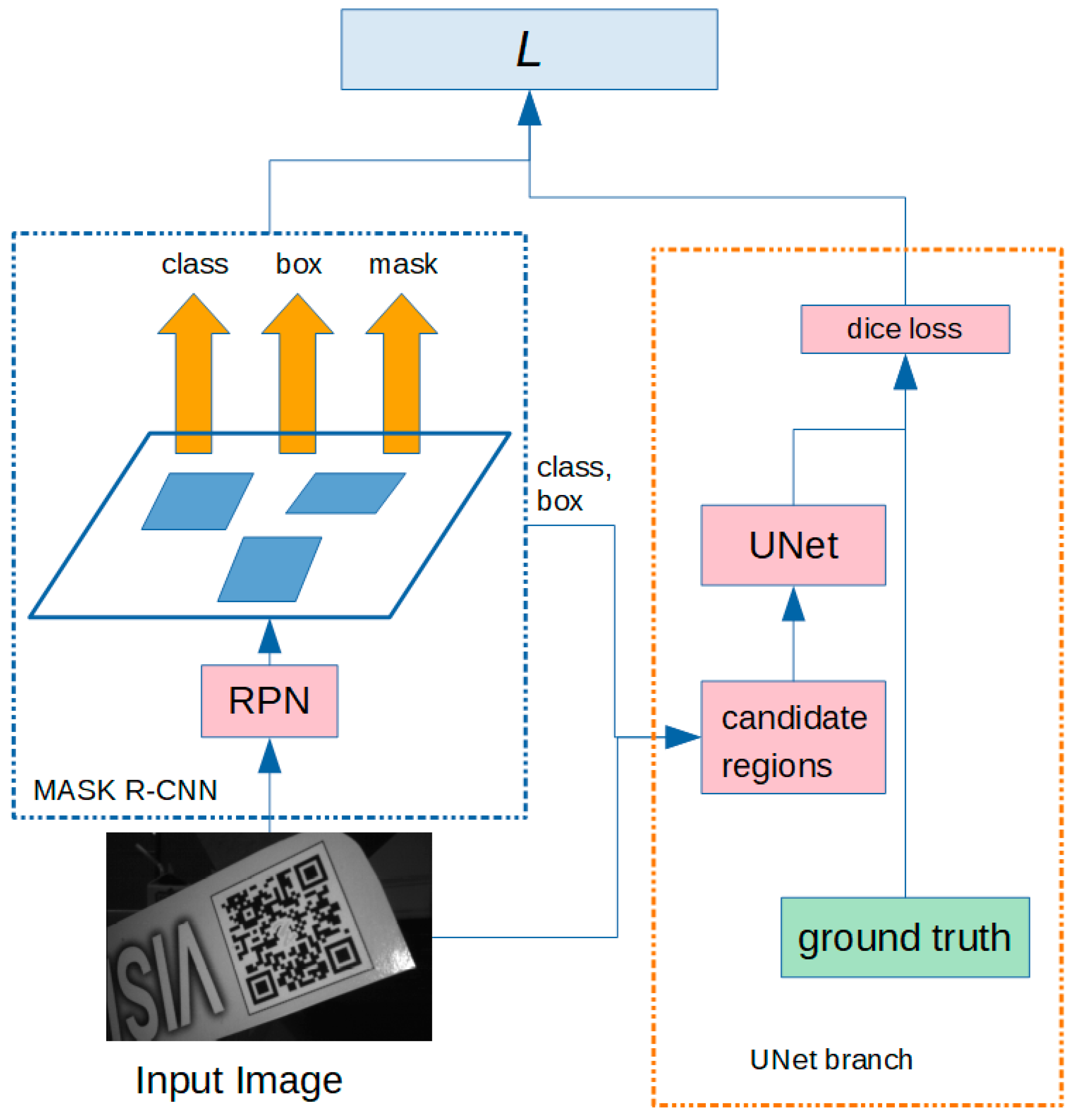
Figure 2, due to the rich texture of the QR tag, low-quality candidate images can lower the value of IoU, making it lacking the ability to accurately measure the mask quality, thus QR tag mask demands a higher level of accuracy than what is desired in natural images. Therefore, it is necessary to propose a network that can reduce the impact of low image quality on IoU calculation. According to the structure of UNet, it can effectively combine low resolution information (providing basis for object classification recognition) and high-resolution information (providing basis for accurate segmentation and positioning) to achieve the purpose of precise segmenting and effective enhancement of texture. Therefore, we modified Mask R-CNN, added UNet branch to evaluate IoU, and proposed our QR tag instance segmentation network. For the convenience of expression, our proposed network is entitled the Mask UNet Region-based Convolutional Neural Network, or MU R-CNN for short. The network structure of MU R-CNN is shown in
Figure 5.
To resolve the problem of poor QR tags’ instance mask of Mask R-CNN, this paper uses pixel-level IoU between the predicted mask and its ground truth mask to describe instance segmentation quality. As shown in
Figure 5, our proposed MU R-CNN mainly consists of two parts: Mask R-CNN branch and UNet branch. The input image first enters Mask R-CNN branch, and the outputs of Mask R-CNN branch are the position, category and mask information of the candidate regions in the image. In Mask R-CNN branch, RPN was constructed in the same way as [
29]. The network architecture for UNet branch is shown in
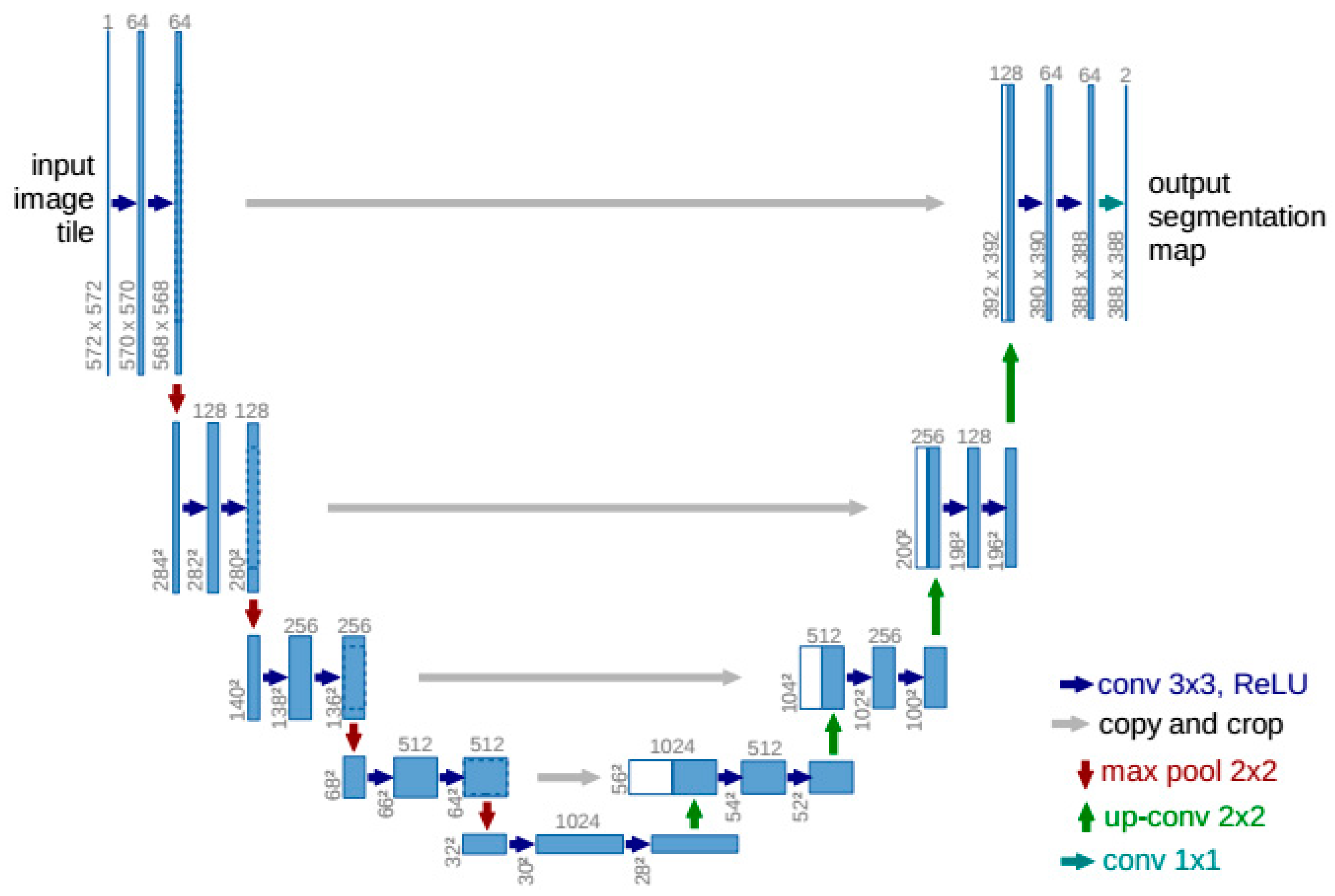
Figure 6. According to the position and category information output by Mask R-CNN branch, we segment candidate images in the input image, and then the candidate images are input into the pre-trained UNet model for prediction, and the prediction results are the fine segmentation of candidate region’s texture information.
The main structure of UNet model [
30] consists of a convolution compression part and up-convolution reduction part, as shown in
Figure 6.
In the convolution compression part, the structure based on two 3×3 convolution layers and one 2×2 maximum pooling layer is adopted repeatedly. Thus, by using the de-sampling effect of the pooling layer, features are extracted layer by layer. In the up-convolution reduction part, the up-convolution of 2×2 is firstly carried out, then two 3×3 convolution layers are connected, and the structure is repeated. In the output layer, a 1×1 convolution layer is used to map the feature graph to the required number of classes. The structure of the UNet model is based on the main idea of FCN [
48] and is better than FCN. It can be seen that UNet has a similar structure compared with the u-shaped symmetry. The first half is a classical VGGNet-16 [
70], while the second half is a reverse up-sampling process. The most important improvement of UNet is the addition of copy and crop channels in the up-sampling section, which enables the network to transfer contextual information from the shallow layer to the deeper layer. This structure allows UNet to achieve better segmentation of small targets and fine textures than FCN.
From the structure of UNet, the convolution layer in the network is 3×3. According to K. Simonyan’s conclusion in VGGNet-16 [
70], two 3×3 convolution layers (without spatial pooling in between) has an effective receptive field of 5×5, three such layers have a 7×7 effective receptive field, and this conclusion is verified by experiments. Compared with a 5×5 or 7×7 convolution of a single layer, multiple layers of 3×3 convolution can increase the network depth and improve the non-linear capacity of the network, but has fewer network parameters, making the network more concise and efficient. The 2×2 pool layer ensures that the scale drops slowly to give smaller targets a chance to train.
Earlier in this article, it is stated that low quality images can lower the IoU significantly, making it lacking the ability to accurately measure the completeness of the instance mask. In this paper, using UNet branch for texture segmentation to achieve de-noising effect is a key innovation of our MU R-CNN, as shown in
Figure 4b. Texture segmentation can achieve good de-noising effect and reduce the impact of low image quality on the IoU, so no additional de-noising algorithm is needed.
In order to optimize the IoU in the training, we need to add a IoU loss in the MU R-CNN. Because dice-loss [
71,
72,
73] is an approach for directly optimizing the IoU measure in deep neural networks, we choose dice-loss to determine IoU loss.
In the MU R-CNN of this paper, dice-loss can be calculated by formula (1) [
73].
where, N is the total number of pixels in the ground truth image, and
and
represent the value of the ith pixel in the binary image of UNet prediction output and ground truth, respectively.
After obtaining dice-loss, it is then added to MU R-CNN in accordance with Equation (2):
where,
,
and
represent class, bounding box and mask loss respectively, which are calculated according to the same method of Mask R-CNN [
29].
is a balancing parameter.
is the dice-loss calculated by formula (1), and
is the total loss of MU R-CNN.
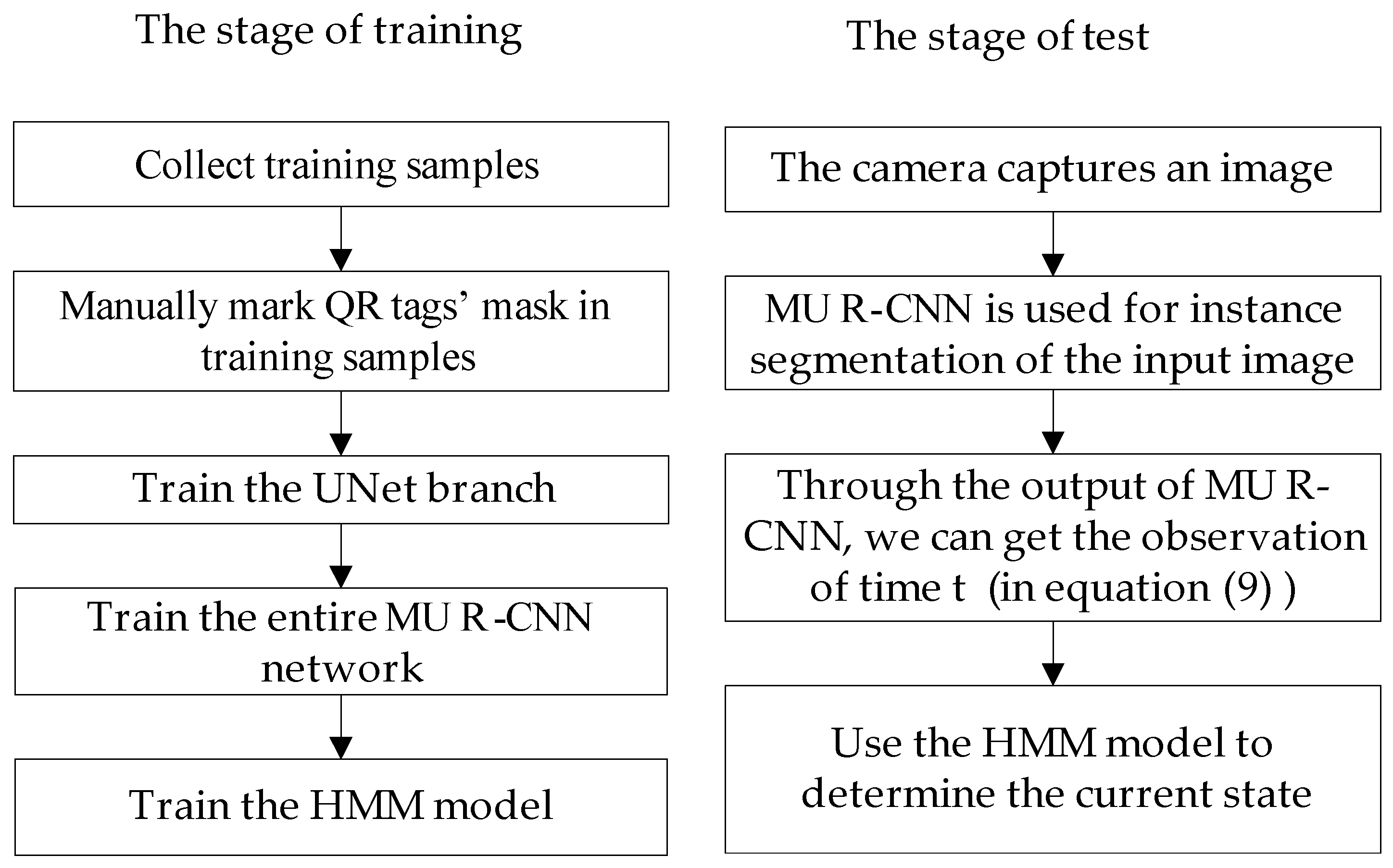
After the completion of the instance segmentation stage, the QR target is tracked by hidden Markov models (HMM). The parameters of the HMM model in this paper are shown in Equations (3)–(11).
Formula (3) indicates the HMM model is composed of 5 parameters, and the meanings of these five parameters are explained in formulaes (4)–(8). S in formula (4) is state transition set, and it stands for a set of states, and means the detected target is true positive, while means false positive. V in Equation (5) is observations state set, and it stands for a set of observation states, and N stands for number of observations of each state being the output. In this paper, N = 3, respectively represent the classification confidence of the target output by MU R-CNN, bonding box’s aspect ratio and the ratio of the white pixels number divided by black pixels number in binarization mask image output by the UNet branch. A in Equation (6) is state transition matrix. B in Equation (7) is confusion matrix. in Equation (8) is the initial probability distribution. in Equation (9) stands for observation of time t. in Equation (10) stands for state of time t. in Equation (11) represent the HMM model parameters.
After setting up the MU R-CNN and HMM model, we build the system architecture as shown in
Figure 7.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}