Simulating the Cost of Cooperation: A Recipe for Collaborative Problem-Solving



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. The Importance of Crowdsourcing
1.2. Limitations of the Extant Literature
1.3. Factors Affecting Group Decision-Making: A Numerical Simulation Approach
1.4. Aim of the Study: Protecting Crowdsourcing from the Costs of Cooperation
2. The Model: Settings and Simulations
- Cardinality equaled the group’s capacity to solve increasingly more challenging tasks (e.g., the collective knowledge of a group) and thus, it was also an integer parameter that was equal to the number of iterations in which one collectivist solved the task, regardless of R. At the beginning of this experiment, it was set at the value of for all groups and then updated to each time one collectivist player solved the task.
- The player’s fitness or payoff represented a player’s own benefit in terms of new knowledge acquired. If a collectivist (C) or an individualist (I) failed to solve the task, their fitness increased only because the others’ contribution of , with equal to the number of cooperators belonging to the group j of player i who solved the task in the game turn. However, if a collectivist solved the task, it contributed an additional fitness of , with becoming the updated cardinality of the group, so having . In addition to the gain shared by the collectivists in the group, an individualist who solved the task gained an additional fitness of (i.e., ), so having .
- Furthermore, the cooperative players in the group needed to coordinate and synchronize the cooperation of solving the problem among each other. On the contrary, individualists did not have to pay this so-called cost for the very fact that they acted alone. To represent this difference, the collectivist player fitness always is computed as , where the term represented an additional cost of cooperation, which was the cost that every collectivist is assumed to pay in order to synchronize his effort with the group. On the contrary, the individualists are not affected by such cost directly. Such a model of payoff aims to represent the idea that collectivists distribute new knowledge both to themselves and to all the others, while individualists keep it for themselves. However, collectivists solved tasks more easily since they worked together, but with potentially less new knowledge (fitness) for each of them separately. In contrast, by working alone, individualists solving harder tasks learned much more since they avoided sharing this new knowledge with the others.
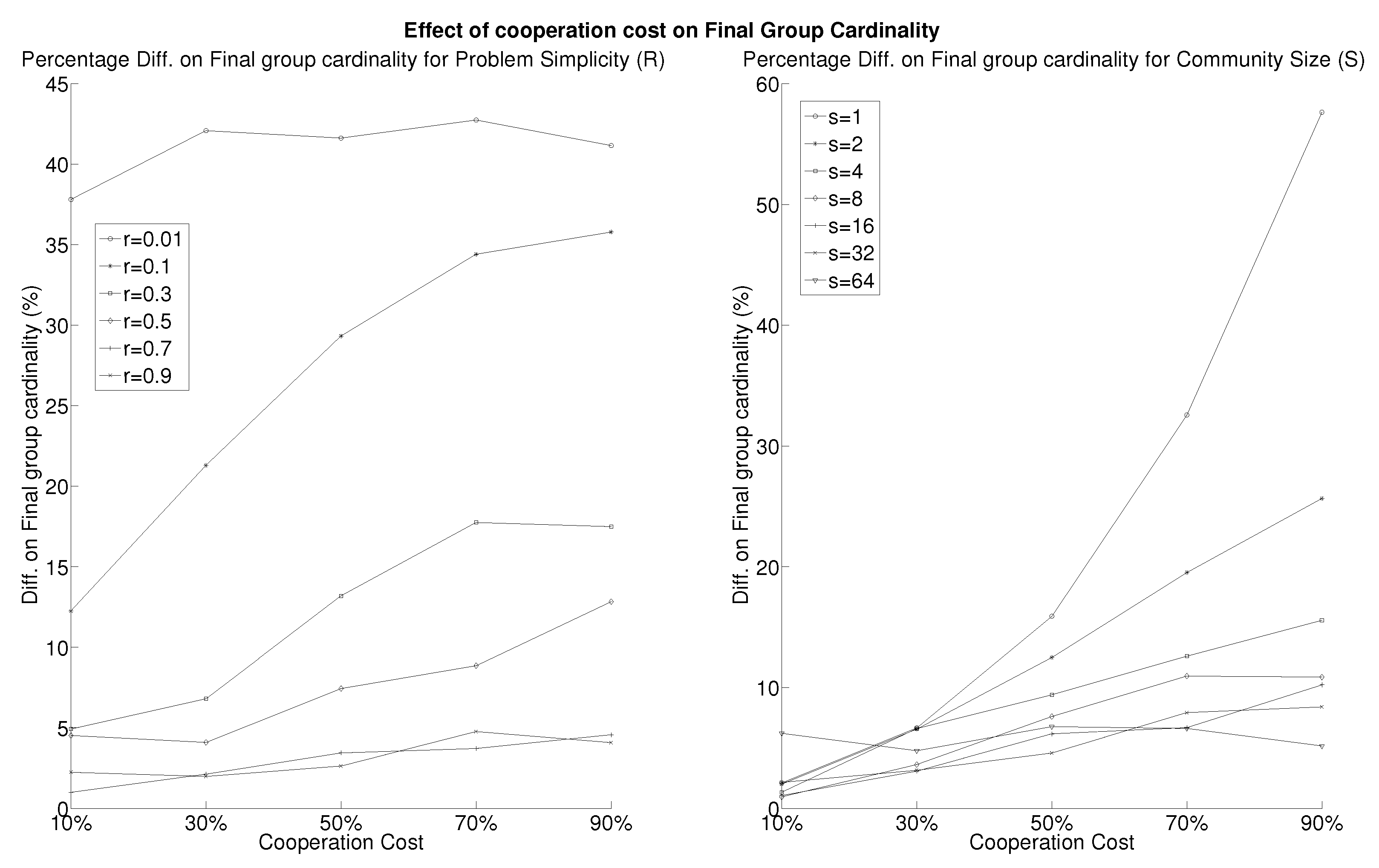
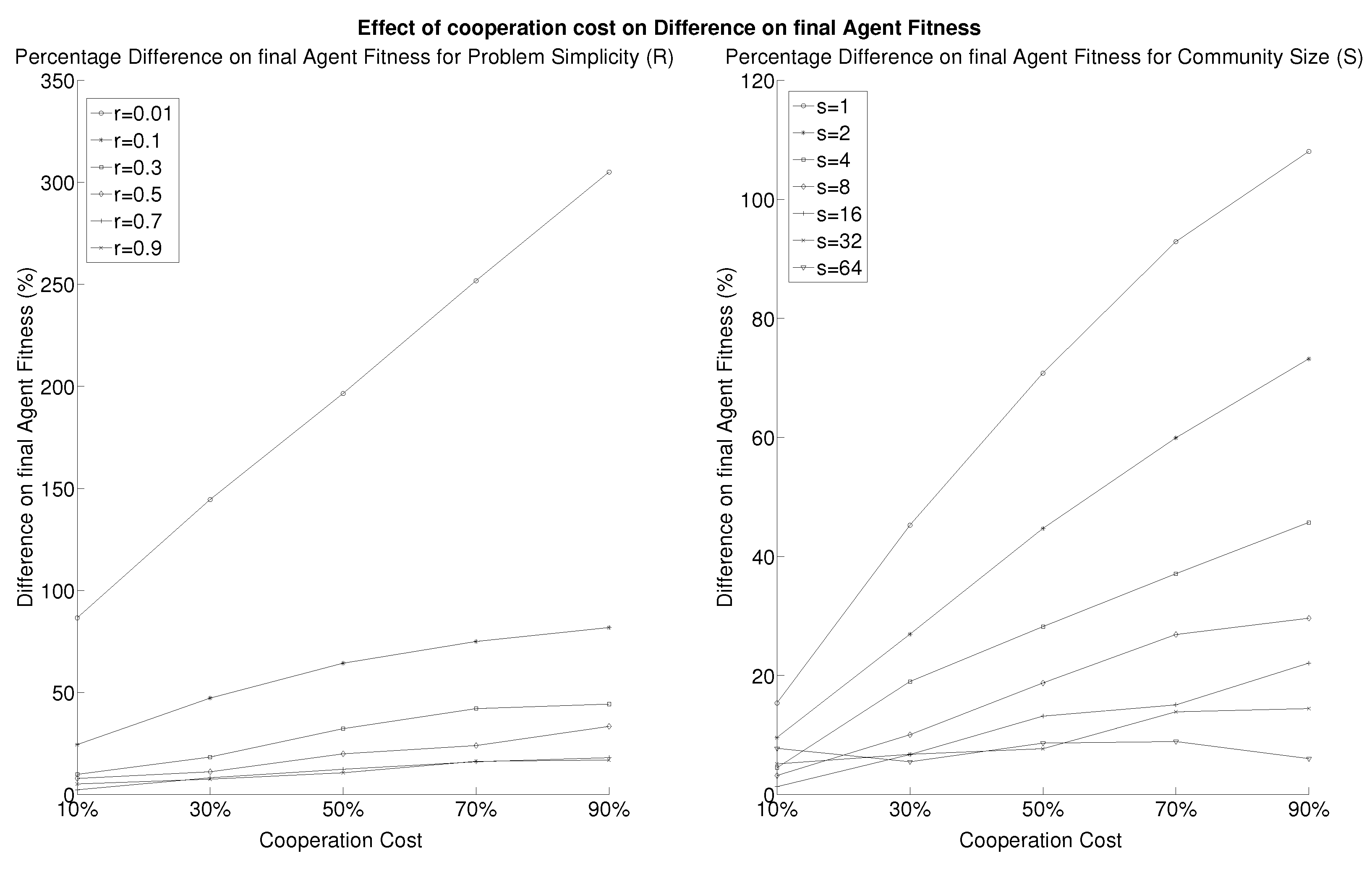
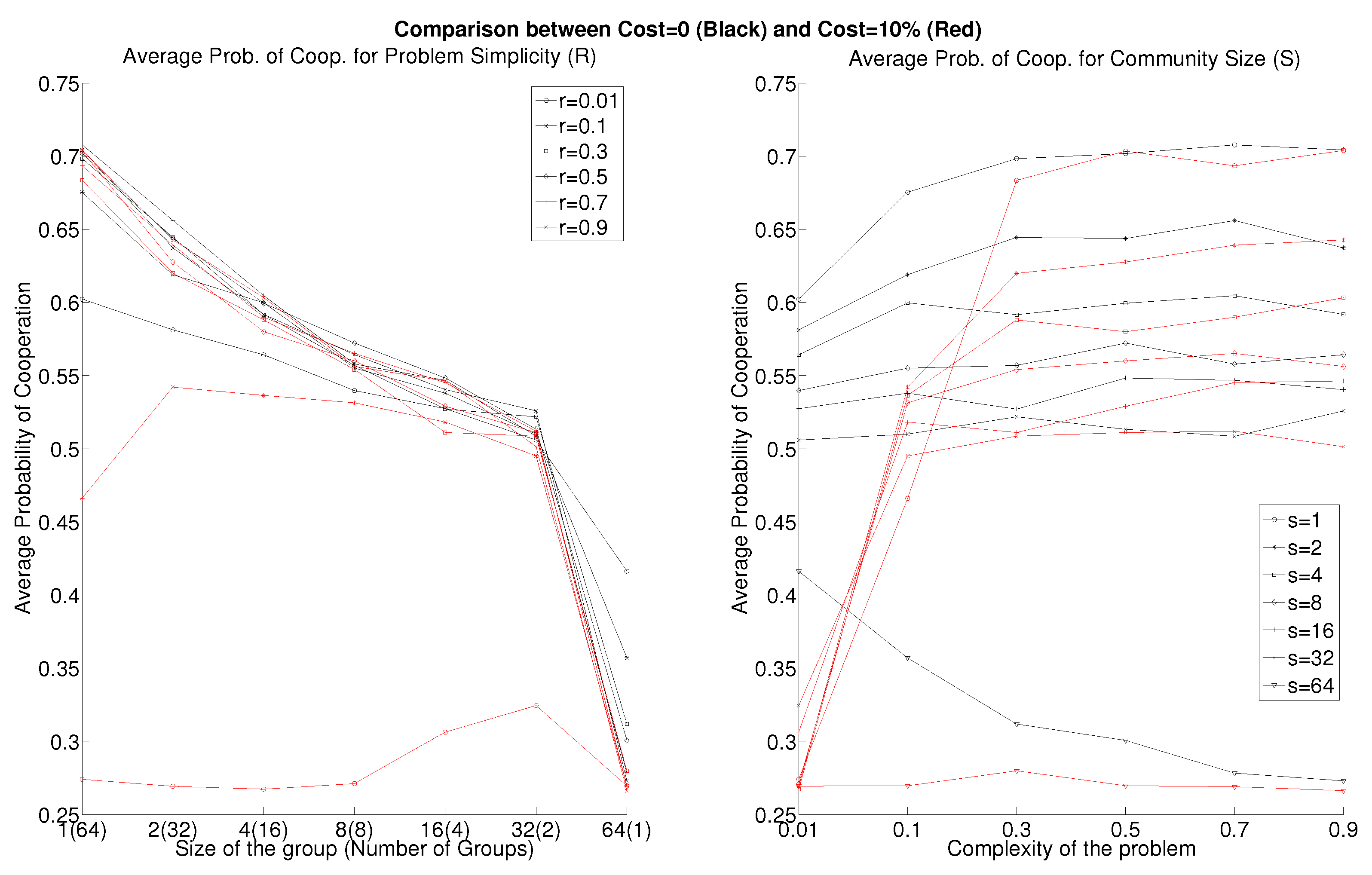
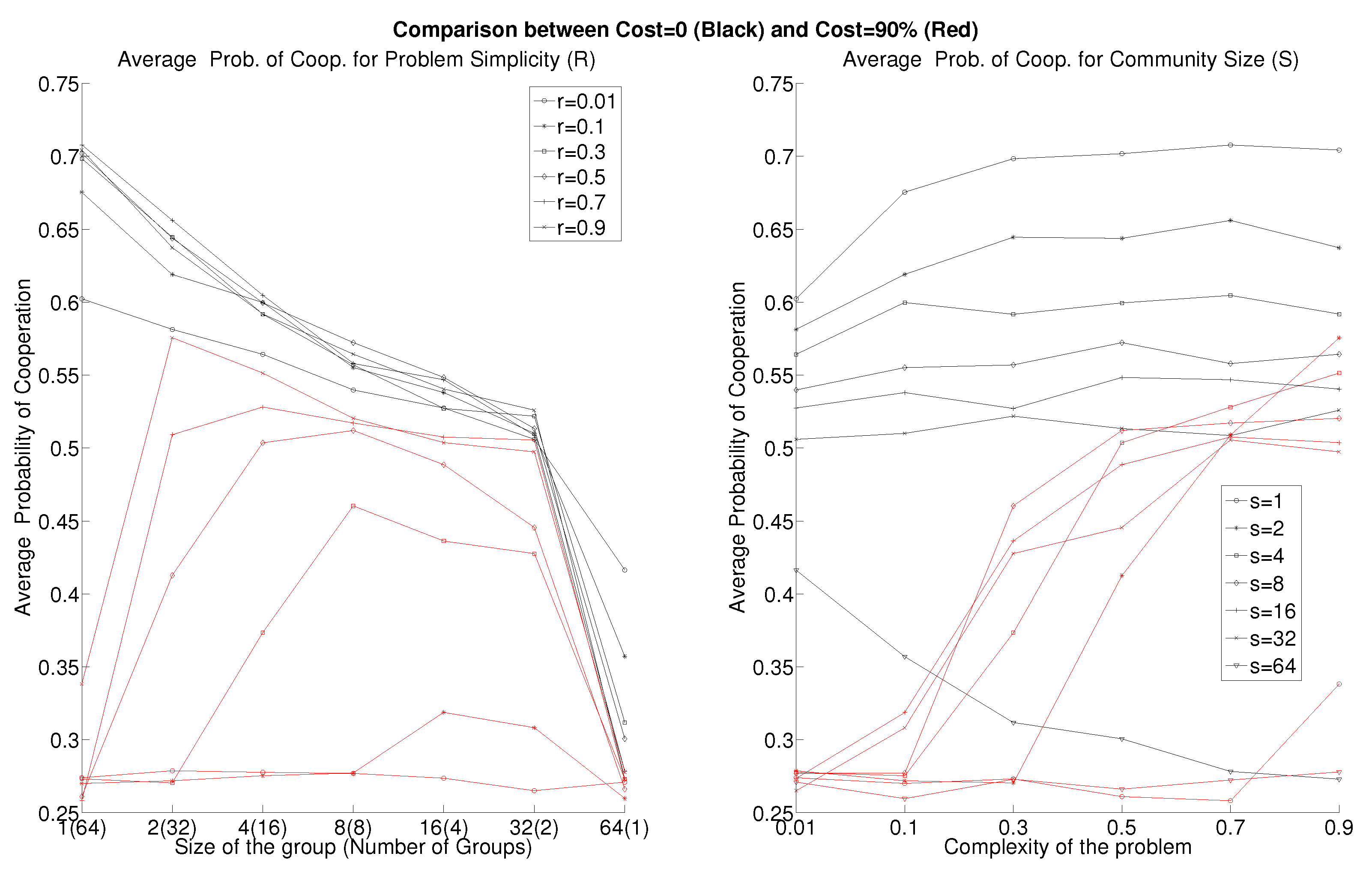
3. Results
4. Conclusions
5. Compliance with Ethical Standards
6. Data Availability Statement
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
| Algorithm A1 Game Round Algorithm. |
|
| Algorithm A2 Crowdsourcing Simulation Algorithm. |
|
References
- Grassi, M.; Morbidoni, C.; Nucci, M. A collaborative video annotation system based on semantic web technologies. Cogn. Comput. 2012, 4, 497–514. [Google Scholar] [CrossRef]
- Squartini, S.; Esposito, A. CO-WORKER: Toward real-time and context-aware systems for human collaborative knowledge building. Cogn. Comput. 2012, 4, 157–171. [Google Scholar] [CrossRef]
- Zhao, N.; Xu, Z.; Liu, F. Group decision making with dual hesitant fuzzy preference relations. Cogn. Comput. 2016, 8, 1119–1143. [Google Scholar] [CrossRef]
- Guazzini, A.; Vilone, D.; Donati, C.; Nardi, A.; Levnajić, Z. Modeling crowdsourcing as collective problem solving. Sci. Rep. 2015, 5, 16557. [Google Scholar] [CrossRef] [PubMed]
- Gowers, T.; Nielsen, M. Massively collaborative mathematics. Nature 2009, 461, 879–881. [Google Scholar] [CrossRef] [PubMed]
- Prpić, J.; Taeihagh, A.; Melton, J. The fundamentals of policy crowdsourcing. Policy Internet 2015, 7, 340–361. [Google Scholar] [CrossRef]
- Mau, B.; Leonard, J. Massive Change: The Institute without Boundaries; Phaidon: London, UK, 2004. [Google Scholar]
- Brabham, D.C. Crowdsourcing as a model for problem solving an introduction and cases. Convergence 2008, 14, 75–90. [Google Scholar] [CrossRef]
- Doan, A.; Ramakrishnan, R.; Halevy, A.Y. Crowdsourcing systems on the world-wide web. Commun. ACM 2011, 54, 86–96. [Google Scholar] [CrossRef]
- Kazai, G. In search of quality in crowdsourcing for search engine evaluation. In Proceedings of the European Conference on Information Retrieval, Dublin, Ireland, 18–21 April 2011; pp. 165–176. [Google Scholar]
- La Vecchia, G.; Cisternino, A. Collaborative workforce, business process crowdsourcing as an alternative of BPO. In Proceedings of the International Conference on Web Engineering, Vienna, Austria, 5–9 July 2010; pp. 425–430. [Google Scholar]
- Mazzola, D.; Distefano, A. Crowdsourcing and the participation process for problem solving: The Case of BP. In Proceedings of the ItAIS 2010 VII Conference of the Italian Chapter of AIS, Naples, Italy, 8–9 October 2010; pp. 42–49. [Google Scholar]
- Chang, E.C.; D’Zurilla, T.J.; Sanna, L.J. Social Problem Solving: Theory, Research, and Training; American Psychological Association: Washington, DC, USA, 2004. [Google Scholar]
- Newell, B.R.; Lagnado, D.A.; Shanks, D.R. Straight Choices: The Psychology of Decision Making; Psychology Press: Hove, UK, 2015. [Google Scholar]
- Baron, R.; Kerr, N. Group Process, Group Decision, Group Action 2/E; McGraw-Hill Education: London, UK, 2003. [Google Scholar]
- Budhathoki, N.R.; Haythornthwaite, C. Motivation for open collaboration crowd and community models and the case of OpenStreetMap. Am. Behav. Sci. 2013, 57, 548–575. [Google Scholar] [CrossRef]
- Barrett, L.; Dunbar, R.; Lycett, J. Human Evolutionary Psychology; Princeton University Press: Princeton, NJ, USA, 2002. [Google Scholar]
- Chanal, V.; Caron-Fasan, M.L. How to invent a new business model based on crowdsourcing: The Crowdspirit® case. In Proceedings of the Conférence de l’Association Internationale de Management Stratégique, Sophia-Antipolis, France, 28–31 May 2008; pp. 1–27. [Google Scholar]
- Whitla, P. Crowdsourcing and its application in marketing activities. Contemp. Manag. Res. 2009, 5. [Google Scholar] [CrossRef]
- Herrmann, B.; Thöni, C.; Gächter, S. Antisocial punishment across societies. Science 2008, 319, 1362–1367. [Google Scholar] [CrossRef] [PubMed]
- Rand, D.G.; Peysakhovich, A.; Kraft-Todd, G.T.; Newman, G.E.; Wurzbacher, O.; Nowak, M.A.; Greene, J.D. Social heuristics shape intuitive cooperation. Nat. Commun. 2014, 5, 3677. [Google Scholar] [CrossRef] [PubMed]
- Salas, E.; Cooke, N.J.; Rosen, M.A. On teams, teamwork, and team performance: Discoveries and developments. Hum. Factor 2008, 50, 540–547. [Google Scholar] [CrossRef] [PubMed]
- Alterman, R. Representation, interaction, and intersubjectivity. Cogn. Sci. 2007, 31, 815–841. [Google Scholar] [CrossRef] [PubMed]
- Cooke, N.J.; Gorman, J.C.; Myers, C.W.; Duran, J.L. Interactive team cognition. Cogn. Sci. 2013, 37, 255–285. [Google Scholar] [CrossRef] [PubMed]
- Kämmer, J.E.; Gaissmaier, W.; Expt, U.C. The environment matters: Comparing individuals and dyads in their adaptive use of decision strategies. Judgm. Decis. Mak. 2013, 8, 299–329. [Google Scholar]
- Wisdom, T.N.; Song, X.; Goldstone, R.L. Social learning strategies in networked groups. Cogn. Sci. 2013, 37, 1383–1425. [Google Scholar] [CrossRef] [PubMed]
- Dávid-Barrett, T.; Dunbar, R. Processing power limits social group size: Computational evidence for the cognitive costs of sociality. Proc. R. Soc. B 2013, 280, 20131151. [Google Scholar] [CrossRef] [PubMed]
- Kim, J. Influence of group size on students’ participation in online discussion forums. Comput. Educ. 2013, 62, 123–129. [Google Scholar] [CrossRef]
- Barcelo, H.; Capraro, V. Group size effect on cooperation in one-shot social dilemmas. Sci. Rep. 2015, 5, 7937. [Google Scholar] [CrossRef] [PubMed]
- Capraro, V.; Barcelo, H. Group size effect on cooperation in one-shot social dilemmas II: Curvilinear effect. PLoS ONE 2015, 10, e0131419. [Google Scholar] [CrossRef] [PubMed]
- Nakatsu, R.T.; Grossman, E.B.; Iacovou, C.L. A taxonomy of crowdsourcing based on task complexity. J. Inf. Sci. 2014, 40, 823–834. [Google Scholar] [CrossRef]
- Milinski, M.; Semmann, D.; Krambeck, H.J. Reputation helps solve the ‘tragedy of the commons’. Nature 2002, 415, 424–426. [Google Scholar] [CrossRef] [PubMed]
- Nowak, M.A.; Sigmund, K.; Dieckmann, U. Evolution of indirect reciprocity by image scoring. Nature 1998, 393, 573. [Google Scholar] [CrossRef] [PubMed]
- Ohtsuki, H.; Iwasa, Y. How should we define goodness?—Reputation dynamics in indirect reciprocity. J. Theor. Biol. 2004, 231, 107–120. [Google Scholar] [CrossRef] [PubMed]
- Fehr, E.; Gächter, S. Altruistic punishment in humans. Nature 2002, 415, 137–140. [Google Scholar] [CrossRef] [PubMed]
- Shinada, M.; Yamagishi, T. Punishing free riders: Direct and indirect promotion of cooperation. Evol. Hum. Behav. 2007, 28, 330–339. [Google Scholar] [CrossRef]
- Sommerfeld, R.D.; Krambeck, H.J.; Semmann, D.; Milinski, M. Gossip as an alternative for direct observation in games of indirect reciprocity. Proc. Natl. Acad. Sci. USA 2007, 104, 17435–17440. [Google Scholar] [CrossRef] [PubMed]
- Piazza, J.; Bering, J.M. Concerns about reputation via gossip promote generous allocations in an economic game. Evol. Hum. Behav. 2008, 29, 172–178. [Google Scholar] [CrossRef]
- Smith, E.R.; Conrey, F.R. Agent-based modeling: A new approach for theory building in social psychology. Pers. Soc. Psychol. Rev. 2007, 11, 87–104. [Google Scholar] [CrossRef] [PubMed]
- Hunter, E.; Mac Namee, B.; Kelleher, J. A Taxonomy for Agent-Based Models in Human Infectious Disease Epidemiology. J. Artif. Soc. Soc. Simul. 2017, 20, 2. [Google Scholar] [CrossRef]
- Ma, Y.; Shen, Z.; Nguyen, D.T. Agent-Based Simulation to Inform Planning Strategies for Welfare Facilities for the Elderly: Day Care Center Development in a Japanese City. J. Artif. Soc. Soc. Simul. 2016, 19, 5. [Google Scholar] [CrossRef]
- Swinscoe, T.; Knoeri, C.; Fleskens, L.; Barrett, J. Agent-based modelling of agricultural water abstraction in response to climate change and policies: In East Anglia, UK. In Proceedings of the Social Simulation Conference, Barcelona, Spain, 1–5 September 2014. [Google Scholar]
- Van Voorn, G.; Ligtenberg, A.; ten Broeke, G. A spatially explicit agent-based model of opinion and reputation dynamics. In Proceedings of the Social Simulation Conference, Barcelona, Spain, 1–5 September 2014. [Google Scholar]
- Clifford, P.; Sudbury, A. A model for spatial conflict. Biometrika 1973, 60, 581. [Google Scholar] [CrossRef]
- Deffuant, G.; Neau, D.; Amblard, F.; Weisbuch, G. Mixing beliefs among interacting agents. Adv. Complex Syst. 2000, 3, 87. [Google Scholar] [CrossRef]
- Sen, P.; Chakrabarti, B.K. Sociophysics—An Introduction; Oxford University Press: Oxford, UK, 2014. [Google Scholar]
- Galam, S. Contrarian deterministic effects on opinion dynamics: “The hung elections scenario”. Physica A 2004, 333, 453. [Google Scholar] [CrossRef]
- Galam, S. Sociophysics: A review of Galam models. Int. J. Mod. Phys. C 2008, 19, 409. [Google Scholar] [CrossRef]
- Vilone, D.; Ramasco, J.J.; Sánchez, A.; San Miguel, M. Social and strategic imitation: The way to consensus. Sci. Rep. 2012, 2, 686. [Google Scholar] [CrossRef] [PubMed]
- Vilone, D.; Ramasco, J.J.; Sánchez, A.; San Miguel, M. Social imitation versus strategic choice, or consensus versus cooperation, in the networked Prisoner’s Dilemma. Phys. Rev. E 2014, 90, 022810. [Google Scholar] [CrossRef] [PubMed]
- Engel, C.; Zhurakhovska, L. When is the risk of cooperation worth taking? The prisoner’s dilemma as a game of multiple motives. Appl. Econ. Lett. 2016, 23, 1157–1161. [Google Scholar] [CrossRef]
- Capraro, V.; Jordan, J.J.; Rand, D.G. Heuristics guide the implementation of social preferences in one-shot Prisoner’s Dilemma experiments. Sci. Rep. 2014, 4, 6790. [Google Scholar] [CrossRef] [PubMed]
- Rajaram, S.; Pereira-Pasarin, L.P. Collaborative memory: Cognitive research and theory. Perspect. Psychol. Sci. 2010, 5, 649–663. [Google Scholar] [CrossRef] [PubMed]
- Maznevski, M.L. Understanding our differences: Performance in decision-making groups with diverse members. Hum. Relat. 1994, 47, 531–552. [Google Scholar] [CrossRef]
- Witte, E.H.; Davis, J.H. Understanding Group Behavior: Volume 1: Consensual Action by Small Groups; Volume 2: Small Group Processes and Interpersonal Relations; Psychology Press: Hove, UK, 2013. [Google Scholar]
- Woolley, A.W.; Chabris, C.F.; Pentland, A.; Hashmi, N.; Malone, T.W. Evidence for a collective intelligence factor in the performance of human groups. Science 2010, 330, 686–688. [Google Scholar] [CrossRef] [PubMed]
- Rachlin, H. Altruism and selfishness. Behav. Brain Sci. 2002, 25, 239–250. [Google Scholar] [CrossRef] [PubMed]
- Fum, D.; Del Missier, F.; Stocco, A. The cognitive modeling of human behavior: Why a model is (sometimes) better than 10,000 words. Cogn. Syst. Res. 2007, 8, 135–142. [Google Scholar] [CrossRef]
- Lewin, K. Field Theory in Social Science; Harpers: Oxford, UK, 1951. [Google Scholar]
- Lewandowsky, S.; Farrell, S. Computational Modeling in Cognition: Principles and Practice; Sage Publications: Thousand Oaks, CA, USA, 2010. [Google Scholar]
- Kennedy, W.G. Cognitive plausibility in cognitive modeling, artificial Intelligence, and social simulation. In Proceedings of the International Conference on Cognitive Modeling (ICCM), Manchester, UK, 24–26 July 2009; pp. 454–455. [Google Scholar]
- Guazzini, A.; Duradoni, M.; Gronchi, G. The selfish vaccine Recipe: A simple mechanism for avoiding free-riding. In Proceedings of the IEEE Winter Simulation Conference (WSC), Arlington, VA, USA, 11–14 December 2016; pp. 3429–3439. [Google Scholar]
- Hofbauer, J.; Sigmund, K. Evolutionary Games and Population Dynamics; University of Cambridge: Cambridge, UK, 1998. [Google Scholar]
- Wang, Y.; Jia, X.; Jin, Q.; Ma, J. Mobile crowdsourcing: Framework, challenges, and solutions. Concur. Comput. Pract. Exp. 2017, 29. [Google Scholar] [CrossRef]
- Van Lange, P.A.; Balliet, D.P.; Parks, C.D. Social Dilemmas: Understanding Human Cooperation; Oxford University Press: Oxford, UK, 2014. [Google Scholar]
- Winther, B.; Riegler, M.; Calvet, L.; Griwodz, C.; Halvorsen, P. Why design matters: Crowdsourcing of complex tasks. In Proceedings of the Fourth International Workshop on Crowdsourcing for Multimedia, Brisbane, Australia, 30 October 2015; pp. 27–32. [Google Scholar]
- Van Lange, P.A.; Kuhlman, D.M. Social value orientations and impressions of partner’s honesty and intelligence: A test of the might versus morality effect. J. Personal. Soc. Psychol. 1994, 67, 126. [Google Scholar] [CrossRef]




© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guazzini, A.; Duradoni, M.; Lazzeri, A.; Gronchi, G. Simulating the Cost of Cooperation: A Recipe for Collaborative Problem-Solving. Future Internet 2018, 10, 55. https://doi.org/10.3390/fi10060055
Guazzini A, Duradoni M, Lazzeri A, Gronchi G. Simulating the Cost of Cooperation: A Recipe for Collaborative Problem-Solving. Future Internet. 2018; 10(6):55. https://doi.org/10.3390/fi10060055
Chicago/Turabian StyleGuazzini, Andrea, Mirko Duradoni, Alessandro Lazzeri, and Giorgio Gronchi. 2018. "Simulating the Cost of Cooperation: A Recipe for Collaborative Problem-Solving" Future Internet 10, no. 6: 55. https://doi.org/10.3390/fi10060055
APA StyleGuazzini, A., Duradoni, M., Lazzeri, A., & Gronchi, G. (2018). Simulating the Cost of Cooperation: A Recipe for Collaborative Problem-Solving. Future Internet, 10(6), 55. https://doi.org/10.3390/fi10060055