StegNet: Mega Image Steganography Capacity with Deep Convolutional Network


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. Steganography Methods
2.2. JPEG RAR Steganography
2.3. LSB (Least Significant Bit) Method
2.4. JPEG Steganography
2.5. Convolutional Neural Network
2.6. Autoencoder Neural Network
2.7. Neural Network for Steganography
3. Convolutional Neural Network for Image Steganography
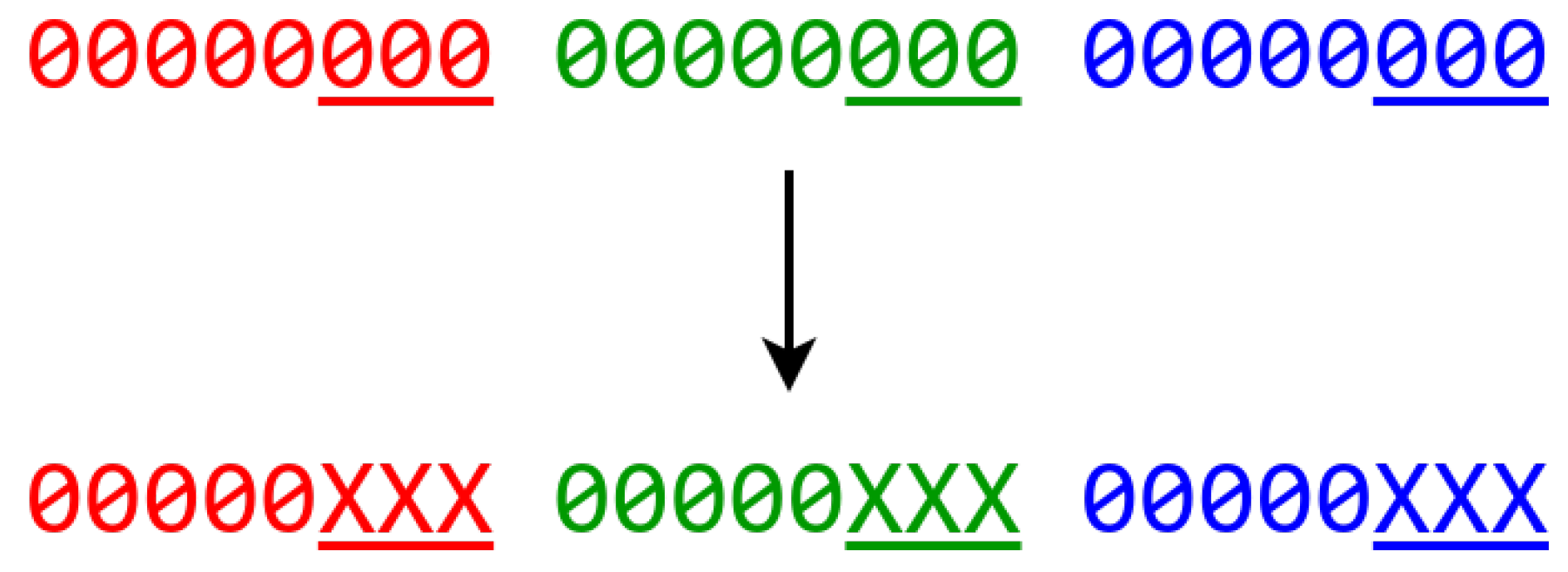
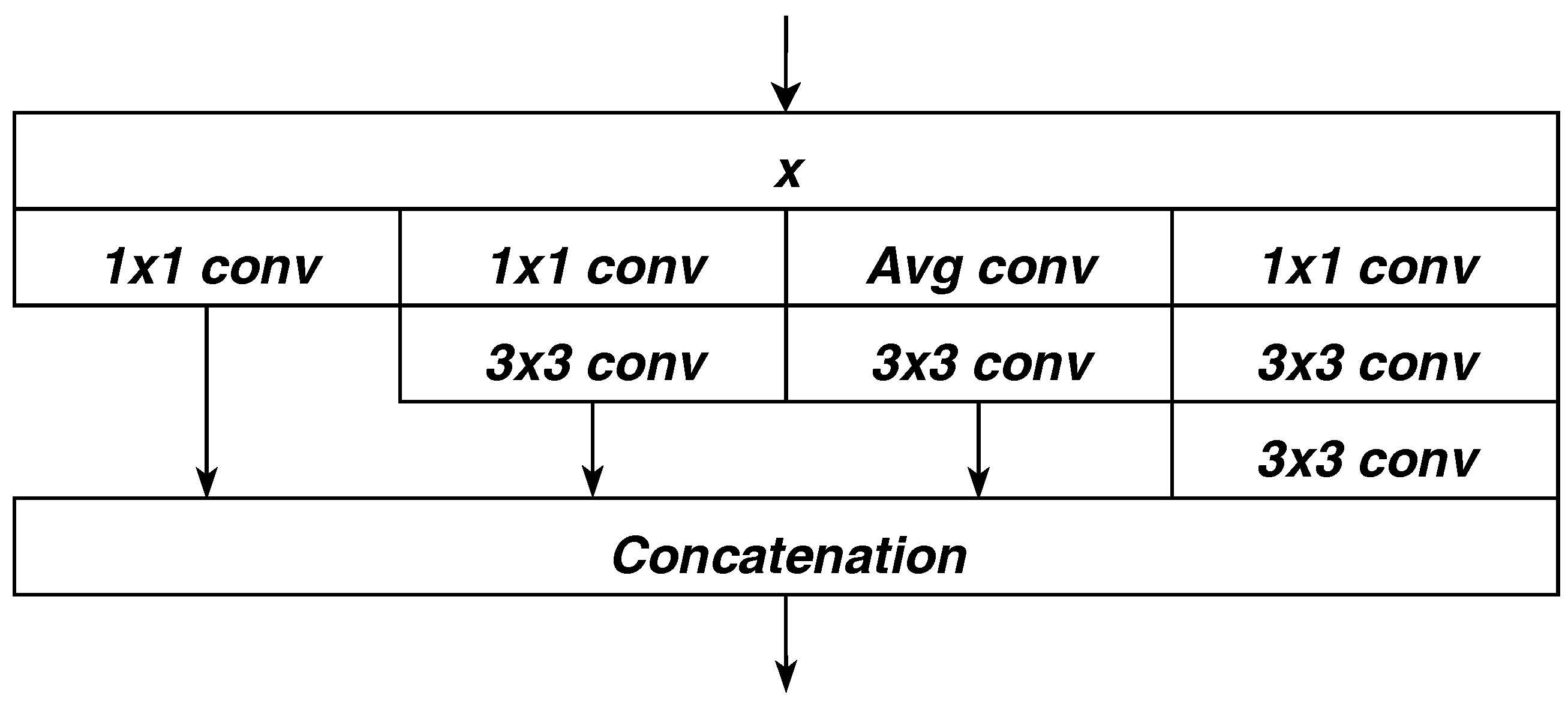
3.1. High-order Transformation
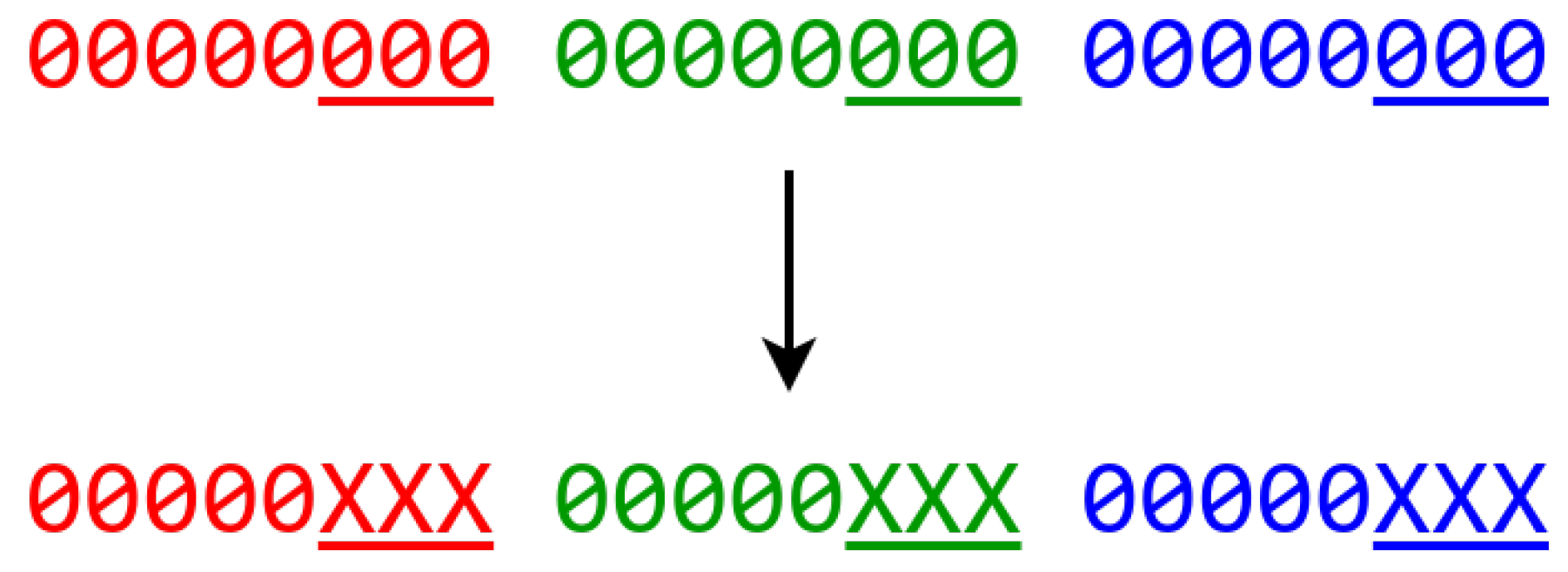
3.2. Trading Accuracy for Capacity
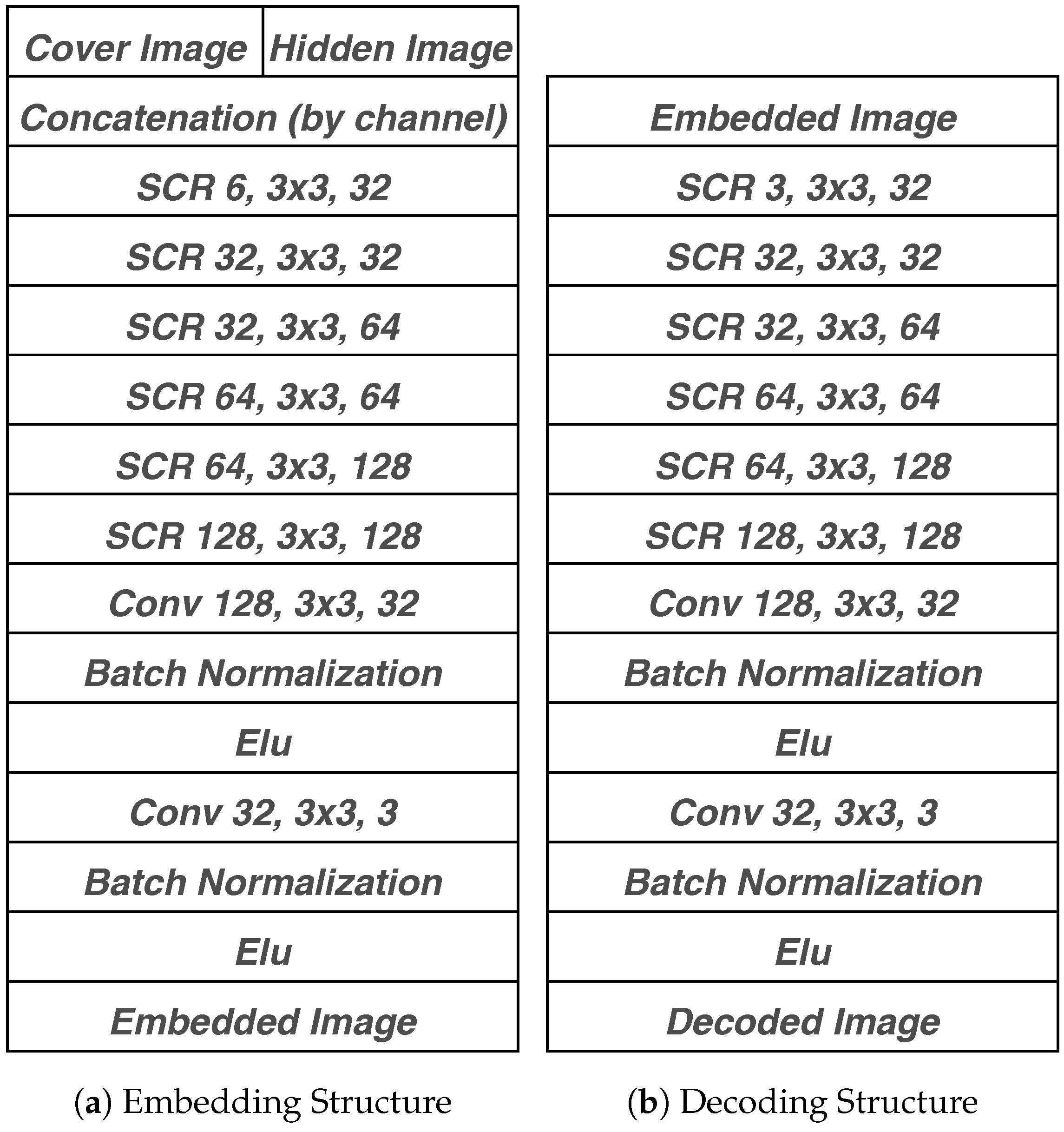
4. Architecture
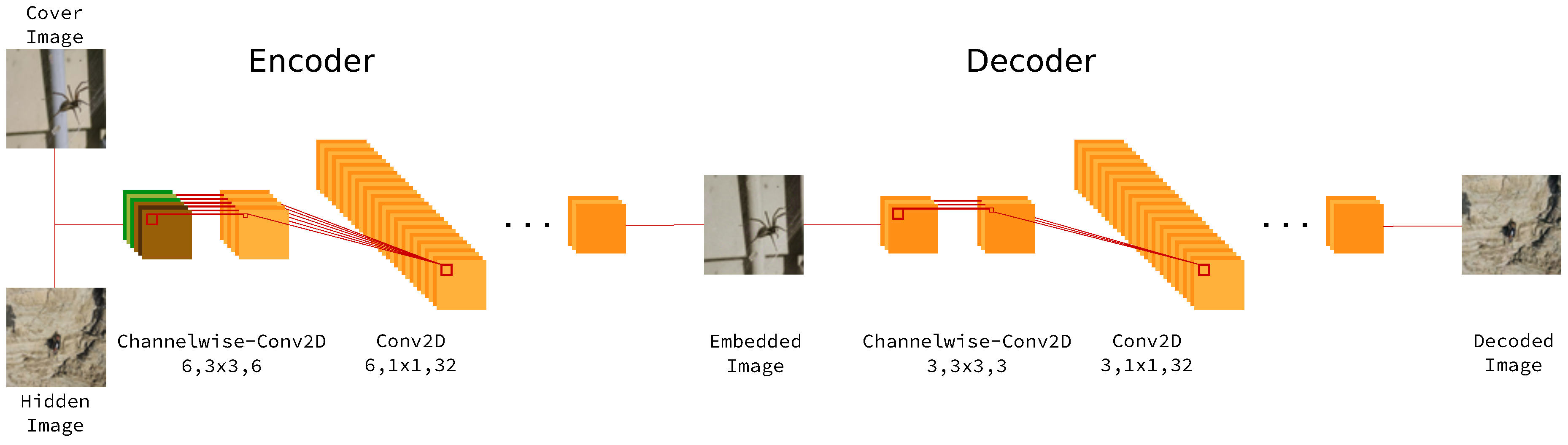
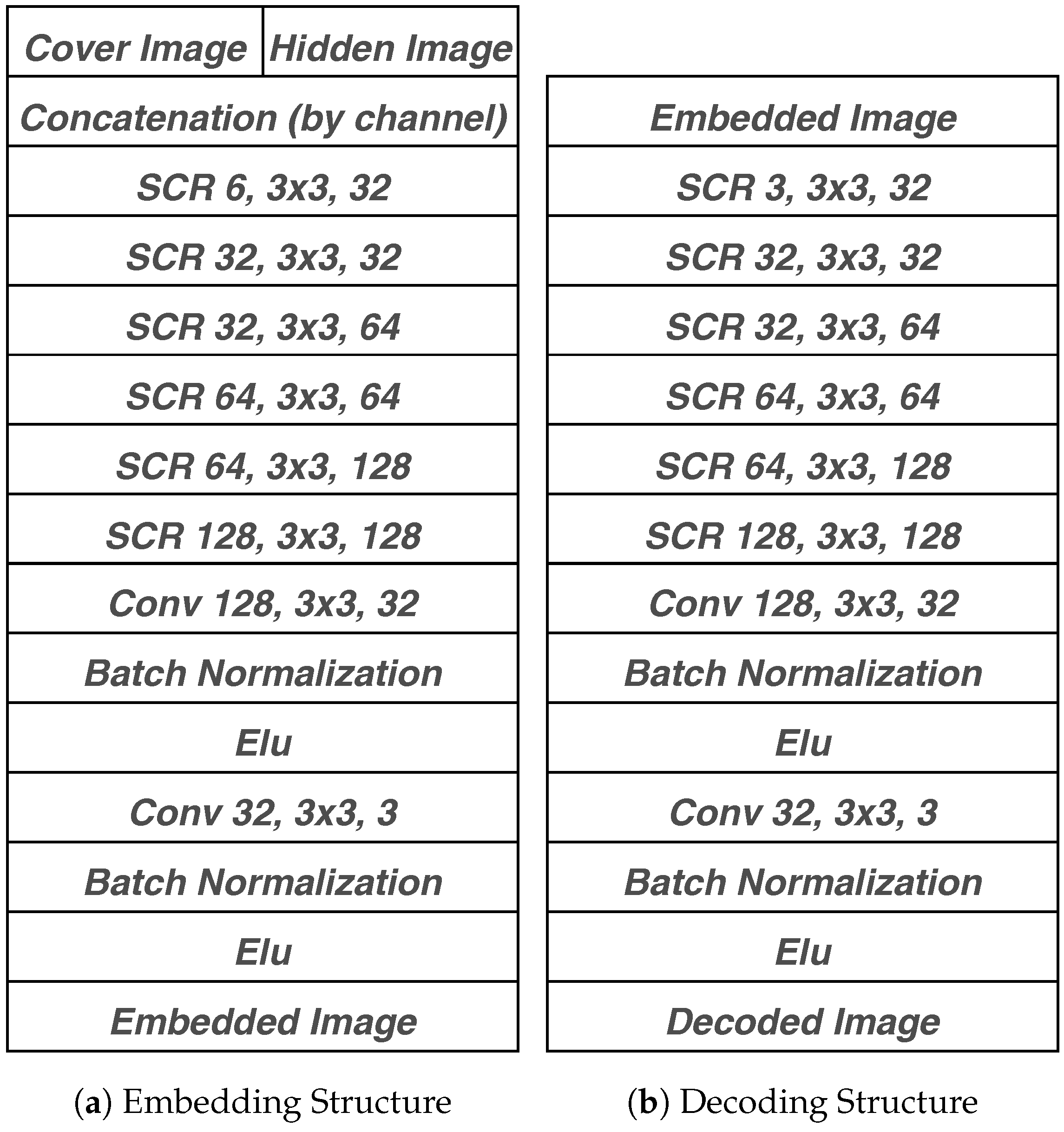
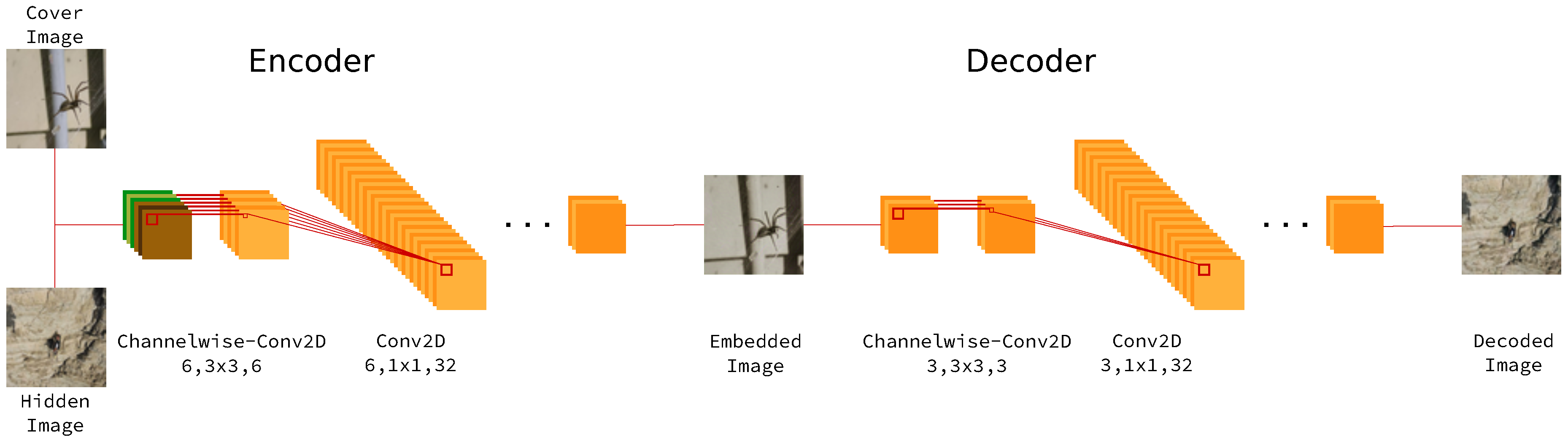
4.1. Architecture Pipeline
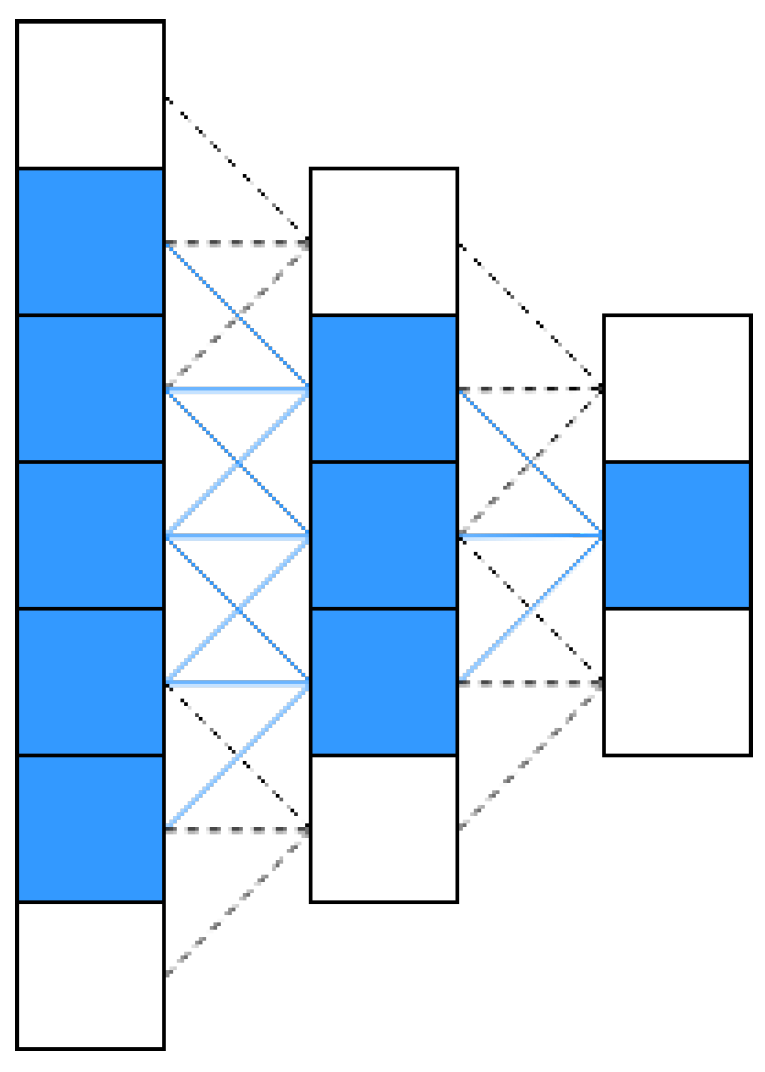
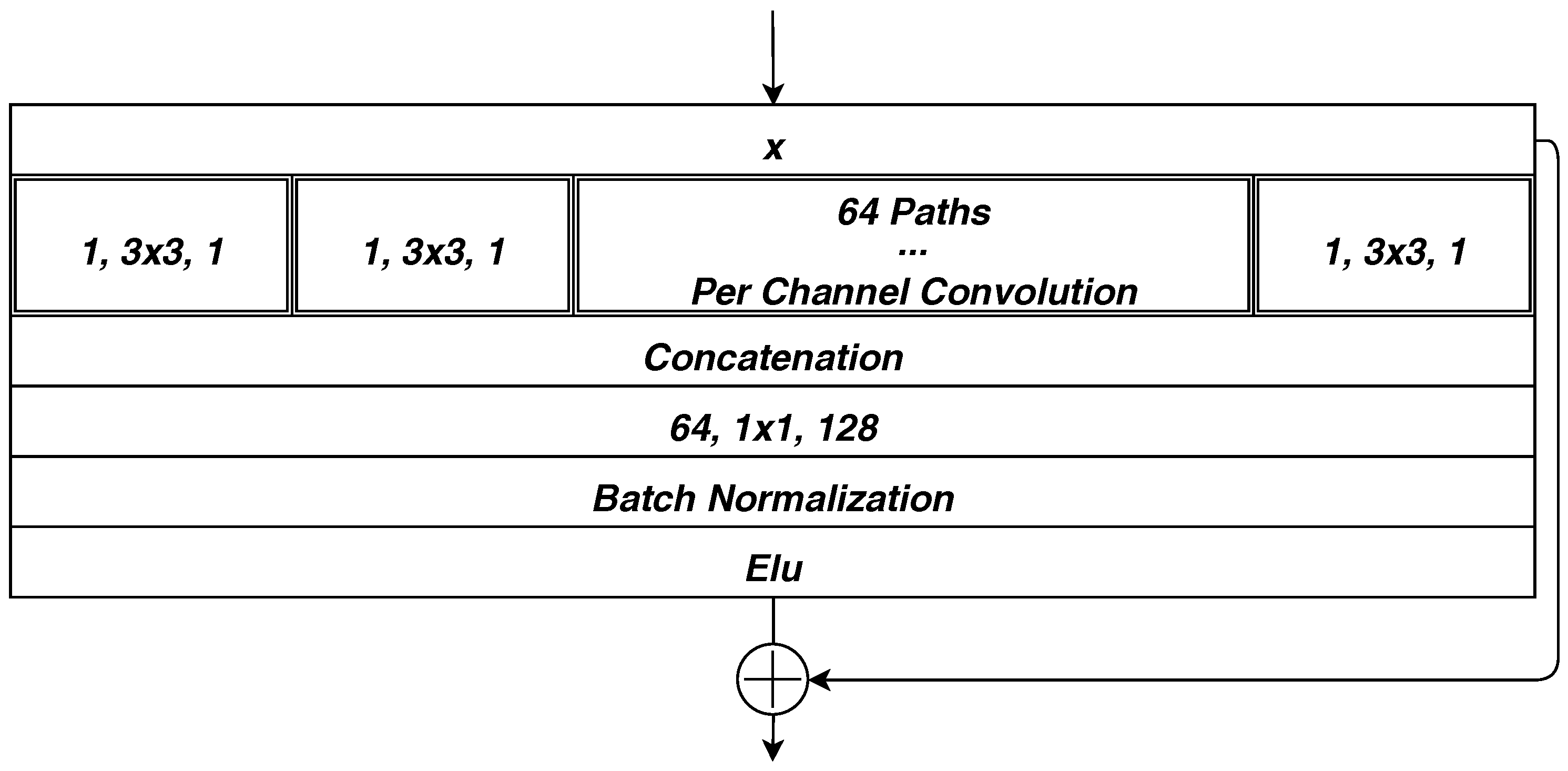
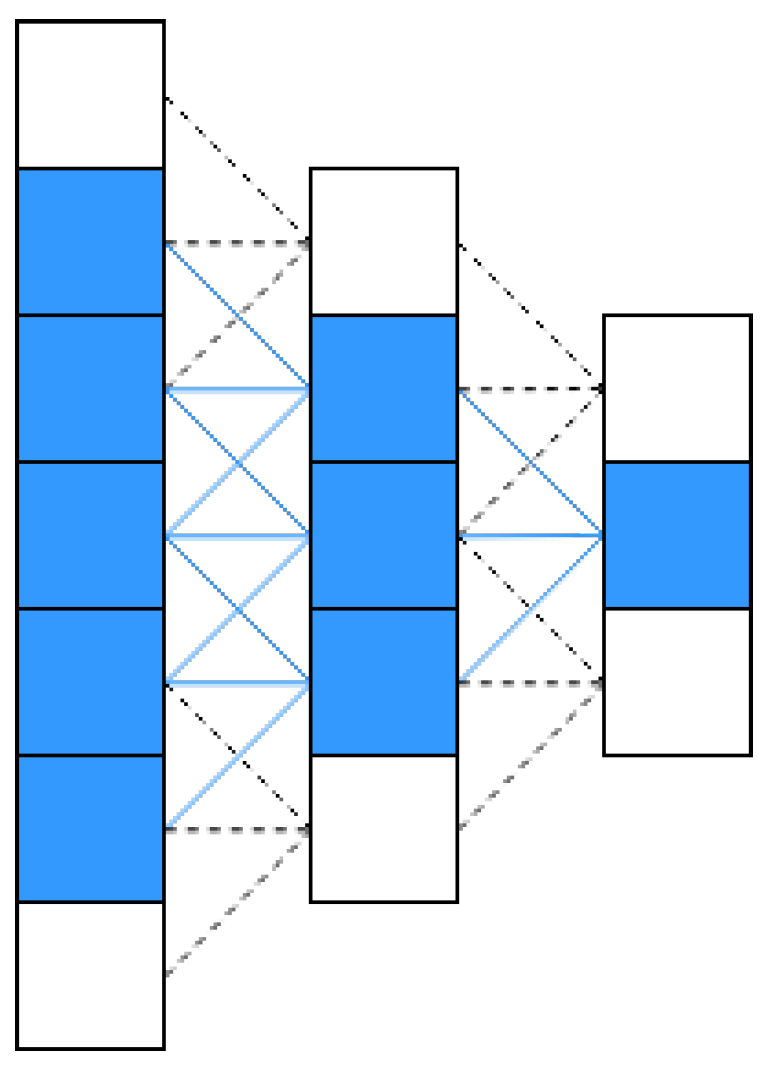
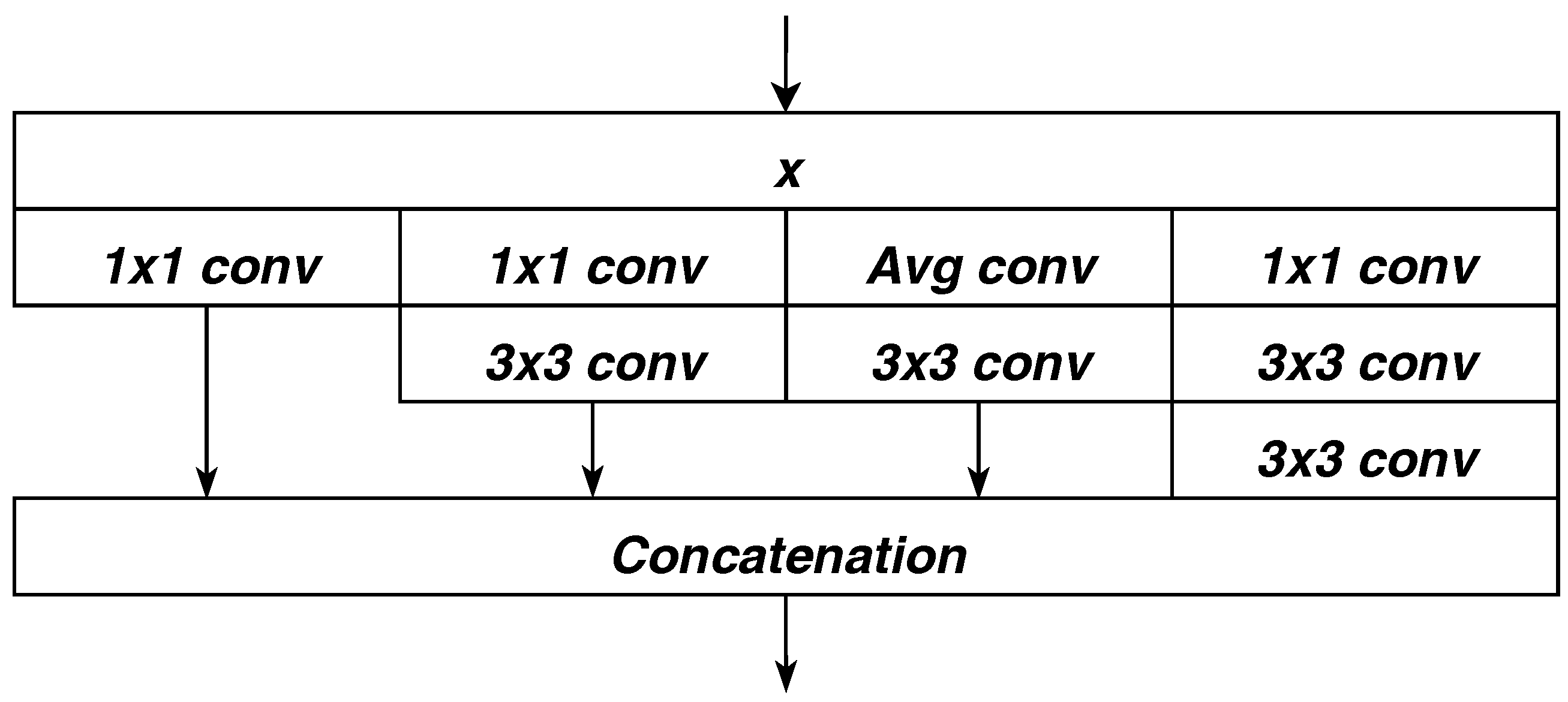
4.2. Separable Convolution with Residual Block
4.3. Training
5. Experiments
5.1. Environment
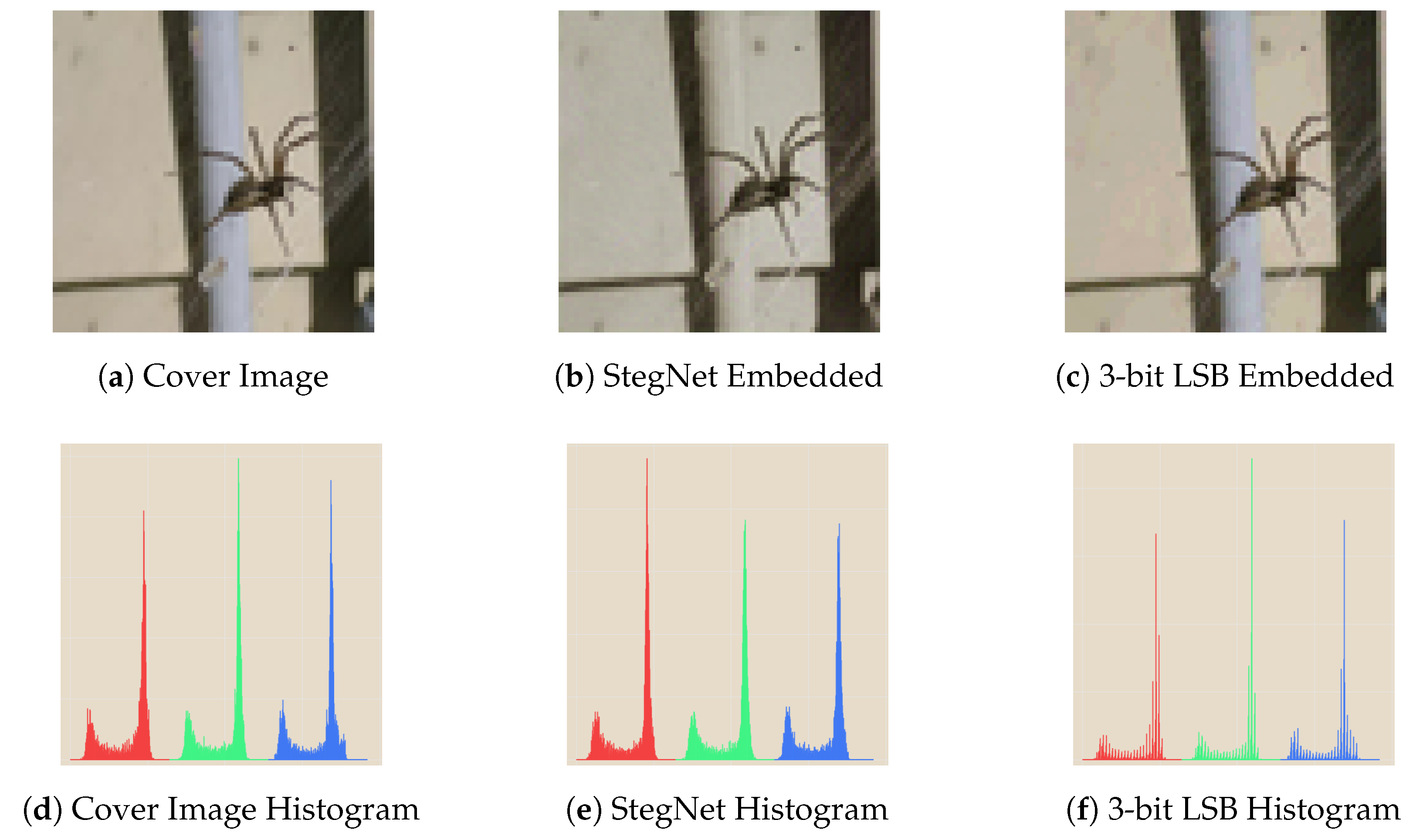
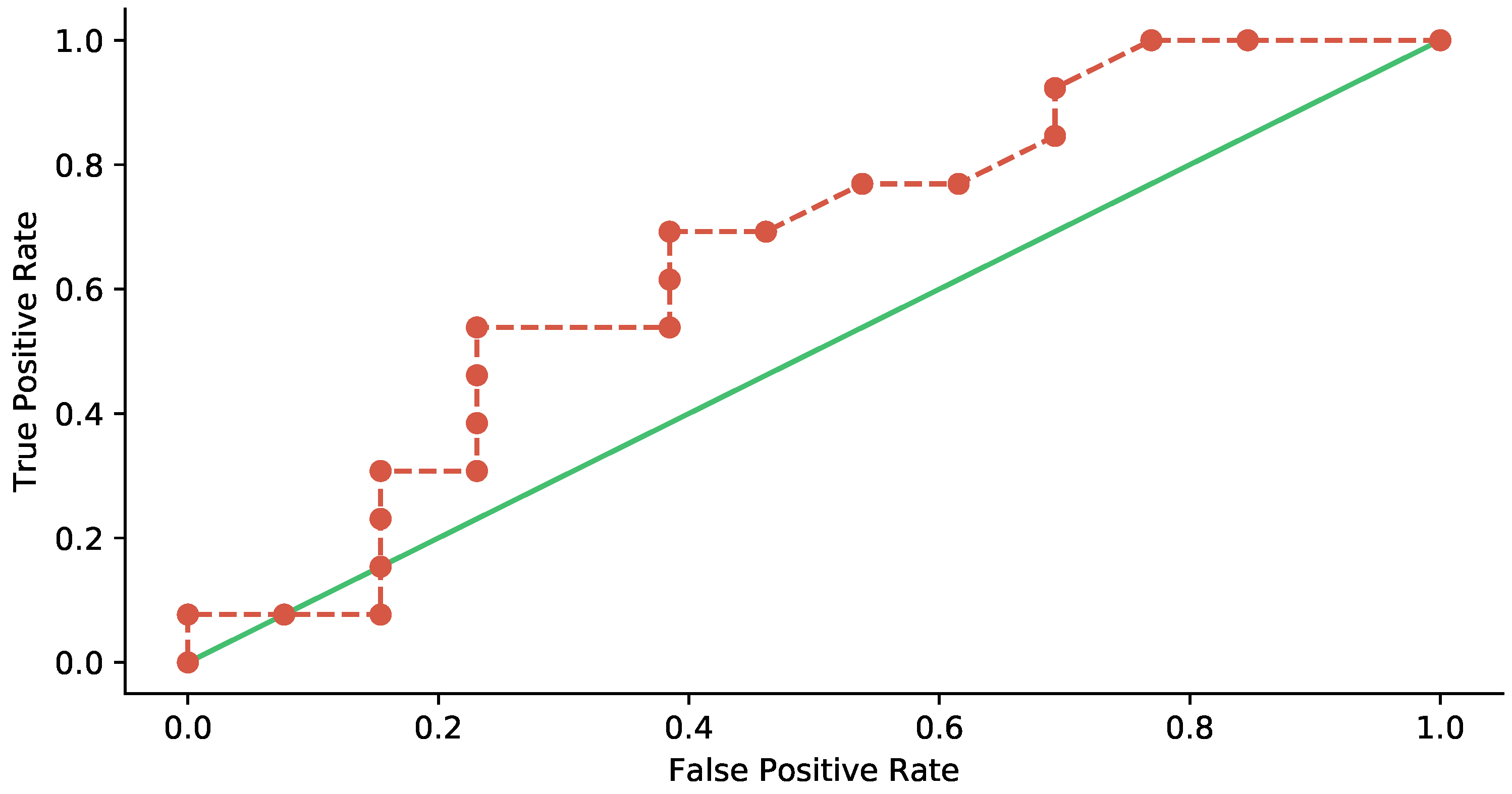
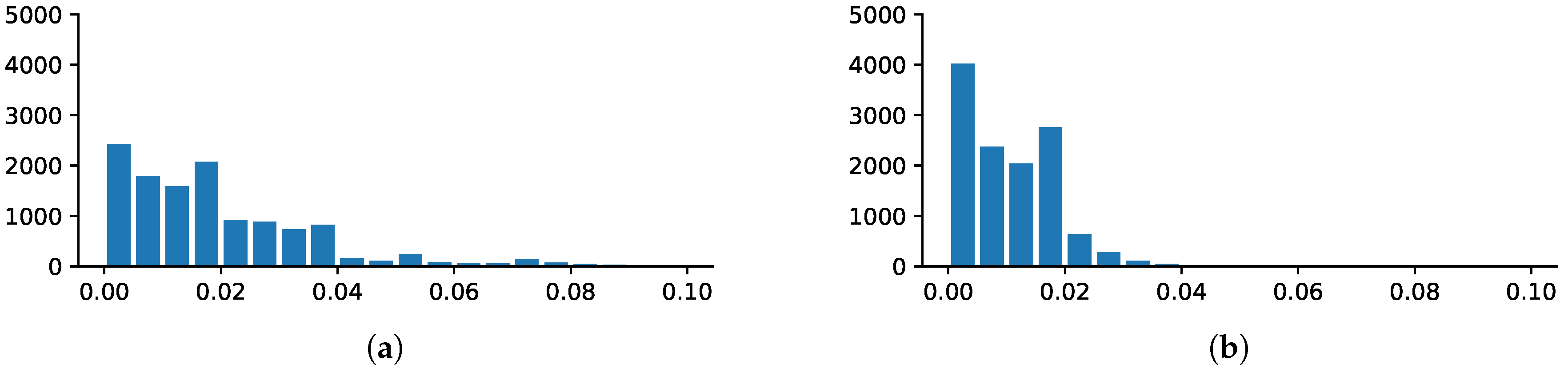
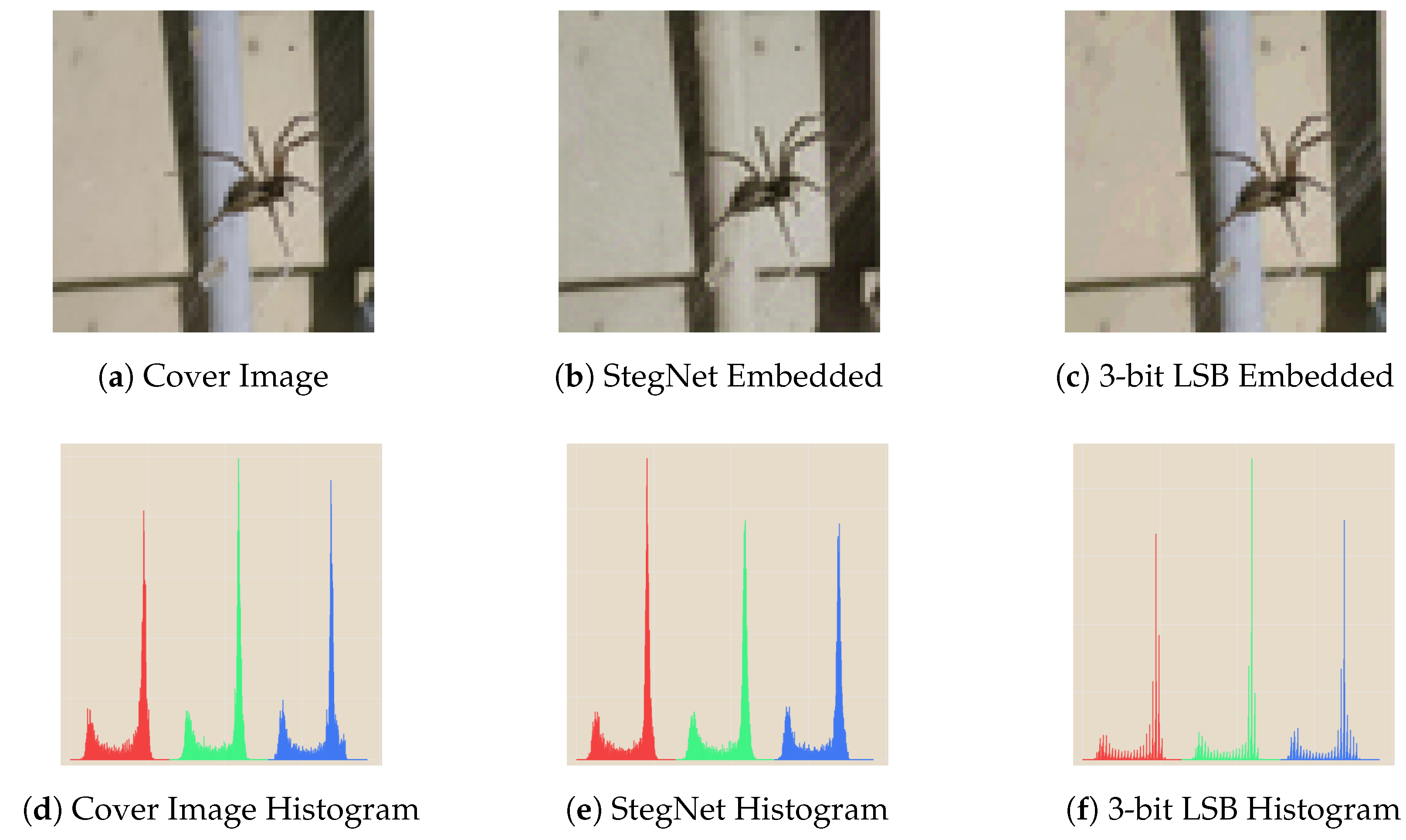
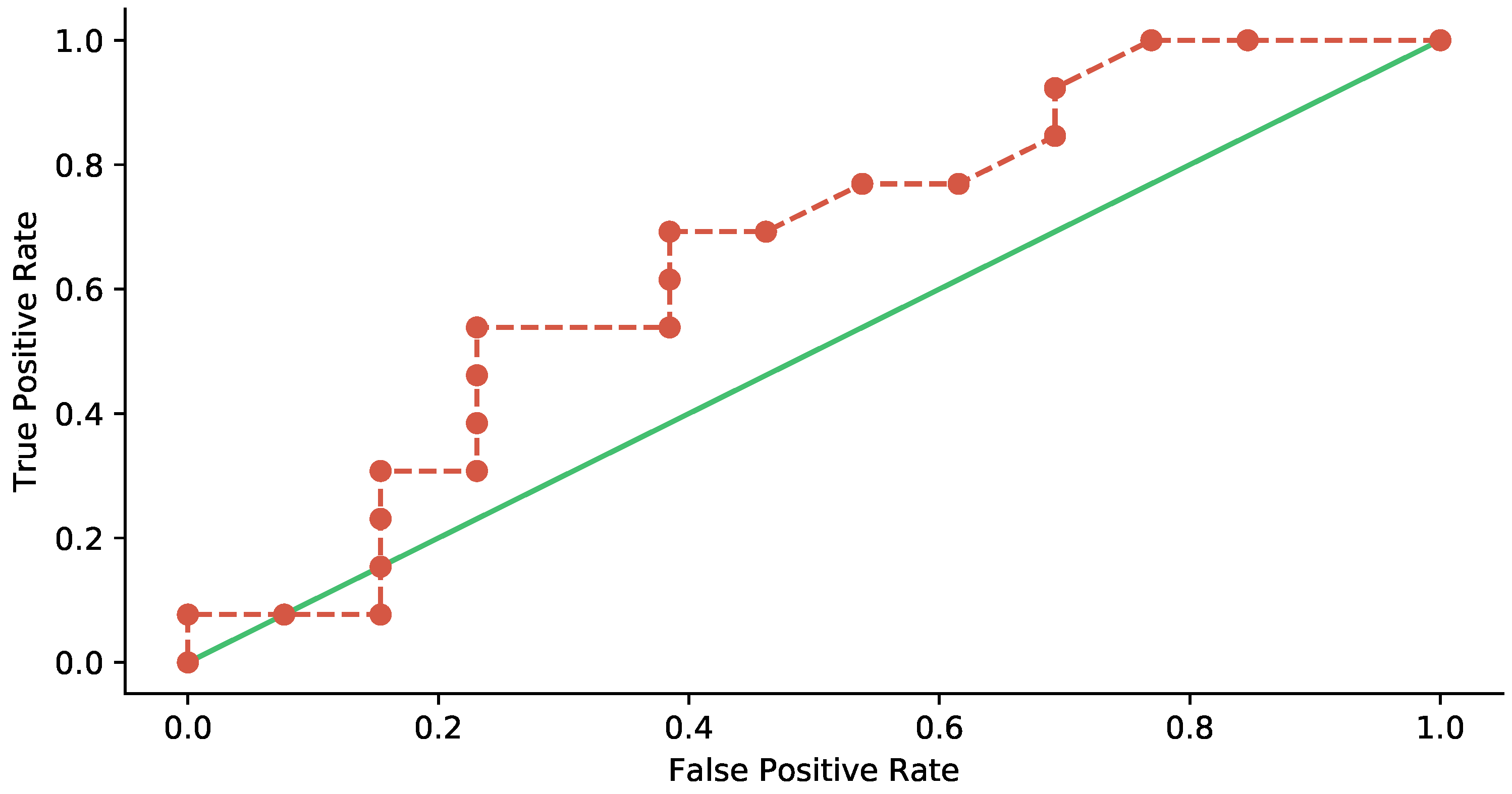
5.2. Statistical Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Mielikainen, J. Lsb matching revisited. IEEE Signal Process. Lett. 2006, 13, 285–287. [Google Scholar] [CrossRef]
- Kawaguchi, E.; Eason, R. Principle and applications of BPCS-Steganography. In Proceedings of the SPIE 3528, Multimedia Systems and Applications, Boston, MA, USA, 22 January 1999. [Google Scholar]
- Almohammad, A.; Hierons, R.M.; Ghinea, G. High Capacity Steganographic Method Based Upon JPEG. In Proceedings of the Third International Conference on Availability, Reliability and Security, Barcelona, Spain, 4–7 March 2008. [Google Scholar]
- Pevný, T.; Filler, T.; Bas, P. Using High-Dimensional Image Models to Perform Highly Undetectable Steganography. In Information Hiding; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; pp. 161–177. [Google Scholar]
- Holub, V.; Fridrich, J. Designing steganographic distortion using directional filters. In Proceedings of the 2012 IEEE International Workshop on Information Forensics and Security (WIFS), Tenerife, Spain, 2–5 December 2012; pp. 234–239. [Google Scholar]
- Holub, V.; Fridrich, J.; Denemark, T. Universal distortion function for steganography in an arbitrary domain. EURASIP J. Inf. Secur. 2014, 2014. [Google Scholar] [CrossRef]
- Sedighi, V.; Cogranne, R.; Fridrich, J. Content-Adaptive Steganography by Minimizing Statistical Detectability. IEEE Trans. Inf. Forensics Secur. 2016, 11, 221–234. [Google Scholar] [CrossRef]
- Cogranne, R.; Sedighi, V.; Fridrich, J. Practical strategies for content-adaptive batch steganography and pooled steganalysis. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2122–2126. [Google Scholar]
- Digital Compression and Coding of Continuous-Tone Still Images: Requirements and Guidelines; Technical Report ISO/IEC 10918-1:1994; Joint Photographic Experts Group Committee: La Jolla, CA, USA, 1994.
- Roshal, A. RAR 5.0 Archive Format. 2017. Available online: https://www.rarlab.com/technote.htm (accessed on 5 October 2017).
- Juneja, M.; Sandhu, P. Designing of robust image steganography technique based on LSB insertion and encryption. In Proceedings of the IEEE International Conference on Advances in Recent Technologies in Communication and Computing, Kerala, India, 27–28 October 2009; pp. 302–305. [Google Scholar]
- Chang, C.C.; Chen, T.S.; Chung, L.Z. A steganographic method based upon JPEG and quantization table modification. Inf. Sci. 2002, 141, 123–138. [Google Scholar] [CrossRef]
- Lecun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to hand-written zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. arXiv, 2017; arXiv:1709.01507. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully Convolutional Instance-aware Semantic Segmentation. arXiv, 2017; arXiv:1611.07709. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Bolzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; Volume 27, pp. 807–814. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Sobel, I.; Feldman, G. An Isotropic 3 × 3 Image Gradient Operator. In Pattern Classification and Scene Analysis; Wiley: Hoboken, NJ, USA, 1973; pp. 271–272. [Google Scholar]
- Fischer, S.; Sroubek, F.; Perrinet, L.U.; Redondo, R.; Cristóbal, G. Self-invertible 2D log-Gabor wavelets. Int. J. Comput. Vis. 2007, 75, 231–246. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Volume 8689, pp. 818–833. [Google Scholar] [CrossRef]
- Olah, C.; Mordvintsev, A.; Schubert, L. Feature Visualization. Distill 2017. [Google Scholar] [CrossRef]
- Mahendran, A.; Vedaldi, A. Understanding Deep Image Representations by Inverting Them. arXiv, 2015; arXiv:1412.0035. [Google Scholar]
- Hinton, G.E.; Zemel, R.S. Autoencoders, minimum description length and Helmholtz free energy. In Proceedings of the Advances in Neural Information Processing Systems, Denver, Colorado, 28 November–1 December 1994; pp. 3–10. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Wang, W.; Huang, Y.; Wang, Y.; Wang, L. Generalized autoencoder: A neural network framework for dimensionality reduction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 490–497. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv, 2013; arXiv:1312.6114. [Google Scholar]
- El-emam, N.N. Embedding a large amount of information using high secure neural based steganography algorithm. Int. J. Inf. Commun. Eng. 2008, 4, 223–232. [Google Scholar]
- Saleema, A.; Amarunnishad, T. A New Steganography Algorithm Using Hybrid Fuzzy Neural Networks. Procedia Technol. 2016, 24, 1566–1574. [Google Scholar] [CrossRef]
- Volkhonskiy, D.; Nazarov, I.; Borisenko, B.; Burnaev, E. Steganographic Generative Adversarial Networks. arXiv, 2017; arXiv:1703.05502. [Google Scholar]
- Shi, H.; Dong, J.; Wang, W.; Qian, Y.; Zhang, X. SSGAN: Secure Steganography Based on Generative Adversarial Networks. arXiv, 2017; arXiv:1707.01613. [Google Scholar]
- Baluja, S. Hiding Images in Plain Sight: Deep Steganograph. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 2069–2079. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in neural information processing systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning—Volume 37, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv, 2015; arXiv:1511.07289. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway Networks. arXiv, 2015; arXiv:1505.00387. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv, 2016; arXiv:1512.03385. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv, 2017; arXiv:1611.05431. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv, 2016; arXiv:1610.02357. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. arXiv, 2015; arXiv:1409.4842. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv, 2017; arXiv:1602.07261. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Boehm, B. StegExpose - A Tool for Detecting LSB Steganography. arXiv, 2014; arXiv:1410.6656. [Google Scholar]
- Dumitrescu, S.; Wu, X.; Wang, Z. Detection of LSB steganography via sample pair analysis. IEEE Trans. Signal Process. 2003, 51, 1995–2007. [Google Scholar] [CrossRef]
- Fridrich, J.; Goljan, M. Reliable Detection of LSB Steganography in Color and Grayscale Images. U.S. Patent 6,831,991, 14 December 2004. [Google Scholar]
- Westfeld, A.; Pfitzmann, A. Attacks on steganographic systems. In Proceedings of the International workshop on information hiding, Dresden, Germany, 29 September–1 October 1999; pp. 61–76. [Google Scholar]
- Dumitrescu, S.; Wu, X.; Memon, N. On steganalysis of random LSB embedding in continuous-tone images. In Proceedings of the 2002 International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; Volume 3, pp. 641–644. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I. Adversarial Autoencoders. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–8 August 2017; pp. 214–223. [Google Scholar]
- Berthelot, D.; Schumm, T.; Metz, L. BEGAN: Boundary Equilibrium Generative Adversarial Networks. arXiv, 2017; arXiv:1703.10717. [Google Scholar]







© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, P.; Yang, Y.; Li, X. StegNet: Mega Image Steganography Capacity with Deep Convolutional Network. Future Internet 2018, 10, 54. https://doi.org/10.3390/fi10060054
Wu P, Yang Y, Li X. StegNet: Mega Image Steganography Capacity with Deep Convolutional Network. Future Internet. 2018; 10(6):54. https://doi.org/10.3390/fi10060054
Chicago/Turabian StyleWu, Pin, Yang Yang, and Xiaoqiang Li. 2018. "StegNet: Mega Image Steganography Capacity with Deep Convolutional Network" Future Internet 10, no. 6: 54. https://doi.org/10.3390/fi10060054
APA StyleWu, P., Yang, Y., & Li, X. (2018). StegNet: Mega Image Steganography Capacity with Deep Convolutional Network. Future Internet, 10(6), 54. https://doi.org/10.3390/fi10060054