TwinNet: A Double Sub-Network Framework for Detecting Universal Adversarial Perturbations

Abstract
:1. Introduction
2. Related Work
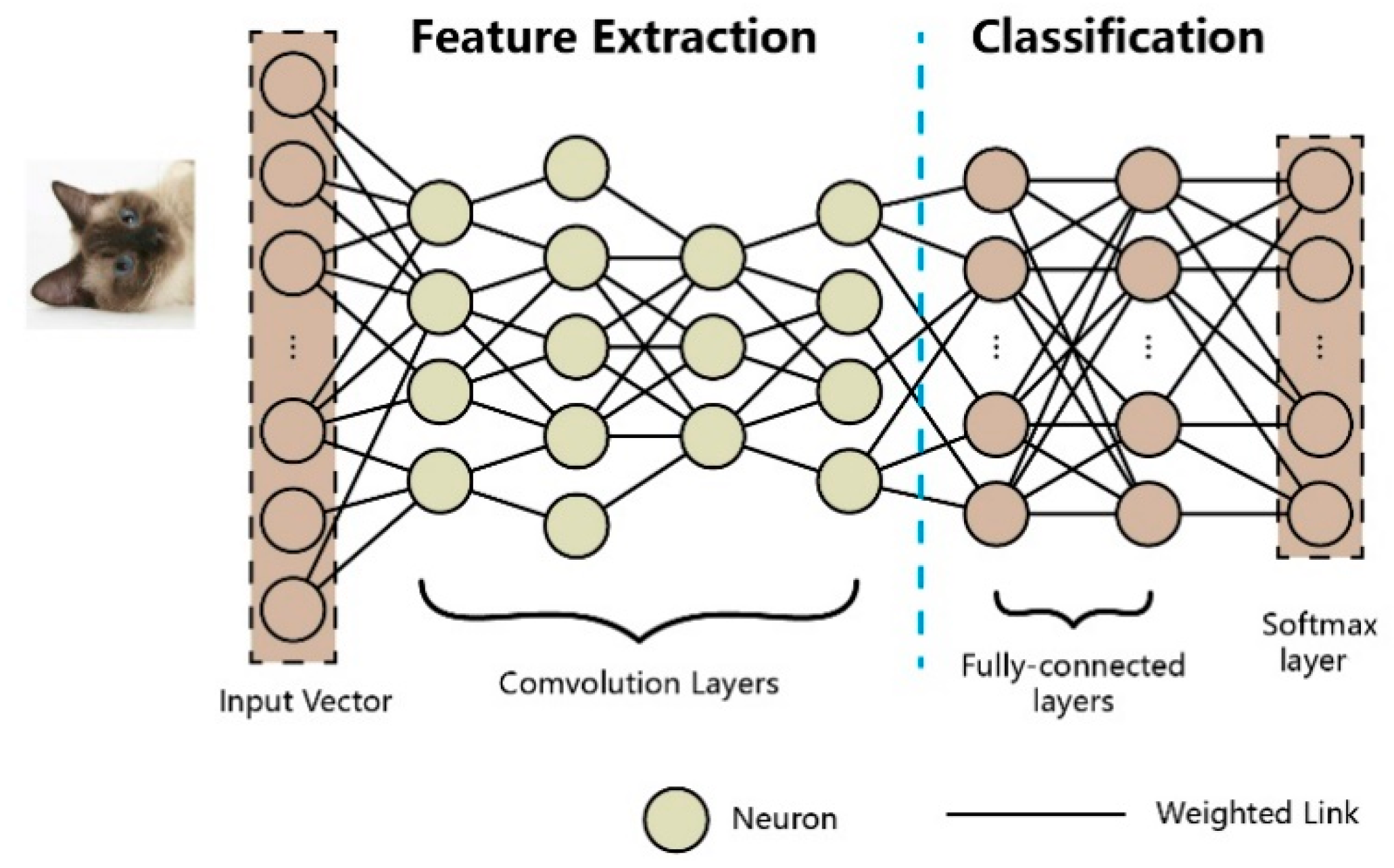
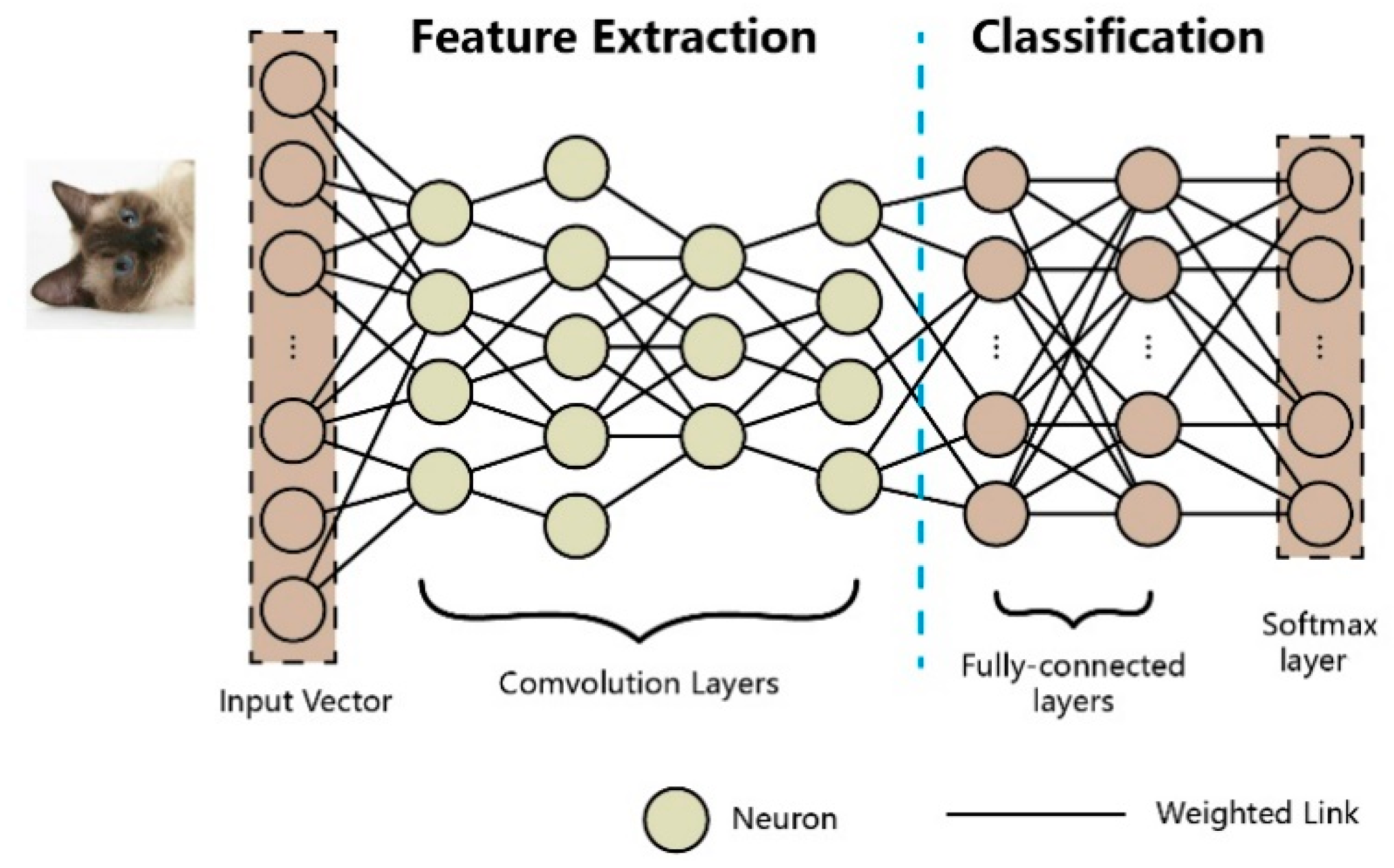
2.1. Deep Neural Networks
2.2. Existing Adversarial Attacks and Defenses
2.3. Double Sub-Network System
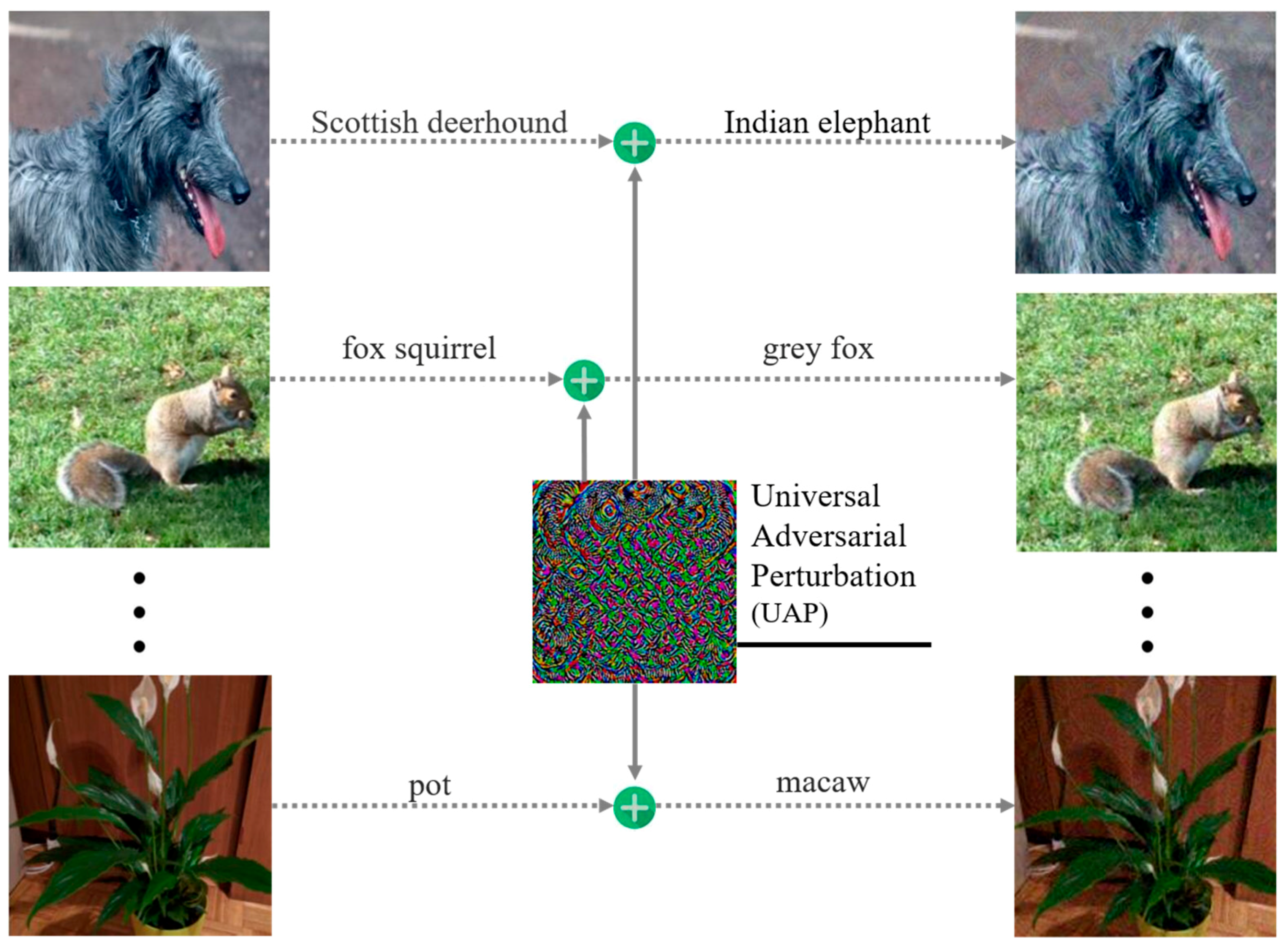
3. Threat Model
4. Method
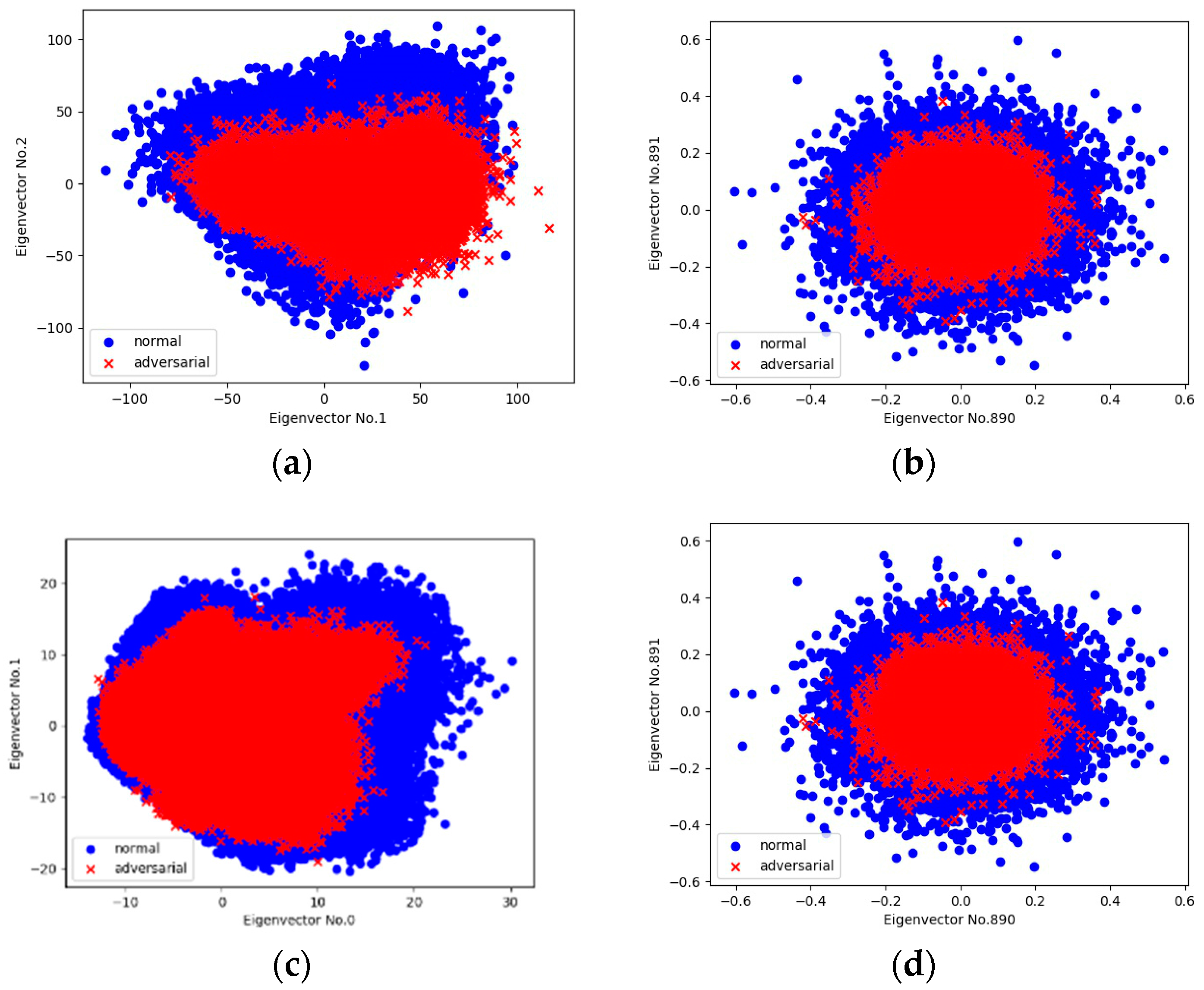
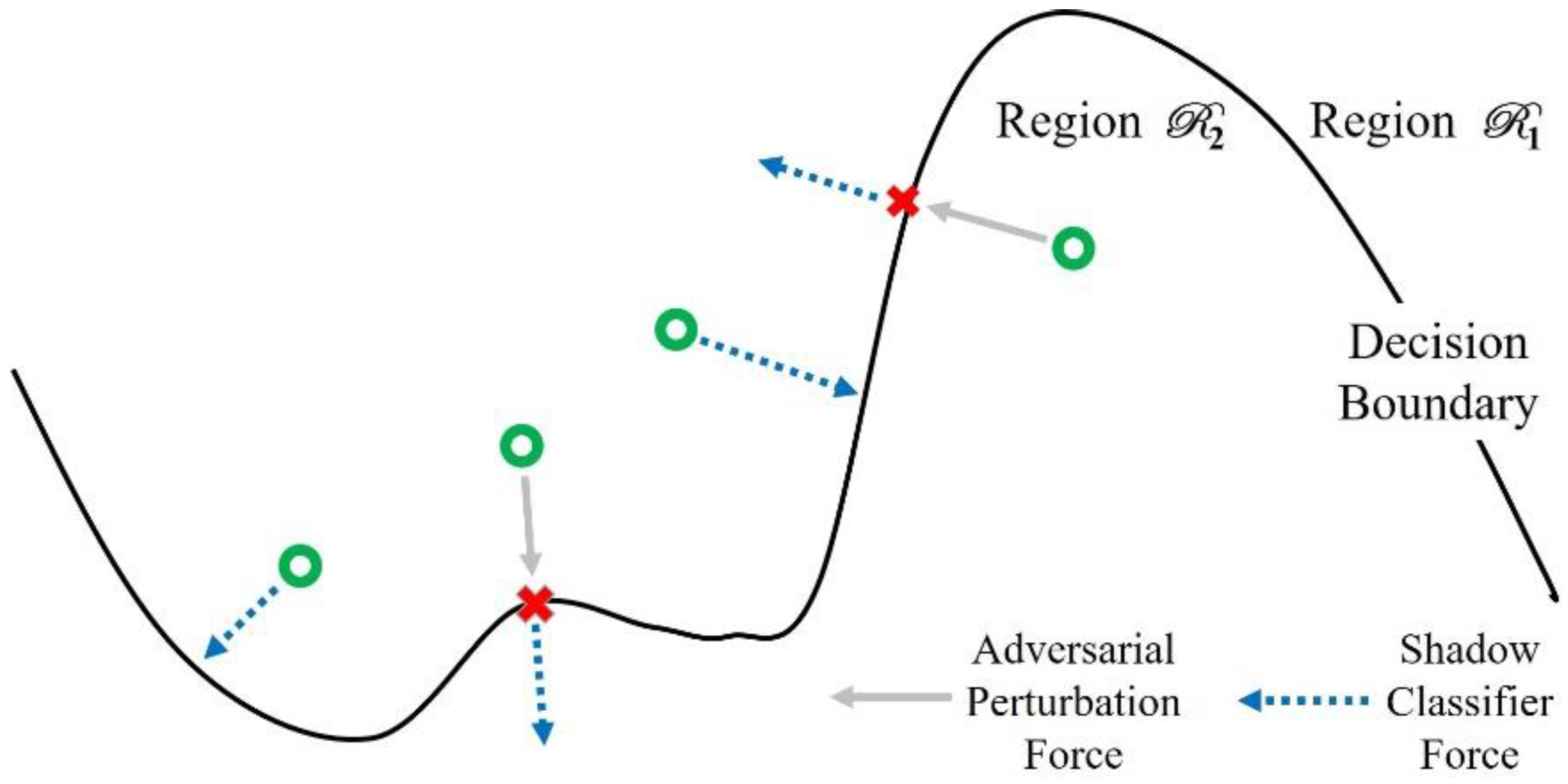
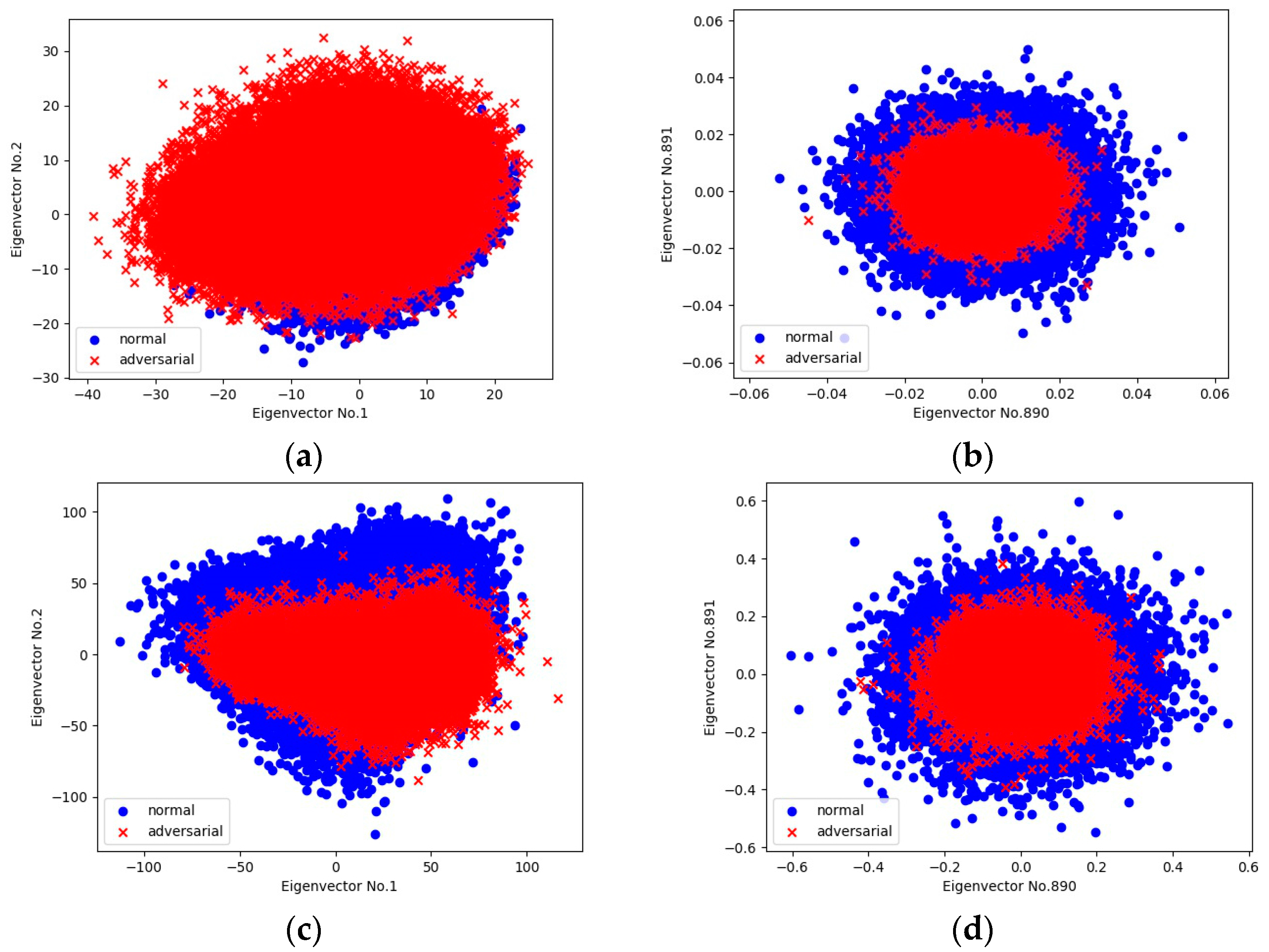
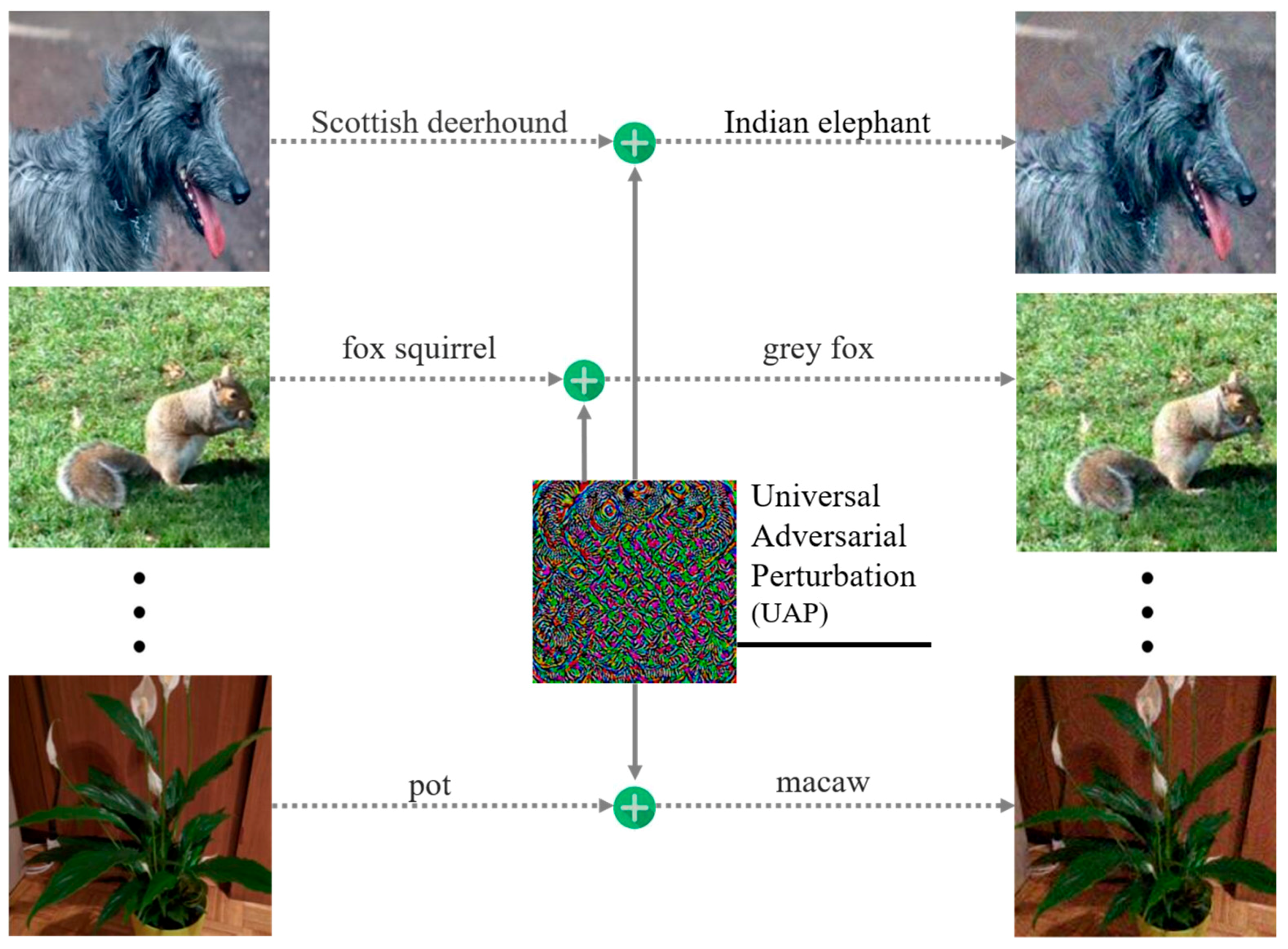
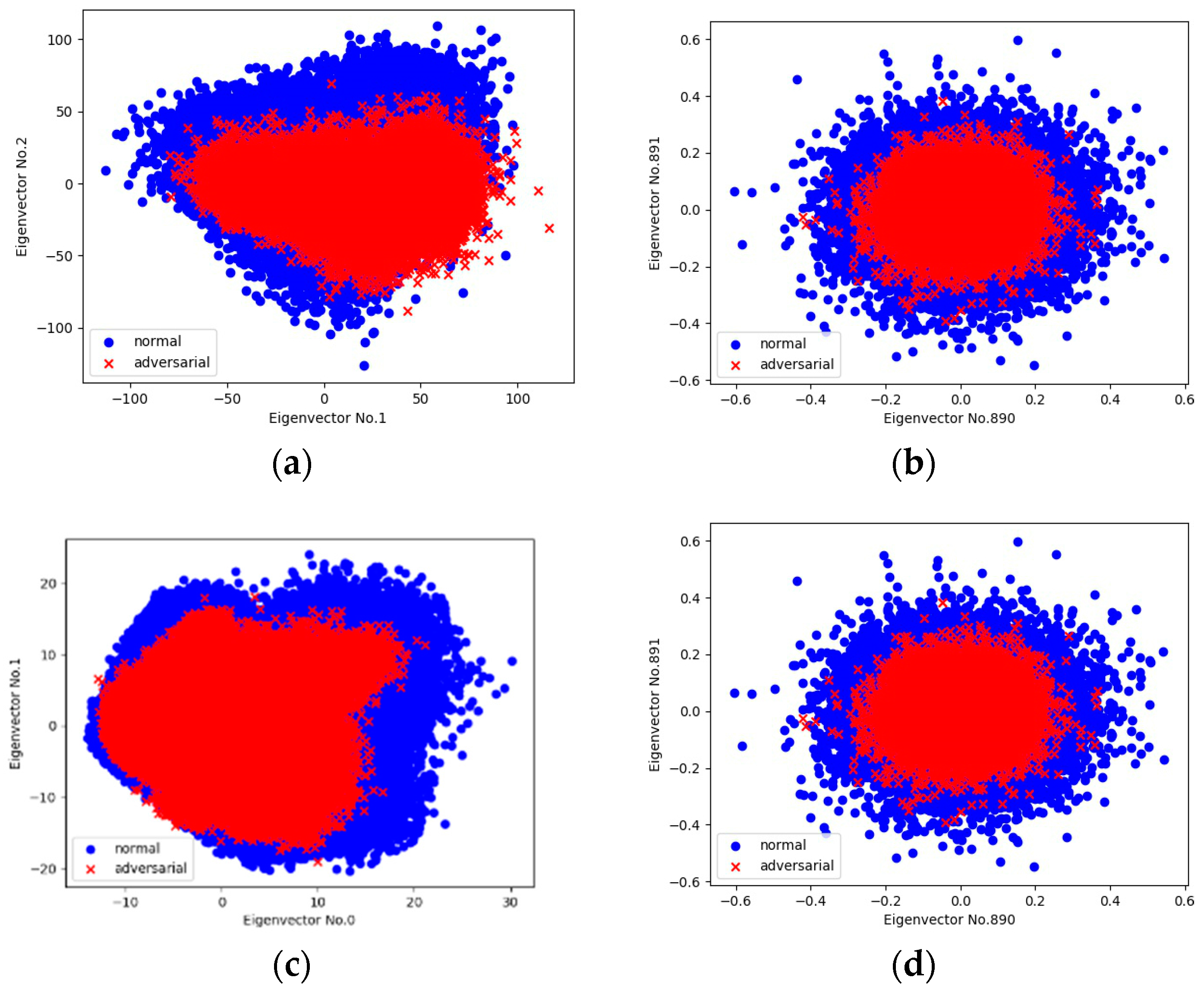
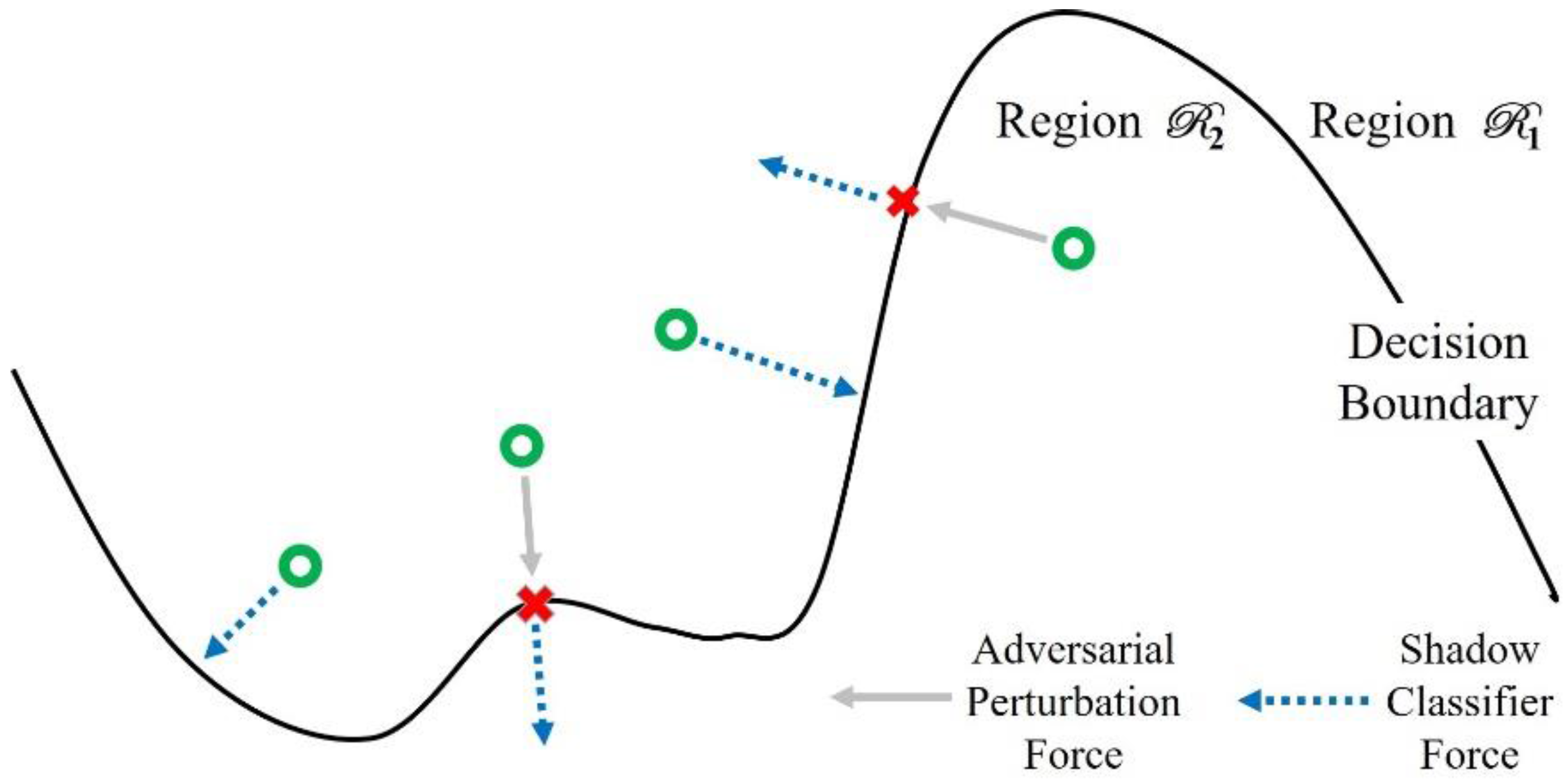
4.1. Properties of Adversarial Perturbations
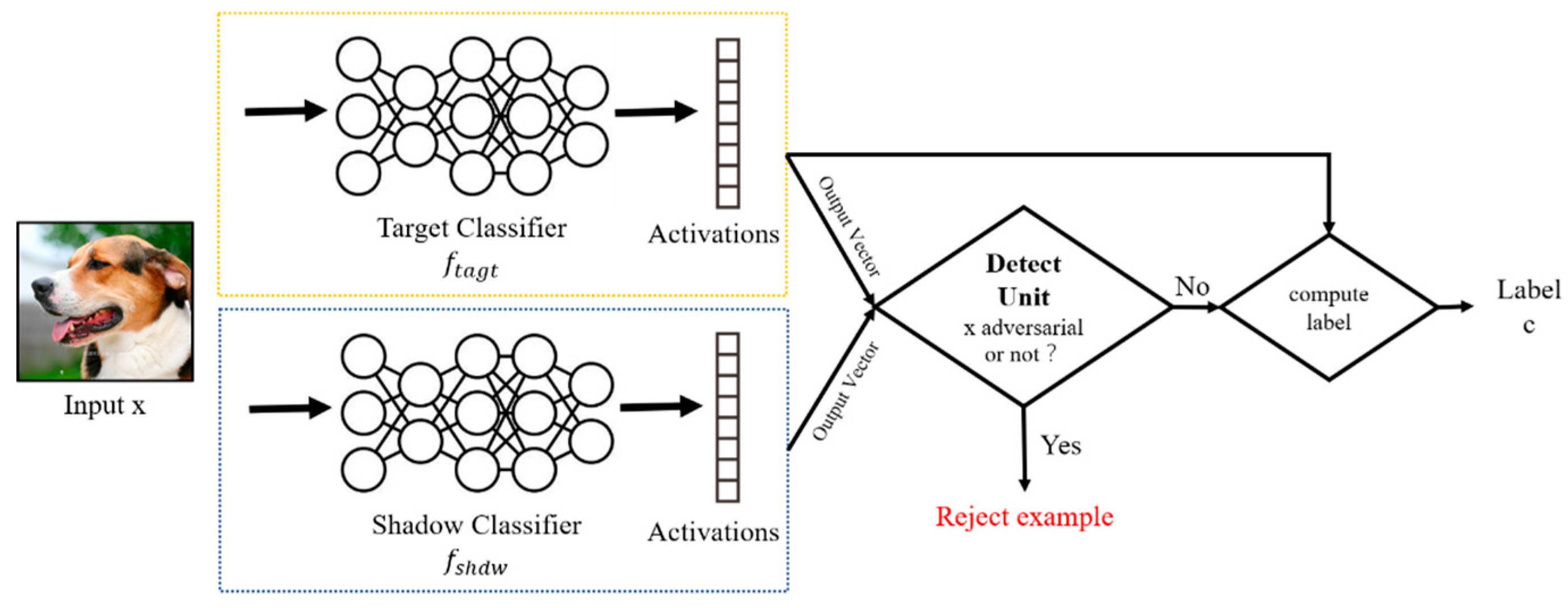
4.2. Architecture of the TwinNet Framework
4.3. Shadow Classifier
| Algorithm 1 Constructing Hybrid Training Set |
| Input: ←normal example set, ←classification function of target classifier, ←universal adversarial perturbation |
| Output: ←hybrid training set |
| 1: Initialize ← |
| 2: for in : |
| 3: if |
| 4: ←classification label |
| 5: ←bottleneck activations of |
| 6: ←bottleneck activations of |
| 7: ← |
| 8: ← |
| 9: return |
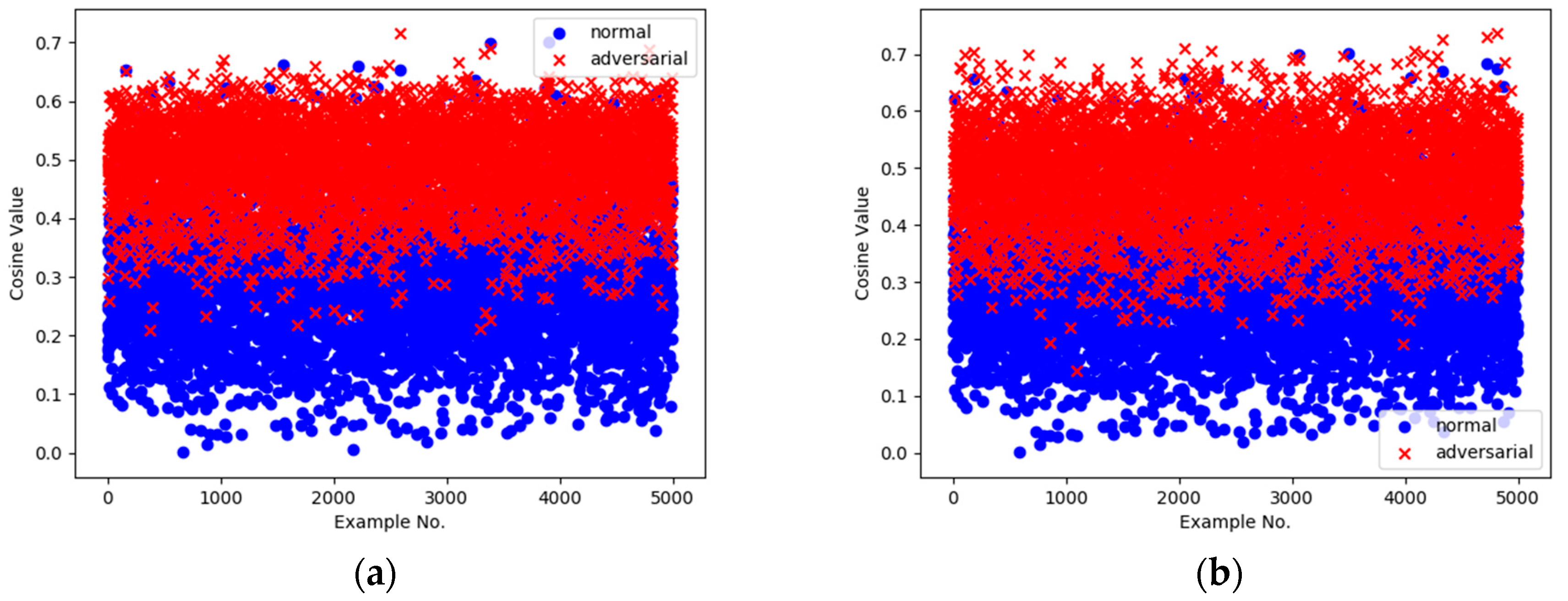
4.4. Identifying Adversarial Perturbations
5. Experiment
5.1. Setting
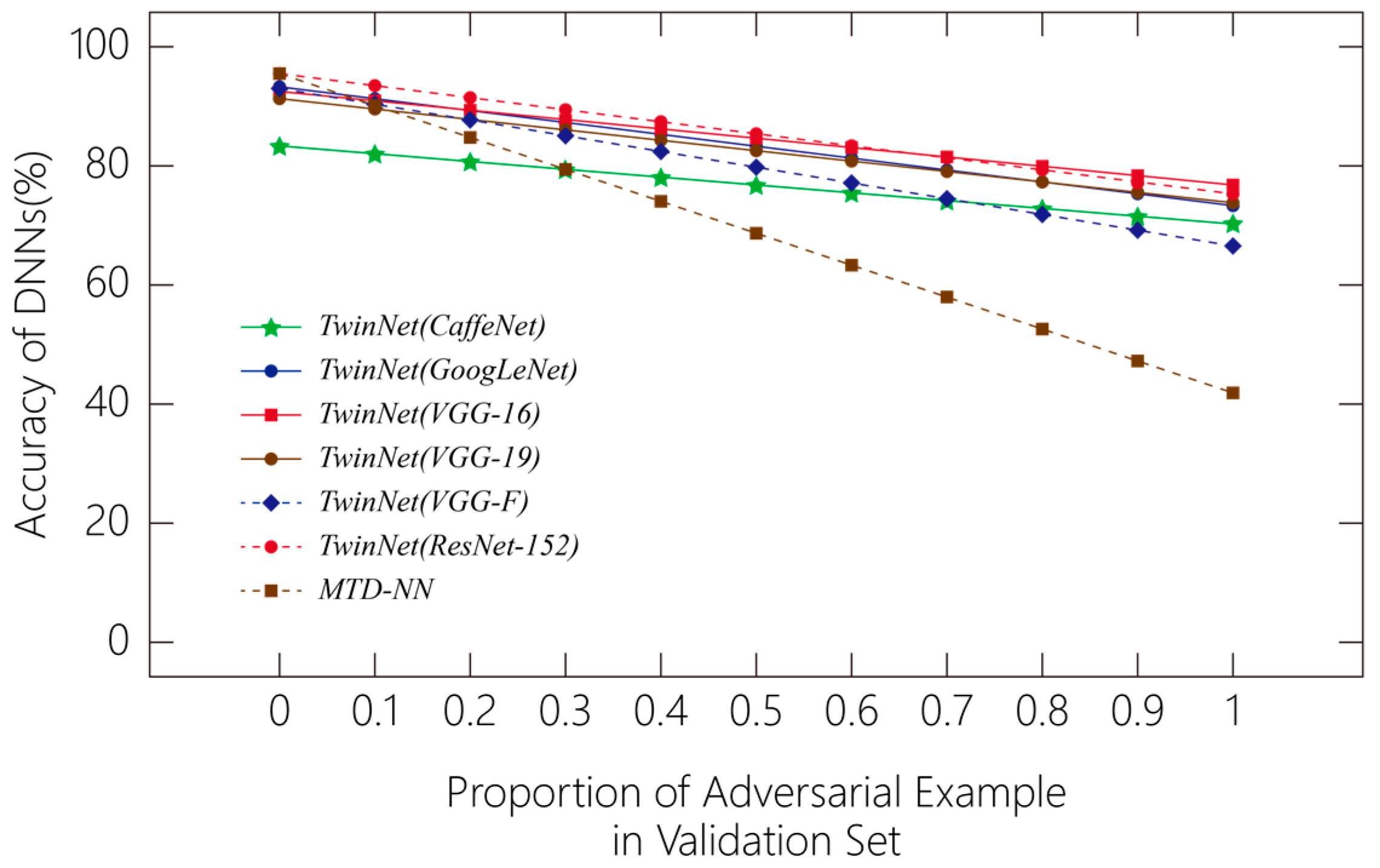
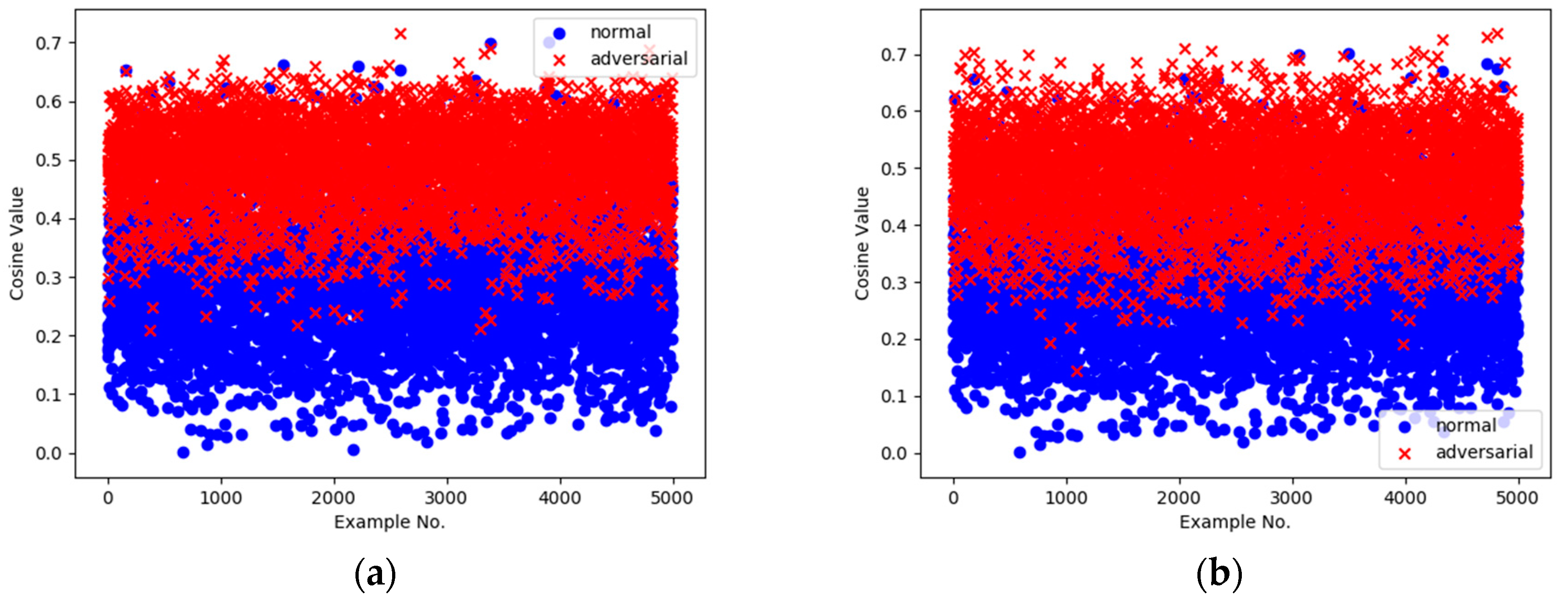
5.2. Experiment Results and Analysis
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv, 2013; arXiv:1312.6199. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Papernot, N.; Mcdaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against deep learning systems using adversarial examples. arXiv, 2016; arXiv:1602.02697. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv, 2016; arXiv:1607.02533. [Google Scholar]
- Moosavidezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. arXiv, 2016; arXiv:1610.08401. [Google Scholar]
- Li, X.; Li, F. Adversarial examples detection in deep networks with convolutional filter statistics. arXiv, 2016; arXiv:1612.07767. [Google Scholar]
- Molchanov, P.; Gupta, S.; Kim, K.; Kautz, J. Hand gesture recognition with 3d convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 8–10 June 2015; pp. 1–7. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv, 2014; arXiv:1412.6572. [Google Scholar]
- Narodytska, N.; Kasiviswanathan, S.P. Simple black-box adversarial perturbations for deep networks. arXiv, 2016; arXiv:1612.06299. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv, 2016; arXiv:1611.01236. [Google Scholar]
- Zheng, S.; Song, Y.; Leung, T.; Goodfellow, I. Improving the robustness of deep neural networks via stability training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 4480–4488. [Google Scholar]
- Papernot, N.; Mcdaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 23–25 May 2016. [Google Scholar]
- Lu, J.; Issaranon, T.; Forsyth, D. Safetynet: Detecting and rejecting adversarial examples robustly. arXiv, 2017; arXiv:1704.00103. [Google Scholar]
- Metzen, J.H.; Genewein, T.; Fischer, V.; Bischoff, B. On detecting adversarial perturbations. arXiv, 2017; arXiv:1702.04267. [Google Scholar]
- Meng, D.; Chen, H. Magnet: A two-pronged defense against adversarial examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar]
- Sengupta, S.; Chakraborti, T.; Kambhampati, S. Securing deep neural nets against adversarial attacks with moving target defense. arXiv, 2017; arXiv:1705.07213. [Google Scholar]
- Bhagoji, A.N.; Cullina, D.; Mittal, P. Dimensionality reduction as a defense against evasion attacks on machine learning classifiers. arXiv, 2017; arXiv:1704.02654. [Google Scholar]
- Tanay, T.; Griffin, L. A boundary tilting persepective on the phenomenon of adversarial examples. arXiv, 2016; arXiv:1608.07690. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis; Springer: New York, NY, USA, 2005; pp. 41–64. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Tech Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. Decaf: A deep convolutional activation feature for generic visual recognition. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Hardt, M.; Recht, B.; Singer, Y. Train faster, generalize better: Stability of stochastic gradient descent. arXiv, 2015; arXiv:1509.01240. [Google Scholar]
- Moosavidezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Precomputed Universal Perturbations for Different Classification Models. Available online: https://github.com/LTS4/universal/tree/master/precomputed (accessed on 11 March 2017).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. arXiv, 2014; arXiv:1409.48427. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, San Francisco, CA, USA, 27 October–1 November 2013; pp. 675–678. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv, 2014; arXiv:1405.3531. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Training Method | transfer learning |
| Optimization Method | stochastic gradient descent (SGD) |
| Learning Rate | 0.001 |
| Dropout | - |
| Batch Size | 100 |
| Steps | 28,000 |
| Network Architecture | Classification Accuracy/(%) | Fooling Rate/(%) | Fooling Rate (applying TwinNet)/(%) |
|---|---|---|---|
| GoogLeNet [26] | 93.3 | 78.9 | 26.68 |
| CaffeNet [27] | 83.6 | 93.3 | 29.79 |
| VGG-F [28] | 92.9 | 93.7 | 33.45 |
| VGG-16 [29] | 92.5 | 78.3 | 23.17 |
| VGG-19 [29] | 92.5 | 77.8 | 26.19 |
| ResNet-152 [30] | 95.5 | 84 | 24.7 |
| Network Architecture | Detecting Hit Rate/% | False Alarm Rate/% |
|---|---|---|
| GoogLeNet | 73.32 | 6.06 |
| CaffeNet | 70.21 | 6.23 |
| VGG-F | 66.55 | 6.5 |
| VGG-16 | 76.83 | 6.01 |
| VGG-19 | 73.81 | 6.06 |
| ResNet-152 | 75.3 | 6.08 |
| Network Architecture of Adversary | Detecting Hit Rate/(%) | False Alarm Rate/(%) |
|---|---|---|
| CaffeNet | 67.84 | 6.7 |
| VGG-F | 58.76 | 6.3 |
| VGG-16 | 76.54 | 6.76 |
| VGG-19 | 73.22 | 6.26 |
| ResNet-152 | 75 | 6.26 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruan, Y.; Dai, J. TwinNet: A Double Sub-Network Framework for Detecting Universal Adversarial Perturbations. Future Internet 2018, 10, 26. https://doi.org/10.3390/fi10030026
Ruan Y, Dai J. TwinNet: A Double Sub-Network Framework for Detecting Universal Adversarial Perturbations. Future Internet. 2018; 10(3):26. https://doi.org/10.3390/fi10030026
Chicago/Turabian StyleRuan, Yibin, and Jiazhu Dai. 2018. "TwinNet: A Double Sub-Network Framework for Detecting Universal Adversarial Perturbations" Future Internet 10, no. 3: 26. https://doi.org/10.3390/fi10030026
APA StyleRuan, Y., & Dai, J. (2018). TwinNet: A Double Sub-Network Framework for Detecting Universal Adversarial Perturbations. Future Internet, 10(3), 26. https://doi.org/10.3390/fi10030026