Abstract
Timely and accurate detection of forest fires is crucial for protecting forest ecosystems. However, traditional monitoring methods face significant challenges in effectively detecting forest fires, primarily due to the dynamic spread of flames and smoke, irregular morphologies, and the semi-transparent nature of smoke, which make it extremely difficult to extract key visual features. Additionally, deploying these detection systems to edge devices with limited computational resources remains challenging. To address these issues, this paper proposes a lightweight hybrid receptive field model (LHRF-YOLO), which leverages deep learning to overcome the shortcomings of traditional monitoring methods for fire detection on edge devices. Firstly, a hybrid receptive field extraction module is designed by integrating the 2D selective scan mechanism with a residual multi-branch structure. This significantly enhances the model’s contextual understanding of the entire image scene while maintaining low computational complexity. Second, a dynamic enhanced downsampling module is proposed, which employs feature reorganization and channel-wise dynamic weighting strategies to minimize the loss of critical details, such as fine smoke textures, while reducing image resolution. Furthermore, a scale weighted Fusion module is introduced to optimize multi-scale feature fusion through adaptive weight allocation, addressing the issues of information dilution and imbalance caused by traditional fusion methods. Finally, the Mish activation function replaces the SiLU activation function to improve the model’s ability to capture flame edges and faint smoke textures. Experimental results on the self-constructed Fire-SmokeDataset demonstrate that LHRF-YOLO achieves significant model compression while further improving accuracy compared to the baseline model YOLOv11. The parameter count is reduced to only 2.25M (a 12.8% reduction), computational complexity to 5.4 GFLOPs (a 14.3% decrease), and mAP50 is increased to 87.6%, surpassing the baseline model. Additionally, LHRF-YOLO exhibits leading generalization performance on the cross-scenario M4SFWD dataset. The proposed method balances performance and resource efficiency, providing a feasible solution for real-time and efficient fire detection on resource-constrained edge devices with significant research value.
1. Introduction
Forests, as a vital component of the Earth’s ecosystem, not only provide habitats for numerous species but also play a pivotal role in maintaining ecological balance, regulating climate, and conserving soil and water [1]. However, with the intensification of global warming trends, the frequency of forest fires has increased significantly, and the scale of fires continues to expand, posing substantial threats to forest resources and ecological environments [2]. Statistical data reveal that the 2018 California wildfires [3] resulted in total economic losses of USD 148.5 billion, causing severe financial damage, while the 2020 Australian bushfires [4] led to the death of approximately 3 billion animals, inflicting catastrophic ecological destruction. Forest fires in their initial stages often exhibit specific flame and smoke characteristics that form distinct contrasts with the natural environmental background. If these early signals can be accurately identified and the ignition points precisely located through advanced monitoring techniques, it will significantly reduce the difficulty, risks, and costs of subsequent fire suppression efforts. Therefore, establishing a timely and accurate forest fire monitoring system is of paramount importance for protecting forest resources and the ecological environment.
Traditional forest fire monitoring systems primarily rely on watchtower observations, manual patrols, and satellite remote sensing. Bao et al. [5] proposed a modeling method to optimize the spatial coverage of forest fire watchtowers, providing a scientific basis for watchtower placement. In reference [6], the authors developed a wireless sensor system for wildfire monitoring, advancing the development of fire-related sensor systems. Although these studies have contributed practical foundations and reference directions for wildfire monitoring technology, these conventional methods still exhibit significant limitations. Watchtower observations depend on manual monitoring and are highly susceptible to weather conditions, terrain, and visibility constraints, often leading to missed detections and false alarms [7]. Manual patrols are limited by terrain complexity and labor costs, resulting in restricted coverage and inefficient time consumption [8]. Satellite remote sensing faces challenges from cloud interference, hindering timely fire detection [9]. While infrared sensors offer real-time capabilities, they are prone to environmental interference and entail high deployment costs [10].
With the continuous advancement of machine learning techniques, the application of machine learning methods for extracting and analyzing various physical characteristics of flames and smoke (e.g., color, motion, spectral, spatial, temporal, and texture features) has become increasingly prevalent in forest fire detection. Khatami et al. [11] integrated the Particle Swarm Optimization (PSO) algorithm with the K-medoids clustering algorithm to detect flame color features, achieving effective fire detection. Zhang et al. [12] proposed an improved probabilistic fire detection method that combines flame color and motion features, enhancing detection performance while reducing false alarms and missed detection rates. Chen et al. [13] developed a multi-feature fusion-based video flame detection approach, incorporating motion, color, and flicker characteristics of flames, which significantly improved both the speed and accuracy of fire detection. Toereyin et al. [14] utilized wavelet transform for processing infrared videos, thereby increasing the accuracy and efficiency of flame detection. Benjamin et al. [15] implemented a low-complexity yet efficient fire detection method by employing the Gray-Level Co-occurrence Matrix (GLCM) for texture analysis combined with color-based detection. Compared to traditional methods, these machine learning-based fire detection approaches offer advantages such as higher automation, faster detection speed, and broader coverage, effectively improving both the efficiency and accuracy of fire detection. However, conventional machine learning methods often require extensive feature engineering and parameter tuning when dealing with complex backgrounds and dynamic fire scenarios, which limits their generalization capability and consequently affects their practical performance [16].
In recent years, the development of deep learning has provided new approaches for fire detection, attracting increasing attention due to its capability for automatic feature extraction and complex pattern learning. Convolutional Neural Network (CNN)-based object detection models have been widely applied in fire detection through end-to-end feature learning. Muhammad et al. [17] proposed a fast and efficient CNN-based fire detection and localization method that achieves a balance between detection accuracy and efficiency by using small convolutional kernels and a fully connection-free network architecture with increased model depth. Wong et al. [18] significantly reduced model size while maintaining detection performance by combining SSD with optimized network structures, enabling effective fire detection. Zheng et al. [19] further validated the effectiveness of deep learning in fire detection using Fast R-CNN, with experiments demonstrating its strong performance in small object detection scenarios. The YOLO series models have become a research focus due to their speed and efficiency. An et al. [20] developed a dynamic convolution-based YOLOv5 fire detection model that improves both accuracy and speed through optimized anchor box clustering, dynamic convolution, and pruning techniques. Talaat et al. [21] proposed an improved YOLOv8-based fire detection method for smart city environments that achieves a balance between high accuracy and low false alarm rates, further verifying the effectiveness of YOLO models. However, the inherent local receptive field of CNNs presents challenges when dealing with the dynamic diffusion and semi-transparent characteristics of flames and smoke. The thin and widely distributed nature of flames and smoke leads to feature extraction difficulties, resulting in higher rates of missed detections and false alarms in practical scenarios [22]. To address these limitations, researchers have introduced attention mechanisms to enhance global context awareness and improve both holistic perception of fire/smoke and local feature details. Majid et al. [23] developed an attention mechanism and transfer learning-based CNN model for fire detection and localization in real-world images, demonstrating improved detection accuracy. Yar et al. [24] proposed an optimized dual flame attention network for efficient and accurate flame detection, enhancing accuracy on edge devices. However, while attention mechanism-based improvement schemes can enhance global contextual awareness, their quadratic computational complexity significantly increases model parameters. This poses deployment challenges for resource-constrained edge devices such as drones, making them difficult to adapt to edge computing platforms [25,26].
In recent years, an increasing number of researchers have focused on lightweight algorithm research to better adapt to resource-constrained UAV edge devices, enabling real-time forest fire detection through drone-based systems. Almeida et al. [27] proposed a lightweight CNN model named EdgeFireSmoke for real-time video-based fire and smoke detection using RGB images. This model can perform image processing on edge devices, demonstrating the feasibility of deploying fire detection models on UAVs. Building upon the original EdgeFireSmoke approach, Almeida et al. [28] further developed an improved fire detection model called EdgeFireSmoke++ by integrating artificial neural networks with deep learning techniques, achieving enhanced detection accuracy and efficiency. Guan et al. [29] introduced a modified instance segmentation model for forest fire segmentation in UAV aerial images, which improves drone-based fire detection performance by optimizing the MaskIoU branch in the U-Net architecture to reduce segmentation errors. Huang et al. [30] proposed an ultra-lightweight network for real-time forest fire detection on embedded sensing devices, improving both detection speed and accuracy through optimized lightweight network design and model compression techniques. Lin et al. [31] developed a lightweight dynamic model that enhances the accuracy and efficiency of forest fire and smoke detection while improving its applicability on UAV platforms through lightweight technology integration. Although these works have significantly advanced the development of lightweight fire detection technology, their detection accuracy still requires further improvement.
In summary, breakthroughs in deep learning technology have facilitated advancements in forest fire object detection, while the widespread adoption of edge devices like UAVs has provided new approaches for fire detection tasks. However, existing methods still face challenges in addressing missed detections and false alarms caused by difficulties in feature extraction when dealing with the dynamic spread and semi-transparent characteristics of flames and smoke. Although introducing attention mechanisms into models can alleviate these issues, the excessive model parameters and computational demands create deployment challenges and reduced efficiency when applied to resource-constrained edge devices such as drones. To address these challenges, this paper proposes a lightweight hybrid receptive field model (LHRF-YOLO), aiming to further improve forest fire detection accuracy while reducing false alarms and missed detections. The model achieves an efficient balance between lightweight design and detection precision to better adapt to the computational resource limitations of edge devices like UAVs. The main contributions of this work are as follows:
- (1)
- Multi-Receptive Field Extraction Module: By integrating the 2D Selective Scan Mechanism (SS2D) into Residual Multi-Branch Efficient Layer Aggregation Networks (RMELANs), we achieve hybrid extraction of both global and local features, enabling precise flame localization while maintaining linear computational complexity.
- (2)
- Optimized Downsampling Approach: The proposed Dynamic Enhanced Patch Merge Downsampling (DEPMD) module employs feature reorganization and channel-wise dynamic enhancement strategies. This design effectively reduces spatial resolution while strengthening semantic representation, preserving fine-grained features with minimal computational overhead.
- (3)
- Enhanced Multi-Scale Fusion: The introduced Scaling Weighted Fusion (SWF) module optimizes feature contribution allocation through dynamic scaling factors, effectively addressing the issues of feature dilution and fusion difficulties in traditional multi-scale approaches.
- (4)
- Improved Texture Feature Extraction: Replacing SiLU with the Mish activation function significantly enhances the model’s capability to capture flame edges and sparse smoke texture features.
2. Materials and Methods
2.1. Dataset
This study constructs a novel fire detection dataset named Fire-Smoke Dataset (FSDataset) for forest fire scenario training. To address annotation issues such as ambiguous boundaries and misclassification in the Fire and Smoke Dataset [32], we have optimized the dataset quality based on the original dataset. Specifically, after identifying erroneous samples through image quality assessment, we performed meticulous manual annotation on these problematic samples using the LabelImg tool [33]. The newly constructed FSDataset comprises 19,866 high-quality images. To mitigate potential training instability caused by sample bias, we applied randomization by splitting the dataset into training (12,083 images), validation (5640 images), and test (2143 images) sets at a ratio of 6:3:1. Comparative experiments and ablation studies in this research were conducted using FSDataset. Detailed specifications of FSDataset are presented in Table 1, while Figure 1 showcases representative samples from the dataset.

Table 1.
FSDataset dataset details.

Figure 1.
Partial display of FSDataset: (a–d) demonstrate daytime scenarios containing (a) fire and smoke, (b) fire-only, (c) smoke-only, and (d) UAV-captured scenes; (e,f) present vegetation fire scenarios under daylight conditions; (g,h) depict nighttime scenarios showing (g) fire with smoke and (h) fire-only situations.
To comprehensively evaluate the generalization performance of the proposed method, this study employs the Multiple scenarios, Multiple weather conditions, Multiple lighting levels and Multiple wildfire objects Synthetic Forest Wildfire Dataset(M4SFWD) [34] for experimental validation. This dataset provides forest fire remote sensing data encompassing diverse terrain types, weather conditions, light flux densities, and varying quantities of wildfire objects. It enables the evaluation of model generalization capabilities across different environmental scenarios, effectively validating the model’s ability to learn and generalize abstract fire-related features. Figure 2 presents partial samples from the M4SFWD dataset.

Figure 2.
Partial display of dataset M4SFWD.
2.2. Methods
2.2.1. YOLOv11
YOLOv11 [35] was officially released on 27 September 2024 by Glenn Jocher and Jing Qiu from Ultralytics. As the latest version in the Ultralytics YOLO series of real-time object detectors, this iteration achieves superior performance through significant innovations in architecture design and training methodology, building upon the remarkable progress of previous YOLO versions. Its overall architecture consists of three key components: backbone, neck, and head, as illustrated in Figure 3.
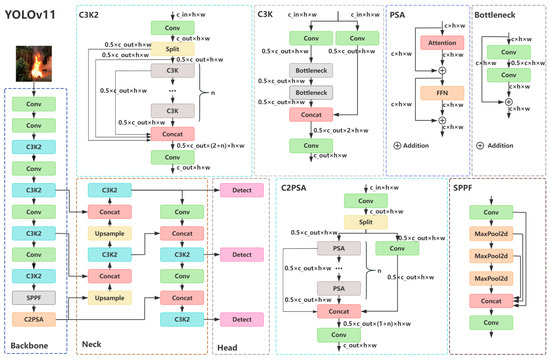
Figure 3.
YOLOv11 network architecture diagram. C3K2 represents the Cross Stage Partial with kernel size 2 block, SPPF represents the Spatial Pyramid Pooling—Fast module, and C2PSA represents the Convolutional block with Parallel Spatial Attention module.
The backbone [35] serves as the core feature extraction component of YOLOv11, responsible for extracting multi-level semantic information (e.g., edges, textures, shapes) from input images. It primarily consists of Conv, C3K2, SPPF, and C2PSA modules. The Conv module in the backbone mainly performs image downsampling, composed of standard 2D convolution, BatchNorm2d [36], and the SiLU [37] activation function, adjusting the feature map dimensions throughout the backbone network. The C3K2 module is responsible for multi-level semantic feature extraction and channel adjustment. As an improved version of the C2F module in YOLOv8, it introduces dynamic module selection and unified kernel design based on the traditional CSP (Cross Stage Partial) [38] structure, enabling more flexible feature extraction and enhancing semantic information capture. The SPPF module enhances multi-scale feature perception by cascading max-pooling layers, efficiently extracting contextual information at different scales. and improving the model’s ability to detect objects of varying sizes. The C2PSA module strengthens the model’s global contextual awareness by incorporating a multi-head self-attention mechanism, thereby enhancing its global perception capability.
The neck [35] serves as the core component of YOLOv11’s multi-scale feature fusion, responsible for integrating features across different scales. It adopts the Path Aggregation Network (PANet) [39] architecture, which enhances the top-down pathway of the Feature Pyramid Network (FPN) [40] by incorporating an additional bottom-up augmentation pathway, thereby forming a bidirectional feature pyramid. This structure effectively consolidates multi-level features extracted from the backbone, significantly improving the model’s detection capability for targets of varying scales. The primary modules within the neck include the Conv module, C3K2 module, and Upsample module. The Conv module performs downsampling to reduce image dimensions, while the C3K2 module facilitates feature fusion and channel adjustment. The Upsample module employs nearest-neighbor interpolation for image upsampling. Architecturally, the neck follows the FPN framework, leveraging multi-level feature maps generated by the backbone to construct a top-down feature pyramid. This design enables the fusion of deep semantic features with shallow detail features, enhancing the model’s overall detection performance.
The head [35] serves as the core component of YOLOv11 for final object localization and classification and is responsible for outputting bounding box coordinates, class probabilities, and confidence scores. It primarily adopts a dual-branch structure and a dual-label assignment strategy to achieve efficient detection. By employing the dual-branch structure, the classification and regression tasks are decoupled to prevent task interference, thereby improving task accuracy. The dual-label assignment strategy is utilized during training, where a one-to-many label assignment strategy enriches supervision signals while a one-to-one label assignment strategy reduces redundant predictions. During inference, only the results from the one-to-one label assignment strategy are retained, enabling NMS-free detection.
2.2.2. Hybrid Receptive Field Feature Extraction
In YOLOv11, the C3K2 module is employed as the core feature extraction unit, as shown in Figure 3. Although C3K2 achieves multi-level semantic information fusion through its dynamic selection architecture, its receptive field remains constrained by the local perception characteristics of standard convolution kernels. In fire detection scenarios, flames and smoke exhibit dynamic diffusion and semi-transparent properties, making it challenging for traditional convolutional structures to effectively model long-range spatial dependencies. This limitation results in insufficient extraction of global contextual features from deep semantic information. To address this issue, this study introduces the 2D Selective Scan Mechanism (SS2D) [41] to enhance the model’s global perception capability. Additionally, based on Efficient Layer Aggregation Networks (ELANs) [42], we propose the Residual Multi-Branch Efficient Layer Aggregation Networks (RMELANs), which combine local and global feature extraction. This hybrid design resolves the C3K2 module’s weakness in capturing global features from deep semantic information, resulting in a mixed receptive field feature extraction module that simultaneously possesses both global and local feature extraction capabilities.
- (1)
- Selective Scan
- (a)
- Selective Scan Mechanism
The Selective Scan Mechanism (S6), proposed by Gu et al. in Mamba [26], is a Selective State Space Model based on State Space Models (SSMs). The core SSMs originate from the Kalman filter [43] and can be regarded as a linear time-invariant (LTI) system. This system processes an input through a hidden state to produce an output , with its mathematical formulation expressed as follows:
In Equations (1) and (2), denotes the hidden state matrix, governing the evolution of hidden states over time, while represents the weight matrix that maps the input into the state space. Additionally, corresponds to the observation matrix, responsible for projecting the hidden state to the output . Since computer systems require the discretization of continuous models, the zero-order hold (ZOH) method is employed to discretize the SSMs. The mathematical formulation of this discretization process is expressed as follows:
In Equations (3) and (4),
In Equations (5) and (6), represent the input timestep used to adjust the model’s timescale, while and denote the discretized counterparts of the corresponding matrices at this timescale, with being the identity matrix. To enable efficient computation, the recursive calculation of the time series is unrolled, transforming the SSMs into a convolutional operation form. The mathematical expression for this transformation is given as follows:
In Equation (7),
In Equation (8), denotes the length of the input sequence.
- (b)
- 2D Selective Scan Mechanism
Although the selective scan operation of S6 demonstrates excellent performance in processing sequential data for NLP tasks, its application to vision tasks presents significant challenges, as visual data is non-sequential and contains spatial information. To address this issue, Liu et al. [41] proposed the 2D Selective Scan Mechanism (SS2D) for vision tasks. In SS2D, visual data undergoes three key operations: cross-scanning, S6 processing, and cross-merging, thereby extending the Selective Scan Mechanism to two dimensions. This approach enables each pixel in an image to aggregate global contextual information while maintaining linear computational complexity, effectively constructing a global receptive field. The main process is illustrated in Figure 4.
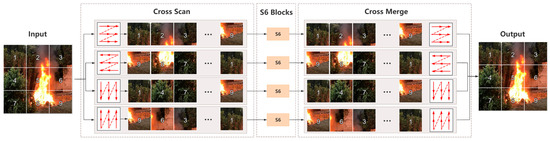
Figure 4.
2D Selective Scan Mechanism (SS2D) processing flow.
- (c)
- Selective Scan Block
The Selective Scan Block (SSBlock) serves as the core module integrating SS2D, endowing the model with global context awareness. In the architectural design of SSBlock, we adopt the paradigm of Transformer [44], which consists of two components: global context perception and nonlinear feature transformation. For the global context perception part, traditional Transformer architectures employ attention mechanisms to achieve global interaction, but their inherent quadratic computational complexity limits application efficiency in image processing scenarios. To address this bottleneck, we innovatively introduce SS2D, which leverages its superior linear computational complexity to model global contexts, maintaining comparable global modeling capability to self-attention mechanisms while reducing both parameters and computational overhead. Meanwhile, for the nonlinear feature transformation part, traditional Transformer architectures predominantly use Feed Forward Networks (FFNs) [44]. However, in image processing scenarios, FFN’s global connections fail to effectively capture the local structural features of images. To address this issue, we innovatively introduce the Convolutional Gated Linear Unit (CGLU) [45], where depthwise convolution explicitly establishes neighborhood relationships, enhancing detail recognition and improving local feature extraction. The detailed architecture of SSBlock is illustrated in Figure 5. In SSBlock, for any input feature , LayerNorm [46] is first applied to maintain training stability and convergence while providing regularization. Subsequently, SS2D performs global context modeling, followed by another LayerNorm for regularization, before CGLU is applied to achieve nonlinear feature transformation and local enhancement, ultimately yielding the output feature . The mathematical formulation of SS2D is as follows:
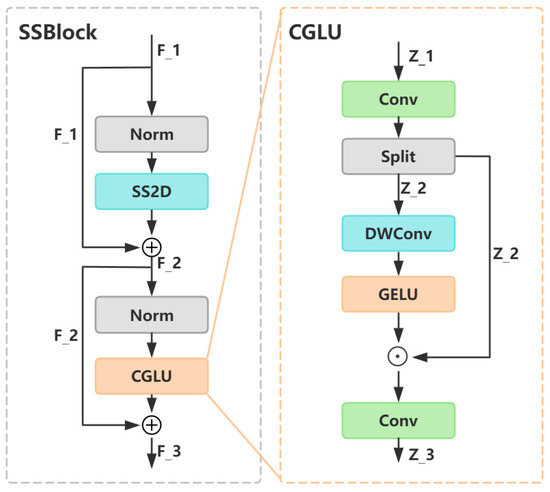
Figure 5.
SSBlock and CGLU architecture details.
In Equation (10), for any input feature , CGLU first applies a convolution for linear feature transformation. The linearly transformed features are then processed via depthwise convolution to capture local spatial information. Finally, the extracted spatial neighborhood features are converted into gating signals through an activation function and multiplied element-wise with the linearly transformed features, yielding the locally enhanced output feature . The mathematical expression of CGLU is as follows:
In Equation (12), GELU denotes the activation function Gaussian Error Linear Unit [47].
- (2)
- Residual Multi-Branch Efficient Layer Aggregation Networks
The Efficient Layer Aggregation Network (ELAN) [42] is a modular design aimed at enhancing feature representation efficiency and training stability in neural networks, which has been applied in the C3K2 module of YOLOv11. By controlling gradient propagation paths, ELAN addresses the issues of gradient vanishing and explosion in deep network training while employing a cross-layer feature reuse strategy to improve parameter utilization and inference efficiency. However, the existing ELAN architecture lacks an end-to-end feature transmission mechanism, limiting its feature representation efficiency. Additionally, while this study introduces the SSBlock to achieve dynamic enhancement of local receptive fields and global context awareness, the introduced SSBlock branch structure exhibits architectural compatibility conflicts with the traditional ELAN’s unidirectional aggregation paradigm. To address this issue, we innovatively propose the Residual Multi-branch Efficient Layer Aggregation Networks (RMELANs). First, residual connections [48] between inputs and outputs are established to ensure stable feature transmission and gradient flow. Second, a heterogeneous multi-branch hybrid unit is designed to effectively integrate local convolutional capabilities while introducing the SSBlock module to enhance global perception. Finally, implicit channel dimension transformation replaces explicit channel splitting, reducing parameter count and computational overhead while maintaining the effectiveness of feature transmission and channel variation.
In the specific design of RMELANs, to accommodate the dynamic diffusion and semi-transparent characteristics of flames and smoke, a dual-branch hybrid structure is adopted. One branch employs a strategy of SS2D followed by BottleNeck [48], where prioritizing SS2D allows the model to focus first on critical fire regions, enhancing the saliency of target areas through dynamic weight allocation. Subsequently, the Bottleneck structure compresses high-dimensional features and enables channel interaction, reducing redundant computations while preserving key information. The other branch adopts a strategy of BottleNeck followed by SS2D, where prioritizing BottleNeck enables the model to perform basic feature extraction on raw features, lowering computational complexity. Subsequently, SS2D refines the features for finer adjustments. Compared to a single-branch design, the dual-branch hybrid structure achieves complementary benefits—early key region capture and deep semantic feature optimization—thereby improving the model’s adaptability to complex fire scenarios. The detailed architecture of RMELAN is illustrated in Figure 6.
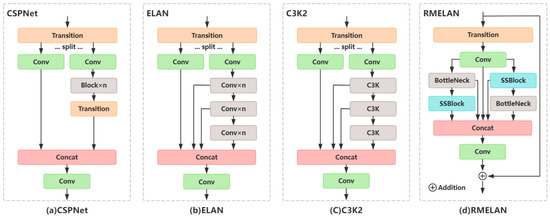
Figure 6.
Comparison chart between our architecture design and mainstream architecture design:(a) CSPNet [38], (b) ELAN [42], (c) C3K2, and (d) the proposed RMELAN.
2.2.3. Efficient Downsampling
- (1)
- Patch Merge Downsampling
Patch Merge Downsampling (PMD) [49] is a downsampling method based on image patch reorganization. Its core idea involves spatially reorganizing and channel-wise fusing local patches of the input feature map to reduce spatial resolution while enhancing semantic representation capability. Specifically, it first samples and merges every alternate pixel in the input image, generating four 2× downsampled images corresponding to the top-left, top-right, bottom-left, and bottom-right regions. Subsequently, channel compression is applied to these four downsampled images, achieving a downsampling effect that halves the height and width while doubling the channel count. Compared to conventional convolutional downsampling, PMD preserves local structural information through patch reorganization, minimizing information loss. Additionally, it eliminates the need for trainable convolutional kernels, relying solely on tensor reshaping and linear projection, resulting in fewer parameters and higher computational efficiency. The internal processing flow of PMD is illustrated in Figure 7.
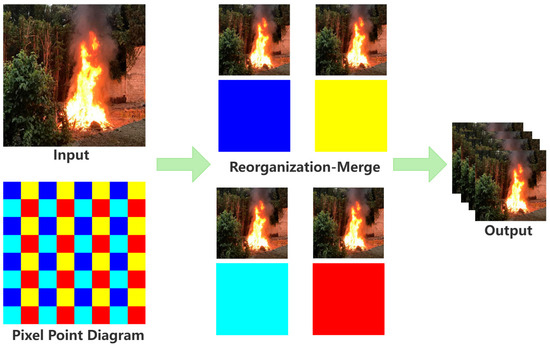
Figure 7.
Patch Merge Downsampling (PMD) diagram.
- (2)
- Squeeze-and-Excitation
Squeeze-and-Excitation (SE) [50] is a neural network structure that dynamically adjusts channel-wise feature importance. In traditional convolution operations, features from different channels are treated equally, whereas, in reality, their contributions to the final task vary. SE explicitly models inter-channel dependencies, enabling adaptive recalibration of channel importance, thereby enhancing model performance with minimal computational overhead. The SE architecture is illustrated in Figure 8.
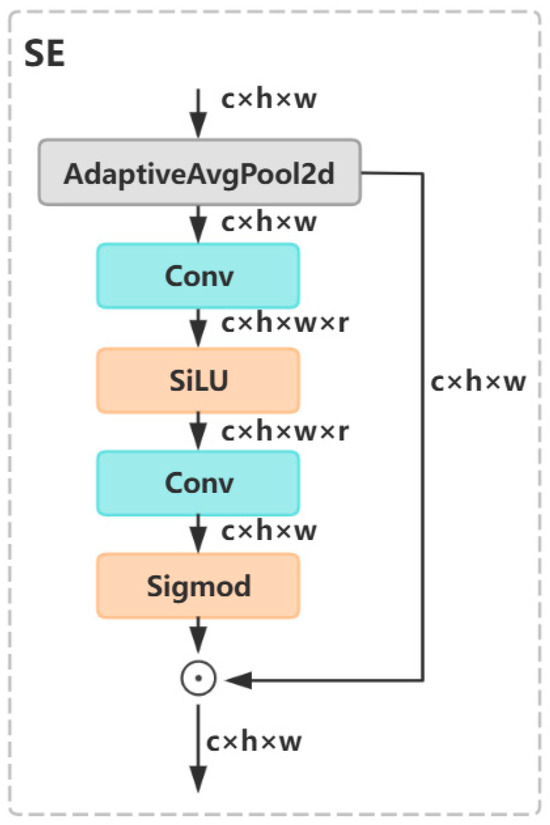
Figure 8.
Squeeze-and-Excitation (SE) architecture diagram.
- (3)
- Dynamic Enhanced Patch Merge Downsampling
In forest fire object detection tasks, the feature extraction efficiency and detail preservation capability of downsampling operations critically determine model performance. In YOLOv11, image downsampling is implemented through convolution operations, which may lose small targets and detailed textures of flames/smoke during the process, affecting high-level feature representation and detection accuracy. To address this issue, this study innovatively proposes Dynamic Enhanced Patch Merge Downsampling (DEPMD), which combines PMD’s detail retention capability with SE’s dynamic feature enhancement, effectively mitigating detail loss and efficiency issues caused by traditional convolutional downsampling. For any input feature , the feature first undergoes PMD for downsampling to reduce the computational cost, then achieves the final DEPMD through dynamic SE feature enhancement. The mathematical expression of DEPMD is as follows:
In Equation (13), is a learnable parameter that dynamically adjusts the SE weights.
2.2.4. Multi-Scale Fusion
- (1)
- Weighted Feature Fusion
Weighted Feature Fusion (WFF) is a feature fusion method proposed in the Bidirectional Feature Pyramid Network (BiFPN) [51], which addresses the issue of imbalanced contribution allocation for multi-scale features in the Feature Pyramid Network (FPN) [40] by introducing learnable normalized weight parameters. Its mathematical expression is as follows:
In Equation (14), represents the input feature, and are learnable weight parameters, and is a small constant introduced to prevent numerical instability.
- (2)
- Scaling Weighted Fusion
In addressing fire object detection tasks, the YOLOv11 model employs Path Aggregation Network (PANet) [39] in its neck section. While demonstrating excellent performance in multi-scale feature fusion, its traditional concatenation-based fusion approach tends to cause imbalanced contribution allocation across multi-scale features. Although the Bidirectional Feature Pyramid Network’s (BiFPN) Weighted Feature Fusion (WFF) can optimize feature contribution ratios through learnable weights, under the complex conditions of irregular flame shapes, sparse smoke features, and gradient sparsity in fire scenarios, the WFF mechanism may lead to attenuation of critical features during weight adjustment. To overcome these challenges, this study innovatively proposes Scaling Weighted Fusion (SWF), which introduces dynamic scaling factors to enhance feature contribution, effectively mitigating feature dilution in traditional weighted fusion. Its mathematical expression is as follows:
In Equation (14), denotes the input feature, where , , and are trainable weight parameters, and is a small constant added to ensure numerical stability.
2.2.5. Detail Texture Enhancement
- (1)
- Sigmoid Linear Unit
The Sigmoid Linear Unit (SiLU) [37] activation function is an adaptive nonlinear activation function that combines characteristics of the Sigmoid function and linear operations and is employed in YOLOv11. Its mathematical expression is as follows:
In Equation (16), denotes the Sigmoid activation function. Its mathematical expression is as follows:
- (2)
- Mish
The SiLU activation function multiplies input x by the output of the Sigmoid function, combining both linear and nonlinear characteristics to enhance the model’s feature representation capability and stability. However, in fire object detection scenarios, the blurred boundaries caused by the diffusion characteristics of flames and smoke pose challenges for the model. To address this, this study replaces the SiLU activation function with the Mish activation function [52], introducing additional nonlinearity to improve the model’s edge texture fitting capability. The mathematical expression of the Mish activation function is as follows:
2.2.6. Lightweight Hybrid Receptive Field Model
To address the challenges of YOLOv11 in forest fire detection scenarios, we enhance global context awareness by introducing RMELAN in high-level semantic feature extraction, achieve efficient downsampling through DEPMD in low-level feature extraction, improve multi-scale feature modulation and fusion via SWF in the neck module, and boost detail texture capture capability using the Mish activation function. Ultimately, we propose LHRF-YOLO, a lightweight hybrid receptive field object detection model specifically optimized for forest fire detection. The network architecture of LHRF-YOLO is illustrated in Figure 9.
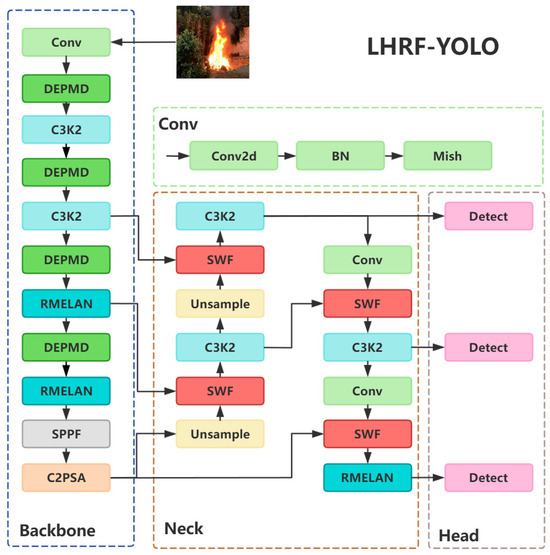
Figure 9.
LHRF-YOLO network architecture diagram.
3. Results
3.1. Experimental Environment
The detailed specifications of the experimental setup are provided in Table 2, while the hyperparameter configuration of the model is presented in Table 3.
Table 2.
Experimental environment.
Table 3.
Hyperparameter configuration.
3.2. Evaluation Metrics
In forest fire object detection tasks, to comprehensively and effectively evaluate the model, this paper adopts multi-dimensional metrics, including Precision (), Recall (), F1-score (), mean Average Precision (), Frames Per Second (), Parameters, and GFLOPs.
Precision () reflects the proportion of true fire samples among those detected as fires, calculated as follows:
In Equation (19), represents true positive, indicating the number of correctly detected fire samples. represents false positive, indicating the number of misclassified fire samples.
Recall () reflects the proportion of actual fire samples that are correctly detected, calculated as follows:
In Equation (20), represents false negative, indicating the number of undetected fire samples.
F1-score () is the harmonic mean of Precision () and Recall (), reflecting the model’s overall performance when balancing false alarms and missed detections. Its formula is as follows:
The mean Average Precision () reflects the model’s Average Precision () under different Intersection over Union () thresholds, evaluating its comprehensive performance in both localization and classification. The formulas for , , and are as follows:
In Equation (22), represents the overlapping area between predicted and ground truth bounding boxes, while denotes their combined total area. In Equation (23), the AP calculation is based on the area under the Precision–Recall Curve (PR curve), where indicates Precision values at different Recall levels. In Equation (24), represents the number of categories. For metrics, uses an threshold of 0.5; uses 0.75; uses 0.95; and 50–95 averages precision across thresholds from 0.5 to 0.95 with 0.05 increments.
Frames Per Second () measures the number of images the model can process per second, calculated as follows:
In Equation (25), represents preprocessing time, Inference Time denotes model inference time, and indicates post-processing time.
Parameters reflect the model’s spatial complexity, representing the total number of trainable parameters in the model, which directly affects storage requirements and memory consumption.
GFLOPs reflect the model’s temporal complexity, representing the number of floating-point operations required for one forward pass, which directly impacts computational resource consumption.
3.3. Ablation Experiment
To validate the effectiveness of the proposed improvement modules, we designed systematic ablation experiments conducted on the FSDataset. Using YOLOv11n as the baseline model, this experiment progressively introduces Residual Multi-Branch Efficient Layer Aggregation Networks (RMELANs), Dynamic Enhanced Patch Merge Downsampling (DEPMD), Scaling Weighted Fusion (SWF), and the detail texture enhancement strategy of replacing SiLU with the Mish activation function, analyzing the impact of each component on model performance. Key evaluation metrics include Precision (), Recall (), F1-score (), , and 50–95, as well as model complexity indicators Parameters and GFLOPs. Detailed experimental results are presented in Table 4.
Table 4.
Results of model ablation experiments. (✓ represents the addition of this module).
As shown in Table 4, the baseline model (YOLOv11n) demonstrates fundamental detection capability in forest fire scenarios but exhibits certain performance bottlenecks, with mAP50 of 87.3% and mAP50–95 of 56.7%. The model’s parameter count of 2.58M and GFLOPs of 6.3 indicate significant optimization potential. Replacing the SiLU activation function with Mish maintains the parameter count while improving mAP50 to 87.4%, with mAP50–95 stabilizing around 56.6%. This demonstrates Mish’s smoother gradient characteristics enhance edge feature extraction and mitigate gradient vanishing in fire detection. Introducing RMELAN increases mAP50 to 87.4% and mAP50–95 to 56.8% without parameter growth, as its hybrid SS2D global modeling and residual connections strengthen spatial context modeling of fire regions. DEPMD alone reduces parameters to 2.32M but decreases mAP50 to 87.0%, indicating dynamic downsampling trades some accuracy for efficiency when used independently, though subsequent experiments reveal its synergistic benefits. SWF integration maintains parameter stability while boosting mAP50 to 87.4%, as adaptive weight scaling optimizes multi-scale feature fusion. Combining Mish and RMELAN achieves 87.5% mAP50 and 56.7% mAP50–95, showing their synergy in enhancing flame edge and structural perception.
Ablation studies demonstrate that the LHRF-YOLO model integrating RMLEAN, DEPMD, SWF, and Mish activation achieves an optimal balance between performance and efficiency. The model attains 87.6% mAP50 and 57.0% mAP50–95, representing improvements of 0.3% and 0.3%, respectively, over the baseline model. The F1-score reaches 81.9%, showing a 0.6% enhancement compared to the baseline, indicating superior Precision–Recall balance. The parameter count is compressed to 2.25M (12.8% reduction), and computational complexity is reduced to 5.4 GFLOPs (14.3% decrease), effectively validating the lightweight design approach.
To comprehensively validate the effectiveness of the Mish activation function in enhancing texture representation, we specifically designed comparative experiments to evaluate its performance against commonly used activation functions, including SiLU, ReLU, Swish, and GELU. As illustrated in Figure 10 and Figure 11, the experimental results demonstrate that the Mish activation function exhibits significantly superior performance over other candidate solutions across all key evaluation metrics examined in this study. Consequently, adopting Mish as the core activation function plays a pivotal role in improving both the model’s texture perception capability and its recognition accuracy in forest fire detection.
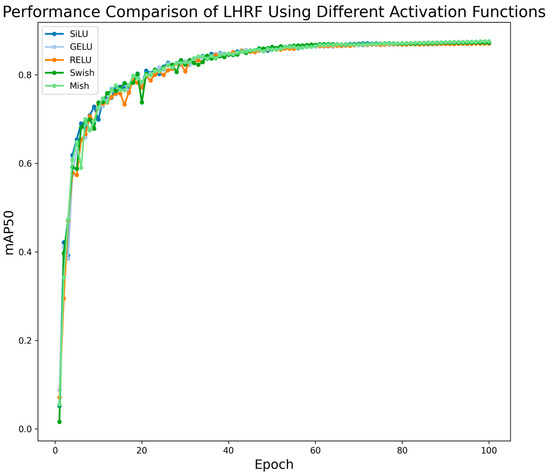
Figure 10.
Performance comparison of LHRF using different activation functions.
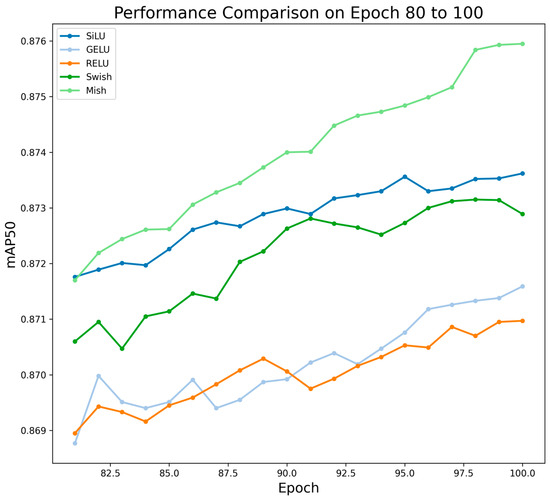
Figure 11.
Performance comparison of LHRF using different activation functions from Epoch 80 to 100.
3.4. Comparative Experiment
To verify the effectiveness of the proposed LHRF-YOLO model in forest fire scenarios, we conducted comparative experiments with multiple baseline models from the YOLO series as well as traditional models on the FSDataset. The evaluation metrics encompass detection accuracy (Precision, Recall, F1-score), multi-threshold average precision (mAP50, mAP75, mAP95, mAP50–95), inference speed (FPS), and model complexity (parameters and GFLOPs). Experimental results demonstrate that LHRF-YOLO achieves significant performance improvements while maintaining a lightweight architecture. Detailed experimental results are presented in Table 5. Additionally, for a more intuitive performance comparison between LHRF-YOLO and different models, we plotted comparative curves, as shown in Figure 12 and Figure 13.
Table 5.
Results of model comparison experiments.
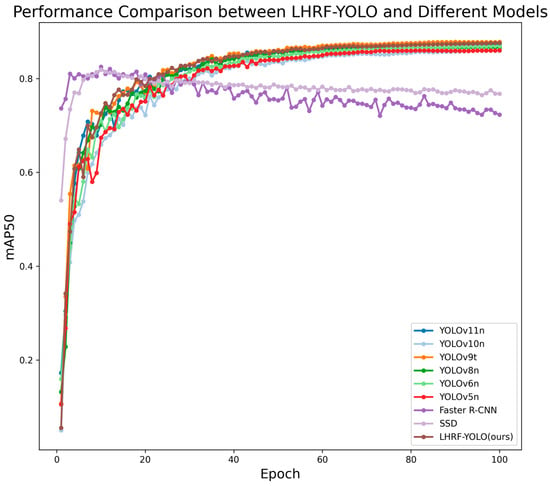
Figure 12.
Performance comparison between LHRF-YOLO and different models.
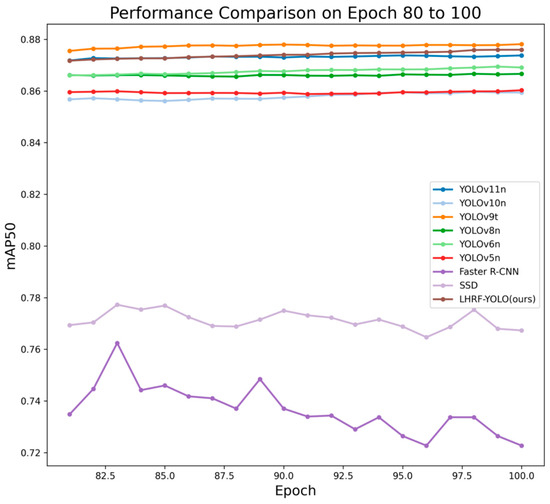
Figure 13.
Performance comparison between LHRF-YOLO and other models from Epoch 80 to 100.
As shown in Table 5, LHRF-YOLO demonstrates significantly superior comprehensive performance compared to traditional models, confirming the advantages of YOLO-series models in fire object detection scenarios. LHRF-YOLO achieves superior Precision (84.2%) and F1-score (81.9%) compared to all YOLO baseline models, while its Recall (79.8%) is only slightly lower than YOLOv9t (80.0%). Compared to the latest version YOLOv11n (Precision 83.5%, Recall 79.3%), LHRF-YOLO demonstrates improvements of 0.7% in Precision, 0.5% in Recall, and 0.6% in F1-score, indicating a better balance between flame localization accuracy and target coverage. LHRF-YOLO outperforms YOLOv11n in key metrics, including mAP50 (87.6%), mAP75 (62.2%), and mAP95 (2.7%), particularly showing a 0.3% improvement under a high threshold (mAP95). While its mAP50–95 reaches 57.0%, slightly lower than YOLOv9t (57.1%), these results demonstrate LHRF-YOLO’s stronger robustness across varying detection difficulties, especially in identifying small fire spots and occluded flames. With 2.25M parameters and 5.4 GFLOPs, LHRF-YOLO achieves a 12.8% parameter reduction and a 14.3% computation reduction compared to YOLOv11n (2.58M and 6.3). This lightweight design makes it more suitable for edge device deployment without compromising core detection performance.
It is worth noting that YOLOv9t slightly outperforms LHRF-YOLO on certain metrics, such as mAP50–95. This performance difference directly results from our model’s design philosophy of reducing computational complexity. Compared to YOLOv9t’s computation-intensive architecture, LHRF-YOLO maintains fundamental detection capabilities while significantly decreasing computational requirements; this deliberate design trade-off accounts for the minor performance gap in mAP metrics. LHRF-YOLO achieves a superior F1-score (81.9% vs. 81.7%), demonstrating a better balance between reducing missed detections and false alarms in practical applications. Moreover, LHRF-YOLO’s mAP95 (2.7%) outperforms YOLOv9t (2.5%) by 0.2%, confirming its more precise localization of high-confidence targets. Although LHRF-YOLO has slightly more parameters than YOLOv9t, its DEPMD-based dynamic downsampling optimizes computational pathways, resulting in significantly lower GFLOPs. Combined with SS2D’s global enhancement capability, this architecture achieves a higher F1-score and mAP95. Comprehensively, experiments demonstrate that LHRF-YOLO delivers optimal overall performance for forest fire detection, particularly suitable for real-world scenarios requiring both real-time operation and high accuracy.
In order to better demonstrate the comparison between LHRF-YOLO and other advanced models, Figure 14 and Figure 15, respectively, demonstrate the fire detection performance comparison between LHRF-YOLO and other baseline models under different environmental scenarios. As shown in Figure 14, in low-concentration, highly-diffused smoke scenarios where comparative models exhibit missed detections for both widespread and locally concentrated smoke, LHRF-YOLO successfully detects both types simultaneously with significantly improved accuracy, benefiting from its innovative global context modeling module and multi-scale texture perception mechanism. Figure 15 illustrates that in low-light complex backgrounds with coexisting flames and smoke, compared to other models suffering from localization deviations and low accuracy, LHRF-YOLO achieves more precise bounding box annotations with higher detection confidence than baseline models. Experimental results confirm the algorithm’s superior feature perception capability and anti-interference performance in complex fire scenarios compared to existing methods.

Figure 14.
Comparative detection results of LHRF-YOLO versus different models in low-concentration, high-diffusion smoke scenarios, where the bounding boxes represent smoke targets detected by the models and the numerical values indicate confidence scores.

Figure 15.
Comparative detection results of different models under low-light complex backgrounds.
To more intuitively validate LHRF-YOLO’s perception capability of critical fire features and its advantages over other advanced models, we generated heatmaps based on Grad-CAM [53] and conducted comparisons with other models in typical diffused fire scenarios. These heatmaps visually demonstrate the relative intensity of the model’s attention across spatial locations in the input image when performing fire detection tasks. The activation intensity in the heatmaps is normalized to the range [0, 1], where red indicates high-attention regions and blue represents low-attention areas (Figure 16). As demonstrated in Figure 16, under identical scenarios, LHRF-YOLO’s heatmaps exhibit superior feature-focusing capability: high-activation regions tightly conform to flame contours with more precise edge detail capture, while core areas show stronger activation intensity. These visualizations further substantiate LHRF-YOLO’s advantages—its enhanced spatial-context modeling effectively captures subtle flame edge variations while maintaining lightweight characteristics, ultimately improving fire detection reliability and precision.
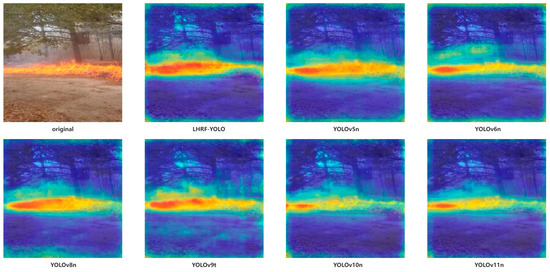
Figure 16.
Comparative analysis of heatmap visualizations in different models, where red indicates high-attention regions and blue represents low-attention areas.
3.5. Generalization Experiment
To validate the cross-scenario adaptability of LHRF-YOLO and its generalization capability in understanding fire-related features, we conducted generalization experiments comparing LHRF-YOLO with multiple YOLO baseline models on the test sets of both the M4SFWD dataset and the original Fire and Smoke Dataset. The experimental results demonstrate that LHRF-YOLO achieves significantly superior generalization performance compared to baseline models while maintaining its lightweight architecture. Detailed experimental results are presented in Table 6 and Table 7.
Table 6.
Results of model generalization experiments using Fire and Smoke Dataset Test.
Table 7.
Results of model generalization experiments using M4SFWD.
As shown in Table 6, on the test set of the Fire and Smoke Dataset, LHRF-YOLO demonstrates significant advantages in key metrics, highlighting its superiority as an improved version of YOLOv11n. Its F1-score reaches 82.1%, tying with the strongest baseline model, YOLOv9t, for the top position. Meanwhile, its Precision (84.4%) is notably higher than that of YOLOv9t (83.7%), showcasing its outstanding capability in reducing false detections—a critical feature for minimizing false alarms in real-world scenarios. The mAP50 of LHRF-YOLO (88.6%) is only 0.2% lower than that of YOLOv9t (88.8%), and in the more challenging mAP95 metric (4.0%), it trails YOLOv9t (4.2%) by merely 0.2%, indicating highly competitive performance in detecting difficult samples. Compared to baseline models such as YOLOv5n and YOLOv8n, LHRF-YOLO achieves F1-score improvements of 1.4%–2.1% and mAP50 gains of 1.5%–2.6%, validating the effectiveness of its enhanced modules. Although LHRF-YOLO’s composite metric mAP50–95 (61.3%) is slightly lower than that of YOLOv9t (62.1%) by 0.8%, it excels in reducing false detections and Precision, better aligning with the practical requirements of high accuracy and low error rates in real-world fire detection tasks.
As shown in Table 7, on the M4SFWD dataset, LHRF-YOLO achieves comprehensive improvements over the original YOLOv11n model. With an F1-score of 38.4%, it ties with YOLOv9t for the top position among baseline models, while its Precision (52.9%) significantly surpasses that of YOLOv9t (51.8%), demonstrating superior performance in reducing false alarms. LHRF-YOLO attains the highest values in both mAP50 (30.2%) and mAP75 (4.9%), with particularly notable improvement in the high-confidence threshold mAP95—a 200% increase over YOLOv9t (from 0.02% to 0.06%). These results indicate enhanced capability in identifying challenging samples (e.g., small fire spots, low-light flames). Compared to YOLOv5n/v6n/v8n, LHRF-YOLO shows 2.1%–2.4% F1-score improvement and 2.3%–2.7% mAP50 enhancement, validating the effectiveness of its improved modules. While leading in most metrics, LHRF-YOLO’s mAP50–95 (10.3%) slightly trails YOLOv9t (10.8%). However, its superior false alarm reduction better aligns with practical fire detection requirements.
In summary, through generalization experiments conducted on the M4SFWD dataset and the original Fire and Smoke Dataset test set, we have validated the effectiveness of our proposed LHRF-YOLO model, which incorporates targeted improvements based on YOLOv11. The model demonstrates superior generalization capability on unseen complex data, outperforming baseline models and successfully confirming its feasibility as the optimal solution.
4. Discussion
The proposed LHRF-YOLO model in this study achieves an optimal balance between accuracy and efficiency for forest fire detection through multi-module collaborative optimization, with its innovative improvements providing new technical pathways for lightweight object detection model design.
The experimental results demonstrate that the Receptive-field Mixed Enhancement Module (RMELAN) effectively addresses the insufficient global perception capability of traditional CNN models by incorporating SS2D’s global scanning mechanism. When dealing with the dynamic diffusion characteristics of flames and smoke, RMELAN exhibits superior feature representation capability. Compared with attention mechanism improvements, SS2D achieves equivalent global context modeling while maintaining linear computational complexity, validating its feasibility for visual tasks. The Dynamic Enhanced Patch Merge Downsampling module (DEPMD) preserves relatively complete feature information transmission while reducing computational cost and parameter count through PMD’s spatial reorganization and SE’s channel weighting. The innovative Scaling Weighted Fusion (SWF) module introduces a scaling factor mechanism that adaptively adjusts the contribution of multi-scale features, effectively mitigating feature dilution. This enables simultaneous detection of initial micro-fire sources and large-scale smoke diffusion, verifying the effectiveness of the multi-scale feature contribution allocation mechanism. Regarding model performance comparison, LHRF-YOLO demonstrates a remarkable balance between lightweight design and accuracy. With only 5.4 GFLOPs and 2.25M parameters, it shows superior suitability for edge computing deployment scenarios. In high-threshold detection scenarios, it achieves 12.5% higher precision than YOLOv11n, confirming enhanced capability for high-precision localization requirements. Furthermore, in cross-scenario testing on M4SFWD, its mAP50 surpasses YOLOv11n by 4.5%, demonstrating superior generalization capability in complex environments.
Despite the significant progress achieved by LHRF-YOLO, several limitations and shortcomings remain. First, the model’s generalization capability still requires further enhancement. While it demonstrates superior performance compared to baseline models in generalization experiments, its effectiveness remains susceptible to fluctuations when encountering interference factors such as climate variations, geographical changes, visibility shifts, motion blur, atmospheric scattering, smoke occlusion, and intense illumination. To address these challenges, we must intensify research on extreme environmental factors while simultaneously constructing high-quality datasets encompassing more complex scenarios to strengthen the model’s feature learning capacity. Second, while the model shows significant improvements over the original YOLOv11n, comparative analysis with YOLOv9t reveals that certain performance metrics have not yet been comprehensively surpassed, indicating room for further optimization. Although the current real-time performance (FPS) meets basic requirements for real-time detection, there remains optimization potential compared to YOLOv11n. Finally, the model’s consideration of complex environmental factors remains incomplete. Practical forest conditions (e.g., soil characteristics) and inherent sensor detection limits directly affect the visual representation consistency of fire regions, particularly threatening the detection reliability of small targets (small fire spots, thin smoke) and challenging the model’s generalization capability. Enhanced adaptability to representation variations caused by such image uncertainties is required.
Future research will focus on optimizing model pruning techniques [54,55] and innovating efficient computation methods to enhance computational efficiency while maintaining accuracy. Concurrently, we will explore multimodal learning frameworks [56] that integrate multi-source environmental parameters (meteorological, vegetation, terrain data, and soil moisture) with infrared data. Additionally, we will develop robust algorithms [57] specifically designed for low-quality images (high noise, blur, occlusion) and small target detection while conducting in-depth investigations into how sensor detection limits affect model performance boundaries.
5. Conclusions
To address the core challenges in forest fire detection, including the difficulty of modeling dynamic diffusion characteristics of flames and smoke, insufficient extraction of semi-transparent features, and the demand for edge device deployment, this study proposes LHRF-YOLO. By integrating SS2D with RMELAN, it achieves collaborative modeling of local details and global context while maintaining linear computational complexity. Through DEPMD’s feature reorganization and channel-wise dynamic weighting optimization, it enhances semantic representation capacity while reducing spatial resolution. The SWF module’s dynamic scaling factors optimize multi-scale feature contribution allocation, resolving the feature dilution problem in traditional fusion methods. Replacing SiLU with the Mish activation function improves the capture capability for flame edges and sparse smoke textures.
Experimental results demonstrate that LHRF-YOLO achieves remarkable model compression, with only 2.25M parameters (12.8% reduction compared to YOLOv11n) and 5.4 GFLOPs computational complexity (14.3% decrease versus YOLOv11n), effectively meeting the lightweight deployment requirements for edge devices like forest monitoring drones. The model has been successfully deployed on NVIDIA Jetson series edge computing platforms. The demonstrated effectiveness in forest fire detection tasks, combined with its lightweight architecture, suggests strong transfer potential for similar application scenarios, including fire and smoke detection in industrial plants, petrochemical facilities, and other critical areas. Through transfer learning [58], the model can be further adapted to environment-specific characteristics and target morphologies in industrial settings. This study provides a novel technical approach for forest ecological security monitoring and holds significant practical value for advancing the development of lightweight fire detection technologies. The proposed methodology not only addresses current limitations in forest fire monitoring but also establishes a foundation for broader applications in various safety-critical domains.
Author Contributions
Conceptualization, Y.M. and W.S.; methodology, Y.M. and W.S.; software, Y.M.; validation, Y.M., Y.S. and M.W. (Mengyu Wang); writing—original draft preparation, Y.M.; writing—review and editing, Y.M., W.S. and M.W. (Maofa Wang); supervision, W.S.; project administration, Y.M. and W.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Science and Technology Innovation Program for Postgraduate students in IDP subsidized by Fundamental Research Funds for the Central Universities (ZY20260306), the Spark Program of Earthquake Sciences (XH25080C), the National Natural Science Foundation of China (42164002), and the Langfang Science and Technology Research and Development Plan (2025011003).
Data Availability Statement
The data pertinent to this research are available from the corresponding authors upon request.
Acknowledgments
The authors appreciate the editors and anonymous reviewers for their valuable recommendations.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Watson, J.E.M.; Evans, T.; Venter, O.; Williams, B.; Tulloch, A.; Stewart, C.; Thompson, I.; Ray, J.C.; Murray, K.; Salazar, A.; et al. The exceptional value of intact forest ecosystems. Nat. Ecol. Evol. 2018, 2, 599–610. [Google Scholar] [CrossRef] [PubMed]
- Marengo, J.A.; Souza, C.M.; Thonicke, K.; Burton, C.; Halladay, K.; Betts, R.A.; Alves, L.M.; Soares, W.R. Changes in Climate and Land Use Over the Amazon Region: Current and Future Variability and Trends. Front. Earth Sci. 2018, 6, 228. [Google Scholar] [CrossRef]
- Williams, A.P.; Abatzoglou, J.T.; Gershunov, A.; Guzman-Morales, J.; Bishop, D.A.; Balch, J.K.; Lettenmaier, D.P. Observed Impacts of Anthropogenic Climate Change on Wildfire in California. Earth’s Future 2019, 7, 892–910. [Google Scholar] [CrossRef]
- Bowman, D.; Williamson, G.J.; Gibson, R.K.; Bradstock, R.A.; Keenan, R.J. The severity and extent of the Australia 2019-20 Eucalyptus forest fires are not the legacy of forest management. Nat. Ecol. Evol. 2021, 5, 1003–1010. [Google Scholar] [CrossRef] [PubMed]
- Bao, S.; Xiao, N.; Lai, Z.; Zhang, H.; Kim, C. Optimizing watchtower locations for forest fire monitoring using location models. Fire Saf. J. 2015, 71, 100–109. [Google Scholar] [CrossRef]
- Tomizuka, M.; Doolin, D.M.; Sitar, N. Wireless sensors for wildfire monitoring. In Proceedings of the Smart Structures and Materials 2005: Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems, National Harbor, MD, USA, 17 May 2005. [Google Scholar]
- Akay, A.E.; Wing, M.; Büyüksakalli, H.; Malkoçoglu, S. Evaluation of Fire Lookout Towers Using GIS-based Spatial Visibility and Suitability Analyzes. Šumarski List 2020, 144, 279–288. [Google Scholar] [CrossRef]
- Tapete, D. Earth Observation, Remote Sensing, and Geoscientific Ground Investigations for Archaeological and Heritage Research. Geosciences 2019, 9, 161. [Google Scholar] [CrossRef]
- Saydirasulovich, S.N.; Mukhiddinov, M.; Djuraev, O.; Abdusalomov, A.; Cho, Y.I. An Improved Wildfire Smoke Detection Based on YOLOv8 and UAV Images. Sensors 2023, 23, 8374. [Google Scholar] [CrossRef]
- Usamentiaga, R.; Venegas, P.; Guerediaga, J.; Vega, L.; Molleda, J.; Bulnes, F.G. Infrared thermography for temperature measurement and non-destructive testing. Sensors 2014, 14, 12305–12348. [Google Scholar] [CrossRef]
- Khatami, A.; Mirghasemi, S.; Khosravi, A.; Lim, C.P.; Nahavandi, S. A new PSO-based approach to fire flame detection using K-Medoids clustering. Expert. Syst. Appl. 2017, 68, 69–80. [Google Scholar] [CrossRef]
- Zhang, Z.; Shen, T.; Zou, J. An Improved Probabilistic Approach for Fire Detection in Videos. Fire Technol. 2012, 50, 745–752. [Google Scholar] [CrossRef]
- Chen, J.; He, Y.; Wang, J. Multi-feature fusion based fast video flame detection. Build. Environ. 2010, 45, 1113–1122. [Google Scholar] [CrossRef]
- Toereyin, B.U.; Cinbis, R.G.; Dedeoglu, Y.; Çetin, A.E. Fire Detection in Infrared Video Using Wavelet Analysis. Opt. Eng. 2007, 46, 067204. [Google Scholar] [CrossRef]
- Benjamin, S.G.; Radhakrishnan, B.; Nidhin, T.G.; Suresh, L.P. Extraction of Fire Region from Forest Fire Images Using Color Rules and Texture Analysis. In Proceedings of the 2016 International Conference on Emerging Technological Trends (ICETT), Kollam, India, 21–22 October 2016. [Google Scholar]
- Jain, P.; Coogan, S.C.P.; Subramanian, S.G.; Crowley, M.; Taylor, S.; Flannigan, M.D. A Review of Machine Learning Applications in Wildfire Science and Management. Environ. Rev. 2020, 28, 478–505. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient Deep CNN-Based Fire Detection and Localization in Video Surveillance Applications. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1419–1434. [Google Scholar] [CrossRef]
- Wong, A.; Shafiee, M.J.; Li, F.; Chwyl, B. Tiny SSD: A Tiny Single-shot Detection Deep Convolutional Neural Network for Real-time Embedded Object Detection. In Proceedings of the 2018 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8–10 May 2018. [Google Scholar]
- Zheng, X.; Chen, F.; Lou, L.; Cheng, P.; Huang, Y. Real-Time Detection of Full-Scale Forest Fire Smoke Based on Deep Convolution Neural Network. Remote Sens. 2022, 14, 536. [Google Scholar] [CrossRef]
- An, Q.; Chen, X.; Zhang, J.; Shi, R.; Yang, Y.; Huang, W. A Robust Fire Detection Model Via Convolution Neural Networks for Intelligent Robot Vision Sensing. Sensors 2022, 22, 2929. [Google Scholar] [CrossRef]
- Talaat, F.M.; ZainEldin, H. An Improved Fire Detection Approach Based on YOLO-v8 for Smart Cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Lin, J.; Lin, H.; Wang, F. A Semi-Supervised Method for Real-Time Forest Fire Detection Algorithm Based on Adaptively Spatial Feature Fusion. Forests 2023, 14, 361. [Google Scholar] [CrossRef]
- Majid, S.; Alenezi, F.; Masood, S.; Ahmad, M.; Gunduz, E.S.; Polat, K. Attention Based CNN Model for Fire Detection and Localization in Real-World Images. Expert Syst. Appl. 2022, 189, 116114. [Google Scholar] [CrossRef]
- Yar, H.; Hussain, T.; Agarwal, M.; Khan, Z.A.; Gupta, S.K.; Baik, S.W. Optimized Dual Fire Attention Network and Medium-Scale Fire Classification Benchmark. IEEE Trans. Image Process. 2022, 31, 6331–6343. [Google Scholar] [CrossRef] [PubMed]
- Jin, C.; Wang, T.; Alhusaini, N.; Zhao, S.; Liu, H.; Xu, K.; Zhang, J. Video Fire Detection Methods Based on Deep Learning: Datasets, Methods, and Future Directions. Fire 2023, 6, 315. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv 2024, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Almeida, J.S.; Huang, C.; Nogueira, F.G.; Bhatia, S.; de Albuquerque, V.H.C. EdgeFireSmoke: A Novel Lightweight CNN Model for Real-Time Video Fire–Smoke Detection. IEEE Trans. Ind. Inform. 2022, 18, 7889–7898. [Google Scholar] [CrossRef]
- Almeida, J.S.; Jagatheesaperumal, S.K.; Nogueira, F.G.; de Applications, V.H.C. EdgeFireSmoke++: A Novel Lightweight Algorithm for Real-Time Forest Fire Detection and Visualization Using Internet of Things-Human Machine Interface. Expert Syst. Appl. 2023, 221, 119747. [Google Scholar] [CrossRef]
- Guan, Z.; Miao, X.; Mu, Y.; Sun, Q.; Ye, Q.; Gao, D. Forest Fire Segmentation from Aerial Imagery Data Using an Improved Instance Segmentation Model. Remote Sens. 2022, 14, 3159. [Google Scholar] [CrossRef]
- Huang, L.; Ding, Z.; Zhang, C.; Ye, R.; Yan, B.; Zhou, X.; Xu, W.; Gou, J. YOLO-ULNet: Ultra-Lightweight Network for Real-Time Detection of Forest Fire on Embedded Sensing Devices. IEEE Sensors J. 2024, 24, 25175–25185. [Google Scholar] [CrossRef]
- Lin, Z.; Yun, B.; Zheng, Y. LD-YOLO: A Lightweight Dynamic Forest Fire and Smoke Detection Model with Dysample and Spatial Context Awareness Module. Forests 2024, 15, 1630. [Google Scholar] [CrossRef]
- Catargiu, C.; Cleju, N.; Ciocoiu, I.B. A Comparative Performance Evaluation of YOLO-Type Detectors on a New Open Fire and Smoke Dataset. Sensors 2024, 24, 5597. [Google Scholar] [CrossRef]
- LabelImg. Available online: https://github.com/tzutalin/labelImg (accessed on 2 December 2024).
- Wang, G.; Li, H.; Li, P.; Lang, X.; Feng, Y.; Ding, Z.; Xie, S. M4SFWD: A Multi-Faceted Synthetic Dataset for Remote Sensing Forest Wildfires Detection. Expert Syst. Appl. 2024, 248, 123489. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar] [CrossRef]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Swish: A Self-Gated Activation Function. arXiv 2017, arXiv:1710.05941v1. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Lu, Y. VMamba: Visual State Space Model. arXiv 2024, arXiv:2401.10166. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Yeh, I.-H. Designing Network Design Strategies Through Gradient Path Analysis. arXiv 2023, arXiv:2211.04800. [Google Scholar] [CrossRef]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Shi, D. TransNeXt: Robust Foveal Visual Perception for Vision Transformers. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Misra, D. Mish: A Self Regularized Non-Monotonic Activation Function. arXiv 2020, arXiv:1908.08681. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks Via Gradient-Based Localization. Int.J. Comput. Vis. 2019, 128, 336–359. [Google Scholar] [CrossRef]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning Both Weights and Connections for Efficient Neural Networks. arXiv 2015, arXiv:1506.02626. [Google Scholar] [CrossRef]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets. arXiv 2017, arXiv:1608.08710. [Google Scholar]
- Khaled, B.; Raja, K.; Fayçal, H.; Mtibaa, A. A Survey on Deep Multimodal Learning for Computer Vision: Advances, Trends, Applications, and Datasets. Vis. Comput. 2021, 38, 2939–2970. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, P.; Liu, K.; Wang, P.; Fu, Y.; Lu, C.-T.; Aggarwal, C.C.; Pei, J.; Zhou, Y. A Comprehensive Survey on Data Augmentation. arXiv 2024, arXiv:2405.09591. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).