1. Introduction
Forest fire detection is a critical challenge in ecological conservation and disaster prevention. It plays a vital role in preserving biodiversity, mitigating carbon emissions, and safeguarding public safety. In recent years, Unmanned Aerial Vehicles (UAVs) equipped with visible-light sensors, integrated with deep learning models, have emerged as a mainstream solution for real-time fire monitoring [
1,
2]. However, smoke obscures the thermal core features of flames, high-reflectivity regions are frequently misclassified as fire, and nighttime conditions result in diminished target visibility. The perceptual capacity of visible-light systems is severely constrained in scenarios involving smoke occlusion, strong light reflection, and low-light environments.
Multimodal forest fire detection has emerged as a promising solution to enhance detection performance in complex environments, gaining increasing traction in recent research and applications [
3,
4]. By integrating complementary data from RGB and thermal imaging modalities, visible-light sensors capture visual features such as smoke texture and flame color, while infrared sensors utilize thermal radiation signals to penetrate obscurants like smoke and identify heat sources under low-visibility conditions. This synergistic fusion enables robust environmental perception, overcoming limitations of single-sensor systems and ensuring reliable all-weather detection capabilities [
5,
6].
Recent studies indicate that fusing multimodal features can substantially enhance the accuracy of forest fire detection [
7]. The degree of enhancement is influenced by both the fusion stage and the specific strategies employed. Studies demonstrate that features extracted independently from single-modal data, such as visible light and infrared, can generate independent detection results. These results are subsequently combined through decision-level fusion strategies [
8], including weighted averaging and voting mechanisms, thereby integrating complementary information from multiple modalities [
3,
5,
6,
9]. Recent advances in multimodal fusion methodologies have introduced sophisticated strategies to address key challenges such as heterogeneous modality alignment [
10,
11], modality imbalance [
12,
13], and representation learning [
14]. These approaches leverage attention mechanisms and feature pyramids to improve inter-modal interactions. However, persistent limitations in cross-modal feature interaction efficiency persist: (1) Feature confusion arises between the high-temperature infrared radiation signatures of flame cores and high-brightness regions in visible light domains, compounded by disparities between the semi-transparent visual characteristics of smoke and its weak infrared signatures. (2) Challenging forest environments, characterized by dense vegetation, complex terrain, and dynamic lighting variations, hinder model performance by diverting attention from essential fire-related features, which leads to both missed detections and an increased rate of false alarms.
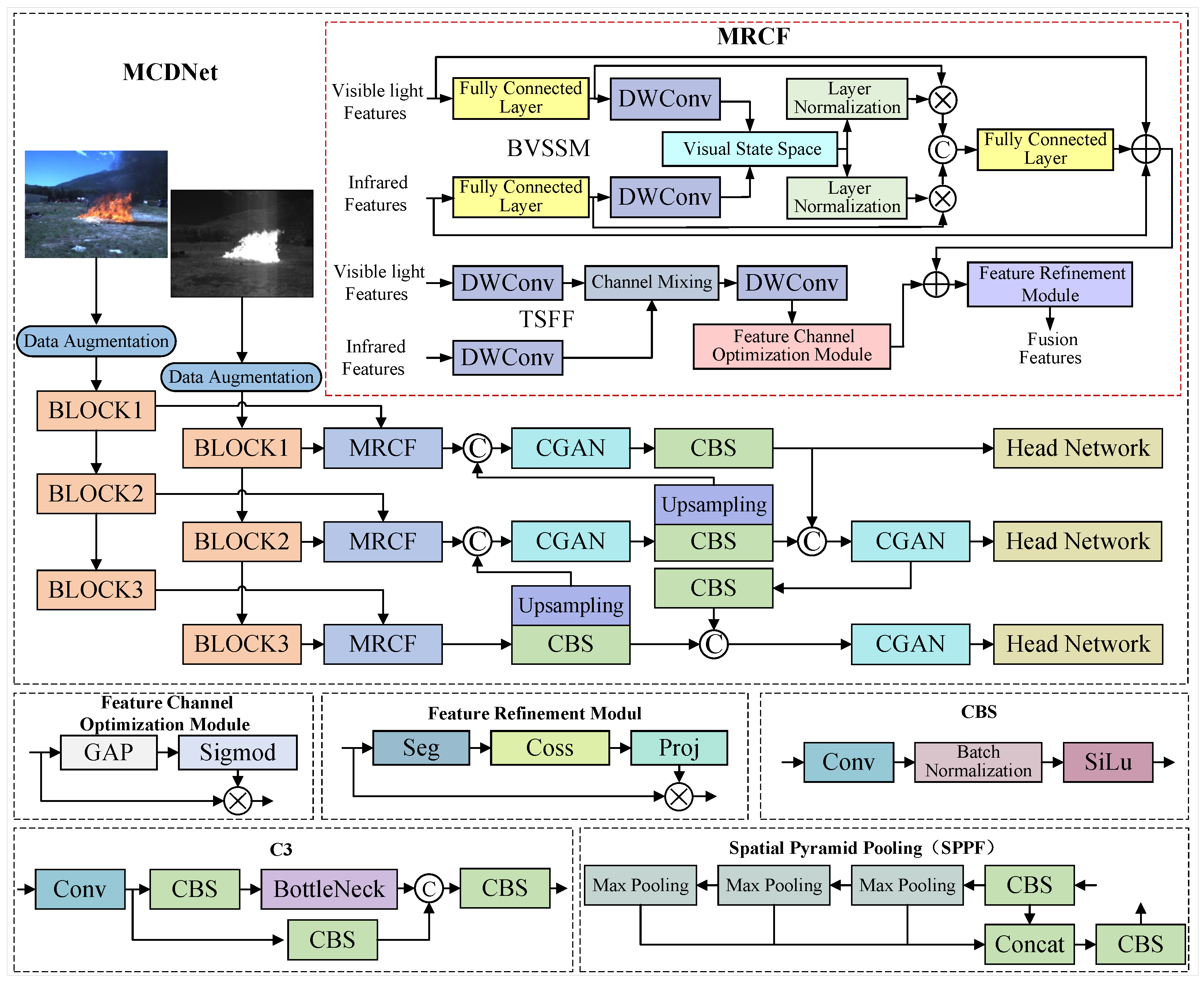
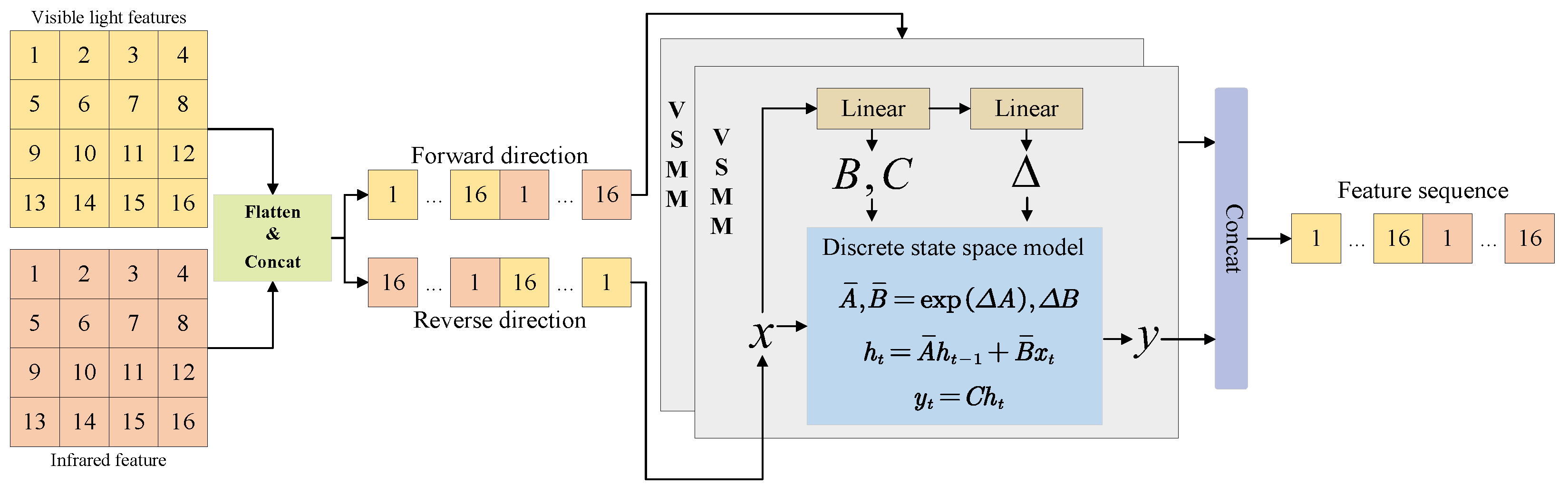
To this end, this paper proposes a target-aware multimodal forest fire detection framework, MCDet. We first introduce Multidimensional Representation Collaborative Fusion (MRCF) to address feature interference arising from the visual confusion between high-temperature infrared radiation cores of flames and high-brightness regions in visible light, as well as the disparity between the semi-transparent appearance of smoke in visible spectra and its weak infrared signatures. The MRCF employs a discrete State Space Model (SSM) to extract spatial features from sequential images and incorporates a selective scanning mechanism to establish global cross-modal interactions. Integrated with deformable convolutions for enhanced local detail perception, this architecture forms a global–local collaborative fusion framework. Then, to resolve challenges in feature focusing due to vegetation occlusion and terrain interference, we design a content-guided attention network (CGAN). The CGAN module dynamically generates dual-dimensional spatial and channel attention weights through a gating mechanism, enabling adaptive feature aggregation. In addition, we adopt the WIoU loss function, which adjusts the gradient weights of hard samples via a non-monotonic focusing mechanism. It suppresses misleading gradient propagation in high-frequency noisy regions, thereby mitigating localization errors caused by blurred smoke boundaries and flame occlusion. Extensive experiments demonstrate that our MCDet achieves advanced performance across four challenging benchmark datasets. The main contributions of this paper are as follows:
We propose a novel MRCF, which integrates discrete state-space modeling and global–local cross-modal interactions, effectively resolving visual confusion between flame infrared radiation and visible light interference.
We propose CGAN, a model that captures fire targets’ spatial distribution and high-response channel features using content-guided attention. Its dynamic gating mechanism improves feature discrimination amid vegetation occlusion and terrain interference.
The WIoU loss function is introduced to significantly improve target focusing in complex scenarios. In addition, two large-scale multimodal forest fire datasets, D-Fire and Fire-dataset, are constructed, enriching the data resources in this field.
The paper is organized as follows:
Section 2 reviews object detection and multimodal fire detection methods.
Section 3 details the proposed MCDet.
Section 4 presents experimental validation through comparative tests, ablation studies, and cross-scenario evaluations. Finally,
Section 5 concludes with future research directions.
4. Experiments
This section begins by introducing the selected dataset and experimental configuration. Subsequently, the experimental setup is publicly released to ensure reproducibility. The methodology is then validated through comparative evaluations across four benchmark datasets, followed by an in-depth analysis of the results. Finally, ablation studies are conducted to isolate the contributions of individual components.
4.1. Datasets
- (1)
Corsican Fire dataset
The Corsican Fire dataset [
58] consists of 635 pairs of real visible and near-infrared fire images acquired at the University of Corsica. All flames and smoke are annotated to facilitate detection accuracy assessment, with dense smoke clusters labeled and sparse smoke excluded. Flames originating from the same source are jointly annotated.
- (2)
D-Fire dataset
The D-Fire dataset [
59] is a publicly accessible resource designed for flame and smoke detection via simulated forest fire scenarios, widely employed to evaluate fire detection models. It comprises 21,527 images categorized by fire event type: 1164 with flames only, 5867 with smoke only, 4658 with both flames and smoke, and 9838 unlabeled background samples. The dataset includes annotations for 14,692 flame instances and 11,865 smoke instances. After removing unlabeled or erroneously labeled images, 11,681 images were retained, allocated into training (9388), validation (1146), and test (1147) sets.
To generate high-quality cross-modal simulation data, this study trains a CUT (Contrastive Unpaired Translation) model [
60] for visible-to-infrared image conversion based on the Corsican Fire dataset [
58]. The model adopts an unsupervised image translation framework grounded in contrastive learning, with its core mechanism leveraging contrastive loss to capture semantic correspondences between deep features of input (visible) and generated (infrared) images. Specifically, CUT employs an encoder-generator architecture with shared weights: the encoder extracts multi-level features from input visible images, while the generator reconstructs images in the target domain (infrared) style based on these features. The critical contrastive learning strategy forces the model to precisely preserve the original image’s content structures (e.g., fire field morphology, object contours) while transforming styles (e.g., thermal radiation patterns), by maximizing the similarity between features of input image patches and their corresponding generated patches (positive pairs) while minimizing similarity to unrelated patches (negative pairs). This explicit feature correspondence learning not only enhances model interpretability but also fundamentally ensures strong semantic consistency between generated and original images, establishing a theoretical foundation for reliable simulated data. During training, input images were uniformly resized to 512 × 512 pixels, and the model underwent 200 epochs to ensure full convergence, with other hyperparameters following default settings from the original literature [
60]. Using the trained CUT model, we performed cross-modal translation on visible images from the D-Fire and Fire-datasets, generating a corresponding infrared simulation dataset with high semantic consistency.
- (3)
Fire-dataset
The Fire-dataset [
61] is a simulated dataset developed for fire detection and emergency response systems research. It encompasses five primary fire scenario categories—forest, urban, industrial, indoor, and urban-rural interface—under diverse environmental conditions, including variations in lighting, weather, and terrain. While the dataset exclusively provides visible light images with annotated flame objects, this work synthesizes infrared modality data using the Corsican Fire bimodal dataset.
- (4)
LLVIP dataset
Due to the scarcity of multimodal datasets for forest fire scenes, in order to comprehensively assess the model’s detection performance, this paper further conducted experiments on the publicly available pedestrian detection dataset LLVIP. The LLVIP dataset [
62] is a benchmark resource tailored for multimodal vision tasks in low-light conditions, primarily utilized for developing pedestrian detection methods through infrared and visible light fusion.
4.2. Experimental Details
All experiments are performed on a system running Ubuntu 22.04, utilizing an NVIDIA GTX 3090 GPU for training and testing. Unless otherwise stated, the training configuration included 120 iterations, a batch size of 12, and an initial learning rate of 0.01, optimized with Stochastic Gradient Descent (SGD). The hyperparameters for the YOLOv5s baseline network strictly adhered to the official configurations. To ensure comparability with prior research, evaluation metrics consistent with those employed in existing studies are adopted.
4.3. Comparative Experiment
4.3.1. Comparison on the D-Fire Dataset
We conducted experiments on the D-Fire simulation dataset and compared the proposed MCDet method with advanced approaches both quantitatively and qualitatively.
Table 1 summarizes the performance comparison of various models on the dataset. As shown in
Table 1, MCDet achieves 2.2% higher precision than YOLOv10s and a 14.7% improvement in mAP@0.5:0.95 over ICAFusion. This performance advantage stems from MCDet’s content-guided attention network, which generates spatial importance maps that selectively modulate the feature pyramid to enhance target regions while suppressing background noise. Faster R-CNN’s anchor-based selection mechanism demonstrates limitations in handling small fire targets and occlusions, constrained by predefined anchor ratios and pooling-layer quantization errors. MCDet addresses these limitations with a 6.8% precision advantage. While YOLOv11s employs dynamic anchor matching to address class imbalance between flame and smoke categories, achieving strong performance in single-modality detection, its reliance on unimodal data limits feature representation in complex scenarios, resulting in inferior performance compared to MCDet. Among multimodal approaches, ICAFusion’s iterative cross-attention mechanism introduces feature redundancy during multimodal interaction, explaining MCDet’s superior performance with a 13.6% higher mAP@0.5. For other comparison algorithms, we use their default parameter settings and select the best results from multiple experiments. The results of MCDet are averaged over 10 experiments, with standard deviation values for precision, recall, mAP@0.5, and mAP@0.5:0.95 being 5.57 × 10
−4, 5.22 × 10
−4, 6.68 × 10
−5, and 2.90 × 10
−4, respectively.
Figure 4 illustrates a comparison of detection outcomes on the D-Fire simulation dataset. In the first and second columns, smoke and tree interference result in missed flame detections by the YOLOv5s model. The third column demonstrates that feature similarities between clouds and smoke lead to the failure of YOLOv5s in detecting smoke. In contrast, the MCDet method successfully identifies both flames and smoke undetected by YOLOv5s under complex interference conditions, showcasing its robustness.
4.3.2. Comparison on the Corsican Fire Dataset
The Corsican Fire dataset comprises two target classes: smoke and flames. Primarily composed of low-light scenarios, the dataset features black smoke that is prone to blending with background elements due to low contrast.
Table 2 summarizes the benchmarking results of various models on this dataset. The low-contrast nature of black smoke in dim environments renders its edge features indistinct, while the high brightness of flame regions causes attention shifts during feature extraction, reducing model sensitivity to smoke targets. Consequently, smoke detection recall decreases significantly, resulting in a combined recall rate of just 51.8% for both fire and smoke. Furthermore, the dataset lacks occlusion cases, and flames’ relatively larger size enhances their distinguishability from low-light backgrounds. Notably, the MCDet model demonstrates superior precision in flame detection, achieving 84.4% precision for both fire and smoke, outperforming other models substantially. The MDCNet results of standard deviation values for precision, recall, mAP@0.5, and mAP@0.5:0.95 being 6.57 × 10
−4, 6.99 × 10
−4, 4.25 × 10
−2, and 6.74 × 10
−4, respectively.
Figure 5 depicts a comparative analysis of detection performance on the Corsican Fire dataset. YOLOv5s exhibits notable limitations in detecting low-contrast targets. In the first column, the color characteristics of the black smoke closely resemble the background, causing the feature extraction network to struggle with distinguishing smoke features, resulting in missed detections. Examination of the second and third columns reveals that while YOLOv5s can partially identify low-contrast targets, its predicted bounding boxes display significant positional offsets. However, after integrating the content-guided attention network, MCDet effectively enhances edge and contour features of low-contrast smoke targets, thereby significantly improving both detection accuracy and localization precision under low-contrast conditions.
4.3.3. Comparison on the Fire-Dataset
Table 3 summarizes the performance of various models on the Fire-dataset. The MCDet framework, employing a content-guided attention network, effectively reduces smoke occlusion interference and achieves superior scores across multiple evaluation metrics compared to baseline models. YOLOv11s demonstrates a notable advantage in recall performance due to its optimized target anchor matching strategy; however, its robustness is compromised in fire scenarios with substantial smoke interference, resulting in lower mAP@0.5 and mAP@0.5:0.95 scores compared to MCDet. While the METAFusion model integrates a meta-learning-assisted fusion strategy to address modality discrepancies, it encounters delayed feature responses under significant flame scale variations. MCDet surpasses METAFusion by a margin of 10.6% in the mAP@0.5:0.95 metric. The MDCNet results of standard deviation values for precision, recall, mAP@0.5, and mAP@0.5:0.95 are 4.37 × 10
−4, 5.51 × 10
−4, 4.40 × 10
−3, and 6.58 × 10
−4, respectively.
Figure 6 displays a comparison of detection results on the Fire simulation dataset. In the first column, YOLOv5s exhibits evident missed-detection instances. The second and third columns demonstrate that while YOLOv5s successfully identifies the core flame region, the predicted bounding box centers are significantly offset, and the edge coverage exhibits substantial discrepancies compared to the ground truth. This limitation is primarily attributed to YOLOv5s’ inability to effectively integrate shallow texture details with deep semantic information in its prediction head, resulting in reduced accuracy when localizing flame boundaries. By implementing a content-guided attention network, flame-edge localization capabilities are markedly improved, thereby enhancing the model’s overall detection performance.
4.3.4. Comparison on the LLVIP Dataset
Table 4 compares the detection performance of representative models on the LLVIP dataset. MCDet demonstrates superior performance under the AP@0.5:0.95 metric. The integration of an attention mechanism enables MCDet to enhance target localization accuracy in complex scenarios, particularly in addressing common challenges of infrared imagery, such as low contrast and occlusion. While MCDet is marginally outperformed by Fusion-Mamba on the AP@0.5 metric, it maintains superior performance in more stringent comprehensive evaluations, suggesting enhanced robustness and multi-scale adaptability. The MDCNet results of standard deviation values for mAP@0.5, and mAP@0.5:0.95 being 3.14 × 10
−2, and 6.87 × 10
−4, respectively.
4.3.5. Ablation Experiments
In this section, we first conduct ablation studies on individual components of MCDNet. Then we investigate the impact of the dual branches in MRCF. Finally, critical parameters of the loss function are examined.
4.3.6. Ablation on MCDet
Table 5 illustrates the impact of the content-guided attention network (CGAN) and loss function selection on model performance. The introduction of CGAN enhances texture feature extraction at smoke spreading edges, yielding a 0.9% improvement in smoke detection performance (mAP@0.5:0.95). Analysis of loss functions reveals that incorporating the Efficient Intersection over Union (EIoU) loss introduces an aspect ratio constraint, mitigating flame bounding box deformation and improving flame mAP@0.5:0.95 by 1%. In contrast, the static angle penalty of the Structured Intersection over Union (SIoU) loss increases smoke precision by 1.7% but reduces flame mAP@0.5:0.95 by 0.8%, as its rigid shape constraints conflict with the irregular morphology of flames. Notably, the Wise Intersection over Union (WIoU) loss employs a dynamic weighting strategy that prioritizes low-brightness flame samples, enhancing flame precision by 0.6% and smoke mAP@0.5:0.95 by 2.5%. These performance variations arise from intrinsic differences between smoke and flame characteristics. Smoke detection relies on spatial continuity features and regular geometric spreading patterns, which MCDet’s spatial attention module optimizes by enforcing boundary aspect ratio consistency via EIoU. Conversely, flames exhibit irregular edges, high brightness gradients, and localized highlights. WIoU’s dynamic focus adaptively strengthens gradient responses in high-brightness flame regions, while MCDet’s channel-spatial fusion enhances saliency detection in bright areas. Critically, SIoU’s angle penalty underperforms WIoU in recall, mAP@0.5, and mAP@0.5:0.95 metrics due to its over-constraint on the stochastic shapes of both smoke and flames.
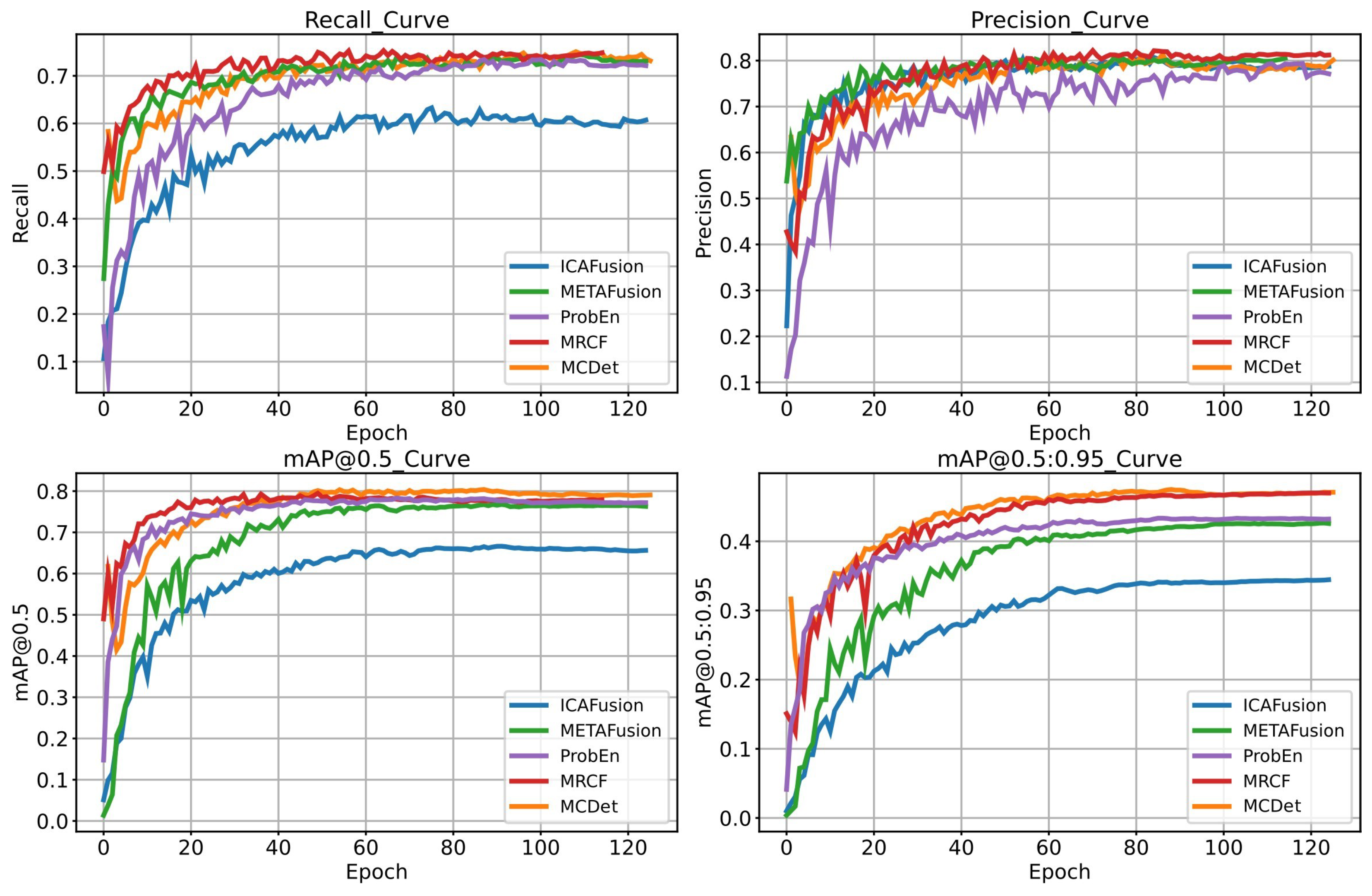
Figure 7 illustrates the variation curves of precision, recall, mAP@0.5, and mAP@0.5:0.95 for MRCF and MCDet models during training.
Table 6 details the efficiency of our method under various configurations. The basic bimodal detection approach using feature-level direct addition (Addition) exhibits the smallest parameter count of 14M and an inference speed of 7.6 ms. However, the introduction of the MRCF incurs the most significant inference latency, with the time surging to 20.8 ms. This is primarily attributed to the substantial increase in GFLOPs caused by its complex cross-modal feature interaction operations. Subsequently, adding the CGAN module only slightly increased the inference time to 22.2 ms. Following the introduction of the WIOU loss function, the online inference overhead remains manageable. The MRCF module is crucial for achieving the performance leap but also constitutes the primary computational bottleneck; in contrast, CGAN and WIOU further enhance model accuracy or robustness with acceptable efficiency costs or zero overhead.
4.3.7. Ablation on MRCF
Table 7 demonstrates the performance impact of the MRCF module. To eliminate confounding effects from multimodal inputs, a bimodal YOLOv5s baseline was employed for ablation studies. In the modality fusion stage, a naive element-wise addition approach (denoted as “addition”) was initially tested. As shown in the table, this method produced suboptimal results, as the inherent disparities between visible and infrared features caused additive noise amplification and redundant feature propagation, thereby degrading model performance. Subsequent implementation of the TSFF framework with deformable convolutions improved irregular flame shape representation, yielding measurable gains: +1.9% recall, +2.8% mAP@0.5, and +5.8% mAP@0.5:0.95, particularly for smoke detection. The BVSSM module further enhanced performance through long-range cross-modality dependency modeling, achieving comparable results to TSFF while demonstrating superior global context integration but limited local feature capture. Ultimately, the MRCF module delivered the most substantial improvements—4.1% precision, 4.6% mAP@0.5, and 9% mAP@0.5:0.95 gains—confirming its robustness in complex forest environments through adaptive feature fusion and enhanced generalization capacity.
Visible light modalities have advantages in characterizing the texture details of flames and smoke, while infrared modalities are sensitive to thermal radiation, capable of penetrating environmental obstructions to capture the thermal characteristics of obscured fire sources. Different fusion strategies create variations in cross-modal joint feature representations. To verify the capability of existing fusion strategies in constructing cross-modal joint representations and to visually demonstrate the impact of different fusion mechanisms on multimodal information interaction, this section compares the results of different fusion methods (
Figure 8).
The additive fusion retains the most in other noisy non-fire backgrounds. The TSFF method utilizes deformable convolution to deeply integrate local features, resulting in enhanced brightness and sharpened edges in the flame center of the fusion image, with some background effectively suppressed to a dark tone. The BVSSM method excels in processing global information, effectively presenting the details of large target areas. The images generated by the TSFF method appear brighter in small target flame areas and have clearer flame edges, while the fusion images produced by the BVSSM method are brighter and clearer in large flame areas. The MRCF fusion method combines advantages: it retains BVSSM’s ability to handle global information while enhancing local flame details through TSFF. The image background is mostly dark-toned, with very low redundant noise interference, significantly highlighting the flame area. Therefore, the MRCF module can effectively leverage multimodal complementary information, improving the detection performance of fire targets in complex forest environments.
4.3.8. Ablation on Loss Function
Table 8 presents the ablation study for the dynamic factor
, with a fixed anomaly-degree benchmark
. This experiment investigates how adjusting
influences the decay rate of gradient gain and its subsequent impact on detection performance. Results indicate that the model achieves optimal performance at
, where the gradient gain decay optimally balances the learning weights of high- and low-quality samples. When
exceeds 1.4, the accelerated decay rate excessively suppresses gradient contributions from certain samples, significantly degrading detection performance for smoke and flames. For instance, at
, precision decreases by 2.9% and mAP@0.5:0.95 declines by 4.4%.
In the ablation study of the anomaly-degree benchmark
(with
fixed),
Table 9 demonstrates that
yields the best overall detection performance, achieving optimal results across all four evaluation metrics. As a dynamic threshold for anchor box anomaly degree,
governs the model’s attention to samples of varying quality by modulating the gradient gain allocation strategy. At
, gradient gain peaks, directing the model’s focus to medium-quality anchor boxes and significantly enhancing detection accuracy for translucent smoke regions. Deviations from
reduce performance: at
, premature decay of gradient gain lowers precision by 1.8%, while at
, the excessively high threshold causes neglect of medium-quality samples, further diminishing performance.
4.4. Discussion
This paper proposes the MCDet framework to address core challenges in multimodal forest fire detection, including feature confusion between infrared radiation and visible light highlights, missed detections due to vegetation occlusion, and increased false alarm rates. The global–local cross-modal interaction mechanism established by the MRCF module significantly mitigates visual confusion between flame infrared radiation and visible light highlights. The dynamic gating weight generation capability of the CGAN successfully overcomes feature dispersion defects caused by vegetation occlusion and terrain interference. Meanwhile, the WIoU loss function optimizes localization accuracy in scenarios with blurred smoke boundaries and flame occlusion. Comprehensive superiority across four benchmark tests validates the framework’s robustness: achieving a 9% improvement in mAP@0.5:0.95 on the D-Fire dataset, increasing smoke detection precision by 4.1% in low-contrast Corsican scenarios, reducing localization error by 2.5% in flame occlusion tests on the Fire-dataset, and notably demonstrating cross-scene generalization with 69.8% AP@0.5:0.95 on the LLVIP dataset.
Despite excellent performance in controlled forest areas, the model faces inherent limitations when transferred to wildfire and urban fire scenarios: extreme thermal convection and flying ember dispersion in wildfires may impair MRCF’s thermal feature extraction capability, such as turbulence interference from rapidly spreading firelines. In urban environments, thermal reflections from glass curtain walls and high-temperature interference sources like vehicle engines exhibit feature distribution differences compared to forest highlights, leading to increase in false alarms for CGAN’s attention mechanism during industrial fire tests. Future work will focus on two breakthroughs: developing dynamic feature decoupling modules to enhance generalization for wildfire embers and urban thermal interference sources, and integrating fire spread physical models to construct cross-scene prediction mechanisms. This will advance the detection framework’s paradigm shift from confined forest areas to open disaster scenarios.
5. Conclusions
To address the challenges of cross-modal feature confusion and occlusion in multimodal fire detection, this paper proposes a multimodal fusion framework based on multidimensional representation synergy, named MCDet. First, the Multidimensional Representation Collaborative Fusion Module (MRCF), which employs state-space modeling and deformable convolution to facilitate global–local cross-modal feature interactions, thereby enhancing complementary feature extraction. Then, the content-guided attention network (CGAN), designed to adaptively aggregate multidimensional features via dynamic gating mechanisms, suppressing background interference while enhancing discriminative representations of fire events. Finally, a WIoU loss function that improves localization of challenging samples by dynamically adjusting gradient weights, thereby mitigating misdirection from high-frequency noise. Experimental results demonstrate that our framework significantly enhances detection accuracy and robustness, enabling precise distinction between flames, smoke, and background interference in complex forest environments. Notably, the framework is compatible with both single-stage and two-stage detectors while maintaining lightweight inference capabilities. Building on this multidimensional representation synergy strategy, future work will explore its potential applications in multimodal disaster monitoring systems.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}