
A Study on Airborne Hyperspectral Tree Species Classification Based on the Synergistic Integration of Machine Learning and Deep Learning

Abstract
1. Introduction
2. Overview of the Study Area and Data Acquisition
2.1. Overview of the Study Area
2.2. UAV-Based Hyperspectral Data Acquisition
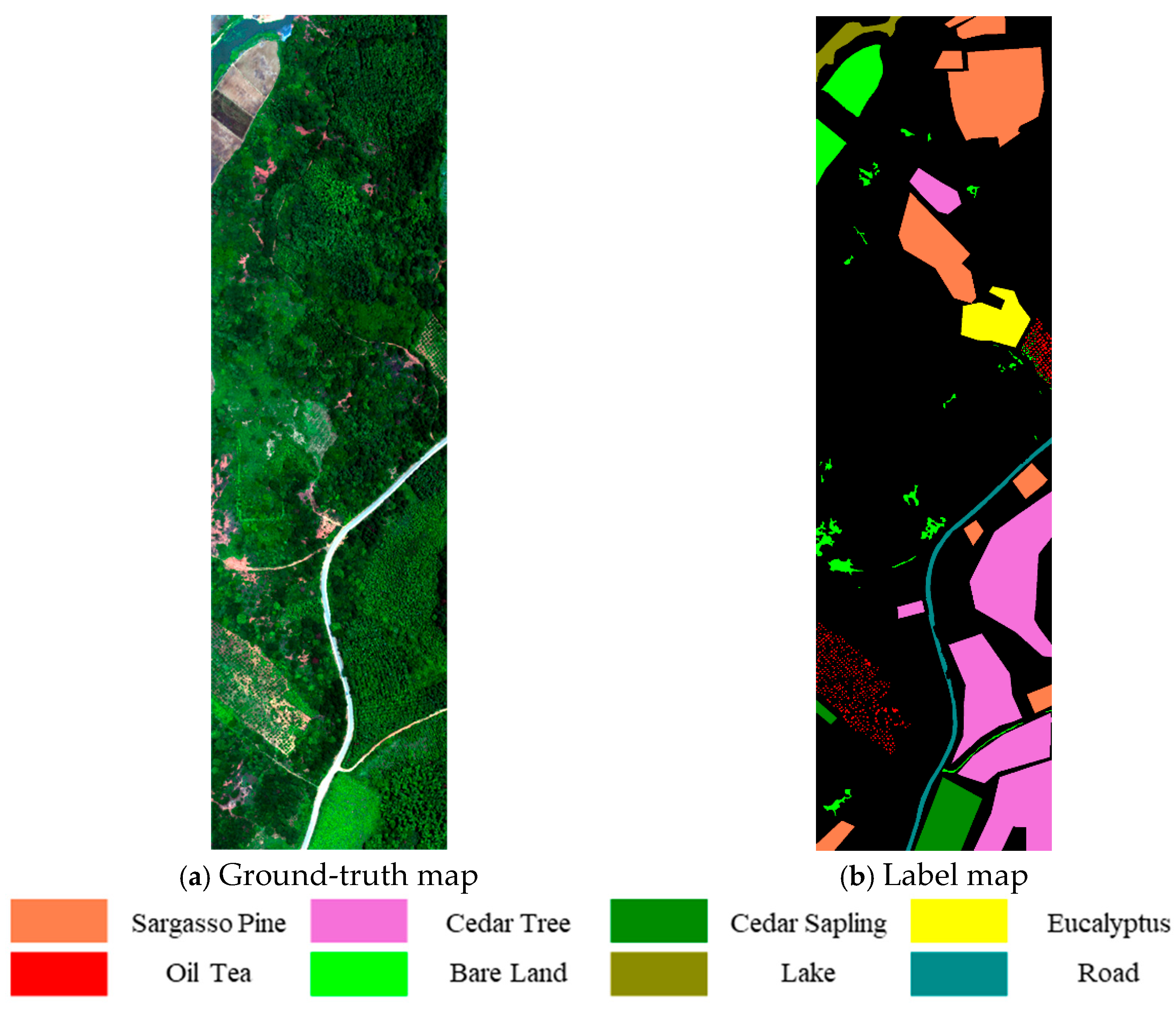
2.3. Ground Survey Data Collection
3. Research Methods
- (1)
- Dataset Preparation:
- (2)
- Construction of the Baseline 2D CNN Network:
- (3)
- Baseline Model Optimization:
- (4)
- Development of the 2D CNN-SVM Classification Model:
- (5)
- Accuracy Evaluation:
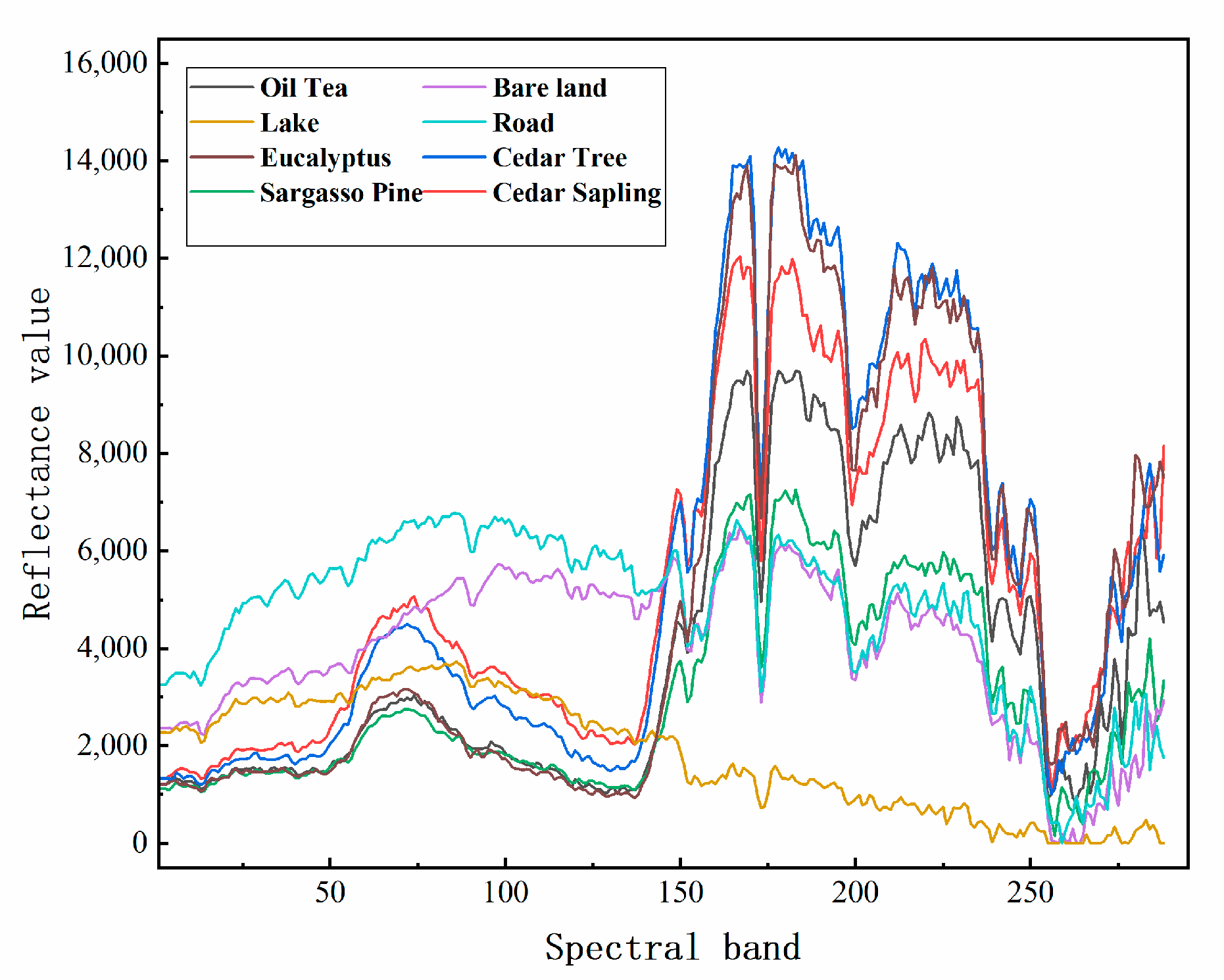
3.1. Dataset Preparation
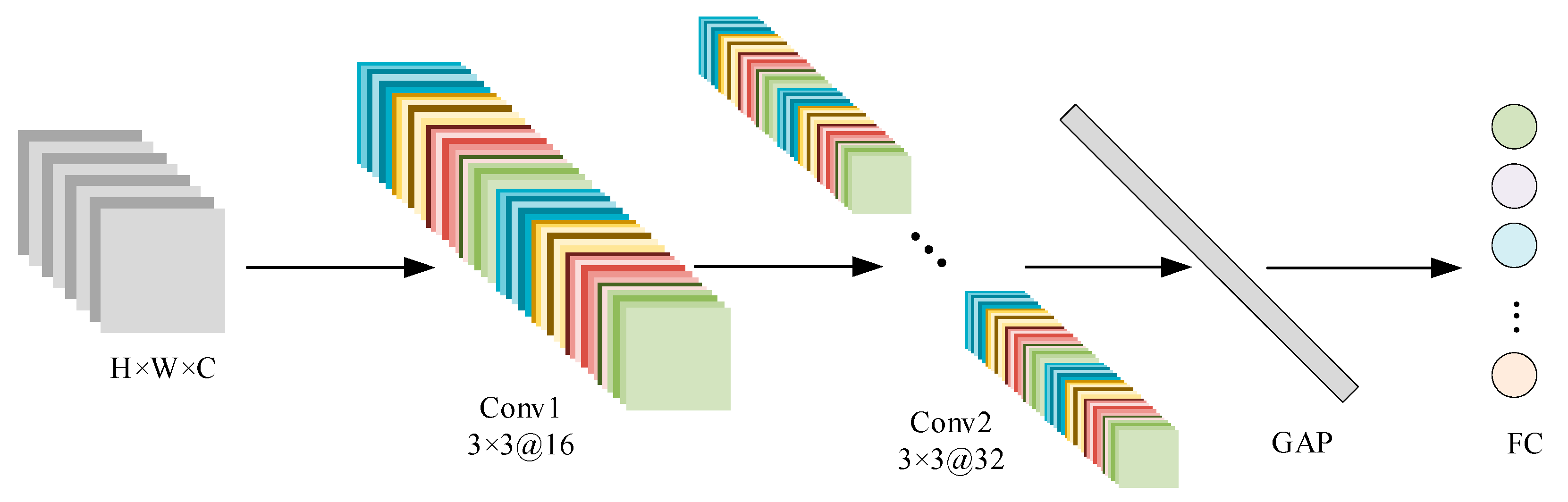
3.2. 2D Convolutional Neural Network (2DCNN) Classification Model
- (1)
- Convolutional Module:
- (2)
- Pooling and Flattening Layer:
- (3)
- Fully Connected Layer:
3.3. Optimization of the 2DCNN Model
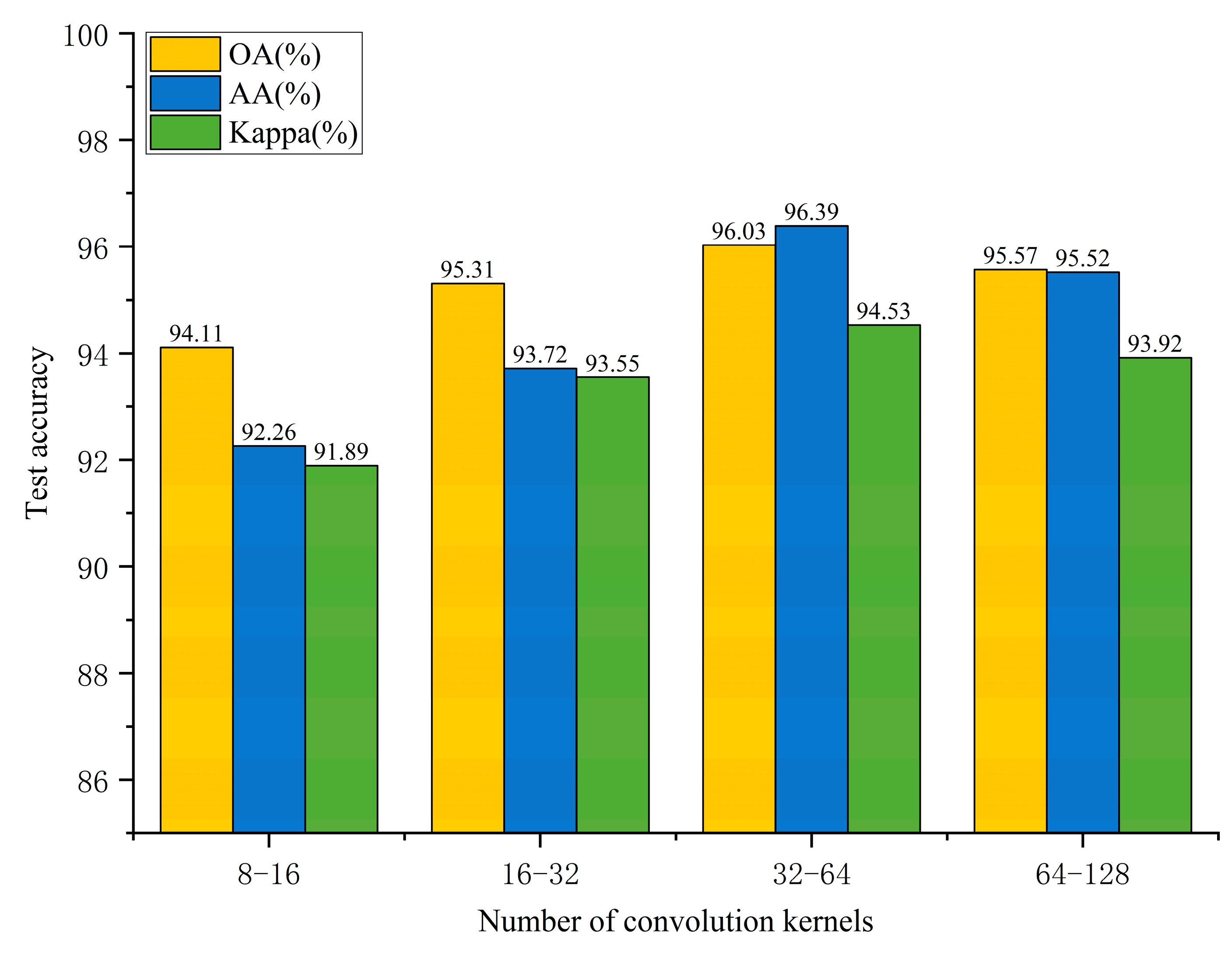
3.3.1. Optimization of the Number of Convolutional Kernels
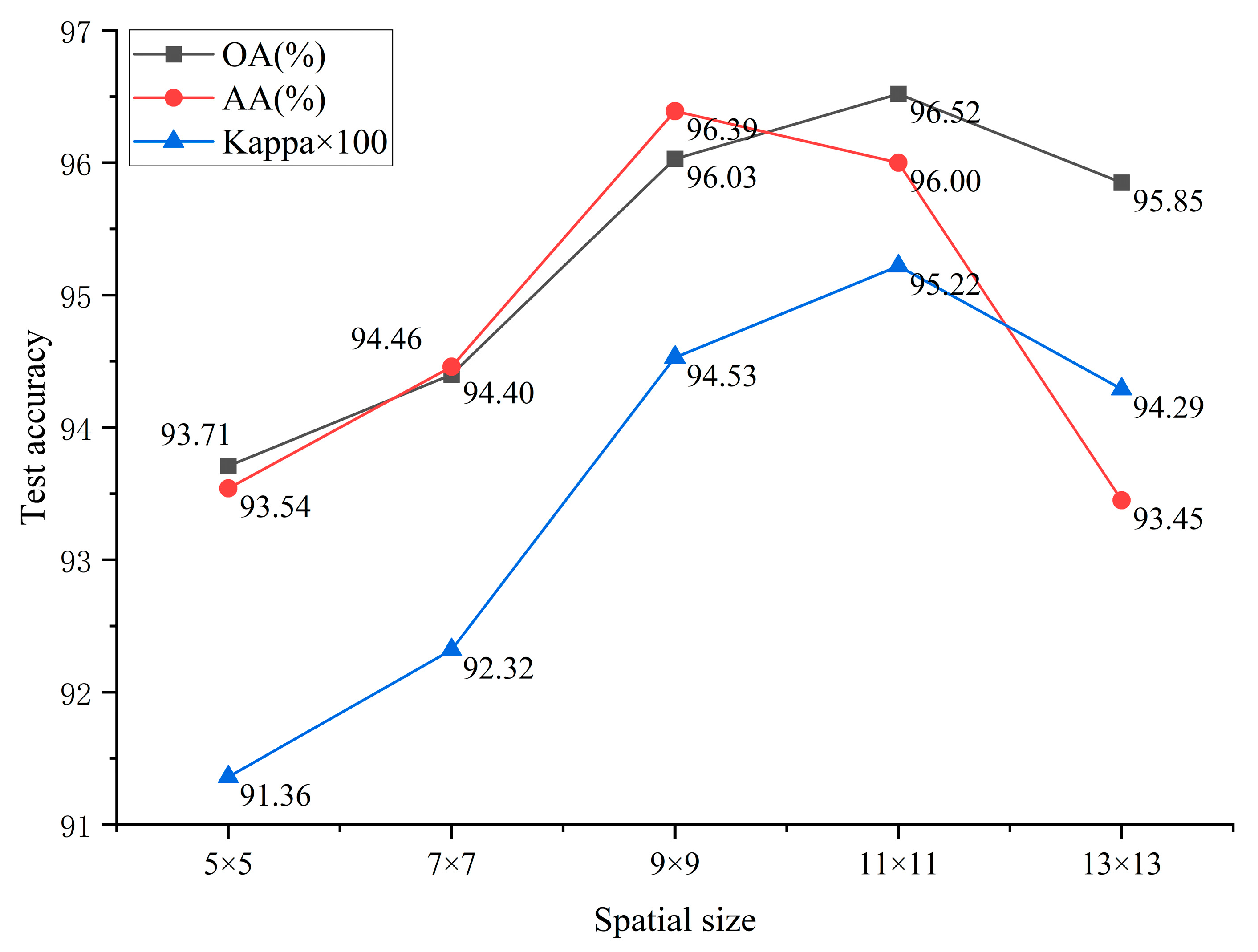
3.3.2. Optimization of Spatial Size
3.3.3. Learning Rate Optimization
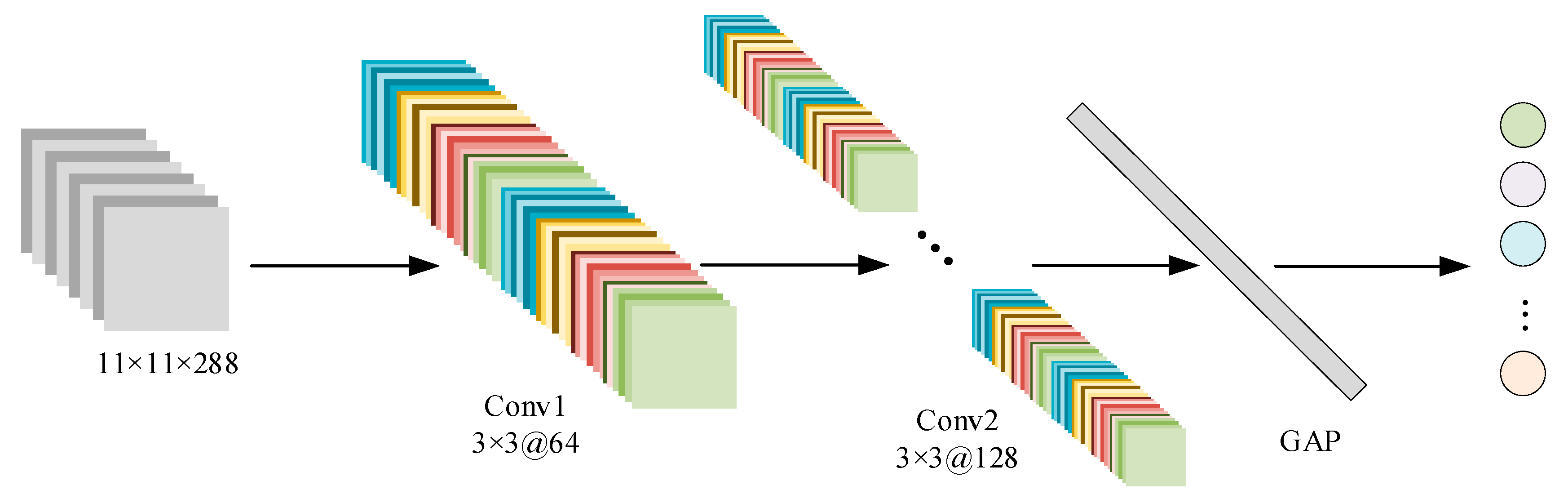
3.4. Construction of the 2DCNN-SVM Classification Model
3.4.1. Parameter Settings
3.4.2. Selection of the Optimal Classifier Combining Machine Learning and Deep Learning
3.4.3. Construction of the 2DCNN-SVM Classification Model
3.5. Evaluation Metrics
3.6. Environmental Settings
4. Classification Results and Analysis
4.1. Classification Results of the 2DCNN Model
4.2. Comparative Analysis Between the 2DCNN-SVM Model and Mainstream Classification Models
4.2.1. Comparative Experiment Analysis
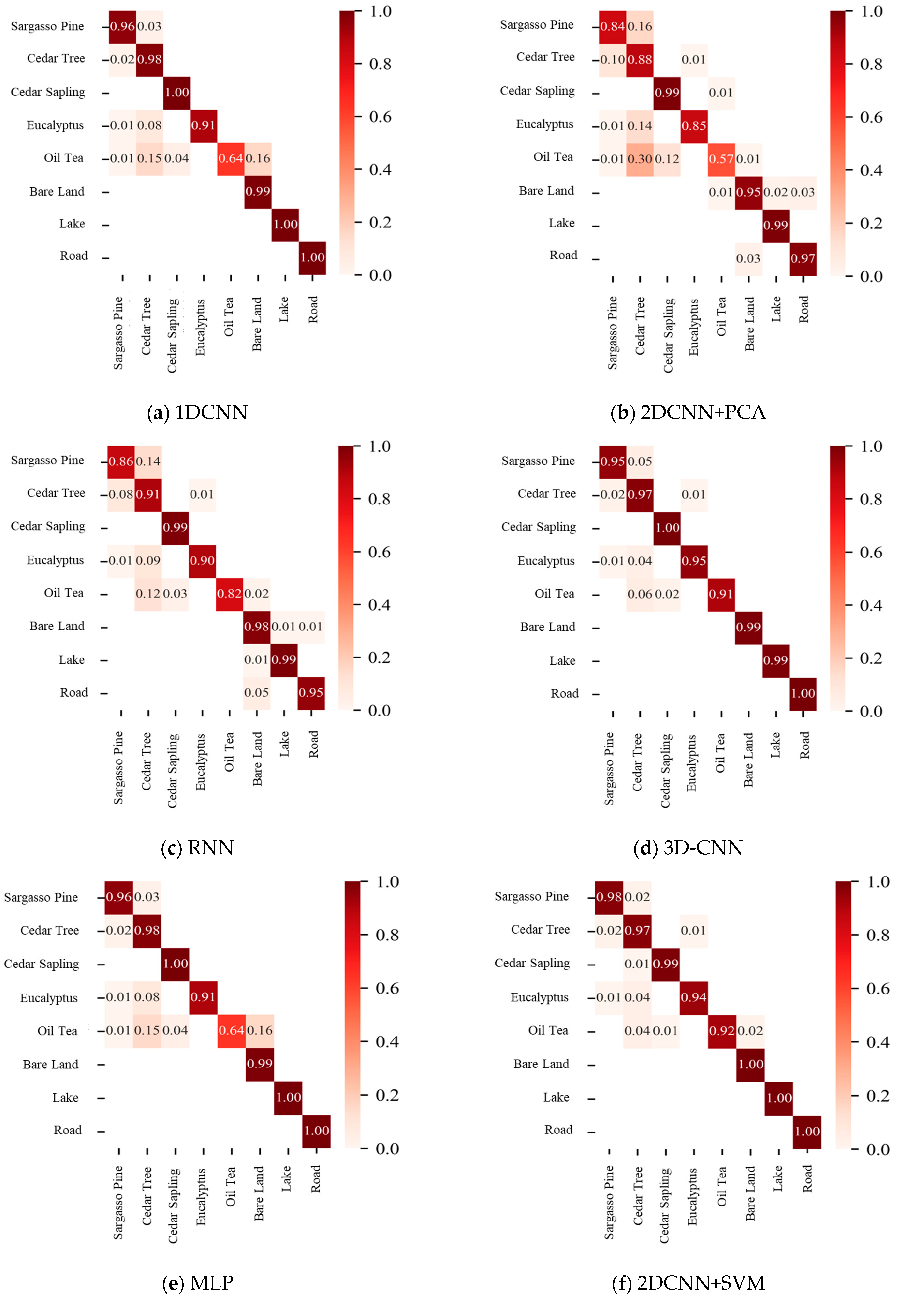
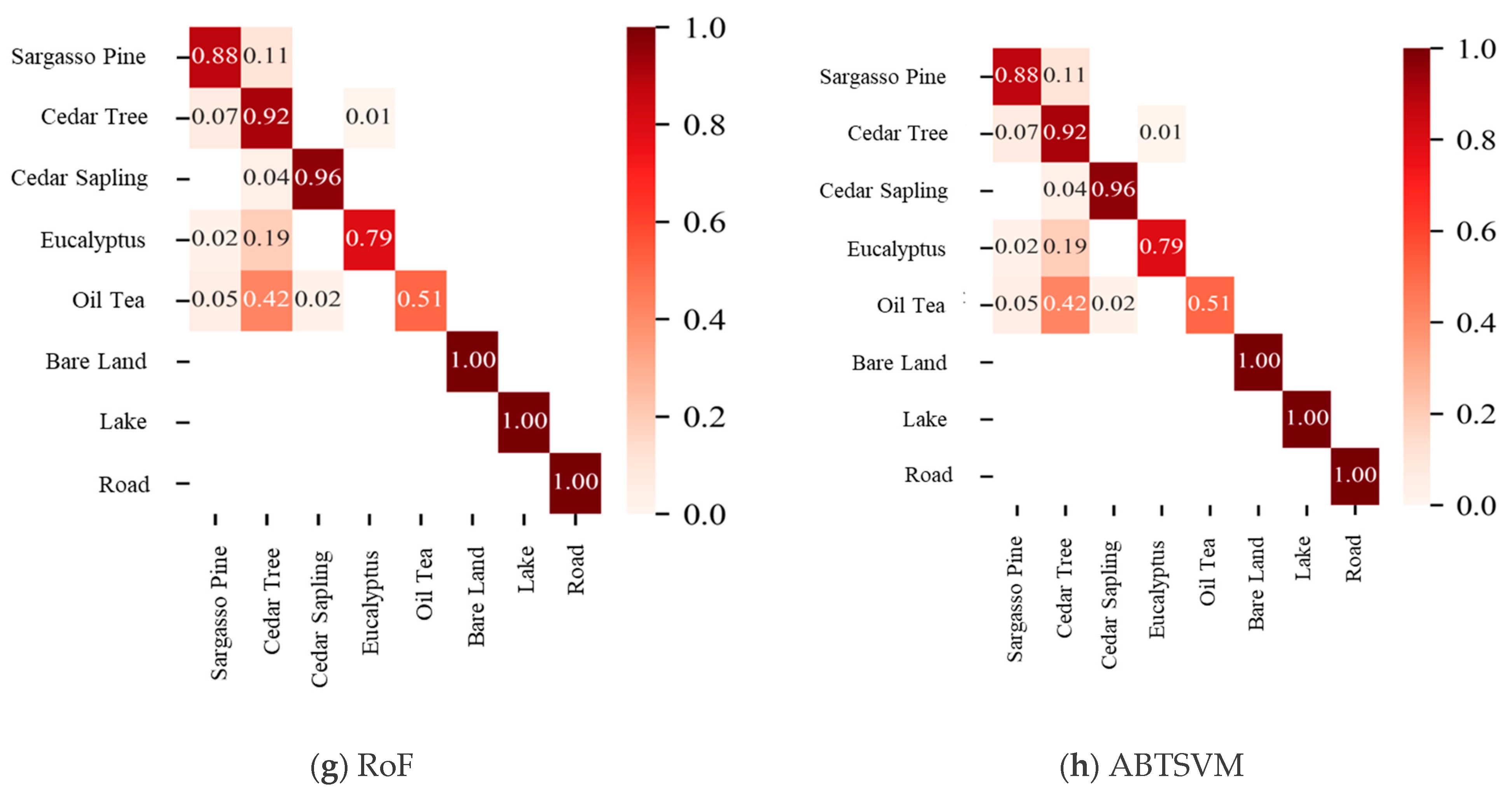
4.2.2. Visualization Analysis of Classification Results from Different Models
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kampouri, M.; Kolokoussis, P.; Argialas, D.; Karathanassi, V. Mapping of Forest Tree Distribution and Estimation of Forest Biodiversity using Sentinel-2 Imagery in the University Research Forest Taxiarchis in Chalkidiki, Greece. Geocarto Int. 2018, 34, 1273–1285. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Fassnacht, F.E.; Latifi, H.; Stereńczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- Markov, N.G.; Machuca, C.R. Deep learning models and methods for solving the problems of remote monitoring of forest resources. Bull. Tomsk. Polytech. Univ. Geo Assets Eng. 2024, 35. [Google Scholar]
- Sothe, C.; De, A.C.M.; Schimalski, M.B.; La, R.L.E.C.; Castro, J.D.B.; Feitosa, R.Q.; Dalponte, M.; Lima, C.L.; Liesenberg, V.; Miyoshi, G.T.; et al. Comparative performance of convolutional neural network, weighted and conventional support vector machine and random forest for classifying tree species using hyperspectral and photogrammetric data. GISci. Remote Sens. 2020, 57, 369–394. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, Z.; Chen, Z. AMS: A hyperspectral image classification method based on SVM and multi-modal attention network. Knowl.-Based Syst. 2025, 314, 113236. [Google Scholar] [CrossRef]
- Wang, H.; Li, G.; Wang, Z. Fast SVM classifier for large-scale classification problems. Inf. Sci. 2023, 642, 119136. [Google Scholar] [CrossRef]
- Pan, S.; Guan, H.; Yu, Y.; Li, J.; Peng, D. A Comparative Land-Cover Classification Feature Study of Learning Algorithms: DBM, PCA, and RF Using Multispectral LiDAR Data. IEEE J.-Stars 2019, 12, 1314–1326. [Google Scholar] [CrossRef]
- Bhavatarini, N.; Akash, B.N.; Akshay, H.M. Object Detection and Classification of Hyperspectral Images Using K-NN. In Proceedings of the 2023 Second International Conference on Electrical, Electronics, Information and Communication Technologies, Trichirappalli, India, 5–7 April 2023; pp. 1–7. [Google Scholar]
- Pal, M.; Charan, T.B.; Poriya, A. K-nearest neighbour-based feature selection using hyperspectral data. Remote Sens. Lett. 2021, 12, 132–141. [Google Scholar] [CrossRef]
- Yang, H.; Wang, J.; Su, B. Fast processing method of high resolution remote sensing image based on decision tree classification. Aerosp. Electron. 2020, 1, 1–11. [Google Scholar]
- Abidi, S.; Sellami, A. Attention-driven multi-feature fusion for hyperspectral image classification via multi-criteria optimization and multi-view convolutional neural networks. Eng. Appl. Artif. Intel. 2024, 138, 109434. [Google Scholar] [CrossRef]
- Liu, J.M.; Zheng, C.; Zhang, L.M.; Zou, Z.H. Hyperspectral Image Classification Based on Image Reconstruction and Feature Fusion. Laser Infrared 2021, 48, 203–212. [Google Scholar]
- Li, D.; Huang, Y.H.; Sun, Z.Y.; Zhang, W.Q.; Gan, X.H.; Wang, Z.L.; Sun, H.B.; Yang, L. Hyperspectral Classification of Tree Species in Bagang Wetland Park, Shenzhen, Based on Machine Learning. Infrared 2019, 40, 47–52. [Google Scholar]
- Soleimannejad, L.; Ullah, S.; Abedi, R.; Dees, M.; Koch, B. Evaluating the potential of sentinel-2, landsat-8, and irs satellite images in tree species classification of Hyrcanian Forest of Iran using random forest. J. Sustain. For. 2019, 38, 615–628. [Google Scholar] [CrossRef]
- Tariq, A.; Yan, J.; Gagnon, A.S.; Riaz Khan, M.; Mumtaz, F. Mapping of cropland, cropping patterns and crop types by combining optical remote sensing images with decision tree classifier and random forest. Geo-Spat. Inf. Sci. 2023, 26, 302–320. [Google Scholar] [CrossRef]
- Zhao, P.; Tang, Y.H.; Li, Z.Y. Tree Species Classification of Hyperspectral Microscopic Imaging Wood Based on Support Vector Machine with Composite Kernel Function. Spectrosc. Spectr. Anal. 2019, 39, 3776–3782. [Google Scholar]
- Zhu, M.Y.; Hou, J.W.; Sun, S.Q.; Wang, Y.J. Domestic Research Progress on Remote Sensing Image Recognition Based on Deep Learning. Geomat. Spat. Inf. Technol. 2021, 44, 67–73. [Google Scholar]
- Zheng, P.; Fang, P.; Liu, P.; Dai, Q.; Li, J. Classifying Dominant Tree Species Over a Large Mountainous Area Based On Multitemporal Sentinel-2 Data. In Proceedings of the 2021 IEEE 23rd Int Conf on High Performance Computing & Communications; 7th Int Conf on Data Science & Systems; 19th Int Conf on Smart City; 7th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/Smart City/DependSys), Haikou, China, 20–22 December 2021; pp. 1755–1760. [Google Scholar]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Cao, J.; Liu, K.; Zhuo, L.; Liu, L.; Zhu, Y.; Peng, L. Combining UAV-based hyperspectral and LiDAR data for mangrove species classification using the rotation forest algorithm. Int. J. Appl. Earth Obs. 2021, 102, 102414. [Google Scholar] [CrossRef]
- Du, P.; Tan, K.; Xing, X. A novel binary tree support vector machine for hyperspectral remote sensing image classification. Opt. Commun. 2012, 285, 3054–3060. [Google Scholar] [CrossRef]

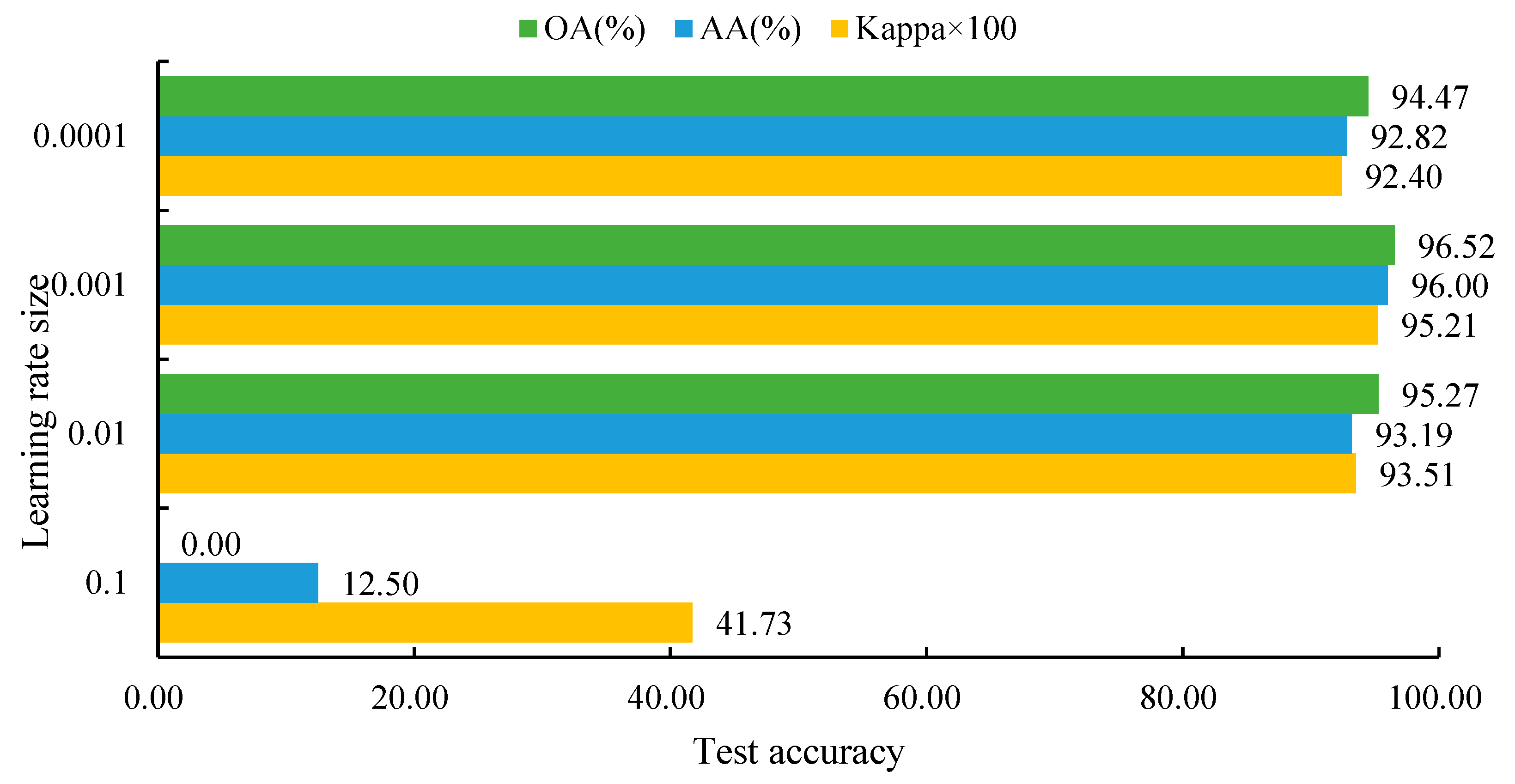


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title 1 | Parameter Name | Parameter |
|---|---|---|
| Spectral Parameters | Spectral Range | 400–1000 nm (visible to near-infrared) |
| Number of Spectral Channels | 288 spectral channels | |
| Spectral Resolution | <5 nm (FWHM) | |
| Spatial Parameters | Number of Spatial Pixels | 1920 spatial pixels (1840 effective pixels) |
| Imaging Parameters | Field of View Angle | Total field of view: 36.6°; instantaneous field of view: 0.36 mad |
| Data Storage and Processing | Data Recording Capability | 480 GB memory, capable of recording approximately 3 h of data (calculated at 40 fps) |
| Other Functions | GPS/IMU Integration | Optional GPS/IMU supports integration with other sensors (e.g., LiDAR) |
| Train | Test | Total | |
|---|---|---|---|
| Sargasso Pine | 1271 | 127,400 | 128,671 |
| Cedar Tree | 1952 | 190,092 | 192,044 |
| Cedar Sapling | 303 | 28,638 | 28,941 |
| Eucalyptus | 224 | 23,336 | 23,560 |
| Oil Tea | 101 | 10,288 | 10,389 |
| Bare Land | 453 | 47,238 | 47,691 |
| Lake | 114 | 10,656 | 10,770 |
| Road | 183 | 17,887 | 18,070 |
| total | 4601 | 455,535 | 460,136 |
| Method | CatBoost | DT | KNN | LifhtGMB | RF | SVM |
|---|---|---|---|---|---|---|
| Masson pine (%) | 96.88 | 94.38 | 96.83 | 97.31 | 96.82 | 97.68 |
| Fir tree (%) | 97.02 | 95.23 | 96.43 | 97.32 | 97.20 | 97.06 |
| Fir saplings (%) | 99.56 | 98.15 | 99.47 | 99.42 | 99.36 | 99.43 |
| Eucalyptus (%) | 92.81 | 89.82 | 93.40 | 93.17 | 92.69 | 94.48 |
| Oil Tea (%) | 85.90 | 83.00 | 87.73 | 87.69 | 86.90 | 92.36 |
| Bare land (%) | 99.50 | 98.81 | 99.42 | 99.57 | 99.59 | 99.60 |
| Lake (%) | 99.53 | 98.78 | 99.47 | 99.61 | 99.45 | 99.65 |
| Road (%) | 99.86 | 97.55 | 99.54 | 99.14 | 99.43 | 99.51 |
| OA(%) | 97.10 | 95.17 | 96.88 | 97.38 | 97.15 | 97.56 |
| AA(%) | 96.39 | 94.47 | 96.54 | 96.66 | 96.43 | 97.47 |
| Kappa | 0.9602 | 0.9336 | 0.9572 | 0.9640 | 0.9608 | 0.9665 |
| Network Layer | Name | Convolution Kernel | Step Length | Fill | Normalization Layer | Activation Function |
|---|---|---|---|---|---|---|
| 1 | Convolutional layer 1 | 3 × 3@64 | 2 | 1 | True | ReLu |
| 2 | Convolutional layer 2 | 3 × 3@128 | 2 | 1 | True | ReLu |
| 3 | Pooling layer | Global average pooling | ||||
| 4 | Classification layer | SVM | ||||
| Reference | Predicted | Producer’s Accuracy (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Sargasso Pine | Cedar Tree | Cedar Sapling | Eucalyptus | Oil Tea | Bare Land | Lake | Road | Total | ||
| Sargasso Pine | 120,830 | 6367 | 0 | 91 | 70 | 42 | 0 | 0 | 127,400 | 94.84 |
| Cedar Tree | 6627 | 181,133 | 234 | 1599 | 289 | 197 | 0 | 13 | 190,092 | 95.28 |
| Cedar Sapling | 2 | 215 | 28,366 | 0 | 53 | 0 | 0 | 2 | 28,638 | 99.05 |
| Eucalyptus | 395 | 1383 | 0 | 21,504 | 54 | 0 | 0 | 0 | 23,336 | 92.14 |
| Oil Tea | 157 | 1667 | 357 | 125 | 7668 | 312 | 0 | 2 | 10,288 | 74.53 |
| Bare Land | 55 | 0 | 0 | 0 | 12 | 47,171 | 0 | 0 | 47,238 | 99.86 |
| Lake | 0 | 15 | 0 | 0 | 0 | 51 | 10,590 | 0 | 10,656 | 99.38 |
| Road | 0 | 2 | 0 | 0 | 0 | 951 | 3 | 16,931 | 17,887 | 94.66 |
| Classified Total | 126,797 | 192,420 | 28,786 | 22,800 | 8854 | 47,607 | 10,526 | 17,745 | 45,553 | - |
| User’s Accuracy (%) | 94.35 | 94.94 | 97.96 | 92.22 | 94.13 | 96.81 | 99.97 | 99.9 | - | - |
| 1DCNN | 2DCNN+PCA | RNN | 3D-CNN | MLP | 2DCNN+SVM | RoF | ABTSVM | |
|---|---|---|---|---|---|---|---|---|
| Sargasso Pine | 96.33 | 84.24 | 85.82 | 94.75 | 84.05 | 97.68 | 88.33 | 92.80 |
| Cedar Tree | 97.76 | 87.87 | 90.81 | 96.77 | 86.80 | 97.06 | 91.92 | 94.14 |
| Cedar Sapling | 99.60 | 98.92 | 99.47 | 99.61 | 96.38 | 99.43 | 96.23 | 99.27 |
| Eucalyptus | 91.31 | 84.73 | 90.41 | 95.24 | 58.17 | 94.48 | 78.75 | 91.66 |
| Oil Tea | 64.15 | 56.61 | 82.34 | 91.03 | 35.42 | 92.36 | 50.57 | 92.96 |
| Bare Land | 99.44 | 94.57 | 97.78 | 99.37 | 99.71 | 99.60 | 99.53 | 99.85 |
| Lake | 99.50 | 99.43 | 99.33 | 99.18 | 99.70 | 99.65 | 99.91 | 100.00 |
| Road | 99.52 | 96.86 | 94.87 | 99.97 | 98.24 | 99.51 | 99.52 | 99.94 |
| OA (%) | 96.67 | 87.99 | 90.83 | 96.62 | 86.10 | 97.56 | 90.82 | 94.89 |
| AA (%) | 93.45 | 87.90 | 92.60 | 96.98 | 82.31 | 97.47 | 88.09 | 96.33 |
| Kappa | 0.9541 | 0.8345 | 0.8737 | 0.9536 | 0.8069 | 0.9665 | 0.8727 | 0.9297 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, D.; Song, J.; Huang, C.; Yang, F.; Han, Y.; Wang, R. A Study on Airborne Hyperspectral Tree Species Classification Based on the Synergistic Integration of Machine Learning and Deep Learning. Forests 2025, 16, 1032. https://doi.org/10.3390/f16061032
Yang D, Song J, Huang C, Yang F, Han Y, Wang R. A Study on Airborne Hyperspectral Tree Species Classification Based on the Synergistic Integration of Machine Learning and Deep Learning. Forests. 2025; 16(6):1032. https://doi.org/10.3390/f16061032
Chicago/Turabian StyleYang, Dabing, Jinxiu Song, Chaohua Huang, Fengxin Yang, Yiming Han, and Ruirui Wang. 2025. "A Study on Airborne Hyperspectral Tree Species Classification Based on the Synergistic Integration of Machine Learning and Deep Learning" Forests 16, no. 6: 1032. https://doi.org/10.3390/f16061032
APA StyleYang, D., Song, J., Huang, C., Yang, F., Han, Y., & Wang, R. (2025). A Study on Airborne Hyperspectral Tree Species Classification Based on the Synergistic Integration of Machine Learning and Deep Learning. Forests, 16(6), 1032. https://doi.org/10.3390/f16061032