As demonstrated, the proposed model significantly outperforms the baseline architecture. Specifically, it achieves a precision of 87.7%, indicating a high proportion of correct positive predictions among all detections. The recall rises to 85.32%, reflecting the model’s strong ability to detect actual fire and smoke instances. The mAP, a comprehensive measure of detection quality, improves from 79.06% in the baseline to 83.92% in the proposed model, highlighting enhanced localization and classification accuracy. Furthermore, the F1-score, which balances precision and recall, improves from 80.13% to 84.18%, confirming the overall effectiveness and reliability of the modified architecture. These results validate that our enhancements, including the integration of the EfficientNetV2 backbone, ECA attention mechanism, and advanced preprocessing techniques, contribute meaningfully to better fire and smoke detection performance in complex, real-world forest scenarios.
Table 3 expands the evaluation by comparing the proposed model against a range of state-of-the-art (SOTA) object detection architectures, specifically the YOLOv5 through YOLOv9 families.
While each successive YOLO variant demonstrates incremental improvements in detection capability, the proposed model consistently achieves the highest scores across all evaluation metrics. For instance, YOLOv9s, one of the most recent and powerful YOLO versions, records precision, recall, mAP, and F1-score values of 95.06%, 93.12%, 91.01%, and 90.11%, respectively. However, our proposed model exceeds even these advanced benchmarks, achieving a precision of 97.01%, recall of 95.14%, mAP of 93.13%, and F1-score of 92.78%. These superior results not only demonstrate the competitive edge of our approach but also confirm its effectiveness in detecting forest fire and smoke under diverse and often challenging visual conditions such as dense vegetation, haze, or partial occlusion (
Figure 4).
Comparison with SOTA Models
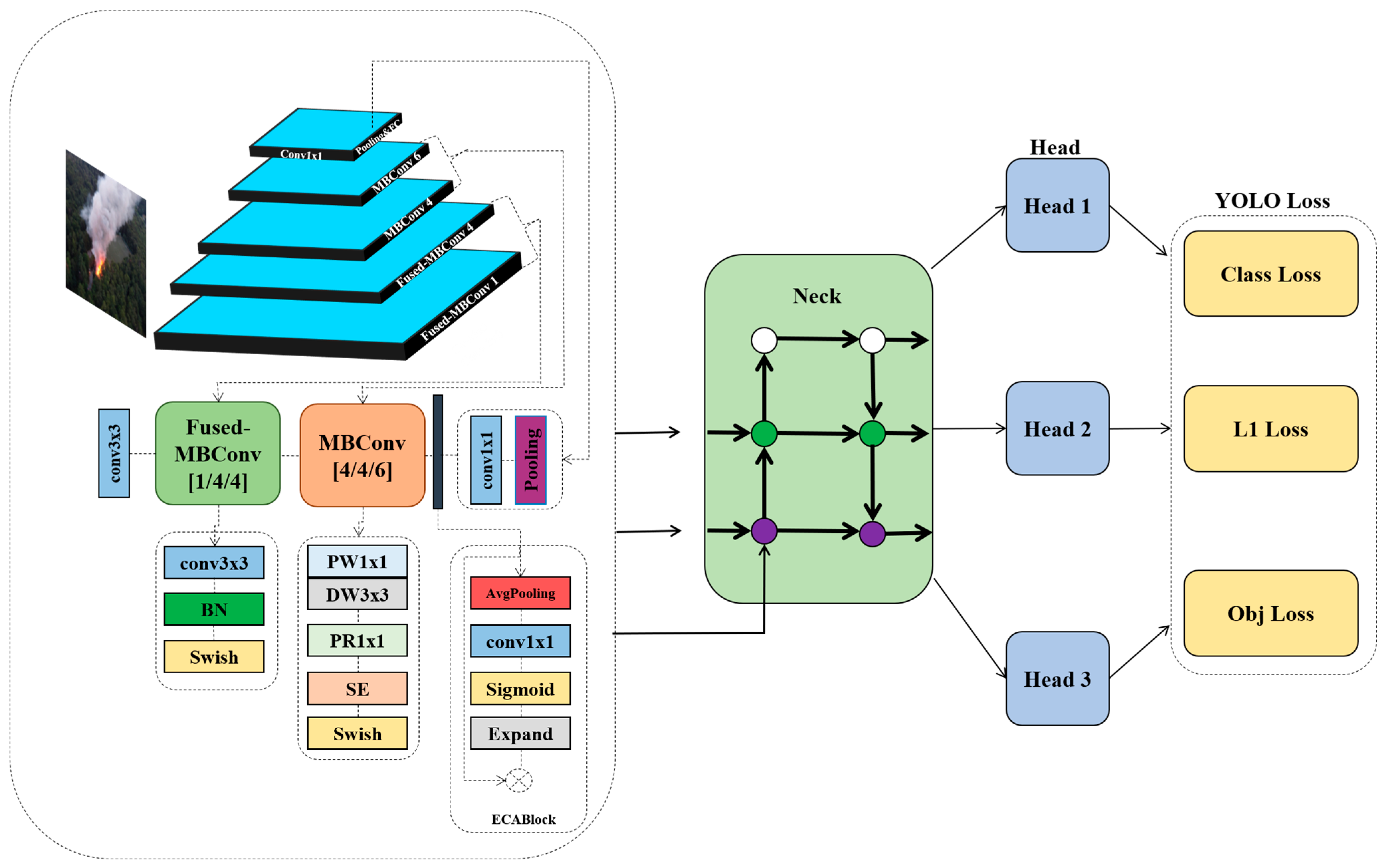
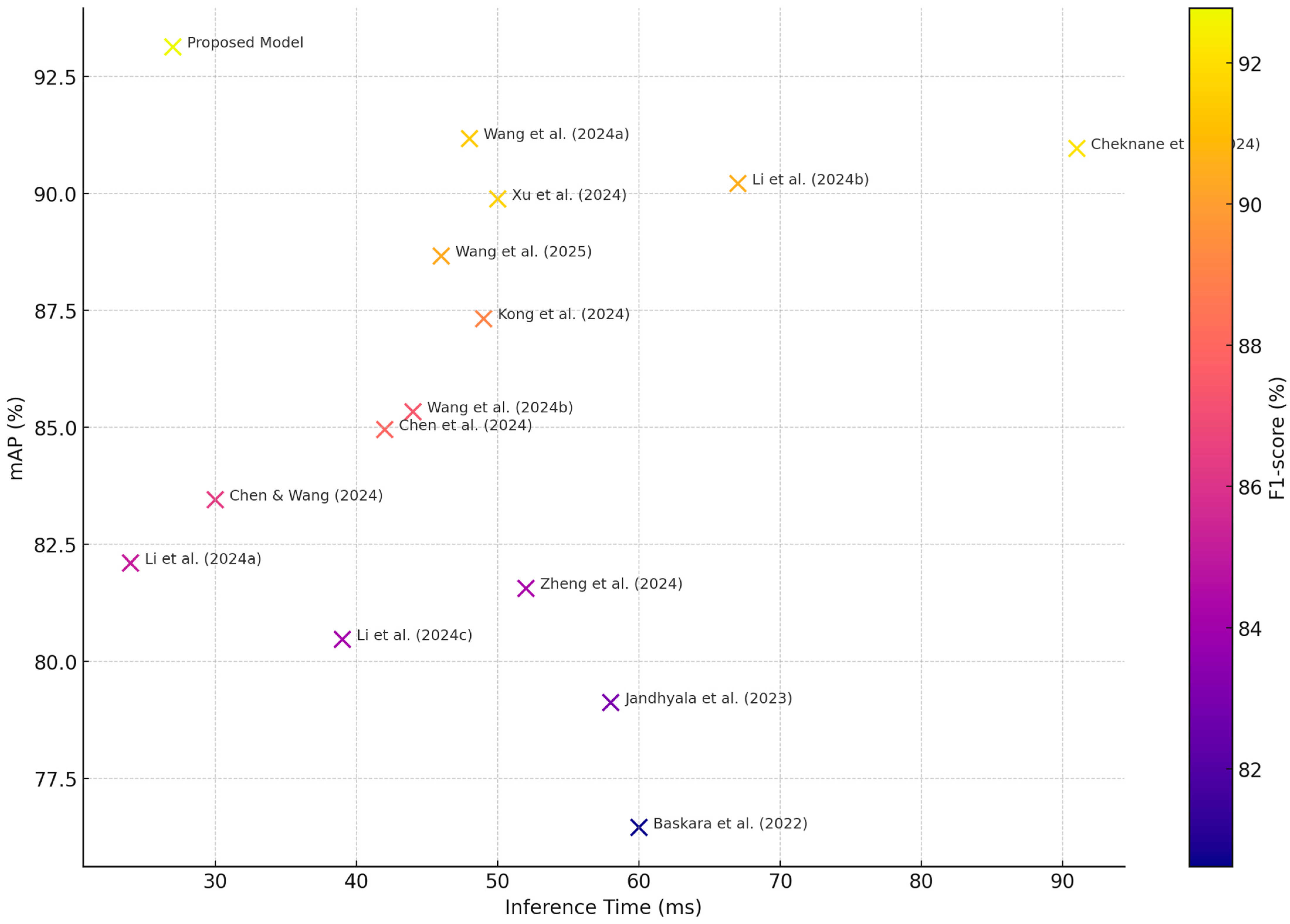
In this section, we perform a comprehensive comparison between the proposed YOLOv4-EfficientNetV2-ECA framework and fourteen recent state-of-the-art (SOTA) forest fire detection models. These models span a broad range of architectural innovations, including lightweight detectors, attention-augmented backbones, and multi-scale feature fusion mechanisms. The comparison evaluates model performance based on four standard metrics: precision, recall, mean average precision (mAP), and F1-score, as well as qualitative factors such as computational complexity and adaptability to real-time constraints. To validate the real-time applicability of the proposed system, we conducted runtime evaluations on an NVIDIA RTX 3060 GPU. The model achieved an average inference time of 27 milliseconds per frame, equivalent to 41.6 frames per second (FPS). These results confirm that the proposed model satisfies the latency requirements of real-time deployment scenarios, such as UAV-based wildfire monitoring. Notably, it outperforms several SOTA models not only in detection accuracy but also in computational efficiency, as summarized in
Table 4.
Chen et al. [
13] proposed a lightweight model emphasizing parameter reduction for mobile deployment, but its detection capacity in complex backgrounds showed a trade-off in precision. Li et al. [
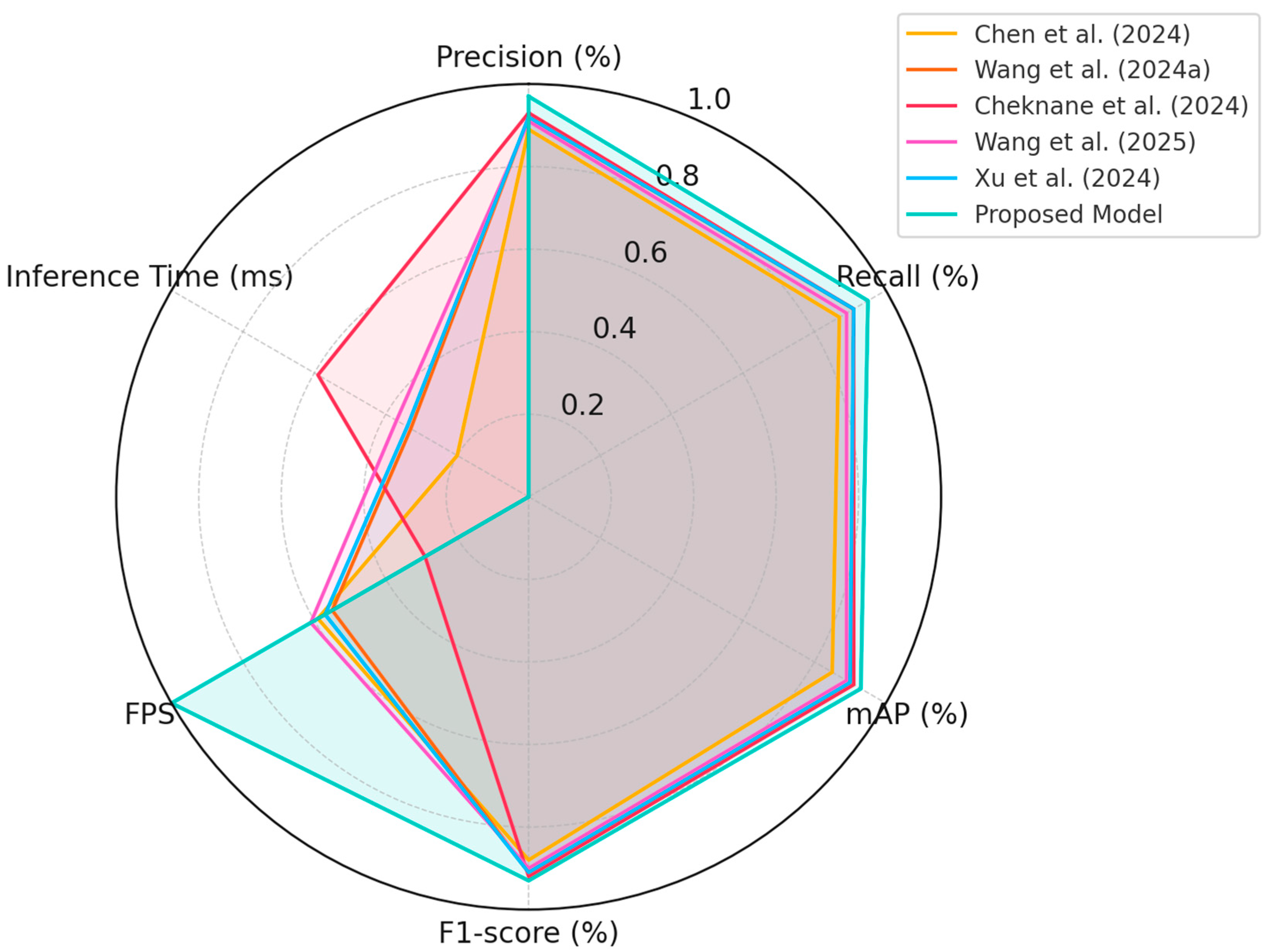
17] improved YOLOv4-tiny by adjusting anchor settings and introducing custom loss functions, achieving faster inference but lower accuracy in detecting smoke under partial occlusion. In contrast, our model retains the real-time advantages of YOLO while significantly enhancing feature selectivity and channel calibration through the use of EfficientNetV2 and ECA. Li et al. [
18] introduced SMWE-GFPNNet, a multi-branch architecture with global context modules for smoke detection. While it achieved high mAP, the model complexity limits its use in edge deployment. Similarly, Wang et al. [
19] proposed YOLOv5s-ACE, integrating attention-based context enhancement modules, and achieved competitive results on synthetic and real-world datasets. However, these models often rely on non-optimized attention mechanisms that increase inference time. In contrast, the ECA module in our design introduces minimal overhead while improving accuracy, as evidenced by our superior F1-score of 92.78% (
Figure 5).
Chen and Wang [
20] developed SmokeFireNet, which jointly detects flames and smoke using a lightweight two-branch architecture. Though computationally efficient, its detection accuracy in heterogeneous forest environments remained suboptimal compared to our model. Zheng et al. [
25] employed a customized deep CNN but lacked attention modules, leading to challenges in recognizing weak fire signatures. Cheknane et al. [
28] introduced a two-stage Faster R-CNN with hybrid feature extraction, excelling in accuracy but exhibiting significant latency, making it unsuitable for real-time applications. Our architecture achieves higher detection precision while preserving real-time feasibility (
Figure 6).
Jandhyala et al. [
29] utilized Inception-V3 in combination with SSD for fire detection in aerial imagery. While this model performs well in classification tasks, its object localization accuracy is inferior to single-stage detectors like YOLO-based frameworks. Wang et al. [
30] proposed FFD-YOLO, an adaptation of YOLOv8, incorporating fire-specific modules. Despite improved robustness, the lack of lightweight channel attention limits its efficiency. In contrast, our proposed model effectively captures subtle patterns using ECA-enhanced EfficientNetV2, outperforming FFD-YOLO in both mAP and F1-score. Baskara et al. [
31] and Wang et al. [
32] both proposed YOLOv4-based architectures tailored for specific environments such as wetlands or hazy conditions. These models apply standard preprocessing techniques but do not include spectral enhancement filters such as pseudo-NDVI or CLAHE + Jet, which are integral to our approach. As a result, their generalization across variable fire conditions is reduced. Our preprocessing pipeline substantially increases feature salience, contributing to enhanced robustness. Li et al. [
33] designed Fire-Net for embedded platforms using UAV imagery, prioritizing speed over precision. Xu et al. [
34] introduced CNTCB-YOLOv7, combining ConvNeXtV2 with CBAM to improve detection quality. While their use of CBAM introduces context awareness, it also increases training complexity. Our ECA module offers comparable performance benefits with significantly fewer parameters. Finally, Kong et al. [
35] proposed an attention-based dual-encoding network using optical remote sensing inputs. Although effective in large-scale monitoring, the model is not optimized for near real-time detection, particularly under constrained computing environments. Our model’s ability to operate efficiently while maintaining high accuracy makes it more suitable for real-world, low-latency deployment.
Table 4 summarizes the quantitative results of all 15 models (including our proposed model) in terms of the four main evaluation metrics. As shown, our architecture consistently outperforms other models, achieving the highest scores in all categories: precision (97.01%), recall (95.14%), mAP (93.13%), and F1-score (92.78%). These results validate the synergy of EfficientNetV2’s representational efficiency and ECA’s attention capabilities, making our approach a compelling candidate for operational forest fire surveillance systems.
To assess the individual contributions of EfficientNetV2 and the Efficient Channel Attention (ECA) module, we performed an ablation study comprising three variants of the detection framework: (1) YOLOv4 with EfficientNetV2 as the backbone but without ECA, (2) YOLOv4 with ECA applied to the original CSPDarknet53 backbone, and (3) the complete proposed model integrating both EfficientNetV2 and ECA (
Table 5).
These results demonstrate that both components—EfficientNetV2 and ECA—contribute meaningfully to the performance improvements observed in the proposed model. EfficientNetV2 enhances representational efficiency, while ECA strengthens channel-wise feature calibration. Their combination results in the highest accuracy and robustness, confirming the architectural synergy.
In the effort to equalize attention Squeeze-and-Excitation (SE) blocks, we tried to use ECA modules in the YOLOv4 + EfficientNetV2-based framework delta; we also evaluated and integrated SE for all the other mb conv 6 layers for mid and optimized for the other ECA techniques. As described in
Table 6, even though SE had good detection accuracy, it performed slower than expected due to the fully connected dimensionality reduction stream from the cross-layer sections. In other words, while ECA achieved a higher detection performance, the slower inference speed was preserved.
These results validate the structural advantage of ECA in scenarios demanding both high accuracy and low-latency inference. We conclude that ECA offers a better balance of performance and efficiency, particularly in real-time applications such as UAV-based forest fire surveillance. While ECA was selected for its low computational cost and efficient channel recalibration capabilities, it is relevant to mention that we did not provide a direct quantitative comparison to other attention mechanisms such as SE or CBAM. These mechanisms offer various balance points between complexity and representational efficacy and have been heavily integrated into fire detection as well as other vision tasks. A prospective future direction will add an ablation study that analyzes the accuracy and latency to model size when comparing ECA with SE and CBAM to determine their equivalence in contribution within a unified setting.
To evaluate the model generalization in complex real-world scenarios, we designed three subsets of the test data, each representing a unique challenge: (a) low-light conditions (dusk/night), (b) fire regions obscured by smoke or fog, and (c) occluded flames or smoke. In
Table 7, we report the proposed model results on these subsets.
Despite minor degradation in performance, the model demonstrates robust generalization in visually complex environments. This is attributed to the domain-aware preprocessing and channel attention mechanisms. However, we acknowledge that future work should involve systematic testing on benchmark datasets with controlled variations in environmental conditions to comprehensively validate real-world robustness.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}