
Enhancing Deforestation Detection Through Multi-Domain Adaptation with Uncertainty Estimation

 ,
,  ,
,  and
and 
Abstract
1. Introduction
- Two distinct scenarios of domain adaptation (DA) are presented. The first, termed multi-target, involves a single source domain and multiple target domains. The second, known as multisource, consists of multiple source domains adapting to a single target domain;
- Two configurations of the domain discriminator component were evaluated: multi-domain discriminator and source-target discriminator;
- Inclusion and assessment of an expert audit phase designed to target areas of highest uncertainty, utilizing uncertainty estimation from the predictions made by the DL model in a domain adaptation context;
- Experiments are conducted in three different domains associated with Brazilian biomes, and our approach is validated by comparing the results obtained with single-target and baseline experiments.
2. Materials and Methods
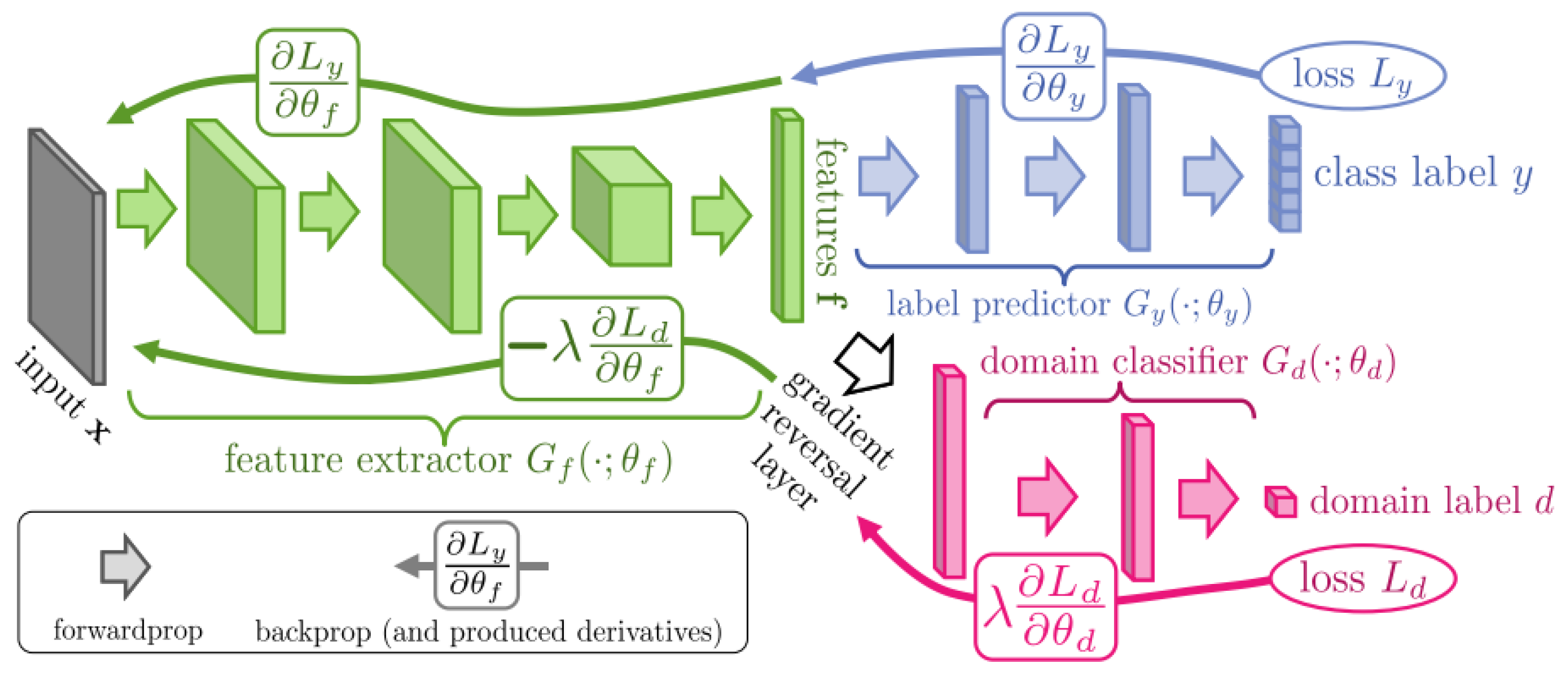
2.1. Domain Adversarial Neural Network (DANN)
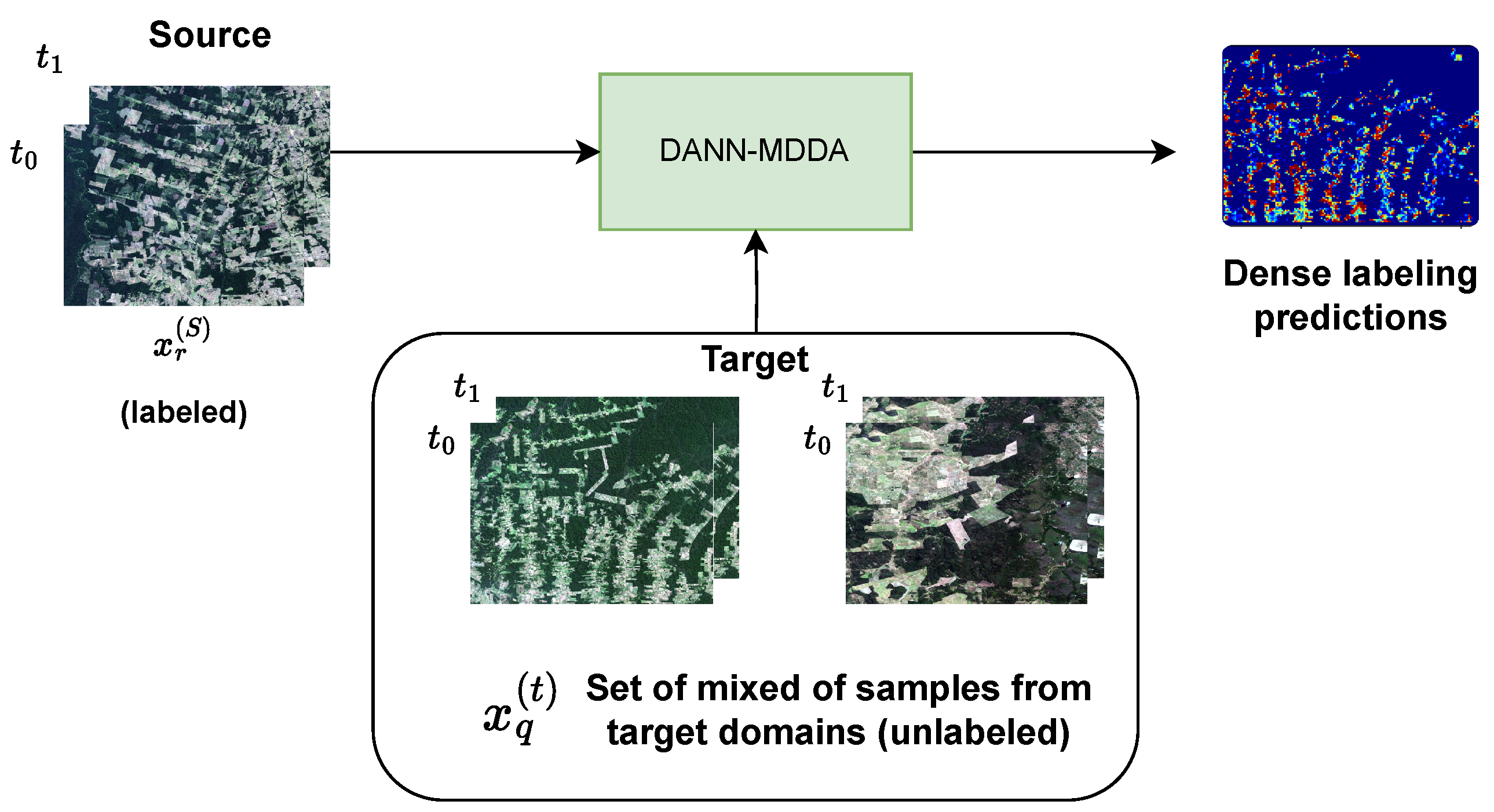
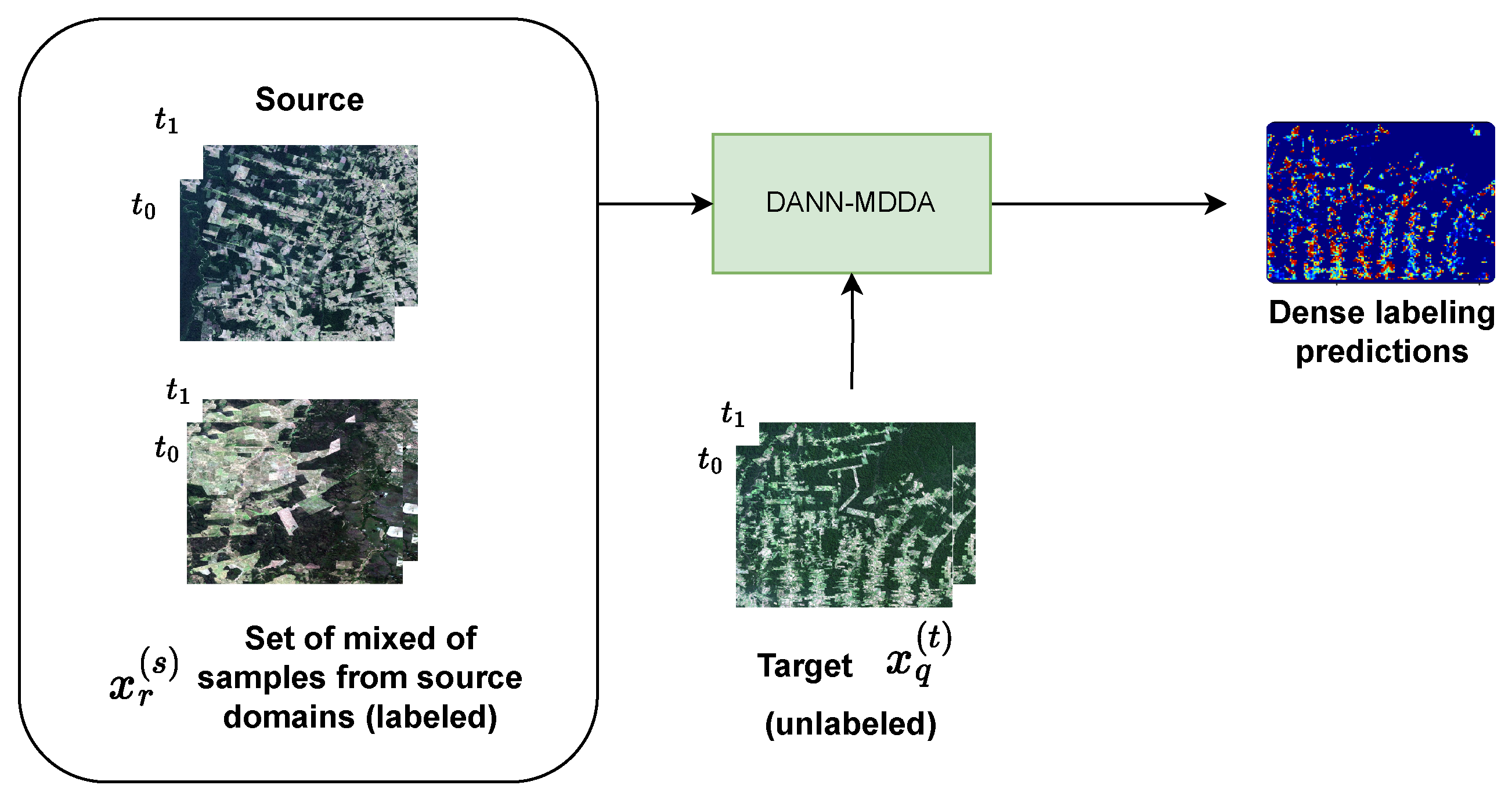
2.2. Dense Multi-Domain Adaptation
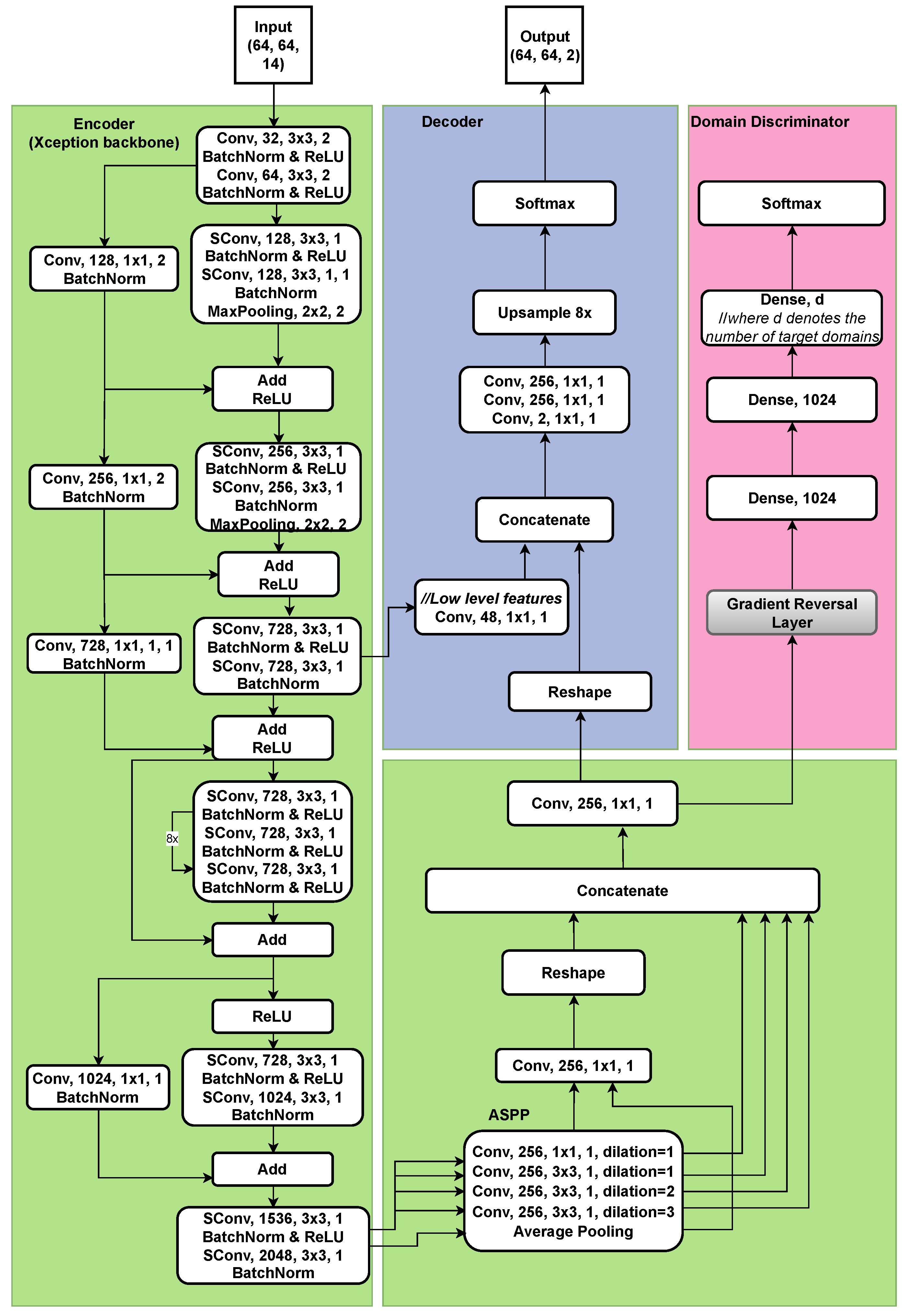
2.3. Deep Learning Model Architecture
2.4. Uncertainty Estimation
3. Experimental Protocol
3.1. Experiment Plan
- Baselines: Validation of the deep learning architecture and establishment of reference benchmarks;
- DMDA multi-target;
- DMDA multi-source;
- Uncertainty estimation with review phase.
3.2. Datasets
3.3. Model Training Setup
3.4. Hardware and Configuration
3.5. Metrics
4. Results
4.1. Baseline and Multi-Target Results
4.2. Multi-Source Results
4.3. Overall Multi-Domain Results
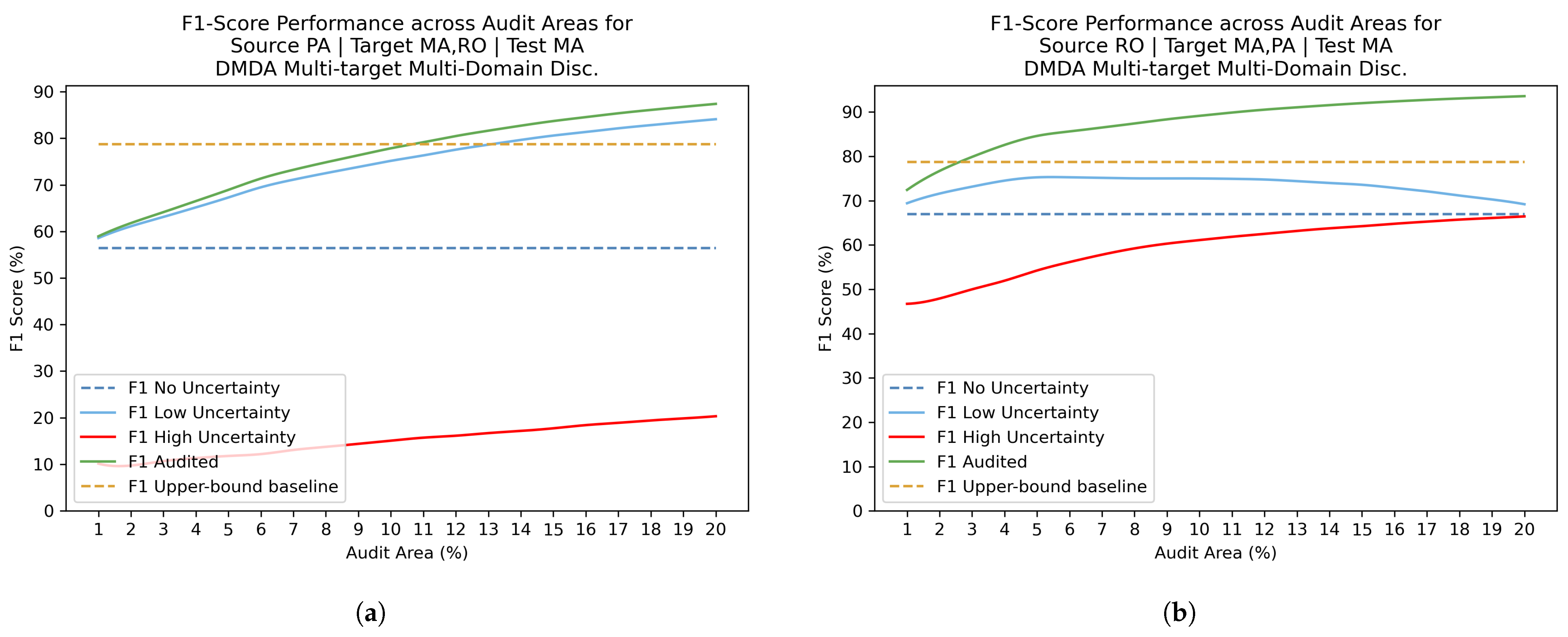
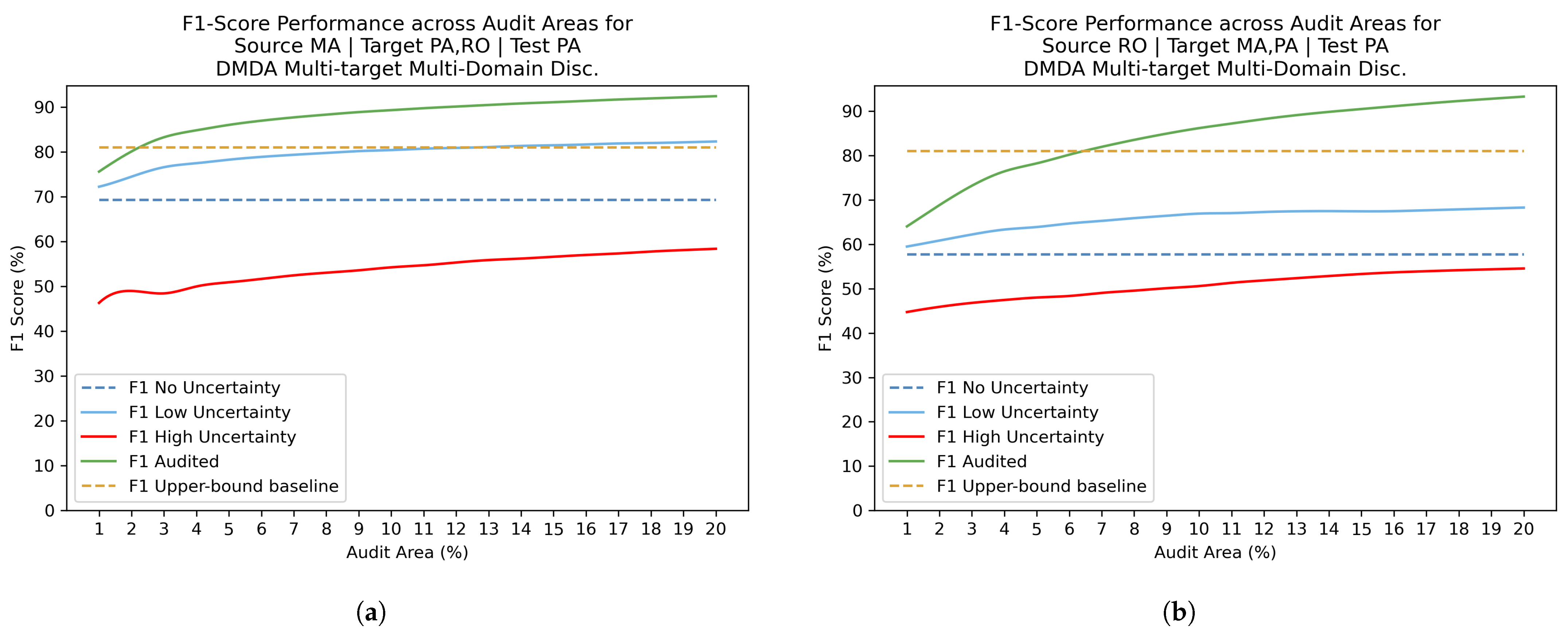
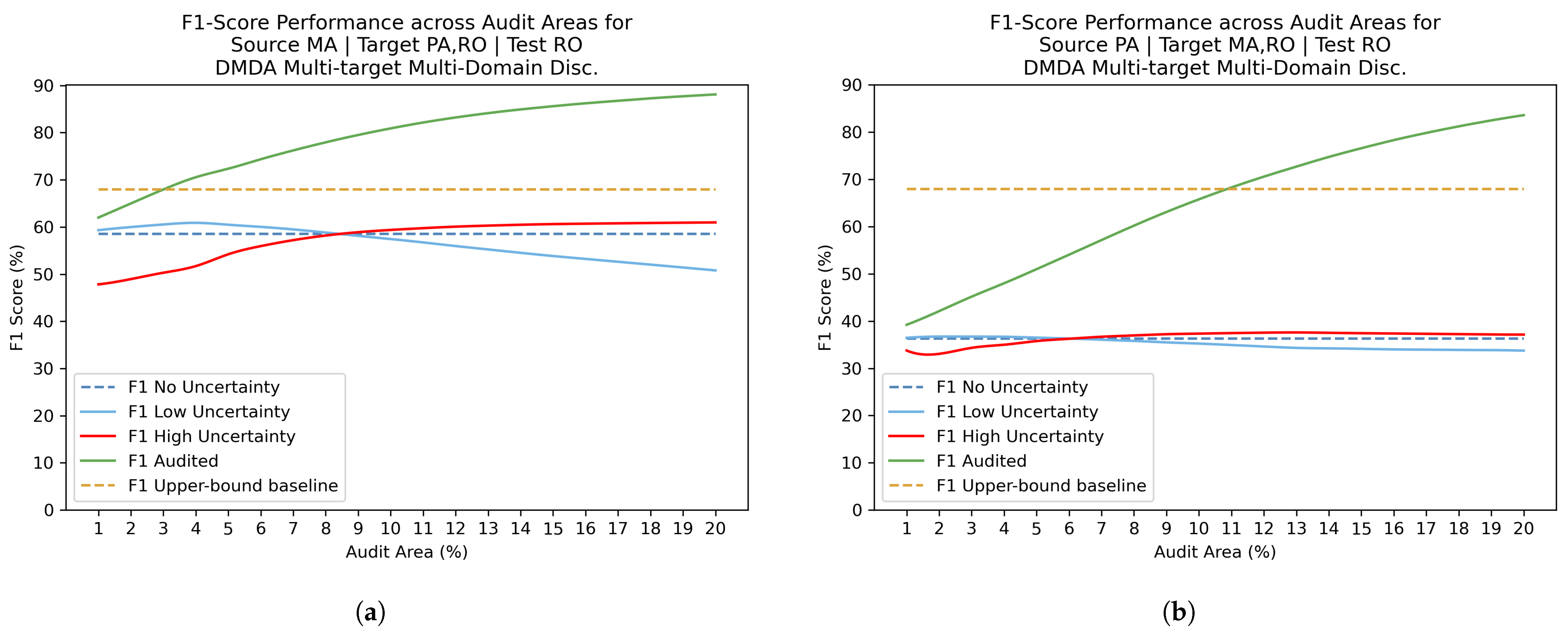
4.4. Uncertainty Estimation with Review Phase Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RS | Remote Sensing |
| INPE | Instituto Nacional de Pesquisas Espaciais |
| PRODES | Programa de Monitoramento da Floresta Amazônica Brasileira por Satélite |
| IBGE | Instituto Brasileiro de Geografia e Estatística |
| DL | Deep Learning |
| CycleGAN | Cycle-Consistent Adversarial Networks |
| ADDA | Adversarial Discriminative Domain Adaptation |
| DMDA | Dense Multi-Domain Adaptation |
| DANN | Domain Adaptation Neural Networks |
| DA | Domain Adaptation |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
References
- Dirzo, R.; Raven, P.H. Global state of biodiversity and loss. Annu. Rev. Environ. Resour. 2003, 28, 137–167. [Google Scholar] [CrossRef]
- Laurance, W.F.; Cochrane, M.A.; Bergen, S.; Fearnside, P.M.; Delamônica, P.; Barber, C.; D’Angelo, S.; Fernandes, T. The Future of the Brazilian Amazon. Science 2001, 291, 438–439. [Google Scholar] [CrossRef] [PubMed]
- Barber, C.P.; Cochrane, M.A.; Souza, C.M., Jr.; Laurance, W.F. Roads, deforestation, and the mitigating effect of protected areas in the Amazon. Biol. Conserv. 2014, 177, 203–209. [Google Scholar] [CrossRef]
- Colman, C.B.; Guerra, A.; Almagro, A.; de Oliveira Roque, F.; Rosa, I.M.D.; Fernandes, G.W.; Oliveira, P.T.S. Modeling the Brazilian Cerrado land use change highlights the need to account for private property sizes for biodiversity conservation. Sci. Rep. 2024, 14, 4559. [Google Scholar] [CrossRef]
- Rash, A.; Mustafa, Y.; Hamad, R. Quantitative assessment of Land use/land cover changes in a developing region using machine learning algorithms: A case study in the Kurdistan Region, Iraq. Heliyon 2023, 9, e21253. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef]
- De Almeida, C.A. Metodologia Utilizada nos Projetos Prodes e Deter; INPE: São José dos Campos, Brazil, 2019; Available online: http://www.obt.inpe.br/OBT/assuntos/programas/amazonia/prodes (accessed on 4 October 2024).
- INPE. Avaliação da Acurácia do Mapeamento do PRODES 2022; Technical Report, Brazilian National Institute for Space Research; INPE: São José dos Campos, Brazil, 2022; Available online: https://terrabrasilis.dpi.inpe.br/download/terrabrasilis/technicalnotes/nota_tecnica_avaliacao_PRODES2022.pdf (accessed on 9 September 2024).
- Jiang, H.; Peng, M.; Zhong, Y.; Xie, H.; Hao, Z.; Lin, J.; Ma, X.; Hu, X. A Survey on Deep Learning-Based Change Detection from High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 1552. [Google Scholar] [CrossRef]
- Wittich, D.; Rottensteiner, F. Appearance based deep domain adaptation for the classification of aerial images. ISPRS J. Photogramm. Remote Sens. 2021, 180, 82–102. [Google Scholar] [CrossRef]
- Neves, C.N.; Ortega Adarme, M.X.; Feitosa, R.Q.; Doblas Prieto, J.; Giraldi, G.A. Deep network based approaches to mitigate seasonal effects in SAR images for deforestation monitoring. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2024, 10, 261–267. [Google Scholar] [CrossRef]
- Ferreira, M.P.; dos Santos, D.R.; Ferrari, F.; Coelho, L.C.T.; Martins, G.B.; Feitosa, R.Q. Improving urban tree species classification by deep-learning based fusion of digital aerial images and LiDAR. Urban For. Urban Green. 2024, 94, 128240. [Google Scholar] [CrossRef]
- Höhl, A.; Obadic, I.; Fernández-Torres, M.Á.; Najjar, H.; Oliveira, D.A.B.; Akata, Z.; Dengel, A.; Zhu, X.X. Opening the Black Box: A systematic review on explainable artificial intelligence in remote sensing. IEEE Geosci. Remote Sens. Mag. 2024, 12, 261–304. [Google Scholar] [CrossRef]
- Voelsen, M.; Rottensteiner, F.; Heipke, C. Transformer models for Land Cover Classification with Satellite Image Time Series. PFG–J. Photogramm. Remote Sens. Geoinf. Sci. 2024, 92, 547–568. [Google Scholar] [CrossRef]
- Santillan, J.R.; Heipke, C. Assessing Patterns and Trends in Urbanization and Land Use Efficiency Across the Philippines: A Comprehensive Analysis Using Global Earth Observation Data and SDG 11.3. 1 Indicators. PFG–J. Photogramm. Remote Sens. Geoinf. Sci. 2024, 92, 569–592. [Google Scholar] [CrossRef]
- Ferranti, T.; Cardoso, D.L.; Figueiredo, R.L.; Oliveira, D.A.; Moneva, J.; Fuza, M. Mapeamento da diversidade florística a partir de imagens de drone usando poucas anotações. Proc. Ser. Braz. Soc. Comput. Appl. Math. 2025, 11, 1–2. [Google Scholar]
- Habeeb, H.N.; Mustafa, Y.T. Deep Learning-Based Prediction of Forest Cover Change in Duhok, Iraq: Past and Future. Forestist 2025, 75, 1–13. [Google Scholar] [CrossRef]
- Instituto Brasileiro de Geografia e Estatística—IBGE. Manual Técnico da Vegetação Brasileira; IBGE: Rio de Janeiro, Brazil, 2012; pp. 55–57. [Google Scholar]
- Quesada, C.A.; Hodnett, M.G.; Breyer, L.M.; Santos, A.J.; Andrade, S.; Miranda, H.S.; Miranda, A.C.; Lloyd, J. Seasonal variations in soil water in two woodland savannas of central Brazil with different fire histories. Tree Physiol. 2008, 28, 405–415. [Google Scholar] [CrossRef]
- Instituto Nacional de Pesquisas Espaciais (INPE). Estimativa de Desmatamento na Amazônia Legal para 2024 é de 6.288 km2; Nota Técnica 1031; INPE: São José dos Campos, Brazil, 2024. [Google Scholar]
- Deng, X.; Zhu, Y.; Tian, Y.; Newsam, S. Scale Aware Adaptation for Land-Cover Classification in Remote Sensing Imagery. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 2159–2168. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, X.; Ding, X.; Pun, M.O.; Ma, S. Decomposition-Based Unsupervised Domain Adaptation for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5645118. [Google Scholar] [CrossRef]
- Luo, M.; Ji, S. Cross-spatiotemporal land-cover classification from VHR remote sensing images with deep learning based domain adaptation. ISPRS J. Photogramm. Remote Sens. 2022, 191, 105–128. [Google Scholar] [CrossRef]
- Soto Vega, P.J.; Costa, G.A.O.P.d.; Feitosa, R.Q.; Ortega Adarme, M.X.; Almeida, C.A.d.; Heipke, C.; Rottensteiner, F. An unsupervised domain adaptation approach for change detection and its application to deforestation mapping in tropical biomes. ISPRS J. Photogramm. Remote Sens. 2021, 181, 113–128. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2020, arXiv:1703.10593. [Google Scholar]
- Noa, J.; Soto, P.J.; Costa, G.A.O.P.; Wittich, D.; Feitosa, R.Q.; Rottensteiner, F. Adversarial discriminative domain adaptation for deforestation detection. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, V-3-2021, 151–158. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial Discriminative Domain Adaptation. arXiv 2017, arXiv:1702.05464. [Google Scholar]
- Soto, P.J.; Costa, G.A.; Feitosa, R.Q.; Ortega, M.X.; Bermudez, J.D.; Turnes, J.N. Domain-Adversarial Neural Networks for Deforestation Detection in Tropical Forests. IEEE Geosci. Remote Sens. Lett. 2022, 19, 2504505. [Google Scholar] [CrossRef]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1180–1189. [Google Scholar]
- Vega, P.J.S.; da Costa, G.A.O.P.; Adarme, M.X.O.; Castro, J.D.B.; Feitosa, R.Q. Weak Supervised Adversarial Domain Adaptation for Deforestation Detection in Tropical Forests. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 14, 1–16. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar]
- Martinez, J.A.C.; da Costa, G.A.O.P.; Messias, C.G.; de Souza Soler, L.; de Almeida, C.A.; Feitosa, R.Q. Enhancing deforestation monitoring in the Brazilian Amazon: A semi-automatic approach leveraging uncertainty estimation. ISPRS J. Photogramm. Remote Sens. 2024, 210, 110–127. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2017, arXiv:1610.02357. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1050–1059. [Google Scholar]
- Sensoy, M.; Kaplan, L.; Kandemir, M. Evidential deep learning to quantify classification uncertainty. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles. Adv. Neural Inf. Process. Syst. 2017, 30, 6405–6416. [Google Scholar]
- Vega, P.J.S.; Torres, D.L.; Andrade-Miranda, G.X.; Feitosa, R.Q. Assessing the Generalization Capacity of Convolutional Neural Networks and Vision Transformers for Deforestation Detection in Tropical Biomes. ISPRS Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2024, 48, 519–525. [Google Scholar] [CrossRef]
- Torres, D.L.; Turnes, J.N.; Soto Vega, P.J.; Feitosa, R.Q.; Silva, D.E.; Marcato Junior, J.; Almeida, C. Deforestation detection with fully convolutional networks in the Amazon Forest from Landsat-8 and Sentinel-2 images. Remote Sens. 2021, 13, 5084. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat.-Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Peng, J.; Huang, Y.; Sun, W.; Chen, N.; Ning, Y.; Du, Q. Domain Adaptation in Remote Sensing Image Classification: A Survey. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9842–9859. [Google Scholar] [CrossRef]
- Xu, M.; Wu, M.; Chen, K.; Zhang, C.; Guo, J. The Eyes of the Gods: A Survey of Unsupervised Domain Adaptation Methods Based on Remote Sensing Data. Remote Sens. 2022, 14, 4380. [Google Scholar] [CrossRef]
- Chen, X.; Yang, Y.; Liu, D.; Wang, S. Sample-prototype optimal transport-based universal domain adaptation for remote sensing image classification. Complex Intell. Syst. 2024, 11, 97. [Google Scholar] [CrossRef]
- Tan, J.; Zhang, H.; Yao, N.; Yu, Q. One-shot adaptation for cross-domain semantic segmentation in remote sensing images. Pattern Recognit. 2025, 162, 111390. [Google Scholar] [CrossRef]
- Li, W.; Gao, H.; Su, Y.; Momanyi, B.M. Unsupervised Domain Adaptation for Remote Sensing Semantic Segmentation with Transformer. Remote Sens. 2022, 14, 4942. [Google Scholar] [CrossRef]
- Kim, J.; Lee, L.; Park, S.; Musungu, L. Improving Deforestation Detection Accuracy in Noisy Satellite Images with Contrastive Learning-based Approach. J. Stud. Res. 2023, 12, 1–10. [Google Scholar] [CrossRef]
- Xu, R.; Samat, A.; Zhu, E.; Li, E.; Li, W. Unsupervised Domain Adaptation with Contrastive Learning-Based Discriminative Feature Augmentation for RS Image Classification. Remote Sens. 2024, 16, 1974. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domains | RO | PA | MA |
|---|---|---|---|
| Vegetation | Open Ombrophilous | Dense Ombrophilous | Seasonal Deciduous and Semi-Deciduous |
| Date 1 | 18 July 2016 | 2 August 2016 | 18 August 2017 |
| Date 2 | 21 July 2017 | 20 July 2017 | 21 August 2018 |
| Deforested pixels | 225,635 (2%) | 82,970 (3%) | 71,265 (3%) |
| Not deforested pixels | 3,816,981 (29%) | 1,867,929 (65%) | 1,389,844 (57%) |
| Previously deforested pixels | 9,013,384 (69%) | 903,901 (65%) | 986,891 (40%) |
| Domains | RO | PA | MA |
|---|---|---|---|
| Dimension (pixels) | 2550 × 5120 | 1098 × 2600 | 1700 × 1440 |
| Tiles (image subsets) | 100 | 15 | 15 |
| Tiles for training | 2, 6, 13, 24, 28, 35, 37, 46, 47, 53, 58, 60, 64, 71, 75, 82, 86, 88, 93 | 1, 7, 9, 13 | 1, 5, 12, 13 |
| Tiles for validation | 8, 11, 26, 49, 78 | 5, 12 | 6, 7 |
| % for training | 20% | 26% | 26% |
| % for validation | 5% | 13% | 13% |
| % for testing | 75% | 60% | 60% |
| Source | MA | PA | RO | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Target * | PA,RO | PA,RO | MA,RO | MA,RO | MA,PA | MA,PA | ||||||
| Test | PA | RO | MA | RO | MA | PA | ||||||
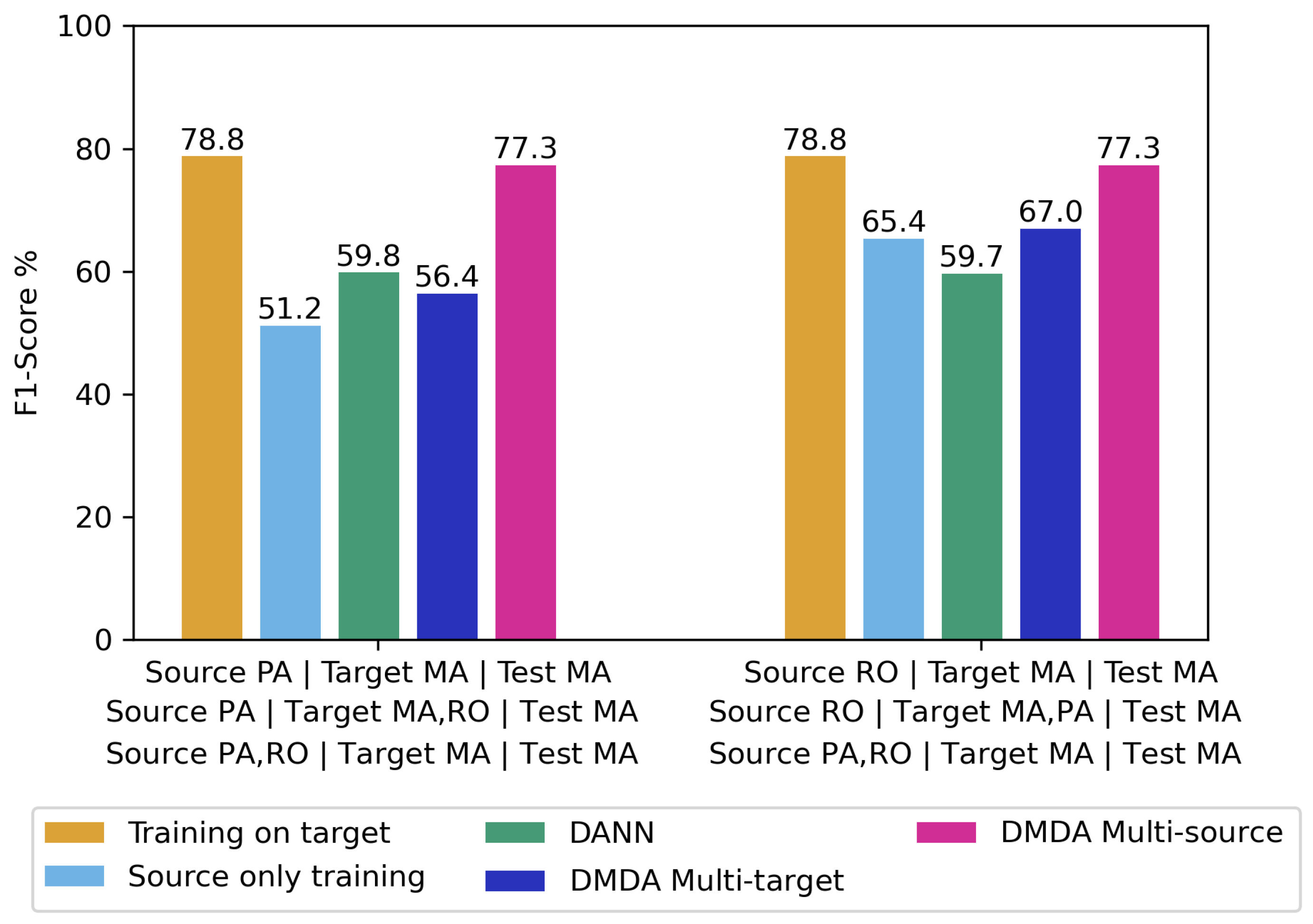
| Experiments | F1 | F1 | F1 | F1 | F1 | F1 | ||||||
| Training on target | 81.0 | 68.0 | 78.8 | 68.0 | 78.8 | 81.0 | ||||||
| Source-only training | 70.3 | 47.3 | 51.2 | 20.9 | 65.4 | 40.8 | ||||||
| Single-target DA | 68.8 | 59.1 | 59.8 | 31.8 | 59.7 | 57.1 | ||||||
| DMDA Multi-target multi-domain disc. | 69.3 | 58.5 | 56.4 | 36.3 | 67.0 | 57.7 | ||||||
| DMDA multi-target source-target disc. | 70.8 | 55.4 | 55.5 | 31.5 | 67.8 | 57.3 | ||||||
| Source | MA | PA | RO | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Target * | PA,RO | PA,RO | MA,RO | MA,RO | MA,PA | MA,PA | ||||||
| Test | PA | RO | MA | RO | MA | PA | ||||||
| Pairs of Experiments | Acc. | p-Val | Acc. | p-Val | Acc. | p-Val | Acc. | p-Val | Acc. | p-Val | Acc. | p-Val |
| DMDA Multi-target Multi-Domain Disc. vs. Source-only training | H0 | 0.26 | H1 | 0.01 | H0 | 0.06 | H1 | <0.01 | H0 | 0.55 | H1 | <0.01 |
| DMDA Multi-target Source-Target Disc. vs. Source-only training | H0 | 0.15 | H1 | 0.02 | H0 | 0.20 | H1 | <0.01 | H0 | 0.77 | H1 | <0.01 |
| Source | MA 1, PA 2 | PA 1, RO 2 | MA 1, RO 2 | |||
|---|---|---|---|---|---|---|
| Target | RO | MA | PA | |||
| Test | RO | MA | PA | |||
| Experiments | F1 | F1 | F1 | |||
| Source-only training 1 | 47.3 | 51.2 | 70.3 | |||
| Source-only training 2 | 20.9 | 65.4 | 40.8 | |||
| Multi-source only training (No DA) | 44.2 | 77.8 | 62.4 | |||
| DMDA Multi-source multi-domain Disc. | 52.8 | 77.3 | 67.6 | |||
| DMDA Multi-source source-target Disc. | 53.4 | 77.5 | 67.1 | |||
| Source | MA 1, PA 2 | PA 1, RO 2 | MA 1, RO 2 | |||
|---|---|---|---|---|---|---|
| Target | RO | MA | PA | |||
| Test | RO | MA | PA | |||
| Experiments | Acc. | p-Val | Acc. | p-Val | Acc. | p-Val |
| Multi-source only training (No DA) vs Source-only training 1 | H0 | 0.67 | H1 | <0.01 | H0 | 0.98 |
| Multi-source only training (No DA) vs. Source-only training 2 | H1 | <0.01 | H1 | <0.01 | H1 | <0.01 |
| DMDA Multi-source multi-domain Disc. vs. Source-only training 1 | H1 | 0.04 | H1 | <0.01 | H0 | 0.88 |
| DMDA Multi-source multi-domain Disc. vs. Source-only training 2 | H1 | <0.01 | H1 | <0.01 | H1 | <0.01 |
| Domain Pairs (Source-Target) | Single-Target DA Compared to Lower-Bound | Domain Included in Multi-Domain Methods | DMDA Multi-Target Multi-Domain Disc. Compared to Single-Target DA | DMDA Multi-Source Multi-Domain Disc. Compared to Single-Target DA |
|---|---|---|---|---|
| PA-RO | +10.9 | MA | +4.5 | +21.0 |
| RO-PA | +16.3 | MA | +0.6 | +10.5 |
| PA-MA | +8.6 | RO | −3.4 | +17.5 |
| MA-RO | +11.8 | PA | −0.6 | −6.3 |
| RO-MA | −5.7 | PA | +7.3 | +17.6 |
| MA-PA | −1.5 | RO | +0.5 | −1.2 |
| Source | MA | |||||||
|---|---|---|---|---|---|---|---|---|
| Target * | PA, RO | PA, RO | ||||||
| Test | PA | RO | ||||||
| Experiments | ||||||||
| Training on target | 81.0 | 89.3 | 64.3 | 92.9 | 68.0 | 71.7 | 52.5 | 77.0 |
| Source only training | 70.3 | 78.0 | 48.6 | 84.3 | 47.3 | 47.8 | 45.7 | 57.9 |
| DA Single-target | 68.8 | 73.1 | 58.0 | 81.4 | 59.1 | 61.3 | 50.0 | 68.8 |
| DMDA Multi-target Multi-Domain Disc. | 69.3 | 76.6 | 48.4 | 83.3 | 58.5 | 60.5 | 50.3 | 67.9 |
| DMDA Multi-target Source-Target Disc. | 70.8 | 77.0 | 53.6 | 83.6 | 55.4 | 57.4 | 47.1 | 65.3 |
| Source | PA | |||||||
|---|---|---|---|---|---|---|---|---|
| Target * | MA, RO | MA, RO | ||||||
| Test | MA | RO | ||||||
| Experiments | ||||||||
| Training on target | 78.8 | 86.6 | 27.5 | 87.6 | 68.0 | 71.7 | 52.5 | 77.0 |
| Source-only training | 51.2 | 56.7 | 9.0 | 57.7 | 20.9 | 19.1 | 28.9 | 30.0 |
| DA Single-target | 59.8 | 66.1 | 10.8 | 67.1 | 31.8 | 30.7 | 36.8 | 41.6 |
| DMDA Multi-target multi-domain disc. | 56.4 | 63.1 | 10.7 | 64.1 | 36.3 | 36.7 | 34.3 | 45.2 |
| DMDA Multi-target source-target disc. | 55.5 | 61.3 | 11.1 | 62.3 | 31.5 | 30.7 | 34.9 | 41.6 |
| Source | RO | |||||||
|---|---|---|---|---|---|---|---|---|
| Target * | MA, PA | MA, PA | ||||||
| Test | MA | PA | ||||||
| Experiments | ||||||||
| Training on target | 78.8 | 86.6 | 27.5 | 87.6 | 81.0 | 89.3 | 64.3 | 92.9 |
| Source only training | 65.4 | 71.7 | 41.9 | 77.0 | 40.8 | 37.6 | 48.9 | 58.1 |
| DA Single-target | 59.7 | 63.5 | 47.5 | 71.3 | 57.1 | 60.1 | 49.9 | 71.8 |
| DMDA Multi-target Multi-Domain Disc. | 67.0 | 73.2 | 50.0 | 79.9 | 57.7 | 62.2 | 46.8 | 73.2 |
| DMDA Multi-target Source-Target Disc. | 67.8 | 74.9 | 33.3 | 77.7 | 57.3 | 60.4 | 48.6 | 70.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Moura, L.F.; Vega, P.J.S.; da Costa, G.A.O.P.; Mota, G.L.A. Enhancing Deforestation Detection Through Multi-Domain Adaptation with Uncertainty Estimation. Forests 2025, 16, 742. https://doi.org/10.3390/f16050742
de Moura LF, Vega PJS, da Costa GAOP, Mota GLA. Enhancing Deforestation Detection Through Multi-Domain Adaptation with Uncertainty Estimation. Forests. 2025; 16(5):742. https://doi.org/10.3390/f16050742
Chicago/Turabian Stylede Moura, Luiz Fernando, Pedro Juan Soto Vega, Gilson Alexandre Ostwald Pedro da Costa, and Guilherme Lucio Abelha Mota. 2025. "Enhancing Deforestation Detection Through Multi-Domain Adaptation with Uncertainty Estimation" Forests 16, no. 5: 742. https://doi.org/10.3390/f16050742
APA Stylede Moura, L. F., Vega, P. J. S., da Costa, G. A. O. P., & Mota, G. L. A. (2025). Enhancing Deforestation Detection Through Multi-Domain Adaptation with Uncertainty Estimation. Forests, 16(5), 742. https://doi.org/10.3390/f16050742