
YOLO-UFS: A Novel Detection Model for UAVs to Detect Early Forest Fires


Abstract
1. Introduction
- A New Early Forest Fire Detection Model, YOLO-UFS Model: We propose a novel detection model, YOLO-UFS, designed to enhance drone-based early forest fire and smoke detection by addressing low computational cost, low latency, complex background interference, and the coexistence of smoke and fire.
- Self-Built Dataset: A custom dataset was created, comprising three types of data: small flames only, smoke only, and combined small flames and smoke. Experiments were conducted to compare its performance with classical algorithms.
- New Method Improvements: We propose the C3-MNV4 module to replace the original C3 module, effectively reducing the number of parameters while enhancing feature extraction capabilities. Additionally, the AF-IoU loss function is introduced to optimize detection accuracy, particularly for small targets in complex background environments.
- Integration of Existing Improvements: The NAM attention mechanism is employed to concentrate the kernel within the target region, improving detection precision. Meanwhile, ObjectBox and BiFPN are incorporated to enhance detail retention and model generalization. These upgrades collectively make YOLO-UFS more accurate and efficient for early forest fire detection.
2. Materials and Methods
2.1. Construct an Early Forest Fire Dataset
2.1.1. Image Acquisition of Early Forest Fires
- a.
- Target Identification
- b.
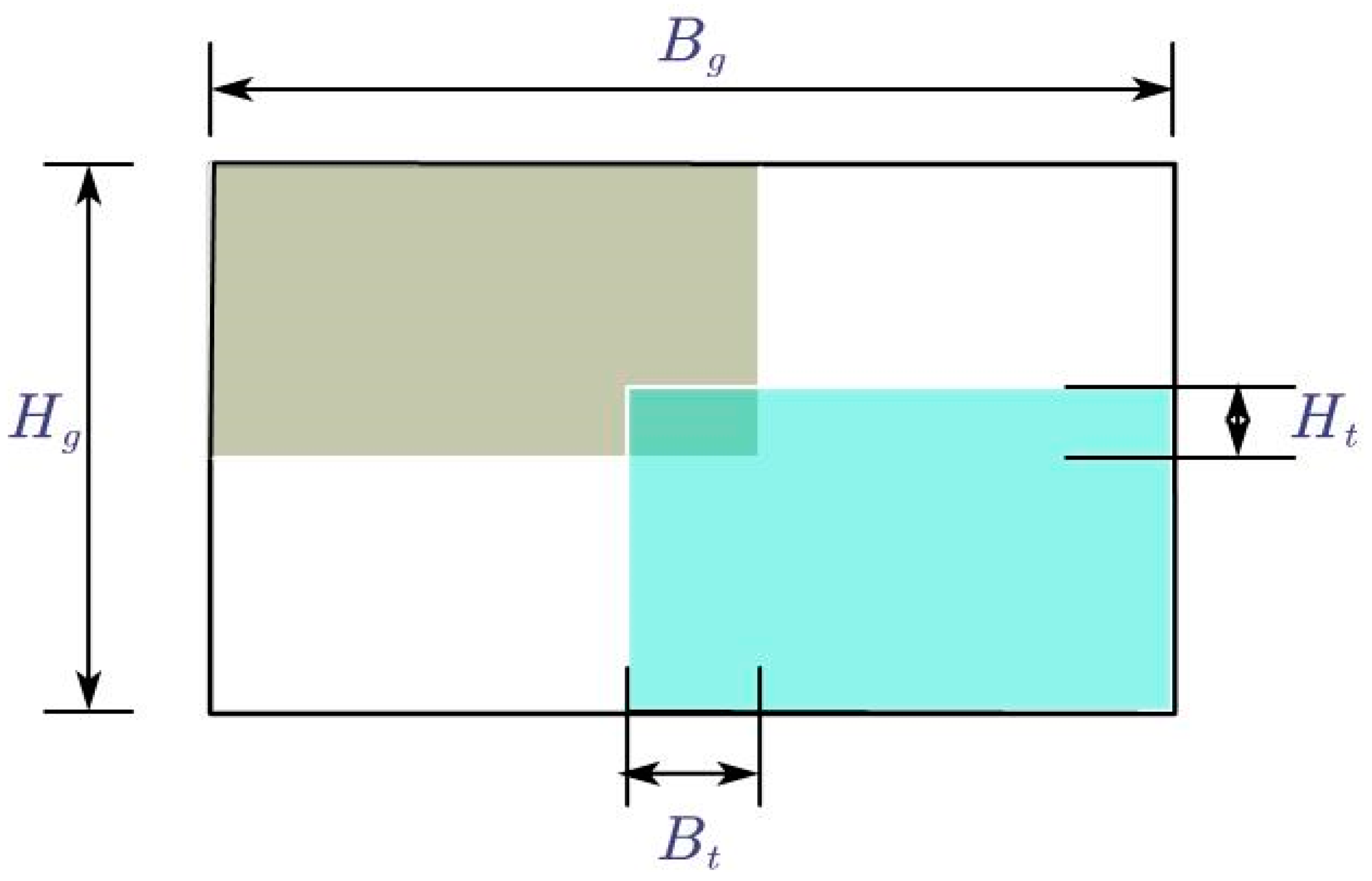
- Interference with Detection Targets
- c.
- Position of Detection Targets
2.1.2. Data Augmentation Processing
2.1.3. Dataset Composition
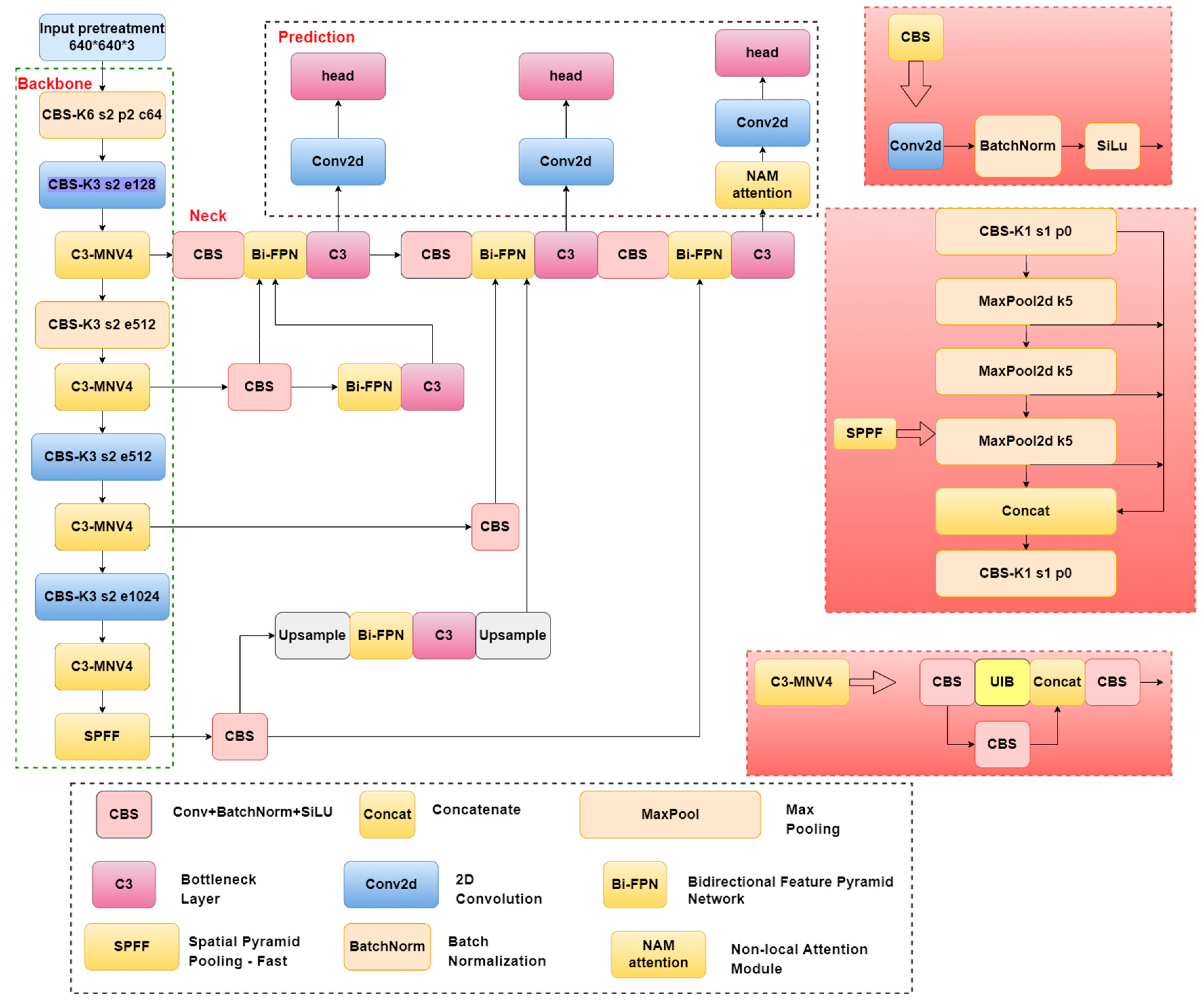
2.2. The YOLO-UFS Model
2.2.1. Replace the C3 Module
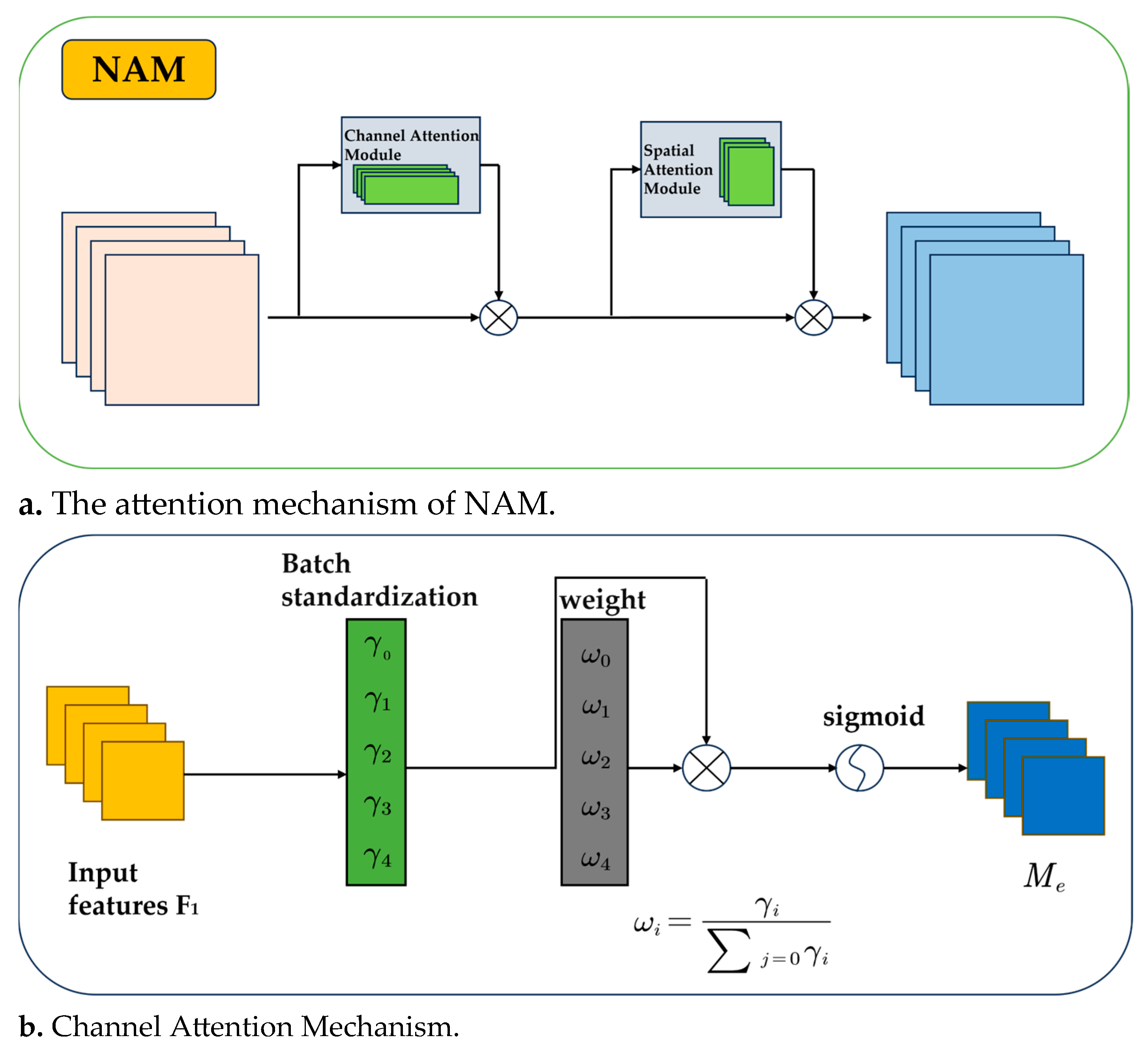
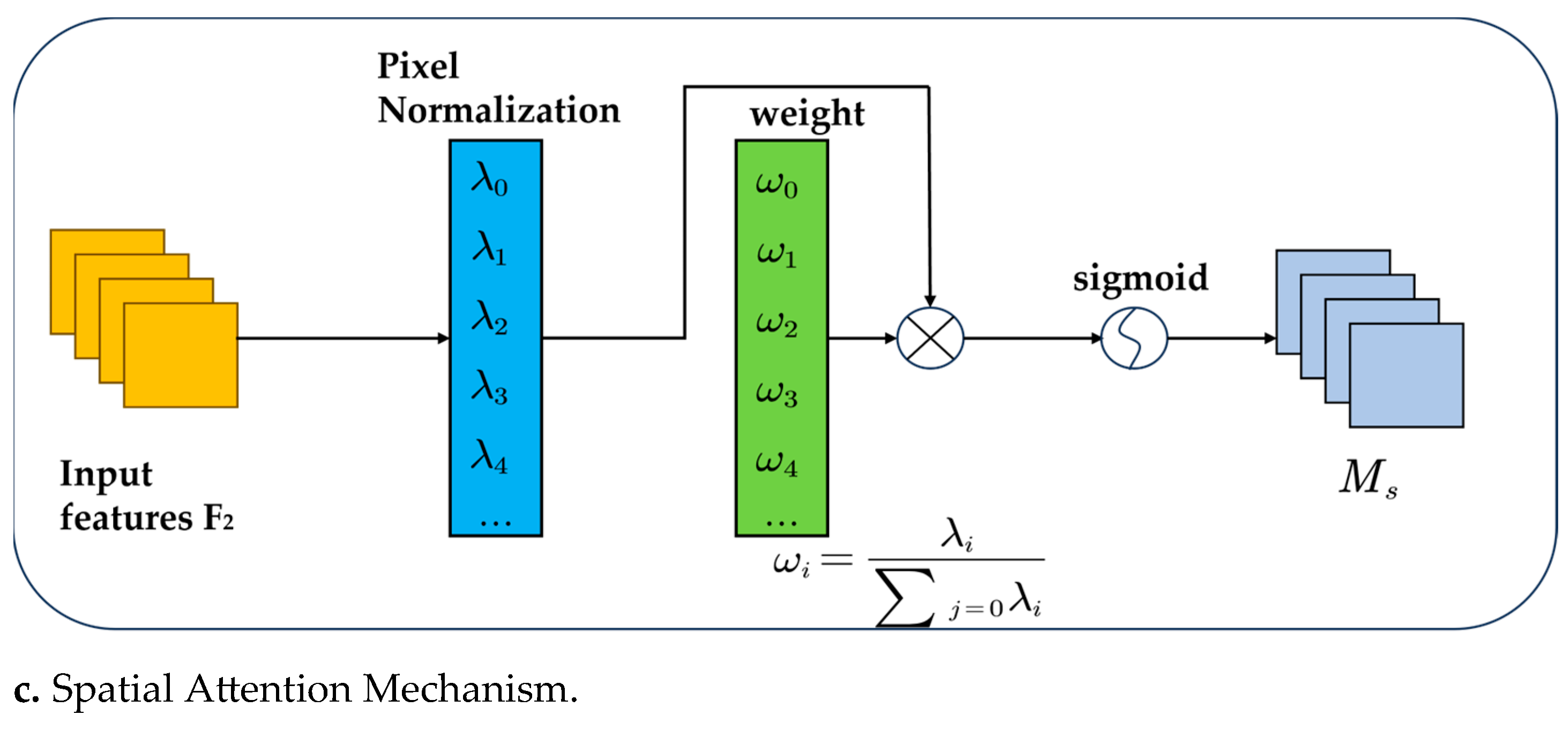
2.2.2. Introduction of the Attention Mechanism NAM
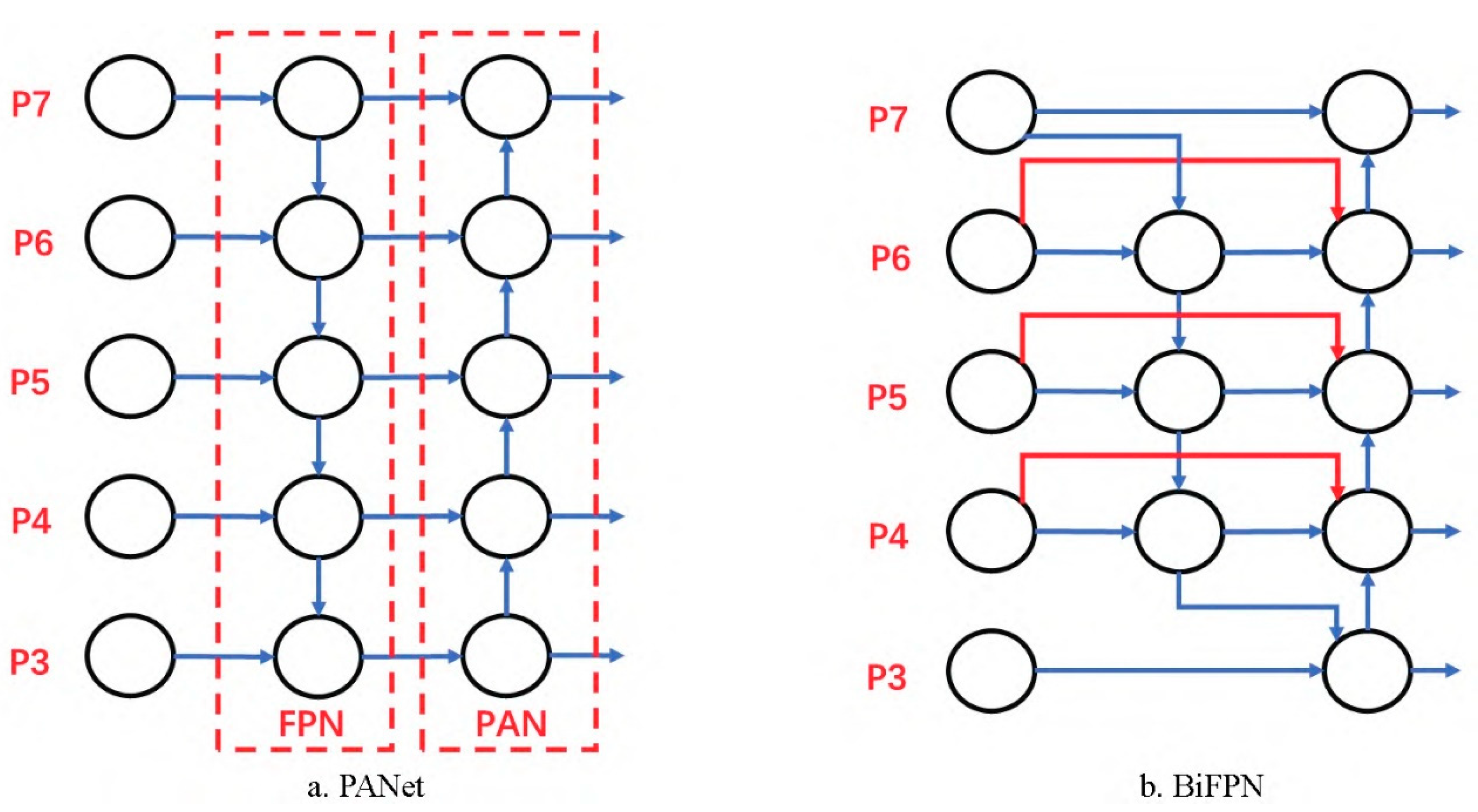
2.2.3. Bidirectional Characteristic Pyramid Network (BiFPN)
2.2.4. ObjectBox Detector
2.2.5. Optimize the Loss Function
3. Experiments and Analysis of Results
3.1. Test Conditions and Indicators
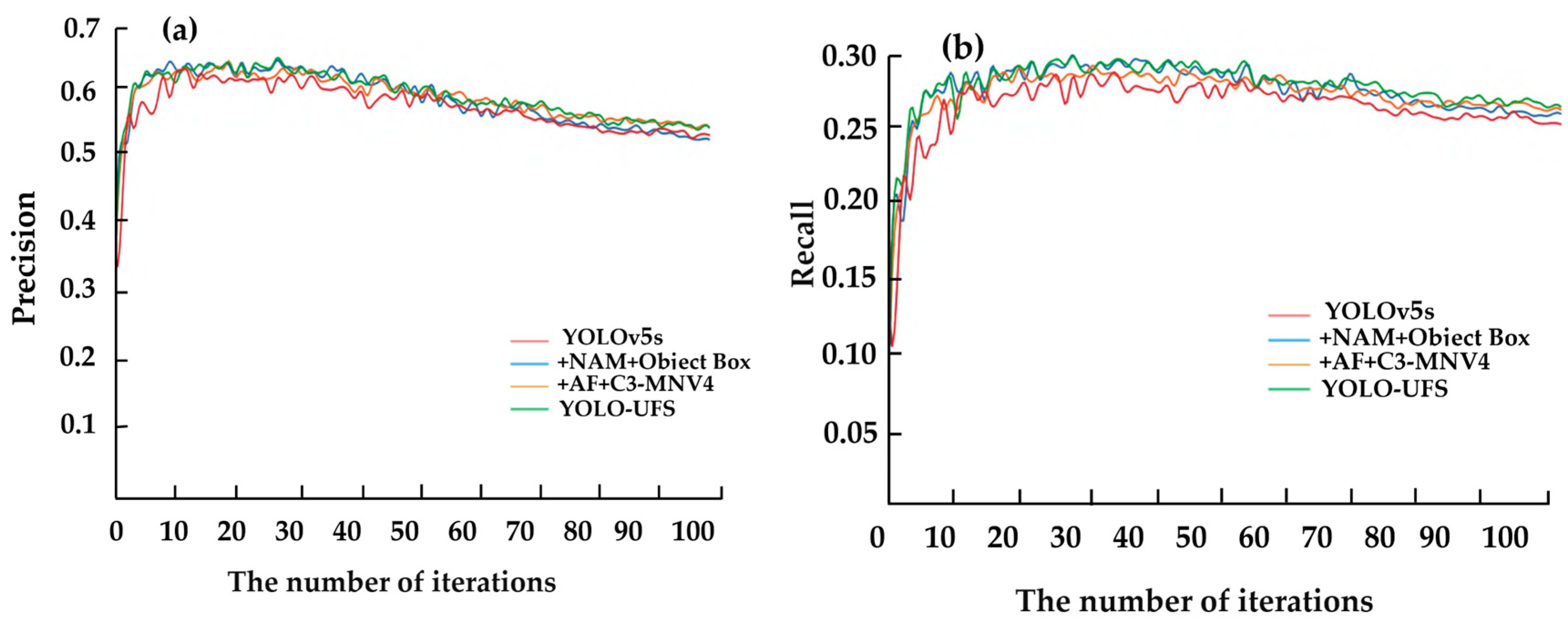
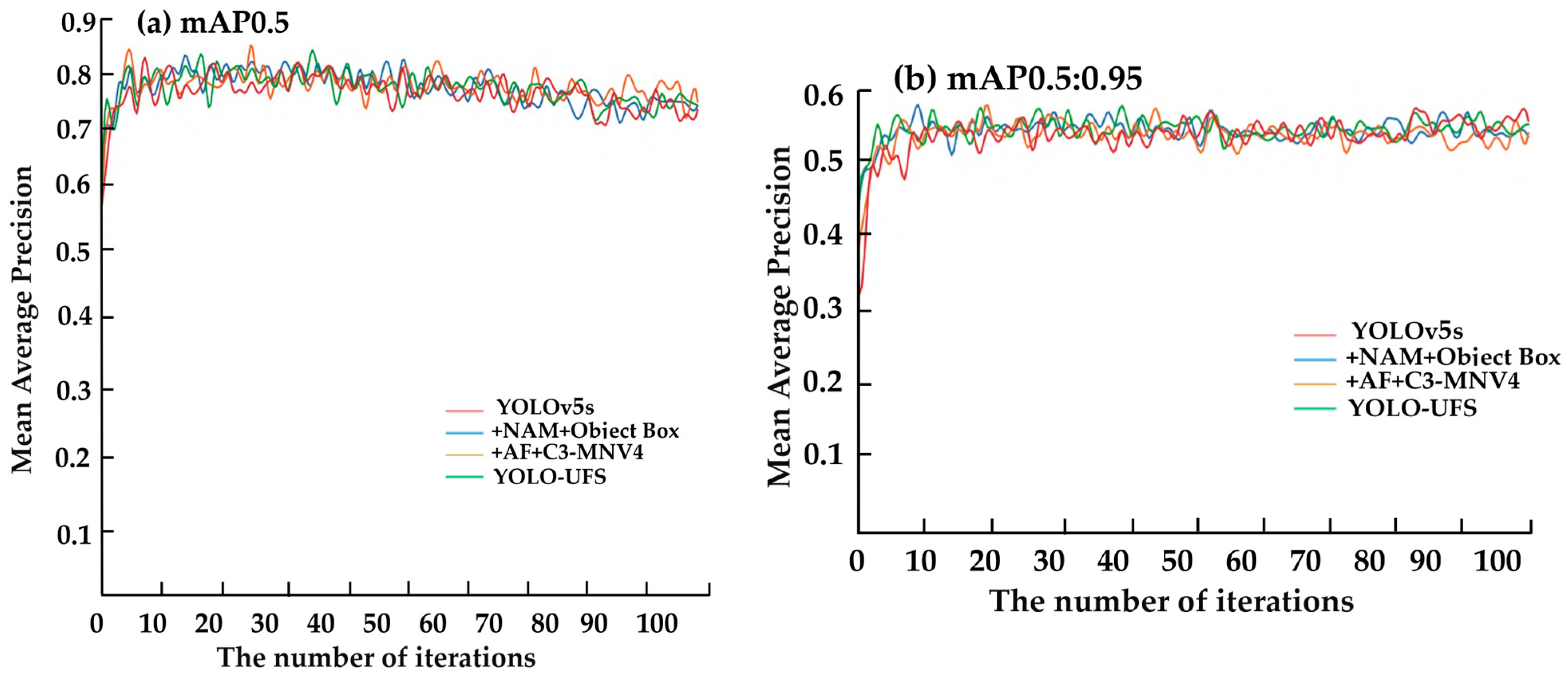
3.2. Comparative Experiments
3.3. Ablation Experiments
3.4. Generalization Experiment
3.4.1. Generalization Comparison Experiments
3.4.2. Generalized Ablation Experiments
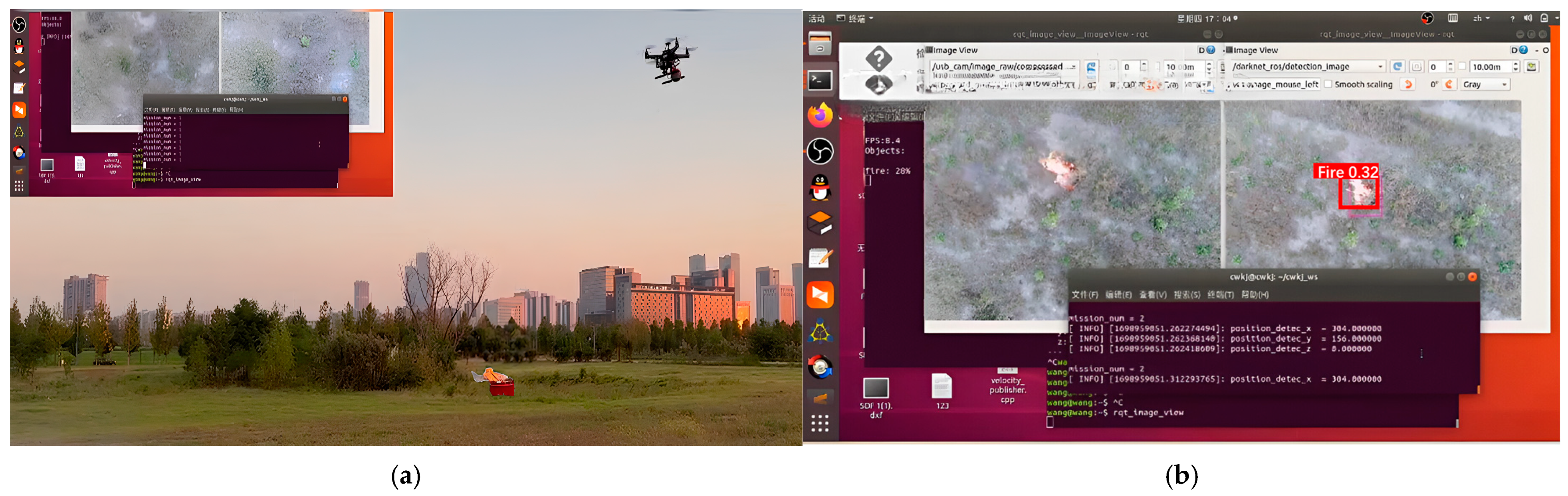
3.5. Actual Machine Verification Experiments
3.5.1. Field Experiment Environment and UAV Configuration
3.5.2. Real-World Experimental Analysis
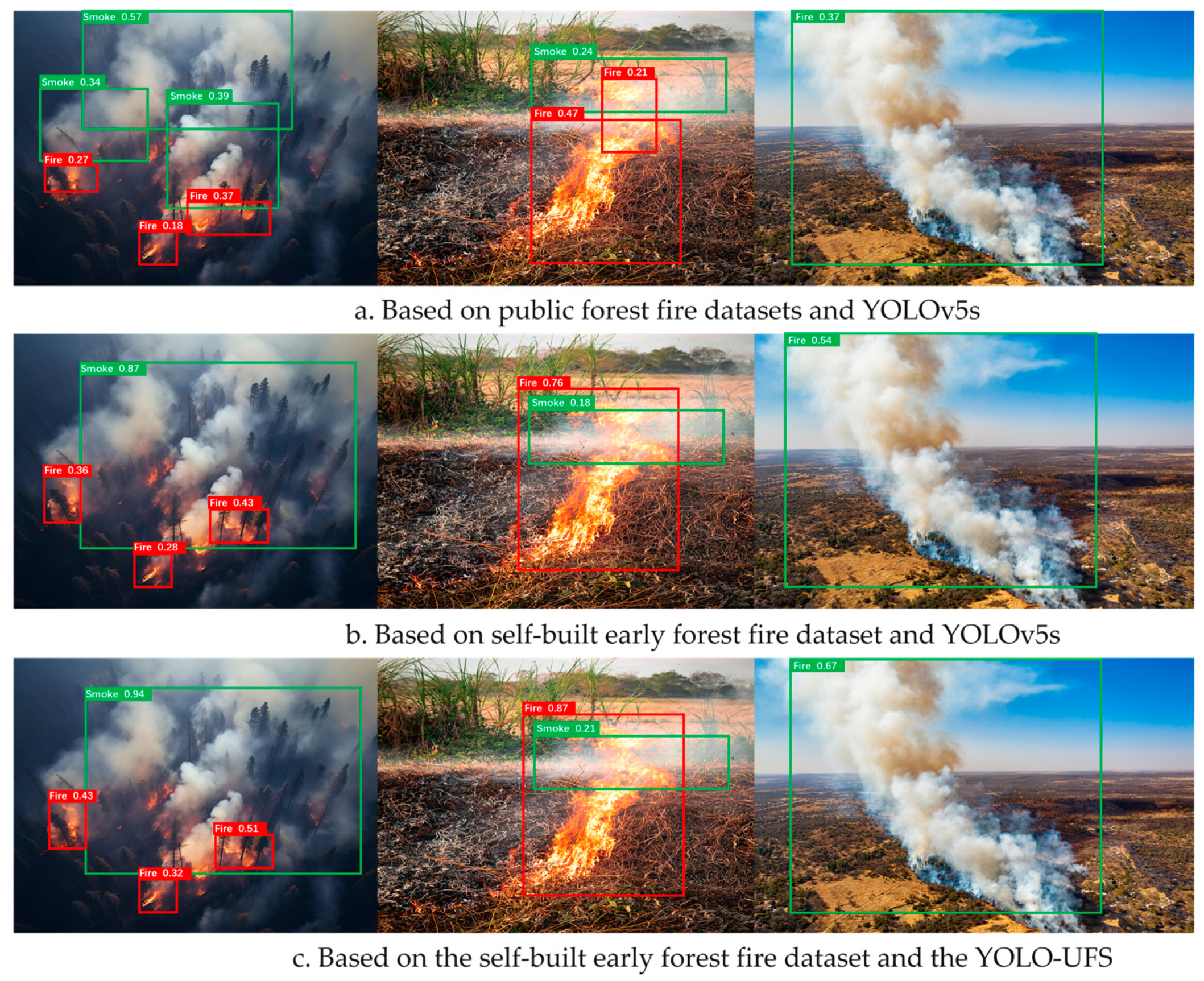
4. Visual Analysis and Discussion
4.1. Visual Analysis
4.2. Discussion of Future Work
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cui, R.K.; Qian, L.H.; Wang, Q.H. Research progress on fire protection function evaluation of forest road network. World For. Res. 2023, 36, 32–37. [Google Scholar]
- National Bureau of Statistics. Statistical Bulletin of the People’s Republic of China on National Economic and Social Development for 2023. 2024. Available online: https://www.stats.gov.cn/sj/zxfb/202402/t20240228_1947915.html (accessed on 4 November 2024).
- Abid, F. A survey of machine learning algorithms based forest fires prediction and detection systems. Fire Technol. 2021, 57, 559–590. [Google Scholar] [CrossRef]
- Alkhatib, A.A.A. A review on forest fire detection techniques. Int. J. Distrib. Sens. Netw. 2014, 10, 597368. [Google Scholar] [CrossRef]
- Bao, C.; Cao, J.; Hao, Q.; Cheng, Y.; Ning, Y.; Zhao, T. Dual-YOLO architecture from infrared and visible images for object detection. Sensors 2023, 23, 2934. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Gao, D.; Lin, H.; Sun, Q. Wildfire detection using sound spectrum analysis based on the internet of things. Sensors 2019, 19, 5093. [Google Scholar] [CrossRef] [PubMed]
- Lai, X.L. Research and Design of Forest Fire Monitoring System Based on Data Fusion and Iradium Communication. Ph.D. Thesis, Beijing Forestry University, Beijing, China, 2015. [Google Scholar]
- Nan, Y.L.; Zhang, H.C.; Zheng, J.Q.; Yang, K.Q. Application of deep learning to forestry. World For. Res. 2021, 34, 87–90. [Google Scholar]
- Yuan, C.; Zhang, Y.M.; Liu, Z.X. A survey on technologies for automatic forest fire monitoring, detection, and fighting using unmanned aerial vehicles and remote sensing techniques. Can. J. For. Res. 2015, 45, 783–792. [Google Scholar] [CrossRef]
- Han, Z.S.; Fan, X.Q.; Fu, Q.; Ma, C.Y.; Zhang, D.D. Multi-source information fusion target detection from the perspective of unmanned aerial vehicle. Syst. Eng. Electron. Technol. 2025, 47, 52–61. Available online: https://link.cnki.net/urlid/11.2422.tn.20240430.1210.003 (accessed on 4 November 2024).
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A review on early forest fire detection systems using optical remote sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef]
- Li, D. The Research on Early Forest Fire Detection Algorithm Based on Deep Learning. Ph.D. Thesis, Central South University of Forestry & Technology, Changsha, China, 2023. [Google Scholar]
- Xue, Z.; Lin, H.; Wang, F. A small target forest fire detection model based on YOLOv5 improvement. Forests 2022, 13, 1332. [Google Scholar] [CrossRef]
- Zhao, L.; Zhi, L.; Zhao, C.; Zheng, W. Fire-YOLO: A small target object detection method for fire inspection. Sustainability 2022, 14, 4930. [Google Scholar] [CrossRef]
- Zu, X.P. Research on Forest Fire Smoke Recognition Method Based on Deep Learning. Ph.D. Thesis, Northeast Forestry University, Harbin, China, 2023. [Google Scholar]
- Su, X.D.; Hu, J.X.; Chenlin, Z.T.; Gao, H.J. Fire image detection algorithm for UAV based on improved YOLOv5. Comput. Meas. Control. 2023, 31, 41–47. [Google Scholar]
- Pi, J.; Liu, Y.H.; Li, J.H. Research on lightweight forest fire detection algorithm based on YOLOv5s. J. Graph. 2023, 44, 26–32. [Google Scholar]
- Wang, Y.; Li, J.; Chen, M. Hybrid Transformer-CNN architecture for enhanced forest fire detection. IEEE Trans. Ind. Inform. 2024, 20, 1345–1357. [Google Scholar]
- Chen, X.; Liu, Y.; Zhao, Q. Multi-modal fusion for early fire detection using infrared and visible images. Sensors 2024, 24, 3215–3227. [Google Scholar]
- Zhang, L.; Guo, S.; Sun, J. Adaptive YOLOv8 with dynamic attention mechanism for smoke detection in forest fires. IEEE Access 2025, 13, 102345–102359. [Google Scholar]
- Guo, H.; Deng, F.; Zhou, R. Self-supervised pre-training for improved small object detection in aerial fire monitoring. Neurocomputing 2025, 495, 443–455. [Google Scholar]
- Li, W.; Zhang, T.; Ma, F. Edge-cloud collaborative lightweight model for real-time forest fire detection. IEEE Internet Things J. 2024, 11, 3241–3252. [Google Scholar]
- Zhou, Q.; Sun, Y.; Tang, D. Federated learning based distributed fire detection system for forest environments. J. Netw. Comput. Appl. 2024, 186, 103133. [Google Scholar]
- He, J.; Liu, Z.; Wang, R. Adversarial training for robust YOLO-based detection in complex fire scenarios. Pattern Recognit. 2025, 121, 108055. [Google Scholar]
- Sun, X.; Sun, L.; Huang, Y. Forest fire smoke recognition based on convolutional neural network. J. For. Res. 2020, 32, 1921–1927. [Google Scholar] [CrossRef]
- Lu, K.; Huang, J.; Li, J.; Zhou, J.; Chen, X.; Liu, Y. MTL-FFDET: A multi-task learning-based model for forest fire detection. Forests 2022, 13, 1448. [Google Scholar] [CrossRef]
- Prema, C.E.; Vinsley, S.S.; Suresh, S. Multi-feature analysis of smoke in YUV color space for early forest fire detection. Fire Technol. 2016, 52, 1319–1342. [Google Scholar] [CrossRef]
- Xu, Y.Q.; Li, J.M.; Zhang, F.Q. A UAV-based forest fire patrol path planning strategy. Forests 2022, 13, 1952. [Google Scholar] [CrossRef]
- Zu, X.; Li, D. Forest fire smoke recognition method based on UAV images and improved YOLOv3-SPP algorithm. J. For. Eng. 2022, 7, 142–149. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Y.; Gong, C.; Chen, Y.; Yu, H. Applications of deep learning for dense scenes analysis in agriculture: A review. Sensors 2020, 20, 1520. [Google Scholar] [CrossRef]
- Bu, H.; Fang, X.; Yang, G. Object detection algorithm for remote sensing images based on multi-dimensional information interaction. J. Heilongjiang Inst. Technol. 2022, 22, 58–65. [Google Scholar] [CrossRef]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B.; et al. MobileNetV4: Universal models for the mobile ecosystem. arXiv 2024, arXiv:2404.10518. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Yang, Y. Research on Image Data Augmentation Method Based on Generative Adversarial Network. Ph.D. Thesis, Strategic Support Force Information Engineering University, Zhengzhou, China, 2022. [Google Scholar]
- Xiu, Y.; Zheng, X.; Sun, L.; Fang, Z. FreMix: Frequency-based Mixup for data augmentation. Wirel. Commun. Mob. Comput. 2022, 2022, 5323327. [Google Scholar] [CrossRef]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based attention module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Yao, X. Research on Airtight Water Inspection Method of Closed Container Based on Deep Separable Convolutional Neural Network. Ph.D. Thesis, Xijing University, Xi’an, China, 2022. [Google Scholar] [CrossRef]
- Tan, M.X.; Pang, R.M.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zand, M.; Etemad, A.; Greenspan, M. ObjectBox: From centers to boxes for anchor-free object detection. In Lecture Notes in Computer Science; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 390–406. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Sample Type | Number of Samples | Total | |
|---|---|---|---|---|
| Training set | Positive sample | only flames only smoke Flames, smoke coexist | 2720 1776 5980 | 10,476 |
| Validation set | Positive sample | only flames only smoke Flames, smoke coexist | 2181 1141 4098 | 7685 |
| Negative samples | 639 | 639 | ||
| Total | 18,800 | |||
| Method | mAP/% | Flops/G | Parameters/Piece |
|---|---|---|---|
| YOLOV3-Tiny | 79.7 | 13.2 | 8,849,182 |
| YOLOv5s | 87.7 | 15.8 | 7,015,519 |
| YOLOv8 | 89.2 | 28.4 | 11,126,358 |
| YOLOXs | 86.9 | 9.6 | 2,975,226 |
| YOLO-UFS | 91.3 | 4 | 1,525,465 |
| Number | ObjectBox | BiFPN | NAM | AF | C3- MNV4 | Weight/MB | Precision/% | Recall/% | mAP/% | FloPs/G | Parameters Piece |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 14.2 | 85.3 | 80.4 | 88.4 | 15.8 | 7,015,519 | |||||
| 2 | √ | 14.0 | 85.7 | 80.7 | 88.6 | 3.5 | 1,630,157 | ||||
| 3 | √ | 14.1 | 85.6 | 80.6 | 88.7 | 4.6 | 1,685,145 | ||||
| 4 | √ | 14.1 | 85.4 | 80.5 | 88.6 | 4.3 | 1,944,973 | ||||
| 5 | √ | 14.0 | 86.2 | 81.3 | 88.8 | 5.3 | 5,015,519 | ||||
| 6 | √ | 14.0 | 87.8 | 81.2 | 89.2 | 4.4 | 1,014,517 | ||||
| 7 | √ | √ | 14.2 | 85.4 | 80.7 | 88.4 | 3.8 | 1,447,897 | |||
| 8 | √ | √ | 14.0 | 87.1 | 80.6 | 88.6 | 4.5 | 1,944,973 | |||
| 9 | √ | √ | 14.1 | 88.3 | 82.3 | 90.4 | 4.3 | 3,499,378 | |||
| 10 | √ | √ | √ | 14.1 | 88.4 | 81.6 | 90.6 | 3.9 | 1,447,897 | ||
| 11 | √ | √ | √ | 14.1 | 87.8 | 81.4 | 90.3 | 4 | 1,525,465 | ||
| 12 | √ | √ | √ | 14.2 | 88.2 | 82.6 | 91.4 | 4 | 1,477,634 | ||
| 13 | √ | √ | √ | √ | √ | 14.0 | 88.6 | 83.7 | 91.3 | 4 | 1,525,465 |
| Method | Weight/MB | Enter a Size | Precision/% | Recall/% | Mean of Average Accuracy/% | F1 | Recognition Rate/(Frame × s−1) |
|---|---|---|---|---|---|---|---|
| YOLOv3 | 120.5 | 640 | 70.9 | 59.9 | 63.1 | 64.9 | 39.7 |
| YOLOv4 | 18.1 | 640 | 73.2 | 59.3 | 64.4 | 65.5 | 71.0 |
| YOLOv5s | 14.2 | 640 | 75.4 | 57.3 | 62.3 | 65.1 | 85.6 |
| YOLOv7 | 135.0 | 640 | 76.2 | 52.9 | 79.4 | 62.4 | 35.3 |
| YOLOX | 15.5 | 640 | 74.2 | 53.5 | 77.4 | 62.2 | 169.5 |
| YOLO-UFS | 14.0 | 640 | 74.9 | 58.7 | 82.3 | 65.8 | 172.4 |
| Model | PA-S | PA-M | PA-L | RA-S | RA-M | RA-L |
|---|---|---|---|---|---|---|
| YOLOv5s | 18.3 | 27.0 | 22.1 | 30.7 | 43.8 | 27.6 |
| YOLO-UFS | 23.8 | 29.8 | 27.6 | 34.2 | 47.2 | 37.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Z.; Xu, H.; Xing, Y.; Zhu, C.; Jiao, Z.; Cui, C. YOLO-UFS: A Novel Detection Model for UAVs to Detect Early Forest Fires. Forests 2025, 16, 743. https://doi.org/10.3390/f16050743
Luo Z, Xu H, Xing Y, Zhu C, Jiao Z, Cui C. YOLO-UFS: A Novel Detection Model for UAVs to Detect Early Forest Fires. Forests. 2025; 16(5):743. https://doi.org/10.3390/f16050743
Chicago/Turabian StyleLuo, Zitong, Haining Xu, Yanqiu Xing, Chuanhao Zhu, Zhupeng Jiao, and Chengguo Cui. 2025. "YOLO-UFS: A Novel Detection Model for UAVs to Detect Early Forest Fires" Forests 16, no. 5: 743. https://doi.org/10.3390/f16050743
APA StyleLuo, Z., Xu, H., Xing, Y., Zhu, C., Jiao, Z., & Cui, C. (2025). YOLO-UFS: A Novel Detection Model for UAVs to Detect Early Forest Fires. Forests, 16(5), 743. https://doi.org/10.3390/f16050743