1. Introduction
Forest fires cause serious damage to ecosystems and infrastructure and also cause casualties. Forest fire monitoring can help people find and extinguish fires in the early stages of a fire, prevent the spread of a fire, and greatly reduce the cost and loss of firefighting [
1]. Early forest fire monitoring methods mainly rely on manual patrols, observation posts, and manual alarms. These methods are simple to operate but the monitoring scope is limited, and there are risks of response delays and false alarms [
2]. At the end of the 20th century and the beginning of the 21st century, fire monitoring technology based on computer vision began to be studied. Fire monitoring methods based on computer vision can be divided into traditional image processing-based methods and deep learning-based methods [
3]. Traditional image processing methods are mainly based on three features: color [
4], motion [
5], and geometric features [
6,
7]. The above methods based on color, motion, and geometric features have the problems of low accuracy, high false alarm rate, and the inability to detect long-distance or small-scale fires. In addition, image processing methods require a lot of prior knowledge, complex feature engineering, and tedious operations, and the robustness of the models is poor.
In recent years, CNNs based on deep learning have achieved good results in image classification and target monitoring [
8]. Different from the traditional fire monitoring technology based on image processing, CNNs can automatically extract and learn complex features, reducing the need for manual feature engineering. At present, many CNNs have been applied to fire monitoring tasks, and significant progress has been made in improving detection accuracy [
9]. Khan et al. [
10] proposed a forest fire detection method, FFireNet, based on deep learning. This method uses a MobileNetV2 pre-training convolution layer and adds a full connection layer to achieve a classification accuracy of 97.42%, which is excellent in fire and non-fire image classification. While this approach benefits from MobileNetV2’s efficient depthwise separable convolutions, its reliance on the full MobileNetV2 backbone results in relatively high computational complexity, making real-time execution challenging on resource-constrained edge devices. Moreover, the study focused solely on binary fire/non-fire classification, limiting its applicability in scenarios requiring smoke detection—a critical feature for early forest fire warning systems. Peng et al. [
11] proposed a smoke monitoring algorithm combining manual features and deep learning features, which can distinguish smoke from non-smoke, which is easily confused, and achieved an accuracy of 97.12% in the test set. The hybrid design enhances interpretability through manual features while maintaining the representational power of deep learning. However, the manual feature engineering component increases development complexity and may lack adaptability to new environments. Additionally, the computational overhead of extracting dual feature sets limits real-time performance, making it impractical for large-scale sensor networks. Zhang et al. [
12] proposed an ATT Squeeze U-Net based on U-Net and SqueezeNet, achieving 93% recognition accuracy. The attention modules effectively highlight fire-related regions while suppressing background interference. However, the accuracy remains lower than other contemporary approaches, particularly in challenging scenarios with small or occluded fire regions. Compared with the early fire monitoring method, the fire monitoring method based on CNNs has higher accuracy and robustness, especially suitable for dealing with complex forest fire scenarios.
Although CNNs are considered to be the best model for monitoring forest fire events [
13], their computing-intensive and memory-intensive characteristics limit their direct deployment on edge devices with limited resources. Most CNN-based forest fire monitoring systems have high hardware requirements [
14]. Currently, most CNN-based fire monitoring systems adopt an “edge collection + cloud computing” approach, where edge devices collect fire images and transmit data to cloud servers for analysis and recognition [
15]. The literature [
16] points out that if a large number of edge devices are added, a large amount of terminal data will be transmitted to the cloud for processing, and the data transmission performance will be reduced, eventually leading to a significant increase in data transmission delay and energy consumption. Edge cloud architecture makes use of the powerful computing power of the cloud and can handle complex CNN models. However, because the forest fire monitoring environment is a field with poor network conditions, the delay of data transmissions and the uncontrollability of the network will lead to the reduced recognition effect. In addition to the “edge cloud architecture”, Ref. [
17] also proposed another edge deployment scheme for CNNs, that is, using UAVs (Unmanned Aerial Vehicles) to deploy CNNs. The reason why the UAV can realize CNN edge computing is that the UAV is equipped with a high-performance processor, and the CNN algorithm can be directly deployed on the UAV platform, which solves the above problems of CNN deployment. However, this scheme is expensive, not suitable for promotion, and cannot achieve intensive deployment. It is only suitable for fire monitoring after fire detection and cannot achieve long-term monitoring effects. Therefore, research on how to use a CNN forest fire monitoring algorithm to quickly execute in low-cost, performance-constrained edge terminals is the key to promoting the application of a CNN model in forest fire monitoring.
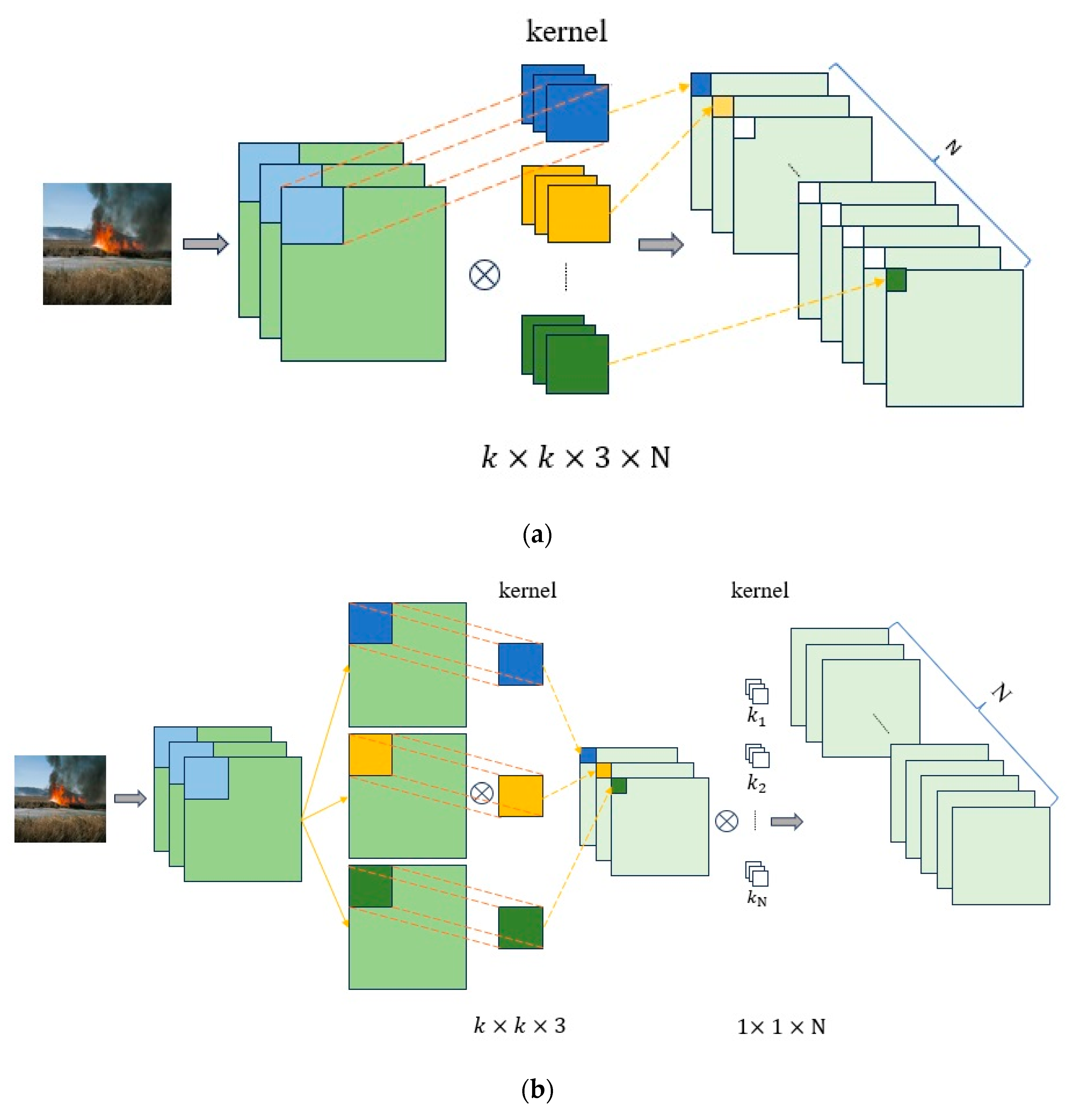
The key to deploying the CNN model in resource-constrained edge devices is to design lightweight CNNs. In recent years, more and more lightweight networks have been explored, such as MobileNet [
18], SqueezeNet [
19], and ShuffleNet [
20]. Almida et al. [
21] proposed a new lightweight CNN model EdgeFireSmoke, which can detect wildfires through RGB (red, green, blue) images and can be used to monitor wildfires through aerial images of UAVs (Unmanned Aerial Vehicles) and video surveillance systems. The classification time is about 30 ms per frame, and the accuracy rate is 98.97%. Wang et al. [
22] proposed a lightweight fire detection algorithm based on the improved Pruned + KD model, which has the advantages of fewer model parameters, low memory requirements, and fast reasoning speed.
In addition to lightweight model design, hardware acceleration is also an effective way to solve the bottleneck of CNN computing. As a common hardware acceleration device, GPU has strong parallel computing capability, which can significantly improve the speed of fire recognition. However, the high power consumption and high cost of GPU limit its application in long-term field monitoring. In contrast, FPGA, with its advantages of low power consumption, small size, and high customizability, has gradually become an ideal choice for accelerating CNNs in edge environments [
23]. FPGA can optimize the calculation process of CNNs through a hardware circuit, realize high parallel calculation, and achieve an acceleration effect close to GPU under low power consumption [
24]. Although FPGA acceleration technology has significant advantages, it also faces the challenge of resource constraints. Due to the limited resources in a FPGA chip, the ability of a single FPGA to accelerate a complex CNN model is limited, and the model design needs to make trade-offs between resource allocation and optimization. Therefore, we have to simplify the model or adopt a more efficient hardware design to ensure that the model can run normally on an FPGA and achieve the expected performance goals.
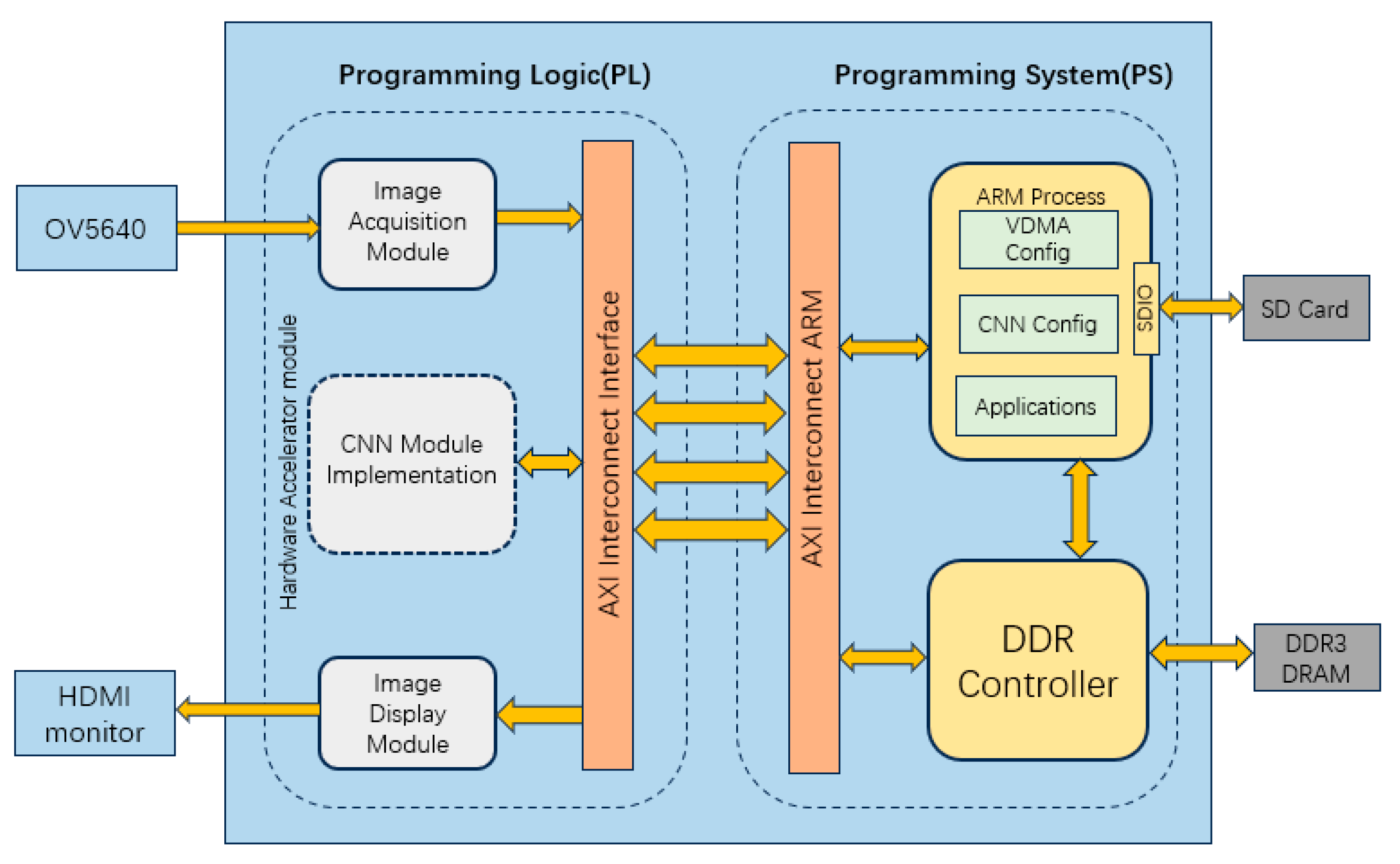
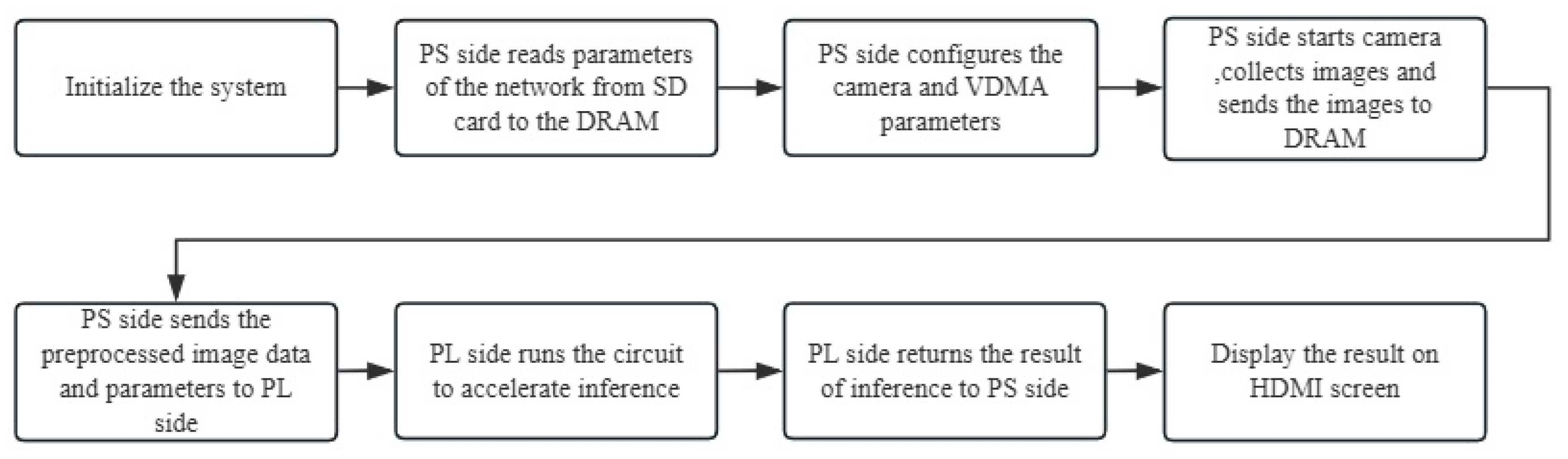
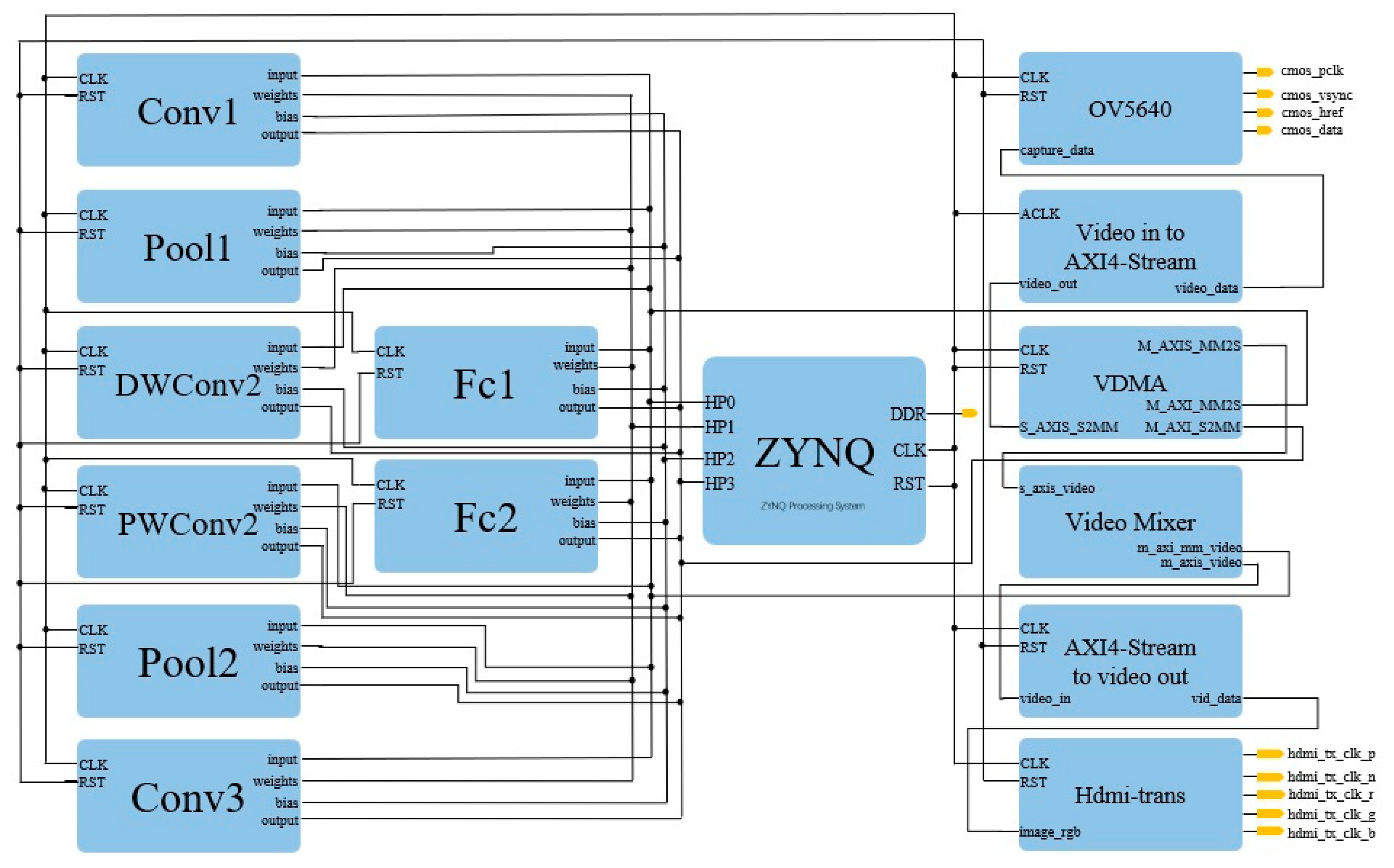
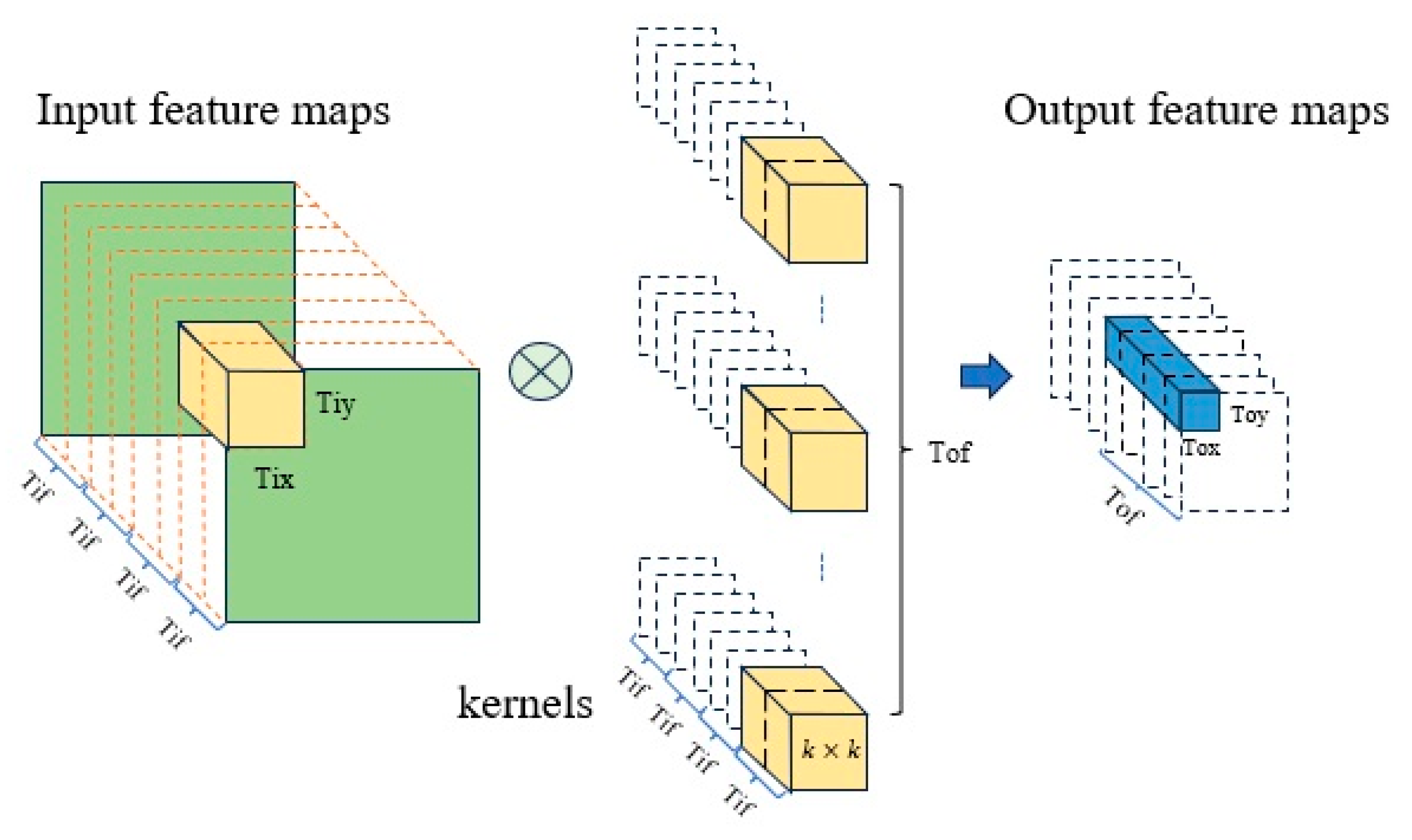
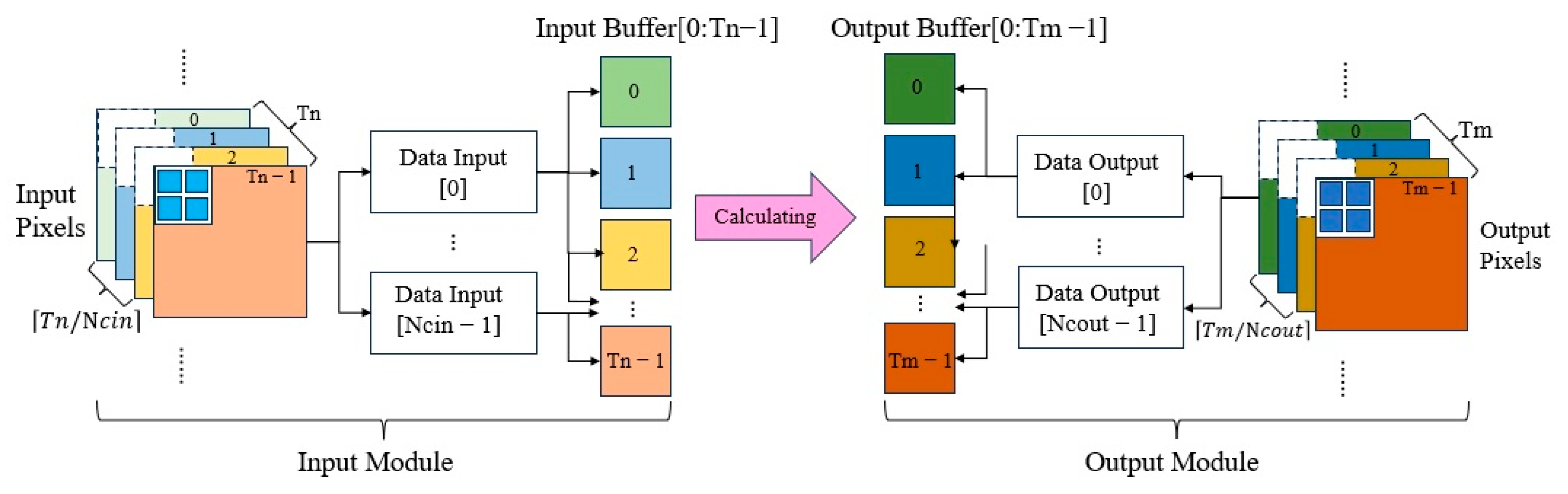
To address these challenges, we propose a FPGA-accelerated lightweight CNN framework for forest fire recognition. Our solution combines two key innovations: (1) a compact network architecture designed with hardware efficiency in mind, leveraging depthwise separable convolution and knowledge distillation to maintain accuracy while minimizing computational complexity; (2) a hardware–software co-design approach that optimizes the FPGA implementation through parallel computing strategies (e.g., a loop tiling ping-pong buffer) and memory access optimization.
The main contributions of this work include:
A novel lightweight CNN model tailored for edge deployment in forest fire monitoring.
An optimized FPGA acceleration framework that bridges the gap between algorithmic efficiency and hardware constraints.
Comprehensive evaluation comparing the proposed system with alternative computing platforms.
The remainder of this paper is organized as follows:
Section 2 describes the materials and methodology,
Section 3 presents the experimental results, and
Section 4 discusses the implications and future work.
3. Results
3.1. Evaluation Metrics
In order to evaluate the recognition effect of LightFireNet in identifying a forest fire, seven indicators—model size, parameter quantity, calculation quantity, recall rate, accuracy, accuracy, and F1 score—were selected. The details are as follows:
Recall is the ratio of the number of correctly detected positive samples to the total number of positive samples and is given by the following equation:
Precision is the ratio of the number of positive samples correctly detected to the total number of negative samples detected and is given by the following equation:
Accuracy is the most commonly used performance evaluation metric to measure the overall performance of a model. It represents the ratio of the number of correctly detected samples to the total number of datasets and is given by the following equation:
where
TP denotes true positive,
TN denotes true negative,
FP denotes false positive, and
FN denotes false negative. The
F1 score, which is a metric used to comprehensively assess recall and precision, can be calculated using the following equation:
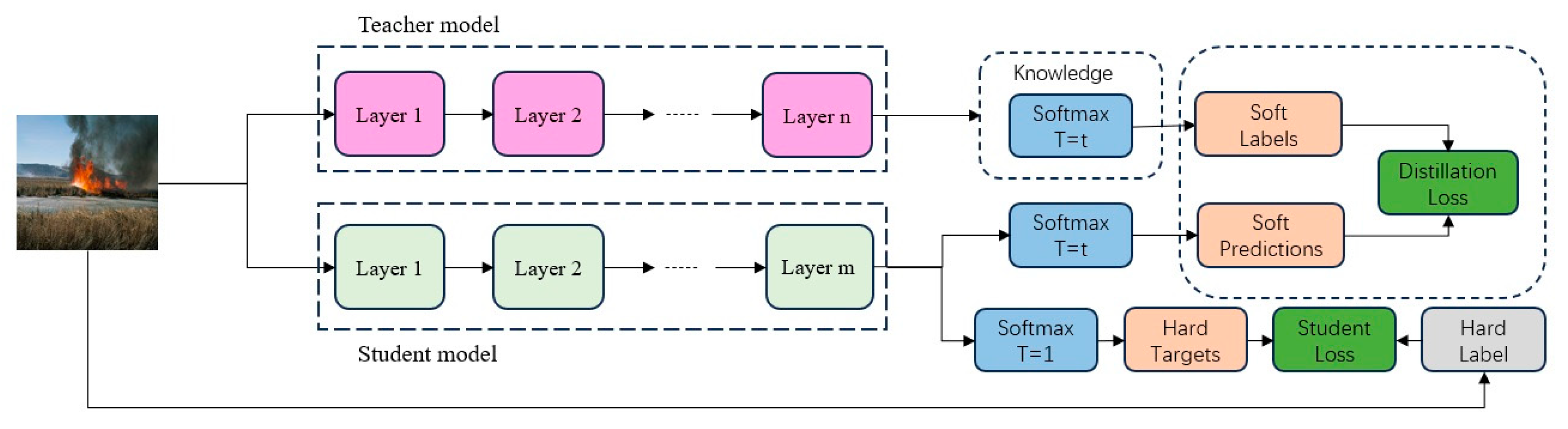
3.2. Knowledge Distillation Experimental Results
To ensure the accuracy of LightFireNet, the teacher model was chosen to supervise the training of its fire recognition model. The baseline models were selected to cover diverse architectures (deep networks for high-accuracy and lightweight networks for edge compatibility) and their proven effectiveness in image classification tasks. Experiments were conducted to compare the performance of various classical networks (including GoogLeNet [
32], ResNet [
33], MobileNet, SqueezeNet, ShuffleNet, EfficientNet [
34], and InceptionV3 [
35]) on the selected fire dataset, where GoogLeNet and ResNet are deep CNNs commonly used for complex classification tasks, while SqueezeNet, ShuffleNet, MobileNet, and EfficientNet are lightweight networks commonly used for mobile devices.
Table 3 shows the performance of various network models on the fire dataset.
It can be seen from
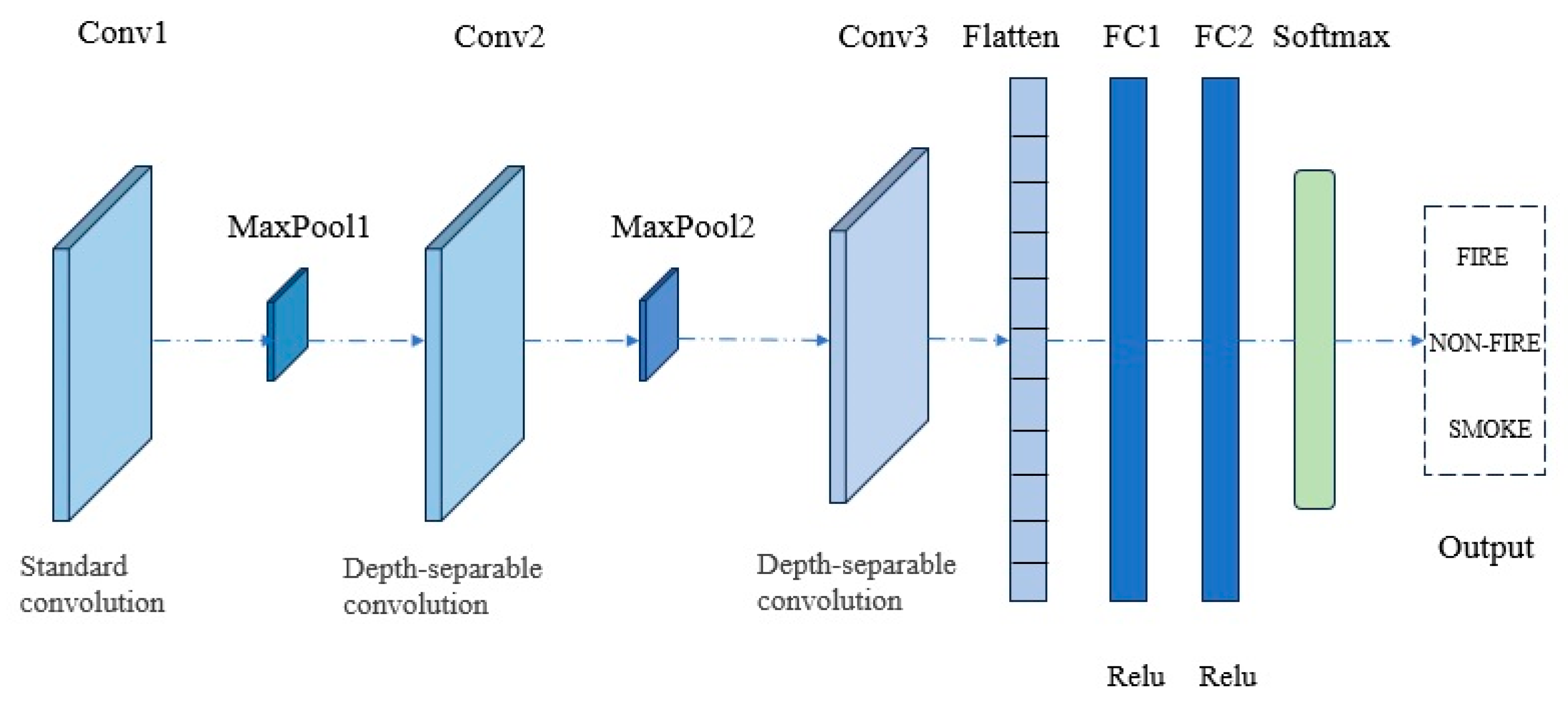
Table 3 that ResNet-50 has the best recognition effect, with an F1 score of 98.89%, followed by MobileNet-V2 and GoogLeNet, with F1 scores of 97.76%. Therefore, ResNet-50 was selected as the teacher network supervision for LightFireNet training. The accuracy of LightFireNet after the final knowledge distillation was 97.60%, and the F1 score was 97.60%. The recognition effect was improved compared with that before the knowledge distillation. It is worth noting that in our dataset, the recognition effect of MobileNet-V2 as a lightweight network is almost the same as that of GoogLeNet, a deep CNN, but the amount of parameters and calculations is much smaller than that of GoogLeNet. This is also the reason why LightFireNet adopts the same convolution method (depth-separable convolution) as MobileNet-V2 in its convolution layer design. After knowledge distillation, the parameter quantity of LightFireNet is only 1‰ of ResNet-50, and the calculation quantity is only 1.2% of ResNet50.
3.3. Forest Fire Recognition Effect of LightFireNet
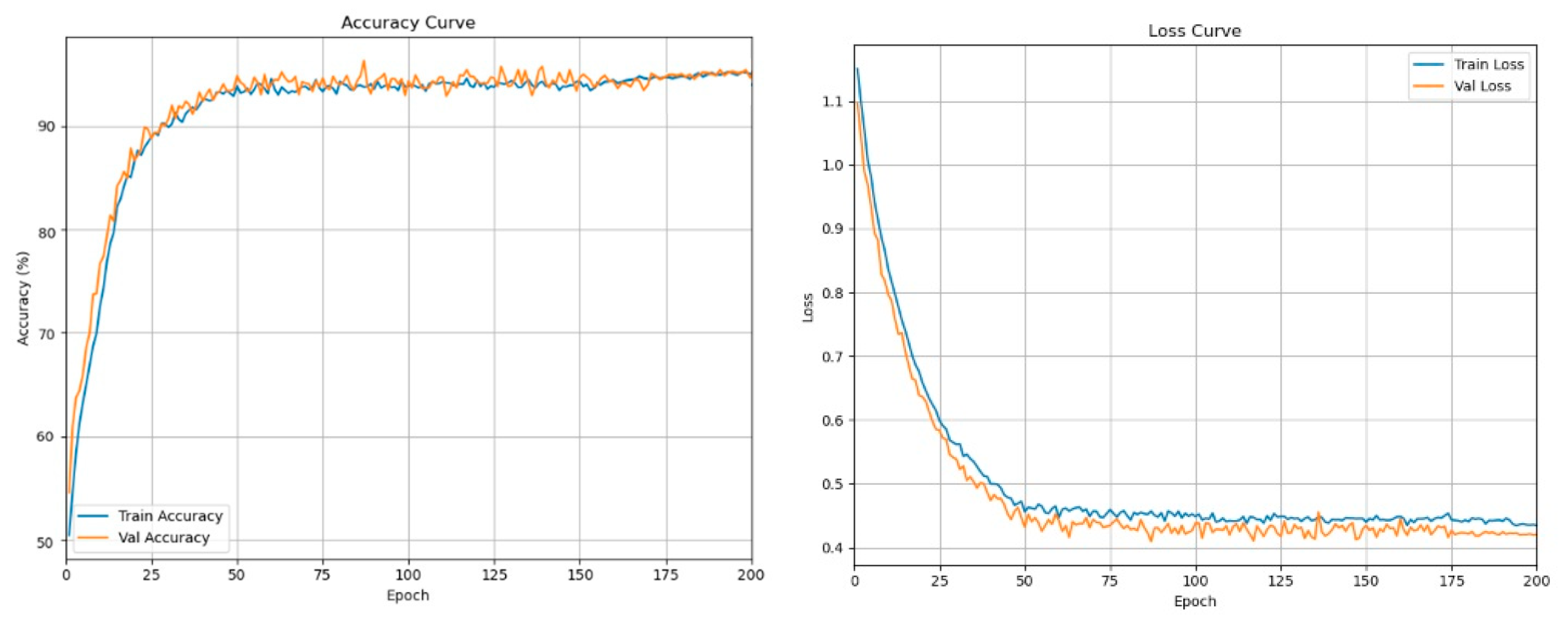
Figure 14 illustrates the training and validation curves, where both accuracy curves converge closely and loss curves decline steadily without divergence, indicating no overfitting. The recognition effect of LightFireNet on the test set is shown in
Figure 15. It can be seen from the confusion matrix that the classification performance of the LightFireNet model on the test set is excellent. The model shows high accuracy in distinguishing fire, non-fire, and smoke, and can effectively realize the function of fire monitoring in a complex outdoor environment.
All recognition results and error analyses presented in this section are based on the 3 × 96 × 96 input size determined through our spatial resolution experiments in
Section 3.4. This resolution was selected as the optimal balance between recognition accuracy and hardware deployment constraints, as detailed in
Section 3.4 and
Section 3.5.
Figure 16 shows an example of the wrong image of the LightFireNet model for the classification of outdoor forest fire smoke. The first three “fire” pictures are predicted to be “non-fire” or “smoke”, which may be because the flame is partially obscured by smoke or the flame intensity is not enough to enable the model to extract significant features. The most obvious feature is that the proportion of the flame area in the picture is very small, while the proportion of the smoke area is very large, which causes the model to learn more about the characteristics of smoke. The same situation occurs in the “smoke” picture. Some scenes with thick smoke are wrongly classified as “fire”. It may be that the texture of smoke in the image is similar to that of fire, which leads to model confusion. In addition, the fourth “non-fire” scene was mistakenly predicted as a “smoke” category, which may be because the background in these images, such as remote haze, clouds, etc., is relatively similar to the smoke characteristics, leading to the inability of the model to distinguish correctly. From the misclassified examples in
Figure 16, it is evident that the model occasionally struggles with highly ambiguous scenarios, such as smoke-obscured flames or scenes where smoke resembles clouds or haze. These cases are inherently challenging even for human observers, as the visual features of fire and smoke often overlap in complex environments. Despite these edge cases, LightFireNet achieves an accuracy of 97.60%, demonstrating robust performance in distinguishing fire, smoke, and non-fire scenes—a significant improvement over traditional binary classification approaches. This high accuracy, combined with the model’s lightweight design, validates its suitability for real-world forest fire monitoring.
3.4. Impact of Input Image Size on Model
In order to determine the impact of different input sizes on the recognition effect of LightFireNet, we conducted a comparative experiment with different input sizes. The experimental results are shown in
Table 4. The experimental results show that when the input size is set to 3 × 48 × 48, the recognition effect of the network is the worst, and the accuracy is less than 96%. When the input size is set to 3 × 128 × 128, the recognition effect of the network is the best, with an accuracy rate of 98.25% and an F1 score of 98.23%. However, when the input size is further increased to 3 × 224 × 224, the recognition accuracy is not further improved but the model parameters and computational complexity are significantly increased, which is not conducive to the deployment of lightweight models on edge devices. We chose 3 × 96 × 96 as the final input size. The recognition accuracy, precision recall rate, and F1 score of this size are less than 0.7 percentage points lower than those of 3 × 128 × 128 but the parameter amount is only 17% of the latter, and the calculation amount is only 55% of the latter. The final selection of 3 × 96 × 96 as the input size is based on the comprehensive consideration of the accuracy of the model and the balance of computing resource consumption. This size meets the computing power limit of the FPGA platform while achieving a better fire recognition effect.
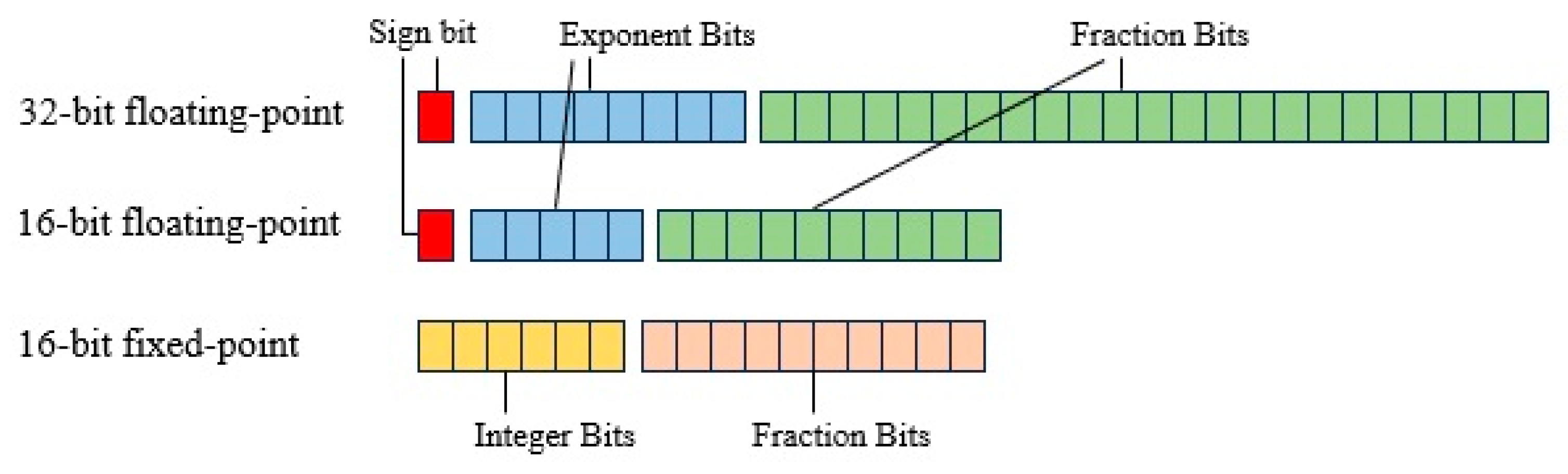
3.5. The Influence of Data Quantization on LightFireNet Hardware Circuit
In order to study the influence of different data types on the LightFireNet hardware circuit, we conducted experiments on three data types: single-precision floating point (32-bits), half-precision floating point (16-bits), and 16-bit fixed-point ap_fixed16. The experimental results show that when the data type is float32, the resource required by the optimized LightFireNet hardware circuit greatly exceeds the maximum resource provided by FPGA, so it cannot be successfully deployed in the specified FPGA. The half type and ap_fixed type can successfully accelerate FPGA implementation.
Table 5 shows the resource consumption of three data types of LightFireNet circuits. The difference between the half type and ap_fixed fixed-point digital type in DSP, FF, and LUT consumption is relatively small.
Table 5 shows that in terms of model accuracy, the accuracy of the half type is 97.48%, and that of the ap_fixed type is 96.70%. Although the accuracy of the ap_fixed16 type is slightly lower than that of the half type, its resource consumption is lower. Considering the accuracy and resource consumption of the model, the ap_fixed16 type performs better in the FPGA.
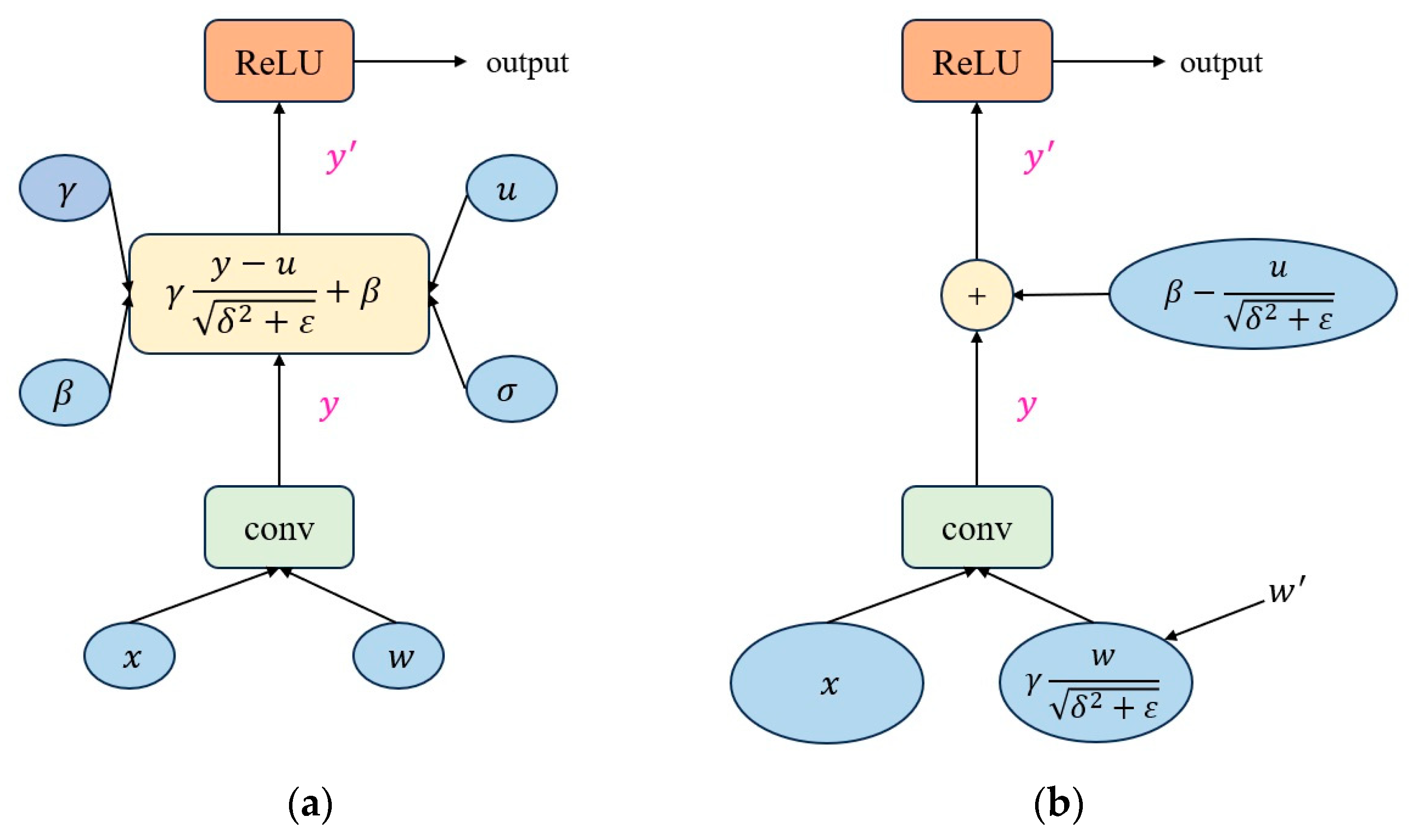
3.6. Influence of Traditional Convolution and Depth-Separable Convolution on Complexity and Accuracy of Forest Fire Recognition Network
In order to optimize the computational complexity and model performance of LightFireNet, we compared the impact of Conventional Convolution and Separate Convolution on the recognition network. The results are shown in
Table 6. The experimental results showed that the use of depth-separable convolution significantly reduces the amount of parameters and computation of the model while maintaining a high recognition accuracy. Among them, the size of the LightFireNet model implemented by Conventional Revolution is 0.64 MB, the number of parameters is 0.17 M, and the calculation amount is 21.21 M times. However, the size, parameter amount, and calculation amount of the LightFireNet model of Separate Revolution are far smaller than the former, which are 0.024 M, 0.09 M, and 9.11 M times, respectively. In terms of the recognition effect, the accuracy rate of depth-separable convolution is only 0.35 percentage points lower than that of traditional convolution, and the F1 score is only 0.36 percentage points lower than that of traditional convolution. Although the recognition effect has slightly declined, the decline is small and has a limited impact on the performance in practical applications.
3.7. Influence of Loop Tiling Processing on LightFireNet Convolution Layer Circuits
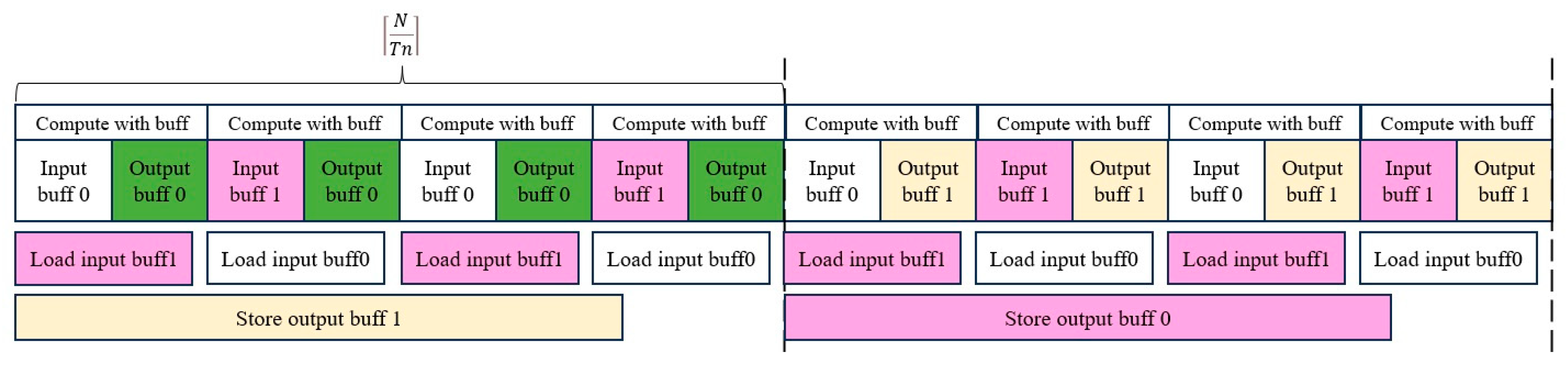
Table 7 shows the impact of loop tiling on LightFireNet convolution layer circuits. Taking depthwise separable convolution as an example, when loop tiling is not used, the hardware resources consumed by convolution layer circuits include BRAM_18K: 26, DSP: 12, FF: 7557, and LUT: 7086. At this time, the delay of the convolution layer circuit is 5.55 Mcycles. When the loop tiling strategy is adopted, the hardware resources consumed by the convolution layer circuit increase significantly, which include BRAM_18K: 62, DSP: 51, FF: 16,549, and LUT: 22,506, in which the DSP usage of the latter is about four times that of the former, but at this time, the delay of the convolutional layer circuit is 0.33 Mcycles, which is 94.1% lower than that of the circuit without loop tiling. The loop tiling strategy makes full use of the limited resources of FPGA; cooperates with cyclic switching, the ping-pong buffer, and other technologies to exchange resources for time; greatly reduces the delay of convolution circuit; and speeds up the recognition process of forest fires.
3.8. Comparison of Forest Fire Recognition Effect Between FPGA and Other Devices (CPU, GPU, Raspberry Pie)
In this study, the processing effects of different computing platforms on forest fire recognition tasks were compared and analyzed. By comparing FPGA with a traditional central processing unit (CPU), graphics processing unit (GPU), and embedded system (such as raspberry pie), its performance in forest fire recognition was evaluated. The specific results are shown in
Table 8. The CPU is a laptop computer and the GPU is mounted on the CPU, forming a “GPU+CPU” graphic workstation. See the table notes for the specific models of each device.
First of all, the accuracy rate of FPGA is 96.70%, and that of other platforms is 97.60. This is because the network implemented by all devices is LightFireNet, while FPGA uses ap_fixed16-type data, and devices other than FPGA use float-type data. However, in other performance indicators, FPGA shows obvious advantages. In terms of processing speed, the recognition delay of FPGA is only 64 ms. Compared with 1 ms of CPU, 0.3 ms of GPU+CPU, 230 ms of Raspberry Pie, and 10 ms of Android, the speed performance of FPGA is at a medium level. However, in terms of power consumption, the energy efficiency performance of FPGA is excellent, and the power consumption is only 2.23 W. Compared with 35.8 W of CPU and 28.5 W of GPU+CPU, the low power consumption characteristics of FPGA make it have obvious application advantages in edge devices. Raspberry pie and Android are also competitive in terms of power consumption, which are 4.2 W and 4.86 W, respectively. Raspberry pie reasoning speed is significantly slower than FPGA, and Android device reasoning speed is faster than FPGA. The power consumption data are the instantaneous power during forest fire recognition, including GPU+CPU. The power of raspberry pie and Android is measured by HWiNFO software (Version 8.16-5600), and the power consumption of FPGA edge devices is directly measured by a power meter. In addition, in terms of price, FPGA and raspberry pie are more affordable than CPU, GPU+CPU, Android, and other high-performance computing platforms. FPGA is only CNY 850, while raspberry pie costs only CNY 300. The accuracy rate of FPGA in forest fire recognition is equivalent to that of CPU, GPU, and Android but it has the lowest power consumption, a smaller size, and stronger portability and mobility. Compared with raspberry pie, FPGA has similar portability and a slightly higher price but it has more advantages in power consumption and disease recognition speed. Overall, FPGA is superior to other devices in speed, accuracy, power consumption, portability, and price and is suitable for real-time forest fire recognition as an edge device in complex field environments.
3.9. Performance Testing Under Real Fire Video Conditions
To validate the effectiveness of the proposed FPGA-accelerated LightFireNet model in real-world scenarios, we conducted experiments using three real fire videos collected from online sources, which documented actual forest fire incidents and normal forest scenes. These raw videos were categorized and edited into three 30 s clips (30 fps) representing fire, non-fire, and smoke scenarios, respectively. Each processed video contains 900 frames in total. Due to the recognition speed of the FPGA device (64 ms per frame), the system processes every other frame to ensure real-time performance. Thus, out of 900 frames, 450 frames were actually recognized, achieving a practical recognition rate of 15 fps (450 frames/30 s). This demonstrates that the system can meet the real-time monitoring requirements for forest fires.
The experimental results are shown in
Table 9. The accuracy of the system was calculated based on the correctly recognized frames. The results indicate that the proposed method maintains high accuracy even under real fire conditions, further validating its practical applicability.
The results demonstrate that the FPGA-accelerated LightFireNet model achieves an average accuracy of 98.00% across the three video categories, with fire recognition at 98.44%, non-fire at 98.89%, and smoke at 96.67%. These values are consistent with the performance on the test dataset (
Section 3.3), confirming the robustness of the system in real-world scenarios. The high recognition accuracy for fire and non-fire categories can be attributed to two factors: (1) the inherent strong performance of the LightFireNet model as demonstrated in
Section 3.3 and (2) the relatively stable scenes in these test videos with limited background variations. Notably, most misclassifications occurred in Video 3 (smoke category), where scenes containing both smoke and fire were frequently identified as “fire”—a pattern consistent with the error cases analyzed in
Section 3.3 (
Figure 16). These results validate the practical effectiveness of the FPGA-based forest fire recognition system while highlighting its tendency to prioritize fire detection in ambiguous smoke-fire scenarios, which aligns with the safety-critical nature of fire monitoring applications.
4. Discussion
The experimental results demonstrate that the proposed LightFireNet framework achieves an accuracy of 96.70% in the FPGA, with a processing speed of 64 ms per frame and a power consumption of only 2.23 W. These metrics highlight the effectiveness of the lightweight CNN design and FPGA acceleration in balancing computational efficiency and recognition performance. The success of this approach stems from several key innovations, including depthwise separable convolution, knowledge distillation, and hardware-aware optimizations such as loop tiling and data quantization. By reducing the model parameters to just 24 K and computations to 9.11 M, LightFireNet proves suitable for deployment in resource-constrained edge devices, offering a practical alternative to cloud-based or high-power GPU solutions.
The FPGA-accelerated LightFireNet framework presents significant practical value for forest science and management, particularly in the context of early fire detection and ecological monitoring. Its lightweight and low-power design enables flexible deployment across diverse environments, including forest watchtowers, tree canopies, and high-rise buildings. Due to its low cost, the system can be densely deployed to achieve large-scale, real-time monitoring of forest areas, addressing the limitations of traditional manual patrols and observation posts. Unlike cloud-based solutions that require high-bandwidth data transmission, this edge-computing approach minimizes the reliance on network connectivity—a critical advantage in remote forest areas with poor communication infrastructure. By processing data locally on FPGA devices, only the recognition results (e.g., fire alerts) need to be transmitted to central servers, significantly reducing latency and energy consumption while ensuring timely fire detection.
While IoT-based systems are valuable for large-scale environmental monitoring, they often face challenges such as high data transmission delays and dependency on stable network conditions. The proposed FPGA-accelerated solution complements IoT frameworks by offloading computationally intensive tasks to edge devices, thereby alleviating the storage and computing burdens typically associated with centralized systems. This hybrid approach enhances the scalability and responsiveness of forest fire monitoring systems, making them more adaptable to dynamic field conditions.
The fixed architecture of LightFireNet allows for easy updates by simply replacing the parameters stored on the SD card, without requiring hardware modifications. This feature ensures long-term adaptability to evolving monitoring needs, such as integrating additional sensors (e.g., thermal or infrared cameras) to improve detection robustness under varying environmental conditions. Future work could explore automated parameter updates and edge–cloud collaboration to further optimize performance.
Despite its advantages, the current implementation has limitations, such as a slight accuracy drop due to fixed-point quantization, which may affect performance in edge cases like heavily obscured fires. Future research could investigate hybrid quantization strategies or multi-modal data fusion to enhance detection accuracy. Additionally, real-world field testing is needed to validate the system’s reliability under extreme weather conditions or long-term operational stress.
5. Conclusions
This study bridges the gap between computer science innovations and practical forest management needs by providing a cost-effective, energy-efficient solution for early fire detection. The methodologies developed here can also be extended to other ecological applications, such as biodiversity monitoring or tree health assessment, contributing to the broader goals of sustainable forest management and conservation. By combining edge computing with lightweight AI, this work lays the foundation for scalable, intelligent monitoring systems tailored to the challenges of modern forestry.
Beyond its technical contributions, this work addresses critical challenges in forest management by providing a low-cost, energy-efficient solution for early fire detection, particularly in areas with unreliable network connectivity. While IoT systems play a valuable role in large-scale monitoring, our approach prioritizes edge computing to ensure real-time responsiveness, offering a complementary solution that can operate independently or within broader IoT networks. The methodologies developed here, including model compression and hardware acceleration techniques, are not limited to fire detection; they can be adapted to other ecological applications such as biodiversity monitoring or tree health assessment, extending their impact across environmental research.
Looking ahead, future work will explore hybrid architectures combining FPGA efficiency with IoT scalability, as well as multi-modal sensor integration, to enhance detection robustness. We aim to foster collaboration between computer scientists and forest researchers, ensuring that these innovations translate into tangible benefits for wildfire prevention and ecosystem conservation. This study underscores the potential of lightweight, edge-optimized AI to transform forest monitoring, offering both theoretical insights and practical tools for sustainable land management.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}