Abstract
The classification and recognition of flame images play an important role in avoiding forest fires. Deep learning technology has shown good performance in flame image recognition tasks. In order to further improve the accuracy of classification, this paper combines deep learning technology with the idea of three-way decision-making. First, a ResNet34 network is used for initial classification. The probability value calculated by the SoftMax function is used as the decision evaluation criterion for initial classification. Using the idea of three-way decision-making, the flame image is divided into positive domain, negative domain, and boundary domain based on decision evaluation indicators. Furthermore, we perform secondary classification on images divided into boundary domains. In the secondary classification, a DualArchClassNet structure was constructed to extract new features and combine them with the features of the initial classification. The integrated features are optimized and used to reclassify images in uncertain domains to improve overall classification accuracy. The experimental results show that the proposed method improves the accuracy of flame image recognition compared to using a single ResNet34 network.
1. Introduction
The research on flame image classification is of great significance in the field of forest fire prevention and fire safety [1]. Traditional forest fire prevention methods, such as manual patrols and monitoring, suffer from low efficiency and susceptibility to factors such as weather and terrain. By utilizing flame image classification technology, early detection and rapid response to forest fires can be achieved, significantly improving fire prevention efficiency and accuracy. Flame classification and recognition based on video surveillance systems play an important role in preventing forest fires due to their advantages of real-time warning and facilitating data processing [2]. Many flame recognition methods based on video surveillance have been proposed. In [3], a dual-stream network was constructed using an attention-guided mechanism for classifying forest wildfires under video surveillance. In [4], a Dilation Repconv Cross Stage Partial Network was proposed to enhance the multi-scale flame detection capability.
Traditional flame image classification methods mainly rely on researchers designing features to describe flames, such as color, shape, texture, and wavelet features. Reference [5] summarizes the relevant techniques for smoke and fire detection using RGB and HSI color models. Zaidi et al. classified flame and non-flame images using RGB color space and YCbCr color space, respectively, to evaluate the performance of the two color spaces [6]. Celik et al. use a YCbCr color space to describe flame characteristics for flame detection [7]. Reference [8] uses various image processing techniques such as filtering, color space conversion, image segmentation, and morphological operations to recognize forest flame images captured by unmanned aerial vehicles. In [9], the author detected flames in video images by analyzing shape features such as area, centroid displacement, and perimeter of flame images. Real-time evaluation of forest fire status based on the combination of spatiotemporal feature extraction and dynamic texture analysis was reported in [10]. Harkat et al. used wavelet decomposition to extract features such as wavelet length and achieved fire detection and classification in RGB and infrared image data [11]. Although traditional feature extraction methods can achieve good results in specific environments, they need to be continuously improved and optimized to adapt to complex and changing environmental conditions.
In deep learning-based flame image classification methods, Convolutional Neural Networks (CNNs) and various variants and improved methods play important roles. The core idea of CNNs is to automatically learn effective feature representations from data through a combination of convolutional layers, pooling layers, and fully connected layers. In flame image classification, CNNs can automatically extract the features of flames, thereby achieving accurate classification of flame images. Lu et al. designed a lightweight TSCNN Flame network based on CNN architecture, which integrates temporal and spatial features to detect flame regions in videos [12]. Li et al. combined the attention mechanism into the DenseNet network for detecting smoke and flames to improve recognition accuracy [13]. ResNet34 has a relatively simple network structure and maintains good performance [14]. By introducing the residual connection mechanism, ResNet34 can be trained deeper and more stably, thereby extracting richer feature information. Tsalera et al. combined different CNNs (including ResNet 50) with transfer learning for flame detection, achieving high detection accuracy [15]. Muksimova et al. utilized ResNet50, VGG16, and EfficientNet-B3 networks as pre-trained models to extract features from multiple scales for flame image analysis [16]. Some studies combine smoke detection with flame detection to improve the effectiveness of flame recognition [17,18]. Considering the complexity and computational efficiency of the model, this paper chooses ResNet 34 for flame image classification.
Although CNNs perform well, classification errors can still occur in flame classification problems. This is mainly because flame image classification faces various challenges such as illumination changes, occlusions, and diverse flame shapes, making it difficult for a single CNN to accurately capture all key features. Introducing a secondary classification strategy has become an effective method to improve classification accuracy. Secondary classification, which further subdivides or validates difficult-to-distinguish samples based on the initial classification, can fully utilize the advantages of different classifiers to explore flame features from different perspectives or deeper levels, thereby effectively reducing misclassification. In the task of flame image classification, we need to determine whether an image is a flame image. In this paper, we first use the ResNet34 network to determine whether or not an image is a flame image. After the ResNet network’s determination, we obtain a probability value, which is the indicator used to evaluate whether the image belongs to a flame image. If the probability value is higher than a certain threshold, the image will be classified as a flame category. If it is lower than a certain probability value, we will determine that it does not belong to a flame image, that is, it is a non-flame image. At the same time, there are still some images in the middle range, and there is still insufficient confidence in the accuracy of the determination results for these images. At this point, we hope to add new features to make further decisions. This idea perfectly conforms to the theoretical framework of the Three Decisions. The Three Decisions is a theoretical model proposed by scholars such as Yao on the basis of rough sets [19]. Its core idea is to divide the whole into three parts, adopt different strategies for different domains, and establish corresponding decision rules [20]. The three domains of the Three Decisions are positive domain, negative domain, and boundary domain. A positive domain decision means acceptance, a negative domain means rejection, and a boundary domain means not making a decision at that moment [21]. Therefore, this article takes the results of the ResNet network for flame image classification as the initial classification. Images with high probability values in decision evaluation are classified as flames in the positive domain, while images with low probability values are classified as non-flames in the negative domain. For images in the middle, they are classified as boundary domains. Images entering the boundary domain need to be subjected to secondary classification based on new features. The overall architecture of the method proposed in this paper is shown in Figure 1.
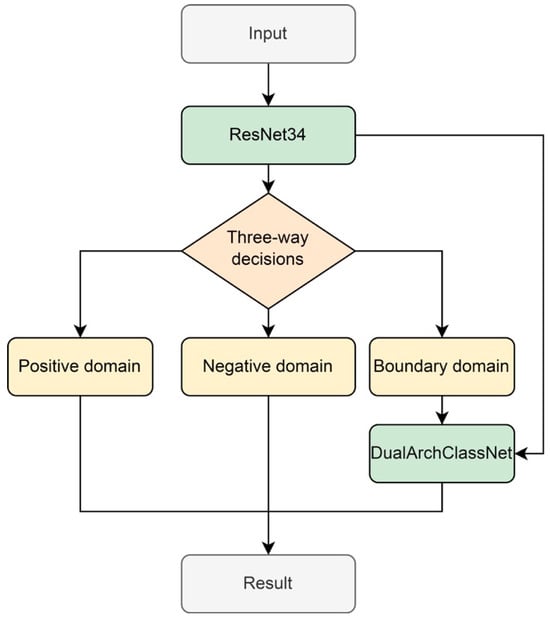
Figure 1.
The overall framework of the method proposed in this work.
In the process of secondary classification, we attempted to adopt a relatively lightweight network structure that maintains good performance while having lower computational costs. Therefore, this paper improved DABNet and combined it with the features extracted by ResNet34 to improve the accuracy of delayed decision-making. DABNet was originally used in the field of semantic segmentation of images [22]. By constructing bottleneck structures through deep asymmetric convolution and dilated convolution, DABNet can significantly reduce computational costs while maintaining high levels of performance. This efficient feature extraction capability is equally important in flame image classification tasks, allowing the network to extract more useful feature information with limited computing resources. Meanwhile, DABNet’s DAB module adopts a dual-branch structure, which facilitates the fusion of multi-scale information. In flame image classification tasks, features of different scales can provide more comprehensive image descriptions. For this purpose, we designed a DualArchClassNet for secondary classification tasks, which consists of two stages: feature extraction and classification. In the feature extraction stage, it inherits the characteristics of the encoder in DABNet and is used to extract key features from images, which are then concatenated and fused with the features extracted by ResNet34 to design a Feature Refinement Structure (FRS) during the classification stage to more accurately identify the presence of flames in the image.
The remainder of this paper is organized as follows: Section 2 presents the method of initial classification using ResNet34. Section 3 introduces three-way decision-making and the strategy for partitioning boundary domains. Section 4 presents the design of the DualArchClassNet network to fuse new features for secondary classification. Section 5 compares the experimental results of using only initial classification and introduces three-way decision-making for secondary classification. Section 6 concludes the proposed work with a summary.
2. Initial Classification Bases on ResNet34
Convolutional Neural Networks (CNNs) have excellent feature extraction capabilities. In the initial classification task, considering both network performance and computational speed, ResNet34 was chosen as the preliminary classification model in this work. As shown in Figure 2, ResNet34 utilizes the superposition of residual modules to form a 34-layer neural network. The front end of the network uses a standard convolution with a kernel size of 7 for feature extraction, and then max pooling is used to reduce the size of the feature map. By successively stacking multiple residual modules, the network is able to gradually extract multi-level features from the image like building blocks. Each residual module adopts a three-layer “bottleneck” design. Firstly, the number of channels is streamlined by 1 × 1 small convolution, which reduces the computational complexity. Subsequently, the core features are extracted by 3 × 3 standard convolution. Finally, the number of channels is adjusted by 1 × 1 convolution, which ensures a smooth connection with the subsequent modules. Due to the issue of latitude matching, there are differences in the connection methods in the network. In Figure 2, module a uses residual connections to increase 1 × 1 convolution and reduce the size of the feature map, so that the dimensions of the residual image match those of the original image. The residual module can be obtained by Equation (1). Assuming that the input to the module is , two consecutive 3 × 3 convolutions (F3×3) are used, and the final output is the post-convolution feature map summed with the original input to the module as follows:
where F3×3 is the 3 × 3 standard convolution; U and are the original input and final output of the module. Finally, global pooling focuses on the global information of the feature map and connects it with the fully connected layer to predict the final flame recognition result. ResNet34 uses residual connections to add the residual image to the original image, resulting in a new image that integrates the original information and residual details. This new image serves as the input for the next layer of the neural network, enabling the network to learn more accurately by utilizing both the original information and residual details.
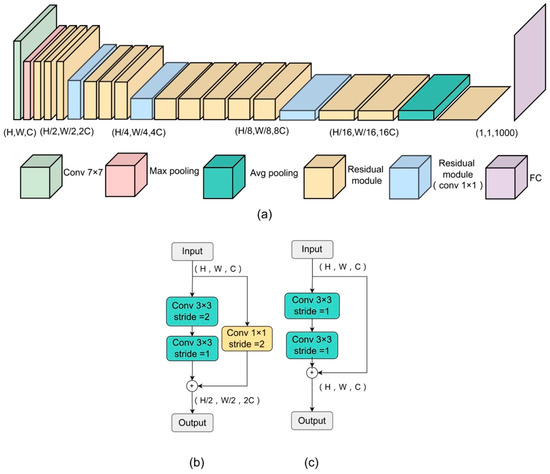
Figure 2.
Overall network architecture and module composition of ResNet34, where (a) is the ResNet34 structure, (b) is the residual module (conv 1 × 1), and (c) is the residual module.
3. Three-Way Decision-Making Framework in This Work
After the initial classification, the ResNet34 network makes a determination on whether the given image belongs to a flame image, but there is a possibility of errors in this process. Based on the idea of three-way decision-making, we provide a decision evaluation index for the initial classification results. Here, we use the SoftMax function, that is, we use the probability value output by SoftMax to evaluate the results. If this probability value is high, it indicates that the cost of failing to classify image samples into flames is low.
The mathematical expression of the SoftMax function is as follows:
where Xi represents the linear output of the ith element in the input vector; N represents the total number of categories (dimension of input vector); and SoftMax(xi) represents the probability value corresponding to the ith category after passing through the SoftMax function. There are two types of samples in this study, where i = 1 represents flame images and i = 2 represents non-flame images. Pr(X|Xi) is the probability of the output, which is used to represent the confidence level of the model that the sample belongs to each category. When the ResNet34 network decides to classify an image into the positive domain (flame), the expected cost of this misclassification, i.e., the positive domain cost, can be calculated using the probability output by SoftMax. Similarly, when the model classifies the sample into the negative domain (non-flame), the probability output by SoftMax can be used to calculate the negative domain cost.
Unlike traditional three-way decision-making methods that use parameter estimation to determine the boundary domain, this paper considers the classification task and uses the output probability of the SoftMax function to divide the positive domain, negative domain, and boundary domain. By using the SoftMax function, the prediction probabilities, Pr(X|X1) and Pr(X|X2), corresponding to the categories of fire and non-fire can be obtained. The maximum value Pyi = max(Pr(X|X1), Pr(X|X2)) in our two probabilities is used as the final classification result, where Pr(X|X1) represents the probability of flames in the image, and vice versa, Pr(X|X2) represents the probability of no flames in the image. It is worth noting that in this work if the probability of an image being classified as a flame image is low, the probability of it being classified as a non-flame image will be high. Therefore, we form the following rules for dividing positive, negative, and boundary domains:
- (1)
- If and , then and the ith image is classified into the positive domain (fire image);
- (1)
- If and , then , which means that the ith image is classified into the negative domain (non-fire image);
- (1)
- If , then , which indicates that the image is classified into the boundary domain (delayed processing).
This indicates that the current information is insufficient for clear classification. Therefore, more information is required for subsequent secondary classification.
4. Secondary Classification by Designing a DualArchClassNet
For images that are initially classified and assigned to the boundary domain, making more accurate decisions in the boundary domain is a challenging task. To address this challenge, we designed a DualArchClassNet network architecture specifically for secondary classification tasks. The DualArchClassNet network has undergone targeted optimization and improvement based on inheriting the characteristics of the DABNet encoder. It abandoned the decoder stage in DABNet and instead designed a new classifier to more efficiently distinguish flame images. By introducing additional feature information and combining it with the features of ResNet34, the DualArchClassNet network can further improve the accuracy of delayed decision-making. The DualArchClassNet network is divided into two stages: feature extraction and classification. The overall architecture of the DualArchClassNet network is shown in Figure 3.
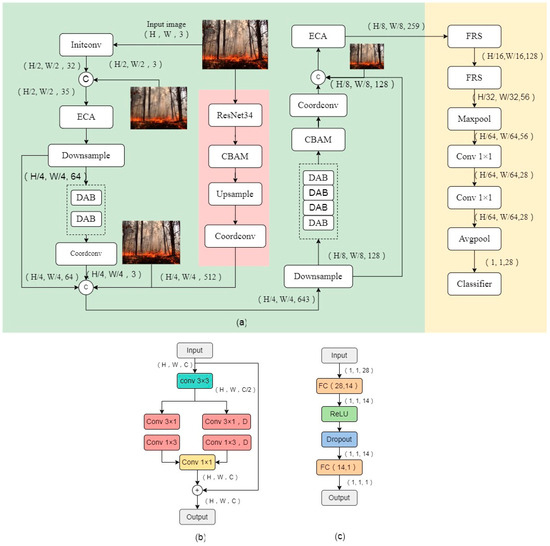
Figure 3.
Overall structure and module composition of DualArchClassNet: (a) the network architecture, (b) the DAB module, and (c) the network classifier design.
4.1. Feature Extraction Stage
In the feature extraction stage, we achieve precise feature extraction by building efficient convolutional blocks. Two convolutional blocks are stacked with two and four DAB modules, respectively. The standard convolution is first used to extract features from the input, and then a dual-branch structure is used to superimpose multiple discontinuous convolutions and discontinuous dilated convolutions in parallel. This design can expand the convolutional receptive field and capture more complex features, which is beneficial for determining the presence of flames in obscured states. The combination of different expansion rates can capture multi-scale information. The complementary features of different scales can provide richer information and more accurate feature representations, improving the classification performance of the model. Finally, the dual-branch feature maps are combined with different information from the branches, and a 1 × 1 standard convolution is used to enhance the representation of the synthesized feature maps. Finally, the feature map is fused with the original image to enhance the performance of the module, while preserving the original detailed information. The ResNet34 feature map is upsampled to the corresponding size in the middle of two convolutional blocks and then concatenated with the original feature layer. The feature concatenation of different layers can be regarded as a non-linear feature combination, which facilitates the transmission of multi-scale information in the network, enriches the expression of features, and enables the model to capture more complex feature information.
It is worth noting that we have taken multiple measures to improve the performance of the feature extraction stage: (1) The use of ECA [23] and CBAM attention modules [24] focuses on feature extraction in both spatial and channel dimensions, which can significantly enhance the feature representation ability of Convolutional Neural Networks. (2) In the feature extraction stage, the network only performs three downsampling operations to preserve image information effectively, and establishes a direct connection between multiple downsampling of the original image and convolutional blocks, enhancing the feature expression ability of the model and compensating for the loss generated in feature extraction. (3) We use CoordConv [25] to increase the spatial awareness of the network after convolutional blocks.
4.2. Classification Stage
In the model classification stage, we optimize the extracted feature maps and design a Feature Refinement Structure (FRS). As shown in Figure 4, we first use max pooling to downsample the feature map. By selecting the maximum value within a local region, we help the network focus on the most significant features and reduce irrelevant information. After reducing the image resolution, 1 × 1 convolution, 3 × 3 convolution, 1 × 1 convolution, and a skip connection are sequentially used to add and fuse features, achieving refinement of output features and interaction of features. Feature Refinement Structures can help models better capture and represent details in images, maintaining robustness to target objects and reducing sensitivity to interference when dealing with complex scenes and diverse backgrounds, thereby improving classification accuracy. The principle of Feature Refinement Structure can be summarized as follows:
where is the max pooling operation, and are the standard convolutions with convolution kernels of 1 and 3, is the extracted feature, and is the final output.
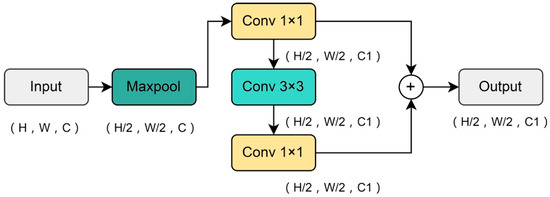
Figure 4.
FRS structure in DualArchClassNet.
In the design of the FireNet classifier, since the fully connected layer can learn the global features of the input data, we designed the first layer with an input dimension of 28 and an output dimension of 14, and the second layer with an input dimension of 14 and an output dimension of 1. We stacked the two fully connected layers and introduced non-linearity through an activation function. However, the fully connected layer has a large number of parameters, which can easily lead to overfitting. We insert a Dropout layer after the activation function and reduce the co-adaptability between neurons by randomly discarding them during training, thereby preventing overfitting and enhancing the model’s generalization ability. Ultimately, a complex non-linear classifier is constructed to enhance its expressive power. The classifier is summarized by the following equation:
where FC is the fully connected layer, Fdrop is the Dropout operation, and Fcla is the final classifier output. The overall process of the final classification stage is as follows:
where Fr is the FRS structure, Fmax and Favg are the max pooling and average pooling operations, is the standard convolution with kernel 1, and are the information extracted through different operations, and is the final classification stage output.
5. Experimental Results
To verify the effectiveness of the method, we conducted experiments on two public datasets: the FLAME forest fire detection dataset [26] and the Kaggle fire dataset [27]. The FLAME dataset consists of 47,992 images, including 30,155 fire images and 17,837 non-fire images, which contain images in various states. Figure 5 shows some images in different states in the FLAME dataset. The fire recorded in this dataset occurred on 16 January 2020, in a pine forest in Arizona, USA. During the data processing, the dataset is divided into a training set and a testing set, with 39,375 images used for training and 8617 images used for testing. This partitioning ensures that the training set can effectively cover different types of fire and non-fire scenarios, thereby improving the learning performance of the model. The Kaggle dataset consists of 999 images, with 755 representing fire images and 244 representing non-fire images. Figure 6 shows the images in some states of the Kaggle dataset, with 799 images used for training and 200 images used for testing. In order to improve the generalization ability of the model, this paper applies a series of data augmentation techniques during the training process, including left and right, up and down flipping, and color jitter techniques to increase the diversity of the training samples.

Figure 5.
Sample images of different states extracted from the FLAME dataset.

Figure 6.
Sample images of different states extracted from the Kaggle dataset.
5.1. Experimental Parameter Settings
The experiment was conducted on a Linux operating system using an Nvidia GeForce GTX 2080Ti GPU. This article uses the PyTorch (1.11.0) deep learning framework. During the training process, for the ResNet34 network for initial classification, the stochastic gradient descent (SGD) optimizer is used, with the optimization objective being the cross entropy loss function. The initial learning rate is set to 0.01, momentum is set to 0.9, and the training rounds are 100. In the secondary classification DualArchClassNet network, an adaptive moment estimation optimizer is adopted, with the optimization objective of a binary cross entropy loss function with Logits. The initial learning rate is set to 0.00001, the momentum is 0.9, and the training rounds are 50.
In order to better adapt to the training needs of different stages, this paper adopts an adjustment strategy based on the LambdaLR learning rate scheduler [28]. We used the cosine annealing learning rate in LambdaLR and employed a warm-up strategy during the initial training phase. Assuming the initial learning rate is lr_init, and the number of warm-up iterations is num_warm_up, the preheating strategy can be expressed as follows:
where t is the current iteration count, num_warm_up is the preheating stage iteration count, and lr_init is the initial learning rate. The cosine annealing learning rate adjustment strategy can be expressed as follows:
where x is the current number of training rounds, S is the total number of training rounds, where y1 and y2 are ranges for the learning rate. In this work, the down regulation learning rate method in the initial classification network are setted as (10,20,40,60). The down regulation learning rate methods in secondary classification networks are setted as (5,15,30,40).
5.2. Initial Classification Results and Boundary Domain Division
In this work, classification accuracy was selected as the evaluation metric, which mainly focuses on the overall classification performance. To demonstrate the effectiveness of the three decision-making methods in dividing positive, negative, and boundary domains, we calculated the positive domain accuracy (POSp), the negative domain accuracy (NEGp), and the boundary domain accuracy (BNDp), respectively, after the initial classification as follows:
where POSS, BNDS, and NEGS represent the population sample size in the positive domain, boundary domain, and negative domain, respectively. POSp1, BNDp1, and NEGp1 represent the number of correctly classified samples in the positive, boundary, and negative domains.
After the initial classification of images using the ResNet34 network, the classification accuracy of the test set was 86.93%. Although the ResNet34 model can maintain good performance in complex and noisy environments, it still has significant errors for images in complex environments such as high occlusion and open spaces with smoke. Therefore, this paper introduces three-way decision-making for the secondary classification of images in the boundary domain.
The selection of threshold α determines the images entering the boundary domain. We conducted experiments with different threshold α, and the results are shown in Table 1. It can be seen that the accuracy of images divided into the boundary domain is much lower than that of the entire sample. We chose α = 0.90 as the threshold, achieving a good balance between positive domain accuracy, negative domain accuracy, and uncertain domain accuracy. If the value of α is too large, although the accuracy of the positive domain is higher, more correctly classified samples will enter the boundary domain. If the value of α is too small, it will result in lower accuracy of the positive domain.

Table 1.
The results of initial categorization and three-way decision-making (%).
5.3. Analysis of Secondary Classification Results
For images divided into boundary domains, this paper uses DualArchClassNet for secondary classification. To demonstrate the feature extraction performance of the DualArchClassNet network, Figure 7 shows the extracted feature maps at different stages. It can be seen that the features extracted by the Initial Features layer are relatively scattered. After fusing multi-scale features and introducing a channel attention mechanism, the features extracted by the Enhanced Features layer enhance the expression ability of key regions.
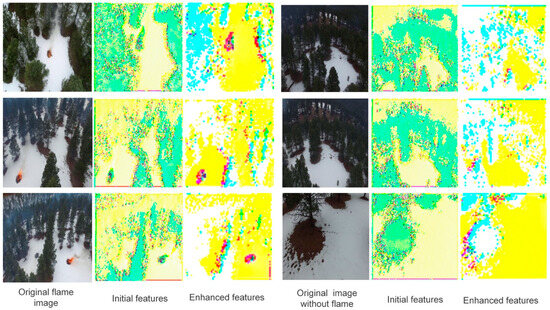
Figure 7.
Visualization of features at different stages. Original images extracted from the FLAME dataset.
In order to verify the classification performance based on the three-way decision-making and DualArchClassNet network, we compared the results of our method with those of using the initial classification network alone and directly using the secondary classification network without using the three-way decision-making. From Table 2, it can be seen that for the FLAME dataset, after using three-way decision-making and secondary classification, the classification accuracy of our method improved by 2.44 compared to the initial classification. In order to demonstrate the effectiveness of the three decision methods, we conducted experiments using a single secondary classification network (DualArchClassNet) to directly classify all images in the test set. It can be seen that its classification accuracy is lower than the method proposed in this paper, and it also proves that the classification accuracy can be significantly improved after partitioning the uncertain domain. Meanwhile, on the FLAME dataset, we also compared our proposed method with other existing studies, and it can be seen that our method outperforms the other four methods in terms of classification accuracy. For the Kaggle dataset (Table 3), due to its relative simplicity and small number of images, the initial classification network has already achieved good results, so the method proposed in this paper only slightly improves. The experiments on the Kaggle dataset also demonstrate that the method proposed in this paper has strong scene adaptability. It is worth noting that the classification accuracy of our method in the FLAME dataset is lower than that in the Kaggle dataset because the recognition of the FLAME dataset presents certain challenges. The images in the FLAME dataset were captured by drones, which present challenges such as small flame areas, complex backgrounds, and the presence of obstructions. We visually demonstrated the classification performance of the proposed method among different categories through the confusion matrix, as shown in Figure 8. The classification error rate of flame images in the FLAME dataset was slightly higher than that of non-fire images. In the Kaggle dataset, the classification error rate of non-fire images is higher than that of flame images. Through the analysis of misclassified images, we found that misclassification is prone to occur when the flame area is small or the background area has similarities to the flame, which is also related to whether there are enough images in the dataset for training. Overall, the method proposed in this article achieves better classification results for images with a larger proportion of flame area and vivid colors.
Table 2.
Performance comparison of different classification networks in the FLAME dataset.
Table 3.
Performance comparison of different classification networks in the Kaggle dataset.
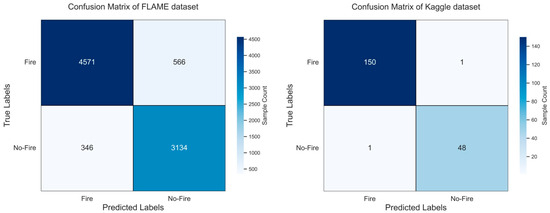
Figure 8.
Confusion matrix of the proposed method on different datasets.
5.4. Ablation Experiment
To better demonstrate the effectiveness of the method proposed in this paper, Table 4 and Table 5, respectively, show the impact of each module on classification accuracy under different datasets. During the training process, we removed the CBAM, ECA, and FRS modules from the secondary classification network. The results show that these modules have a significant contribution to the model performance in terms of accuracy, thus proving their improvement effect on DualArchClassNet. In the Kaggle dataset, removing the FRS module improved performance, mainly due to the presence of an image in the test set with a small flame area surrounded by thick smoke. In this case, the maxpool operation of the FRS module failed to effectively capture flame features, resulting in a decrease in detection performance. However, on the FLAME dataset, the performance of the FRS module is significantly better than that without the FRS module, indicating its stronger robustness in complex scenarios. Therefore, considering the performance of different datasets comprehensively, this method still retains the FRS module for secondary classification to ensure the stability and accuracy of the model in various environments.
Table 4.
The impact of each module on classification results in the FLAME dataset.
Table 5.
The impact of each module on classification results in the Kaggle dataset.
6. Discussion
The flame classification based on video images plays an important role in the application of fire prevention and emergency response. With the development of deep learning, it has achieved good performance in the field of flame image recognition. However, in complex and ever-changing fire scenarios, the classification accuracy of a single network still faces significant challenges. The strategy proposed in this article, which combines three-way decision-making with deep learning, can help improve classification accuracy. Below, we will discuss the noteworthy aspects of using three-way decision-making for flame classification, as well as the correlation between flame image classification and fire protection systems.
- (1)
- Lessons learned from using three-way decision-making strategies
When combining three-way decision-making with deep learning techniques for flame classification, both methods have demonstrated mutual advantages, but there are still some issues worth noting. One issue is the mechanism of boundary domain partitioning. It is the key factor for the three-way decision-making. The determination of the threshold is quite important. The choice of threshold has a significant impact on the partitioning results of a boundary domain. By adjusting the threshold, the classification accuracy of positive and negative domains can be balanced with the size of the boundary domain. Reasonable threshold selection can ensure that the boundary domain contains as many classification-uncertain images as possible while avoiding too many determined images from being mistakenly classified into the boundary domain. The second issue is that when performing secondary classification, the chosen method should be different from the network used for the initial classification, which can make them complementary when merging with each other. This is beneficial for correctly classifying images entering the boundary domain during secondary classification.
- (2)
- The application potential of the proposed flame classification method
The results of flame image classification have a certain application potential. The classification results determine whether there is a flame in the monitored image, which can be integrated with other parts of the fire protection system, such as alarm and emergency response modules. When the flame classification method outputs a classification result (i.e., fire and no-fire), it can be output to the alarm module of the fire protection system. After receiving the information, the alarm module can send the alarm information to the monitoring center or designated personnel. After receiving the flame classification results, the fire department should quickly confirm their authenticity.
7. Conclusions
This article focuses on the classification and recognition of flame images using deep learning techniques and three-way decision-making strategies. In order to improve the accuracy of flame image classification using a single deep learning network, this article uses the probability value calculated by the SoftMax function to determine the credibility of the initial classification based on the ResNet34 network. Using the idea of three-way decision-making, samples with low classification probability values are divided into the boundary domain, and further, the images divided into the boundary domain are subjected to secondary classification. In the secondary classification, the DAB network is combined with ResNet34 to construct a DualArchClassNet network structure, which extracts new features to reclassify the images in the boundary domain. The results indicate that the overall classification accuracy has been improved after using three-way decision-making ideas and the DualArchClassNet network for secondary classification.
In the future, we will continue to explore the application of deep learning technology in the field of fire prevention and early warning, especially the application of lightweight networks with real-time capability and a network structure deployed in hardware and edge computing, to enhance the application value of the method.
Author Contributions
Conceptualization, X.Z.; methodology, X.Z., D.M. and L.G.; software, D.M. and L.G.; validation, X.Z., D.M. and L.G.; formal analysis, X.Z., D.M. and L.G.; investigation, X.Z. and D.M.; resources, X.Z., D.M. and L.G.; data curation, X.Z., D.M. and L.G.; writing—original draft preparation, X.Z., D.M. and L.G.; writing—review and editing, X.Z.; visualization, D.M. and L.G.; supervision, X.Z.; project administration, X.Z.; funding acquisition, X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China (no. 61771418).
Data Availability Statement
The data presented in this study are available from the following resources available in the public domain: the fire dataset was obtained from Kaggle [https://www.kaggle.com/datasets/phylake1337/fire-dataset, accessed on 15 January 2025], reference number [22]; the FLAME dataset was obtained from IEEE Dataport [https://ieee-dataport.org/open-access/flame-dataset-aerial-imagery-pile-burn-detection-using-drones-uavs, accessed on 15 January 2025], reference number [21].
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bai, Y.; Wang, D.; Li, Q.; Liu, T.; Ji, Y. Advanced Multi-Label Fire Scene Image Classification via BiFormer, Domain-Adversarial Network and GCN. Fire 2024, 7, 322. [Google Scholar] [CrossRef]
- Töreyin, B.U.; Dedeoğlu, Y.; Güdükbay, U.; Cetin, A.E. Computer vision based method for real-time fire and flame detection. Pattern Recogn. Lett. 2006, 27, 49–58. [Google Scholar]
- Islam, A.M.; Masud, F.B.; Ahmed, R.; Ibn Jafar, A.; Ullah, J.R.; Islam, S.; Shatabda, S.; Islam, A.K.M.M. An Attention-Guided Deep-Learning-Based Network with Bayesian Optimization for Forest Fire Classification and Localization. Forests 2023, 14, 2080. [Google Scholar] [CrossRef]
- Wang, G.; Li, H.; Xiao, Q.; Yu, P.; Ding, Z.; Wang, Z.; Xie, S. Fighting against forest fire: A lightweight real-time detection approach for forest fire based on synthetic images. Expert Syst. Appl. 2024, 262, 125620. [Google Scholar]
- Umar, M.M.; Silva, L.C.D.; Bakar, M.S.A.; Petra, M.I. State of the art of smoke and fire detection using image processing. Int. J. Signal Imaging Syst. Eng. 2017, 10, 22–30. [Google Scholar]
- Binti Zaidi, N.I.; binti Lokman NA, A.; bin Daud, M.R.; Achmad, H.; Chia, K.A. Fire recognition using RGB and YCbCr color space. ARPN J. Eng. Appl. Sci. 2015, 10, 9786–9790. [Google Scholar]
- Çelik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar]
- Yuan, C.; Liu, Z.; Zhang, Y. UAV-Based forest fire detection and tracking using image processing techniques. In Proceedings of the 2015 International Conference on Unmanned Aircraft Systems, ICUAS, IEEE, Denver, CO, USA, 9–12 June 2015; pp. 639–643. [Google Scholar]
- Zhou, Q.; Yang, X.; Bu, L. Analysis of shape features of flame and interference image in video fire detection. In Proceedings of the 2015 Chinese Automation Congress (CAC), Wuhan, China, 27–29 November 2015; pp. 633–637. [Google Scholar]
- Rao, G.N.; Rao, P.J.; Duvvuru, R.; Bendalam, S.; Gemechu, R. An enhanced real-time forest fire assessment algorithm based on video by using texture analysis. Perspect. Sci. 2016, 8, 618–620. [Google Scholar]
- Harkat, H.; Ahmed, H.F.T.; Nascimento, J.M.; Bernardino, A. Early fire detection using wavelet based features. Measurement 2024, 242, 115881. [Google Scholar]
- Lu, P.; Zhao, Y.; Xu, Y. A Two-Stream CNN Model with Adaptive Adjustment of Receptive Field Dedicated to Flame Region Detection. Symmetry 2021, 13, 397. [Google Scholar] [CrossRef]
- Li, H.; Ma, Z.; Xiong, S.-H.; Sun, Q.; Chen, Z.-S. Image-based fire detection using an attention mechanism and pruned dense network transfer learning. Inf. Sci. 2024, 670, 120633. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tsalera, E.; Papadakis, A.; Voyiatzis, I.; Samarakou, M. CNN-based, contextualized, real-time fire detection in computational resource-constrained environments. Energy Rep. 2023, 9, 247–257. [Google Scholar]
- Muksimova, S.; Umirzakova, S.; Abdullaev, M.; Cho, Y.-I. Optimizing Fire Scene Analysis: Hybrid Convolutional Neural Network Model Leveraging Multiscale Feature and Attention Mechanisms. Fire 2024, 7, 422. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, Z.; Xiao, W.; Zhang, X.; Xiao, S. Flame and Smoke Detection Algorithm Based on ODConvBS-YOLOv5s. IEEE Access 2023, 11, 34005–34014. [Google Scholar]
- Yun, B.; Zheng, Y.; Lin, Z.; Li, T. FFYOLO: A Lightweight Forest Fire Detection Model Based on YOLOv8. Fire 2024, 7, 93. [Google Scholar] [CrossRef]
- Yao, Y.; Zhao, Y. Attribute reduction in decision-theoretic rough set models. Inf. Sci. 2008, 178, 3356–3373. [Google Scholar]
- Yu, H.; Chu, S.; Yang, D. Autonomous Knowledge-oriented Clustering Using Decision-Theoretic Rough Set Theory. Fundam. Informaticae 2012, 115, 141–156. [Google Scholar]
- Qian, Y.; Zhang, H.; Sang, Y.; Liang, J. Multigranulation decision-theoretic rough sets. Int. J. Approx. Reason. 2014, 55, 225–237. [Google Scholar]
- Li, G.; Yun, I.; Kim, J.; Kim, J. Dabnet: Depth-wise asymmetric bottleneck for real-time semantic segmentation. arXiv 2019, arXiv:1907.11357. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liu, R.; Lehman, J.; Molino, P.; Such, F.P.; Frank, E.; Sergeev, A.; Yosinski, J. An intriguing failing of convolutional neural networks and the coordconv solution. Adv. Neural Inf. Process. Syst. 2018, 31, 9628–9639. [Google Scholar]
- Shamsoshoara, A.; Afghah, F.; Razi, A.; Zheng, L.; Fulé, P.Z.; Blasch, E. Aerial imagery pile burn detection using deep learning: The FLAME dataset. Comput. Netw. 2021, 193, 108001. [Google Scholar]
- Saied, A. FIRE Dataset. Retrieved October 2020. Available online: https://www.kaggle.com/phylake1337/fire-dataset (accessed on 15 January 2025).
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Zhang, L.; Wang, M.; Fu, Y.; Ding, Y. A forest fire recognition method using UAV images based on transfer learning. Forests 2022, 13, 975. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A.; Mseddi, W.S. Deep Learning and Transformer Approaches for UAV-Based Wildfire Detection and Segmentation. Sensors 2022, 22, 1977. [Google Scholar] [CrossRef] [PubMed]
- Yan, Z.; Wang, L.; Qin, K.; Zhou, F.; Ouyang, J.; Wang, T.; Hou, X.; Bu, L. Unsupervised Domain Adaptation for Forest Fire Recognition Using Transferable Knowledge from Public Datasets. Forests 2022, 14, 52. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).