

Exploring Thematic Evolution in Interdisciplinary Forest Fire Prediction Research: A Latent Dirichlet Allocation–Bidirectional Encoder Representations from Transformers Model Analysis


Abstract
1. Introduction
2. Related Work
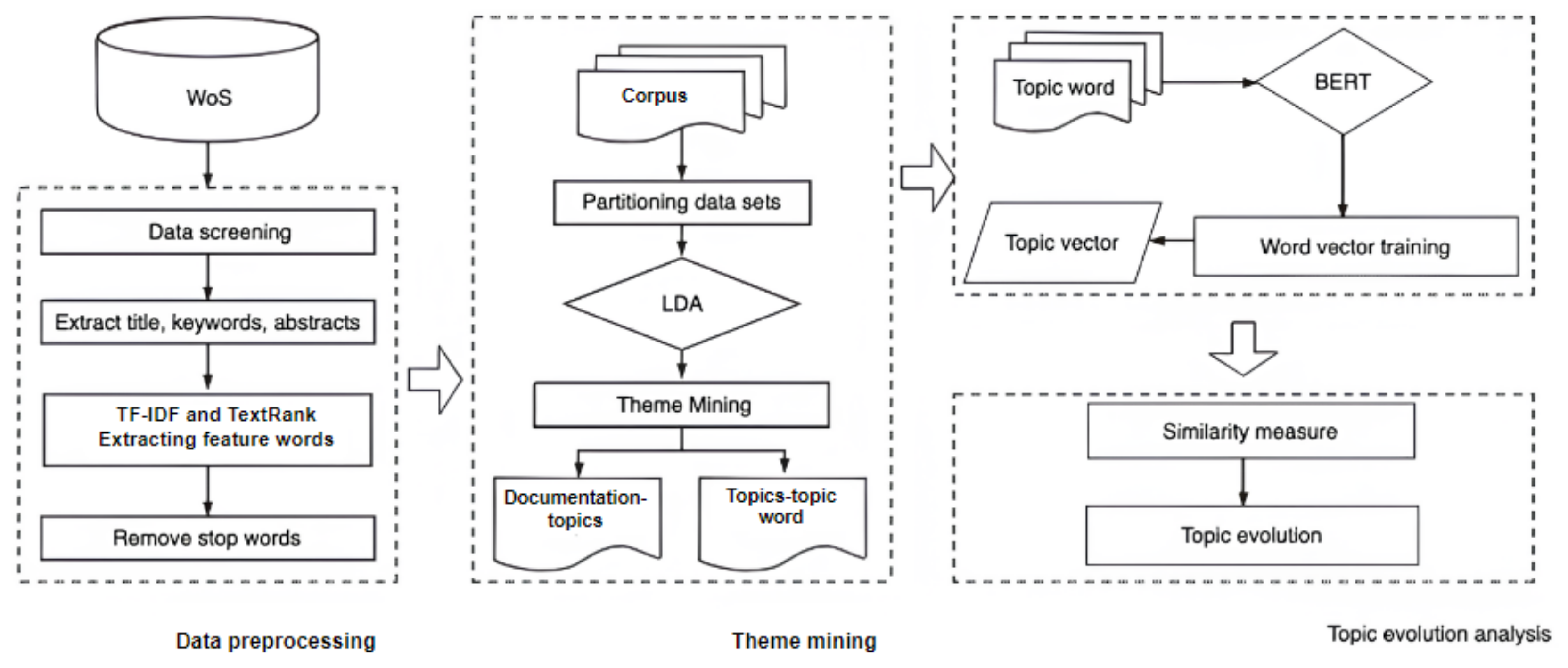
3. Methods
3.1. Data Preprocessing and Thematic Mining
- : The frequency of term in document .
- : The total number of terms in document .
- : The total number of documents in the corpus.
- : The number of documents in which term appears.
- : The weight of node in the graph.
- d: A damping factor, typically set to 0.85, represents the probability of continuing to the next node.
- : The set of nodes that have edges pointing to .
- : The weight of the edge from node to node .
- : The set of nodes that points to.
- : The weight of node .
- : The probability that word belongs to topic k, given the current state of all other words.
- : The number of words in document m that are assigned to topic k.
- : The prior parameter for topic k in the Dirichlet distribution.
- : The number of times word v is assigned to topic k.
- : The prior parameter for word v in the Dirichlet distribution.
- K: The total number of topics.
- V: The total number of unique words in the vocabulary.
- : The coherence score for topic t.
- M: The number of top words used to calculate the coherence.
- and : The mth and lth top words in topic t.
- : The document frequency of the pair of words and occurring together.
- : The document frequency of word .
- : A small constant to avoid division by zero.
3.2. Word Vector Training
3.3. Similarity Measure
4. Empirical Research
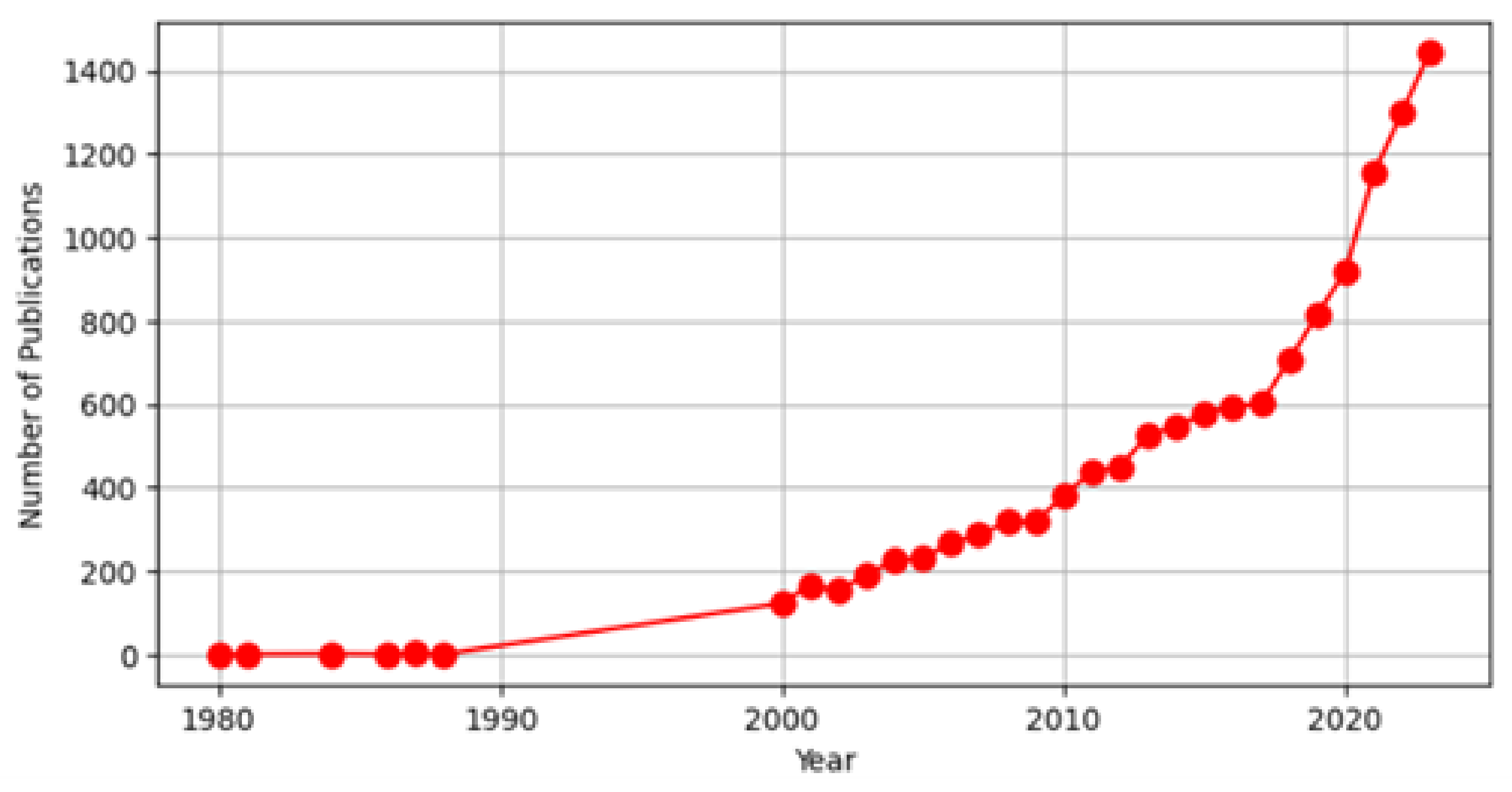
4.1. Data Acquisition
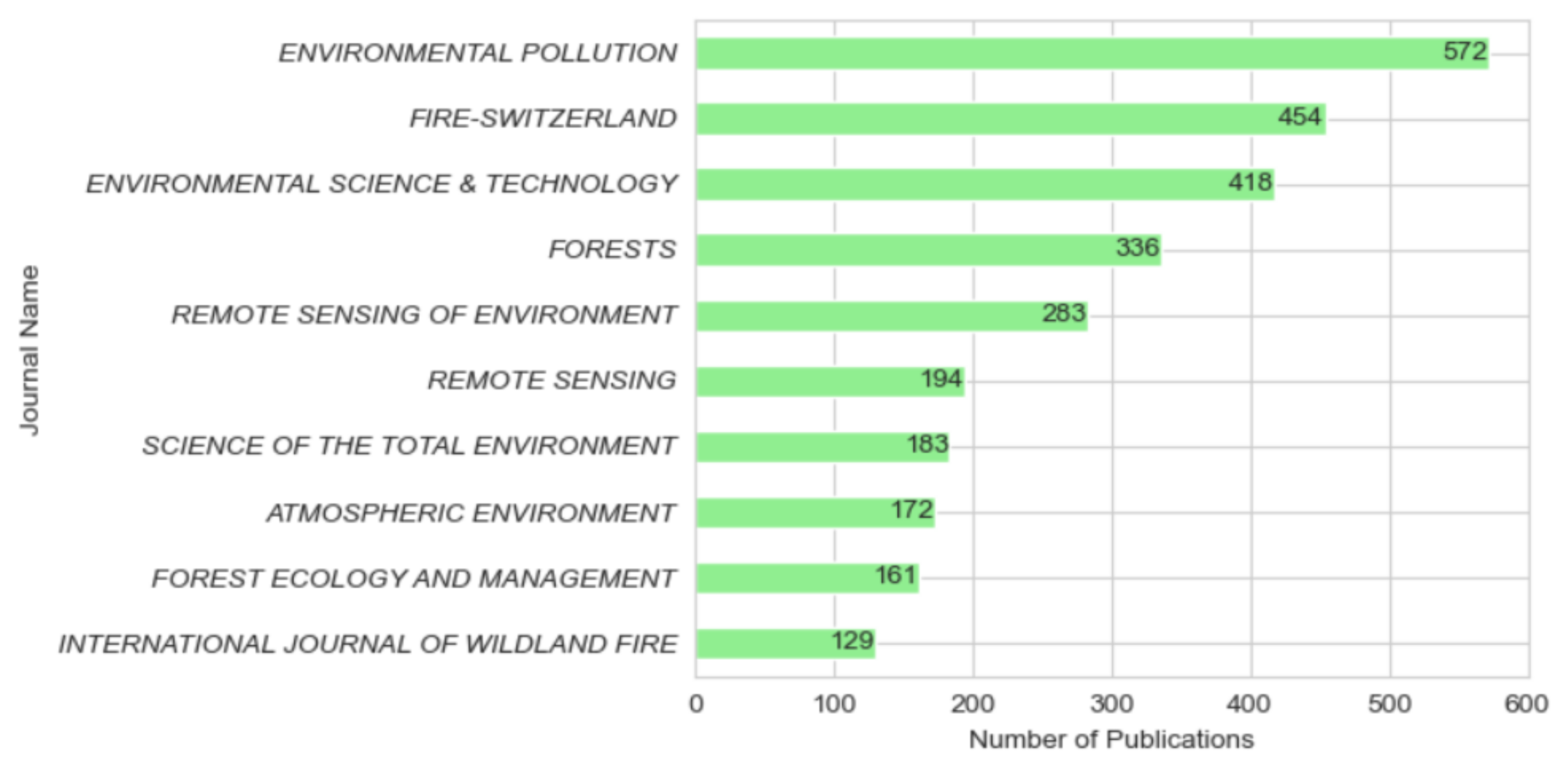
4.2. Exploratory Analysis
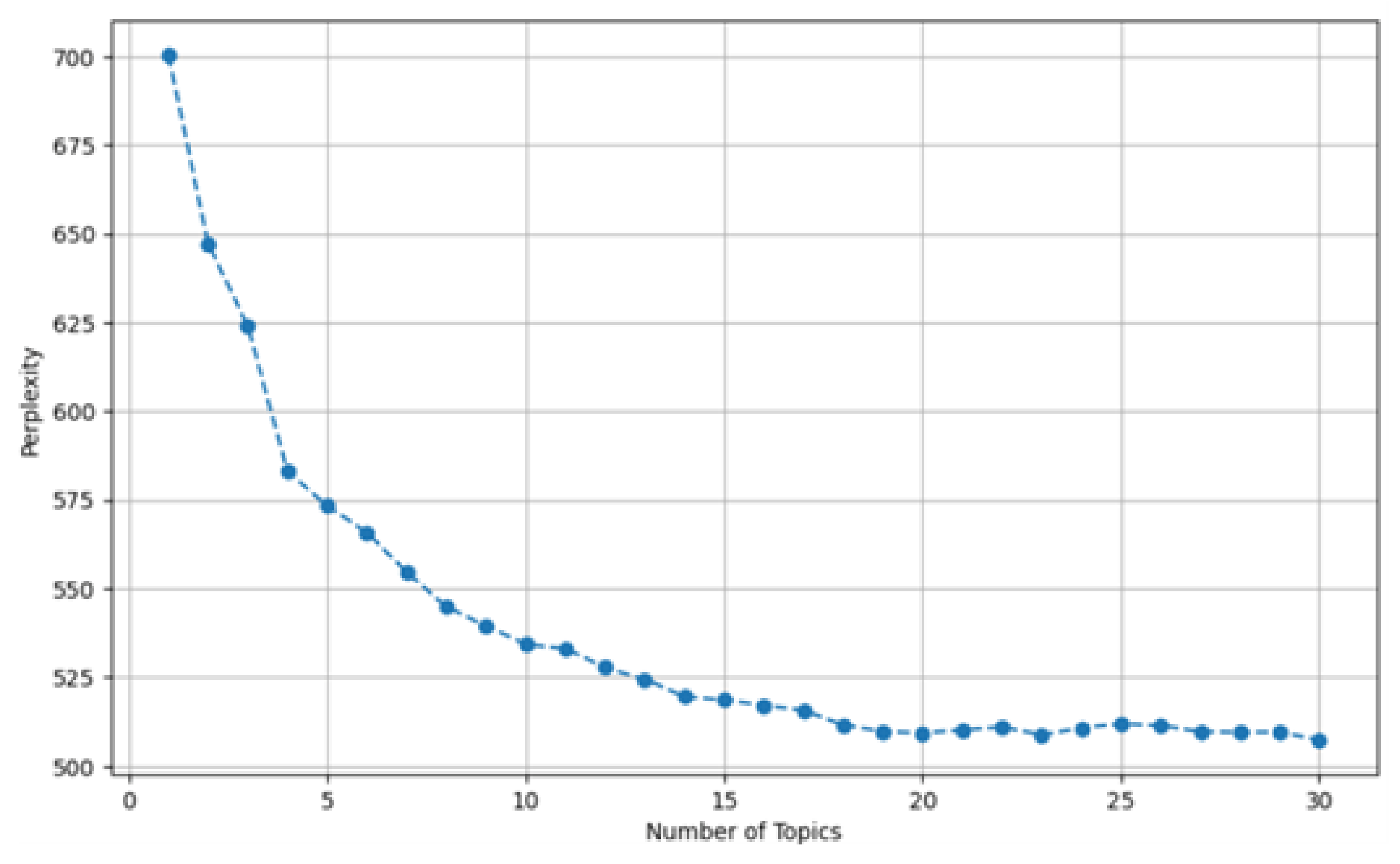
4.3. Theme Mining
4.4. Thematic Evolution Analysis
5. Discussion
- Shift from Macro to Micro Level: Early research (pre-2000s, as indicated by the literature review and keyword analysis) predominantly focused on broad-scale factors like general climate patterns and large-scale vegetation classifications. More recent work (post-2010, evident in the increased prominence of terms like “model,” “data,” and “prediction,” and specific technologies) emphasizes finer scale analyses, incorporating detailed data on the fuel moisture, localized weather conditions, and individual fire behaviour. This shift is directly linked to advancements in remote sensing, data availability, and computational power.
- Integration of Human Dimensions: While early research acknowledged human influence, the focus has sharpened considerably. The “Wildfire Risk Management” theme explicitly highlights the increasing importance of understanding the wildland-urban interface, human-caused ignitions, and the socioeconomic impacts of fires. This reflects a growing recognition that fire prediction and management are not solely ecological or technological problems but also deeply social ones.
- Technological Advancement: The prominence of themes related to ”Modelling and Data Analysis” underscores the increasing reliance on sophisticated computational tools. This includes using machine learning algorithms, GIS, and remote sensing data to improve the prediction accuracy, assess the management effectiveness, and understand complex fire dynamics.
- Emphasis on Climate Change: The increasing frequency of ”climate”- and ”change”-related terms is a crucial takeaway. Regarding the interaction among themes, Theme 6 is essential, demonstrating that scientists are increasingly considering climate alterations’ role in fire regimes.
- Optimize Theme Representation: Further, refine the selection of theme-representative words by incorporating semantic analysis and expert knowledge to improve accuracy. Explore methods for capturing the semantic diversity and relationships between words within themes.
- Develop Adaptive Thresholds: Investigate the rationality of threshold settings and develop adaptive thresholding methods to suit different datasets and research questions better. This could involve machine learning techniques that learn optimal thresholds from the data.
- Enhance Model Evaluation: Expand the model performance evaluation framework to include metrics that assess the interpretability and generalization ability alongside traditional metrics like perplexity. Consider evaluating the model’s performance in real-world scenarios using case studies or simulations.
- Integrate Emerging Technologies: Explore incorporating emerging technologies, such as advanced deep learning algorithms and big data processing techniques, to improve prediction accuracy and timeliness.
- Strengthen Interdisciplinary Collaboration: Foster deeper interdisciplinary collaboration to promote knowledge sharing and collaborative innovation. This includes developing common frameworks and tools for researchers from different disciplines.
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A review on early forest fire detection systems using optical remote sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef] [PubMed]
- Sivrikaya, F.; Küçük, Ö. Modeling forest fire risk based on GIS-based analytical hierarchy process and statistical analysis in Mediterranean region. Ecol. Inform. 2022, 68, 101537. [Google Scholar] [CrossRef]
- Mohajane, M.; Costache, R.; Karimi, F.; Pham, Q.B.; Essahlaoui, A.; Nguyen, H.; Laneve, G.; Oudija, F. Application of remote sensing and machine learning algorithms for forest fire mapping in a Mediterranean area. Ecol. Indic. 2021, 129, 107869. [Google Scholar] [CrossRef]
- Alkhatib, R.; Sahwan, W.; Alkhatieb, A.; Schütt, B. A brief review of machine learning algorithms in forest fires science. Appl. Sci. 2023, 13, 8275. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, X.; Cao, X.; Huang, C.; Liu, E.; Qian, S.; Liu, X.; Wu, Y.; Dong, F.; Qiu, C.-W.; et al. Artificial intelligence: A powerful paradigm for scientific research. Innovation 2021, 2, 100179. [Google Scholar] [CrossRef]
- Machado, H.P.V.; Elias, M.L.G.G.R. Knowledge management: The field’s constitution, themes, and research perspectives. Transinformação 2020, 32, e200037. [Google Scholar] [CrossRef]
- Fudolig, M.I.; Alshaabi, T.; Arnold, M.V.; Danforth, C.M.; Dodds, P.S. Sentiment and structure in word co-occurrence networks on Twitter. Appl. Netw. Sci. 2022, 7, 1–27. [Google Scholar] [CrossRef]
- Tura, N.; Ojanen, V. Sustainability-oriented innovations in smart cities: A systematic review and emerging themes. Cities 2022, 126, 103716. [Google Scholar] [CrossRef]
- Donthu, N.; Gremler, D.D.; Kumar, S.; Pattnaik, D. Mapping of Journal of Service Research themes: A 22-year review. J. Serv. Res. 2022, 25, 187–193. [Google Scholar] [CrossRef]
- Climent, R.C.; Haftor, D.M. Value creation through the evolution of business model themes. J. Bus. Res. 2021, 122, 353–361. [Google Scholar] [CrossRef]
- Sott, M.K.; Nascimento, L.d.S.; Foguesatto, C.R.; Furstenau, L.B.; Faccin, K.; Zawislak, P.A.; Mellado, B.; Kong, J.D.; Bragazzi, N.L. A bibliometric network analysis of recent publications on digital agriculture to depict strategic themes and evolution structure. Sensors 2021, 21, 7889. [Google Scholar] [CrossRef] [PubMed]
- Feng, S.; Yan, Y.; Li, H.; Zhang, L.; Yang, S. Thermal management of 3D chip with non-uniform hotspots by integrated gradient distribution annular-cavity micro-pin fins. Appl. Therm. Eng. 2021, 182, 116132. [Google Scholar] [CrossRef]
- Ye, Y.; Jiao, B.; Kong, Y.; Liu, R.; Du, X.; Jia, K.; Yun, S.; Chen, D. Experimental investigations on the thermal superposition effect of multiple hotspots for embedded microfluidic cooling. Appl. Therm. Eng. 2022, 202, 117849. [Google Scholar] [CrossRef]
- Zhang, Z.; Parulian, N.N.; Ji, H.; Elsayed, A.S.; Myers, S.; Palmer, M. Fine-grained information extraction from biomedical literature based on knowledge-enriched abstract meaning representation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021), Bangkok, Thailand, 1–6 August 2021. [Google Scholar]
- Yang, Y.; Wang, L.; Xie, D.; Deng, C.; Tao, D. Multi-sentence auxiliary adversarial networks for fine-grained text-to-image synthesis. IEEE Trans. Image Process. 2021, 30, 2798–2809. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Pan, B.; Cai, D.; Sun, H. Topnet: Learning from neural topic model to generate long stories. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, 14–18 August 2021; pp. 1997–2005. [Google Scholar]
- Bai, X.; Zhang, X.; Li, K.X.; Zhou, Y.; Yuen, K.F. Research topics and trends in the maritime transport: A structural topic model. Transport Policy 2021, 102, 11–24. [Google Scholar] [CrossRef]
- Martin, F.; Borup, J. Online learner engagement: Conceptual definitions, research themes, and supportive practices. Educ. Psychol. 2022, 57, 162–177. [Google Scholar] [CrossRef]
- Ouyang, H.; Tang, X.; Zhang, R. Research Themes, trends and future priorities in the field of climate change and Health: A Review. Atmosphere 2022, 13, 2076. [Google Scholar] [CrossRef]
- Blei, D.; Ng, A.; Jordan, M. Latent Dirichlet Allocation. Adv. Neural Inf. Process. Syst. 2001, 14, 993–1022. [Google Scholar]
- Alaparthi, S.; Mishra, M. Bidirectional Encoder Representations from Transformers (BERT): A sentiment analysis odyssey. arXiv 2020, arXiv:2007.01127. [Google Scholar]
- Jayady, S.H.; Antong, H. Theme Identification using Machine Learning Techniques. J. Integr. Adv. Eng. (JIAE) 2021, 1, 123–134. [Google Scholar] [CrossRef]
- Carter, P.; Gee, M.; McIlhone, H.; Lally, H.; Lawson, R. Comparing manual and computational approaches to theme identification in online forums: A case study of a sex work special interest community. Methods Psychol. 2021, 5, 100065. [Google Scholar] [CrossRef]
- Maier, D.; Waldherr, A.; Miltner, P.; Wiedemann, G.; Niekler, A.; Keinert, A.; Pfetsch, B.; Heyer, G.; Reber, U.; Häussler, T.; et al. Applying LDA topic modeling in communication research: Toward a valid and reliable methodology. In Computational Methods for Communication Science; Routledge: New York, NY, USA, 2021; pp. 13–38. [Google Scholar]
- Choubey, D.K.; Kumar, M.; Shukla, V.; Tripathi, S.; Dhandhania, V.K. Comparative analysis of classification methods with PCA and LDA for diabetes. Curr. Diabetes Rev. 2020, 16, 833–850. [Google Scholar] [PubMed]
- Cao, J.; Xia, T.; Li, J.; Zhang, Y.; Tang, S. A density-based method for adaptive LDA model selection. Neurocomputing 2009, 72, 1775–1781. [Google Scholar] [CrossRef]
- Nguyen, D.Q.; Billingsley, R.; Du, L.; Johnson, M. Improving topic models with latent feature word representations. Trans. Assoc. Comput. Linguist. 2015, 3, 299–313. [Google Scholar] [CrossRef]
- Yang, J.; Yu, H.; Kunz, W. An efficient LDA algorithm for face recognition. In Proceedings of the International Conference on Automation, Robotics, and Computer Vision (ICARCV 2000), Singapore, 5–8 December 2000; pp. 34–47. [Google Scholar]
- Zhou, H.; Yu, H.; Hu, R.; Hu, J. A survey on trends of cross-media topic evolution map. Knowl.-Based Syst. 2017, 124, 164–175. [Google Scholar] [CrossRef]
- Han, W.; Han, X.; Zhou, S.; Zhu, Q. The development history and research tendency of medical informatics: Topic evolution analysis. JMIR Med. Inform. 2022, 10, e31918. [Google Scholar] [CrossRef]
- Yu, H.; Zhang, G.; Shen, Y. Hidden Markov-based LDA Internet Sensitive Information Text Filtering. In Proceedings of the 2020 IEEE 11th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 16–18 October 2020; pp. 1–6. [Google Scholar]
- Lu, X.; An, J. Evolution Analysis of Network Public Opinion Theme Based on LDA Model. In Proceedings of the 2022 4th International Conference on Applied Machine Learning (ICAML), Changsha, China, 23–25 July 2022; pp. 396–400. [Google Scholar]
- Xie, Q.; Zhang, X.; Ding, Y.; Song, M. Monolingual and multilingual topic analysis using LDA and BERT embeddings. J. Inf. 2020, 14, 101055. [Google Scholar] [CrossRef]
- Atagün, E.; Hartoka, B.; Albayrak, A. Topic modeling using LDA and BERT techniques: Teknofest example. In Proceedings of the 2021 6th International Conference on Computer Science and Engineering (UBMK), Ankara, Turkey, 15–17 September 2021; pp. 660–664. [Google Scholar]
- Havrlant, L.; Kreinovich, V. A simple probabilistic explanation of term frequency-inverse document frequency (tf-idf) heuristic (and variations motivated by this explanation). Int. J. Gen. Syst. 2017, 46, 27–36. [Google Scholar] [CrossRef]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topic | Five High-Probability Words Related to the Topic |
|---|---|
| Topic 1 | ‘species’, ‘plant’, ‘habitat’, ‘vegetation’, ‘sites’ |
| Topic 2 | ‘forest’, ‘tree’, ‘pine’, ‘forests’, ‘trees’ |
| Topic 3 | ‘risk’, ‘wildfire’, ‘management’, ‘wildfires’, ‘assessment’ |
| Topic 4 | ‘soil’, ‘vegetation’, ‘burned’, ‘area’, ‘data’ |
| Topic 5 | ‘emissions’, ‘biomass’, ‘burning’, ‘carbon’, ‘emission’ |
| Topic 6 | ‘climate’, ‘change’, ‘soil’, ‘forest’, ‘carbon’ |
| Topic 7 | ‘pm’, ‘smoke’, ‘air’, ‘concentrations’, ‘quality’ |
| Topic 8 | ‘forest’, ‘model’, ‘data’, ‘models’, ‘based’ |
| Topic 9 | ‘fires’, ‘weather’, ‘conditions’, ‘model’, ‘surface’ |
| Topic 10 | ‘fuel’, ‘moisture’, ‘model’, ‘models’, ‘spread’ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S. Exploring Thematic Evolution in Interdisciplinary Forest Fire Prediction Research: A Latent Dirichlet Allocation–Bidirectional Encoder Representations from Transformers Model Analysis. Forests 2025, 16, 346. https://doi.org/10.3390/f16020346
Zhang S. Exploring Thematic Evolution in Interdisciplinary Forest Fire Prediction Research: A Latent Dirichlet Allocation–Bidirectional Encoder Representations from Transformers Model Analysis. Forests. 2025; 16(2):346. https://doi.org/10.3390/f16020346
Chicago/Turabian StyleZhang, Shuo. 2025. "Exploring Thematic Evolution in Interdisciplinary Forest Fire Prediction Research: A Latent Dirichlet Allocation–Bidirectional Encoder Representations from Transformers Model Analysis" Forests 16, no. 2: 346. https://doi.org/10.3390/f16020346
APA StyleZhang, S. (2025). Exploring Thematic Evolution in Interdisciplinary Forest Fire Prediction Research: A Latent Dirichlet Allocation–Bidirectional Encoder Representations from Transformers Model Analysis. Forests, 16(2), 346. https://doi.org/10.3390/f16020346