
An Efficient and Lightweight Detection Model for Forest Smoke Recognition


Abstract
1. Introduction
- We propose an efficient and lightweight forest smoke detection model to successfully detect and localize smoke in the early stages of forest fire spread. Edge devices with limited computing resources and memory can achieve real-time object detection. New ideas and insights are provided for forest fire detection.
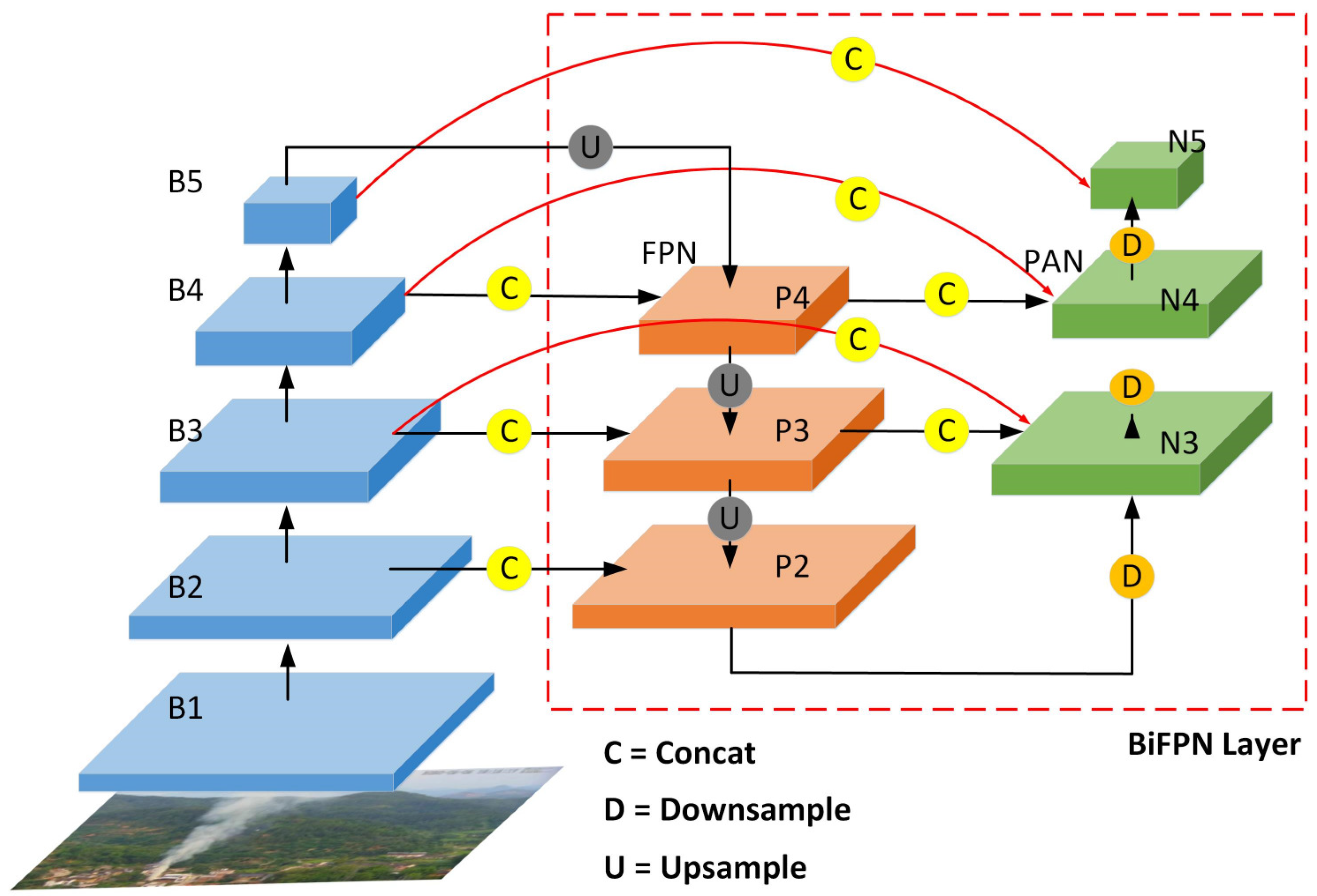
- We introduce a BiFPN module in the neck of YOLOv8. This enables the network to aggregate features at different resolutions by incorporating learnable weights to learn the importance of different input features, thus improving the performance of detecting forest smoke.
- SimAM is introduced into the YOLOv8 model to effectively suppress the interference of redundant information on the network by enhancing the attention of the down-sampling unit and the basic unit in the convolutional neural network. To expand the sensory field, SPPF is replaced with focal modulation to learn coarse-grained spatial information and fine-grained feature information to improve the performance of the network.
- The proposed detection model significantly outperforms other methods in the self-built forest smoke detection dataset. Compared with the original YOLOv8s, the mean average precision of forest smoke detection is improved by 3%. The number of parameters and the computational complexity of the model are reduced by 30.07% and 10.49%, respectively.
2. Materials and Methods
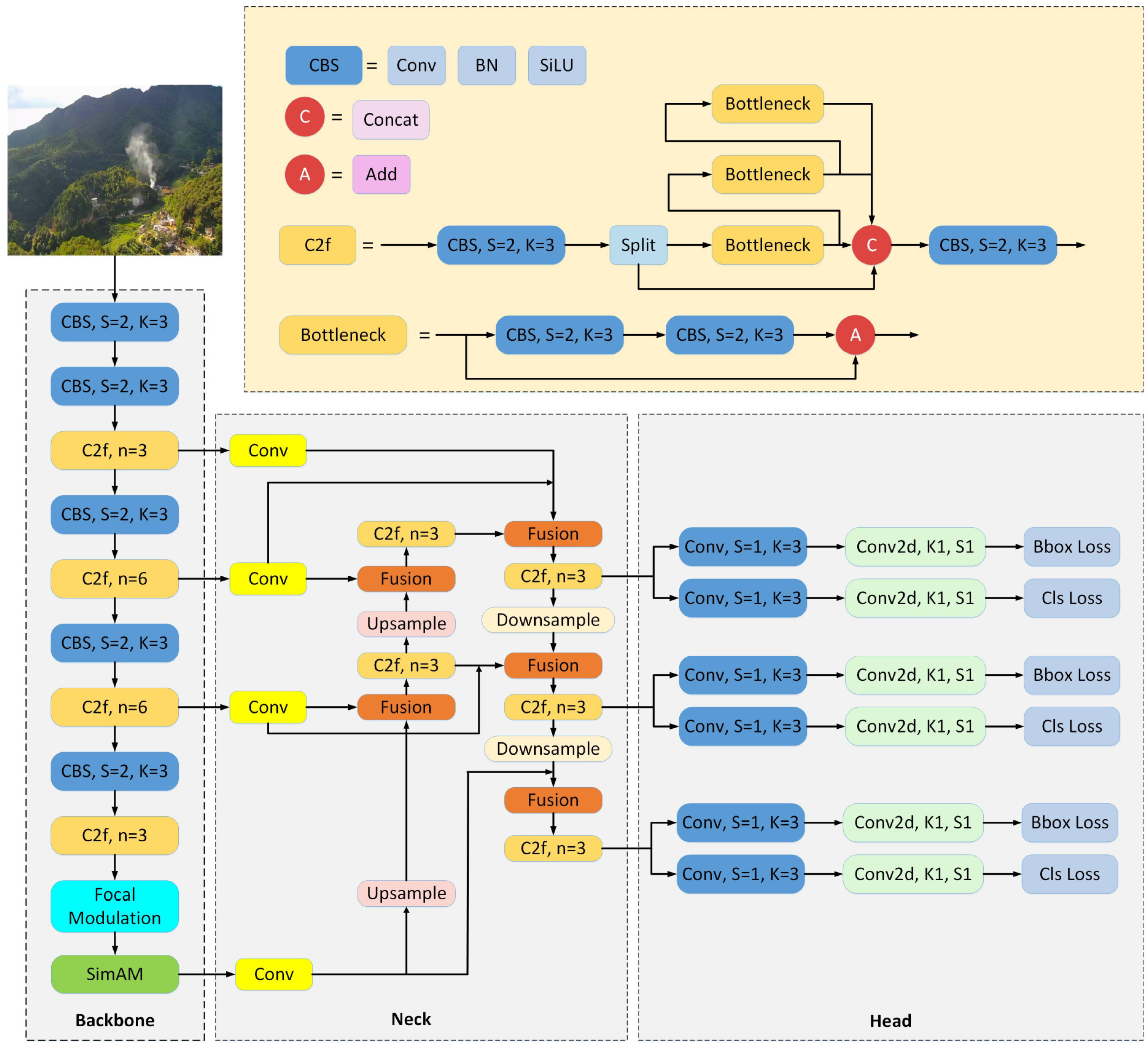
2.1. Forest Smoke Detection Based on YOLOv8 Architecture
2.2. Bidirectional Feature Pyramid Network (BiFPN)
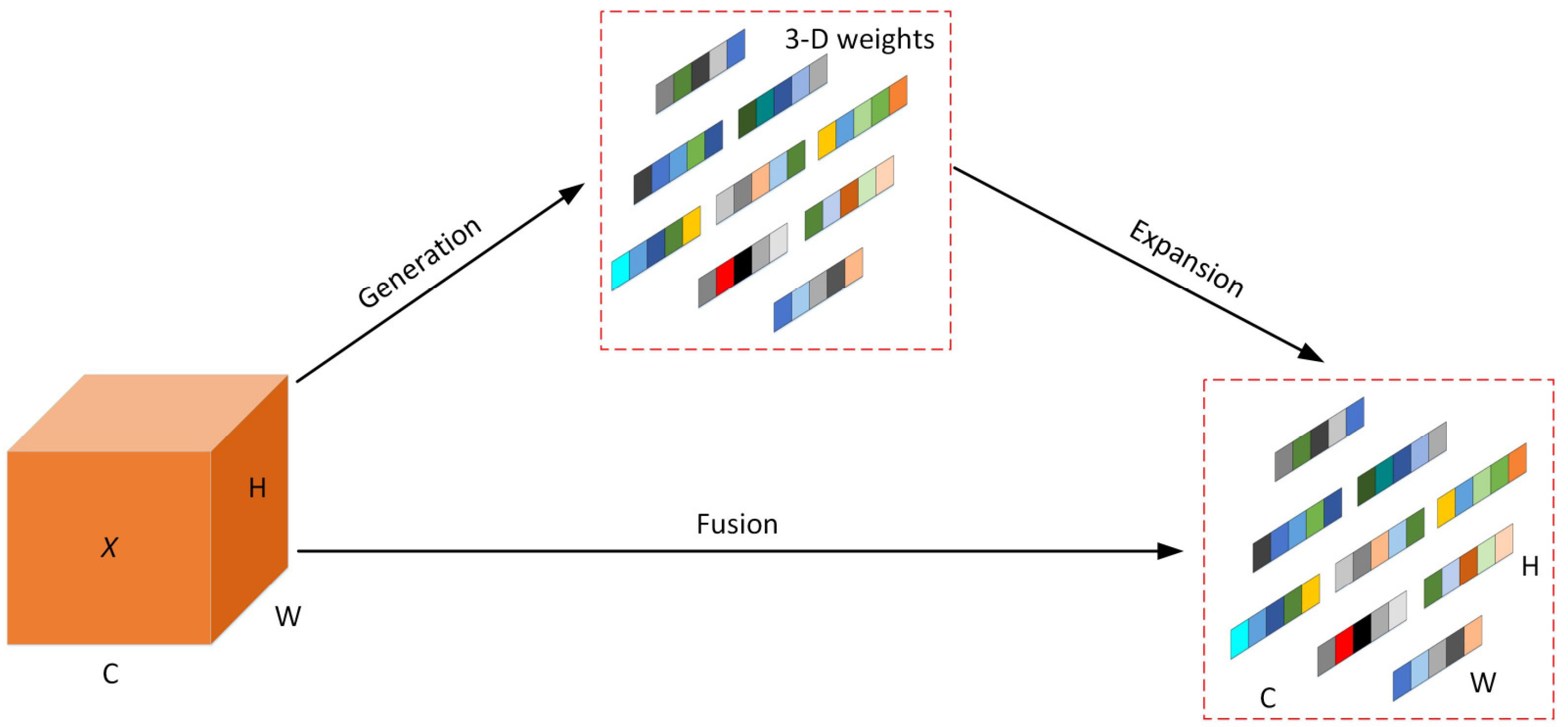
2.3. Focal Modulation
2.4. Simple and Parameter-Free Attention Module (SimAM)
3. Results and Analysis
3.1. Datasets and Implementation Details
3.2. Evaluation Metrics
3.3. Effect of Different Attention Mechanisms
3.4. Effects of Different Detection Models
3.5. Ablation Experiment
3.6. Effects of Different Datasets
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Galván, L.; Magaña, V. Forest fires in Mexico: An approach to estimate fire probabilities. Int. J. Wildland Fire 2020, 29, 753–763. [Google Scholar] [CrossRef]
- Management, Fire and Rescue Department Ministry of Emergency. The Emergency Management Department Released the Basic Information of National Natural Disasters in 2022. Available online: https://www.119.gov.cn/qmxfgk/sjtj/2023/34793.shtml (accessed on 13 January 2023).
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Toreyin, B.U.; Dedeoglu, Y.; Cetin, A.E. Contour based smoke detection in video using wavelets. In Proceedings of the European Signal Processing Conference, Florence, Italy, 4–8 September 2006; pp. 1–5. [Google Scholar]
- Cui, Y.; Dong, H.; Zhou, E. An Early Fire Detection Method Based on Smoke Texture Analysis and Discrimination. In Proceedings of the Congress on Image and Signal Processing, Sanya, China, 27–30 May 2008; Volume 3, pp. 95–99. [Google Scholar]
- Chen, J.; You, Y.; Peng, Q. Dynamic analysis for video based smoke detection. Int. J. Comput. Sci. Issues 2013, 10, 298. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2969239–2969250. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN:Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. NIPS 2016, 2, 379–387. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition CVPR, Long Beach, CA, USA, 15–20 June 2019; Volume 2, pp. 821–830. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ultralytics-YOLOv5. Available online: https://github.com/ultralytics/YOLOv5 (accessed on 5 June 2022).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhang, Q.; Lin, G.; Zhang, Y.; Xu, G.; Wang, J.-J. Wildland forest fire smoke detection based on faster R-CNN using synthetic smoke images. Procedia Eng. 2018, 211, 441–446. [Google Scholar] [CrossRef]
- Chaoxia, C.; Shang, W.; Zhang, F. Information-guided flame detection based on faster R-CNN. IEEE Access 2020, 8, 58923–58932. [Google Scholar] [CrossRef]
- Zhou, M.; Wu, L.; Liu, S.; Li, J. UAV forest fire detection based on lightweight YOLOv5 model. Multimed. Tools Appl. 2023, 1–12. [Google Scholar] [CrossRef]
- Chen, G.; Zhou, H.; Li, Z.; Gao, Y.; Bai, D.; Xu, R.; Lin, H. Multi-Scale Forest Fire Recognition Model Based on Improved YOLOv5s. Forests 2023, 14, 315. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 January 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Yang, J.; Li, C.; Dai, X.; Gao, J. Focal modulation networks. Adv. Neural Inf. Process. Syst. 2022, 35, 4203–4217. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing, Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision ECCV, Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Almeida Borges de Venâncio, P.V.; Lisboa, A.C.; Barbosa, A.V. An automatic fire detection system based on deep convolutional neural networks for low-power, resource-constrained devices. Neural Comput. Appl. 2022, 34, 15349–15368. [Google Scholar] [CrossRef]
- Chen, S.; Zhao, Q. Shallowing deep networks: Layer-wise pruning based on feature representations. IEEE Trans. Pattern Analy-Sis Mach. Intell. 2018, 41, 3048–3056. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Banner, R.; Nahshan, Y.; Soudry, D. Post training 4-bit quantization of convolutional networks for rapid-deployment. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Denton, E.L.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting linear structure within convolutional networks for efficient evaluation. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Yang, S.; Xie, Z.; Peng, H.; Xu, M.; Sun, M.; Li, P. Dataset pruning: Reducing training data by examining generalization influence. arXiv 2022, arXiv:2205.09329. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Environment | Details |
|---|---|
| Programming language | Python 3.9 |
| Operating system | Windows 11 |
| Deep learning framework | PyTorch 1.10.0 |
| Run device | NVIDIA GeForce GTX 3090 |
| Training Parameters | Details |
|---|---|
| Epochs | 200 |
| Batch size | 32 |
| Image size (pixels) | 640 × 640 |
| Learning rate | 0.001 |
| Optimizer | SGD |
| Models | Precision (%) | Recall (%) | mAP50 (%) | Parameter (MB) | GFLOPs |
|---|---|---|---|---|---|
| YOLOv8s [20] | 86.1 | 82.6 | 87.1 | 11.14 | 28.6 |
| +GAM [27] | 88.3 | 85.1 | 90.2 | 17.68 | 33.7 |
| +EMA [29] | 86.3 | 83.9 | 89.6 | 11.18 | 28.9 |
| +CBAM [28] | 85.6 | 85.0 | 89.3 | 11.39 | 28.7 |
| +SE [30] | 82.4 | 86.7 | 89.4 | 11.16 | 28.6 |
| +CoordAttetion [31] | 86.8 | 80.8 | 89.8 | 11.15 | 28.4 |
| + SimAM [26] | 86.6 | 85.3 | 90.4 | 11.14 | 28.6 |
| Models | mAP50 (%) | Parameter (MB) | GFLOPs (G) | FPS | F1-Score |
|---|---|---|---|---|---|
| Faster-RCNN [7] | 82.8 | 137.1 | 370.2 | 56 | 0.51 |
| SSD [13] | 76.28 | 26.29 | 62.75 | 85 | 0.7 |
| EfficientDet [14] | 89.37 | 3.83 | 4.74 | 92 | 0.8 |
| YOLOv3-tiny [10] | 87.9 | 8.67 | 12.9 | 223 | 0.84 |
| YOLOv5 [11] | 86.7 | 7.23 | 16.4 | 119 | 0.84 |
| YOLOv5+ShuffleNet [32] | 75.9 | 3.8 | 8.0 | 93 | 0.74 |
| YOLOv8s [20] | 87.1 | 11.14 | 28.6 | 103 | 0.84 |
| Ours | 90.1 | 7.79 | 25.6 | 100 | 0.89 |
| BiFPN | Focal Modulation | SimAM | Precision (%) | mAP50 (%) | Parameter (MB) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|
| 86.1 | 87.1 | 11.14 | 28.6 | 103 | |||
| √ | 86.6 | 88.9 | 7.37 | 25.2 | 98 | ||
| √ | 86.0 | 88.5 | 11.54 | 28.8 | 111 | ||
| √ | 86.6 | 90.4 | 11.14 | 28.6 | 109 | ||
| √ | √ | 86.5 | 89.3 | 7.79 | 25.6 | 95 | |
| √ | √ | √ | 87.1 | 90.1 | 7.79 | 25.6 | 100 |
| Dataset | Models | Precision (%) | mAP50(%) | Parameter (MB) | GFLOPs | FPS |
|---|---|---|---|---|---|---|
| The D-Fire Dataset | EfficientDet [14] | 66.3 | 71 | 3.79 | 4.7 | 90 |
| YOLOv3-tiny [10] | 62 | 68.7 | 8.6 | 12.5 | 211 | |
| YOLOv5 [11] | 64.8 | 67.1 | 7.2 | 16.2 | 120 | |
| YOLOv4-tiny [33] | 60.9 | 62 | 5.9 | 16 | 197 | |
| YOLOv4 [33] | 69.8 | 73 | 65 | 142 | 40 | |
| YOLOv8s [20] | 64.9 | 71.9 | 11.12 | 28.4 | 103 | |
| The improved YOLOv8s | 70.6 | 74 | 7.77 | 25.3 | 98 | |
| The Forest Smoke Dataset | Ours | 87.1 | 90.1 | 7.79 | 25.6 | 100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Cao, Y.; Hu, T. An Efficient and Lightweight Detection Model for Forest Smoke Recognition. Forests 2024, 15, 210. https://doi.org/10.3390/f15010210
Guo X, Cao Y, Hu T. An Efficient and Lightweight Detection Model for Forest Smoke Recognition. Forests. 2024; 15(1):210. https://doi.org/10.3390/f15010210
Chicago/Turabian StyleGuo, Xiao, Yichao Cao, and Tongxin Hu. 2024. "An Efficient and Lightweight Detection Model for Forest Smoke Recognition" Forests 15, no. 1: 210. https://doi.org/10.3390/f15010210
APA StyleGuo, X., Cao, Y., & Hu, T. (2024). An Efficient and Lightweight Detection Model for Forest Smoke Recognition. Forests, 15(1), 210. https://doi.org/10.3390/f15010210